
Low-Flow Identification in Flood Frequency Analysis: A Case Study for Eastern Australia



Abstract
1. Introduction
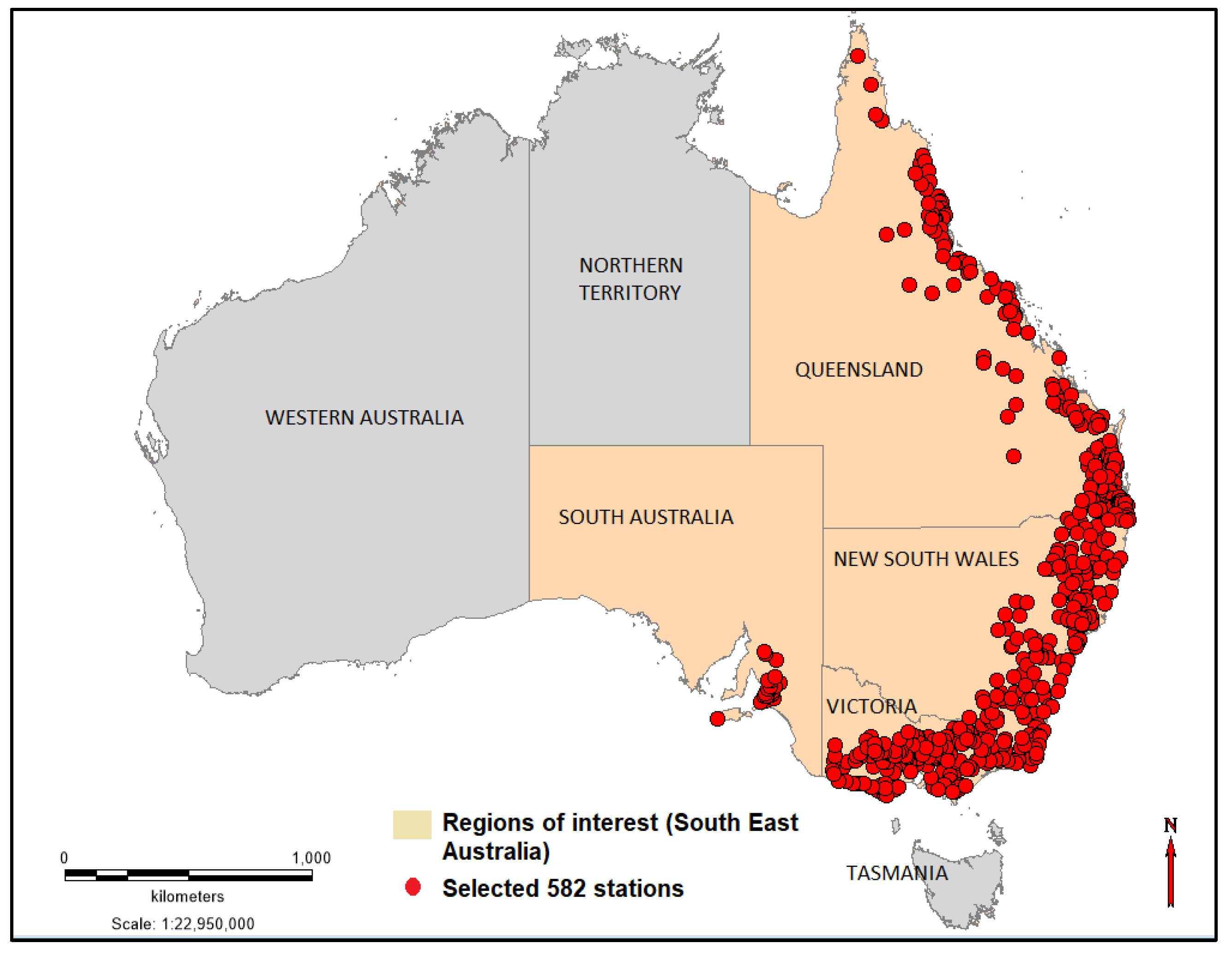
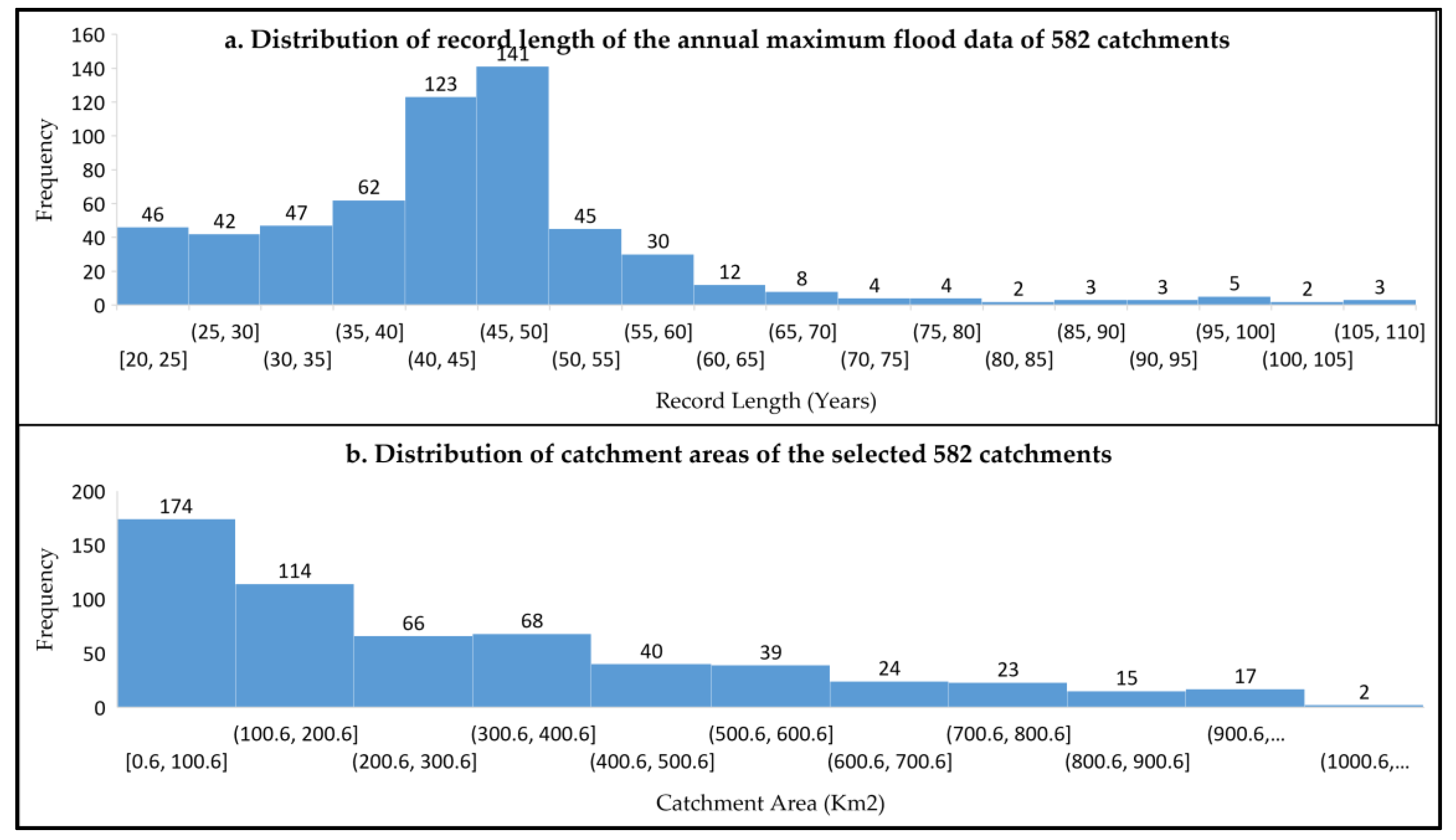
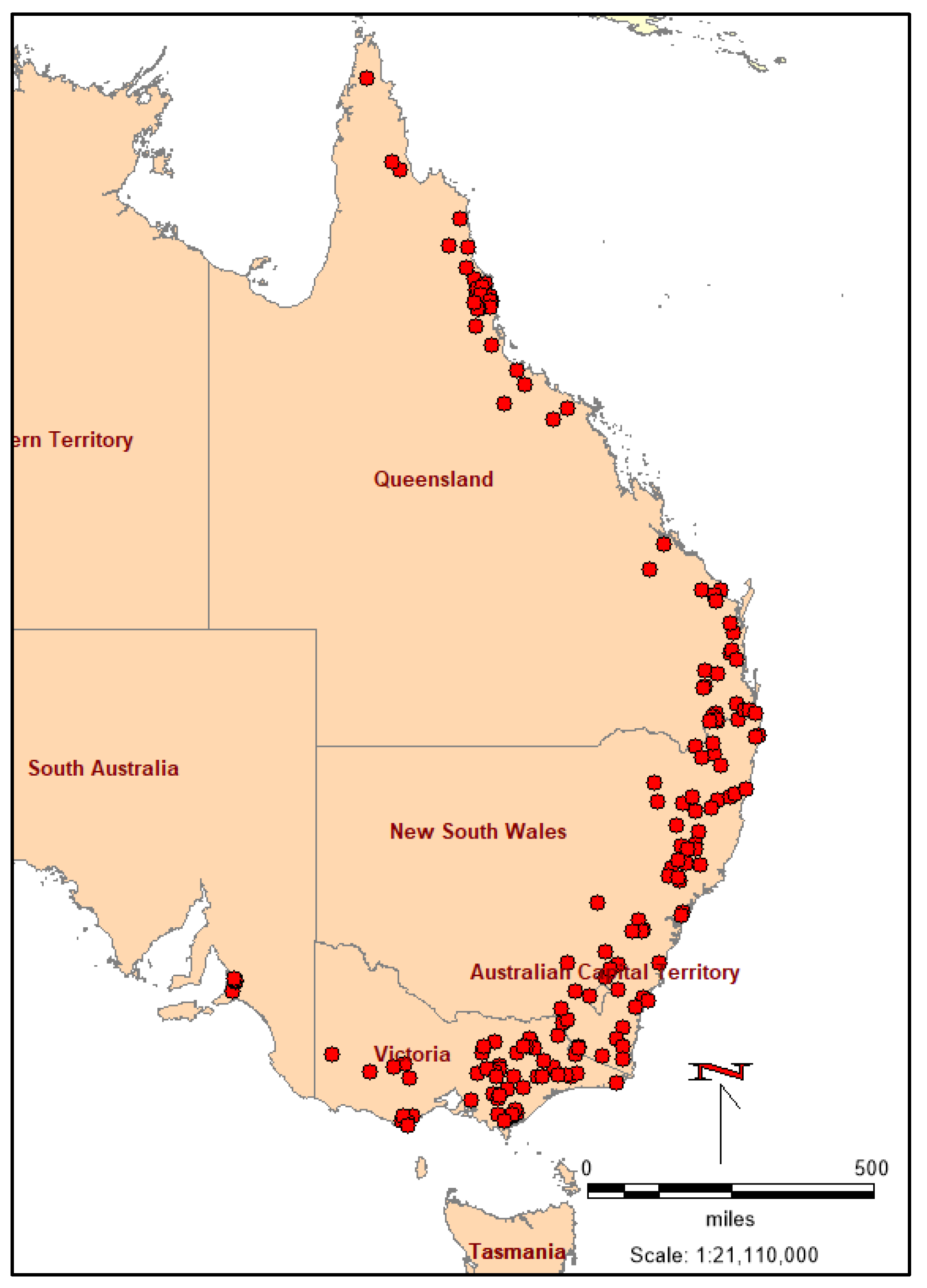
2. Study Area and Data
3. Methodology
3.1. Log-Pearson Type III Distribution
3.2. Generalized Extreme Value Distribution
3.3. Parameter Estimation Method
3.4. Multiple Grubbs–Beck Test
3.5. Comparison of Results
3.6. Regression Analysis
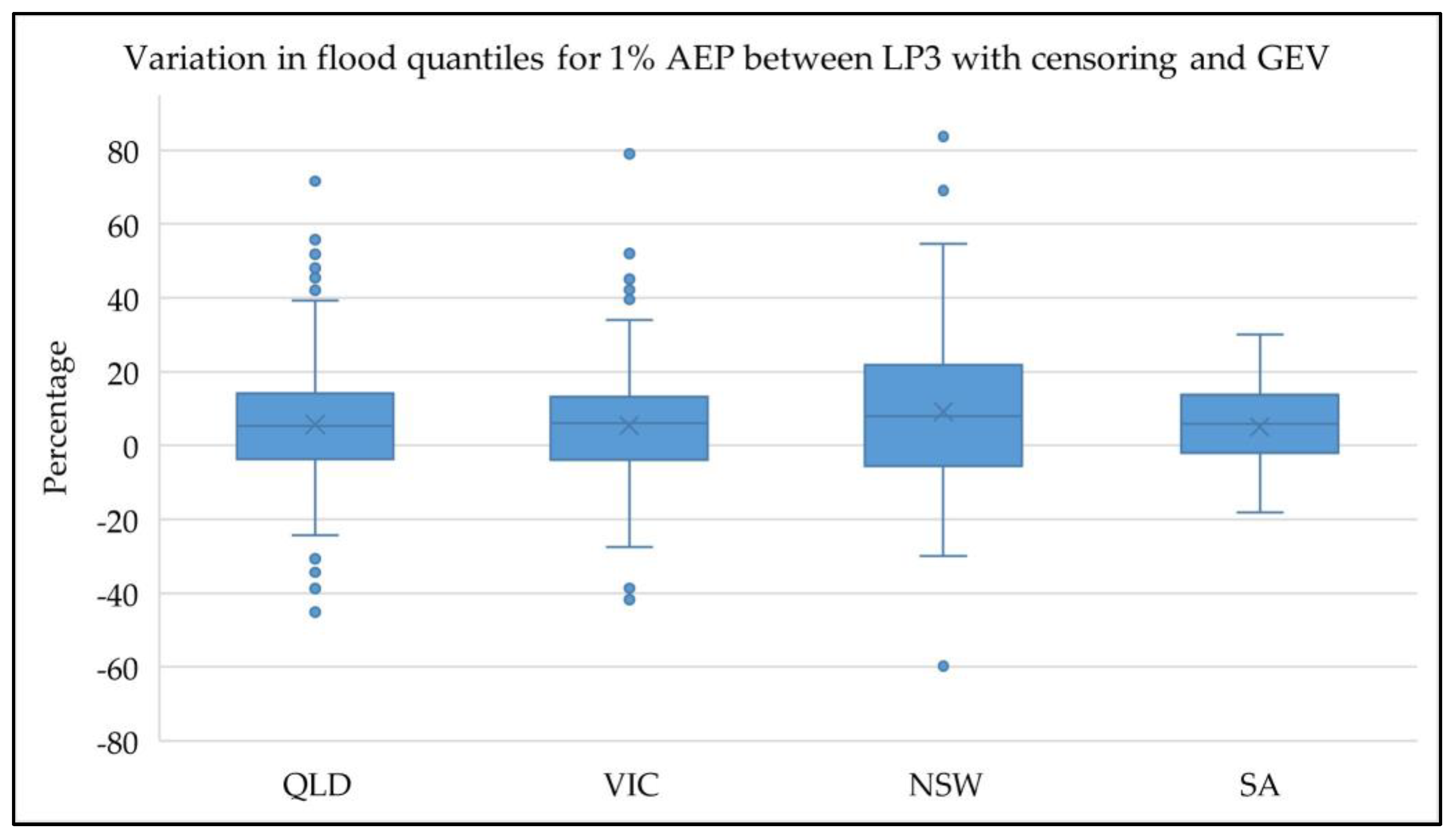
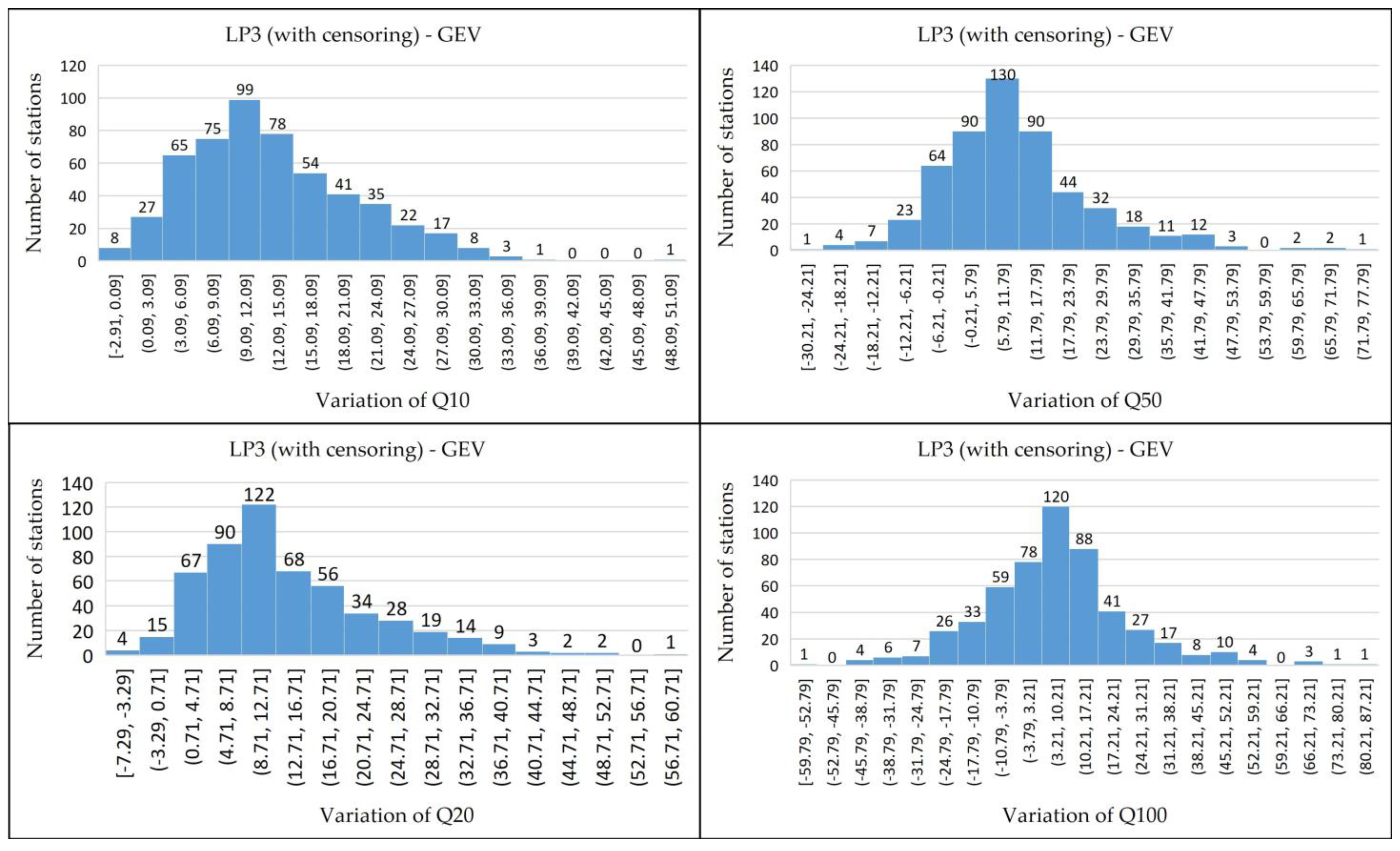
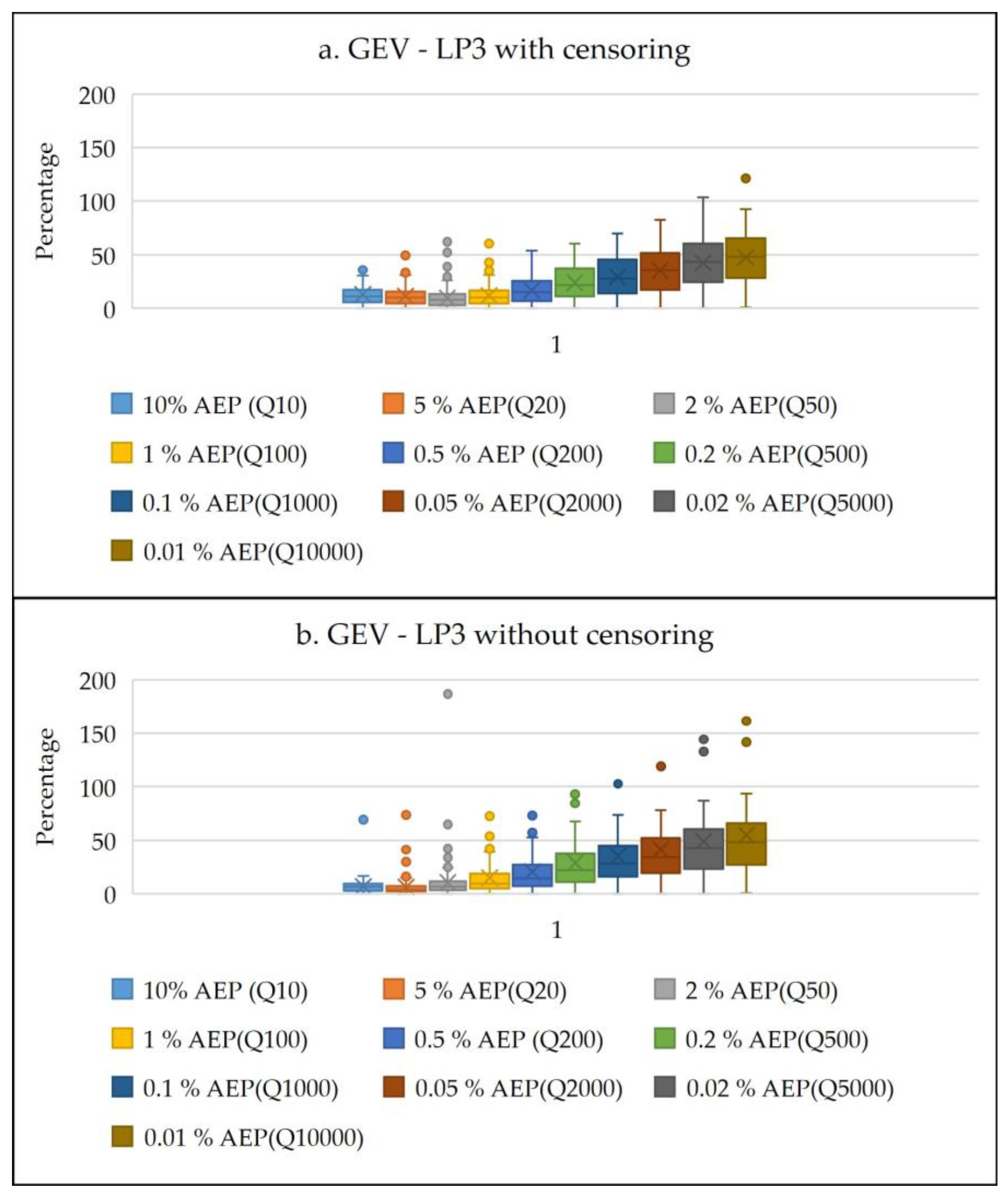
4. Results and Discussion
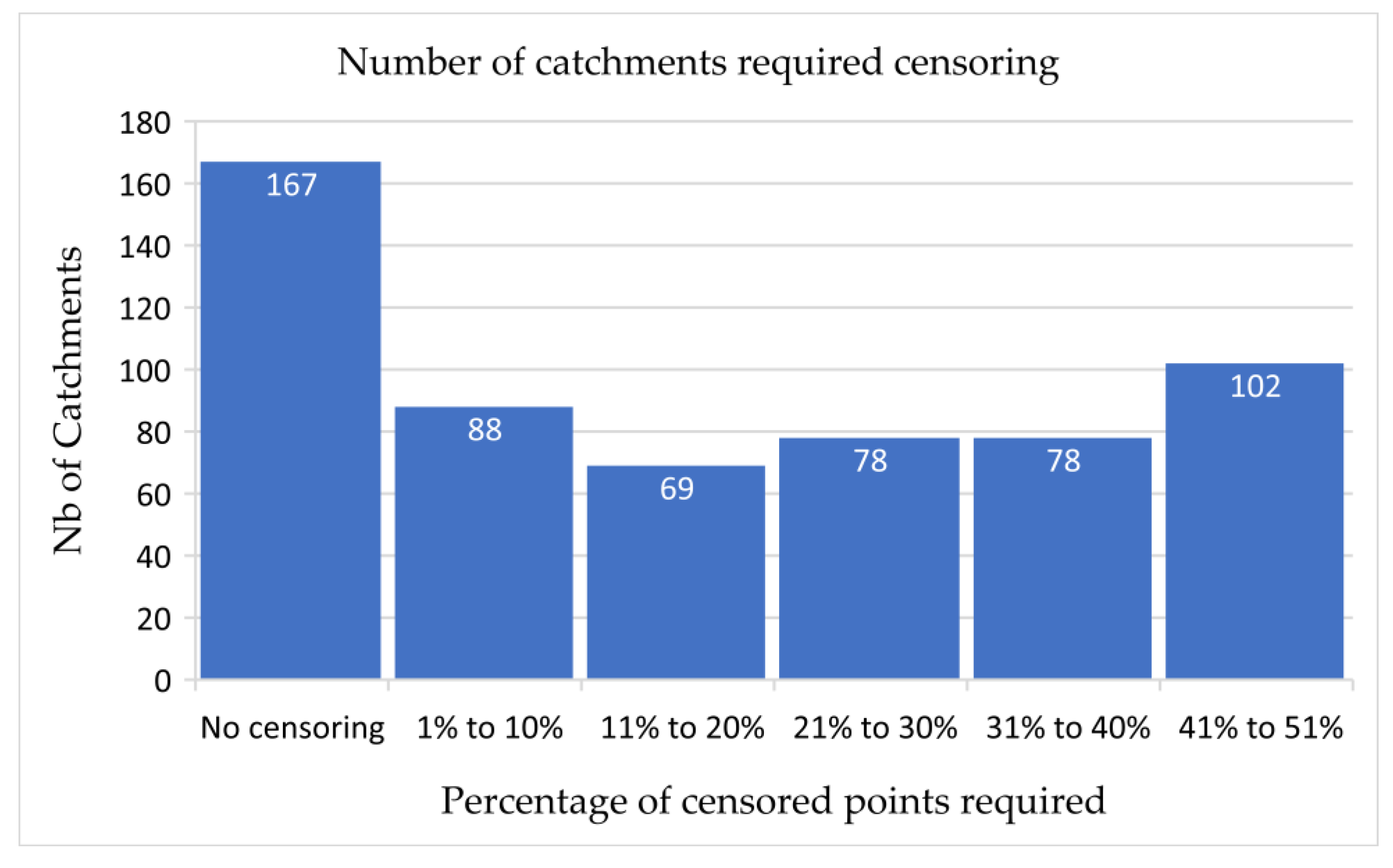
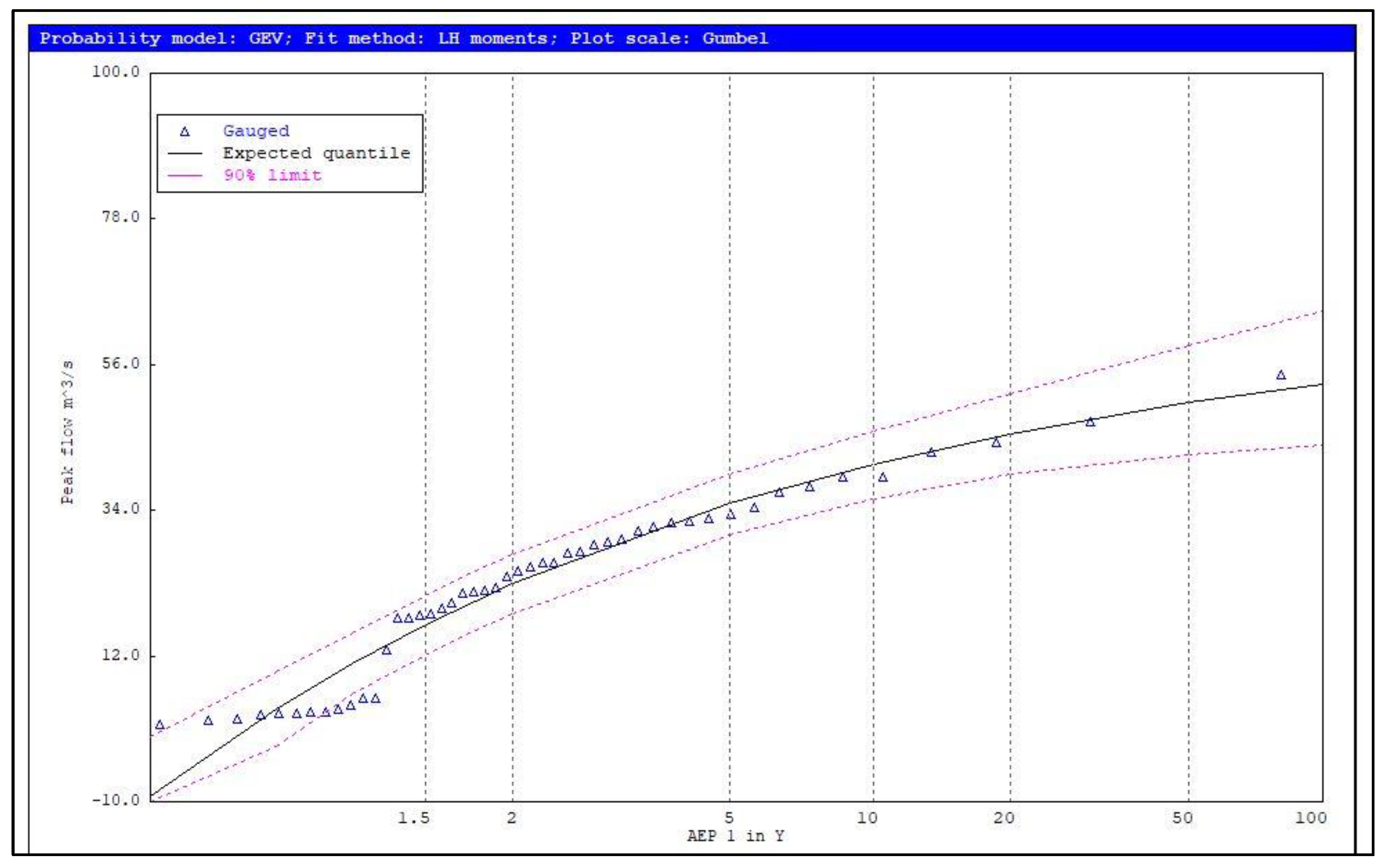
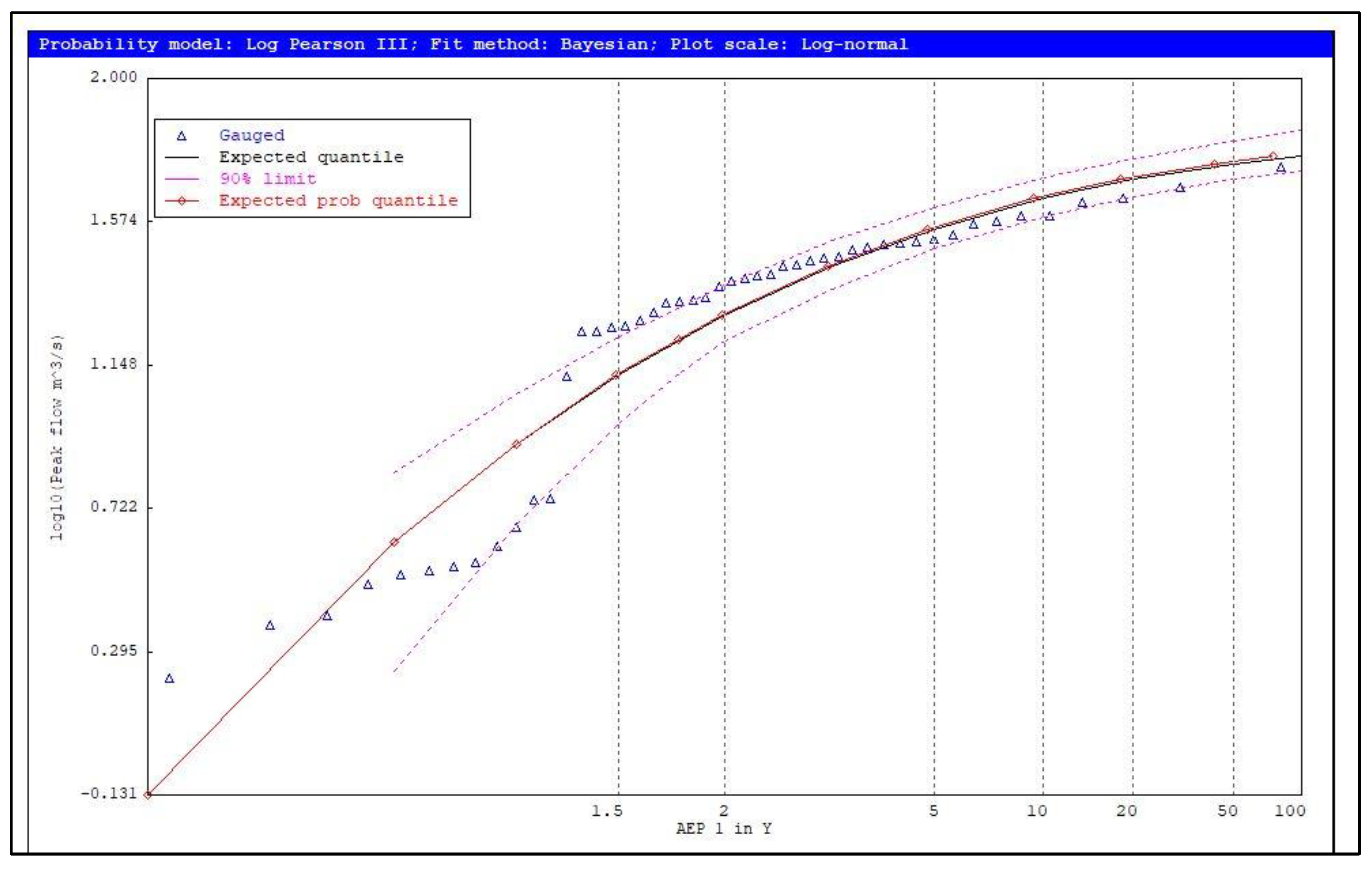
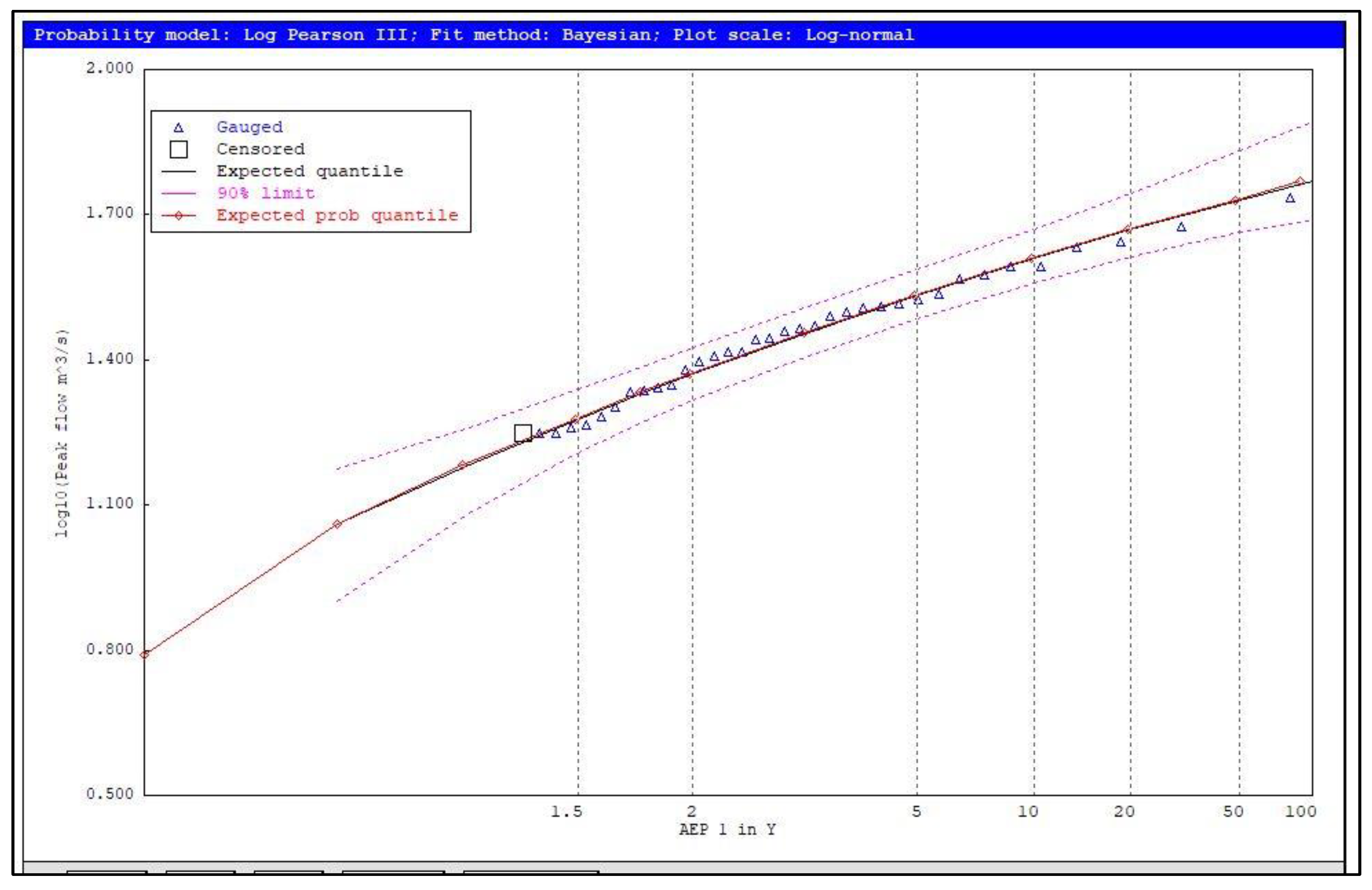
4.1. Identification of Potentially Influential Low Flows (PILFs)
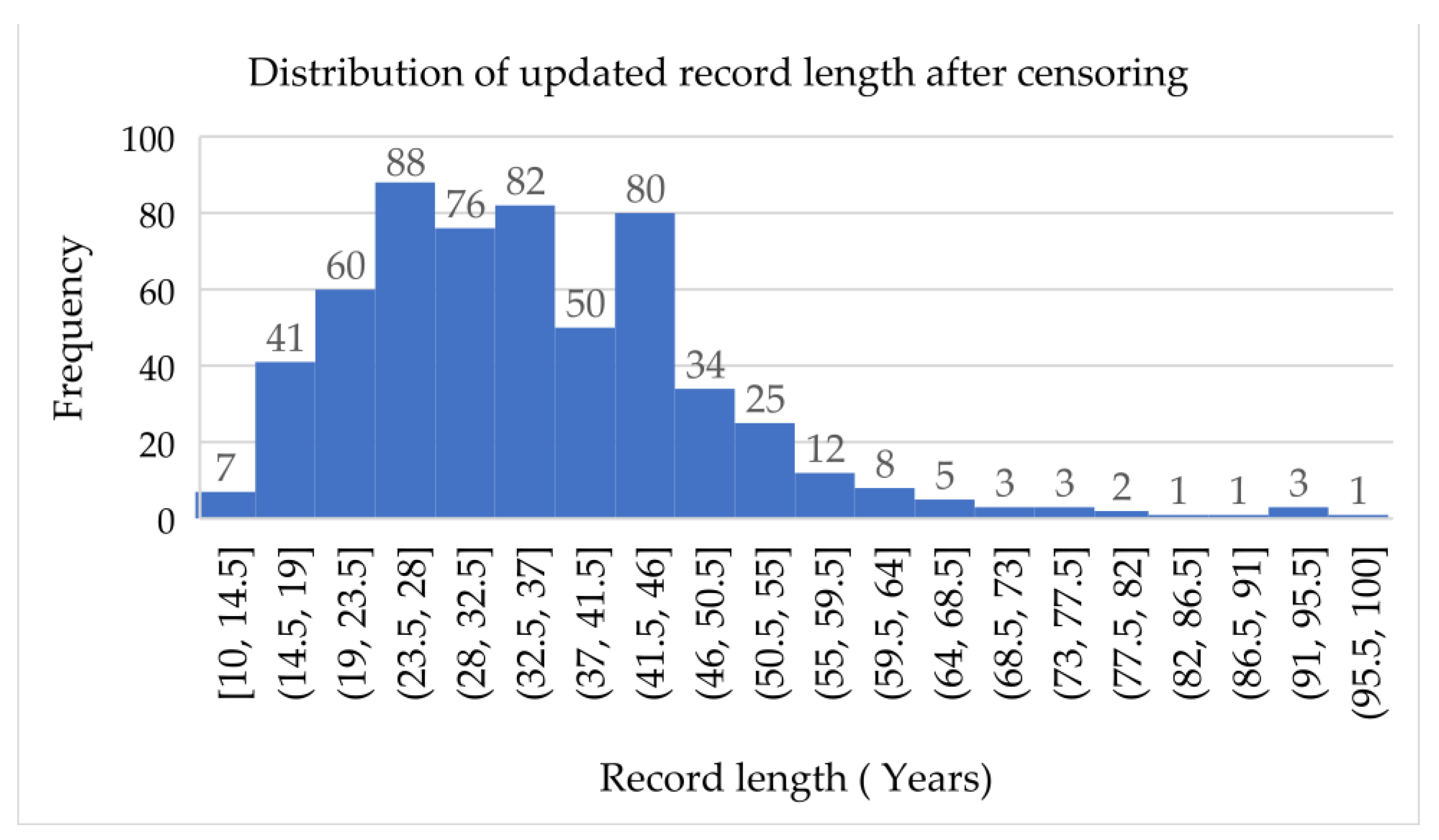
4.2. Relationship between Number of Censored Data Points and Catchment Characteristics
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Stefanidis, S.; Stathis, D. Assessment of flood hazard based on natural and anthropogenic factors using analytic hierarchy process (AHP). Nat. Hazards 2013, 68, 569–585. [Google Scholar] [CrossRef]
- Insurance Council of Australia (ICA). Updated Data Shows 2022 Flood Was Australia’s Costliest. Available online: https://insurancecouncil.com.au/wp-content/uploads/2022/05/220503-East-Coast-flood-event-costs-update.pdf (accessed on 3 May 2022).
- Ahmad, I.; Waqas, M.; Almanjahie, I.M.; Saghir, A.; Haq, E.U. Regional flood frequency analysis using linear moments and partial linear moments: A case study. Appl. Ecol. Environ. Res. 2019, 17, 3819–3836. [Google Scholar] [CrossRef]
- Ekeu-Wei, I.T.; Blackburn, G.A.; Giovannettone, J. Accounting for the Effects of Climate Variability in Regional Flood Frequency Estimates in Western Nigeria. J. Water Resour. Prot. 2020, 12, 690. [Google Scholar] [CrossRef]
- Garmdareh, E.S.; Vafakhah, M.; Eslamian, S.S. Regional flood frequency analysis using support vector regression in arid and semi-arid regions of Iran. Hydrol. Sci. J. 2018, 63, 426–440. [Google Scholar] [CrossRef]
- Haddad, K.; Rahman, A.; Weinmann, P.E.; Kuczera, G.; Ball, J. Streamflow data preparation for regional flood frequency analysis: Lessons from southeast Australia. Australas. J. Water Resour. 2010, 14, 17–32. [Google Scholar] [CrossRef]
- Requena, A.I.; Ouarda, T.B.; Chebana, F. Flood frequency analysis at ungauged sites based on regionally estimated streamflows. J. Hydrometeorol. 2017, 18, 2521–2539. [Google Scholar] [CrossRef]
- Desai, S.; Ouarda, T.B. Regional hydrological frequency analysis at ungauged sites with random forest regression. J. Hydrol. 2021, 594, 125861. [Google Scholar] [CrossRef]
- Kousar, S.; Khan, A.R.; Ul Hassan, M.; Noreen, Z.; Bhatti, S.H. Some best-fit probability distributions for at-site flood frequency analysis of the Ume River. J. Flood Risk Manag. 2020, 13, e12640. [Google Scholar] [CrossRef]
- Rahman, A.S.; Rahman, A.; Zaman, M.A.; Haddad, K.; Ahsan, A.; Imteaz, M. A study on selection of probability distributions for at-site flood frequency analysis in Australia. Nat. Hazards 2013, 69, 1803–1813. [Google Scholar] [CrossRef]
- Ahn, K.H.; Palmer, R. Regional flood frequency analysis using spatial proximity and basin characteristics: Quantile regression vs. parameter regression technique. J. Hydrol. 2016, 540, 515–526. [Google Scholar] [CrossRef]
- Stojković, M.; Prohaska, S.; Zlatanović, N. Estimation of flood frequencies from data sets with outliers using mixed distribution functions. J. Appl. Stat. 2017, 44, 2017–2035. [Google Scholar] [CrossRef]
- Grubbs, F.E.; Beck, G. Extension of sample sizes and percentage points for significance tests of outlying observations. Technometrics 1972, 14, 847–854. [Google Scholar] [CrossRef]
- Barnett, V.; Lewis, T. Outliers in Statistical Data; John Wiley and Sons: New York, NY, USA, 1994. [Google Scholar]
- Grubbs, F.E. Procedures for detecting outlying observations in samples. Technometrics 1969, 11, 1–21. [Google Scholar] [CrossRef]
- Interagency Advisory Committee on Water Data (IAWCD). Guidelines for Determining Flood Flow Frequency: Bulletin 17-B; Technical Report; Interagency Advisory Committee on Water Data (IAWCD): Washington, DC, USA, 1982; 28p. [Google Scholar]
- Cohn, T.A.; England, J.F.; Berenbrock, C.E.; Mason, R.R.; Stedinger, J.R.; Lamontagne, J.R. A generalized Grubbs-Beck test statistic for detecting multiple potentially influential low outliers in flood series. Water Resour. Res. 2013, 49, 5047–5058. [Google Scholar] [CrossRef]
- Interagency Advisory Committee on Water Data (IAWCD). Robust National Flood Frequency Guidelines: What Is an Outlier? Bulletin 17C; IAWCD: Washington, DC, USA, 2013. [Google Scholar]
- England, J.F., Jr.; Cohn, T.A. Bulletin 17B flood frequency revisions: Practical software and test comparison results. In Proceedings of the World Environmental and Water Resources Congress 2008: Ahupua’A, Honolulu, HI, USA, 12–16 May 2008; pp. 1–11. [Google Scholar]
- Rosner, B. On the detection of many outliers. Technometrics 1975, 17, 221–227. [Google Scholar] [CrossRef]
- Rosner, B. Percentage points for a generalized ESD many-outlier procedure. Technometrics 1983, 25, 165–172. [Google Scholar] [CrossRef]
- Rahman, A.S.; Haddad, K.; Rahman, A. Impacts of outliers in flood frequency analysis: A case study for Eastern Australia. J. Hydrol. Environ. Res. 2014, 2, 17–30. [Google Scholar]
- Blagojević, B.; Mihailović, V.; Plavšić, J. Outlier treatment in the flood flow statistical analysis. In Međunarodna konferencija Savremena dostignuća u građevinarstvu 25; Građevinski Fakultet: Subotica, Serbia, 2014; Volume 30, pp. 603–609. [Google Scholar]
- Lamontagne, J.R.; Stedinger, J.R.; Yu, X.; Whealton, C.A.; Xu, Z. Robust flood frequency analysis: Performance of EMA with multiple Grubbs-Beck outlier tests. Water Resour. Res. 2016, 52, 3068–3084. [Google Scholar] [CrossRef]
- Jaiswal, R.K.; Nayak, T.R.; Lohani, A.K.; Galkate, R.V. Regional flood frequency modeling for a large basin in India. Nat. Hazards 2021, 111, 1845–1861. [Google Scholar] [CrossRef]
- Mitchell, J.N.; Wagner, D.M.; Veilleux, A.G. Magnitude and Frequency of Floods on Kaua‘i, O‘ahu, Moloka‘i, Maui, and Hawai‘i, State of Hawai‘i, Based on Data through Water Year 2020 (No. 2023-5014); US Geological Survey: Reston, VA, USA, 2023. [Google Scholar]
- Stedinger, J.R. Frequency analysis of extreme events. In Handbook of Hydrology; McGraw Hill: New York, NY, USA, 1993. [Google Scholar]
- Chow, V.T. A general formula for hydrologic frequency analysis. Eos Trans. Am. Geophys. Union 1951, 32, 231–237. [Google Scholar]
- Barth, N.A.; Villarini, G.; Nayak, M.A.; White, K. Mixed populations and annual flood frequency estimates in the western United States: The role of atmospheric rivers. Water Resour. Res. 2017, 53, 257–269. [Google Scholar] [CrossRef]
- Hosking, J.R. L-moments: Analysis and estimation of distributions using linear combinations of order statistics. J. R. Stat. Soc. Ser. B Methodol. 1990, 52, 105–124. [Google Scholar] [CrossRef]
- Kuczera, G.; Franks, S. At-Site Flood Frequency Analysis. Australian Rainfall and Runoff: A Guide to Flood Estimation; Geoscience Australia: Canberra, Australia, 2016; pp. 5–99. [Google Scholar]
- Paretti, N.V.; Kennedy, J.R.; Cohn, T.A. Evaluation of the Expected Moments Algorithm and a Multiple Low-Outlier Test for Flood Frequency Analysis at Streamgaging Stations in Arizona (No. 2014-5026); US Geological Survey: Reston, VA, USA, 2014. [Google Scholar]
- Plavšić, J.; Mihailović, V.; Blagojević, B. Assessment of methods for outlier detection and treatment in flood frequency analysis. In Proceedings of the Mediterranean Meeting on Monitoring, Modelling and Early Warning of Extreme Events Triggered by Heavy Rainfalls, PON 01_01503-MED-FRIEND Project University of Calabria, Cosenza, Italy, 26–28 June 2014; pp. 181–192. [Google Scholar]
- Rahman, A.; Haddad, K.; Kuczera, G.; Weinmann, E. Regional flood methods. In Australian Rainfall and Runoff: A Guide to Flood Estimation; Book 3, Peak Flow Estimation; Geoscience, Commonwealth of Australia: Canberra, Australia, 2019; pp. 105–146. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Authors | Source | Number of Stations | Country | Comments |
|---|---|---|---|---|---|
| 1969, 1972 | Grubbs & Beck | [13,15] | GB test detected one outlier at a time. | ||
| 1982 | IAWCD | [16] | USA | GB test was recommended in Bulletin 17B. | |
| 1975, 1983 | Rosner | [20,21] | Generalisation of the GB test that can detect multiple outliers was discussed. | ||
| 2013 | Cohn et al. | [17] | MGB test identified multiple potentially influential low flows (PILFs) in AM flood series. | ||
| 2013 | IAWCD | [18] | USA | MGB test was proposed in Bulletin 17C. | |
| 2014 | Rahman et al. | [22] | 10 stations | Australia | Flood quantile estimates produced from MGB with LP3 were more consistent than estimates derived from GB-LP3 method. |
| 2014 | Blagojević et al. | [23] | 68 stations | Serbia | Outlier detection was found to an important step in design flood estimation. |
| 2016 | Lamontagne et al. | [24] | California, USA | Censoring PILFs improved FFA results. | |
| 2017 | Stojkovi et al. | [12] | Serbia | Detecting low outliers improved design flood estimates. | |
| 2019 | Ahmad et al. | [3] | 10 stations | Pakistan | Censoring outperformed un-censoring case in FFA. |
| 2020 | Rahman et al. | [4] | 88 stations | Australia | Censoring PILFs reduced skewness of the available AM flood data significantly. |
| 2020 | Ekeu-Wei et al. | [25] | 17 stations | Western Nigeria | Used MGB test to identify outliers in AM flood data. |
| 2021 | Jaiswal et al. | [26] | 26 stations | India | Used GB test to censor outlier data points from AM flood data series in FFA. |
| 2023 | Mitchell et al. | [13,15] | 238 stations | State of Hawaii | Used MGB test to identify and censor low outliers from AM flood data series in FFA. |
| Distribution | Percentage of Absolute Variation for Q100 | |||||||
|---|---|---|---|---|---|---|---|---|
| QLD | VIC | |||||||
| Min | Max | Mean | St. Dev. | Min | Max | Mean | St. Dev. | |
| GEV—LP3 with censoring | 0.29 | 46.57 | 11.45 | 8.57 | 1.10 | 41.62 | 12.46 | 10.24 |
| GEV-LP3 (no censoring) | 0.60 | 69.48 | 10.47 | 12.77 | 0.10 | 321.69 | 16.59 | 42.25 |
| LP3 (censoring)—LP3 (no censoring) | 0.32 | 57.18 | 12.32 | 11.74 | 0.63 | 291.43 | 18.68 | 38.16 |
| Distribution | Percentage of Absolute Variation of Q100 | |||||||
| NSW | SA | |||||||
| Min | Max | Mean | St. Dev. | Min | Max | Mean | St. Dev. | |
| GEV—LP3 with censoring | 0.01 | 37.60 | 12.67 | 7.38 | 0.15 | 30.03 | 11.77 | 8.50 |
| GEV-LP3 (no censoring) | 0.35 | 55.91 | 10.83 | 12.81 | 0.10 | 27.93 | 9.73 | 8.55 |
| LP3(censoring)—LP3 (no censoring) | 0.40 | 72.79 | 14.13 | 14.21 | 0.48 | 53.66 | 16.18 | 15.88 |
| Regression Statistics | Coefficients | Standard Error | t Stat | p-Value | ||
|---|---|---|---|---|---|---|
| Multiple R | 0.66 | Intercept | 9.64 | 8.281 | 1.164 | 0.256 |
| R2 | 0.43 | BFI (volume factor) | −12.04 | 9.439 | −1.28 | 0.215 |
| Adjusted R2 | 0.33 | BFI (peak factor) | 29.917 | 21.478 | 1.393 | 0.177 |
| Standard error | 6.2 | (MAR) (mm) | −0.016 | 0.007 | −2.31 | 0.03 |
| Observations | 28 | SF | 12.822 | 5.599 | 2.29 | 0.032 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rima, L.; Haddad, K.; Rahman, A. Low-Flow Identification in Flood Frequency Analysis: A Case Study for Eastern Australia. Water 2024, 16, 535. https://doi.org/10.3390/w16040535
Rima L, Haddad K, Rahman A. Low-Flow Identification in Flood Frequency Analysis: A Case Study for Eastern Australia. Water. 2024; 16(4):535. https://doi.org/10.3390/w16040535
Chicago/Turabian StyleRima, Laura, Khaled Haddad, and Ataur Rahman. 2024. "Low-Flow Identification in Flood Frequency Analysis: A Case Study for Eastern Australia" Water 16, no. 4: 535. https://doi.org/10.3390/w16040535
APA StyleRima, L., Haddad, K., & Rahman, A. (2024). Low-Flow Identification in Flood Frequency Analysis: A Case Study for Eastern Australia. Water, 16(4), 535. https://doi.org/10.3390/w16040535