
An Empirical Relation for Estimating Sediment Particle Size in Meandering Gravel-Bed Rivers


Abstract
1. Introduction
2. Materials and Methods
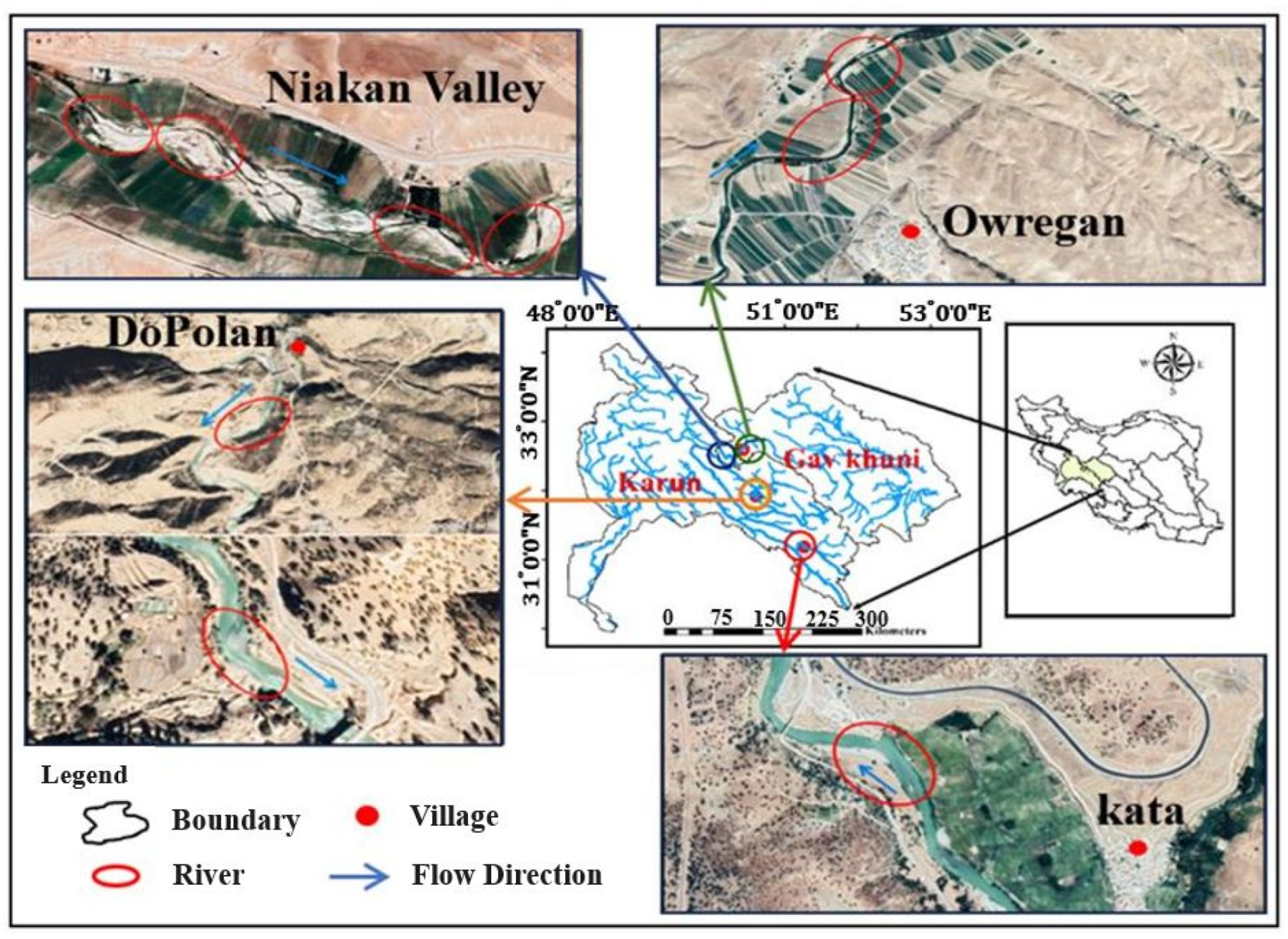
2.1. Field Measurements
2.2. Dimensional Analysis
2.3. Correlation Analysis between Variables
3. Results
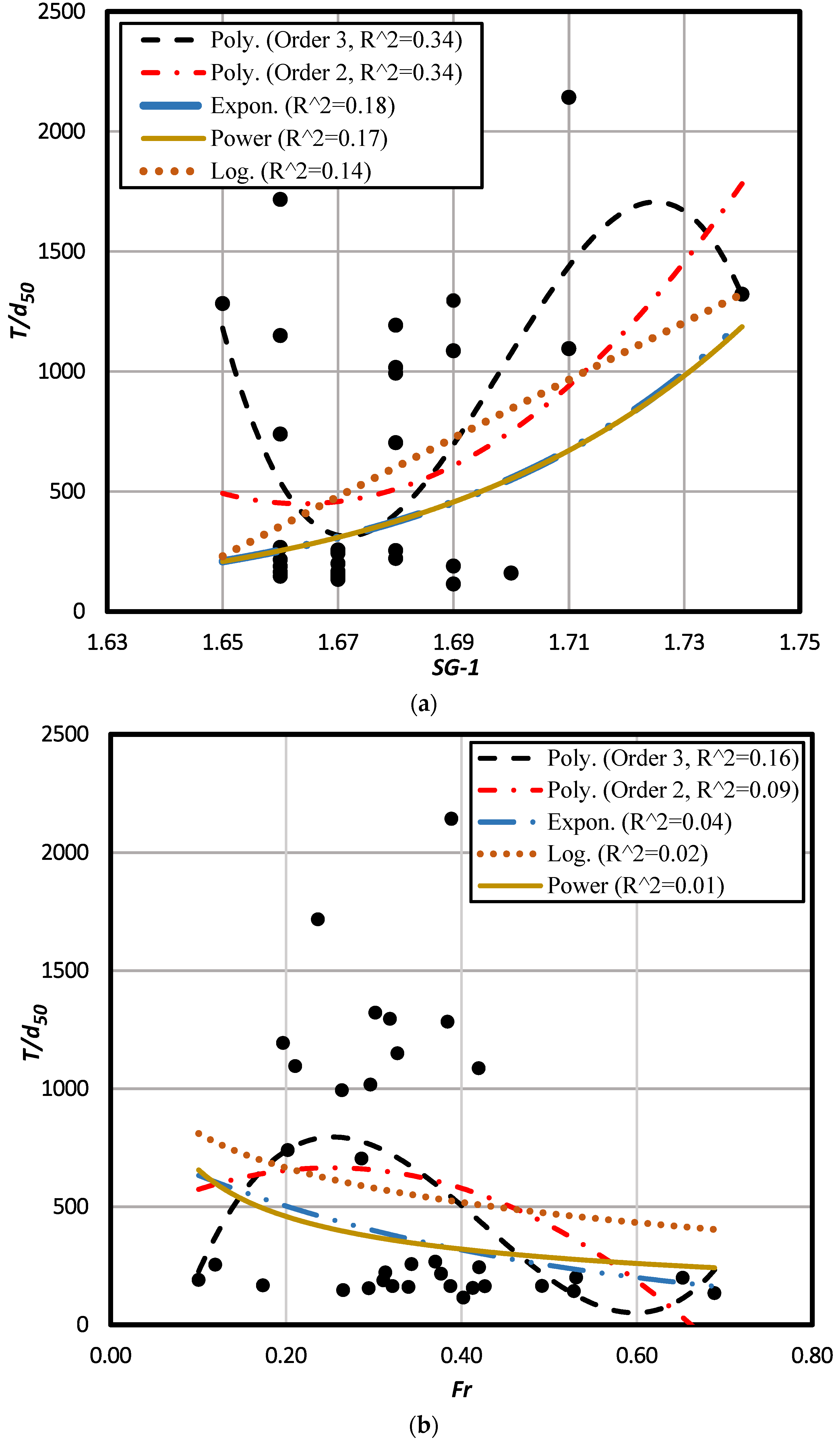
3.1. Power Regression Model
3.2. GAM Model
3.3. MARS Model
4. Discussion
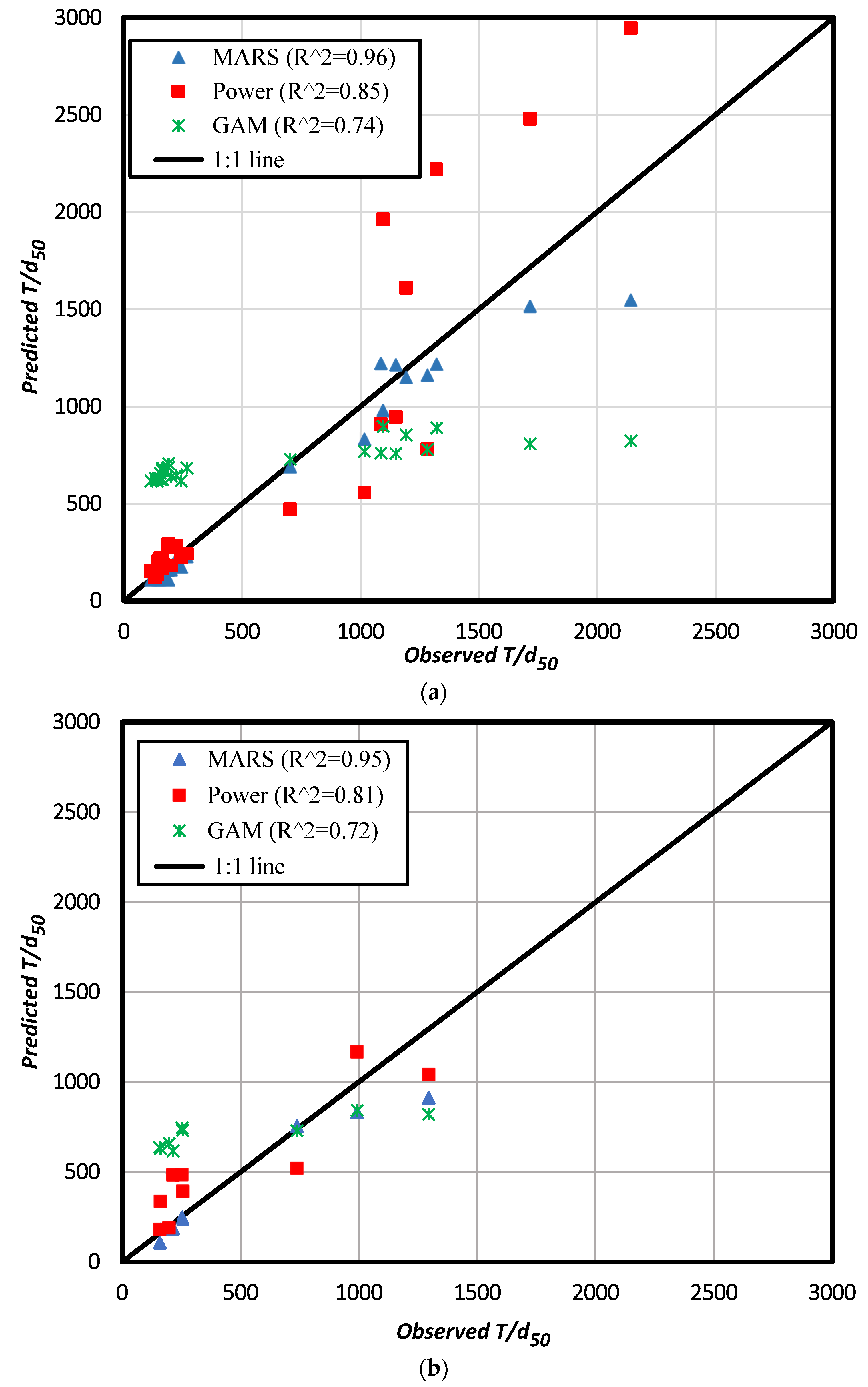
4.1. Comparison of the Models
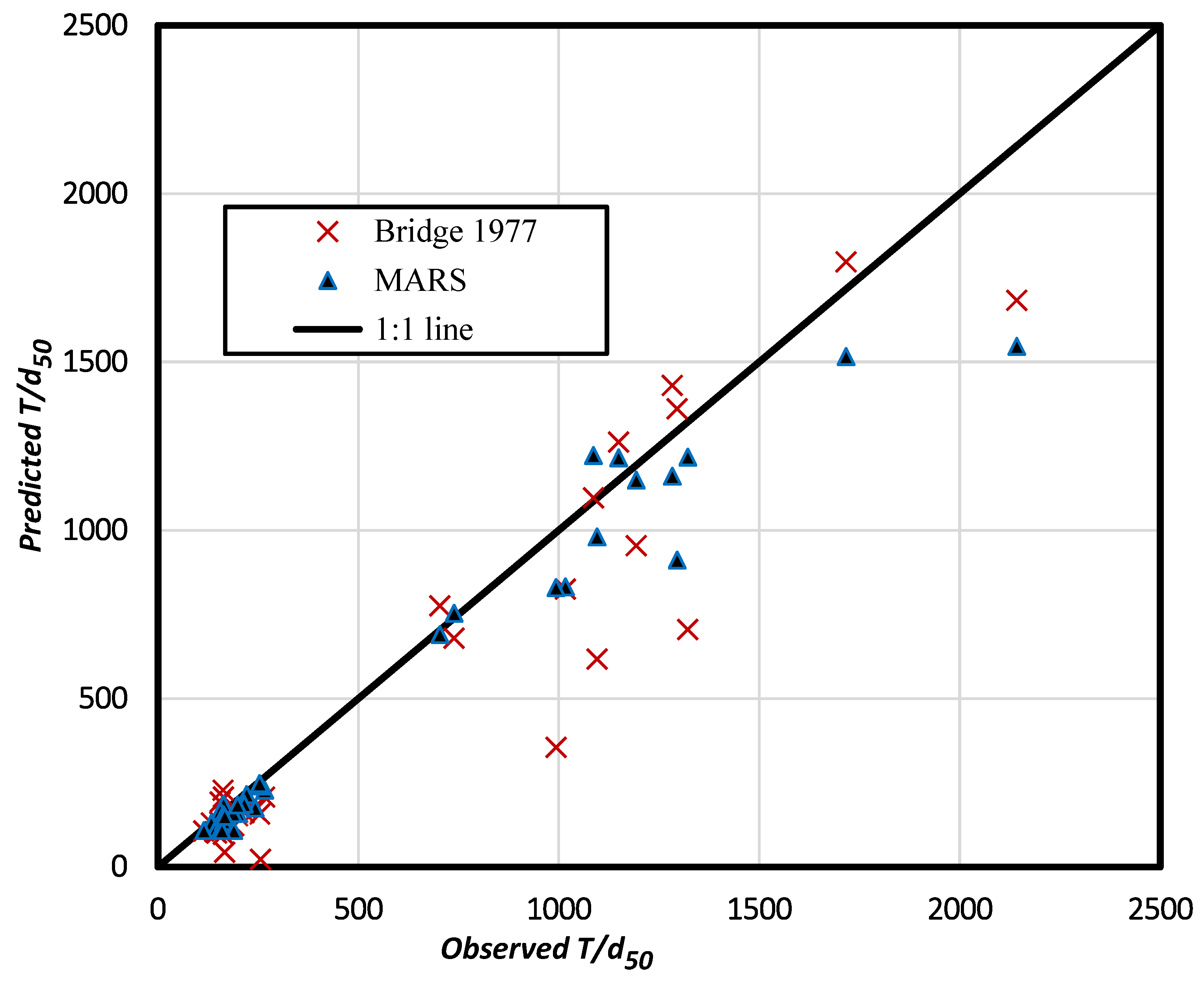
4.2. Comparison of MARS with Analytical Method
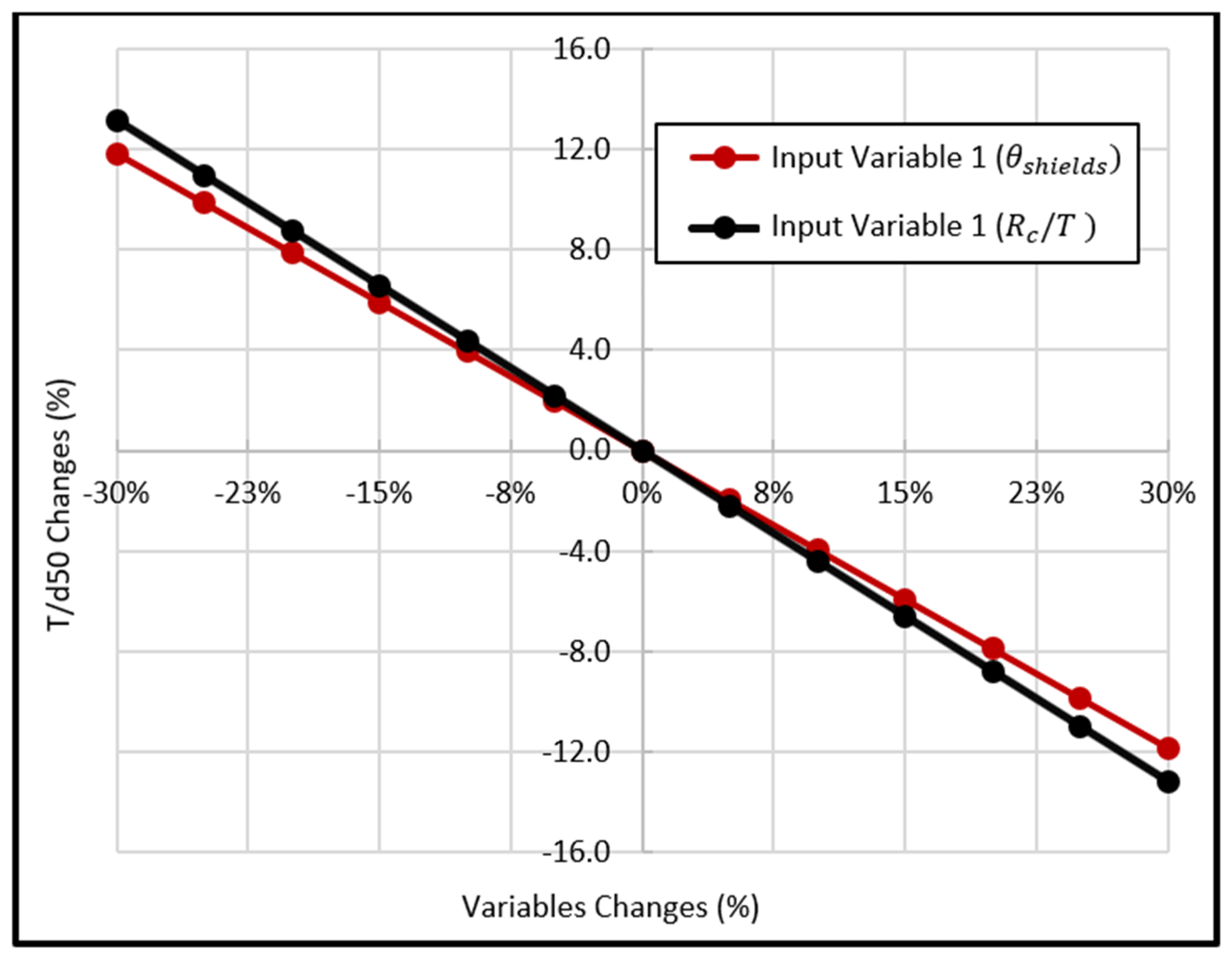
4.3. Sensitivity and Uncertainty Analysis for MARS Model
5. Conclusions
- It was found that two parameters, and , are the most important in affecting . This means that and from the flow hydraulic and channel geometry characteristics are the significant parameters to determine in meandering river bends.
- The MARS formula showed that it was a better match with the observed data than power and GAM and had less error compared with the analytical model of Bridge. Although this needs to be assessed in more rivers, it can be an appropriate relation to calculate in gravel channel bends in engineering applications within parameter ranges.
- There have been rare studies to determine the sediment particle sizes in river bends, and the existing relations, such as Bridge’s model, do not provide physical insight on how bend parameters affect sediment size. The proposed relation in this current article provides a reliable evaluation of sediment sizes based on bend characteristics.
- After MARS, the power model created better outputs. Even if this is a traditional approach, it presents a simpler relation with fairly good results for determining the size of sediment particles in bends.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rovira, A.; Núñez-González, F.; Ibañez, C. Dependence of Sediment Sorting on Bedload Transport Phase in a River Meander. Earth Surf. Process. Landf. 2018, 43, 2077–2088. [Google Scholar] [CrossRef]
- Cordier, F.; Tassi, P.; Claude, N.; Crosato, A.; Rodrigues, S.; Pham Van Bang, D. Bar Pattern and Sediment Sorting in a Channel Contraction/Expansion Area: Application to the Loire River at Bréhémont (France). Adv. Water Resour. 2020, 140, 103580. [Google Scholar] [CrossRef]
- Fernández, R.; Vitale, A.J.; Parker, G.; García, M.H. Hydraulic Resistance in Mixed Bedrock-Alluvial Meandering Channels. J. Hydraul. Res. 2021, 59, 298–313. [Google Scholar] [CrossRef]
- Li, J.; He, X.; Wei, J.; Bao, Y.; Tang, Q.; de Nambajimana, J.D.; Nsabimana, G.; Khurram, D. Multifractal Features of the Particle-Size Distribution of Suspended Sediment in the Three Gorges Reservoir, China. Int. J. Sediment Res. 2021, 36, 489–500. [Google Scholar] [CrossRef]
- Bridge, J.S. Flow, Bed Topography, Grain Size and Sedimentary Structure in Open Channel Bends: A Three-Dimensional Model. Earth Surf Process. 1977, 2, 401–416. [Google Scholar] [CrossRef]
- Odgaard, A.J. Grain Size Distribution of River Bed Armor Layers. J. Hydraul. Eng. 1984, 110, 1479–1484. [Google Scholar] [CrossRef]
- Milhous, R.T. Effect of Sediment Transport and Flow Regulation on the Ecology of Gravel-Bed Rivers; John Wiley & Sons: Chichester, UK, 1982; pp. 819–842. [Google Scholar]
- Julien, P.Y.; Anthony, D.J. Bed Load Motion and Grain Sorting in a Meandering Stream. J. Hydraul. Res. 2002, 40, 125–133. [Google Scholar] [CrossRef]
- Wright, S.; Parker, G. Modeling Downstream Fining in Sand-Bed Rivers. I: Formulation. J. Hydraul. Res. 2010, 43, 613–620. [Google Scholar] [CrossRef]
- Jang, J.-H.; Ho, H.; Yen, C. Effects of Lifting Force on Bed Topography and Bed-Surface Sediment Size in Channel Bend. J. Hydraul. Eng. 2011, 137, 911–920. [Google Scholar] [CrossRef]
- Kuhnle, R.A.; Wren, D.G.; Langendoen, E.J. Structural Changes of Mobile Gravel Bed Surface for Increasing Flow Intensity. J. Hydraul. Eng. 2019, 146, 04019065. [Google Scholar] [CrossRef]
- McKie, C.W.; Juez, C.; Plumb, B.D.; Annable, W.K.; Franca, M.J. How Large Immobile Sediments in Gravel Bed Rivers Impact Sediment Transport and Bed Morphology. J. Hydraul. Eng. 2021, 147, 04020096. [Google Scholar] [CrossRef]
- White, D.C.; Nelson, P.A. Flume Investigation Into Mechanisms Responsible for Particle Sorting in Gravel-Bed Meandering Channels. J. Geophys. Res. Earth Surf. 2023, 128, e2022JF006821. [Google Scholar] [CrossRef]
- Yen, C.; Lee, K.T. Bed Topography and Sediment Sorting in Channel Bend with Unsteady Flow. J. Hydraul. Eng. 1995, 121, 591–599. [Google Scholar] [CrossRef]
- Pitlick, J.; Mueller, E.R.; Segura, C.; Cress, R.; Torizzo, M. Relation between Flow, Surface-Layer Armoring and Sediment Transport in Gravel-Bed Rivers. Earth Surf. Process. Landf. 2008, 33, 1192–1209. [Google Scholar] [CrossRef]
- Naito, K.; Ma, H.; Nittrouer, J.A.; Zhang, Y.; Wu, B.; Wang, Y.; Fu, X.; Parker, G. Extended Engelund–Hansen Type Sediment Transport Relation for Mixtures Based on the Sand-Silt-Bed Lower Yellow River, China. J. Hydraul. Res. 2019, 57, 770–785. [Google Scholar] [CrossRef]
- Bateni, S.M.; Vosoughifar, H.R.; Truce, B.; Jeng, D.S. Estimation of Clear-Water Local Scour at Pile Groups Using Genetic Expression Programming and Multivariate Adaptive Regression Splines. J. Waterw. Port Coast. Ocean. Eng. 2019, 145, 04018029. [Google Scholar] [CrossRef]
- Bazrkar, M.H.; Chu, X. Development of Category-Based Scoring Support Vector Regression (CBS-SVR) for Drought Prediction. J. Hydroinform. 2022, 24, 202–222. [Google Scholar] [CrossRef]
- Rajesh, M.; Rehana, S. Prediction of River Water Temperature Using Machine Learning Algorithms: A Tropical River System of India. J. Hydroinform. 2021, 23, 605–626. [Google Scholar] [CrossRef]
- Abbasi, M.; Farokhnia, A.; Bahreinimotlagh, M.; Roozbahani, R. A Hybrid of Random Forest and Deep Auto-Encoder with Support Vector Regression Methods for Accuracy Improvement and Uncertainty Reduction of Long-Term Streamflow Prediction. J. Hydrol. 2021, 597, 125717. [Google Scholar] [CrossRef]
- Park, S.; Hamm, S.Y.; Jeon, H.T.; Kim, J. Evaluation of Logistic Regression and Multivariate Adaptive Regression Spline Models for Groundwater Potential Mapping Using R and GIS. Sustainability 2017, 9, 1157. [Google Scholar] [CrossRef]
- Asquith, W.H. Regression Models of Discharge and Mean Velocity Associated with Near-Median Streamflow Conditions in Texas: Utility of the U.S. Geological Survey Discharge Measurement Database. J. Hydrol. Eng. 2013, 19, 108–122. [Google Scholar] [CrossRef]
- Asquith, W.H.; Herrmann, G.R.; Cleveland, T.G. Generalized Additive Regression Models of Discharge and Mean Velocity Associated with Direct-Runoff Conditions in Texas: Utility of the U.S. Geological Survey Discharge Measurement Database. J. Hydrol. Eng. 2013, 18, 1331–1348. [Google Scholar] [CrossRef]
- Adnan, R.M.; Parmar, K.S.; Heddam, S.; Shahid, S.; Kisi, O. Suspended Sediment Modeling Using a Heuristic Regression Method Hybridized with Kmeans Clustering. Sustainability 2021, 13, 4648. [Google Scholar] [CrossRef]
- Faraway, J.J. Extending the Linear Model with R: Generalized Linear, Mixed Effects and Nonparametric Regression Models, 2nd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2016; pp. 1–395. [Google Scholar] [CrossRef]
- Hagemann, M.; Kim, D.; Park, M.H. Estimating Nutrient and Organic Carbon Loads to Water-Supply Reservoir Using Semiparametric Models. J. Environ. Eng. 2016, 142, 04016036. [Google Scholar] [CrossRef]
- Mehdizadeh, S.; Behmanesh, J.; Khalili, K. Using MARS, SVM, GEP and Empirical Equations for Estimation of Monthly Mean Reference Evapotranspiration. Comput. Electron. Agric. 2017, 139, 103–114. [Google Scholar] [CrossRef]
- Mohanta, A.; Patra, K.C. MARS for Prediction of Shear Force and Discharge in Two-Stage Meandering Channel. J. Irrig. Drain. Eng. 2019, 145, 04019016. [Google Scholar] [CrossRef]
- Ihaka, R.; Gentleman, R. R: A Language for Data Analysis and Graphics. J. Comput. Graph. Stat. 1996, 5, 299. [Google Scholar] [CrossRef]
- Germaine, J.T.; Germaine, A.V. Geotechnical Laboratory Measurements for Engineers; John Wiley & Sons: Hoboken, NJ, USA, 2009; pp. 1–351. [Google Scholar] [CrossRef]
- Buckingham, E. On Physically Similar Systems; Illustrations of the Use of Dimensional Equations. Phys. Rev. 1914, 4, 345. [Google Scholar] [CrossRef]
- Ferreira da Silva, A.M.; Ebrahimi, M. Meandering Morphodynamics: Insights from Laboratory and Numerical Experiments and Beyond. J. Hydraul. Eng. 2017, 143, 03117005. [Google Scholar] [CrossRef]
- Ferreira da Silva, A.M.; Ana, M. Fluvial Processes (IAHR Monograph), 2nd ed.; CRC Press: Leiden, The Netherlands, 2017; pp. 1–289. [Google Scholar] [CrossRef]
- Bartlett, M.S. Properties of Sufficiency and Statistical Tests. Proc. R. Soc. London. Ser. A Math. Phys. Sci. 1937, 160, 268–282. [Google Scholar] [CrossRef]
- Froehlich, D.C. Neural Network Prediction of Maximum Scour in Bends of Sand-Bed Rivers. J. Hydraul. Eng. 2020, 146, 04020065. [Google Scholar] [CrossRef]
- McCuen, R.H.; Leahy, R.B.; Johnson, P.A. Problems with Logarithmic Transformations in Regression. J. Hydraul. Eng. 1990, 116, 414–428. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Oliveto, G. Riprap Incipient Motion for Overtopping Flows with Machine Learning Models. J. Hydroinform. 2020, 22, 749–767. [Google Scholar] [CrossRef]
- Finch, W.H. Multivariate Analysis of Variance for Multilevel Data: A Simulation Study Comparing Methods. J. Exp. Educ. 2022, 90, 173–190. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R. Generalized Additive Models, 1st ed.; ChapMan & Hall: Boca Raton, FL, USA, 1990; pp. 1–335. [Google Scholar]
- Nejat Dehkordi, A.; Sharafati, A.; Mehraein, M.; Hoseini, S.A. Modelling of Sediment Grains Size Distribution in River Bend Using Generalized Additive Model. Water Irrig. Manag. 2022, 11, 713–724. [Google Scholar] [CrossRef]
- Leathwick, J.R.; Elith, J.; Hastie, T. Comparative Performance of Generalized Additive Models and Multivariate Adaptive Regression Splines for Statistical Modelling of Species Distributions. Ecol. Modell. 2006, 199, 188–196. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Transformations. In Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2011; pp. 305–349. [Google Scholar] [CrossRef]
- Moisen, G.G.; Frescino, T.S. Comparing Five Modelling Techniques for Predicting Forest Characteristics. Ecol. Model. 2002, 157, 209–225. [Google Scholar] [CrossRef]
- Catalano, G.A.; D’Urso, P.R.; Maci, F.; Arcidiacono, C. Influence of Parameters in SDM Application on Citrus Presence in Mediterranean Area. Sustainability 2023, 15, 7656. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling, 1st ed.; Springer Science & Business Media: New York, NY, USA, 2013; pp. 1–595. [Google Scholar] [CrossRef]
- Amininia, K.; Saghebian, S.M. Uncertainty Analysis of Monthly River Flow Modeling in Consecutive Hydrometric Stations Using Integrated Data-Driven Models. J. Hydroinform. 2021, 23, 897–913. [Google Scholar] [CrossRef]
- Sattar, A.M.A. Gene Expression Models for the Prediction of Longitudinal Dispersion Coefficients in Transitional and Turbulent Pipe Flow. J. Pipeline Syst. Eng. Pract. 2013, 5, 04013011. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Units | Minimum | Maximum |
|---|---|---|---|
| Flow depth, | m | 0.15 | 1.97 |
| Channel top width, | m | 3.60 | 58.5 |
| Flow velocity, u | m/s | 0.10 | 1.44 |
| Mean sediment size, | mm | 15 | 53 |
| Specific Gravity, | - | 2.66 | 2.74 |
| Angle of integral friction, 𝜑 | ° | 24 | 32 |
| Curvature radius, | m | 50 | 287 |
| Longitudinal slope, γ | - | 0.005 | 0.01 |
| Transverse slope, α | - | 0.0015 | 0.0075 |
| Variables | ||||
|---|---|---|---|---|
| 100 | 26 | −30 | −18 | |
| 26 | 100 | −23 | −22 | |
| −30 | −23 | 100 | 29 | |
| −18 | −22 | 29 | 100 |
| Combination of Independent Variables | RMSE | MAE | ||
|---|---|---|---|---|
| Training | Testing | Training | Testing | |
| 525.97 | 608.34 | 419.99 | 379.70 | |
| 416.95 | 632.43 | 270.43 | 473.38 | |
| 551.72 | 689.03 | 389.27 | 523.99 | |
| 462.39 | 512.70 | 300.02 | 315.26 | |
| , | 582.82 | 407.16 | 252.70 | 441.27 |
| , | 600.90 | 529.84 | 379.52 | 416.06 |
| , | 436.20 | 556.10 | 284.49 | 364.76 |
| , | 409.28 | 580.50 | 262.30 | 398.90 |
| , | 325.61 | 440.31 | 224.85 | 329.45 |
| , | 456.88 | 515.11 | 291.77 | 310.20 |
| , , | 369.94 | 541.79 | 254.82 | 392.73 |
| , , | 311.40 | 365.47 | 214.74 | 281.36 |
| , | 301.26 | 386.83 | 200.28 | 271.23 |
| , | 437.61 | 549.43 | 282.11 | 367.02 |
| , ,, | 287.65 | 320.99 | 197.53 | 247.61 |
| Variables | p-value | Result |
|---|---|---|
| 0.31230 > 0.05 | No significant level | |
| 0.05 < 0.05448 < 0.1 | Medium significant level | |
| 0.00021 < 0.001 | High significant level | |
| 0.00002 ≪ 0.001 | High significant level |
| Variables | ||||
|---|---|---|---|---|
| Best form | Polynomial | Polynomial | Polynomial | Logarithmic |
| Order | 2 | 3 | 3 | - |
| R2 | 0.34 | 0.16 | 0.87 | 0.77 |
| Training | Testing | |||||
|---|---|---|---|---|---|---|
| Index | MARS | Power | GAM | MARS | Power | GAM |
| R2 | 0.96 | 0.85 | 0.74 | 0.95 | 0.81 | 0.72 |
| RMSE | 140.64 | 287.65 | 523.06 | 140.47 | 320.99 | 382.49 |
| MAE | 79.12 | 197.53 | 472.59 | 84.80 | 247.61 | 367.57 |
| MAPE (%) | 14.39 | 31.13 | 188.93 | 13.75 | 44.10 | 143.79 |
| Index | MARS | Analytical Model |
|---|---|---|
| R2 | 0.96 | 0.89 |
| RMSE | 140.64 | 200.21 |
| MAE | 78.78 | 116.44 |
| MAPE (%) | 14.22 | 23.46 |
| Model | Mean Prediction Error | Width of Confidence Band | 95% Confidence Interval of Mean Prediction Error |
|---|---|---|---|
| MARS | −63.27 | 42.22 | −105.49–21.05 |
| Analytical model | −90.09 | 62.43 | −152.52–27.66 |
| Power | 91.71 | 108.00 | −16.29–199.71 |
| GAM | 145.76 | 159.75 | −13.99–305.51 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dehkordi, A.N.; Sharafati, A.; Mehraein, M.; Hosseini, S.A. An Empirical Relation for Estimating Sediment Particle Size in Meandering Gravel-Bed Rivers. Water 2024, 16, 444. https://doi.org/10.3390/w16030444
Dehkordi AN, Sharafati A, Mehraein M, Hosseini SA. An Empirical Relation for Estimating Sediment Particle Size in Meandering Gravel-Bed Rivers. Water. 2024; 16(3):444. https://doi.org/10.3390/w16030444
Chicago/Turabian StyleDehkordi, Arman Nejat, Ahmad Sharafati, Mojtaba Mehraein, and Seyed Abbas Hosseini. 2024. "An Empirical Relation for Estimating Sediment Particle Size in Meandering Gravel-Bed Rivers" Water 16, no. 3: 444. https://doi.org/10.3390/w16030444
APA StyleDehkordi, A. N., Sharafati, A., Mehraein, M., & Hosseini, S. A. (2024). An Empirical Relation for Estimating Sediment Particle Size in Meandering Gravel-Bed Rivers. Water, 16(3), 444. https://doi.org/10.3390/w16030444