
Estimation of Hydraulic and Water Quality Parameters Using Long Short-Term Memory in Water Distribution Systems



Abstract
1. Introduction
2. Materials and Methods
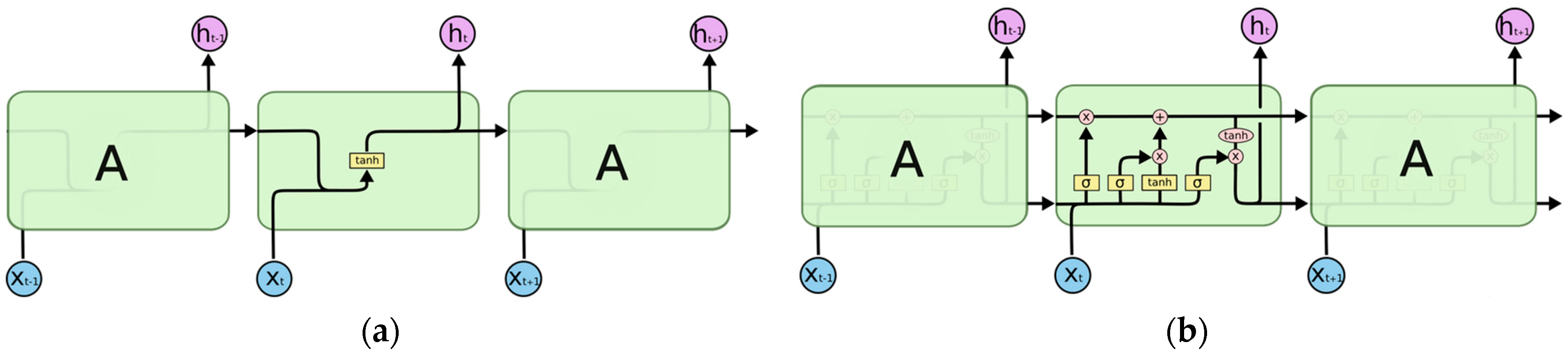
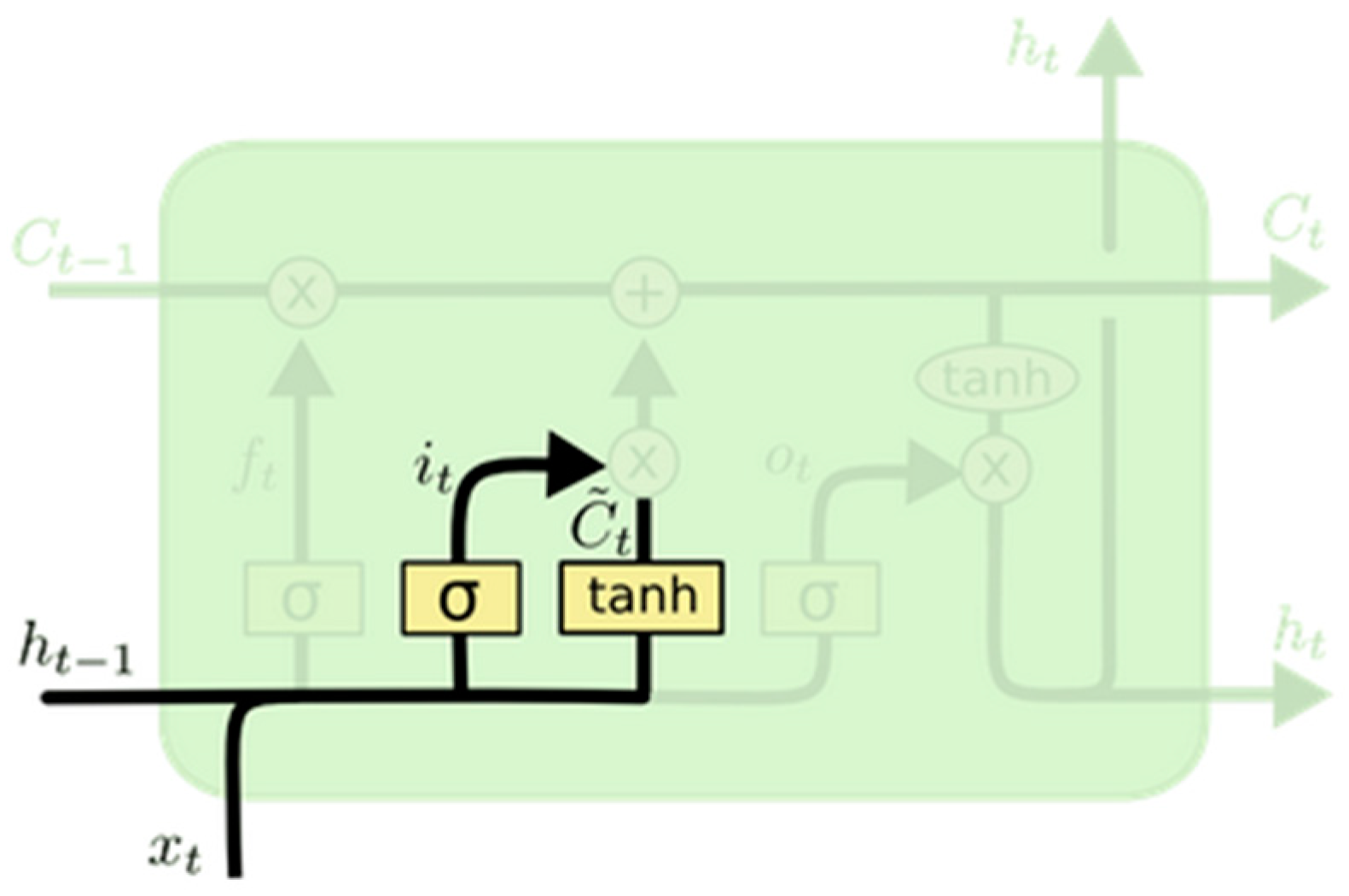
2.1. Long Short-Term Memory Principle
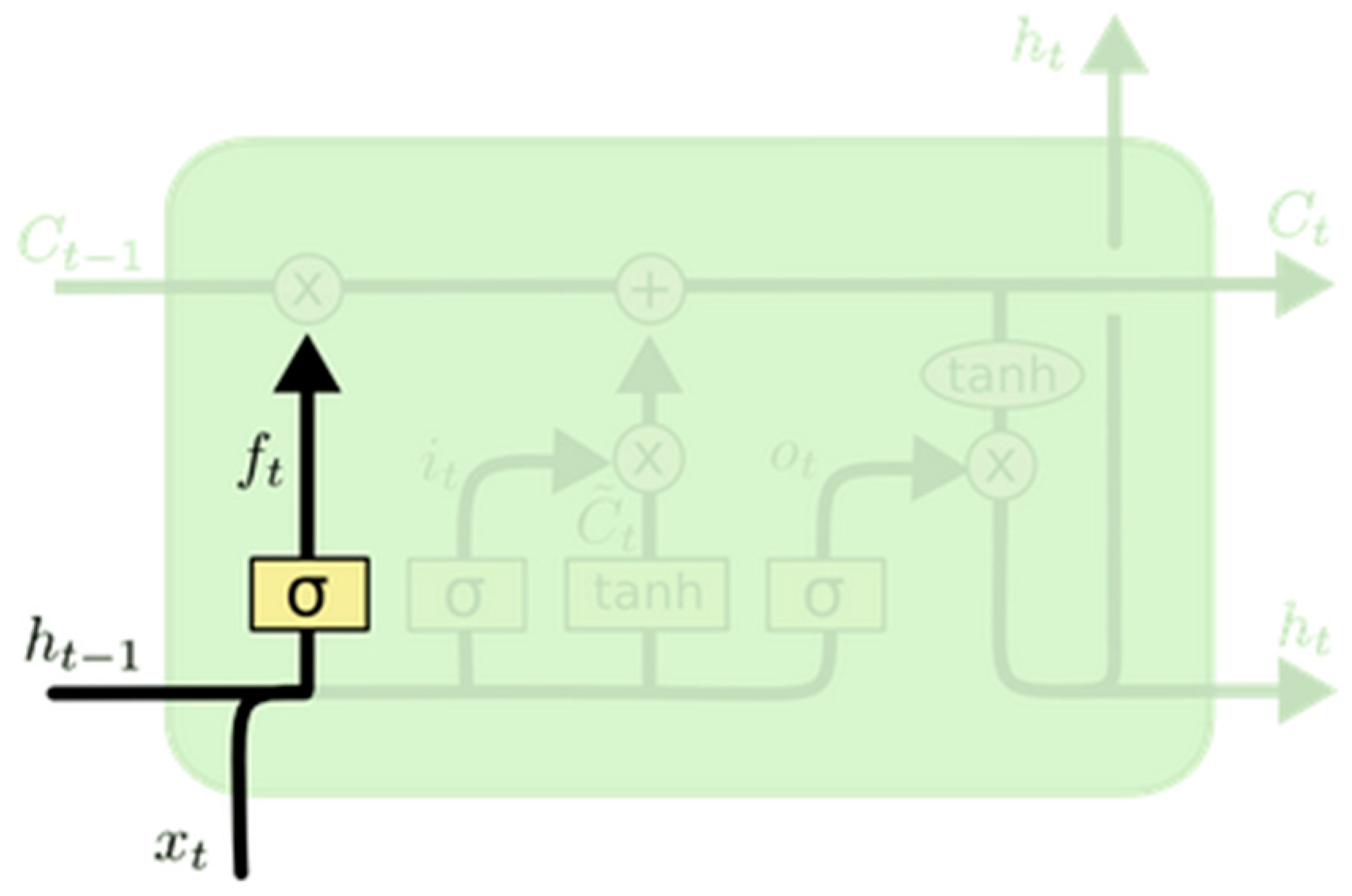
- Forget gate layer is a sigmoid layer that examines the input, , and the previous hidden state. It generates a value between 0 and 1 to determine whether to retain or discard the information as illustrated by Equation (1) and Figure 2.
- The output gate layer is a sigmoid layer deciding which part of the cell state will be generated as output according to Equations (5) and (6) and as depicted in Figure 4.
- : the current time cycle input.
- : the previous time cycle hidden state.
- W: the hidden state weight matrix.
- b: the input weight matrix.
- : the cell input activation vector.
- : the cell state vector.
- : the logistic sigmoid function expressed as in Equation (7) [22]:
2.2. Long Short-Term Memory Network
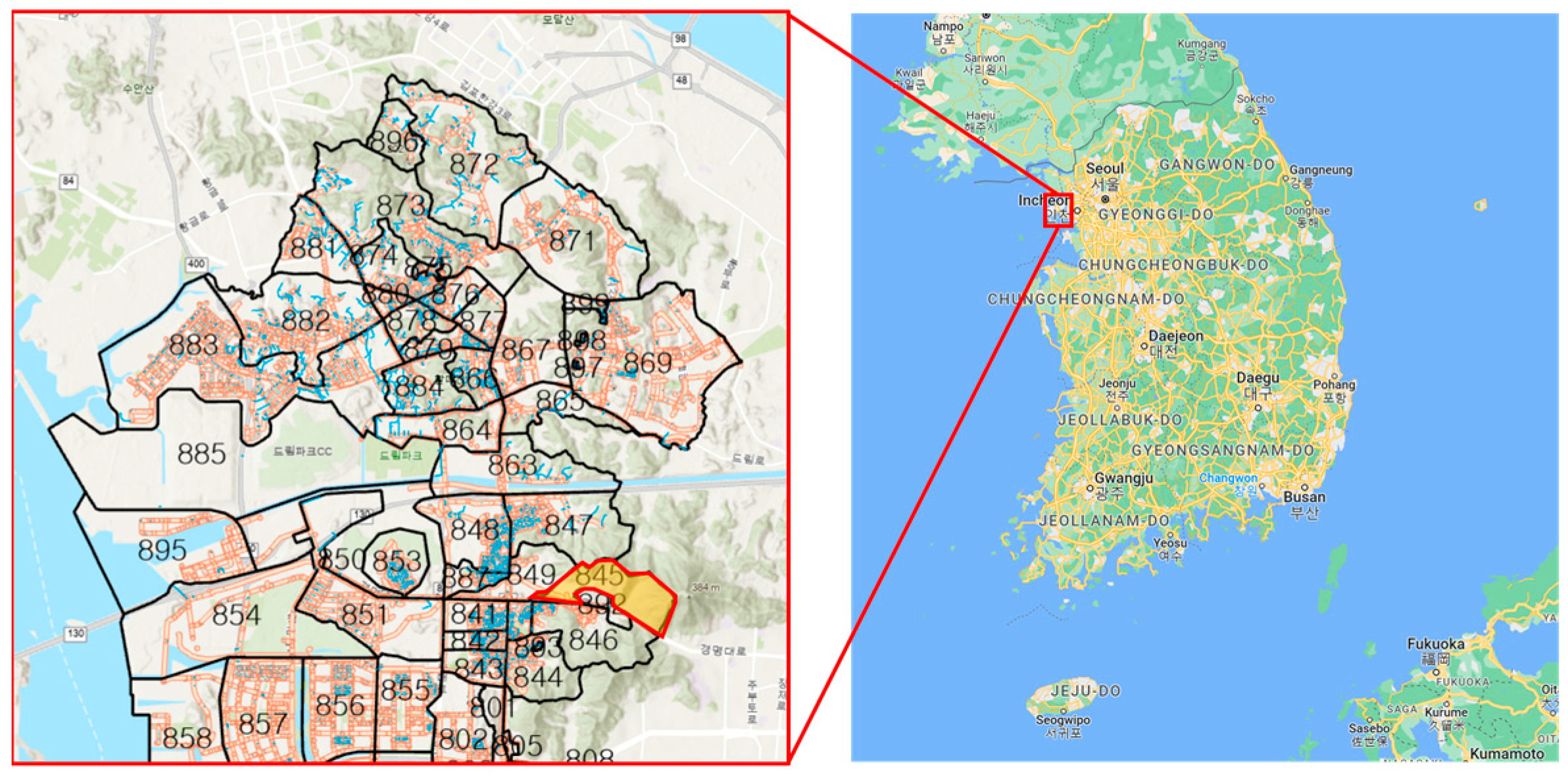
2.2.1. Study Area
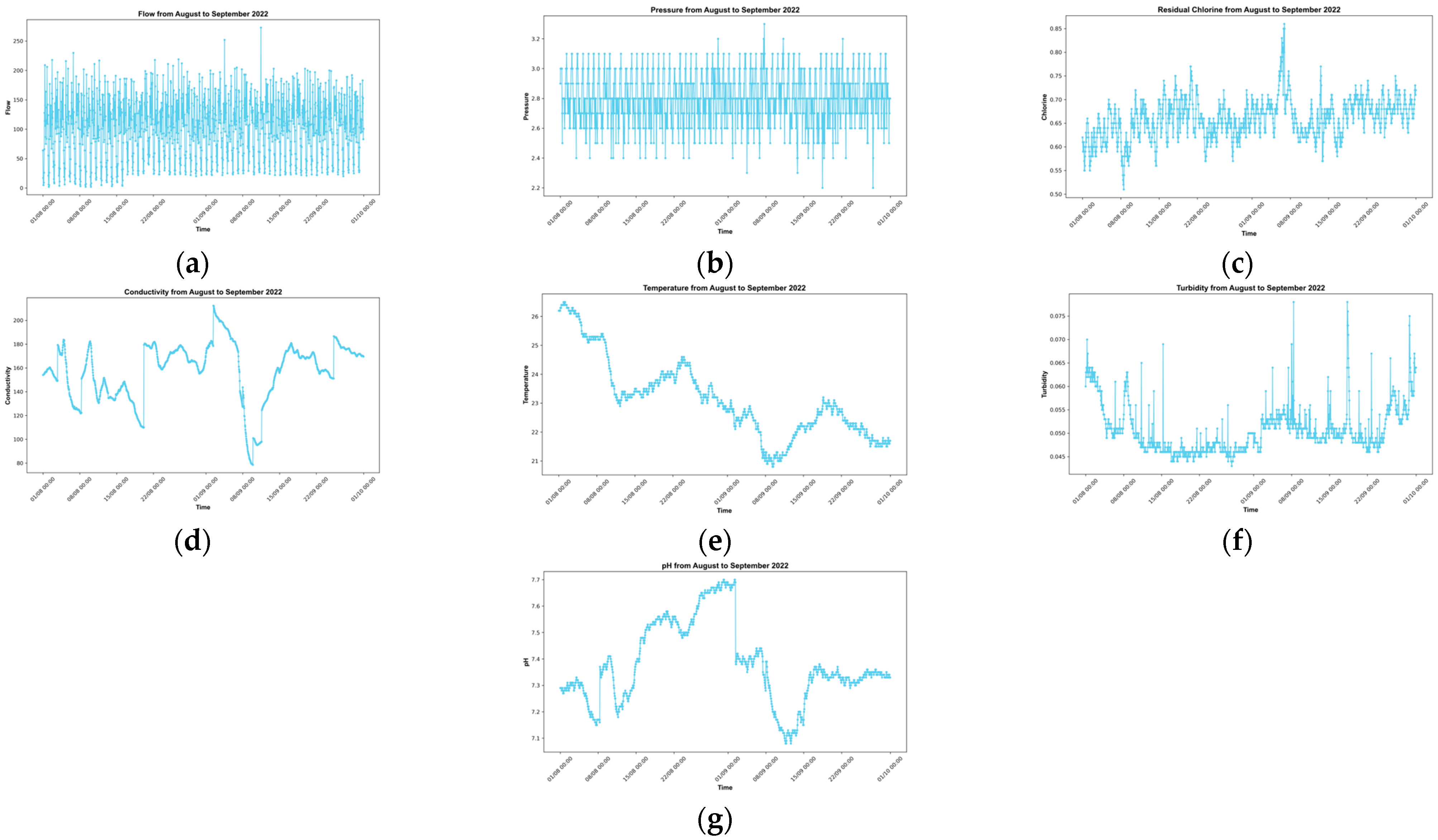
2.2.2. Input Data
2.2.3. The Algorithm’s Parameters
- n: number of data points
- : observed value of data point
- : predicted value of data point
- : mean of observed values
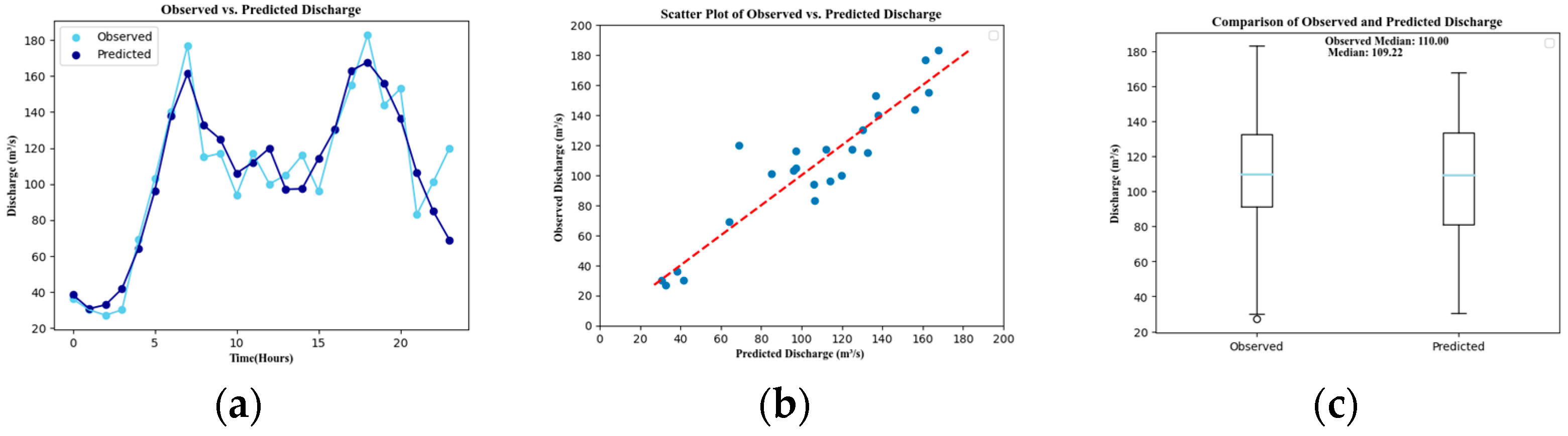
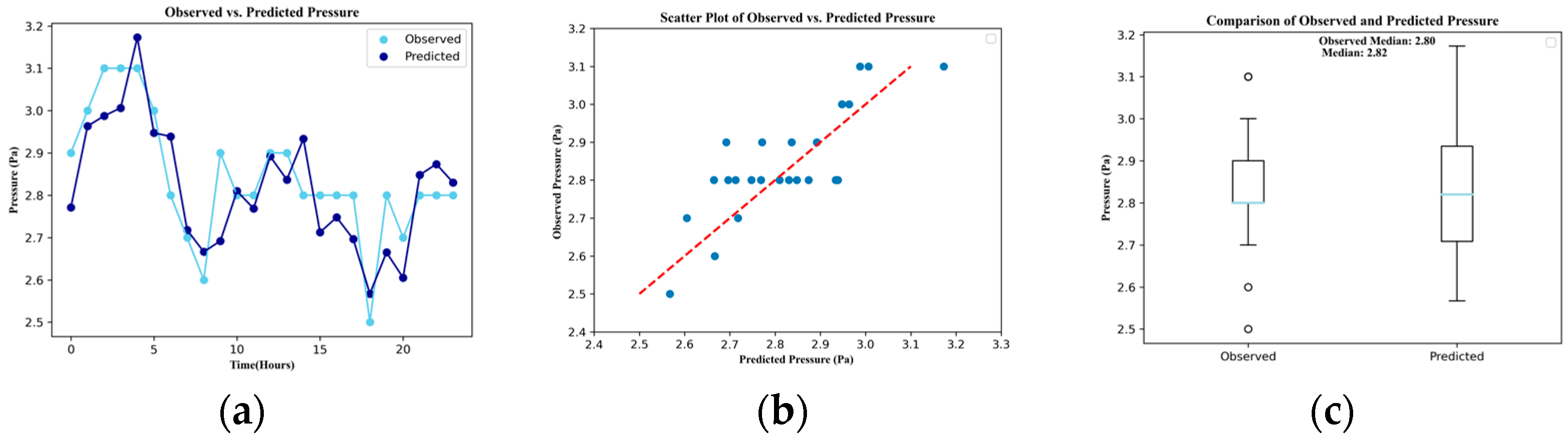
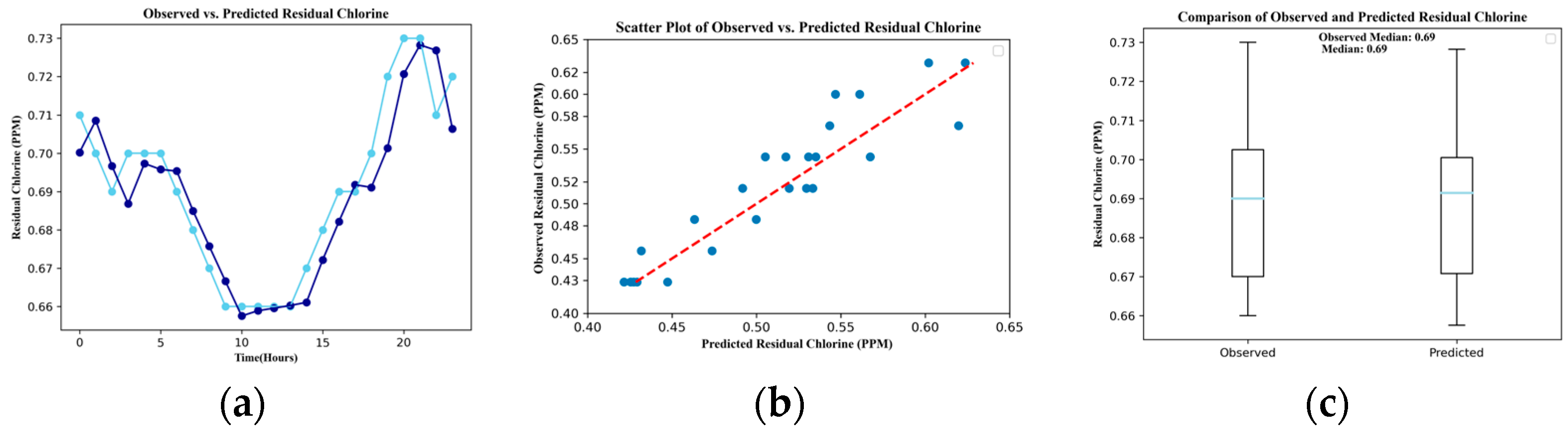
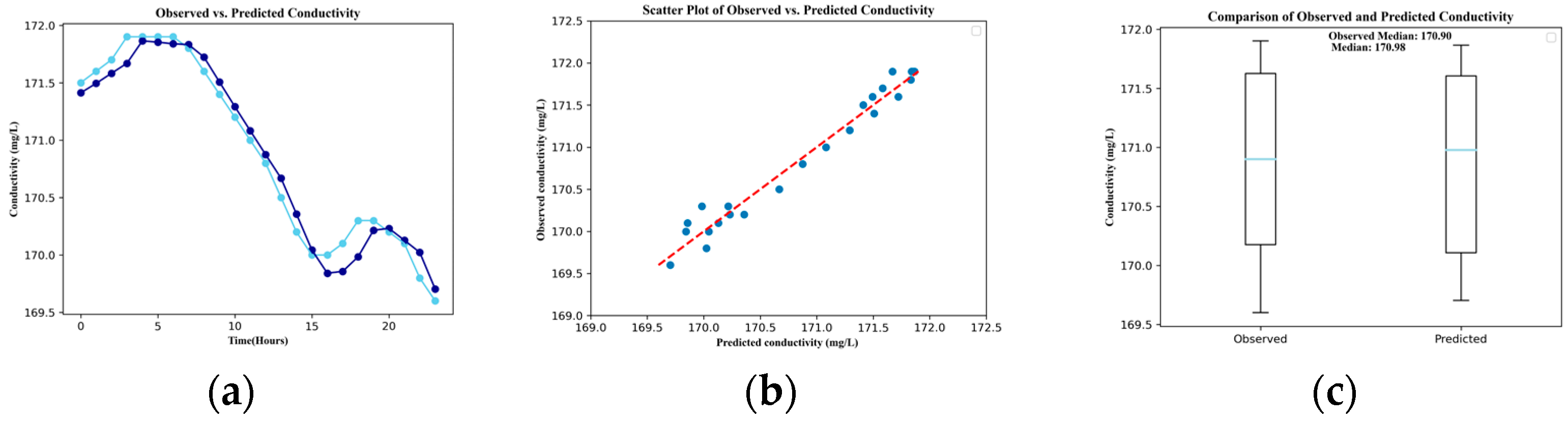
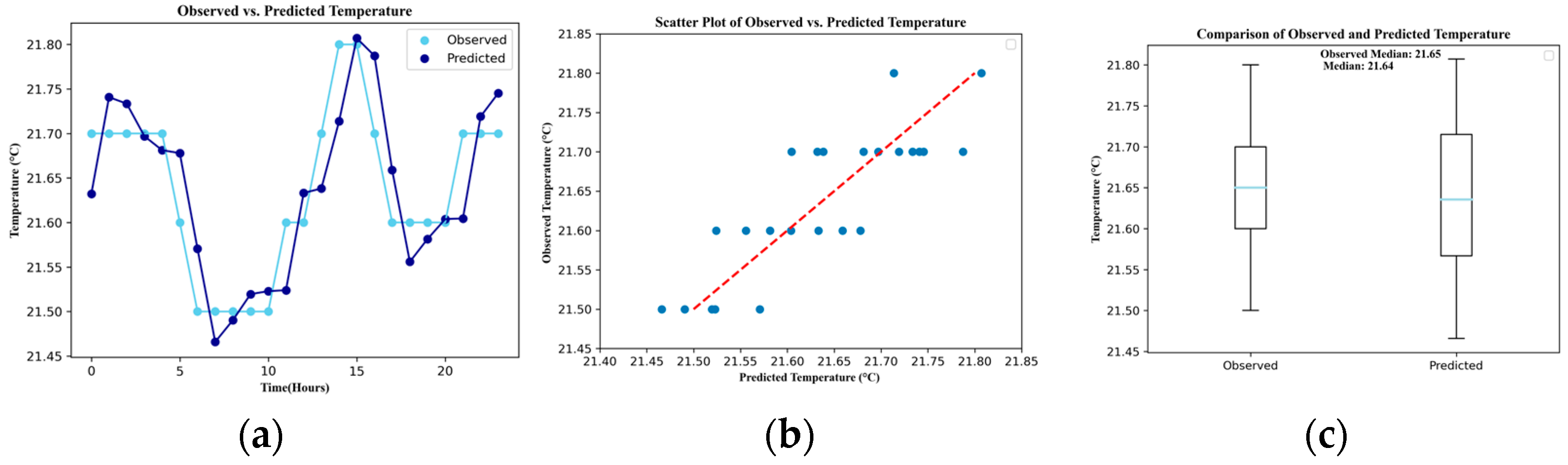
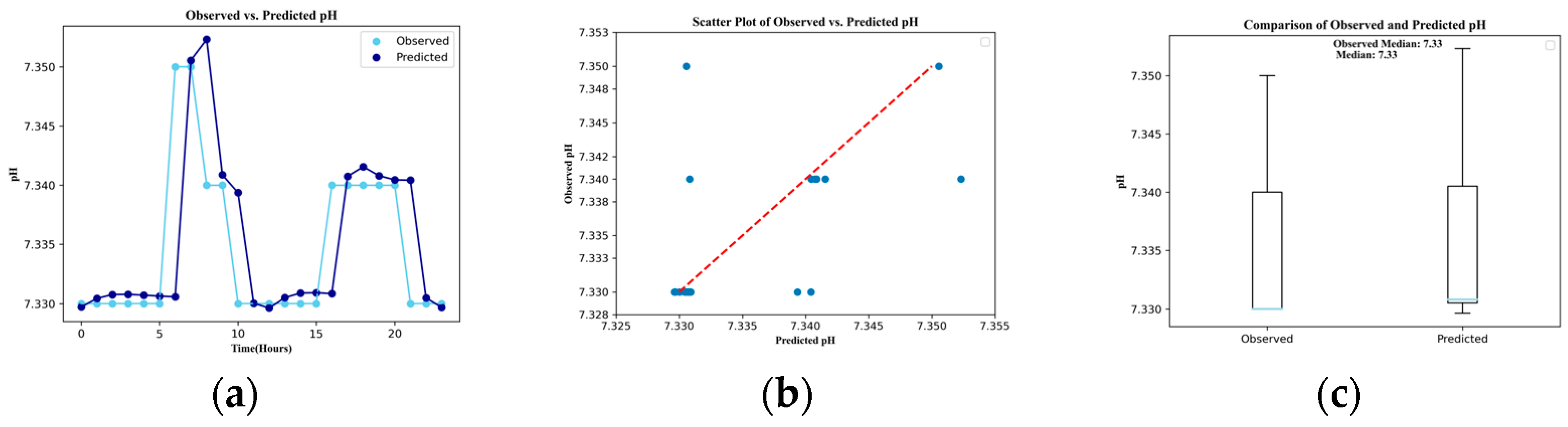
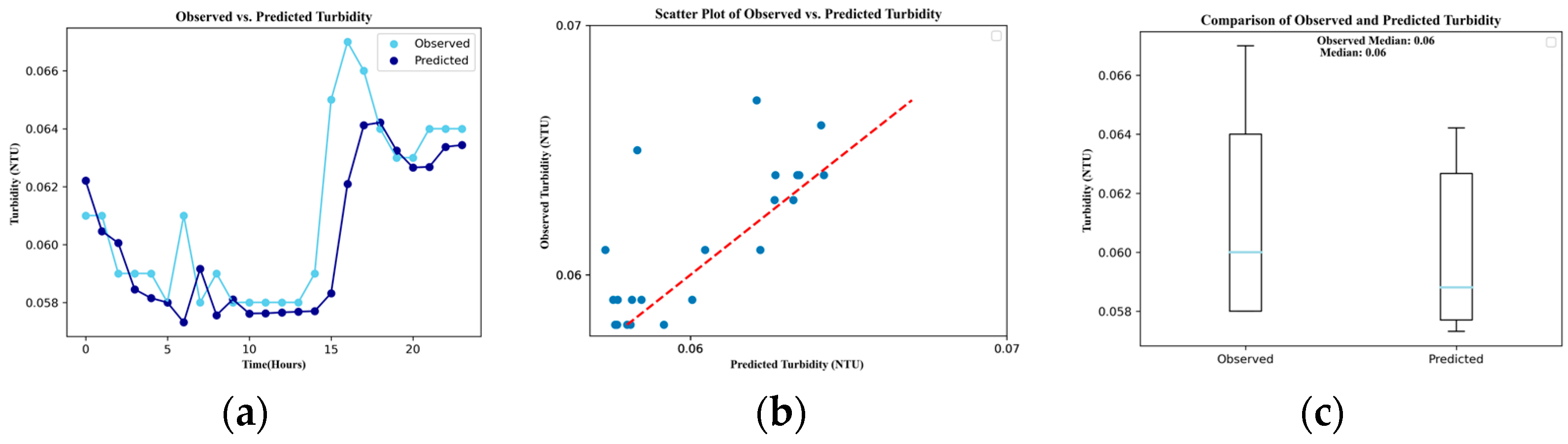
3. Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kavya, M.; Mathew, A.; Shekar, P.R.; Sarwesh, P. Short Term Water Demand Forecast Modelling Using Artificial Intelligence for Smart Water Management. Sustain. Cities Soc. 2023, 95, 104610. [Google Scholar] [CrossRef]
- Haghiabi, A.H.; Nasrolahi, A.H.; Parsaie, A. Water Quality Prediction Using Machine Learning Methods. Water Qual. Res. J. 2018, 53, 3–13. [Google Scholar] [CrossRef]
- Barzegar, R.; Asghari Moghaddam, A.; Adamowski, J.; Fijani, E. Comparison of Machine Learning Models for Predicting Fluoride Contamination in Groundwater. Stoch. Environ. Res. Risk Assess 2017, 31, 2705–2718. [Google Scholar] [CrossRef]
- Guo, G.; Liu, S.; Wu, Y.; Li, J.; Zhou, R.; Zhu, X. Short-Term Water Demand Forecast Based on Deep Learning Method. J. Water Resour. Plan. Manag. 2018, 144, 04018076. [Google Scholar] [CrossRef]
- Antunes, A.; Andrade-Campos, A.; Sardinha-Lourenço, A.; Oliveira, M.S. Short-Term Water Demand Forecasting Using Machine Learning Techniques. J. Hydroinform. 2018, 20, 1343–1366. [Google Scholar] [CrossRef]
- Bougadis, J.; Adamowski, K.; Diduch, R. Short-Term Municipal Water Demand Forecasting. Hydrol. Process. 2005, 19, 137–148. [Google Scholar] [CrossRef]
- Zhou, S.L.; McMahon, T.A.; Walton, A.; Lewis, J. Forecasting Daily Urban Water Demand: A Case Study of Melbourne. J. Hydrol. 2000, 236, 153–164. [Google Scholar] [CrossRef]
- Braun, M.; Bernard, T.; Piller, O.; Sedehizade, F. 24-Hours Demand Forecasting Based on SARIMA and Support Vector Machines. Procedia Eng. 2014, 89, 926–933. [Google Scholar] [CrossRef]
- Aissaoui, O.E.; El madani, Y.E.A.; Oughdir, L.; Allioui, Y.E. Combining Supervised and Unsupervised Machine Learning Algorithms to Predict the Learners’ Learning Styles. Procedia Comput. Sci. 2019, 148, 87–96. [Google Scholar] [CrossRef]
- Botvinick, M.; Ritter, S.; Wang, J.X.; Kurth-Nelson, Z.; Blundell, C.; Hassabis, D. Reinforcement Learning, Fast and Slow. Trends Cogn. Sci. 2019, 23, 408–422. [Google Scholar] [CrossRef]
- Taye, M.M. Understanding of Machine Learning with Deep Learning: Architectures, Workflow, Applications and Future Directions. Computers 2023, 12, 91. [Google Scholar] [CrossRef]
- Ahmed, S.F.; Alam, S.B.; Hassan, M.; Rozbu, M.R.; Ishtiak, T.; Rafa, N.; Mofijur, M.; Shawkat Ali, A.B.M.; Gandomi, A.H. Deep Learning Modelling Techniques: Current Progress, Applications, Advantages, and Challenges. Artif. Intell. Rev. 2023, 56, 13521–13617. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep Learning Applications and Challenges in Big Data Analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Mandic, D.; Chambers, J. Recurrent Neural Networks for Prediction: Learning Algorithms, Architectures and Stability; Wiley: Chichester, UK, 2001; ISBN 978-0-471-49517-8. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Kuhnert, C.; Gonuguntla, N.; Krieg, H.; Nowak, D.; Thomas, J. Application of LSTM Networks for Water Demand Prediction in Optimal Pump Control. Water 2021, 13, 644. [Google Scholar] [CrossRef]
- Liu, P.; Wang, J.; Sangaiah, A.K.; Xie, Y.; Yin, X. Analysis and Prediction of Water Quality Using LSTM Deep Neural Networks in IoT Environment. Sustainability 2019, 11, 2058. [Google Scholar] [CrossRef]
- Nasser, A.; Rashad, M.; Hussein, S. A Two-Layer Water Demand Prediction System in Urban Areas Based on Micro-Services and LSTM Neural Networks. IEEE Access 2020, 8, 147647–147661. [Google Scholar] [CrossRef]
- Xu, Z.; Ying, Z.; Li, Y.; He, B.; Chen, Y. Pressure Prediction and Abnormal Working Conditions Detection of Water Supply Network Based on LSTM. Water Supply 2020, 20, 963–974. [Google Scholar] [CrossRef]
- Zanfei, A.; Brentan, B.; Menapace, A.; Righetti, M. A Short-Term Water Demand Forecasting Model Using Multivariate Long Short-Term Memory with Meteorological Data. J. Hydroinform. 2022, 24, 1053–1065. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Purba, M.R.; Akter, M.; Ferdows, R.; Ahmed, F. A Hybrid Convolutional Long Short-Term Memory (CNN-LSTM) Based Natural Language Processing (NLP) Model for Sentiment Analysis of Customer Product Reviews in Bangla. J. Discret. Math. Sci. Cryptogr. 2022, 25, 2111–2120. [Google Scholar] [CrossRef]
- Lin, Y.; Lin, Z.; Liao, Y.; Li, Y.; Xu, J.; Yan, Y. Forecasting the Realized Volatility of Stock Price Index: A Hybrid Model Integrating CEEMDAN and LSTM. Expert Syst. Appl. 2022, 206, 117736. [Google Scholar] [CrossRef]
- Ghadekar, P.; Bongulwar, A.; Jadhav, A.; Ahire, R.; Dumbre, A.; Ali, S. Bi-LSTM Based Interdependent Prediction of Physiological Signals. In Proceedings of the 2023 International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 1–3 March 2023; pp. 1–6. [Google Scholar]
- Munagala, N.V.L.M.K.; Langoju, L.R.R.; Rani, A.D.; Reddy, D.V.R.K. A Smart IoT-Enabled Heart Disease Monitoring System Using Meta-Heuristic-Based Fuzzy-LSTM Model. Biocybern. Biomed. Eng. 2022, 42, 1183–1204. [Google Scholar] [CrossRef]
- Neog, H.; Dutta, P.E.; Medhi, N. Health Condition Prediction and Covid Risk Detection Using Healthcare 4.0 Techniques. Smart Health 2022, 26, 100322. [Google Scholar] [CrossRef]
- Oruh, J.; Viriri, S.; Adegun, A. Long Short-Term Memory Recurrent Neural Network for Automatic Speech Recognition. IEEE Access 2022, 10, 30069–30079. [Google Scholar] [CrossRef]
- Zhang, X.; Shi, J.; Yang, M.; Huang, X.; Usmani, A.S.; Chen, G.; Fu, J.; Huang, J.; Li, J. Real-Time Pipeline Leak Detection and Localization Using an Attention-Based LSTM Approach. Process Saf. Environ. Prot. 2023, 174, 460–472. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall–Runoff Modelling Using Long Short-Term Memory (LSTM) Networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, Y.; Zhang, X.; Ye, M.; Yang, J. Developing a Long Short-Term Memory (LSTM) Based Model for Predicting Water Table Depth in Agricultural Areas. J. Hydrol. 2018, 561, 918–929. [Google Scholar] [CrossRef]
- Kammoun, M.; Kammoun, A.; Abid, M. LSTM-AE-WLDL: Unsupervised LSTM Auto-Encoders for Leak Detection and Location in Water Distribution Networks. Water Resour Manag. 2023, 37, 731–746. [Google Scholar] [CrossRef]
- Mu, L.; Zheng, F.; Tao, R.; Zhang, Q.; Kapelan, Z. Hourly and Daily Urban Water Demand Predictions Using a Long Short-Term Memory Based Model. J. Water Resour. Plan. Manag. 2020, 146, 05020017. [Google Scholar] [CrossRef]
- Olah, C. Understanding LSTM Networks. Available online: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 26 September 2024).
- Patro, S.G.K.; Sahu, K.K. Normalization: A Preprocessing Stage. arXiv 2015, arXiv:1503.06462. [Google Scholar] [CrossRef]
- Team, K. Keras Documentation: LSTM Layer. Available online: https://keras.io/api/layers/recurrent_layers/lstm/#lstm-layer (accessed on 9 September 2023).
- Tf.Keras.Layers.LSTM|TensorFlow v2.13.0. Available online: https://www.tensorflow.org/api_docs/python/tf/keras/layers/LSTM (accessed on 9 September 2023).
- Chen, Z.C.; Zhang, Y.; Chen, W. Effective Adam-Optimized LSTM Neural Network for Electricity Price Forecasting | EndNote Click. Available online: https://click.endnote.com/viewer?doi=10.1109%2Ficsess.2018.8663710&token=WzM5OTg5MDksIjEwLjExMDkvaWNzZXNzLjIwMTguODY2MzcxMCJd.Gi79-GZTnwTfEjmlGD7s1Mah4nI (accessed on 23 October 2023).
- Chai, T.; Draxler, R. Root Mean Square Error (RMSE) or Mean Absolute Error (MAE)? Geosci. Model Dev. 2014, 7, 1525–1534. [Google Scholar] [CrossRef]
- Gupta, H.V.; Kling, H. On Typical Range, Sensitivity, and Normalization of Mean Squared Error and Nash-Sutcliffe Efficiency Type Metrics. Available online: https://agupubs.onlinelibrary.wiley.com/doi/10.1029/2011WR010962 (accessed on 22 November 2023).
- Madsen, T.; Franz, K.; Hogue, T. Evaluation of a Distributed Streamflow Forecast Model at Multiple Watershed Scales. Water 2020, 12, 1279. [Google Scholar] [CrossRef]
- Colin Cameron, A.; Windmeijer, F.A.G. An R-Squared Measure of Goodness of Fit for Some Common Nonlinear Regression Models. J. Econom. 1997, 77, 329–342. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Mean. | Min. | Max. | SD |
|---|---|---|---|---|
| Discharge (m3/h) | 104.03 | 2.00 | 273.00 | 49.64 |
| Pressure (Pa) | 2.80 | 2.20 | 3.20 | 0.167 |
| Residual chlorine (mg/L) | 0.659 | 0.510 | 0.860 | 0.043 |
| Conductivity (µS/cm) | 157.59 | 78.60 | 212.40 | 24.76 |
| Temperature (°C) | 23.15 | 20.80 | 26.50 | 1.363 |
| pH | 7.380 | 7.080 | 7.700 | 0.153 |
| Turbidity (NTU) | 0.051 | 0.043 | 0.078 | 0.005 |
| LSTM | Dense | Batch Size | Epochs | Window Size |
|---|---|---|---|---|
| 50 | 1 | 1000 | 500 | 24 |
| Parameter | RMSE | R2 | MAE | MAPE | NSE | PBIAS |
|---|---|---|---|---|---|---|
| Discharge | 16.205 | 0.857 | 12.499 | 13.103 | 0.857 | −0.775 |
| Pressure | 0.091 | 0.600 | 0.077 | 2.734 | 0.600 | −0.808 |
| Residual chlorine | 0.024 | 0.850 | 0.020 | 3.728 | 0.850 | −1.243 |
| Conductivity | 0.137 | 0.970 | 0.114 | 0.067 | 0.970 | −0.005 |
| Temperature | 0.052 | 0.673 | 0.043 | 0.199 | 0.673 | 0.000 |
| pH | 0.005 | 0.178 | 0.003 | 0.041 | 0.178 | 0.008 |
| Turbidity | 0.002 | 0.520 | 0.001 | 2.000 | 0.520 | −1.512 |
| Metric | Discharge | Pressure | Residual Chlorine | Conductivity | Temperature | pH | Turbidity | |
|---|---|---|---|---|---|---|---|---|
| Mean | Obs.1 | 105.88 | 2.84 | 0.69 | 170.89 | 21.64 | 7.33 | 0.06 |
| Pred.2 | 105.05 | 2.82 | 0.69 | 170.88 | 21.64 | 7.34 | 0.06 | |
| Median | Obs. | 110.00 | 2.80 | 0.69 | 170.90 | 21.65 | 7.33 | 0.06 |
| Pred. | 109.22 | 2.82 | 0.69 | 170.98 | 21.64 | 7.33 | 0.06 | |
| Standard deviation | Obs. | 42.95 | 0.86 | 0.02 | 0.79 | 0.02 | 0.09 | 0.08 |
| Pred. | 40.90 | 0.14 | 0.02 | 0.77 | 0.02 | 0.09 | 0.07 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sadiki, N.; Jang, D.-W. Estimation of Hydraulic and Water Quality Parameters Using Long Short-Term Memory in Water Distribution Systems. Water 2024, 16, 3028. https://doi.org/10.3390/w16213028
Sadiki N, Jang D-W. Estimation of Hydraulic and Water Quality Parameters Using Long Short-Term Memory in Water Distribution Systems. Water. 2024; 16(21):3028. https://doi.org/10.3390/w16213028
Chicago/Turabian StyleSadiki, Nadia, and Dong-Woo Jang. 2024. "Estimation of Hydraulic and Water Quality Parameters Using Long Short-Term Memory in Water Distribution Systems" Water 16, no. 21: 3028. https://doi.org/10.3390/w16213028
APA StyleSadiki, N., & Jang, D.-W. (2024). Estimation of Hydraulic and Water Quality Parameters Using Long Short-Term Memory in Water Distribution Systems. Water, 16(21), 3028. https://doi.org/10.3390/w16213028