
Assessing Recession Constant Sensitivity and Its Interaction with Data Adjustment Parameters in Continuous Hydrological Modeling in Data-Scarce Basins: A Case Study Using the Xinanjiang Model


Abstract
1. Introduction
2. Materials and Methods
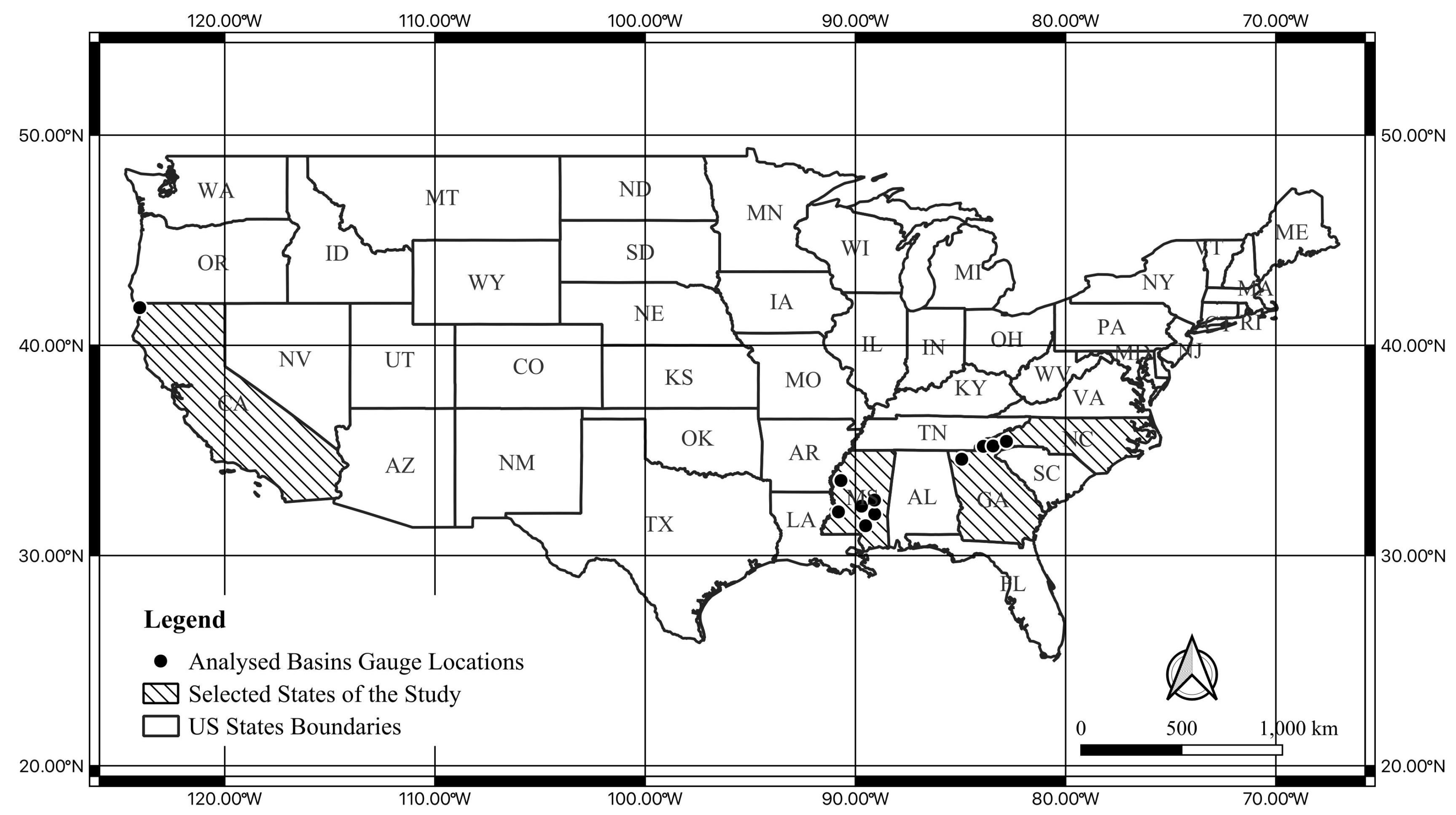
2.1. Study Basins
2.2. Data Description
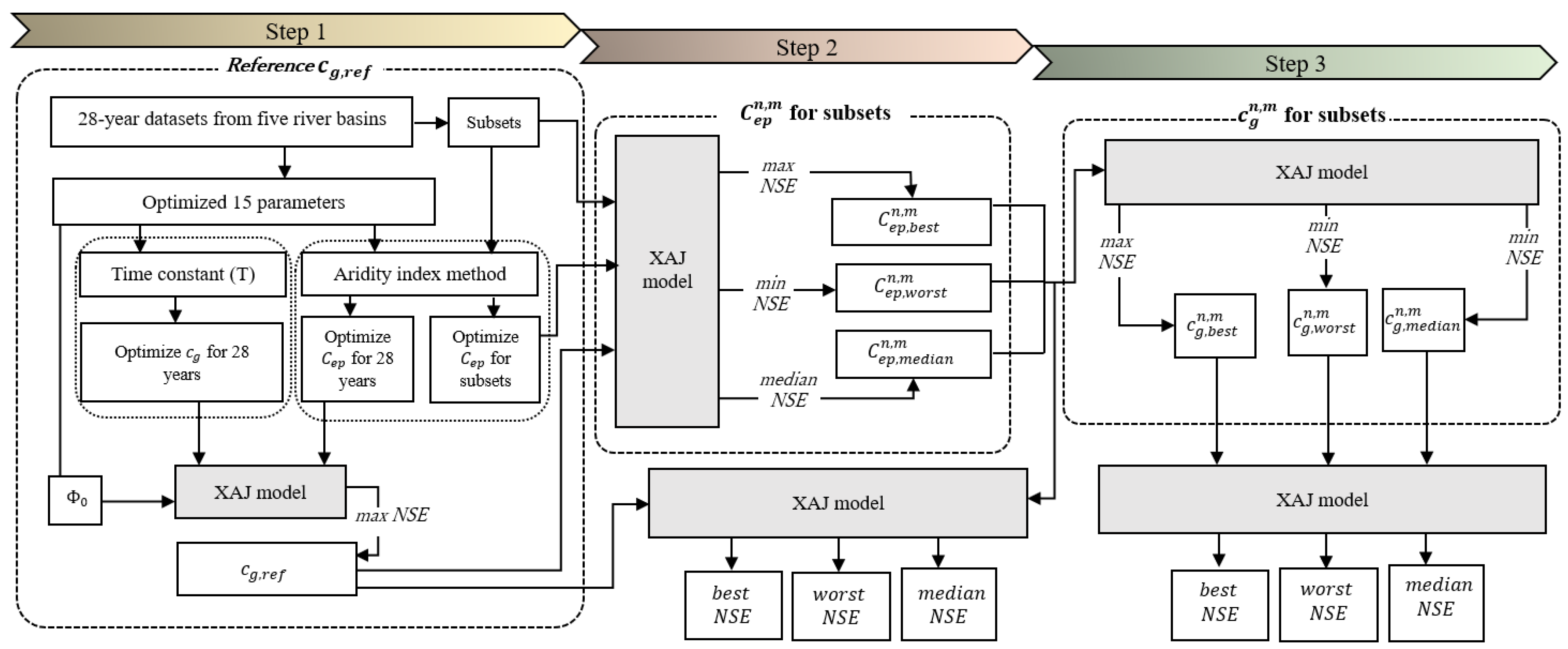
2.3. Analytical Framework of the Study
- Step 1:
- Involves the selection of the XAJ model, followed by parameter optimization and calibration using a 28-year dataset to estimate the reference recession constant (cg,ref).
- Step 2:
- Encompasses the calculation and evaluation of the Cep values for each subset, and is achieved through the model calibration with cg,ref.
- Step 3:
- Outlines the procedure for evaluating the recession constant for the subsets, . The evaluation is based on the model output obtained while running with .A detailed explanation of each step will be provided in the subsequent sections.
2.4. Description of XAJ Model and Its Parameters
2.4.1. Selection and Calibration of Model Parameters
- Group 1:
- Data adjustment parameters, sensitive on the annual scale.
- Group 2:
- Runoff component separation and routing-controlling parameters, sensitive on the daily scale.
- Group 3:
- Runoff generation-controlling parameters, sensitive on the annual scale while the Group 1 parameters are kept constant.
2.4.2. Relationship between Data Adjustment Parameter (Cep) and Recession Constant (cg)
2.4.3. Assessment of Data Adjustment Parameter (Cep)
2.4.4. Assessment of Recession Constant (cg)
2.4.5. XAJ Model Calibration
2.4.6. Evaluation of Model Performance Using Nash–Sutcliffe Efficiency
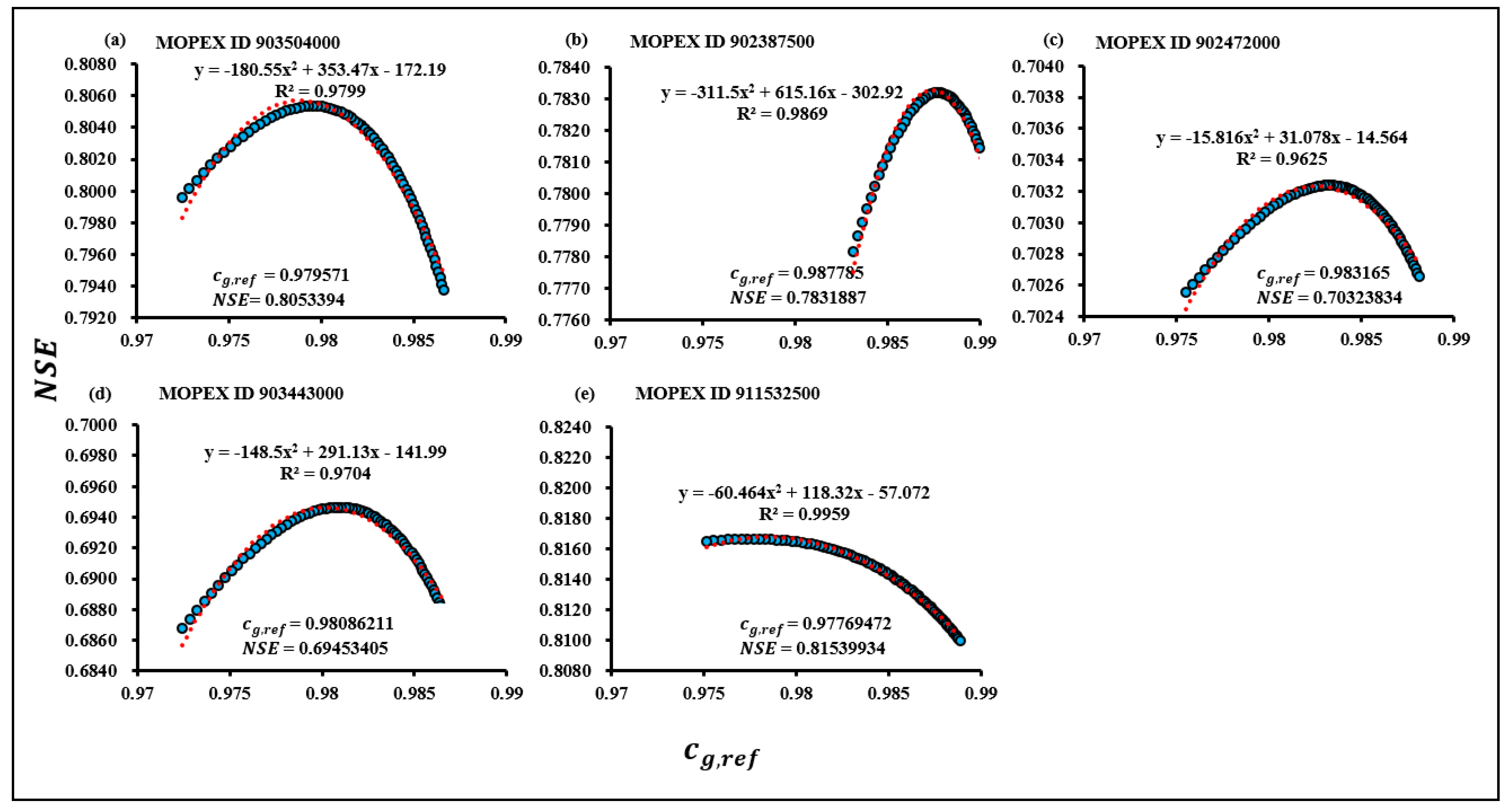
2.4.7. Estimation of Reference Recession Constant (cg,ref)
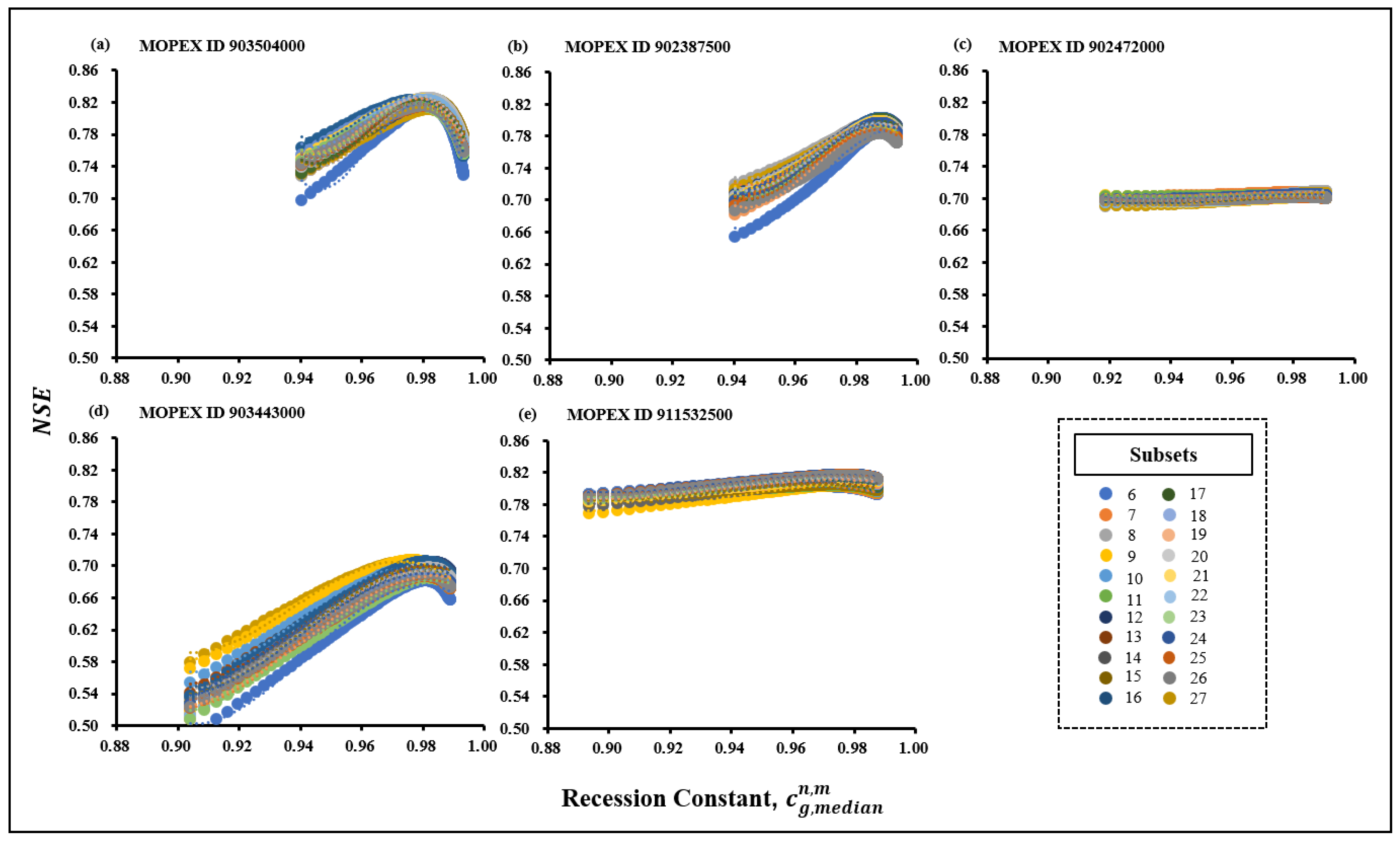
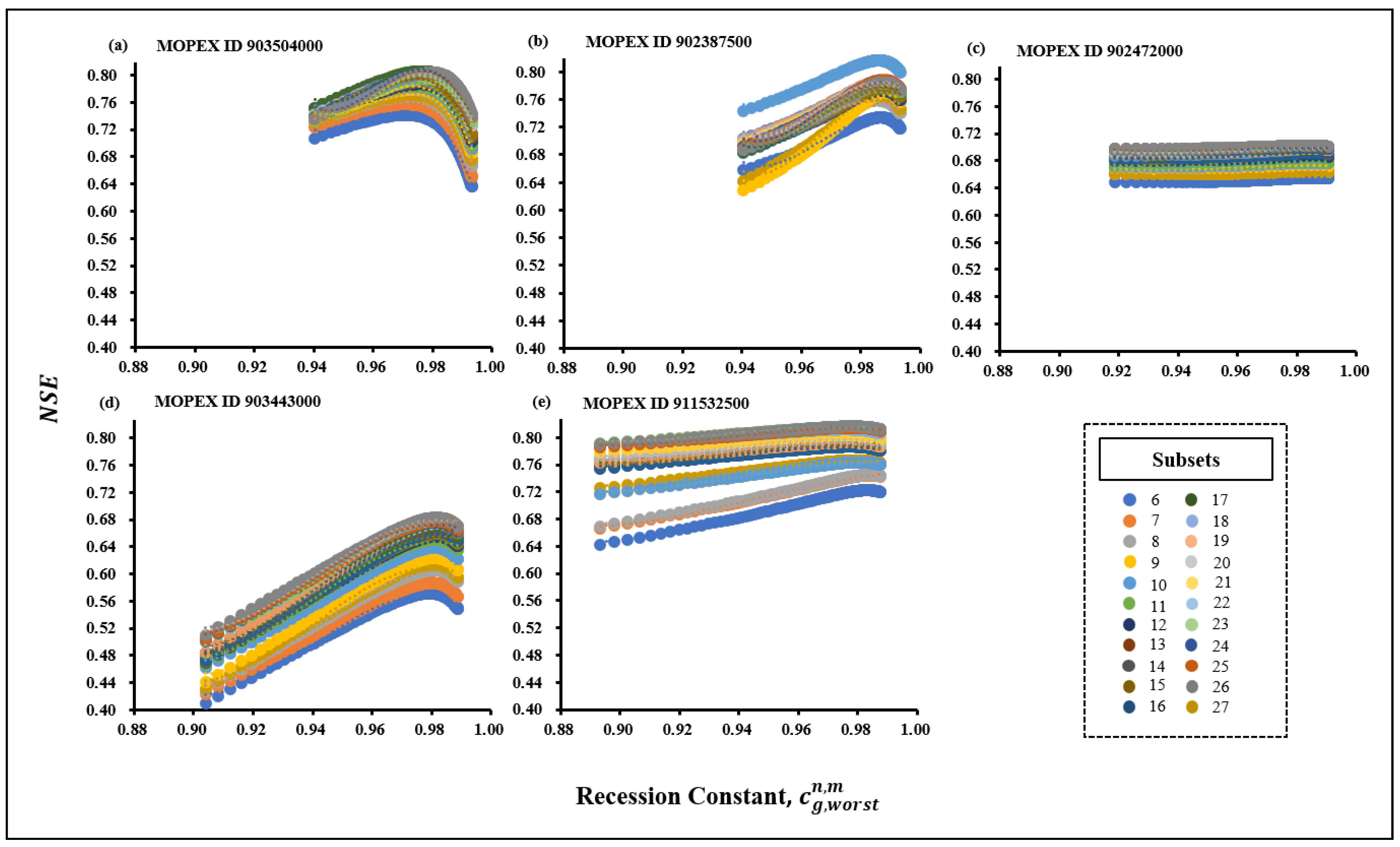
2.5. Estimation of for Subsets
2.6. Estimation of for Subsets
2.7. Comparative Evaluation of Recession Constant Sensitivity in Subsets
2.8. Application of Linear Polynomial Regression Analysis for Data Comparison
3. Results and Discussion
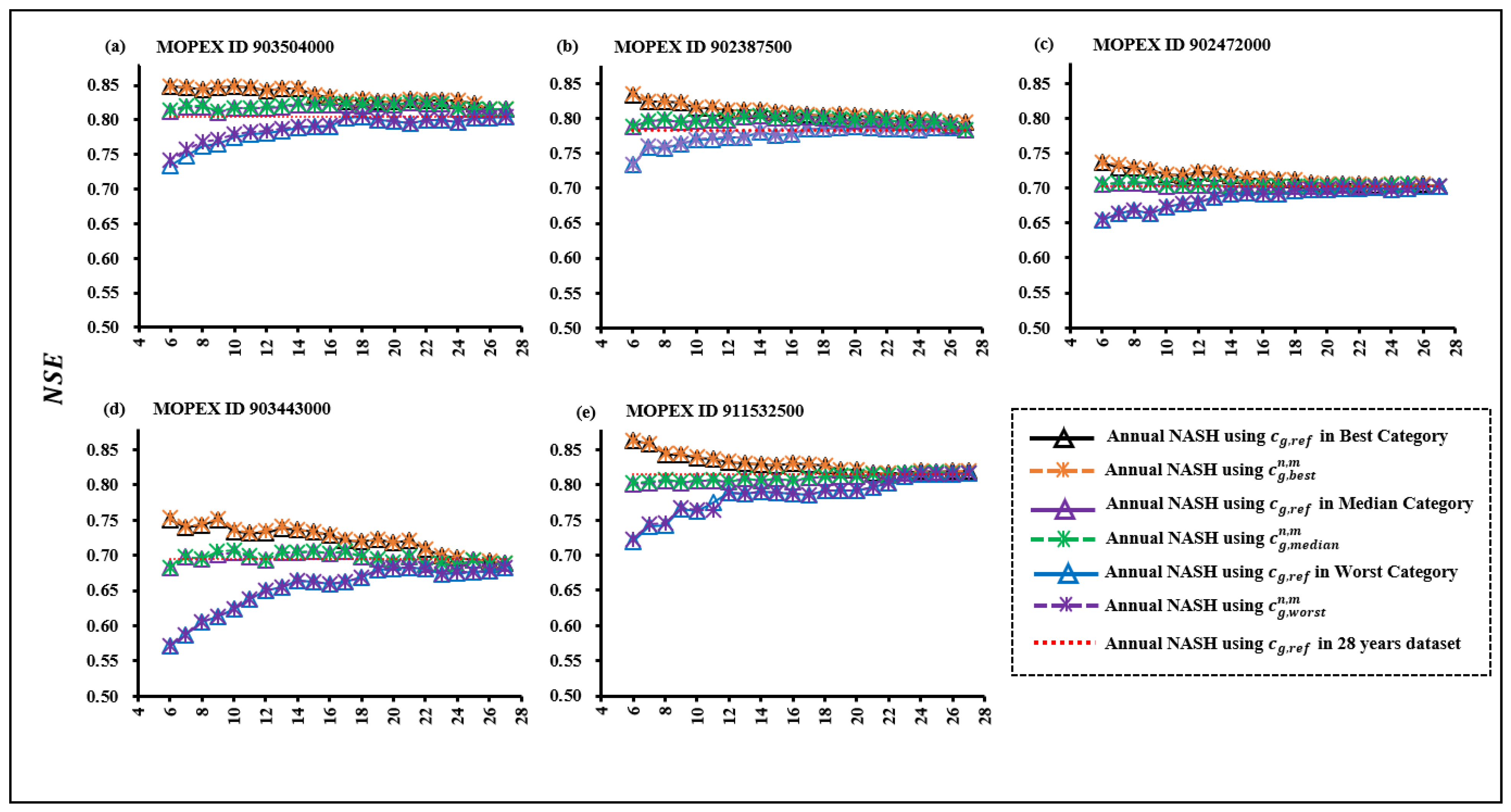
3.1. Reference cg for 28-Year Datasets (cg,ref)
3.2. Derivation of Data Adjustment Parameter ()
- (i)
- (selected when the annual Nash values, NSE, are highest after the model calibration with cg,ref in each subset, In,m);
- (ii)
- (selected when the annual Nash values, NSE, are median after the model calibration with cg,ref in each subset, In,m);
- (iii)
- (selected when the annual Nash values, NSE, are lowest after the model calibration with cg,ref in each subset, In,m).Subsequently, the polynomial regression analysis was conducted to determine the corresponding for the subsets in each category (, , and ) respectively.
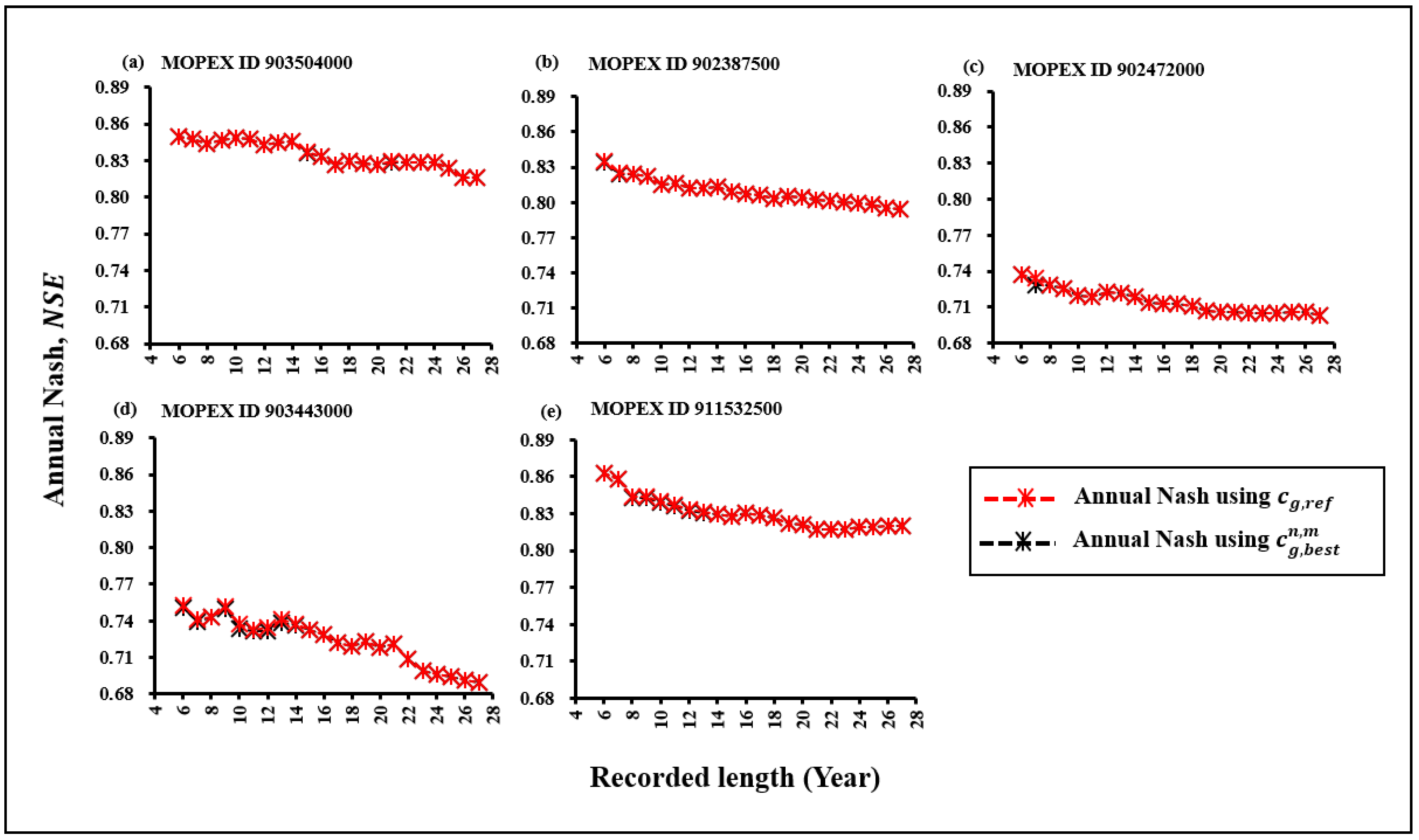
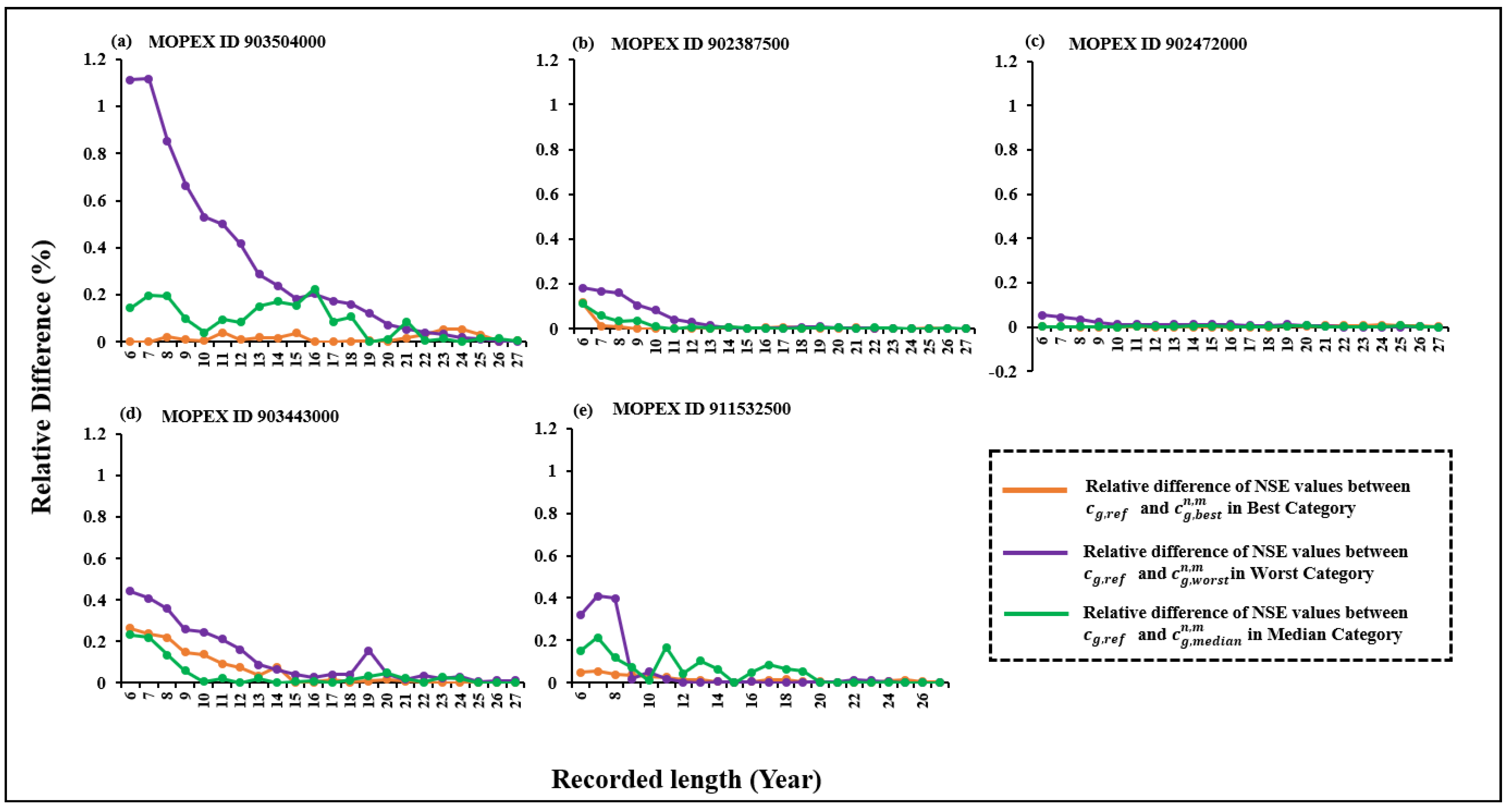
3.3. Comparative Evaluation of Annual Nash Results, NSE, Using and in Subsets
3.4. Comparative Evaluation of Annual Nash Results, NSE, Using and in Subsets
3.5. Comparative Assessment of Annual Nash Results, NSE, Using and in Subsets
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| XAJ | Xinanjiang model |
| Data adjustment parameter | |
| Recession constant | |
| Pan aridity index | |
| n | Length of datasets |
| m | Number of subsets |
| T | Time constant |
| Data adjustment parameter for 28-year data length | |
| Data adjustment parameter for subsets | |
| Thirteen pre-optimized parameter values | |
| Data adjustment parameter with maximum NSE for subsets | |
| Data adjustment parameter with median NSE for subsets | |
| Data adjustment parameter with minimum NSE for subsets | |
| Reference recession constant | |
| Recession constant for subsets | |
| Recession constant with maximum NSE for subsets | |
| Recession constant with median NSE for subsets | |
| Recession constant with minimum NSE for subsets | |
| P | Daily precipitation |
| Potential evaporation | |
| R | Annual runoff depth |
| S | Water storage |
| Input datasets | |
| Observed runoff | |
| Simulated runoff | |
| NSE | Nash–Sutcliffe efficiency |
References
- Devia, G.K.; Ganasri, B.P.; Dwarakish, G.S. A review on hydrological models. Aquat. Procedia 2015, 4, 1001–1007. [Google Scholar] [CrossRef]
- Peel, M.C.; Blöschl, G. Hydrological modelling in a changing world. Prog. Phys. Geogr. 2011, 35, 249–261. [Google Scholar] [CrossRef]
- Birkholz, S.; Muro, M.; Jeffrey, P.; Smith, H.M. Rethinking the relationship between flood risk perception and flood management. Sci. Total Environ. 2014, 478, 12–20. [Google Scholar] [CrossRef] [PubMed]
- Adikari, Y.; Yoshitani, J. Global Trends in Water-Related Disasters: An Insight for Policymakers; World Water Assessment Programme Side Publication Series, Insights; The United Nations, UNESCO: London, UK; International Centre for Water Hazard and Risk Management (ICHARM): Ibaraki-ken, Japan, 2009; pp. 1–24. [Google Scholar]
- Modarres, R.; Ouarda, T.B. Modeling rainfall–runoff relationship using multivariate GARCH model. J. Hydrol. 2013, 499, 1–18. [Google Scholar] [CrossRef]
- Hamilton, S. Completing the loop: From data to decisions and back to data. Hydrol. Process. 2007, 21, 3105–3106. [Google Scholar] [CrossRef]
- Loucks, D.P.; Van Beek, E. Water Resource Systems Planning and Management: An Introduction to Methods, Models, and Applications; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Refsgaard, J.C.; Knudsen, J. Operational validation and intercomparison of different types of hydrological models. Water Resour. Res. 1996, 32, 2189–2202. [Google Scholar] [CrossRef]
- Ramos, M.H.; Mathevet, T.; Thielen, J.; Pappenberger, F. Communicating uncertainty in hydro-meteorological forecasts: Mission impossible? Meteorol. Appl. 2010, 17, 223–235. [Google Scholar] [CrossRef]
- Raje, D.; Krishnan, R. Bayesian parameter uncertainty modeling in a macroscale hydrologic model and its impact on Indian river basin hydrology under climate change. Water Resour. Res. 2012, 48. [Google Scholar] [CrossRef]
- Zhao, F.; Wu, Y.; Qiu, L.; Sun, Y.; Sun, L.; Li, Q.; Niu, J.; Wang, G. Parameter uncertainty analysis of the SWAT model in a mountain-loess transitional watershed on the Chinese Loess Plateau. Water 2018, 10, 690. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, S.; Huang, Z.; Yan, W. Parameter optimization, sensitivity, and uncertainty analysis of an ecosystem model at a forest flux tower site in the United States. J. Adv. Model. Earth Syst. 2014, 6, 405–419. [Google Scholar] [CrossRef]
- Bárdossy, A.; Singh, S. Robust estimation of hydrological model parameters. Hydrol. Earth Syst. Sci. 2008, 12, 1273–1283. [Google Scholar] [CrossRef]
- Gupta, H.V.; Sorooshian, S.; Yapo, P.O. Status of automatic calibration for hydrologic models: Comparison with multilevel expert calibration. J. Hydrol. Eng. 1999, 4, 135–143. [Google Scholar] [CrossRef]
- McMillan, H.; Clark, M. Rainfall-runoff model calibration using informal likelihood measures within a Markov chain Monte Carlo sampling scheme. Water Resour. Res. 2009, 45. [Google Scholar] [CrossRef]
- Gou, J.; Miao, C.; Duan, Q.; Tang, Q.; Di, Z.; Liao, W.; Wu, J.; Zhou, R. Sensitivity analysis-based automatic parameter calibration of the VIC model for streamflow simulations over China. Water Resour. Res. 2020, 56, e2019WR025968. [Google Scholar] [CrossRef]
- Renard, B.; Kavetski, D.; Kuczera, G.; Thyer, M.; Franks, S.W. Understanding predictive uncertainty in hydrologic modeling: The challenge of identifying input and structural errors. Water Resour. Res. 2010, 46. [Google Scholar] [CrossRef]
- Muleta, M.K.; Nicklow, J.W. Sensitivity and uncertainty analysis coupled with automatic calibration for a distributed watershed model. J. Hydrol. 2005, 306, 127–145. [Google Scholar] [CrossRef]
- Jeremiah, E.; Sisson, S.A.; Sharma, A.; Marshall, L. Efficient hydrological model parameter optimization with Sequential Monte Carlo sampling. Environ. Model. Softw. 2012, 38, 283–295. [Google Scholar] [CrossRef]
- Celeux, G.; Hurn, M.; Robert, C.P. Computational and inferential difficulties with mixture posterior distributions. J. Am. Stat. Assoc. 2000, 95, 957–970. [Google Scholar] [CrossRef]
- Bates, B.C.; Campbell, E.P. A Markov chain Monte Carlo scheme for parameter estimation and inference in conceptual rainfall-runoff modeling. Water Resour. Res. 2001, 37, 937–947. [Google Scholar] [CrossRef]
- Vrugt, J.A.; Ter Braak, C.J.; Clark, M.P.; Hyman, J.M.; Robinson, B.A. Treatment of input uncertainty in hydrologic modeling: Doing hydrology backward with Markov chain Monte Carlo simulation. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
- Gottschalk, F.; Sun, T.; Nowack, B. Environmental concentrations of engineered nanomaterials: Review of modeling and analytical studies. Environ. Pollut. 2013, 181, 287–300. [Google Scholar] [CrossRef]
- Kuczera, G.; Parent, E. Monte Carlo assessment of parameter uncertainty in conceptual catchment models: The Metropolis algorithm. J. Hydrol. 1998, 211, 69–85. [Google Scholar] [CrossRef]
- Micevski, T.; Kuczera, G. Combining site and regional flood information using a Bayesian Monte Carlo approach. Water Resour. Res. 2009, 45. [Google Scholar] [CrossRef]
- Sorooshian, S.; Gupta, V.K. Automatic calibration of conceptual rainfall-runoff models: The question of parameter observability and uniqueness. Water Resour. Res. 1983, 19, 260–268. [Google Scholar] [CrossRef]
- Thyer, M.; Renard, B.; Kavetski, D.; Kuczera, G.; Franks, S.W.; Srikanthan, S. Critical evaluation of parameter consistency and predictive uncertainty in hydrological modeling: A case study using Bayesian total error analysis. Water Resour. Res. 2009, 45. [Google Scholar] [CrossRef]
- Wagener, T.; McIntyre, N.; Lees, M.; Wheater, H.; Gupta, H. Towards reduced uncertainty in conceptual rainfall-runoff modelling: Dynamic identifiability analysis. Hydrol. Process. 2003, 17, 455–476. [Google Scholar] [CrossRef]
- Pande, S.; Savenije, H.H.; Bastidas, L.A.; Gosain, A.K. A parsimonious hydrological model for a data scarce dryland region. Water Resour. Manag. 2012, 26, 909–926. [Google Scholar] [CrossRef]
- Nyeko, M. Hydrologic modelling of data scarce basin with SWAT model: Capabilities and limitations. Water Resour. Manag. 2015, 29, 81–94. [Google Scholar] [CrossRef]
- Bergström, S. Principles and confidence in hydrological modelling. Hydrol. Res. 1991, 22, 123–136. [Google Scholar] [CrossRef]
- Parajka, J.; Viglione, A.; Rogger, M.; Salinas, J.; Sivapalan, M.; Blöschl, G. Comparative assessment of predictions in ungauged basins–Part 1: Runoff-hydrograph studies. Hydrol. Earth Syst. Sci. 2013, 17, 1783–1795. [Google Scholar] [CrossRef]
- Lu, M.; Li, X. Time scale dependent sensitivities of the XinAnJiang model parameters. Hydrol. Res. Lett. 2014, 8, 51–56. [Google Scholar] [CrossRef]
- Rahman, M.M.; Lu, M. Model spin-up behavior for wet and dry basins: A case study using the Xinanjiang model. Water 2015, 7, 4256–4273. [Google Scholar] [CrossRef]
- Rahman, M.M.; Lu, M.; Kyi, K.H. Variability of soil moisture memory for wet and dry basins. J. Hydrol. 2015, 523, 107–118. [Google Scholar] [CrossRef]
- Zin, T.T.; Lu, M. Influence of Data Length on the Determination of Data Adjustment Parameters in Conceptual Hydrological Modeling: A Case Study Using the Xinanjiang Model. Water 2022, 14, 3012. [Google Scholar] [CrossRef]
- Gan, T.Y.; Dlamini, E.M.; Biftu, G.F. Effects of model complexity and structure, data quality, and objective functions on hydrologic modeling. J. Hydrol. 1997, 192, 81–103. [Google Scholar] [CrossRef]
- Beven, K.J. Rainfall-Runoff Modelling: The Primer; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Lu, M. Recent and future studies of the Xinanjiang Model. J. Hydraul. Eng. 2021, 52, 432–441. [Google Scholar]
- Gan, Y.; Duan, Q.; Gong, W.; Tong, C.; Sun, Y.; Chu, W.; Ye, A.; Miao, C.; Di, Z. A comprehensive evaluation of various sensitivity analysis methods: A case study with a hydrological model. Environ. Model. Softw. 2014, 51, 269–285. [Google Scholar] [CrossRef]
- Li, X.; Lu, M. Application of aridity index in estimation of data adjustment parameters in the Xinanjiang model. J. Jpn. Soc. Civ. Eng. Ser (Hydraul. Eng.) 2014, 70, I_163–I_168. [Google Scholar] [CrossRef]
- Rahman, M.M.; Lu, M.; Kyi, K.H. Seasonality of hydrological model spin-up time: A case study using the Xinanjiang model. Hydrol. Earth Syst. Sci. Discuss. 2016, prepirnt. [Google Scholar]
- Schaake, J.; Cong, S.; Duan, Q. US MOPEX Data Set; Technical Report; Lawrence Livermore National Lab. (LLNL): Livermore, CA, USA, 2006. [Google Scholar]
- Ren-Jun, Z. The Xinanjiang model applied in China. J. Hydrol. 1992, 135, 371–381. [Google Scholar] [CrossRef]
- Hapuarachchi, H.; Li, Z.; Wang, S. Application of SCE-UA method for calibrating the Xinanjiang watershed model. J. Lake Sci. 2001, 13, 304–314. [Google Scholar]
- Zhao, R.; Liu, X. Computer Models of Watershed Hydrology. In The Xinanjiang Model; Singh, V.P., Ed.; Water Resources Publications: Littleton, CO, USA, 1995. [Google Scholar]
- Li, X.; Lu, M. Multi-step optimization of parameters in the Xinanjiang model taking into account their time scale dependency. J. Jpn. Soc. Civ. Eng. Ser. (Hydraulic Eng.) 2012, 68, I_145–I_150. [Google Scholar] [CrossRef] [PubMed]
- Morris, M.D. Factorial sampling plans for preliminary computational experiments. Technometrics 1991, 33, 161–174. [Google Scholar] [CrossRef]
- Singh,, V.P. (Ed.) Computer Models of Watershed Hydrology; Water Resources Publications: Highlands Ranch, CO, USA, 1995; Volume 1130. [Google Scholar]
- Garrick, M.; Cunnane, C.; Nash, J. A criterion of efficiency for rainfall-runoff models. J. Hydrol. 1978, 36, 375–381. [Google Scholar] [CrossRef]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef]
- Gupta, H.V.; Kling, H. On typical range, sensitivity, and normalization of Mean Squared Error and Nash-Sutcliffe Efficiency type metrics. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- Houghton-Carr, H. Assessment criteria for simple conceptual daily rainfall-runoff models. Hydrol. Sci. J. 1999, 44, 237–261. [Google Scholar] [CrossRef]
- McCuen, R.H.; Knight, Z.; Cutter, A.G. Evaluation of the Nash–Sutcliffe efficiency index. J. Hydrol. Eng. 2006, 11, 597–602. [Google Scholar] [CrossRef]
- Schaefli, B.; Gupta, H.V. Do Nash values have value? Hydrol. Process. 2007, 21, 2075–2080. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Kutner, M.H. Applied Linear Statistical Models; McGraw-hill: New York, NY, USA, 2005. [Google Scholar]
- Ostertagová, E. Modelling using polynomial regression. Procedia Eng. 2012, 48, 500–506. [Google Scholar] [CrossRef]
- McCuen, R.H. The role of sensitivity analysis in hydrologic modeling. J. Hydrol. 1973, 18, 37–53. [Google Scholar] [CrossRef]
- Li, C.Z.; Wang, H.; Liu, J.; Yan, D.H.; Yu, F.L.; Zhang, L. Effect of calibration data series length on performance and optimal parameters of hydrological model. Water Sci. Eng. 2010, 3, 378–393. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MOPEX ID | Location | Drainage Area (km2) | Data Length (year) | MP * (mm/year) | MPE * (mm/year) | ||
|---|---|---|---|---|---|---|---|
| Long | Lat | State | |||||
| 903504000 | −83.62 | 35.13 | NC | 135.00 | 28 | 1893 | 762.00 |
| 902387500 | −84.94 | 34.58 | GA | 4144.0 | 28 | 1480 | 901.00 |
| 902472000 | −89.41 | 31.71 | MS | 1924.0 | 28 | 1492 | 1060.0 |
| 903443000 | −83.62 | 35.29 | NC | 740.00 | 28 | 2156 | 817.00 |
| 911532500 | −124.05 | 41.79 | CA | 1577.0 | 28 | 2687 | 740.00 |
| MOPEX ID | Mean Precipitation (mm/year) | Median Precipitation (mm/year) | Minimum Precipitation (mm/year) | Maximum Precipitation (mm/year) | Standard Deviation |
|---|---|---|---|---|---|
| 903504000 | 1890 | 2051.98 | 1427.09 | 4424.72 | 571.450 |
| 902387500 | 1480 | 1481.05 | 1046.53 | 1930.67 | 228.240 |
| 902472000 | 1492 | 1550.62 | 1135.21 | 4615.13 | 674.880 |
| 903443000 | 2156 | 2064.90 | 1349.55 | 6646.70 | 1018.10 |
| 911532500 | 2687 | 2718.04 | 1644.96 | 7172.92 | 1176.72 |
| Parameter | Physical Meaning | Range | Pre-Optimized Values, | ||||
|---|---|---|---|---|---|---|---|
| MOPEX ID | |||||||
| 903504000 | 902387500 | 902472000 | 903443000 | 911532500 | |||
| Group I | |||||||
| Ratio of measured | |||||||
| Cp | precipitation to actual | 0.8–1.2 | 1 | 1 | 1 | 1 | 1 |
| precipitation | |||||||
| Ratio of potential | |||||||
| Cep | evaporation to pan | 0.8–1.2 | 0.7908 | 1.25 | 1.2806 | 0.9865 | 0.7184 |
| evaporation | |||||||
| Group II | |||||||
| Areal mean free water | |||||||
| SM | capacity of the surface | 1–50 | 40 | 30 | 50 | 40 | 30 |
| soil layer (mm) | |||||||
| Areal mean of the free | |||||||
| EX | water capacity of the | 0.5–2.5 | 1.2 | 0.5 | 0.5 | 1.2 | 0.5 |
| surface soil layer (mm) | |||||||
| Outflow coefficients of | 0–0.7; | ||||||
| KI | the free water storage to | KI + KG = 0.7 | 0.1 | 0.3 | 0.55 | 0.1 | 0.3 |
| interflow | |||||||
| Outflow coefficients of | 0–0.7; | ||||||
| KG | the free water storage to | KI + KG = 0.7 | 0.6 | 0.4 | 0.15 | 0.6 | 0.4 |
| groundwater | |||||||
| cs | Recession constant of the | 0.5–0.9 | 0.6 | 0.85 | 0.75 | 0.6 | 0.4 |
| lower interflow storage | |||||||
| Recession constant for | |||||||
| ci | the lower interflow | 0.5–0.9 | 0.9 | 0.75 | 0.8 | 0.9 | 0.75 |
| storage | |||||||
| cg | Recession constant of the | 0.9835–0.998 | 0.98 | 0.987 | 0.983 | 0.98 | 0.983 |
| groundwater storage | |||||||
| Group III | |||||||
| b | Exponent of the tension–water | 0.1–0.3 | 0.3 | 0.15 | 0.15 | 0.3 | 0.15 |
| capacity curve | |||||||
| Ratio of the impervious | |||||||
| imp | to the total area of the | 0–0.005 | 0.02 | 0.01 | 0.01 | 0.02 | 0.01 |
| basin | |||||||
| WUM | Water capacity in the | 5–20 | 20 | 20 | 20 | 20 | 20 |
| upper soil layer (mm) | |||||||
| WLM | Water capacity in the | 60–90 | 80 | 80 | 80 | 80 | 80 |
| lower soil layer (mm) | |||||||
| WDM | Water capacity | 10–100 | 60 | 160 | 160 | 160 | 160 |
| in the deeper soil layer (mm) | |||||||
| C | Coefficient of deep | 0.1–0.3 | 0.15 | 0.15 | 0.15 | 0.15 | 0.15 |
| evapotranspiration | |||||||
| MOPEX ID | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Subsets | (a) 903504000 | (b) 902387500 | (c) 902472000 | (d) 903443000 | (e) 911532500 | |||||
| 6 | 0.5869 | 0.98155 | 1.1664 | 0.98673 | 1.3523 | 0.98702 | 0.9408 | 0.97941 | 0.9584 | 0.98318 |
| 7 | 0.6114 | 0.98235 | 1.1331 | 0.98548 | 1.2522 | 0.98411 | 0.9662 | 0.98022 | 0.9644 | 0.98413 |
| 8 | 0.6705 | 0.98235 | 1.1894 | 0.98548 | 1.2689 | 0.98381 | 0.9467 | 0.98096 | 0.9351 | 0.98413 |
| 9 | 0.6877 | 0.98182 | 1.2826 | 0.98728 | 1.2907 | 0.98426 | 0.952 | 0.98060 | 0.8556 | 0.97952 |
| 10 | 0.6992 | 0.98098 | 1.2653 | 0.98825 | 1.3156 | 0.98522 | 0.9688 | 0.98096 | 0.8752 | 0.98058 |
| 11 | 0.6954 | 0.98182 | 1.2574 | 0.98597 | 1.2822 | 0.98547 | 0.9863 | 0.98114 | 0.8559 | 0.98058 |
| 12 | 0.6940 | 0.98155 | 1.1682 | 0.98687 | 1.311 | 0.98496 | 0.9907 | 0.98131 | 0.8166 | 0.97678 |
| 13 | 0.7099 | 0.98209 | 1.1957 | 0.98715 | 1.3273 | 0.98559 | 0.9997 | 0.98165 | 0.8366 | 0.97791 |
| 14 | 0.7289 | 0.98235 | 1.1779 | 0.98741 | 1.3046 | 0.98534 | 1.0104 | 0.98165 | 0.7986 | 0.97653 |
| 15 | 0.7337 | 0.98209 | 1.2303 | 0.98754 | 1.3123 | 0.98702 | 0.9983 | 0.98214 | 0.815 | 0.97701 |
| 16 | 0.7322 | 0.98260 | 1.2374 | 0.98754 | 1.3199 | 0.98692 | 0.9905 | 0.98182 | 0.8059 | 0.97653 |
| 17 | 0.7379 | 0.97750 | 1.2769 | 0.98754 | 1.3247 | 0.98672 | 0.9973 | 0.98198 | 0.8224 | 0.97747 |
| 18 | 0.7377 | 0.98182 | 1.2919 | 0.98741 | 1.3103 | 0.98692 | 1.0057 | 0.98198 | 0.8428 | 0.97724 |
| 19 | 0.7517 | 0.97972 | 1.2381 | 0.98715 | 1.3158 | 0.98712 | 1.014 | 0.98317 | 0.8347 | 0.97653 |
| 20 | 0.7450 | 0.98037 | 1.2190 | 0.98741 | 1.2928 | 0.98454 | 0.9987 | 0.98275 | 0.8278 | 0.97701 |
| 21 | 0.7474 | 0.98155 | 1.2240 | 0.98754 | 1.2918 | 0.98454 | 0.9687 | 0.98165 | 0.805 | 0.97678 |
| 22 | 0.7543 | 0.98005 | 1.2330 | 0.98754 | 1.265 | 0.98349 | 0.9558 | 0.98198 | 0.7971 | 0.97578 |
| 23 | 0.7510 | 0.98037 | 1.2326 | 0.98766 | 1.2587 | 0.98265 | 0.9592 | 0.98182 | 0.8002 | 0.97604 |
| 24 | 0.7526 | 0.97938 | 1.2303 | 0.98766 | 1.2779 | 0.98349 | 0.9655 | 0.98198 | 0.8067 | 0.97653 |
| 25 | 0.7591 | 0.98037 | 1.2255 | 0.98754 | 1.2717 | 0.98282 | 0.9467 | 0.98131 | 0.8231 | 0.97791 |
| 26 | 0.7672 | 0.98037 | 1.2239 | 0.98766 | 1.2755 | 0.98426 | 0.9531 | 0.98149 | 0.8193 | 0.97813 |
| 27 | 0.7797 | 0.98005 | 1.2413 | 0.98766 | 1.2699 | 0.98349 | 0.9608 | 0.98149 | 0.801 | 0.97791 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zin, T.T.; Lu, M.; Ogura, T. Assessing Recession Constant Sensitivity and Its Interaction with Data Adjustment Parameters in Continuous Hydrological Modeling in Data-Scarce Basins: A Case Study Using the Xinanjiang Model. Water 2024, 16, 286. https://doi.org/10.3390/w16020286
Zin TT, Lu M, Ogura T. Assessing Recession Constant Sensitivity and Its Interaction with Data Adjustment Parameters in Continuous Hydrological Modeling in Data-Scarce Basins: A Case Study Using the Xinanjiang Model. Water. 2024; 16(2):286. https://doi.org/10.3390/w16020286
Chicago/Turabian StyleZin, Thandar Tun, Minjiao Lu, and Takahiro Ogura. 2024. "Assessing Recession Constant Sensitivity and Its Interaction with Data Adjustment Parameters in Continuous Hydrological Modeling in Data-Scarce Basins: A Case Study Using the Xinanjiang Model" Water 16, no. 2: 286. https://doi.org/10.3390/w16020286
APA StyleZin, T. T., Lu, M., & Ogura, T. (2024). Assessing Recession Constant Sensitivity and Its Interaction with Data Adjustment Parameters in Continuous Hydrological Modeling in Data-Scarce Basins: A Case Study Using the Xinanjiang Model. Water, 16(2), 286. https://doi.org/10.3390/w16020286