
Application of HKELM Model Based on Improved Seahorse Optimizer in Reservoir Dissolved Oxygen Prediction


Abstract
1. Introduction
2. Materials and Methods
2.1. Seahorse Optimization Algorithm
2.1.1. SHO
- (1)
- initialize
- (2)
- Motor behavior of the hippocampus
- (3)
- Predatory behavior of seahorses
- (4)
- The reproductive behavior of seahorses
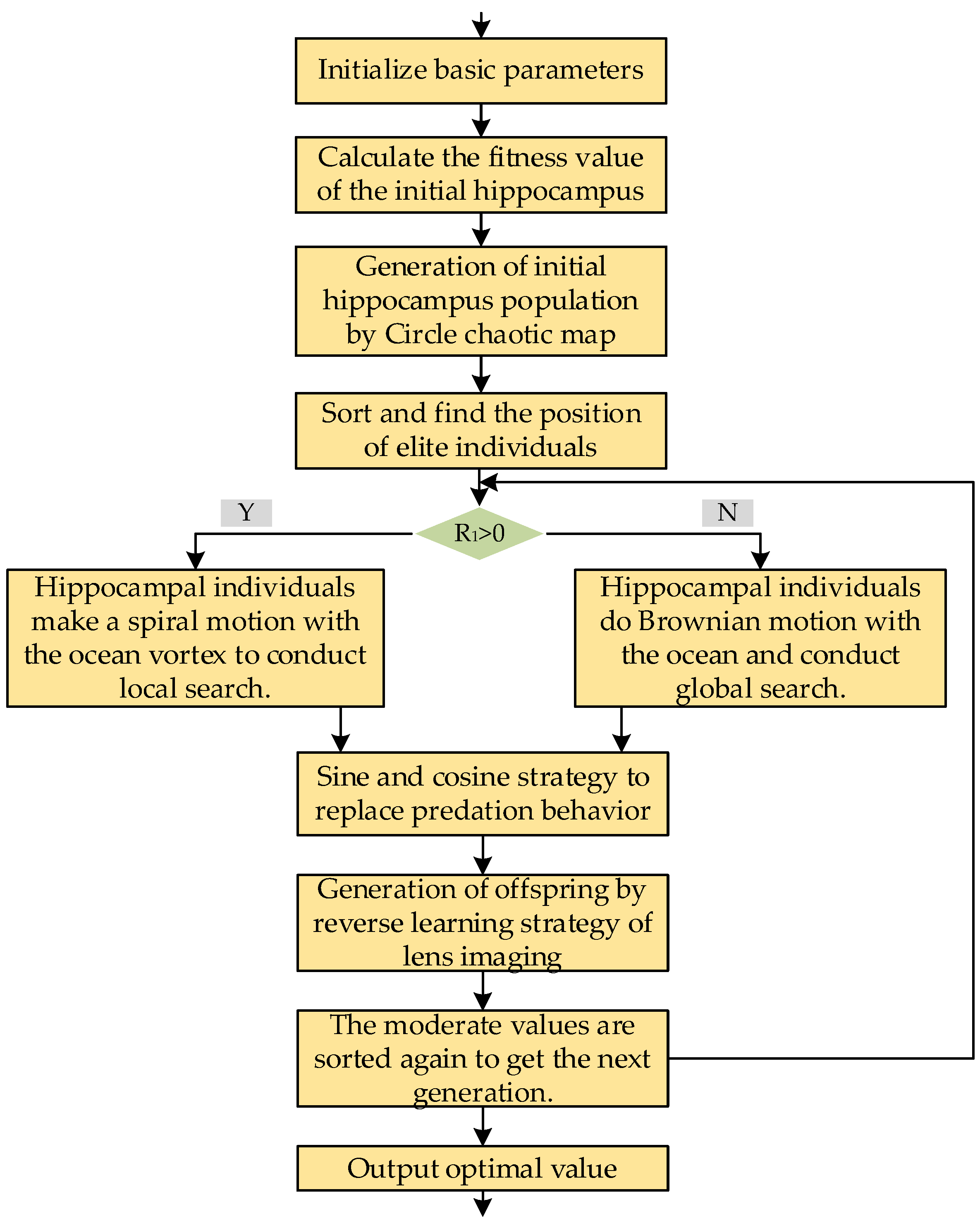
2.1.2. Improved Seahorse Optimizer
- (1)
- Circle chaotic mapping
- (2)
- Sine–cosine strategy replaces hippocampal predation
- (3)
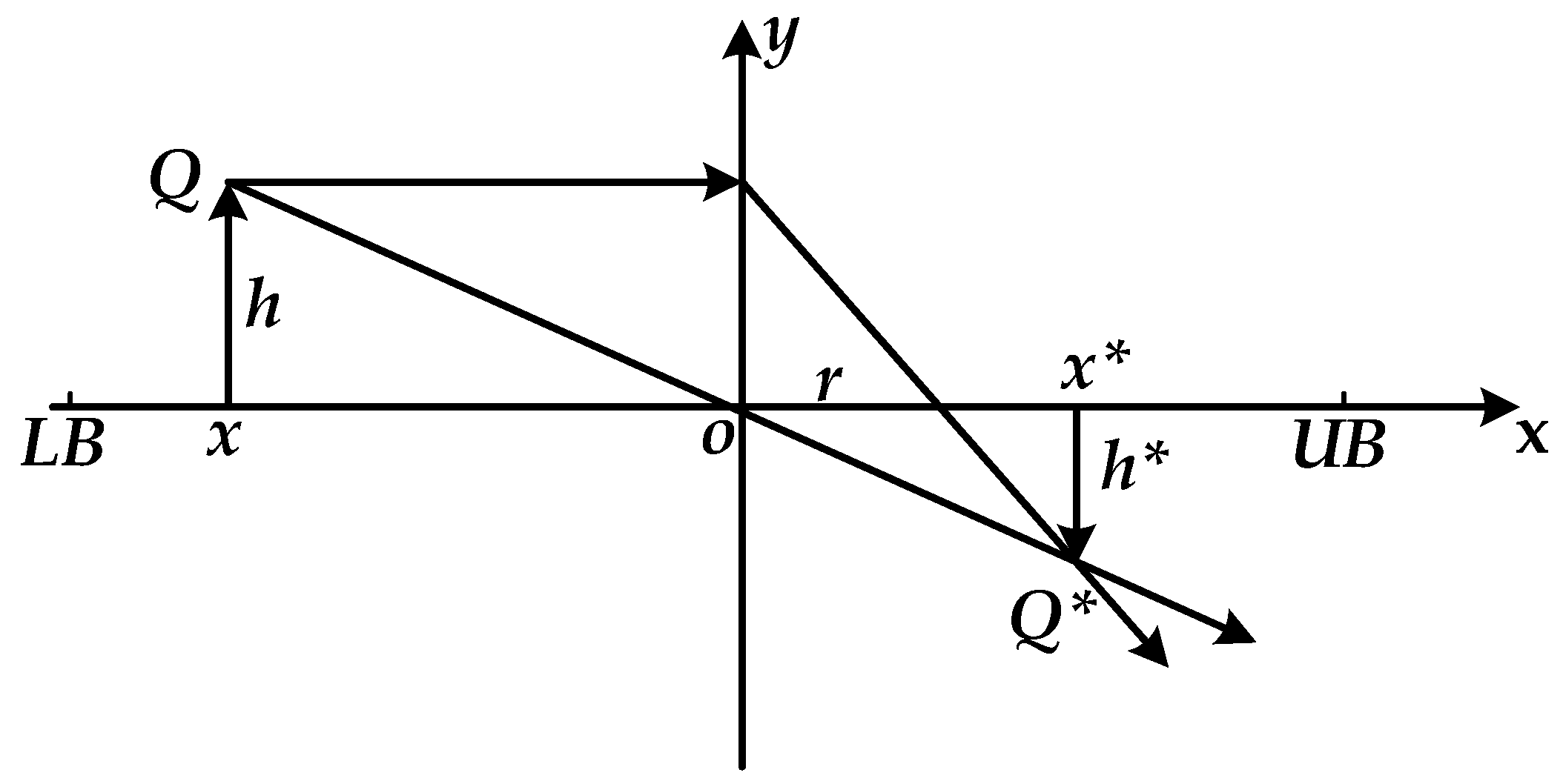
- Lens imaging reverse learning strategy
2.1.3. Improve the Implementation Steps of Seahorse Algorithm
2.2. Performance Test
2.2.1. Benchmark Test Function
2.2.2. Performance Comparison and Test of CZTSHO Algorithm
2.3. Water Quality Prediction Model of CZTSHO-HKELM
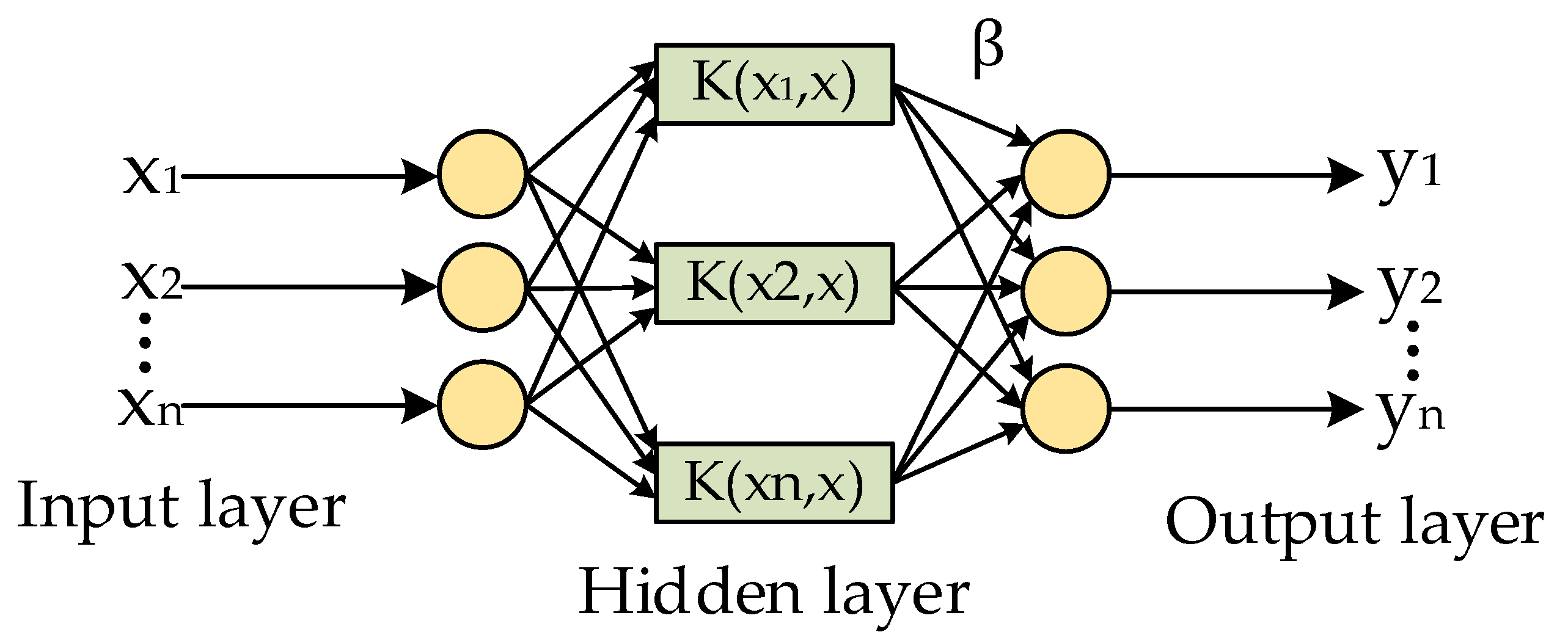
2.3.1. Hybrid Kernel Extreme Learning Machine
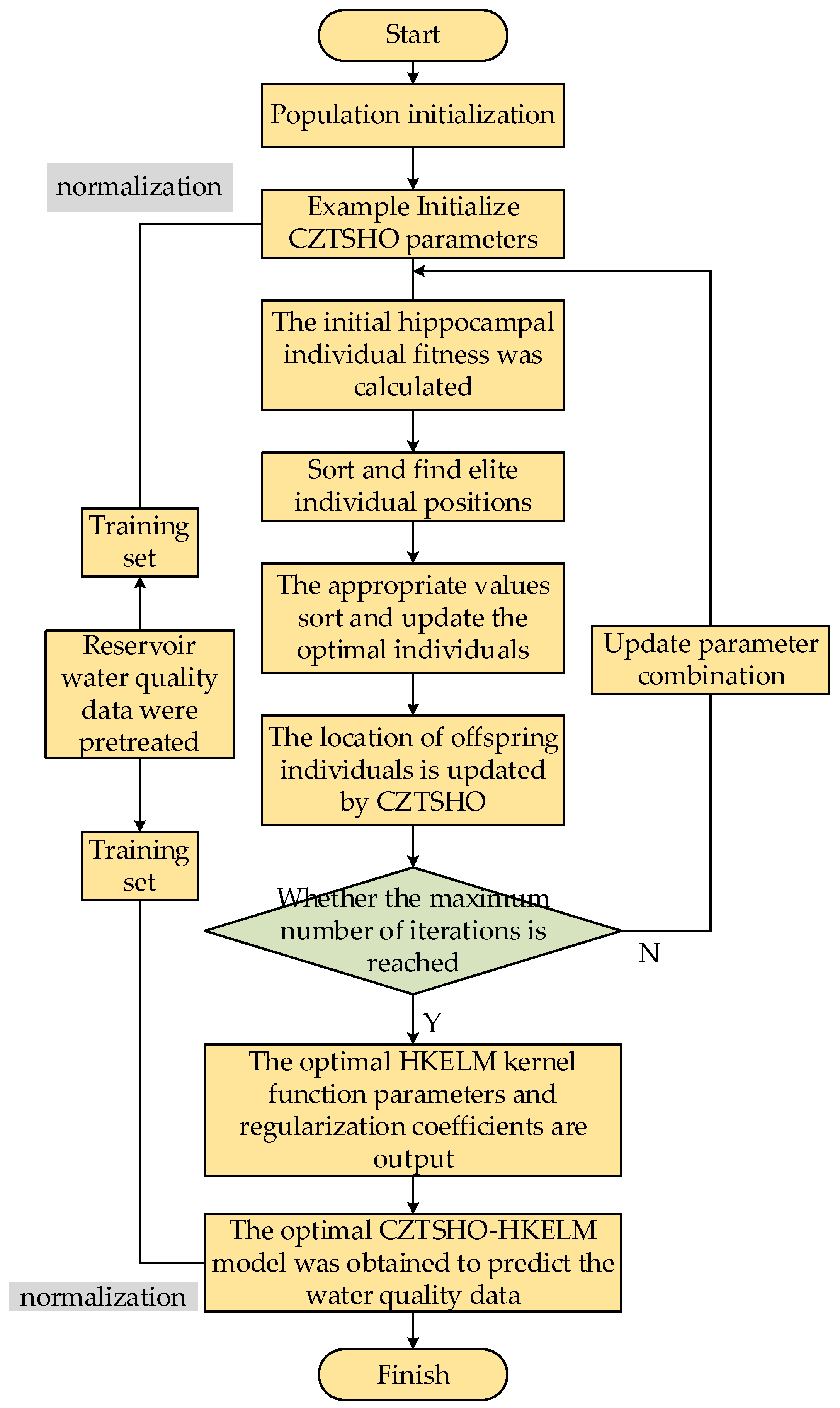
2.3.2. Optimization of Water Quality Prediction Steps of HKELM via the Improved Seahorse Optimizer
- (1)
- Obtain the monitored water quality data, conduct data analysis (introduced in the next chapter), divide the proportion of training set and test set, input the feature dimension, and normalize the data;
- (2)
- Initialize CZTSHO parameters: set the population size to 30, the maximum number of iterations is 500, and set the optimized upper and lower bounds and dimensions;
- (3)
- Set the parameters of the HKELM: take the regularization coefficient C, the kernel parameter of the RBF kernel function, the parameters and of the Poly kernel function, and the mixed weight coefficient ;
- (4)
- Calculate the fitness of hippocampus individuals, sort them to find the position of elite individuals, and judge the search mode. Sine and cosine strategies are used to replace predation behavior, and lens imaging reverse learning is used to generate offspring, and then the position of predator offspring is updated according to the CZTSHO update formula;
- (5)
- Determine whether the maximum number of iterations is reached, if not, update the parameter combination and return to step (4); if the maximum number of iterations is reached, the optimal parameter model is retained, and the optimization ends.
3. Experiment and Result Analysis
- (a)
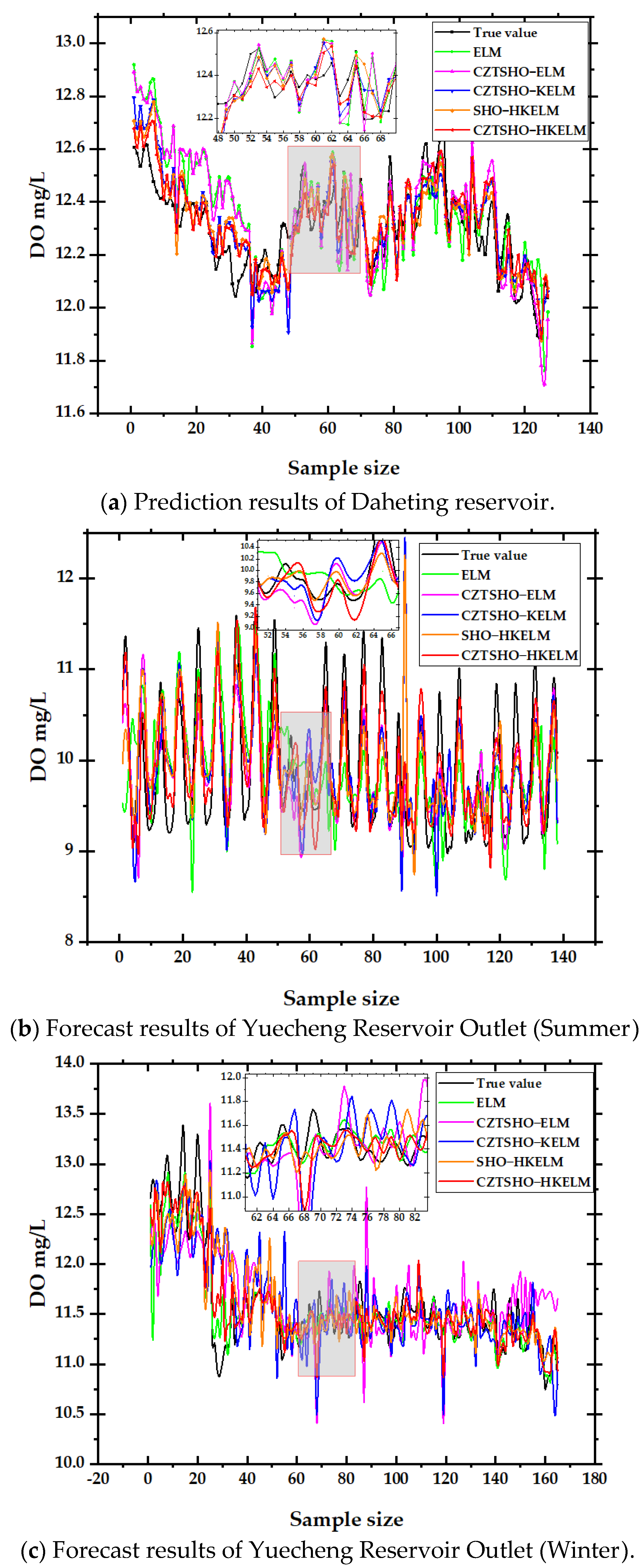
- The proposed hybrid model can achieve high prediction accuracy and closely aligns with the original sequence. It can also make accurate predictions for the two seasons with significant differences in data levels, indicating that the model has strong universality and generalization. Although all models can predict the change trend of the true value, there are still fitting errors at sample points with a large fluctuation range, and the prediction accuracy of a single extreme learning machine is poor. The coefficient of determination (R2) at the outlet of Yuecheng Reservoir in summer is only 0.543;
- (b)
- Taking the Daheting Reservoir as an example, the improved Seahorse Optimizer optimized the extreme learning machine and kernel extreme learning machine, respectively, and the unimproved Seahorse Optimizer optimized the hybrid kernel extreme learning machine. Compared with the ELM, the RMSE was reduced by 11.1%, 20.0%, and 25.8%, MAE was reduced by 9.9%, 26.3%, and 29.6%, and R2 was improved by 5.5%, 3.3%, and 3.4%, while the ELM using the improved Seahorse Optimizer to optimize the hybrid kernel function had a 35.8% reduction in RMSE, a 37.3% reduction in MAE, and a 7.4% increase in R2 compared with other models. It has the highest prediction accuracy and the largest determination coefficient, and its performance is better than other models. It is more suitable for predicting data with strong volatility such as water quality;
- (c)
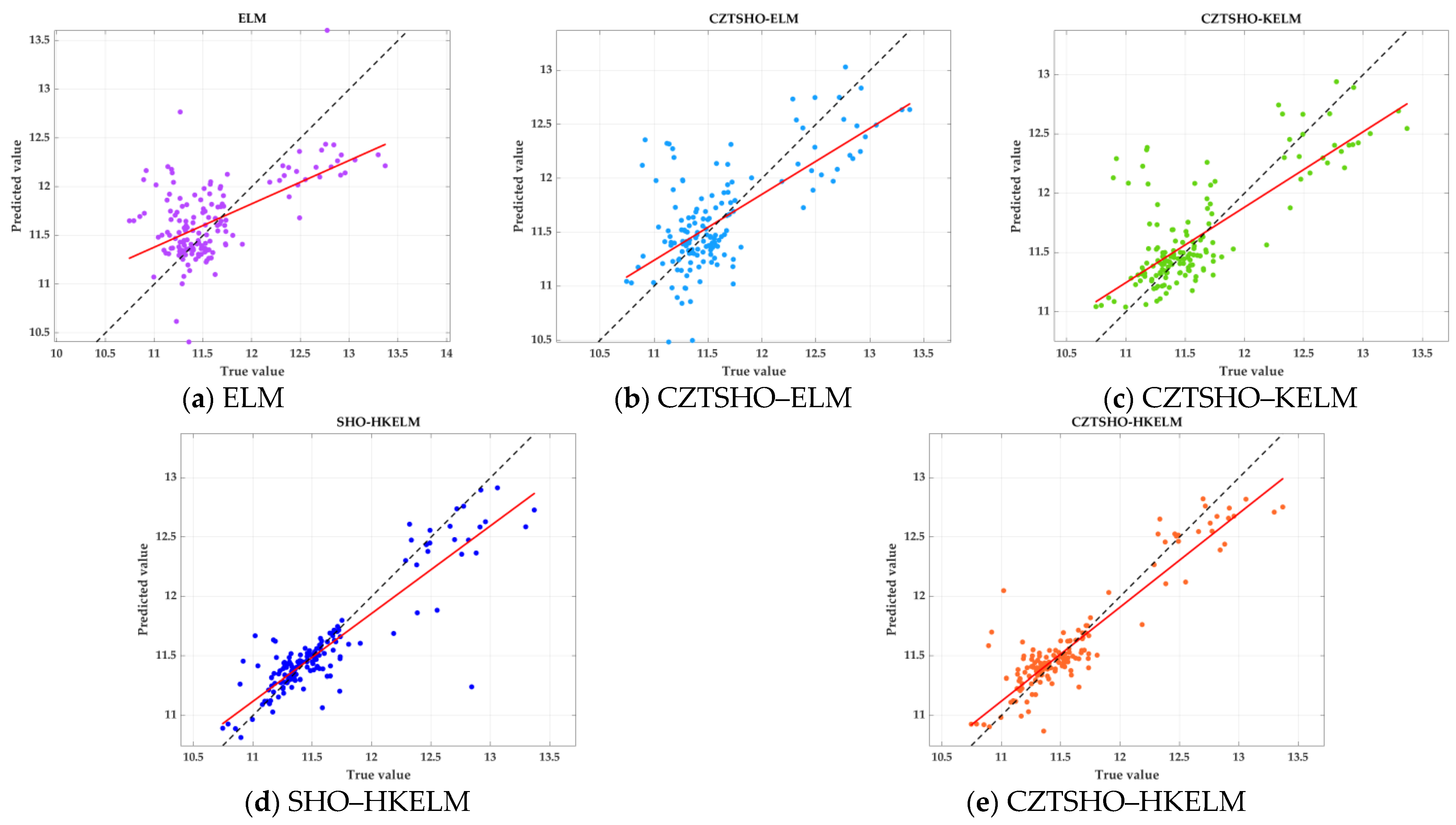
- From the scatter plot, we can see that the smaller the angle between the regression line of each model and , the better the prediction effect. Clearly, the ELM has the largest angle with and the worst prediction effect. As model complexity and algorithm improvements increase, the angle gradually becomes smaller, and prediction accuracy improves. CZTSHO–HKELM is very close to this straight line, indicating that it is the optimal model. When the dissolved oxygen value is around 11–12, the predicted values of each model are closer to the actual values. However, after exceeding 12, the effectiveness of each model decreases slightly;
- (d)
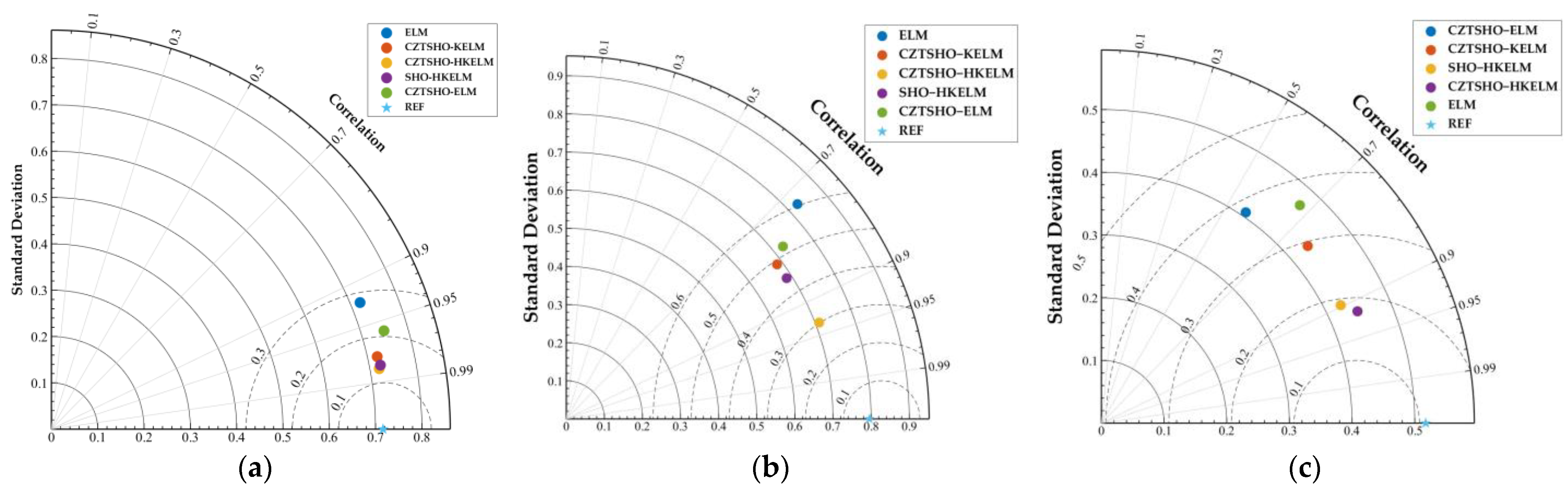
- From the Taylor diagram and violin plot, it can be seen that CZTSHO–HKELM has the best performance among the compared models, with correlations ranging between 0.9 and 0.95. In contrast, SHO-HKELM and CZTSHO-KELM exhibit similar prediction effects at Daheiting Reservoir, with correlations around 0.8. However, the prediction effects differ at the outlet of the Yuecheng Reservoir in winter and summer. Both models are susceptible to data fluctuations, with the ELM showing a correlation as low as 0.7;
- (e)
- The evaluation standard of the summer and winter models at the outlet of Yuecheng Reservoir is the same as that of Daheiting Reservoir, and CZTSHO-HKELM has the best prediction effect, which shows that the prediction model of hybrid kernel extreme learning machine optimized with the improved Seahorse Optimizer can accurately predict the dissolved oxygen concentration in water quality in different reservoirs or rivers and in different seasons, effectively reflecting the water quality parameters. The model exhibits lower error in winter compared to summer and is less affected by abrupt weather changes and other factors. Additionally, the model can be used to predict other water quality parameters, such as ammonia nitrogen and conductivity, and can also be applied to other fields, such as wind speed and runoff prediction.
4. Conclusions
- (1)
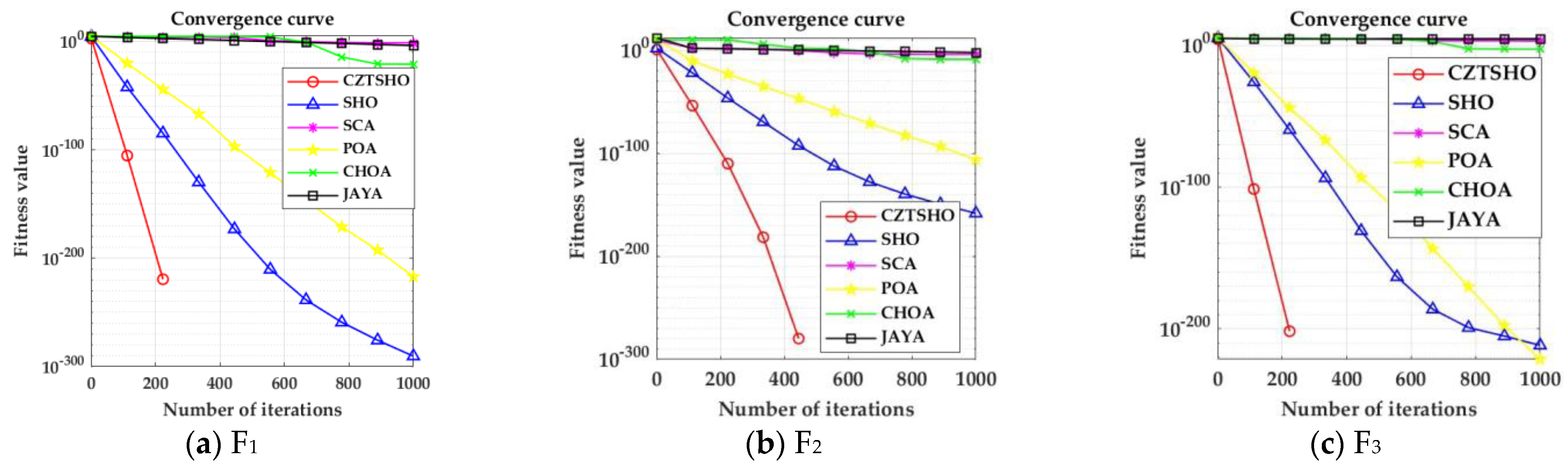
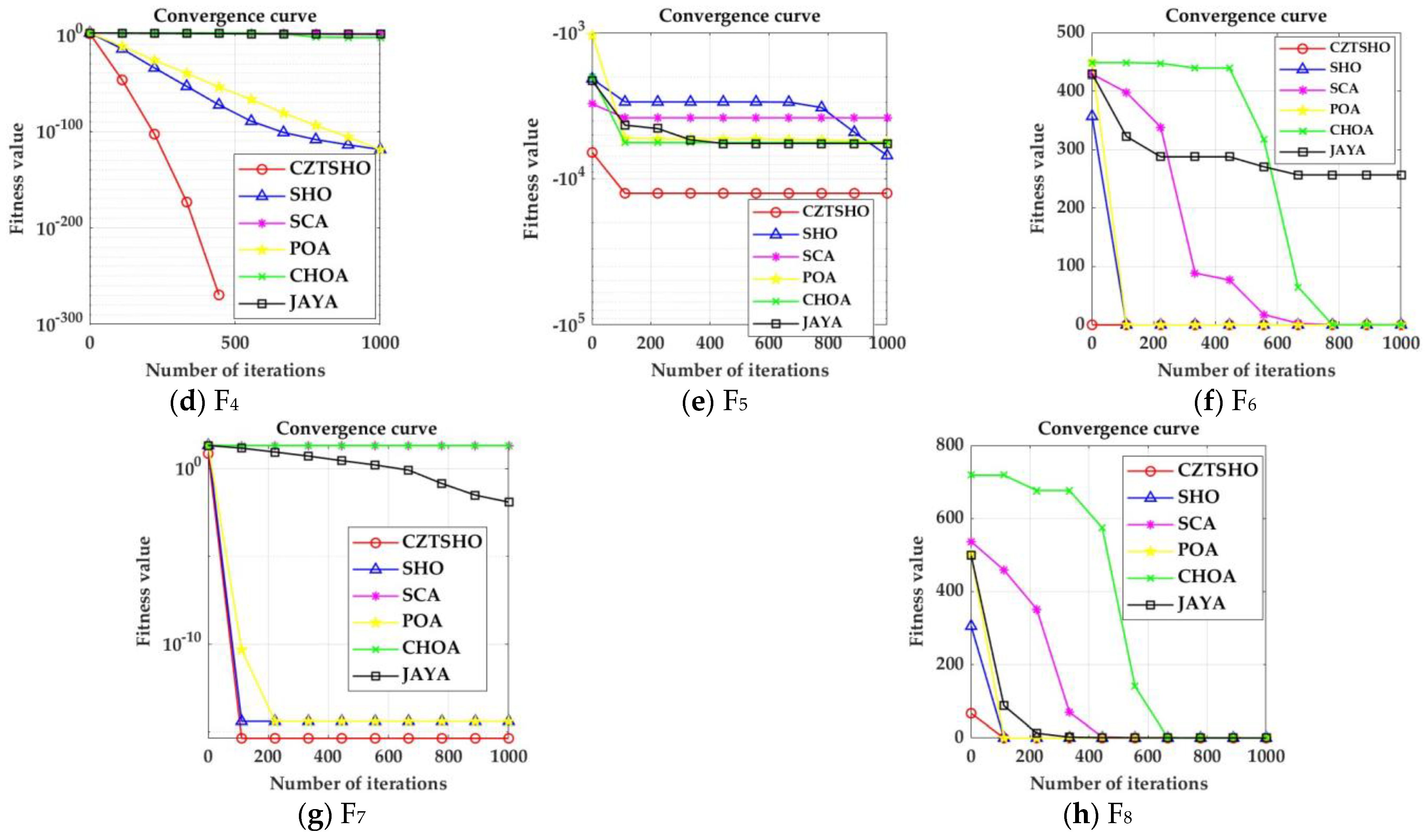
- The Seahorse Optimizer, improved by circle chaos mapping, the sine–cosine strategy, and lens imaging reverse learning strategy, enhances the ergodic properties of the population, increases the randomness of the search, and improves the global search capability. It can also prevent hippocampal individuals from falling into local optima and demonstrates that the optimal solution can be reached in about 200 iterations for the selected eight benchmark functions, whereas other algorithms may require up to 600 iterations to achieve the optimal value;
- (2)
- The experimental results show that the water quality prediction model based on CZTSHO–HKELM outperforms CZTSHO–KELM, CZTSHO–KELM, CZTSHO–ELM, and the ELM in terms of prediction accuracy (such as the RMSE and MAE) and exhibits the strongest correlation, and the HKELM can extract deep information in water quality time series, overcoming the limitation of the ELM model with which it is difficult to capture high correlation features due to the single-hidden-layer structure. Compared with other models, the RMSE and MAE are reduced under three different water quality conditions, and the prediction accuracy is improved, and the model has the ability to accurately predict water quality parameters under different water quality and external conditions;
- (3)
- For different reservoirs, influenced by factors such as water flow state and reservoir depth, the model maintains good accuracy. The prediction results are scientifically sound and effectively reflect water quality parameters, which is crucial for water environment protection. However, within the same reservoir, seasonal temperature variations impact prediction accuracy. In summer, the large temperature differences between day and night lead to reduced accuracy and increased error, while in winter, the smaller temperature differences have minimal impact on the prediction effectiveness.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
| Algorithm A1 The pseudo-code for the improved Seahorse Optimizer |
| Input: The population size , the maximum number of iterations , and the variable dimension Output: The optimal search agent and its fitness value 1: Initialize seahorses () by using Equation (11) 2: Calculate the best seahorse 3: Determine the best seahorse 4: while () do /* Movement behavior*/ 5: if do 6: Set constant parameters 7: Rotation angle Rand 8: Generate Levy coefficient 9: Update positions of the seahorses by using Equation (3) 10: else if do 11: Set constant parameter 12: Update positions of the seahorses by using Equation (4) 13: end if /* Sine and cosine strategy */ 14: Set constant parameter 15: Update positions of the seahorses by using Equations (14) and (15) 16: Handle variables out of bounds 17: Calculate the fitness value of each sea-horse /* Breeding behavior*/ 18: Select mothers and fathers by using Equations (8) and (9) 19: Breed offspring by using Equation (10) 20: Lens imaging reverse learning by using Equation (17) 21: Handle variables out of bounds 22: Calculate the fitness value of each offspring 23: Select the next iteration population from the offspring and parents ranked top pop in fitness values 24: Update elite () position 25: 26:end while |
References
- Valadkhan, D.; Moghaddasi, R.; Mohammadinejad, A. Groundwater quality prediction based on LSTM RNN: An Iranian experience. Int. J. Environ. Sci. Technol. 2022, 19, 11397–11408. [Google Scholar] [CrossRef] [PubMed]
- van Vliet, M.T.H.; Thorslund, J.; Strokal, M.; Hofstra, N.; Flörke, M.; Ehalt Macedo, H.; Nkwasa, A.; Tang, T.; Kaushal, S.S.; Kumar, R.; et al. Global river water quality under climate change and hydroclimatic extremes. Nat. Rev. Earth Environ. 2023, 4, 687–702. [Google Scholar] [CrossRef]
- Li, R.; Zhu, G.; Lu, S.; Sang, L.; Meng, G.; Chen, L.; Jiao, Y.; Wang, Q. Effects of urbanization on the water cycle in the Shiyang River basin: Based on a stable isotope method. Hydrol. Earth Syst. Sci. 2023, 27, 4437–4452. [Google Scholar] [CrossRef]
- M, G.J. Secure water quality prediction system using machine learning and blockchain technologies. J. Environ. Manag. 2024, 350, 119357. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Lei, Y.; Yang, S. Mid-long term load forecasting model based on support vector machine optimized by improved sparrow search algorithm. Energy Rep. 2022, 8, 491–497. [Google Scholar] [CrossRef]
- Gai, R.; Zhang, H. Prediction model of agricultural water quality based on optimized logistic regression algorithm. EURASIP J. Adv. Signal Process. 2023, 2023, 21. [Google Scholar] [CrossRef]
- Banda, T.D.; Kumarasamy, M. Artificial Neural Network (ANN)-Based Water Quality Index (WQI) for Assessing Spatiotemporal Trends in Surface Water Quality—A Case Study of South African River Basins. Water 2024, 16, 1485. [Google Scholar] [CrossRef]
- Yan, J.; Liu, J.; Yu, Y.; Xu, H. Water Quality Prediction in the Luan River Based on 1-DRCNN and BiGRU Hybrid Neural Network Model. Water 2021, 13, 1273. [Google Scholar] [CrossRef]
- Huang, G.-B.; Wang, D.H.; Lan, Y. Extreme learning machines: A survey. Int. J. Mach. Learn. Cybern. 2011, 2, 107–122. [Google Scholar] [CrossRef]
- Anmala, J.; Turuganti, V. Comparison of the Performance of Decision Tree (DT) Algorithms and ELM model in the Prediction of Water Quality of the Upper Green River watershed. Water Environ. Res. A Res. Publ. Water Environ. Fed. 2021, 93, 2360–2373. [Google Scholar] [CrossRef]
- Javad, A.; Ewees, A.A.; Sepideh, A.; Shamsuddin, S.; Mundher, Y.Z. A new insight for real-time wastewater quality prediction using hybridized kernel-based extreme learning machines with advanced optimization algorithms. Environ. Sci. Pollut. Res. Int. 2021, 29, 20496–20516. [Google Scholar]
- Liu, T.; Liu, W.; Liu, Z.; Zhang, H.; Liu, W. Ensemble water quality forecasting based on decomposition, sub-model selection, and adaptive interval. Environ. Res. 2023, 237, 116938. [Google Scholar] [CrossRef]
- Pang, J.; Luo, W.; Yao, Z.; Chen, J.; Dong, C.; Lin, K. Water Quality Prediction in Urban Waterways Based on Wavelet Packet Denoising and LSTM. Water Resour. Manag. 2024, 38, 2399–2420. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, T.; Ma, S.; Wang, M. Sea-horse optimizer: A novel nature-inspired meta-heuristic for global optimization problems. Appl. Intell. 2022, 53, 11833–11860. [Google Scholar] [CrossRef]
- Arora, S.; Anand, P. Chaotic grasshopper optimization algorithm for global optimization. Neural Comput. Appl. 2018, 31, 4385–4405. [Google Scholar] [CrossRef]
- Herbadji, D.; Derouiche, N.; Belmeguenai, A.; Herbadji, A.; Boumerdassi, S. A Tweakable Image Encryption Algorithm Using an Improved Logistic Chaotic Map. Trait. Signal 2019, 36, 407–417. [Google Scholar] [CrossRef]
- Ge, Z.; Feng, S.; Ma, C.; Dai, X.; Wang, Y.; Ye, Z. Urban river ammonia nitrogen prediction model based on improved whale optimization support vector regression mixed synchronous compression wavelet transform. Chemom. Intell. Lab. Syst. 2023, 240, 104930. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A Sine Cosine Algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Li, Y.; Sun, K.; Yao, Q.; Wang, L. A dual-optimization wind speed forecasting model based on deep learning and improved dung beetle optimization algorithm. Energy 2024, 286, 129604. [Google Scholar] [CrossRef]
- Trojovský, P.; Dehghani, M. Pelican Optimization Algorithm: A Novel Nature-Inspired Algorithm for Engineering Applications. Sensors 2022, 22, 855. [Google Scholar] [CrossRef]
- Khishe, M.; Mosavi, M.R. Chimp Optimization Algorithm. Expert. Syst. Appl. 2020, 149, 113338. [Google Scholar] [CrossRef]
- Rao, R.V. Jaya: A simple and new optimization algorithm for solving constrained and unconstrained optimization problems. Int. J. Ind. Eng. Comput. 2016, 7, 19–34. [Google Scholar]
- Zhang, Q.; Tsang, E.C.C.; Hu, M.; He, Q.; Chen, D. Fuzzt Set-Based Kernel Extreme Learning Machine Autoencoder for Multi-Label Classification. In Proceedings of the 2021 International Conference on Machine Learning and Cybernetics (ICMLC), Adelaide, Australia, 4–5 December 2021; pp. 1–6. [Google Scholar]
- Li, J.; Hai, C.; Feng, Z.; Li, G. A Transformer Fault Diagnosis Method Based on Parameters Optimization of Hybrid Kernel Extreme Learning Machine. IEEE Access 2021, 9, 126891–126902. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function Expression | Hunting Zone |
|---|---|
| [−100, 100] | |
| [−10, 10] | |
| [−100, 100] | |
| [−100, 100] | |
| [−500, 500] | |
| [−5.12, 5.12] | |
| [−32, 32] | |
| [−600, 600] |
| Variable | Mean | SD | Min | Max | Median | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|
| DO | 12.62 | 0.38 | 9.17 | 13.95 | 12.56 | −0.83 | 12.14 |
| EC | 603.87 | 56.92 | 0.47 | 636.06 | 616.77 | −9.20 | 94.70 |
| NH3-N | 0.04 | 0.03 | 0.03 | 0.80 | 0.04 | 19.00 | 435.05 |
| SS | 1.35 | 0.81 | 0.23 | 4.57 | 1.20 | 1.95 | 3.50 |
| T | 5.58 | 3.33 | 1.48 | 22.56 | 4.35 | 1.08 | 0.62 |
| TN | 4.87 | 0.33 | 0.50 | 7.19 | 4.93 | −3.14 | 49.82 |
| TP | 0.02 | 0.00 | 0.01 | 0.03 | 0.02 | 0.10 | −0.05 |
| pH | 8.16 | 0.09 | 7.05 | 8.37 | 8.16 | −2.56 | 35.31 |
| Network Model | Hyperparameter |
|---|---|
| ELM | |
| CZTSHO–ELM | |
| CZTSHO–KELM | |
| SHO–HKELM | |
| CZTSHO–HKELM |
| Locations | Model | RMSE | MAE | R2 |
|---|---|---|---|---|
| Daheting Reservoir | ELM | 0.135 | 0.101 | 0.841 |
| CZTSHO–ELM | 0.120 | 0.091 | 0.888 | |
| CZTSHO–KELM | 0.096 | 0.067 | 0.918 | |
| SHO–HKELM | 0.089 | 0.064 | 0.919 | |
| CZTSHO–HKELM | 0.077 | 0.057 | 0.954 | |
| Yuecheng Reservoir Outlet (Summer) | ELM | 0.946 | 0.718 | 0.543 |
| CZTSHO–ELM | 0.917 | 0.644 | 0.572 | |
| CZTSHO–KELM | 0.775 | 0.591 | 0.674 | |
| SHO–HKELM | 0.748 | 0.559 | 0.731 | |
| CZTSHO–HKELM | 0.561 | 0.406 | 0.849 | |
| Yuecheng Reservoir Outlet (Winter) | ELM | 0.511 | 0.258 | 0.661 |
| CZTSHO–ELM | 0.441 | 0.348 | 0.726 | |
| CZTSHO–KELM | 0.391 | 0.261 | 0.763 | |
| SHO–HKELM | 0.371 | 0.257 | 0.815 | |
| CZTSHO–HKELM | 0.261 | 0.182 | 0.898 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, L.; Hu, X. Application of HKELM Model Based on Improved Seahorse Optimizer in Reservoir Dissolved Oxygen Prediction. Water 2024, 16, 2232. https://doi.org/10.3390/w16162232
Guo L, Hu X. Application of HKELM Model Based on Improved Seahorse Optimizer in Reservoir Dissolved Oxygen Prediction. Water. 2024; 16(16):2232. https://doi.org/10.3390/w16162232
Chicago/Turabian StyleGuo, Lijin, and Xiaoyan Hu. 2024. "Application of HKELM Model Based on Improved Seahorse Optimizer in Reservoir Dissolved Oxygen Prediction" Water 16, no. 16: 2232. https://doi.org/10.3390/w16162232
APA StyleGuo, L., & Hu, X. (2024). Application of HKELM Model Based on Improved Seahorse Optimizer in Reservoir Dissolved Oxygen Prediction. Water, 16(16), 2232. https://doi.org/10.3390/w16162232