1. Introduction
Water scarcity represents a significant constraint regarding social integration and economic development. While agriculture accounts for 80% of water usage, domestic demand is also rising due to population growth, lifestyle changes, and global warming. These factors are decreasing water availability and increasing demand, necessitating better planning for water reserves, recycling, and efficient use, as well as real-time monitoring systems [
1].
Enhancing water distribution efficiency requires pro-active management based on consumption forecasting, rather than reactive management based on current consumption. Accurate forecasting can reduce operating costs by approximately 18% [
2], underscoring the importance of selecting the right model for specific dataset characteristics.
There is a considerable body of research work that deals with time series forecasting for water demand [
3,
4,
5,
6]. However, most of these studies use time series data from urban areas or, if focusing on rural areas, they correspond to a large number of users within the water distribution systems [
7]. Moreover, many authors direct their forecasts towards short-term periods (hourly, daily, or time steps less than a week). On the other hand, forecasting for the medium term (weekly to monthly) or long term (longer than a month) has not yet been fully explored. Medium- and long-term demand forecasting are important for planning and design of water supply systems, managing water resources, and maintenance activities [
8].
This work focuses primarily on monitoring of water flow rates in distribution networks in rural areas characterized by low populational density and water scarcity. It aims to forecast the medium- and long-term water demand in rural areas using both classical and modern forecasting methods. Among the classical models, two statistical approaches were considered: the simpler Holt–Winters models and the more advanced AutoRegressive Integrated Moving Average (ARIMA). The modern methods used are the Long-Short-Term Memory (LSTM), a type of deep learning neural network that has gained wide popularity in time series prediction, and Prophet, a recent regression forecasting model that has been successfully used in several time series forecasting tasks, but not yet explored enough in water demand forecasting.
This paper is organized as follows:
Section 2—Selected Models and Related Research provides an overview of the research field and of the characteristics of the models used;
Section 3—Materials and Methods describes the datasets, the pre-processing and analysis steps, and the model parameter definitions; and
Section 4—Results presents the forecasting results for the different time series. The discussion of the results and the conclusions are presented in
Section 5—Discussion and
Section 6—Conclusions, respectively.
2. Selected Models and Related Research
Holt–Winters and ARIMA are examples of parametric or statistical models, because they require knowledge of the distribution characteristics of the time series. The three main characteristics of a time series are trend, seasonality, and residuals. The trend, which can be increasing or decreasing, may take on a wide variety of patterns such as linear, exponential, dampened, and polynomial. Seasonality refers to cyclic patterns that repeat at constant time intervals. Residuals are short-term fluctuations that are neither systematic nor predictable [
3].
The Holt–Winters model is a well-regarded forecasting method for time series data that exhibit both trend and seasonality. It extends the simple exponential smoothing model by incorporating two additional smoothing equations: one for the trend component and one for the seasonal component. The model comes in two variations, additive and multiplicative, chosen based on whether the seasonal variations are roughly constant or proportional to the level of the series. The Holt–Winters method is particularly effective for short-term forecasting, as it dynamically updates the level, trend, and seasonal components to adapt to changes in the data. By smoothing these components separately, the model provides a comprehensive approach to capturing the underlying patterns in time series data, making it suitable for various practical applications in forecasting.
The ARIMA algorithm combines three components: autoregressive (AR), differencing (I for integrated), and moving average (MA). The AR part involves regressing the variable on its own lagged values, the I part involves differencing the data to achieve stationarity, and the MA part models the error term as a linear combination of error terms occurring contemporaneously and at various times in the past. The parameters (p, d, q) of the ARIMA model represent the order of the autoregressive part, the degree of differencing, and the order of the moving average part, respectively. This algorithm is particularly effective for short-term forecasting due to its ability to capture various types of temporal structures in time series data.
Classical time series forecasting models like ARIMA and Holt–Winters have been extensively used in various domains [
3,
9]. For instance, a study comparing ARIMA and Holt–Winters models for COVID-19 forecasting in India over a 20-day time horizon found that ARIMA achieved over 99% accuracy, outperforming Holt–Winters [
9]. These results highlight ARIMA’s strength in short-term predictions, particularly when dealing with datasets exhibiting clear trends and seasonality.
Machine learning involves non-parametric models that do not require a prior knowledge about the characteristics of the datasets. These methods demonstrate good performance even in cases where time series exhibit non-linear behaviors. Examples of such methods include Support Vector Regression, k-Nearest Neighbor, and Artificial Neural Networks [
5,
10]. In recent years, machine learning algorithms in the field of deep learning networks have grown in popularity. Among these, the Long-Short-Term Memory (LSTM) neural networks have achieved excellent performance in several forecasting tasks [
11,
12].
LSTM is a type of recurrent neural network that is well suited for time series forecasting due to its ability to capture long-term dependencies in sequential data. Unlike traditional RNNs, LSTMs are designed to avoid the problem of an exploding/vanishing gradient that arises in long-term dependencies. It uses a set of gates (input, forget, and output gates) to control the flow of information. These gates allow the LSTM to retain or discard information over long periods, making it highly effective for tasks where past information is crucial for predicting future values. The architecture includes memory cells that store information, and these cells are updated by the gates based on the input data and previous cell states. This design enables LSTM models to perform exceptionally well in capturing trends and seasonality in time series data, making them a powerful tool for forecasting applications [
13,
14]. It is worth noting that, when applied to time series, LSTM models can be further classified as univariate, if only a single time series is used, or multivariate, which incorporates multiple variables to enhance predictive accuracy.
LSTM models have shown promise in improving time series forecasts in different fields [
15,
16]. In a study conducted in Yazd, Iran, a univariate and a multivariate LSTM model were compared to predict monthly water consumption based on climate effects [
13], where the multivariate model included monthly air temperature values besides water consumption values. The results showed that the multivariate model had lower prediction errors.
Similarly, LSTM models have proven to be effective for next-day water consumption predictions to optimize pumping systems, showing superiority over autoregressive models [
17]. When comparing the effectiveness of the classic ARIMA model with the LSTM model applied to a time series of financial index values, a substantial reduction in the error metric is observed with the LSTM model, thus indicating a much higher performance of the LSTM compared to ARIMA [
18].
The Prophet model is a relatively new regression forecasting model developed by researchers form Facebook [
19]. This model was designed to handle time series data with strong seasonal effects and missing data points. It is particularly well suited for time series data that display daily, weekly, and yearly seasonality patterns. Prophet uses an additive model to decompose the time series into trend, seasonality, and holidays, as expressed in the following equation:
where
is the predicted value,
is the trend,
is the seasonality,
is the holiday effect, and
is the error associated with each time step
t. The trend can be modelled as a linear function or as a non-linear function called saturation growth (Equation (1)).
where
C is the carrying capacity,
k is the growth rate,
m is an offset parameter, a is a binary value indicating the presence of the effect from change point
t, and
is the rate change adjustment.
The seasonality is modelled using a standard Fourier series, as in Equation (2),
where
P is the regular period the series is expected to have, and
N is automatically selected for the different periods. The holiday term is incorporated in the model as a list of holidays.
Unlike traditional models, Prophet is resilient to missing data and shifts in the trend, making it highly effective for real-world forecasting scenarios.
In the original publication, the Prophet model is used to forecast the number of events created on Facebook by its users, and outperforms traditional models such as ARIMA, exponential smoothing, and Random Walk. Prophet has since been used in a variety of forecasting applications, such as in oil production [
20], energy demand [
21], and healthcare [
22]. However, reports on the use of the Prophet model for forecasting water demand are scarce [
23]. To our knowledge, it has not yet been applied for medium- or long-term water demand forecasting.
A comparison of ARIMA, LSTM, and Prophet models applied to oil production time series showed that the ARIMA and LSTM models outperformed Prophet. However, Prophet uniquely captured winter fluctuations [
20]. In the healthcare sector, a comparison of ARIMA and Prophet models showed that Prophet generally outperformed ARIMA [
22]. However, ARIMA performed better when strong seasonal patterns were absent. Additionally, Prophet was less reliable in handling data with many outliers due to measurement errors.
One of the important aspects of forecasting is the horizon of the predictions: short-term forecast (less than a week), medium-term forecast (week to month), and long-term forecast (more than a month) [
8]. Most of the research works focus on short-term water consumption predictions. In [
24], forecasts are made for the next hour; in [
17], the aim is to predict the following day’s water consumption as a global value; and in [
25], hourly forecasts are made. Few studies aim to provide forecasts in the medium and long term [
13,
26]. Frequently, climatic factors such as air temperature were used alongside the distributed flow data as additional training information [
8].
The present study focuses on hourly predictions for both medium-term (ten days) and long-term (three months) forecasts. Due to the difficulty in obtaining reliable climatic forecasts for these time horizons, the predictions are solely based on historical flow data, and additionally, in the case of the multivariate LSTM model, on the corresponding temporal features.
3. Materials and Methods
This section details the methodologies applied for collecting, preprocessing, and analyzing time series data of water flow in rural Portuguese supply sectors.
3.1. Data Acquisition and Preprocessing
This study uses real water flow measurements from four supply sectors located in rural, low-density populated areas in Portugal: Janeiro de Cima (638 inhabitants), Aldeia de Joanes (1168 inhabitants), Degolados (866 inhabitants), and Alcáçova (4798 inhabitants). Data, which were collected from monitoring systems and stored in databases, were made available by the company responsible for the water supply. Data spanning October 2021 to December 2022 were used for training and testing the predictive models.
Preprocessing involved several steps to ensure data quality and uniformity: concatenating files into a single DataFrame, retaining only the datetime and water flow rate columns and converting data types. Equidistance of the time series data was ensured by interpolating missing values and correcting timestamp anomalies. Data recorded at 5 min intervals were resampled to an hourly frequency by averaging the cleaned and processed data that were exported for the analysis.
3.2. Data Description
The final datasets contained hourly water flow records for each location, structured uniformly for model application. Each dataset provided a comprehensive representation of water flow dynamics, essential for effective time series forecasting.
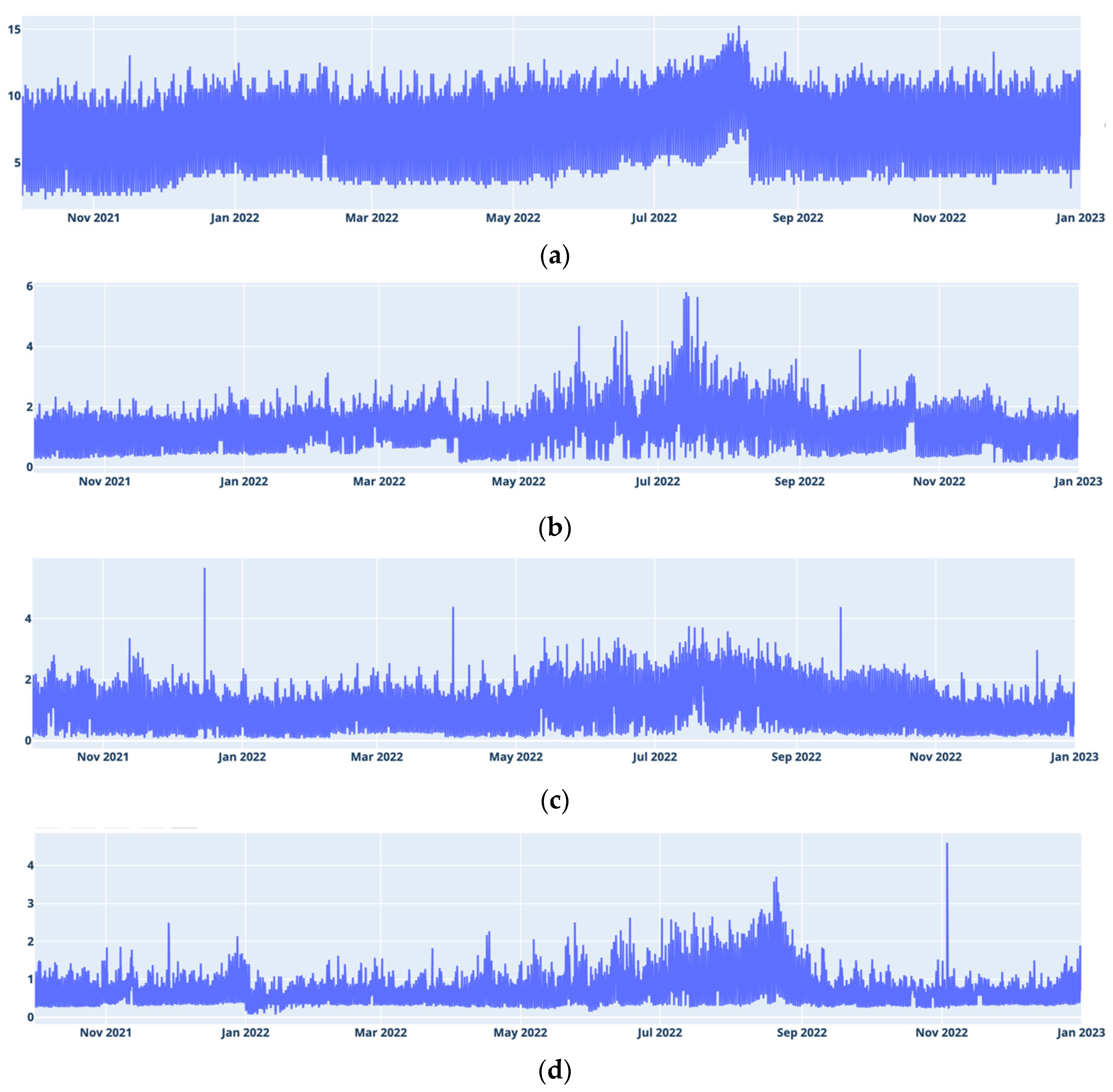
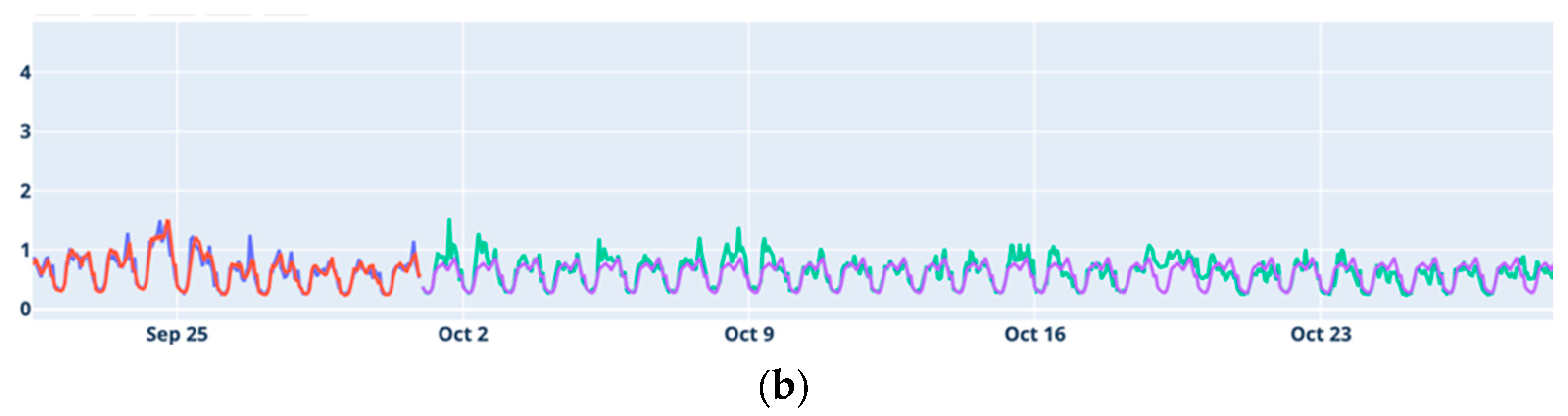
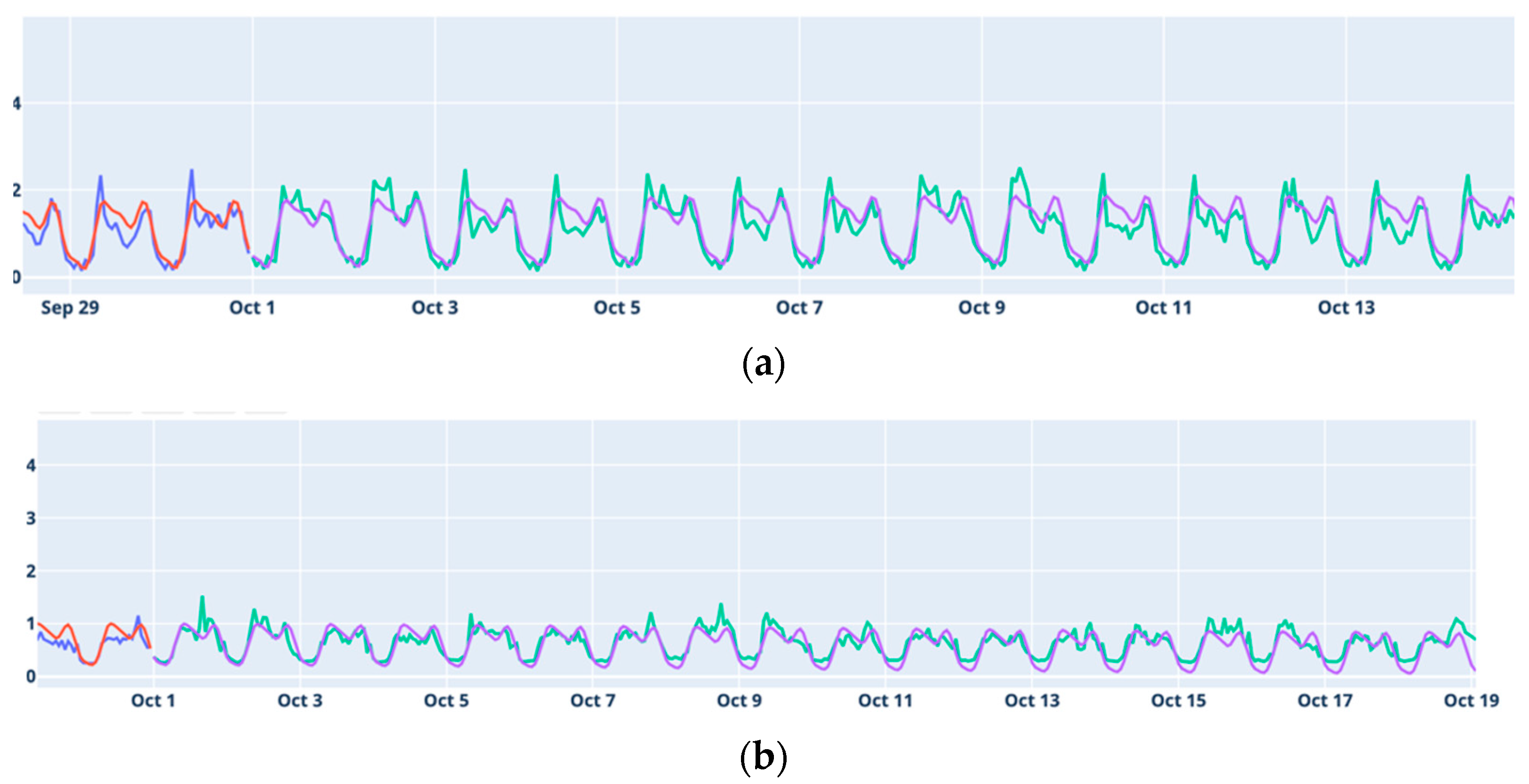
The plots presented in
Figure 1 illustrate that each dataset has its own particular characteristics. In Alcáçovas, a significant increase in the average was observed, peaking in August, followed by a sharp decline. This pattern corresponds to a rupture in the distribution network, which was initially undetectable on the surface. Aldeia de Joanes, Janeiro de Cima, and Degolados exhibit high variability, especially during the summer months. These locations are small villages with few permanent residents, but they experience a significant increase in population during the summer, a time when temperatures are also notably high. The effect of the summer is less pronounced in Degolados.
3.3. Data Analysis
Data analysis procedures were implemented to prepare and ensure that the time series data meet the assumptions for the forecasting models used. Analyses of the datasets were performed regarding stationarity, autocorrelation, decomposition, and normality distribution assessment. To verify stationarity, the Augmented Dickey–Fuller (ADF) test, the Kwiatkowski–Phillips–Schmidt–Shin (KPSS) test, and the Philips–Perron (PP) test were employed. The ADF and PP tests check for the presence of a unit root, suggesting non-stationarity, while the KPSS test checks for stationarity. Differentiation was applied to transform non-stationary series into stationary ones by computing differences between consecutive observations. The appropriate order of differencing was determined iteratively, followed by re-evaluation using stationarity tests. The autocorrelation function (ACF) and partial autocorrelation function (PACF) plots were used to identify patterns and determine the order of the autoregressive components in the ARIMA model. Time series decomposition was performed to separate the series into trend, seasonality, and residual components using an additive model. To determine if the data followed a normal distribution, the Shapiro–Wilk and Anderson–Darling tests were conducted. These tests assess whether the data deviate significantly from a normal distribution, which is essential for many statistical modeling techniques. In cases where normality was not observed, logarithmic and cubic root transformations were applied to the series, and the normality of the transformed series was reassessed.
For model training and testing, each dataset was divided into a training set consisting of the first 12 months of the time series and a test set including the last 3 months. For the LSTM model, validation data were also necessary: the first 9 months were used for training, the next 3 months for validation, and the final 3 months for testing.
3.4. Parametrization of the Models
This section describes how the four chosen forecasting models were applied to data.
The Holt–Winters method, which applies exponential smoothing to level, trend, and seasonal components, was preferred in its additive form due to the consistent nature of seasonal variations in the data.
The parameters of the ARIMA model were determined using autocorrelation and partial autocorrelation functions and the observed seasonality, aiming to minimize the Akaike Information Criterion (AIC). Residual correlation was also analyzed to finalize parameter selection.
The LSTM models employed in this study included both univariate and multivariate configurations. After optimization, the chosen architectures are represented in
Table 1. The input layer is always a matrix of shape (
n × 24,
k), where
n is the number of days considered (
n = 10 for medium-term forecasting;
n = 30 for long-term forecasting) and
k is the number of features considered in each model. The output layer is always a vector of size
n × 24 that contains the hourly prediction of the
n following days.
The univariate model received as input the single time series input, specifically the normalized water flow data. The multivariate model received as input both the normalized water flow time series and four additional variables representing the time information codified by Fourier series decomposition. In both cases, the activation function for the LSTM layers was the rectified linear unit, the optimization algorithm used was the Adam optimizer, and the loss function was the Mean Squared Error.
The parameters for the Prophet model were selected to handle seasonality, trend changes, and holiday effects. The growth parameter was set to “linear”. Yearly and weekly seasonalities were enabled by default, while daily seasonality was added if significant daily patterns were detected. Custom holiday effects were included to account for impactful days, specified based on context and expertise. The seasonality order was adjusted to capture complex seasonal patterns, and the model detected changepoints to reflect significant trend shifts.
3.5. Evaluation Metrics
Model performance was assessed using three key metrics: Mean Absolute Error (MAE), Root Mean Square Error (RMSE), and Coefficient of Determination (R2). MAE (3) provides a direct measure of the average absolute error predictions but is not sensitive to outliers. RMSE (4) captures the standard deviation of prediction errors, emphasizing larger errors due to its quadratic nature. R2 (5) indicates the goodness of fit, as it measures the proportion of variance in the observed data explained by the model. In the majority of cases, it is a very reliable indicator for model performance.
The equations of the metrics are as follows:
where
N is the number of observations;
is the predicted value for observation
;
is the measured value of observation
; and
is the mean of the observed values.
3.6. Software and Equipment
The computational tasks were performed on a MacBook Pro equipped with a 2.6 GHz Intel Core i7 processor, 16 GB RAM, and AMD Radeon Pro 5300 M GPU Key software that included the Anaconda Navigator for managing Python environments and dependencies; Visual Studio Code as the integrated development environment (IDE) for code development; and Python libraries, including
Pandas for data manipulation,
statsmodels for statistical modeling,
scikit-learn for evaluation metrics, and
TensorFlow/
Keras [
27,
28] for the LSTM implementation.
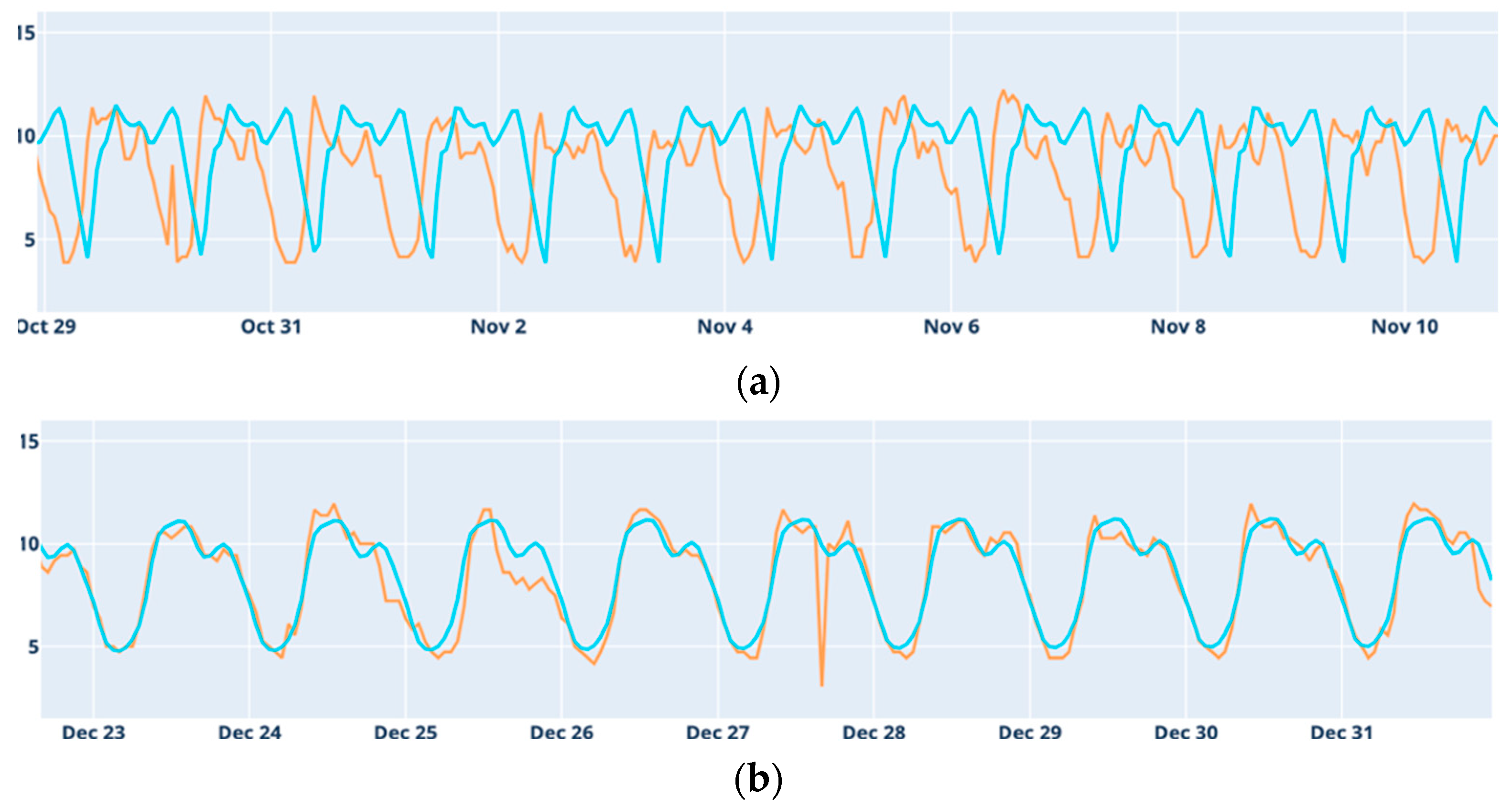
5. Discussion
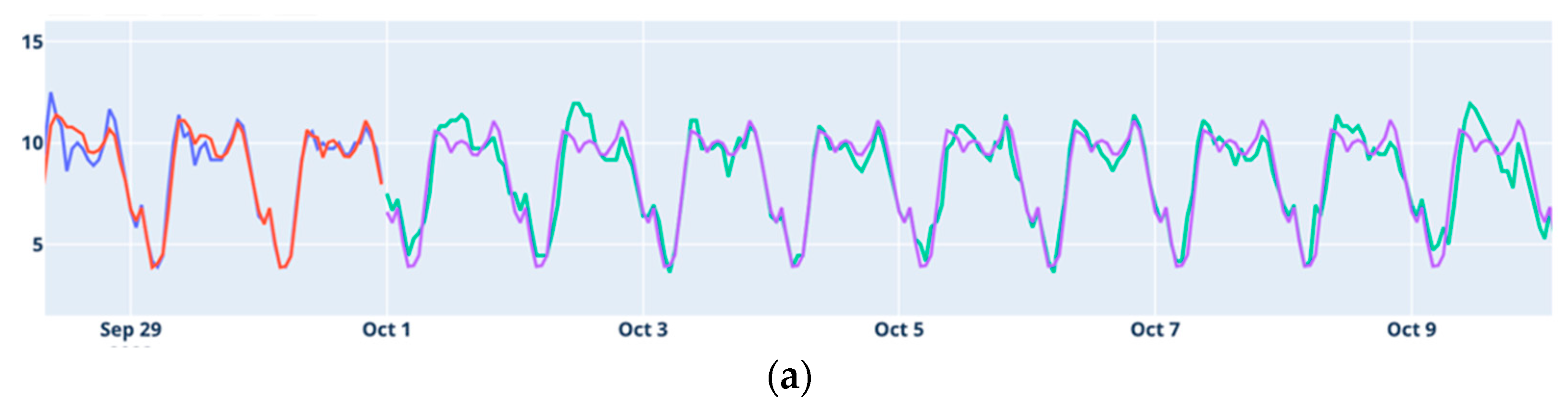
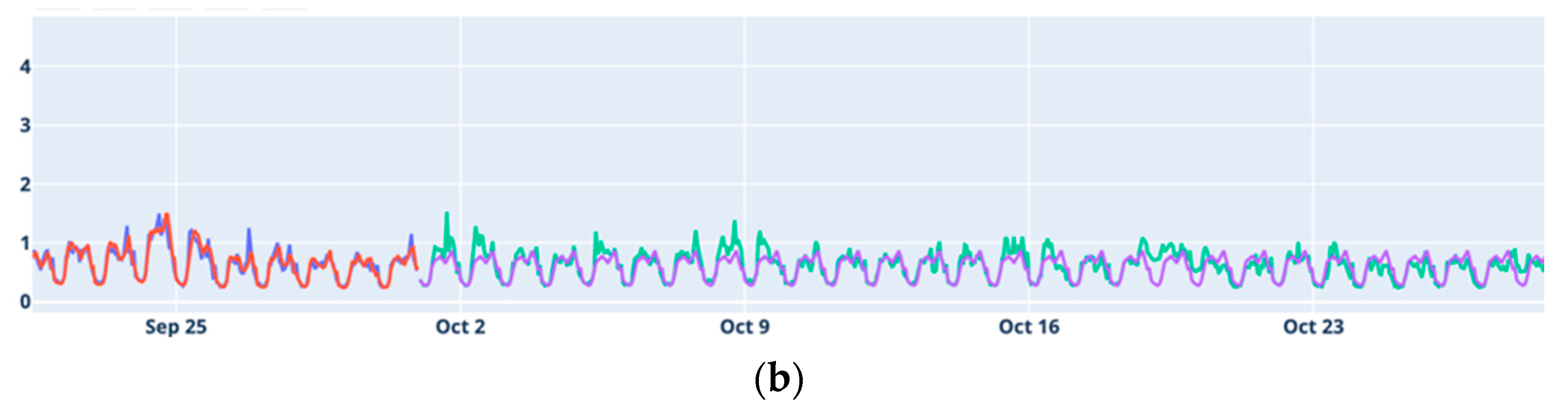
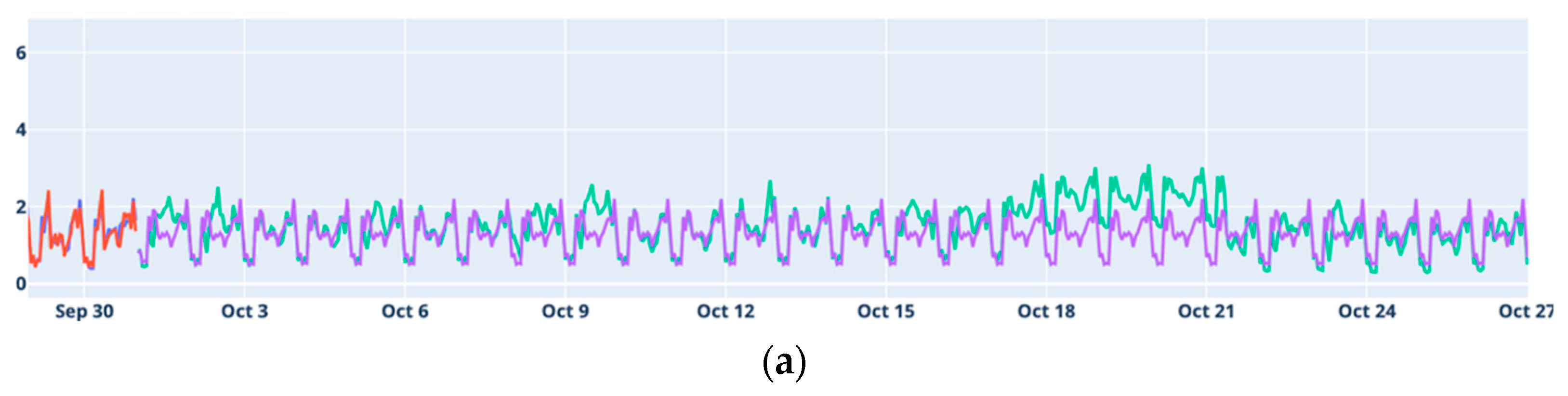
The results obtained in this work show that, overall, the ability to forecast accurately varies significantly by location. Alcáçova and Degolados showed the most reliable forecasting results, benefiting from clear temporal patterns that models could effectively capture. In contrast, Aldeia de Joanes and Janeiro de Cima presented more challenges, particularly for long-term forecasts, likely due to higher data variability and weak seasonal patterns. These findings emphasize the importance of tailoring forecasting models to the specific characteristics of each location’s data to achieve optimal results.
Considering Holt–Winters and ARIMA as classical models and LSTM and Prophet as modern models, the results indicate that the classical models generally perform better for medium-term forecasting. Conversely, the modern models tend to yield better results for long-term predictions.
According to the study referenced in [
10], which compares the Holt–Winters model with the ARIMA model, it was expected that ARIMA would significantly outperform the Holt–Winters model. While this was observed to some extent in the medium term, the difference was not substantial. Surprisingly, in the long term, the Holt–Winters model performed better than ARIMA. This underperformance of the ARIMA model can be attributed to certain characteristics of the data series, such as poor stationarity, high autocorrelation, and a distribution far from normal. These factors likely impacted its effectiveness.
Contrary to the findings in [
15], which suggest that neural network-based models perform well only for short-term horizons (predicting the next value), our results show that the LSTM model tested in this study provided better long-term forecasts. This model was evaluated in a manner that mimicked its application in a production environment, predicting value by value and compiling the results. When comparing our findings with the existing literature, where LSTM models often show extraordinary results under controlled laboratory conditions (e.g., [
29]), we concluded that our results are more realistic and reflective of actual performance.
Regarding the ability to capture seasonality, all four models adjusted well to daily seasonality. However, only the LSTM and Prophet models managed to capture annual seasonality effectively. The Holt–Winters and ARIMA models did not account for patterns from the same period in the previous year, being more influenced by recent data leading up to the forecast period. This implies that these models lose accuracy when series exhibit strong seasonal patterns. This limitation of the ARIMA model was also noted in [
22] during a comparison with the Prophet model.
On the other hand, the LSTM and Prophet models showed strong tendencies to adhere to annual seasonal patterns. This contradicts the implications in [
22], which suggested that the LSTM model might not handle annual seasonality well. The Prophet model demonstrated a good fit for both daily and annual seasonality. However, it exhibited a significant limitation in the amplitude of its forecast curves. This limitation was particularly noticeable for series with high variability in maximum flow values during summer (Aldeia de Joanes and Janeiro de Cima). This raises concerns about the Prophet model’s accuracy if the forecast period includes the summer, as it might significantly under-predict the actual values. This is of special concern in datasets corresponding to low-population-density areas where the population increases significantly during summer, such as in the cases of Aldeia de Joanes and Janeiro de Cima.
The LSTM model proved to be the best at respecting annual seasonality, making predictions based on what happened in the same periods of the previous year. It only encountered issues during the transition period between training and testing, making it difficult to achieve good medium-term forecasts.
The Prophet model showed performance comparable to the LSTM model regarding annual seasonality. However, its limitation in the amplitude of predictions prevented it from achieving better results.
For the ARIMA and Holt–Winters models, the inability to implement annual seasonality renders them accurate for medium-term forecasting but imprecise for long-term forecasting. In a water distribution network, if the number of breaks continues to increase, these models will be unable to alert us as they do not consider the need to make predictions based on similar periods in previous years.
This work has some limitations. A primary constraint was the quality and availability of historical data, as incomplete, noisy, and high-variability data can lead to inaccuracies. Most notably, for one of the datasets used in this work (Aldeia de Joanes), none of the models provided satisfactory results for either medium-term or long-term forecasts. Similarly, for another dataset (Janeiro de Cima), none of the models used for long-term forecasting provided satisfactory results. Each forecasting model, including ARIMA and Holt–Winters, has inherent limitations; for example, ARIMA struggles with non-stationary data and pronounced seasonal patterns, particularly for long-term predictions. The complexity of selecting optimal parameters and the significant computational resources required for training advanced models like LSTM further constrained this study. Additionally, the findings and models are tailored to the specific dataset used, raising concerns about their generalizability to other datasets without further adjustments. The effectiveness of multivariate models is also heavily dependent on the careful selection and preprocessing of input features, where suboptimal choices can degrade model performance. Furthermore, this study does not incorporate additional external variables (e.g., climatic factors) that could potentially enhance forecasting accuracy, especially for modern models like LSTM. These limitations underscore the challenges in developing accurate and robust forecasting models, highlighting the need for meticulous data handling, model tuning, and validation. Further research could focus on the investigation of hybrid models for improvement in a water demand forecast. Hybrid models combining classical and deep learning approaches have been studied for water demand forecasting problems. For instance, combining ARIMA with a type of neural network called the General Regression Neural Network improved daily water forecasting in Saudi Arabia [
30]. Another study found that a hybrid model with Holt–Winters, ANN, and SARIMA performed best for industrial water consumption forecasting [
25]. More recently, advanced hybrid methods using different machine learning approaches, such as Convolutional Neural Networks, LSTM, and LSTM with attention mechanisms, have been exploited for water demand forecasting and have been shown to lead to very promising results [
23].





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}