3.2.1. Principal Component Analysis
The applicability of PCA is not limited to specific data distribution types. Its strength lies in its ability to identify the main directional features in the data, and this is not strictly constrained by the distribution of the data. This is one of the reasons why PCA is considered in this study. PCA has excellent variance explanatory power, which makes the principal components relatively good in interpretability, effectively capturing the most significant features in the data. Through dimensionality reduction technology, the principal component analysis method reduces linear combinations of multiple indicators with specific correlations in the original variables into a few comprehensive indicators [
18]. It makes the new variables reflect as much as possible on the premise that they are unrelated. The information on the original variable is widely used in indicator synthesis. The first principal component is the direction of the most significant data variation. Only taking the first principal component is an extreme method of forcibly discarding dimensionality reduction. The premise is that the variance contribution rate of the first principal component is large enough. The specific steps of PCA are as follows:
First, establish the autocorrelation matrix
R, and calculate its eigenvalues
and eigenvectors
namely,
In the formula:
X* is the normalized data matrix [
19].
Then determine the number of principal components, variance contribution rate
and cumulative variance contribution rate
, which are respectively [
20]:
When the cumulative variance contribution rate is between 75% and 95%, the principal components with eigenvalues greater than 1 contain the information of m original input data, and the number of principal components is
P [
21]. Then the eigenvectors corresponding to the
P principal components are:
Then the matrix of
P principal components of n features is:
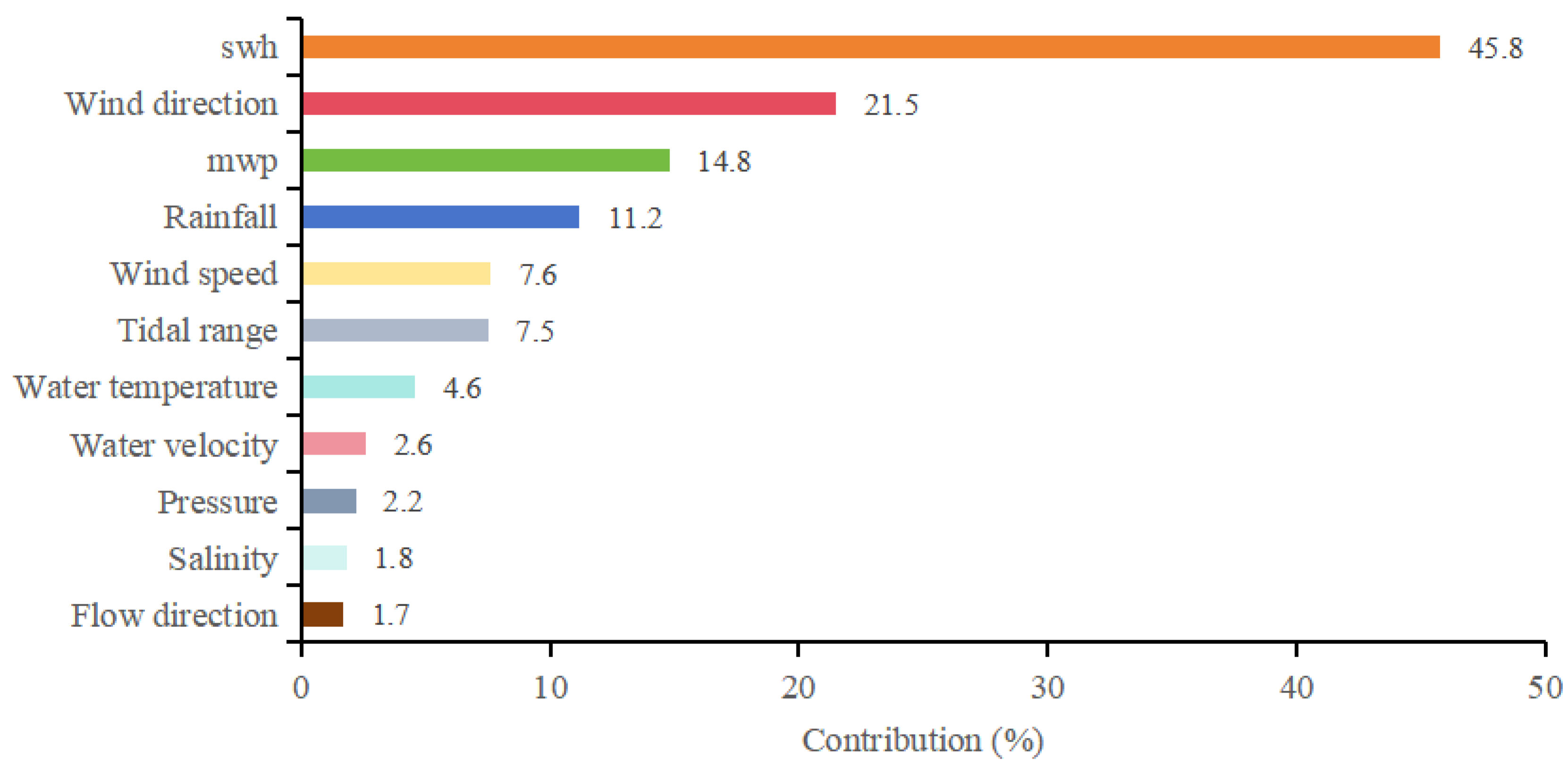
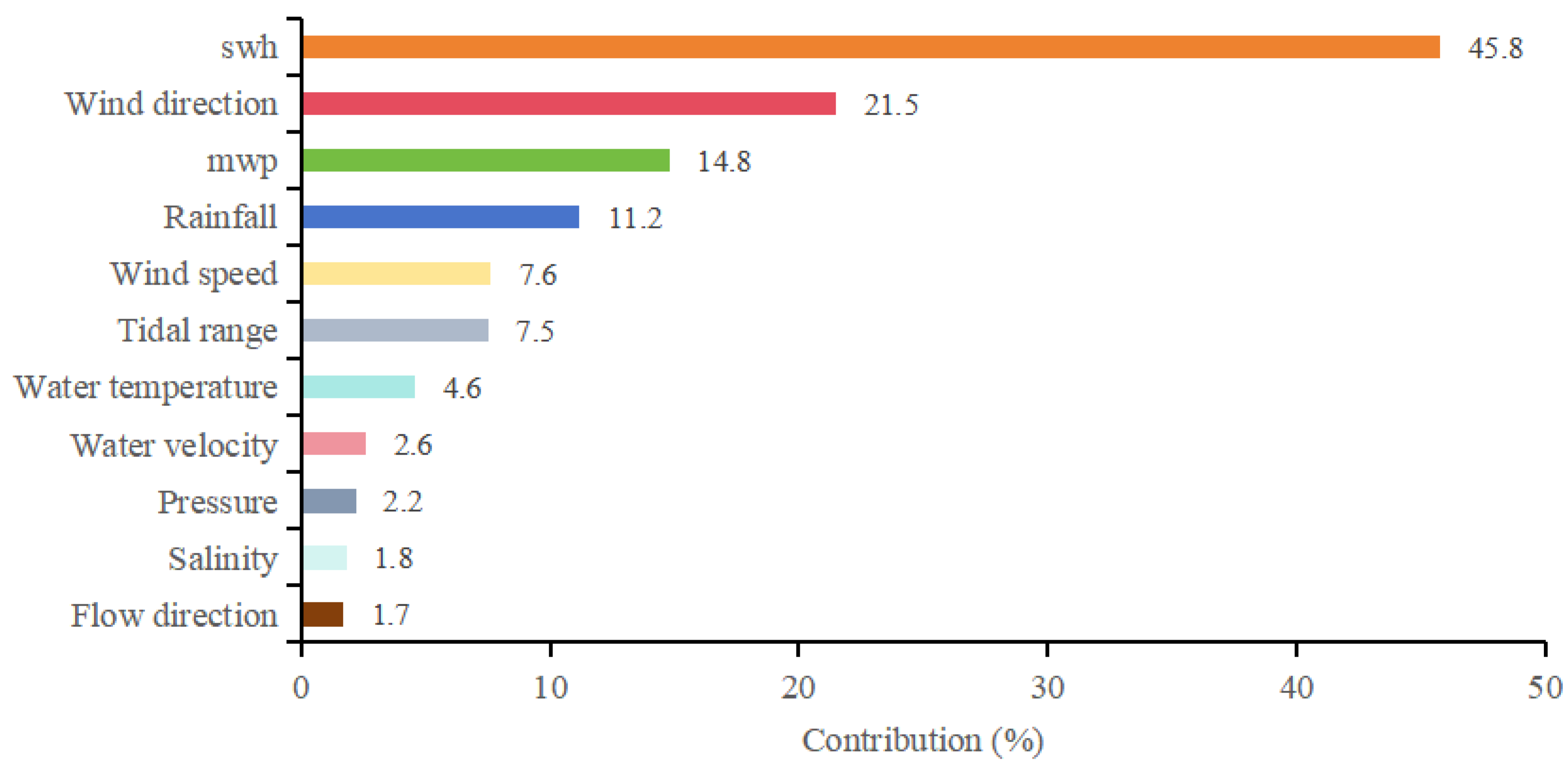
This paper collects data on as many as 12 characteristics related to SSC changes. The PCA algorithm can reduce the original feature data’s dimension and eliminate redundancy’s influence.
3.2.2. Long and Short-Term Memory Neural Network (LSTM)
The LSTM is a type of time-recurrent neural network that inherits most of the characteristics of the Recurrent Neural Network (RNN) model. Simultaneously, it solves the problem of gradient disappearance. Based on RNN, LSTM adds a “memory cell structure” for judging whether the information is valid or not, that is, a cell. We use the LSTM cell described in
Figure 2 [
6], which slightly simplifies the cell described by Graves et al. [
22].
i,
f,
o,
c, and
g are vectors of input gates, acquisition gates, output gates, and cell activation and input modulation gates, respectively. Each cell includes an input gate, a forget gate, and an output gate. Each piece of data entering the LSTM network can be judged on whether it will be helpful for training [
23]. Only useful information is retained, and information judged useless will be discarded through the forget gate [
23]. This work proves effective for data exhibiting challenges related to long-term serial dependencies [
24].
Wherein: ⊙ refers to the point multiplication of matrix by element;
is the deviation vector of each layer output;
is the activation function;
is the weight matrix of the corresponding layer;
is used to update cell status; Input gate
controls information flow into memory cell
; Output gate
controls information in memory cell;
at the current time can flow into the currently hidden
[
23].
3.2.5. Optimizing the PCA-LSTM Framework
- (1)
Constructing a Multi-Source Dataset
Merging data from multiple sources into a single dataset can be achieved through techniques such as time stamp alignment and matching of common keywords. Data from different sources may exhibit format differences, time disparities, or other inconsistencies. When merging data, these disparities can be addressed through techniques such as timestamp alignment and matching keywords, improving the consistency and quality of the data. This process of data cleaning and integration helps ensure that analyses are based on high-quality, consistent information. The high-precision meteorological data from ERA-5 provide critical information about meteorological conditions during typhoons. The observational data from the four hydrological stations at East China Normal University offer directly measured hydrological and water quality information, serving as an essential source for understanding the hydrological conditions in the estuarine region. Tidal range data from the Shanghai Maritime Safety Administration is of significant importance in comprehending the impact of tides and the transport of suspended sediments. By integrating data from these diverse sources, we gain a comprehensive understanding of the environmental conditions in the Yangtze River Estuary during typhoons, allowing for a thorough exploration of the variations in SSC and its relationship with meteorological and hydrological conditions.
- (2)
Dealing with Non-Zero Missing Values
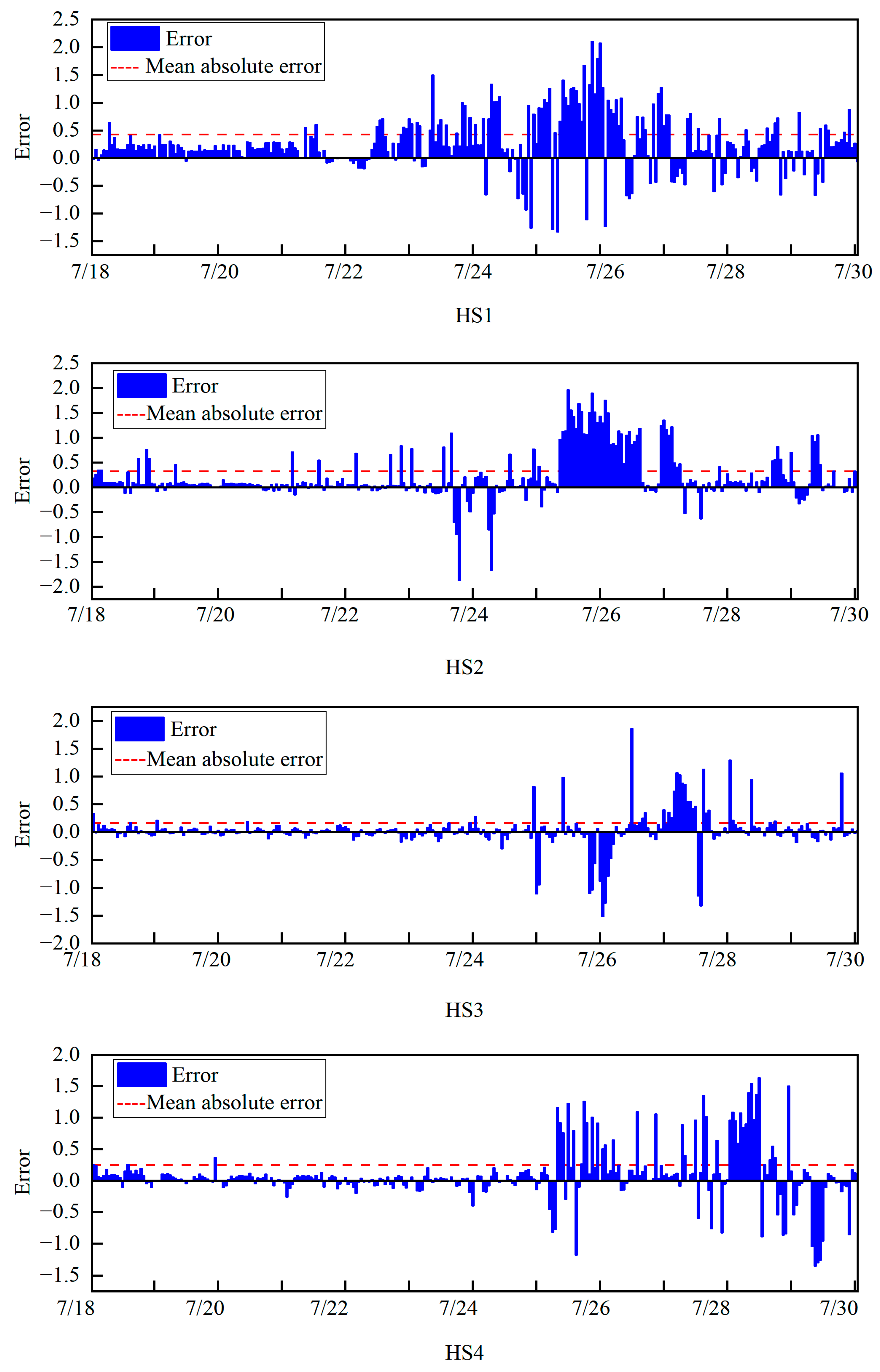
We addressed non-zero missing values in the multi-source dataset. Due to sensor malfunctions and data transmission issues during typhoons, missing values are inevitable, with the range of missing values within 5%. The linear interpolation method is employed to handle the missing values to avoid the impact of missing values on simulation SSC results.
Linear interpolation is a simple and efficient interpolation method. Despite the nonlinear trends in data, there exists local linearity between adjacent data points. In such cases, linear interpolation can sufficiently approximate the primary features of the data without introducing the additional complexity of higher-order interpolation.
Linear interpolation is calculated using the following formula:
Yt is the estimate for a missing value, where Yt−1 and Yt+1 are adjacent known data points, and Xt is the position corresponding to the missing value. For each missing value, we first determine its temporal or spatial position Xt. Subsequently, we use the aforementioned linear interpolation formula to calculate the estimated value Yt. This involves acquiring neighboring known data points, computing their rate of change, and using this information for interpolation. The calculated estimated value Yt is then used to replace the missing value in the original dataset.
- (3)
Normalization process
In order to accelerate the gradient descent process of the model, data normalization is performed. The formula for normalization is:
In the formula,
m represents the normalized value,
x represents the original data, and
and
represent the minimum and maximum values of the original data sequence.
- (4)
Data dimensionality reduction
Due to the raw data having a dimensionality of 12, using the raw data as input for the model directly would reduce the simulation effectiveness of the model and make it difficult to obtain satisfactory results within a reasonable training time. Therefore, reducing the dimensionality of the feature data is necessary to eliminate redundant information. PCA can transform multiple indicators into several comprehensive indicators (principal components) through orthogonal transformation, thereby reducing the interference of redundant data.
- (5)
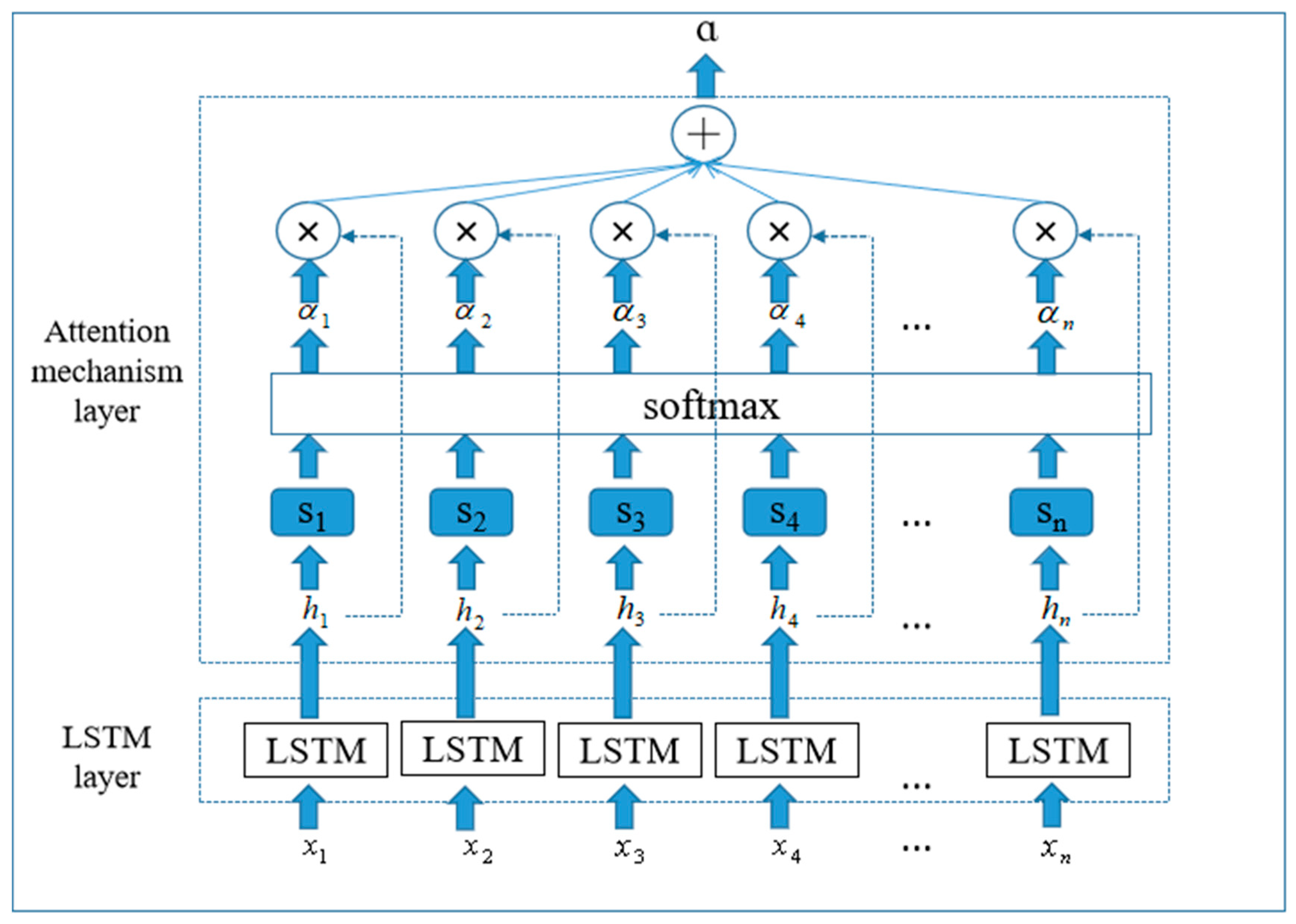
Add attention mechanism layer
Adding an attention mechanism layer in the LSTM network allows for the allocation of weights to different parts of the input sequence, improving the ability to focus on important information (
Figure 3). The dimensionality-reduced data is fed into the LSTM layer, and the hidden state
ht is output for each time step. Unlike the unoptimized LSTM that uses the last hidden state to calculate the prediction, the attention-based LSTM inputs the hidden state for each time step into a self-attention layer. Through an attention scoring function, the self-attention layer calculates the attention distribution α, and then combines the
ht for each time step to calculate the final prediction, taking into account the
ht of the time step.
- (6)
Parameter tuning and results output
In this paper, we use the DE algorithm to determine the hyperparameters of the LSTM network. The feature data reduced by the PCA method is used as the input variable for the model. The maximum training time is 100 with a training accuracy of 0.001, a learning rate of 0.01, a batch size of 5, 3 hidden layers with 9 hidden nodes, and the output variable is SSC. The model is trained using these settings to obtain the simulated SSC results.




 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}