
A Deep Learning Model of Spatial Distance and Named Entity Recognition (SD-NER) for Flood Mark Text Classification

Abstract
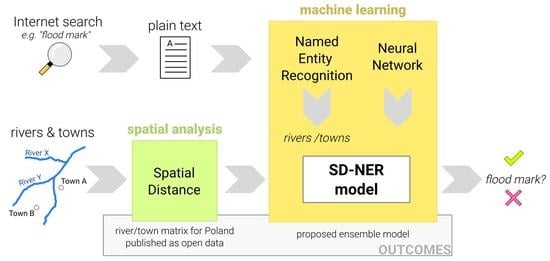
:
1. Introduction
2. Related Work
2.1. Web Scraping
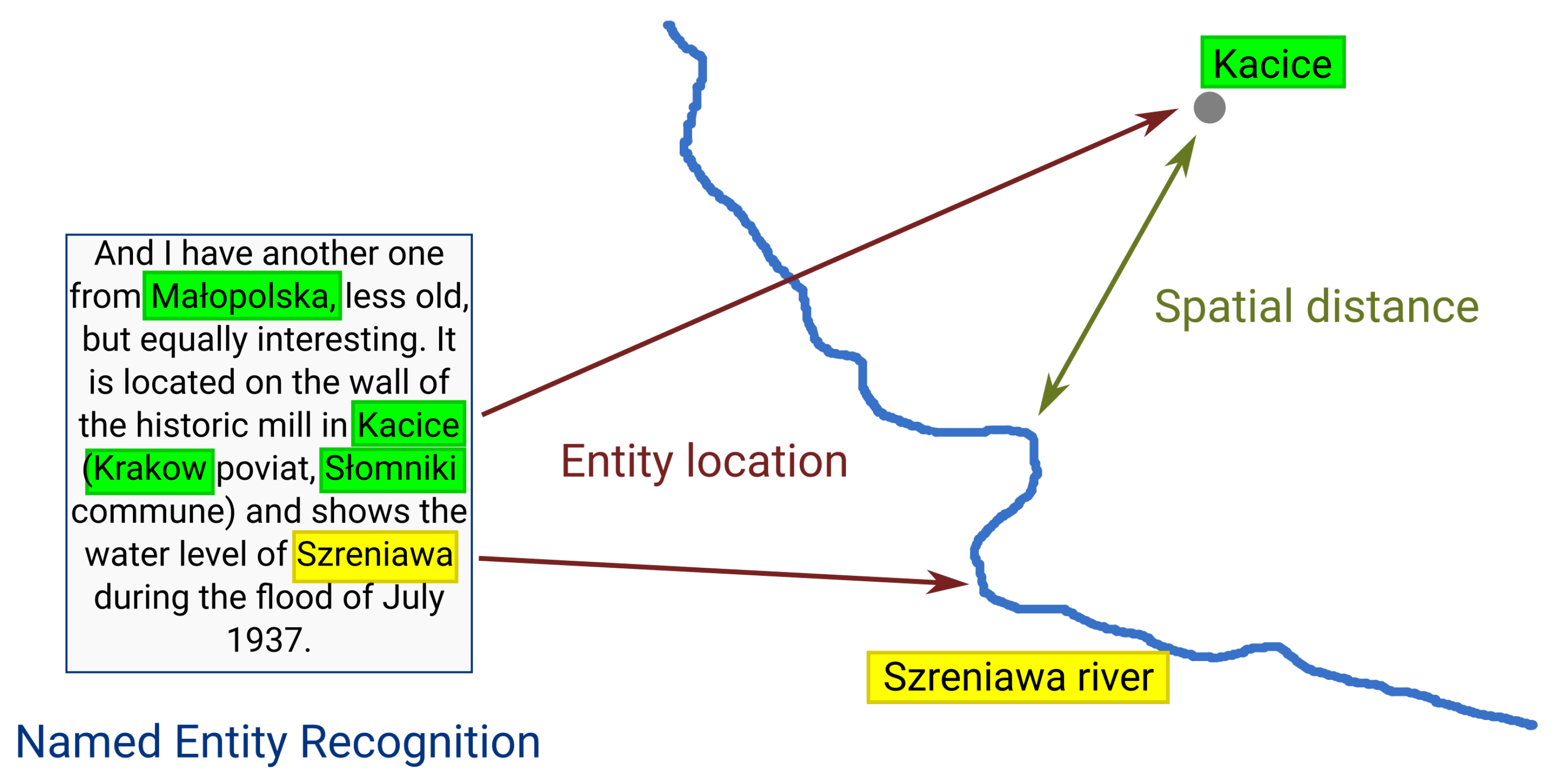
2.2. Toponym Extraction by Named Entity Recognition
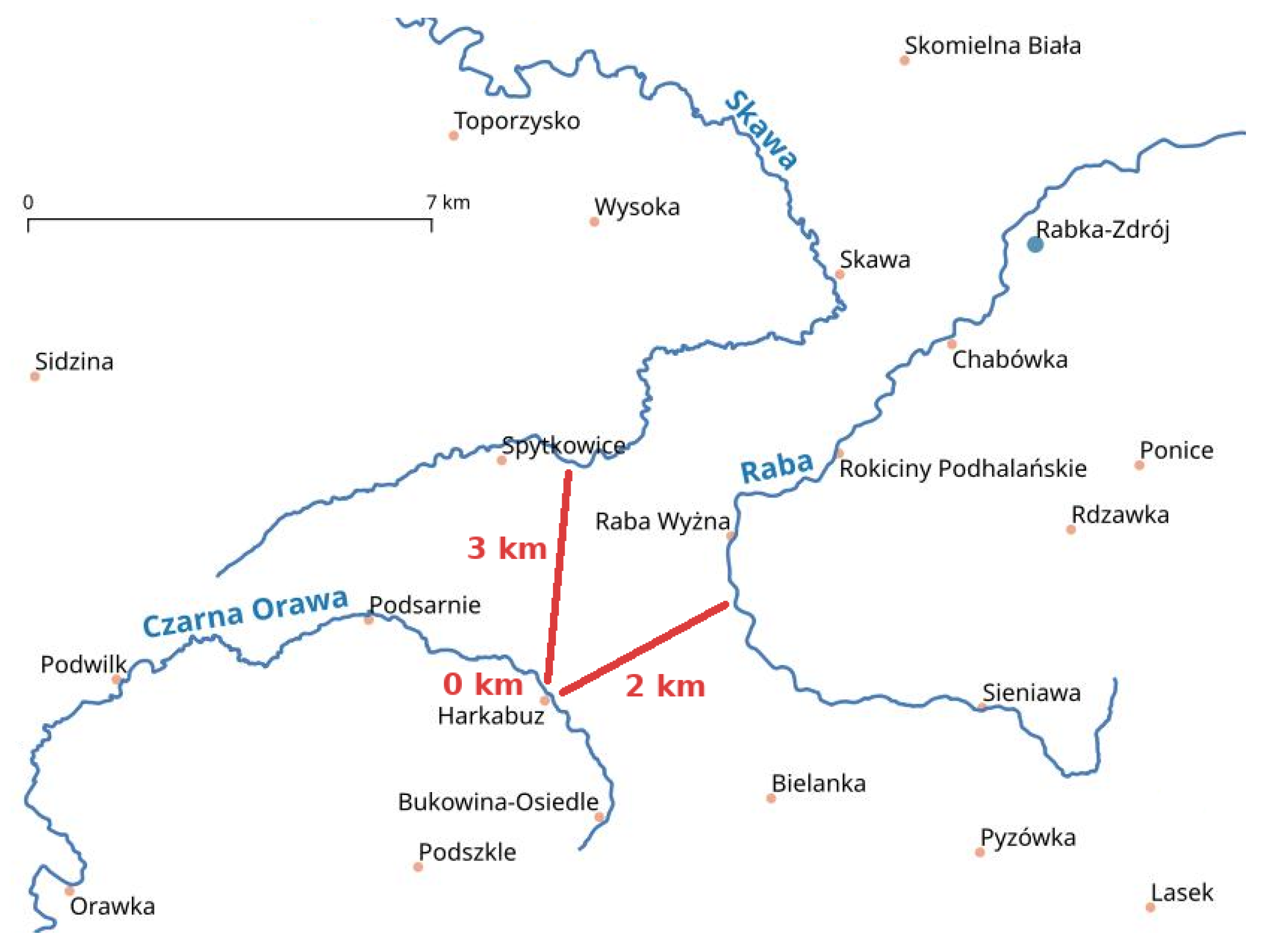
2.3. Spatial Distance
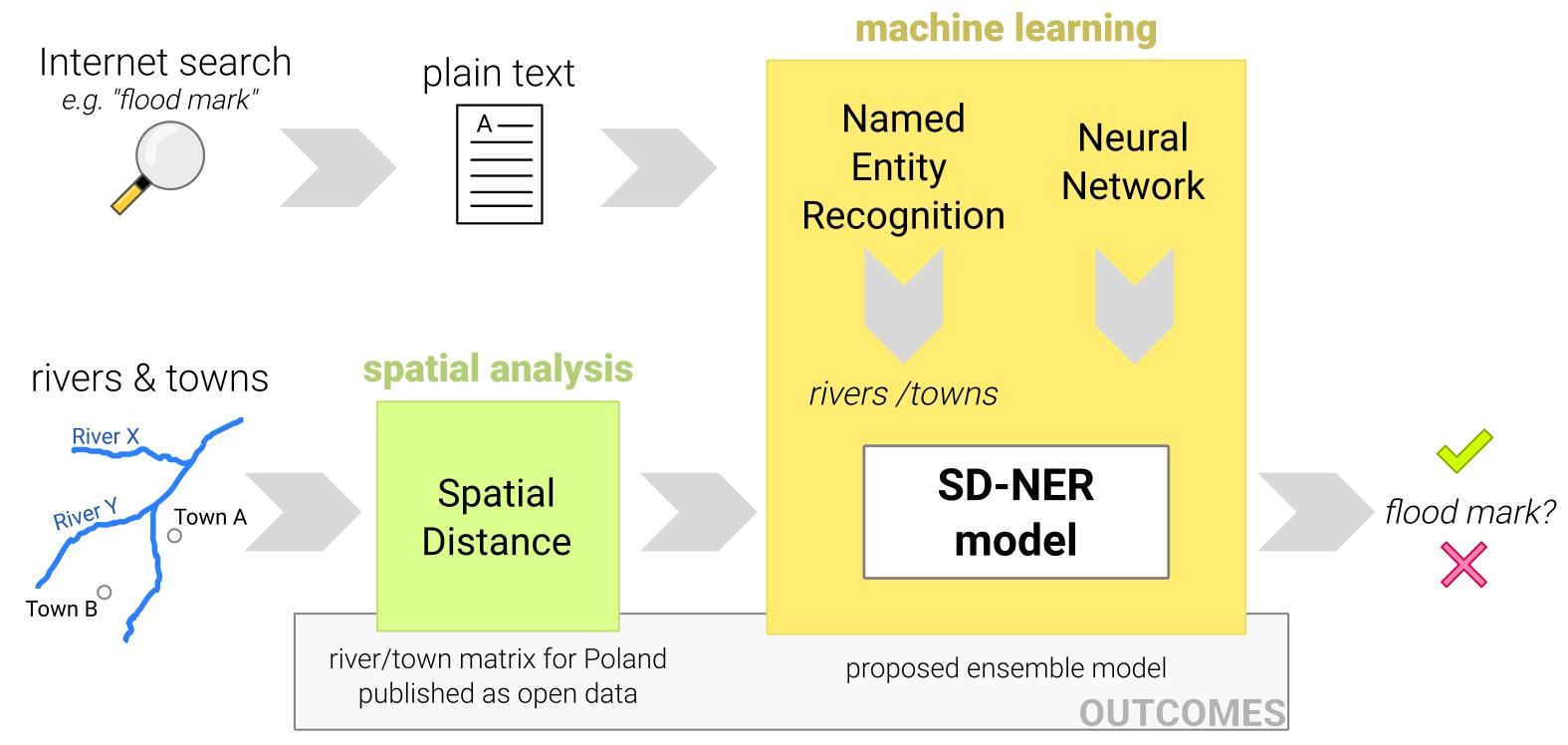
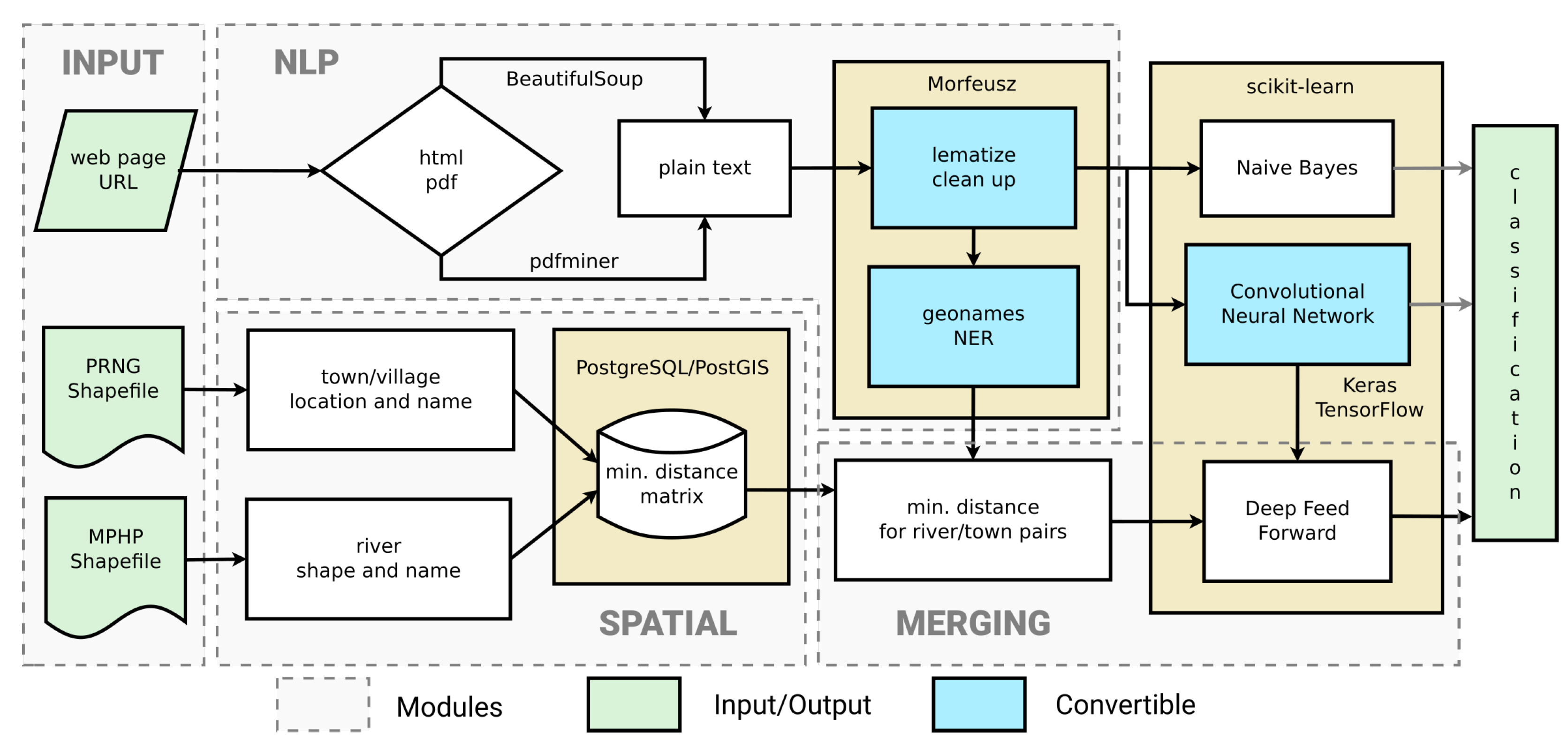
3. Materials and Methods
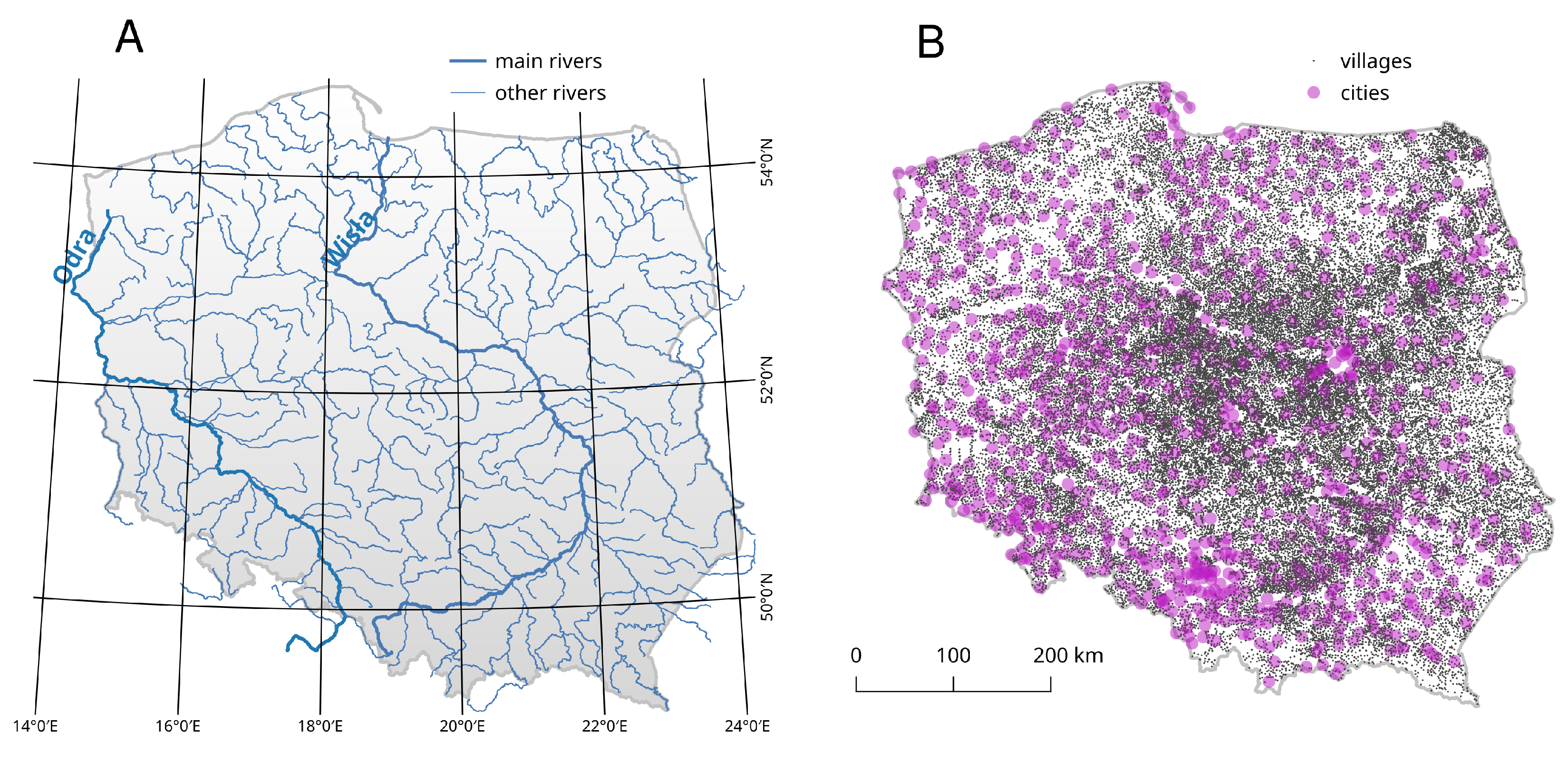
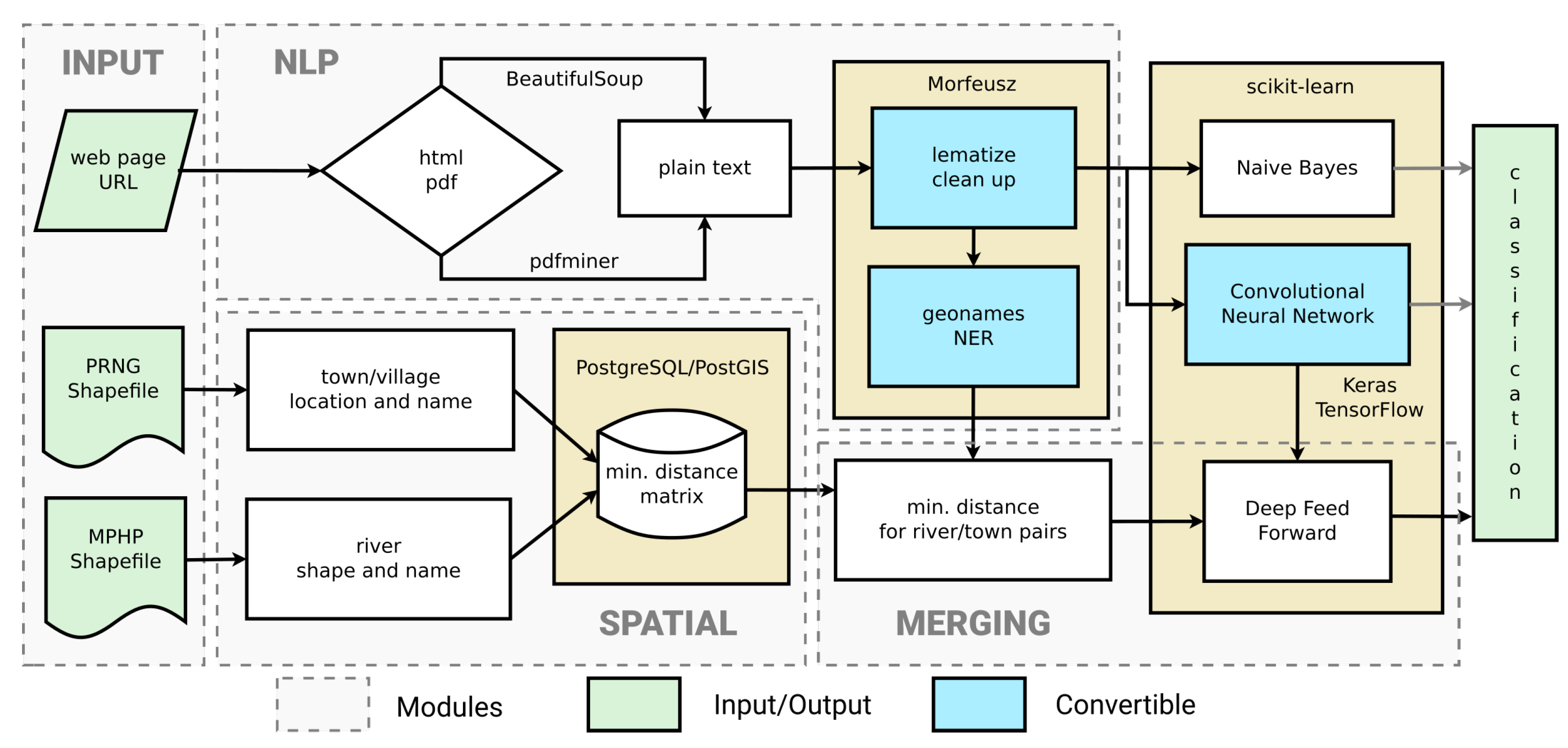
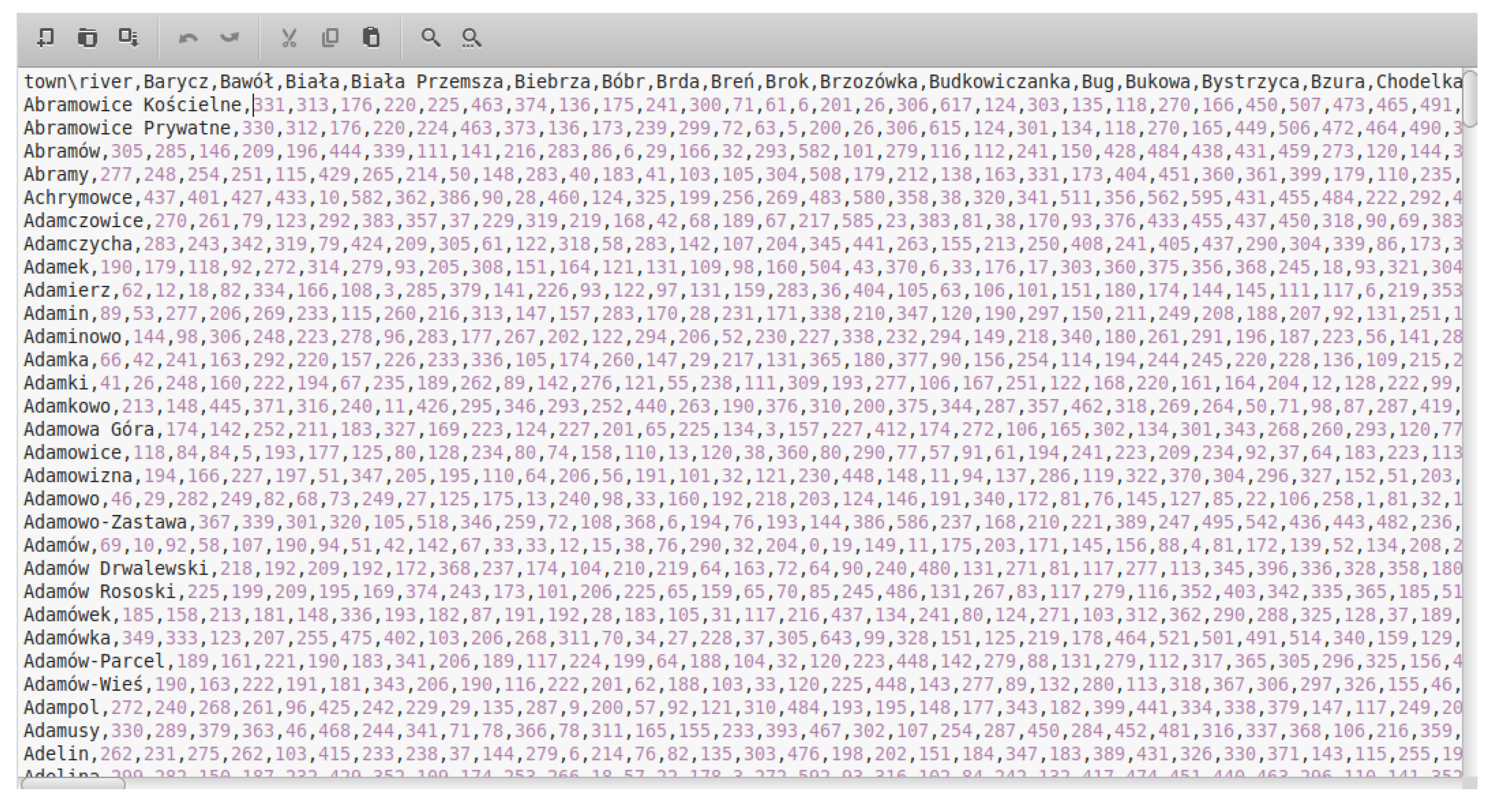
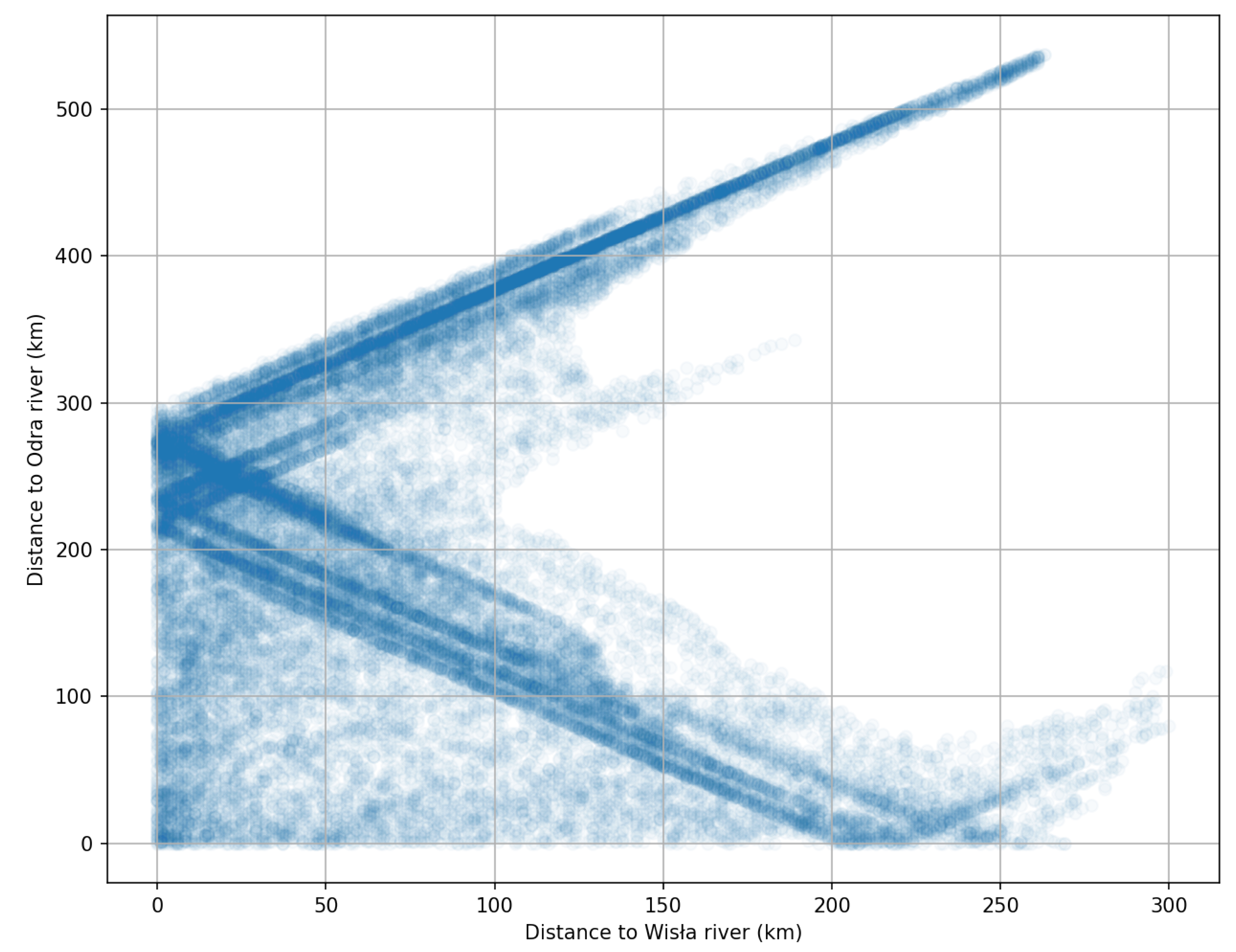
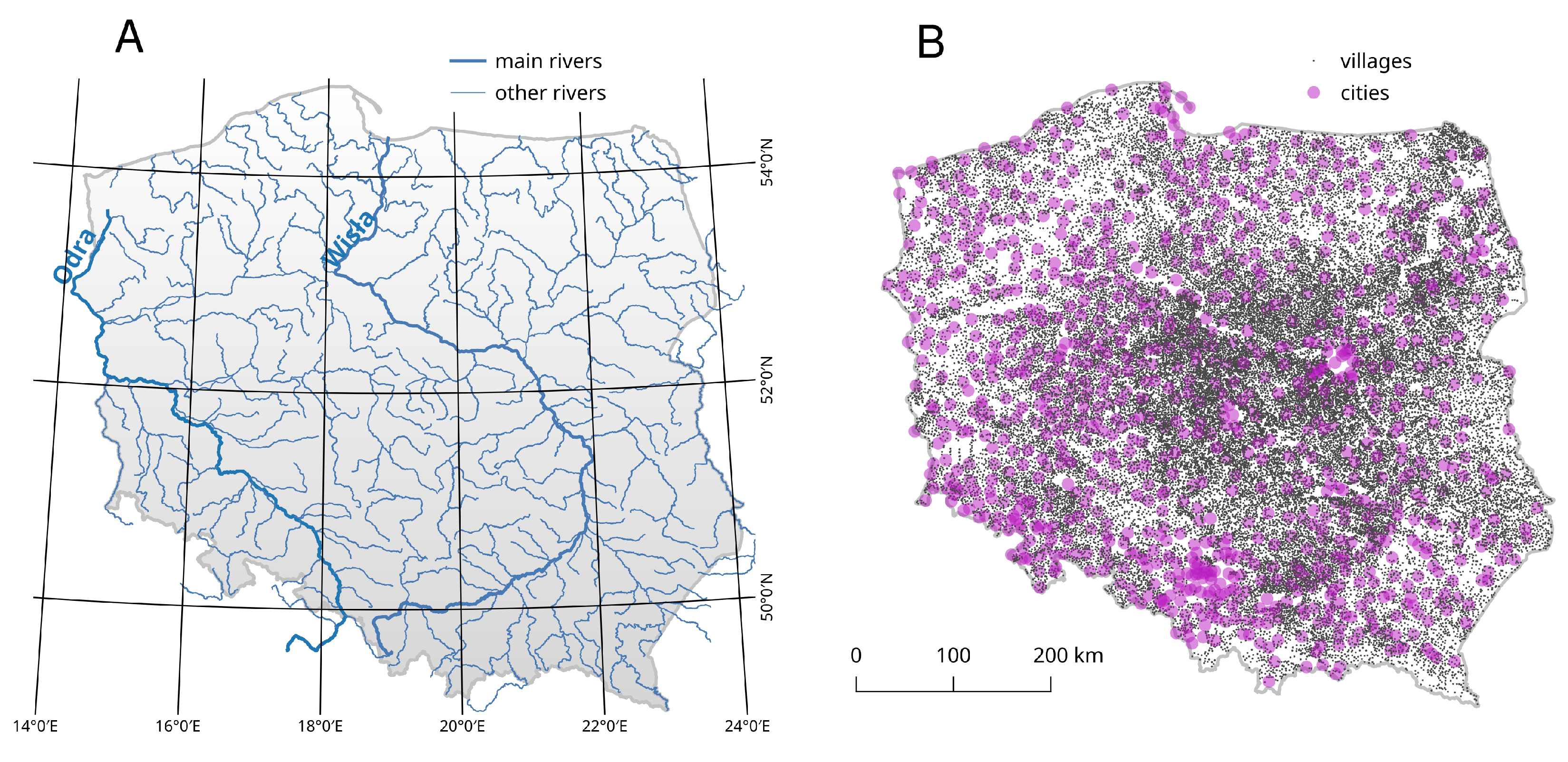
3.1. Materials
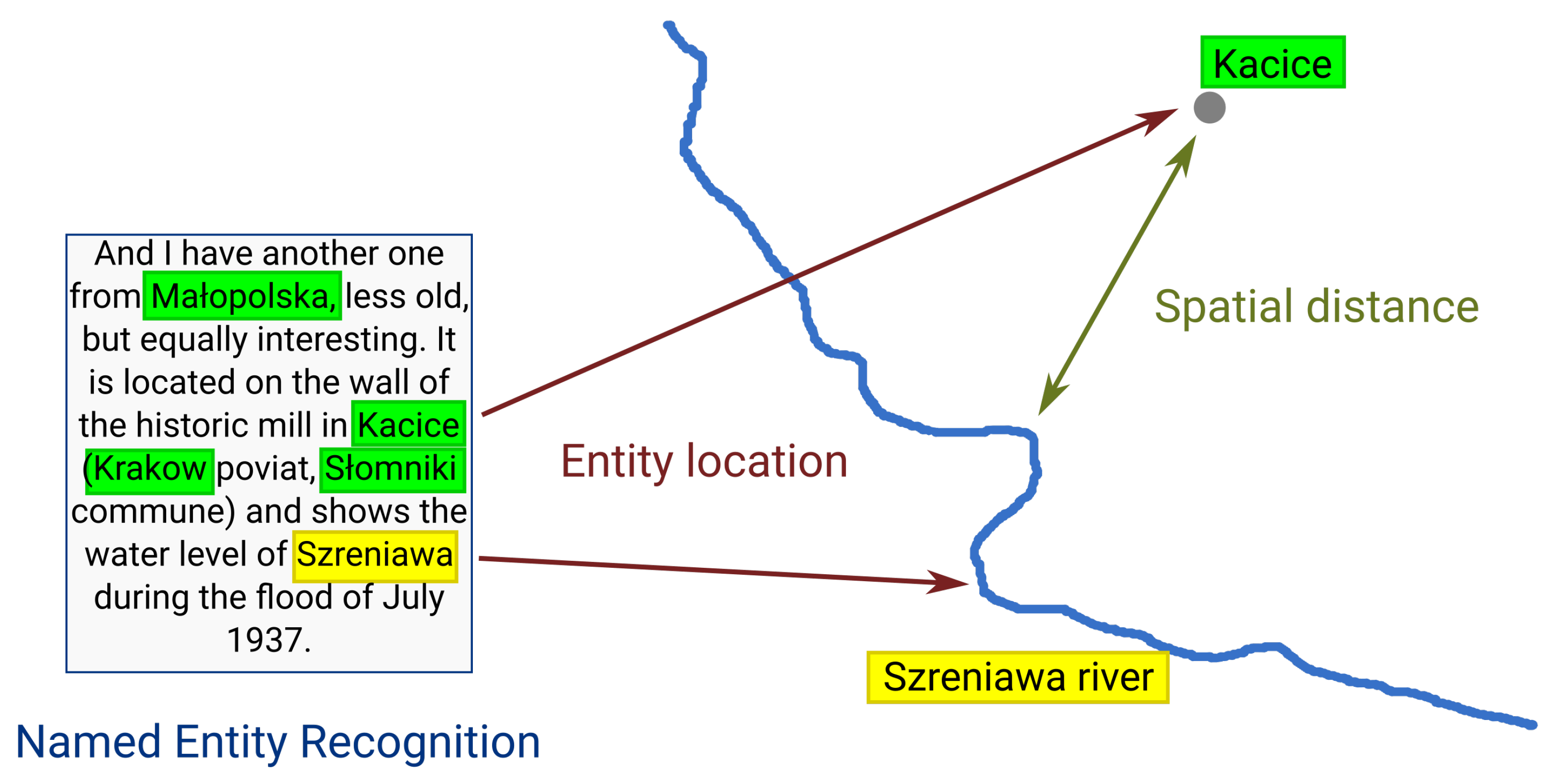
3.2. Methods
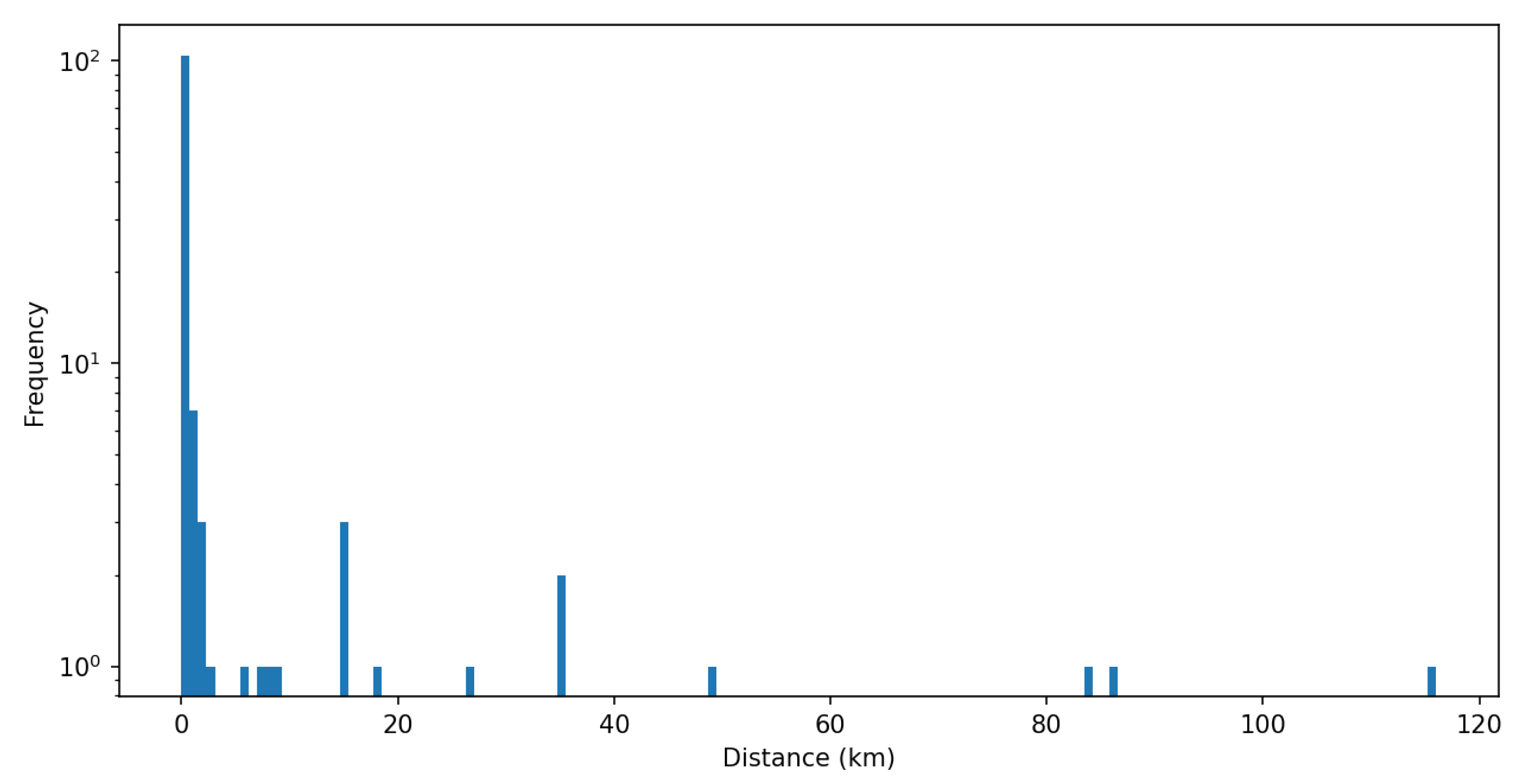
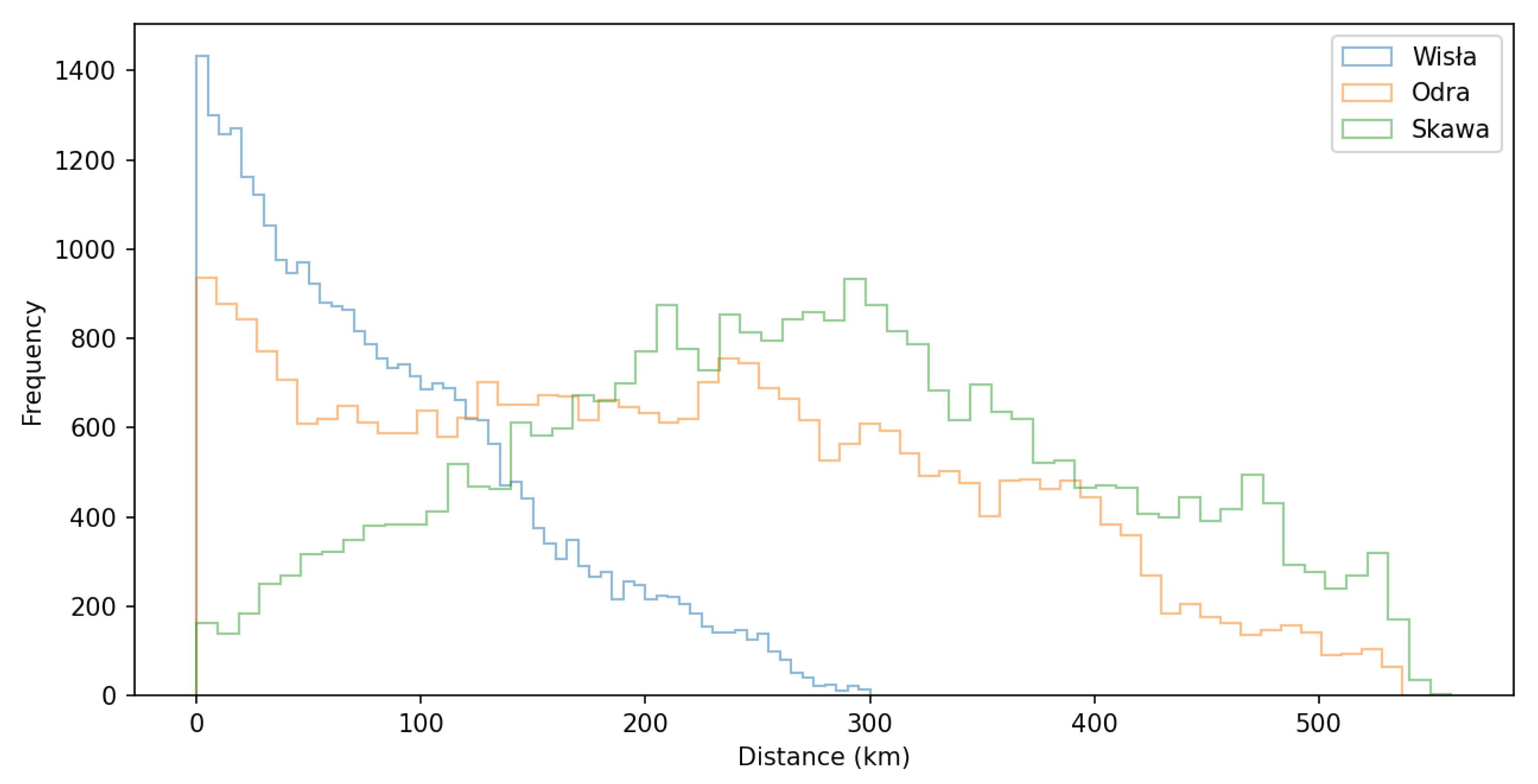
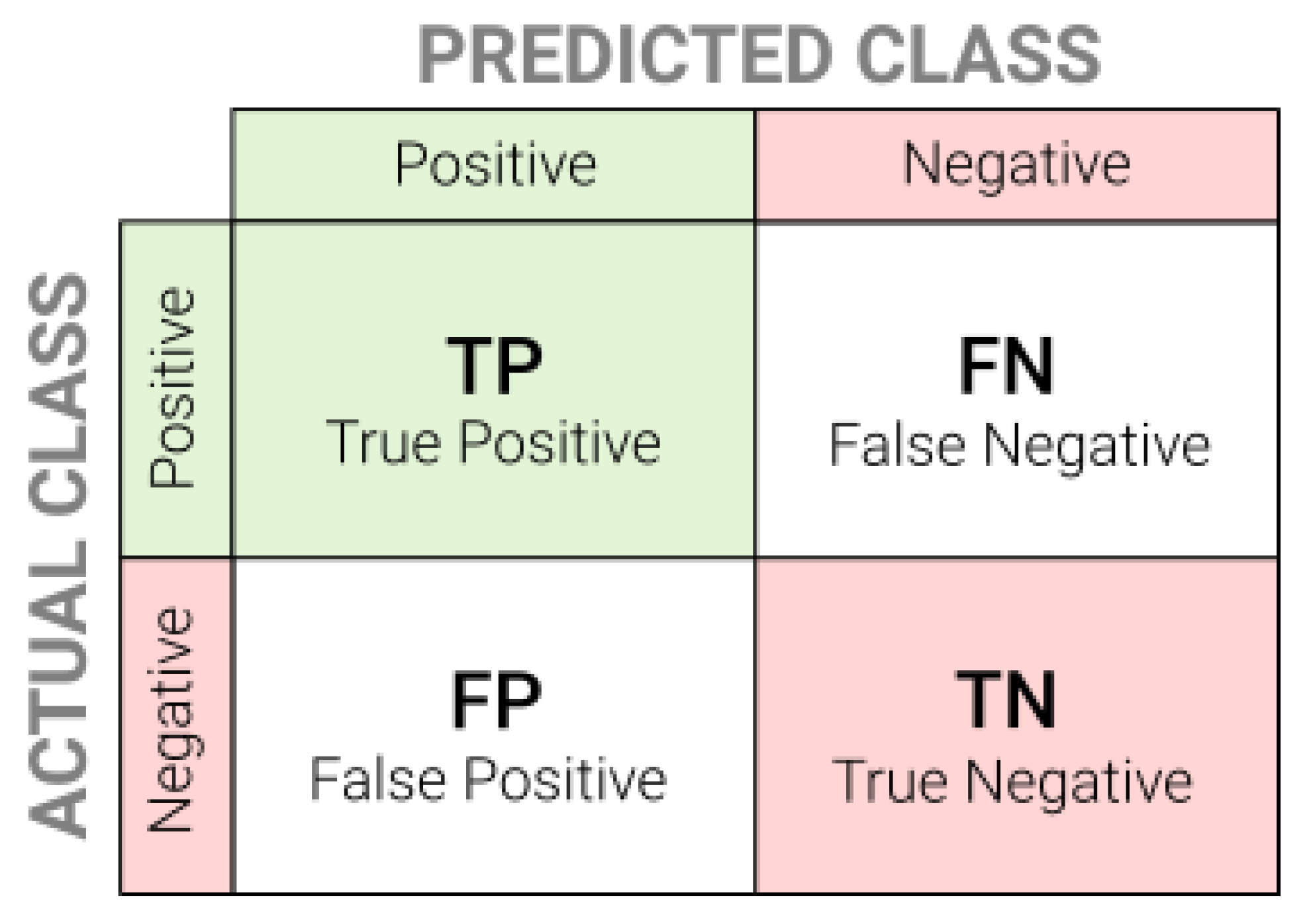
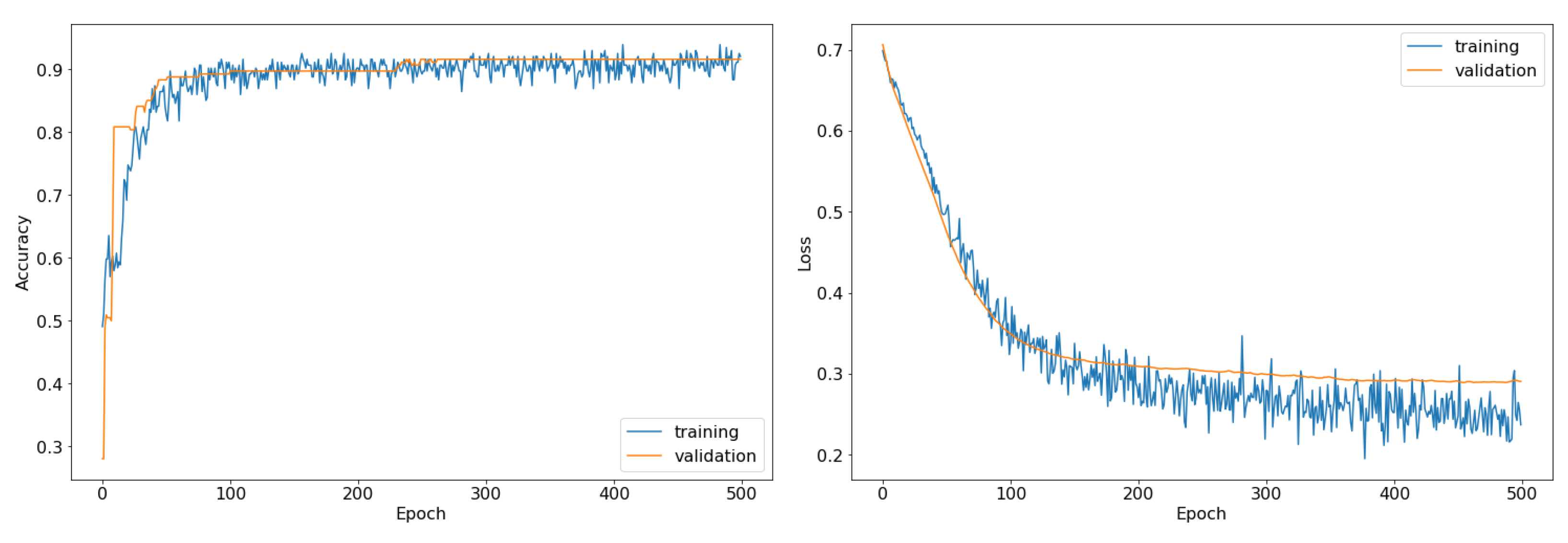
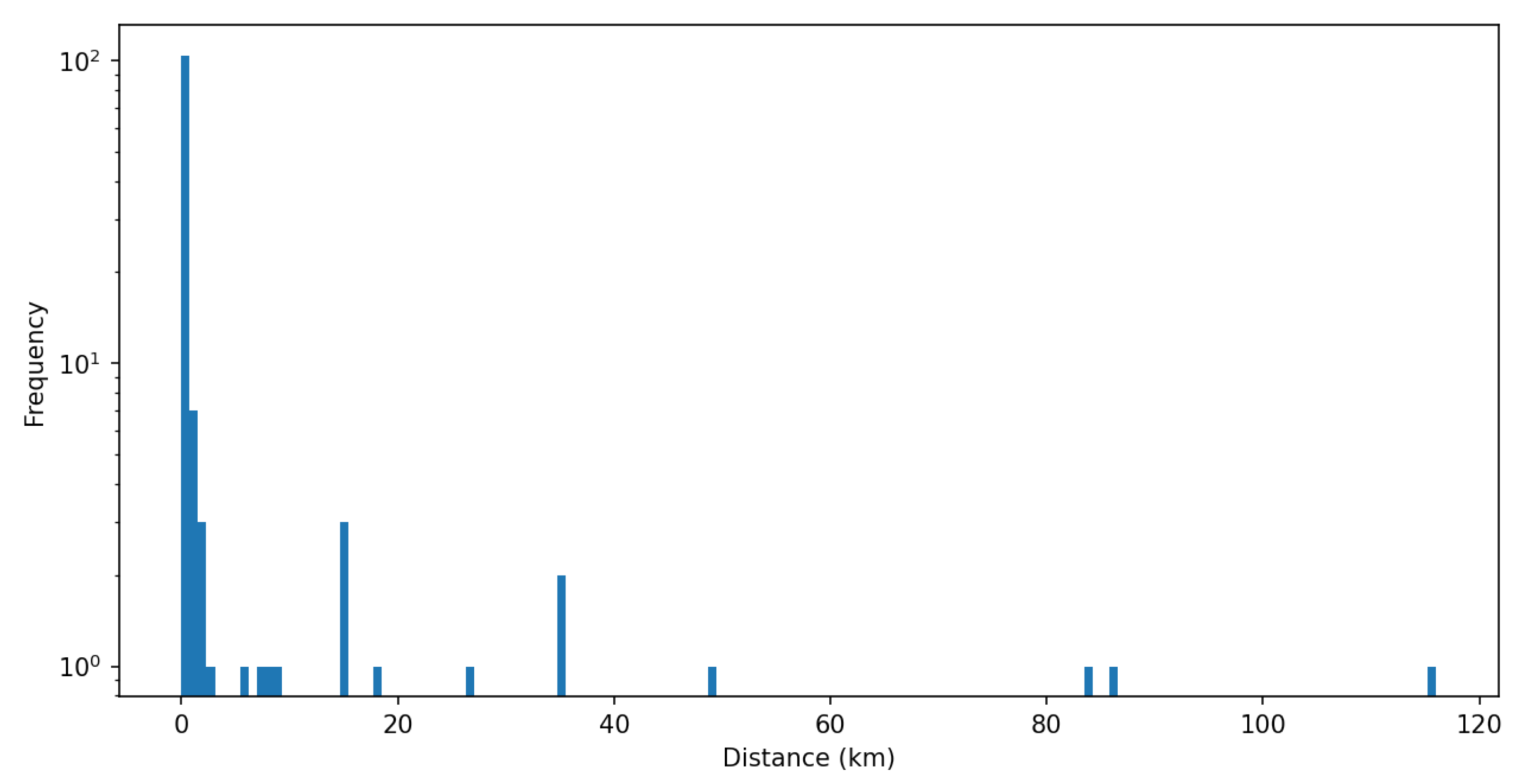
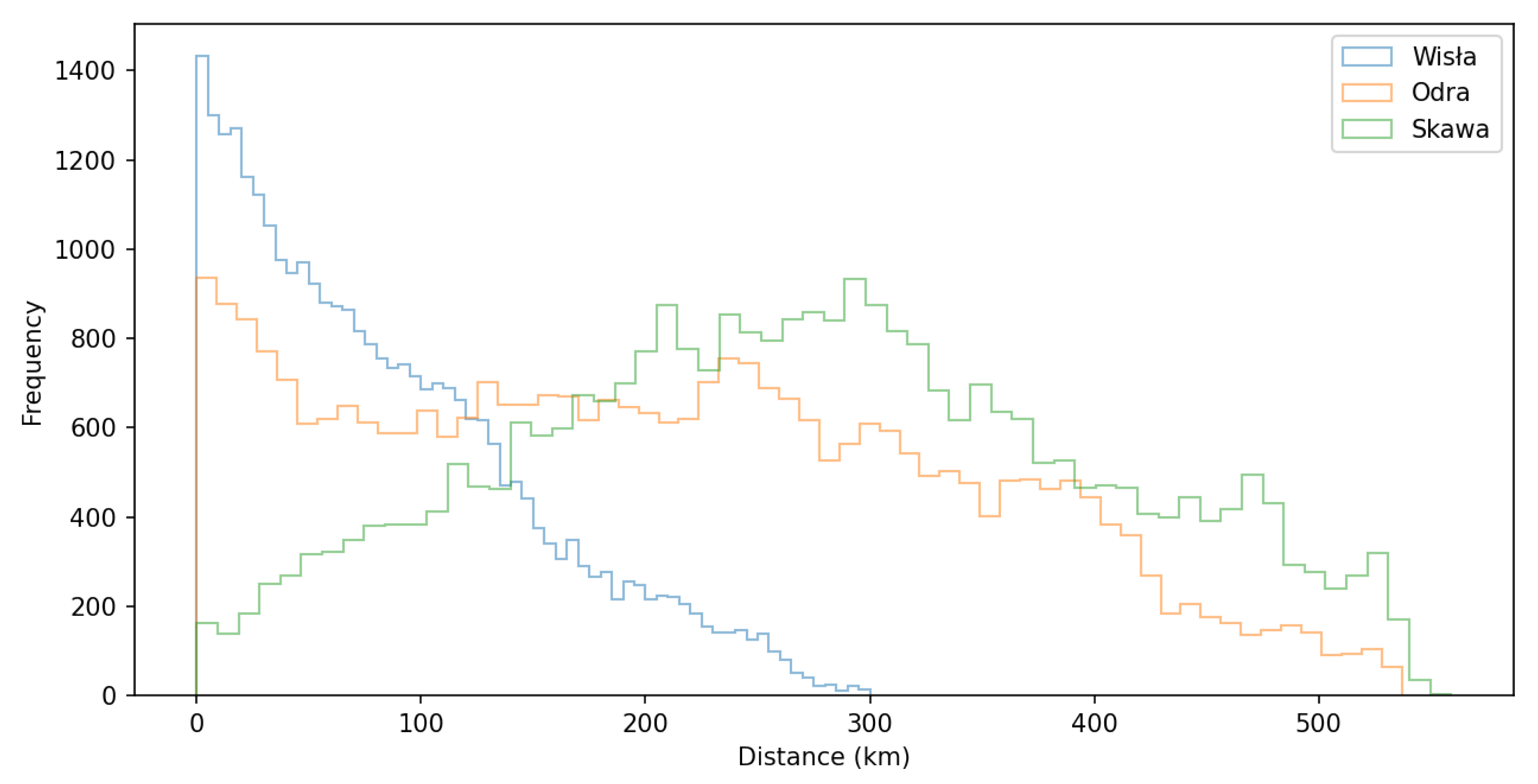
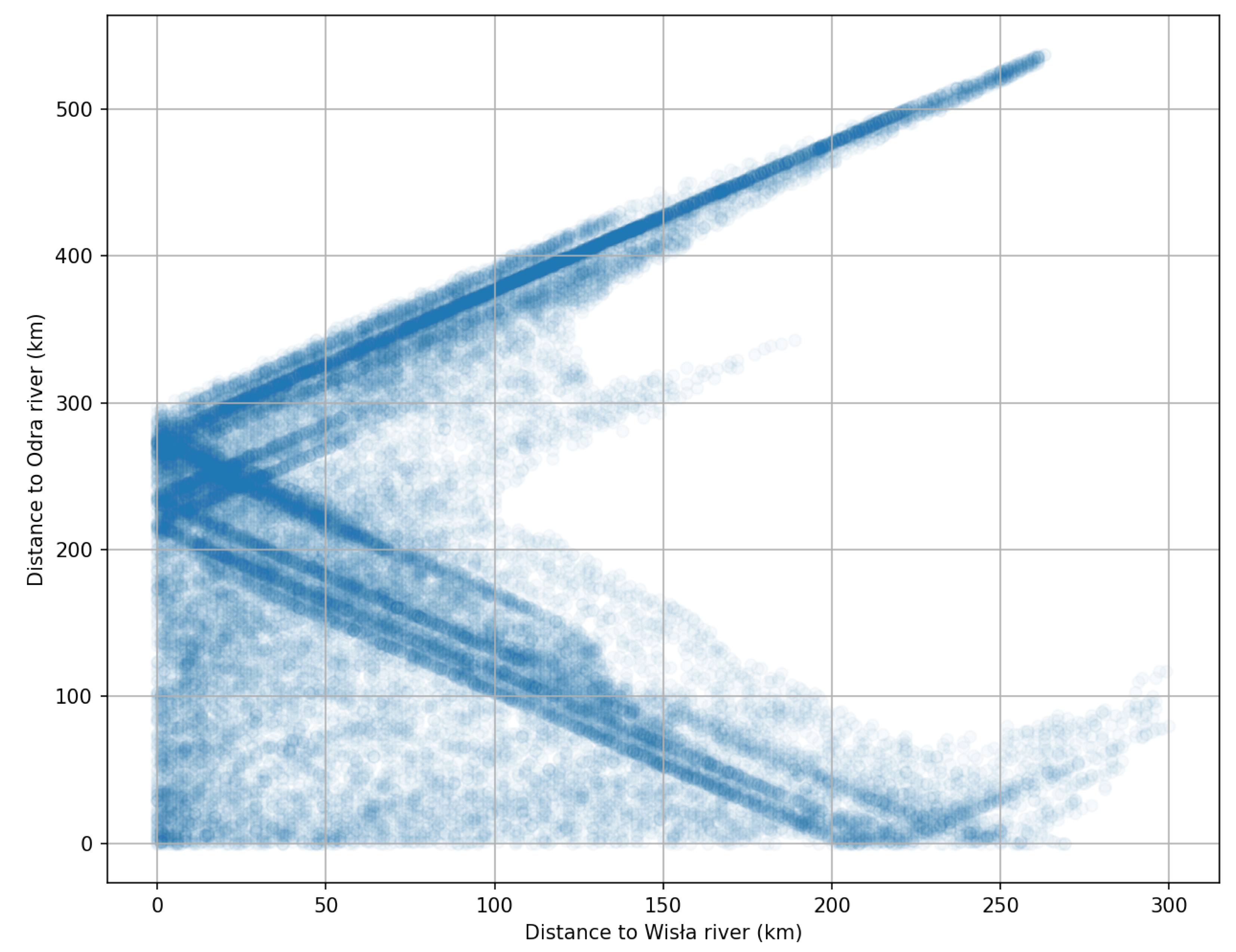
4. Results
5. Discussion
6. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dritsa, K.; Sotiropoulos, T.; Skarpetis, H.; Louridas, P. Search Engine Similarity Analysis: A Combined Content and Rankings Approach. In Proceedings of the International Conference on Web Information Systems Engineering, Amsterdam, The Netherlands, 20–24 October 2020; Springer: Cham, Switzerland, 2020; pp. 21–37. [Google Scholar] [CrossRef]
- Jusoh, S. A study on NLP applications and ambiguity problems. J. Theor. Appl. Inf. Technol. 2018, 96, 6. [Google Scholar]
- Dumbacher, B.; Diamond, L.K. SABLE: Tools for web crawling, web scraping, and text classification. In Proceedings of the Federal Committee on Statistical Methodology Research Conference, Washington, DC, USA, 7–9 March 2018. [Google Scholar]
- Arnarsson, I.Ö.; Frost, O.; Gustavsson, E.; Stenholm, D.; Jirstrand, M.; Malmqvist, J. Supporting knowledge re-use with effective searches of related engineering documents—A comparison of search engine and natural language processing-based algorithms. In Proceedings of the Design Society: International Conference on Engineering Design, Delft, The Netherlands, 5–8 August 2019; Cambridge University Press: Cambridge, MA, USA, 2019; Volume 1, pp. 2597–2606. [Google Scholar] [CrossRef] [Green Version]
- Pekárová, P.; Halmová, D.; Mitkova, V.B.; Miklánek, P.; Pekár, J.; Skoda, P. Historic flood marks and flood frequency analysis of the Danube River at Bratislava, Slovakia. J. Hydrol. Hydromech. 2013, 61, 326. [Google Scholar] [CrossRef] [Green Version]
- Koenig, T.A.; Bruce, J.L.; O’Connor, J.; McGee, B.D.; Holmes, R.R., Jr.; Hollins, R.; Forbes, B.T.; Kohn, M.S.; Schellekens, M.; Martin, Z.W.; et al. Identifying and Preserving High-Water Mark Data; Technical Report; US Geological Survey: Washington, DC, USA, 2016. [CrossRef]
- Wyżga, B.; Radecki-Pawlik, A.; Galia, T.; Plesiński, K.; Škarpich, V.; Dušek, R. Use of high-water marks and effective discharge calculation to optimize the height of bank revetments in an incised river channel. Geomorphology 2020, 356, 107098. [Google Scholar] [CrossRef]
- Grela, J. Assessment of the Potential Flood Hazard and Risk in the Event of Disasters of Hydrotechnical Facilities—The Exemplary Case of Cracow (Poland). Water 2023, 15, 403. [Google Scholar] [CrossRef]
- Balasch, J.; Ruiz-Bellet, J.; Tuset, J.; Martín de Oliva, J. Reconstruction of the 1874 Santa Tecla’s rainstorm in Western Catalonia (NE Spain) from flood marks and historical accounts. Nat. Hazards Earth Syst. Sci. 2010, 10, 2317–2325. [Google Scholar] [CrossRef] [Green Version]
- Bösmeier, A.S.; Himmelsbach, I.; Seeger, S. Reliability of flood marks and practical relevance for flood hazard assessment in southwestern Germany. Nat. Hazards Earth Syst. Sci. 2022, 22, 2963–2979. [Google Scholar] [CrossRef]
- McEwen, L.; Jones, O. Building local/lay flood knowledges into community flood resilience planning after the July 2007 floods, Gloucestershire, UK. Hydrol. Res. 2012, 43, 675–688. [Google Scholar] [CrossRef]
- Gorączko, M. Flood Marks in Poland and Their Significance in Water Management and Flood Safety Education. In Management of Water Resources in Poland; Springer: Cham, Switzerland, 2021; pp. 253–267. [Google Scholar] [CrossRef]
- Le Coz, J.; Patalano, A.; Collins, D.; Guillén, N.F.; García, C.M.; Smart, G.M.; Bind, J.; Chiaverini, A.; Le Boursicaud, R.; Dramais, G.; et al. Crowdsourced data for flood hydrology: Feedback from recent citizen science projects in Argentina, France and New Zealand. J. Hydrol. 2016, 541, 766–777. [Google Scholar] [CrossRef] [Green Version]
- Szczepanek, R.; Toś, C.; Bodziony, M. Temporary flood marks proposal: What we learned after losing the baroque artifact from Cracow, Poland. Int. J. Disaster Risk Reduct. 2022, 74, 102942. [Google Scholar] [CrossRef]
- Guo, J.; He, H.; He, T.; Lausen, L.; Li, M.; Lin, H.; Shi, X.; Wang, C.; Xie, J.; Zha, S.; et al. GluonCV and GluonNLP: Deep Learning in Computer Vision and Natural Language Processing. J. Mach. Learn. Res. 2020, 21, 1–7. [Google Scholar]
- Sit, M.; Demiray, B.Z.; Xiang, Z.; Ewing, G.J.; Sermet, Y.; Demir, I. A comprehensive review of deep learning applications in hydrology and water resources. Water Sci. Technol. 2020, 82, 2635–2670. [Google Scholar] [CrossRef]
- Szczepanek, R. Daily Streamflow Forecasting in Mountainous Catchment Using XGBoost, LightGBM and CatBoost. Hydrology 2022, 9, 226. [Google Scholar] [CrossRef]
- Maskey, M.; Ramachandran, R.; Miller, J.J.; Zhang, J.; Gurung, I. Earth science deep learning: Applications and lessons learned. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: New York, NY, USA, 2018; pp. 1760–1763. [Google Scholar] [CrossRef] [Green Version]
- Sit, M.A.; Koylu, C.; Demir, I. Identifying disaster-related tweets and their semantic, spatial and temporal context using deep learning, natural language processing and spatial analysis: A case study of Hurricane Irma. Int. J. Digit. Earth 2019, 12, 11. [Google Scholar] [CrossRef]
- Karthikeyan, T.; Sekaran, K.; Ranjith, D.; Vinoth, K.; Balajee, J. Personalized content extraction and text classification using effective web scraping techniques. Int. J. Web Portals (IJWP) 2019, 11, 41–52. [Google Scholar] [CrossRef]
- Uzun, E.; Yerlikaya, T.; Kirat, O. Comparison of Python libraries used for Web data extraction. Fundam. Sci. Appl. 2018, 24, 87–92. [Google Scholar]
- Plattner, T.; Orel, D.; Steiner, O. Flexible data scraping, multi-language indexing, entity extraction and taxonomies: Tadam, a Swiss tool to deal with huge amounts of unstructured data. In Proceedings of the Computation+ Journalism Symposium, Boston, MA, USA, 20–21 March 2016. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:arXiv:1301.3781. [Google Scholar] [CrossRef]
- Adiba, F.I.; Islam, T.; Kaiser, M.S.; Mahmud, M.; Rahman, M.A. Effect of corpora on classification of fake news using naive Bayes classifier. Int. J. Autom. Artif. Intell. Mach. Learn. 2020, 1, 80–92. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:arXiv:1810.04805. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Kharya, P.; Alvi, A. Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, the World’s Largest and Most Powerful Generative Language Model. 2021. Available online: https://www.microsoft.com/en-us/research/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/ (accessed on 7 February 2023).
- Yu, F.; Wang, D.; Shangguan, L.; Zhang, M.; Tang, X.; Liu, C.; Chen, X. A Survey of Large-Scale Deep Learning Serving System Optimization: Challenges and Opportunities. arXiv 2021, arXiv:arXiv:2111.14247. [Google Scholar] [CrossRef]
- Nadkarni, P.M.; Ohno-Machado, L.; Chapman, W.W. Natural language processing: An introduction. J. Am. Med. Inform. Assoc. 2011, 18, 544–551. [Google Scholar] [CrossRef] [Green Version]
- Kumar, S.A.; Nasralla, M.M.; García-Magariño, I.; Kumar, H. A machine-learning scraping tool for data fusion in the analysis of sentiments about pandemics for supporting business decisions with human-centric AI explanations. PeerJ Comput. Sci. 2021, 7, e713. [Google Scholar] [CrossRef] [PubMed]
- Yu, M.; Huang, Q.; Qin, H.; Scheele, C.; Yang, C. Deep learning for real-time social media text classification for situation awareness—Using Hurricanes Sandy, Harvey, and Irma as case studies. Int. J. Digit. Earth 2019, 12, 1230–1247. [Google Scholar] [CrossRef]
- Medlock, B.W. Investigating Classification for Natural Language Processing Tasks; Technical Report; University of Cambridge, Computer Laboratory: Cambdringe, UK, 2008. [Google Scholar] [CrossRef]
- Hu, Y.H.; Ge, L. A Supervised Machine Learning Approach to Toponym Disambiguation. In The Geospatial Web: How Geobrowsers, Social Software and the Web 2.0 are Shaping the Network Society; Scharl, A., Tochtermann, K., Eds.; Springer: London, UK, 2007; pp. 117–128. [Google Scholar] [CrossRef]
- Won, M.; Murrieta-Flores, P.; Martins, B. Ensemble Named Entity Recognition (NER): Evaluating NER Tools in the Identification of Place Names in Historical Corpora. Front. Digit. Humanit. 2018, 5, 2. [Google Scholar] [CrossRef] [Green Version]
- Viola, L.; Verheul, J. Machine Learning to Geographically Enrich Understudied Sources: A Conceptual Approach. In Proceedings of the ICAART (1), Valletta, Malta, 21–24 February 2020; pp. 469–475. [Google Scholar] [CrossRef]
- Wang, J.; Hu, Y.; Joseph, K. NeuroTPR: A neuro-net toponym recognition model for extracting locations from social media messages. Trans. GIS 2020, 24, 719–735. [Google Scholar] [CrossRef]
- Scheele, C.; Yu, M.; Huang, Q. Geographic context-aware text mining: Enhance social media message classification for situational awareness by integrating spatial and temporal features. Int. J. Digit. Earth 2021, 14, 1–23. [Google Scholar] [CrossRef]
- Tempelmeier, N.; Gottschalk, S.; Demidova, E. GeoVectors: A Linked Open Corpus of OpenStreetMap Embeddings on World Scale; Association for Computing Machinery: New York, NY, USA, 2021; pp. 4604–4612. [Google Scholar] [CrossRef]
- Mai, G.; Janowicz, K.; Zhu, R.; Cai, L.; Lao, N. Geographic Question Answering: Challenges, Uniqueness, Classification, and Future Directions. AGILE GISci. Ser. 2021, 2, 1–21. [Google Scholar] [CrossRef]
- Contractor, D.; Goel, S.; Singla, P. Joint Spatio-Textual Reasoning for Answering Tourism Questions. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 1978–1989. [Google Scholar] [CrossRef]
- Plum, A.; Ranasinghe, T.; Orǎsan, C. Toponym detection in the bio-medical domain: A hybrid approach with deep learning. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019), Varna, Bulgaria, 2–4 September 2019; pp. 912–921. [Google Scholar]
- Yadav, V.; Laparra, E.; Wang, T.T.; Surdeanu, M.; Bethard, S. University of Arizona at semeval-2019 task 12: Deep-affix named entity recognition of geolocation entities. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 1319–1323. [Google Scholar] [CrossRef]
- Dadas, S. Combining neural and knowledge-based approaches to named entity recognition in polish. In Proceedings of the Artificial Intelligence and Soft Computing, Zakopane, Poland, 16–20 June 2019; Rutkowski, L., Scherer, R., Korytkowski, M., Pedrycz, W., Tadeusiewicz, R., Zurada, J.M., Eds.; Springer: Cham, Switzerland, 2019; pp. 39–50. [Google Scholar]
- Przepiórkowski, A.; Bańko, M.; Górski, R.L.; Lewandowska-Tomaszczyk, B.; Łaziński, M.; Pęzik, P. National corpus of polish. In Proceedings of the 5th Language & Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics, Poznan, Poland, 21–23 April; 2011; pp. 259–263. [Google Scholar]
- Savary, A.; Piskorski, J. Language resources for named entity annotation in the National Corpus of Polish. Control. Cybern. 2011, 40, 361–391. [Google Scholar]
- Woliński, M.; Saloni, Z.; Wołosz, R.; Gruszczyński, W.; Skowrońska, D.; Bronk, Z. Słownik Gramatyczny Języka Polskiego; SGJP: Warsaw, Poland, 2020. [Google Scholar]
- Kieraś, W.; Woliński, M. Morfeusz 2 – analizator i generator fleksyjny dla języka polskiego. Język Pol. 2017, XCVII, 75–83. [Google Scholar]
- Halterman, A. Mordecai: Full text geoparsing and event geocoding. J. Open Source Softw. 2017, 2, 91. [Google Scholar] [CrossRef]
- Kaczmarek, I.; Iwaniak, A.; Świetlicka, A.; Piwowarczyk, M.; Harvey, F. Spatial Planning Text Information Processing with Use of Machine Learning Methods. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 6, 95–102. [Google Scholar] [CrossRef]
- Medad, A.; Gaio, M.; Moncla, L.; Mustière, S.; Le Nir, Y. Comparing supervised learning algorithms for spatial nominal entity recognition. AGILE Gisci. Ser. 2020, 1, 2020. [Google Scholar] [CrossRef]
- Radford, B.J. Regressing Location on Text for Probabilistic Geocoding. arXiv 2021, arXiv:2107.00080. [Google Scholar]
- Kaczmarek, I.; Iwaniak, A.; Świetlicka, A.; Piwowarczyk, M.; Nadolny, A. A machine learning approach for integration of spatial development plans based on natural language processing. Sustain. Cities Soc. 2022, 76, 103479. [Google Scholar] [CrossRef]
- Sheela, A.S.; Jayakumar, C. Comparative study of syntactic search engine and semantic search engine: A survey. In Proceedings of the 2019 Fifth International Conference on Science Technology Engineering and Mathematics (ICONSTEM), Chennai, India, 14–15 March 2019; IEEE: New York, NY, USA, 2019; Volume 1, pp. 1–4. [Google Scholar] [CrossRef]
- Woliński, M. Morfeusz Reloaded. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; pp. 1106–1111. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://github.com/keras-team/keras (accessed on 7 February 2023).
- Panoutsopoulos, H.; Brewster, C.; Espejo-Garcia, B. Developing a Model for the Automated Identification and Extraction of Agricultural Terms from Unstructured Text. Chem. Proc. 2022, 10, 94. [Google Scholar] [CrossRef]
- Aldana-Bobadilla, E.; Molina-Villegas, A.; Lopez-Arevalo, I.; Reyes-Palacios, S.; Muñiz-Sanchez, V.; Arreola-Trapala, J. Adaptive Geoparsing Method for Toponym Recognition and Resolution in Unstructured Text. Remote Sens. 2020, 12, 3041. [Google Scholar] [CrossRef]
- Mroczkowski, R.; Rybak, P.; Wróblewska, A.; Gawlik, I. HerBERT: Efficiently pretrained transformer-based language model for Polish. arXiv 2021, arXiv:2105.01735. [Google Scholar]
- Kłeczek, D. Polbert: Attacking Polish NLP Tasks with Transformers. In Proceedings of the PolEval 2020 Workshop, Warsaw, Poland, 26 October 2020; pp. 79–88. Available online: http://poleval.pl/files/poleval2020.pdf (accessed on 7 February 2023).
- Denisiuk, A.; Ganzha, M.; Wasielewska-Michniewska, K.; Paprzycki, M. Feature Extraction for Polish Language Named Entities Recognition in Intelligent Office Assistant. In Proceedings of the HICSS, Maui, HI, USA, 4–7 January 2022; pp. 1–10. [Google Scholar]
- Murphy, J.T.; Ozik, J.; Collier, N.T.; Altaweel, M.; Lammers, R.B.; Kliskey, A.; Alessa, L.; Cason, D.; Williams, P. Water relationships in the US southwest: Characterizing water management networks using natural language processing. Water 2014, 6, 1601–1641. [Google Scholar] [CrossRef] [Green Version]
- Faulkner, C.M.; Lambert, J.E.; Wilson, B.M.; Faulkner, M.S. The human right to water and sanitation: Using natural language processing to uncover patterns in academic publishing. Water 2021, 13, 3501. [Google Scholar] [CrossRef]
- Tian, X.; Vertommen, I.; Tsiami, L.; van Thienen, P.; Paraskevopoulos, S. Automated Customer Complaint Processing for Water Utilities Based on Natural Language Processing—Case Study of a Dutch Water Utility. Water 2022, 14, 674. [Google Scholar] [CrossRef]
- Fan, R.; Wang, L.; Yan, J.; Song, W.; Zhu, Y.; Chen, X. Deep learning-based named entity recognition and knowledge graph construction for geological hazards. ISPRS Int. J. Geo Inf. 2019, 9, 15. [Google Scholar] [CrossRef] [Green Version]
- Dewandaru, A.; Widyantoro, D.H.; Akbar, S. Event geoparser with pseudo-location entity identification and numerical argument extraction implementation and evaluation in Indonesian news domain. ISPRS Int. J. Geo Inf. 2020, 9, 712. [Google Scholar] [CrossRef]
- Yuan, W.; Yang, L.; Yang, Q.; Sheng, Y.; Wang, Z. Extracting Spatio-Temporal Information from Chinese Archaeological Site Text. ISPRS Int. J. Geo Inf. 2022, 11, 175. [Google Scholar] [CrossRef]
- Tao, L.; Xie, Z.; Xu, D.; Ma, K.; Qiu, Q.; Pan, S.; Huang, B. Geographic Named Entity Recognition by Employing Natural Language Processing and an Improved BERT Model. ISPRS Int. J. Geo Inf. 2022, 11, 598. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, J. Global Flood Disaster Research Graph Analysis Based on Literature Mining. Appl. Sci. 2022, 12, 3066. [Google Scholar] [CrossRef]
- Bombini, A.; Alkhansa, A.; Cappelli, L.; Felicetti, A.; Giacomini, F.; Costantini, A. A Cloud-Native Web Application for Assisted Metadata Generation and Retrieval: THESPIAN-NER. Appl. Sci. 2022, 12, 12910. [Google Scholar] [CrossRef]
- Ning, H.; Li, Z.; Hodgson, M.E.; Wang, C. Prototyping a social media flooding photo screening system based on deep learning. ISPRS Int. J. Geo Inf. 2020, 9, 104. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source Link | Scraped URLs | Scraped Documents (pdf) | Labeled as Flood Mark |
|---|---|---|---|
| 382 | 34 | 151 | |
| DuckDuckGo | 110 | 6 | 30 |
| Total | 492 | 40 | 181 |
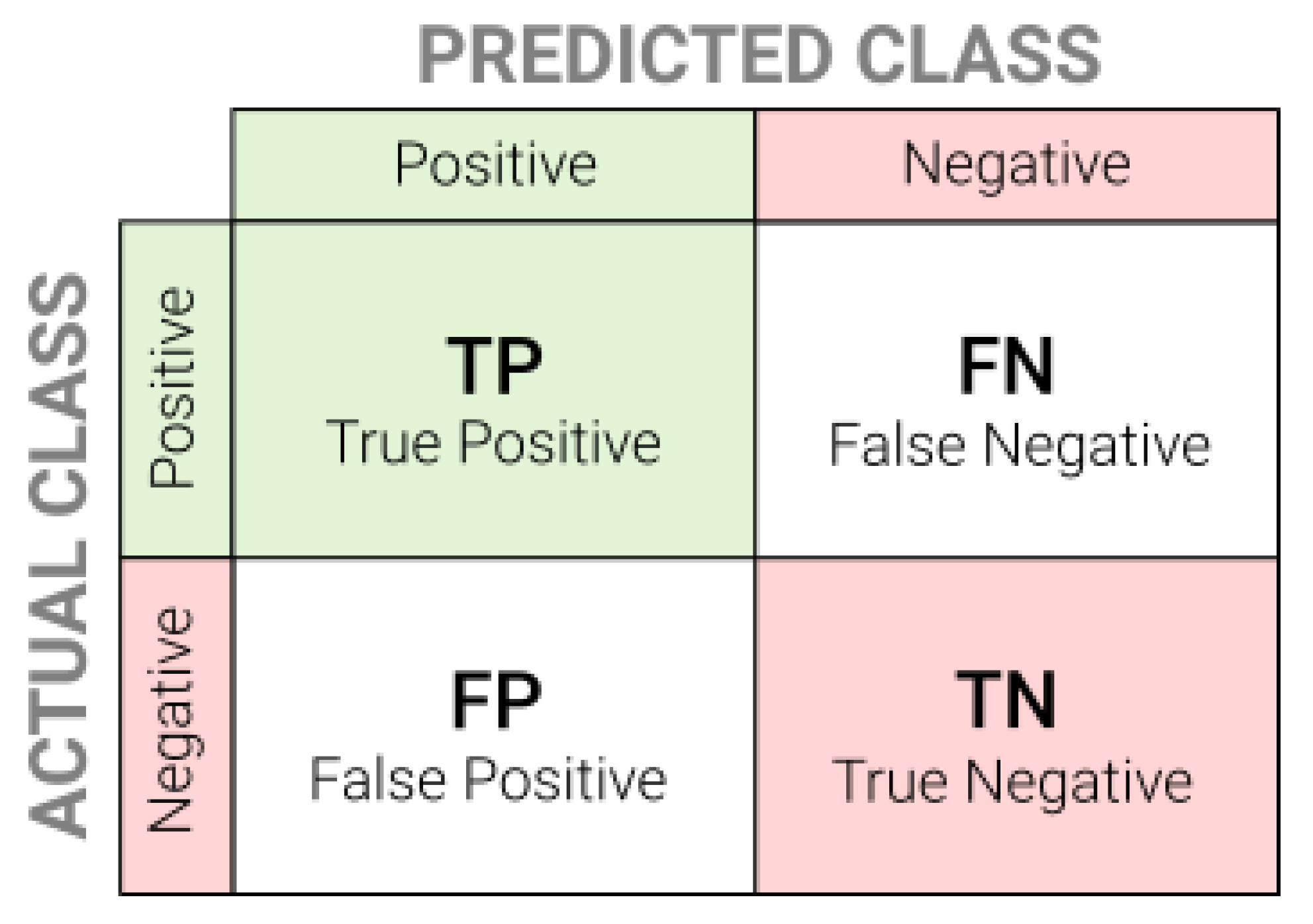
| Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Naive Bayes | 0.829 | 0.850 | 0.472 | 0.607 |
| CNN | 0.868 | 0.810 | 0.772 | 0.786 |
| SD-NER (proposed) | 0.914 | 0.930 | 0.910 | 0.920 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Szczepanek, R. A Deep Learning Model of Spatial Distance and Named Entity Recognition (SD-NER) for Flood Mark Text Classification. Water 2023, 15, 1197. https://doi.org/10.3390/w15061197
Szczepanek R. A Deep Learning Model of Spatial Distance and Named Entity Recognition (SD-NER) for Flood Mark Text Classification. Water. 2023; 15(6):1197. https://doi.org/10.3390/w15061197
Chicago/Turabian StyleSzczepanek, Robert. 2023. "A Deep Learning Model of Spatial Distance and Named Entity Recognition (SD-NER) for Flood Mark Text Classification" Water 15, no. 6: 1197. https://doi.org/10.3390/w15061197