
Extreme Rainfall Event Classification Using Machine Learning for Kikuletwa River Floods

 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Preparation
2.2. Model Building
2.3. Model Evaluation
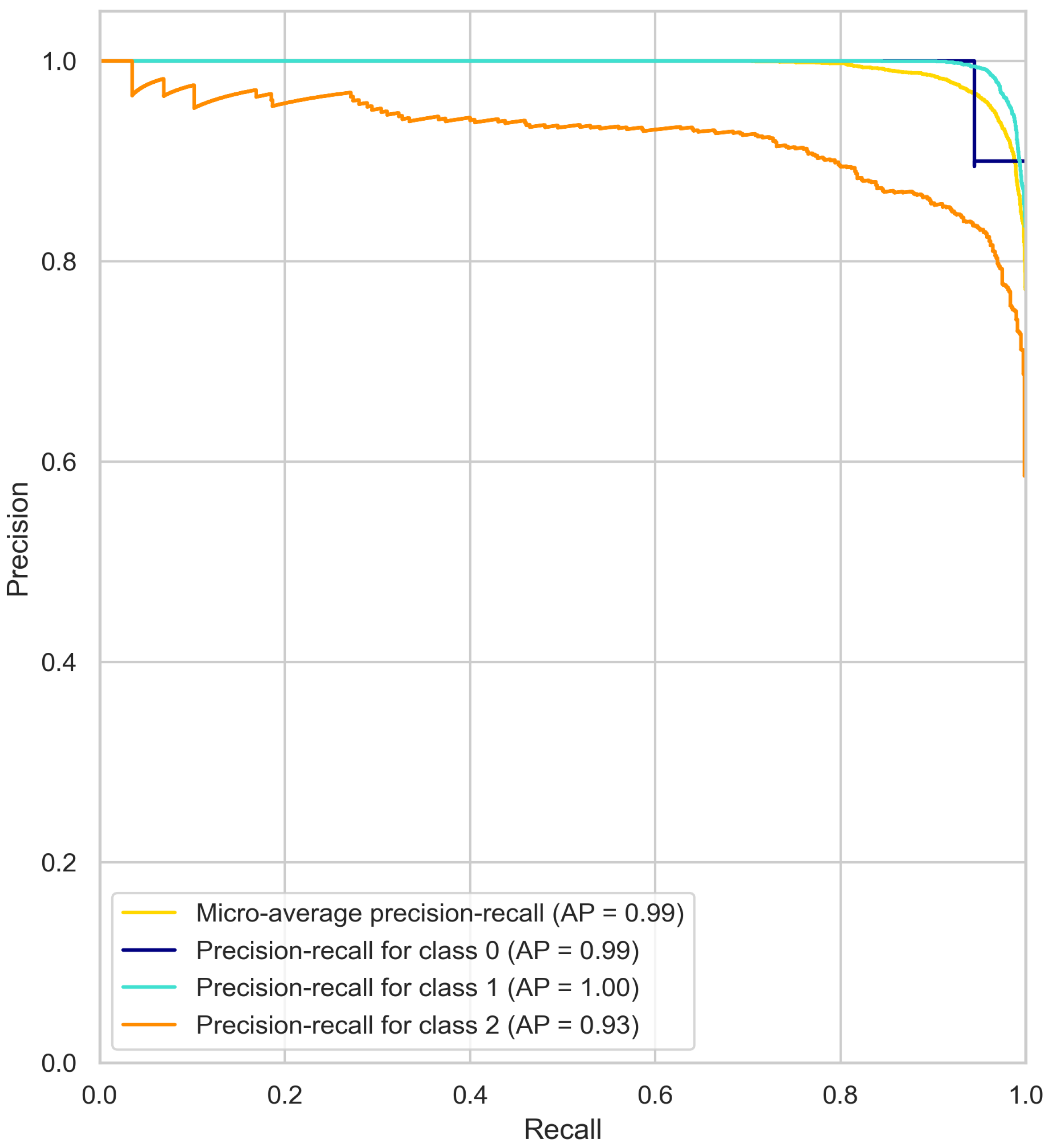
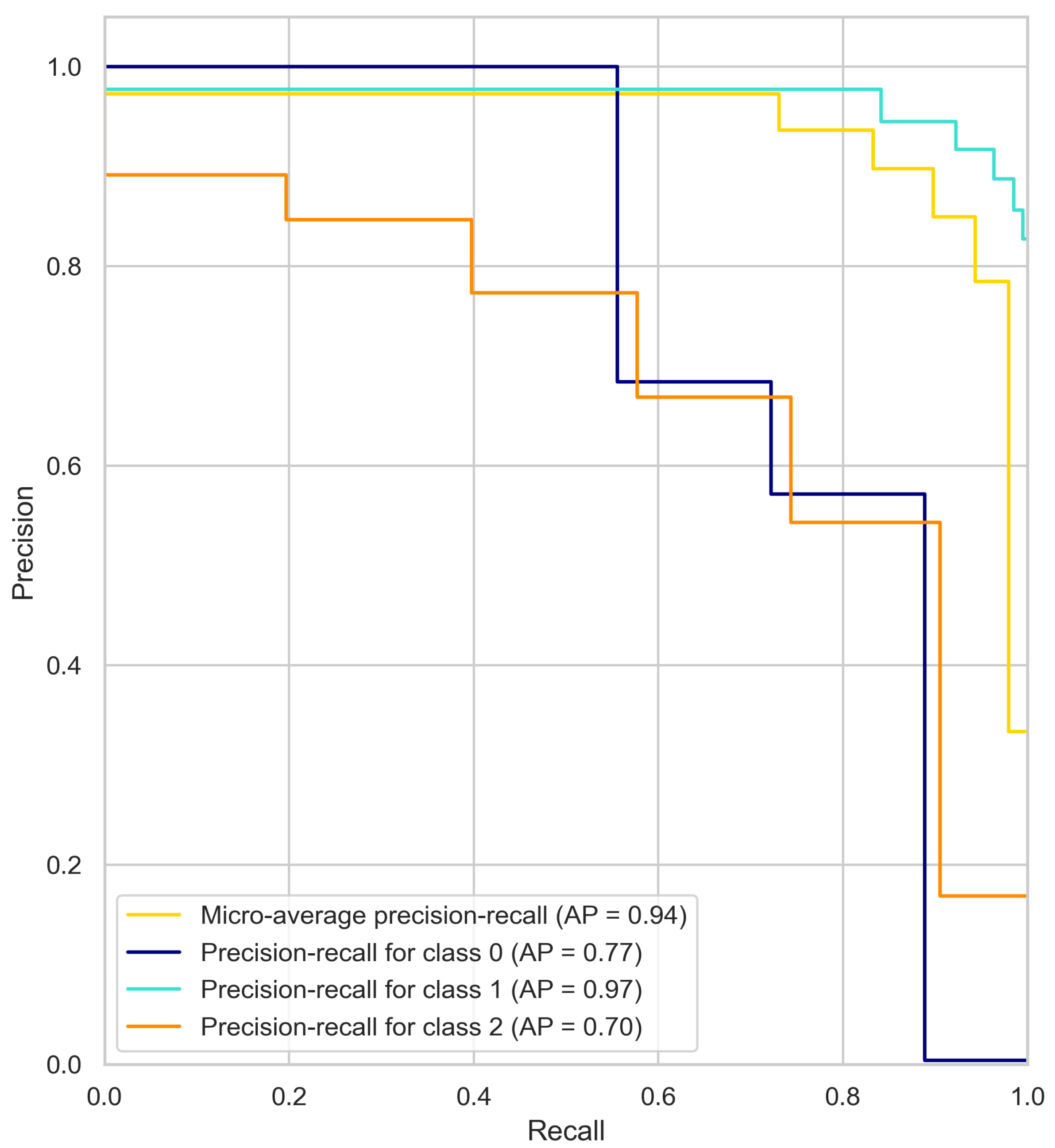
3. Results
4. Discussion
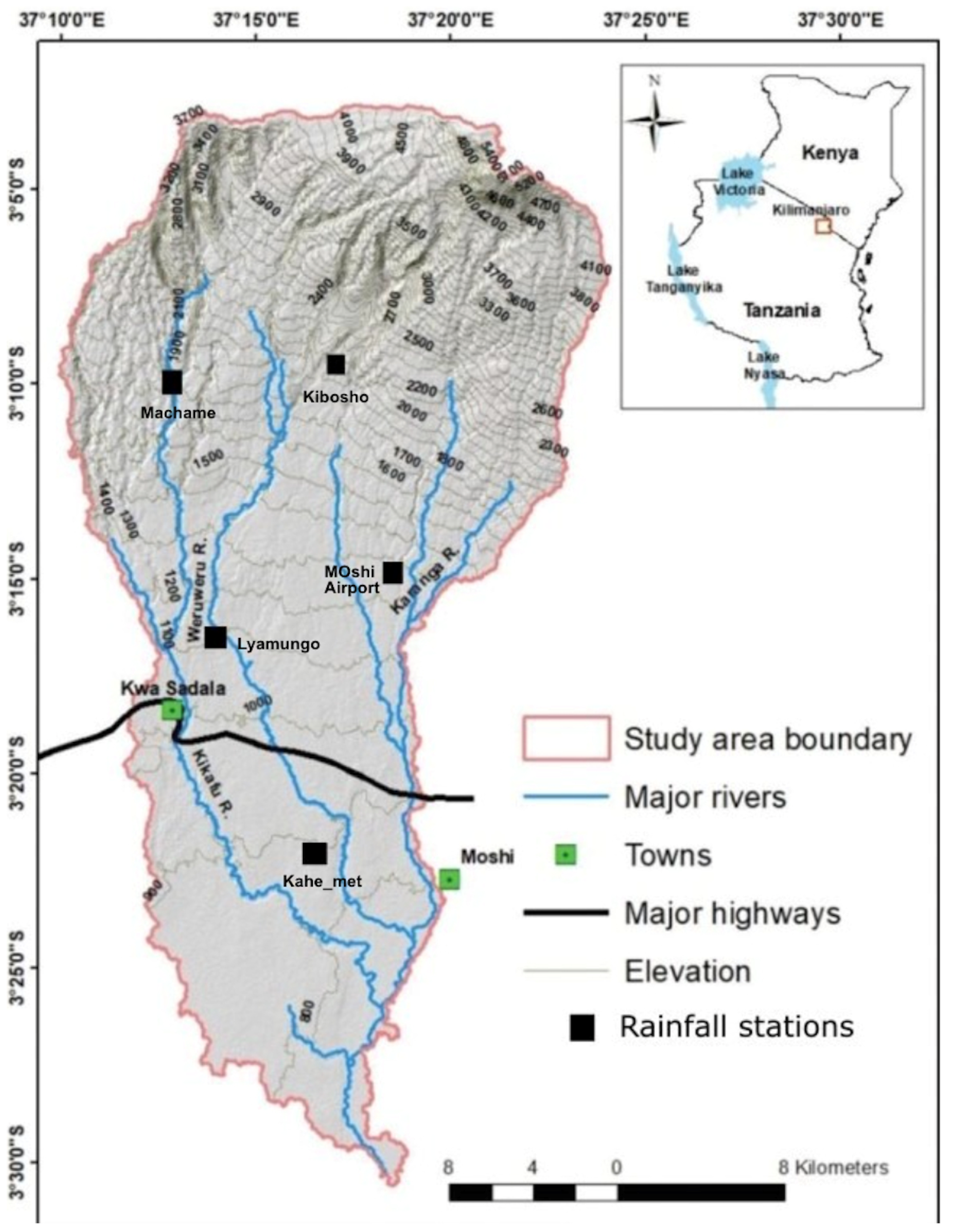
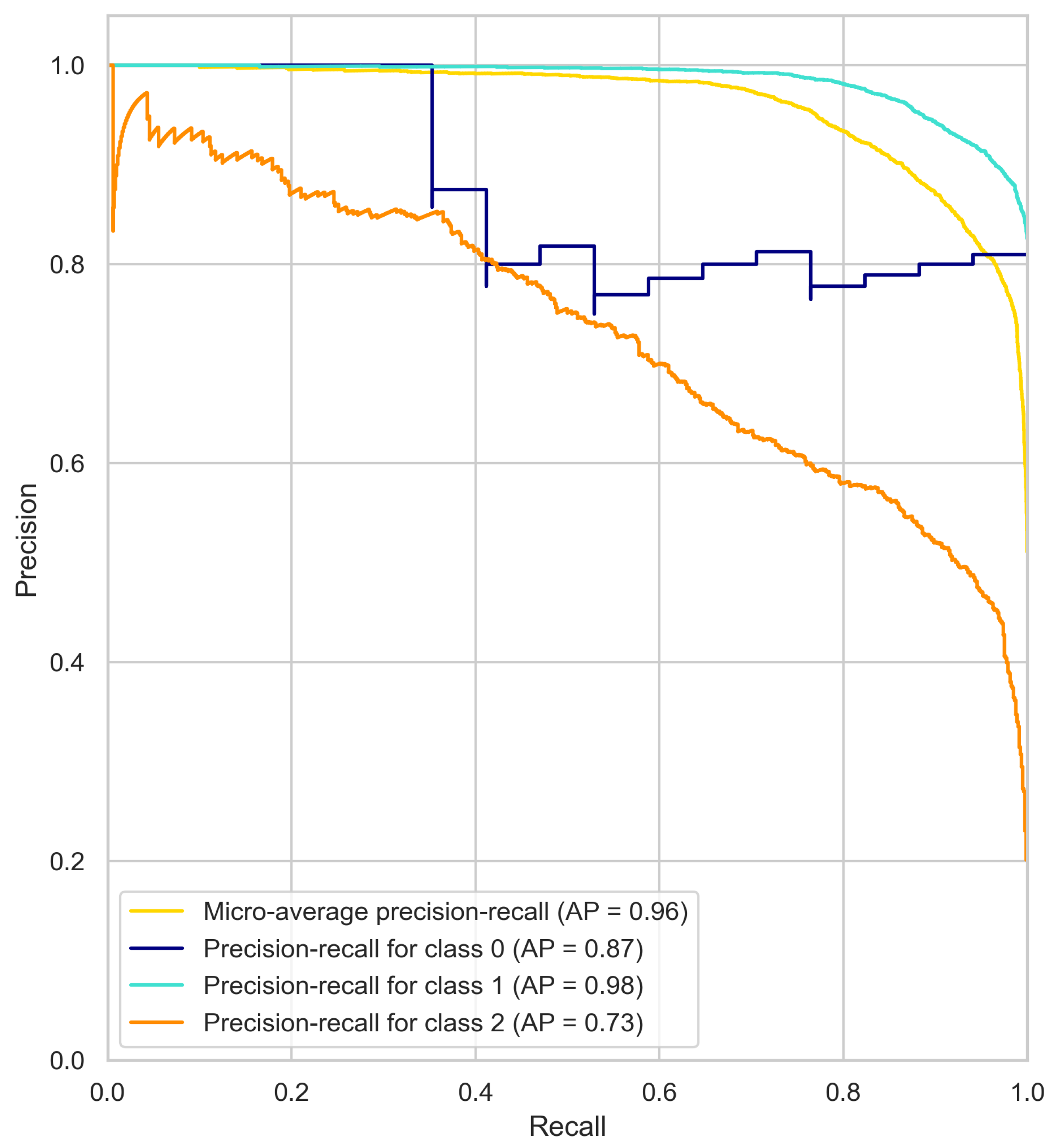
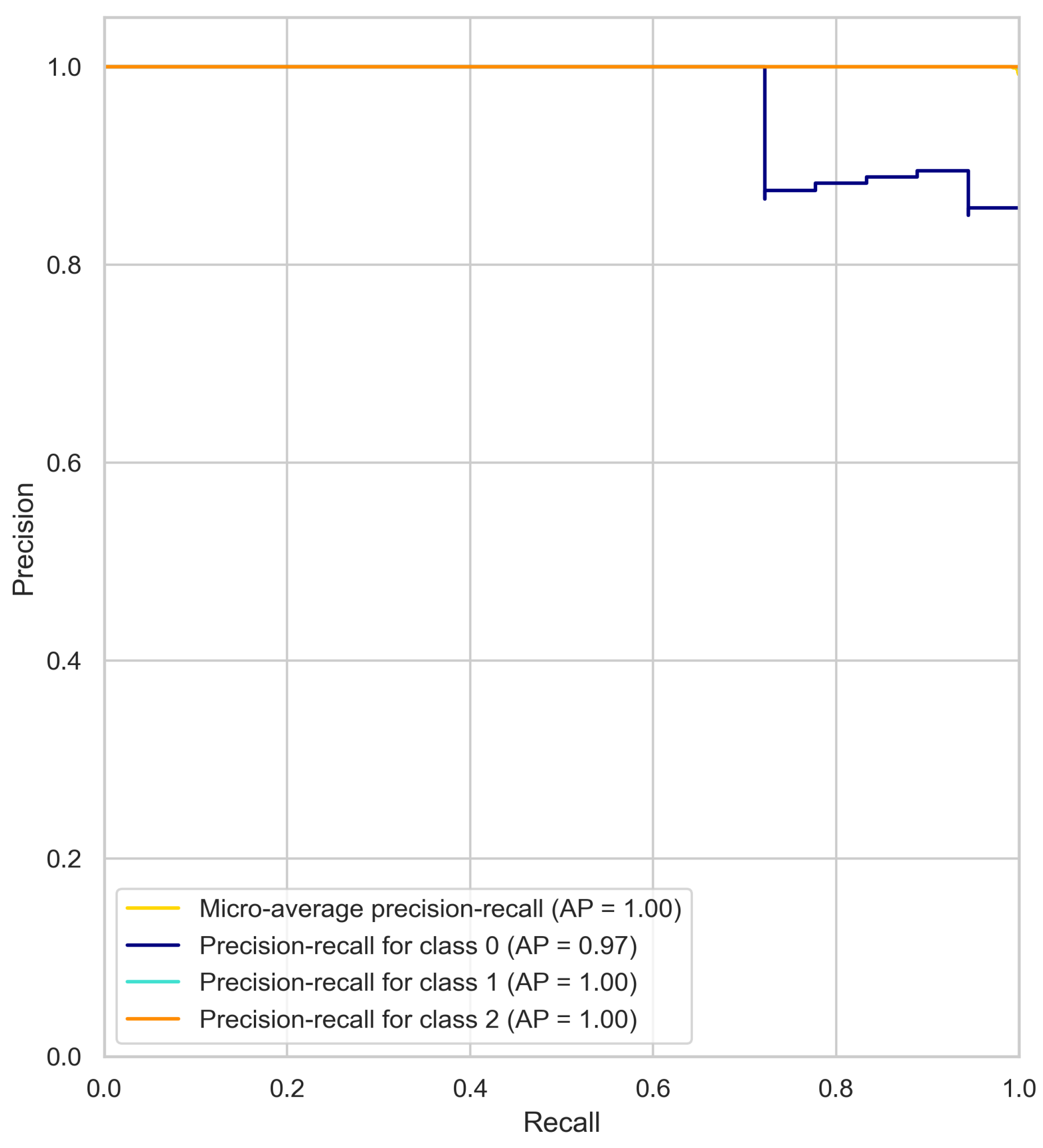
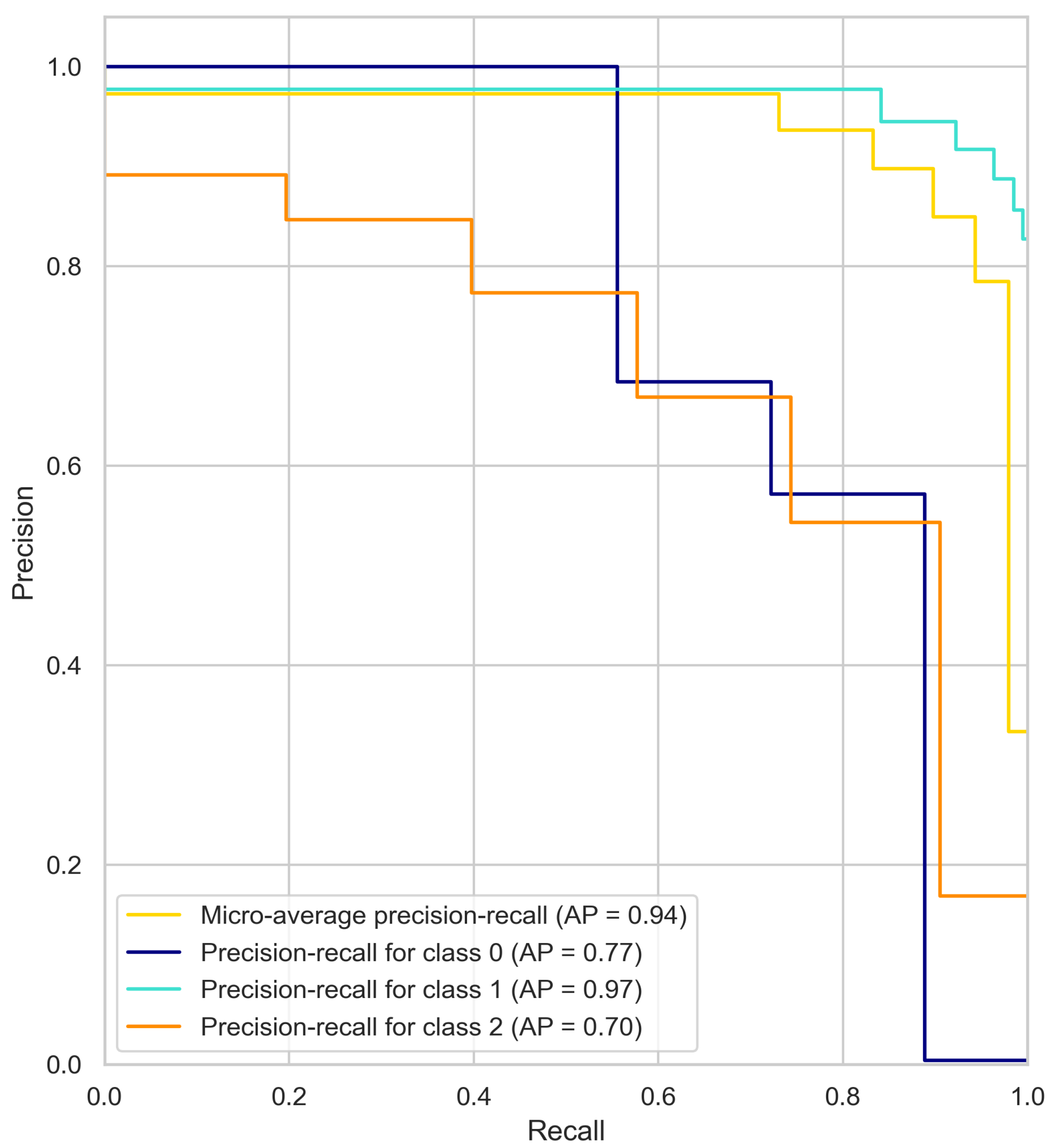
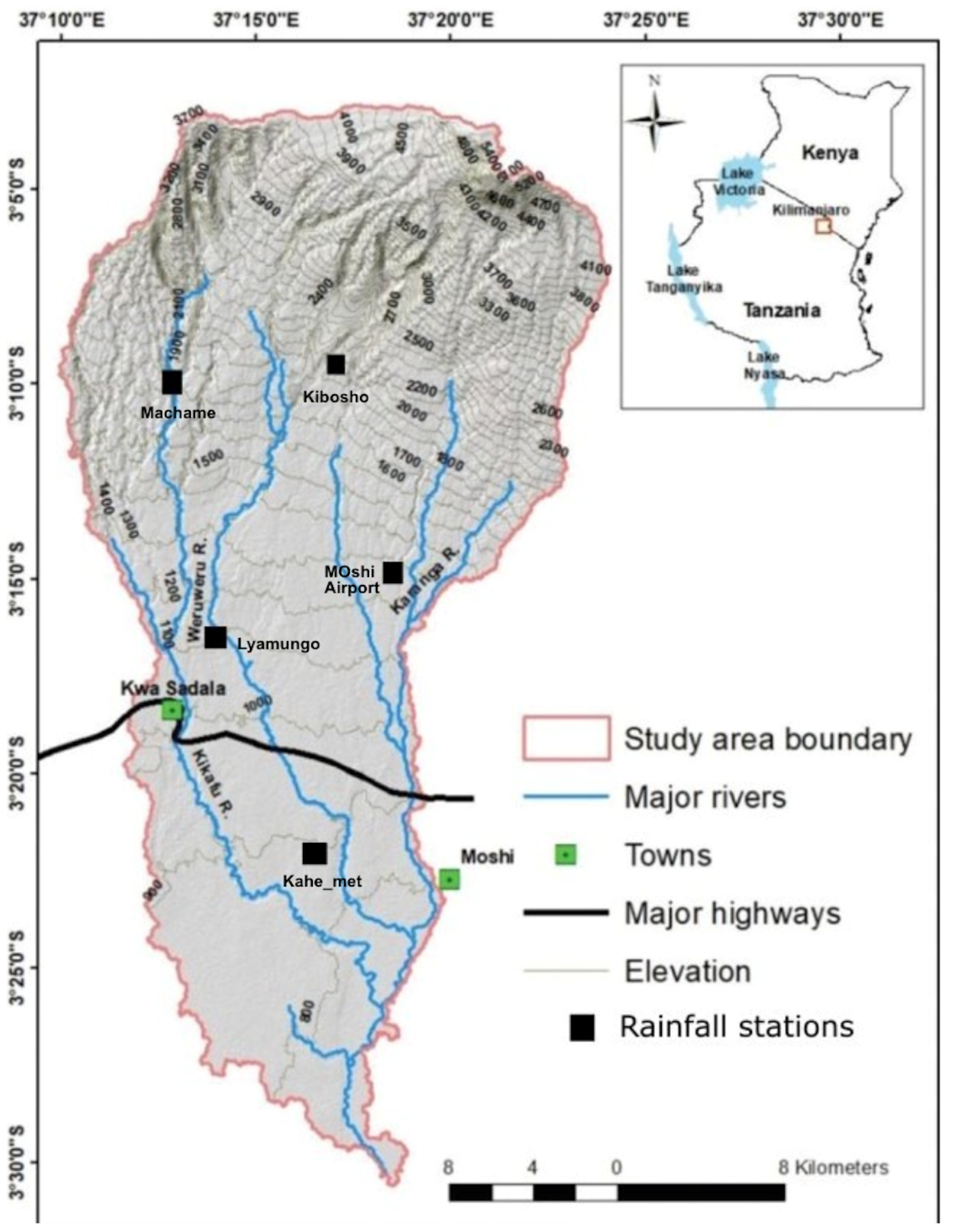
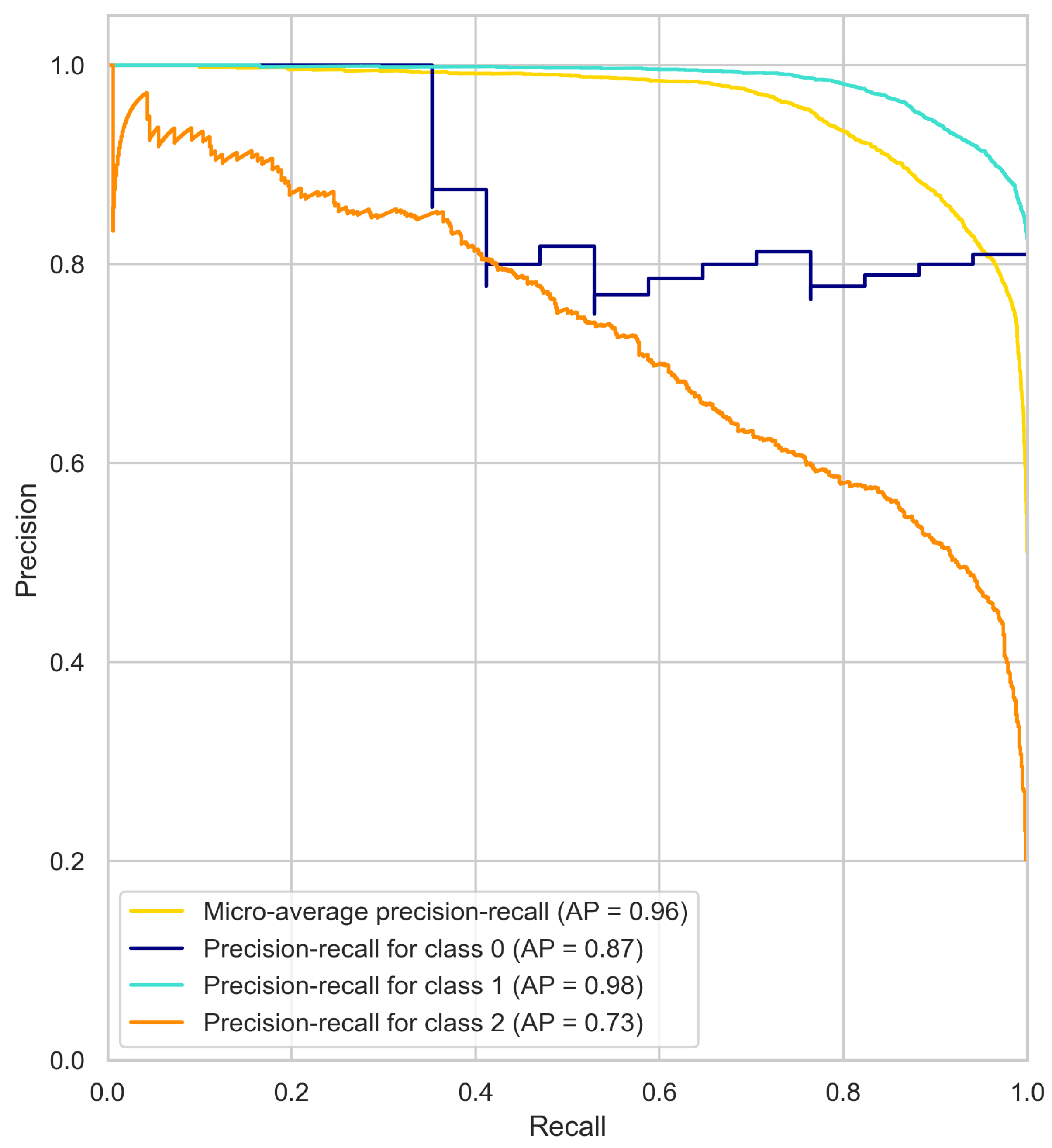
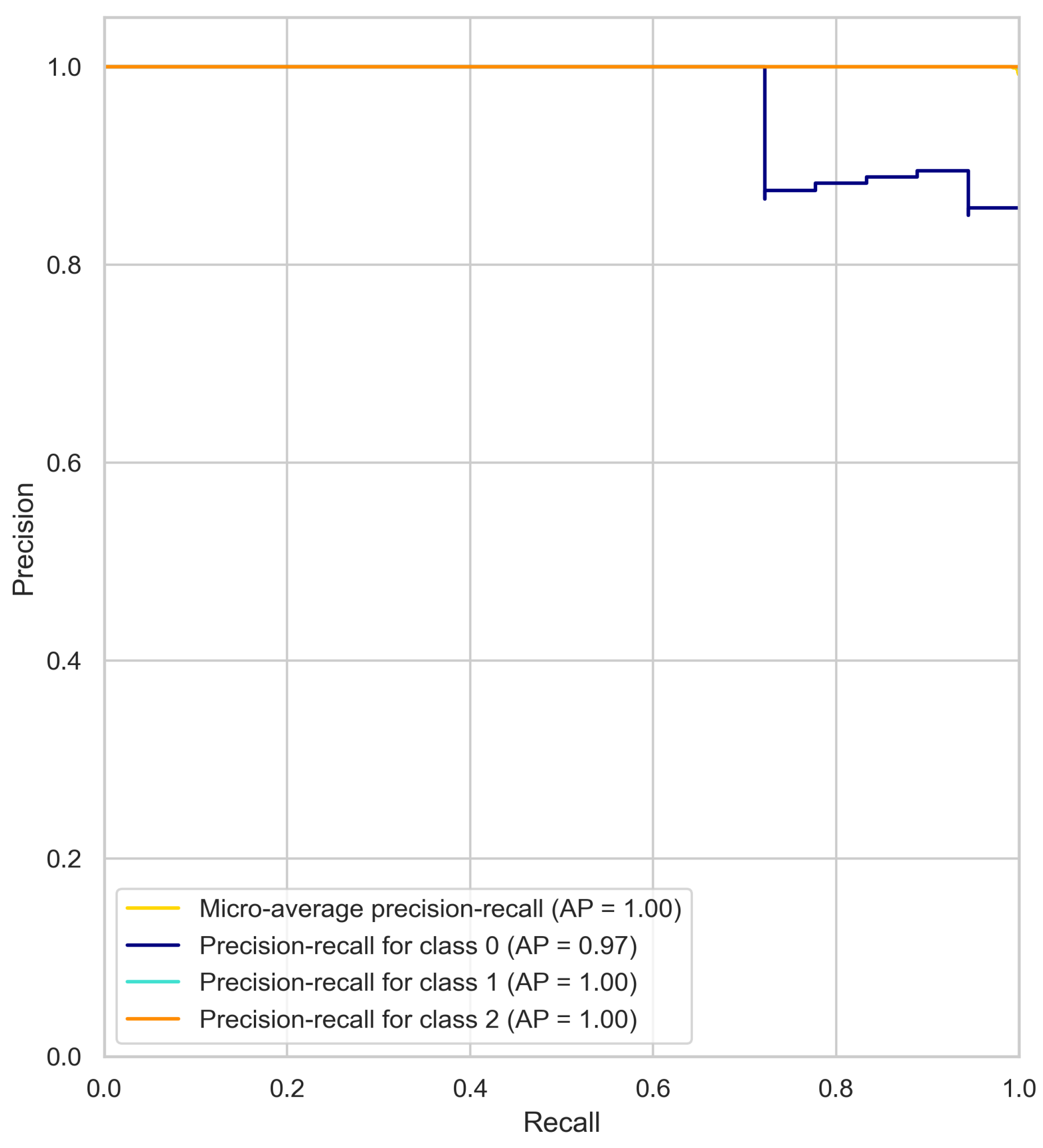
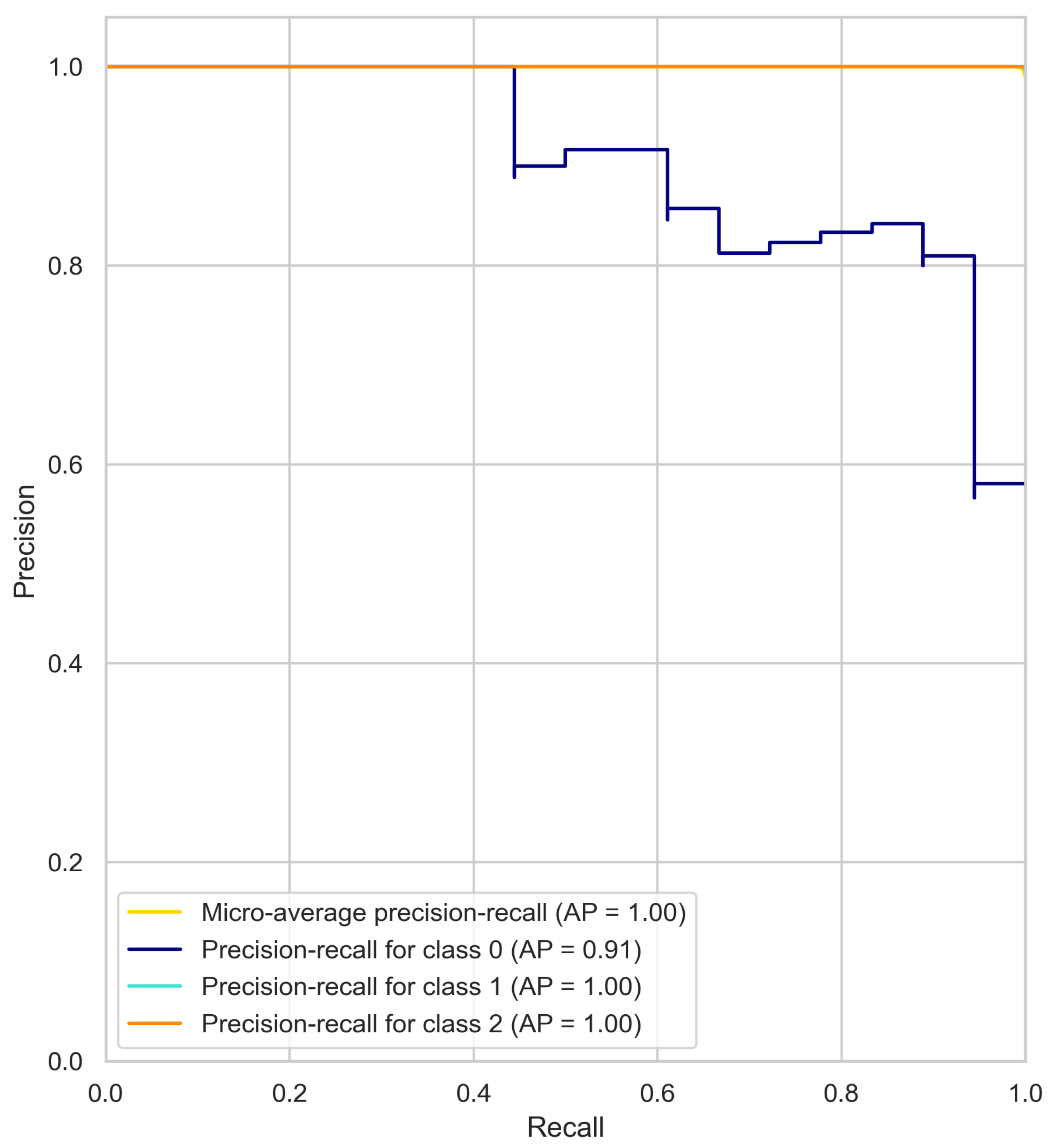
4.1. Precision–Recall Curve Results Analysis
4.2. F1_score Results Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| XGBoost | eXtreme Gradient Boost |
| KNN | k-Nearest Neighbors |
| ML | Machine Learning |
| SVM | Support Vector Machine |
| MLP | Multi-Layer Perceptron |
| PBWB | Pangani Basin Water Board |
| TMA | Tanzania Meteorological Agency |
| KWK | Karanga–Weruweru–Kikavu |
| OvR | One-vs-the-Rest |
| ROC | Receiver Operating Characteristic |
| AUC | Area Under the Curve |
References
- World Health Organization. Floods. 2021. Available online: https://www.who.int/health-topics/floods (accessed on 17 February 2023).
- Jonkman, S.N. Global perspectives on loss of human life caused by floods. Nat. Hazards 2005, 34, 151–175. [Google Scholar] [CrossRef]
- Tanzania Meteorological Agency. Annual Technical Report on Meteorology, Hydrology and Climate Services 2020–2021 Update. 2021. Available online: https://www.meteo.go.tz/uploads/publications/sw1628770614-TMA%20BOOK%202020%20-2021%20UPDATE.pdf (accessed on 17 February 2023).
- Kimambo, O.N.; Chikoore, H.; Gumbo, J.R. Understanding the Effects of Changing Weather: A Case of Flash Flood in Morogoro on January 11, 2018. Adv. Meteorol. 2019, 2019, 8505903. [Google Scholar] [CrossRef]
- Nayak, M.A.; Ghosh, S. Prediction of extreme rainfall event using weather pattern recognition and support vector machine classifier. Theor. Appl. Climatol. 2013, 114, 583–603. [Google Scholar] [CrossRef]
- Parmar, A.; Mistree, K.; Sompura, M. Machine learning techniques for rainfall prediction: A review. In Proceedings of the International Conference on Innovations in information Embedded and Communication Systems, Coimbatore, India, 17–18 March 2017; Volume 3. [Google Scholar]
- Stein, L.; Pianosi, F.; Woods, R. Event-based classification for global study of river flood generating processes. Hydrol. Process. 2020, 34, 1514–1529. [Google Scholar] [CrossRef]
- Pham, Q.B.; Yang, T.C.; Kuo, C.M.; Tseng, H.W.; Yu, P.S. Combing random forest and least square support vector regression for improving extreme rainfall downscaling. Water 2019, 11, 451. [Google Scholar] [CrossRef] [Green Version]
- Grazzini, F.; Craig, G.C.; Keil, C.; Antolini, G.; Pavan, V. Extreme precipitation events over northern Italy. Part I: A systematic classification with machine-learning techniques. Q. J. R. Meteorol. Soc. 2020, 146, 69–85. [Google Scholar] [CrossRef] [Green Version]
- Szczepanek, R. Daily Streamflow Forecasting in Mountainous Catchment Using XGBoost, LightGBM and CatBoost. Hydrology 2022, 9, 226. [Google Scholar] [CrossRef]
- Davenport, F.V.; Diffenbaugh, N.S. Using machine learning to analyze physical causes of climate change: A case study of US Midwest extreme precipitation. Geophys. Res. Lett. 2021, 48, e2021GL093787. [Google Scholar] [CrossRef]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do We Need Hundreds of Classifiers to Solve Real World Classification Problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Khoshgoftaar, T.M.; Golawala, M.; Hulse, J.V. An Empirical Study of Learning from Imbalanced Data Using Random Forest. In Proceedings of the 19th IEEE International Conference on Tools with Artificial Intelligence (ICTAI 2007), Patras, Greece, 29–31 October 2007; Volume 2, pp. 310–317. [Google Scholar] [CrossRef]
- Liu, X.Y.; Wu, J.; Zhou, Z.H. Exploratory Undersampling for Class-Imbalance Learning. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2009, 39, 539–550. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Deng, C.; Wang, S. Imbalance-XGBoost: Leveraging weighted and focal losses for binary label-imbalanced classification with XGBoost. Pattern Recognit. Lett. 2020, 136, 190–197. [Google Scholar] [CrossRef]
- Pilario, K.E.; Shafiee, M.; Cao, Y.; Lao, L.; Yang, S.H. A Review of Kernel Methods for Feature Extraction in Nonlinear Process Monitoring. Processes 2020, 8, 24. [Google Scholar] [CrossRef] [Green Version]
- He, Y.; Ma, J.; Ye, X. A support vector machine classifier for the prediction of osteosarcoma metastasis with high accuracy. Int. J. Mol. Med. 2017, 40, 1357–1364. [Google Scholar] [CrossRef] [Green Version]
- Chychkarov, Y.; Serhiienko, A.; Syrmamiikh, I.; Kargin, A. Handwritten Digits Recognition Using SVM, KNN, RF and Deep Learning Neural Networks. In Proceedings of the Fourth International Workshop on Computer Modeling and Intelligent Systems (CMIS), Zaporizhzhia, Ukraine, 27 April 2021. [Google Scholar]
- Mcroberts, R. A two-step nearest neighbors algorithm using satellite imagery for predicting forest structure within species composition classes. Remote Sens. Environ. 2009, 113, 532–545. [Google Scholar] [CrossRef]
- Azorin-Molina, C.; Ali, Z.; Hussain, I.; Faisal, M.; Nazir, H.M.; Hussain, T.; Shad, M.Y.; Mohamd Shoukry, A.; Hussain Gani, S. Forecasting Drought Using Multilayer Perceptron Artificial Neural Network Model. Adv. Meteorol. 2017, 2017, 5681308. [Google Scholar] [CrossRef] [Green Version]
- Dinku, T.; Ceccato, P.; Grover-Kopec, E.; Lemma, M.; Connor, S.J.; Ropelewski, C.F. Validation of satellite rainfall products over East Africa’s complex topography. Int. J. Remote Sens. 2007, 28, 1503–1526. [Google Scholar] [CrossRef]
- Hamis, M.M. Validation of Satellite Rainfall Estimates Using Gauge Rainfall Over Tanzania. Master’s Thesis, University of Nairobi, Nairobi, Kenya, 2013. [Google Scholar]
- Lu, S.; ten Veldhuis, M.C.; van de Giesen, N. Evaluation of Four Satellite Precipitation Products over Tanzania; EGU General Assembly Conference Abstracts: Vienna, Austria, 2018; p. 1403. [Google Scholar]
- Cook, J.; Ramadas, V. When to consult precision-recall curves. Stata J. 2020, 20, 131–148. [Google Scholar] [CrossRef]
- Li, W.; Guo, Q. Plotting receiver operating characteristic and precision–recall curves from presence and background data. Ecol. Evol. 2021, 11, 10192–10206. [Google Scholar] [CrossRef] [PubMed]
- Erenel, Z.; Altincay, H. Improving the precision-recall trade-off in undersampling-based binary text categorization using unanimity rule. Neural Comput. Appl. 2012, 22, 83–100. [Google Scholar] [CrossRef]
- Brabec, J.; Komárek, T.; Franc, V.; Machlica, L. On Model Evaluation Under Non-constant Class Imbalance. In Proceedings of the Computational Science—ICCS 2020, Amsterdam, The Netherlands, 3–5 June 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 74–87. [Google Scholar]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Handling imbalanced datasets: A review. GESTS Int. Trans. Comput. Sci. Eng. 2006, 30, 25–36. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Davis, J.; Goadrich, M. The Relationship between Precision-Recall and ROC Curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 233–240. [Google Scholar] [CrossRef] [Green Version]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Chen, C.; He, W.; Zhou, H.; Huang, Y.; Sun, H. A comparative study among machine learning and numerical models for simulating groundwater dynamics in the Heihe River Basin, northwestern China. Sci. Rep. 2020, 10, 3904. [Google Scholar] [CrossRef] [Green Version]
- Gumiere, S.J.; Camporese, M.; Botto, A.; Lafond, J.A.; Paniconi, C.; Gallichand, J.; Rousseau, A.N. Machine Learning vs. Physics-Based Modeling for Real-Time Irrigation Management. Front. Water 2020, 56. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Count | Mean | Std. Dev. | Min | 25th Percentile | 75th Percentile |
|---|---|---|---|---|---|---|
| Max temperature (°C) | 10,389 | 22.71 | 3.08 | 13.26 | 20.53 | 24.93 |
| Min temperature (°C) | 10,389 | 12.90 | 1.96 | 5.71 | 11.61 | 14.41 |
| Precipitation (mm) | 10,389 | 3.17 | 6.34 | 0.00 | 0.15 | 3.66 |
| Wind (m/s) | 10,389 | 2.49 | 0.55 | 0.65 | 2.14 | 2.87 |
| Relative humidity (%) | 10,389 | 0.76 | 0.10 | 0.32 | 0.69 | 0.84 |
| Solar (MJ/) | 10,389 | 16.92 | 7.23 | 0.00 | 11.18 | 22.19 |
| Random Forest | XGBoost | Support Vector Machine | KNN | Multi-Layer Perceptron |
|---|---|---|---|---|
| 0.998 | 0.998 | 0.878 | 0.898 | 0.950 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mdegela, L.; Municio, E.; De Bock, Y.; Luhanga, E.; Leo, J.; Mannens, E. Extreme Rainfall Event Classification Using Machine Learning for Kikuletwa River Floods. Water 2023, 15, 1021. https://doi.org/10.3390/w15061021
Mdegela L, Municio E, De Bock Y, Luhanga E, Leo J, Mannens E. Extreme Rainfall Event Classification Using Machine Learning for Kikuletwa River Floods. Water. 2023; 15(6):1021. https://doi.org/10.3390/w15061021
Chicago/Turabian StyleMdegela, Lawrence, Esteban Municio, Yorick De Bock, Edith Luhanga, Judith Leo, and Erik Mannens. 2023. "Extreme Rainfall Event Classification Using Machine Learning for Kikuletwa River Floods" Water 15, no. 6: 1021. https://doi.org/10.3390/w15061021