
Building and Validating Multidimensional Datasets in Hydrology for Data and Mapping Web Service Compliance
 , ,
, ,  and
and
Abstract
:1. Introduction
1.1. Storing and Sharing Multidimensional Data
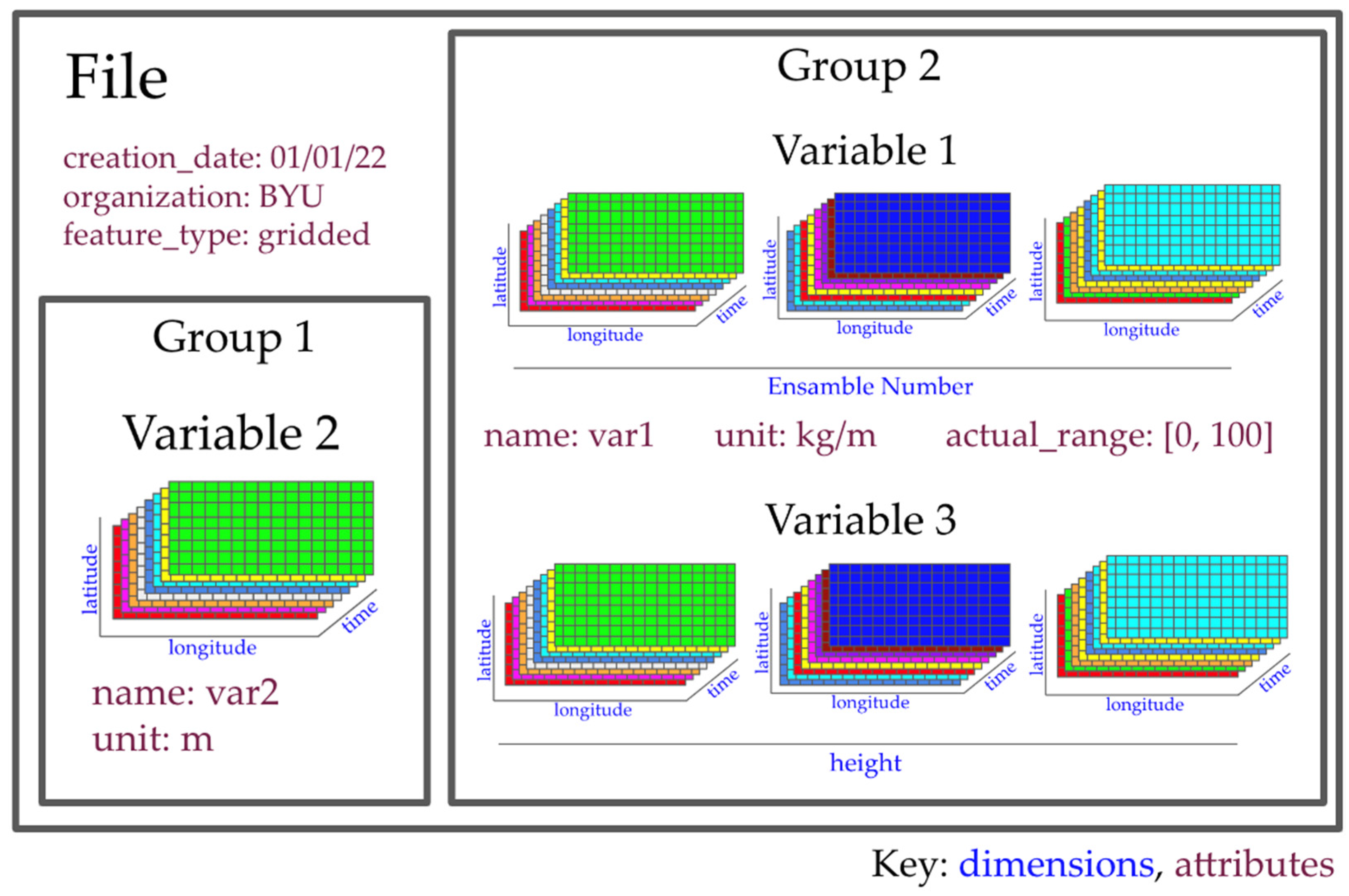
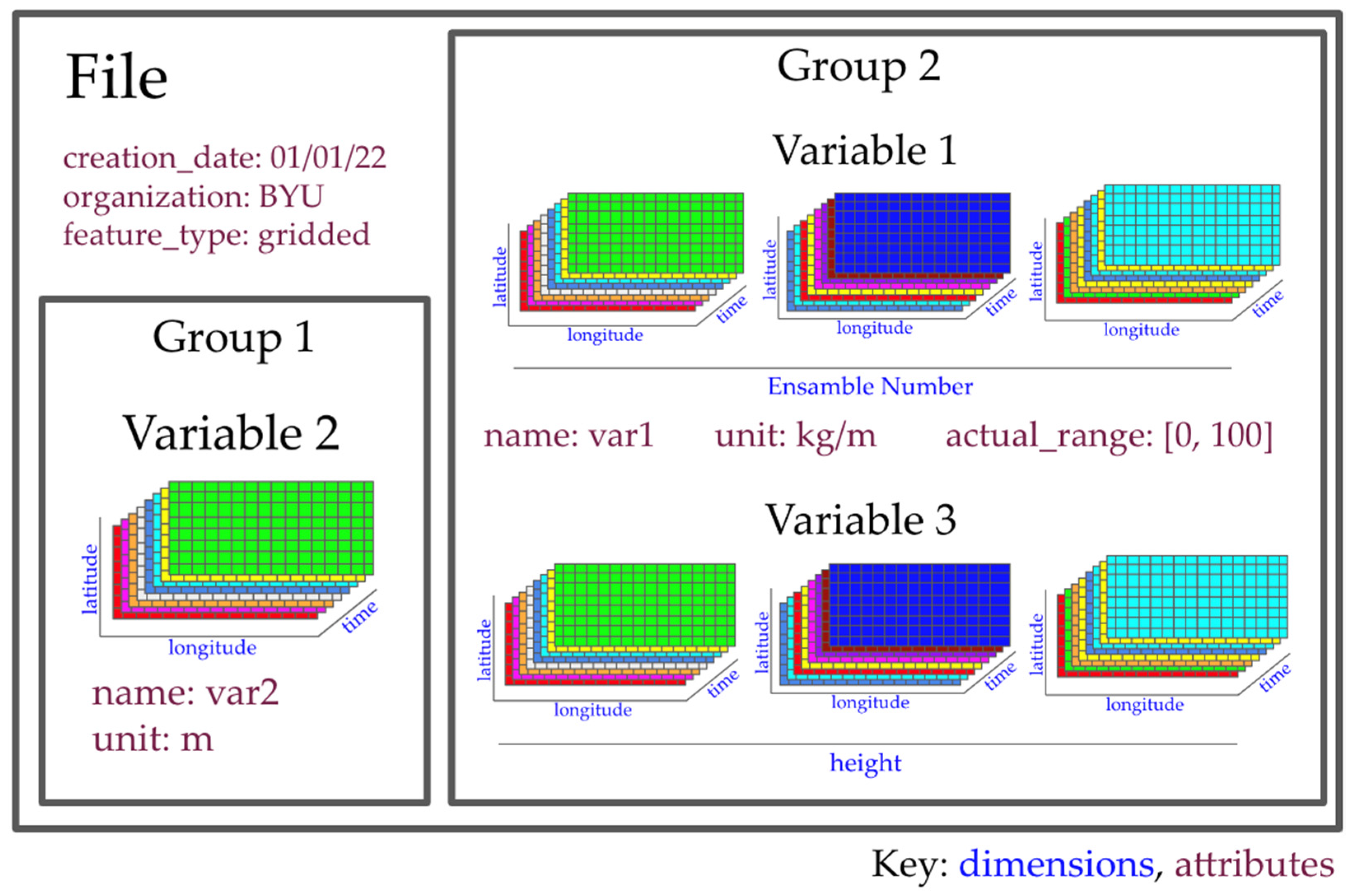
1.2. NetCDF Data Structure
1.3. Conventions for Organizing netCDF Datasets
1.4. Research Goals
- The ability to generate a netCDF markup language (NcML) file that displays the organization of the data and that generates the metadata necessary to make the dataset compliant with the specified conventions;
- The ability for the dataset creator to manually enter or modify any metadata or file configuration properties that cannot be auto-configured;
- The package must run on any netCDF file and generate information about the contents of the file;
- The initial version of the package must have support for the CF conventions version 1.9 and ACDD version 1.3;
- The package must be usable by people unfamiliar with the ACDD and CF conventions;
- The package must produce a dataset that is sufficiently compliant with the CF conventions to be compatible with a TDS and OPeNDAP.
1.5. Limitations of Work
2. Methods
2.1. Requirements for Compliance with ACDD
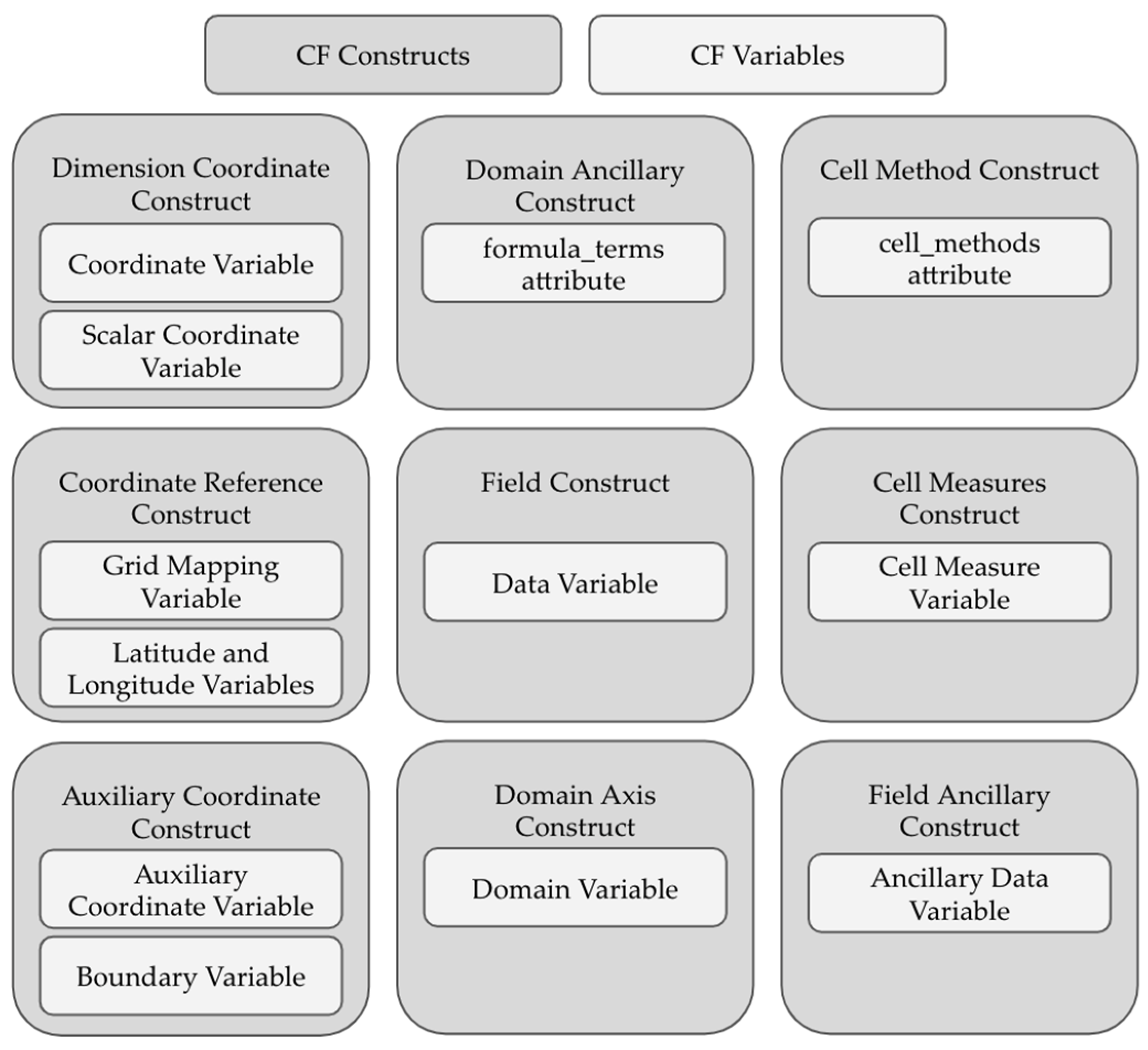
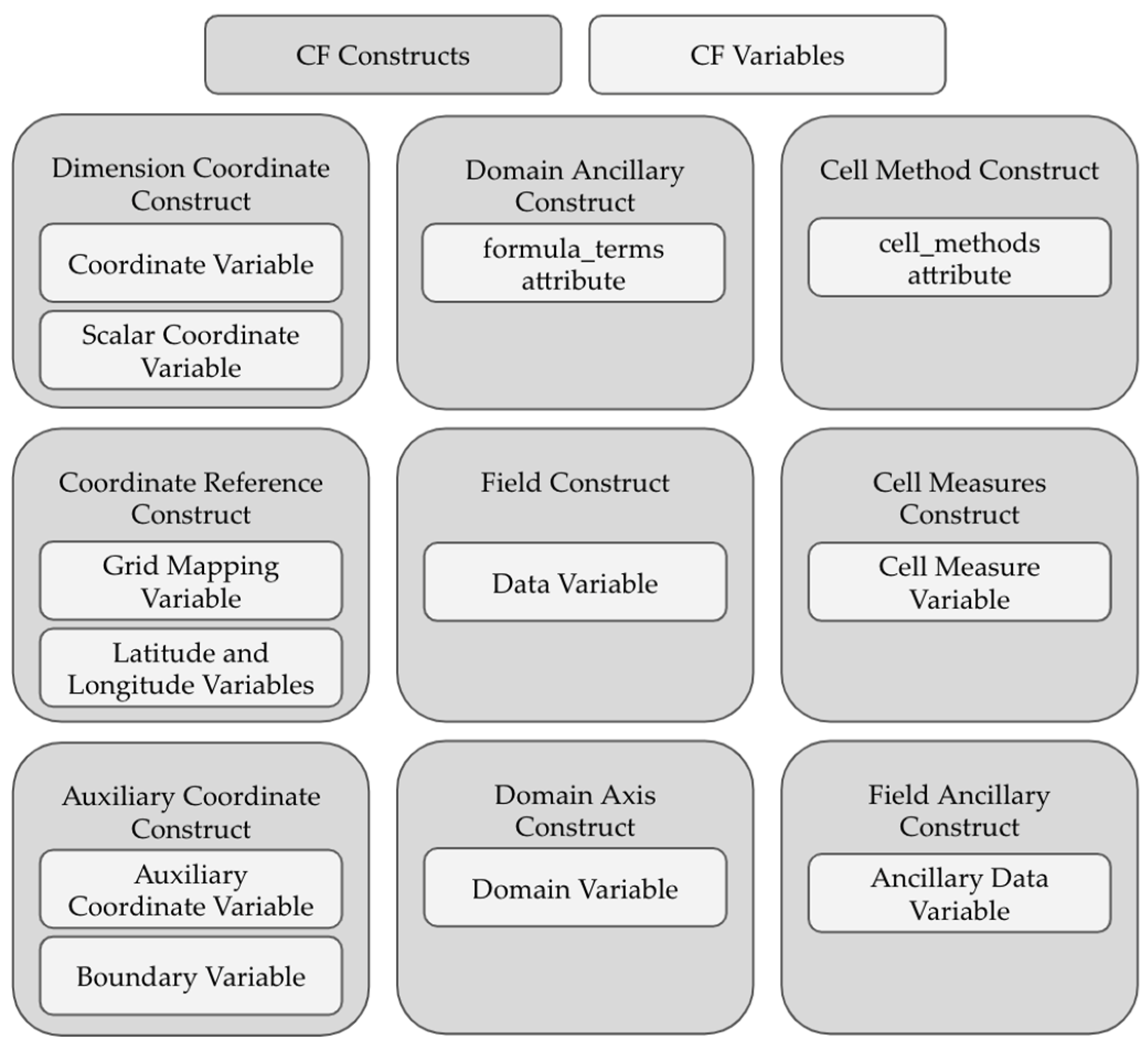
2.2. Requirements for Compliance with CF Conventions
2.3. Requirements for Compatability with OPeNDAP and Other Sofware
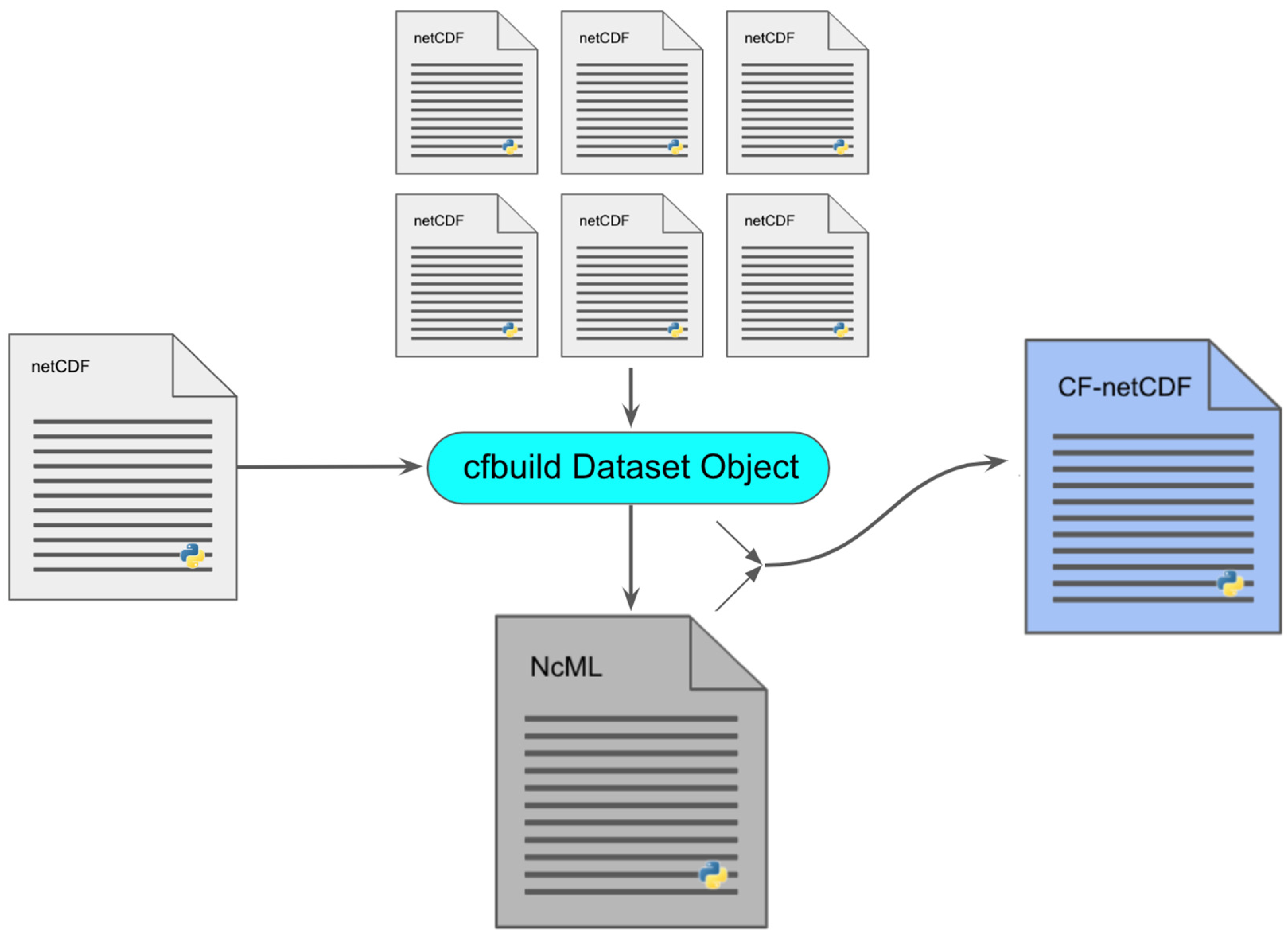
2.4. Development of the cfbuild Python Package
- Open the specified file or dataset.
- Sort the dataset into global attributes, dimensions, and variables.
- Determine the variable types.
- Assign the appropriate metadata.
- Write the data structure with the assigned metadata to an NcML file.
- Read the modified NcML file.
- Create a new netCDF file.
- Write the updated dataset to the new netCDF file.
- Close all netCDF files.
2.5. Parsing the Dataset
2.6. Building an NcML File
2.7. Building the NetCDF Dataset
2.8. Limitations of the cfbuild Python Package
3. Results
3.1. Testing the cfbuild Python Package
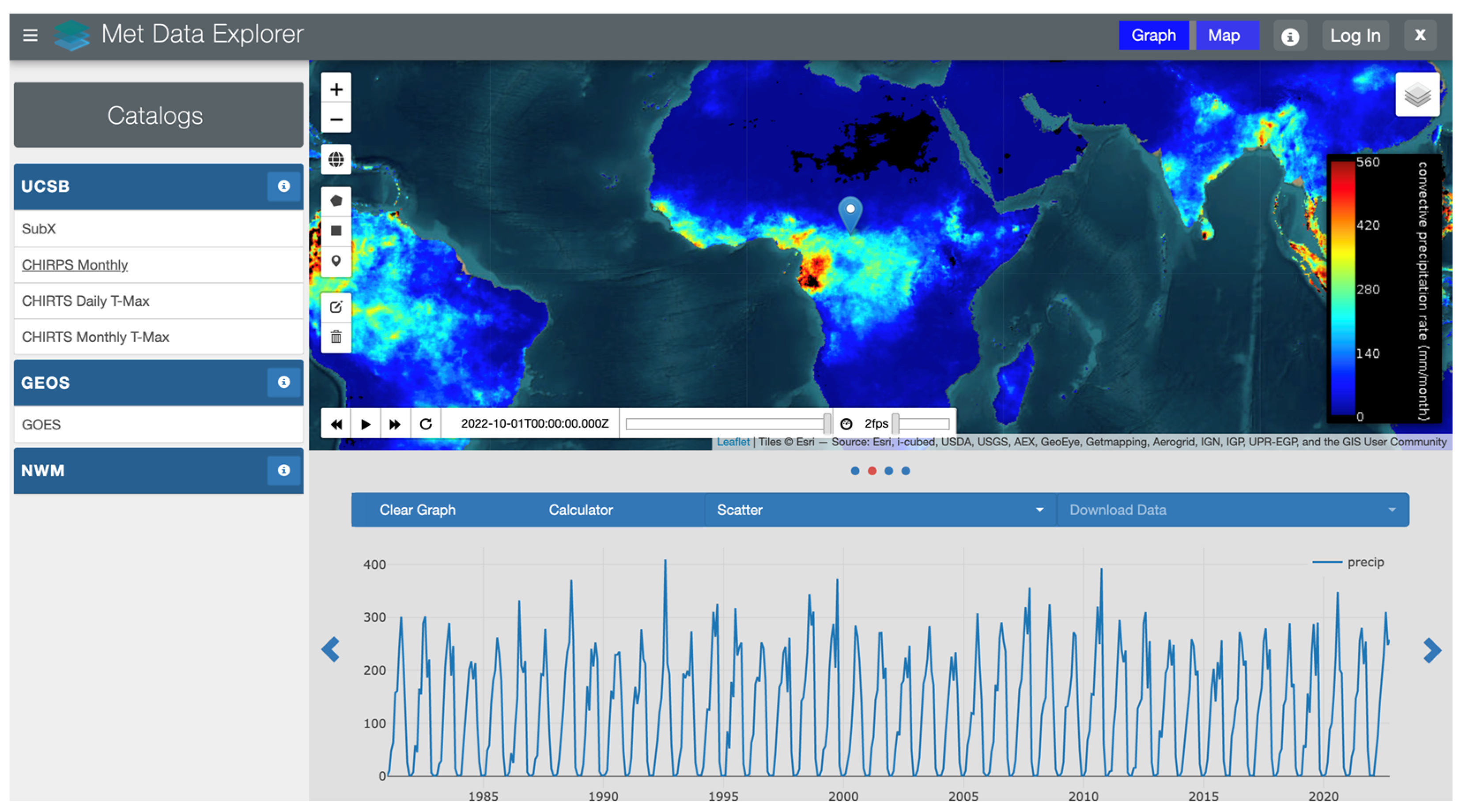
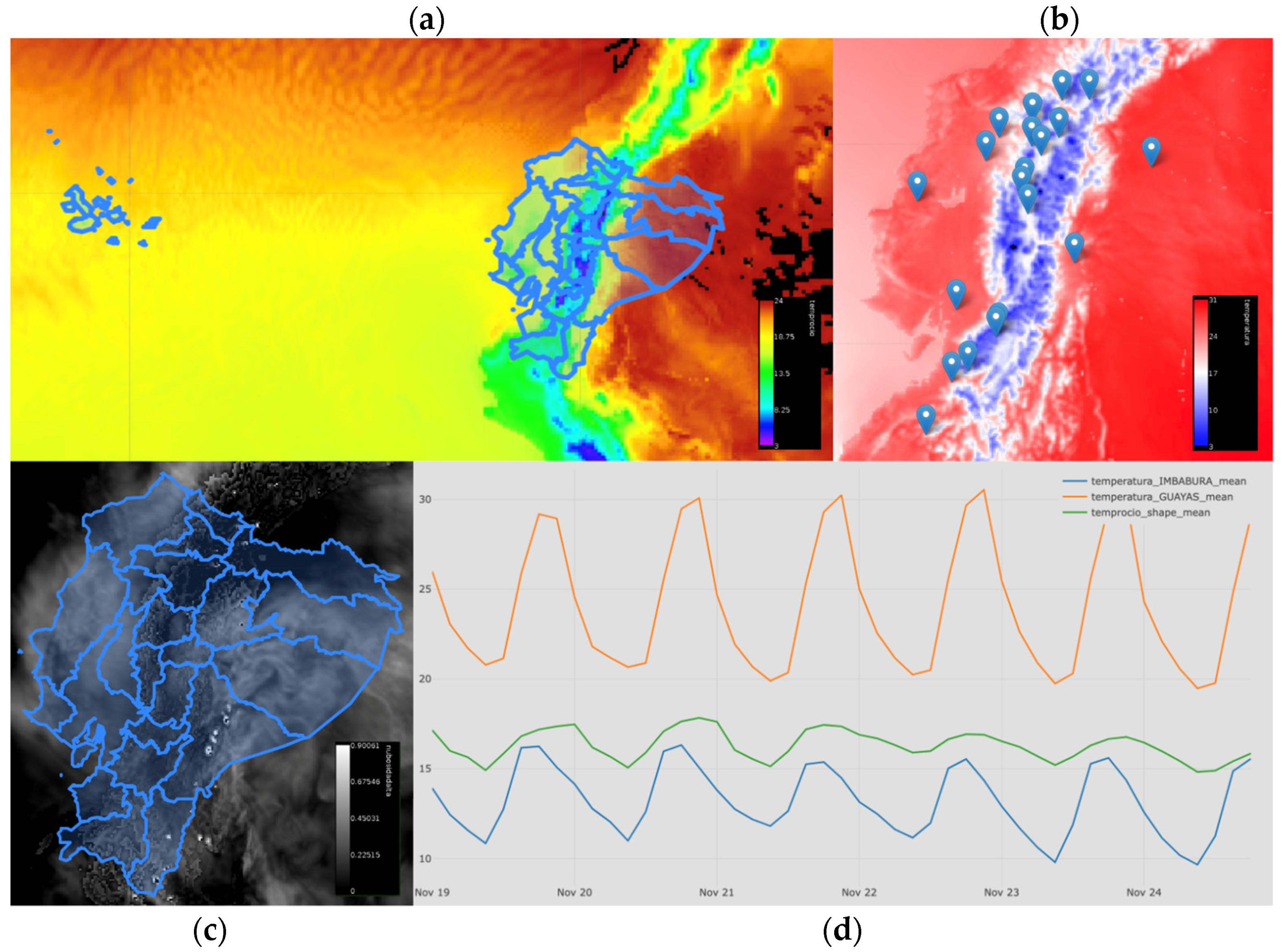
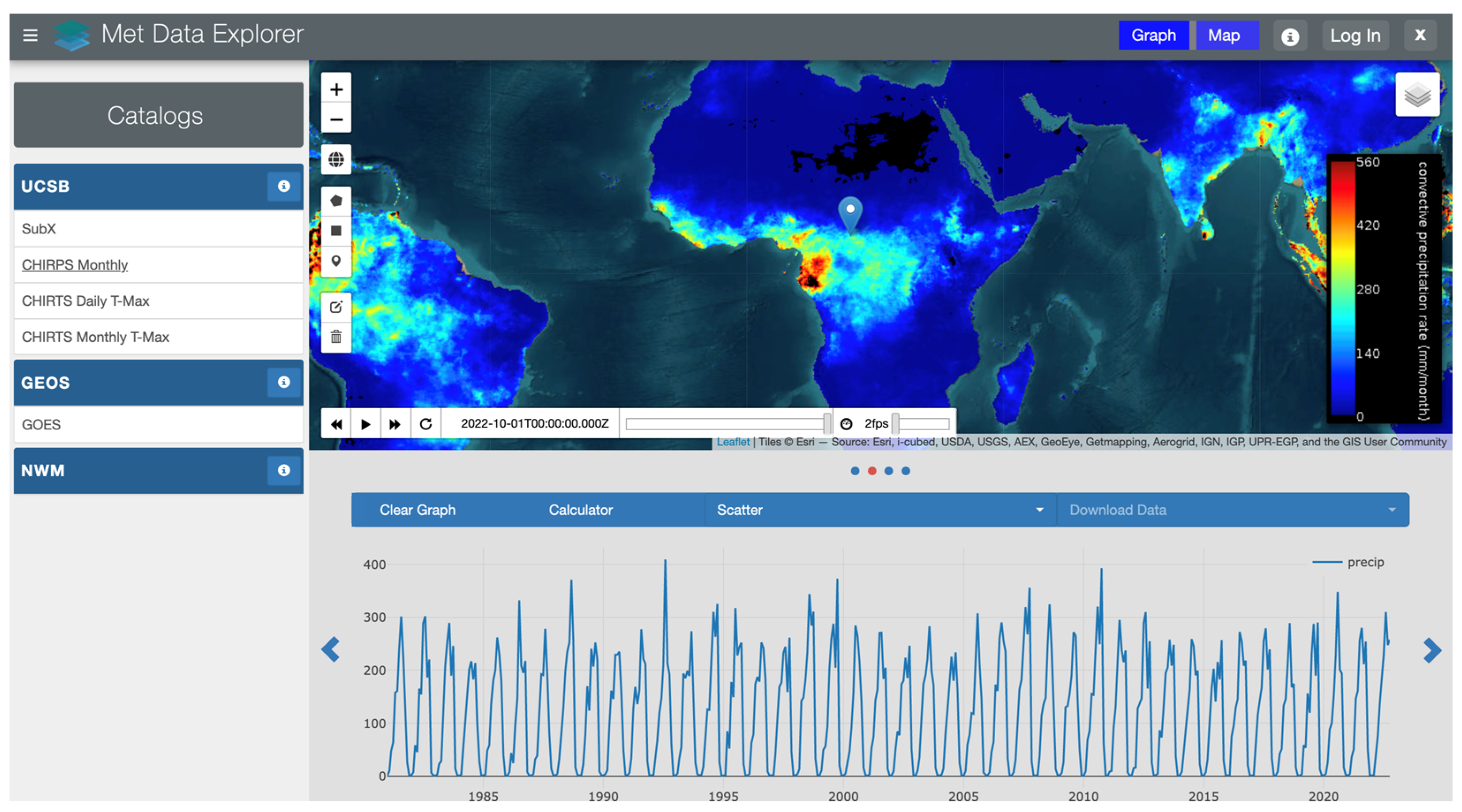
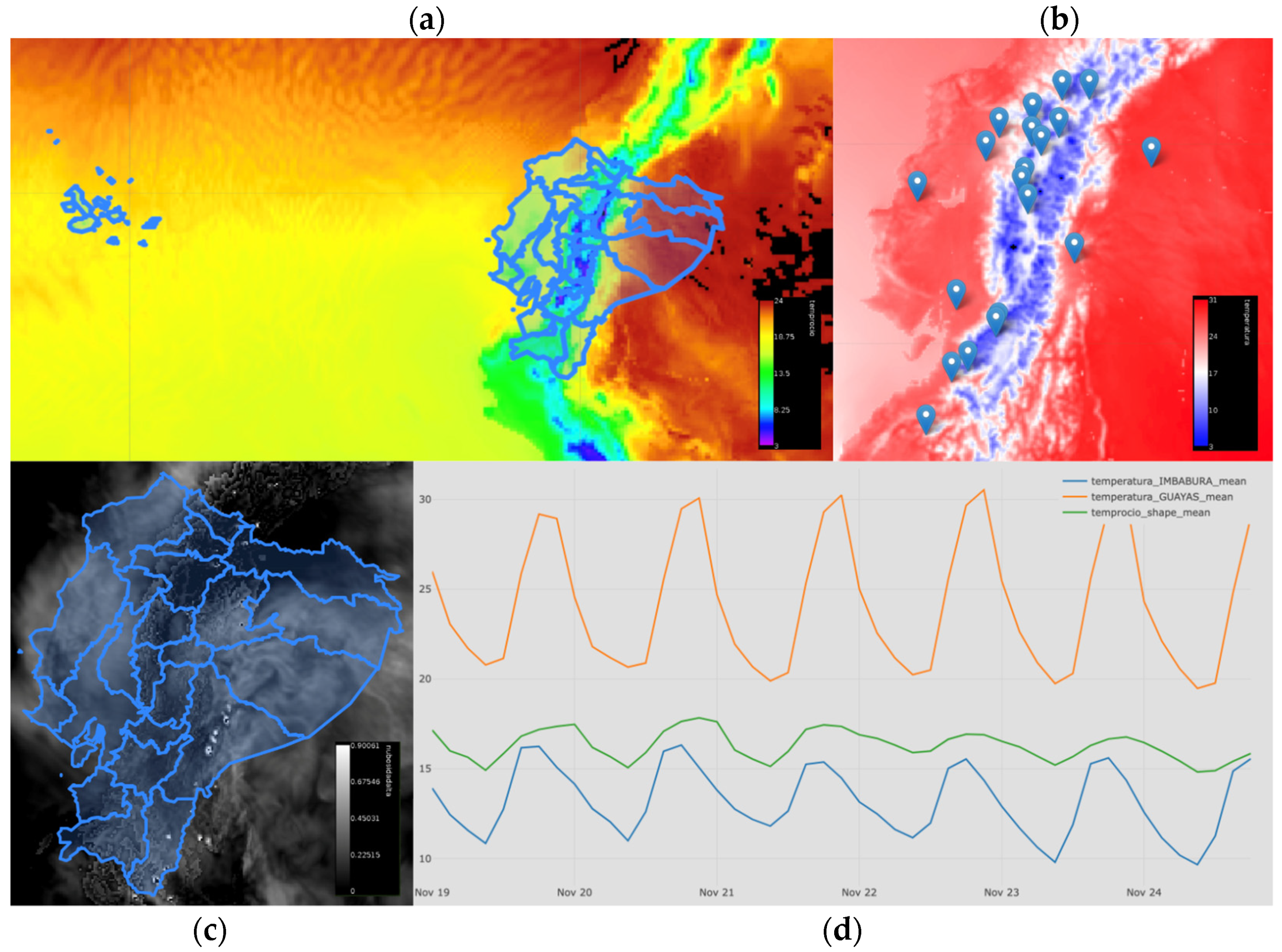
3.2. A Web Application Test Case
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alcantara, M.A.S.; Kesler, C.; Stealey, M.J.; Nelson, E.J.; Ames, D.P.; Jones, N.L. Cyberinfrastructure and Web Apps for Managing and Disseminating the National Water Model. JAWRA J. Am. Water Resour. Assoc. 2018, 54, 859–871. [Google Scholar] [CrossRef]
- “Global Forecast System (GFS),” National Centers for Environmental Information (NCEI), 12 August 2020. Available online: https://www.ncei.noaa.gov/products/weather-climate-models/global-forecast (accessed on 15 November 2022).
- Guillory, A. “ERA5,” ECMWF, 3 November 2017. Available online: https://www.ecmwf.int/en/forecasts/datasets/reanalysis-datasets/era5 (accessed on 15 November 2022).
- NOAA Open Data Dissemination (NODD). Available online: http://www.noaa.gov/information-technology/open-data-dissemination (accessed on 16 June 2022).
- Hales, R.C.; Nelson, E.J.; Williams, G.P.; Jones, N.; Ames, D.P.; Jones, J.E. The Grids Python Tool for Querying Spatiotemporal Multidimensional Water Data. Water 2021, 13, 2066. [Google Scholar] [CrossRef]
- Rew, R.; Davis, G. NetCDF: An interface for scientific data access. IEEE Comput. Graph. Appl. 1990, 10, 76–82. [Google Scholar] [CrossRef]
- Eaton, B.; Gregory, J.; Drach, B.; Taylor, K.; Hankin, S.; Blower, J.; Caron, J.; Signell, R.; Bentley, P.; Rappa, G.; et al. NetCDF Climate and Forecast (CF) Metadata Conventions, Version 1.9. 2021. Available online: https://cfconventions.org/cf-conventions/cf-conventions.html (accessed on 10 September 2022).
- Cornillon, P.; Gallagher, J.; Sgouros, T. OPeNDAP: Accessing data in a distributed, heterogeneous environment. Data Sci. J. 2003, 2, 164–174. [Google Scholar] [CrossRef] [Green Version]
- THREDDS Data Server Downloads. Available online: https://downloads.unidata.ucar.edu/tds/ (accessed on 23 June 2022).
- Unidata THREDDS Data Server (TDS). Available online: https://www.unidata.ucar.edu/software/tds/ (accessed on 23 June 2022).
- Hassell, D.; Gregory, J.; Blower, J.; Lawrence, B.N.; Taylor, K.E. A Data Model of the Climate and Forecast Metadata.pdf. 2017. Available online: https://gmd.copernicus.org/articles/10/4619/2017/gmd-10-4619-2017.pdf (accessed on 5 February 2022).
- “Attribute Convention for Data Discovery 1-3,” Federation of Earth Science Information Partners, 30 March 2022. Available online: https://wiki.esipfed.org/Attribute_Convention_for_Data_Discovery_1-3 (accessed on 19 April 2022).
- UNIDATA, “CF Standard Name Table,” CF Standard Name Table, 19 March 2022. Available online: https://cfconventions.org/Data/cf-standard-names/current/build/cf-standard-name-table.html (accessed on 14 December 2022).
- Writing a Client-OPeNDAP Documentation. Available online: https://docs.opendap.org/index.php/Writing_a_Client#Writing_your_own_OPeNDAP_client (accessed on 2 August 2022).
- NetCDF Users Guide: DAP2 Protocol Support. Available online: https://docs.unidata.ucar.edu/nug/current/dap2.html (accessed on 2 August 2022).
- Nativi, S.; Caron, J.; Davis, E.; Domenico, B. Design and implementation of netCDF markup language (NcML) and its GML-based extension (NcML-GML). Comput. Geosci. 2005, 31, 1104–1118. [Google Scholar] [CrossRef]
- Compliance Checker. Available online: https://podaac-tools.jpl.nasa.gov/mcc/ (accessed on 24 June 2022).
- CF-Convention Compliance Checker for NetCDF Format. Available online: https://pumatest.nerc.ac.uk/cgi-bin/cf-checker.pl (accessed on 2 September 2022).
- Hatcher, R. cfchecker: The NetCDF Climate Forecast Conventions Compliance Checker. [MacOS, POSIX :: Linux]. Available online: http://cfconventions.org/compliance-checker.html (accessed on 2 September 2022).
- Weather Research & Forecasting Model (WRF) Mesoscale & Microscale Meteorology Laboratory. Available online: https://www.mmm.ucar.edu/models/wrf (accessed on 15 September 2022).
- NASA GISS: Panoply 5 netCDF, HDF and GRIB Data Viewer. Available online: https://www.giss.nasa.gov/tools/panoply/ (accessed on 26 October 2022).
- Blower, J.; Haines, K.; Santokhee, A.; Liu, C. GODIVA2: Interactive visualization of environmental data on the Web. Philos. Trans. R. Soc. A: Math. Phys. Eng. Sci. 2009, 367, 1035–1039. [Google Scholar] [CrossRef] [PubMed]
- CHIRPS: Rainfall Estimates from Rain Gauge and Satellite Observations | Climate Hazards Center-UC Santa Barbara. Available online: https://chc.ucsb.edu/data/chirps (accessed on 15 November 2022).
- Funk, C.; Peterson, P.; Peterson, S.; Shukla, S.; Davenport, F.; Michaelsen, J.; Knapp, K.R.; Landsfeld, M.; Husak, G.; Harrison, L.; et al. A High-Resolution 1983–2016 Tmax Climate Data Record Based on Infrared Temperatures and Stations by the Climate Hazard Center. J. Clim. 2019, 32, 5639–5658. [Google Scholar] [CrossRef]
- Met Data Explorer. Available online: https://inamhi.geoglows.org/apps/metdataexplorer/#1 (accessed on 21 November 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Type | Method of Identification |
|---|---|
| Coordinate Variable | Contains the axis attribute |
| Auxiliary Coordinate Variable | Listed in the coordinate attribute of a variable |
| Scalar Coordinate Variable | A zero-dimensional, single-valued variable |
| Data Variable | All other variables that do not fit a different type |
| Ancillary Data Variable | Listed in the ancillary attribute of a data variable |
| Domain Variable | Contains the dimensions attribute |
| Boundary Variable | Listed in the bounds attribute of a variable |
| Grid-Mapping Variable | Contains the grid_mapping_name attribute |
| Cell Measure Variable | Listed in the cell_measures attribute of a variable |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jones, J.E.; Hales, R.C.; Larco, K.; Nelson, E.J.; Ames, D.P.; Jones, N.L.; Iza, M. Building and Validating Multidimensional Datasets in Hydrology for Data and Mapping Web Service Compliance. Water 2023, 15, 411. https://doi.org/10.3390/w15030411
Jones JE, Hales RC, Larco K, Nelson EJ, Ames DP, Jones NL, Iza M. Building and Validating Multidimensional Datasets in Hydrology for Data and Mapping Web Service Compliance. Water. 2023; 15(3):411. https://doi.org/10.3390/w15030411
Chicago/Turabian StyleJones, J. Enoch, Riley Chad Hales, Karina Larco, E. James Nelson, Daniel P. Ames, Norman L. Jones, and Maylee Iza. 2023. "Building and Validating Multidimensional Datasets in Hydrology for Data and Mapping Web Service Compliance" Water 15, no. 3: 411. https://doi.org/10.3390/w15030411