

Water Quality Classification and Machine Learning Model for Predicting Water Quality Status—A Study on Loa River Located in an Extremely Arid Environment: Atacama Desert



Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Datasets and Data Preparation
2.2.1. Historical Data
2.2.2. Data Standardization
2.3. Water Quality Regulations and Threshold Values
2.4. Predictive Models and Random Forest
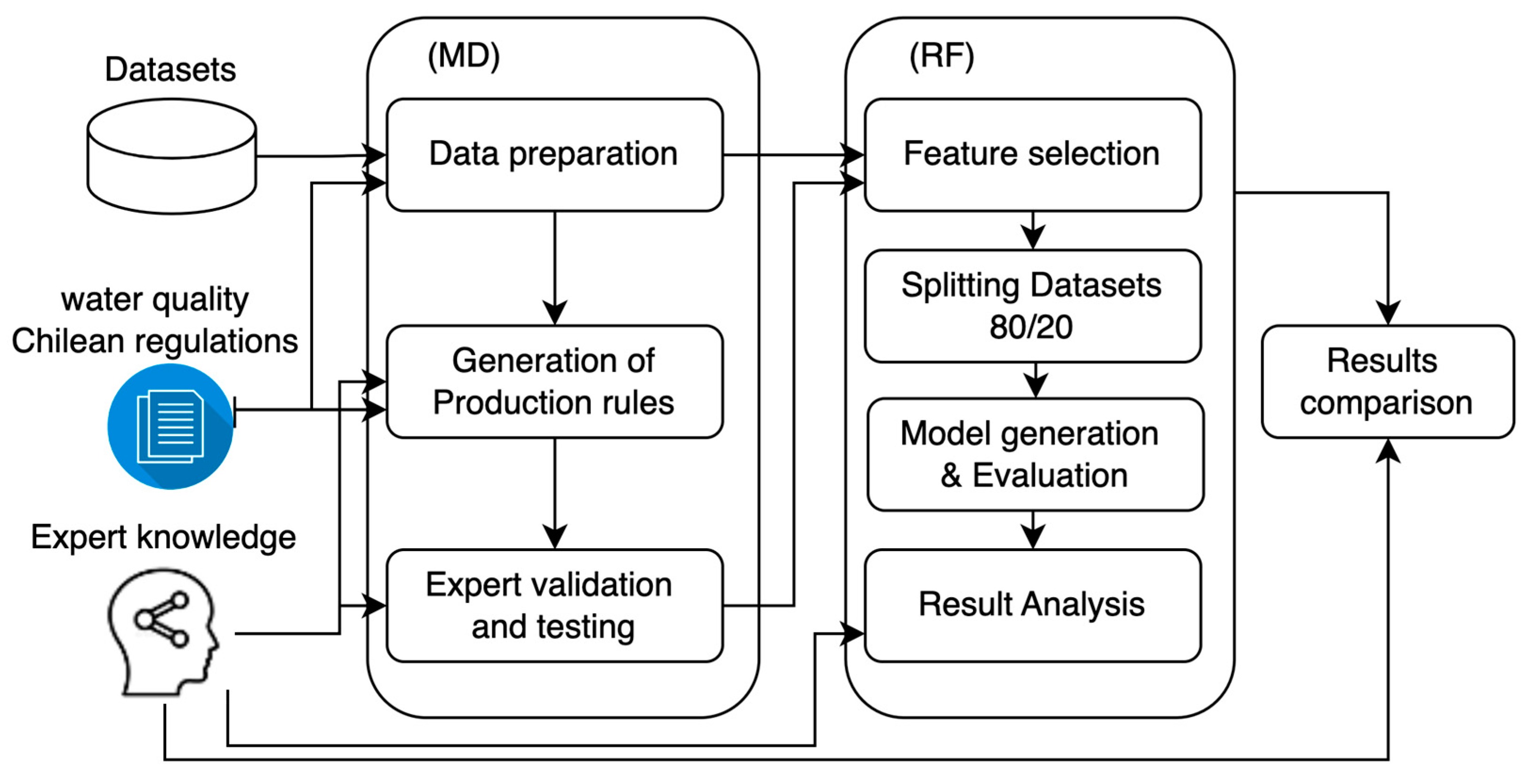
3. Model Construction
- Data preparation. Records of the monitoring points in Table 1 were prepared by removing outliers. Next, a data improvement process was developed, as described in Data Standardization.
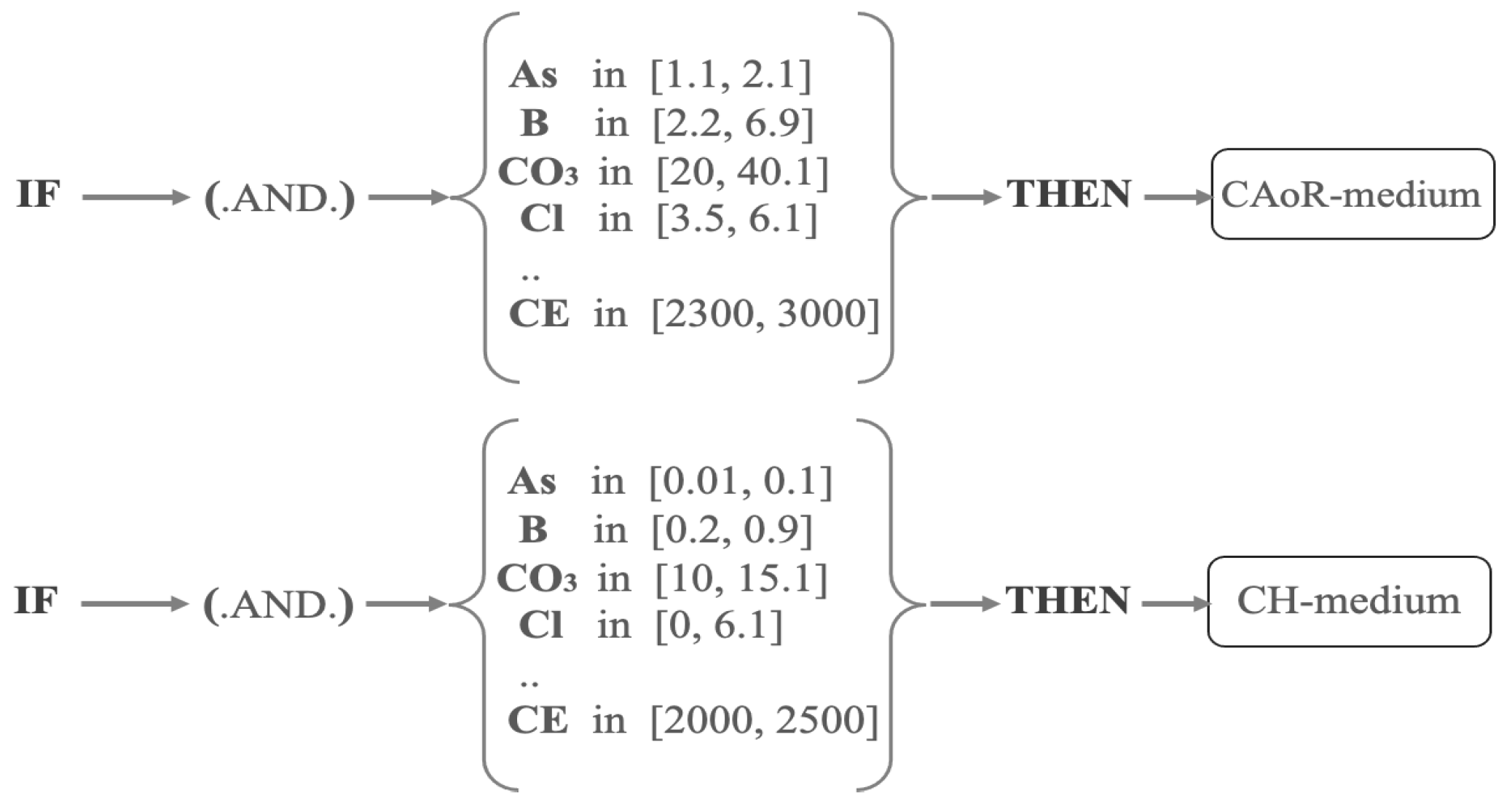
- Generation of production rules. Using the threshold values in Table 2 and expert knowledge, as described in the previous paragraph, ranges of physicochemical parameter values were defined, as shown in Table 3. Then, using the ranges and descriptive statistical values shown in Supplementary Materials Table S1 (particular for the study domain in Atacama Desert), production rules were defined.
- 3.
- Expert validation and testing. For validation, randomly selected records from the different datasets (about 15% from each dataset) were used as input for WQ labels. The result was validated by a disciplinary expert.
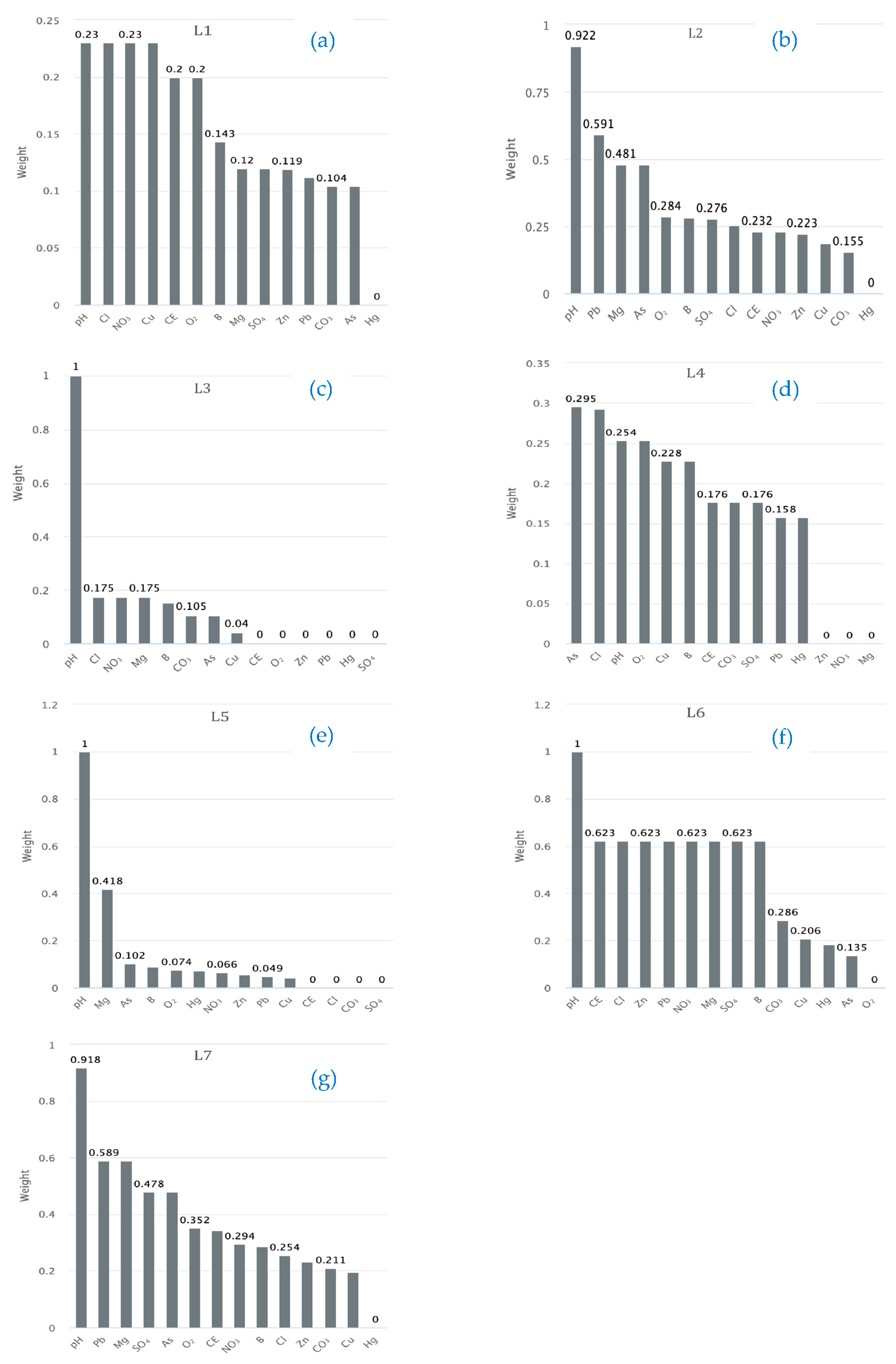
- Feature Selection. This stage consisted in filtering and selecting WQ significant predictor variables. Selection criteria were based on expert knowledge and the interpretation of pairwise relationships to identify possible prior dependency relationships between predictor variables. Python was used to identify these types of relationships, particularly the scatter matrix function with the diagonal = “KDE” parameter.
- Splitting Datasets. In this stage, the original data from each of the monitoring points were divided (split) into 80% for training and tuning hyperparameters and 20% for testing the final model to obtain an unbiased estimate. The optimal model was found using K-fold cross-validation with five folds.
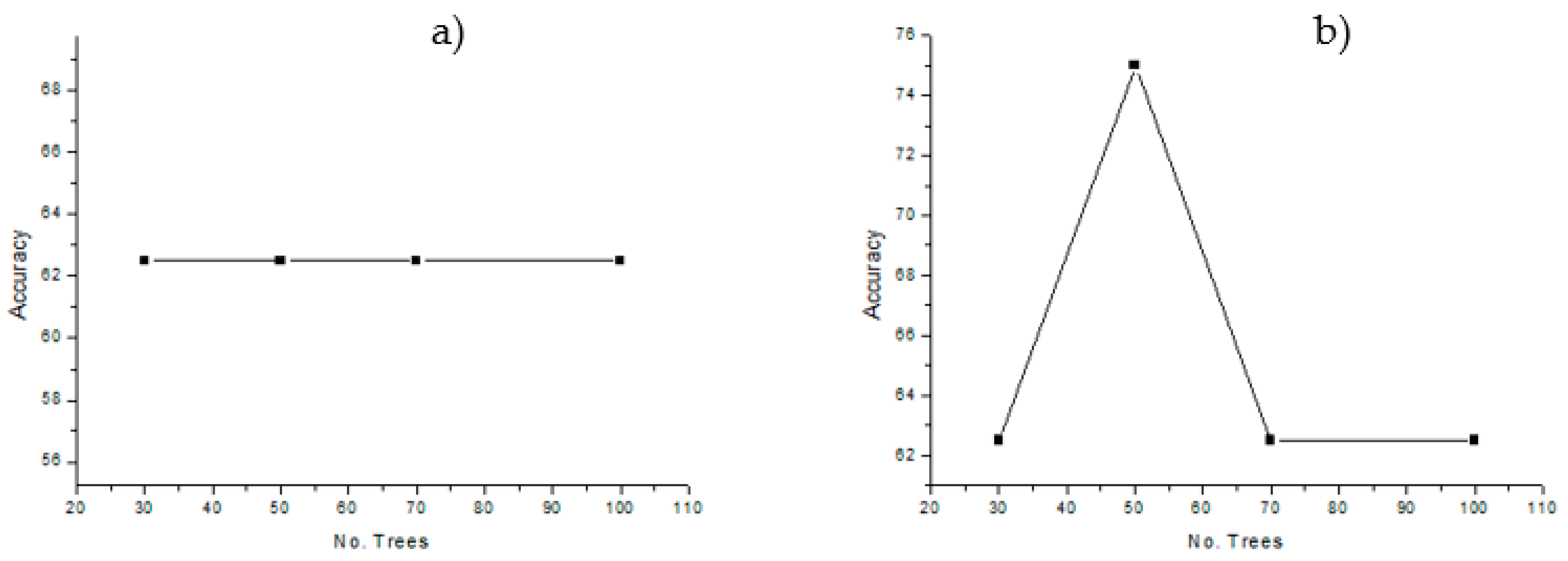
- Model Generation and Evaluation. In this stage, the RF models for each monitoring point were generated, and the results of the models were estimated and analyzed to determine their validity. Evaluation consisted in checking the performance of the models obtained with RF for each dataset. To accomplish this, values of certainty, such as accuracy, recall, and precision, were calculated and analyzed. The calculation of these values of certainty and their importance for the model quality are described below.
- Result Analysis. This was performed by analyzing aspects such as how optimal variable parametrization was or how well training set instances were classified (confusion matrix values).
4. Results
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Muñoz-Farías, S.; Ritter, B.; Dunai, T.J.; Morales-Leal, J.; Campos, E.; Spikings, R.; Riquelme, R. Geomorphological significance of the Atacama Pediplain as a marker for the climatic and tectonic evolution of the Andean forearc, between 26° to 28° S. Geomorphology 2023, 420, 108504. [Google Scholar] [CrossRef]
- Alnahit, A.O.; Mishra, A.K.; Khan, A.A. Quantifying climate, streamflow, and watershed control on water quality across Southeastern US watersheds. Sci. Total Environ. 2020, 739, 139945. [Google Scholar] [CrossRef] [PubMed]
- Muharemi, F.; Logofătu, D.; Leon, F. Machine learning approaches for anomaly detection of water quality on a real-world data set. J. Inf. Telecommun. 2019, 3, 294–307. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Lu, J. Identification of river water pollution characteristics based on projection pursuit and factor analysis. Environ. Earth Sci. 2014, 72, 3409–3417. [Google Scholar] [CrossRef]
- USEPA. Parameters of Water Quality: Interpretation and Standards; Environmental Protection Agency: Wexford, Ireland, 2001. [Google Scholar]
- Méndez, M.; Prieto, M.; Godoy, M. Production of subterranean resources in the Atacama Desert: 19th and early 20th-century mining/water extraction in The Taltal district, northern Chile. Political Geogr. 2020, 81, 102194. [Google Scholar] [CrossRef]
- Kereszturi, Á. Unique and potentially Mars-relevant flow regime and water sources at a high Andes-Atacama site. Astrobiology 2020, 20, 723–740. [Google Scholar] [CrossRef]
- Tapia, J.; González, R.; Townley, B.; Oliveros, V.; Álvarez, F.; Aguilar, G.; Calderón, M. Geology and geochemistry of the Atacama Desert. Antonie Leeuwenhoek 2018, 111, 1273–1291. [Google Scholar] [CrossRef]
- Arias-Carrasco, R.; Rojas-Herrera, M.; Sepúlveda-Hermosilla, G.; Maracaja-Coutinho, V.; Huanca-Mamani, W.; Cárdenas-Ninasivincha, S.; Bastáas, E. Long Non-Coding RNAs Responsive to Salt and Boron Stress in the Hyper-Arid Lluteno Maize from Atacama Desert. Genes 2018, 9, 170. [Google Scholar]
- Arriaza, B.; Amarasiriwardena, D.; Starkings, J.; Ogalde, J.P. Use of LA-ICP-MS to evaluate mercury exposure or diagenesis in Inca and non-Inca mummies from northern Chile. Archaeol. Anthropol. Sci. 2022, 14, 76. [Google Scholar] [CrossRef]
- Bull, A.T.; Asenjo, J.A. Microbiology of hyper-arid environments: Recent insights from the Atacama Desert, Chile. Antonie Leeuwenhoek 2013, 103, 1173–1179. [Google Scholar] [CrossRef]
- Flores-Varas, A.; Heine-Fuster, I.; López-Allendes, C.; Pizarro, H.; Castro, D.; Luque, J.A.; Aránguiz-Acuña, A. Ascotán, and Carcote salt flats as sensors of humidity fluctuations and anthropic impacts in the transition zone of the Andean Altiplano. J. S. Am. Earth Sci. 2021, 105, 102934. [Google Scholar] [CrossRef]
- Pino-Vargas, E.; Chavarri-Velarde, E. Evidence of climate change in the hyper-arid region of the southern coast of Peru, head of the Atacama Desert. Tecnol. Cienc. Agua 2022, 13, 333–375. [Google Scholar] [CrossRef]
- Díaz, F.P.; Latorre, C.; Carrasco-Puga, G.; Wood, J.R.; Wilmshurst, J.M.; Soto, D.C.; Gutiérrez, R.A. Multiscale climate change impacts on plant diversity in the Atacama Desert. Glob. Chang. Biol. 2019, 25, 1733–1745. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Wei, J.; Peng, W.; Zhang, R.; Zhang, H. Contents and spatial distribution patterns of heavy metals in the hinterland of the Tengger Desert, China. J. Arid. Land. 2022, 14, 1086–1098. [Google Scholar] [CrossRef]
- Vargas-Machuca, B.D.; Zanetta-Colombo, N.; De Pol-Holz, R.; Latorre, C. Variations in local heavy metal concentrations over the last 16,000 years in the central Atacama Desert (22° S) measured in rodent middens. Sci. Total Environ. 2021, 775, 145849. [Google Scholar] [CrossRef]
- Yang, L.; Ma, X.; Luan, Z.; Yan, J. The spatial-temporal evolution of heavy metal accumulation in the offshore sediments along the Shandong Peninsula over the last 100 years: Anthropogenic and natural impacts. Environ. Pollut. 2021, 289, 117894. [Google Scholar] [CrossRef]
- López-Berenguer, G.; Pérez-García, J.M.; García-Fernández, A.J.; Martínez-López, E. High levels of heavy metals detected in feathers of an avian scavenger warn of a high pollution risk in the Atacama Desert (Chile). Arch. Environ. Contam. Toxicol. 2021, 81, 227–235. [Google Scholar] [CrossRef]
- Moreno, M.L.; Piubeli, F.; Bonfá, M.R.L.; García, M.T.; Durrant, L.R.; Mellado, E. Analysis and characterization of the cultivable extremophilic hydrolytic bacterial community in heavy-metal-contaminated soils from the Atacama Desert and their biotechnological potentials. J. Appl. Microbiol. 2012, 113, 550–559. [Google Scholar] [CrossRef]
- Lintern, A.; Webb, J.A.; Ryu, D.; Liu, S.; Bende-Michl, U.; Waters, D.; Leahy, P.; Western, A.W. Key factors influencing differences in stream water quality across space. Wiley Interdiscip. Rev. Water 2018, 5, e1260. [Google Scholar] [CrossRef] [Green Version]
- Abuzir, S.Y.; Abuzir, Y.S. Machine learning for water quality classification. Water Qual. Res. J. 2022, 57, 152–164. [Google Scholar] [CrossRef]
- Ahmed, A.N.; Othman, F.B.; Afan, H.A.; Ibrahim, R.K.; Fai, C.M.; Hossain, M.S.; Ibrahim, R.K.; Fai, C.M.; Hossain Md Ehteram, M.; Elshafie, A. Machine learning methods for better water quality prediction. J. Hydrol. 2019, 578, 124084. [Google Scholar] [CrossRef]
- Gayen, A.; Pourghasemi, H.R.; Saha, S.; Keesstra, S.; Bai, S. Gully erosion susceptibility assessment and management of hazard-prone areas in India using different machine learning algorithms. Sci. Total Environ. 2019, 668, 124–138. [Google Scholar] [CrossRef]
- Plazas-Nossa, L.; Ávila Angulo, M.A.; Torres, A. Detection of outliers and imputing of missing values for water quality UV-Vis absorbance time series. Ingeniería 2017, 22, 111–124. [Google Scholar] [CrossRef]
- Avila-Perez, H.; Flores-Munguía, E.J.; Rosas-Acevedo, J.L.; Gallardo-Bernal, I.; Ramirez-delReal, T.A. Comparative Analysis of Water Quality Applying Statistic and Machine Learning Method: A Case Study in Coyuca Lagoon and Tecpan River, Mexico. Water 2023, 15, 640. [Google Scholar] [CrossRef]
- Flores, V. Determination of Trees Predictive Models for Surface Roughness in High-Speed Machining (HSP): A Study in Steel and Aluminum Metalworking Industry. In Research Highlights in Mathematics and Computer Science; BP International: Karuppur, India, 2023; Volume 4, pp. 42–66. [Google Scholar]
- Flores, V.; Keith, B. Gradient boosted trees predictive models for surface roughness in high-speed milling in the steel and aluminum metalworking industry. Complexity 2019, 2019, 1536716. [Google Scholar] [CrossRef] [Green Version]
- Zanetta-Colombo, N.C.; Fleming, Z.L.; Gayo, E.M.; Manzano, C.A.; Panagi, M.; Valdés, J.; Siegmund, A. Impact of mining on the metal content of dust in indigenous villages of northern Chile. Environ. Int. 2022, 169, 107490. [Google Scholar] [CrossRef]
- Ruffino, B.; Campo, G.; Crutchik, D.; Reyes, A.; Zanetti, M. Drinking Water Supply in the Region of Antofagasta (Chile): A Challenge between Past, Present and Future. Int. J. Environ. Res. Public Health 2022, 19, 14406. [Google Scholar] [CrossRef]
- Min, D.H.; Yoon, H.K. Suggestion for a new deterministic model coupled with machine learning techniques for landslide susceptibility mapping. Sci. Rep. 2021, 11, 6594. [Google Scholar] [CrossRef]
- INN-NCh409; Official Chilean Drinking Water Standard. National Institute for Standardization. INN: Santiago, Chile, 2005.
- INN-NCh1333; Official Chilean Standard NCh1333 Water Quality Requirements for Different Uses. INN, National Institute for Standardization: Santiago, Chile, 1987.
- Dritsas, E.; Trigka, M. Efficient Data-Driven Machine Learning Models for Water Quality Prediction. Computation 2023, 11, 16. [Google Scholar] [CrossRef]
- Alnahit, A.O.; Mishra, A.K.; Khan, A.A. Stream water quality prediction using boosted regression tree and random forest models. Stoch. Environ. Res. Risk Assess. 2022, 36, 2661–2680. [Google Scholar] [CrossRef]
- Mori, T. Information gain ratio as term weight: The case of summarization of ir results. In Proceedings of the En Coling 2002: The 19th International Conference on Computational Linguistics, Taipei, Taiwan, 24 August–1 September 2002. [Google Scholar]
- Johansson, C.; Zhang, Z.; Engardt, M.; Stafoggia, M.; Ma, X. Improving 3-day deterministic air pollution forecasts using machine learning algorithms. Atmos. Chem. Phys. Discuss. 2023; preprint. [Google Scholar]
- Zhu, M.; Wang, J.; Yang, X.; Zhang, Y.; Zhang, L.; Ren, H.; Bing, W.; Ye, L. A review of the application of machine learning in water quality evaluation. Eco-Environ. Health 2022, 1, 107–116. [Google Scholar] [CrossRef]
- Molina, M.; Flores, V. A knowledge-based approach for automatic generation of summaries of behavior. In Proceedings of the Artificial Intelligence: Methodology, Systems, and Applications: 12th International Conference, AIMSA 2006, Varna, Bulgaria, 12–15 September 2006; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Legasa, M.N.; Manzanas, R.; Calviño, A.; Gutiérrez, J.M. A posteriori random forests for stochastic downscaling of precipitation by predicting probability distributions. Water Resour. Res. 2022, 58, e2021WR030272. [Google Scholar] [CrossRef]
- Regier, P.; Duggan, M.; Myers-Pigg, A.; Ward, N. Effects of random forest modeling decisions on biogeochemical time series predictions. Limnol. Oceanogr. Methods 2023, 21, 40–52. [Google Scholar] [CrossRef]
- Herrera, C.; Godfrey, L.; Urrutia, J.; Custodio, E.; Jordan, T.; Jódar, J.; Barrenechea, F. Recharge and residence times of groundwater in hyper-arid areas: The confined aquifer of Calama, Loa River Basin, Atacama Desert, Chile. Sci. Total Environ. 2021, 752, 141847. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sampling Sites | Location Name | S Latitude | W Longitude |
|---|---|---|---|
| L1 | Salado River at Sifón Ayquina | 22°17′21″ | 68°20′41″ |
| L2 | Chiu Chiu Well | 22°20′22″ | 68°35′56″ |
| L3 | Loa River before Salado River Intersection | 22°21′51″ | 68°39′06″ |
| L4 | Loa River at Escorial | 22°26′43″ | 68°53′25″ |
| L5 | Loa River at Yalquincha | 22°27′02″ | 68°52′45″ |
| L6 | Loa River at Angostura | 22°27′00″ | 68°43′00″ |
| L7 | Loa River at Finca | 22°30′34″ | 68°59′27″ |
| No. | Physicochemical Parameter | Maximum Value [31] | Maximum Value [32] | |
|---|---|---|---|---|
| General consumption | Human consumption | Human consumption | ||
| 1 | Aluminum (Al) | ≤5.0 mg/L | ≤5.0 mg/L | ≤5.0 mg/L |
| 2 | Copper (Cu) | ≤3.0 mg/L | ≤2.0 mg/L | ≤2.0 mg/L |
| 3 | Total chromium (Cr) | ≤0.05 mg/L | ≤0.05 mg/L | ≤0.05 mg/L |
| 4 | Fluorine (F) | ≤1.5 mg/L | ≤1.5 mg/L | ≤1.5 mg/L |
| 5 | Iron (Fe) | ≤0.5 mg/L | ≤0.3 mg/L | ≤0.3 mg/L |
| 6 | Magnesium (Mg) | ≤135 mg/L | ≤125 mg/L | ≤125 mg/L |
| 7 | Selenium (Se) | ≤0.1 mg/L | ≤0.01 mg/L | ≤0.01 mg/L |
| 8 | Zinc (Zn) | ≤4.0 mg/L | ≤3.0 mg/L | ≤3.0 mg/L |
| 9 | Arsenic (As) | ≤3.0 mg/L | ≤0.1 mg/L | ≤0.1 mg/L |
| 10 | Sulfate (SO4) | ≤0.1 mg/L | ≤0.01 mg/L | ≤0.01 mg/L |
| 11 | Mercury (Hg) | ≤0.2 mg/L | ≤0.001 mg/L | ≤0.001 mg/L |
| 12 | Nitrate (NO3) | ≤50 mg/L | ≤40 mg/L | ≤40 mg/L |
| 13 | Lead (Pb) | ≤0.5 mg/L | ≤0.05 mg/L | ≤0.05 mg/L |
| 14 | Boron (B) | ≤0.75 mg/L | ≤0.75 mg/L | ≤0.75 mg/L |
| 15 | pH | (6.5 and 9.5). | (6.5 and 8.5) | (6.5 and 8.5) |
| (a) | ||||||||
| No. | State | As | B | SO4 | Co | Cu | Mg | Hg |
| 1 | CH-High | [0, 0.01] | [0, 0.65] | [0, 0.1] | [0, 0.03] | [0, 0.1) | [0, 125) | [0, 0.01] |
| 2 | CH-Medium | [0.01, 0.1] | [0.65, 0.75] | [0, 0.1] | [0.03, 0.05] | [0.1, 0.2) | [126, 135) | [0, 0.01] |
| 3 | CH-Low | [0.1, >0.2] | [0.76, >0.85] | [0.01, >0.02] | [0.05, 0.07] | [0.2, 0.4] | [136, 142] | [0, 0.01] |
| 4 | CAoR-High | [0, <0.2] | [0, 0.75) | [0, 0.1] | [0, 0.03] | [0, 0.2) | [0, 125) | [0, 0.01] |
| 5 | CAoR-Medium | [0, 0.2] | [0.75, 0.85] | [0, 0.1] | [0.03, 0.05] | [0.2, 0.4) | [125, >125] | [0, 0.01] |
| 6 | CAoR-Low | [0.2, >0.3] | [0.76, >0.85] | [0.01, >0.02] | [0.05, 0.07] | [0.4, 0.5] | [125, >125] | [0, 0.01] |
| (b) | ||||||||
| No. | State | NO3 | Pb | Zn | Cl | O2 | pH | EC |
| 1 | CH-High | [0, 50) | [0, 0.05] | [0, 2) | [0, 200) | [0, 2) | [6.5, 8.3) | [1000, 1700) |
| 2 | CH-Medium | [0, 50) | [0.05, 2) | [2, 4) | [201, 400) | [2, 4) | [6.5, 8.3) | [1700, 2000) |
| 3 | CH-Low | [50, 60] | [2, 4] | [3, >4) | [201, 400) | [4, 5) | [6.5, 9) | [2000, 2500) |
| 4 | CAoR-High | [0, 50) | [0, 1) | [0, 2) | [0, 200) | [0, 2) | [6.5, 8.3) | [1650, 2000) |
| 5 | CAoR-Medium | [0, 50) | [1, 4) | [2, 4) | [201, 400) | [2, 5) | [6.5, 8.3) | [2001, 2400) |
| 6 | CAoR-Low | [50, 60] | [4, >5) | [3, >4) | [201, 400) | [5, >5) | [6.5, 9) | [2400, 7000] |
| Dataset | Class Precision | Cl-Err | acc | p | r |
|---|---|---|---|---|---|
| L1 | 98.9910 | 0.0173 | 0.8891 | 89.6631 | 0.9991 |
| L2 | 99.9920 | 0.0142 | 0.9993 | 94.8289 | 1.0000 |
| L3 | 100.0000 | 0.0703 | 0.9987 | 97.3427 | 1.0000 |
| L4 | 99.9970 | 0.0159 | 0.9891 | 96.8731 | 1.0000 |
| L5 | 99.4430 | 0.0369 | 0.9957 | 91.5359 | 1.0000 |
| L6 | 93.6570 | 0.0407 | 0.9899 | 98.1137 | 1.0000 |
| L7 | 99.8950 | 0.0077 | 0.9778 | 91.4342 | 1.0000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Flores, V.; Bravo, I.; Saavedra, M. Water Quality Classification and Machine Learning Model for Predicting Water Quality Status—A Study on Loa River Located in an Extremely Arid Environment: Atacama Desert. Water 2023, 15, 2868. https://doi.org/10.3390/w15162868
Flores V, Bravo I, Saavedra M. Water Quality Classification and Machine Learning Model for Predicting Water Quality Status—A Study on Loa River Located in an Extremely Arid Environment: Atacama Desert. Water. 2023; 15(16):2868. https://doi.org/10.3390/w15162868
Chicago/Turabian StyleFlores, Víctor, Ingrid Bravo, and Marcelo Saavedra. 2023. "Water Quality Classification and Machine Learning Model for Predicting Water Quality Status—A Study on Loa River Located in an Extremely Arid Environment: Atacama Desert" Water 15, no. 16: 2868. https://doi.org/10.3390/w15162868
APA StyleFlores, V., Bravo, I., & Saavedra, M. (2023). Water Quality Classification and Machine Learning Model for Predicting Water Quality Status—A Study on Loa River Located in an Extremely Arid Environment: Atacama Desert. Water, 15(16), 2868. https://doi.org/10.3390/w15162868