
Runoff Prediction Based on Dynamic Spatiotemporal Graph Neural Network

Abstract
:1. Introduction
- Using new technologies, models, and methods emerging from deep learning. Lv et al. [5] extracted hydrological features such as rainfall, reservoir water level, and flow, and used LSTM to model the rainfall runoff process. The results showed that LSTM was capable of long-term and short-term hydrological forecasting. Tao et al. [6] proposed a multi-scale LSTM model with the self-attention mechanism (MLSTM-AM) for predicting monthly precipitation at stations in the Yangtze River Basin. Wang et al. [7] used attention mechanisms for hydrological sequence features for runoff prediction, and experimental results showed that the attention module improved learning and generalization capabilities. Xie et al. [8] used an integrated learning model of 1D CNN and 2D CNN to improve the daily runoff prediction accuracy.
- Using different optimization algorithms to improve the performance of existing models. The hyperparameter has a significant impact on the performance of the depth model. Through the optimization algorithm, the correct combination of hyperparameter values can be found, and the maximum performance can be achieved in a reasonable time, which can improve the prediction accuracy and robustness of the model. Zhao et al. [9] designed a hybrid model IGWO-GRU which combed GRU and improved grey wolf optimizer to predict the monthly runoff at the Fenhe reservoir station. Khadr et al. [10] constructed an optimization simulation framework based on implicit stochastic optimization, genetic algorithm, and recurrent neural network to predict reservoir inflow and water use, and guide reservoir scheduling. Qiu et al. [11] used the particle swarm optimization algorithm and back propagation neural network to predict river water temperature using input variables such as temperature, flow, and date.
- Using signal decomposition or denoising techniques to preprocess data. Data preprocessing mainly involves using various signal decomposition and denoising techniques to stabilize the runoff series, decompose it into simpler or meaningful components, and then model them separately. Bai et al. [12] proposed the MDFL method for predicting the daily inflow of reservoirs. The method uses the empirical mode decomposition and Fourier transform to extract trend, periodic, and random features, and then trains them with three deep belief networks. Finally, the prediction results are reconstructed. Li et al. [13] developed a hybrid model of adaptive variational mode decomposition and bidirectional long short-term memory (Bi-LSTM) based on energy entropy to predict daily inflow. Huang et al. [14] presented a prediction model combining the ensemble empirical mode decomposition and LSTM to predict the runoff of the irrigated paddy areas in Southern China.
- (1)
- A runoff prediction model has been proposed, which decomposes runoff formation into the runoff production process and river network convergence process, integrating physical processes on the basis of data-driven models;
- (2)
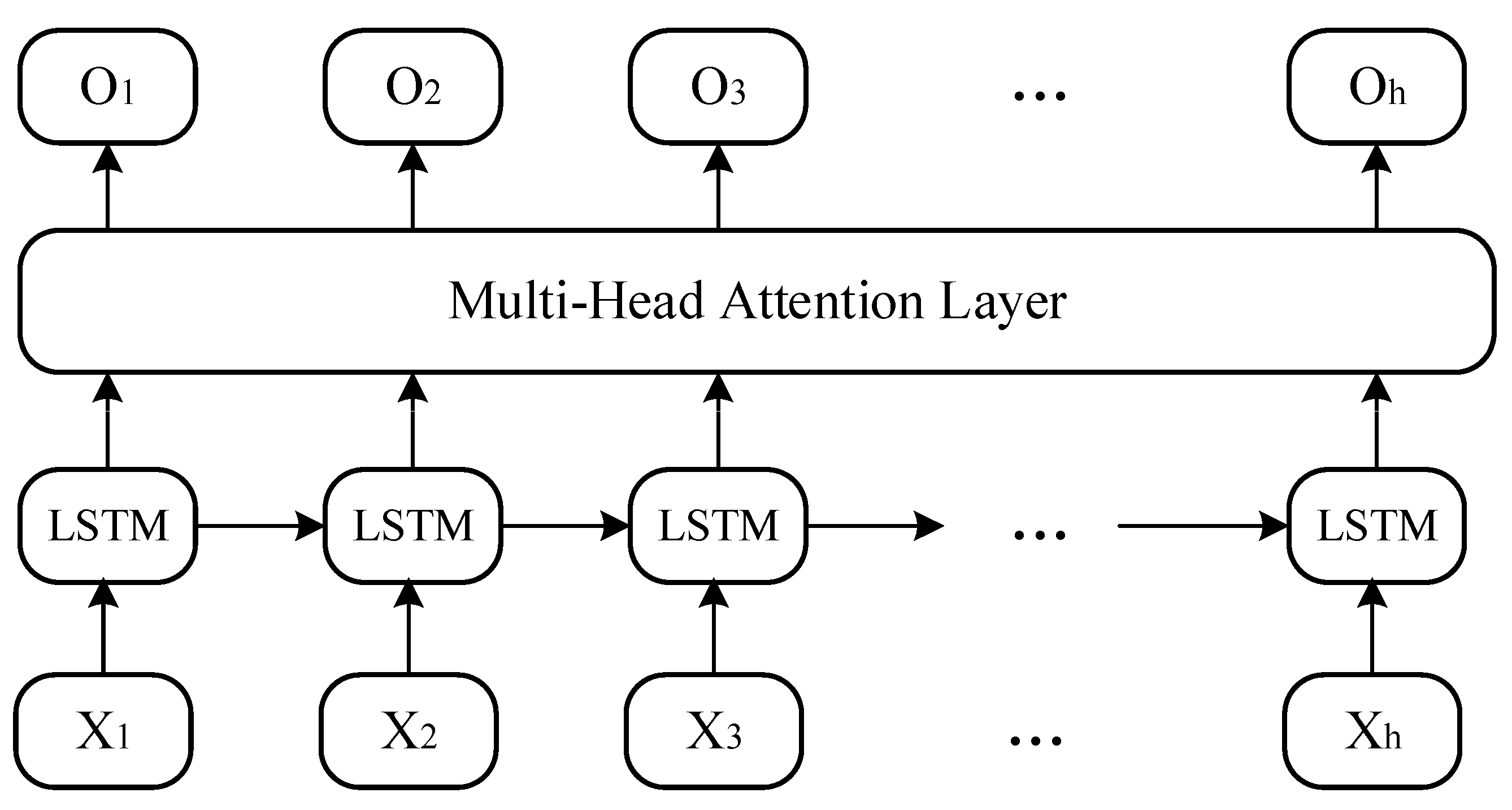
- Under the above framework, the LSTM model with the self-attention mechanism is used to enhance the ability to capture the time-series characteristics of runoff. Construct a directed graph of upstream stations pointing towards downstream stations based on the geographic spatial structure of a tree-like river network, and capture the spatial relationships of stations within the watershed through a graph neural network;
- (3)
- This model is applicable to the entire watershed, mining the runoff characteristics of the entire watershed, and providing multi-step runoff prediction for all stations within the watershed in advance.
2. Multiple Stations Runoff Prediction
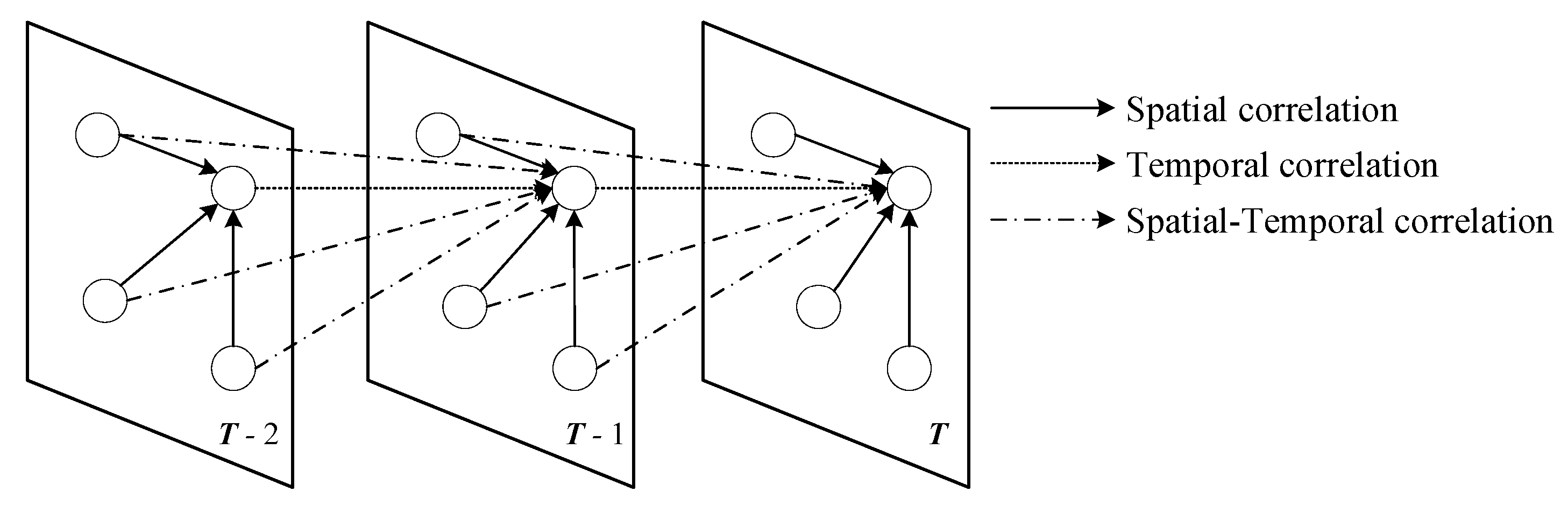
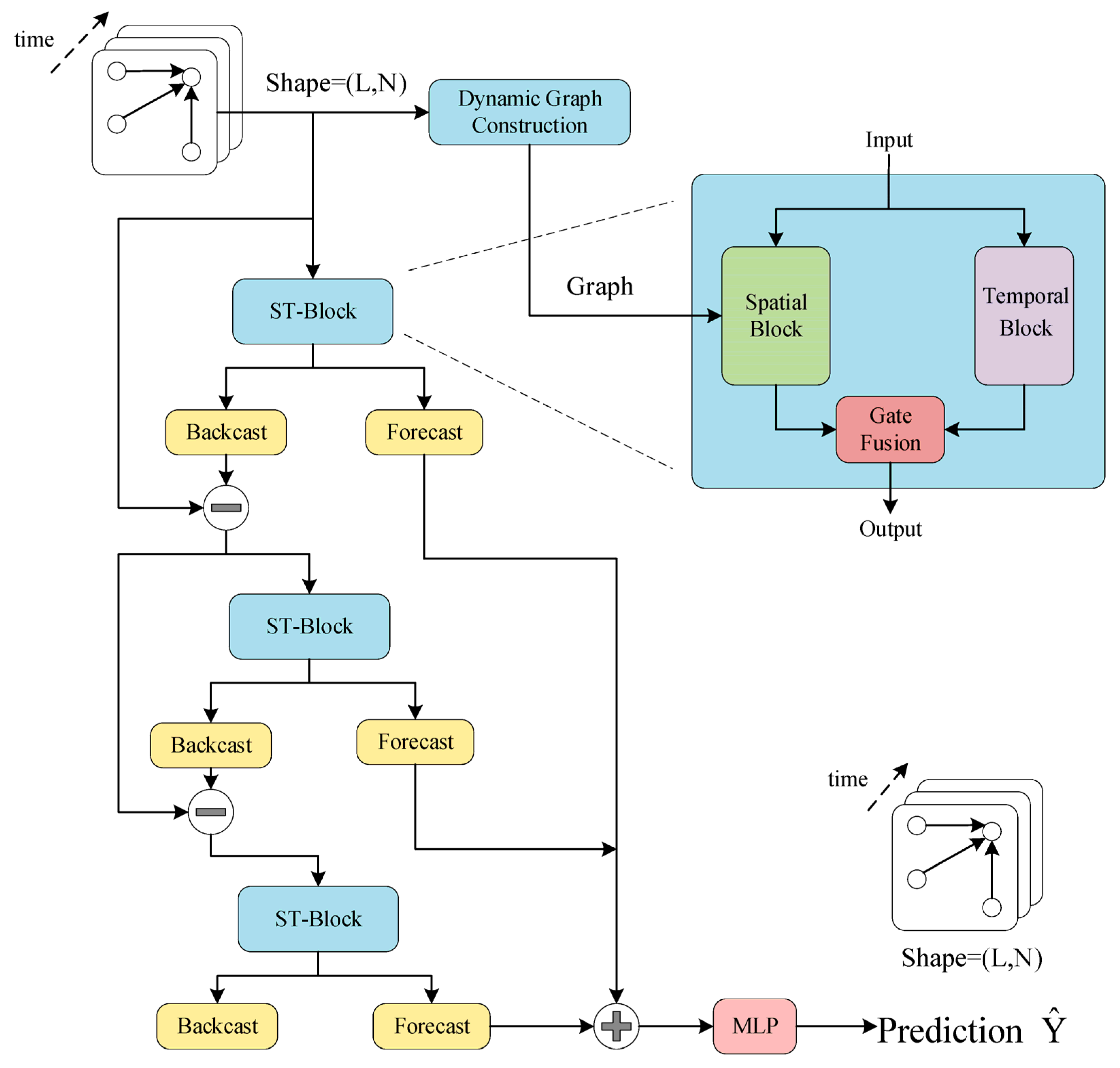
3. Dynamic Graph Neural Network Prediction Model
3.1. Temporal Block
3.2. Spatial Block
3.2.1. Distance Weight Matrix
| Algorithm 1: Distance weight matrix D. |
| Input: Adjacency matrix A |
| Output: Distance weight matrix D |
| 1 Initialize matrix D = A |
| 2 for k = 1 to N do |
| 3 for i = 1 to N do |
| 4 for j = 1 to N do |
| 5 D[i][j] = min(D[i][j], D[i][k] + D[k][j]) |
| // Calculate the shortest distance according to Floyd algorithm |
| 6 end for |
| 7 for i = 1 to N do |
| 8 for j = 1 to N do |
| 9 Calculate D[i][j], as shown in Equation (13) |
| 10 end for |
| 11 Return D |
3.2.2. Dynamic Matrix
3.3. Spatiotemporal Fusion and Model Prediction
| Algorithm 2: Overall training process of DSTGNN. |
| Input: the historical runoff sequence X, adjacency matrix A, number of layers K |
| Output: predication |
| 1 Calculate the distance weight matrix D according to Algorithm 1 |
| 2 Calculate the dynamic matrix , as shown in Equation (15) |
| 3 |
| 4 for k = 1 to K do |
| 5 Calculate temporal feature using temporal block |
| 6 Calculate spatial feature using spatial block |
| 7 Calculate , as shown in Equations (17) and (18) |
| 8 Calculate next level of input , as shown in Equations (19)–(21) |
| 9 end for |
| 10 Calculate predication , as shown in Equation (22) |
| 11 Calculate MSE loss, update parameters using back propagation algorithm and Adam optimizer |
4. Experiment and Analysis
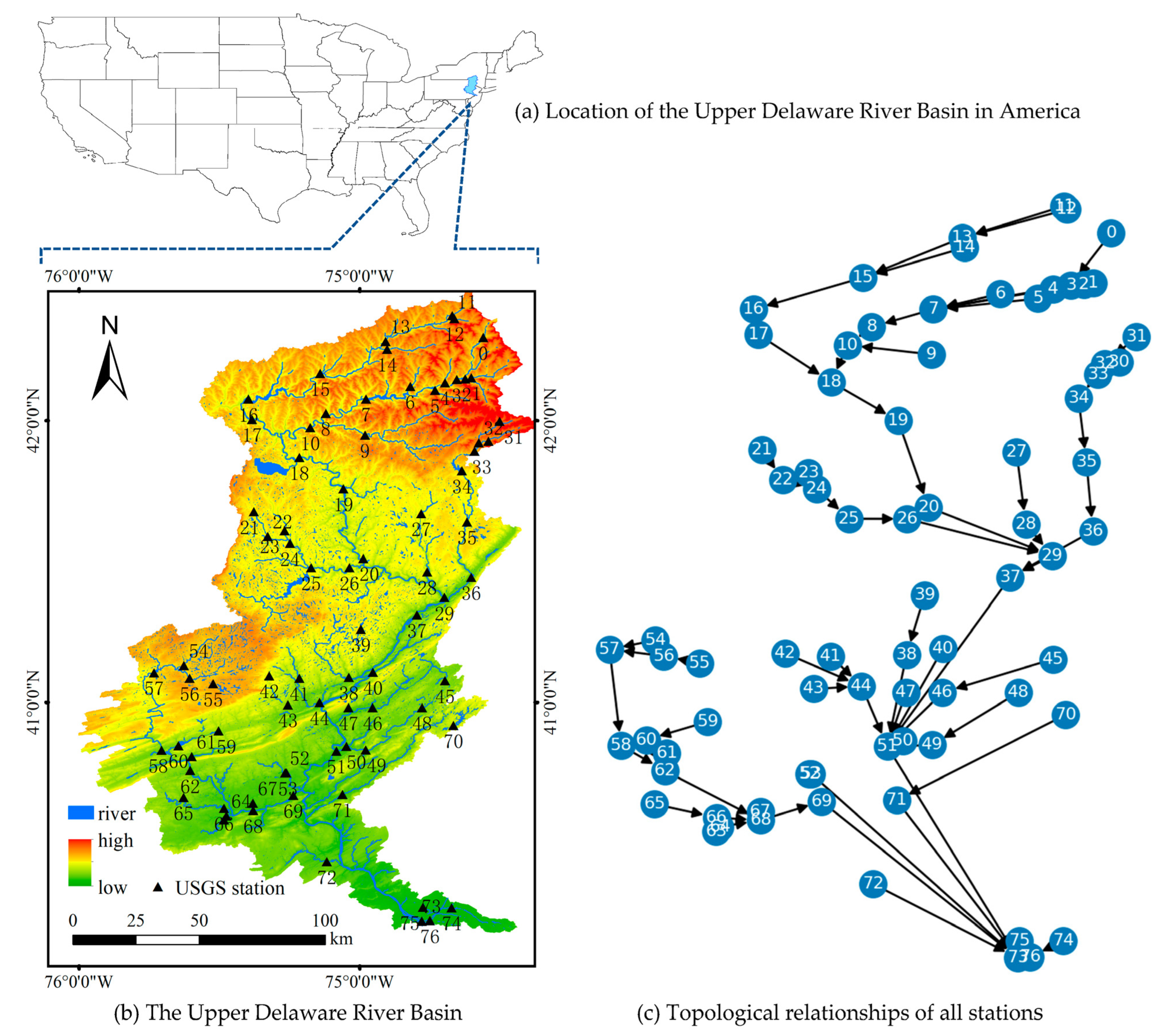
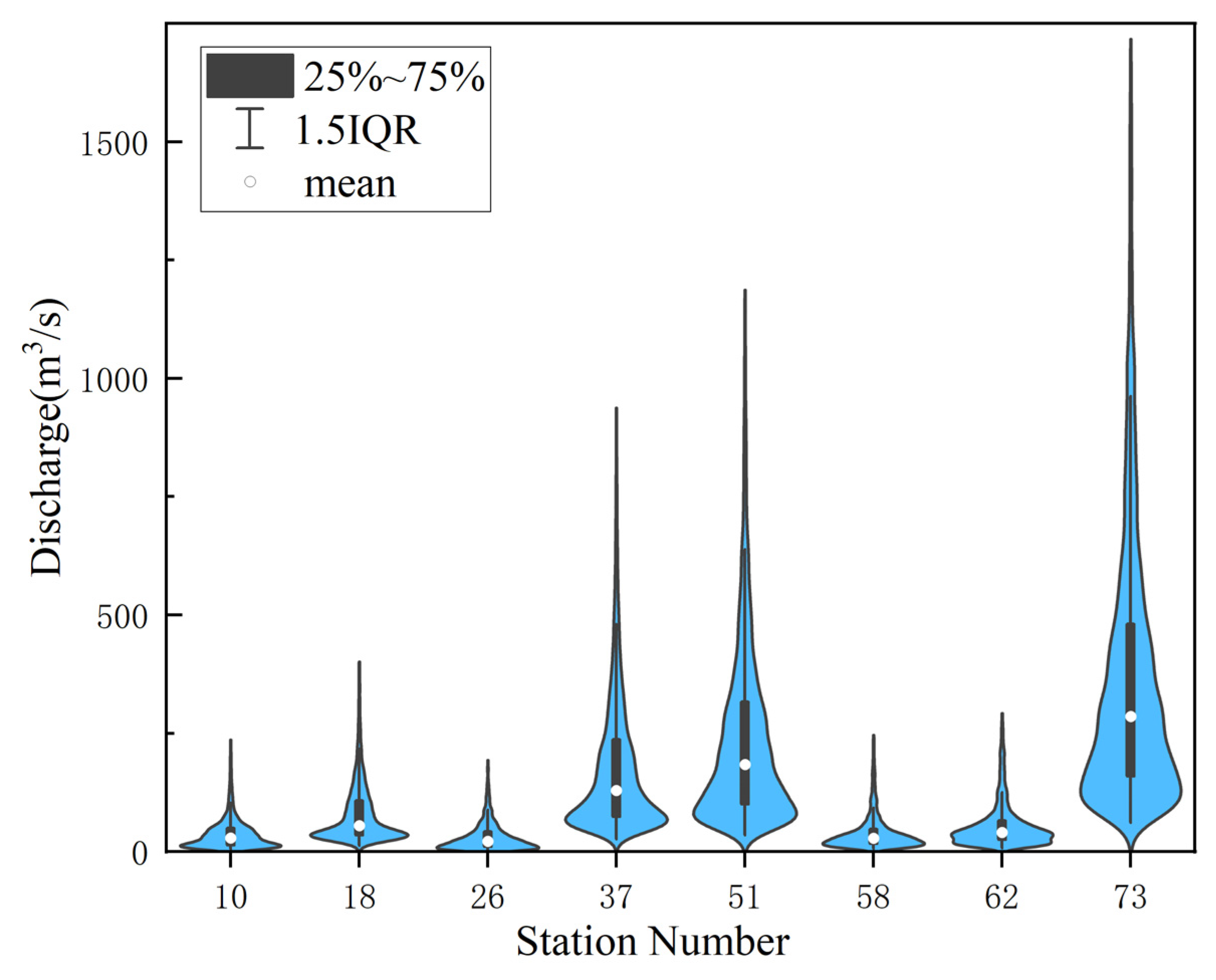
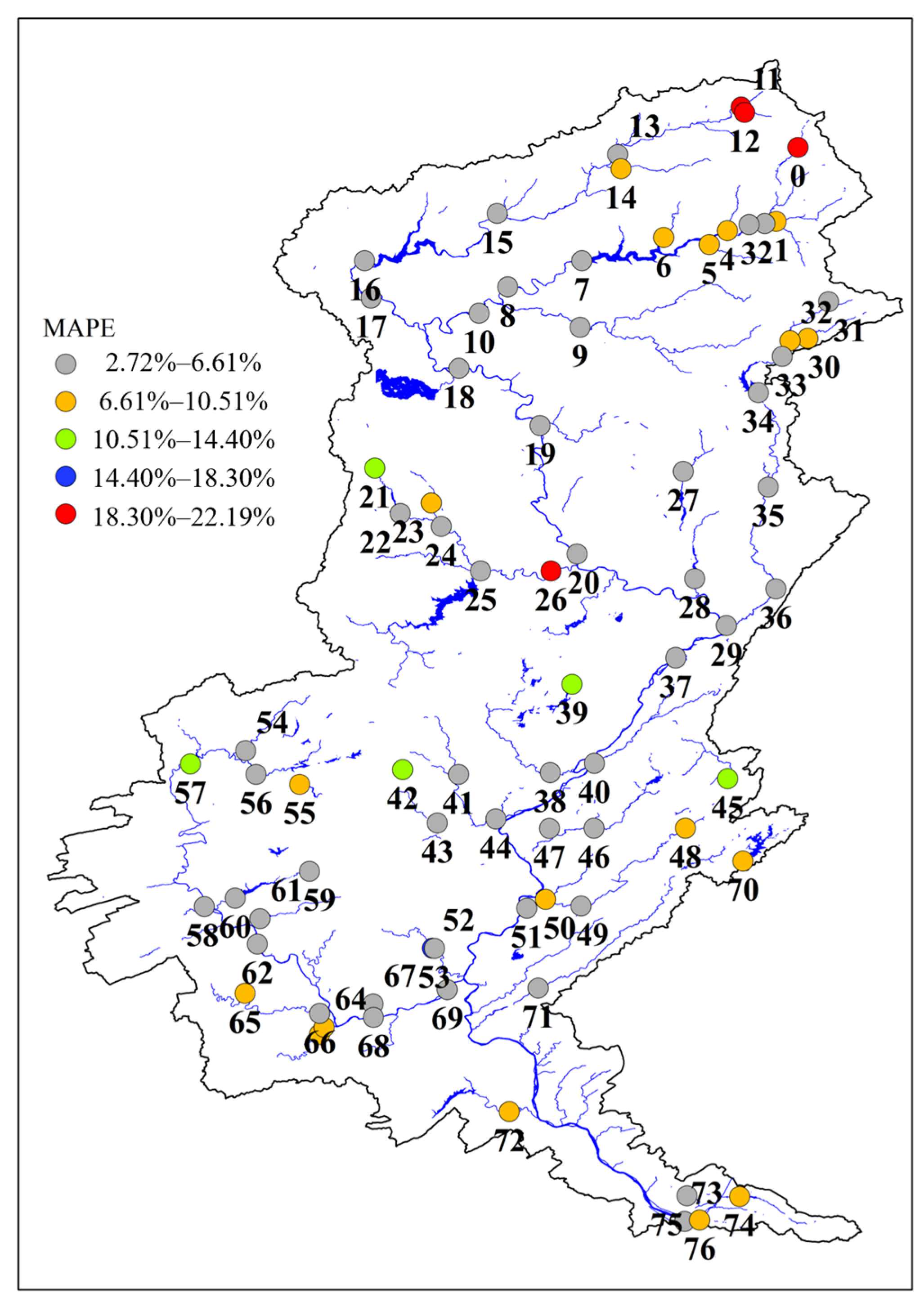
4.1. Data Set
4.2. Comparison Model and Evaluation Indicators
- (1)
- GraphSAGE [29]: It includes sampling and aggregation. First, the neighbors are sampled according to the connection relationship of nodes, and then the information of adjacent nodes is fused together through the aggregate function. Use the fused information to predict node labels.
- (2)
- GRU: Gated recurrent neural network. The addition of a gating mechanism alleviates the long-term dependency problem of general RNNs.
- (3)
- DCRNN [30]: In the gating of GRU, graph diffusion convolution is used, which combines temporal and spatial information, and outputs predictive information through the encoder–decoder architecture.
- (4)
- Graph-WaveNet [31]: Serializing graph convolution and hole convolution to capture spatiotemporal correlation. At the same time, an adaptive adjacency matrix is proposed to capture hidden spatial dependencies.
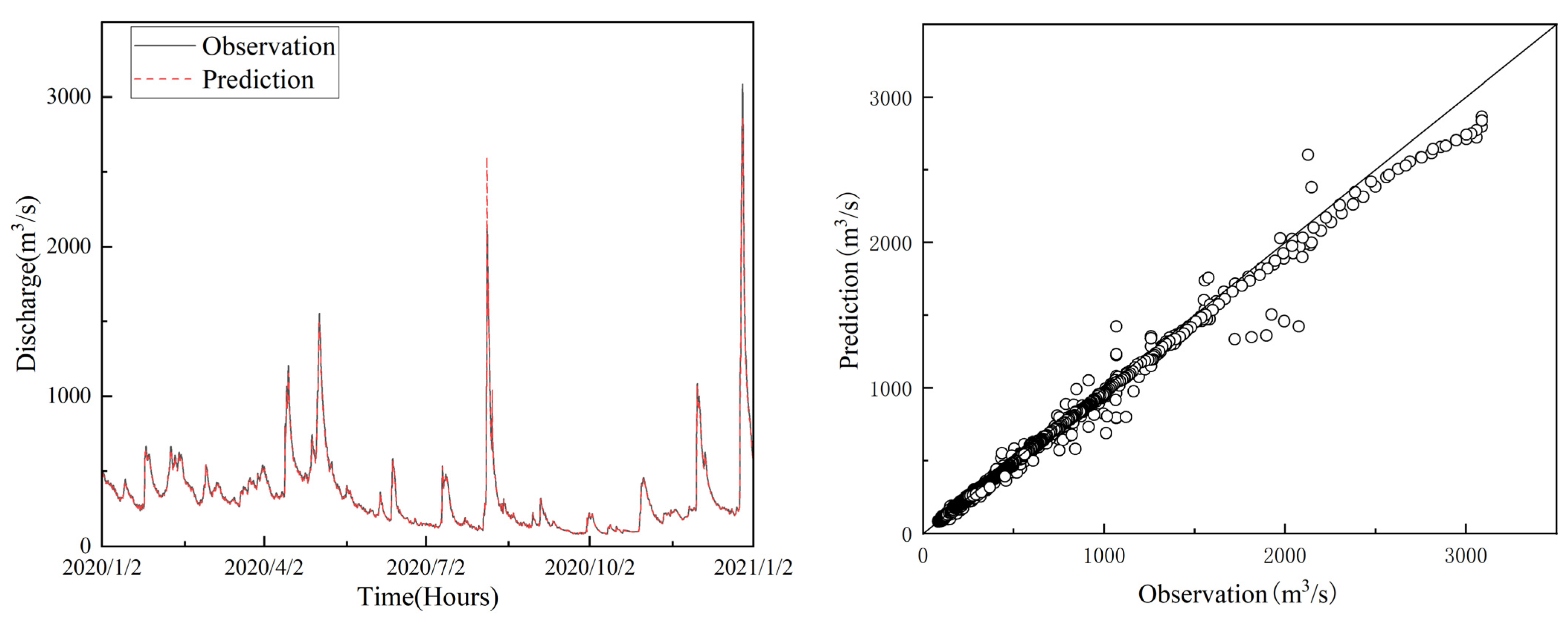
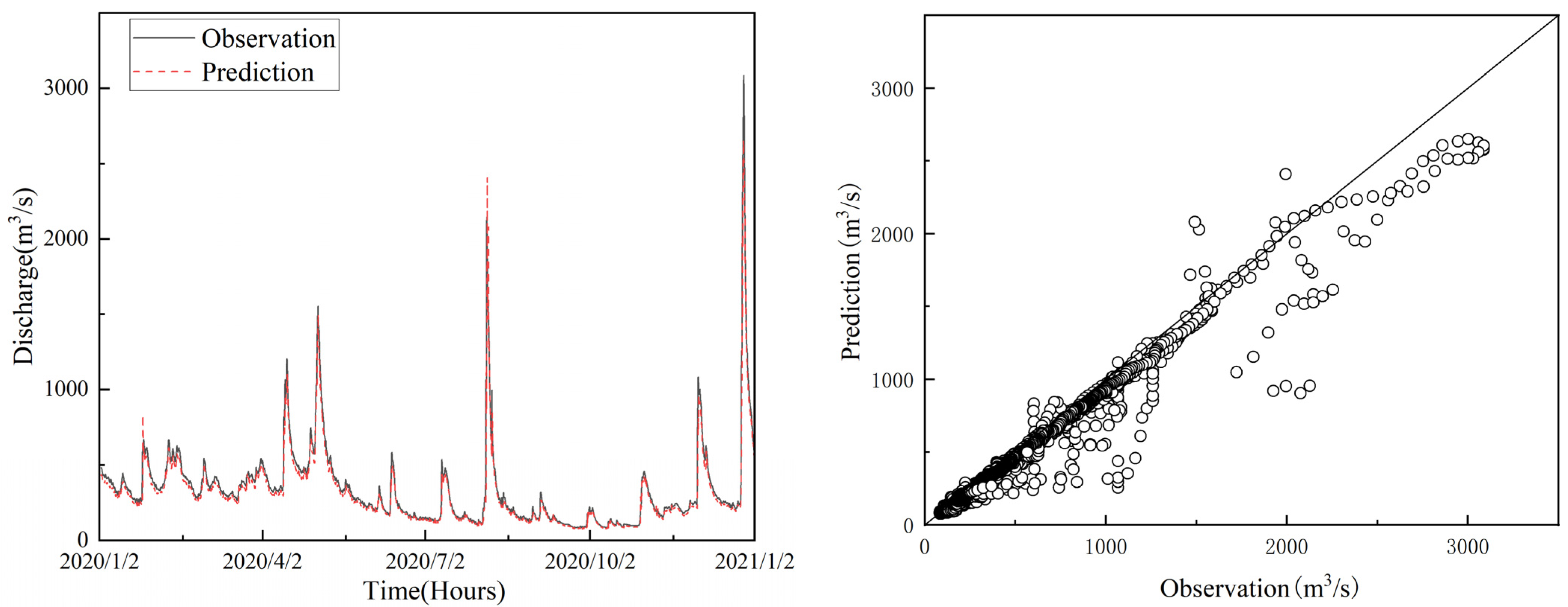
4.3. Result and Analysis
- (1)
- Spatiotemporal fusion has a large improvement on the prediction performance. The performance index of GRU with temporal modeling is better than that of GraphSAGE with spatial modeling, indicating that the sequence model has advantages in temporal prediction. Compared with GRU, which only considers a single time-series dependence, the model in this paper extracts the topological relationship of the basin and exploits the spatial and temporal dependence of the flow at upstream and downstream hydrological stations, so the accuracy is greatly improved.
- (2)
- The attention mechanism has improved the performance of long-time prediction. The robustness and generalization of all models gradually deteriorate as the prediction step length increases. In this paper, the performance of the long-term prediction model is improved by introducing the attention mechanism to mine the potential patterns of the time series, while incorporating multiple upstream site features and considering the time lag.
5. Conclusions
- (1)
- The simulation accuracy of the model is much higher at low flows than at high flows, and the model underestimates the effect of discrete values to make the overall performance better. If the model can predict the abrupt change point of the flow sequence in advance, it can undoubtedly improve the prediction accuracy under a high flow rate, which is an area that needs to be improved in future work.
- (2)
- In the subsequent research, this paper needs to consider more physical factors of the water cycle and combine relevant domain knowledge in the model to enhance the accuracy and physical interpretability of the model; secondly, it is necessary to combine the relevant research results of distributed hydrological models and introduce fine subsurface characteristics, such as soil type and surface plant cover, into the model.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; Deng, L.; Wu, B.; Gao, S.; Xiao, Y. Low-Impact Optimal Operation of a Cascade Sluice-Reservoir System for Water-Society-Ecology Trade-Offs. Water Resour. Manag. 2022, 36, 6131–6148. [Google Scholar] [CrossRef]
- Nourani, V.; Baghanam, A.H.; Adamowski, J.; Kisi, O. Applications of hybrid wavelet–Artificial Intelligence models in hydrology: A review. J. Hydrol. 2014, 514, 358–377. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Shen, C. A Transdisciplinary Review of Deep Learning Research and Its Relevance for Water Resources Scientists. Water Resour. Res. 2018, 54, 8558–8593. [Google Scholar] [CrossRef]
- Lv, N.; Liang, X.; Chen, C.; Zhou, Y.; Li, J.; Wei, H.; Wang, H. A long Short-Term memory cyclic model with mutual information for hydrology forecasting: A Case study in the xixian basin. Adv. Water Resour. 2020, 141, 10. [Google Scholar] [CrossRef]
- Tao, L.; He, X.; Li, J.; Yang, D. A multiscale long short-term memory model with attention mechanism for improving monthly precipitation prediction. J. Hydrol. 2021, 602, 13. [Google Scholar] [CrossRef]
- Wang, H.; Qin, H.; Liu, G.; Liu, S.; Qu, Y.; Wang, K.; Zhou, J. A novel feature attention mechanism for improving the accuracy and robustness of runoff forecasting. J. Hydrol. 2023, 618, 129200. [Google Scholar] [CrossRef]
- Xie, Y.; Sun, W.; Ren, M.; Chen, S.; Huang, Z.; Pan, X. Stacking ensemble learning models for daily runoff prediction using 1D and 2D CNNs. Expert Syst. Appl. 2023, 217, 119469. [Google Scholar] [CrossRef]
- Zhao, X.; Lv, H.; Wei, Y.; Lv, S.; Zhu, X. Streamflow Forecasting via Two Types of Predictive Structure-Based Gated Recurrent Unit Models. Water 2021, 13, 91. [Google Scholar] [CrossRef]
- Khadr, M.; Schlenkhoff, A. GA-based implicit stochastic optimization and RNN-based simulation for deriving multi-objective reservoir hedging rules. Environ. Sci. Pollut. Res. 2021, 28, 19107–19120. [Google Scholar] [CrossRef]
- Qiu, R.; Wang, Y.; Wang, D.; Qiu, W.; Wu, J.; Tao, Y. Water temperature forecasting based on modified artificial neural network methods: Two cases of the Yangtze River. Sci. Total Environ. 2020, 737, 12. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Chen, Z.; Xie, J.; Li, C. Daily reservoir inflow forecasting using multiscale deep feature learning with hybrid models. J. Hydrol. 2016, 532, 193–206. [Google Scholar] [CrossRef]
- Li, F.; Ma, G.; Chen, S.; Huang, W. An Ensemble Modeling Approach to Forecast Daily Reservoir Inflow Using Bidirectional Long- and Short-Term Memory (Bi-LSTM), Variational Mode Decomposition (VMD), and Energy Entropy Method. Water Resour. Manag. 2021, 35, 2941–2963. [Google Scholar] [CrossRef]
- Huang, S.; Yu, L.; Luo, W.; Pan, H.; Li, Y.; Zou, Z.; Wang, W.; Chen, J. Runoff Prediction of Irrigated Paddy Areas in Southern China Based on EEMD-LSTM Model. Water 2023, 15, 1704. [Google Scholar] [CrossRef]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; pp. 729–734. [Google Scholar]
- Wang, Y.; Wang, H.; Jin, H.; Huang, X.; Wang, X. Exploring graph capsual network for graph classification. Inf. Sci. 2021, 581, 932–950. [Google Scholar] [CrossRef]
- Chang, J.X.; Gao, C.; Zheng, Y.; Hui, Y.Q.; Niu, Y.A.; Song, Y.; Jin, D.P.; Li, Y. Sequential Recommendation with Graph Neural Networks. In Proceedings of the Sigir 21—Proceedings of the 44th International Acm Sigir Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; pp. 378–387. [Google Scholar] [CrossRef]
- Zhao, T.; Hu, Y.; Valsdottir, L.R.; Zang, T.; Peng, J. Identifying drug–target interactions based on graph convolutional network and deep neural network. Brief. Bioinform. 2021, 22, 2141–2150. [Google Scholar] [CrossRef]
- Deng, A.L.; Hooi, B. Graph Neural Network-Based Anomaly Detection in Multivariate Time Series. Proc. AAAI Conf. Artif. Intell. 2021, 35, 4027–4035. [Google Scholar] [CrossRef]
- Sun, A.Y.; Jiang, P.; Yang, Z.-L.; Xie, Y.; Chen, X. A graph neural network (GNN) approach to basin-scale river network learning: The role of physics-based connectivity and data fusion. Hydrol. Earth Syst. Sci. 2022, 26, 5163–5184. [Google Scholar] [CrossRef]
- Liu, G.; Ouyang, S.; Qin, H.; Liu, S.; Shen, Q.; Qu, Y.; Zheng, Z.; Sun, H.; Zhou, J. Assessing spatial connectivity effects on daily streamflow forecasting using Bayesian-based graph neural network. Sci. Total Environ. 2023, 855, 158968. [Google Scholar] [CrossRef]
- Xiang, Z.; Demir, I. Fully distributed rainfall-runoff modeling using spatial-temporal graph neural network. EarthArXiv 2022. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wang, X.; Ma, Y.; Wang, Y.; Jin, W.; Wang, X.; Tang, J.; Jia, C.; Yu, J. Traffic flow prediction via spatial temporal graph neural network. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1082–1092. [Google Scholar]
- Oreshkin, B.N.; Carpov, D.; Chapados, N.; Bengio, Y. N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. arXiv 2019, arXiv:1905.10437. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- De Cicco, L.; Lorenz, D.; Hirsch, R.; Watkins, W.; Johnson, M. dataRetrieval: R Packages for Discovering and Retrieving Water Data Available from US Federal Hydrologic Web Services; US Geological Survey: Reston, VA, USA, 2022. [CrossRef]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv 2017, arXiv:1707.01926. [Google Scholar]
- Wu, Z.H.; Pan, S.R.; Long, G.D.; Jiang, J.; Zhang, C.Q. Graph WaveNet for Deep Spatial-Temporal Graph Modeling. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 1907–1913. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | 3 h | 6 h | 9 h | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | MSE | MAPE | NSE | MAE | MSE | MAPE | NSE | MAE | MSE | MAPE | NSE | |
| GraphSAGE | 1.27 | 8.76 | 6.01% | 0.83 | 2.57 | 15.73 | 9.87% | 0.74 | 3.09 | 21.58 | 11.83% | 0.61 |
| GRU | 1.22 | 6.54 | 5.45% | 0.85 | 2.21 | 9.24 | 9.12% | 0.76 | 2.79 | 12.66 | 10.51% | 0.62 |
| DCRNN | 1.10 | 5.69 | 5.38% | 0.89 | 2.15 | 8.61 | 8.15% | 0.79 | 2.81 | 11.53 | 10.34% | 0.68 |
| Graph-WaveNet | 1.07 | 5.67 | 5.21% | 0.89 | 2.07 | 8.21 | 7.64% | 0.80 | 2.73 | 10.33 | 9.01% | 0.67 |
| DSTGNN | 1.05 | 4.92 | 5.11% | 0.90 | 2.03 | 7.70 | 6.97% | 0.83 | 2.71 | 9.37 | 8.52% | 0.71 |
| Model | MAE | MSE | MAPE |
|---|---|---|---|
| w/o static | 1.93 | 9.54 | 9.50% |
| w/o dynamic | 1.95 | 9.64 | 9.55% |
| w/o spatial | 1.97 | 10.61 | 10.05% |
| full | 1.91 | 9.37 | 8.52% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Zhang, Y.; Zhang, Z. Runoff Prediction Based on Dynamic Spatiotemporal Graph Neural Network. Water 2023, 15, 2463. https://doi.org/10.3390/w15132463
Yang S, Zhang Y, Zhang Z. Runoff Prediction Based on Dynamic Spatiotemporal Graph Neural Network. Water. 2023; 15(13):2463. https://doi.org/10.3390/w15132463
Chicago/Turabian StyleYang, Shuai, Yueqin Zhang, and Zehua Zhang. 2023. "Runoff Prediction Based on Dynamic Spatiotemporal Graph Neural Network" Water 15, no. 13: 2463. https://doi.org/10.3390/w15132463
APA StyleYang, S., Zhang, Y., & Zhang, Z. (2023). Runoff Prediction Based on Dynamic Spatiotemporal Graph Neural Network. Water, 15(13), 2463. https://doi.org/10.3390/w15132463