
An Automated Machine Learning Engine with Inverse Analysis for Seismic Design of Dams



Abstract
1. Introduction
2. Automated Machine Learning (AutoML)
2.1. ML-Based Response Evaluation of Dams
2.2. Underpinning Theory
- Linear models: minimizing a regularized empirical loss with stochastic gradient descent (SGD), and Bayesian Automatic Relevance Determination (ARD) regression;
- Ensemble models: Adaboost, random forest (and decision trees), extra trees, gradient boosting;
- Probabilistic model: Gaussian process (GP) regression;
- K-nearest neighbor (KNN) and support vector regression (SVR);
- Neural networks: Multilayer perceptron (MLP).

3. Design Variables
3.1. Dam Shape
- (50, 150) m.
- = ; ⟶ (0, 7) m.
- = ; ⟶ (7, 40) m.
- = ; ⟶ (6, 35) m.
- = ; ⟶ (20, 140) m.
- = ; ⟶ (55, 235) m.
- = ; ⟶ (40, 200) m.
- = ;
3.2. Material Properties
3.3. Loads
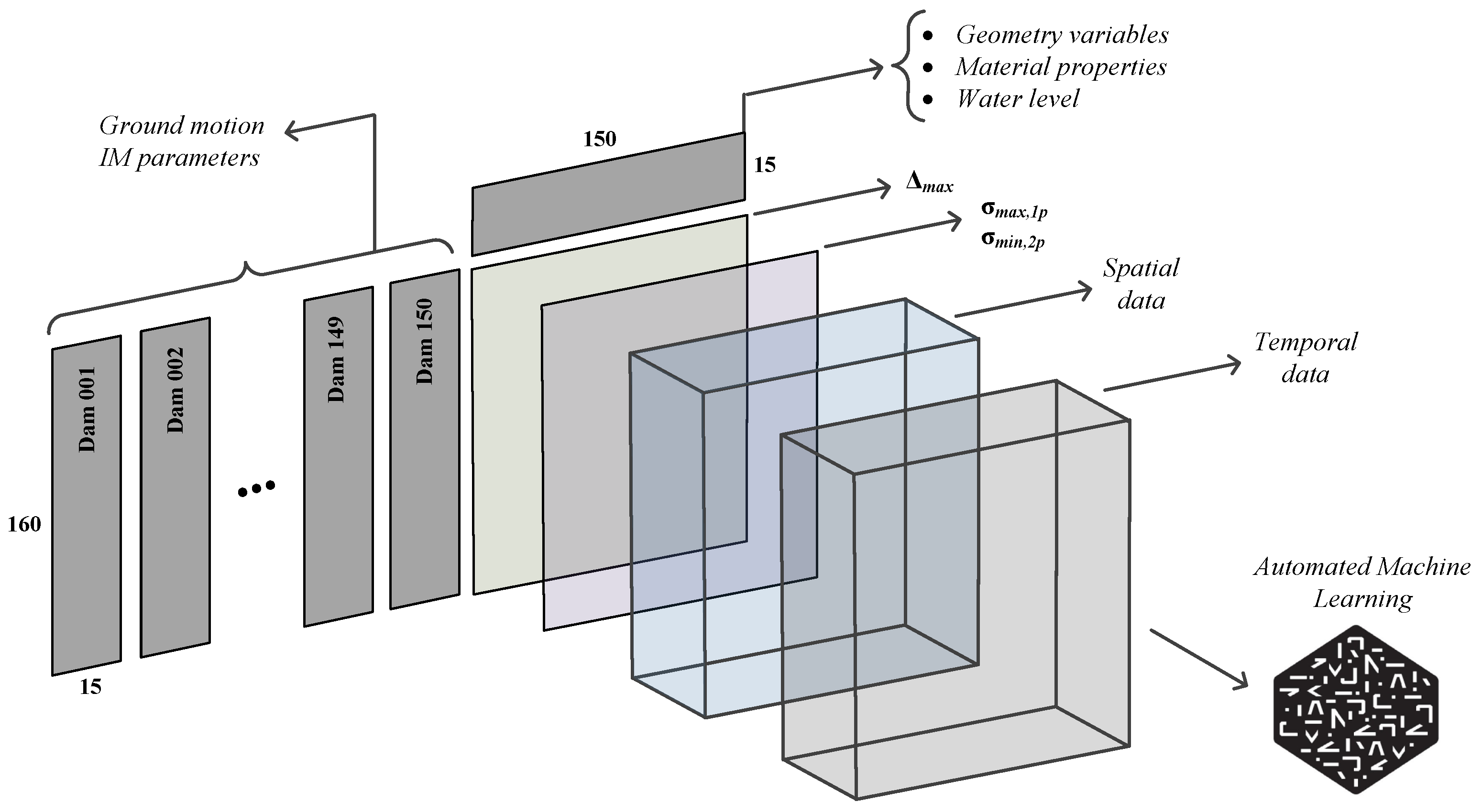
4. Data Structure
4.1. Software
4.2. Input-Output Coverage
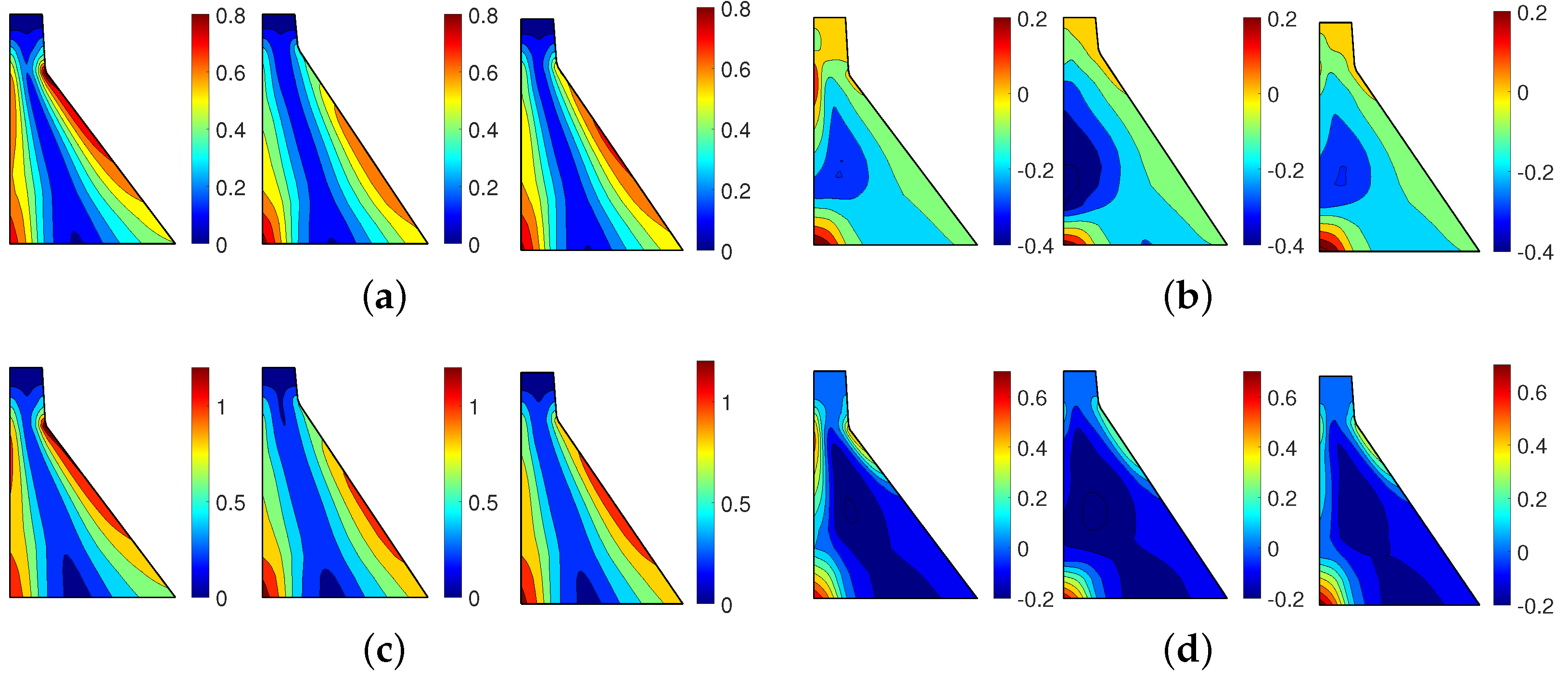
- Scalar quantities cover the maximum (or minimum) response of the dam at a particular location and the entire duration of the applied ground motion. For example, maximum crest displacement shows the “global” behavior of the dam under the applied motion. Similarly, the maximum first principal stress at the dam heel is a “local” metric that presents the onset of cracking (if exceeds the tensile strength). Other peaks (i.e., maximum or minimum) response quantities can be extracted from displacement, stress, and strain results.
- Vector quantities cover the responses over time, or they present the spatial distribution of the response parameters. Cumulative inelastic duration (CID) shows the time intervals in which the stress at a particular location exceeds the tensile strength. The overstressed area (OA) illustrates the spatial distribution of regions within the dam body where the tensile strength exceeds the tensile strength (or a multiplayer of it).
- Out1: maximum horizontal crest displacement,
- Out2: maximum first principal stress at heel,
- Out3: maximum first principal stress at upstream face 5% from the heel,
- Out4: maximum first principal stress at toe,
- Out5: minimum third principal stress at the heel,
- Out6: minimum third principal stress at the toe,
- Out7: CID for demand capacity ratio exceeds one at the heel,
- Out8: CID for demand capacity ratio exceeds two at the heel,
- Out9: Overstressed area for demand capacity ratio exceeds one at the heel,
- Out10: Overstressed area for demand capacity ratio exceeds two at the heel,
5. Results: Surrogate Model
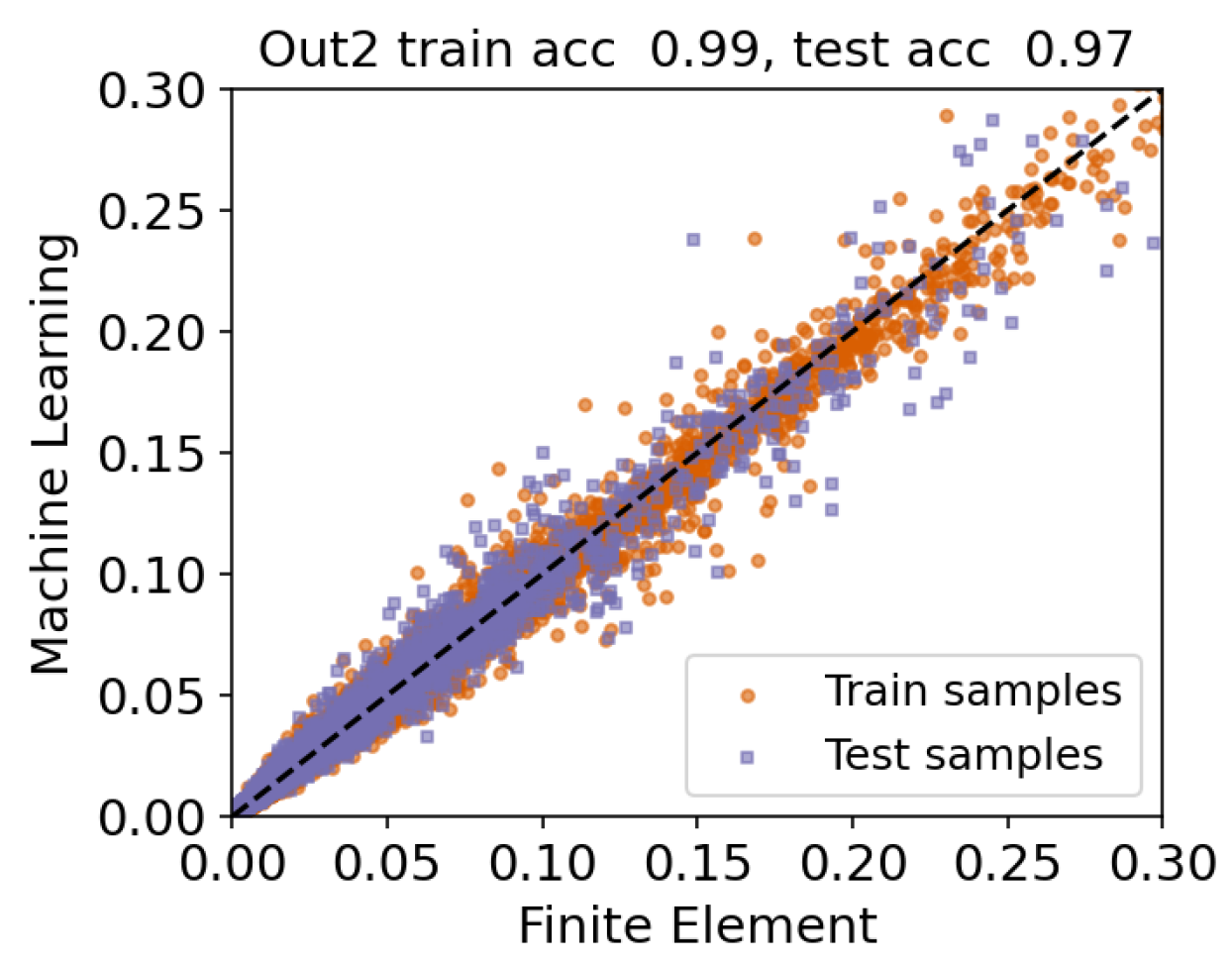
5.1. Scenario 1: Single Output
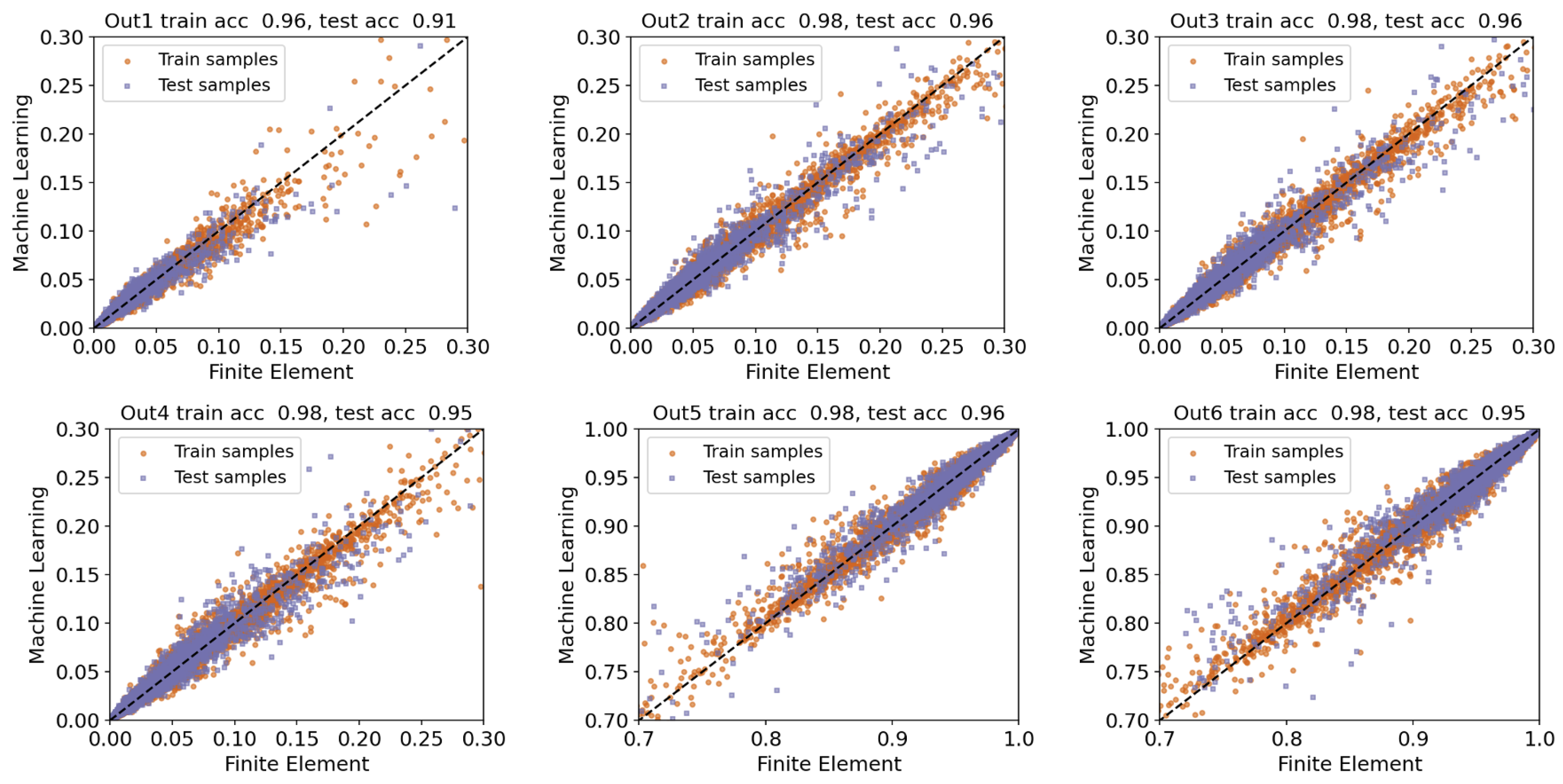
5.2. Scenario 2: Multi-Output, Out1 through Out6
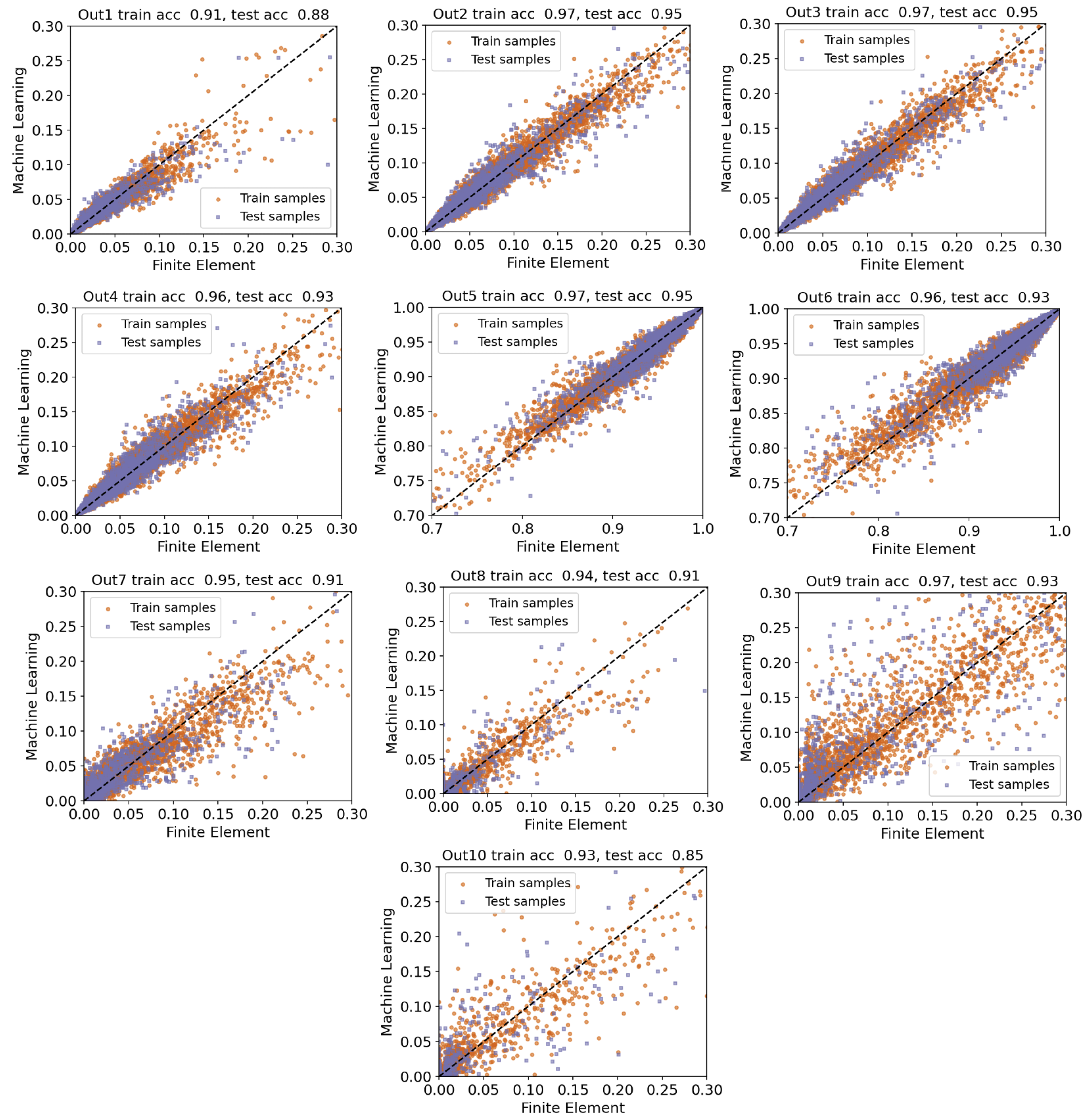
5.3. Scenario 3: Multi-Output, Out1 through Out10
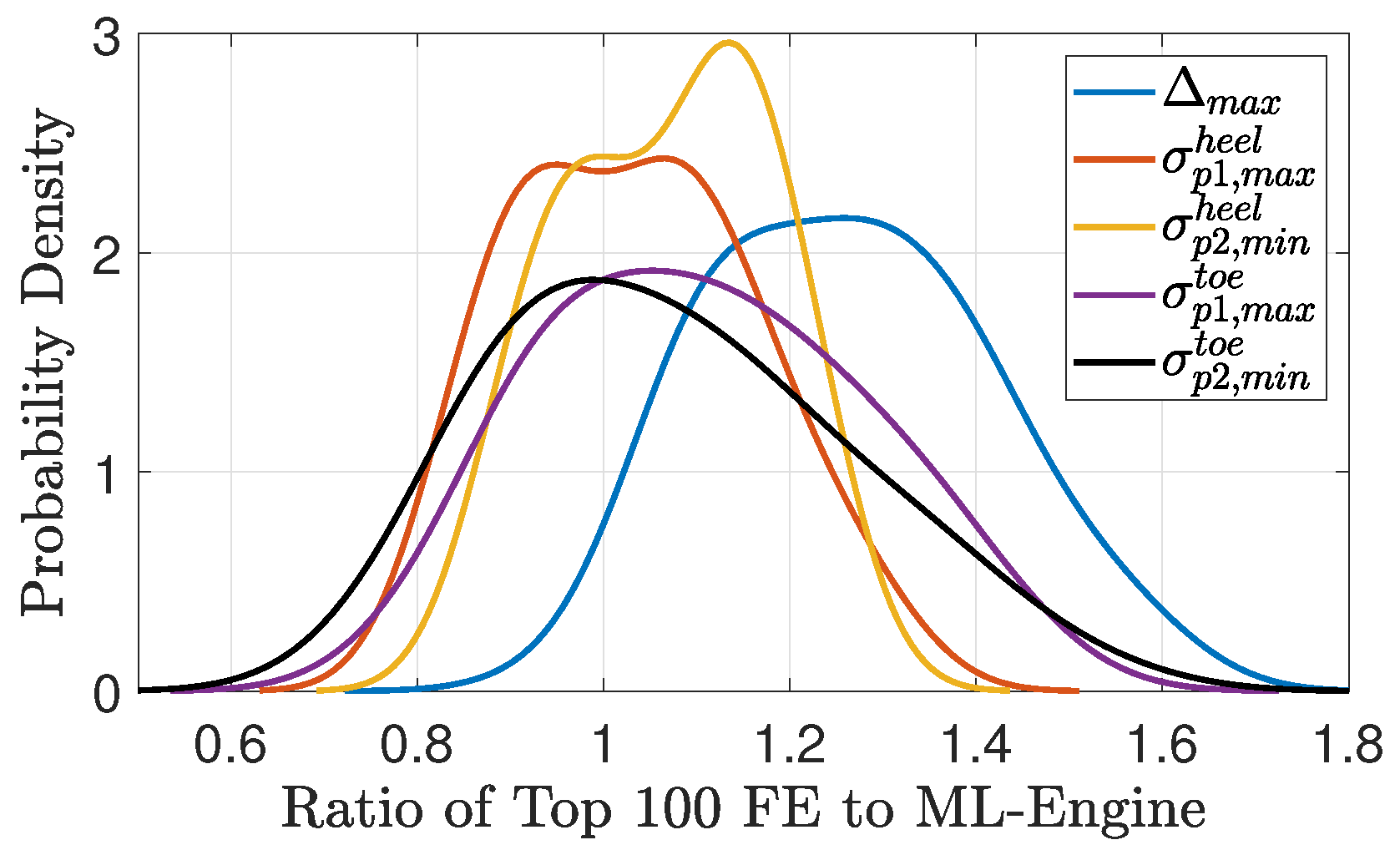
6. Results: Dam Design Engine
- ICOLD recommendations There are two basic seismic loads for the design of new dams [70]: Operating Basis Earthquake (OBE) which represents the seismic intensity level at the dam site for which only minor (easily repairable) damage is acceptable and the dam should remain functional. The OBE corresponds to the return period of 145 years (50% probability of exceedance in 100 years). Safety Evaluation Earthquake (SEE) represents the seismic intensity level at the dam site for which a dam must be able to resist without the uncontrolled release of the reservoir water. The SEE ground motion can be obtained from a probabilistic and/or deterministic seismic hazard analysis. For large and high consequence dams, SEE is defined as (a) Maximum Credible Earthquake (MCE) from DSHA where the parameters should be estimated at the 84th percentile level, (b) Maximum Design Earthquake (MDE) from PSHA corresponding to return period of 10,000 years (1% probability of exceedance in 100 years) [71,72].
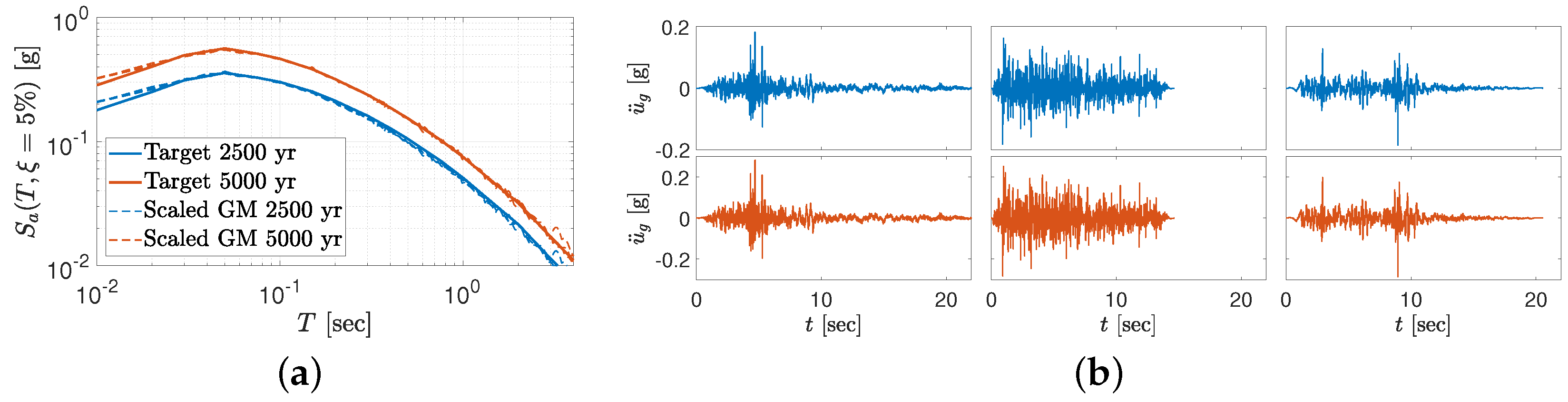
- FEMA recommendations Time-based performance assessment evaluates a dam’s performance over a period considering all earthquakes that may occur in that period, and the probability that each will occur [73]. This procedure follows the following main steps: (a) generate a seismic hazard curve, i.e., vs. , (b) compute seismic intensity range and split it into equal intervals, (c) develop a target response spectrum, , for each intensity range, and (d) select and scale suites of ground motions for each spectrum.
| Algorithm 1: Estimation of the fundamental period of the coupled system [74,75]. |
Inputs: [m], [m], [MPa], [MPa], Output: [sec].
|

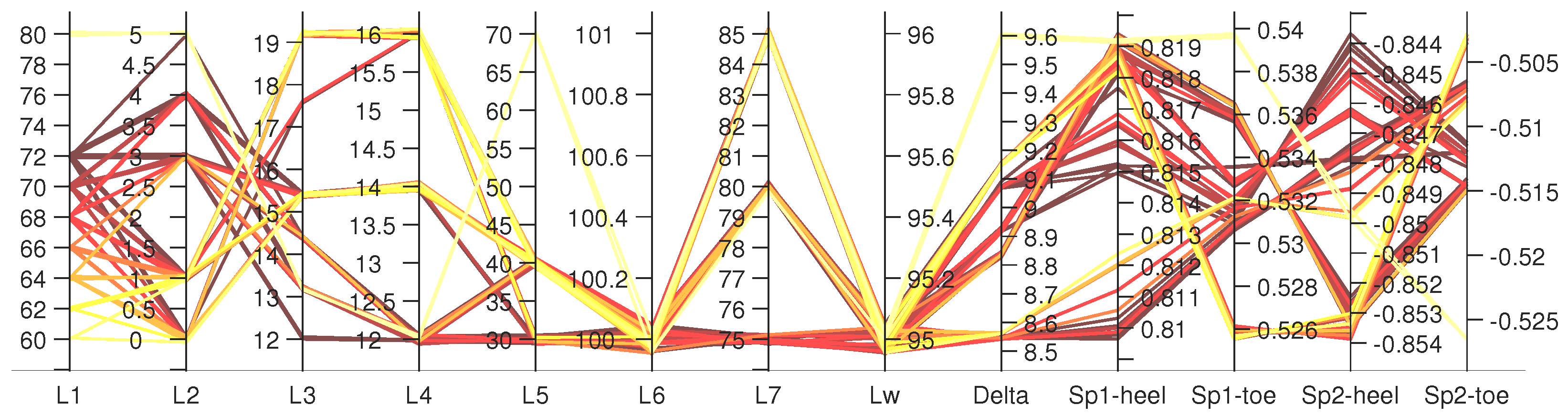
Example of AutoML Seismic Design
- Candidate 1: m, , m, m, m, m.
- Candidate 2: m, , m, m, m, m.
- Candidate 3: m, , m, m, m, m.
7. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chopra, A. Earthquake analysis of arch dams: Factors to be considered. J. Struct. Eng. 2012, 138, 205–214. [Google Scholar] [CrossRef]
- Rezaiee-Pajand, M.; Kazemiyan, M.; Aftabi Sani, A. A Literature Review on Dynamic Analysis of Concrete Gravity and Arch Dams. Arch. Comput. Methods Eng. 2021, 28, 4357–4372. [Google Scholar] [CrossRef]
- Saouma, V.E.; Hariri-Ardebili, M.A. Aging, Shaking, and Cracking of Infrastructures: From Mechanics to Concrete Dams and Nuclear Structures; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Fardis, M.N. From force-to displacement-based seismic design of concrete structures and beyond. In Recent Advances in Earthquake Engineering in Europe. ECEE 2018. Geotechnical, Geological and Earthquake Engineering; Pitilakis, K., Ed.; Springer: Cham, The Netherlands, 2018; pp. 101–122. [Google Scholar]
- USBR. Design of Gravity Dams; Technical Report; U.S. Department of the Interior Bureau of Reclamation: Denver, CO, USA, 1976.
- USACE. Gravity Dam Design; Technical Report EM 1110-2-2200; Department of the Army, U.S. Army Corps of Engineers: Washington, DC, USA, 1995.
- Chopra, A.K. Earthquake Engineering for Concrete Dams: Analysis, Design, and Evaluation; John Wiley & Sons: Hoboken, NJ, USA, 2020. [Google Scholar]
- Andonov, A.G.; Iliev, A.; Apostolov, K.S. Towards Displacement-Based Seismic Assessment of Concrete Dams Using Non-linear Static and Dynamic Procedures. Struct. Eng. Int. 2013, 23, 132–140. [Google Scholar] [CrossRef]
- Priestley, M. Performance based seismic design. Bull. New Zealand Soc. Earthq. Eng. 2000, 33, 325–346. [Google Scholar] [CrossRef]
- Collins, K.R.; Wen, Y.K.; Foutch, D.A. Dual-level seismic design: A reliability-based methodology. Earthq. Eng. Struct. Dyn. 1996, 25, 1433–1467. [Google Scholar] [CrossRef]
- Sinković, N.L.; Brozovič, M.; Dolšek, M. Risk-based seismic design for collapse safety. Earthq. Eng. Struct. Dyn. 2016, 45, 1451–1471. [Google Scholar] [CrossRef]
- Cimellaro, G.P.; Renschler, C.; Bruneau, M. Introduction to resilience-based design (RBD). In Computational Methods, Seismic Protection, Hybrid Testing and Resilience in Earthquake Engineering; Springer: Berlin/Heidelberg, Germany, 2015; pp. 151–183. [Google Scholar]
- Ferguson, K.; Dummer, J.; VanderPlaat, T. Risk Informed Design of a New Scoggings RCC Dam, Oregon Under Extreme Seismic Loading Conditions. In Proceedings of the 34th Annual USSD Conference, San Francisco, CA, USA, 7–11 April 2014. [Google Scholar]
- Ramakrishnan, C.; Francavilla, A. Structural shape optimization using penalty functions. J. Struct. Mech. 1974, 3, 403–422. [Google Scholar] [CrossRef]
- Akbari, J.; Sadoughi, A. Shape optimization of structures under earthquake loadings. Struct. Multidiscip. Optim. 2013, 47, 855–866. [Google Scholar] [CrossRef]
- Banerjee, A.; Paul, D.; Acharyya, A. Optimization and safety evaluation of concrete gravity dam section. KSCE J. Civ. Eng. 2015, 19, 1612–1619. [Google Scholar] [CrossRef]
- Zhang, M.; Li, M.; Shen, Y.; Zhang, J. Isogeometric shape optimization of high RCC gravity dams with functionally graded partition structure considering hydraulic fracturing. Eng. Struct. 2019, 179, 341–352. [Google Scholar] [CrossRef]
- Khatibinia, M.; Khosravi, S. A hybrid approach based on an improved gravitational search algorithm and orthogonal crossover for optimal shape design of concrete gravity dams. Appl. Soft Comput. 2014, 16, 223–233. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Y.; Ma, X. Updated Kriging-Assisted Shape Optimization of a Gravity Dam. Water 2021, 13, 87. [Google Scholar] [CrossRef]
- Talatahari, S.; Aalami, M.; Parsiavash, R. Risk-based arch dam optimization using hybrid charged system search. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part Civ. Eng. 2018, 4, 04018008. [Google Scholar] [CrossRef]
- Fengjie, T.; Lahmer, T. Shape optimization based design of arch-type dams under uncertainties. Eng. Optim. 2018, 50, 1470–1482. [Google Scholar] [CrossRef]
- Abdollahi, A.; Amini, A.; Hariri-Ardebili, M. An uncertainty–aware dynamic shape optimization framework: Gravity dam design. Reliab. Eng. Syst. Saf. 2022, 222, 108402. [Google Scholar] [CrossRef]
- Sevieri, G.; De Falco, A.; Andreini, M.; Matthies, H.G. Hierarchical Bayesian framework for uncertainty reduction in the seismic fragility analysis of concrete gravity dams. Eng. Struct. 2021, 246, 113001. [Google Scholar] [CrossRef]
- Hariri-Ardebili, M.A.; Pourkamali-Anaraki, F. Structural uncertainty quantification with partial information. Expert Syst. Appl. 2022, 198, 116736. [Google Scholar] [CrossRef]
- Salazar, F.; Morán, R.; Toledo, M.Á.; Oñate, E. Data-based models for the prediction of dam behaviour: A review and some methodological considerations. Arch. Comput. Methods Eng. 2015, 24, 1–21. [Google Scholar] [CrossRef]
- Mata, J.; Salazar, F.; Barateiro, J.; Antunes, A. Validation of Machine Learning Models for Structural Dam Behaviour Interpretation and Prediction. Water 2021, 13, 2717. [Google Scholar] [CrossRef]
- Chen, J.Y.; Xu, Q.; Li, J.; Fan, S.L. Improved response surface method for anti-slide reliability analysis of gravity dam based on weighted regression. J. Zhejiang Univ.-Sci. A 2010, 11, 432–439. [Google Scholar] [CrossRef]
- Karimi, I.; Khaji, N.; Ahmadi, M.; Mirzayee, M. System identification of concrete gravity dams using artificial neural networks based on a hybrid finite element–boundary element approach. Eng. Struct. 2010, 32, 3583–3591. [Google Scholar] [CrossRef]
- Gaspar, A.; Lopez-Caballero, F.; Modaressi-Farahmand-Razavi, A.; Gomes-Correia, A. Methodology for a probabilistic analysis of an RCC gravity dam construction. Modelling of temperature, hydration degree and ageing degree fields. Eng. Struct. 2014, 65, 99–110. [Google Scholar] [CrossRef]
- Gu, H.; Wu, Z.; Huang, X.; Song, J. Zoning modulus inversion method for concrete dams based on chaos genetic optimization algorithm. Math. Probl. Eng. 2015, 2015, 817241. [Google Scholar] [CrossRef]
- Su, H.; Wen, Z.; Zhang, S.; Tian, S. Method for Choosing the Optimal Resource in Back-Analysis for Multiple Material Parameters of a Dam and Its Foundation. J. Comput. Civ. Eng. 2016, 30, 04015060. [Google Scholar] [CrossRef]
- Hariri-Ardebili, M.; Pourkamali-Anaraki, F. Support vector machine based reliability analysis of concrete dams. Soil Dyn. Earthq. Eng. 2018, 104, 276–295. [Google Scholar] [CrossRef]
- Hariri-Ardebili, M.; Pourkamali-Anaraki, F. Simplified reliability analysis of multi hazard risk in gravity dams via machine learning techniques. Arch. Civ. Mech. Eng. 2018, 18, 592–610. [Google Scholar] [CrossRef]
- Hariri-Ardebili, M.; Sudret, B. Polynomial chaos expansion for uncertainty quantification of dam engineering problems. Eng. Struct. 2020, 203, 109631. [Google Scholar] [CrossRef]
- Amini, A.; Abdollahi, A.; Hariri-Ardebili, M.; Lall, U. Copula-based reliability and sensitivity analysis of aging dams: Adaptive Kriging and polynomial chaos Kriging methods. Appl. Soft Comput. 2021, 109, 107524. [Google Scholar] [CrossRef]
- Segura, R.; Padgett, J.E.; Paultre, P. Metamodel-Based Seismic Fragility Analysis of Concrete Gravity Dams. J. Struct. Eng. 2020, 146, 04020121. [Google Scholar] [CrossRef]
- Macedo, J.; Liu, C.; Soleimani, F. Machine-learning-based predictive models for estimating seismically-induced slope displacements. Soil Dyn. Earthq. Eng. 2021, 148, 106795. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhang, Y.; Pang, R.; Xu, B. Seismic fragility analysis of high concrete faced rockfill dams based on plastic failure with support vector machine. Soil Dyn. Earthq. Eng. 2021, 144, 106587. [Google Scholar] [CrossRef]
- Cheng, L.; Tong, F.; Li, Y.; Yang, J.; Zheng, D. Comparative Study of the Dynamic Back-Analysis Methods of Concrete Gravity Dams Based on Multivariate Machine Learning Models. J. Earthq. Eng. 2018, 25, 1–22. [Google Scholar] [CrossRef]
- Salazar, F.; Hariri-Ardebili, M.A. Coupling machine learning and stochastic finite element to evaluate heterogeneous concrete infrastructure. Eng. Struct. 2022, 260, 114190. [Google Scholar] [CrossRef]
- Hariri-Ardebili, M.A.; Mahdavi, G.; Abdollahi, A.; Amini, A. An RF-PCE Hybrid Surrogate Model for Sensitivity Analysis of Dams. Water 2021, 13, 302. [Google Scholar] [CrossRef]
- Segura, R.L.; Fréchette, V.; Miquel, B.; Paultre, P. Dual layer metamodel-based safety assessment for rock wedge stability of a free-crested weir. Eng. Struct. 2022, 268, 114691. [Google Scholar] [CrossRef]
- Hariri-Ardebili, M.A.; Chen, S.; Mahdavi, G. Machine learning-aided PSDM for dams with stochastic ground motions. Adv. Eng. Inform. 2022, 52, 101615. [Google Scholar] [CrossRef]
- Li, Z.; Wu, Z.; Lu, X.; Zhou, J.; Chen, J.; Liu, L.; Pei, L. Efficient seismic risk analysis of gravity dams via screening of intensity measures and simulated non-parametric fragility curves. Soil Dyn. Earthq. Eng. 2022, 152, 107040. [Google Scholar] [CrossRef]
- He, X.; Zhao, K.; Chu, X. AutoML: A survey of the state-of-the-art. Knowl.-Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- Wever, M.; Tornede, A.; Mohr, F.; Hüllermeier, E. AutoML for multi-label classification: Overview and empirical evaluation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3037–3054. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Koh, J.; Spangenberg, G.; Kant, S. Automated machine learning for high-throughput image-based plant phenotyping. Remote Sens. 2021, 13, 858. [Google Scholar] [CrossRef]
- Cerrada, M.; Trujillo, L.; Hernández, D.; Correa Zevallos, H.; Macancela, J.; Cabrera, D.; Vinicio Sánchez, R. AutoML for Feature Selection and Model Tuning Applied to Fault Severity Diagnosis in Spur Gearboxes. Math. Comput. Appl. 2022, 27, 6. [Google Scholar] [CrossRef]
- Gerling, A.; Ziekow, H.; Hess, A.; Schreier, U.; Seiffer, C.; Abdeslam, D. Comparison of algorithms for error prediction in manufacturing with AutoML and a cost-based metric. J. Intell. Manuf. 2022, 33, 555–573. [Google Scholar] [CrossRef]
- Bonidia, R.; Santos, A.; de Almeida, B.; Stadler, P.; da Rocha, U.; Sanches, D.; de Carvalho, A. BioAutoML: Automated feature engineering and metalearning to predict noncoding RNAs in bacteria. Briefings Bioinform. 2022, 23, bbac218. [Google Scholar] [CrossRef]
- Chen, W.; Zhang, L. An automated machine learning approach for earthquake casualty rate and economic loss prediction. Reliab. Eng. Syst. Saf. 2022, 225, 108645. [Google Scholar] [CrossRef]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; Hutter, F. Efficient and Robust Automated Machine Learning. In Proceedings of the Conference on Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–10 December 2015; pp. 2962–2970. [Google Scholar]
- Feurer, M.; Eggensperger, K.; Falkner, S.; Lindauer, M.; Hutter, F. Auto-Sklearn 2.0: Hands-free AutoML via Meta-Learning. arXiv 2020, arXiv:2007.04074. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Krawczyk, B.; Minku, L.; Gama, J.; Stefanowski, J.; Woźniak, M. Ensemble learning for data stream analysis: A survey. Inf. Fusion 2017, 37, 132–156. [Google Scholar] [CrossRef]
- Gain, U.; Hotti, V. Low-code AutoML-augmented data pipeline–a review and experiments. J. Physics Conf. Ser. 2021, 1828, 012015. [Google Scholar] [CrossRef]
- Hariri-Ardebili, M.; Saouma, V. Probabilistic seismic demand model and optimal intensity measure for concrete dams. Struct. Saf. 2016, 59, 67–85. [Google Scholar] [CrossRef]
- Hariri-Ardebili, M.; Barak, S. A series of forecasting models for seismic evaluation of dams based on ground motion meta-features. Eng. Struct. 2020, 203, 109657. [Google Scholar] [CrossRef]
- Fenves, G.; Chopra, A. EAGD-84: A Computer Program for Earthquake Analysis of Concrete Gravity Dams; University of California, Earthquake Engineering Research Center: Los Angeles, CA, USA, 1984. [Google Scholar]
- Fenves, G.; Chopra, A. Earthquake analysis of concrete gravity dams including reservoir bottom absorption and dam-water-foundation rock interaction. Earthq. Eng. Struct. Dyn. 1984, 12, 663–680. [Google Scholar] [CrossRef]
- MATLAB. Version 9.11 (R2021b); The MathWorks Inc.: Natick, MA, USA, 2021. [Google Scholar]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Zimmaro, P.; Stewart, J.P. Probabilistic Seismic Hazard Analysis for a Dam Site in Calabria (Southern Italy); Technical Report; University of California, Los Angeles, Department of Civil and Environmental Engineering: Los Angeles, CA, USA, 2015. [Google Scholar]
- Bommer, J.J. Deterministic vs. probabilistic seismic hazard assessment: An exaggerated and obstructive dichotomy. J. Earthq. Eng. 2002, 6, 43–73. [Google Scholar] [CrossRef]
- Haftani, M.; Gheshmipour, A.A.; Mehinrad, A.; Binazadeh, K. Geotechnical characteristics of Bakhtiary dam site, SW Iran: The highest double-curvature dam in the world. Bull. Eng. Geol. Environ. 2014, 73, 479–492. [Google Scholar] [CrossRef]
- Harris, D.W.; Snorteland, N.; Dolen, T.; Travers, F. Shaking table 2-D models of a concrete gravity dam. Earthq. Eng. Struct. Dyn. 2000, 29, 769–787. [Google Scholar] [CrossRef]
- Uchita, Y.; Shimpo, T.; Saouma, V. Dynamic centrifuge tests of concrete dams. Earthq. Eng. Struct. Dyn. 2005, 34, 1467–1487. [Google Scholar] [CrossRef]
- Hariri-Ardebili, M. Concrete Dams: From Failure Modes to Seismic Fragility. In Encyclopedia of Earthquake Engineering; Beer, M., Kougioumtzoglou, I.A., Patelli, E., Au, I.S.K., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 1–26. [Google Scholar]
- ICOLD. Selecting Seismic Parameters for Large Dams, Guidelines, Bulletin 148 (Revision of Bulletin 72); Technical Report; International Commission on Large Dams: Paris, France, 2010. [Google Scholar]
- Wieland, M. Seismic hazard and seismic design and safety aspects of large dam projects. In Perspectives on European Earthquake Engineering and Seismology; Springer: Berlin/Heidelberg, Germany, 2014; pp. 627–650. [Google Scholar]
- Wieland, M. What seismic hazard information the dam engineers need from seismologists and geologists? In Proceedings of the 2nd European Conference on Earthquake Engineering and Seismology, Istanbul, Turkey, 25–29 August 2014. [Google Scholar]
- FEMA. Seismic Performance Assessment of Buildings, Volume 1: Methodology; Technical Report FEMA-58-1; Federal Emergency Management Agency: Redwood City, CA, USA, 2012.
- Løkke, A.; Chopra, A. Response spectrum analysis of concrete gravity dams including dam-water-foundation interaction. J. Struct. Eng. 2014, 141, 04014202. [Google Scholar] [CrossRef]
- Hariri-Ardebili, M.A.; Saouma, V.E. Random response spectrum analysis of gravity dam classes: Simplified, practical, and fast approach. Earthq. Spectra 2018, 34, 941–975. [Google Scholar] [CrossRef]
- Hariri-Ardebili, M.; Saouma, V. Quantitative failure metric for gravity dams. Earthq. Eng. Struct. Dyn. 2015, 44, 461–480. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Description of IM | Symbol | Mathematical Model |
|---|---|---|---|
| 1 | Peak ground acceleration | ||
| 2 | Peak ground velocity | ||
| 3 | Peak ground displacement | ||
| 4 | Acceleration spectrum intensity | ||
| 5 | Velocity spectrum intensity | ||
| 6 | First-mode spectral acceleration | ||
| 7 | First-mode spectral velocity | ||
| 8 | First-mode spectral displacement | ||
| 9 | First-mode spectral acceleration | ||
| 10 | Root-mean-square of acceleration | ||
| 11 | Root-mean-square of velocity | ||
| 12 | Arias intensity | ||
| 13 | Specific energy density | ||
| 14 | Cumulative absolute velocity | ||
| 15 | Significant duration |
| Rank | Ensemble Weight | Type | Duration |
|---|---|---|---|
| 1 | Gradient Boosting | ||
| 2 | Gradient Boosting | ||
| 3 | Gradient Boosting | ||
| 4 | ARD Regression | ||
| 5 | Gradient Boosting | ||
| 6 | Gradient Boosting | ||
| 7 | Gradient Boosting | ||
| 8 | Gradient Boosting | ||
| 9 | Gradient Boosting | ||
| 10 | ARD Regression |
| Rank | Ensemble Weight | Type | Duration |
|---|---|---|---|
| 1 | Extra Trees | ||
| 2 | Random Forest | ||
| 3 | K-Nearest Neighbor |
| Output | RMSE | MAE | |
|---|---|---|---|
| Out1 | |||
| Out2 | |||
| Out3 | |||
| Out4 | |||
| Out5 | |||
| Out6 | |||
| Overall |
| Rank | Ensemble Weight | Type | Duration |
|---|---|---|---|
| 1 | Decision Tree | ||
| 2 | Decision Tree | ||
| 3 | Decision Tree | ||
| 4 | Decision Tree | ||
| 5 | Decision Tree | ||
| 6 | Decision Tree | ||
| 7 | Decision Tree | ||
| 8 | Decision Tree | ||
| 9 | Decision Tree | ||
| 10 | Decision Tree | ||
| 11 | K-Nearest Neighbor | ||
| 12 | K-Nearest Neighbor |
| Output | RMSE | MAE | |
|---|---|---|---|
| Out1 | |||
| Out2 | |||
| Out3 | |||
| Out4 | |||
| Out5 | |||
| Out6 | |||
| Out7 | |||
| Out8 | |||
| Out9 | |||
| Out10 | |||
| Overall |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hariri-Ardebili, M.A.; Pourkamali-Anaraki, F. An Automated Machine Learning Engine with Inverse Analysis for Seismic Design of Dams. Water 2022, 14, 3898. https://doi.org/10.3390/w14233898
Hariri-Ardebili MA, Pourkamali-Anaraki F. An Automated Machine Learning Engine with Inverse Analysis for Seismic Design of Dams. Water. 2022; 14(23):3898. https://doi.org/10.3390/w14233898
Chicago/Turabian StyleHariri-Ardebili, Mohammad Amin, and Farhad Pourkamali-Anaraki. 2022. "An Automated Machine Learning Engine with Inverse Analysis for Seismic Design of Dams" Water 14, no. 23: 3898. https://doi.org/10.3390/w14233898
APA StyleHariri-Ardebili, M. A., & Pourkamali-Anaraki, F. (2022). An Automated Machine Learning Engine with Inverse Analysis for Seismic Design of Dams. Water, 14(23), 3898. https://doi.org/10.3390/w14233898