
Harmonizing and Extending Fragmented 100 Year Flood Hazard Maps in Canada’s Capital Region Using Random Forest Classification


Abstract
:1. Introduction
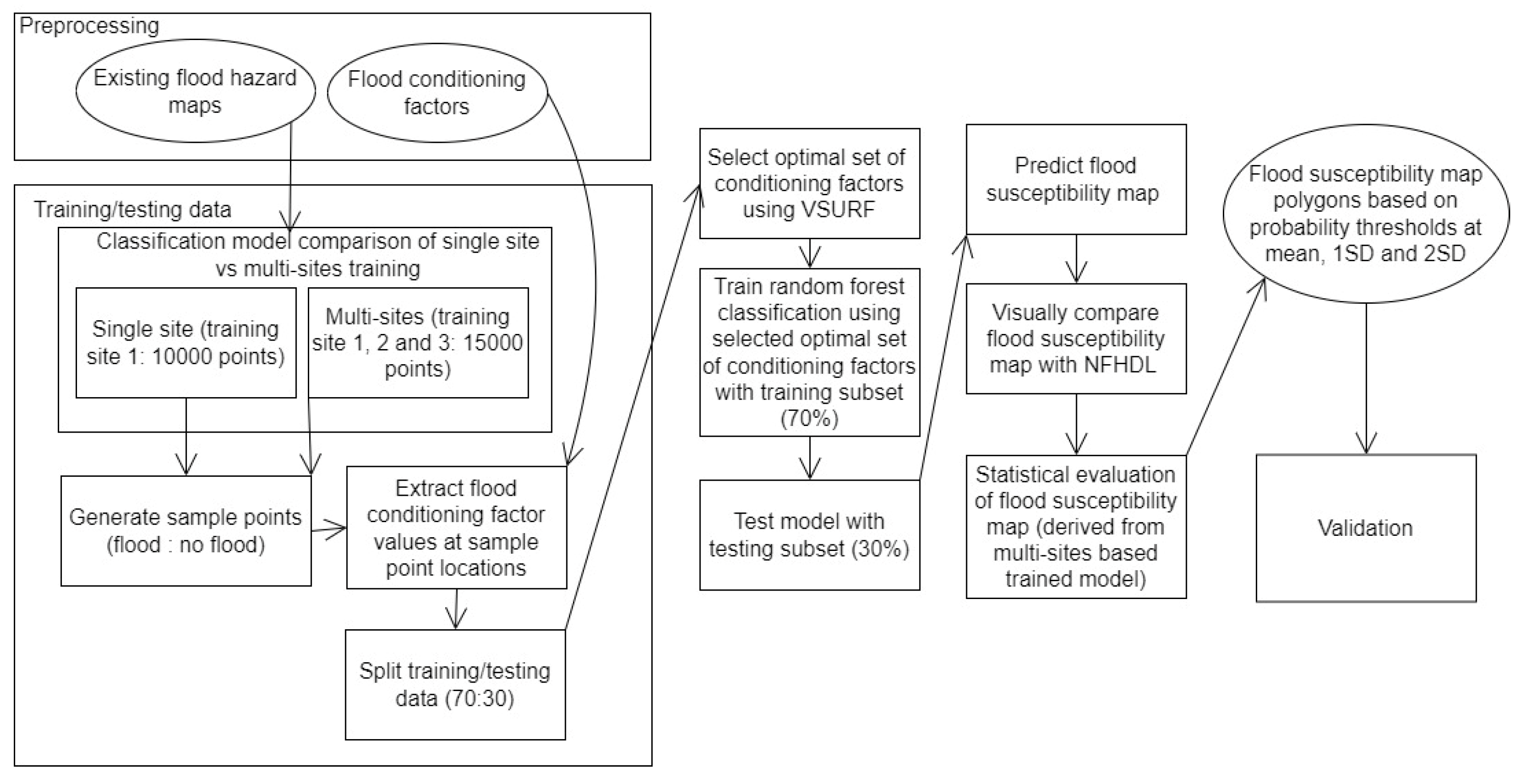
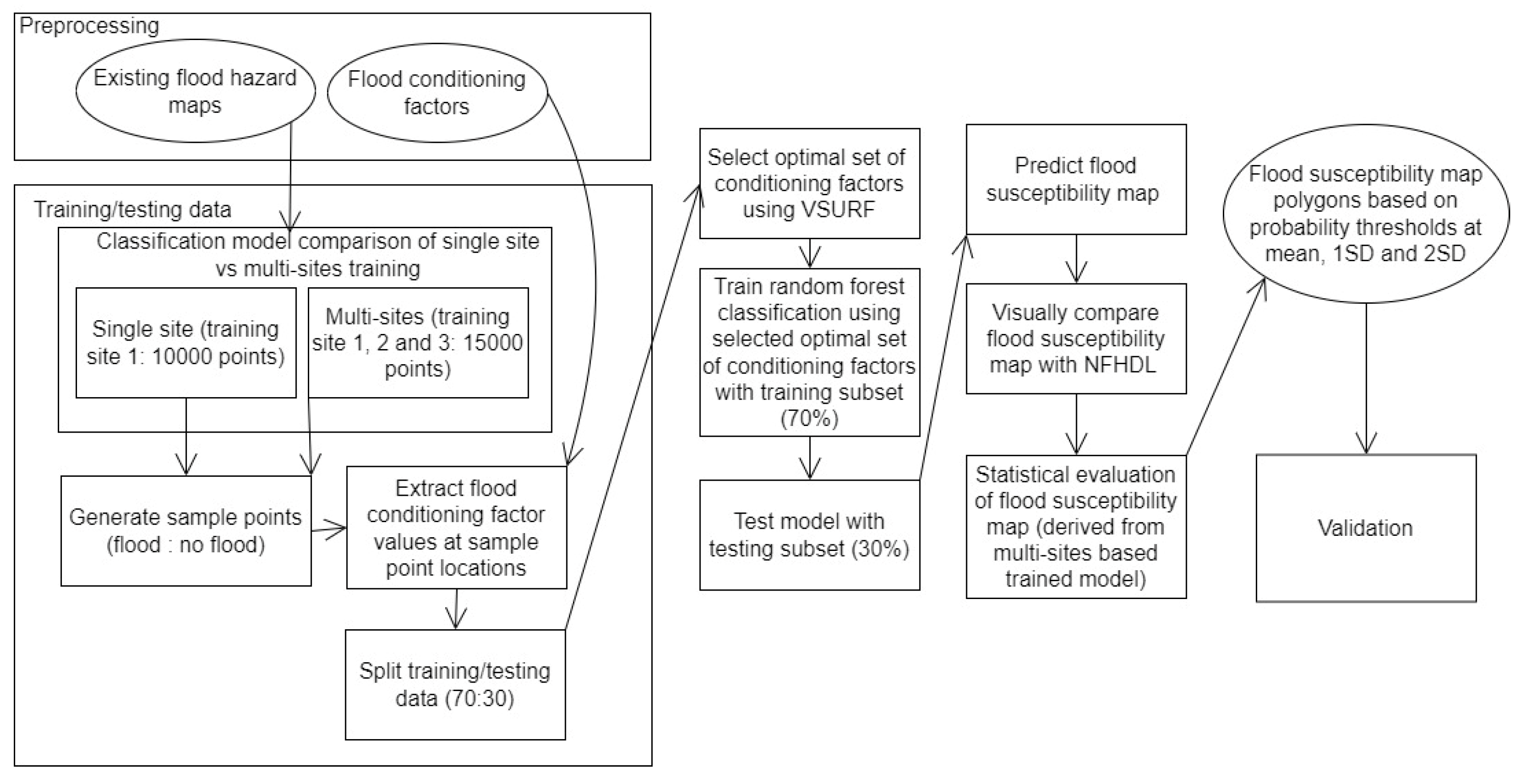
2. Materials and Methods
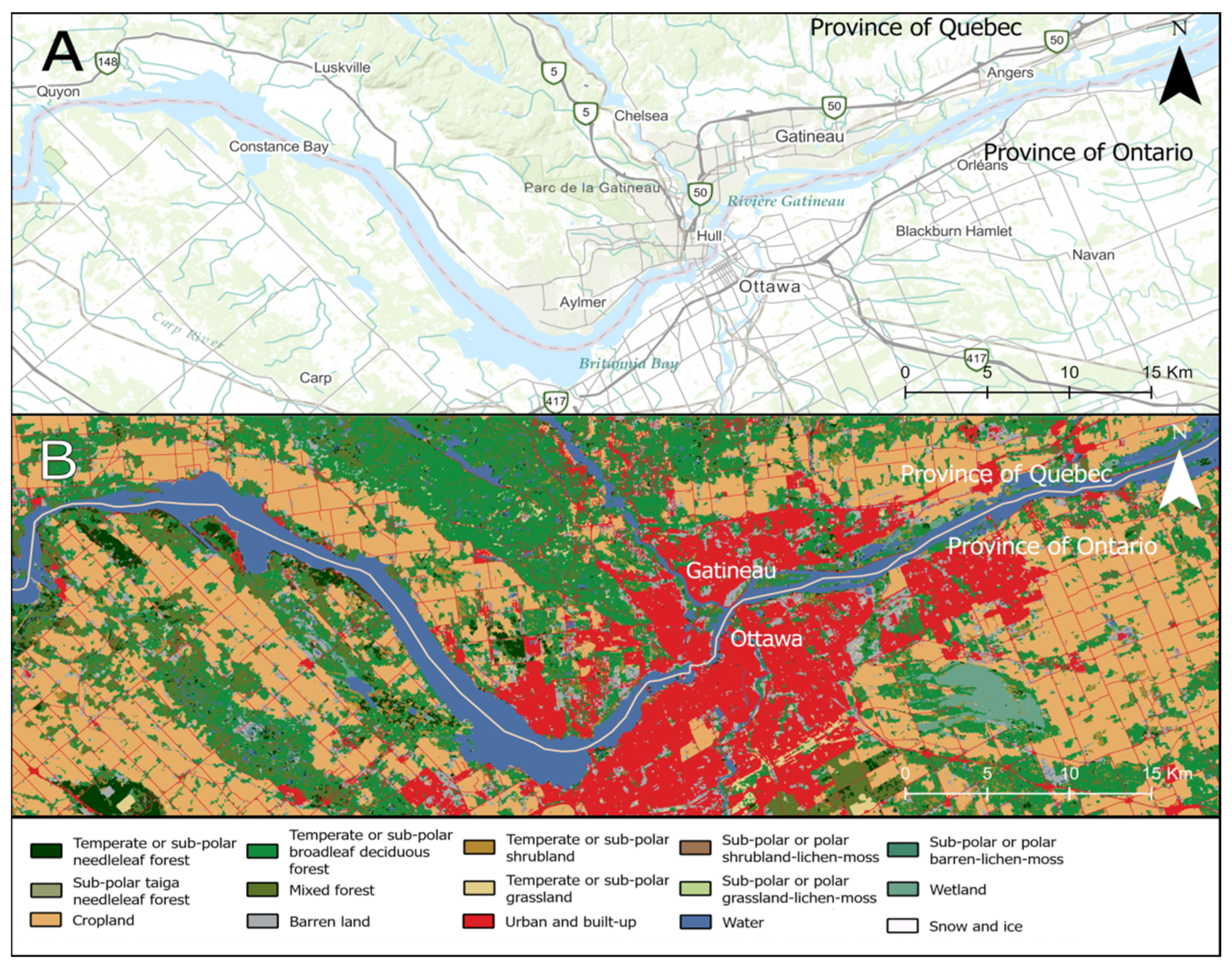
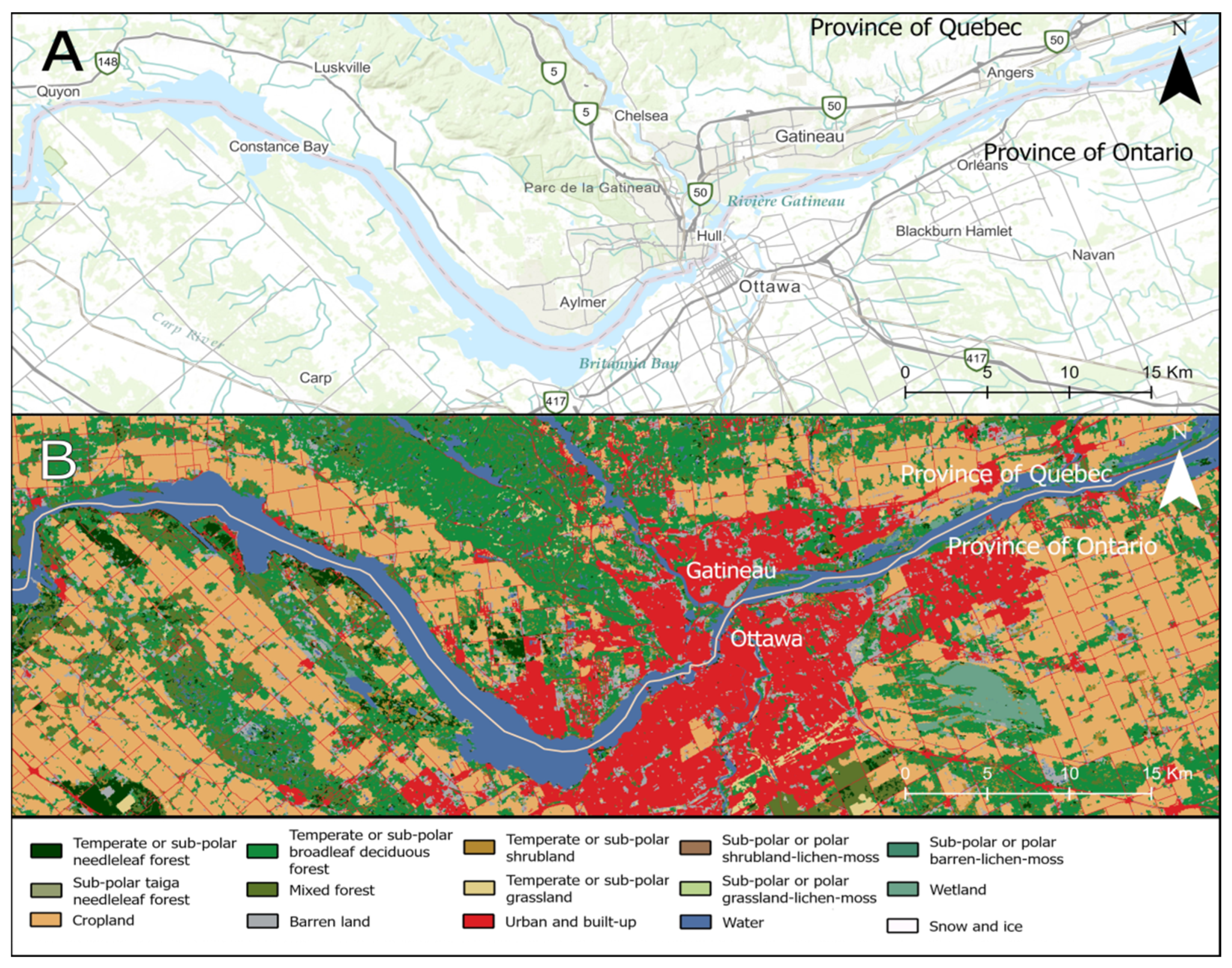
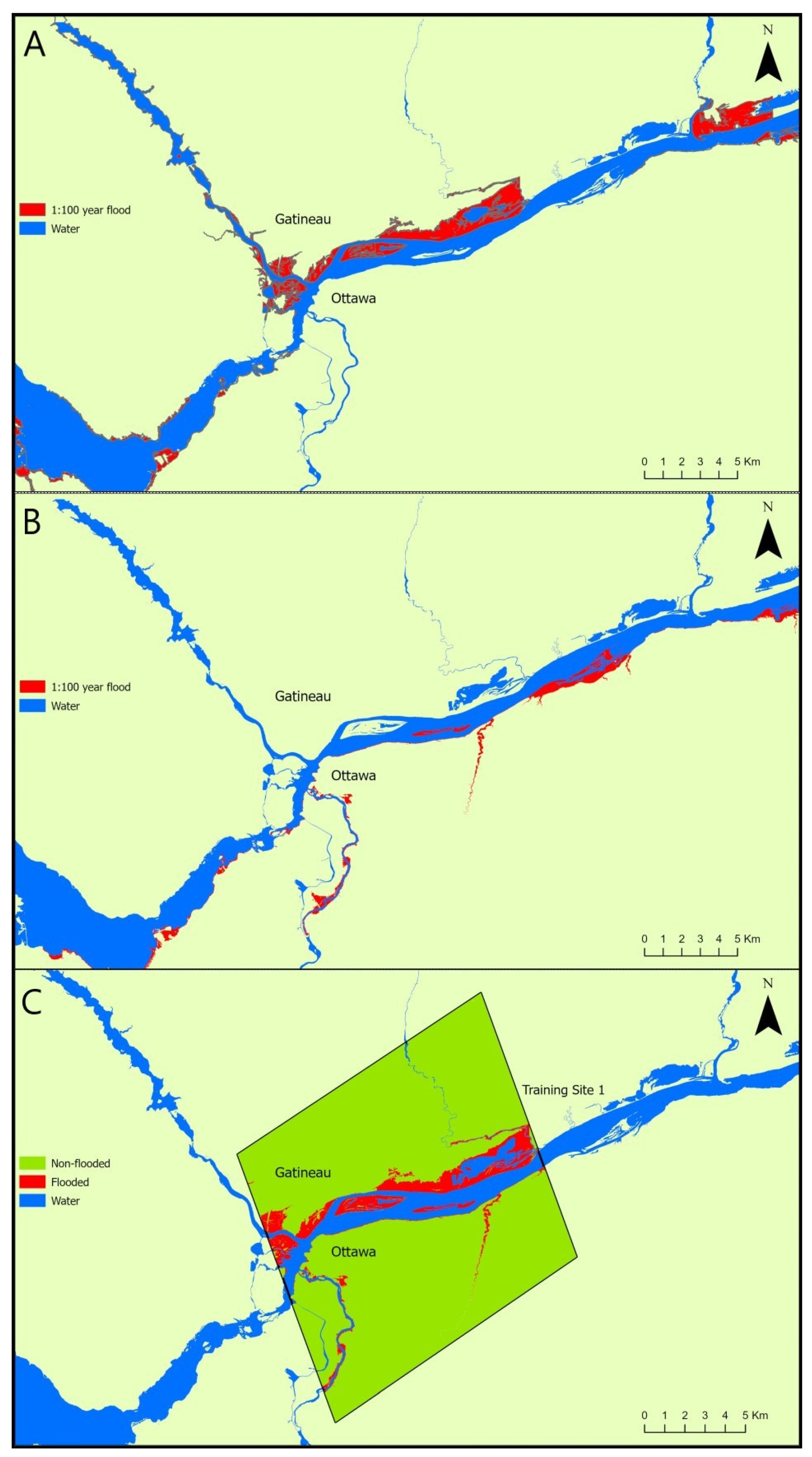
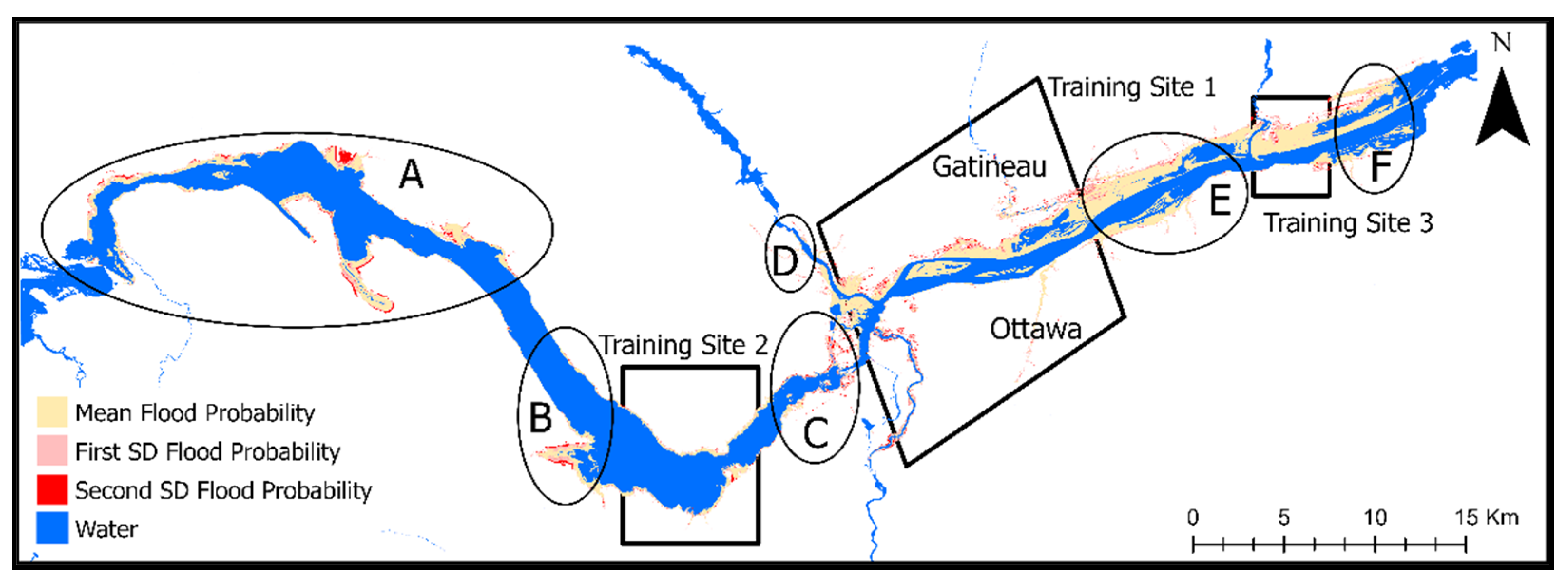
2.1. Study Area
2.2. Random Forest Classification
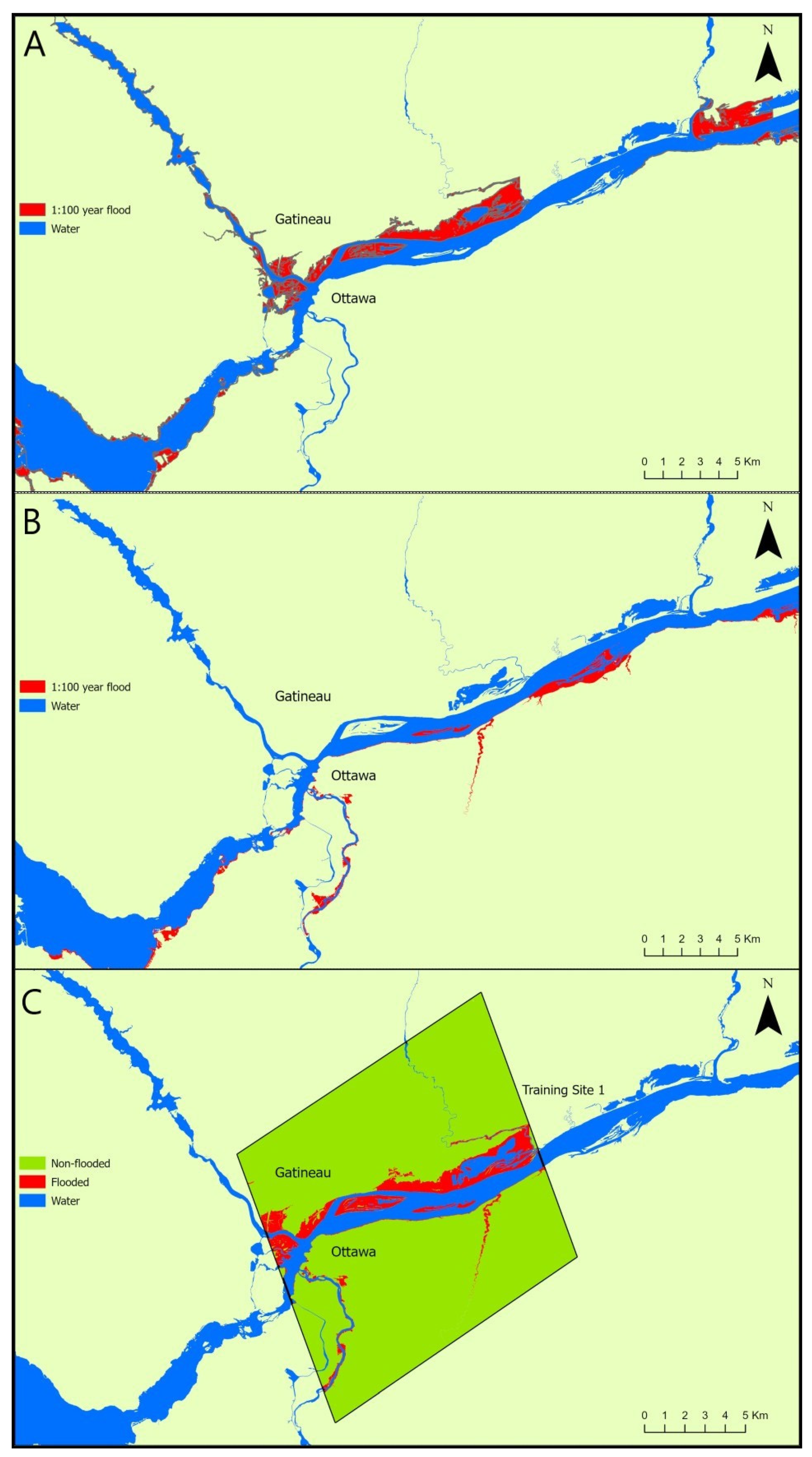
2.3. Existing Flood Hazard Maps Used for Training Random Forest Classification
2.4. Flood Conditioning Factors as Predictors of Flood

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flood Conditioning Factors | Resolution | References |
|---|---|---|
| 1 m | City of Ottawa for the Ontario side [46] and the Ministry of Forest Wildlife and Parks [47] for the Quebec side |
| 1 m | derived from 1 m resolution elevation [46,47] and National Hydrographic Network (NHN) [44] |
| 1 m | derived from 1 m resolution elevation [46,47] |
| 1 m | derived from 1 m resolution elevation [46,47] |
| 1 m | derived from 1 m resolution elevation [46,47] |
| 1 m | derived from 1 m resolution elevation [46,47] |
| 1 m | derived from 1 m resolution elevation [46,47] |
| 1 m | derived from 1 m resolution elevation [46,47] |
| 1 m | derived from 1 m resolution elevation [46,47] |
| 30 m | derived from a 30 m resolution elevation dataset obtained from the Open Government Portal [48] |
| 1 m | calculated using the National Hydrological Network (NHN) [49]. |
| 1 m | calculated based on the road network obtained from the City of Ottawa and City of Gatineau [50,51]. |
| 30 m | Natural Resources Canada [52] |
| 25 m | Natural Resources Canada [53] |
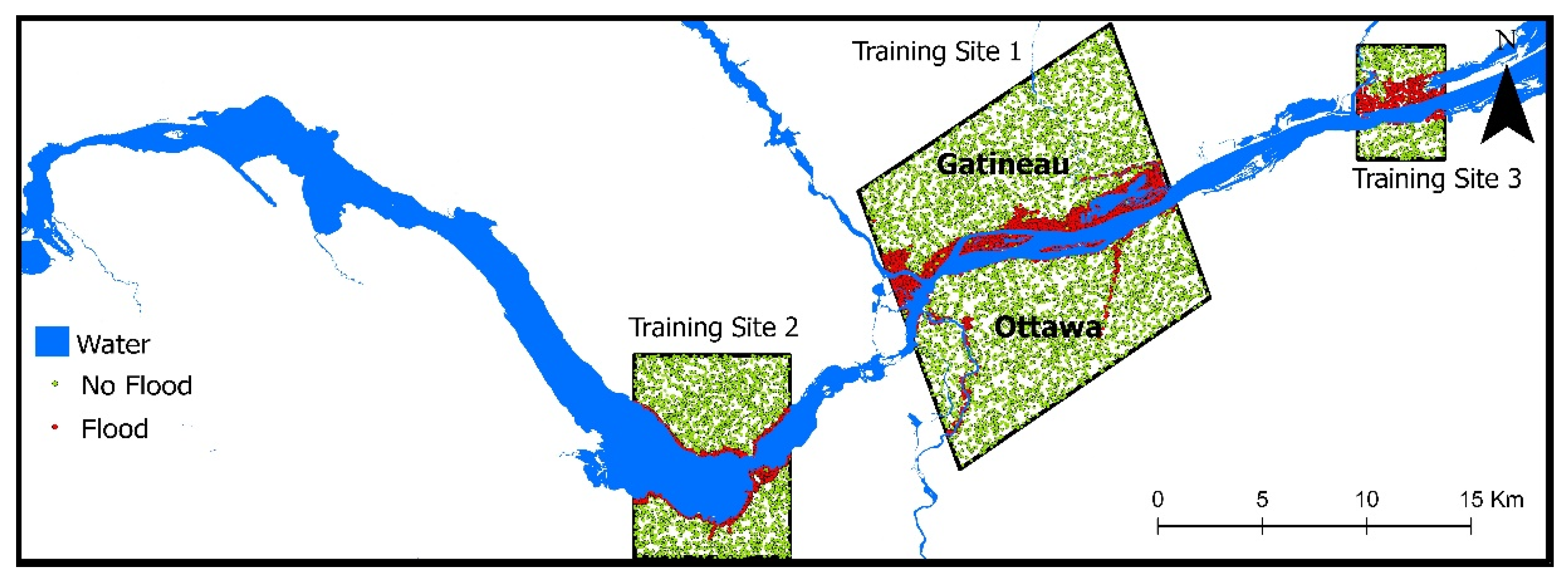
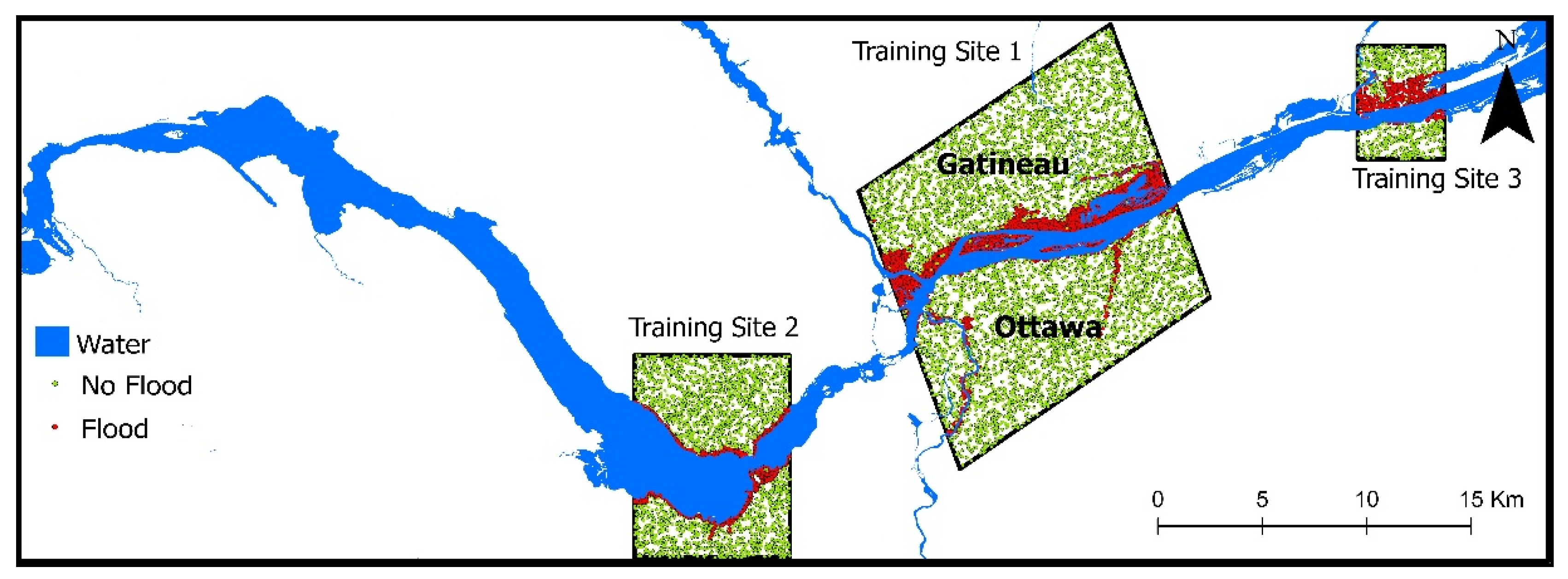
2.5. Training and Testing Data for the Random Forest Classification
2.6. Selecting Optimal Set of Flood Conditioning Factors and Single Site Training and Extrapolation
2.7. Multi-Sites Training and Extrapolation: Extending Training and Testing Data to Improve Extrapolation
2.8. Flood Probability Thresholds to Delineate Final Flood Susceptibility Map Polygons and Validation against NFHDL Maps
3. Results
3.1. VSURF Output for Single Site and Multi-Sites Training
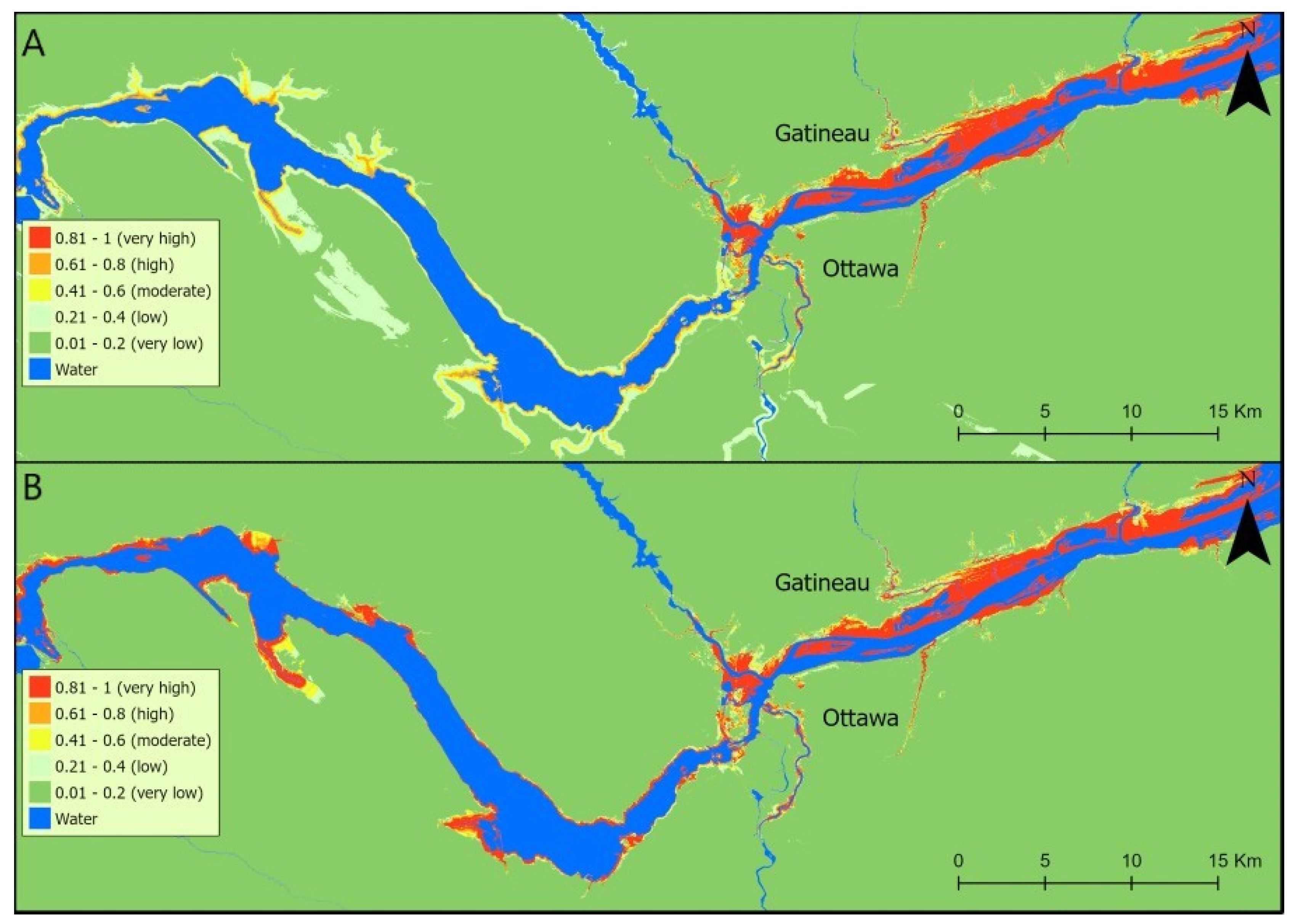
3.2. Single Site Training vs. Multi-Sites Training Performances against NFHDL Maps
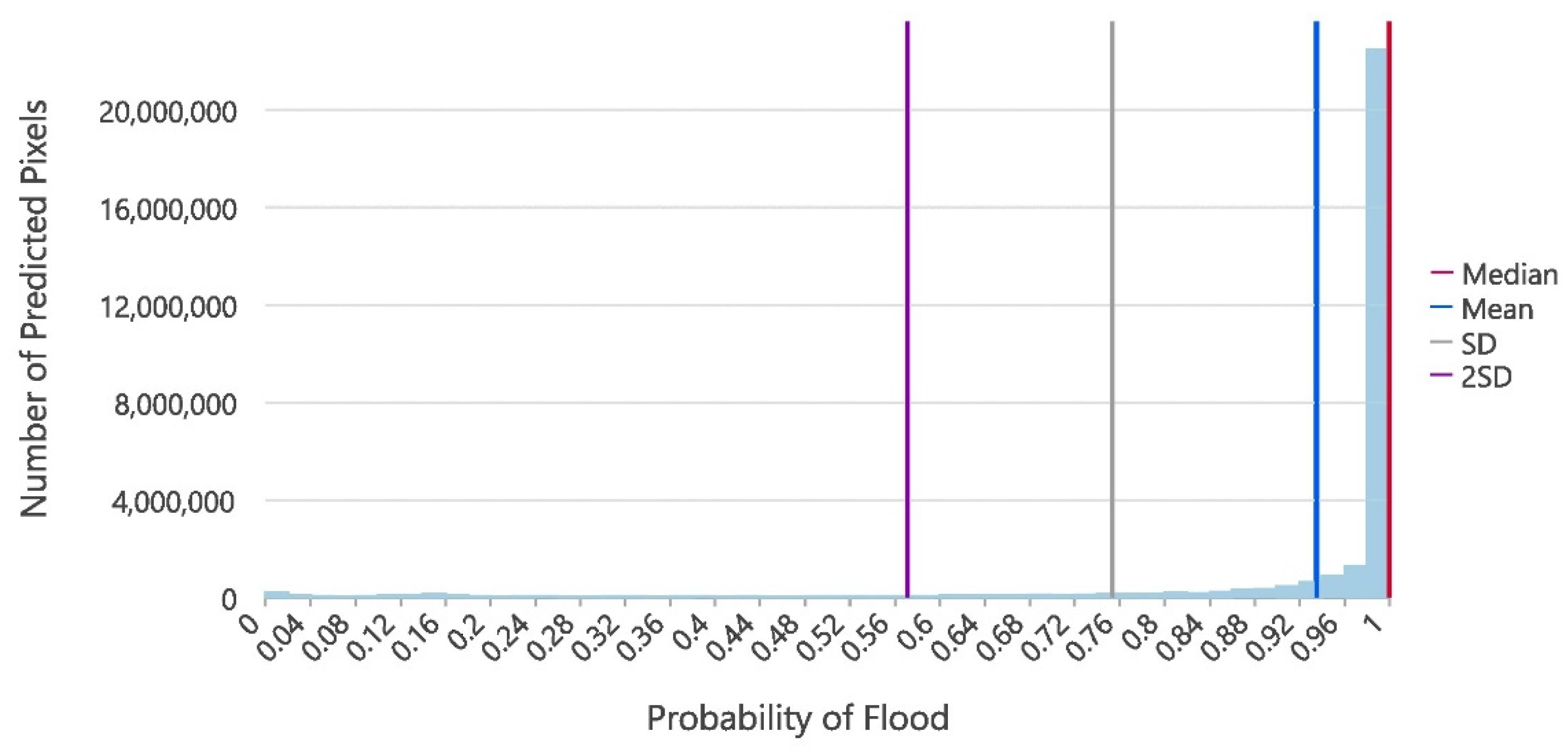
3.3. Statistical Evaluation of Flood Probability Thresholds: Used for Delineating Final Flood Susceptibility Map Polygons
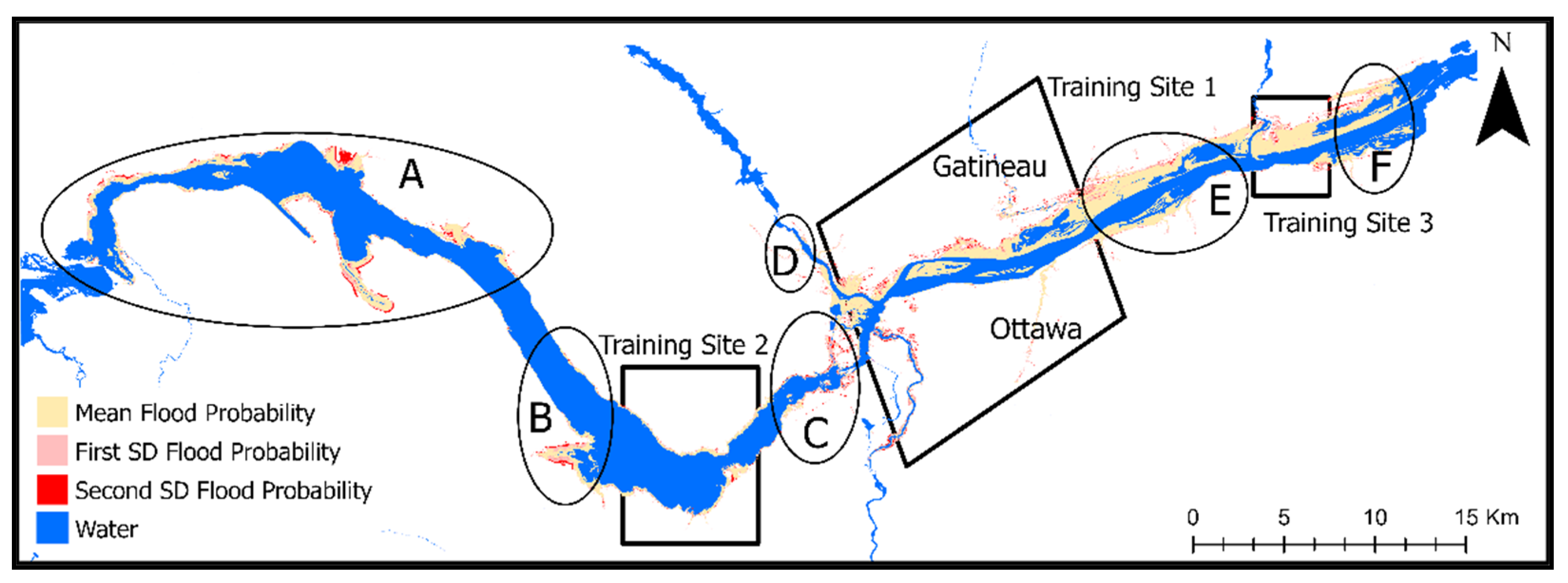
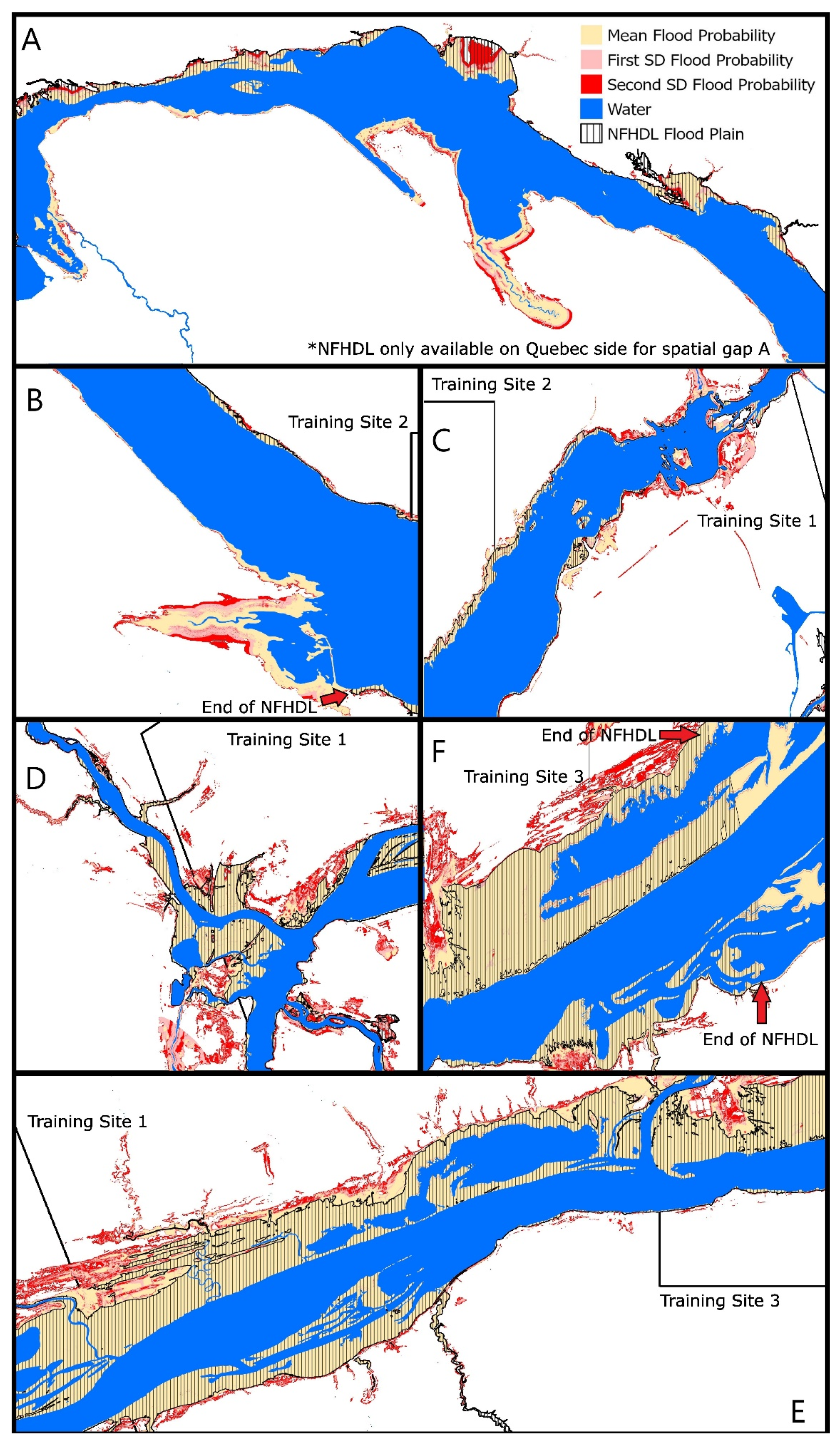
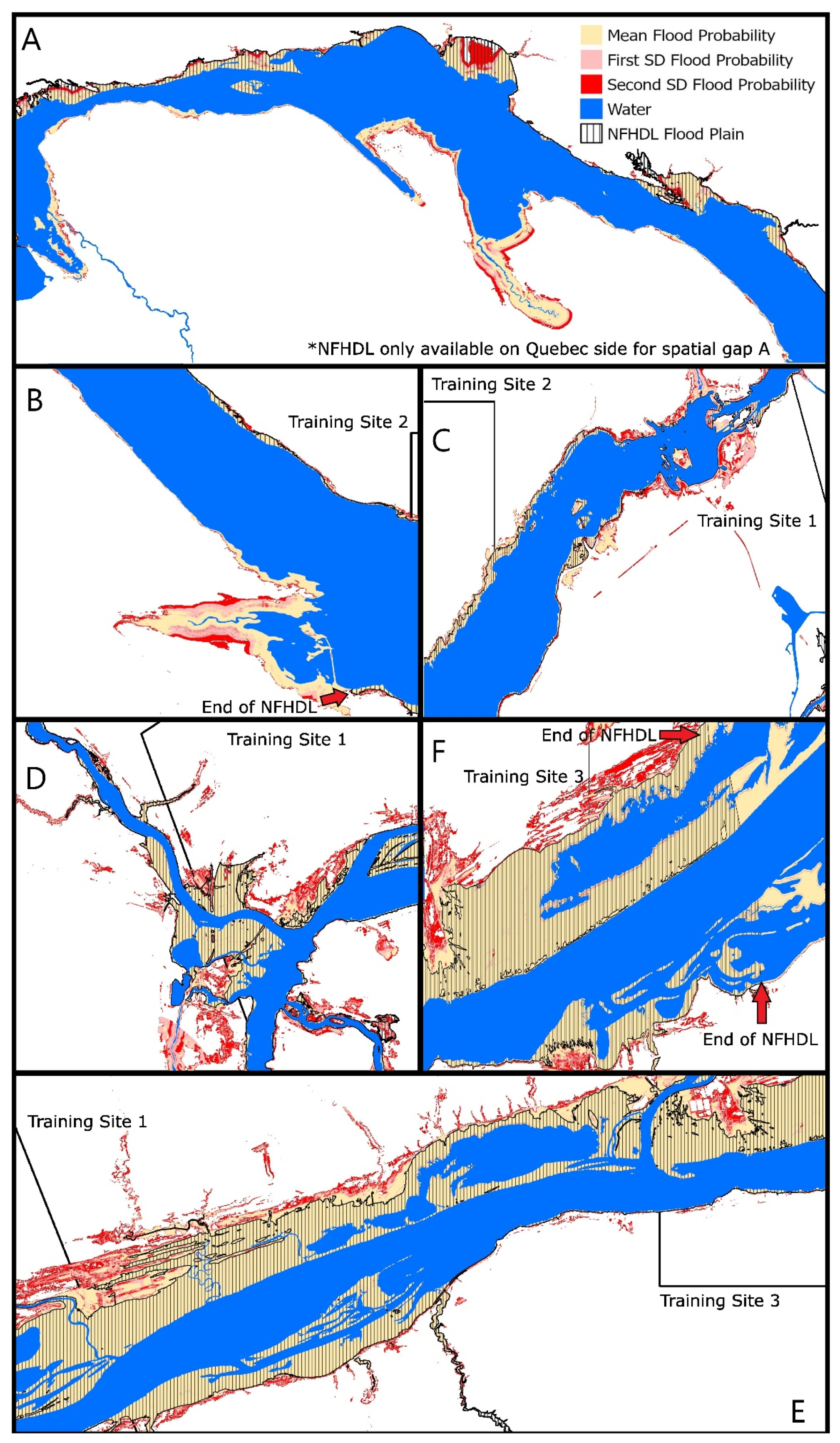
3.4. Validation of the Final Flood Susceptibility Map Polygons at the Locations of Existing Spatial Gaps within the FDRP Flood Hazard Areas against the NFHDL Maps
4. Discussion
4.1. Evaluate Random Forest Classification (Single Site Training vs. Multi-Sites Training) Performance against NFHDL Maps
4.2. Final Flood Susceptibility Map Polygons Based on Flood Probability Thresholds and Validating Existing Spatial Gaps within the FDRP Maps against NFHDL Maps
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schiermeier, Q. Increased Flood Risk Linked to Global Warming. Nature 2011, 470, 316. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ciszewski, D.; Grygar, T.M. A Review of Flood-Related Storage and Remobilization of Heavy Metal Pollutants in River Systems. Water. Air. Soil Pollut. 2016, 227, 239. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mcgrath, H.; Stefanakis, E.; Nastev, M. Sensitivity Analysis of Flood Damage Estimates: A Case Study in Fredericton, New Brunswick. Int. J. Disaster Risk Reduct. 2015, 14, 379–387. [Google Scholar] [CrossRef]
- Bush, E.; Lemmen, D.S. (Eds.) Canada’s Changing Climate Report; Government of Canada: Ottawa, ON, Canada, 2019; ISBN 9780660302225. [Google Scholar]
- Gaur, A.; Gaur, A.; Simonovic, S.P. Future Changes in Flood Hazards across Canada under a Changing Climate. Water 2018, 10, 1441. [Google Scholar] [CrossRef] [Green Version]
- Ottawa RIVERKEEPER 6 Things You Should Know about the 2019 Flooding—Ottawa Riverkeeper|Garde-Rivière Des Outaouais. Available online: https://ottawariverkeeper.ca/6-things-you-should-know-about-the-2019-flooding/ (accessed on 22 July 2022).
- Hodgson, C. Explainer: Is Climate Change the Cause of the 2019 Ottawa River Flooding?—Ecology Ottawa. Available online: https://www.ecologyottawa.ca/2019-05-02-explainer-is-climate-change-the-cause-of-the-2019-ottawa-river-flooding (accessed on 22 July 2022).
- Ottawa Riverkeeper Dams. Available online: https://www.ottawariverkeeper.ca/home/explore-the-river/dams/ (accessed on 8 November 2020).
- Ottawa River Regulation Planning Board. 2019 Spring Flood—Questions and Answers; Ottawa River Regulation Planning Board: Gatineau, QC, Canada, 2019; pp. 1–18. Available online: https://ottawariver.ca/information/publications/ (accessed on 22 November 2020).
- McNeil, D. Ontario Government Report on 2019 Flooding of the Ottawa River. Available online: https://www.merrileefullerton.ca/ontario_government_report_on_2019_flooding_of_the_ottawa_river (accessed on 7 December 2020).
- Tehrany, M.; Jones, S.; Shabani, F. Identifying the Essential Flood Conditioning Factors for Flood Prone Area Mapping Using Machine Learning Techniques. Catena 2019, 175, 174–192. [Google Scholar] [CrossRef]
- Natural Resources Canada and Public Safety Canada Federal Hydrologic and Hydraulic Procedures for Floodplain Delineation Version 1.0; Government of Canada: Ottawa, ON, Canada, 2019.
- Natural Resources Canada and Public Safety Canada Federal Flood Mapping Framework Version 2.0; Government of Canada: Ottawa, ON, Canada, 2018.
- Marin Watershed Program Hydrology and Hydraulic (H&H) Modeling. Available online: https://www.marinwatersheds.org/resources/projects/hydrology-and-hydraulic-hh-modeling (accessed on 15 August 2022).
- Exponent Hydrology & Hydraulics. Available online: https://www.exponent.com/services/practices/engineering/civil-engineering/capabilities/water-resources/hydrology--hydraulics/?serviceId=13098ca1-18b8-4603-af33-8b88d9905164&loadAllByPageSize=true&knowledgePageSize=7&knowledgePageNum=0&newseventPageSize=7&newseventPageNum=0&professionalsPageNum=1 (accessed on 15 August 2022).
- Esfandiari, M.; Abdi, G.; Jabari, S.; McGrath, H.; Coleman, D. Flood Hazard Risk Mapping Using a Pseudo Supervised Random Forest. Remote Sens. 2020, 12, 3206. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood Susceptibility Mapping Using a Novel Ensemble Weights-of-Evidence and Support Vector Machine Models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Ho, T.K. Random Decision Forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Yue, J.; Tu, T. Mapping Flood Susceptibility in Mountainous Areas on a National Scale in China. Sci. Total Environ. 2018, 615, 1133–1142. [Google Scholar] [CrossRef]
- Esfandiari, M.; Jabari, S.; McGrath, H.; Coleman, D. Flood Mapping Using Random Forest and Identifying the Essential Conditioning Factors; A Case Study in Fredericton, New Brunswick, Canada. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 5, 609–615. [Google Scholar] [CrossRef]
- Wang, Z.; Lai, C.; Chen, X.; Yang, B.; Zhao, S.; Bai, X. Flood Hazard Risk Assessment Model Based on Random Forest. J. Hydrol. 2015, 527, 1130–1141. [Google Scholar] [CrossRef]
- William, B.; Scriven, G. Flood Susceptibility Mapping in the Red River Valley, Manitoba, Using Machine Learning; Natural Resources Canada: Ottawa, ON, Canada, 2019. [Google Scholar]
- Shafapour Tehrany, M.; Shabani, F.; Neamah Jebur, M.; Hong, H.; Chen, W.; Xie, X. GIS-Based Spatial Prediction of Flood Prone Areas Using Standalone Frequency Ratio, Logistic Regression, Weight of Evidence and Their Ensemble Techniques. Geomat. Nat. Hazards Risk 2017, 8, 1538–1561. [Google Scholar] [CrossRef] [Green Version]
- Kia, M.B.; Pirasteh, S.; Pradhan, B.; Mahmud, A.R.; Sulaiman, W.N.A.; Moradi, A. An Artificial Neural Network Model for Flood Simulation Using GIS: Johor River Basin, Malaysia. Environ. Earth Sci. 2012, 67, 251–264. [Google Scholar] [CrossRef]
- Water Science School Impervious Surfaces and Flooding. Available online: https://www.usgs.gov/special-topics/water-science-school/science/impervious-surfaces-and-flooding (accessed on 22 July 2022).
- Environment and Climate Change Canada. An Examination of Governance, Existing Data, Potential Indicators and Values in the Ottawa River Watershed; Environment and Climate Change Canada: Gatineau QC, Canada, 2019; ISBN 9780660310534.
- Ottawa Riverkeeper Watershed Facts. Available online: https://ottawariverkeeper.ca/watershed-fact/ (accessed on 22 October 2022).
- Giovannettone, J.; Copenhaver, T.; Burns, M.; Choquette, S. A Statistical Approach to Mapping Flood Susceptibility in the Lower Connecticut River Valley Region. Water Resour. Res. 2018, 54, 7603–7618. [Google Scholar] [CrossRef]
- McGrath, H.; Gohl, P.N. Accessing the Impact of Meteorological Variables on Machine Learning Flood Susceptibility Mapping. Remote Sens. 2022, 14, 1656. [Google Scholar] [CrossRef]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do We Need Hundreds of Classifiers to Solve Real World Classification Problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression by RandomForest. R News 2002, 2, 18–22. [Google Scholar]
- Natural Resources Canada Flood Mapping Community. Available online: https://www.nrcan.gc.ca/science-and-data/science-and-research/natural-hazards/flood-mapping-community/24229 (accessed on 21 August 2022).
- Ahmed, F.; Mikalson, D.; Ghioureliotis, P.; Liu, E.; Larsen, A. Ottawa River Flood Risk Mapping from Shirley’s Bay to Cumberland; Rideau Valley Conservation Authority: Ottawa, ON, Canada, 2014. [Google Scholar]
- RVCA Rideau Valley Conservation Authority. Available online: https://www.rvca.ca/ (accessed on 3 April 2022).
- Bates, P.D.; Marks, K.J.; Horritt, M.S. Optimal Use of High-Resolution Topographic Data in Flood Inundation Models. Hydrol. Process. 2003, 17, 537–557. [Google Scholar] [CrossRef]
- Van Etten, J.; Sumner, M.; Cheng, J.; Baston, D.; Bevan, A.; Bivand, R.; Busetto, L.; Canty, M.; Fasoli, B.; Forrest, D.; et al. Package “Raster”. Spat. Data Sci. 2022. Available online: https://rspatial.org/raster/ (accessed on 13 October 2020).
- Wu, Q. Andrew Brown Whitebox. Available online: https://giswqs.github.io/whiteboxR/ (accessed on 3 April 2022).
- Čučković, Z. Terrain Position Index for QGIS. Available online: https://landscapearchaeology.org/2019/tpi/ (accessed on 23 October 2022).
- Florinsky, I.V. An Illustrated Introduction to General Geomorphometry. Prog. Phys. Geogr. 2017, 41, 723–752. [Google Scholar] [CrossRef]
- Mattivi, P.; Franci, F.; Lambertini, A.; Bitelli, G. TWI Computation: A Comparison of Different Open Source GISs. Open Geospat. Data Softw. Stand. 2019, 4, 6. [Google Scholar] [CrossRef] [Green Version]
- Metcalfe, P.; Buytaert, W. Upslope.Area: Upslope Contributing Area and Wetness Index Calculation in Dynatopmodel: Implementation of the Dynamic TOPMODEL Hydrological Model. Available online: https://rdrr.io/cran/dynatopmodel/man/upslope.area.html (accessed on 3 August 2022).
- Dilt, T. Height Above Nearest Drainage Goes Mainstream in QGIS and ArcGIS. Available online: http://gislandscapeecology.blogspot.com/2020/04/height-above-nearest-drainage-goes.html (accessed on 25 October 2022).
- Dilts, E.; Yang, J.; Weisberg, P.J. Mapping Riparian Vegetation with Lidar Data. ESRI ArcUser Winter, 2010; 18–21. [Google Scholar]
- O’Connor, J.E.; Grant, G.E.; Costa, J.E. The Geology and Geography of Floods. Am. Geophys. Union 2002, 5, 359–385. [Google Scholar] [CrossRef]
- City of Ottawa Index Ottawa (1K) 2015. Available online: https://gsguo.maps.arcgis.com/apps/PublicInformation/index.html?appid=bff582719c85404f9f77a1ef965759cf (accessed on 22 March 2022).
- WMS Ministry of Forests, Wildlife and Parks. Available online: https://mffp.gouv.qc.ca/les-forets/inventaire-ecoforestier/foret-ouverte-wms/ (accessed on 22 March 2022).
- Open Government Portal Canadian Digital Elevation Model, 1945–2011. Available online: https://open.canada.ca/data/en/dataset/7f245e4d-76c2-4caa-951a-45d1d2051333 (accessed on 3 August 2022).
- GeoBase Surface Water Program (GeEAU) National Hydrographic Network. Available online: https://www.nrcan.gc.ca/science-and-data/science-and-research/earth-sciences/geography/topographic-information/geobase-surface-water-program-geeau/national-hydrographic-network/21361 (accessed on 22 March 2022).
- City of Gatineau Road Network. Available online: https://www.gatineau.ca/portail/default.aspx?p=publications_cartes_statistiques_donnees_ouvertes/donnees_ouvertes/jeux_donnees/details&id=872107914 (accessed on 3 April 2022).
- City of Ottawa Road Centrelines. Available online: https://open.ottawa.ca/datasets/road-centrelines/explore (accessed on 3 April 2022).
- Natural Resources Canada 2015 Land Cover of Canada. Available online: https://open.canada.ca/data/en/dataset/4e615eae-b90c-420b-adee-2ca35896caf6 (accessed on 3 April 2022).
- Geological Survey of Canada 2014 Surficial Geology of Canada. Available online: https://doi.org/10.4095/295462 (accessed on 5 October 2020).
- Kuhn, M. The Caret Package. Available online: https://topepo.github.io/caret/ (accessed on 3 April 2022).
- Genuer, R.; Poggi, J.-M.; Tuleau-Malot, C. VSURF: An R Package for Variable Selection Using Random Forests. R J. 2015, 7, 19–33. [Google Scholar] [CrossRef] [Green Version]
- Wright, M.N.; Ziegler, A. Ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhuiyan, S.A.; Bataille, C.P.; McGrath, H. Harmonizing and Extending Fragmented 100 Year Flood Hazard Maps in Canada’s Capital Region Using Random Forest Classification. Water 2022, 14, 3801. https://doi.org/10.3390/w14233801
Bhuiyan SA, Bataille CP, McGrath H. Harmonizing and Extending Fragmented 100 Year Flood Hazard Maps in Canada’s Capital Region Using Random Forest Classification. Water. 2022; 14(23):3801. https://doi.org/10.3390/w14233801
Chicago/Turabian StyleBhuiyan, Shelina A., Clement P. Bataille, and Heather McGrath. 2022. "Harmonizing and Extending Fragmented 100 Year Flood Hazard Maps in Canada’s Capital Region Using Random Forest Classification" Water 14, no. 23: 3801. https://doi.org/10.3390/w14233801
APA StyleBhuiyan, S. A., Bataille, C. P., & McGrath, H. (2022). Harmonizing and Extending Fragmented 100 Year Flood Hazard Maps in Canada’s Capital Region Using Random Forest Classification. Water, 14(23), 3801. https://doi.org/10.3390/w14233801