1. Introduction
As climate change becomes more apparent, strong storms that bring heavy rainfalls occur with unusual patterns in many parts of the world. They can cause severe floods that result in devastating damages to infrastructure and loss of human life. In Thailand, flooding occurs more frequently and can cause enormous damages and huge economic losses of up to
$46.5 billions a year [
1]. On the other hand, drought happened in several parts of Thailand in 2015, notably in the Chao Phraya River Basin, the largest river basin in Thailand. This is consistent with a report from the UNDRR (2020) [
2] that the ongoing drought crisis from 2015 to 2016 was the most severe drought in Thailand in 20 years. Therefore, it is essential to monitor water levels around the country because they form an important basis for making decisions on early warning.
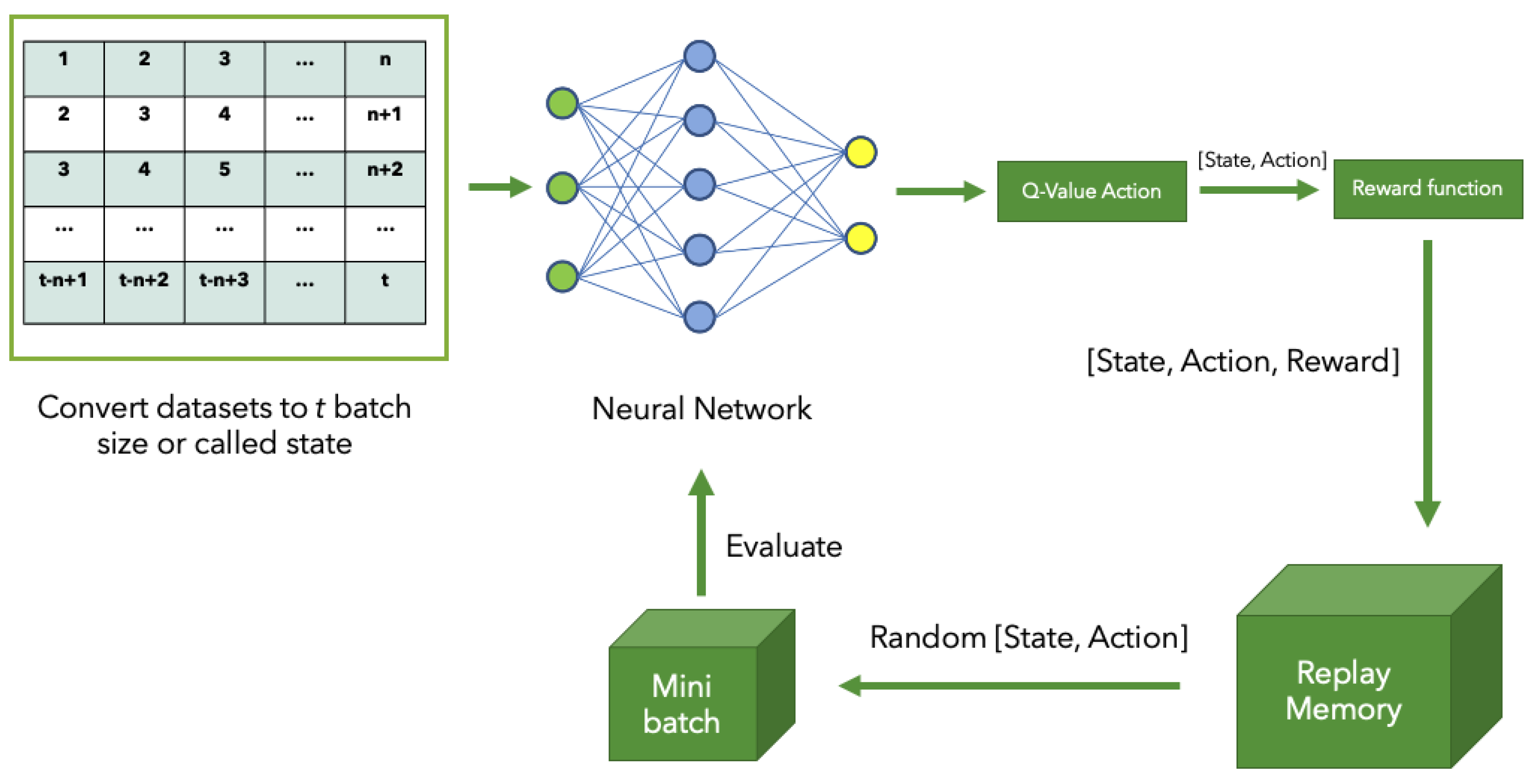
In order to monitor the water levels in rivers, the Hydro Informatics Institute (HII) has been studying, building, and deploying water level telemetry stations around Thailand since 2013. Every ten minutes, each station transmits the measured data to the HII data centre through cellular or satellite networks. However, the water level data collected from telemetry station sensors might be incorrect due to some factors, such as human or animal activity, malfunctioning equipment, or interference of items surrounding the sensors. Any irregularity in the data might result in an inaccurate decision, such as false alarms or missed true alarms. Although water level data may be manually reviewed before being distributed for further analysis, the procedure necessitates the use of skilled specialists who examine the data from each station and make judgments about any probable abnormalities that may exist. This process is slow, very time-consuming and also unreliable. This motivates us to develop an automated approach that can identify irregularities in a more accurate, efficient, and reliable manner.
In our previous work [
3], we studied seven statistics-based models for detecting the anomalies. We found that although an individual model can be used to identify anomalies, it produces too many false alarms for some situations, such as when the water level will dramatically rise before a flood occurs, which is a scenario notably different from the others, and hence led to that the majority of statistical models identify such points as anomalous. We also created two ensembles as the ensemble methods [
4], if constructed properly, have been demonstrated to be able to improve accuracy and reliability over individual models. The first ensemble was built with a simple strategy as it just combines some selected models with majority voting as its decision-making function. However, the test results showed that the simple ensemble models did not work well enough, even though they were usually better than most of the basic individual models. We then developed a complex ensemble method. It basically builds an ensemble of some simple ensembles selected from the candidates with some criteria, and these simple ensembles’ outputs are combined with a weighted function. The findings indicate that a complex ensemble can improve the accuracy and consistency in recognising both abnormal and normal data.
In recent decades, deep machine learning methods have been demonstrated to be more powerful than conventional machine learning techniques in tackling complex problems such as speech recognition, handwriting recognition, image recognition, and natural language processing. One of these methods is the Long Short-Term Memory (LSTM) [
5], outperformed the Multilayer Perceptron (MLP), although trained with only normal data, for detecting anomaly patterns from ECG signals. Moreover, the C-LSTM methods, which integrated a convolutional neural network (CNN), well performed to detect anomaly signals that are difficult to classify in web traffic data as shown in [
6]. Another deep neural network based on anomaly detection technique was recently proposed, called DeepAnt, which consists of a time series predictor that uses CNN to predict the values of the next time step and classify the predicted values as normal or abnormal by passing them to the anomaly detector [
7].
Reinforcement Learning (RL) is an algorithm that imitates the human learning process. It is based on the self-learning process in which an agent learns by interacting with the environment without any assumptions or rules. With the advantage of being able to learn on their own, it can identify unknown anomalies [
8], which gives it an edge over other models. RL has been applied to a variety of applications such as games [
9,
10], robotics [
11,
12], natural language processing [
13,
14], computer vision [
15], etc. It has also been used in some studies to detect anomalies in data, such as an experiment [
16] that shows the use of the deep Q-function network (DQN) algorithm to detect anomalies in time series. Network intrusion detection systems (NIDS) are developed by [
17], based on deep reinforcement learning. They utilised it to identify anomalous traffic on the campus network with a combination of flexible switching, learning, and detection modes. When the detection model performs below the threshold, the model is retrained. In the comparison against three traditional machine learning approaches, their model outperformed on two benchmark datasets, NSL-KDD and UNSW-NB15. A binary imbalanced classification model based on deep reinforcement learning (DRL) was introduced in [
18]. They developed the reward function by setting the rewards for the minority class to be greater than the rewards for the majority class, which made DRL paying more attention to the minority class. They compared it to seven imbalanced learning methods and found that it outperformed other models in text datasets and extremely imbalanced data sets.
Although deep learning and RL methods have achieved excellent results in time series, one common issue is that their performance varies and it is hard to predict when they do better and when they perform relatively poor. In order to improve their consistency and accuracy, ensemble methods can be used. One example of such a method is the technique called particle swarm optimization (PSO), which was developed [
19] to predict the changing trend of the Mexican Stock Exchange by combining several neural networks. An ensemble of MLP, Backpropagation network (BPN), and LSTM, as shown in [
20], was used to make models for detecting anomalous traffic in a network. The ensemble approach that utilises DRL schemes to maximise investment in stock trading was developed in [
21]. They trained a DRL agent and obtained an ensemble trading strategy using three different actor-critics-based algorithms that outperformed the individual algorithm and two baselines in terms of the risk-adjusted return. Another ensemble RL that employed three types of deep neural networks in Q-learning and used ensemble techniques to make the final decision to increase prediction accuracy for wind speed short-term forecasting was suggested [
22].
We discovered that none of the DRL methods have been applied to identify anomalies in telemetry water level data. We wonder whether DRL is applicable for identifying abnormalities in telemetry water level data. Even if the final DRL models perform well on training data, there is no guarantee that they will also perform well on testing data. Previous research has shown that combining many models that were trained in different ways may be more accurate than any of the individual models. So, in this paper, we aim to answer the following two research questions.
- ()
Is DRL applicable and effective for identifying abnormalities in water level data?
- ()
Can we build some ensembles of DRL to improve accuracy and consistency?
To answer them, in this paper, we conducted intensive investigation by evaluated the accuracy of DRL models with real-world data. Then we proposed a strategy to build some ensembles by selecting some suitable DRL models. The testing results show that DRL is applicable for identifying abnormalities in telemetry water level data with the advantage of identifying an unknown anomaly. However, the process of training takes a long time. The constructed ensembles not only improve accuracy and consistency, but also reduce the rate of false alarms.
Thus, the main contributions of this paper are:
- ()
DRL models have been demonstrated to be able to detect anomalies in telemetry water level data.
- ()
The ensembles we have constructed in this research with some suitable DRL models and use a weighted decision-making strategy can improve both accuracy and consistency. The proposed approach has a potential to be further developed and implemented for real-world application.
The rest of the paper is organised as follows:
Section 2 overviews related work for anomaly detection.
Section 3 describes the methodology.
Section 4 presents the experiment design-from data preparation, parameters configurations, to evaluation metrics. Results and discussions are provided in
Section 5 and
Section 6; the conclusion and suggestions for further work are summarised in
Section 7.
2. Related Work
There are many methods for detecting anomalies in time series data. One basic approach is to use statistics-based methods, as reviewed in [
23,
24]. For example, simple and exponential smoothing techniques were used to identify anomalies in a continuous data stream of temperature in an industrial steam turbine [
25]. But in general whilst they provided a baseline, they have a disadvantage in handling trends and periotics, e.g., the water level will dramatically rise before the flood, which differs considerably from the other data points and may lead to an increased false alarm rate. In addition, they can be affected by the types of anomaly and some work well for a certain type of problem. For example, for missing and outlier values, when the data is normally distributed, the
K-means clustering method [
26] is usually used, as it is simple and relatively effective. However, there is unfortunately no general guideline for choosing a method for a given problem.
Change Point Detection (CPD) is an important method for time series analysis. It indicates an unexpected and significant change in the analysed time series stream data and has been studied in many fields, as surveyed in [
27,
28]. However, the CPD has no ability to detect anomalies since not all detected change points are abnormalities. Many studies are being conducted to solve this problem by integrating CPD with other models to increase anomaly detection effectiveness. For example, researchers from [
29] presented new techniques, called rule-based decision systems, that combine the results of anomaly detection algorithms with CPD algorithms to produce a confidence score for determining whether or not a data item is indeed anomalous. They tested their suggested method using multivariate water consumption data collected from smart metres, and the findings demonstrated that anomaly detection can be improved. Moreover, it has been proposed to detect anomalies in file transfer by using the CPD to detect the current bandwidth status from the server, then using this to calculate the expected file transfer time. The server administrator has been notified when observed file transfers take longer than expected, which may mean it may have something wrong [
30]. The author of [
31] investigated the CUSUM algorithm for change point detection to detect SYN flood attacks. The results demonstrated that the proposed algorithm provided robust performance with both high and low intensity attacks. Although change point detection performed well in many domains, the majority of them focused on changes in the behaviour of time series data (sequence anomaly) rather than point anomaly, which is my primary research emphasis. Furthermore, water level data at certain stations is strongly periodic with tidal effects, resulting in numerous data points changing from high tides to low tides each day, which is typical behaviour.
In recent decades, machine learning methods, including deep neural networks (DNNs), have been satisfactorily implemented in various hydrological issues such as outlier detection [
32,
33], water level prediction [
34,
35], data imputation [
36], flood forecasting [
37], streamflow estimation [
38], etc. For example, in [
39], the authors proposed the R-ANFIS (GL) method for modelling multistep-ahead flood forecasts of the Three Gorges Reservoir (TGR) in China, which was developed by combining the recurrent adaptive-network-based fuzzy inference system (R-ANFIS) with the genetic algorithm and the least square estimator (GL). The authors of [
40] presented a flood prediction by comparing the expected typhoon tracking and the historical trajectory of typhoons in Taiwan in order to predict hydrographs from rainfall projections impacted by typhoons. The PCA-SOM-NARX approach was developed by [
41] to forecast urban floods, combining the advantages of three models. Principal component analysis was used to derive the geographical distributions of urban floods (PCA). To construct a topological feature map, high-dimensional inundation recordings were grouped using a self-organizing map (SOM). To build 10-minute-ahead, multistep flood prediction models, nonlinear autoregressive with exogenous inputs (NARX) was utilised. The results showed that not only did the PCA-SOM-NARX approach produce more stable and accurate multistep-ahead flood inundation depth forecasts, but it was also more indicative of the geographical distribution of inundation caused by heavy rain events. Even though we can use forecasting methods to find anomalies by using prediction error as a threshold to classify data points as normal or not, it may take time to find the suitable threshold for each station.
An autoencoder is an unsupervised learning neural network. It is comprised of two parts: an
encoder and a
decoder. The encoder uses the concepts of dimension reduction algorithms to convert the original data into the different representations with the underlying structure of the data remaining and ignoring the noise. Meanwhile, the decoder reconstructs the data from the output of the encoder with as close of a resemblance as possible to the original data. An autoencoder is effectively used to solve many applied problems, from face recognition [
42,
43] and anomaly detection [
44,
45,
46,
47] to noise reduction [
48,
49,
50]. In the time series domain, the authors of [
51] proposed two autoencoder ensemble frameworks for unsupervised outlier identification in time series data based on sparsely connected recurrent neural networks, which addressed the issues from [
52] given the poor results when using an autoencoder with time series data. In one of the frameworks called the Independent Framework, multiple autoencoders are trained independently of one another, whereas in the other framework, the Shared Framework, multiple autoencoders are trained jointly in a manner that is multitask learning. They experimented by using univariate and multivariate real-world datasets. Experimental results revealed that the suggested autoencoder ensembles with a shared framework outperform baselines and state-of-the-art approaches. However, a disadvantage of this method is its high memory consumption when training many autoencoders together. In the hydrological domain, the authors of [
53] presented the SAE-RNN model, which combined the stacked autoencoder (SAE) with a recurrent neural network (RNN) for multistep-ahead flood inundation forecasting. They started with SAE to encode the high dimensionality of input datasets (flood inundation depths), then utilised an LSTM-based RNN model to predict multistep-ahead flood characteristics based on regional rainfall patterns, and then decoded the output by SAE into regional flood inundation depths. They conducted experiments on datasets of flood inundation depths gathered in Yilan County, Taiwan, and the findings demonstrated that SAE-RNN can reliably estimate regional inundation depths in practical applications.
Time series based on ensemble methods have recently attracted attention. In a study by [
54], they introduced the method EN-RTON2, which is an ensemble model with real-time updating using online learning and a submodel for real-time water level forecasts. However, they experimented with fewer datasets, a smaller number of records, and lower data frequency than our datasets. Furthermore, the authors offered no indication of the time necessary for training models and forecasting, which may be inadequate in our case given the number of stations and frequency of data transmission. The ensemble models were proposed by [
55], which applied the sliding window based ensemble method to find the anomaly pattern in sensor data for preventing machine failure. They used a combination of classical clustering algorithms and the principle of biclustering to construct clusters representing different types of structure. Then they used these structures in a one-class classifier to detect outliers. The accuracy of these methods was tested on a time series of real-world datasets from the production of industry. The results have verified the accuracy and the validity of the proposed methods.
Despite the fact that numerous studies have used different anomaly detection techniques to tackle problems in many domains, only a few have focused on finding anomalies in water level data. Furthermore, the various employed sensors, installation area, frequency of data transmission, and measurement purposes lead to a variety of types of anomalies. As a result, techniques that perform well with one set of data may not work well with another.
5. Results
5.1. Accuracies of DRL Models
For each station, various DRL models were generated over a range of epochs from 100 to 10,000, with the intention of investigating how well our proposed DRL method learns at the different points of training. The results are shown in
Table 3.
Using the CPY011 dataset, we observed that and with 1000 training iterations not only earned the highest F1-score of 0.8333, 0.7143 recall, and 1.0000 precision but also provided the highest average F1-score of 0.7433. However, after 1000 epochs of training, the performance of all models, with the exception of decreased and then rose when 10,000 epochs were used.
The top models to identify anomalies on the CPY012 dataset are , with a maximum F1-score of 0.7826 after 10,000 training epochs. However, obtained the greatest average F1-score with 0.7234. Meanwhile, 10,000 training epochs with and delivered the highest F1-score for identifying anomalies in CPY013 data, at 0.8000 F1-score. Furthermore, provided the highest average F1-score of 0.6963.
With just 500 epochs of training on CPY014 data, and delivered the best F1-score of 0.8571. However, the maximum average F1-score achieved by and was just 0.6733. When looking at the results on CPY015 data, the best models are and . This is shown by the fact that their F1-scores were the highest in many training epochs.
was the best model for detecting anomalies in CPY016 data since it not only had the greatest F1-score in almost every training epoch but also had the highest average F1-score of 0.5714. Meanwhile, every model scored the best F1-score of 0.8571, 100 percent recall, and 0.7500 accuracy when trained with 100 epochs on CPY017, with the exception of the model, which achieved just 0.6667 F1-score. While the best models for detecting anomalies on YOM009 are and , which both have the same F1-score of 0.4769, the worst models are while training with 5000 iterations at a 0.2728 F1-score, 0.5538 recall, and 0.1818 precision.
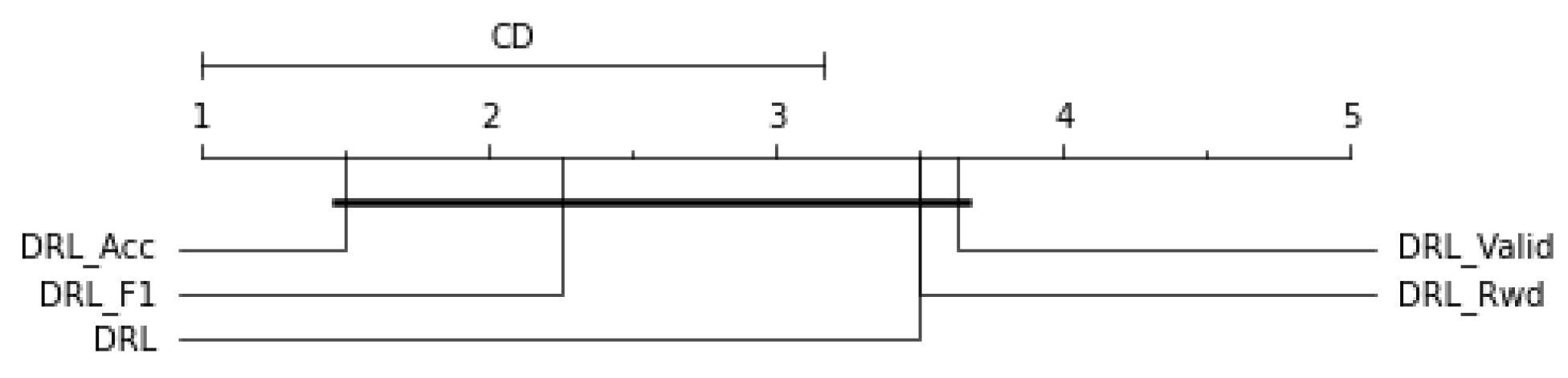
Figure 3 shows the comparison of the critical differences between the different DRL models. The number associated with each algorithm is the average rank of the DRL models on each type of dataset, and solid bars represent groups of classifiers with no significant difference. There is no statistically significant difference across the models, with
ranking first, followed by
,
,
, and
ranking last.
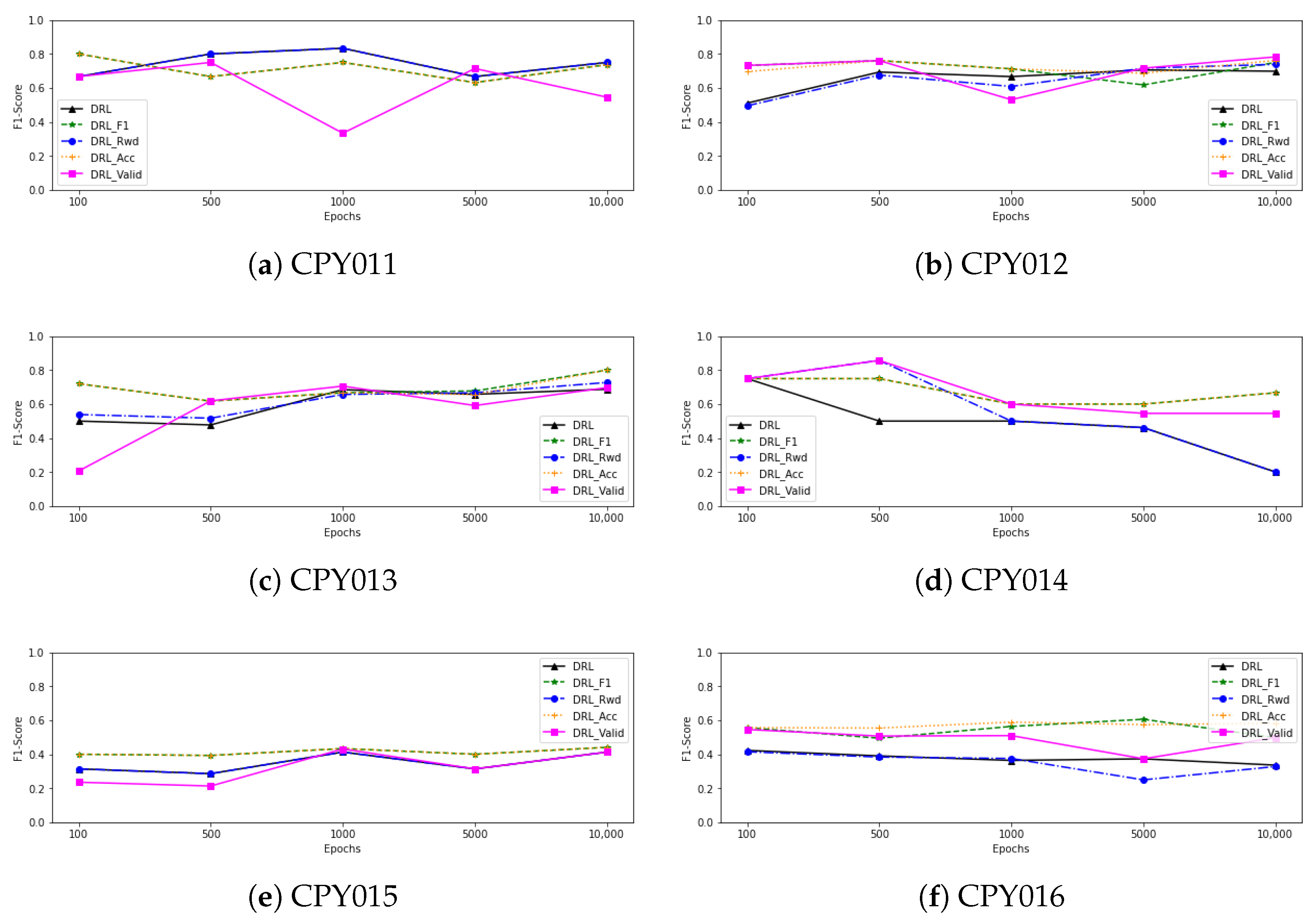
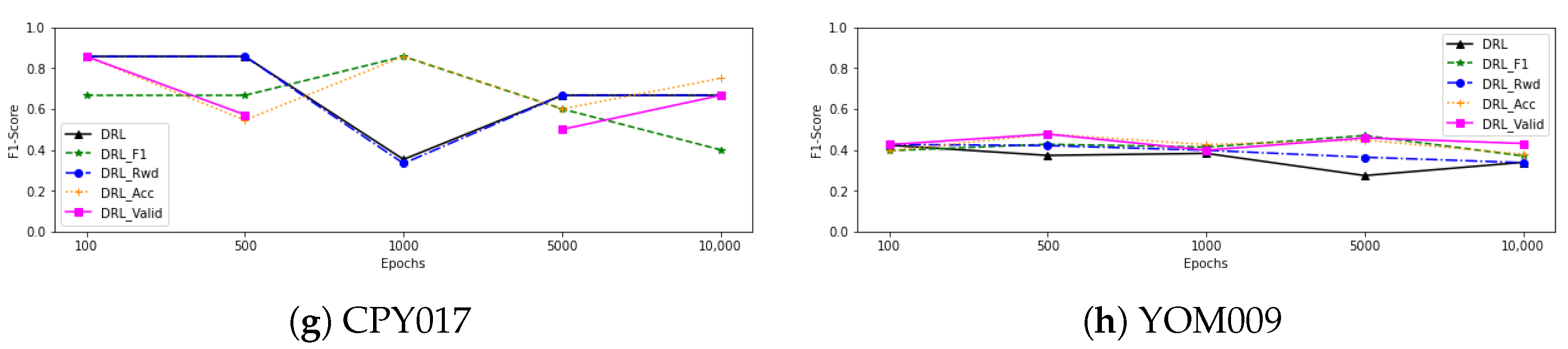
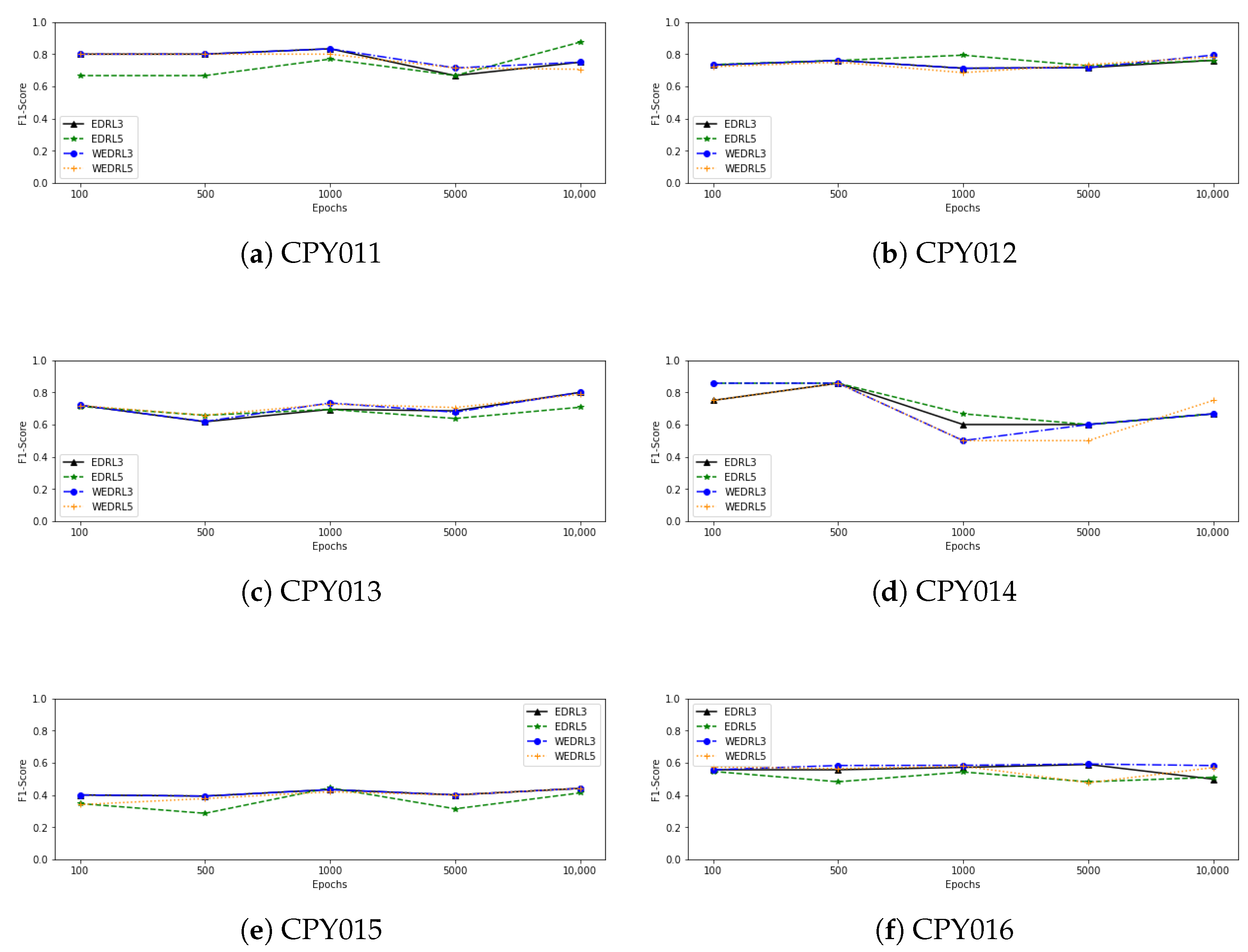
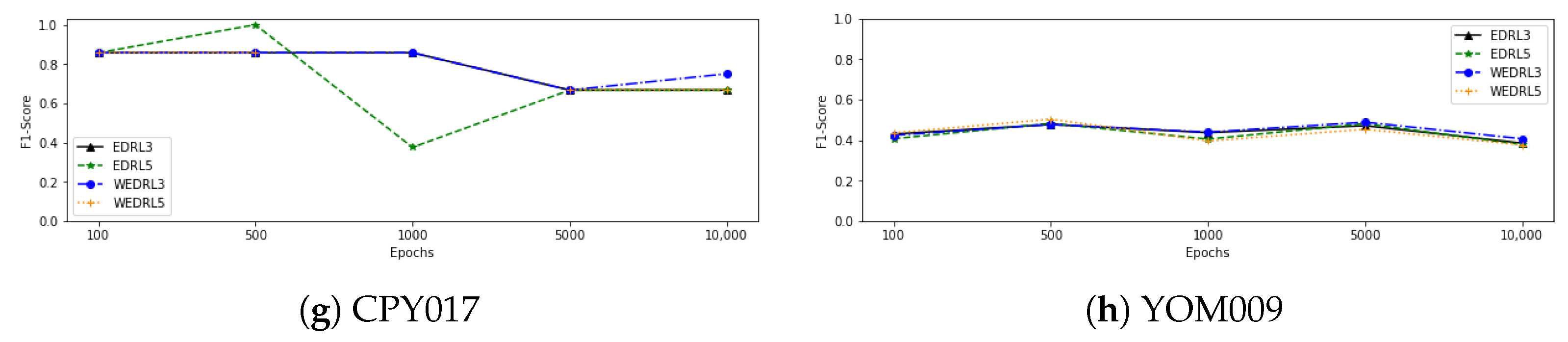
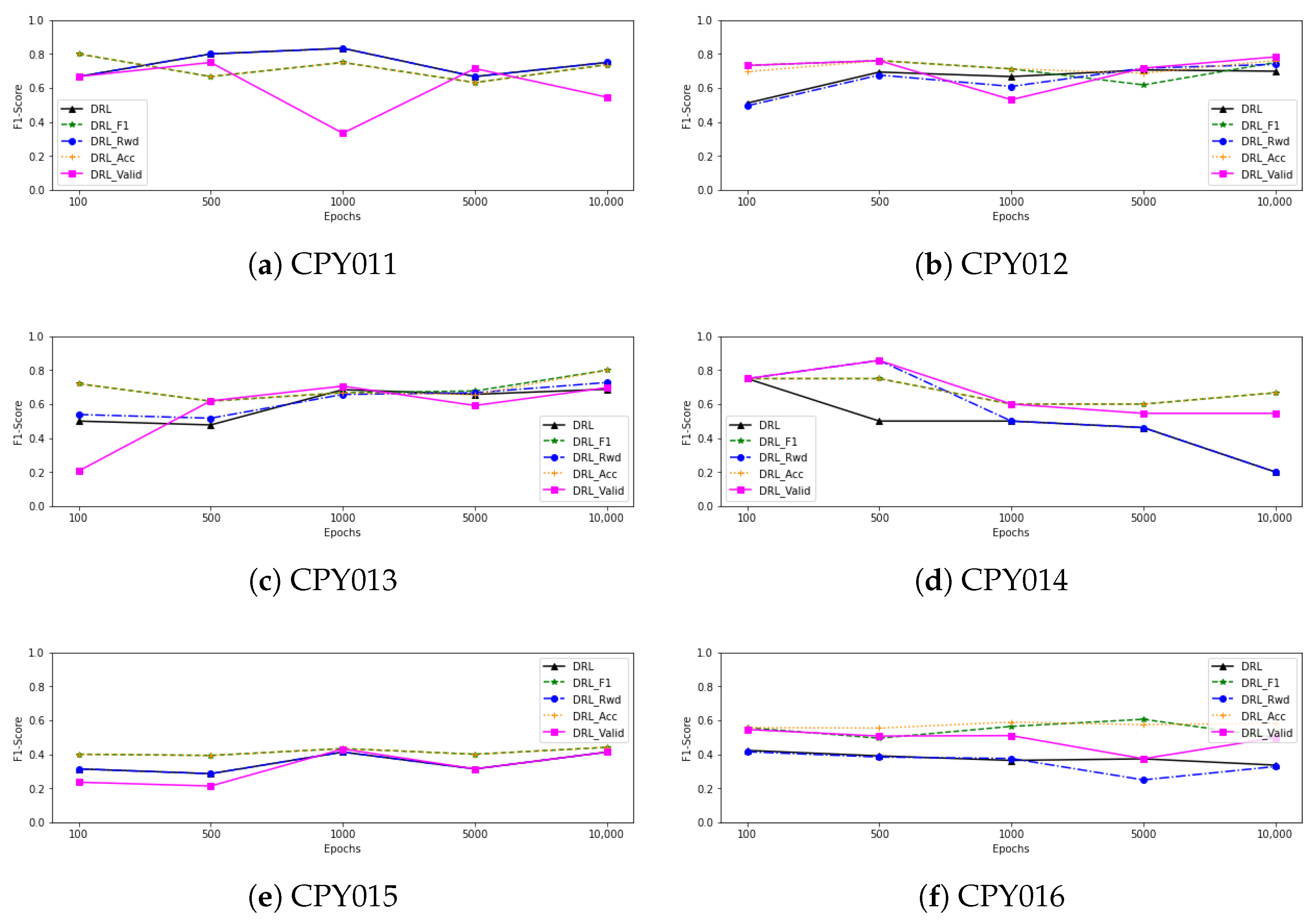
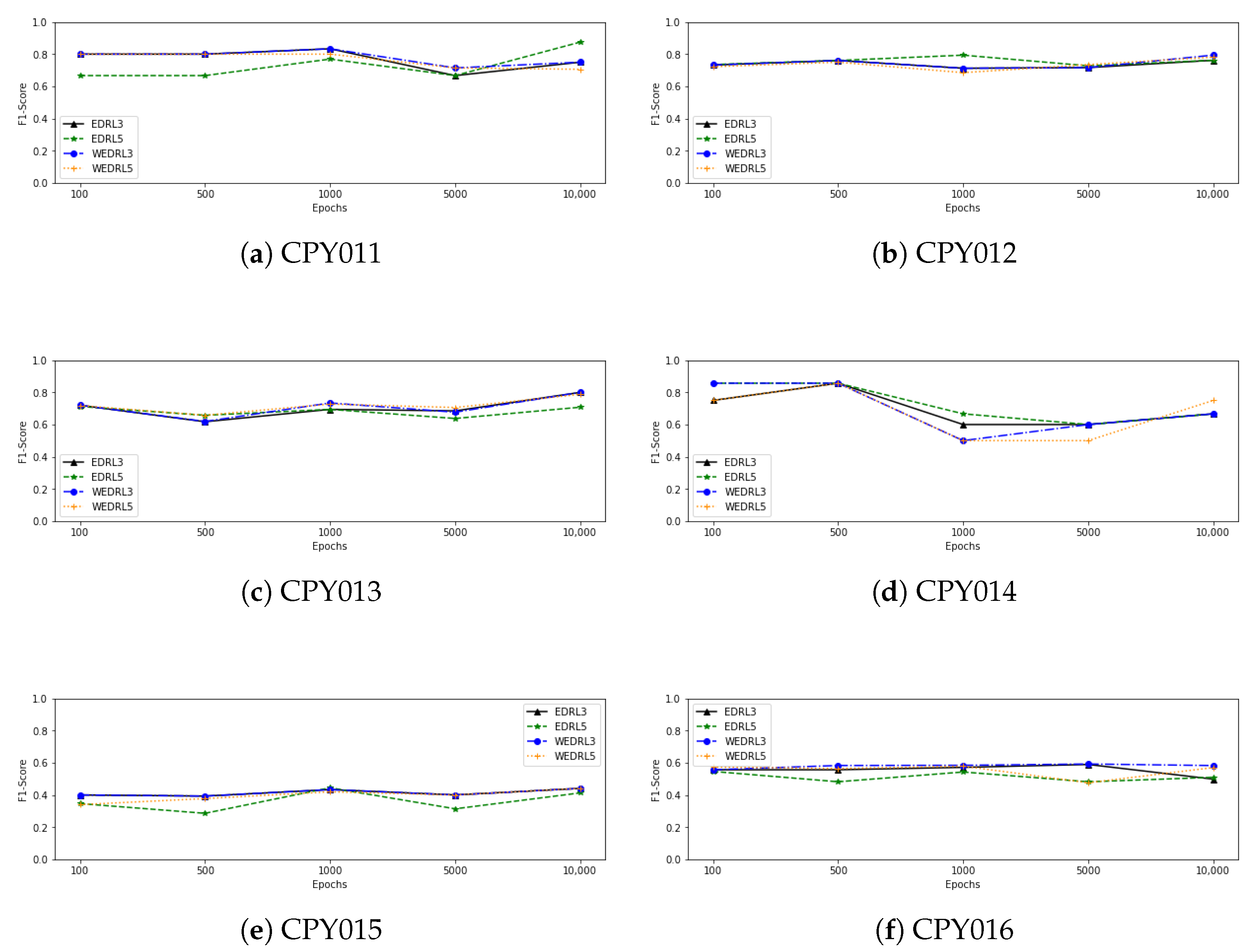
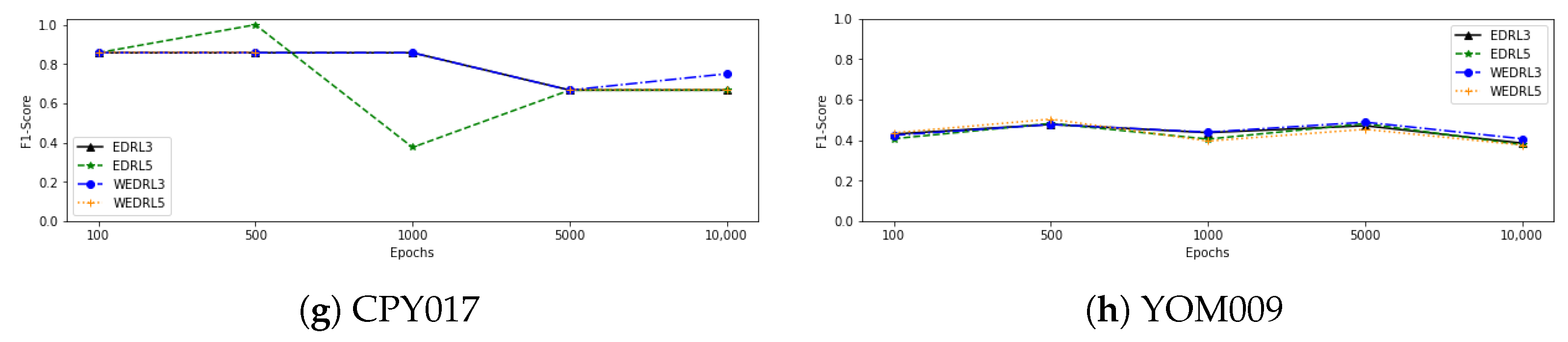
Figure 4 also shows a line graph of the F1-score as the number of epochs of training from each model increases. We can observe that as the number of epochs is increased, the performance of all deep reinforcement learning models using data from CPY012, CPY013, and CPY015 tends to improve. When training with CPY014 data, on the other hand, the F1-score of each model tends to stay the same or go down as the number of epochs goes up. In the case of trained models with CPY016 data, the F1-score of each model tends to stabilise and slightly decrease, with the exception of
, which tends to grow after 5000 epochs of training. When we looked at the models that were trained with the CPY017 dataset, the F1-score of
went up after training with 1000 epochs and then went down. Other models, however, went up when training with more epochs, even though the performance of some models went down after 1000 epochs, while the F1-score of models that have been trained with CPY011 and YOM009 remained stable when training with more epochs.
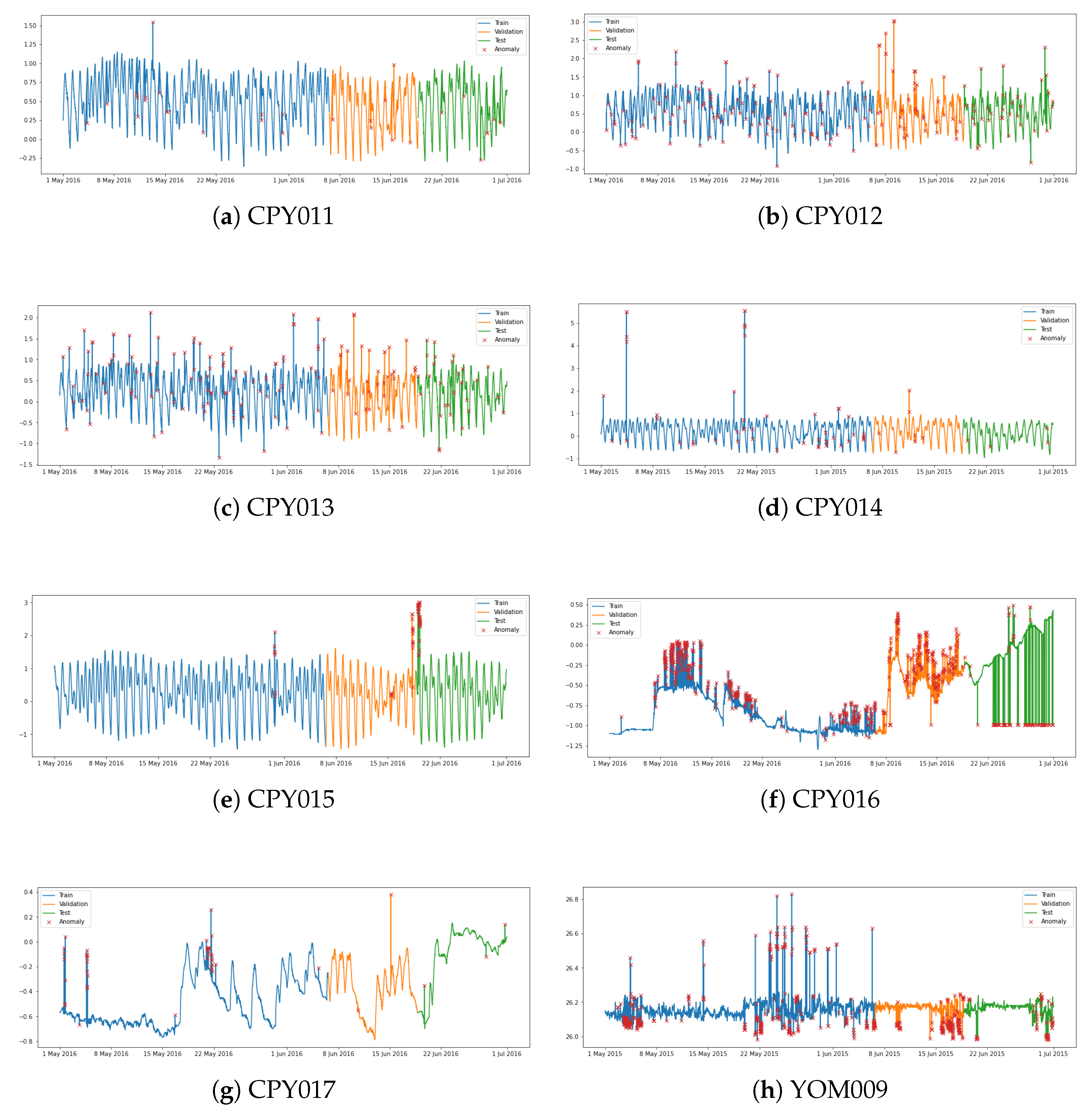
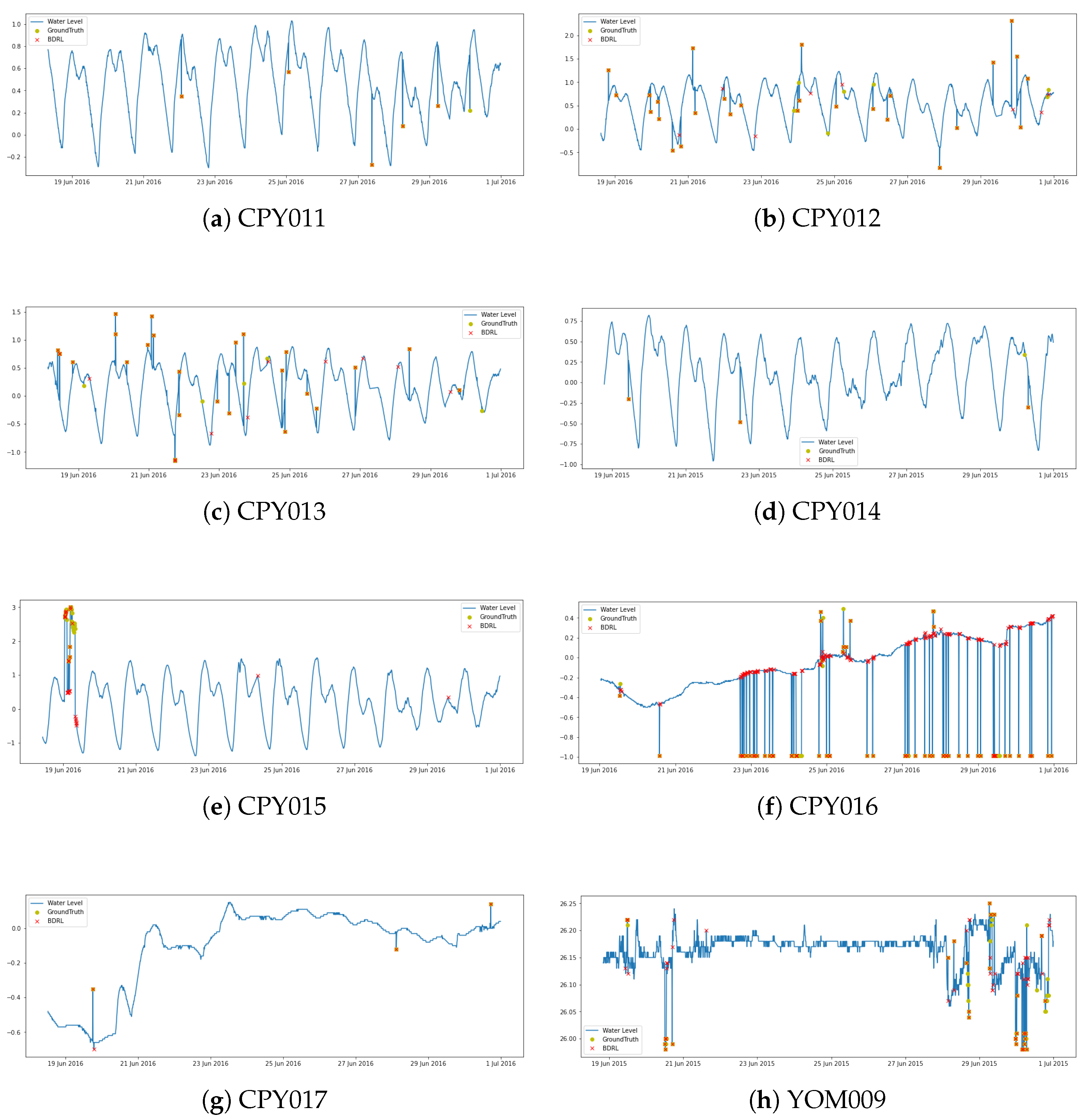
Figure 5 shows the findings of the best DRL model for each station. We can observe that the DRL model performs well, capturing the majority of abnormalities in testing datasets. However, it still did not work well when there were anomalies in data that changed frequently, like when there were anomalies in YOM009 data between 29 June and 1 July 2015, and in CPY015 data on 19 June 2016.
5.2. Performance on the Same Station
We evaluated the performance of our techniques with MLP and LSTM models on eight telemetry water level datasets. The data in each station is first divided into training, validating, and testing parts in a 6:2:2 ratio. The results were averaged after being run ten times and then were compared to the averaged DRL models of each station as shown in
Table 4. It demonstrated that
and
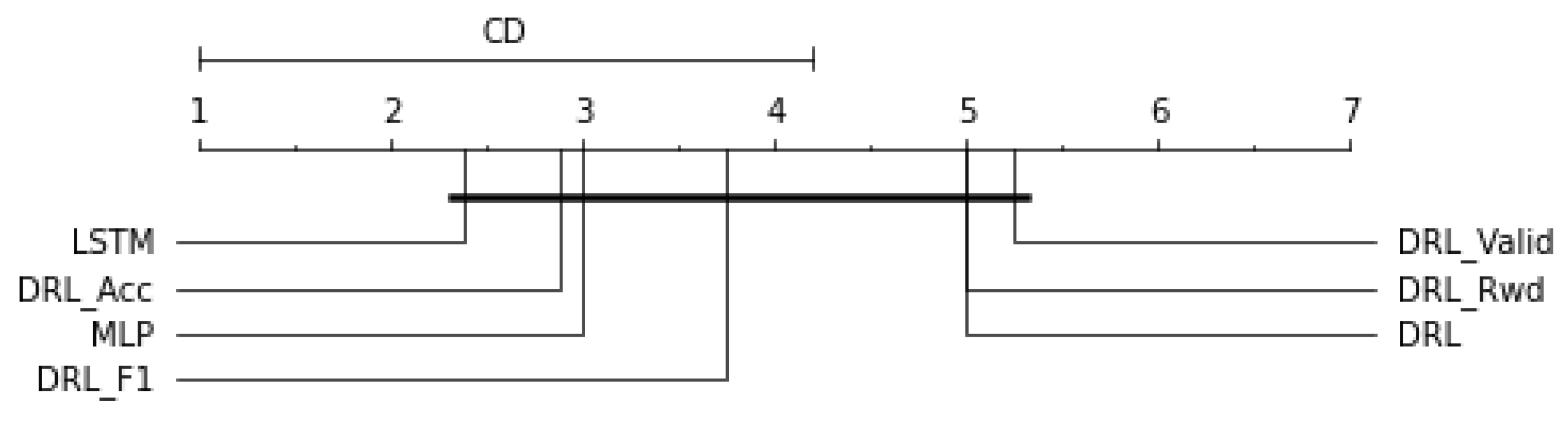
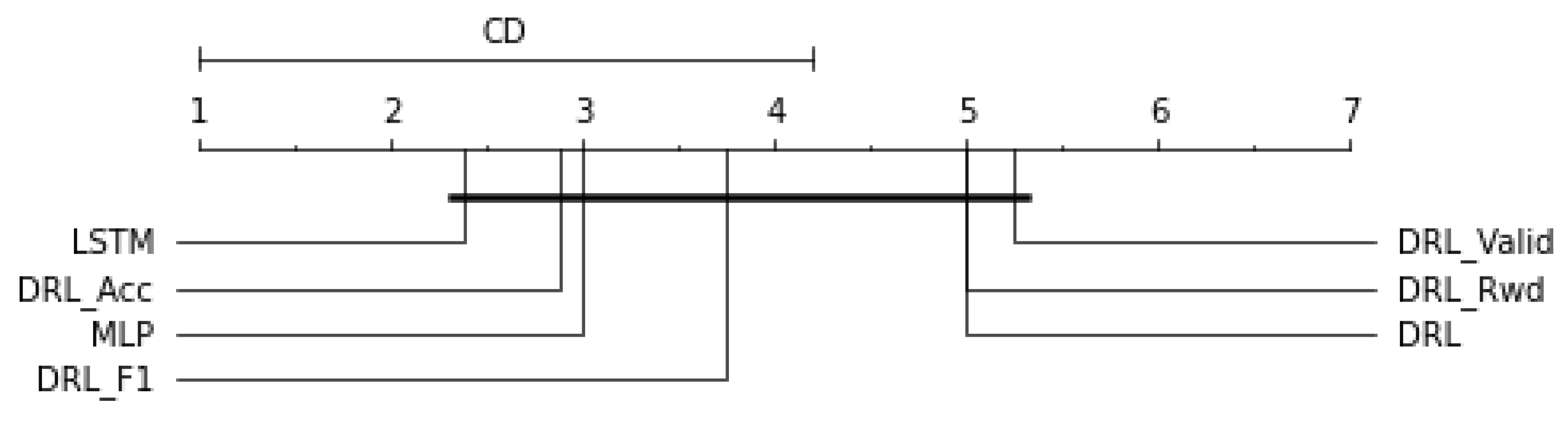
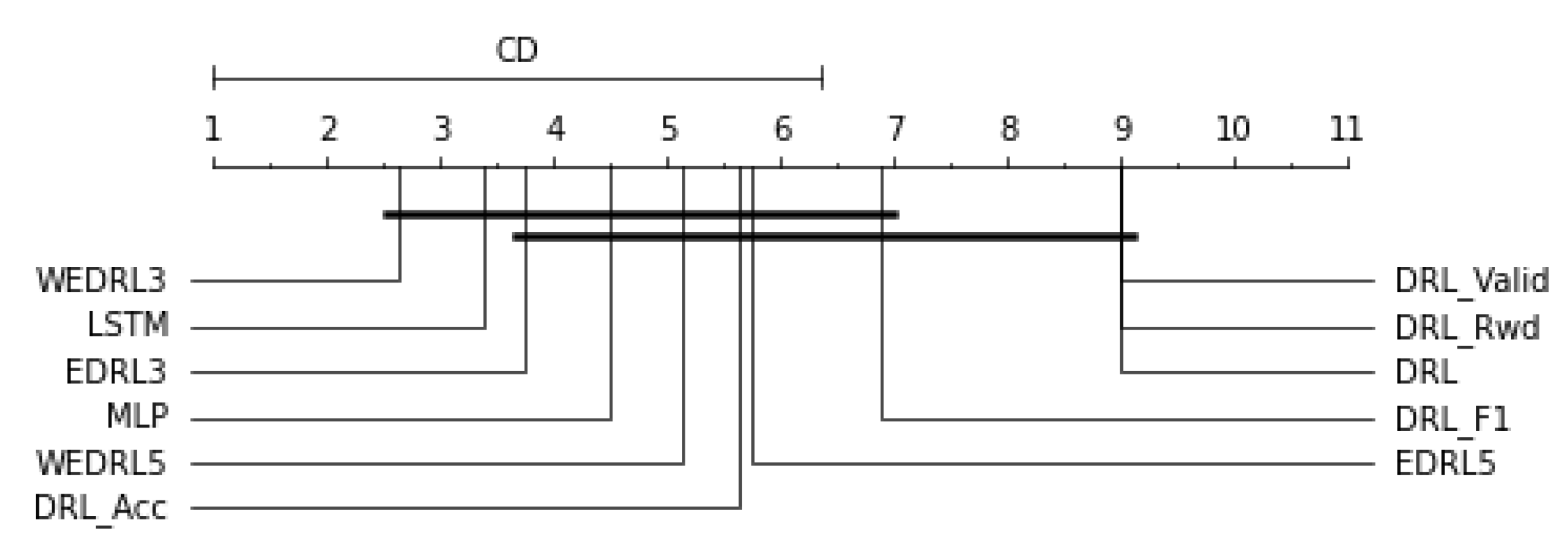
had the highest average F1-scores for detecting anomalies on CPY015, with F1-scores of 0.4133. MLP had the greatest average F1-score when it came to detecting anomalies on CPY011, CPY012, and CPY014 with scores of 0.8505, 0.7822, and 0.8571, respectively. On the other stations, LSTM was the top performing model. According to the CD diagram in
Figure 6, the best LSTM model had the greatest ranking of performance, followed by
and MLP.
We discovered that
and
had the highest average F1-scores for detecting anomalies on CPY015, with F1-scores of 0.4133. MLP had the greatest average F1-score when it came to detecting anomalies on CPY011, CPY012, and CPY014 with scores of 0.8505, 0.7822, and 0.8571, respectively. On the other stations, LSTM was the top performing model. The LSTM model has the highest ranking of performance, according to the CD diagram in
Figure 6, followed by
and MLP.
Since RL models need time to learn until they have enough knowledge to do their task, time costing is the one important thing that we need to be interested in. We calculate the time spent by the best deep learning models (BDRL) and comparative models, as shown in
Table 5. The MLP model requires the least training time per epoch, with an average of 0.30 s, followed by the LSTM model at 0.64 s, and the DRL model at 17.56 s. For MLP and LSTM training with early stopping, they needed an average of 12 and 15 training epochs, respectively, while our method requires around 4638 epochs to get optimal results. It means that the MLP model took an average of 2.97 s to train, while LSTM took 9.20 s and DRL took an average of 78,756 s, which is about 22 h.
5.3. Performance on the Different Station
After generating various models on some stations’ data and testing them with the same stations, we tested these models with the data collected from different stations with the intention of examining their generalisation ability. The F1-scores of each model are provided in
Table 6.
Using -the best model for detecting anomalies by training with CPY011 data and then identifying anomalies from other stations, we can see that, though it works rather well, with F1-scores ranging from 0.4 on CPY014 to 0.65 on CPY013 data, it is unable to detect anomalies on CPY015 and YOM009. Using the BDRL model of the CPY012 training dataset, , although it provided good performance when identifying anomalies in the CPY013, CPY014, and CPY016 datasets with F1-scores greater than 0.61, especially CPY014 with a 0.8571 f1-score, which more than detected anomalies on its own dataset, it provided poor performance, with an F1-score lower than 0.4000, when detecting anomalies in other stations. Similar to , which was trained using CPY013 data, it not only performs well when recognising anomalies on its own dataset but also when detecting anomalies on the CPY014 dataset, with an F1-score of 0.8571. The BDRL model, , that was trained with CPY014 did the worst when it was used to find anomalies in other stations’ data, with an F1-score of less than 0.23 for every dataset and the lowest F1-score of only 0.0255 for CPY011. Similar to the best model on CPY015 datasets, which performed poorly, with the highest F1-score on CPY011 data being 0.4138 and being unable to identify anomalies on CPY014, CPY017, and YOM009. Meanwhile, the best model for detecting anomalies on CPY016 data performed the best for detecting anomalies on CPY013 with a 0.5421 F1-score. The model that was trained on CPY017 did the best of finding anomalies in data from CPY012, CPY013, and CPY014 with an F1-score greater than 0.58. While the best model from the YOM009 training dataset achieved a low F1-score on CPY011, CPY015, and CPY017, 0.0839 is the lowest F1-score. However, when it was used to find outliers on COY012, CPY013, CPY014, and CPY016 with F1-scores higher than 0.59, it did better than its own training data.
It is worth noting that models trained using CPY014 and CPY015 data perform poorly when used to identify anomalies from other stations. This may be due to the fact that the actual number of anomalies in those stations are relatively low and most of them are kind of extreme outliers, as shown in
Figure 2, so the models were trained with only those kinds of anomalies, which may not be enough for the model to learn. In contrast to YOM009, which has a many number and types of anomalies for model to learn, as a result, it can identify abnormalities on CPY012, CPY013, CPY014, and CPY016 better than other models that were trained with another station.
Then, we tested MLP and LSTM using data from different stations to compare our method to the candidate models.
Table 7 represents the results of the MLP models when tested with the datasets from the same and different stations. Using the CPY011 dataset, the MLP models achieved the highest F1-score of 0.5430 on CPY016, despite their being unable to identify anomalies on CPY014 and YOM009. Similar to finding anomalies on CPY012, it offered good results with F1-scores of more than 0.63, with the exception of CPY011, CPY015, and YOOM009, which produced F1-scores of less than 0.4. The best MLP of the CPY013 training dataset provided the highest F1-score on the CPY014 dataset (0.8571 F1-score) and the lowest on CPY015 (0.2093 F1-score). Anomalies on the YOM009 dataset were the most difficult for the MLP models trained on CPY014 to detect, with an F1-score of just 0.1818. However, it performed excellent results in identifying anomalies on CPY017 with a 1.0000 F1-score. Meanwhile, the MLP model on the CPY015 dataset performed poorly when detecting abnormalities from other stations. On the other hand, the MLP models that were trained on CPY016 and CPY017 generated good results when used to identify anomalies from other stations, despite still performing poorly in some stations. In contrast, the MLP model trained on YOM009 worked well when used to detect abnormalities on other stations but performed badly when detecting anomalies on its own data. Furthermore, it performed well on CPY017 data, with a 1.000 F1-score.
In the case of the LSTM model, as depicted in
Table 8. They performed well, with an average F1-score of more than 0.42 for each station except CPY015, which had an average F1-score of 0.1099. However, they generated poor performances in some stations, such as the LSTM of CPY016 that achieved an F1-score of only 0.1754 when used to detect anomalies on the CPY011 dataset, and it was unable to detect anomalies on CPY014, CPY017, and YOM009 datasets with the LSTM that had been trained on the CPY015 dataset. However, it provided excellent performance when detecting anomalies on CPY017 with the LSTM that has been trained on the CPY014 dataset. When the LSTM was trained on YOM009, it did well at finding anomalies from other stations, especially CPY014 and CPY017, with an F1-score of 0.8571.
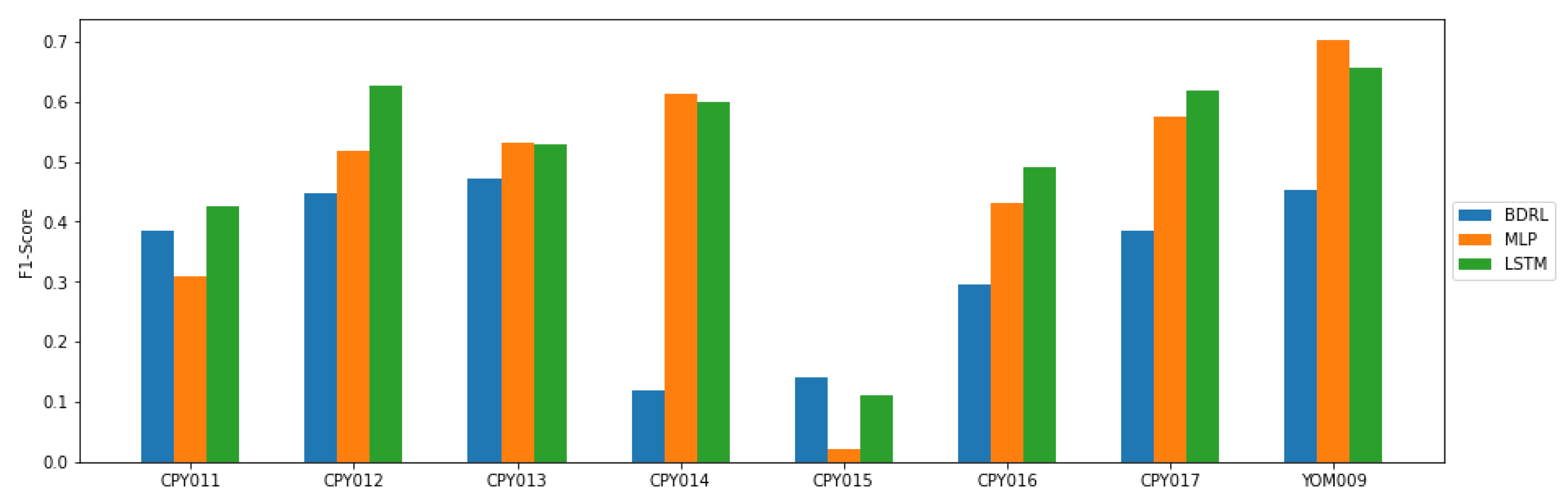
Furthermore, we generated a bar chart to compare the average F1-score from each model when tested with the data collected from different stations, as shown in
Figure 7. When evaluated with data from other stations, the models trained with CPY012 and CPY013 produced an average F1-score greater than 0.4. The models trained on CPY015 earned poor performance when used to identify anomalies from other stations, with an average F1-score lower than 0.2. DRL models that were trained with CPY015 outperform other models in detecting anomalies in data from other stations. LSTM models trained on CPY011, CPY012, CPY016, and CPY017, on the other hand, outperform other models in detecting abnormalities on other datasets. When trained with data from CPY013, CPY014, and YOM009, MLP had the best F1-score for finding outliers in other datasets.
5.4. Ensemble Results
Since we have multiple RL models after each epoch of training, and since each model performs the best in each of the criteria, we then built an ensemble that combined the decisions of all RL models, with the aim of generating a better final decision. In model selection, we select all five models and select the three models with the highest ranking in F1-score to build our ensemble model. For decision making, we used majority voting and weighted voting strategies to make a final decision. So, we have 4 ensemble models for each epoch of training, including a majority voting ensemble model with 3 () and 5 () models, and a weighted ensemble model with 3 () and 5 () models.
5.4.1. Performance on the Same Station
The results of our ensemble models are shown in
Table 9 demonstrated that ensemble with majority voting and weighted voting that were generated from the top three
models of CPY011 provided the best with 0.8333 F1-score, while
that was generated from the DRL model after trained with 10,000 epochs is the best model to detect anomalies in CPY012 datasets with an F1-score of 0.7941. The ensemble model of CPY013 that performs the best is
and
at 0.8000. The best ensemble model for identifying anomalies in CPY014 datasets is the ensemble model that provided the F1-score of 0.8571. With CPY015 data, the models with the highest F1-score are
,
, and
. These models were built based on the individual DRL model, which was trained for 10,000 iterations. Meanwhile,
got the highest F1-score of 0.5922 for CPY016 by combining the best three DRL models that were trained over 5000 iterations. With CPY017,
outperforms other ensemble models with a 100 percent in every metric. The ensemble results of YOM009,
, offered the highest performance with an F1-score of 0.5032 that was generated from the
model after 500 epochs of training.
Figure 8 depicts line charts that indicate the F1-score of each ensemble model that was trained using data from each station. It was clear from the results that the ensemble models not only delivered good performances and had a tendency to either improve or keep their F1-scores steady but also reduced the false alarms by increasing the precision scores. When we compared the results of each training epoch of the individual DRL model and the ensemble model, as shown in
Table 3 and
Table 9, we discovered that ensemble models performed better than every single DRL model in many training epochs. In particular,
on the CPY017 with 500 training epochs generated an excellent score of 1.0000 in every metrics index, resulting from a 25% increase in accuracy and a 15% increase in F1-score. Meanwhile,
on the CPY011 with 10,000 training epochs improved the performance of the best individual model with an F1-score from 0.75 to 0.8750, reached 1.00 in terms of recall, and increased precision by 20%. By combining the DRL models trained on only 500 epochs, the ensemble model on YOM009 got the highest F1-score of 0.5032.
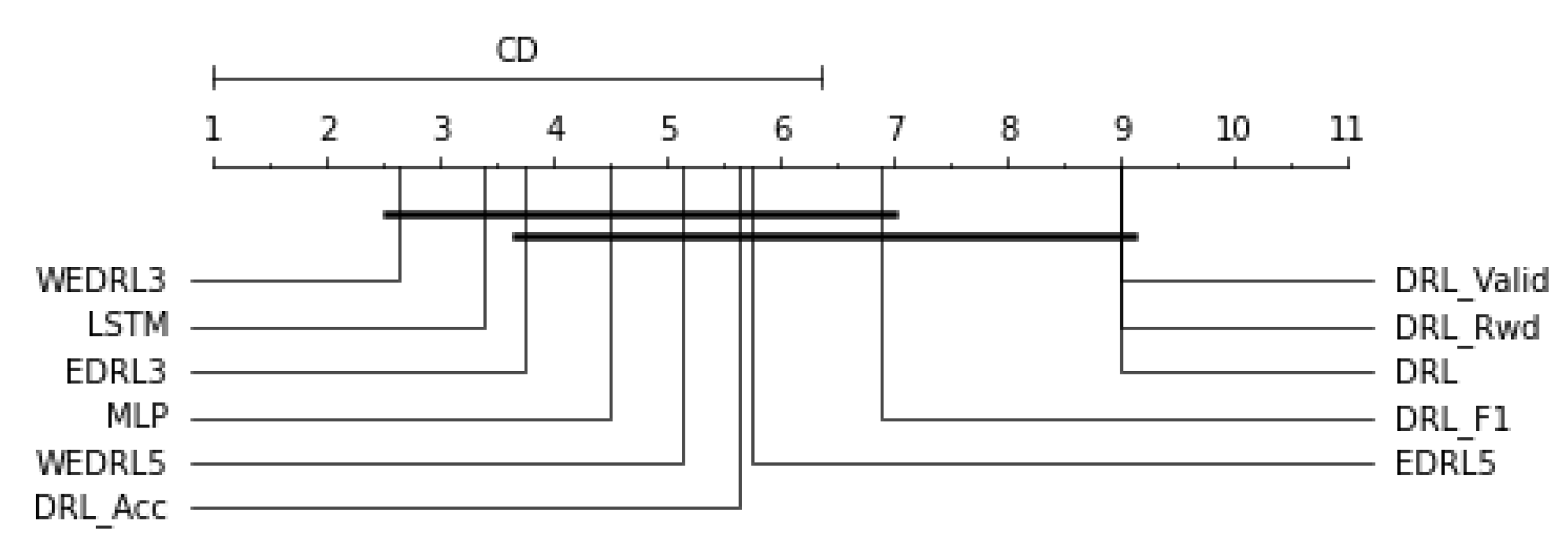
As shown in
Table 10, we evaluated the average F1-score of each individual DRL model and ensemble of DRL models against the other neural network models. We can see that the LSTM model was the best model when detecting anomalies on CPY013, CPY014, CPY016, and CPY017, while
provided the highest average F1-score on CPY015 and YOM009. The highest F1-score was 0.4134 on CPY015, which was provided by
and
. Although MLP and LSTM beat other models in many datasets,
has the greatest average ranking, as shown in
Figure 9. In other words, the ensemble model not only has the potential to improve the performance of a single model, but it also has a higher reliability to deliver excellent performance than a single model.
5.4.2. Performance on the Different Station
We then tested the generalisation ability of the best ensemble (
) with the data collected from different stations. The F1-score of each model is depicted in
Table 11. We can observe that the ensemble model that was created from the model trained on CPY011 data performed well not only on their own dataset but also on CPY017, with an F1-score of 0.8200, similarly to
on CPY012 and CPY013, which recognised anomalies on CPY014 better than their own dataset with F1-scores of 0.8421 and 0.8143, respectively. Inversely, the ensemble model on CPY014, CPY015, and CPY016 trained datasets provided poor performance when used to detect anomalies on other stations. Even though the ensemble model trained on the CPY017 dataset got an F1-score of more than 0.5 on CPY012, CPY013, and CPY014, it did not do well on many stations, with an F1-score of less than 0.3.
scored badly not just on their own dataset but also on others, with F1-scores ranging from 0.0739 on CPY015 to 0.5748 on CPY016.
5.4.3. Ensemble with All Seven Models
Then, to learn more about how well the ensemble worked, we combined our developed DRL models with MLP and LSTM models. In model selection, we selected all seven models and selected the five and three models with the highest ranking in F1-score to build our ensemble model. We used the same strategy to make a final decision. So, we have 6 ensemble model for each epochs of training include majority voting ensemble model with 3 (
), 5 (
), and 7 (
) model, and weighted ensemble model with 3 (
), 5 (
), and 7 (
) models, and the results are displayed in
Table 12.
We can see that, on the CPY011 dataset, the ensemble of the top three models (E3) earned the greatest F1-score of 0.9231 with every epoch of training. On CPY012, the greatest F1-score of 0.8438 was obtained by E5 and WE7 with models trained with 10,000 epochs, and E7 with models trained with 500 epochs, while E3 and WE3 models trained with 10,000 epochs performed the best in identifying anomalies on the CPY013 dataset. With the CPY014 dataset, all ensemble models gave an F1-score of 0.8571, with the exception of the ensemble with majority voting of all seven models trained with 10,000 epochs, which performed badly with an F1-score of 0.6667. WE7 surpassed other ensemble models on the CPY015 and CPY016 datasets, with the greatest F1-score of 0.4615 and 0.6704, respectively. Every ensemble model on CPY017 produced outstanding results with a 1.0000 F1-score, particularly E3, WE3, WE5, and WE7, which produced excellent results with all training epochs. The weighted ensemble with 5 models (WE5) trained with 500 epochs performed the best on the YOM009 dataset, with a 0.5032 F1-score.
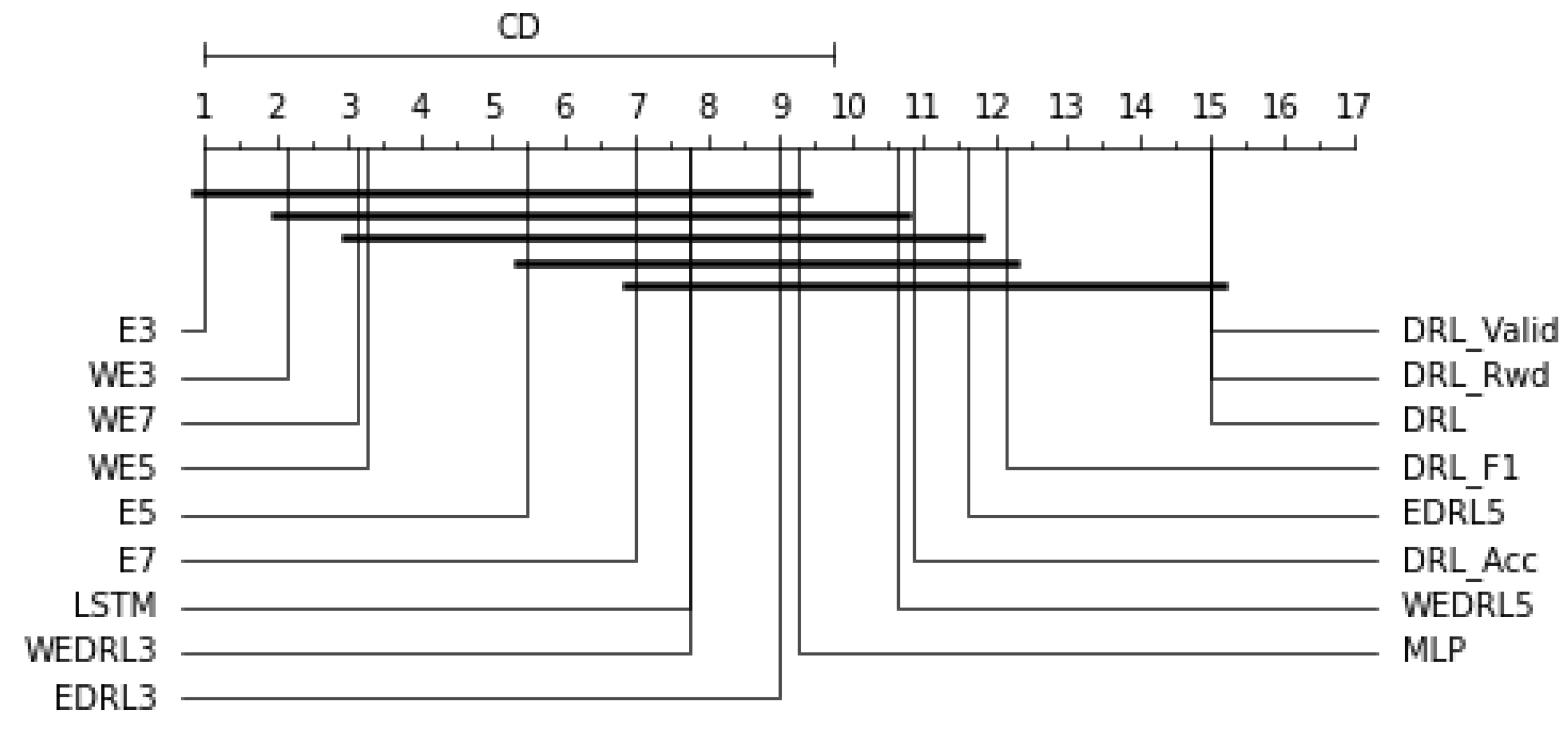
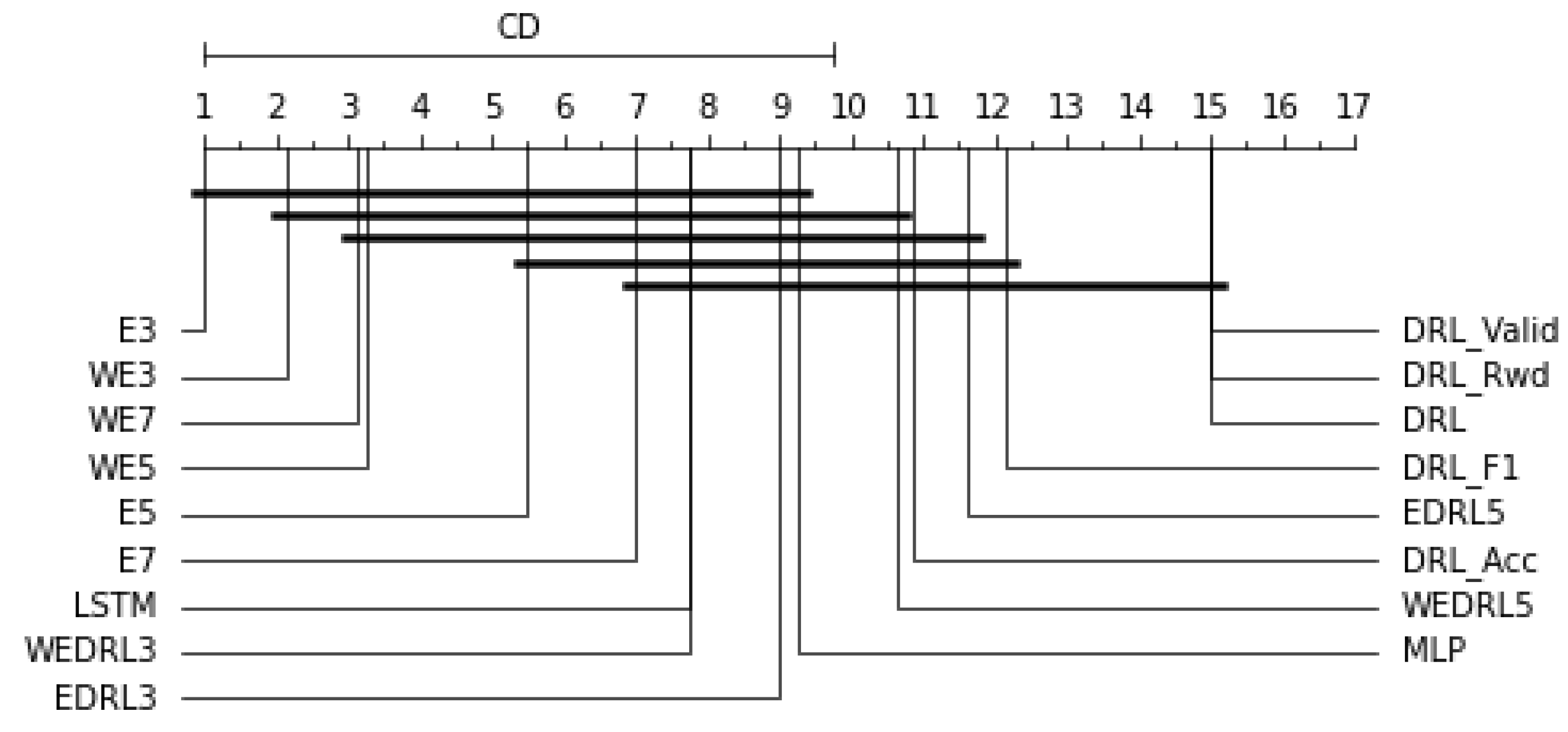
As indicated in
Table 13, we averaged the F1-score of each individual model and ensemble model to compare their performance. We can observe that E3 not only performed the best model with the greatest average F1-score on all datasets but also excellently performed with a 1.0000 F1-score on CPY017 and YOM009. Among the models tested on the CPY014 dataset, the best F1-score of 0.8571 was achieved by MLP, LSTM, E3, E5, WE3, WE5, and WE7. In contrast, on the CPY015 dataset, the model with DRL-based (
, and
) generated the highest F1-score of 0.4134. Furthermore, as shown in
Figure 10, the CD diagram was chosen to make a statistical comparison of our results, which revealed that E3 had the highest ranking, and the ensemble model that combined all seven individual models outperformed both the individual model and the ensemble model created using DRL models. It also demonstrated the ability of ensemble methods to improve the performance of individual DRL models because it represented a significant difference from individual models (
,
, and
).
We then tested the generalisation ability of ensemble models with the data collected from different stations. The F1-score of each station is depicted in
Table 14. Using ensemble E3 with CPY011 data, to identify anomalies from other stations, we can see that it works well with F1-scores of more than 0.5800, but it performed poorly at detecting anomalies on CPY015 and YOM009 with F1-scores of 0.3444 and 0.1017, respectively. E3 on CPY012 performed well when detecting anomalies on CPY014 with a 0.8635 F1-score. Similarly, E3 on CPY013 provided a higher F1-score on their own dataset when detecting anomalies on CPY012 and CPY014 with an F1-score of 0.8060 and 0.8571, respectively. The best ensemble on CPY014 generated excellent performance when identifying anomalies on CPY017 data. In contrast, E3 on CPY015 performed poorly on YOM009 with an F1-score of only 0.0437. While considered E3 on CPY016, although it provided good performance with an F1-score higher than 0.6 on CPY012, CPY013, and CPY014, it performed poorly on CPY011, CPY015, CPY017, and YOM009 with an F1-score lower than 0.45. E3 on CPY017 provided good results with an F1-score of more than 0.69, except on CPY015, CPY016, and YOM009 with an F1-score lower than 0.56. Meanwhile, E3 on YOM009 generated an F1-score on its own of only 0.43, but it performed excellently when detecting anomalies on CPY017 and other datasets with an F1-score higher than 0.65, except on CPY015 with an F1-score of 0.2414.
6. Discussion
We can observe that when the number of training epochs increases, the performance of each model grows or decreases in each epoch, then drops and bounces back. This might indicate that our model is still learning or is learning too much—that is, it is difficult to decide when it is time to stop training.
Even though DRL can do better than other models, it is time-consuming—at least 50 times slower than MLP models on average—because we have to train it until it performs well enough and we cannot predict how long that will take. The size of the windows must also be taken into account. A larger window size takes more time than a smaller window size. The window size has an effect on the comparison of data in windows to identify the anomaly. Additionally, we may add additional neural networks to improve the accuracy of our technique, but training will take longer.
DRL does better than other models when it is trained on datasets with a low number of outliers. This proves the ability to detect unknown anomalies. However, its performance is insufficient, which may be due to an imbalance in our dataset. As a result, models may lack sufficient information to explore and leverage knowledge for adaptive detection of unknown abnormalities.
Moreover, the neural structure that works well with one station may not function well with another. Hence, the problems of this topic include determining the suitable neural structure for each station. Furthermore, the primary parameter that requires further attention is the reward function, since a suitable reward will impact the model’s learning process.
In the case of ensemble models, when all of the individual models in an ensemble perform similarly, majority voting is the best method for determining the final decision. However, when the accuracies of individual models are different, the weighted voting is the best way to utilise the strengths of the good models in making a decision. Furthermore, the ensemble model can also reduce the false alarm rate, as seen by an increased precision score. It should be noted that, although single models performed well on certain stations, they did poorly on others, such as the LSTM model. As a result, we cannot rely on a single model since we do not know if it is the best or not. The ensemble models, on the other hand, are more reliable, even though they may not produce the best accuracy for every station. On the whole, nevertheless, most ensembles, such as performed consistently very well and their accuracies are always ranked highly at every station, whilst the individual models: DRL, MLP and LSTM, are not consistent through out all the stations.
7. Conclusions
In this research, we firstly investigated how deep reinforcement learning (DRL) can be applied to detect anomalies in water level data and then devised two strategies to construct more effective and reliable ensembles. For DRL, we defined a reward function as it plays a key role in determining the success of an RL. We developed ensemble models with five deep reinforcement learning models, generated by the same DRL algorithm but with different criteria of performance measurement. We tested our ensemble approach on telemetry water level data from eight different stations. We compared our approach to two different neural network models. Moreover, we demonstrate the ability to detect unknown anomalies by using the trained model to detect anomalies from other stations’ data.
The results indicate that models are the best individual DRL models, but they performed slightly poor than LSTM. When tested on different stations, LSTM still does better than others, but its accuracy is not satisfactory. When compared to an ensemble approach, LSTM was more accurate in some stations than other ensembles with DRL models, but less accurate in some others. On the whole, the statistical results from the CD diagram showed that our ensemble approach with only 3 members of DRL models, , was superior. Furthermore, all ensemble models that were combined by selecting models from 5 DRL models, MLP, and LSTM outperformed both the best individual model, LSTM, and the best ensemble using DRL models, . This is supported by the highest F1-score and rankings with the CD diagram. It is clear that ensemble methods not only increased the accuracy of a single model but also provided a higher reliability of performance.
In conclusion, DRL is applicable for detecting anomalies in telemetry water level data with added benefit of detecting unknown anomalies. Our ensemble construction methods can be used to build ensemble models from selected single DRL models in order to increase the accuracy and reliability. In general, the ensembles are consistent in producing more accurate classification, although they may not always achieve the best results. Moreover, they are superior in reducing the number of false alarms in identifying abnormalities in water level data, which is very important in real application. The next stage in our study will be to develop more effective and efficient techniques for correcting the identified anomalies in the data.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}