
Comprehensive Feature Analysis for Sewer Deterioration Modeling

 ,
, 
Abstract

1. Introduction
- The overall feature importance in a dataset containing information from several different utilities, including identification of potential drawbacks
- How the performance and feature importance of the models are affected by how the model developer has distinguished between good and bad pipes
- How the feature importance varies between utilities when the parameters in the datasets have been found in the same way for all utilities.
2. Materials and Methods
2.1. Preprocessing of Data
2.2. Model Selection
2.3. Feature Importance
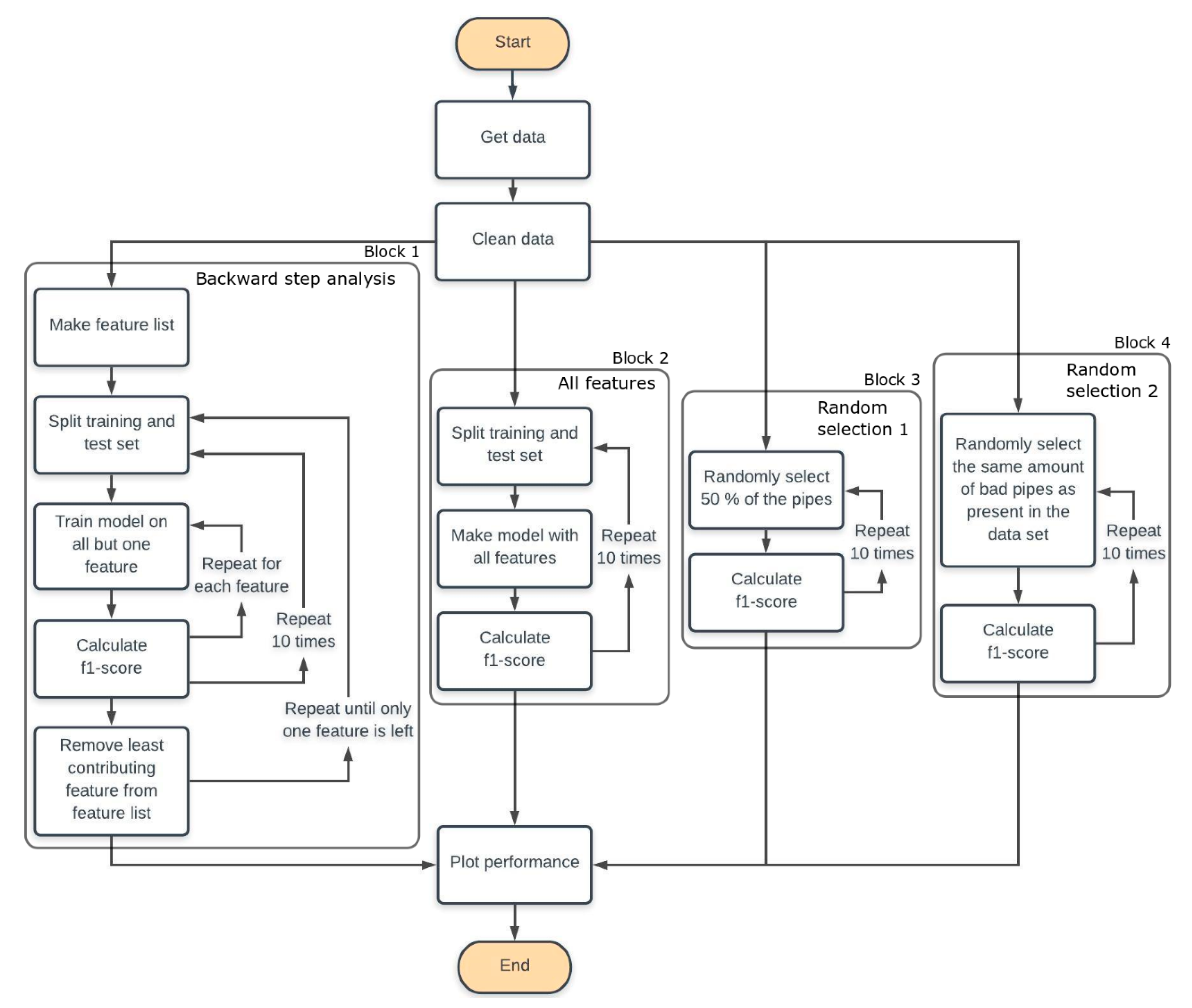
Backward Step Analysis
2.4. Experiments
2.4.1. Baseline
2.4.2. Target Variable
2.4.3. Difference between Utilities
3. Results
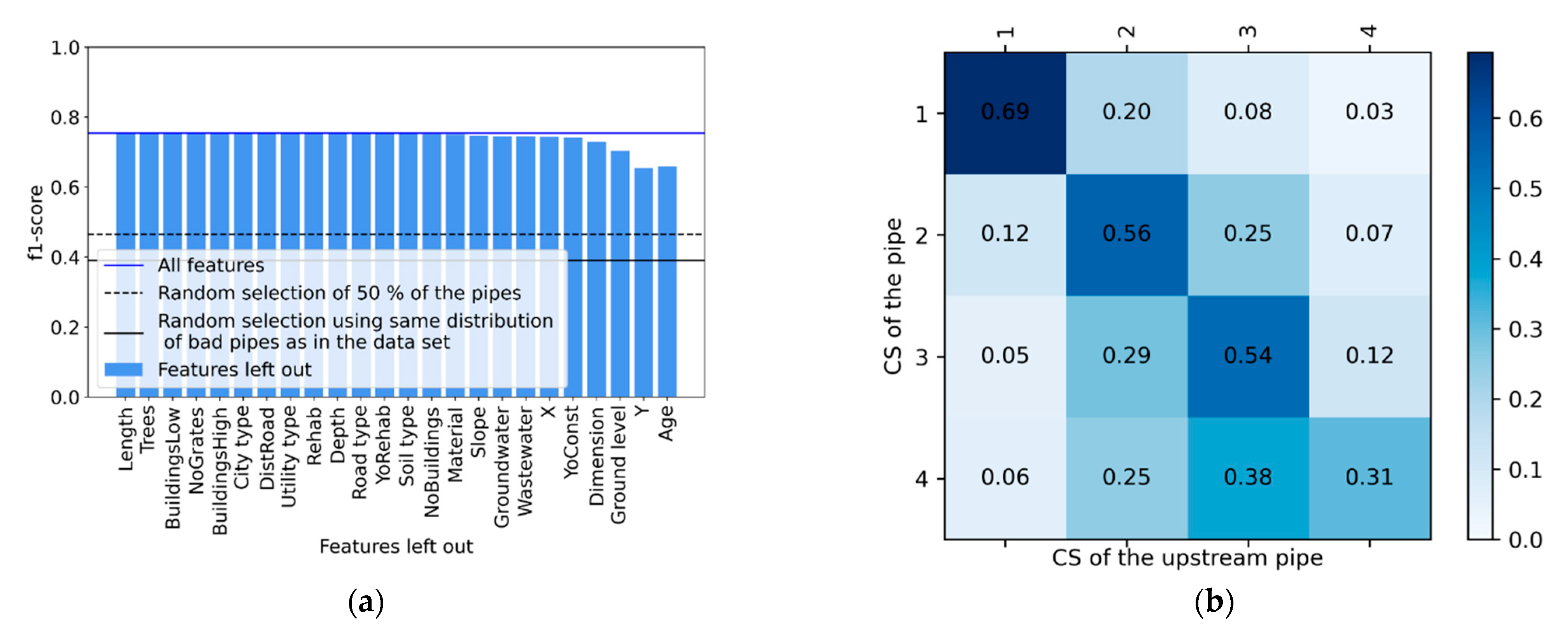
3.1. Baseline
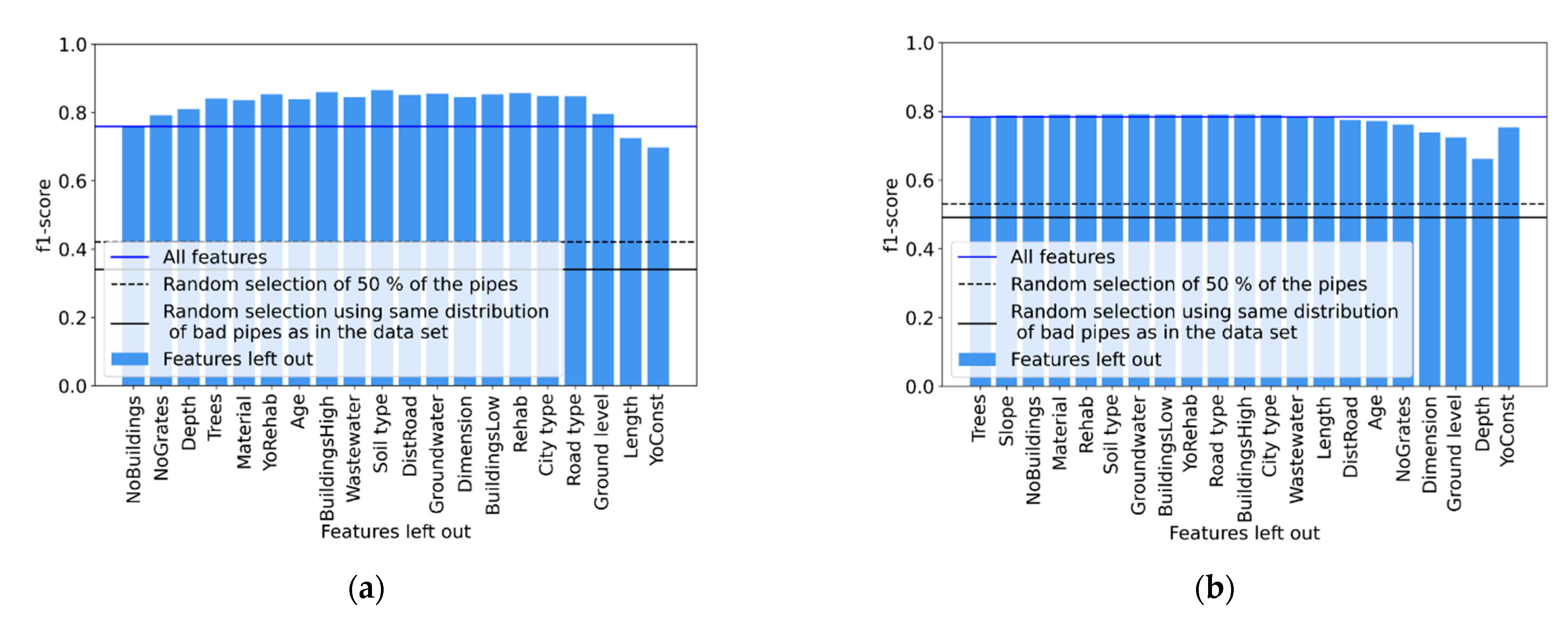
3.2. Target Variable
3.3. Difference between Utilities
4. Discussion
4.1. Representativeness of Data
4.2. Definition of Target Variable
4.3. Size of Datasets
4.4. Irregularities in the Step Analysis
4.5. Comparison to the Literature
4.6. CCTV-Inspection Planning
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tscheikner-Gratl, F.; Caradot, N.; Cherqui, F.; Leitão, J.P.; Ahmadi, M.; Langeveld, J.G.; Le Gat, Y.; Scholten, L.; Roghani, B.; Rodríguez, J.P.; et al. Sewer Asset Management—State of the Art and Research Needs. Urban Water J. 2019, 16, 662–675. [Google Scholar] [CrossRef]
- Marlow, D.; Pearson, L.; MacDonald, D.H.; Whitten, S.; Burn, S. A Framework for Considering Externalities in Urban Water Asset Management. Water Sci. Technol. 2011, 64, 2199–2206. [Google Scholar] [CrossRef] [PubMed]
- Roghani, B.; Cherqui, F.; Ahmadi, M.; Le Gauffre, P.; Tabesh, M. Dealing with Uncertainty in Sewer Condition Assessment: Impact on Inspection Programs. Autom. Constr. 2019, 103, 117–126. [Google Scholar] [CrossRef]
- Dirksen, J.; Clemens, F.H.L.R.; Korving, H.; Cherqui, F.; Le Gauffre, P.; Ertl, T.; Plihal, H.; Müller, K.; Snaterse, C.T.M. The Consistency of Visual Sewer Inspection Data. Struct. Infrastruct. Eng. 2013, 9, 214–228. [Google Scholar] [CrossRef]
- Haurum, J.B.; Moeslund, T.B. A Survey on Image-Based Automation of CCTV and SSET Sewer Inspections. Autom. Constr. 2020, 111, 103061. [Google Scholar] [CrossRef]
- Altarabsheh, A.; Ventresca, M.; Kandil, A. New Approach for Critical Pipe Prioritization in Wastewater Asset Management Planning. J. Comput. Civ. Eng. 2018, 32, 04018044. [Google Scholar] [CrossRef]
- Elmasry, M.; Zayed, T.; Hawari, A. Multi-Objective Optimization Model for Inspection Scheduling of Sewer Pipelines. J. Constr. Eng. Manag. 2019, 145, 04018129. [Google Scholar] [CrossRef]
- Ghavami, S.M.; Borzooei, Z.; Maleki, J. An Effective Approach for Assessing Risk of Failure in Urban Sewer Pipelines Using a Combination of GIS and AHP-DEA. Process Saf. Environ. Prot. 2020, 133, 275–285. [Google Scholar] [CrossRef]
- Elmasry, M.; Hawari, A.; Zayed, T. An Economic Loss Model for Failure of Sewer Pipelines. Struct. Infrastruct. Eng. 2018, 14, 1312–1323. [Google Scholar] [CrossRef]
- Carvalho, G.; Amado, C.; Brito, R.S.; Coelho, S.T.; Leitão, J.P. Analysing the Importance of Variables for Sewer Failure Prediction. Urban Water J. 2018, 15, 338–345. [Google Scholar] [CrossRef]
- Hansen, B.D.; Rasmussen, S.H.; Moeslund, T.B.; Uggerby, M.; Jensen, D.G. Sewer Deterioration Modeling: The Effect of Training a Random Forest Model on Logically Selected Data-Groups. Procedia Comput. Sci. 2020, 176, 291–299. [Google Scholar] [CrossRef]
- Hansen, B.D.; Getreuer Jensen, D.; Rasmussen, S.H.; Tamouk, J.; Uggerby, M.; Moeslund, T.B. General Sewer Deterioration Model Using Random Forest. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 834–841. [Google Scholar]
- Laakso, T.; Kokkonen, T.; Mellin, I.; Vahala, R. Sewer Condition Prediction and Analysis of Explanatory Factors. Water 2018, 10, 1239. [Google Scholar] [CrossRef]
- Park, H.; Ting, S.H.; Jeong, H.D. Procedural Framework for Modeling the Likelihood of Failure of Underground Pipeline Assets. J. Pipeline Syst. Eng. Pract. 2016, 7, 04015023. [Google Scholar] [CrossRef]
- Le Gat, Y. Modelling the Deterioration Process of Drainage Pipelines. Urban Water J. 2008, 5, 97–106. [Google Scholar] [CrossRef]
- Elmasry, M.; Hawari, A.; Zayed, T. Defect Based Deterioration Model for Sewer Pipelines Using Bayesian Belief Networks. Can. J. Civ. Eng. 2017, 44, 675–690. [Google Scholar] [CrossRef]
- Hawari, A.; Alkadour, F.; Elmasry, M.; Zayed, T. Condition Assessment Model for Sewer Pipelines Using Fuzzy-Based Evidential Reasoning. Aust. J. Civ. Eng. 2018, 16, 23–37. [Google Scholar] [CrossRef]
- Kabir, G.; Balek, N.B.C.; Tesfamariam, S. Sewer Structural Condition Prediction Integrating Bayesian Model Averaging with Logistic Regression. J. Perform. Constr. Facil. 2018, 32, 04018019. [Google Scholar] [CrossRef]
- Rokstad, M.M.; Ugarelli, R.M. Evaluating the Role of Deterioration Models for Condition Assessment of Sewers. J. Hydroinform 2015, 17, 789–804. [Google Scholar] [CrossRef]
- Fuchs-Hanusch, D.; Günther, M.; Möderl, M.; Muschalla, D. Cause and Effect Oriented Sewer Degradation Evaluation to Support Scheduled Inspection Planning. Water Sci. Technol. 2015, 72, 1176–1183. [Google Scholar] [CrossRef] [PubMed]
- O’Reilly, M.P.; Rosbrook, R.B.; Cox, G.C.; McCloskey, A. Analysis of Defects in 180 Km of Pipe Sewers in Southern Water Authority; Research Report (Transport and Road Research Laboratory); Ground Engineering Division, Structures Group, Transport and Road Research Laboratory: Berkshire, UK, 1989. [Google Scholar]
- Yin, X.; Chen, Y.; Bouferguene, A.; Al-Hussein, M. Data-Driven Bi-Level Sewer Pipe Deterioration Model: Design and Analysis. Autom. Constr. 2020, 116, 103181. [Google Scholar] [CrossRef]
- Davies, J.P.; Clarke, B.; Whiter, J.; Cunningham, R.; Leidi, A. The Structural Condition of Rigid Sewer Pipes: A Statistical Investigation. Urban Water 2001, 3, 277–286. [Google Scholar] [CrossRef]
- Malek Mohammadi, M.; Najafi, M.; Kermanshachi, S.; Kaushal, V.; Serajiantehrani, R. Factors Influencing the Condition of Sewer Pipes: State-of-the-Art Review. J. Pipeline Syst. Eng. Pract. 2020, 11, 03120002. [Google Scholar] [CrossRef]
- Hawari, A.; Alkadour, F.; Elmasry, M.; Zayed, T. A State of the Art Review on Condition Assessment Models Developed for Sewer Pipelines. Eng. Appl. Artif. Intell. 2020, 93, 103721. [Google Scholar] [CrossRef]
- Guzmán-Fierro, J.; Charry, S.; González, I.; Peña-Heredia, F.; Hernández, N.; Luna-Acosta, A.; Torres, A. Bayesian Network-Based Methodology for Selecting a Cost-Effective Sewer Asset Management Model. Water Sci. Technol. 2020, wst2020299. [Google Scholar] [CrossRef] [PubMed]
- Laden, B.; DANVA. Fotomanualgruppen Fotomanualen: TV-Inspektion af Afløbsledninger; DANVA: Skanderborg, Denmark, 2010; ISBN 978-87-90455-81-1. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13 August 2016; pp. 785–794. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Harvey, R.R.; McBean, E.A. Predicting the Structural Condition of Individual Sanitary Sewer Pipes with Random Forests. Can. J. Civ. Eng. 2014, 41, 294–303. [Google Scholar] [CrossRef]
- Regression Methods for Predicting Rate and Type of Failures of Water Conduits. Ecol. Chem. Eng. A 2017. [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predictor Variable (Abbreviation) | Data Type | Distribution and Units |
|---|---|---|
| Length | Continuous | 43.59 ± 26.54 m |
| Age | Numeric | 25.7 ± 21.1 Years |
| Material | Categorical | Concrete (61.22%), plastic (33.77%), clay (1.50%), full reline (2.23%), other (1.22%) |
| Dimension | Continuous | 306.6 ± 198.9 mm |
| Wastewater type (Wastewater) | Categorical | Sewage (38.18%), rain (31.66%), combined (29.54%) |
| Slope | Continuous | 12.22 ± 11.61 mm/m |
| Year of construction (YoConst) | Numeric | Year 1982.2 ± 21.1 |
| Year of rehabilitation (YoRehab) | Numeric | Year 1983.7 ± 21.6. This is set to YoConst if not rehabilitated |
| Type of rehabilitation (Rehab) | Categorical | Total replacement (5.11%), Full reline, also included as material (2.23%), Punctuate (0.04%), unknown (0.00%) |
| X coordinate (X) | Continuous | Adjusted UTM (m) |
| Y coordinate (Y) | Continuous | Adjusted UTM (m) |
| Utility ID | Numeric | |
| Ground level | Continues | 32.07 ± 24.57 m |
| Depth | Continuous | 2.43 ± 0.89 m |
| Groundwater level according to pipe (Groundwater) | Continuous | −4.48 ± 3.88 m |
| Soil type | Categorical | ML 1 (44.15%), MS 2 (19.38%), OPS 3 (9.79%), FDS 4 (6.53%), MaS 5 (4.28%), MoS 6 (4.15%), OMS 7 (3.45%), FS 8 (2.77%), MC 9 (1.00%), MG 10 (0.46%), Marsk (0.25%), Lake (0.004%) |
| Road type | Categorical | Tertiary (38.99%), secondary (13.54%), primary (13.00%), traffic (3.99%), other (1.88%), no road (28.60%) |
| Distance to road center (DistRoad) | Continuous | 1.91 ± 1.93 m for pipes less than 10 m from road center. The remaining pipes have been assigned the value 99 m |
| Distance to nearest trees (Trees) | Categorical | <4 (6.51%), <12 (25.50%), >12 (74.50%) |
| Number of road grate (NoGrates) | Numeric | 3.46 ± 3.56 grates |
| City type | Categorical | City zone (79% incl. city center and industrial area) city center (18.43%), industrial area (15.22%) |
| Number of buildings (NoBuildings) | Numeric | 6.09 ± 5.22 buildings |
| Area with tall buildings (BuildingHigh) | Binary | 9.44% True |
| Area with low buildings (BuildingLow) | Binary | 77.06% True |
| Settled Deposits | Attached Deposits | Deformation | Obstacle | Displaced Joint | Connection | Infiltration | Intruding Sealing Material | Surface Damage | Transitional Component | CNTP 1 | CNCU 2 | CNDR 3 | Manufacturing Defect | CNCH 4 | Break and Collapse | Roots | Water Level | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Severity 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Severity 1 | 1 | 2 | 1 | 2 | 1 | 2 | 2 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Severity 2 | 2 | 3 | 2 | 3 | 2 | 3 | 3 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Severity 3 | 3 | 4 | 3 | 3 | 3 | 3 | 4 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| Severity 4 | 4 | 4 | 3 | 4 | 4 | 3 | 4 | 4 | 4 | 3 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 3 |
| Dataset | Number of Pipes in Total | Number of Pipes after Cleaning | Number of Features Removed | No. Pipes in CS 3 after Cleaning | No. of Pipes in CS 4 after Cleaning |
|---|---|---|---|---|---|
| All pipes | 318,457 | 196,174 | 0 | 64,969 (33%) | 20,542 (10%) |
| Utility 1 | 20,379 | 17,730 | 0 | 5992 (34%) | 1758 (10%) |
| Utility 2 | 10,062 | 8270 | 0 | 3138 (38%) | 872 (11%) |
| Utility 3 | 9904 | 8469 | 1 | 3666 (43%) | 1103 (13%) |
| Utility 4 | 10,116 | 7913 | 0 | 2166 (27%) | 615 (8%) |
| Utility 5 | 18,745 | 15,830 | 0 | 4477 (28%) | 1162 (7%) |
| Utility 6 | 17,109 | 13,867 | 0 | 5290 (38%) | 1141 (8%) |
| Utility 7 | 4669 | 3108 | 6 | 687 (22%) | 280 (9%) |
| Utility 8 | 4522 | 3315 | 0 | 892 (27%) | 790 (24%) |
| Utility 9 | 12,163 | 9451 | 1 | 2759 (29%) | 1708 (18%) |
| Utility 10 | 734 | 640 | 1 | 135 (21%) | 103 (16%) |
| Utility 11 | 6355 | 5686 | 1 | 1899 (33%) | 469 (8%) |
| Utility 12 | 20,945 | 16,453 | 0 | 5128 (31%) | 987 (6%) |
| Utility 13 | 1779 | 1268 | 0 | 312 (25%) | 120 (9%) |
| Utility 14 | 18,154 | 14,587 | 0 | 6214 (43%) | 2063 (14%) |
| Utility 15 | 2757 | 2027 | 0 | 580 (29%) | 231 (11%) |
| Utility 16 | 18,025 | 15,812 | 4 | 4700 (30%) | 1560 (10%) |
| Utility 17 | 3855 | 3252 | 0 | 1145 (35%) | 311 (10%) |
| Utility 18 | 9655 | 7128 | 0 | 2516 (35%) | 880 (12%) |
| Utility 19 | 9253 | 7006 | 0 | 2092 (30%) | 806 (12%) |
| Utility 20 | 10,520 | 8370 | 0 | 1870 (22%) | 893 (11%) |
| Utility 21 | 7959 | 6914 | 1 | 1868 (27%) | 668 (10%) |
| Utility 22 | 4458 | 4040 | 7 | 1685 (42%) | 381 (9%) |
| Utility 23 | 2974 | 2427 | 0 | 1048 (43%) | 492 (20%) |
| Utility 24 | 14,300 | 11,942 | 1 | 5953 (50%) | 1720 (14%) |
| Utility 25 | 18,879 | 13,978 | 0 | 2348 (17%) | 1360 (10%) |
| Utility 26 | 3864 | 2812 | 0 | 611 (22%) | 274 (10%) |
| Utility 27 | 7171 | 6033 | 1 | 1956 (32%) | 990 (16%) |
| Utility 28 | 16,672 | 14,064 | 1 | 4442 (32%) | 1673 (12%) |
| Utility 29 | 10,939 | 9428 | 0 | 4068 (43%) | 761 (8%) |
| Utility 30 | 5750 | 4540 | 6 | 1940 (43%) | 431 (9%) |
| Utility 31 | 4213 | 3944 | 1 | 1765 (45%) | 560 (14%) |
| Utility 32 | 4877 | 4073 | 0 | 1451 (36%) | 253 (6%) |
| Utility 33 | 6164 | 5661 | 8 | 1092 (19%) | 251 (4%) |
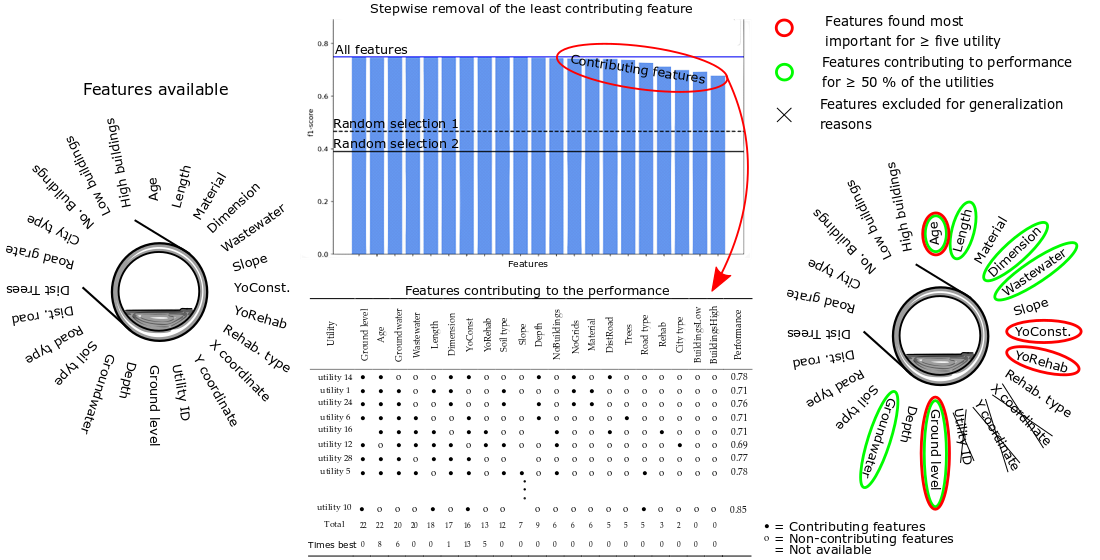
| Utility | Ground Level | Age | Groundwater | Wastewater | Length | Dimension | YoConst | YoRehab | Soil Type | Slope | Depth | NoBuildings | NoGrates | Material | DistRoad | Trees | Road Type | Rehab | City Type | Buildings Low | Buildings High | No. Features Relevant | Performance |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Utility 14 | ● | ● | o | o | o | ● | ● | o | o | o | ● | o | ● | o | ● | o | o | o | o | o | o | 7 | 0.78 |
| Utility 1 | ● | ● | ● | o | ● | ● | o | o | ● | o | o | o | ● | ● | o | o | o | o | o | o | o | 8 | 0.71 |
| Utility 24 | ● | ● | ● | o | o | ● | o | o | ● | ● | o | ● | ● | o | o | o | o | o | o | o | 8 | 0.76 | |
| Utility 6 | ● | ● | ● | ● | o | o | ● | o | o | o | ● | o | o | o | o | ● | o | o | o | o | o | 7 | 0.71 |
| Utility 16 | ● | ● | ● | ● | o | ● | ● | o | o | ● | o | o | ● | o | o | ● | o | o | o | 9 | 0.71 | ||
| Utility 12 | ● | o | ● | ● | ● | ● | o | ● | ● | o | o | ● | o | o | o | o | o | o | ● | o | o | 9 | 0.69 |
| Utility 28 | ● | ● | ● | o | ● | ● | ● | o | o | o | o | o | o | o | o | o | o | o | o | o | 6 | 0.77 | |
| Utility 5 | ● | ● | ● | ● | o | ● | ● | o | ● | ● | o | ● | o | o | o | o | ● | o | o | o | o | 10 | 0.78 |
| Utility 29 | ● | o | ● | ● | ● | ● | ● | ● | ● | ● | o | o | ● | ● | o | ● | o | o | o | o | o | 12 | 0.76 |
| Utility 3 | ● | o | ● | o | o | ● | ● | o | o | o | o | o | o | o | o | o | o | o | o | o | 4 | 0.77 | |
| Utility 9 | ● | ● | ● | ● | ● | o | ● | o | o | o | o | o | o | o | o | o | o | o | o | o | 6 | 0.77 | |
| Utility 2 | o | ● | ● | ● | o | o | o | ● | o | o | o | o | o | o | o | o | o | o | o | o | o | 4 | 0.82 |
| Utility 25 | ● | ● | ● | o | o | ● | o | ● | o | ● | o | o | o | o | o | o | o | o | o | o | o | 6 | 0.77 |
| Utility 18 | ● | ● | o | ● | ● | ● | o | o | ● | o | ● | o | o | ● | o | o | ● | o | o | o | o | 9 | 0.79 |
| Utility 27 | o | o | ● | ● | ● | o | o | ● | o | o | o | o | o | o | o | ● | o | o | o | o | 5 | 0.66 | |
| Utility 19 | o | o | ● | o | ● | o | ● | ● | o | o | o | ● | ● | o | o | ● | o | o | o | o | o | 7 | 0.71 |
| Utility 4 | ● | ● | o | ● | o | ● | o | o | ● | ● | o | o | ● | o | o | ● | o | o | o | o | o | 8 | 0.65 |
| Utility 20 | ● | ● | o | ● | ● | ● | ● | ● | o | ● | o | o | o | o | o | o | o | o | o | o | o | 8 | 0.76 |
| Utility 21 | ● | ● | o | ● | ● | ● | ● | o | o | o | o | o | o | o | o | o | o | o | o | o | 6 | 0.73 | |
| Utility 30 | ● | ● | o | ● | ● | o | o | o | o | o | o | ● | o | o | o | 5 | 0.70 | ||||||
| Utility 11 | o | ● | ● | ● | ● | o | ● | o | o | ● | o | o | o | o | o | ● | o | o | o | o | 7 | 0.69 | |
| Utility 31 | ● | ● | ● | o | ● | o | o | o | ● | o | o | o | ● | ● | o | o | o | o | o | o | 7 | 0.77 | |
| Utility 22 | ● | ● | ● | o | ● | ● | o | o | o | ● | o | o | o | o | 6 | 0.84 | |||||||
| Utility 32 | o | o | ● | ● | o | o | o | ● | o | o | o | o | o | o | o | o | o | o | o | o | o | 3 | 0.71 |
| Utility 8 | ● | o | o | ● | o | ● | o | ● | ● | o | o | ● | o | o | ● | o | o | o | o | o | o | 7 | 0.74 |
| Utility 23 | ● | ● | ● | ● | ● | o | o | o | ● | ● | ● | o | o | o | o | o | o | ● | o | o | o | 9 | 0.80 |
| Utility 17 | o | o | o | o | o | o | ● | o | o | o | o | o | o | o | o | o | o | o | o | o | o | 1 | 0.81 |
| Utility 33 | ● | ● | ● | o | o | o | ● | o | ● | o | o | o | o | 5 | 0.56 | ||||||||
| Utility 7 | o | ● | ● | ● | ● | o | o | ● | ● | ● | o | ● | o | o | o | 8 | 0.71 | ||||||
| Utility 26 | o | ● | o | o | o | o | o | o | ● | o | o | o | o | o | o | o | o | ● | o | o | o | 3 | 0.75 |
| Utility 15 | o | o | o | ● | o | ● | ● | o | o | o | o | o | o | o | ● | o | o | o | ● | o | o | 5 | 0.80 |
| Utility 13 | o | o | o | ● | o | o | ● | ● | o | o | ● | ● | o | o | o | o | o | o | o | o | o | 5 | 0.86 |
| Utility 10 | ● | o | o | o | ● | o | ● | o | o | o | o | o | o | o | o | ● | o | o | o | o | 4 | 0.85 | |
| Total | 22 | 22 | 20 | 20 | 18 | 17 | 16 | 13 | 12 | 7 | 9 | 6 | 6 | 6 | 5 | 5 | 5 | 3 | 2 | 0 | 0 | ||
| Times best | 0 | 8 | 6 | 0 | 0 | 1 | 13 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Predictor Variables | All Utilities | Utilities with More Than 1000 Bad Pipes | ||
|---|---|---|---|---|
| Times Present | Percent of Times Found Relevant | Times Present | Percent of Times Found Relevant | |
| Ground level | 32 | 69 | 27 | 78 |
| Age | 33 | 67 | 28 | 71 |
| Groundwater | 31 | 65 | 26 | 73 |
| Wastewater | 33 | 61 | 28 | 61 |
| Length | 33 | 55 | 28 | 57 |
| Dimension | 33 | 52 | 28 | 57 |
| Year of construction | 33 | 48 | 28 | 46 |
| Year of rehabilitation | 33 | 39 | 28 | 39 |
| Soil type | 33 | 36 | 28 | 36 |
| Slope | 23 | 30 | 19 | 32 |
| Depth | 31 | 29 | 26 | 31 |
| No. buildings | 29 | 21 | 25 | 20 |
| No. grates | 29 | 21 | 25 | 24 |
| Material | 33 | 18 | 28 | 21 |
| Dist. to road center | 29 | 17 | 25 | 16 |
| Dist. to trees | 33 | 15 | 28 | 18 |
| Road types | 33 | 15 | 28 | 14 |
| Rehabilitation type | 33 | 9 | 28 | 7 |
| City type | 30 | 7 | 26 | 4 |
| Building low | 29 | 0 | 25 | 0 |
| Buildings high | 29 | 0 | 25 | 0 |
| Predictor Variables | Results | Mohammadi et al. | ||
|---|---|---|---|---|
| Times Present | Percent of Times Found Relevant | Times Present | Percent of Times Found Relevant | |
| Ground level | 27 | 78 | - | - |
| Age | 28 | 71 | 18 | 78 |
| Groundwater | 26 | 73 | 3 | 100 |
| Wastewater | 28 | 61 | 6 | 83 |
| Length | 28 | 57 | 11 | 91 |
| Dimension | 28 | 57 | 17 | 71 |
| Year of construction | 28 | 46 | - | - |
| Year of rehabilitation | 28 | 39 | - | - |
| Soil type | 28 | 36 | 5 | 20 |
| Slope | 19 | 32 | 12 | 42 |
| Depth | 26 | 31 | 16 | 44 |
| No. buildings | 25 | 20 | - | - |
| No. grates | 25 | 24 | - | - |
| Material | 28 | 21 | 15 | 67 |
| Dist. to road center | 25 | 16 | - | - |
| Dist. to trees | 28 | 18 | - | - |
| Road types | 28 | 14 | 5 | 40 |
| Rehabilitation type | 28 | 7 | - | - |
| City type | 26 | 4 | - | - |
| Building low | 25 | 0 | - | - |
| Buildings high | 25 | 0 | - | - |
| Location | - | - | 5 | 40 |
| Up-invert | - | - | 1 | 0 |
| Down-invert | - | - | 1 | 0 |
| Bedding type | - | - | 2 | 100 |
| Corrosivity | - | - | 2 | 50 |
| Number of trees | - | - | 5 | 60 |
| Traffic | - | - | 1 | 1 |
| Flow | - | - | 3 | 67 |
| Hydrohalic | - | - | 2 | 100 |
| Location | - | - | 5 | 40 |
| Up-invert | - | - | 1 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hansen, B.D.; Rasmussen, S.H.; Uggerby, M.; Moeslund, T.B.; Jensen, D.G. Comprehensive Feature Analysis for Sewer Deterioration Modeling. Water 2021, 13, 819. https://doi.org/10.3390/w13060819
Hansen BD, Rasmussen SH, Uggerby M, Moeslund TB, Jensen DG. Comprehensive Feature Analysis for Sewer Deterioration Modeling. Water. 2021; 13(6):819. https://doi.org/10.3390/w13060819
Chicago/Turabian StyleHansen, Bolette D., Søren H. Rasmussen, Mads Uggerby, Thomas B. Moeslund, and David G. Jensen. 2021. "Comprehensive Feature Analysis for Sewer Deterioration Modeling" Water 13, no. 6: 819. https://doi.org/10.3390/w13060819
APA StyleHansen, B. D., Rasmussen, S. H., Uggerby, M., Moeslund, T. B., & Jensen, D. G. (2021). Comprehensive Feature Analysis for Sewer Deterioration Modeling. Water, 13(6), 819. https://doi.org/10.3390/w13060819