2.1. Study Area and Scope
The Saemangeum Watershed is divided into the Mangyeong River, Dongjin River, and is part of the west coast, with a total area of 3319 km
2. The target water quality of Saemangeum Lake is grade 4 (COD ≤ 8.0 mg/L, TP ≤ 0.100 mg/L, and Chl-a ≤ 35.0 mg/m
3) for the midstream and upstream regions, which comprises agricultural land according to the land use plan, and grade 3 (COD ≤ 5.0 mg/L, TP ≤ 0.050 mg/L, and Chl-a ≤ 20.0 mg/m
3) for the downstream region, planned for tourism and urban development. To achieve the target water quality for Saemangeum Lake, the pollutant load from the Mangyeong and Dongjin Rivers must be minimized first. The area selected for this study was the Dongjin River Basin, with an area of 1397.0 km
2, of which 629.7 km
2 is agricultural land, accounting for approximately 45.1% of the total area. This is approximately twice the average agricultural area in Korea (23%). Thus, the water quality of this region is expected to be significantly affected by agricultural inputs and utilization systems [
11].
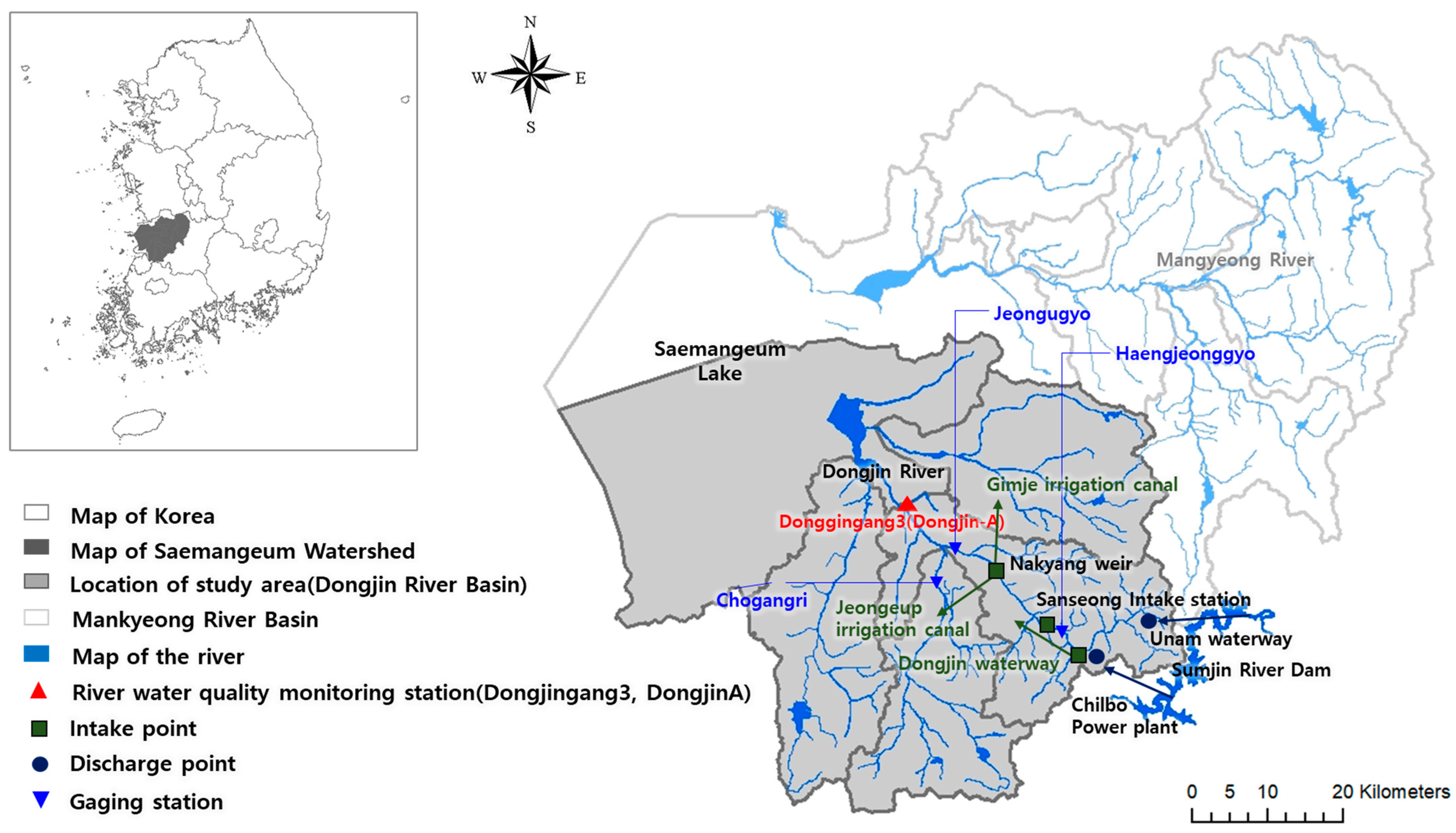
The flow of water through the Dongjin River Basin is illustrated in
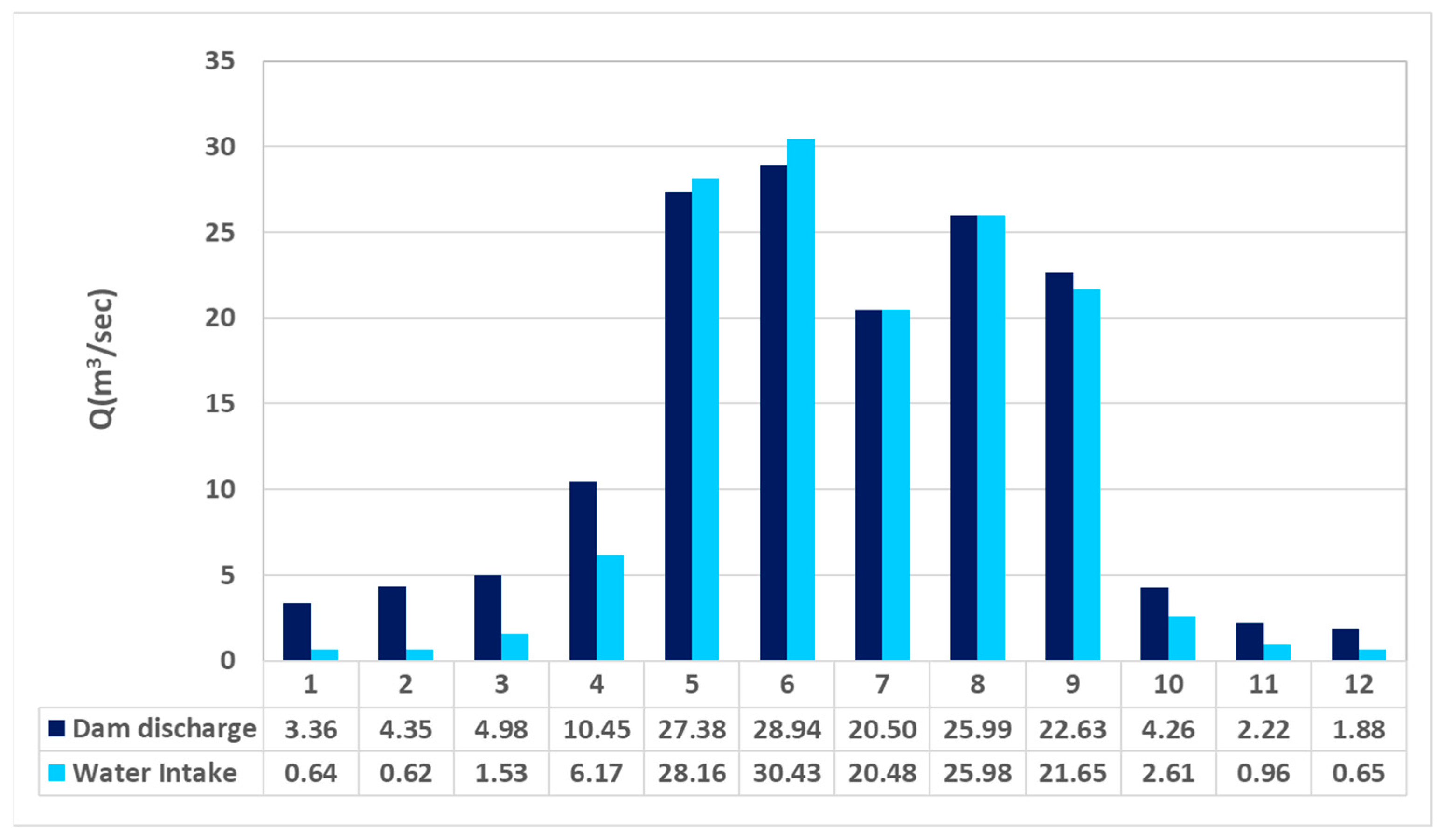
Figure 2. Water from the Seomjin River Dam flows through the Unam waterway and the Chilbo power plant in the upstream part of the Dongjin River. The water from the Chilbo power plant is then diverted into the Dongjin waterway, located immediately downstream of the plant. Some of the water from the Dongjin River is collected at the Sanseong intake station for domestic use. Then, at the Nakyang Weir, located midstream of the Dongjin River, most of the water is supplied for irrigation to the Gimje and Jeongeup irrigation canals. For 11 years (2008–2018), the Dongjin River Basin has received approximately 83% (413.7 million m
3/year) of the total discharge (496.7 million m
3/year) of the Seomjin River Dam. As shown in
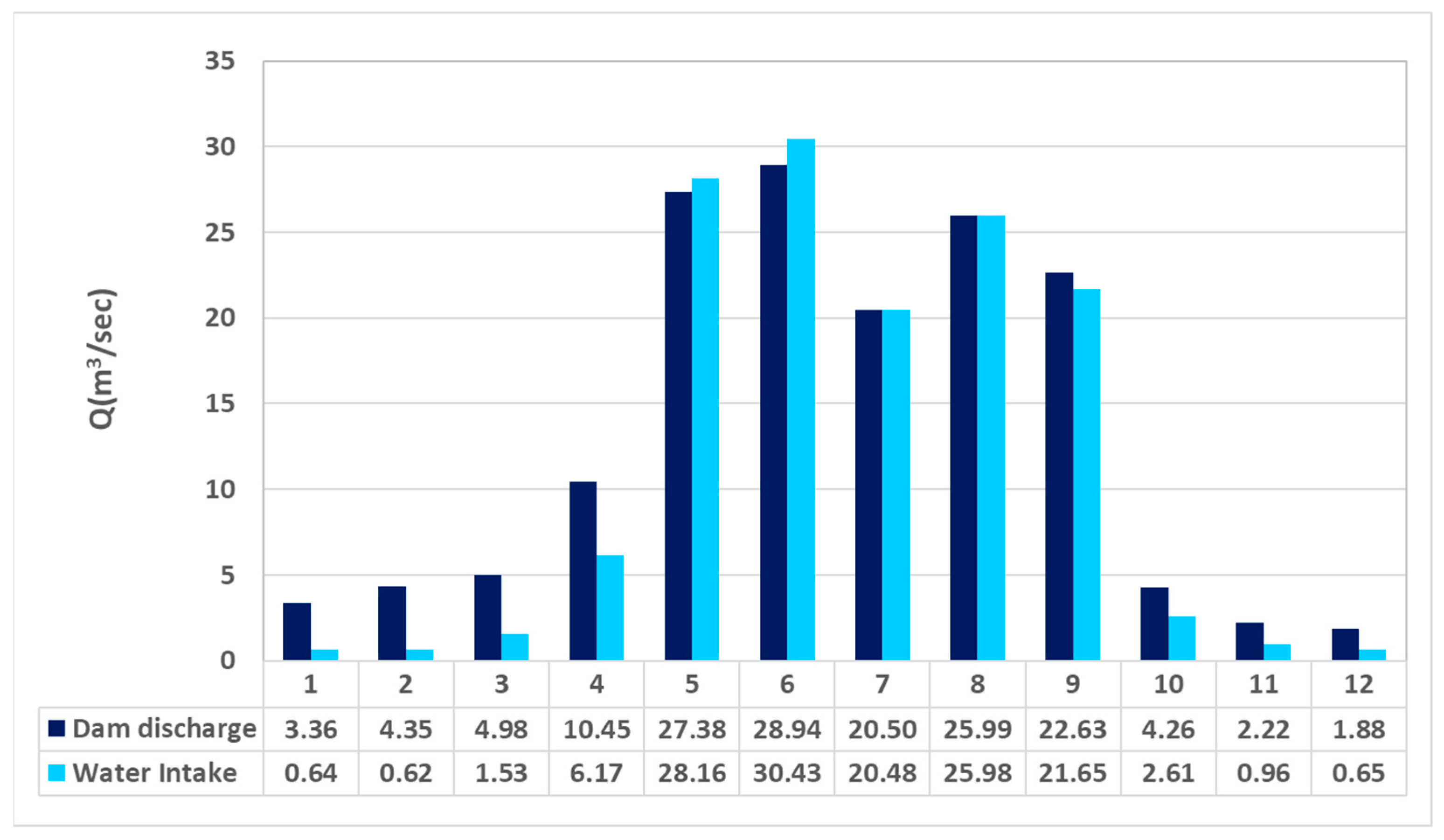
Figure 3, the monthly discharge begins to increase from April with the advent of the irrigation period; it is largest in June at 28.9 m
3/s, and smallest in December at 1.9 m
3/s. Approximately 90% of this discharge is used for agricultural and domestic purposes. Because there are no regulatory standards for water intake, most of the dam discharge is consumed during the irrigation period, except when flooding occurs. Hence, the actual flow rate of water to the main Dongjin River downstream of the Nakyang Weir is very limited.
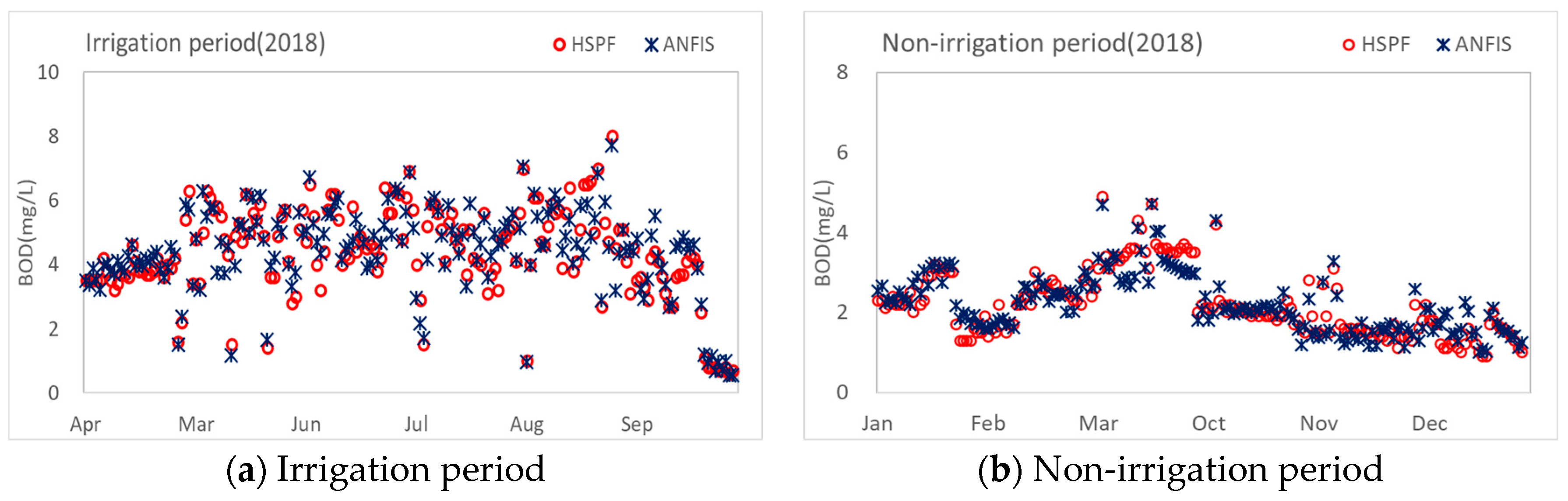
To reflect the hydrological characteristics of the Dongjin River Basin in our water quality predictions, irrigation and non-irrigation periods were differentiated. The irrigation water supply period in the water-use license for the Seomjin River Dam is from 20 April to 30 September annually. Based on this, the period from April to September was set as the irrigation period, and October to March was set as the non-irrigation period.
The Dongjin River 3 (Dongjin A), situated at the end of the Dongjin River, was selected as the site for water quality predictions, as the target water quality is monitored here according to Korea’s Water Environmental Management Plans. Dongjin River 3 is a river management monitoring station situated upstream of the Saemangeum Lake, wherein the target water quality, in terms of biological oxygen demand (BOD), must be achieved within a specific planned year.
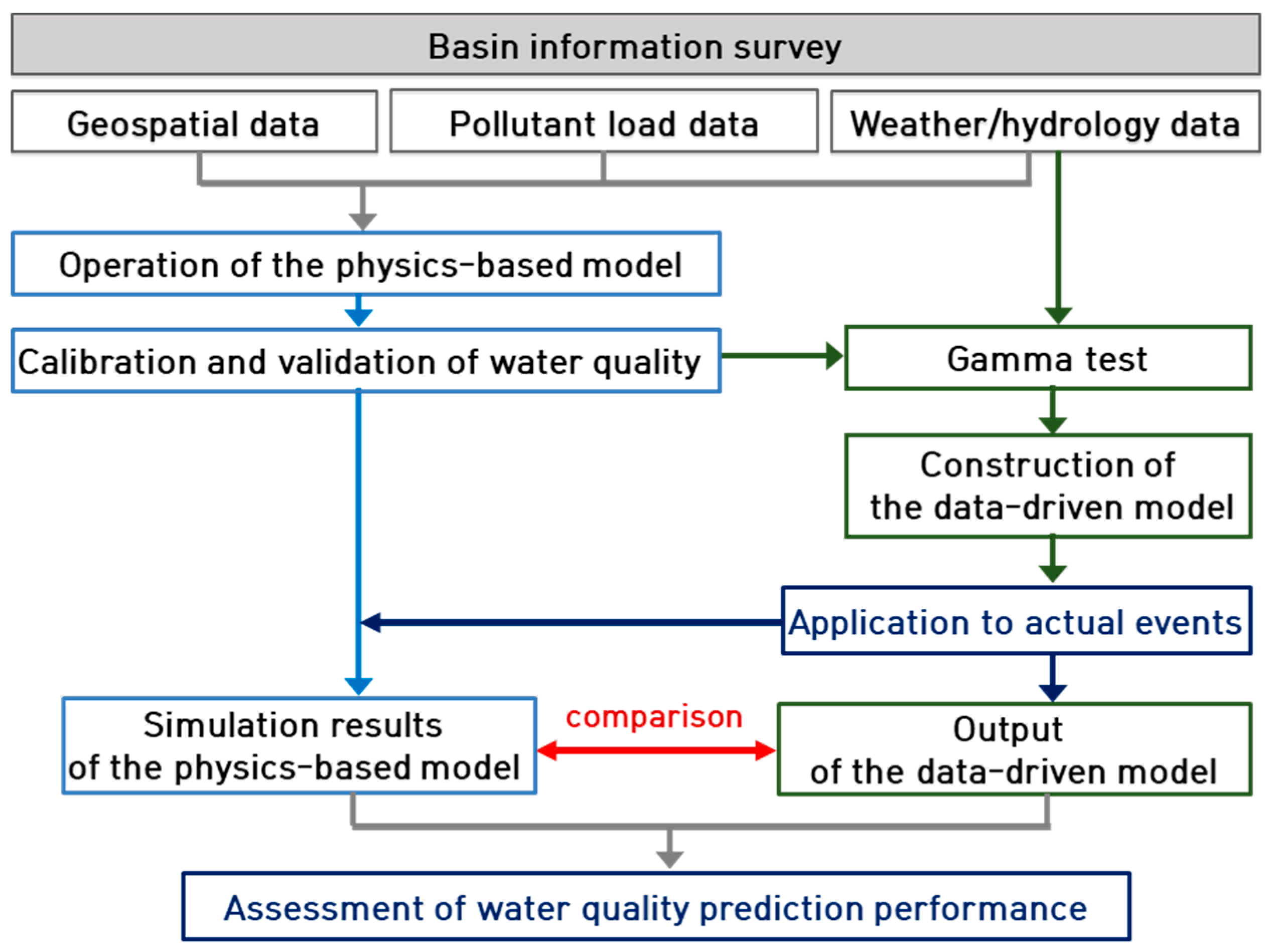
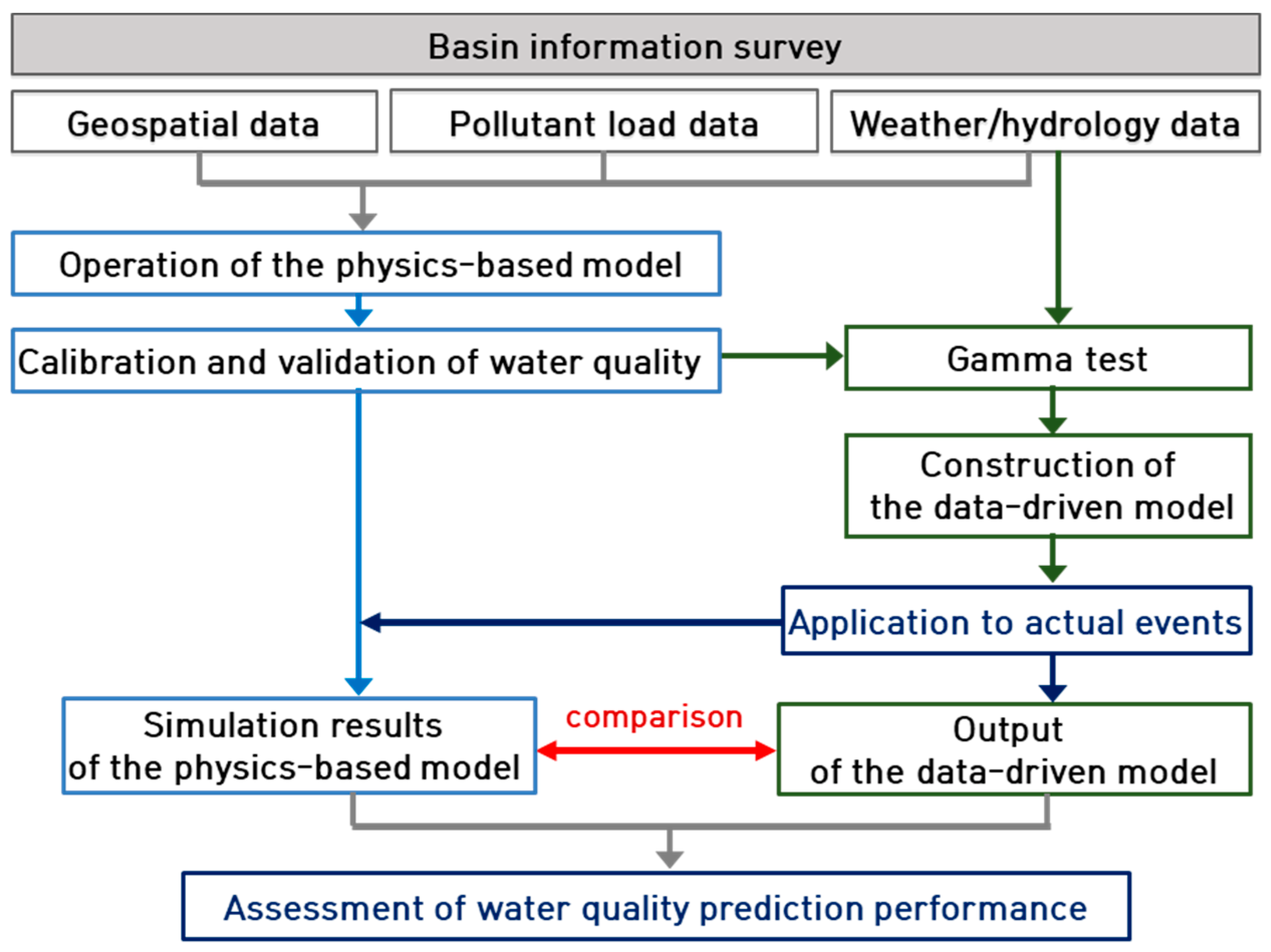
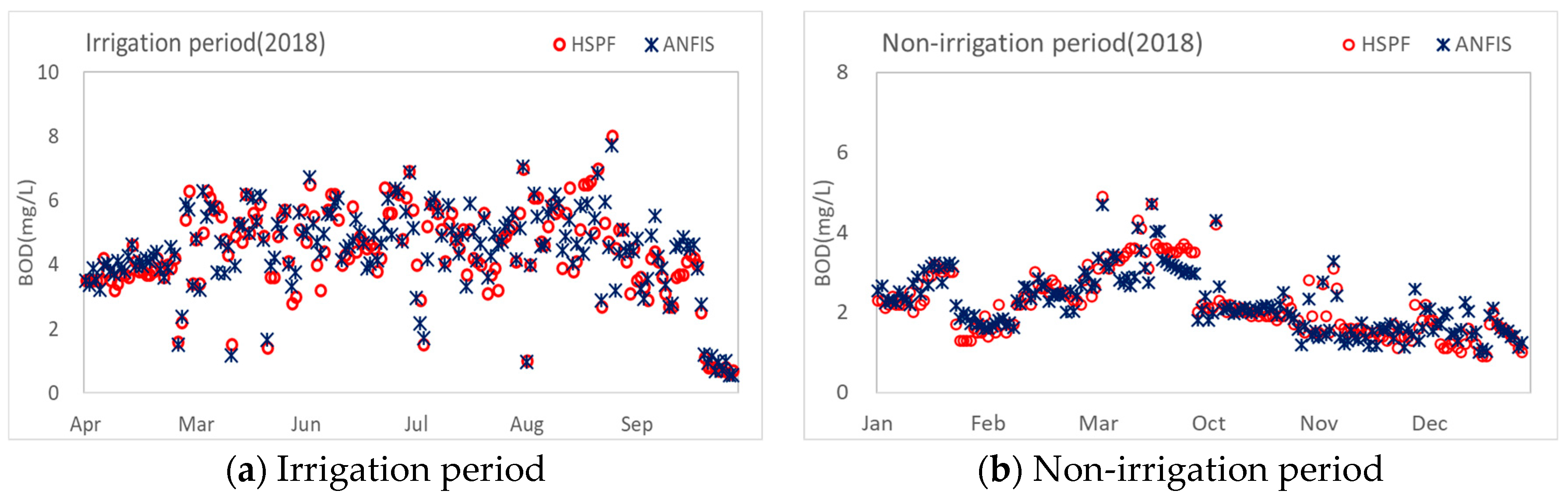
The duration considered for the physics-based model was approximately 11 years (from 2007–2018). Excluding the stabilization period, the calibration and validation periods were set based on recent data. The learning period for constructing the data-driven model was divided into irrigation and non-irrigation periods. Approximately 10 years of data from 2008 to 2017 were used, and the applicability of the data-driven model developed in this study was assessed using the HSPF simulation results for 2018.
2.2. Physics-Based Model
The HSPF model is appropriate for simulating the runoff and water quality of a watershed in both urban and rural or mountainous areas to analyze water quality variations depending on the daily and seasonal pollutant discharge characteristics [
12]. To use the HSPF model, basic information was input using the better assessment science integrating point and non-point sources (BASINS), which is an integrated management system that manages significant amounts of data based on Geographic Information System (GIS) and supports various models. First, a river network was generated by calculating the flow direction and flow accumulation from a digital elevation model, and it was segmented by specifying the exit point of the watershed as the outlet. Land cover was classified into seven categories: urban or built-up land, wetland, agricultural land, forest land, pastureland, barren land, and water. Then, the land use information for each segmented sub-watershed was extracted using the land use and soil definition utility of the model.
With regard to meteorological parameters, seven types of observed values for each hour, including rainfall, temperature, dew point, cloud cover, solar radiation, wind speed, and evapotranspiration were input into the model. Among the disaggregate functions included in WDMUtil, the evapotranspiration function was used to generate evapotranspiration data.
The pollutant load data calculated from the pollutant source data for the 2008–2018 period were input to obtain point-source pollutant load data. The daily water discharge and the quality data of discharged water (BOD, SS, TN, and TP) were collected and input for the sewage treatment facilities which recorded daily average discharges of 500 m3 or higher (Sintaein, Jeongeup, Buan, and Gimje).
Daily hydrological data including dam discharge (Unam waterway and Chilbo power plant) and water intake (Dongjin waterway, Nakyang Weir, and Sanseong intake station) for agricultural and domestic uses were surveyed and used as the daily inputs.
2.3. Calibration and Validation of the HSPF Model
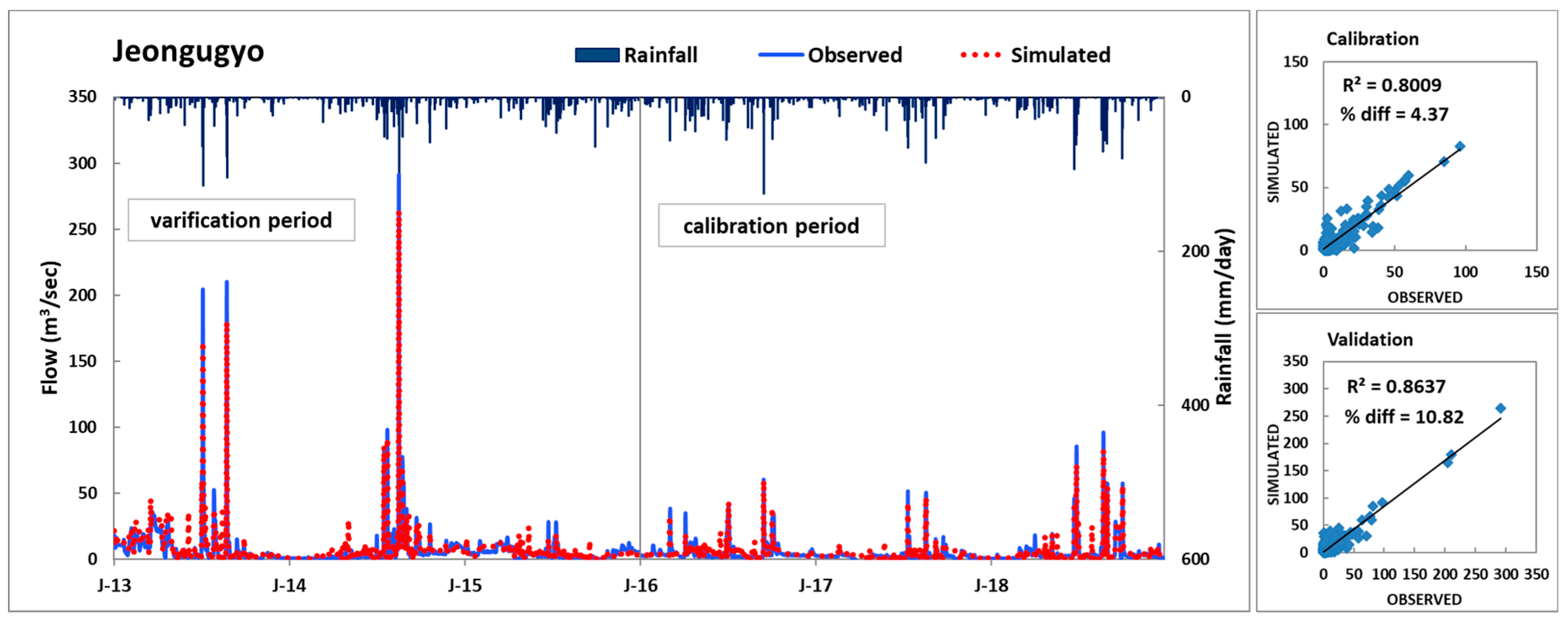
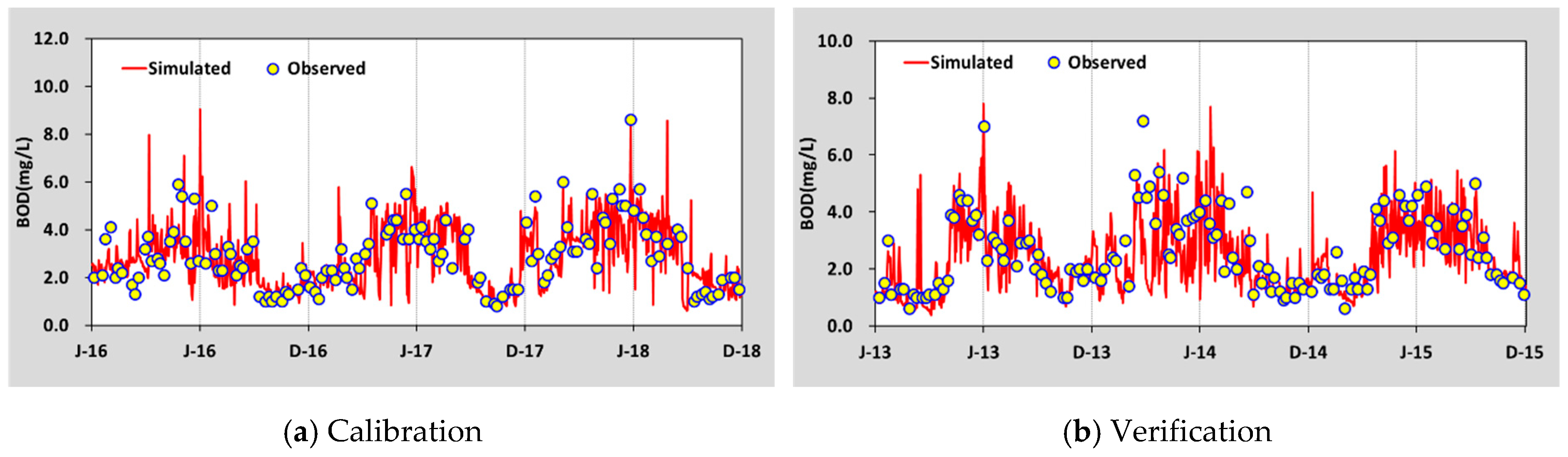
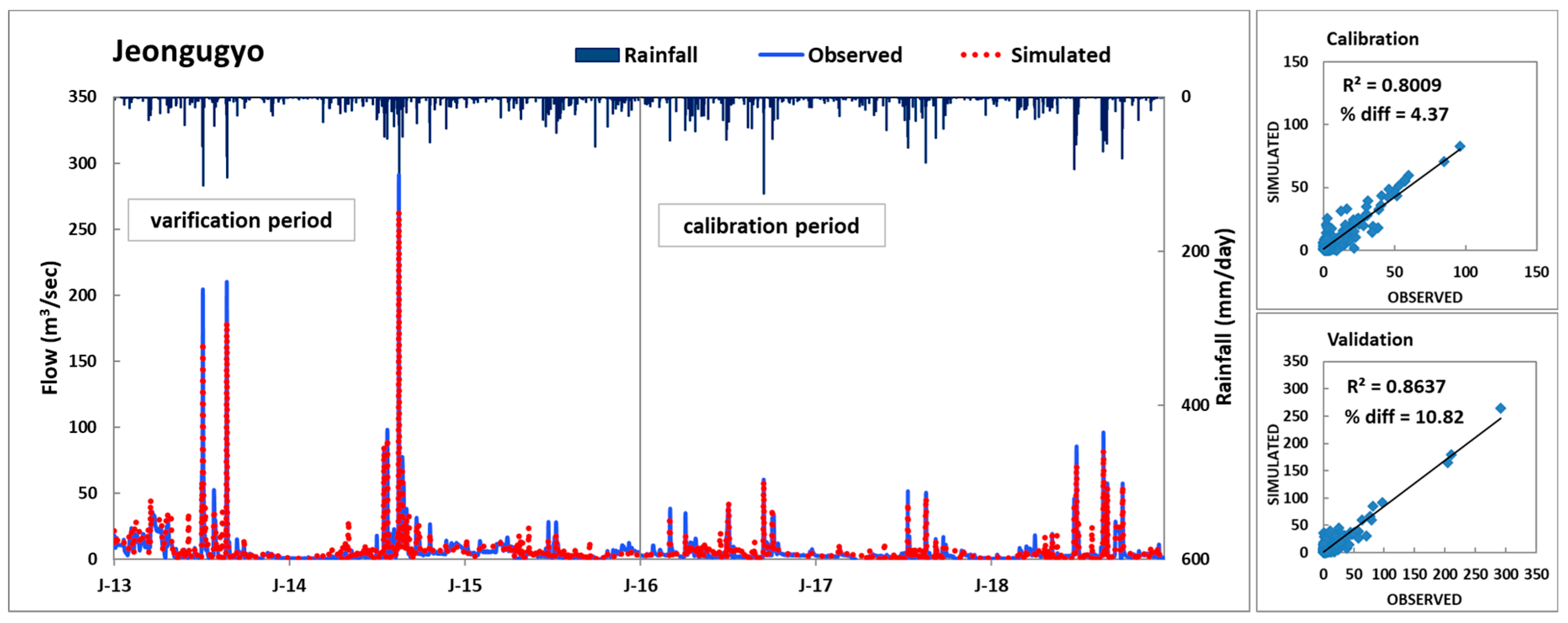
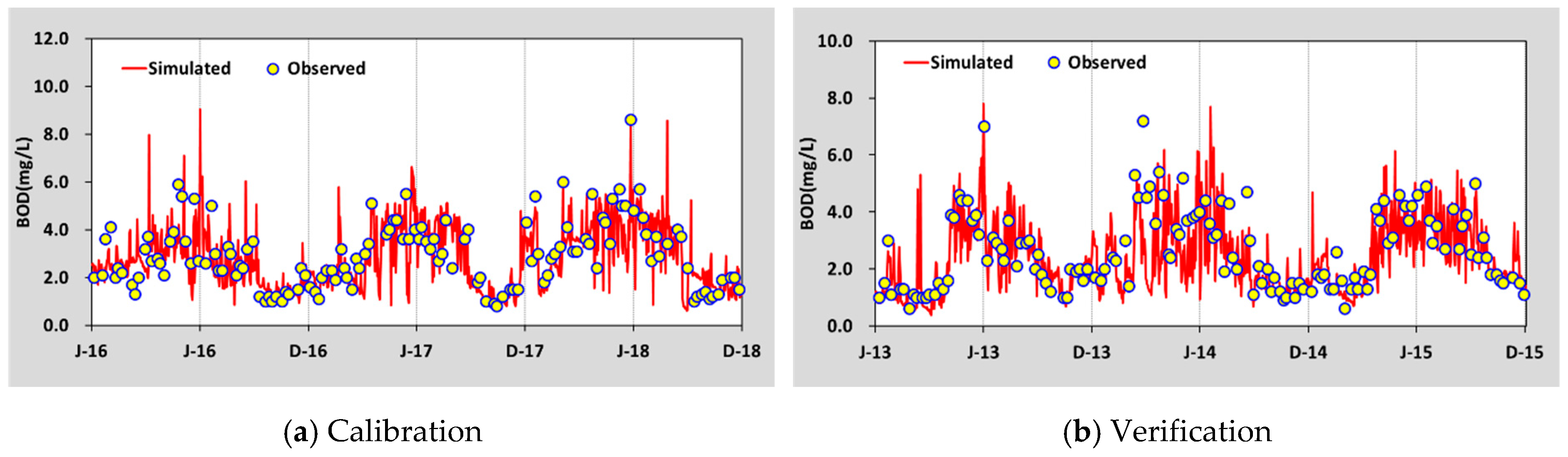
The flow rates measured at the three gauging stations, Haengjeonggyo, Chogangri, and Jeongugyo, were used for the calibration and validation of the HSPF model. The Total Maximum Daily Loads (TMDL) monitoring network data measured at Dongjin A, approximately 40 times per year at the end of each unit of watershed, were used for the water quality assessments. The calibration and validation periods were 2016–2018 and 2013–2015, respectively. The calibration and validation were conducted every three years, and their periods were defined based on the water quality data that could be collected.
To evaluate the accuracy of the calibration and validation results for the flow rate, the coefficient of determination (R
2) was calculated, and the criteria in
Table 1 suggested by Donigian [
13] were used. In the case of water quality, to evaluate the appropriateness of the simulation results for the measured values, the percentage difference confidence interval listed in the BASINS/HSPF Training Lecture (
Table 2) as well as the average (0.89), range (0.71–0.61), and root mean square error (
RMSE) of the actual measured values and the simulation values were calculated.
where
Pi denotes the predicted values,
Oi denotes the observed values, and
N is the total number of observations.
The parameters of flow rate applied in this study were adjusted to the following variables: lower zone nominal soil moisture storage (LZSN), infiltration capacity of the soil (INFILT), basic groundwater recession rate (AGWRC), fraction of groundwater inflow which will enter deep groundwater (DEEPER), interflow inflow (INTEW), and interflow recession (IRC;
Table 3). In the case of water quality calibration, the water temperature and DO were first calibrated, followed by the BOD.
Table 3 and
Table 4 show the parameters applied in this study and those applied in the previous studies.
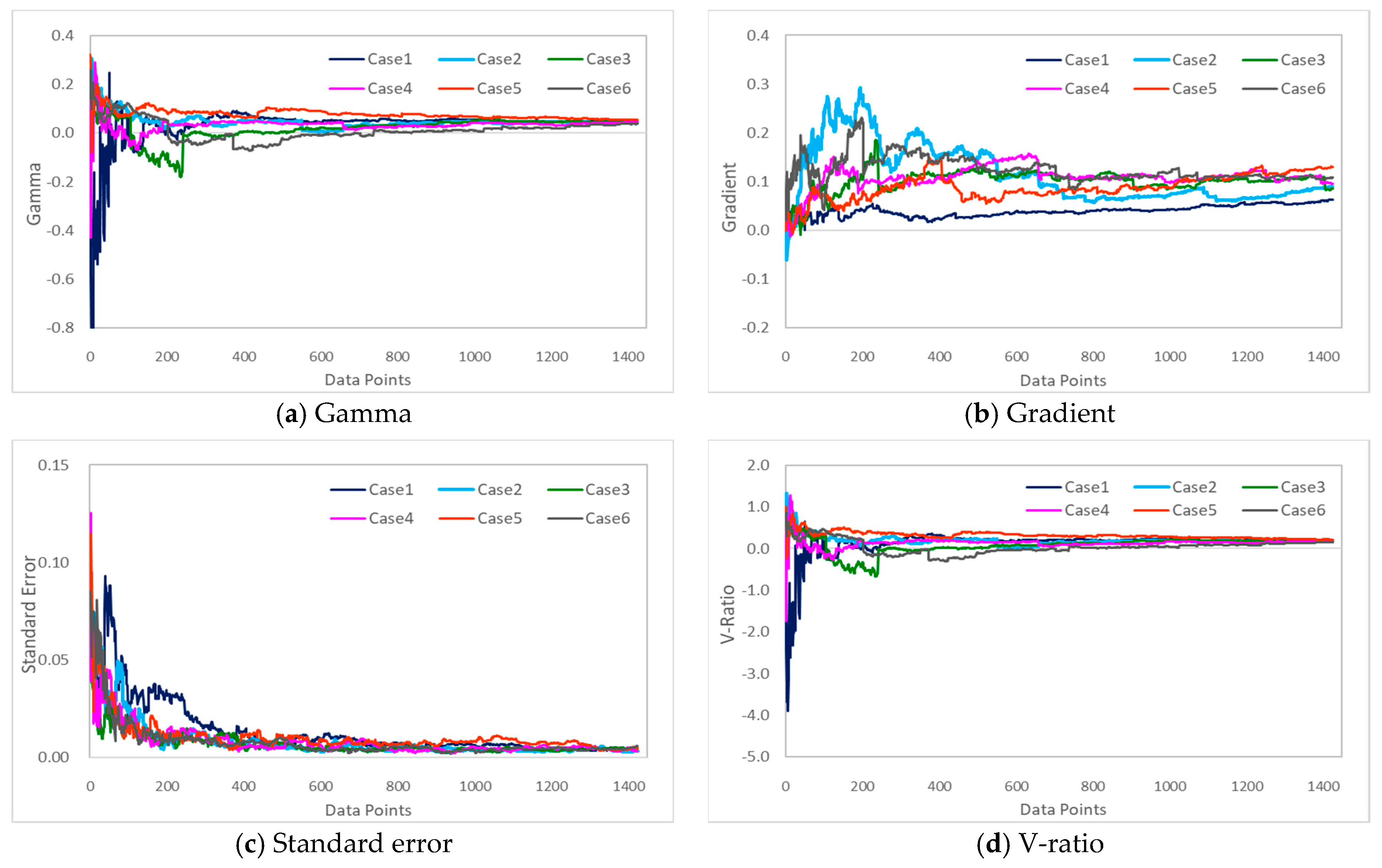
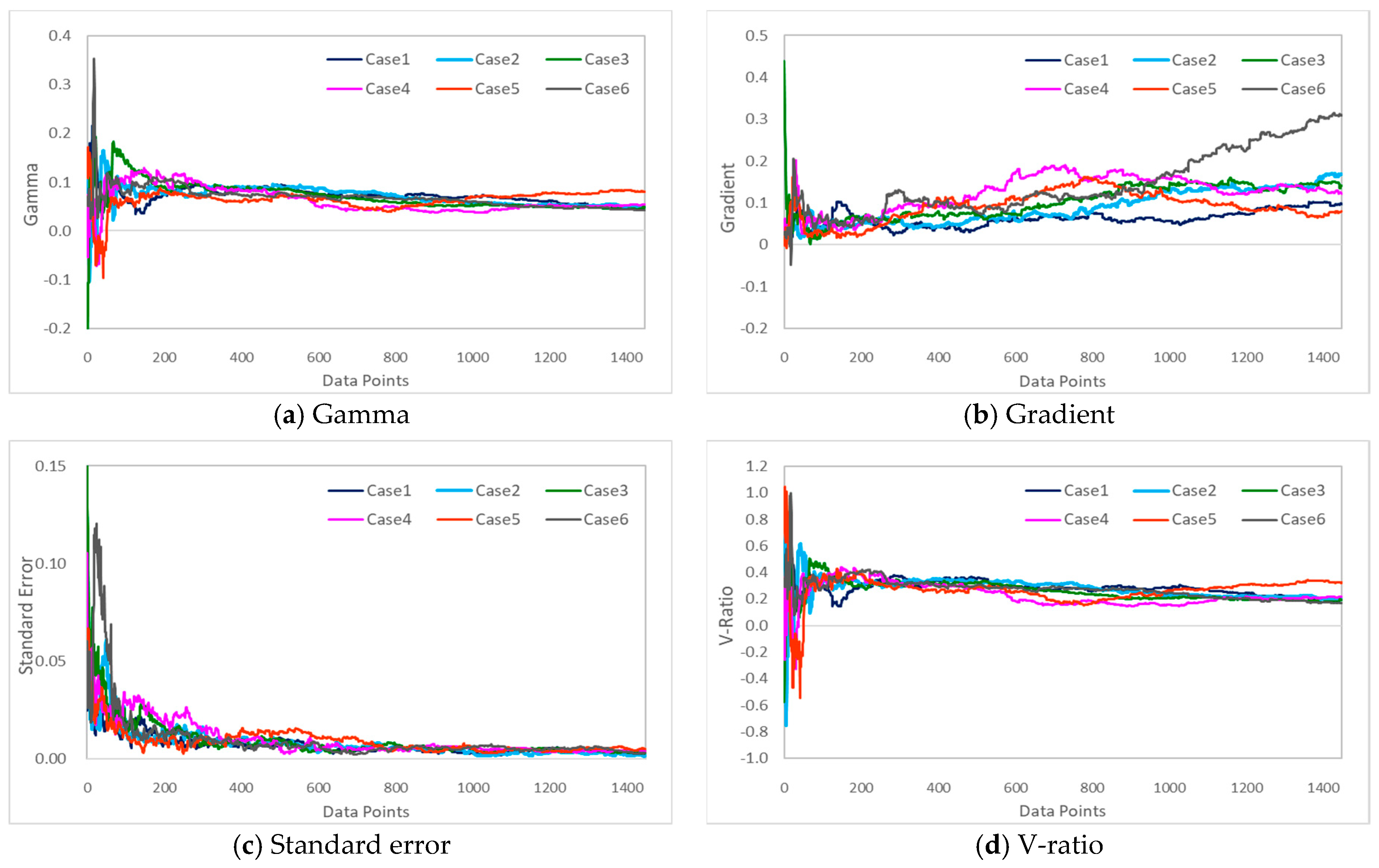
2.4. Gamma Test
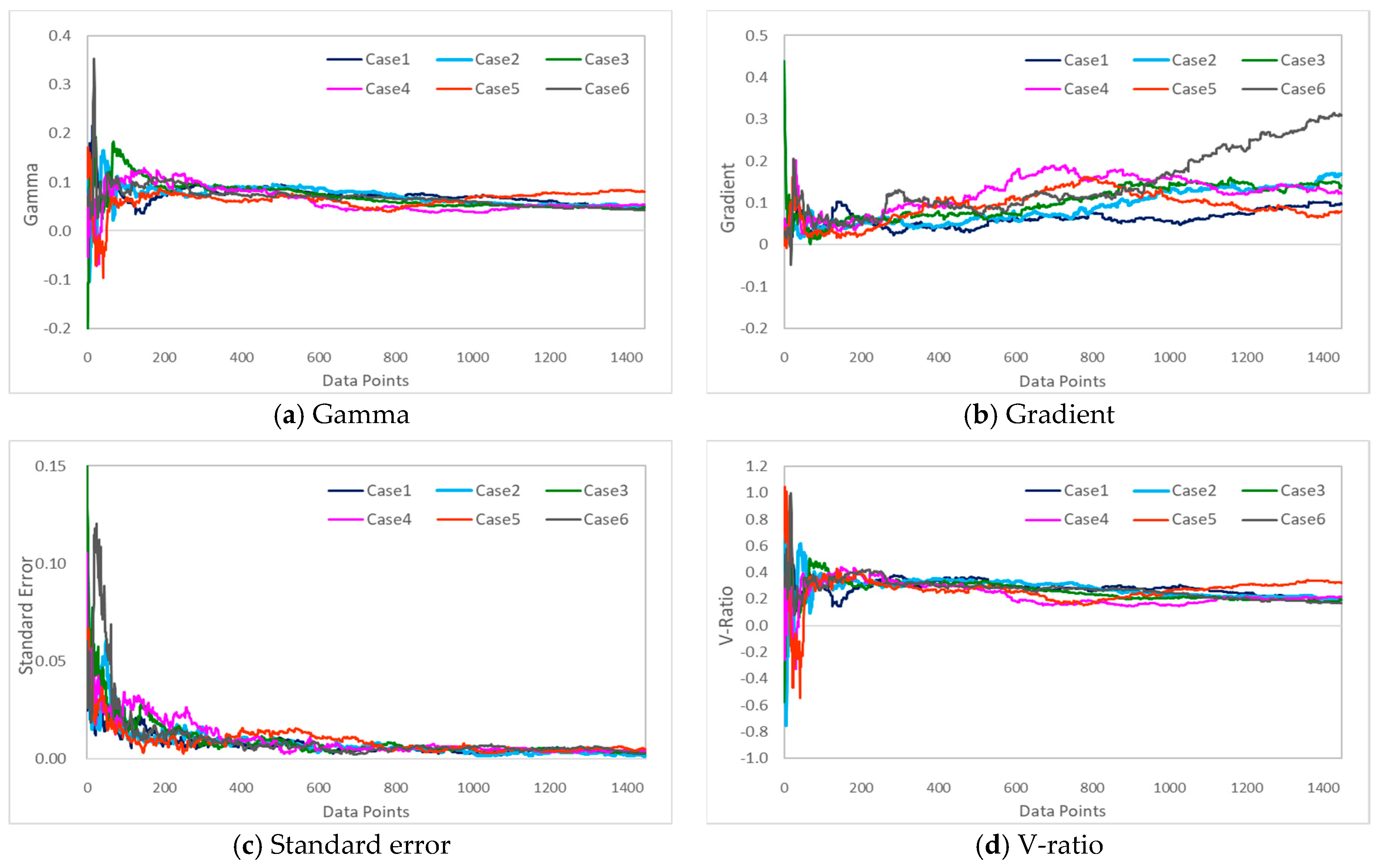
A Gamma test was performed to analyze the correlations between the input and output variables to select the optimal input data combination that shortened the simulation time, while increasing the accuracy of the data-driven model.
A Gamma Test is used to estimate the least mean square error calculated when modeling the data using a continuous nonlinear method. First published by Agalbjorn et al. [
18], the technique has been advanced and established by many researchers [
19]. The basic concept of the Gamma Test differs from conventional preprocessing data analyses using nonlinear methods. The analysis is performed under the assumption that the data are prepared as shown in Equation (2).
Here, the input vector
is limited to the closed set
, and the output
, which corresponds to the result of the general model or the dependent variable, is scalar. Vector
affects the output value
and is the independent variable that can be used as the input for prediction. The basic assumption for the relationship between
and
is as follows:
Here,
is an exponential smoothing function and
is a probability variable indicating noise. In Equation (3), the
value represents the input data, and the
value represents the prediction (target value). The Gamma Test performs a nonlinear analysis based on the kth
closest variable
for each vector
. For each input data
, the mean square root distance to the
closest neighbor data is calculated. This is shown in Equation (4). The mean square root distance with the
closest neighbor data is also calculated using the same method for y, which is the result (or target) value for the independent variable,
x (Equation (5)).
When the relationship with the physical distance to the closest neighbor data is calculated for each variable, the same number of
and
values as the number of data are generated, and a regression equation is derived to calculate
from these two variables. The gamma statistic
is an estimate of the variance of the ANN’s result that cannot be explained by the exponential smoothing data model.
Here,
is used to calculate the
uncertainty index according to a specific combination of input data. In Equation (7),
is the variance of output
, which makes it possible to judge the predictability of the output in terms of whether it can be modeled smoothly and reliably, independent of the output range. A
value close to 0 indicates a high predictability of the output
. The above process can help determine the amount of data required to build a model with a mean square error that approximates the expected noise variance [
20].
2.5. Data-Driven Model (Adaptive Neuro-Fuzzy Inference System; ANFIS)
This study applied the ANFIS model, developed using the neuro-fuzzy model theory combining an ANN with fuzzy theory, which is appropriate for nonlinear prediction and simplifying the complex relationships of the numerous input variables. The ANFIS model has been applied in various fields to combine the advantages of the neural network and fuzzy theory, while minimizing the disadvantages.
Neural networks have an excellent data-based processing ability because of their large flexibility in system configuration. In contrast, fuzzy theory is appropriate for processing and inferring ambiguous information within a logical system. However, membership functions and rules need to be determined through trial and error, and repeated readjustment of the processes is required to build the desired fuzzy theory system [
3].
A neuro-fuzzy model has been proposed to solve these issues. This model automatically adjusts the membership functions and rules in accordance with the control object using the input and output information obtained from the control environment with the structure and learning ability of the neural network. Determining the membership function for fuzzy inference using a neural network has the following advantages [
3]:
Because the membership function is determined by the learning of the neural network instead of the user’s subjective judgment, trial and error and readjustment processes can be omitted, thus shortening the system construction time.
The neural network is nonlinear; thus, the accuracy of the results can be improved by selecting a nonlinear membership function to represent the relationships of nonlinear input and output data.
The rules can be automatically obtained using the learning function of the neural network.
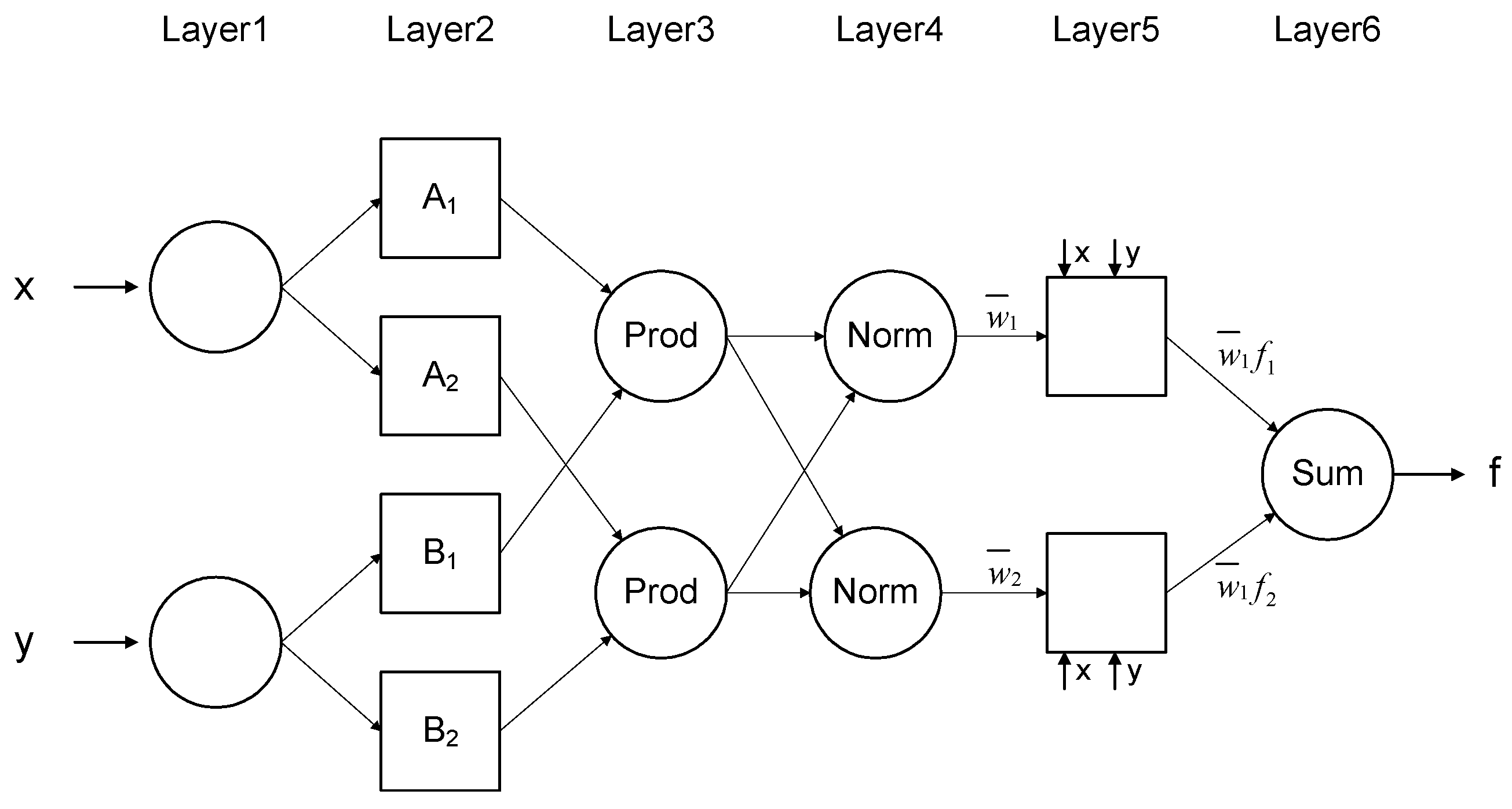
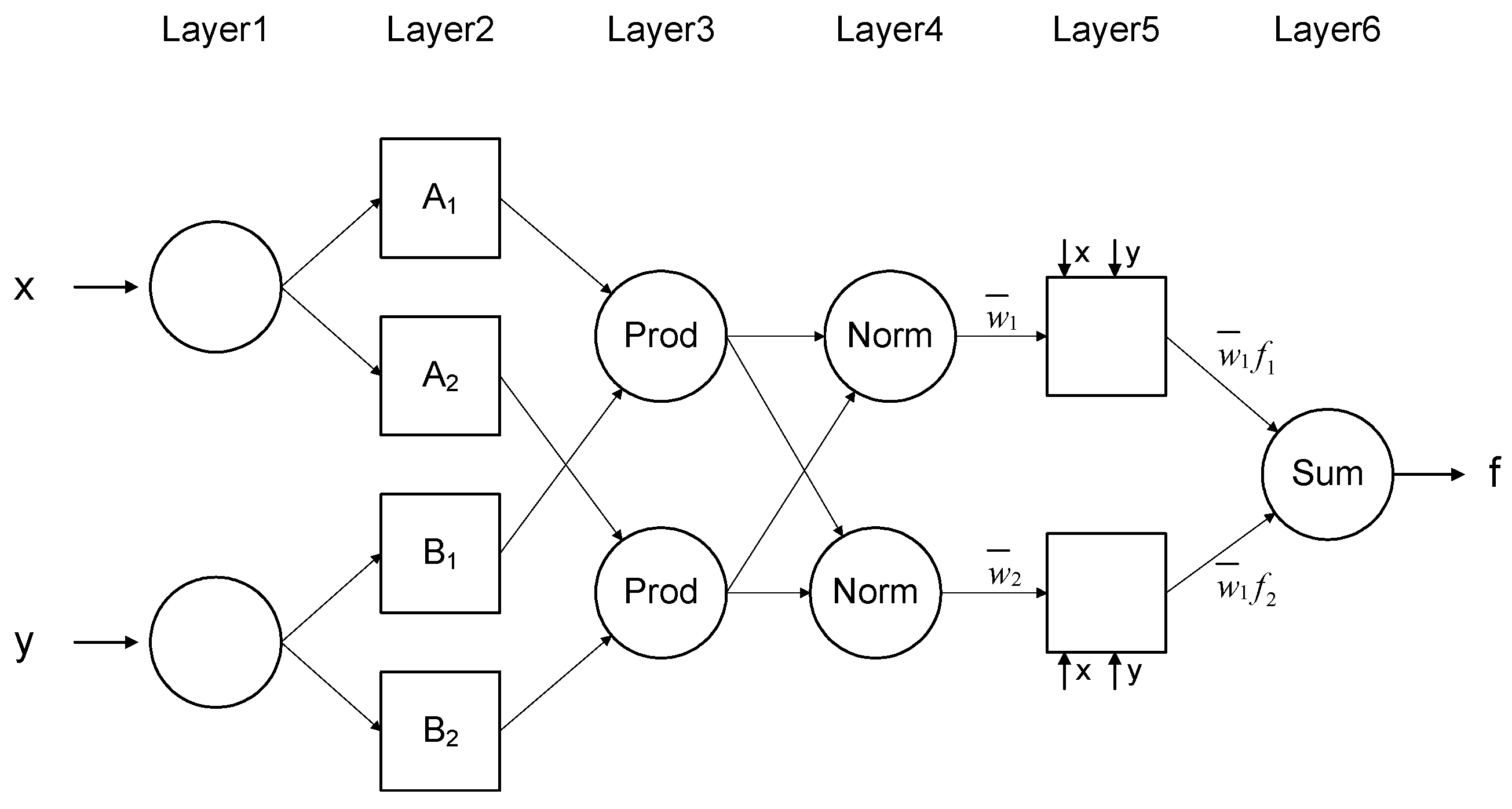
The neuro-fuzzy structure is composed of five layers with a node output in each layer. Layer 1 is an input node and Layer 2 is an adaptive node, and they act as a membership function. Layer 3 is a fixed node indicated as Prod, and the output of each node represents the connection strength. Layer 4 is a fixed node indicated as Norm, and the output represents the normalized connection strength. Layer 5 calculates the weighted value of the output of the previous layer. Layer 6 is represented as the sum of all input signals to calculate the inference result for the entire system (
Figure 4).
We applied the subtractive clustering algorithm for the fuzzy clustering technique in the neuro-fuzzy model. This algorithm assumes that each data point is a potential cluster center and uses the density of object data to determine the object data closest to the cluster center to define the representative cluster center; therefore, it has a high application potential.
In addition, data with low Epochs error values were selected as the parameters through the trial-and-error method, and included the range of influence, squash factor, accept ratio, and reject ratio.
2.6. Composition of Training Data for ANFIS Model Application
The data-driven model must be trained by a combination of variables that have a high correlation with the target variable to predict the target outputs. Thus, this study selected BOD as the target variable for predicting water quality. With regard to the input variables, the discharges of the Seomjin River Dam (Unam and Chilbo), Sanseong water intake, Nakyang Weir water intake (Gimje and Jeongeup irrigation canals), rainfall, and flow rate (t), and the input variables of one day before (t − 1) and one day after (t + 1) were used. These input variables were selected considering the usability of the data-driven model because the corresponding observation data were generated every day, and when they were input into the data-driven model, the water quality (BOD) for Dongjin River 3 point could be predicted without running the HSPF model. A gamma test was performed first to determine which composition of input variables could improve the ability to predict BOD, and thus, the optimal combination of input variables was determined.
The ANFIS model, which was constructed through training, verification, and testing, was employed in this study. The parameters of the membership function were determined through the training and verification processes. As the parameter values of the membership function change based on the conditions used in this process, the results of the ANFIS model also vary. The ANFIS model was built for irrigation and non-irrigation periods, as the target watershed is highly affected by agricultural water intake because of its large irrigation system. To split the input data for learning, the specified indices method, which best reflected the time-series data, was used among the random indices method, blocks of indices method, specified indices method, and interleaved indices method [
21].




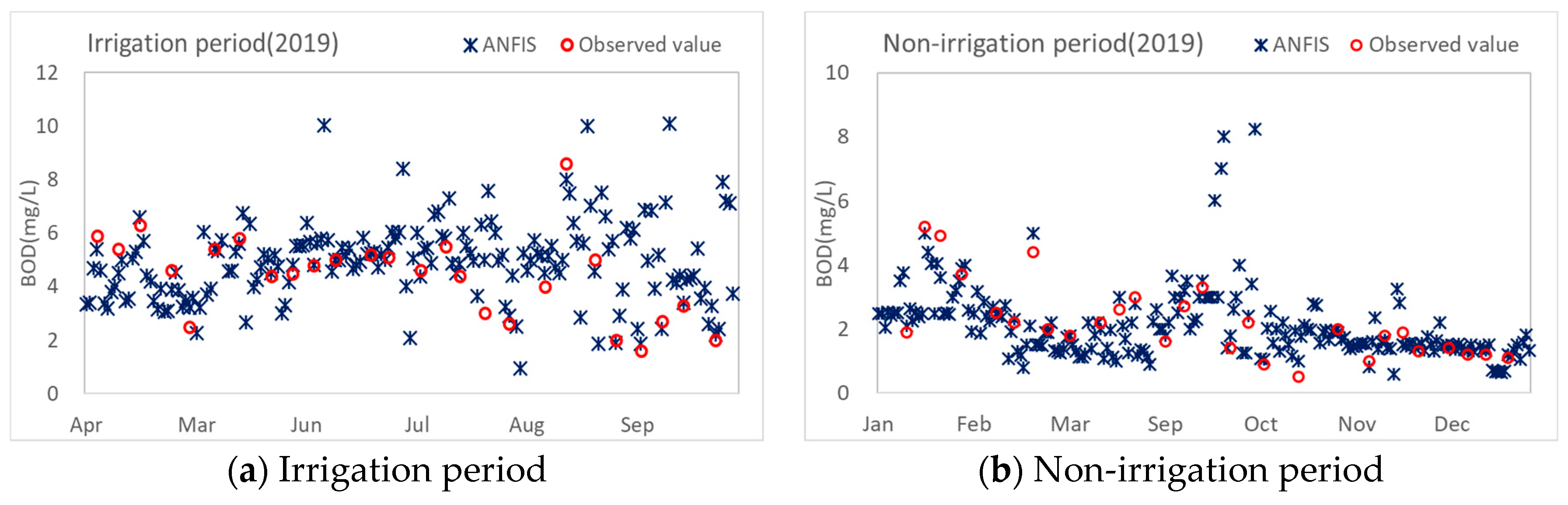

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}