1. Introduction
Natural hazards are a challenging topic for the modeling and managing of the associated risks, mainly due to the low frequency and high impact of their occurrences. As a prime example of such high impact low frequency hazards, we consider (fluvial) flood risk in this paper. We will present two different modeling approaches to estimate marginal flood risk at the municipality level. The first one is based on risk maps to estimate the flood damage distribution in a given municipality, whereas the second approach uses real damage data for the municipalities and extreme value statistics techniques to fit distributions into ranges where previous observations are scarce or not present at all. In order to aggregate the flood damage distribution of individual municipalities to larger areas, we will use a recently proposed dependence structure based on a Brown–Resnick max-stable process for joint discharges at river gauges (see [
1]), which we will adapt to the respective given river network. While the proposed approaches are generally applicable for arbitrary countries and hierarchy levels, throughout this paper we will work with the concrete case of Austria, and the levels of municipality, states (”Bundesländer” in German), and the entire country. The raw loss data on the municipality level will be taken from the Austrian disaster relief fund and are available for four of the nine Austrian states. We will suitably normalize these data to the respective amount of building value and the appropriate building cost index to make the data comparable and usable.
While the use of real damage data is quite scarce in the literature, the first approach for marginal modeling using flood hazard maps is somewhat similar to methods that have already been used in the flood risk literature. Concretely, in a first step, an approximation of the inundation area for a flood of a given return period is evaluated. Subsequently, impact functions are employed that estimate the damage associated with the inundated area. In the following, we briefly summarize some related previous literature following this approach. [
2,
3,
4] estimate the inundation area for different return periods. In [
2] the return period of the yearly maximal discharge (in terms of the present climate) is estimated for present and future climate data runs. The authors then use the interpolation of inundation areas of floods with given return periods (the inundation areas are taken from [
5]) to get the inundation area for a return period of the considered year. In [
4], first, the economic impact of floods with given return periods of 2–5–10–20–50–100–250–500 years are calculated for a set of considered areas. To that end, for a given area, the inundation area of a flood with a given return period is calculated, and then impact functions depending on different land use categories and the inundation are used to estimate the impact of the flood. To get an approximation of the distribution of the flood impact aggregated over the considered areas, a Monte Carlo method is used. That is, the authors generate realizations of the aggregated flood damage for a year. The impact for each area is calculated as the interpolation of the impact of the previously calculated impacts of floods with given return periods. The realization of the aggregated impact is then the sum of the realizations of the individual impacts. In order to combine the results over the considered areas, a copula approach is used for dependence modeling. Using discharges taken from the LISFLOOD model, the concrete choice of copula is estimated within a general flexible family of copulas. The consideration of the dependence structure allows to also estimate quantiles of the damage distribution. Similar to [
4], also in [
3] at first the hazard maps and corresponding impacts are calculated for a set of given return periods for present and future climate and the yearly average damage is calculated by integrating over the damages from the impact curves. Since flood protection measures are not incorporated into the inundation areas in the studies [
2,
3,
4], only damages from floods that exceed given thresholds are considered. The studies [
6,
7] use similar methods as in [
2] to get the inundation area. However, instead of using risk maps for given return periods, the inundation areas are calculated for each year individually from the estimated discharge values. This has the advantage that no interpolation method is needed. The aforementioned studies are all global or continental, meaning that they consider flood risk for larger areas. Consequently, the estimated inundation areas are quite rough, as detailed regional modeling is not feasible.
Flood impact studies that use more detailed models, are for example provided in [
8,
9]. In these studies, besides the inundation areas for a single discharge event with a given return period, a continuous simulation of several years is used to get the river discharge and flood damage from the precipitation. These models are restricted to individual flood river catchments in Germany, although [
9] indicates that the method can in principle work for larger catchments. In fact, [
8] stands out as there a weather generator is used to generate a long time series of flood damages which allows for the calculations of higher quantiles in the flood damage distribution.
In the literature, there are different choices for the units in which the impact of a flood event is expressed. The impact can be measured by the number of affected people (e.g., [
10]); damages to the residential building stock (e.g., [
8,
9]) or damage functions depending on the land use class (e.g., [
4]). In addition to the direct loss estimated by impact functions, some studies consider the indirect impact in terms of welfare losses (e.g., [
6]), or the effects on the finances of countries and implications for risk management (e.g., [
11]).
In this paper, we measure the impact as the damages to the residential building stock. Since the risk maps used in this paper only provide the flood extent and not further variables like inundation depth, we cannot use the advanced damage functions provided in [
12,
13,
14,
15]. Instead, we will use simpler damage functions that rely on two different distributions for the damage, depending on the return period of the flood and the location of the buildings. Further, we will use actual flood damage data on municipality level to calibrate the model. We would like to note that there are considerable uncertainties in the calculation of flood damages [
16,
17] and hence results should not be interpreted as exact values.
We use the HORA risk maps (‘Hochwasserrisikozonierung Austria’, see [
18]) as the hazard map for the estimation of the inundation area. This has the advantage that it takes more details into consideration (e.g., existing concrete flood protection measures in certain areas) than models for larger areas could provide. The downside of this approach is that one can only apply this method for areas where flood risk maps already exist, and that one is restricted to using the available return periods in that map. This is a little critical, since, usually, the smallest considered return period is 30 years. Further, to aggregate the damages of the different inundation areas, a dependence structure has to be used for the calculation of quantiles of the damage distribution (see for instance [
4,
11]). Using such statistical methods for the aggregation of the damages in the individual areas has the disadvantage that physically implausible results may arise from the simulation, see [
9,
19] for a discussion of this problem. However, the principle of statistically combining marginal information with particular dependence shapes is a standard approach in many areas of risk management (see e.g., [
20]), see also [
21] and the two studies [
22], [
23] for the particular flood modeling context. In this paper, we improve on the existing approach from [
21] in two aspects. First, as in [
4] we use the dependence of discharges as a proxy for the dependence of flood losses, but instead of using the flexible yet somewhat arbitrary copula of [
4], we adapt a model for dependence that was recently published in [
1] and that accounts for the river network. The second improvement to the approach in [
21] is the use of satellite data combined with building stock data to intersect building stock data and inundation areas.
As a second approach, we will also use actual loss damage data of municipalities of Austria. In particular, we will utilize Extreme Value Analysis (EVA) to generate a damage model for each municipality and then aggregate the data using the same dependence structure as described above. For the estimation, we will use damage data from the payments of the catastrophe fund for four Austrian federal states, where the timespan of the available data ranges from 26 years for Styria to only 7 years for Upper Austria. The latter is obviously short for statistical purposes. In addition, one may argue that flood risk changes over time. For example, [
14] showed that the main driver of changes in flood risk is urban sprawl, as with increased population cities develop into more flood-prone areas. At the same time, flood risk can also change due to other changes in human behavior. [
24,
25,
26] show how human behavior can change the effects of floods, and that behavior will often depend on recent flood experiences. We do correct the data for the non-stationarity to some extent by normalizing not only for building cost changes (which is a better measure than inflation for our purposes), but also considering the changes in building stock in each area. This second data-driven approach provides an interesting supplement and additional benchmark to the (more common) first method, as it includes the historical evidence in the projections to the extent possible. We would like to point out that the approach followed in this paper can also be interpreted as a counterpart of the analysis in [
27,
28] for storm risk modeling in Austria, where the dependence structure bestowed on a detailed analysis of marginal storm risk was motivated and calibrated with wind speed fields. In the context of flood modeling, we also do not have sufficient historical data to convincingly fit a dependence model based on the data alone, so that we suggest here the use of a dependence model ‘borrowed’ and adapted from one of the river discharges for which sufficient historical data are available.
The paper is structured as follows. In
Section 2 we provide details on the used data and data preparation. In
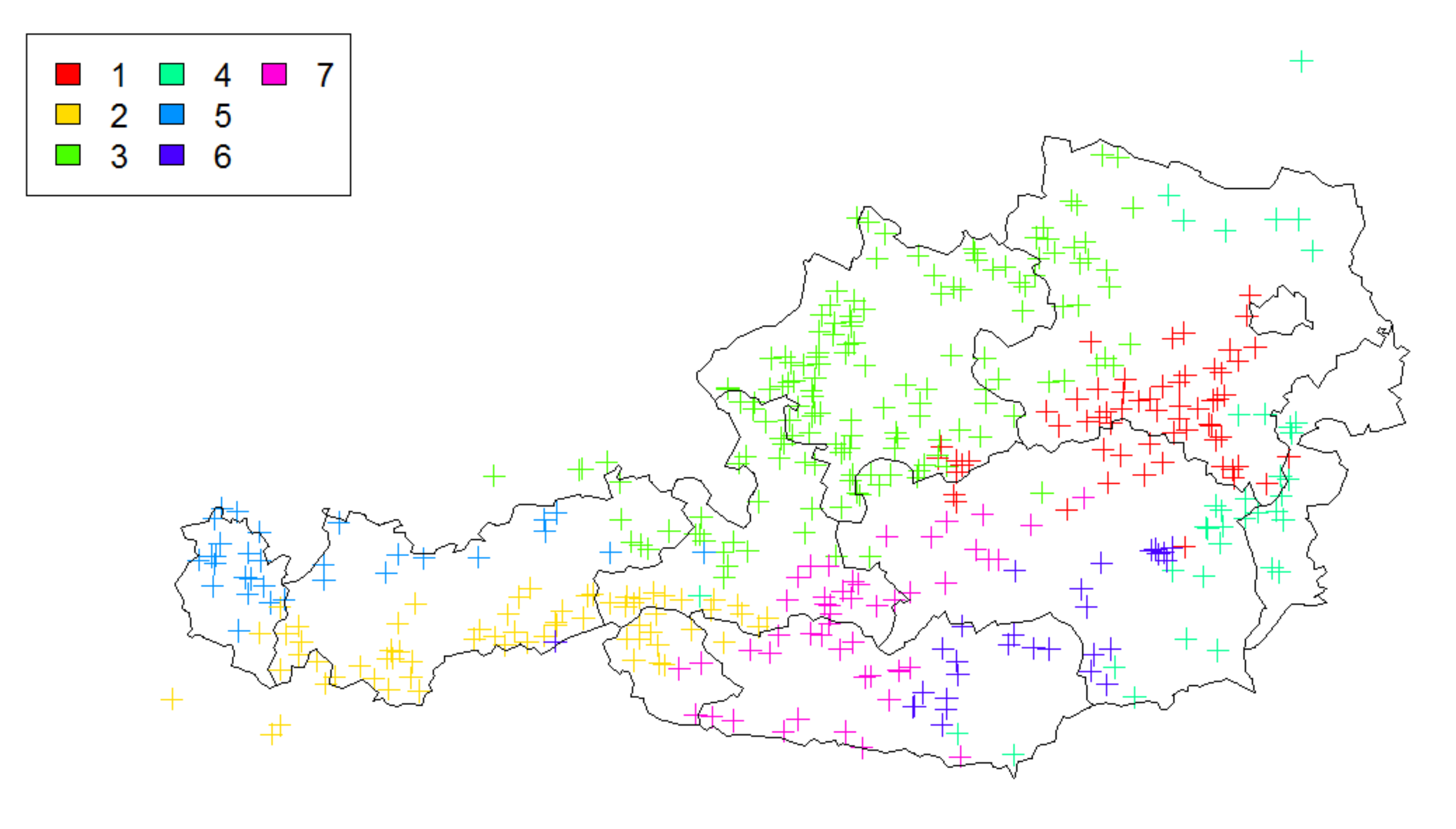
Section 3 we present the used methodology in detail. We start by giving the rationale of identifying clusters that form the core of the hierarchical dependence structure. Subsequently, we adapt the max-stable processes as suggested in [
1] for the dependence modeling of river discharges in river networks to the situation of Austria. This in particular asks for a further branching of hierarchical elements due to the complexity of its topography. We then show how the spatial dependence model that is calibrated on particular measurement stations in the river network can suitably be extended to the level of municipalities. After that, the marginal modeling with both the HORA and the EVA approach is described in detail and compared.
Section 4 gives the results for the estimation of the parameters and discusses their implications on the concrete flood risk quantification for all the levels (municipality, state, and country), including the impact on the resulting flood risk diversification potential across these levels.
Section 5 then provides some final remarks. Throughout the sections, some technical details as well as the statistical analysis underlying, accompanying, and justifying certain assumptions are delegated to the
Appendix A.
5. Discussion and Conclusions
In this paper, we made two main contributions to the flood risk literature. Firstly, we introduced a new approach to model the dependence structure that can be used to aggregate the information of existing risk maps to larger areas. Concretely, we suggested a spatial dependence structure that is calibrated with publicly available data of river discharges and the river network. Hence it is easily applicable to any region in Europe without the need of a hydrological model. The second contribution is to use historical claim data of municipalities for the estimation of future flood risks to obtain an alternative estimate which can either be used directly or as a benchmark for other approaches. We exemplified our approach for the country of Austria.
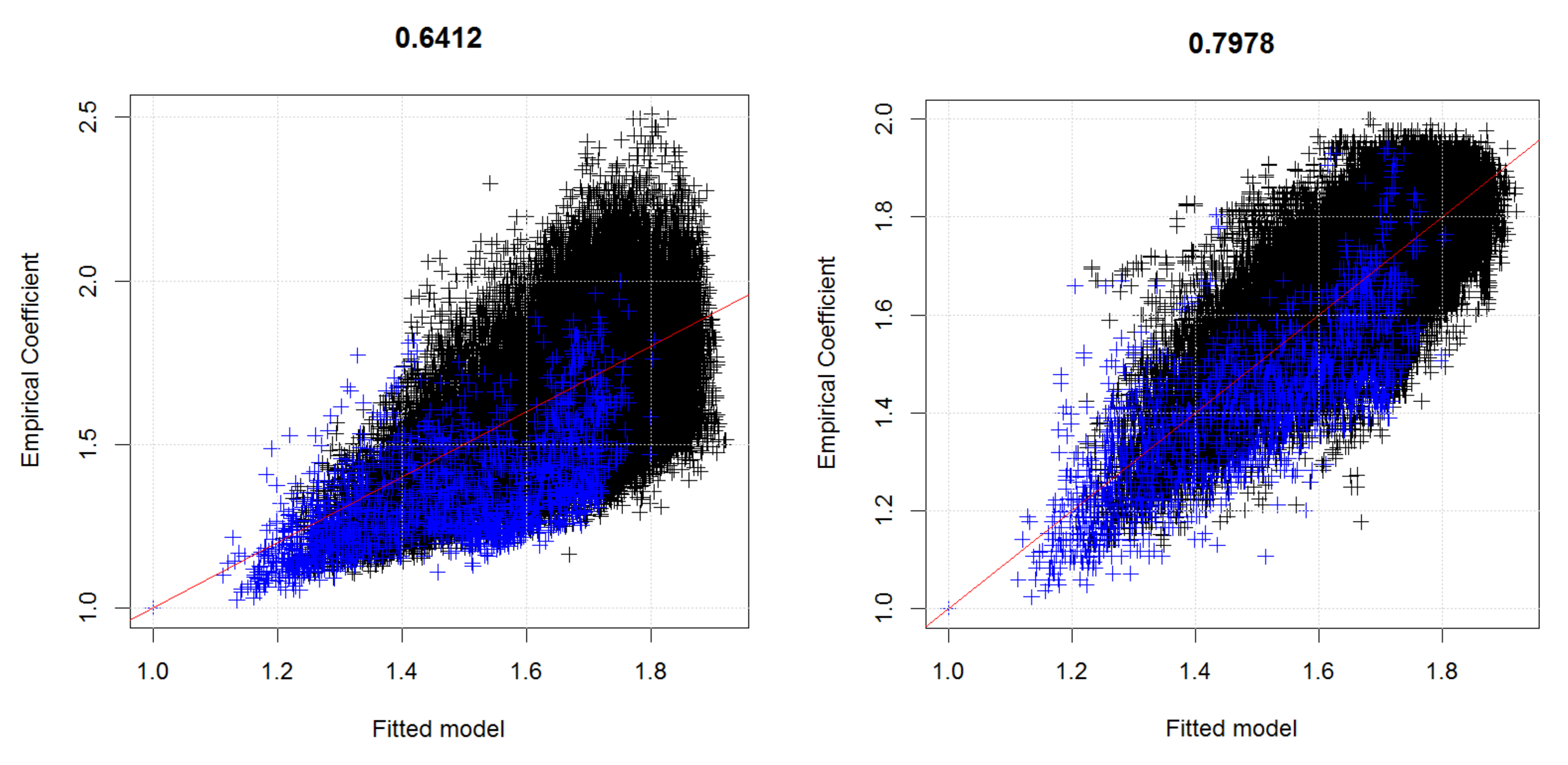
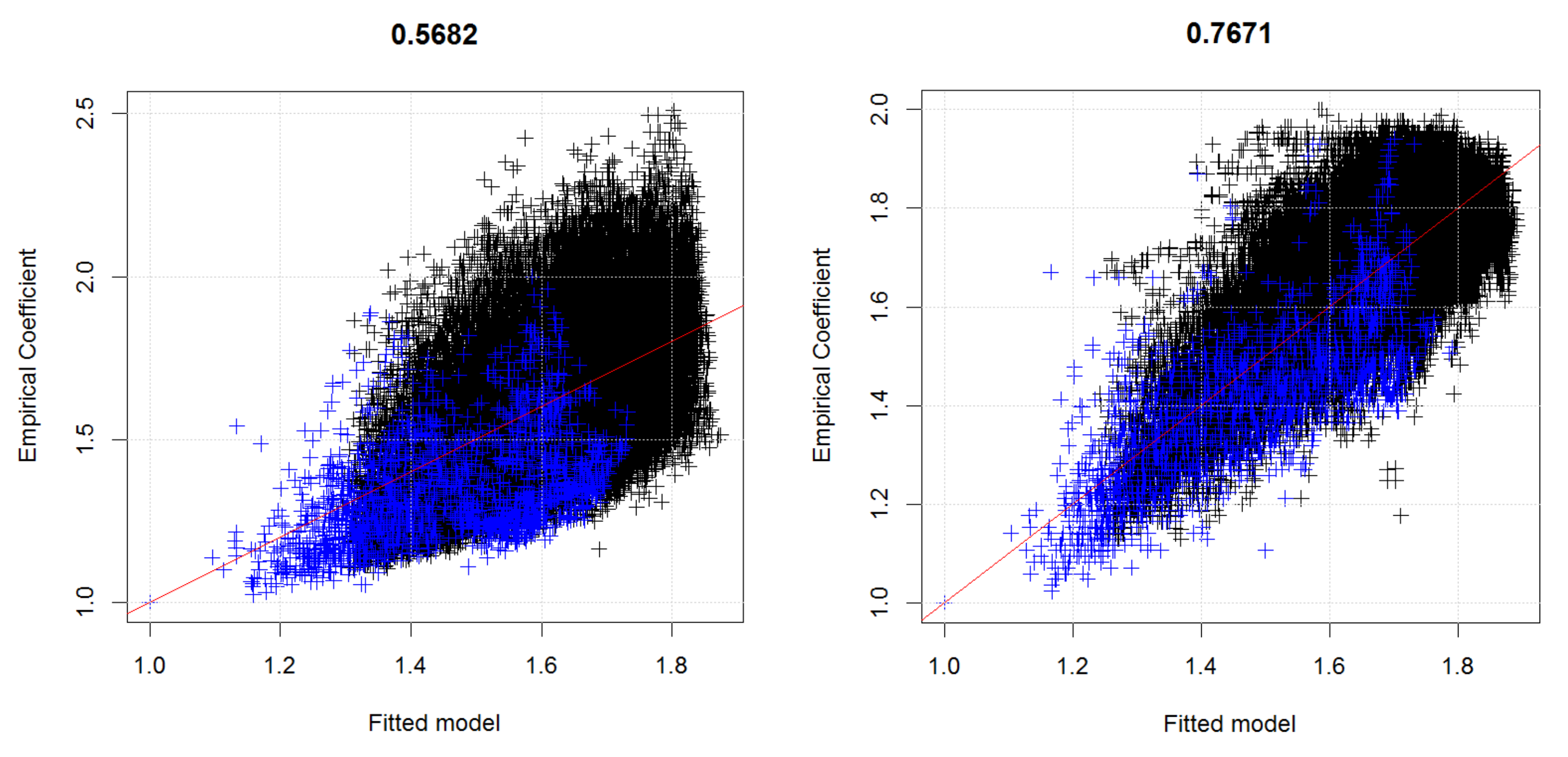
The choice of a dependence structure is a crucial step when aggregating individually modeled risks onto a collective level. For flood risk applications, a reliable dependence structure allows to aggregate the risk of flood damages from individual municipalities to bigger areas like states or the entire country. The resulting aggregate distribution can then be used to estimate important quantities for risk management like the required solvency capital (e.g., the expected damage of a flood with return period of 200 years in the regulatory framework of the European Union). Comparing the required solvency capital for a calibrated dependence structure with the corresponding numbers for comonotone risks subsequently quantifies diversification effects in the process of flood damage aggregation. In this paper, we developed a concrete and detailed case study for Austria. We first used the HORA risk map available in Austria and intertwined it with the building structure at a fine resolution. We then estimated loss distributions for each municipality in Austria for any flood event with a given return period. The obtained marginal flood damage distributions per municipality were then combined with a spatial dependence model based on a max-stable process to obtain the distribution of flood risks on various levels of aggregation. Here the dependence model was calibrated using the joint occurrences of river discharge levels in the Austrian river network. Monte Carlo simulations of joint appearances of return periods were then implemented to obtain flood loss distributions for each municipality and its aggregations.
The resulting model leads to a projected reduction of required solvency capital for the individual states of Austria between 29% for Lower Austria and 13% for Vorarlberg when compared to assuming the risks separately on the individual municipality levels. One also obtains that the states of Salzburg, Upper Austria, Vorarlberg and Burgenland have a higher concentrated risk than the other states. We have also seen that a further aggregation onto the country level is definitely worthwhile and leads to an overall reduction of required solvency capital of about 38% when compared to the sum of capital requirements of all individual municipalities. We additionally compare the results with the ones under an independence and a comonotone dependence assumption between municipalities, which reveals that the actual situation is much closer to comonotonic dependence than to independence, indicating that flood risk in Austria is particularly difficult to diversify and needs a substantial amount of scrutiny in its management.
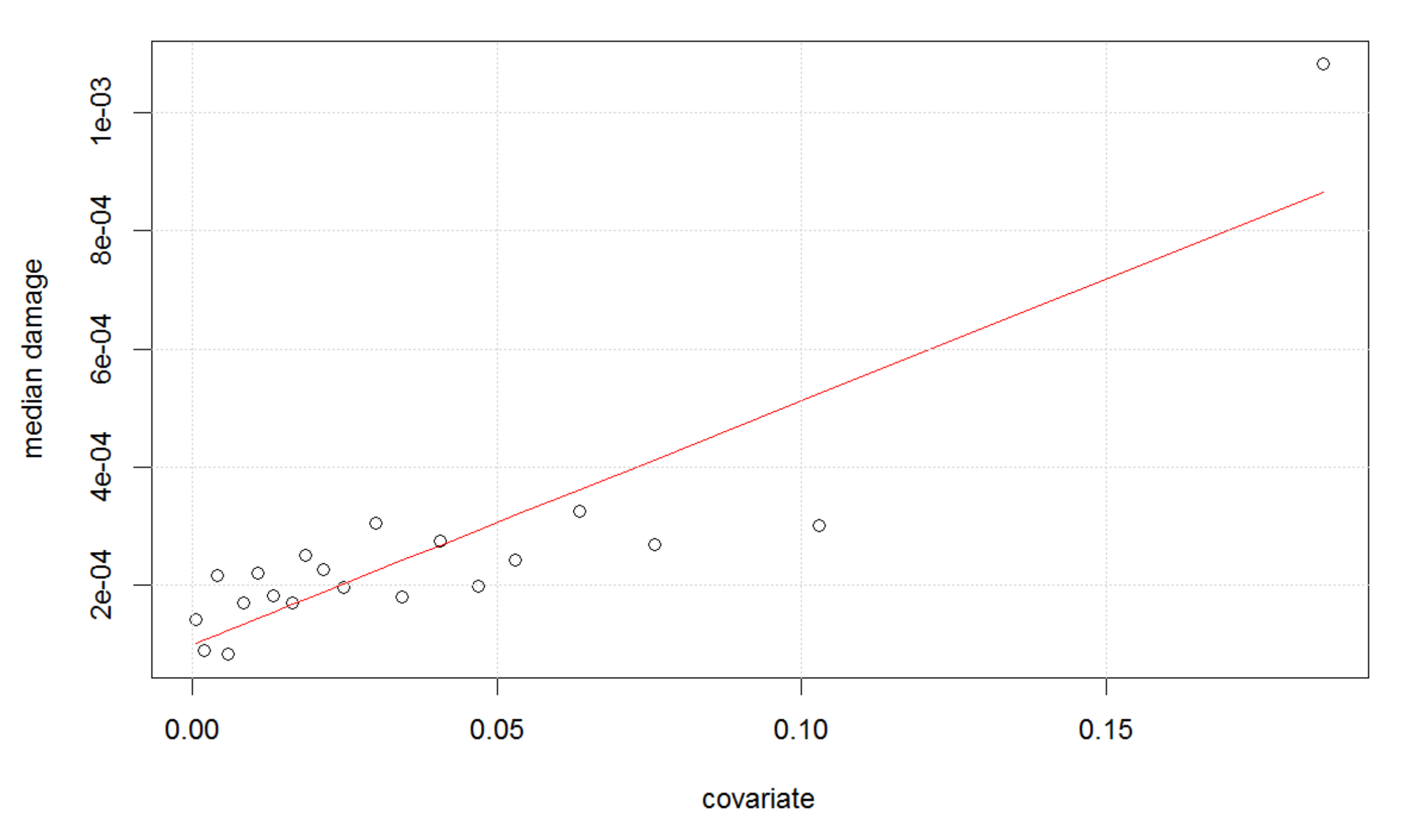
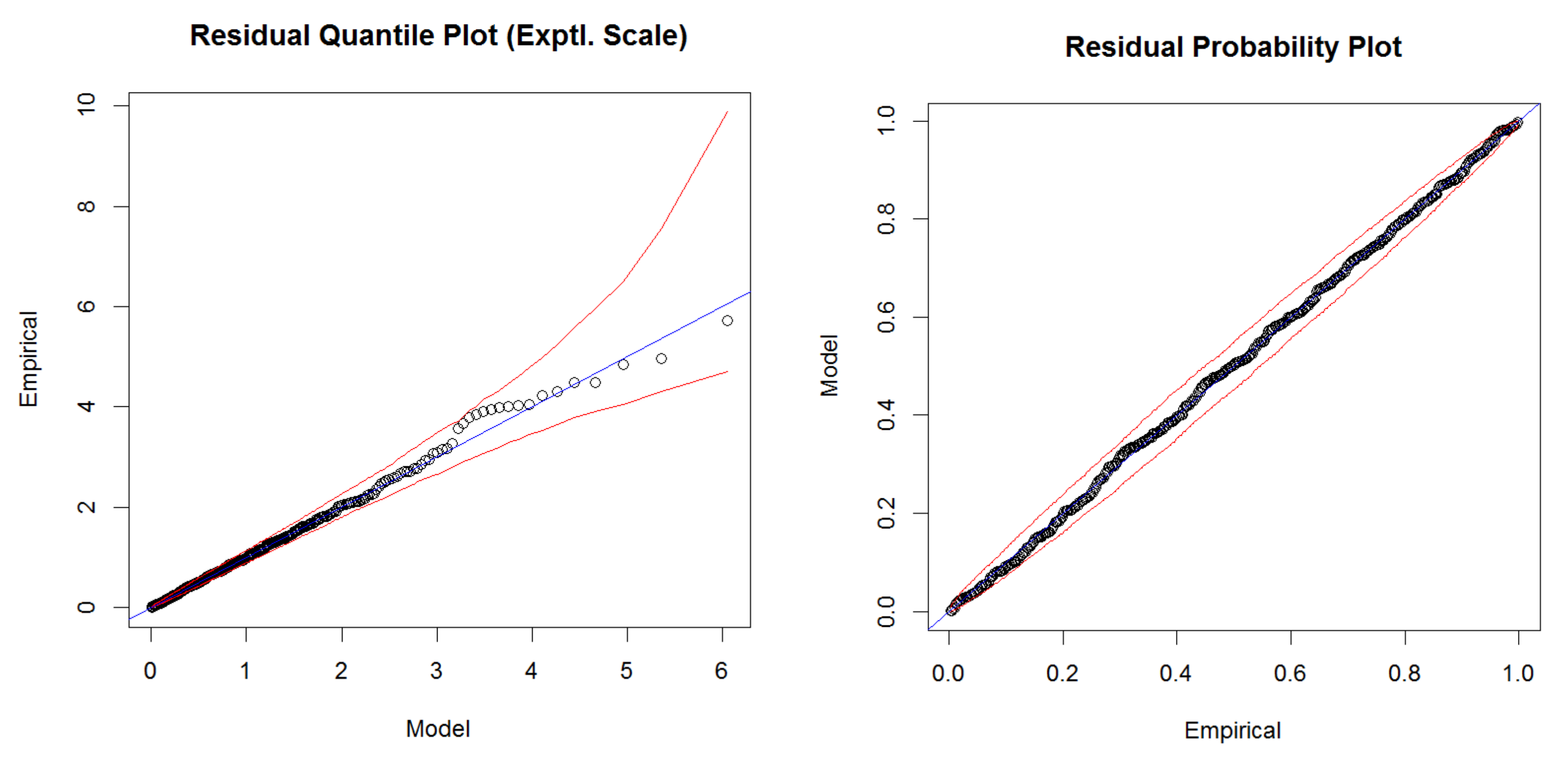
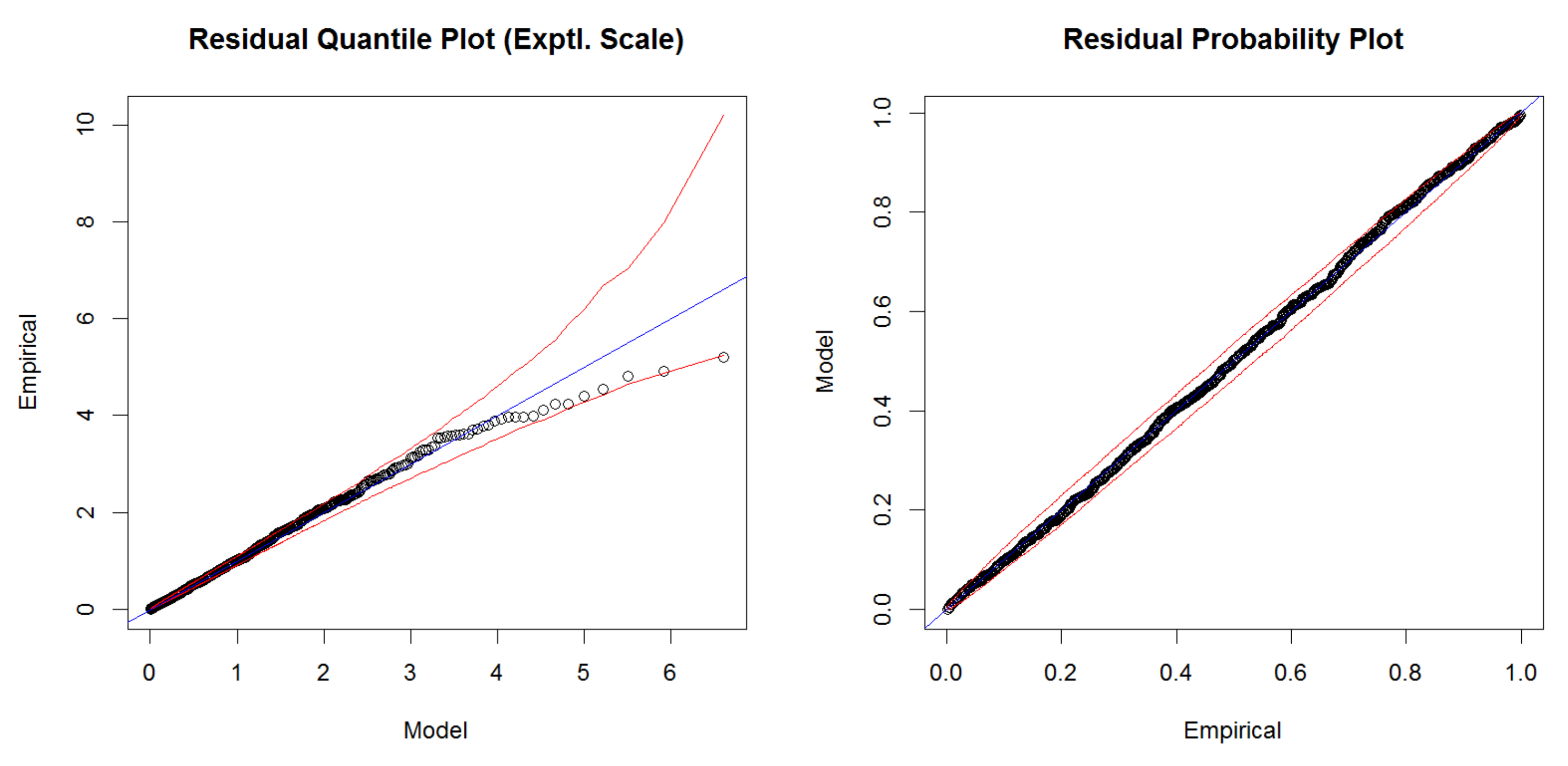
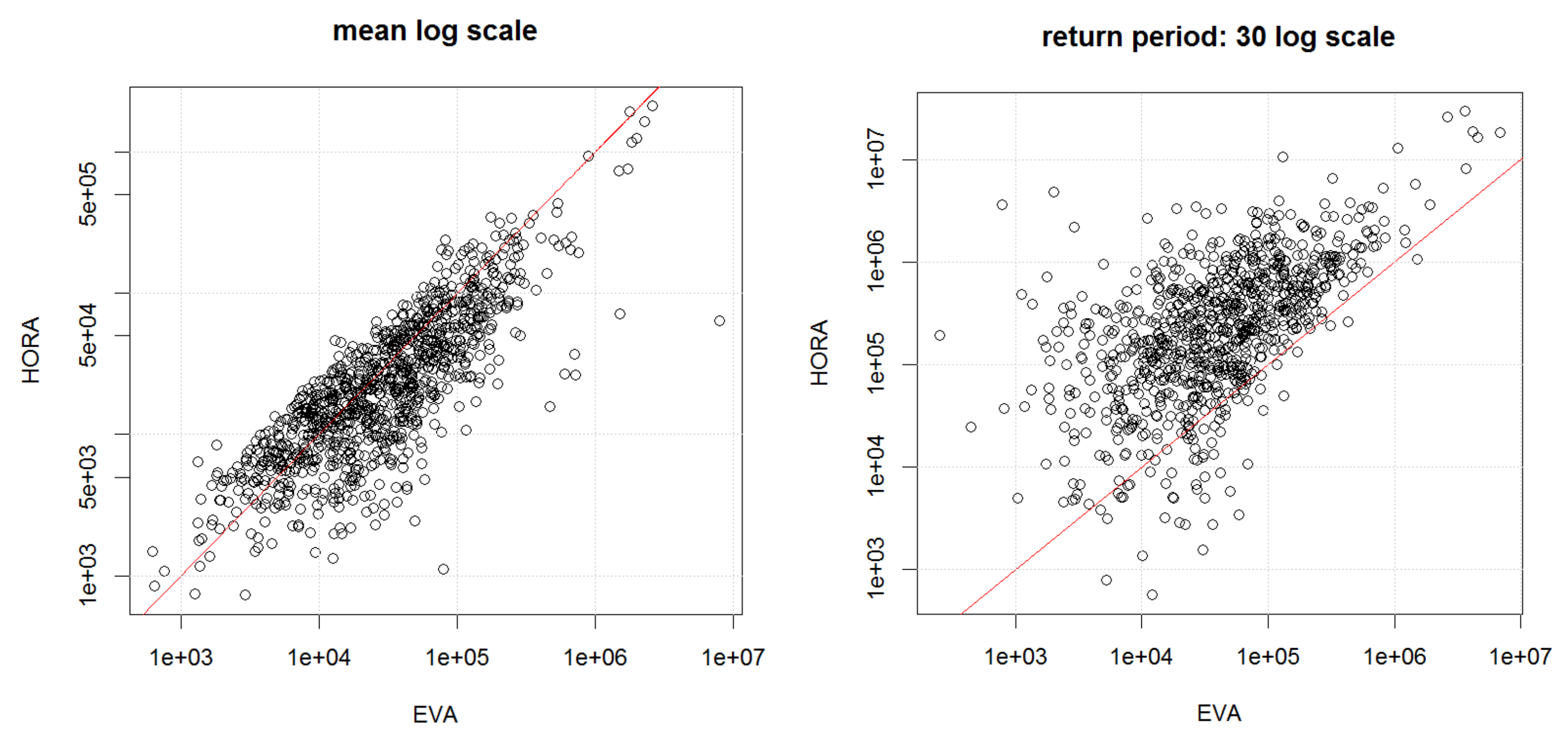
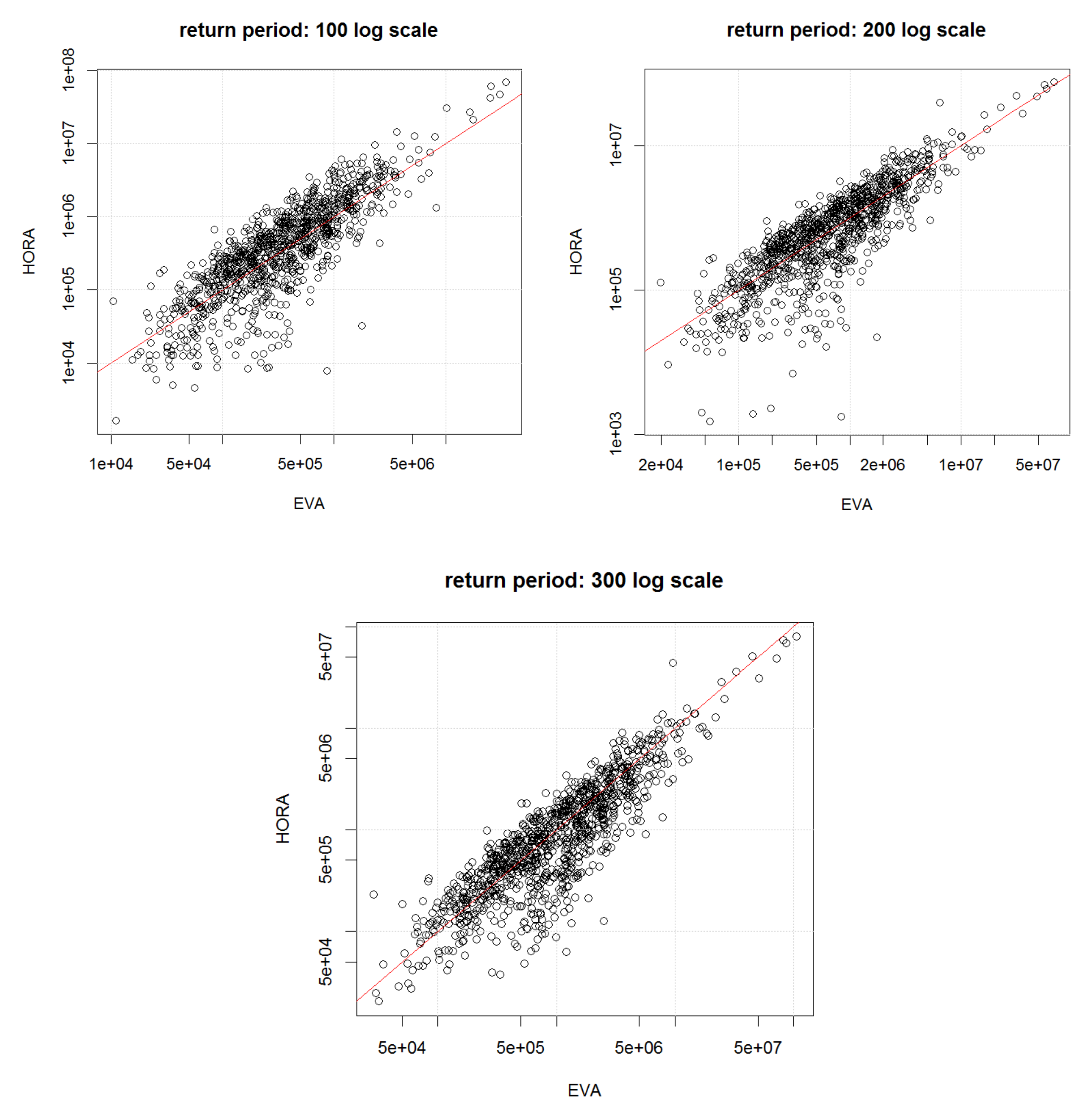
As a complement to the HORA model, we also developed a model based on real historical claim data for Austria and an extreme value analysis (EVA) approach to fit the suitably normalized flood losses for each municipality. Firstly, the actual claim data allowed to challenge the findings of the HORA model as the latter is not based on historical data, suggesting consistency for three of the four states with claim data (although this comparison between the actual claims and the HORA estimates should not be over-emphasized given the limited amount of years with available claim data).
Combining the obtained marginal distributions in the EVA approach again with the same spatial dependence model as for the HORA method then led to an alternative approach to quantify aggregate flood risk on a state and country level. Compared to the earlier study [
21] of flood risk in Austria, the present contribution not only uses a considerably improved dependence model, but also much more refined data for the marginal behavior, so that we were able to sharpen those previous results considerably. The new estimates suggest a reduction of the projected flood damage based on historical claim data compared to the earlier study. In comparison to the HORA model, the EVA approach leads to higher expected annual damages and more mass in the tail of the distribution. Nevertheless, in the range of flood damages for a return period of 200 years, a quantity that is relevant for risk management purposes related to Solvency 2 in the European Union, the results for the HORA and the EVA model are quite similar. This is remarkable, as the two approaches use empirical data and relations in quite a different way, indicating some robustness of the obtained magnitudes.
As mentioned in the introduction, the dependence modeling approach proposed in this paper can be applied to any other country, if marginal modeling experience and river discharge information is available, and it could be nice to see how the respective estimates for average and extreme flood losses compare to findings of other studies, often relying on hydrological models. While the present study took the non-stationarity of flood risk into account in terms of inflation correction, changes in building structure over time, and adaptations to the risk maps, it will be interesting in future research to also combine this approach with longer-term experience and projections due to climate risk. This could for instance include the consideration of time-dependent parameters in the max-stable components based on longer-term experience of flood occurrences (see e.g., [
48]) or even paleo-floods (see e.g., [
49]). Also, one might lift the granular dependence model approach suggested in this paper up one more level to the entire river network of Europe and in that way refine the somewhat coarse Clayton copula approach underlying the interesting findings in [
4].
We would like to finish with some remarks on uncertainties. While one can quantify the error that comes from the numerical evaluation of the quantiles by Monte Carlo estimation from the specified model (and we have done so in the respective tables), the model choice itself naturally is another source of uncertainty for final estimates that cannot be quantified in a straight-forward way, and is, in fact, present in any modeling approach. Uncertainties of the HORA model are already discussed in [
21], and mainly are the number of buildings affected by a flood for a given return period, the average damage of a building in a flood with a given return period and the used dependence structure for aggregating the risk of individual municipalities. Among these, the number of buildings affected by a flood of a given return period is probably the major source of uncertainty about the results, but since this error depends on the geographic characteristics of the municipality, it is hard to quantify with statistical methods. However, in this paper, the HORA model was complemented by a second, different approach using EVA techniques. The latter has considerable uncertainties itself, which mainly stem from the extrapolation nature of the method, but the comparison of the two different methods in fact assesses to some extent model risk in the calculations. Finally, adding the scenarios with comonotone and with independent risks in the analysis of this paper enabled us to establish best- and worst-case bounds for our results concerning the underlying dependence assumptions. In particular, the respective numbers can help to decide, in future studies, whether to focus more particularly on these aspects of the modeling procedure.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












