1. Introduction
Groundwater pollution has become a serious problem in many areas of the world. Numerical simulation of contaminant transport present convenient characteristics and have become useful tools in subsurface contaminant assessment and remediation [
1]. To obtain accurate and stable results from simulations, a small size in both spatial and temporal discretization is usually desired [
2]. However, for large-scale, long-term, and high-resolution real-world three-dimensional (3D) models, the number of cells can reach up to hundreds of millions. These huge computational simulations take hours or days to complete, sometimes are beyond the limit of serial processor computing memory and computation time. For example, Hammond and Lichtner carried out a 3D simulation to model uranium transport at the Harford 300 area. This model involved over 28 million degrees of freedom for 15 chemical components, which exceeded the computing power of a single processor [
3]. Consequently, developing a more efficient method is necessary for such cases.
In recent years, parallel computing has proven to be an effective method for dealing with large computational tasks, and it has attracted the attention of scholars. In the field of groundwater flow and contaminant transport, many scholars have presented different parallel strategies on parallel platforms. For example, HBGC123D [
4], P-PCG [
5], HydroGeoSphere [
6], and MT3DMSP [
7] were parallelized using the OpenMP programming paradigm based on a shared memory architecture. This parallel approach can be implemented with minor modifications to the computer codes but is limited to a relatively small number (i.e., 8–64) of processors [
6]. To overcome this limitation, codes such as TOUGH2 [
8], ParFlow [
9,
10], TOUGH2-MP [
11], and THC-MP [
12], use message passing interface (MPI) distributed memory architecture for parallelism. Although more cores can be involved, considerable code modifications, debugging, and performance optimization work are needed. To further improve the parallel performance, Tang et al. [
13] used the hybrid MPI-OpenMP to parallelize HydroGeoChem 5.0 (Oak Ridge National Laboratory, Oak Ridge, TN, USA) and reduced the calibration time from weeks to a few hours. The hybrid program is structured as an MPI processor at a high level. This program has the same shortcomings of MPI programming and may not be as effective as a pure MPI approach [
14]. In addition, researchers have accelerated simulations by using a graphics processing unit (GPU) [
15,
16,
17]. However, such work requires programming developers to have a good knowledge of the hierarchy of its memory structure. In short, developing an effective parallel code is often a complex problem and challenging task (e.g., understanding the hierarchy of memory, implementing parallel solvers etc.), which may exceed the capabilities of a single research group. With the rapid upgrading of computer architectures, a total rewrite of applications is required to obtain better performance and parallel scalability [
18,
19]. Therefore, convenient parallel development tools are required.
The development of application software based on a parallel computing framework has been gradually recognized and applied in recent years. Researchers and communities have developed efficient toolkits and application infrastructures, such as SAMRAI [
20], Uintah [
21], PETSc [
22], PARAMESH [
23], and J adaptive structured meshes applications infrastructures (JASMIN) [
24]. JASMIN, for example, shields complex parallel details, provides parallel programming interfaces and contains many mature solvers (e.g., HYPRE, which is a scalable linear solvers and multigrid methods). The JASMIN parallel framework facilitate parallel programming and has achieved good results in the field of groundwater simulation. For example, Cheng et al. [
25,
26] used the JASMIN framework to parallelize the well-known groundwater simulation software MODFLOW (USGS, Denver, CO, USA). A good scalability was achieved on thousands of cores. In the field of contaminant transport simulation, modular three-dimensional transport model for multi-species (MT3DMS) [
27] has been widely used [
28,
29] and has been as a core component of a number of commercial software programs (e.g., GMS (Aquaveo, Provo, UT, USA), Visual MODFLOW). Currently, MT3DMS cannot easily perform large-scale, high-resolution simulations that involve millions to hundreds of millions of cells. Although Abdelaziz et al. [
7] developed a parallel code of MT3DMS with OpenMP, the method is limited by memory capacity and the number of processors. Therefore, in this study, a parallel MT3DMS code, JMT3D (JASMIN MT3DMS), was developed using the JASMIN framework.
This paper is organized as follows. First, we briefly introduce the theoretical bias and data structures of the JASMIN framework. Then, we provide the implementation details of JMT3D (i.e., parallel method, communication strategies, solver design, a coupling of flow and solute, etc.). Finally, the correctness and performance of JMT3D are verified and discussed through five types of tests (correctness, steady flow, high heterogeneity, transient flow, and scaling tests) about water soluble inorganic contaminant models.
3. Results and Discussion
To test the correctness and performance of JMT3D, five types of tests were conducted. First, the correctness of the solution was verified by a transient model. Second, the speedup and memory consumption of different iteration methods were analyzed. Third, the effects of high heterogeneity and transient flow on the performance of the model were tested. Finally, a scaling test with 10 million cells was conducted on dozens to hundreds of processors.
3.1. Correctness Verification
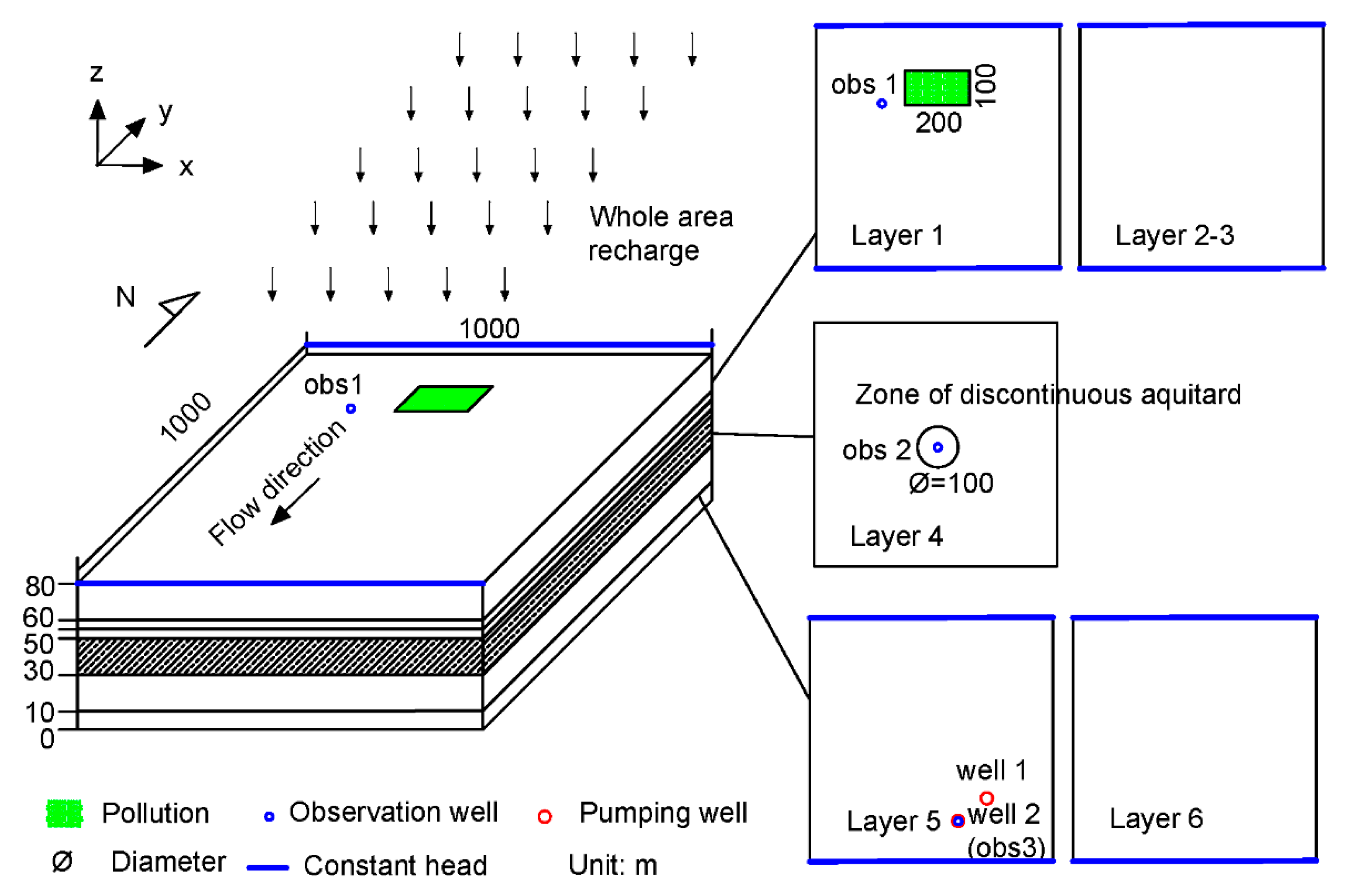
In the correctness verification test, a typical model with three aquifers is designed. The model is composed of an upper sand and gravel aquifer, a lower sand and gravel aquifer, and a middle a clay and silt aquitard with a discontinuous zone in the center of the aquifer. The model is similar to the demo of Waterloo airport in [
33]. To increase the accuracy of the computational task, the upper aquifer is divided into three layers, and the lower aquifer is divided into two layers (
Figure 7).
The numerical model was simulated using a domain covering an area of 1000 × 1000 m2 with a thickness of 80 m. The problem size can be represented as 20 × 20 × 6 in the x, y, and z directions.
The first layer was defined as an unconfined aquifer, and the others were defined as confined aquifers. Except layer 4, all layers were set as specified heads at the north side (68 m) and south side (70 m). Layer 4 was set no-flow boundary all around. The east and west boundaries of all layers were defined as no-flow boundaries. At the center of the fourth layer, a permeable circular area with a diameter of 100 m is observed, and the center coordinate of the circular area is (500, 500). At the fifth layer, two wells located at (725, 225) and (625, 175) with a rate of −800 m
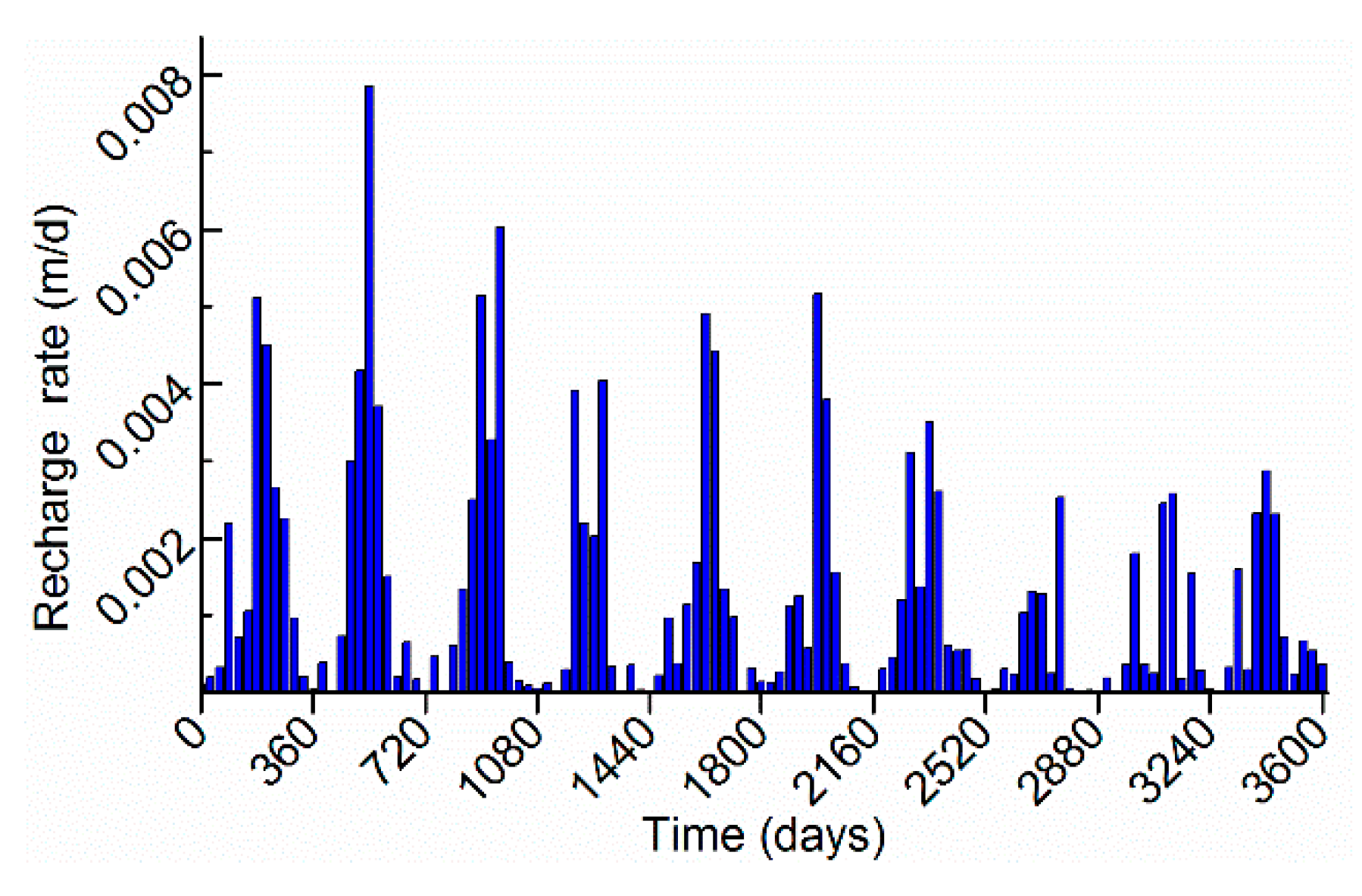
3/d per well. Dynamic recharge occurs at the first layer with the rate in
Figure 8. For the contaminant transport model, a rectangular contaminated area with an area of 200 × 100 m
2 was located in the first layer. The upper left corner of the rectangular area was located at (400, 900). The contaminant area was treated as initial concentration without other sources. The initial concentration was set to 5000 mg/L. Three observation wells were set at obs 1 (325, 825) in layer 1, obs 2 (525, 475) in layer 4, and obs 3 (625, 175) in layer 5. The model was run for 3600 days with 120 stress periods with one time step per stress period. The contaminant transport program automatically calculates transport steps depending on the flow velocity and Courant number. The others parameters of the flow model and contaminant transport model are shown in
Table 1.
The flow and contaminant transport convergence standard were both set to 1 × 10
−6. The test was carried out on an SR4803S Linux workstation with 4 AMD OPTERON 6174 CPUs (2.2 GHz). Each CPU contained 12 processors, and the memory was 64 GB DDR3. The JASMIN framework version 2.1 (CAEP software center for high performance numerical simulation, Beijing, China) and the visual software JAVIS 1.2.3 (CAEP software center for high performance numerical simulation, Beijing, China) were used. All codes were compiled by GCC 4.5.1 with -O2 flags. The solutions of JMT3D on one processor were compared with numerical solutions of MODFLOW-MT3DMS. The root-mean-square error (RMSE) and the coefficient of determination were used to evaluate the correctness. The smaller the RMSE value, the better the result. The closer the coefficient of determination to 1, the better the result.
where RMSE denotes the root-mean-square error,
R2 denotes the coefficient of determination,
Ci MT3DMS denotes the concentration of cell
i of MT3DMS,
Ci JMT3D denotes the concentration of cell
i of JMT3D, and
denotes the average concentration of MT3DMS or JMT3D.
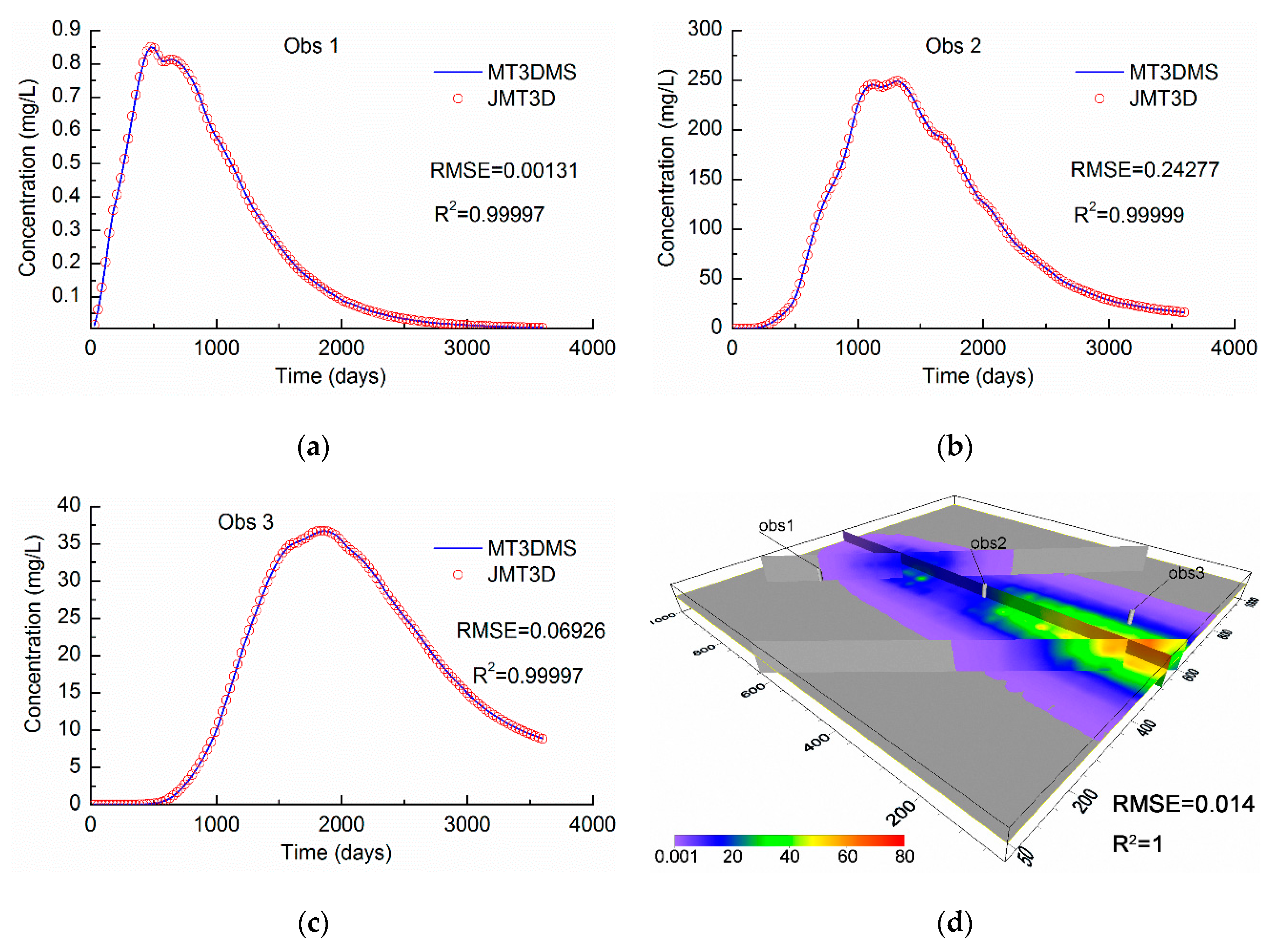
As shown in
Figure 9, all the
R2 values of the observation wells are above 0.99. The concentration at 3600 days presents values of RMSE = 0.014 mg/L and
R2 = 1, and the average relative error is 1.72 × 10
−3. These findings show that the results of JMT3D can maintain a small error compared with the original results from the MODFLOW-MT3DMS program. The reason for the error is that JMT3D continues to use the flow information of JOGFLOW. Although the results of JOGFLOW are consistent with the results of MODFLOW [
25], it is impossible to guarantee that all flow information is exactly the same. The difference of flow will be transmitted to the contaminant transport computation. A comparison of the higher initial concentration and the final concentration shows that the relative errors ranged from 10
−4~10
−6, and the accuracy is sufficient to meet the actual need. In our opinion, the result fits well with the MT3DMS. In addition, some tests were conducted to compare the serial with parallel processes. The relative errors between the serial and parallel processes are less than 10
−6. The errors are affected only by the rounding error at different core numbers.
3.2. The Parallel Performance with Different Iteration Methods
To test the parallel performance of JMT3D, the model for correctness verification was refined 10 times in both the x and y direction. The new problem size can be represented as 200 × 200 × 6 in the x, y, and z directions. The size of each cell is 5 × 5 × N m (N is the thickness of different layers). First, a steady flow was performed, and the rate of recharge was changed to 6 × 10−4 m/d. The other parameters were unchanged. The flow model was solved by the common CG iteration method. The contaminant transport model was solved by the algebraic multigrid (AMG), Bi-conjugate gradient variant algorithm (BiCGSTAB), generalized minimal residual algorithm (GMRES), BiCGSTAB with preconditioner AMG (AMG-BiCGSTAB), and GMRES with preconditioner AMG (AMG-GMRES) methods. Every method was tested on 1, 2, 4, 8, 16, 24, 32, and 46 processors, respectively. The flow and contaminant transport convergence standard were both set to 1 × 10−6, and the maximum iteration number was set to 100. To exclude occasional errors, the model was tested at least three times for each method.
Parallel performance is usually measured by speedup and efficiency [
19,
34]. Speedup represents the ratio of serial wall-clock time to parallel wall-clock time. Linear speedup represents the ratio of the number of parallel processor to the number of basic processor (in general one). When a speedup is larger than the linear speedup, it is called a super-linear speedup. Efficiency represents the ratio of speedup to the number of processors.
where
Sp denotes the speedup,
Ts denotes the wall-clock time in the serial program,
Tp denotes the wall-clock time in the parallel program,
Ep denotes the efficiency of a parallel program, and
P denotes the number of processors.
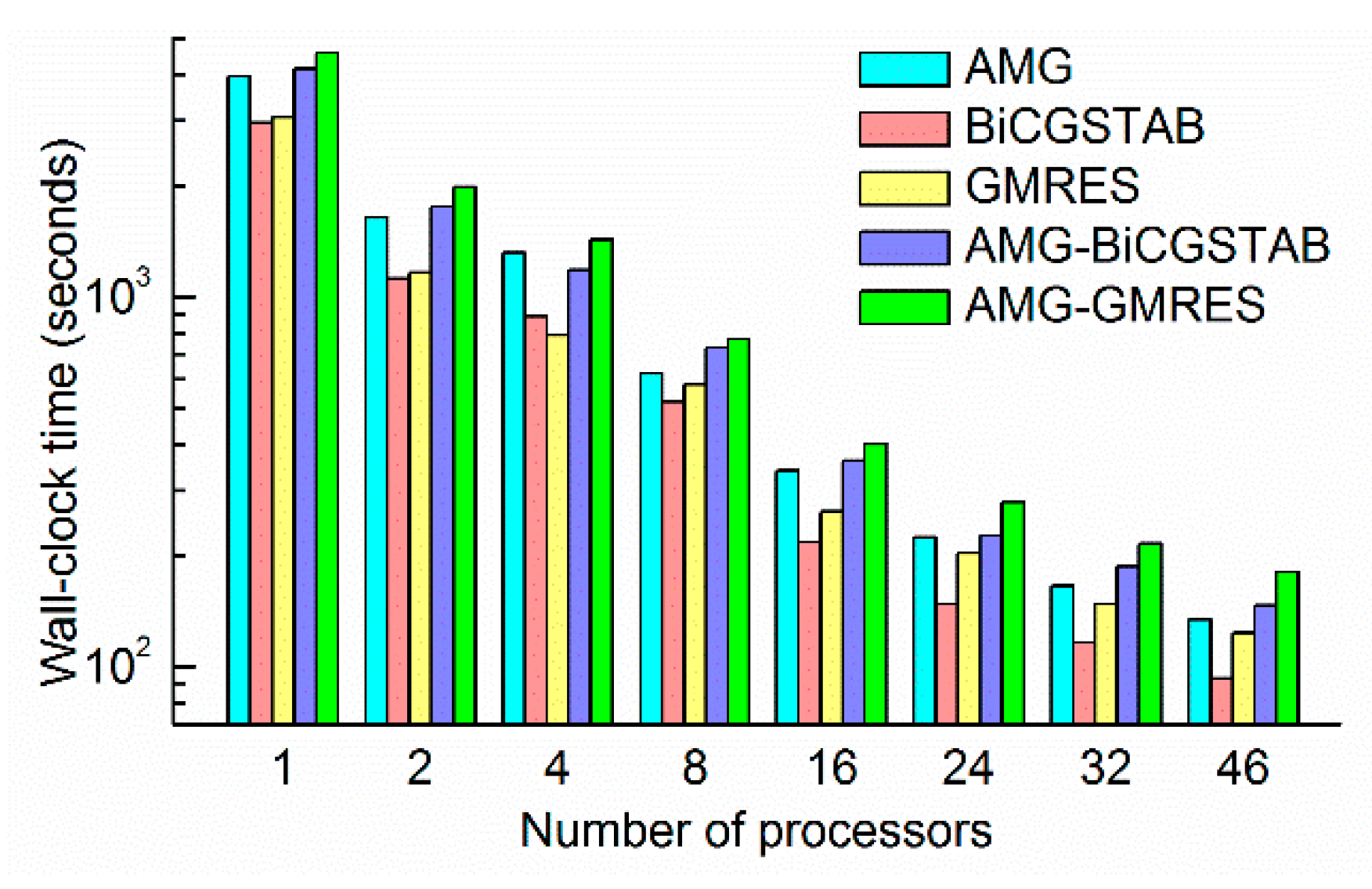
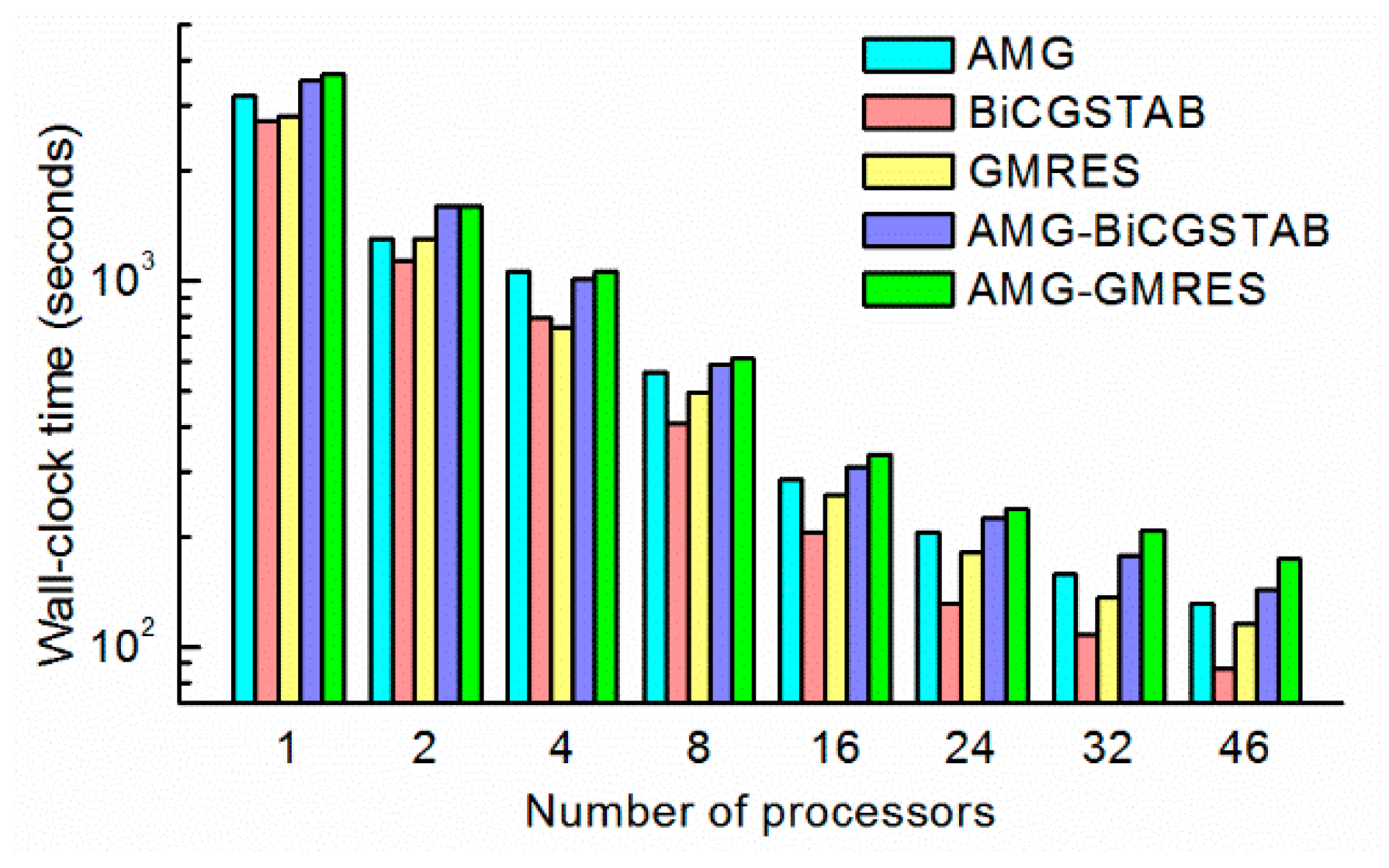
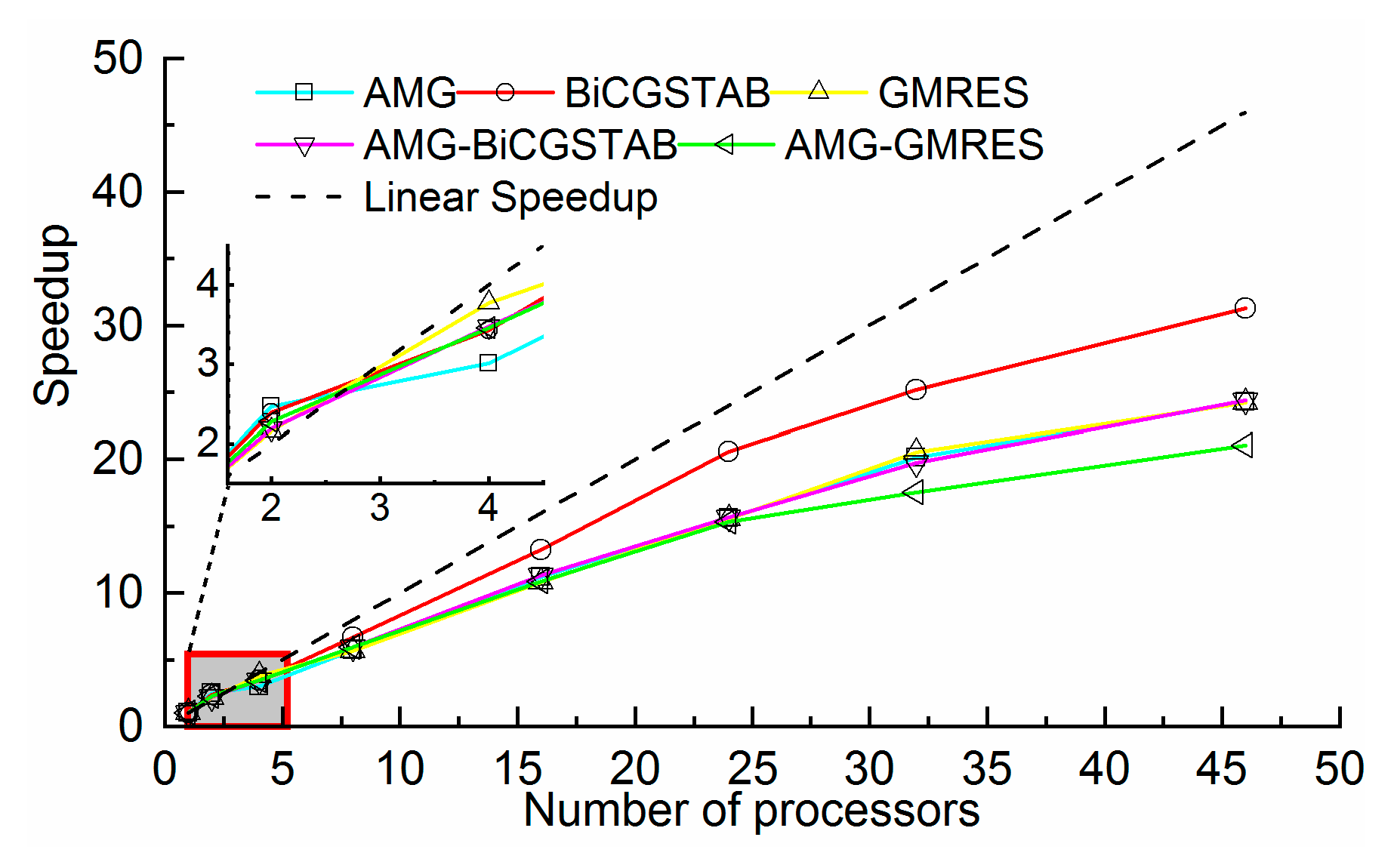
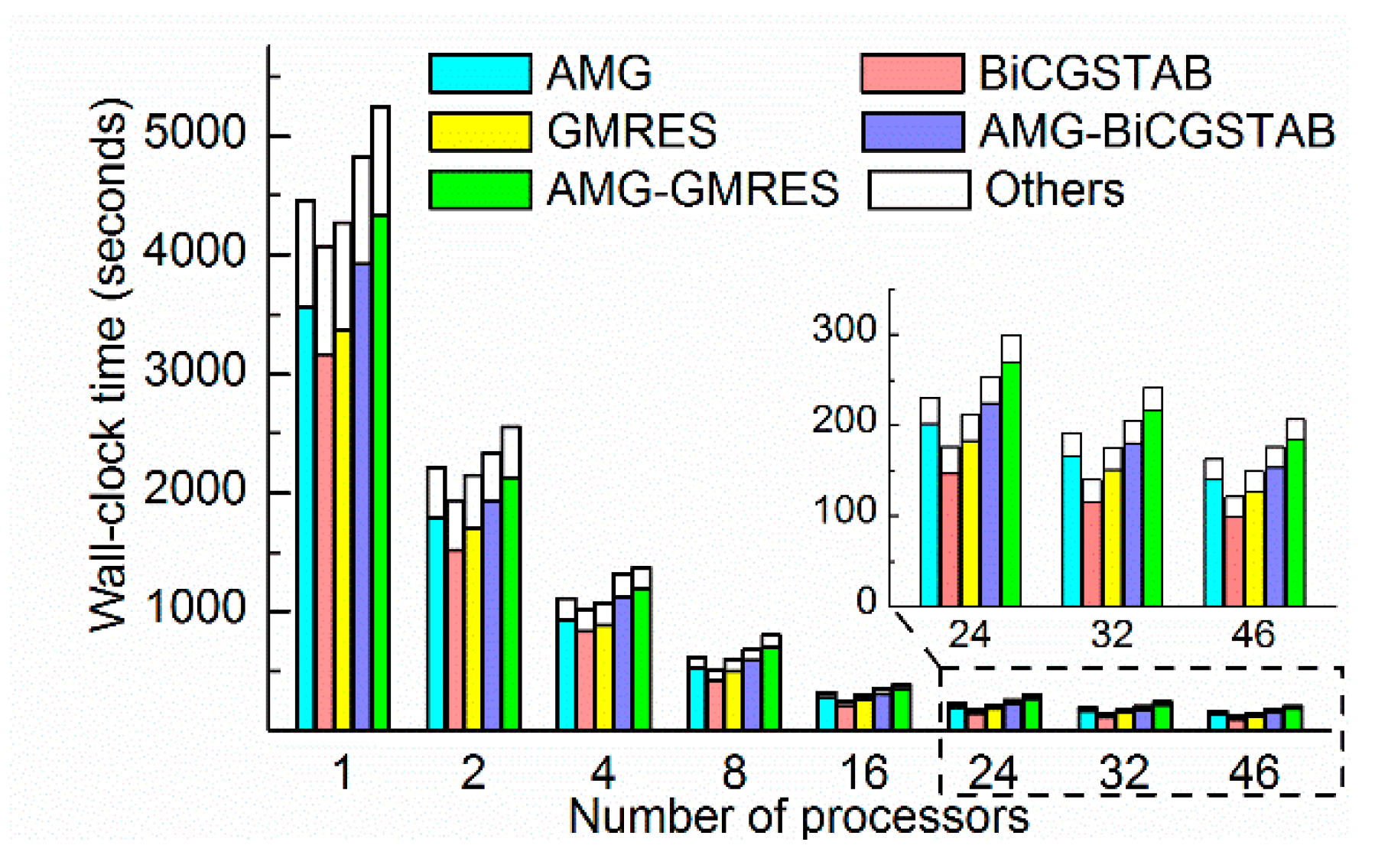
The time-consumption and speedup of each method is shown in
Figure 10 and
Figure 11. All the wall- clock times were gradually reduced as the number of processors increased. Different methods, even with the same number of processors, required a significantly different amount of time. For example, the AMG-GMRES method required 180 s on 46 processors, where the BiCGSTAB method required only 93 s. These findings demonstrate the importance of choosing a convenient solver method. As shown in
Figure 10, the BiCGSTAB method required the least time in most cases. The wall-clock time of BiCGSTAB significantly decreased from 2948 s on one processor to 93 s on 46 processors. The wall-clock time of the GMRES method was slightly lower than that of the BiCGSTAB method with four processors, which indicates that the task of each processor (60 k cells per processor) was more suitable for the GMRES methods. The AMG and AMG as preconditioner methods required more time than the BiCGSTAB and GMRES methods because the AMG required more time for setup and per iteration [
35].
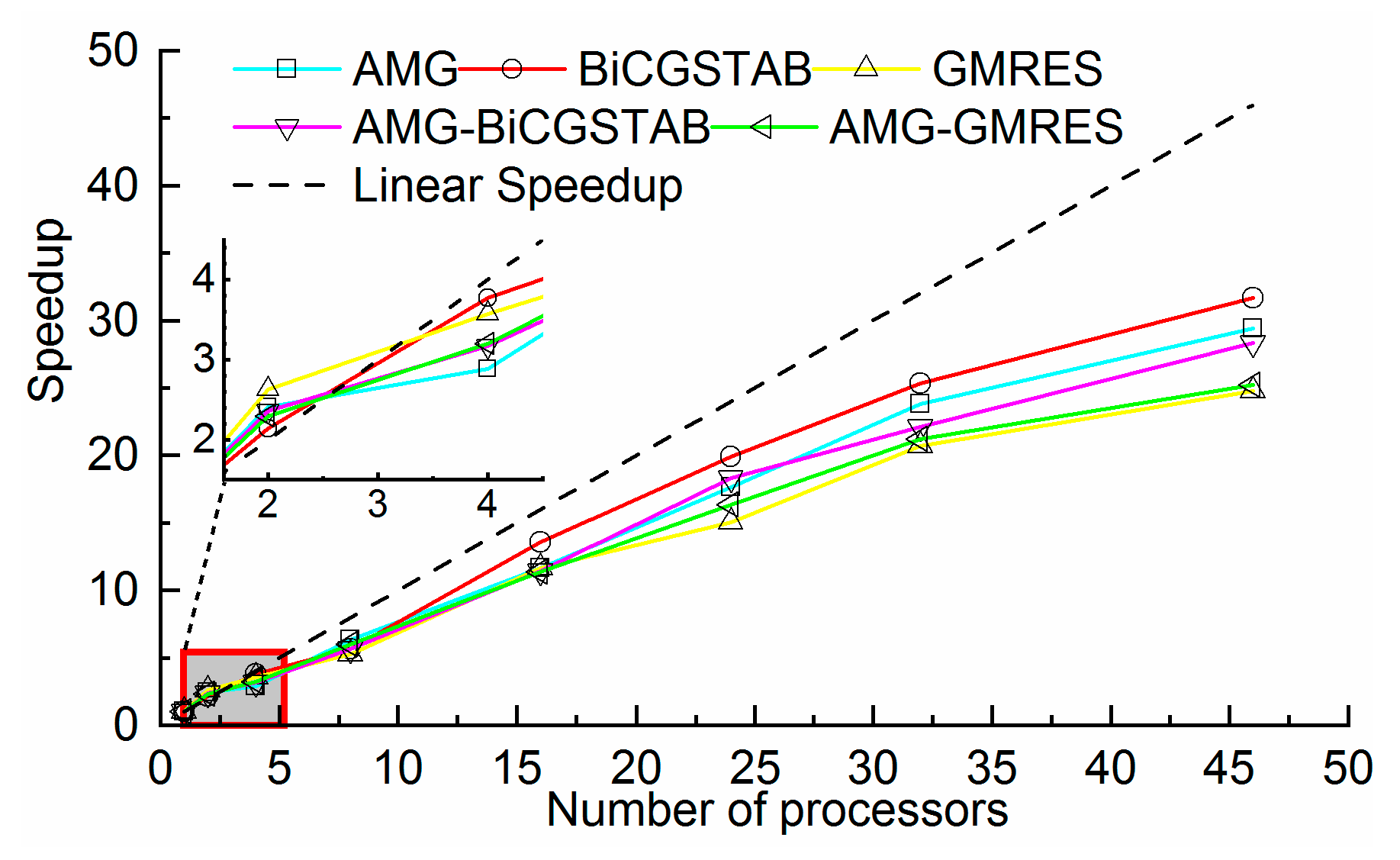
As shown in
Figure 11, the BiCGSTAB method also achieved high speedups, when the number of processors was greater than 16. A maximum speedup 31.7 was achieved with 46 processors. In addition, all methods achieved super-linear speedup on two processors. The speedup of the GMRES method ranked first with an efficiency of 132%. The reason for the super-linear speedup is that the access data fit in the cache of each processor. The time saved by the cache effect offset the communication overhead time in parallel computing. With an increasing number of processors, the parallel communication overhead increased, and the cache effect became obvious. Although the super-linear speedup disappeared, all the methods achieved a good speedup. The parallel efficiency was between 53% and 132%. Therefore, the JMT3D can effectively reduce the time-consumption and achieve high speedup.
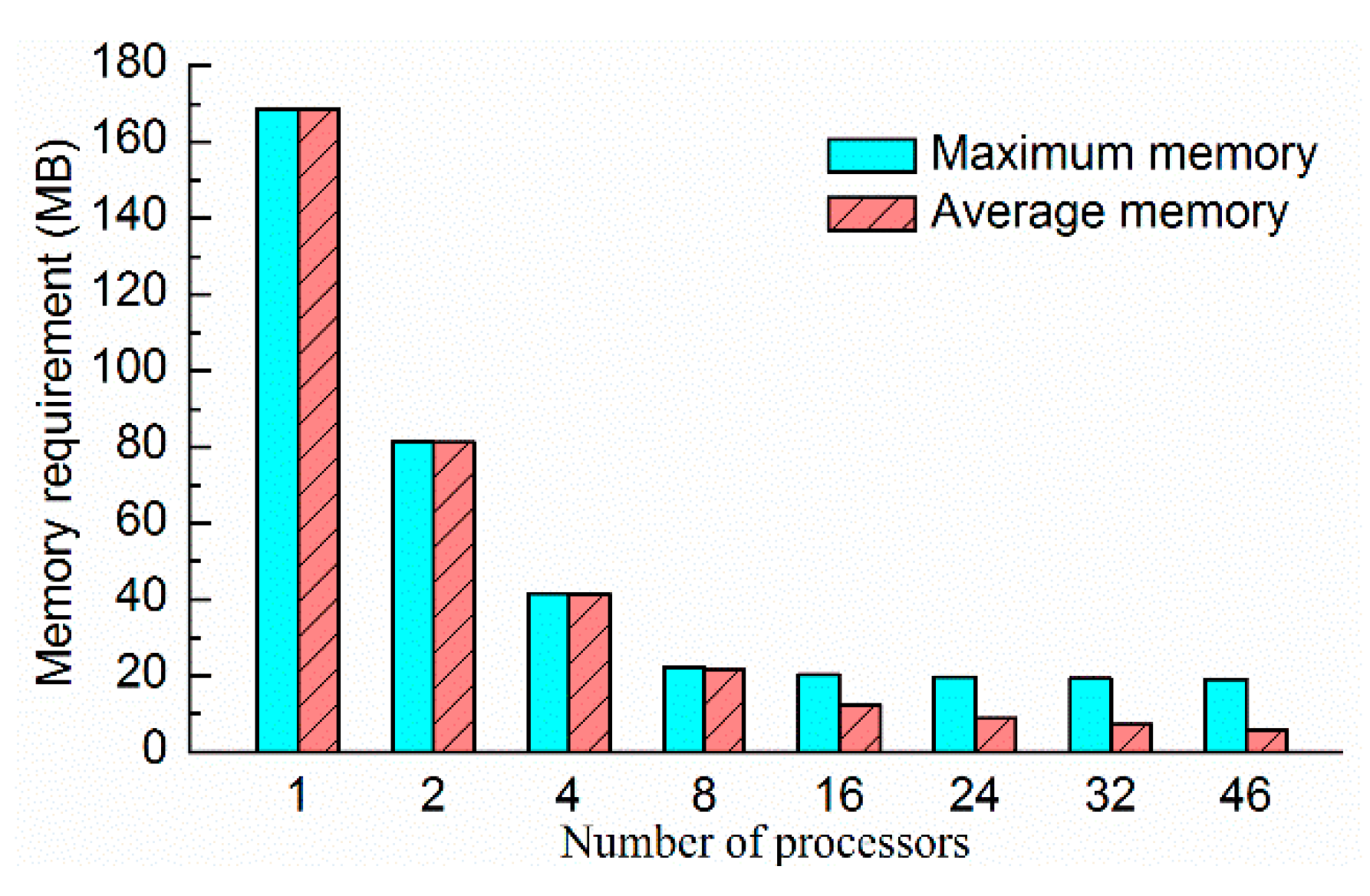
The JMT3D not only reduced the wall-clock time but also reduced the memory consumptions. The memory consumptions of different methods were approximately the same. Taking the AMG method as an example, both the maximum memory consumption and average memory consumption decreased as the number of processors increased. As shown in
Figure 12, the maximum memory consumption was reduced significantly from 169 MB on one processor to 22 MB on eight processors. The maximum memory consumption was slightly reduced as the number of processors increased. Memory consumption is related to global variables and various types of objects for framework running. The maximum memory consumption was determined by the master processor because the master processor is in charge of data initialization, reading, and broadcasting source data. Compared with one processor, the maximum memory consumption on 46 processors decreased by 89%, and the average memory consumption on 46 processors decreased by 96%. The results demonstrate that the JMT3D can reduce both the maximum memory consumption and average memory consumption. Reducing the maximum memory consumption can solve the memory consumption bottleneck problem for large-scale simulations, and reducing the average memory consumption can reduce the hardware demands for the non-master processor.
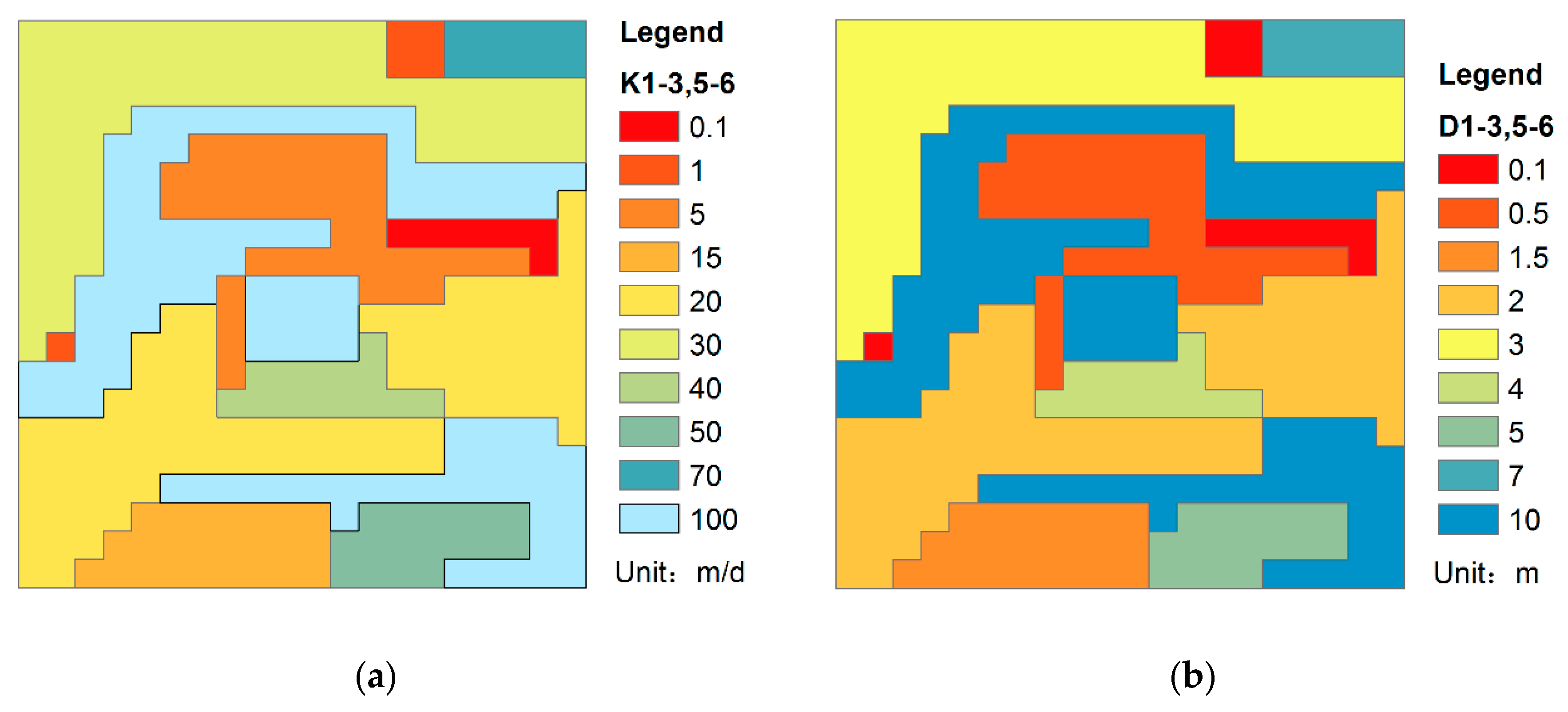
3.3. The Parallel Performance with High Heterogeneity
Heterogeneity usually exists in the study areas and affects contaminant transport. To determine whether heterogeneity will affect parallel performance, random hydraulic conductivity and longitudinal dispersion area were constructed. Except for the fourth level (silt aquitard), all the layers were set as shown
Figure 13. The other parameters were the same as the model in
Section 3.2.
To facilitate the analysis, the model in
Section 3.2 is called the approximately homogeneous model, and the model in this section is called the highly heterogeneous model. As shown in
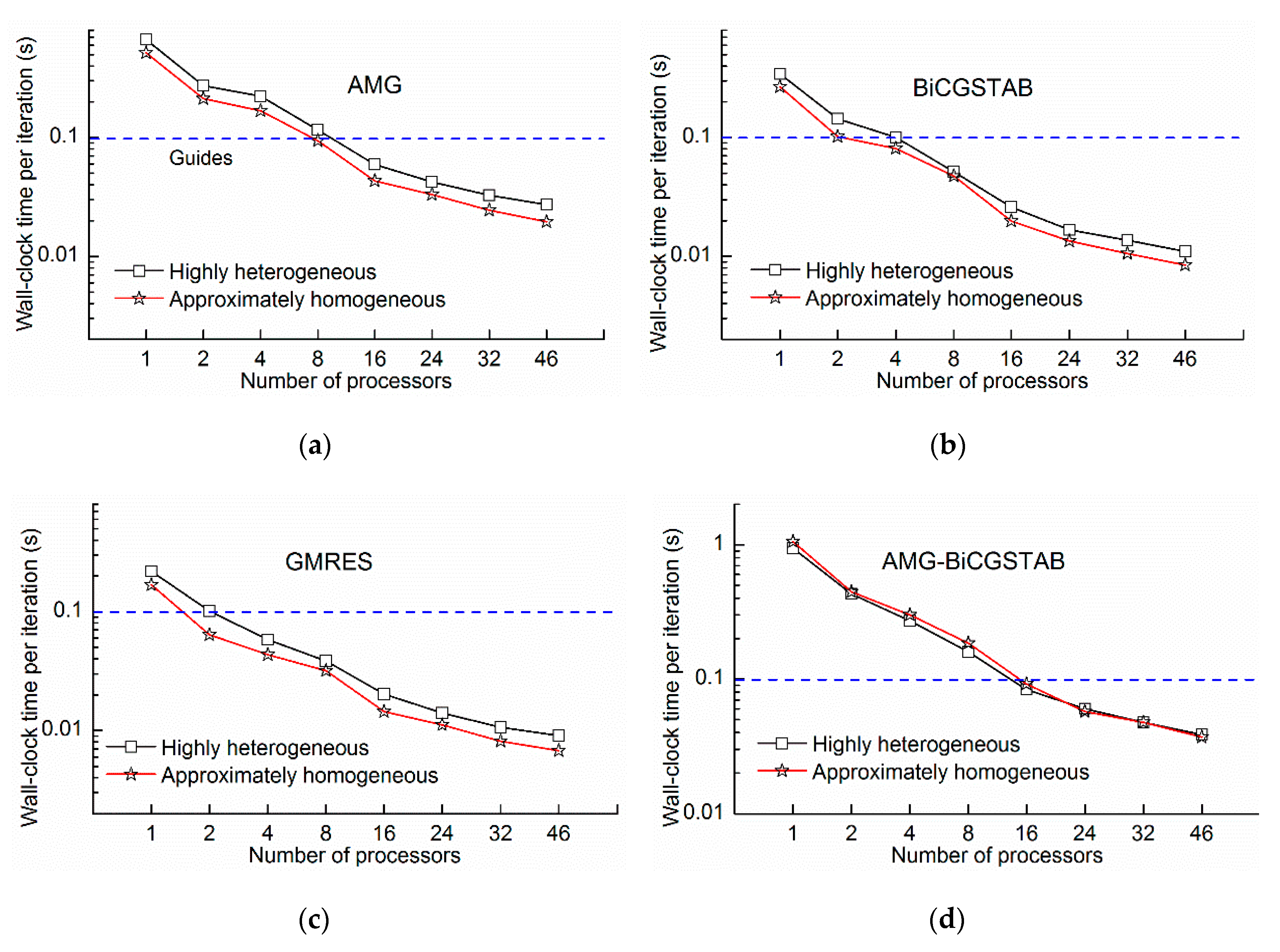
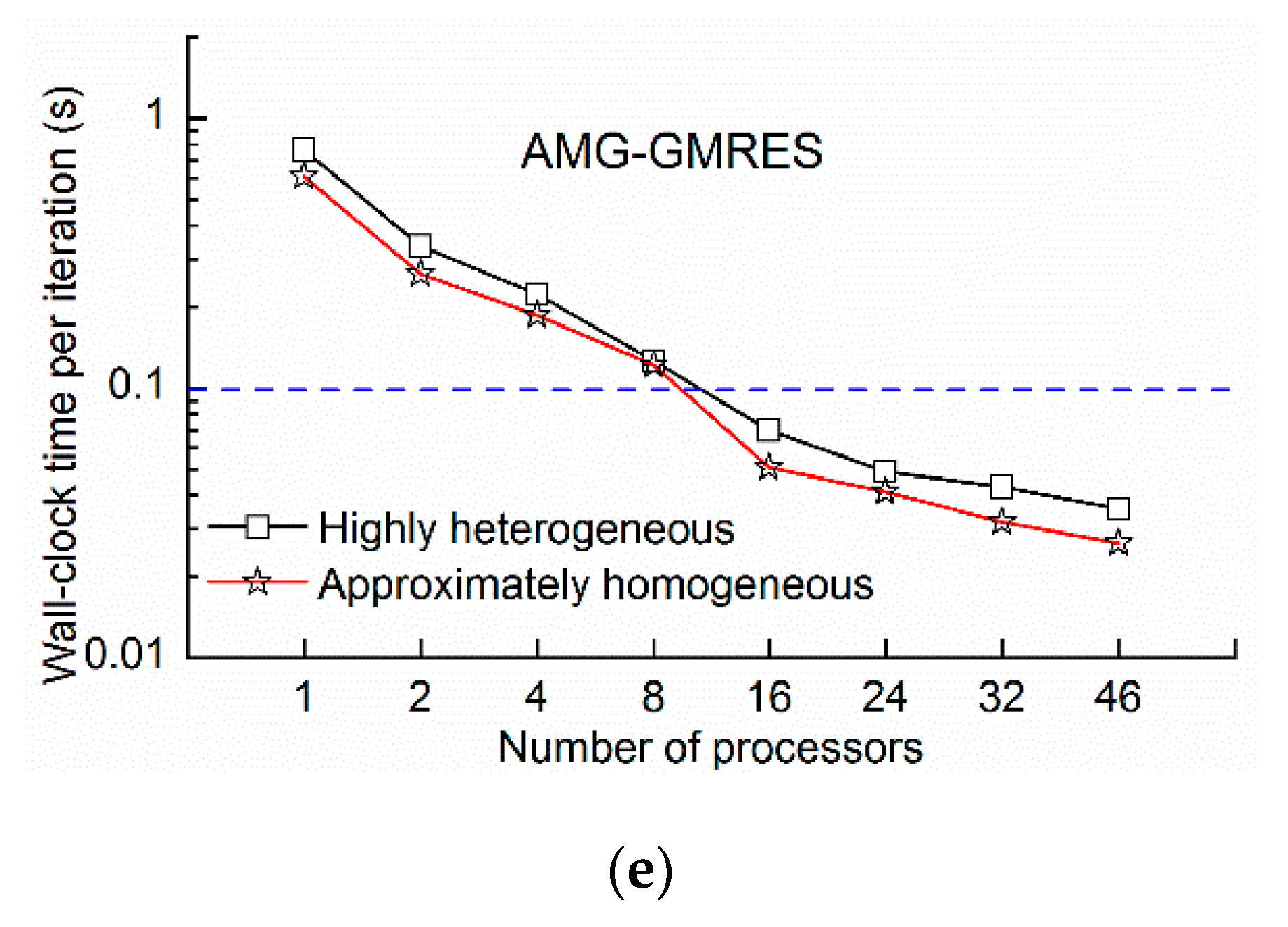
Figure 14, the wall-clock times of the highly heterogeneous model were lower than those of the approximately homogeneous model because the transport step of highly heterogeneous model was 0.97 days compared with the 0.91 days of the approximately homogeneous model, and the number of transport steps decreased. The phenomenon was extensively analyzed by the wall-clock time per iteration. As shown in
Figure 15, the wall-clock times per iteration of the highly heterogeneous model were generally higher than those of the approximately homogeneous model. Due to heterogeneity, the solver does not converge easily. However, the wall-clock time per iteration of the AMG-BiCGSTAB method is almost unchanged for both the highly heterogeneous model and the approximately homogeneous model, which indicated that the AMG-BiCGSTAB model was less affected by heterogeneity.
The GMRES method required the least time per iteration (
Figure 15); however, the convergence of the GMRES was not as good as the other solutions, and it presented the highest number of iterations (
Table 2). Moreover, the number of iterations of BiCGSTAB and GMRES with AMG as the preconditioner was significantly reduced, indicating that AMG improved the convergence abilities of the BiCGSTAB and GMRES method. The iterations of different methods with different numbers of processors remained almost unchanged (
Table 2). The contaminant transport equations should be solved simultaneously by using the stencil-based method. The stencil-based method and domain decomposition method can ensure that the solution accuracy and convergence do not decrease as the number of domains increase, thereby maintaining as much consistency in the results as possible. The difference in the number of iterations of the AMG method was caused by rounding errors on different processors. The greatest difference in the number of iterations was smaller than 2%, which is inconsistent with previous work, which iterations increased with increasing numbers of processors [
6,
19].
As shown in
Figure 16, all the methods achieved super-linear speedup on the two processors. The BiCGSTAB method achieved the largest speedup of 31.3 on 46 processors and presented an efficiency of 68%, and its speedup ranked first on 8, 16, 24, 32, and 46 processors. The speedups of other methods were approximately similar. These results indicate that the heterogeneity had little effect on the speedup performance of JMT3D.
3.4. The Parallel Performance with Transient Flow
To address concern related to the effect of transient flows on performance, the highly heterogeneous steady flow model in
Section 3.3 was changed to a transient flow model. The dynamic recharge and stress periods were the same as that of the model in
Section 3.1. All other parameters were unchanged.
The wall-clock time of contaminant transport and the total wall-clock time (the sum of contaminant transport and others) are shown in
Figure 17. The wall-clock time of contaminant transport accounted for the greatest amount of total wall-clock time (from approximately 80% on one processor to approximately 90% on 46 processors), because the transport step length is automatically reduced with the limit of the Courant number; and a flow time step is refined into more transport steps [
2]. For example, the flow time step is 30 days in this model. To guarantee a value of Courant = 1, the transport step length was adjusted to 0.009~0.28 days depending on the velocity of flow. In the high-resolution contaminant transport simulation, the smaller the mesh size, the shorter the length of transport step. Therefore, solving contaminant transport effectively is the key to performing high-resolution simulation of integrated flow and containment transport.
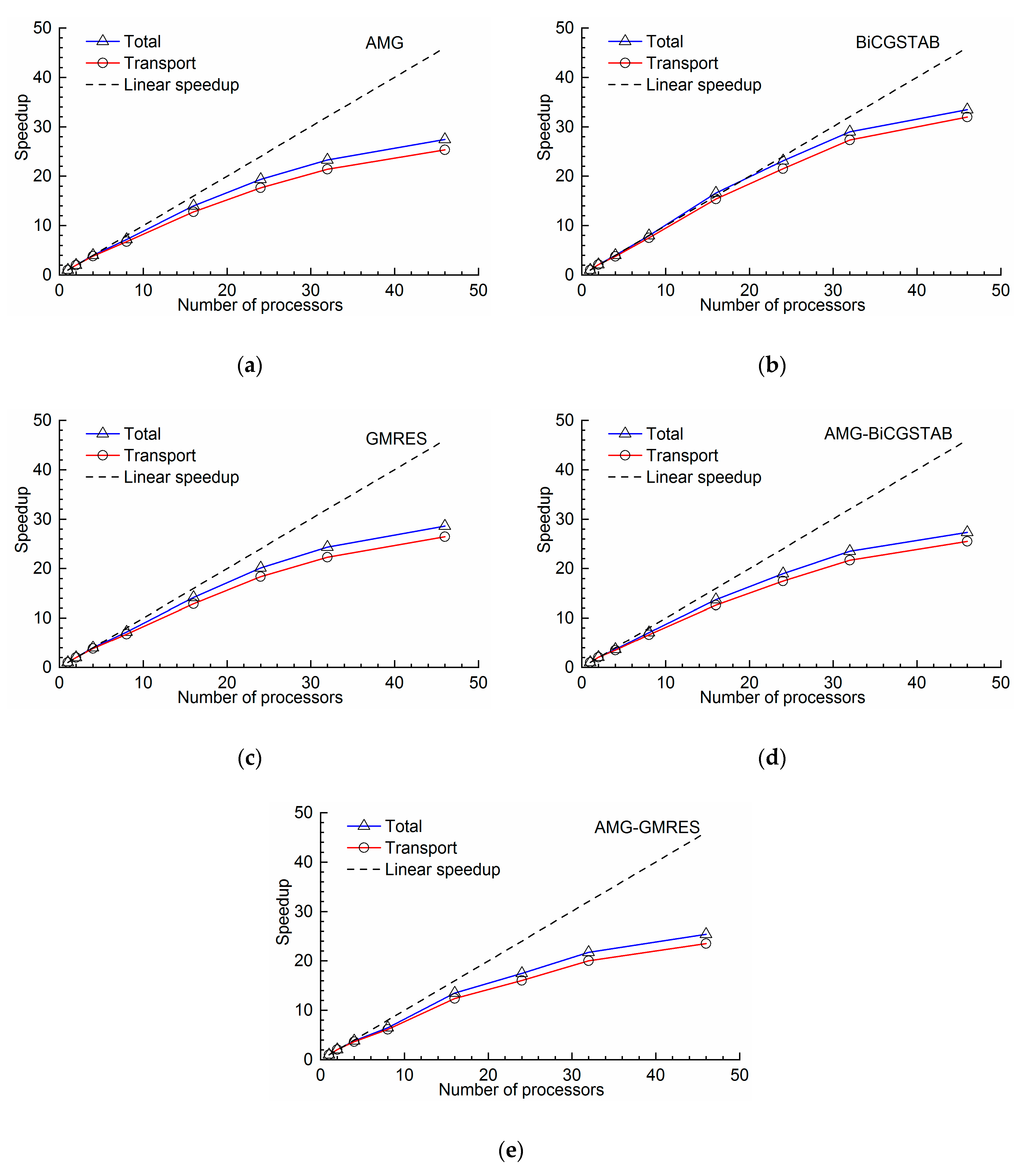
The speedups of total and contaminant transport were shown in
Figure 18. It shows that the total speedup of each method is better than that of contaminant transport. A further detailed analysis of the wall-clock time of each part was conducted. Using the BiCGSTAB method as an example (
Table 3), the flow and contaminant transport account for the major percentage of wall-clock time. The share of flow decreased; and the share of other components slightly increased as the number of processors increased because non-parallel parts, such as initialization and reading recharge sources, exist in the program. These non-parallel parts run in serial and require a constant time. When the total wall-clock time decreases, the proportion of these parts increases. The acceleration of the flow part improved the total speedup. Coupling the flow and contaminant transport in parallel can further increase the parallel efficiency. For example, the BiCGSTAB method achieved remarkable speedup (i.e., 33.45 for the total progress, and 31.98 for the contaminant transport part on 46 processors) (
Figure 18). In addition, the flow and solute results can be outputted instantly without waiting for the computation of all periods of flow to be finished, which is of great significance to the online simulation system.
3.5. Scaling Tests
Scaling tests can be used to evaluate the abilities of parallel programs, and provide the optimal number of processors on a certain type of parallel machine. The performance on a larger processor can be predicted based on the parallel performance of the program on a small scale processor. In this study, strong scalability (the problem size remains fixed as the number of processors increase) [
19] was used to evaluate the performance of JMT3D. The highly heterogeneous model in
Section 3.3 was refined eight times in both the x and y directions. The new model size was fixed to 1600 × 1600 × 6. When the cell size is small, the length of the per transport step changes to 0.08 days with the limitation of the Courant number. The results show that the transport step shortens when the resolution increase. Considering the limitation of computer runtime and testing purposes, 1000 transport steps were performed. Moreover, to ensure that most areas presented concentrations, the concentrations of the 1500th day in the heterogeneous model of the transient flow in
Section 3.4 were used as the initial concentrations. The flow was set to a steady flow in this model. The wall-clock time of flow was less than 1%, which can be disregarded. The test was performed on a petascale supercomputer at the High-Performance Computing Center of the Institute of Applied Physics and Computational Mathematics in Beijing, China. The AMG and BiCGSTAB methods were used to solve the problem on 28, 56, 112, and 224 processors.
As shown in
Table 4, the wall-clock time reduced as the number of processors increased. The BiCGSTAB method achieved the global minimum wall-clock time (516 s) on 224 processors and required less time than the AMG method on a different number of processors. The wall-clock time of AMG method was 2.6 times greater than that of the BiCGSTAB method on 28 processors, which shows that choosing an appropriate method is very important. Although the AMG method required more time, it showed a remarkable scalability in this test and achieved more than 100% efficiency on 112 and 224 processors. The BiCGSTAB method can also achieve good efficiency above 50% on hundreds of processors. The number of iterations of BiCGSTAB was approximately 2.5 times that of the AMG method, which indicates that the AMG method had a better convergence ability than the BiCGSTAB method. The iteration number of different methods on different processors was still unchanged, which demonstrates that the solution accuracy and convergence do not decrease as the region increases. The average consumed memory showed that JMT3D reduced the memory consumption by 80%.
TA and TB denote the wall-clock time of the AMG and BiCGSTAB methods, respectively. EA and EB denote the efficiency of the AMG and BiCGSTAB methods, respectively. IA and IB denote the number of iterations of the AMG and BiCGSTAB methods, respectively.
4. Summary and Outlook
In this study, the high-performance parallel framework JASMIN was used to reconstruct the MT3DMS. To domain decomposition method, ghost cells communication strategy, and stencil-based method were designed and implemented. The flow and contaminant transport simulation were parallel coupled. Then, the developed parallel code JMT3D was verified and tested for correctness and parallel performance using five types of models.
The main contribution and conclusion of this paper are summarized as follows:
The MT3DMS was parallelized by a high-performance parallel framework, and models with hundreds of thousands to tens of millions of cells were simulated on tens to hundreds of processors. The developed parallel JMT3D speeded up 31.7 times and reduced memory consumption by 96% on 46 processors.
A domain decomposition method and stencil-based method were implemented. Equations can be solved simultaneously as a serial program. The number of iterations does not increase as the number of processors. This can ensure that results from serial and parallel are as consistent as possible.
The test results showed that the BiCGSTAB method required the least time and achieved high speedup in most cases. Highly heterogeneity and transient flow have little effect on the speedups. The parallel coupling flow and contaminant transport can further improve the parallel performance, which achieved a 33.45 times greater speedup on 46 processors.
Contaminant transport simulation is the main time-consuming component of high-resolution flow and contaminant transport simulation. The higher the resolution, the greater the proportion of the contaminant transport simulation.
In the next study, chemical reaction modules will be added into JMT3D, and the load balancing strategy for irregular study areas will be considered in realistic problems.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}