Role of Cluster Validity Indices in Delineation of Precipitation Regions



Abstract
:1. Introduction
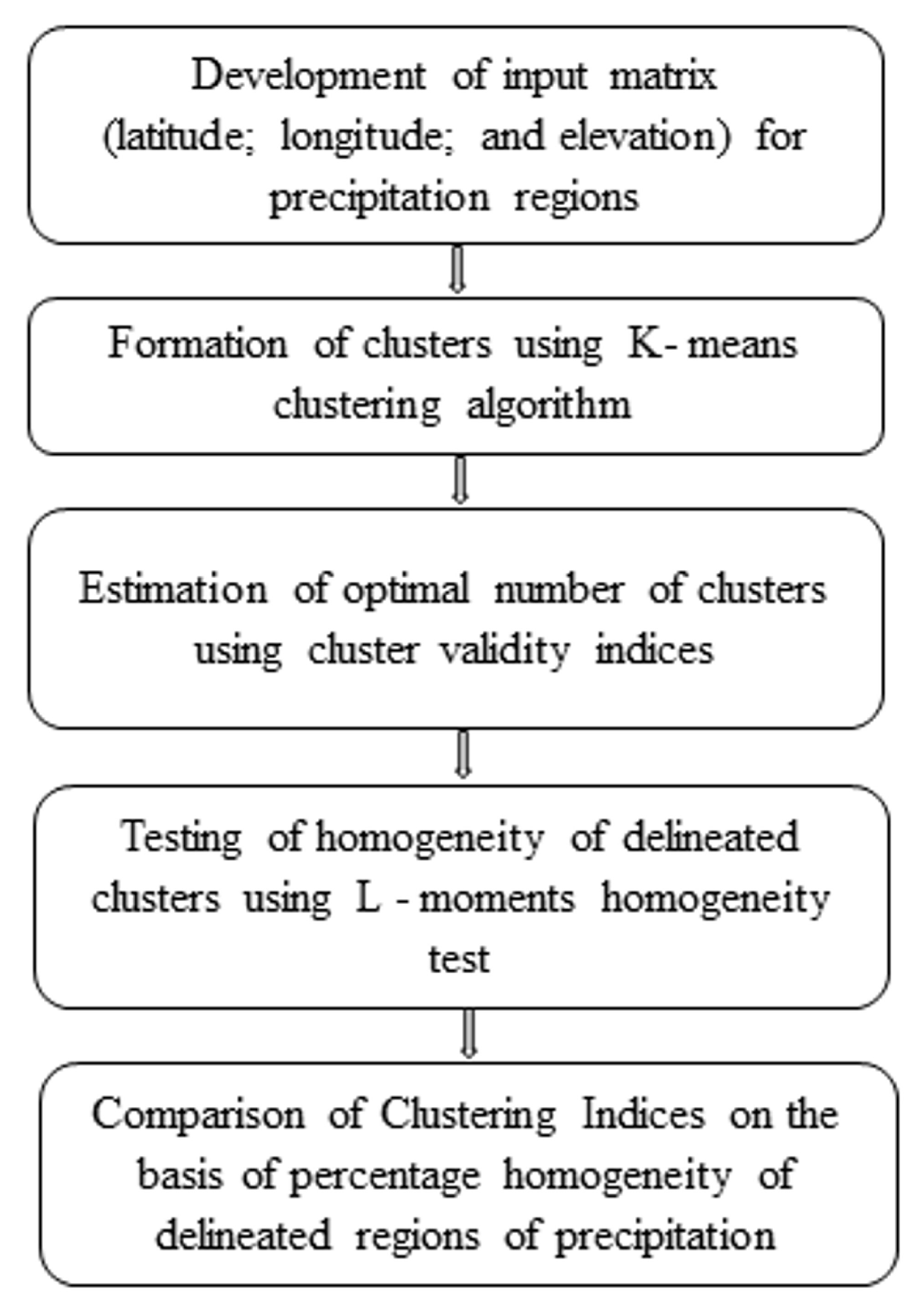
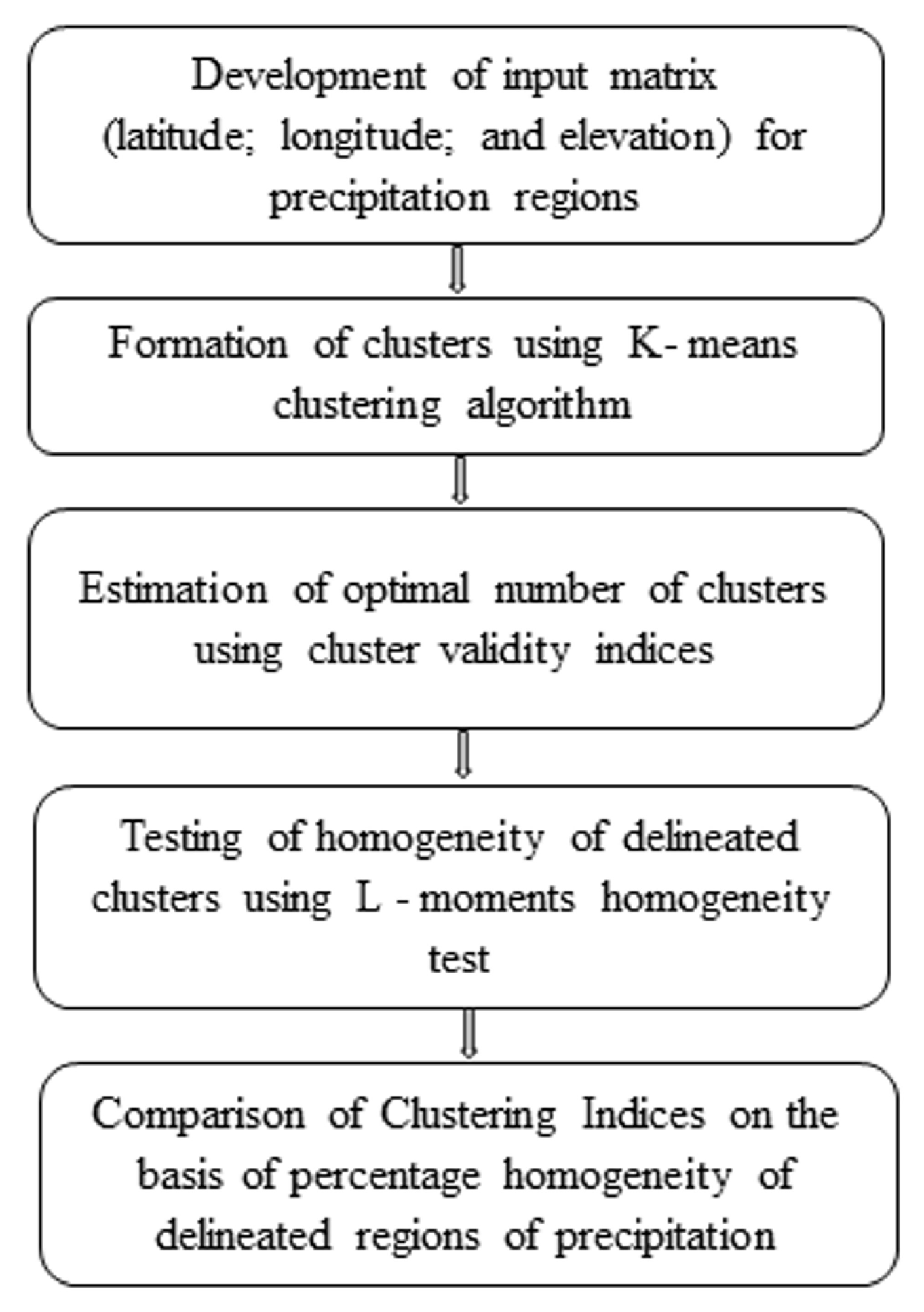
2. Methodology
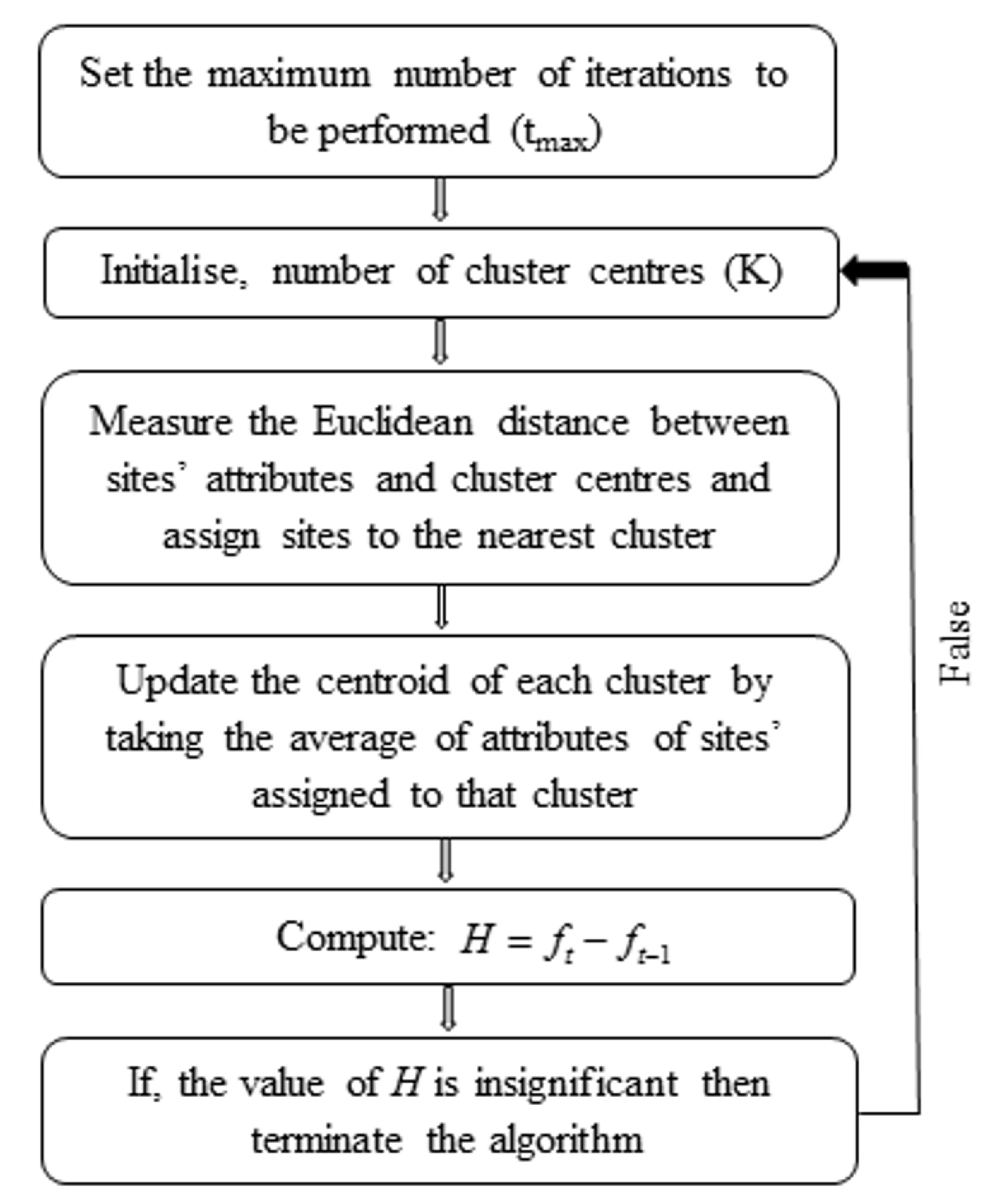
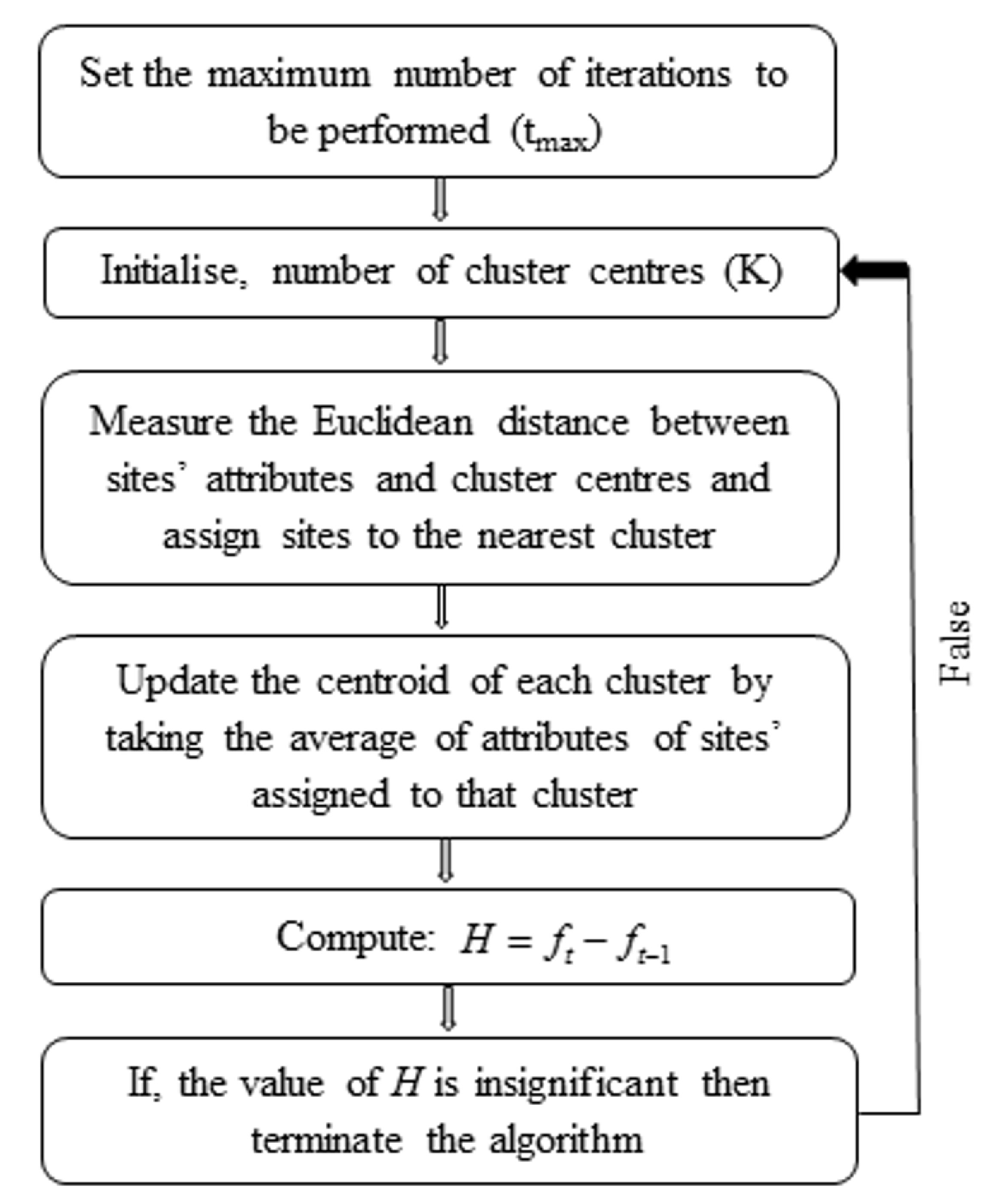
2.1. K–Means Clustering Algorithm
2.2. Cluster Validity Indices (CVIs)
2.3. L-Moments Homogeneity Test
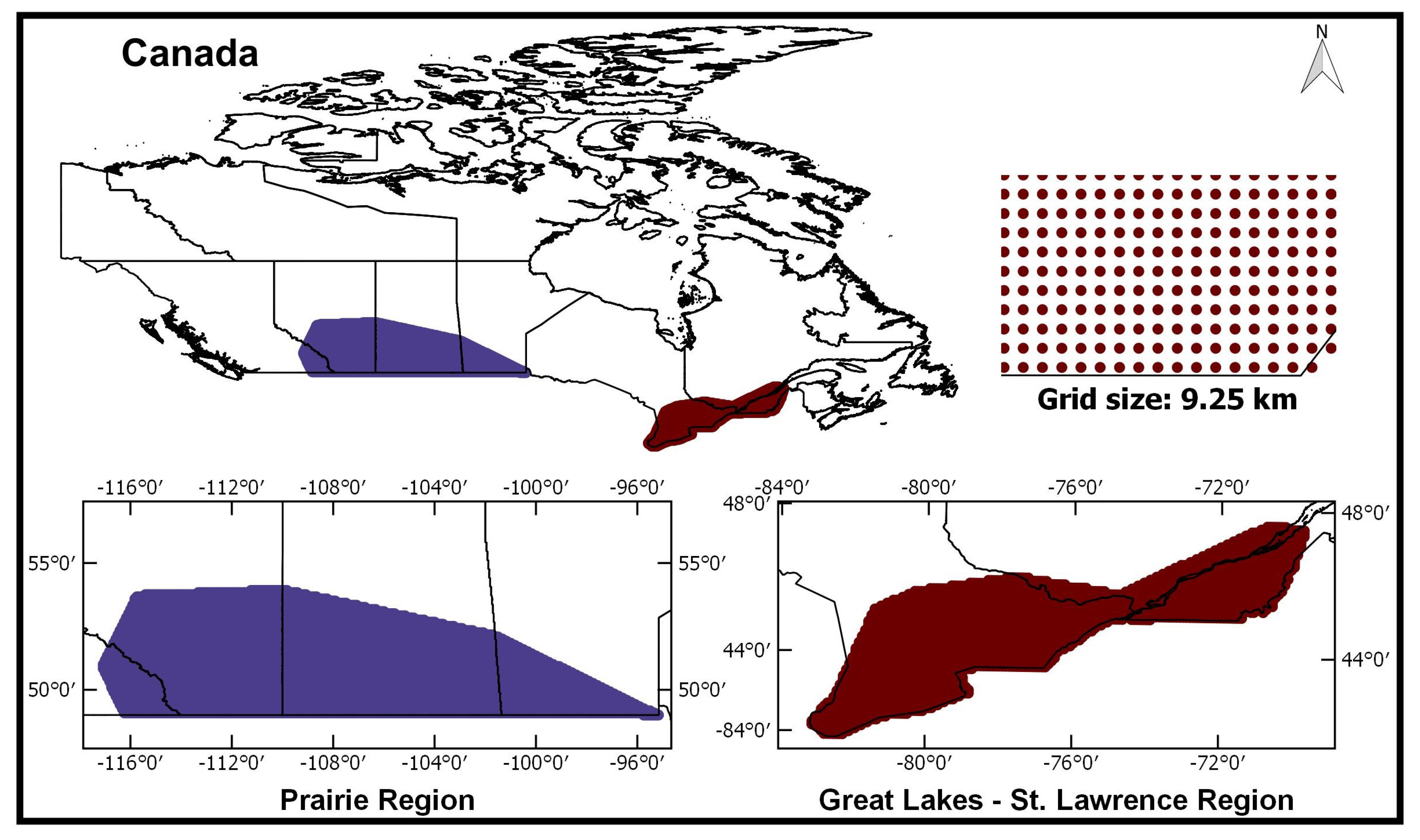
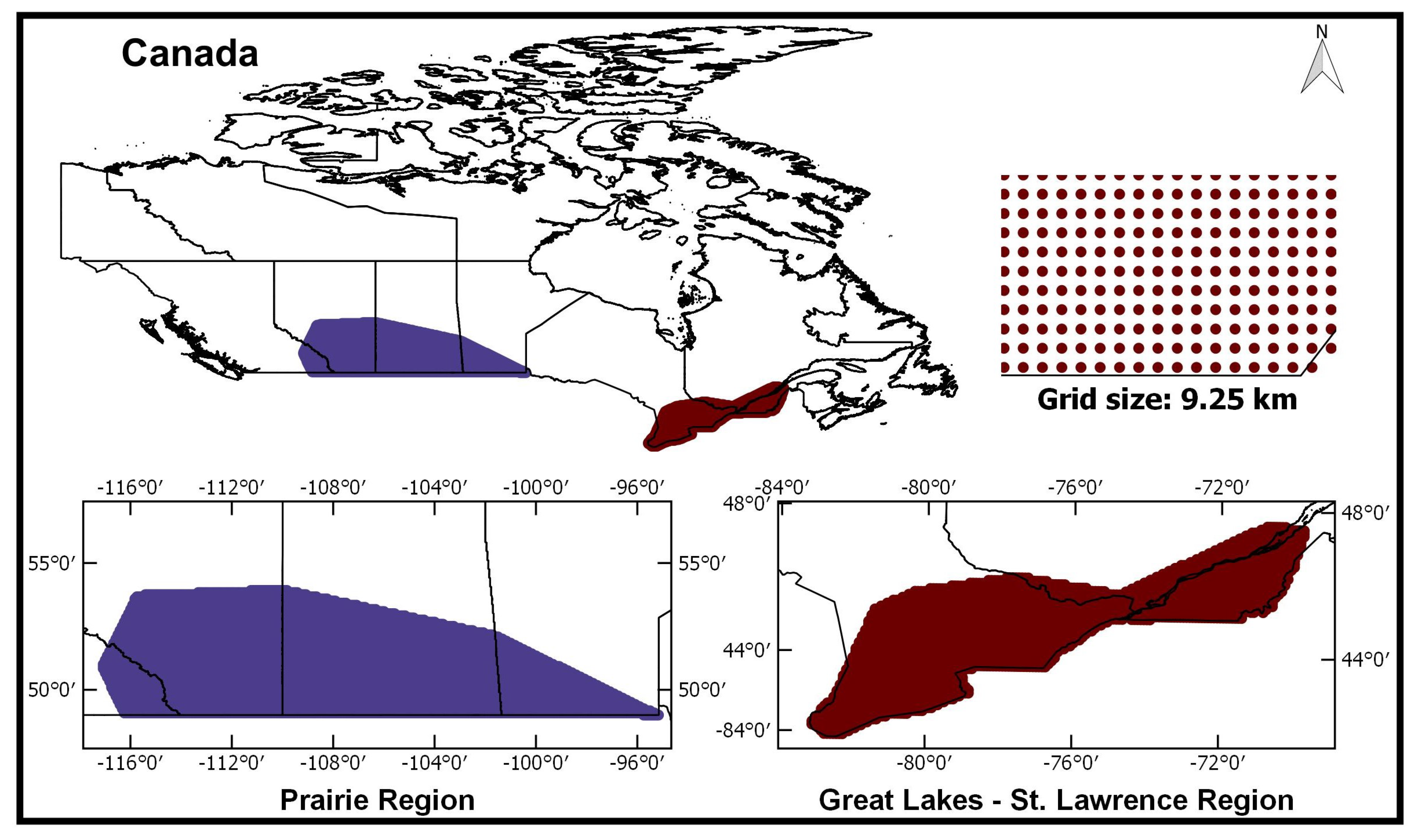
3. Case Study
Data
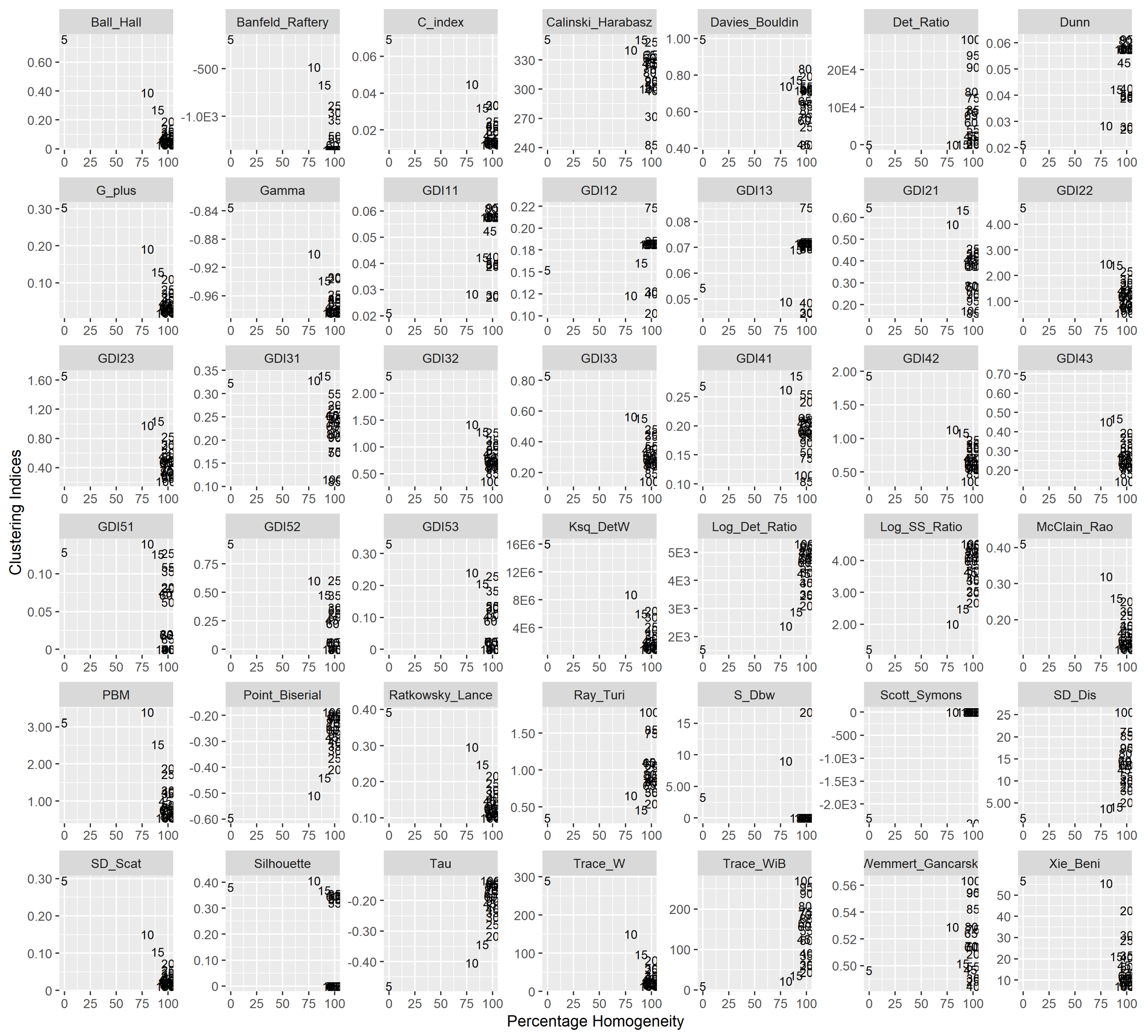
4. Results and Discussion
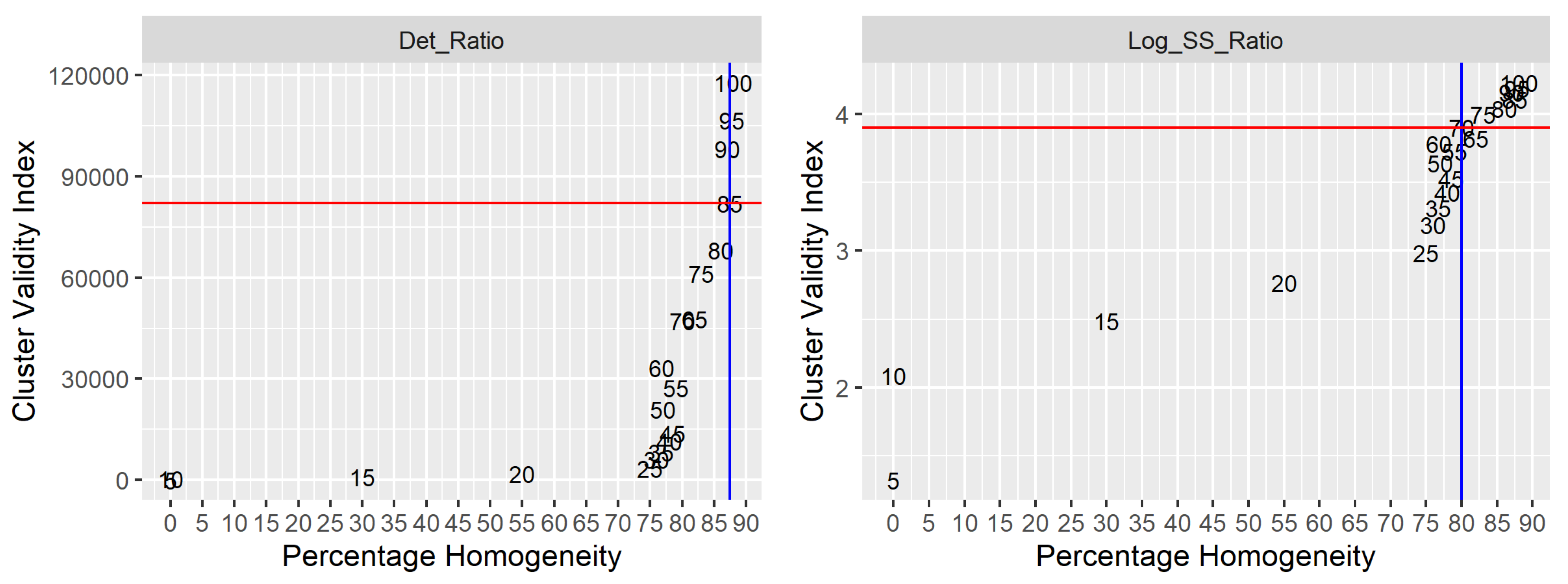
4.1. Performance of the CVIs
4.2. Application to Canadian Regions
4.2.1. Prairie Region
- Winter season: Banfeld–Raftery index, C index, Dunn generalized 1, 3 index, McClain–Rao index, SD [Scat] index, and Xie–Beni index suggest k = 100 as optimal partition giving 89 homogeneous regions amongst them. The Dunn index and their modifications (GDI11) provide a similar percentage of homogeneity (86%) with larger clusters (55 numbers).
- Spring Season: ratio index found to be the best in delineation of the region in 80 clusters out of which 69 clusters are homogeneous.
- Summer season: All the indices except, index and Tr(W-1B) index recommend to divide the area in 100 clusters, which further give 88 homogeneous ones.
- Autumn season: Banfeld–Raftery index, G + index, Point–Biserial index, SD [Scat] index, and Tau index regionalize the area in 100 clusters resulting in 89 homogeneous ones. The Trace_WiB cluster index has resulted in the lower number of clusters (55) with homogeneity of 84%.
4.2.2. Great Lakes-St. Lawrence Lowlands (GL-SL) Region
- It is observed that all the selected 15 CVIs outperform the empirical formula for all the seasons.
- Winter season: All the listed 15 indices have outperformed the results of the empirical formula. Banfeld–Raftery index, G+ index, Point–Biserial index, SD [Scat] index, and Tau index provides 100 clusters of the region which give 98% homogeneous.
- Spring season: Banfeld–Raftery index, Dunn index, Dunn generalized 1, 1 index, Dunn generalized 1, 2 index, Dunn generalized 1, 3 index, SD [Scat] index, Xie–Beni index delineated the region in 100 clusters with 99% homogeneity.
- Summer season: All the listed 15 indices performed better in terms of percentage than the empirical formula. Tr(W-1B) index determined the maximum percentage homogeneity of 99% by delineating into 90 clusters.
- Autumn season: In comparison to all other seasons in this region, it determined 100% homogeneous clusters for all the CVIs. It is observed that the different number of clusters for the region are found to be:
- 100 clusters for Banfeld–Raftery index, G+ index, Point–Biserial index, SD [Scat] index, Tau index and Xie–Beni index.
- 95 clusters for C index, ratio index, and McClain–Rao index.
- 75 clusters for Dunn index, Dunn generalized (1, 1) index, Dunn generalized (1, 2) index, and Dunn generalized (1, 3).
- 55 and 90 clusters for Det_Ratio and Tr(W-1B) index, respectively.
- Winter season: Dunn index and Det_Ratio index.
- Spring season: Det_ratio index.
- Summer season: Det_ratio index and Trace() index.
- Autumn Season: Dunn index, Det_ratio index and Trace() index.
5. Conclusions
Limitations and Future Scope of the Current Work
- Although the k-means algorithm converges well there is a tendency of solutions not reaching global optima. It requires a number of iterations to get the best solution using random sets of initial centroids. The computational burden is high with an increase in number of grid points (or stations) as well as length of records. The performance of the CVI can be evaluated using other clustering algorithms which may elevate above issues. Further, investigation can be carried out to represent/understand the regional processes by studying the similarity, separation, and cohesion of the clusters in the region.
- The process is assumed to be stationary, which may not be true, especially under the effect of climate change. The non-stationary algorithms can be used for delineation of precipitation regions.
- The season-wise performances of CVIs vary significantly in both regions. This could be due to the effect of combined influences of large-scale variables and geophysical characteristics [72]. These attributes are very important to study the effect of climate change on hydrological variables. Moreover, it is envisaged that the selection of appropriate attributes according to the seasons may result in better prediction of rainfall characteristics. In this study attributes are limited to geophysical characteristics. The research is in progress to understand the role of CVI with additional climate-based attributes and their seasonal variations.
- The other limitation is the non-availability of sub-daily data for ANUSPLIN [66,67]. For example, in case of design and management of water infrastructure, the development of intensity-duration-frequency precipitation curves require sub-daily data which is not available in ANUSPLIN. Alternatively, the availability of sub-daily reanalysis data such as NCEP-NARR [73] (updated data release 2016) can be used. Further, a disaggregation model can be adopted to generate sub-daily data from ANUSPLIN.
- The study is in progress to (i) identify the role of climate indices for various combinations of attributes, clustering algorithms, and cluster validity indices; (ii) analyze number of study areas across the globe to generalize the selection of CVI, or to identify the best set of CVIs for their respective climate zones.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster Validity | Mathematical Equation | Selection |
|---|---|---|
| Index | Criteria | |
| Ball-Hall | ||
| (Ball_Hall) | Maximum | |
| where, C is the Cluster Validity Index; M is the matrix of attributes of kth cluster; G is the barycentre of attributes in kth cluster; n is number of sites in kth cluster; K is the total number of clusters | Difference | |
| Banfeld–Raftery | ||
| (Banfeld_Raftery) | Minimum | |
| C | ||
| (C_index) | Minimum | |
| where, N is the number of pairs of distinct sites in a cluster; S is the sum of N distances between all the pairs of sites inside each cluster; S is the sum of N smallest distances between all the pairs of sites in the entire dataset; S is the sum of N largest distances between all the pairs of sites in the entire dataset | ||
| (Log_SS_Ratio) | Minimum | |
| Difference | ||
| McClain–Rao | ||
| (McClain_Rao) | Minimum | |
| where, N is the number of pairs of sites which do not belong to the same cluster; M is the row matrix of ith site’s attributes; d() is the Euclidean distance between sites | ||
| PBM | ||
| (PBM) | Maximum | |
| Point Biserial | ||
| (Point_Biserial) | Maximum | |
| where, N is the total number of pairs of distinct sites in the dataset | ||
| Calinski–Harabasz | ||
| (Calinski_Harabasz) | Maximum | |
| Davies–Bouldin | ||
| (Davies_Bouldin) | Minimum | |
| (Det_Ratio) | Minimum | |
| where, X is the matrix formed by centred vectors for entire dataset; X is the matrix formed by centred vectors for each cluster k; V is the jth observed attribute; is the barycentre of jth observed attribute | Difference | |
| Dunn | ||
| (Dunn) | Maximum | |
| Dunn Generalized (1, 1) | ||
| (GDI11) | Maximum | |
| Dunn Generalized (1, 2) | ||
| (GDI12) | Maximum | |
| Dunn Generalized (1, 3) | ||
| (GDI13) | Maximum | |
| Dunn Generalized (2, 1) | ||
| (GDI21) | Maximum | |
| Dunn Generalized (2, 2) | ||
| (GDI22) | Maximum | |
| Dunn Generalized (2, 3) | ||
| (GDI23) | Maximum | |
| Dunn Generalized (3, 1) | ||
| (GDI31) | Maximum | |
| Dunn Generalized (3, 2) | ||
| (GDI32) | Maximum | |
| Dunn Generalized (3, 3) | ||
| (GDI33) | Maximum | |
| Dunn Generalized (4, 1) | ||
| (GDI41) | Maximum | |
| Dunn Generalized (4, 2) | ||
| (GDI42) | Maximum | |
| Dunn Generalized (4, 3) | ||
| (GDI43) | Maximum | |
| Dunn Generalized (5, 1) | ||
| (GDI51) | Maximum | |
| Dunn Generalized (5, 2) | ||
| (GDI52) | Maximum | |
| Dunn Generalized (5, 3) | ||
| (GDI53) | Maximum | |
| Gamma | ||
| (Gamma) | Maximum | |
| where, is the number of pairs of sites which are not in same cluster and whose distance is less than those which are in same cluster; is the number of pairs which are in same cluster and whose distance is more than those which are in same cluster | ||
| G+ | ||
| (G_plus) | Minimum | |
| (Ksq_DetW) | Maximum | |
| where, det() is the determinant of the matrix | Difference | |
| Wemmet - Gan arski | ||
| (Wemmet _Gancarski) | Maximum | |
| (Log_Det_Ratio) | Minimum | |
| Difference | ||
| Ratkowsky–Lance | ||
| (Ratkowsky_Lance) | Maximum | |
| where, p is the total number of attributes; a is the jth attribute of ith site | ||
| Ray–Turi | ||
| (Ray_Turi) | Minimum | |
| Scott–Symons | ||
| (Scott_Symons) | Minimum | |
| SD [Scat] | ||
| (SD_Scat) | Minimum | |
| where, Var() of the attribute | ||
| SD [Dis] | ||
| (SD_Dis) | Minimum | |
| S-Dbw | ||
| (S_Dbw) | ||
| where, H is the mid-point of G and G ; () is the total number of sites in these kth and k clusters whose distance to the given point is less than | ||
| Minimum | ||
| Silhouette | ||
| (Silhouette) | Maximum | |
| Tr(W) | ||
| (Trace_W) | Maximum | |
| where, Tr() is the trace of the matrix | Difference | |
| Tr(W-1B) | ||
| (Trace_WiB) | Maximum | |
| where, B is the matrix formed in rows by the vectors where | Difference | |
| Xie–Beni | ||
| (Xie_Beni) | Minimum | |
| Tau | ||
| (Tau) | Maximum |
References
- Cowpertwait, P.S.P.; O’Connell, P.E.; Metcalfe, A.V.; Mawdsley, J.A. Stochastic point process modelling of rainfall. II. Regionalisation and disaggregation. J. Hydrol. 1996, 175, 47–65. [Google Scholar] [CrossRef]
- Cowpertwait, P.; O’Connell, P.; Metcalfe, A.; Mawdsley, J. Stochastic point process modelling of rainfall. I. Single-site fitting and validation. J. Hydrol. 1996, 175, 17–46. [Google Scholar] [CrossRef]
- Acreman, M.C.; Werritty, A. Flood frequency estimation in Scotland using index floods and regional growth curves. Trans. R. Soc. Edinburgh Earth Sci. 1987, 78, 305–313. [Google Scholar] [CrossRef]
- Srivastav, R.K.; Srinivasan, K.; Sudheer, K. Simulation-optimization framework for multi-site multi-season hybrid stochastic streamflow modeling. J. Hydrol. 2016, 542, 506–531. [Google Scholar] [CrossRef]
- Srivastav, R.K.; Simonovic, S.P. Multi-site, multivariate weather generator using maximum entropy bootstrap. Clim. Dyn. 2015, 44, 3431–3448. [Google Scholar] [CrossRef]
- Burn, D.H. Catchment similarity for regional flood frequency analysis using seasonality measures. J. Hydrol. 1997, 202, 212–230. [Google Scholar] [CrossRef]
- Comrie, A.C.; Glenn, E.C. Principal components-based regionalization of precipitation regimes across the Southwest United States and Northern Mexico, with an application to monsoon precipitation variability. Clim. Res. 1998, 10, 201–215. [Google Scholar] [CrossRef]
- Satyanarayana, P.; Srinivas, V.V. Regional frequency analysis of precipitation using large–scale atmospheric variables. J. Geophys. Res. 2008, 113, D24110. [Google Scholar] [CrossRef]
- Satyanarayana, P.; Srinivas, V.V. Regionalization of precipitation in data sparse areas using large scale atmospheric variables—A fuzzy clustering approach. J. Hydrol. 2011, 405, 462–473. [Google Scholar] [CrossRef]
- Asong, Z.E.; Khaliq, M.N.; Wheater, H.S. Regionalization of precipitation characteristics in the Canadian Prairie Provinces using large-scale atmospheric covariates and geophysical attributes. Stoch. Environ. Res. Risk Assess. 2015, 29, 875–892. [Google Scholar] [CrossRef]
- Irwin, S.; Srivastav, R.K.; Simonovic, S.P.; Burn, D.H. Delineation of precipitation regions using location and atmospheric variables in two Canadian climate regions: The role of attribute selection. Hydrol. Sci. J. 2017, 62, 191–204. [Google Scholar] [CrossRef]
- Adamowski, K.; Alila, Y.; Pilon, P.J. Regional rainfall distribution for Canada. Atmos. Res. 1996, 10, 75–88. [Google Scholar] [CrossRef]
- Tasker, G.; Hosking, J.R.M.; Wallis, J.R. Regional Frequency Analysis: An Approach Based on L-Moments; Cambridge University Press: Cambridge, UK, 1997; 240p. [Google Scholar]
- Kannan, S.; Ghosh, S. Prediction of daily rainfall state in a river basin using statistical downscaling from GCM output. Stoch. Environ. Res. Risk Assess. 2011, 25, 457–474. [Google Scholar] [CrossRef]
- Goyal, M.K.; Gupta, V. Identification of Homogeneous Rainfall Regimes in Northeast Region of India using Fuzzy Cluster Analysis. Water Resour. Manag. 2014, 28, 4491–4511. [Google Scholar] [CrossRef]
- Wong, C.-L.; Liew, J.; Yusop, Z.; Ismail, T.; Venneker, R.; Uhlenbrook, S. Rainfall Characteristics and Regionalization in Peninsular Malaysia Based on a High Resolution Gridded Data Set. Water 2016, 8, 500. [Google Scholar] [CrossRef] [Green Version]
- Rasheed, A.; Egodawatta, P.; Goonetilleke, A.; McGree, J.M. A Novel Approach for Delineation of Homogeneous Rainfall Regions for Water Sensitive Urban Design—A Case Study in Southeast Queensland. Water 2019, 11, 570. [Google Scholar] [CrossRef] [Green Version]
- Rahman, A.S.; Rahman, A. Application of Principal Component Analysis and Cluster Analysis in Regional Flood Frequency Analysis: A Case Study in New South Wales, Australia. Water 2020, 12, 781. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice Hall: Englewood Cliffs, NJ, USA, 1988. [Google Scholar]
- Halkidi, M.; Vazirgiannis, M. Clustering validity assessment: Finding the optimal partitioning of a data set. In Proceedings of the IEEE International Conference on Data Mining (ICDM 2001), San Jose, CA, USA, 29 November–2 December 2001; pp. 187–194. [Google Scholar]
- Holzinger, K.J.; Harman, H.H. Factor Analysis; University of Chicago Press: Chicago, IL, USA, 1941. [Google Scholar]
- Sneath, P.H.A.; Sokal, R.R. Numerical Taxonomy: The Principles and Practice of Numerical Classification; Freeman: San Francisco, CA, USA, 1973; p. 573. [Google Scholar]
- Sanjuan, E.; Ibekwe-SanJuan, F. Text mining without document context. Inf. Process. Manag. 2006, 42, 1532–1552. [Google Scholar] [CrossRef] [Green Version]
- Perdisci, R.; Giacinto, G.; Roli, F. Alarm clustering for intrusion detection systems in computer networks. Eng. Appl. Artif. Intell. 2006, 19, 429–438. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Plenum Press: New York, NY, USA, 1981. [Google Scholar]
- Mirkin, B. Clustering for Data Mining: A Data Recovery Approach; Chapman & Hall/CRC: Boca Raton, FL, USA, 2005. [Google Scholar]
- Hämäläinen, J.; Jauhiainen, S.; Kärkkäinen, T. Comparison of Internal Clustering Validation Indices for Prototype-Based Clustering. Algorithms 2017, 10, 105. [Google Scholar]
- Chou, C.-H.; Su, M.-C.; Lai, E. A new cluster validity measure and its application to image compression. Pattern Anal. Appl. 2004, 7, 205–220. [Google Scholar] [CrossRef]
- Barbara, D.; Jajodia, S. (Eds.) Applications of Data Mining in Computer Security; Kluwer Academic Publishers: Norwell, MA, USA, 2002. [Google Scholar]
- Gottschalk, L. Hydrologic regionalization of Sweden. Hydrol. Sci. J. 1985, 30, 65–83. [Google Scholar] [CrossRef] [Green Version]
- Burn, D.H. Cluster analysis as applied to regional flood frequency analysis. J. Water Resour. Plan. Manag. 1989, 115, 567–582. [Google Scholar] [CrossRef]
- Cormack, R.M. A Review of Classification. J. R. Stat. Soc. Ser. A (Gen.) 1971, 134, 321–367. [Google Scholar] [CrossRef]
- Everitt, B. Cluster Analysis, 2nd ed.; Halsted Press: New York, NY, USA, 1980. [Google Scholar]
- Althoff, D.; Santos, R.A.; Bazame, H.; Da Cunha, F.F.; Filgueiras, R. Improvement of Hargreaves–Samani Reference Evapotranspiration Estimates with Local Calibration. Water 2019, 11, 2272. [Google Scholar] [CrossRef] [Green Version]
- Feng, Z.-K.; Niu, W.-J.; Zhang, R.; Wang, S.; Cheng, C.-T. Operation rule derivation of hydropower reservoir by k-means clustering method and extreme learning machine based on particle swarm optimization. J. Hydrol. 2019, 576, 229–238. [Google Scholar] [CrossRef]
- Narbondo, S.; Gorgoglione, A.; Crisci, M.; Chreties, C. Enhancing Physical Similarity Approach to Predict Runoff in Ungauged Watersheds in Sub-Tropical Regions. Water 2020, 12, 528. [Google Scholar] [CrossRef] [Green Version]
- Tsegaye, S.; Missimer, T.M.; Kim, J.-Y.; Hock, J. A Clustered, Decentralized Approach to Urban Water Management. Water 2020, 12, 185. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Q.; Zhu, Y.; Wan, D.; Yu, Y.; Lu, Y. Similarity Analysis of Small- and Medium-Sized Watersheds Based on Clustering Ensemble Model. Water 2020, 12, 69. [Google Scholar] [CrossRef] [Green Version]
- Huang, F.; Zhu, Q.; Zhou, J.; Tao, J.; Zhou, X.; Jin, D.; Tan, X.; Wang, L. Research on the Parallelization of the DBSCAN Clustering Algorithm for Spatial Data Mining Based on the Spark Platform. Remote Sens. 2017, 9, 1301. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Ren, C.; Luo, Y.; Tian, J. NS-DBSCAN: A Density-Based Clustering Algorithm in Network Space. ISPRS Int. J. Geo-Inf. 2019, 8, 218. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, R.; Gehrke, J.; Gunopulos, D.; Raghavan, P. Automatic subspace clustering of high dimensional data for data mining applications. In Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data, Seattle, WA, USA, 2–4 June 1998. [Google Scholar]
- Wiltshire, S.E. Identification of homogeneous regions for flood frequency analysis. J. Hydrol. 1986, 84, 287–302. [Google Scholar] [CrossRef]
- Dikbaş, F.; Firat, M.; Koc, A.C.; Gungor, M. Defining Homogeneous Regions for Streamflow Processes in Turkey Using a K-Means Clustering Method. Arab. J. Sci. Eng. 2013, 38, 1313–1319. [Google Scholar] [CrossRef]
- Romesburg, H.C. Cluster Analysis for Researchers; Lifetime Learning Publications: Belmont, CA, USA, 1984. [Google Scholar]
- Everitt, B.S. Cluster Analysis, 3rd ed.; Halsted Press: New York, NY, USA, 1993. [Google Scholar]
- Dubes, R.C. How many clusters are best?—An experiment. Pattern Recognit. 1987, 20, 645–663. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Li, W.Q.; Attikiouzel, Y.; Windham, M. A geometric approach to cluster validity for normal mixtures. Soft Comput. A Fusion Found. Methodol. Appl. 1997, 1, 166–179. [Google Scholar] [CrossRef]
- Shim, Y.; Chung, J.; Choi, I.-C. A comparison study of cluster validity indices using a non-hierarchical clustering algorithm. In Proceedings of the International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC’06), Vienna, Austria, 28–30 November 2005; pp. 199–203. [Google Scholar]
- Arbelaitz, O.; Gurrutxaga, I.; Muguerza, J.; Pérez, J.M.; Perona, I.; Rivero, J.F.M. An extensive comparative study of cluster validity indices. Pattern Recognit. 2013, 46, 243–256. [Google Scholar] [CrossRef]
- Desgraupes, B. Package clusterCrit for R; University of Paris Ouest Lab Modal’X: Nanterre, France, 2017. [Google Scholar]
- Modaresi Rad, A.; Khalili, D. Appropriateness of Clustered Raingauge Stations for Spatio-Temporal Meteorological Drought Applications. Water Resour. Manag. 2015, 29, 4157–4171. [Google Scholar] [CrossRef]
- Mannan, A.; Chaudhary, S.; Dhanya, C.; Swamy, A.K. Regionalization of rainfall characteristics in India incorporating climatic variables and using self-organizing maps. ISH J. Hydraul. Eng. 2017, 24, 147–156. [Google Scholar] [CrossRef]
- McQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Levine, N. CrimeStat Spatial Satistics Program; Version 2.0 Manual; National Institute of Justice: Washington, DC, USA, 1999.
- Tan, B.; Hu, J.; Zhang, P.; Huang, D.; Shabanov, N.; Weiss, M.; Knyazikhin, Y.; Myneni, R. Validation of MODIS LAI product in croplands of Alpilles, France. J. Geophys. Res. 2005, 110, D01107. [Google Scholar] [CrossRef] [Green Version]
- Viglione, A.; Laio, F.; Claps, P. A comparison of homogeneity tests for regional frequency analysis. Water Resour. Res. 2007, 43, W03428. [Google Scholar] [CrossRef] [Green Version]
- D’Orgeville, M.; Peltier, W.R.; Erler, A.R.; Gula, J. Climate change impacts on Great Lakes Basin precipitation extremes. J. Geophys. Res. Atmos. 2014, 119, 10799–10812. [Google Scholar] [CrossRef]
- Shepherd, A.; McGinn, S. Climate change on the Canadian prairies from downscaled GCM data. Atmos. Ocean. 2003, 41, 301–316. [Google Scholar] [CrossRef]
- USEPA. The Great Lakes: An Environmental Atlas and Resource Book. U.S. Environmental Protection Agency. 2012. Available online: http://epa.gov/greatlakes/atlas/glat-ch1.html (accessed on 12 May 2020).
- Sousounis, P.J. Lake effect storms. In Encyclopedia of Atmospheric Sciences; Academic Press: Cambridge, MA, USA, 2001; pp. 1104–1111. [Google Scholar]
- Zhu, Y.; Lin, Z.; Zhao, Y.; Li, H.; He, F.; Zhai, J.; Wang, L.; Wang, Q. Flood Simulations and Uncertainty Analysis for the Pearl River Basin Using the Coupled Land Surface and Hydrological Model System. Water 2017, 9, 391. [Google Scholar] [CrossRef] [Green Version]
- Khan, A.J.; Koch, M. Correction and Informed Regionalization of Precipitation Data in a High Mountainous Region (Upper Indus Basin) and Its Effect on SWAT-Modelled Discharge. Water 2018, 10, 1557. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Shangguan, D.; Liu, S.-Y.; Ding, Y. Evaluation and Hydrological Simulation of CMADS and CFSR Reanalysis Datasets in the Qinghai-Tibet Plateau. Water 2018, 10, 513. [Google Scholar] [CrossRef] [Green Version]
- Hutchinson, M.F.; McKenney, D.W.; Lawrence, K.; Pedlar, J.H.; Hopkinson, R.F.; Milewska, E.; Papadopol, P. Development and testing of Canada wide interpolated spatial models of daily minimum–maximum temperature and precipitation for 1961–2003. J. Appl. Meteorol. Clim. 2009, 48, 725–741. [Google Scholar] [CrossRef]
- Hopkinson, R.F.; McKenney, D.W.; Milewska, E.J.; Hutchinson, M.F.; Papadopol, P.; Vincent, L.A. Impact of aligning climatological day on gridding daily maximum–minimum temperature and precipitation over Canada. J. Appl. Meteorol. Clim. 2011, 50, 1654–1665. [Google Scholar] [CrossRef]
- McKenney, D.W.; Hutchinson, M.F.; Papadopol, P.; Lawrence, K.; Pedlar, J.H.; Campbell, K.; Milewska, E.; Hopkinson, R.F.; Price, D.; Owen, T. Customized Spatial Climate Models for North America. Am. Meteorol. Soc. 2011, 92, 1611–1622. [Google Scholar] [CrossRef]
- Tan, X.; Gan, T.Y.; Chen, Y.D. Synoptic moisture pathways associated with mean and extreme precipitation over Canada for summer and fall. Clim. Dyn. 2019, 52, 2959–2979. [Google Scholar] [CrossRef]
- Lilhare, R.; Déry, S.; Pokorny, S.; Stadnyk, T.; Koenig, K.A. Intercomparison of Multiple Hydroclimatic Datasets across the Lower Nelson River Basin, Manitoba, Canada. Atmos. Ocean 2019, 57, 262–278. [Google Scholar] [CrossRef]
- Guo, B.; Zhang, J.; Meng, X.; Xu, T.; Song, Y. Long-term spatio-temporal precipitation variations in China with precipitation surface interpolated by ANUSPLIN. Sci. Rep. 2020, 10, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Dalton, L.; Ballarin, V.; Brun, M. Clustering Algorithms: On Learning, Validation, Performance, and Applications to Genomics. Curr. Genom. 2009, 10, 430–445. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lang, Y.; Ye, A.; Gong, W.; Miao, C.; Di, Z.; Xu, J.; Liu, Y.; Luo, L.; Duan, Q. Evaluating Skill of Seasonal Precipitation and Temperature Predictions of NCEP CFSv2 Forecasts over 17 Hydroclimatic Regions in China. J. Hydrometeor. 2014, 15, 1546–1559. [Google Scholar] [CrossRef]
- Mesinger, F.; DiMego, G.; Kalnay, E.; Mitchell, K.; Shafran, P.C.; Ebisuzaki, W.; Jovic, D.; Woollen, J.; Rogers, E.; Berbery, E.H.; et al. North American Regional Reanalysis. Bull. Am. Meteorol. Soc. 2006, 87, 343–360. [Google Scholar] [CrossRef] [Green Version]
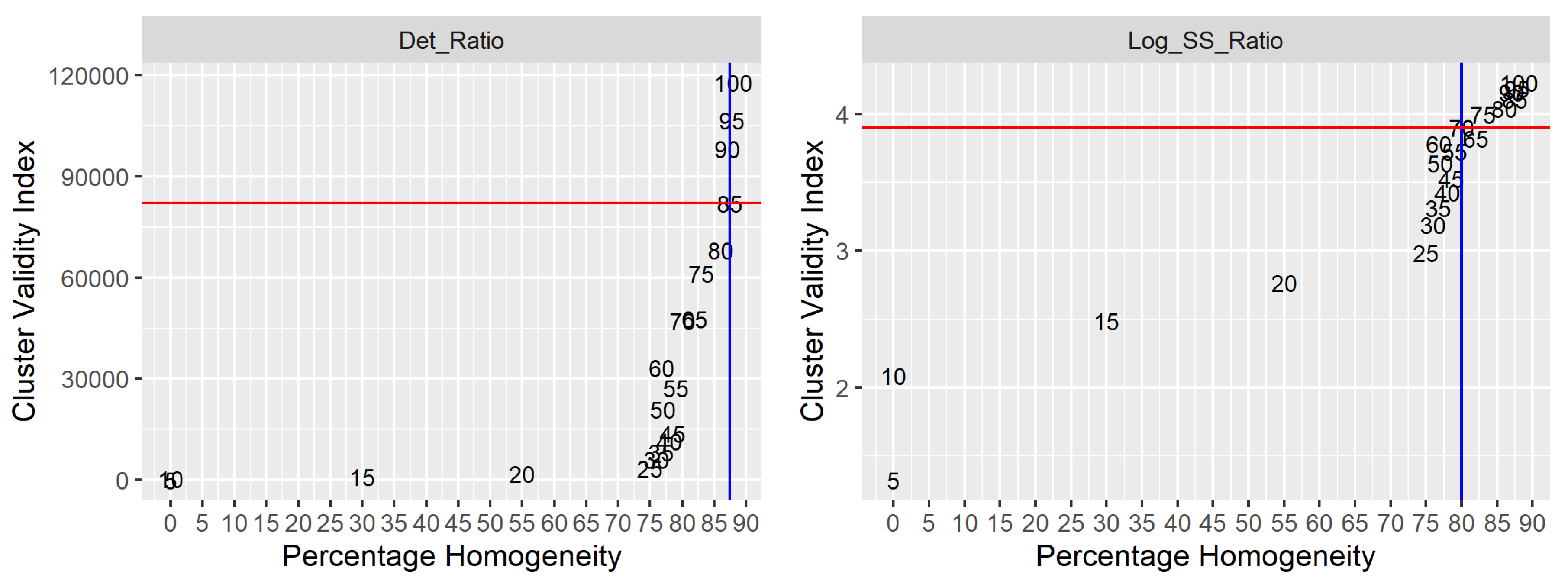








| Clustering Indices | Winter Season | Spring Season | Summer Season | Autumn Season | ||||
|---|---|---|---|---|---|---|---|---|
| #Clusters | %Hom | #Clusters | %Hom | #Clusters | %Hom | #Clusters | %Hom | |
| Banfeld_Raftery | 100 | 89.48 | 100 | 85.26 | 100 | 88.42 | 100 | 89.47 |
| C_index | 100 | 89.48 | 100 | 85.26 | 100 | 88.42 | 95 | 88.89 |
| Det_Ratio | 85 | 87.50 | 80 | 86.67 | 85 | 87.50 | 95 | 88.89 |
| Dunn | 55 | 86.00 | 100 | 85.26 | 100 | 88.42 | 95 | 88.89 |
| G_plus | 95 | 88.89 | 100 | 85.26 | 100 | 88.42 | 100 | 89.47 |
| GDI11 | 55 | 86.00 | 100 | 85.26 | 100 | 88.42 | 95 | 88.89 |
| GDI12 | 80 | 88.00 | 90 | 84.71 | 100 | 88.42 | 95 | 88.89 |
| GDI13 | 100 | 89.48 | 95 | 85.56 | 100 | 88.42 | 95 | 88.89 |
| McClain_Rao | 100 | 89.48 | 100 | 85.26 | 100 | 88.42 | 95 | 88.89 |
| Point_Biserial | 95 | 88.89 | 100 | 85.26 | 100 | 88.42 | 100 | 89.48 |
| SD_Scat | 100 | 89.48 | 100 | 85.26 | 100 | 88.42 | 100 | 89.48 |
| Tau | 95 | 88.89 | 100 | 85.26 | 100 | 88.42 | 100 | 89.48 |
| Trace_WiB | 95 | 88.89 | 75 | 84.29 | 70 | 84.61 | 55 | 84.00 |
| Xie_Beni | 100 | 89.48 | 100 | 85.26 | 100 | 88.42 | 95 | 88.89 |
| Cluster Validity Index | Prairies Region | Great Lakes-St. Lawrence Lowlands Region |
|---|---|---|
| Banfeld_Raftery | Winter and | Autumn Season |
| Autumn Season | ||
| C_index | Winter Season | Autumn Season |
| Det_Ratio | Autumn Season | Autumn Season |
| Davies_Bouldin | - | Autumn Season |
| Dunn | Autumn Season | Autumn Season |
| G_plus | Autumn Season | Autumn Season |
| GDI11 | Autumn Season | Autumn Season |
| GDI12 | Autumn Season | Autumn Season |
| GDI13 | Winter Season | Autumn Season |
| McClain_Rao | Winter Season | Autumn Season |
| Point_Biserial | Autumn Season | Autumn Season |
| SD_Scat | Winter and | Autumn Season |
| Autumn Season | ||
| Tau | Autumn Season | Autumn Season |
| Trace_WiB | Winter Season | Autumn Season |
| Xie_Beni | Winter Season | Autumn Season |
| Clustering Indices | Winter Season | Spring Season | Summer Season | Autumn Season | ||||
|---|---|---|---|---|---|---|---|---|
| #Clusters | %Hom | #Clusters | %Hom | #Clusters | %Hom | #Clusters | %Hom | |
| Banfeld_Raftery | 100 | 98.95 | 100 | 98.95 | 100 | 97.89 | 100 | 100 |
| C_index | 90 | 98.82 | 90 | 98.82 | 85 | 97.50 | 95 | 100 |
| Det_Ratio | 85 | 98.75 | 65 | 98.33 | 25 | 95.00 | 55 | 100 |
| Davies_Bouldin | 90 | 98.82 | 90 | 98.82 | 85 | 97.50 | 95 | 100 |
| Dunn | 85 | 98.75 | 100 | 98.95 | 85 | 97.50 | 75 | 100 |
| G_plus | 100 | 98.95 | 95 | 97.78 | 100 | 97.89 | 100 | 100 |
| GDI11 | 85 | 98.75 | 100 | 98.95 | 85 | 97.50 | 75 | 100 |
| GDI12 | 85 | 98.75 | 100 | 98.95 | 85 | 97.50 | 75 | 100 |
| GDI13 | 75 | 97.15 | 100 | 98.95 | 85 | 97.50 | 75 | 100 |
| McClain_Rao | 90 | 98.82 | 90 | 98.82 | 95 | 97.78 | 95 | 100 |
| Point_Biserial | 100 | 98.95 | 95 | 97.78 | 100 | 97.89 | 100 | 100 |
| SD_Scat | 100 | 98.95 | 100 | 98.95 | 100 | 97.89 | 100 | 100 |
| Tau | 100 | 98.95 | 95 | 97.78 | 100 | 97.89 | 100 | 100 |
| Trace_WiB | 85 | 98.75 | 95 | 97.78 | 90 | 98.82 | 90 | 100 |
| Xie_Beni | 95 | 98.89 | 100 | 98.95 | 95 | 97.78 | 100 | 100 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhatia, N.; Sojan, J.M.; Simonovic, S.; Srivastav, R. Role of Cluster Validity Indices in Delineation of Precipitation Regions. Water 2020, 12, 1372. https://doi.org/10.3390/w12051372
Bhatia N, Sojan JM, Simonovic S, Srivastav R. Role of Cluster Validity Indices in Delineation of Precipitation Regions. Water. 2020; 12(5):1372. https://doi.org/10.3390/w12051372
Chicago/Turabian StyleBhatia, Nikhil, Jency M. Sojan, Slobodon Simonovic, and Roshan Srivastav. 2020. "Role of Cluster Validity Indices in Delineation of Precipitation Regions" Water 12, no. 5: 1372. https://doi.org/10.3390/w12051372
APA StyleBhatia, N., Sojan, J. M., Simonovic, S., & Srivastav, R. (2020). Role of Cluster Validity Indices in Delineation of Precipitation Regions. Water, 12(5), 1372. https://doi.org/10.3390/w12051372