Application of Artificial Neural Networks in Forecasting a Standardized Precipitation Evapotranspiration Index for the Upper Blue Nile Basin



Abstract
1. Introduction
2. Study Area and Data Used
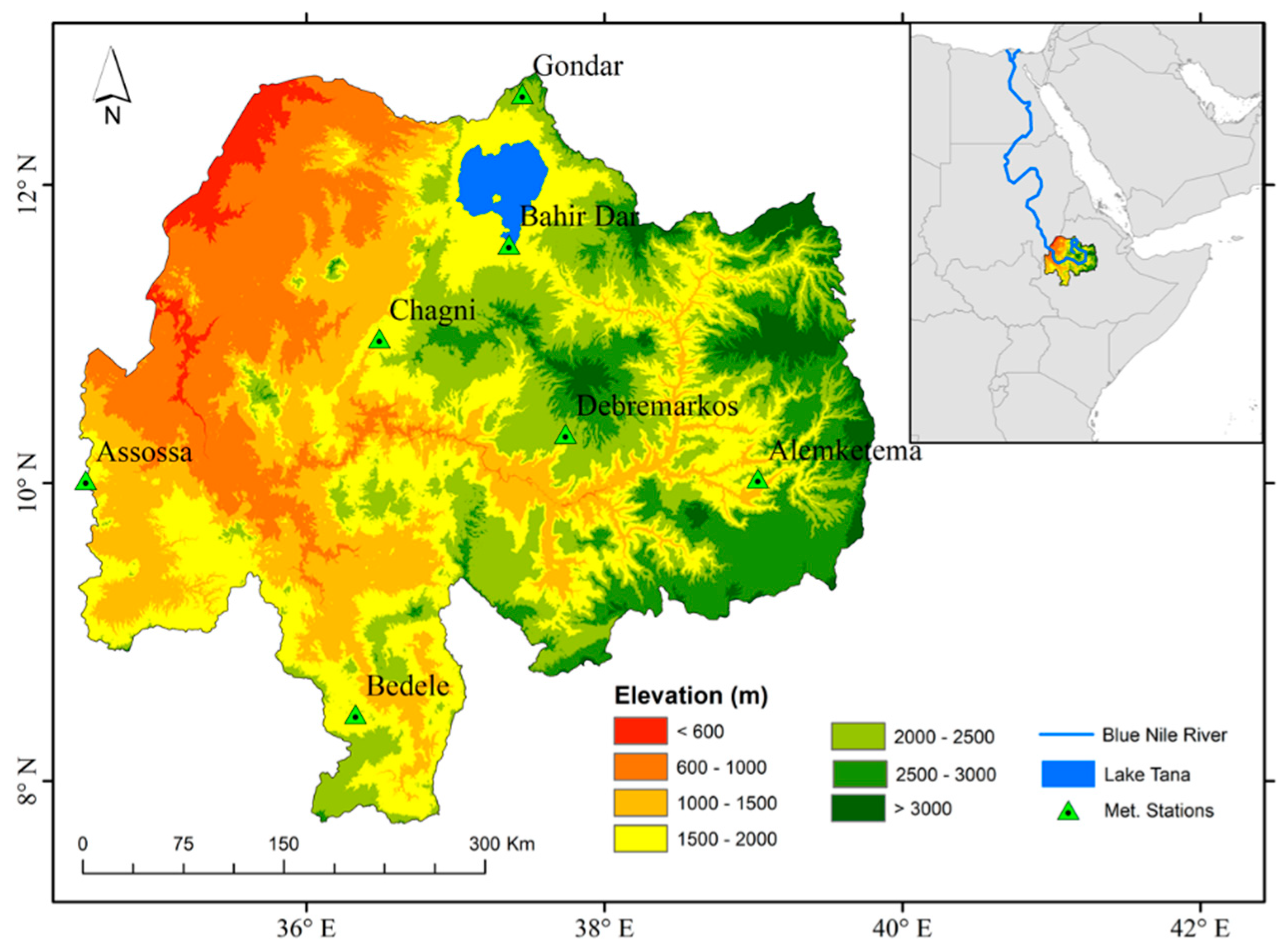
2.1. Study Area
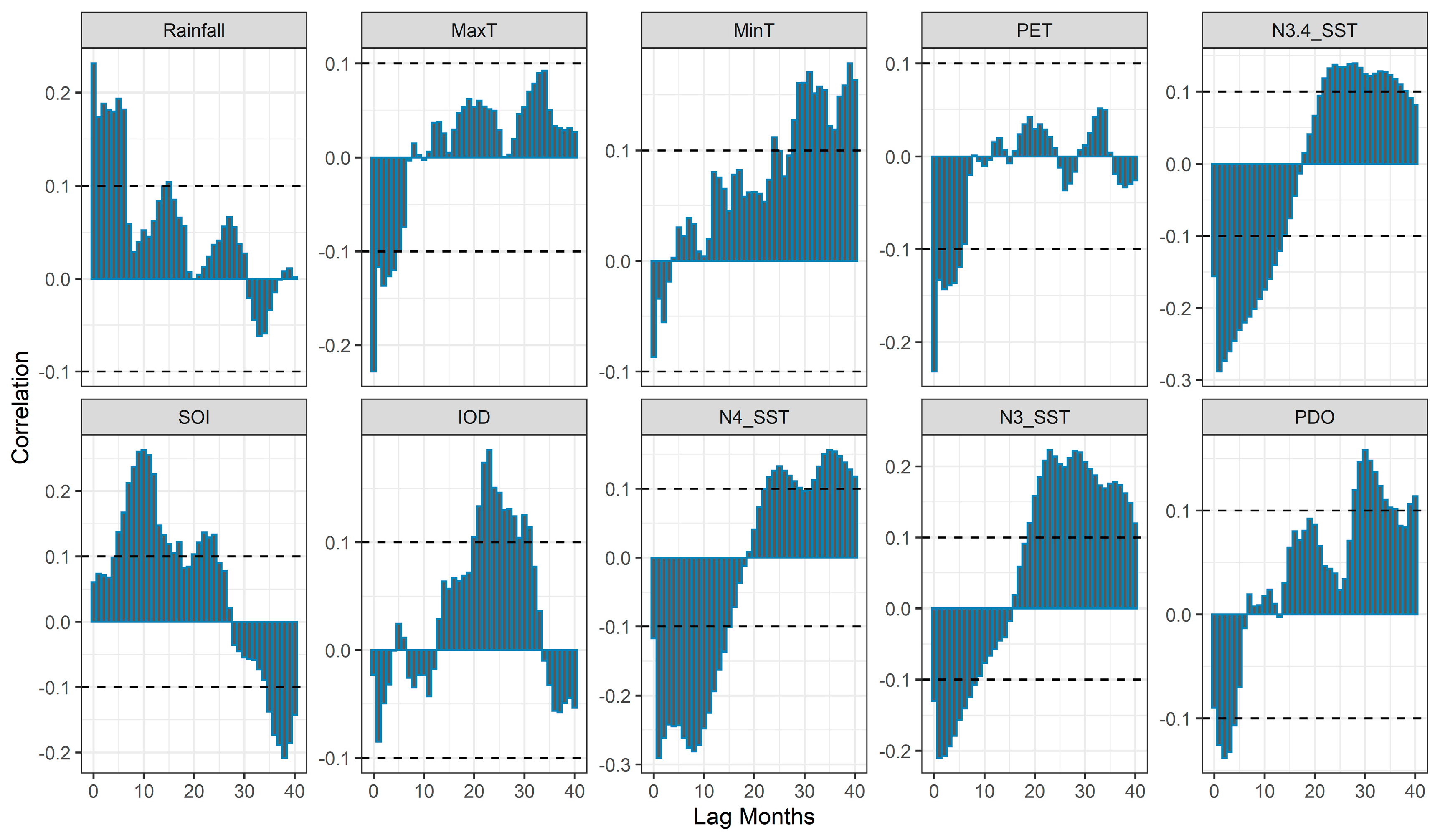
2.2. Data Sources
3. Methodology
3.1. SPEI
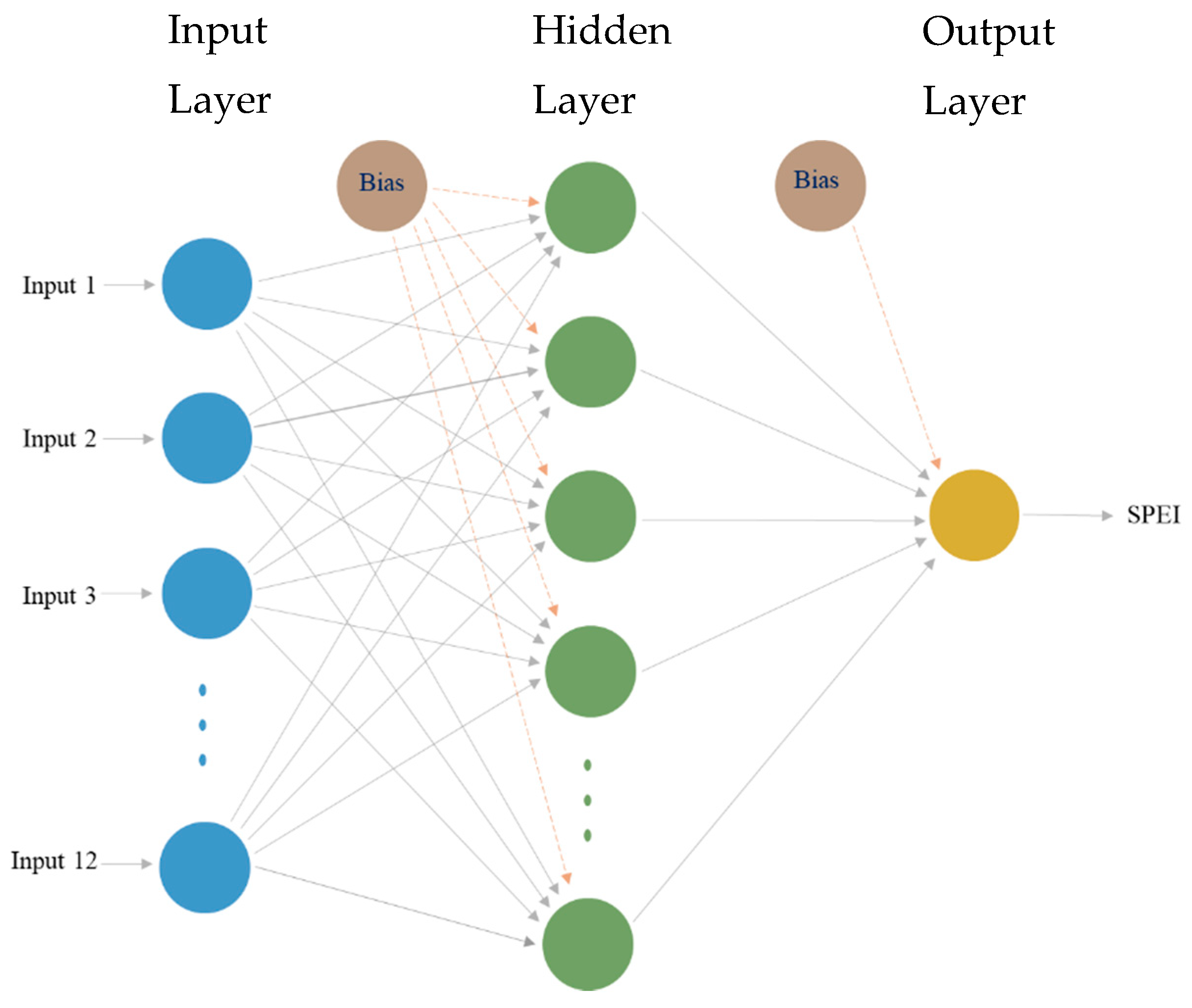
3.2. Artificial Neural Networks (ANNs)
3.3. ANN Model Development
3.4. Statistical Performance Measures
4. Results and Discussions
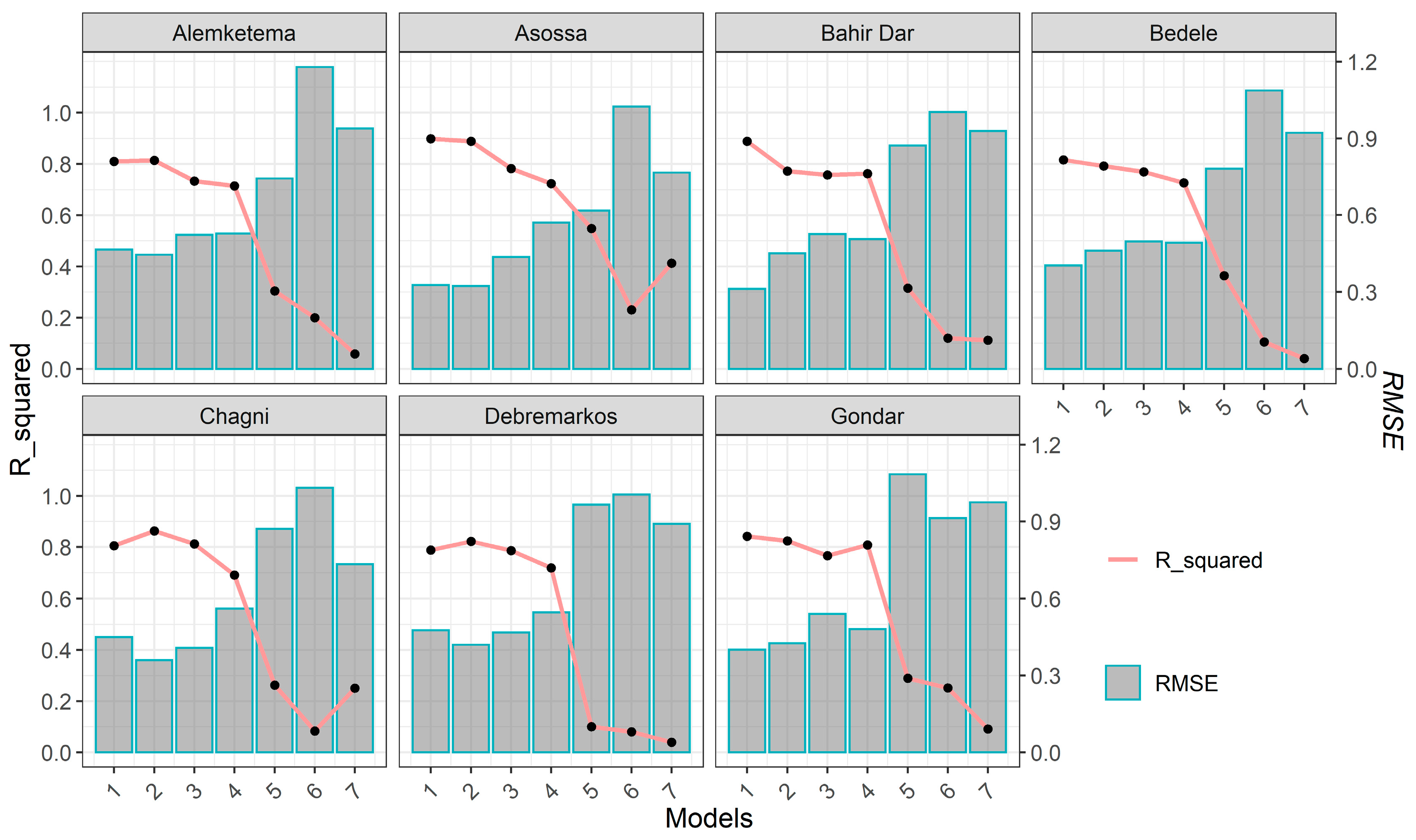
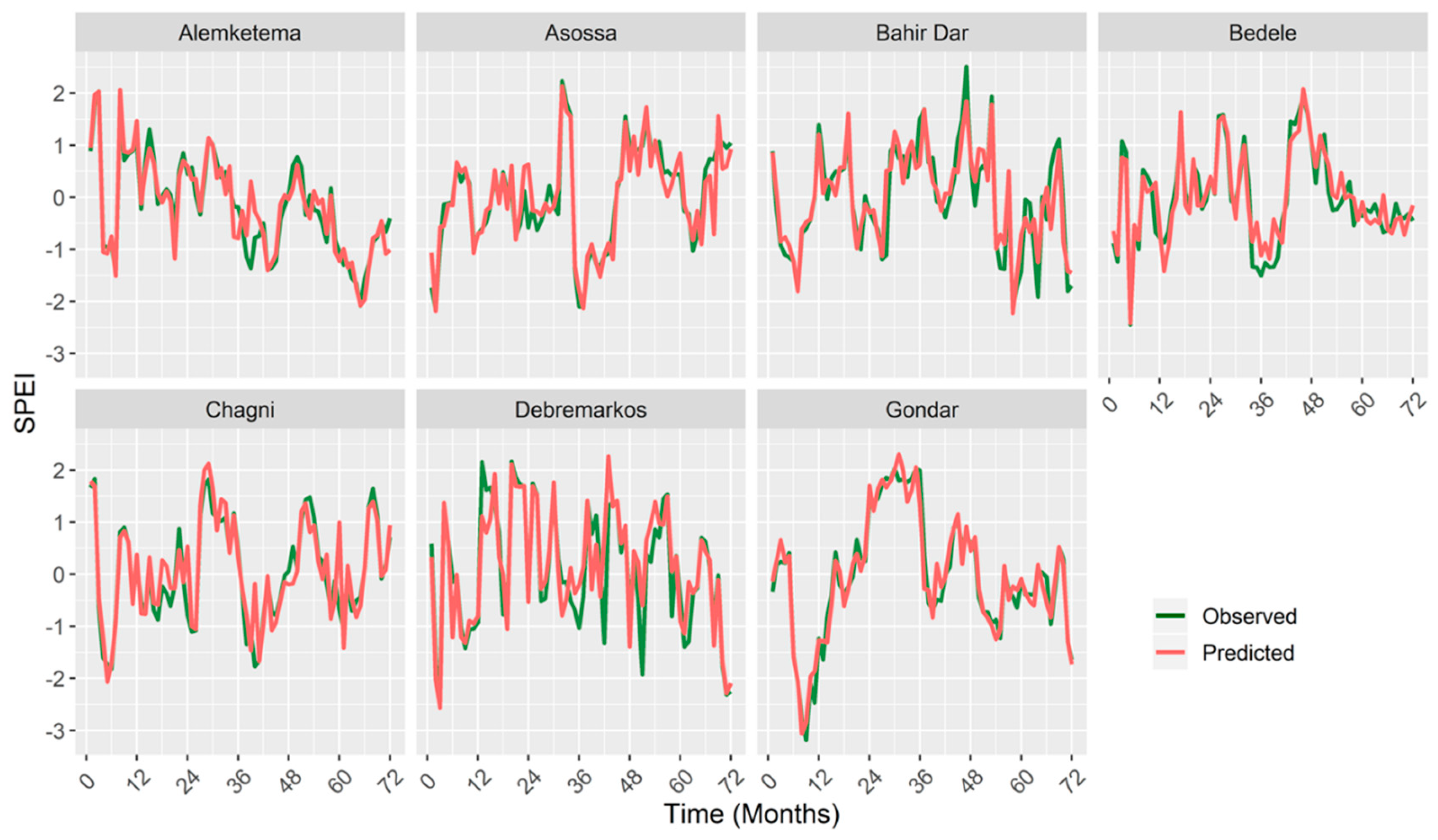
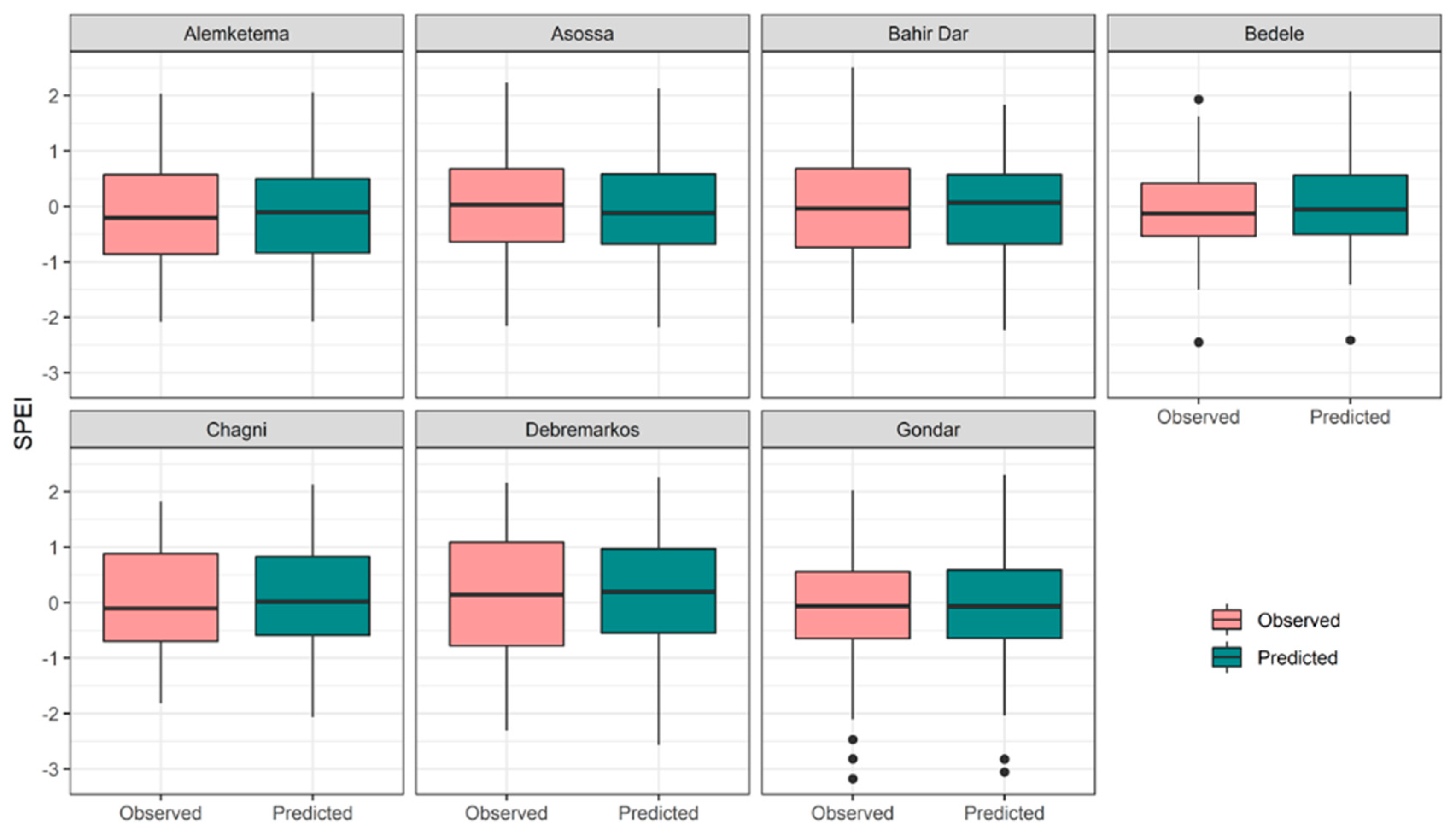
4.1. Model Performance
4.2. Comparison of Different Models
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wilhite, D.A.; Glantz, M.H. Understanding: The drought phenomenon: The role of definitions. Water Int. 1985, 10, 111–120. [Google Scholar] [CrossRef]
- Cheng, C.-H.; Nnadi, F.; Liou, Y.-A. Energy budget on various land use areas using reanalysis data in Florida. Adv. Meteorol. 2014, 2014, 1–13. [Google Scholar] [CrossRef]
- Dorjsuren, M.; Liou, Y.-A.; Cheng, C.-H. Time series MODIS and in situ data analysis for Mongolia drought. Remote Sens. 2016, 8, 509. [Google Scholar] [CrossRef]
- Luo, L.; Apps, D.; Arcand, S.; Xu, H.; Pan, M.; Hoerling, M. Contribution of temperature and precipitation anomalies to the California drought during 2012–2015. Geophys. Res. Lett. 2017, 44, 3184–3192. [Google Scholar] [CrossRef]
- Habibi, B.; Meddi, M.; Torfs, P.J.J.F.; Remaoun, M.; Van Lanen, H.A.J. Characterisation and prediction of meteorological drought using stochastic models in the semi-arid Chéliff–Zahrez basin (Algeria). J. Hydrol. Reg. Stud. 2018, 16, 15–31. [Google Scholar] [CrossRef]
- Liou, Y.A.; Nguyen, A.K.; Li, M.H. Assessing spatiotemporal eco-environmental vulnerability by Landsat data. Ecol. Indic. 2017, 80, 52–65. [Google Scholar] [CrossRef]
- Cheng, C.H.; Nnadi, F.; Liou, Y.A. A regional land use drought index for Florida. Remote Sens. 2015, 7, 17149–17167. [Google Scholar] [CrossRef]
- Liou, Y.A.; Mulualem, G.M. Spatio-temporal assessment of drought in Ethiopia and the impact of recent intense droughts. Remote Sens. 2019, 11, 1828. [Google Scholar] [CrossRef]
- Dutra, E.; Magnusson, L.; Wetterhall, F.; Cloke, H.L.; Balsamo, G.; Boussetta, S.; Pappenberger, F. The 2010–2011 drought in the Horn of Africa in ECMWF reanalysis and seasonal forecast products. Int. J. Climatol. 2013, 33, 1720–1729. [Google Scholar] [CrossRef]
- Wu, X.; Hongxing, C.; Flitma, A. Forecasting monsoon precipitation using artificial neural networks. Adv. Atmos. Sci. 2011, 14, 123. [Google Scholar] [CrossRef]
- Wu, C.L.; Chau, K.W.; Li, Y.S. Predicting monthly streamflow using data-driven models coupled with data-preprocessing techniques. Water Resour. Res. 2009, 45. [Google Scholar] [CrossRef]
- Hao, Z.; Singh, V.P.; Xia, Y. Seasonal Drought Prediction: Advances, Challenges, and Future Prospects. Rev. Geophys. 2018, 56, 108–141. [Google Scholar] [CrossRef]
- Zargar, A.; Sadiq, R.; Naser, B.; Khan, F.I. A review of drought indices. Environ. Rev. 2011, 19, 333–349. [Google Scholar] [CrossRef]
- Vicente-Serrano, S.M.; Beguería, S.; López-Moreno, J.I.; Vicente-Serrano, S.M.; Beguería, S.; López-Moreno, J.I. A multiscalar drought index sensitive to global warming: The standardized precipitation evapotranspiration index. J. Clim. 2010, 23, 1696–1718. [Google Scholar] [CrossRef]
- Almedeij, J. Drought analysis for kuwait using standardized precipitation index. Sci. World J. 2014, 2014. [Google Scholar] [CrossRef] [PubMed]
- Yu, C.; Li, C.; Xin, Q.; Chen, H.; Zhang, J.; Zhang, F.; Li, X.; Clinton, N.; Huang, X.; Yue, Y.; et al. Dynamic assessment of the impact of drought on agricultural yield and scale-dependent return periods over large geographic regions. Environ. Model. Softw. 2014, 62, 454–464. [Google Scholar] [CrossRef]
- Hayes, M.J.; Svoboda, M.D.; Wardlow, B.D.; Anderson, M.C.; Kogan, F. Drought monitoring: Historical and current perspectives. In Remote Sensing of Drought: Innovative Monitoring Approaches; CRC Press: Boca Raton, FL, USA, 2012; pp. 1–19. ISBN 9781439835609. [Google Scholar]
- Yusuf, A.A.; Francisco, H. Climate change vulnerability mapping for Southeast Asia vulnerability mapping for Southeast Asia. East 2009, 181, 1–19. [Google Scholar]
- Mishra, S.S.; Nagarajan, R. Forecasting drought in Tel River Basin using feedforward recursive neural network. Int. Conf. Environ. Biomed. Biotechnol. 2012, 41, 122–126. [Google Scholar]
- Pulwarty, R.S.; Sivakumar, M.V. Information systems in a changing climate: Early warnings and drought risk management. Weather Clim. Extrem. 2014, 3, 14–21. [Google Scholar] [CrossRef]
- Khashei, M.; Bijari, M. An artificial neural network (p, d, q) model for timeseries forecasting. Expert Syst. Appl. 2009, 37, 479–489. [Google Scholar] [CrossRef]
- Barua, S.; Ng, A.W.M.; Perera, B.J.C. Artificial Neural Network–Based drought forecasting using a nonlinear aggregated drought index. J. Hydrol. Eng. 2012, 17, 1408–1413. [Google Scholar] [CrossRef]
- Hardwinarto, S.; Aipassa, M. Rainfall monthly prediction based on Artificial Neural Network: A case study in Tenggarong station, East Kalimantan–Indonesia. Procedia Comput. Sci. 2015, 59, 142–151. [Google Scholar] [CrossRef]
- Morid, S.; Smakhtin, V.; Bagherzadeh, K. Drought forecasting using artificial neural networks and time series of drought indices. Int. J. Climatol. 2007, 27, 2103–2111. [Google Scholar] [CrossRef]
- Liou, Y.A.; Liu, S.F.; Wang, W.J. Retrieving soil moisture from simulated brightness temperatures by a neural network. IEEE Trans. Geosci. Remote Sens. 2001, 39, 1662–1672. [Google Scholar]
- Belayneh, A.; Adamowski, J.; Khalil, B. Short-term SPI drought forecasting in the Awash River Basin in Ethiopia using wavelet transforms and machine learning methods. Sustain. Water Resour. Manag. 2016, 2, 87–101. [Google Scholar] [CrossRef]
- Deo, R.C.; Şahin, M. Application of the Artificial Neural Network model for prediction of monthly standardized precipitation and evapotranspiration index using hydrometeorological parameters and climate indices in eastern Australia. Atmos. Res. 2015, 161–162, 65–81. [Google Scholar] [CrossRef]
- Le, M.H.; Perez, G.C.; Solomatine, D.; Nguyen, L.B. Meteorological drought forecasting based on climate signals using Artificial Neural Network—A case study in Khanhhoa Province Vietnam. Procedia Eng. 2016, 154, 1169–1175. [Google Scholar] [CrossRef]
- Schubert, S.D.; Stewart, R.E.; Wang, H.; Barlow, M.; Berbery, E.H.; Cai, W.; Hoerling, M.P.; Kanikicharla, K.K.; Koster, R.D.; Lyon, B.; et al. Global meteorological drought: A synthesis of current understanding with a focus on SST drivers of precipitation deficits. J. Clim. 2016, 29, 3989–4019. [Google Scholar] [CrossRef]
- Roundy, J.K.; Wood, E.F.; Roundy, J.K.; Wood, E.F. The attribution of land–Atmosphere interactions on the seasonal predictability of drought. J. Hydrometeorol. 2015, 16, 793–810. [Google Scholar] [CrossRef]
- Lyon, B. Seasonal drought in the greater horn of Africa and its recent increase during the March–May long rains. J. Clim. 2014, 27, 7953–7975. [Google Scholar] [CrossRef]
- Hoell, A.; Funk, C.; Hoell, A.; Funk, C. The ENSO-related West Pacific Sea surface temperature gradient. J. Clim. 2013, 26, 9545–9562. [Google Scholar] [CrossRef]
- Behrangi, A.; Nguyen, H.; Granger, S. Probabilistic seasonal prediction of meteorological drought using the bootstrap and multivariate information. J. Appl. Meteorol. Climatol. 2015, 54, 1510–1522. [Google Scholar] [CrossRef]
- Allam, M.M.; Jain Figueroa, A.; McLaughlin, D.B.; Eltahir, E.A.B. Estimation of evaporation over the upper Blue Nile basin by combining observations from satellites and river flow gauges. Water Resour. Res. 2016, 52, 644–659. [Google Scholar] [CrossRef]
- Tekleab, S.; Mohamed, Y.; Uhlenbrook, S. Hydro-climatic trends in the Abay/Upper Blue Nile basin, Ethiopia. Phys. Chem. Earth, Parts A/B/C 2013, 61–62, 32–42. [Google Scholar] [CrossRef]
- Samy, A.; Ibrahim, M.G.; Mahmod, W.E.; Fujii, M.; Eltawil, A.; Daoud, W. Statistical assessment of rainfall characteristics in Upper Blue Nile Basin over the period from 1953 to 2014. Water 2019, 11, 468. [Google Scholar] [CrossRef]
- Broman, D.; Rajagopalan, B.; Hopson, T.; Gebremichael, M. Spatial and temporal variability of East African Kiremt season precipitation and large-scale teleconnections. Int. J. Climatol. 2020, 40, 1241–1254. [Google Scholar] [CrossRef]
- Giannini, A.; Biasutti, M.; Held, I.M.; Sobel, A.H. A global perspective on African climate. Clim. Chang. 2008, 90, 359–383. [Google Scholar] [CrossRef]
- Siam, M.S.; Wang, G.; Demory, M.E.; Eltahir, E.A.B. Role of the Indian Ocean sea surface temperature in shaping the natural variability in the flow of Nile River. Clim. Dyn. 2014, 43, 1011–1023. [Google Scholar] [CrossRef]
- Diro, G.T.; Grimes, D.I.F.; Black, E. Teleconnections between Ethiopian summer rainfall and sea surface temperature: Part II. Seasonal forecasting. Clim. Dyn. 2011, 37, 121–131. [Google Scholar] [CrossRef]
- Alhamshry, A.; Fenta, A.A.; Yasuda, H.; Shimizu, K.; Kawai, T. Prediction of summer rainfall over the source region of the Blue Nile by using teleconnections based on sea surface temperatures. Theor. Appl. Climatol. 2019, 137, 3077–3087. [Google Scholar] [CrossRef]
- Segele, Z.T.; Lamb, P.J.; Leslie, L.M. Seasonal-to-Interannual variability of Ethiopia/Horn of Africa monsoon. Part I: Associations of wavelet-filtered large-scale atmospheric circulation and global sea surface temperature. J. Clim. 2009, 22, 3396–3421. [Google Scholar] [CrossRef]
- Berhane, F.; Zaitchik, B.; Dezfuli, A. Subseasonal analysis of precipitation variability in the Blue Nile River Basin. J. Clim. 2014, 27, 325–344. [Google Scholar] [CrossRef]
- Gebremicael, T.G.; Mohamed, Y.A.; Betrie, G.D.; van der Zaag, P.; Teferi, E. Trend analysis of runoff and sediment fluxes in the Upper Blue Nile basin: A combined analysis of statistical tests, physically-based models and landuse maps. J. Hydrol. 2013, 482, 57–68. [Google Scholar] [CrossRef]
- Coffel, E.D.; Keith, B.; Lesk, C.; Horton, R.M.; Bower, E.; Lee, J.; Mankin, J.S. Future hot and dry years worsen Nile basin water scarcity despite projected precipitation increases. Earth’s Futur. 2019, 7, 967–977. [Google Scholar] [CrossRef]
- Broad, K.; Agrawala, S. The Ethiopia food crisis—Uses and limits of climate forecasts. Science 2000, 289, 1693–1694. [Google Scholar]
- Conway, D. The climate and hydrology of the Upper Blue Nile river. Geogr. J. 2000, 166, 49–62. [Google Scholar] [CrossRef]
- Wagesho, N.; Goel, N.K.; Jain, M.K. Temporal and spatial variability of annual and seasonal rainfall over Ethiopia. Hydrol. Sci. J. 2013, 58, 354–373. [Google Scholar] [CrossRef]
- Mellander, P.-E.; Gebrehiwot, S.G.; Gärdenäs, A.I.; Bewket, W.; Bishop, K. Summer rains and dry seasons in the upper blue Nile Basin: The predictability of half a century of past and future spatiotemporal patterns. PLoS ONE 2013, 8, e68461. [Google Scholar] [CrossRef]
- Thornthwaite, C.W. An approach toward a rational classification of climate. Geogr. Rev. 1948, 38, 55. [Google Scholar] [CrossRef]
- Barton, D.E.; Abramovitz, M.; Stegun, I.A. Handbook of mathematical functions with formulas, graphs and mathematical tables. J. R. Stat. Soc. Ser. A 1965, 128, 593. [Google Scholar] [CrossRef]
- Beguería, S.; Vicente-Serrano, S.M.; Reig, F.; Latorre, B. Standardized precipitation evapotranspiration index (SPEI) revisited: Parameter fitting, evapotranspiration models, tools, datasets and drought monitoring. Int. J. Climatol. 2014, 34, 3001–3023. [Google Scholar] [CrossRef]
- Seo, Y.; Kim, S. River stage forecasting using wavelet packet decomposition and data-driven models. Procedia Eng. 2016, 154, 1225–1230. [Google Scholar] [CrossRef]
- Schuman, C.D.; Birdwell, J.D. Dynamic Artificial Neural Networks with affective systems. PLoS ONE 2013, 8, e80455. [Google Scholar] [CrossRef] [PubMed]
- Günther, F.; Fritsch, S. neuralnet: Training of neural networks. R J. 2010, 2, 30–38. [Google Scholar] [CrossRef]
- Riedmiller, M.; Riedmiller, M.; Braun, H. A direct adaptive method for faster backpropagation learning: The rprop algorithm. IEEE Int. Conf. Neural Netw. 1993, 16, 586–591. [Google Scholar]
- Remesan, R.; Mathew, J. Hydrological Data Driven Modelling: A Case Study Approach; Springer International Pu: New York City, NY, USA, 2016; ISBN 9783319092355. [Google Scholar]
- Sheela, K.G.; Deepa, S.N. Review on methods to fix number of hidden neurons in neural networks. Math. Probl. Eng. 2013, 2013. [Google Scholar] [CrossRef]
- Stathakis, D. How many hidden layers and nodes? Int. J. Remote Sens. 2009, 30, 2133–2147. [Google Scholar] [CrossRef]
- Legates, D.R.; McCabe, G.J. Evaluating the use of “goodness-of-fit” Measures in hydrologic and hydroclimatic model validation. Water Resour. Res. 1999, 35, 233–241. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J. V River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Krause, P.; Boyle, D.P.; Bäse, F. Comparison of different efficiency criteria for hydrological model assessment. Adv. Geosci. 2005, 5, 89–97. [Google Scholar] [CrossRef]
- Willmott, C.J. On the validation of models. Phys. Geogr. 1981, 2, 184–194. [Google Scholar] [CrossRef]
- Beck, M.W. NeuralNetTools: Visualization and analysis tools for neural networks. J. Stat. Softw. 2018, 85, 1. [Google Scholar] [CrossRef] [PubMed]
- Garson, G.D. A comparison of neural network and expert systems algorithms with common multivariate procedures for analysis of social science data. Soc. Sci. Comput. Rev. 1991, 9, 399–434. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station Name | Geographical Locations | Elevation ASL | Annual Mean Rainfall (mm) | Mean Annual Temperature (°C) |
|---|---|---|---|---|
| Alemketema | 10.03° N, 39.03° E | 2280 m | 1049.16 | 19.74 |
| Asossa | 10.02° N, 34.52° E | 1590 m | 1198.57 | 24.61 |
| Bahir Dar | 11.59° N, 37.38° E | 1770 m | 1387.37 | 20.43 |
| Bedele | 8.45° N, 36.33° E | 2030 m | 1809.18 | 17.92 |
| Chagni | 10.97° N, 36.5° E | 1620 m | 1699.58 | 20.34 |
| Debremarkos | 10.33° N, 37.74° E | 2515 m | 1334.15 | 16.27 |
| Gondar | 12.61° N, 37.45° E | 1967 m | 1145.87 | 19.89 |
| SPEI Values | Drought Category |
|---|---|
| SPEI ≥ 2 | Extremely wet |
| 1.5 ≤ SPEI < 1 | Severely wet |
| 1 ≤ SPEI < 1.5 | Moderately wet |
| −1 ≤ SPEI < 1 | Near normal |
| −1.5 ≤ SPEI < −1 | Moderately dry |
| −2 ≤ SPEI < −1.5 | Severely dry |
| SPEI < −2 | Extremely dry |
| Model | No. of Input Variables | Year | Month | Rainfall | Max T | Min T | PET | SOI | IOD | PDO | N3 SST | N3.4 SST | N4 SST |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| M1 | 12 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| M2 | 11 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| M3 | 10 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| M4 | 8 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| M5 | 6 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||
| M6 | 6 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||
| M7 | 4 | ✓ | ✓ | ✓ | ✓ |
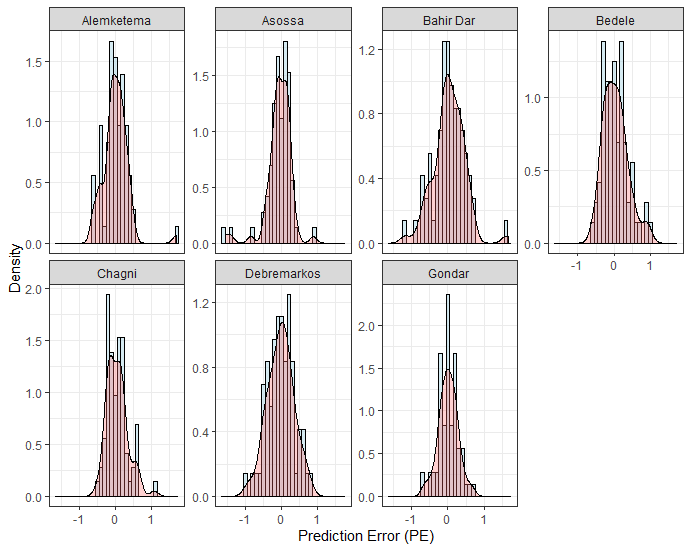
| Station Name | R2 | RMSE | d | E |
|---|---|---|---|---|
| Alemketema | 0.870 | 0.335 | 0.965 | 0.863 |
| Asossa | 0.892 | 0.349 | 0.966 | 0.884 |
| Bahir Dar | 0.820 | 0.428 | 0.946 | 0.818 |
| Bedele | 0.856 | 0.338 | 0.959 | 0.854 |
| Chagni | 0.908 | 0.290 | 0.975 | 0.905 |
| Debremarkos | 0.865 | 0.363 | 0.964 | 0.862 |
| Gondar | 0.949 | 0.263 | 0.987 | 0.949 |
| Overall station average | 0.880 | 0.338 | 0.966 | 0.876 |
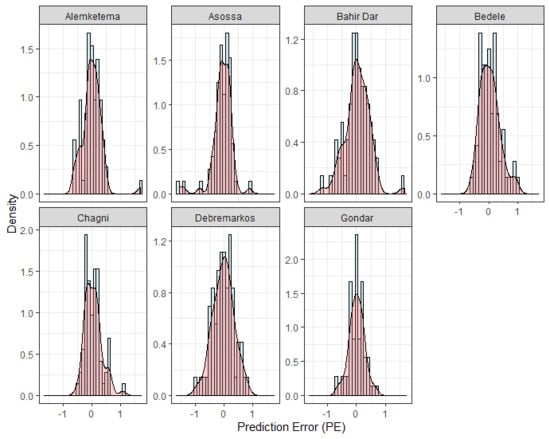
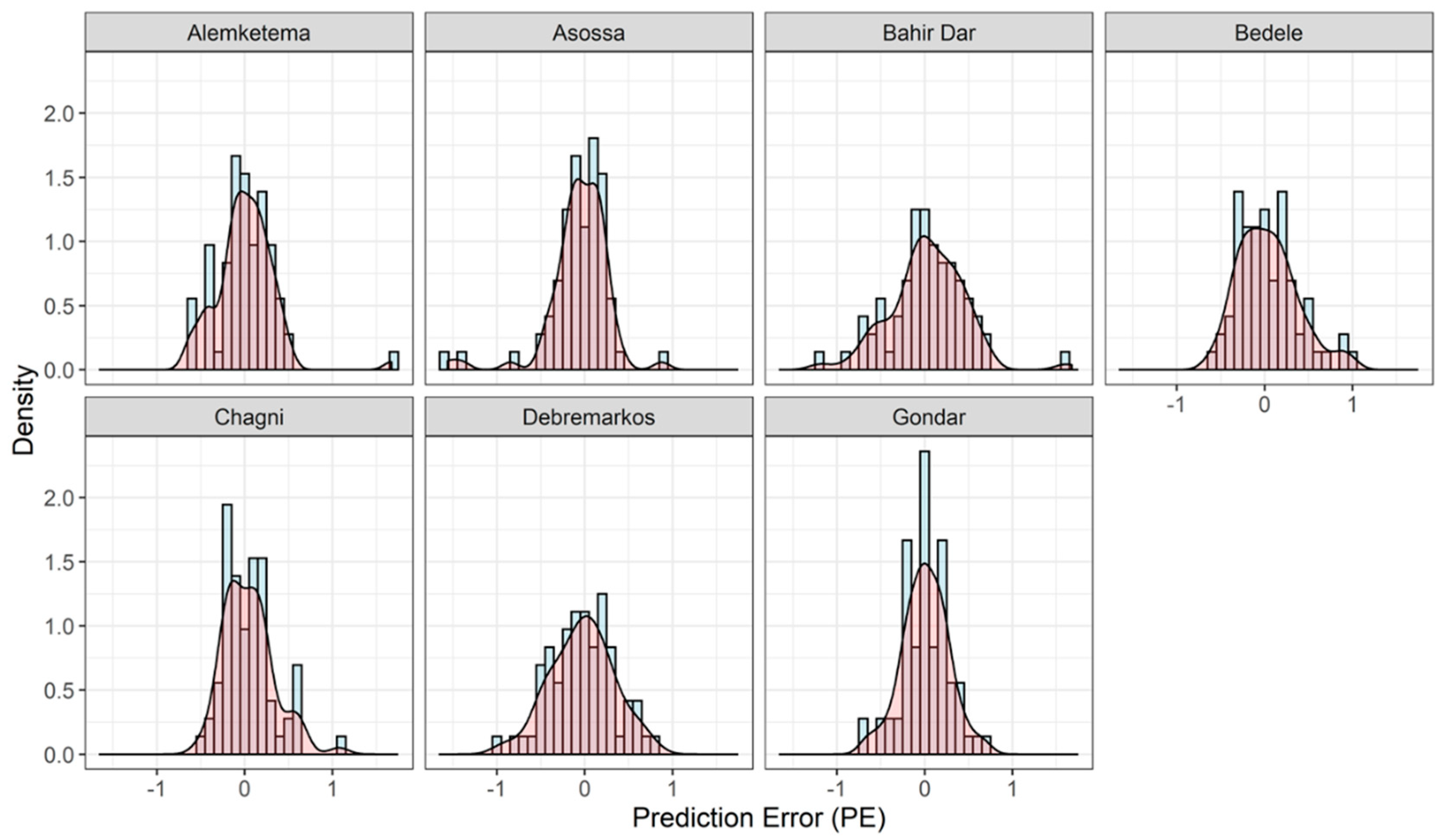
| Station Name | Maximum PE | Minimum PE | Standard Deviation |
|---|---|---|---|
| Alemketema | 1.674 | −0.631 | 0.337 |
| Asossa | 0.877 | −1.561 | 0.346 |
| Bahir Dar | 1.614 | −1.189 | 0.430 |
| Bedele | 0.956 | −0.588 | 0.338 |
| Chagni | 1.075 | −0.518 | 0.288 |
| Debremarkos | 0.799 | −0.964 | 0.364 |
| Gondar | 0.690 | −0.653 | 0.265 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mulualem, G.M.; Liou, Y.-A. Application of Artificial Neural Networks in Forecasting a Standardized Precipitation Evapotranspiration Index for the Upper Blue Nile Basin. Water 2020, 12, 643. https://doi.org/10.3390/w12030643
Mulualem GM, Liou Y-A. Application of Artificial Neural Networks in Forecasting a Standardized Precipitation Evapotranspiration Index for the Upper Blue Nile Basin. Water. 2020; 12(3):643. https://doi.org/10.3390/w12030643
Chicago/Turabian StyleMulualem, Getachew Mehabie, and Yuei-An Liou. 2020. "Application of Artificial Neural Networks in Forecasting a Standardized Precipitation Evapotranspiration Index for the Upper Blue Nile Basin" Water 12, no. 3: 643. https://doi.org/10.3390/w12030643
APA StyleMulualem, G. M., & Liou, Y.-A. (2020). Application of Artificial Neural Networks in Forecasting a Standardized Precipitation Evapotranspiration Index for the Upper Blue Nile Basin. Water, 12(3), 643. https://doi.org/10.3390/w12030643