Use of Ensemble-Based Gridded Precipitation Products for Assessing Input Data Uncertainty Prior to Hydrologic Modeling

 ,
,  , ,
, , 
Abstract
1. Introduction
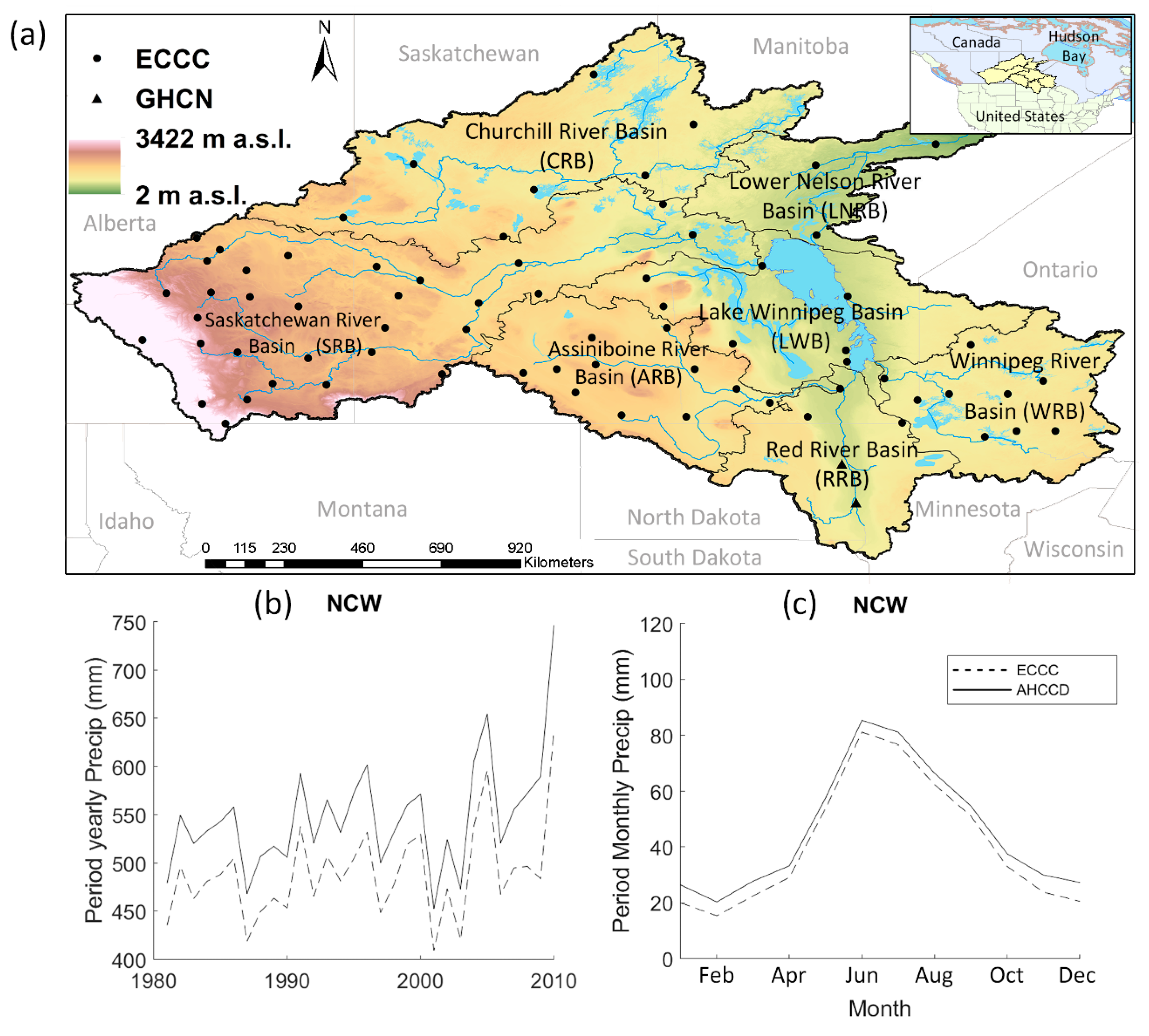
2. Study Area
3. Precipitation Data
3.1. Observed Ground-Based Climate Station Data
3.2. Gridded Precipitation Datasets
4. Methodology
4.1. Performance Assessment
4.1.1. Continuous Statistics
4.1.2. Categorical Statistics
4.1.3. Extreme Indices
4.2. Ensemble Creation
4.3. Spatial Aggregation
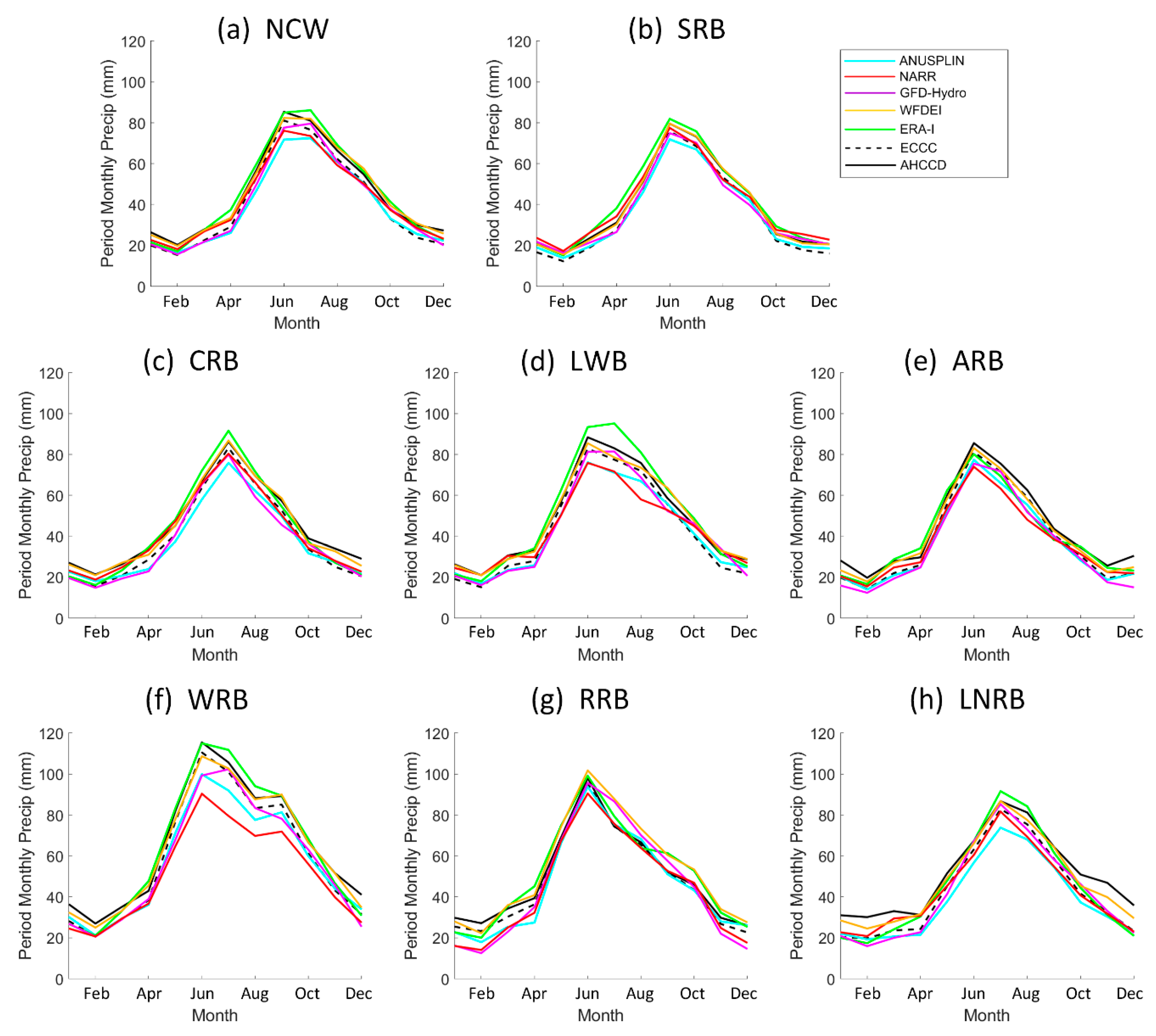
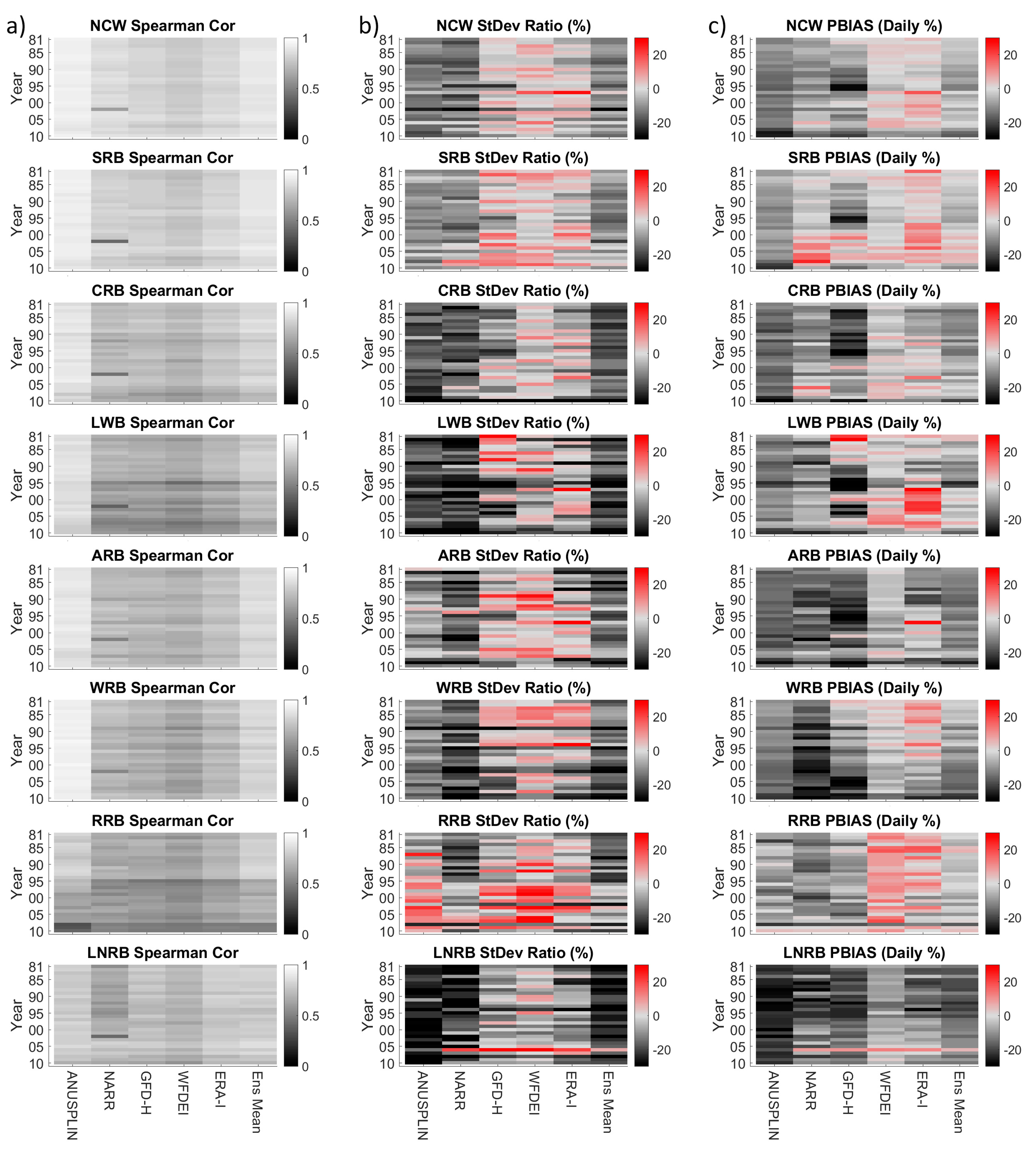
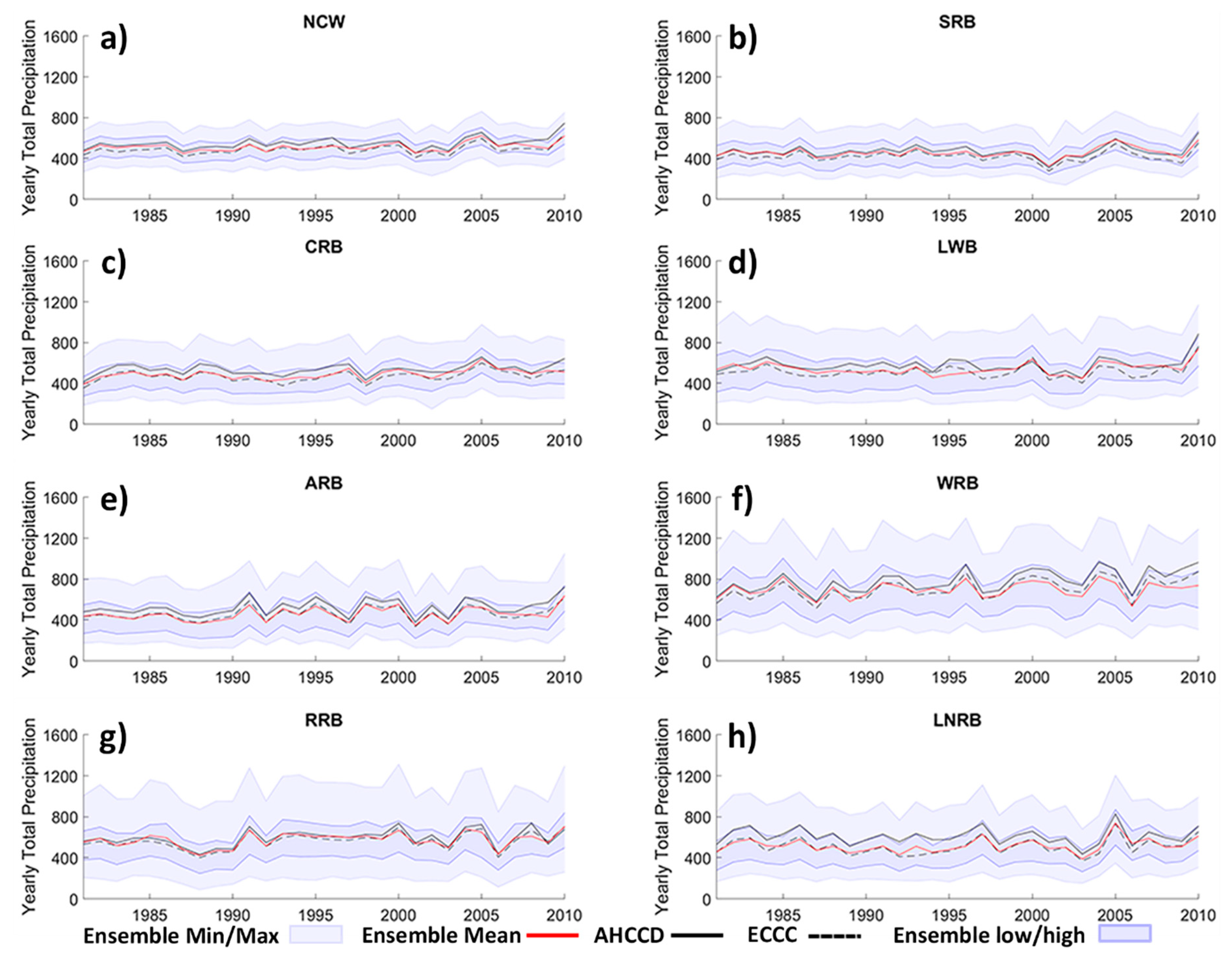
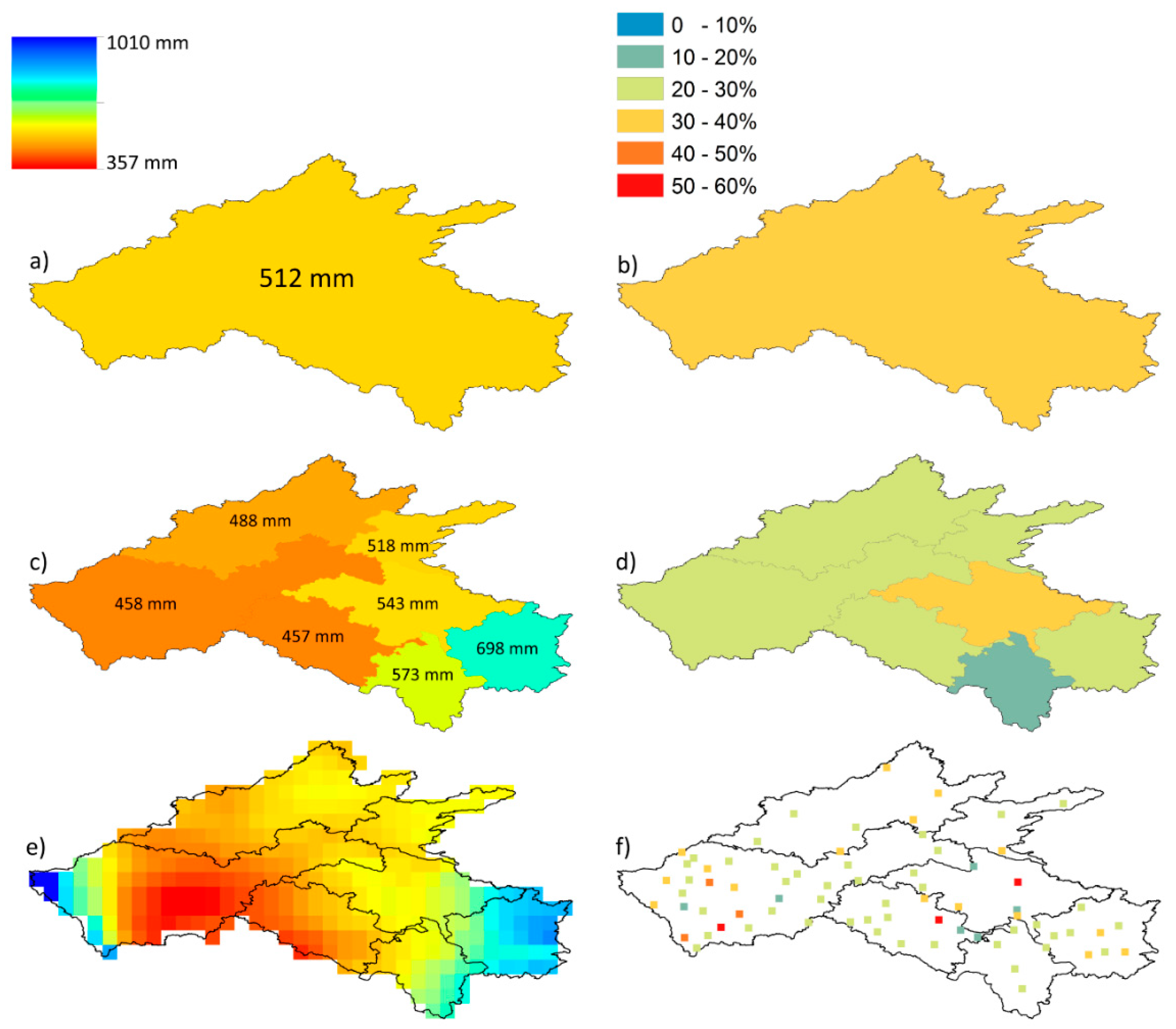
5. Results
5.1. Gridded Dataset Analysis
5.2. Ensemble Analysis
6. Discussion
6.1. Uncertainty from Temporal Period of Analysis
6.2. Uncertainty from Spatial Aggregation
6.3. Ensemble Reliability
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Price, D.T.; McKenney, D.W.; Nalder, I.A.; Hutchinson, M.F.; Kesteven, J.L. A comparison of two statistical methods for spatial interpolation of Canadian monthly mean climate data. Agric. For. Meteorol. 2000, 101, 81–94. [Google Scholar] [CrossRef]
- Mekis, E.; Vincent, L.A. An overview of the second generation adjusted daily precipitation dataset for trend analysis in Canada. Atmosphere-Ocean 2011, 49, 163–177. [Google Scholar] [CrossRef]
- Eum, H.-I.; Dibike, Y.; Prowse, T.; Bonsal, B. Inter-comparison of high-resolution gridded climate data sets and their implication on hydrological model simulation over the Athabasca Watershed, Canada. Hydrol. Process. 2014, 28, 4250–4271. [Google Scholar] [CrossRef]
- Wong, J.S.; Razavi, S.; Bonsal, B.R.; Wheater, H.S.; Asong, Z.E. Inter-comparison of daily precipitation products for large-scale hydro-climatic applications over Canada. Hydrol. Earth Syst. Sci. 2017, 21, 2163–2185. [Google Scholar] [CrossRef]
- ISO. Guide to the Expression of Uncertainty in Measurement; ISO: Geneva, Switzerland, 1995; pp. 4–5. [Google Scholar]
- Matott, L.S.; Babendreier, J.E.; Purucker, S.T. Evaluating uncertainty in integrated environmental models: A review of concepts and tools. Water Resour. Res. 2009, 45, W06421. [Google Scholar] [CrossRef]
- Ajami, N.K.; Duan, Q.; Sorooshian, S. An integrated hydrologic Bayesian multimodel combination framework: Confronting input, parameter, and model structural uncertainty in hydrologic prediction. Water Resour. Res. 2007, 43, W01403. [Google Scholar] [CrossRef]
- Dams, J.; Nossent, J.; Senbeta, T.B.; Willems, P.; Batelaan, O. Multi-model approach to assess the impact of climate change on runoff. J. Hydrol. 2015, 529, 1601–1616. [Google Scholar] [CrossRef]
- Pavelsky, T.M.; Smith, L.C. Intercomparison of four global precipitation data sets and their correlation with increased Eurasian river discharge to the Arctic Ocean. J. Geophys. Res. Space Phys. 2006, 111, D21112. [Google Scholar] [CrossRef]
- Bukovsky, M.S.; Karoly, D.J. A brief evaluation of precipitation from the North American regional reanalysis. J. Hydrometeorol. 2007, 8, 837–846. [Google Scholar] [CrossRef][Green Version]
- Becker, E.J.; Berbery, E.H.; Higgins, R.W. Understanding the characteristics of daily precipitation over the United States using the North American regional reanalysis. J. Clim. 2009, 22, 6268–6286. [Google Scholar] [CrossRef]
- Choi, W.; Kim, S.J.; Rasmussen, P.F.; Moore, A.R. Use of the North American regional reanalysis for hydrological modelling in Manitoba. Can. Water Resour. J. 2009, 34, 17–36. [Google Scholar] [CrossRef]
- Rapaić, M.; Brown, R.; Markovic, M.; Chaumont, D. An evaluation of temperature and precipitation surface-based and reanalysis datasets for the Canadian arctic, 1950–2010. Atmosphere-Ocean 2015, 53, 283–303. [Google Scholar] [CrossRef]
- Kluver, D.; Mote, T.L.; Leathers, D.; Henderson, G.R.; Chan, W.; Robinson, D.A. Creation and validation of a comprehensive 1° by 1° daily gridded North American dataset for 1900–2009: Snowfall. J. Atmos. Ocean. Technol. 2016, 33, 857–871. [Google Scholar] [CrossRef]
- Essou, G.R.C.; Sabarly, F.; Lucas-Picher, P.; Brissette, F.; Poulin, A. Can precipitation and temperature from meteorological reanalyses be used for hydrological modeling? J. Hydrometeorol. 2016, 17, 1929–1950. [Google Scholar] [CrossRef]
- Gbambie, A.S.B.; Poulin, A.; Boucher, M.-A.; Arsenault, R. Added value of alternative information in interpolated precipitation datasets for hydrology. J. Hydrometeorol. 2017, 18, 247–264. [Google Scholar] [CrossRef]
- Boluwade, A.; Zhao, K.-Y.; Stadnyk, T.; Rasmussen, P. Towards validation of the Canadian Precipitation Analysis (CaPA) for hydrologic modeling applications in the Canadian prairies. J. Hydrol. 2018, 556, 1244–1255. [Google Scholar] [CrossRef]
- Fortin, V.; Roy, G.; Stadnyk, T.; Koenig, K.; Gasset, N.; Mahidjiba, A. Ten years of science based on the Canadian precipitation analysis: A CaPA system overview and literature review. Atmosphere-Ocean 2018, 56, 1–19. [Google Scholar] [CrossRef]
- Lespinas, F.; Fortin, V.; Roy, G.; Rasmussen, P.F.; Stadnyk, T.A. Performance evaluation of the Canadian Precipitation Analysis (CaPA). J. Hydrometeorol. 2015, 16, 2045–2064. [Google Scholar] [CrossRef]
- Asong, Z.E.; Razavi, S.; Wheater, H.S.; Wong, J.S. Evaluation of Integrated Multisatellite Retrievals for GPM (IMERG) over southern Canada against ground precipitation observations: A preliminary assessment. J. Hydrometeorol. 2017, 18, 1033–1050. [Google Scholar] [CrossRef]
- Nash, J.; Sutcliffe, J. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Vincent, L.A.; Wang, X.L.; Milewska, E.J.; Wan, H.; Yang, F.; Swail, V. A second generation of homogenized Canadian monthly surface air temperature for climate trend analysis. J. Geophys. Res. Space Phys. 2012, 117, D18110. [Google Scholar] [CrossRef]
- Masson, D.; Knutti, R. Climate model genealogy. Geophys. Res. Lett. 2011, 38, L08703. [Google Scholar] [CrossRef]
- Knutti, R.; Masson, D.; Gettelman, A. Climate model genealogy: Generation CMIP5 and how we got there. Geophys. Res. Lett. 2013, 40, 1194–1199. [Google Scholar] [CrossRef]
- Sanderson, B.; Knutti, R.; Caldwell, P. A representative democracy to reduce interdependency in a multimodel ensemble. J. Clim. 2015, 28, 5171–5194. [Google Scholar] [CrossRef]
- LeDuc, M.; Laprise, R.; De Elía, R.; Šeparović, L. Is institutional democracy a good proxy for model independence? J. Clim. 2016, 29, 8301–8316. [Google Scholar] [CrossRef][Green Version]
- Steinschneider, S.; Wi, S.; Brown, C. The integrated effects of climate and hydrologic uncertainty on future flood risk assessments. Hydrol. Process. 2014, 29, 2823–2839. [Google Scholar] [CrossRef]
- Sillmann, J.; Kharin, V.V.; Zhang, X.; Zwiers, F.; Bronaugh, D. Climate extremes indices in the CMIP5 multimodel ensemble: Part 1. Model evaluation in the present climate. J. Geophys. Res. Atmos. 2013, 118, 1716–1733. [Google Scholar] [CrossRef]
- Hutchinson, M.F.; McKenney, D.W.; Lawrence, K.; Pedlar, J.H.; Hopkinson, R.F.; Milewska, E.; Papadopol, P. Development and testing of Canada-Wide interpolated spatial models of daily minimum–maximum temperature and precipitation for 1961–2003. J. Appl. Meteorol. Clim. 2009, 48, 725–741. [Google Scholar] [CrossRef]
- Mesinger, F.; DiMego, G.; Kalnay, E.; Mitchell, K.; Shafran, P.C.; Ebisuzaki, W.; Jovic, D.; Woollen, J.; Rogers, E.; Berbery, E.H.; et al. North American regional reanalysis. Bull. Am. Meteorol. Soc. 2006, 87, 343–360. [Google Scholar] [CrossRef]
- Berg, P.; Donnelly, C.; Gustafsson, D. Near-real-time adjusted reanalysis forcing data for hydrology. Hydrol. Earth Syst. Sci. 2018, 22, 989–1000. [Google Scholar] [CrossRef]
- Khakbaz, B.; Imam, B.; Hsu, K.; Sorooshian, S. From lumped to distributed via semi-distributed: Calibration strategies for semi-distributed hydrologic models. J. Hydrol. 2012, 418, 61–77. [Google Scholar] [CrossRef]
- Lilhare, R.; Déry, S.J.; Pokorny, S.; Stadnyk, T.A.; Koenig, K.A. Intercomparison of multiple hydroclimatic datasets across the lower nelson river basin, Manitoba, Canada. Atmosphere-Ocean 2019, 57, 1–17. [Google Scholar] [CrossRef]
- Government of Canada. Natural Resources Canada. Available online: https://www.nrcan.gc.ca/home (accessed on 5 July 2018).
- Benke, A.C.; Cushing, C.E. Rivers of North America; Elsevier: Burlington, MA, USA, 2005; pp. 853–888. [Google Scholar]
- McMillan, H.; Krueger, T.; Freer, J. Benchmarking observational uncertainties for hydrology: Rainfall, river discharge and water quality. Hydrol. Process. 2012, 26, 4078–4111. [Google Scholar] [CrossRef]
- Menne, M.J.; Durre, I.; Vose, R.S.; Gleason, B.E.; Houston, T.G. An overview of the global historical climatology network-daily database. J. Atmos. Ocean. Technol. 2012, 29, 897–910. [Google Scholar] [CrossRef]
- Durre, I.; Menne, M.J.; Gleason, B.E.; Houston, T.G.; Vose, R.S. Comprehensive automated quality assurance of daily surface observations. J. Appl. Meteorol. Clim. 2010, 49, 1615–1633. [Google Scholar] [CrossRef]
- Barber, D.G. BaySys—Contributions of Climate Change and Hydroelectric Regulation to the Variability and Change of Freshwater-Marine Coupling in the Hudson Bay System. Available online: http://umanitoba.ca/faculties/environment/departments/ceos/media/BaySys_PROJECT_DESCRIPTION.pdf (accessed on 15 January 2014).
- Dee, D.P.; Uppala, S.M.; Simmons, A.J.; Berrisford, P.; Poli, P.; Kobayashi, S.; Andrae, U.; Balmaseda, M.A.; Balsamo, G.; Bauer, P.; et al. The ERA-interim reanalysis: Configuration and performance of the data assimilation system. Q. J. R. Meteorol. Soc. 2011, 137, 553–597. [Google Scholar] [CrossRef]
- Weedon, G.P.; Balsamo, G.; Bellouin, N.; Gomes, S.; Best, M.; Viterbo, P. The WFDEI meteorological forcing data set: WATCH Forcing Data methodology applied to ERA-Interim reanalysis data. Water Resour. Res. 2014, 50, 7505–7514. [Google Scholar] [CrossRef]
- World Meteorological Organization. Calculation of Monthly and Annual 30-Year Standard Normals; WCDP-No. 10, WMO-TD/No. 341; World Meteorological Organization: Geneva, Switzerland, 1989. [Google Scholar]
- Zhu, Y.; Luo, Y. Precipitation calibration based on the frequency-matching method. Weather Forecast. 2015, 30, 1109–1124. [Google Scholar] [CrossRef]
- Montanari, A. Large sample behaviors of the generalized likelihood uncertainty estimation (GLUE) in assessing the uncertainty of rainfall-runoff simulations. Water Resour. Res. 2005, 41, W08406. [Google Scholar] [CrossRef]
- Tustison, B.; Harris, D.; Foufoula-Georgiou, E. Scale issues in verification of precipitation forecasts. J. Geophys. Res. Space Phys. 2001, 106, 11775–11784. [Google Scholar] [CrossRef]
- Rouse, W.R. Impacts of hudson bay on the terrestrial climate of the Hudson bay lowlands. Arct. Alp. Res. 1991, 23, 24. [Google Scholar] [CrossRef]
- Shabbar, A.; Khandekar, M. The impact of el Niño-Southern oscillation on the temperature field over Canada: Research note. Atmosphere-Ocean 1996, 34, 401–416. [Google Scholar] [CrossRef]
- Trenberth, K.E. The definition of El Niño. Bull. Amer. Meteor. Soc. 1997, 78, 2771–2778. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- Wilks, D.S. Comparison of ensemble-MOS methods in the Lorenz ’96 setting. Meteorol. Appl. 2006, 13, 243. [Google Scholar] [CrossRef]
- Yang, C.; Yan, Z.; Shao, Y. Probabilistic precipitation forecasting based on ensemble output using generalized additive models and Bayesian model averaging. Acta Meteorol. Sin. 2012, 26, 1–12. [Google Scholar] [CrossRef]
- Yao, Y.; Liang, S.; Xie, X.; Cheng, J.; Jia, K.; Li, Y.; Liu, R. Estimation of the terrestrial water budget over northern China by merging multiple datasets. J. Hydrol. 2014, 519, 50–68. [Google Scholar] [CrossRef]
- DeMeritt, D.; Cloke, H.; Pappenberger, F.; Pozo, J.T.-D.; Bartholmes, J.C.; Ramos, M. Ensemble predictions and perceptions of risk, uncertainty, and error in flood forecasting. Environ. Hazards 2007, 7, 115–127. [Google Scholar] [CrossRef]
- Pappenberger, F.; Stephens, E.; Thielen, J.; Salamon, P.; DeMeritt, D.; Van Andel, S.J.; Wetterhall, F.; Alfieri, L. Visualizing probabilistic flood forecast information: Expert preferences and perceptions of best practice in uncertainty communication. Hydrol. Process. 2012, 27, 132–146. [Google Scholar] [CrossRef]
- Pokorny, S.; Stadnyk, T.A.; Ali, G.; Lilhare, R.; Déry, S.J.; Koenig, K. Cumulative effects of uncertainty on simulated streamflow in a hydrologic modeling environment. Elem. Sci. Anth. 2020. [Google Scholar] [CrossRef]
- Westerberg, I.K.; Sikorska-Senoner, A.E.; Viviroli, D.; Vis, M.J.P.; Seibert, J. Hydrological model calibration with uncertain discharge data. Hydrol. Sci. J. 2020, 1–16. [Google Scholar] [CrossRef]
- Vaze, J.; Post, D.; Chiew, F.; Perraud, J.-M.; Viney, N.R.; Teng, J. Climate non-stationarity—Validity of calibrated rainfall–runoff models for use in climate change studies. J. Hydrol. 2010, 394, 447–457. [Google Scholar] [CrossRef]
- Sun, X.; Barros, A. An Evaluation of the statistics of rainfall extremes in rain gauge observations, and satellite-based and reanalysis products using universal multifractals. J. Hydrometeorol. 2010, 11, 388–404. [Google Scholar] [CrossRef]
- Fischer, E.M.; Beyerle, U.; Knutti, R. Robust spatially aggregated projections of climate extremes. Nat. Clim. Chang. 2013, 3, 1033–1038. [Google Scholar] [CrossRef]
- Pendergrass, A.G.; Knutti, R.; Lehner, F.; Deser, C.; Sanderson, B. Precipitation variability increases in a warmer climate. Sci. Rep. 2017, 7, 17966. [Google Scholar] [CrossRef] [PubMed]
- Dingman, S.L. Physical Hydrology, 3rd ed.; Waveland Press: Long Grove, IL, USA, 2015; pp. 47–203. [Google Scholar]
- Carpenter, T.M.; Georgakakos, K.P. Intercomparison of lumped versus distributed hydrologic model ensemble simulations on operational forecast scales. J. Hydrol. 2006, 329, 174–185. [Google Scholar] [CrossRef]
- Shafii, M.; Tolson, B.A.; Matott, L.S. Addressing subjective decision-making inherent in GLUE-based multi-criteria rainfall–runoff model calibration. J. Hydrol. 2015, 523, 693–705. [Google Scholar] [CrossRef]
- Zhou, R.; Li, Y.; Lu, D.; Liu, H.; Zhou, H. An optimization based sampling approach for multiple metrics uncertainty analysis using generalized likelihood uncertainty estimation. J. Hydrol. 2016, 540, 274–286. [Google Scholar] [CrossRef]
- Newman, A.J.; Clark, M.P.; Craig, J.; Nijssen, B.; Wood, A.W.; Gutmann, E.; Mizukami, N.; Brekke, L.; Arnold, J.R. Gridded ensemble precipitation and temperature estimates for the contiguous United States. J. Hydrometeorol. 2015, 16, 2481–2500. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Period (Temporal Resolution) | Domain (Spatial Resolution) | Reference | Product Description |
|---|---|---|---|---|
| The Australian National University spline interpolation (ANUSPLIN) | 1950–2013 (daily) | Canada (~0.1°) | [29] | Interpolated ECCC dataset using trivariate thin-plate smoothing spline between latitude, longitude, and elevation. The version updated to cover 1950–2013 was used; a version extending up to 2016 was released after the completion of this study. |
| North American Regional Reanalysis (NARR) | 1979–~present (3 hourly) | North America (~0.32°) | [30] | A reanalysis dataset with many sources of assimilated data, such as the global reanalysis product GR2, gauge observations, and others. NARR stopped assimilating Canadian station data in 2004, which introduced a detectable statistical break [3]. In 2015, the period of April 2009–January 2015 (and thereafter) was updated to address some data processing issues, which improved border effects along the USA–Canada border, particularly focused on southern Ontario. |
| European Centre for Medium-Range Weather Forecasts interim reanalysis (ERA-Interim; ERA-I) | 1979–~present (3-hourly) | Global (0.75°) | [40] | A reanalysis dataset that assimilates a large number of data sources, such as the Integrated Forecast System (IFS) cy31r2, satellite data, and others. ERA-I is a replacement for the previous ERA-40 dataset, featuring 4D-VAR data assimilation among other improvements to the original ERA-40, which stopped in 2002. |
| European Union Water and Global Change (WATCH) Forcing data ERA-Interim (WFDEI) | 1979–2013 (3-hourly) | Global (0.5°) | [41] | An adjusted version of ERA-I using the European Union Water and Global Change (WATCH) Forcing Data (WFD) methodology, which includes various adjustments and bias corrections. These data are a replacement for the original ERA-40-based WFD dataset. The version updated to cover 1979–2013 was used; a version extending up to 2016 was released after the completion of this study. |
| Global Forcing Data—Hydro (GFD-HYDRO) | 1979–~present (3-hourly) | Global (0.5°) | [31] | GFD-Hydro closely mimics the methodology of WFDEI, with updates to current versions of observed data networks. GFD-HYDRO is meant to be a global product similar to WFDEI, but produced at near real-time. Notable differences between WFDEI and GFD-HYDRO exist for precipitation, due to a reduction in undercatch adjustments. |
| Observed | ||
|---|---|---|
| Simulated | Obs = 1 | Obs = 0 |
| Sim = 1 | Hit (H) | False Positive (F) |
| Sim = 0 | Miss (M) | Correct Negative (C) |
| General Findings |
|
| Specific Findings |
|
| Suggestions |
|
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pokorny, S.; Stadnyk, T.A.; Lilhare, R.; Ali, G.; Déry, S.J.; Koenig, K. Use of Ensemble-Based Gridded Precipitation Products for Assessing Input Data Uncertainty Prior to Hydrologic Modeling. Water 2020, 12, 2751. https://doi.org/10.3390/w12102751
Pokorny S, Stadnyk TA, Lilhare R, Ali G, Déry SJ, Koenig K. Use of Ensemble-Based Gridded Precipitation Products for Assessing Input Data Uncertainty Prior to Hydrologic Modeling. Water. 2020; 12(10):2751. https://doi.org/10.3390/w12102751
Chicago/Turabian StylePokorny, Scott, Tricia A. Stadnyk, Rajtantra Lilhare, Genevieve Ali, Stephen J. Déry, and Kristina Koenig. 2020. "Use of Ensemble-Based Gridded Precipitation Products for Assessing Input Data Uncertainty Prior to Hydrologic Modeling" Water 12, no. 10: 2751. https://doi.org/10.3390/w12102751
APA StylePokorny, S., Stadnyk, T. A., Lilhare, R., Ali, G., Déry, S. J., & Koenig, K. (2020). Use of Ensemble-Based Gridded Precipitation Products for Assessing Input Data Uncertainty Prior to Hydrologic Modeling. Water, 12(10), 2751. https://doi.org/10.3390/w12102751