1. Introduction
Dam-break or tsunami flows cause not only potential dangers to human life, but also great losses of property. These phenomena can be triggered by some natural hazards, such as earthquakes or heavy rainfall. When a dam breaks, a large amount of water is released instantaneously from the dam and will propagate rapidly to the downstream area. Similarly, tsunami waves flowing rapidly from the ocean bring a large volume of water to coastal areas, which endangers human life as well as damages infrastructure. Since natural hazards have very complex characteristics, in terms of the spatial and temporal scales, they are quite difficult to predict precisely. Therefore, it is highly important to study the evolution of such flows as a part of a disaster management, which will be useful for the related stakeholders in decision-making. Such study can be done by developing a mathematical model based on the 2D shallow water equations (SWEs).
Recent numerical models of the 2D SWEs rely, almost entirely, on the computations of (approximate) Riemann solvers, particularly in the applications of the high-resolution Godunov-type methods. The simplicity, robustness, and built-in conservation properties of the Riemann solvers, such as the Roe and HLLC schemes, had led to many successful applications in shallow flow simulations, see [
1,
2,
3,
4,
5], among others. Highly discontinuous flows, including transcritical flows, shock waves and moving wet–dry fronts were accurately simulated.
Generally speaking, a scheme can be regarded as a class of Riemann solvers if it is proposed based on a Riemann problem. The Roe scheme was originally devised by [
6] and was proposed to estimate the interface convective fluxes between two adjacent cells on a spatially-and-temporally discretized computational domain by linearizing the Jacobian matrix of the partial differential equations (PDEs) with regard to its left and right eigenvectors. This linearized part contributes to the computation of the convective fluxes of the PDEs, as a flux difference for the average value of the considered edge taken from its two corresponding cells. Since the eigenstructure of the PDEs—which leads to an approximation of the interface value in connection with the local Riemann problem—must be known in the calculation of the flux difference, the Roe scheme is regarded as an approximate Riemann solver.
More than 20 years later, Toro [
7] then developed a new approximate Riemann solver—HLLC scheme—to simulate shallow water flows, which was an extended version of the Harten-Lax-van Leer (HLL) scheme proposed in [
8]. In the HLL scheme, the solution is approximated directly for the interface fluxes by dividing the region into three parts: left, middle, and right. Both the left and right regions correspond to the values of the two adjacent cells, whereas the middle region consists of a single value separated by intermediate waves. One major flaw of the HLL scheme is related to both contact discontinuities and shear waves leading to a missing contact (middle) wave. Therefore, Toro [
7] fixed this scheme in the HLLC scheme by including the computation of the middle wave speed that now the solution is divided into four regions. There are several ways to calculate the middle wave speed, see [
9,
10,
11]. All the calculations deal with the eigenstructure of the PDEs, which is related to the local Riemann problem, and obviously, this brings the HLLC scheme back to a class of Riemann solvers.
Opposite to the Riemann solvers, Kurganov et al. [
12] proposed the central-upwind (CU) method as a Riemann-solver-free scheme, in which the eigenstructure of the PDEs is not required to calculate the convective fluxes. Instead, the local one-sided speeds of propagation at every edge, which can be computed in a straight-forward manner, are used. This scheme has been proven to be sufficiently robust and at the same time can satisfy both the well-balanced and positivity preserving properties, see [
13,
14,
15].
To solve the time-dependent SWEs, all the aforementioned schemes must be temporally discretized either by using an implicit or an explicit time stepping method. Despite its simplicity, the latter may, however, suffer from a stability computational issue particularly when simulating a very low water on a very rough bed [
16,
17]. The former is unconditionally stable and even is very flexible to use a large time step. However, the computation is admittedly complex. Another way that can be used to overcome the stability issue of the explicit method and to avoid the complexity of the implicit method—is to perform a high-order explicit method, such as the Runge–Kutta high-order scheme. This method is more stable than the explicit method, while the computation remains simple and acceptably cheap as that of the explicit method.
As the high-order time stepping method is now considered, the selection of solvers included in models must be taken into careful consideration, since such solvers—which are the most expensive part in SWEs simulations—need to be computed several times in a single time step. For example, the Runge–Kutta fourth-order (RKFO) method requires the updating of a solver four times to determine the value at the subsequent time step. The more complex the algorithm of a solver is, the more CPU time one obtains.
Nowadays, performing SWE simulations is becoming more and more common on modern hardware/CPUs towards high-performance computing (HPC) using advanced features such as AVX, AVX2, and AVX-512, which support the algorithm vectorization for executing some operations in a single instruction—known as single instruction multiple data (SIMD)—so that a significant computation speed-up can be achieved. Vectorization on such modern hardware employs vector instructions, which can dramatically outperform scalar instructions, thus being quite important for having more efficient computations. Among the other compilers’ optimizations, vectorization can even be regarded as the common ways for utilizing vector-level parallelism, see [
18,
19]. Such a speed-up, however, can only exist if the algorithm formulation is suitable for vectorization instructions either automatically (by compilers) or manually (by users) [
20].
Typically, there are three classes of vectorization: auto vectorization, guided vectorization, and low-level vectorization. The first type is the easiest one utilizing the ability of the compiler to automatically detect loops, which have a potential to be vectorized. This can be done at compiling time, e.g., using the optimization flag or higher. However, some typical problems, e.g., non-contiguous memory access and data-dependency, make vectorization difficult. For this, the second type may be a solution utilizing some compiler hints/pragmas and array notations. This type may successfully vectorize the loops that cannot be auto-vectorized by the compiler. However, if not used carefully, it gives no significant performance or even the results can be wrong. The last type is probably the hardest one since it requires deep-knowledge about intrinsics/assembly programming and vector classes, thus not so popular.
Especially in simulating complex phenomena such as dam-break or tsunami flows as part of disaster planning, accurate results are obviously of particular interest for modelers. However, focusing only on numerical accuracy but ignoring performance efficiency is no longer an option. For instance, in addition to relatively large-sized domains, most of real dam-break and tsunami simulations require performing long real-time computations, e.g., days or even up to weeks. Wasting the performance either due to the complexity level of the solver selected or the code’s inability to utilize the vectorization, is thus undesirable. This becomes our focus in this paper. We compare three common shallow water solvers (HLLC, Roe, and CU schemes) here, where two main findings are pointed out. Firstly, to enable highly-efficient vectorization for all solvers on all the aforementioned hardware, we employ a reordering strategy that we have recently applied in [
21]. This strategy supports guided vectorization and memory access alignment for the array loops attempted in the SWEs’ computations, thus boosting the performance. Secondly, we observe that the CU scheme is capable of outperforming the performance of the HLLC and Roe schemes by exhibiting similar accuracies. These findings would be useful for modelers as a reference to select the numerical solvers to be included in their models as well as to optimize their codes for vectorization.
Some previous studies reporting about vectorization of shallow water solvers are noted here. In [
20], the augmented Riemann solver implemented in a source code Geo Conservation Laws (GeoCLAW) was vectorized using a low-level vectorization with SSE4 and AVX intrinsics. The average speed-up factors of 2.7× and 4.1× (both with single-precision arithmetic) were achieved with SSE4 and AVX machines, respectively. Also using GeoCLAW, the augmented Riemann solver was vectorized in [
22] by changing the data layouts from arrays of structs (AoS) to structs of arrays (SoA), thus requiring a considerably huge task for rewriting the code—and then applying a guided vectorization with
. The average speed-up factors of 1.7× and 4.4× (both with double-precision arithmetic) were achieved with AVX2 and AVX-512 machines, respectively. In [
23], the split HLL Riemann solver was vectorized and parallelized for the flux computation and state computation modules of the SWEs employing low-level vectorization with SSE4 and AVX intrinsics. To the best of our knowledge, this is the first attempt to report the efficiency comparisons of common solvers (both Riemann and non-Riemann solvers) regarding the vectorization on the three modern hardwares without having to perform complex intrinsic functions or to require a lot of work for rewriting the code. We use here an in-house code of the first-author—numerical simulation of free surface shallow water 2D (NUFSAW2D). Some successful applications were shown using NUFSAW2D for varying shallow water-type simulations, e.g., dam-break cases, overland flows, and turbulent flows, see [
17,
21,
24,
25].
This paper is organized as follows. The governing equations and the numerical model are briefly explained in
Section 2. An overview of data structures in our code is presented in
Section 3. The model verifications against the benchmark cases and its performance evaluations are given in
Section 4. Finally, conclusions are given in
Section 5.
2. Governing Equations and Numerical Models
The 2D SWEs are written in conservative form according to [
26] as
where the vectors
,
,
,
, and
are expressed as
The water depth, velocities in
x and
y directions, gravity acceleration, bottom elevation, and Manning coefficient are denoted by
h,
u,
v,
g,
, and
, respectively. Using a cell-centered finite volume (CCFV) method, Equation (
1) is spatially discretized over a domain
as
Applying the Gauss divergence theorem, the convective fluxes of Equation (
3) can be transformed into a line-boundary integral
as
leading to a flux summation for the convective fluxes by
where
and
are the normal vectors outward
,
N is the total number of edges for a cell, and
is the edge length. We will investigate the accuracy and efficiency of the three solvers for solving Equation (
5). The in-house code NUFSAW2D used here implements the modern shock-capturing Godunov-type model, which supports the structured as well as unstructured meshes by storing the average values in each cell-center. Here we use structured rectangular meshes, hence
N = 4. The second-order spatial accuracy was achieved with the MUSCL method utilizing the MinMod limiter function to enforce the monotonicity in multiple dimensions. The bed-slope terms were computed using a Riemann-solution-free technique, with which the bed-slope fluxes can be computed separately from the convective fluxes, thus giving a fair comparison for the three aforementioned solvers. The friction terms were treated semi-implicitly to ensure stability for wet–dry simulations. The RKFO method is now applied to Equation (
4) as
where
A is the cell area,
is the time step,
is the coefficient being 1/4, 1/3 , 1/2, and 1 for
p = 1–4, respectively. The numerical procedures for Equations (
4) and (
6) are given in detail in [
17,
25,
26], thus are not presented here.
3. Overview of Data Structures
3.1. General
Here we explain in detail how the data structures of our code are designed to advance the solutions of Equation (
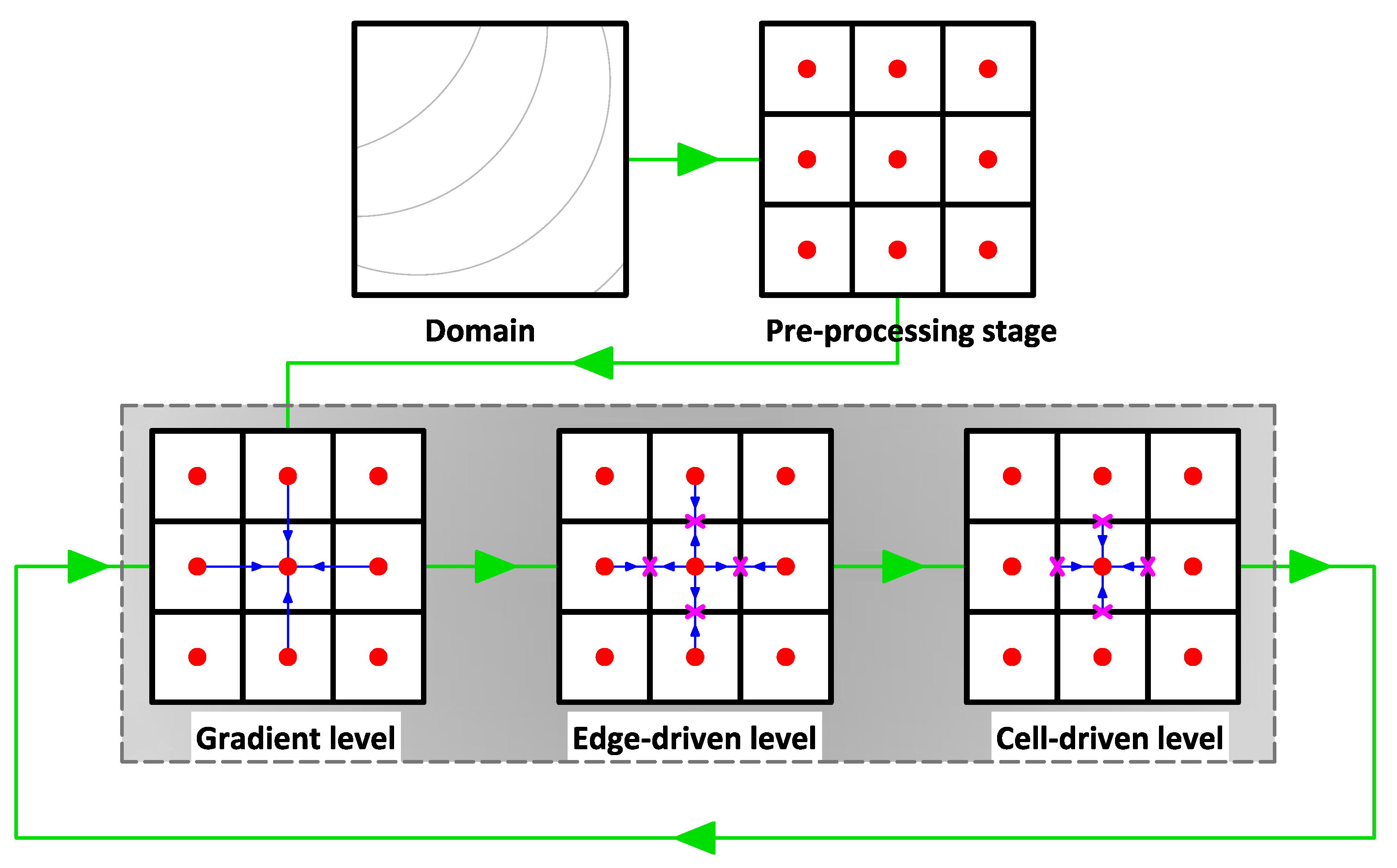
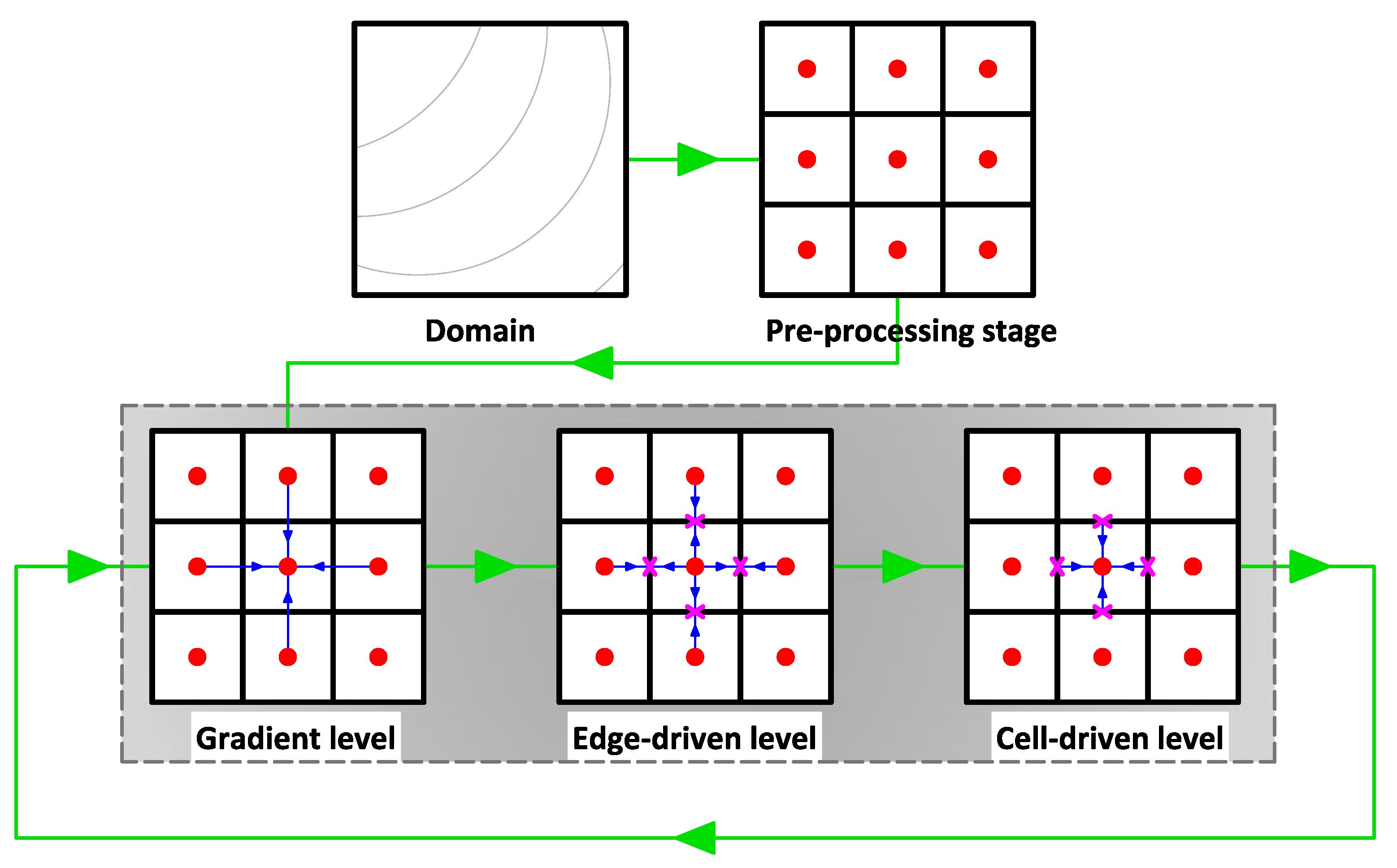
6). Note this is a typical data structure used in many shallow water codes (with implementations of modern finite volume schemes). As shown in
Figure 1, a domain is discretized into several sub-domains (rectangular cells). We call this step the pre-processing stage. Each cell now consists of the values of
and
located at its center. Initially, the values of
h,
u, and
v are given by users at each cell-center.
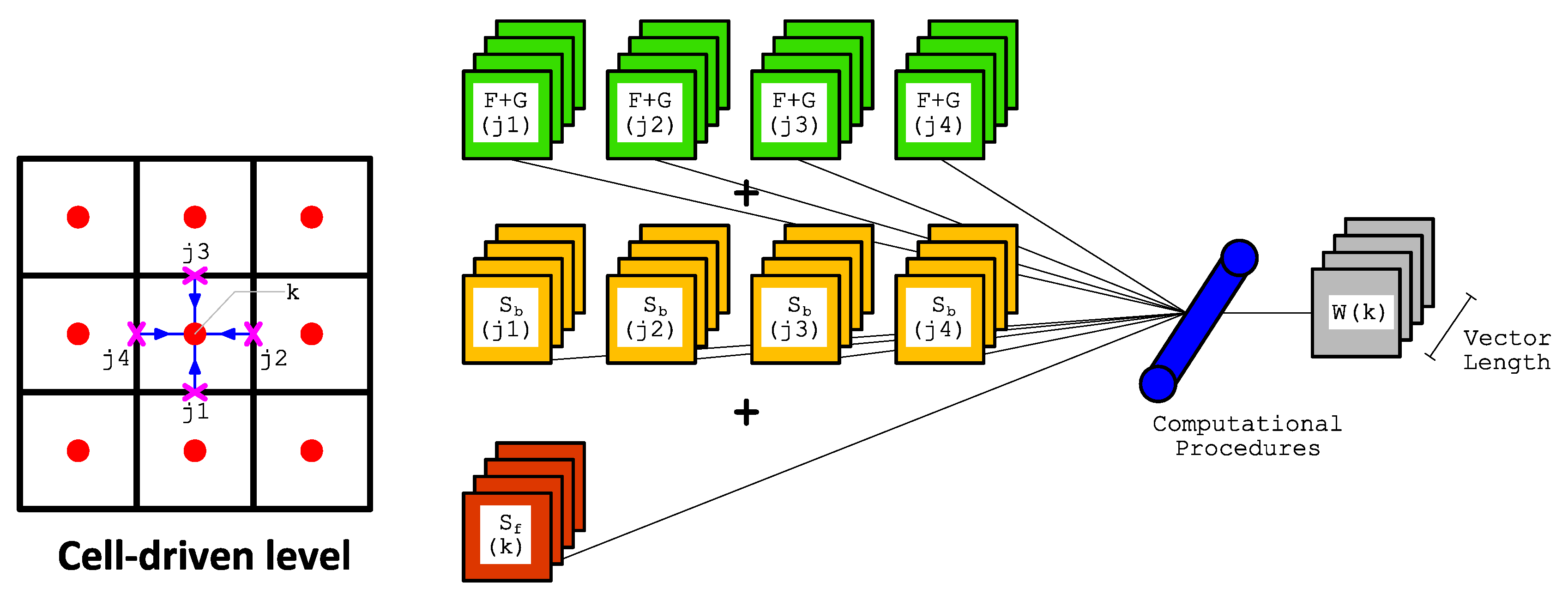
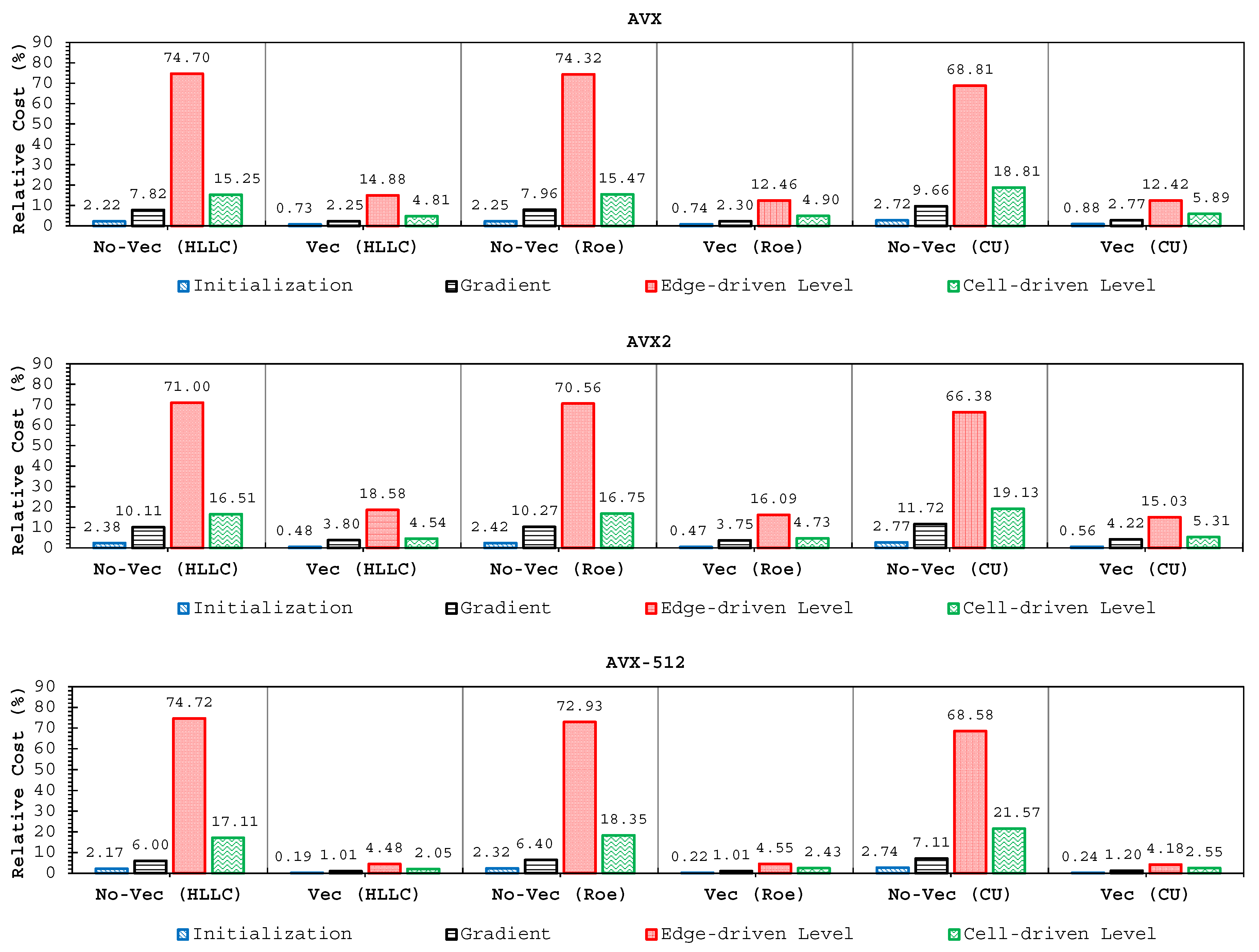
As our model employs a reconstruction process to spatially achieve second-order accuracy with the MUSCL method, it requires the gradient values at cell-center. Therefore, these gradient values must firstly be computed. This step is called the gradient level. Hereafter, one requires to calculate the values at each edge using the values of its two corresponding cell-centers. This stage is then called the edge-driven level. In this level, a solver, e.g., HLLC, Roe, or CU scheme, is required to compute the non-linear values of and at edges. Prior to performing such a solver, the aforementioned reconstruction process with the MUSCL method was employed. Note the values of are also computed at the edge-driven level. After the values of all edges are known, the solution can be advanced for the subsequent time level by also computing the values of . For example, the solutions of at the subsequent time level for a cell-center are updated using the , , and values from its four corresponding edges—and using values located at the cell-center itself. We call this stage the cell-driven level.
Note that the edge-driven level is the most expensive stage among the others; one should thus pay extra attention to its computation. We also point out here that we apply the computation for the edge-driven level in an edge-based manner rather than in a cell-based one, namely we compute the edge values only once per single calculation level. Therefore, one does not need to save the values of in arrays for each cell-center; only the values of are saved corresponding to the total number of edges, instead. The values of an edge are only valid for one adjacent cell—and such values are simply multiplied by () for another cell. It is now a challenging task to design an array structure that can ease vectorization and exploit memory access alignment in both the edge-driven and cell-driven levels.
3.2. Cell-Edge Reordering Strategy for Supporting Vectorization and Memory Access Alignment
We focus our reordering strategy here on tackling the two common problems for vectorization: non-contiguous memory access and data-dependency. Regarding the former, a contiguous array structure is required to provide contiguous memory access giving an efficient vectorization. Typically, one finds this problem when dealing with an indirect array indexing, e.g., using forces the compiler to decode for finding the memory reference of . This is also a typical problem for a non-unit strided access to array, e.g., incrementing a loop by a scalar factor, where non-consecutive memory locations must be accessed in the loop. The vectorization is sometimes still possible for this problem type. However, the performance gain is often not significant. The second problem relates to usage of arrays identical to the previous iteration of the loop, which often destroy any possibility for vectorization, otherwise a special directive should be used.
See
Figure 2, for advancing the solution of
in Equation (
1) for
, one requires
,
, and
from
, where
and
—and
from
itself. Opting
as an operator for defining
leads to a use of an indirect reference in a loop. This is not desired since it may avoid the vectorization. This may be anticipated by directly declaring
into the same array to that of
, e.g.,
, where
and
are scalar. This, however, leads to a data-dependency problem that makes vectorization difficult.
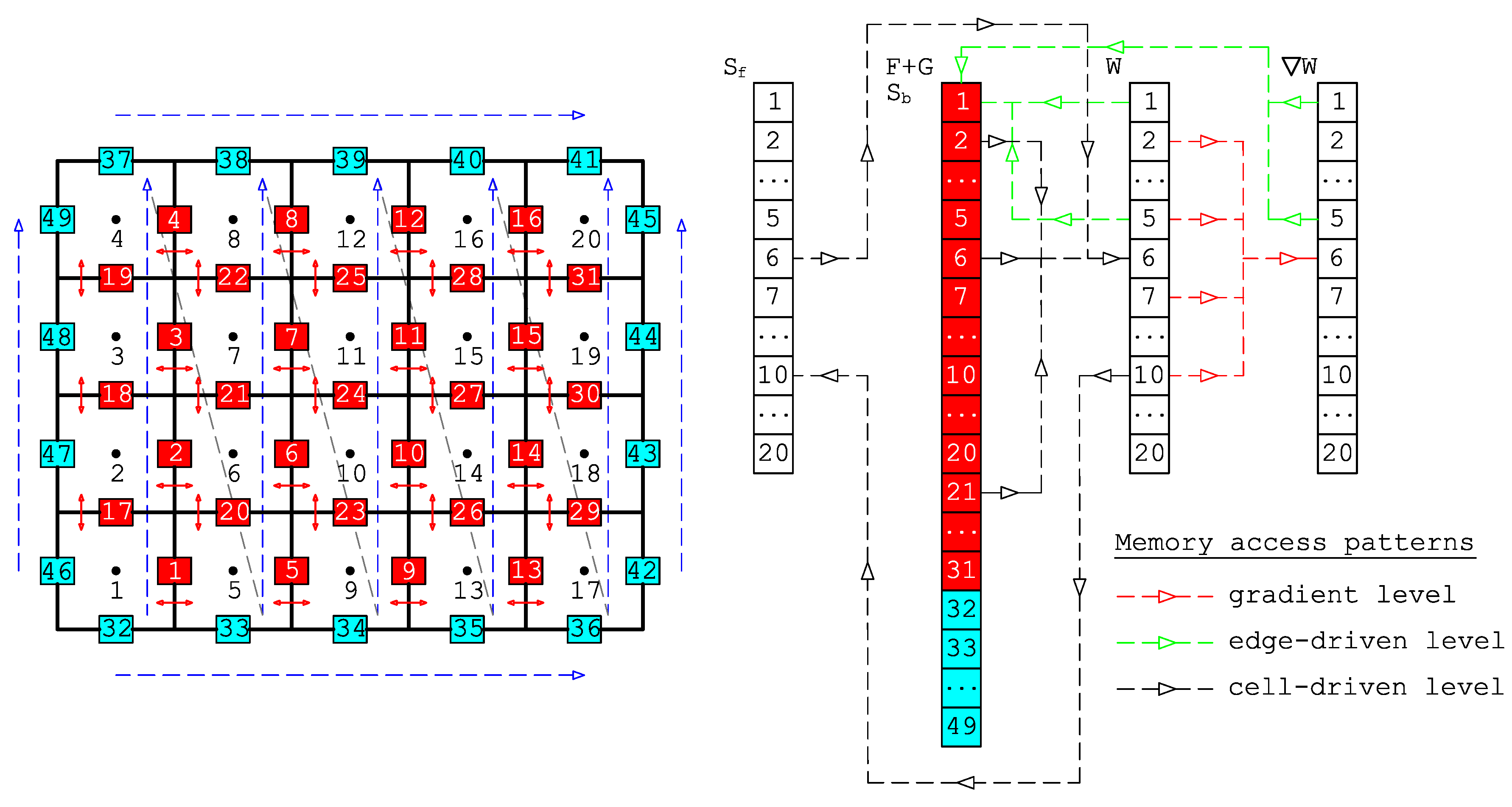
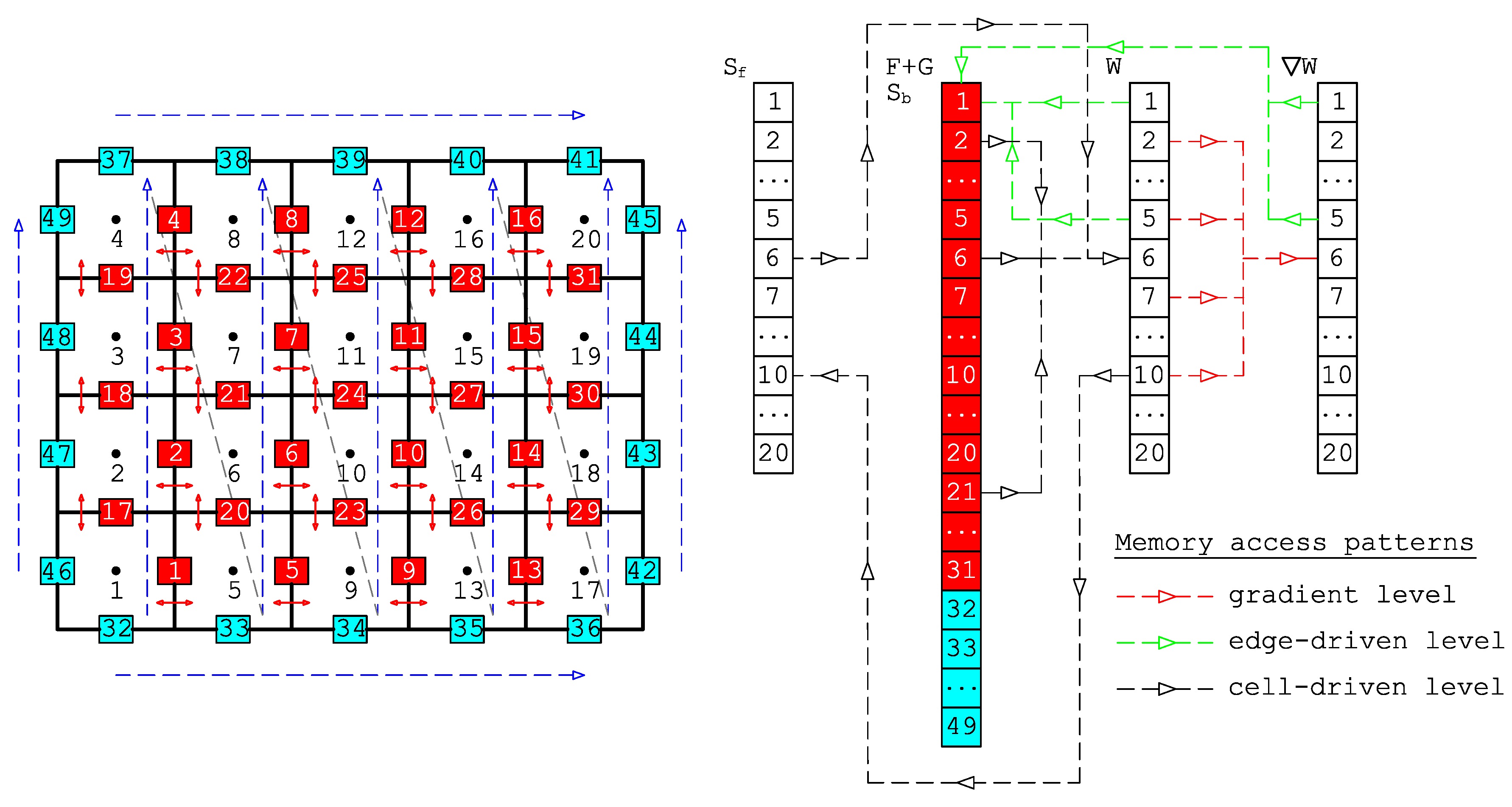
To avoid these problems, we have designed a cell-edge reordering strategy, see
Figure 3, where the loops with similar computational procedures are collected to be vectorized. Note that this strategy is only applied once at the pre-processing stage in
Figure 1. The core idea of this strategy is to build contiguous array patterns between edges and cells for the edge-driven level as well as between cells and edges for the cell-driven level. We point out here that we only employ 1D array configuration in NUFSAW2D, so that the memory access patterns are straightforward, thus easing unit stride and conserving cache entries. The first step is to devise the cell numbering following the Z-pattern, which is intended for the cell-driven level. Secondly, we design the edge numbering for the edge-driven level by classifying the edges into two types: internal and boundary edges in the most contiguous way; the former is the edges that have two neighboring cells (e.g., edges 1–31), whereas the latter is the edges with only one corresponding cell (e.g., edges 32–49). The reason for this classification is the computational complexity between the internal and boundary edges differs from each other, e.g., (1) no reconstruction process is required for the latter, thus having less CPU time than the former—and (2) due to corresponding to two neighboring cells, the former accesses more memories than does the latter; declaring all edges only in one single loop-group therefore deteriorates the memory access patterns, thus decreasing the performance.
For the sake of clarity, we write in Algorithm 1 the pseudo-code of the model’s
employed in NUFSAW2D. Note that Algorithm 1 is a typical form applied in many common and popular shallow water codes. First, we mention that
,
, and
according to
Figure 3, where
,
, and
are the total number of domain segments in
x and
y directions, and the total number of cells, respectively. We now explain the
. The cells are now classified into two groups: internal and boundary cells. Internal cells, e.g., cells 6, 7, 10, 11, 14, and 15 are cells whose gradient computations require accessing two cell values in each direction. For example, computing the
x-gradient of
of cell 6 needs the values of
of cells 2 and 10; this is denoted by
and similarly
. Boundary cells, e.g., cells 1–4, 5, 8, 9, 12, 13, 16, and 17–20, are cells affiliated with boundary edges. These cells may not always require accessing two cell values in each direction for the gradient computation, e.g.,
but
showing that a symmetric boundary condition is applied to cell 8 in
y direction. Considering the fact that the total number of internal cells is significantly larger than that of boundary cells, we group the internal cells into a single loop and distinguish them from the boundary cells, see Algorithm 2.
| Algorithm 1 Typical algorithm for shallow water code (within the Runge–Kutta fourth-order (RKFO) method’s framework) |
- 1:
fordo - 2:
[p=1] [p=4] - 3:
for do - 4:
- 5:
→ - 6:
- 7:
→ - 8:
→ - 9:
→ - 10:
- 11:
→ - 12:
→ - 13:
end for - 14:
end for
|
| Algorithm 2 Pseudo-code for |
- 1:
fordo - 2:
- 3:
- 4:
for do - 5:
- 6:
- 7:
end for - 8:
end for - 9:
- 10:
fordo - 11:
- 12:
- 13:
- 14:
- 15:
- 16:
- 17:
end for - 18:
- 19:
fordo - 20:
- 21:
- 22:
- 23:
- 24:
- 25:
- 26:
end for
|
Algorithm 2 shows three typical loops in the
. The first loop (lines 1–8) is designed sequentially with a factor of
for its outer part to exclude all boundary cells. For its inner part, this loop is constructed based on the outer loop in a contiguous way, thus making vectorization efficient. Each element of array
accesses two elements from array
with the farthest alignment of
, while each element of array
also accesses two elements of array
but only with the farthest alignment of
. The second loop (lines 10–17) is also designed similarly to the first one, but since this loop includes boundary cells, each element of arrays
and
only accesses one array with the farthest alignment of
and
, respectively—whereas the other elements from array
required are contiguously accessed by each element of both
and
. Note in our implementation, none of these two loops can be auto-vectorized by the compiler. Therefore, we apply a guided vectorization with OpenMP directive instead of the Intel one, namely
; this will be explained later in
Section 4.5. The third loop (lines 19–26) is designed for the rest cells, which are not included in the previous two loops. This loop is not devised in a contiguous manner, thus disabling auto vectorization or, although a guided vectorization is possible, it still does not give any significant performance improvement due to non-unit strided access. Despite being unable to be vectorized, the third loop does not significantly decrease the performance of our model for the entire simulation as it only has an array dimension of
(quite small compared to the other two loops).
We now discuss the and sketch it in Algorithm 3. Note for the sake of brevity, only the pseudo-code for internal edges is represented in Algorithm 3; for boundary edges, the pseudo-code is similar but computed without . The first loop corresponds to the edges 1–16 and the second one to the edges 17–31. In the first loop (lines 1–7), each flux computation accesses the array with the farthest alignment of , whereas the arrays are designed in the second loop (lines 8–17) to have contiguous patterns. Every edge has a certain pattern for its two corresponding cells, where no data-dependency exists, thus enabling an efficient vectorization. Note with this pattern, both loops can be auto-vectorized; however, we still implement a guided vectorization as it gives a better performance.
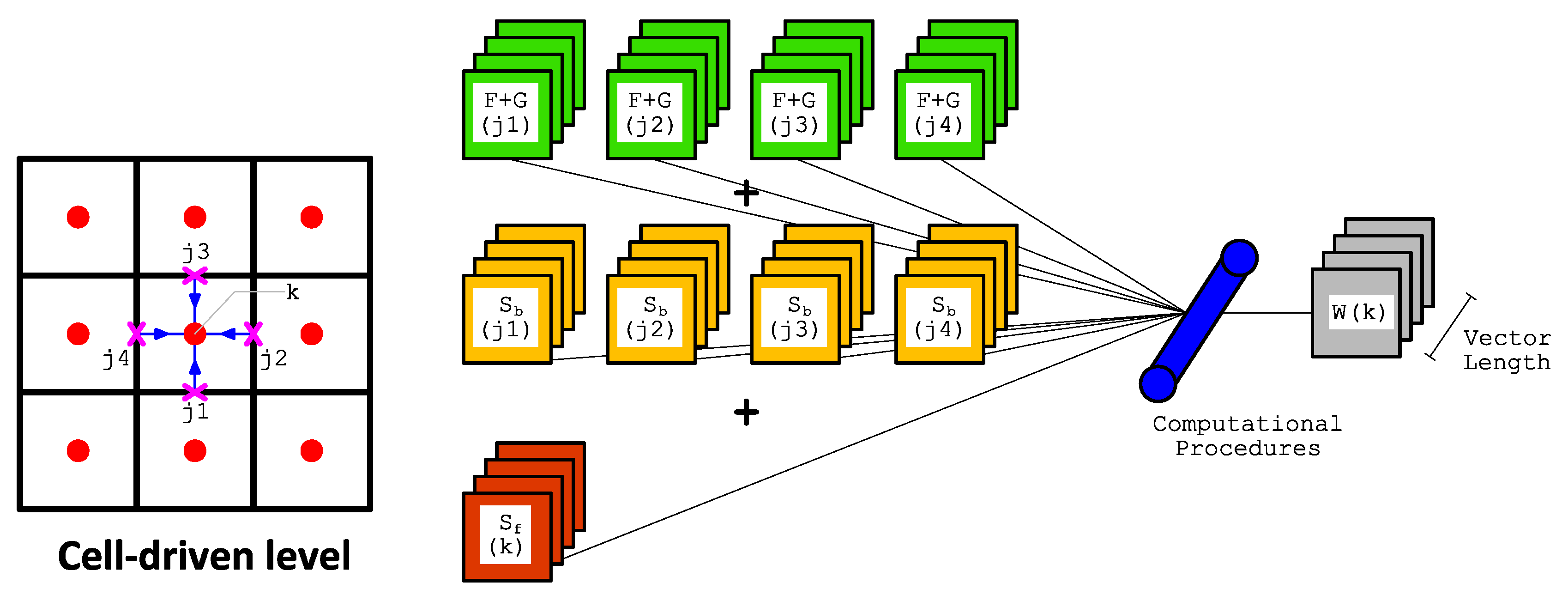
Finally, we sketch the in Algorithm 4. Again, for the sake of brevity only the pseudo-code for internal cells is given. Similar to the internal cell in the , the loop is designed sequentially with a factor of for the outer part. In the inner part the arrays access patterns are, however, different to those of the gradient computation, where accesses , , and from the corresponding edges—and from the corresponding cell; in other words, more array accesses are required in this loop. Nevertheless, the vectorization gives a significant performance improvement since the array accesses patterns are contiguous. However, there is a part that cannot be vectorized in this cell-driven level due to non-unit strided access, similar to that shown in Algorithm 2. Again, since the dimension of this non-vectorizable loop is considerably smaller than the others, there is no significant performance alleviation for the entire simulation.
| Algorithm 3 Pseudo-code for (only for internal edges) |
- 1:
- 2:
fordo - 3:
- 4:
- 5:
- 6:
- 7:
end for - 8:
fordo - 9:
- 10:
- 11:
for do - 12:
- 13:
- 14:
- 15:
- 16:
end for - 17:
end for
|
| Algorithm 4 Pseudo-code for (only for internal cells) |
- 1:
fordo - 2:
- 3:
- 4:
for do - 5:
- 6:
- 7:
- 8:
- 9:
- 10:
end for - 11:
end for
|
3.3. Avoiding Skipping Iteration for Vectorization of Wet–Dry Problems
In reality, almost all shallow flow simulations deal with wet–dry problems. To this end, the computations of both solver and bed-slope terms in the
must satisfy the well-balanced and positivity-preserving properties as well, see [
27,
28], among others. Similarly, the calculations of the friction terms in the
must also consider the wet–dry phenomena, otherwise errors are obtained. For example, in the edge-driven level, a wet–dry or dry–dry interface of an edge may exist since one or two cell-centers consist of no water; for both cases, the MUSCL method for achieving second-order accuracy is sometimes not required or even if this method is still computed, it must be turned back to first-order accuracy to ensure computational stability by simply defining the edge values according to the corresponding centers. Another example is in the cell-driven level, where the transformation of the unit discharges (
and
) back to the velocities (
u and
v) are required for computing the friction terms by a division of a water depth (
h); very low water depth may thus cause significant errors. To anticipate these problems, one often employs some skipping iterations in the loops, see Algorithm 5.
| Algorithm 5 Pseudo-code of some possible skipping iterations |
- 1:
!== This is a typical skipping iteration in the SUBROUTINE edge-driven level ==! - 2:
if[wet–dry or dry-dry interfaces at edges]then - 3:
NO MUSCL_method: calculate first-order scheme - 4:
else - 5:
compute MUSCL_method: calculate second-order scheme - 6:
if [velocities are not monotone] then - 7:
back to first-order scheme - 8:
end if - 9:
- 10:
end if - 11:
!== This is a typical skipping iteration in the SUBROUTINE cell-driven level ==! - 12:
if[depths at cell-centers > depth limiter] then - 13:
compute friction_term - 14:
else - 15:
unit discharges and velocities are set to very small values - 16:
- 17:
end if
|
Typically, the two skipping iterations in Algorithm 5 are important to ensure the correctness of shallow water models. Unfortunately, such layouts may destroy auto vectorization—or although a guided vectorization is possible, it does not give any significant improvement or may even decrease the performance significantly. This is because the SIMD instructions simultaneously work only for sets of arrays, which have contiguous positions. In our experiences, a guided vectorization was indeed possible for both iterations; the speed-up factors, however, were not so significant. Borrowing the idea of [
22], we therefore change the layouts in Algorithm 5 to those in Algorithm 6, where the early exit condition is moved to the end of the algorithm. Using the new layouts in Algorithm 6, we significantly observed up to 48% more improvements of the vectorization from those given in Algorithm 5. Note that the results given by Algorithms 5 and 6 should be similar because no computational procedure is changed but only the layouts.
| Algorithm 6 Pseudo-code of the solutions of the skipping iterations in Algorithm 5 |
- 1:
!== A solution for the skipping iteration in the SUBROUTINE edge-driven level ==! - 2:
compute MUSCL_method: calculate second-order scheme - 3:
- 4:
if[velocities are not monotone]then - 5:
back to first-order scheme - 6:
end if - 7:
- 8:
if[wet–dry or dry-dry interfaces at edges]then - 9:
NO MUSCL_method: calculate first-order scheme - 10:
end if - 11:
!== A solution for the skipping iteration in the SUBROUTINE cell-driven level ==! - 12:
compute friction_term - 13:
- 14:
if[depths at cell-centers ≤ depth limiter]then - 15:
unit discharges and velocities are set to very small values - 16:
- 17:
end if
|
3.4. Parallel Computation
We explain briefly here the parallel computing implementation of NUFSAW2D according to [
21]. Our idea is to decompose and parallelize the domain based on its complexity level. NUFSAW2D employs hybrid MPI-OpenMP parallelization, thus is applicable to parallel simulations with multi-nodes. However, as we focus here on the vectorization, which no longer influences the scalability beyond one node [
20], we limit our study on single-node implementations and thus only employ OpenMP for parallelization. Further, we examine the memory bandwidth effect when using only one core or 16 cores (AVX), 28 cores (AVX2), and 64 cores (AVX-512).
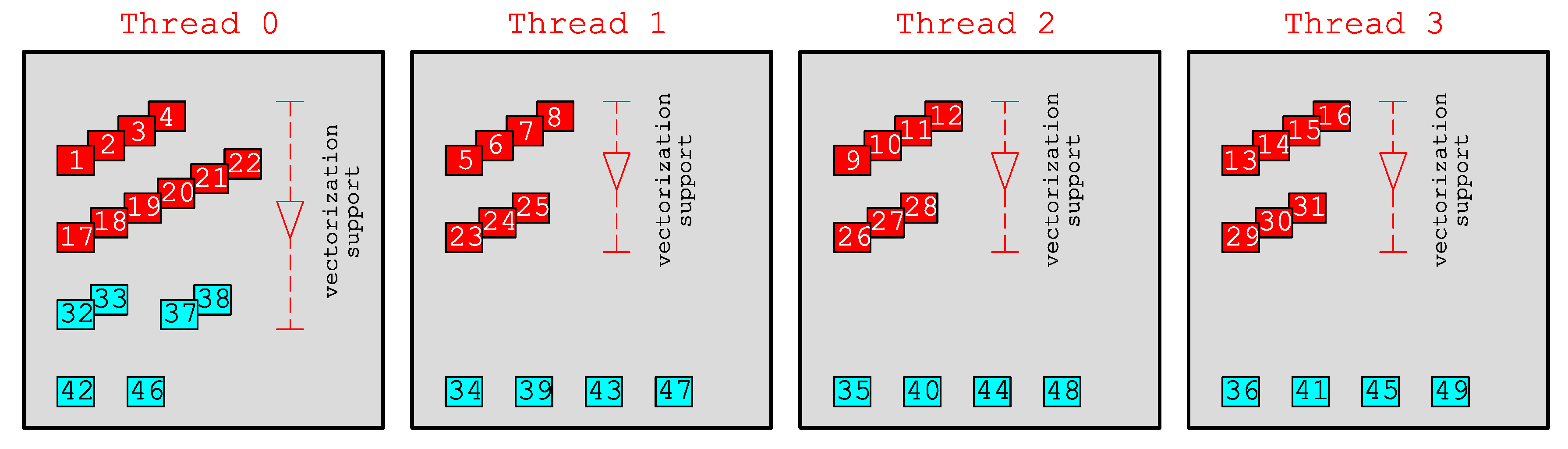
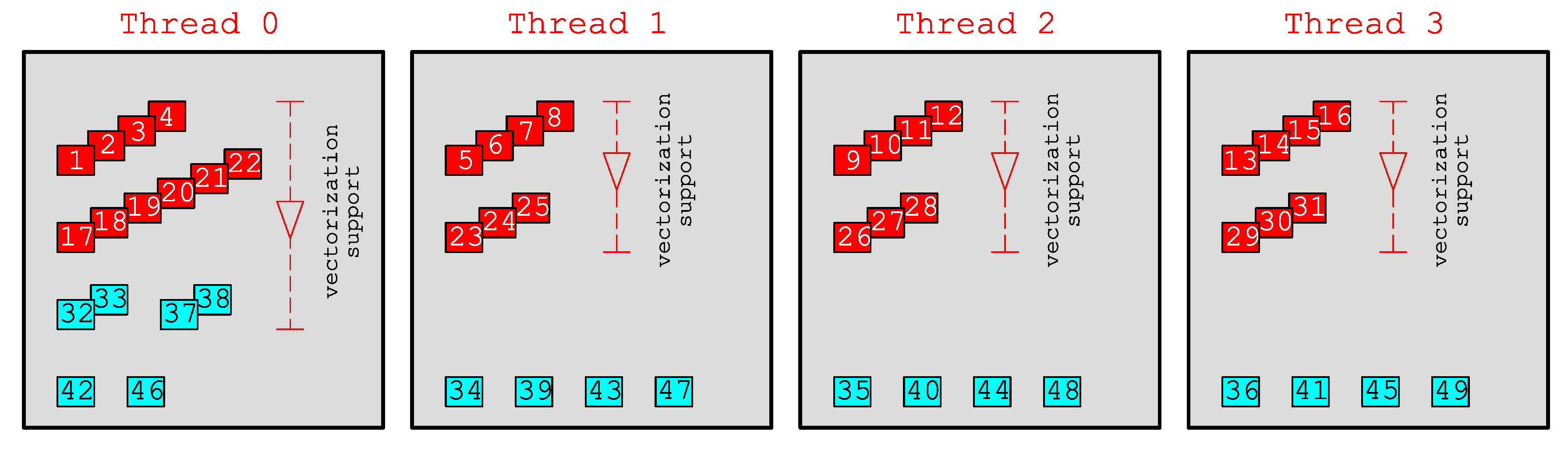
In
Figure 4 we show an example of the decomposition of the domain in
Figure 3 using four threads; for the sake of brevity, the illustration is given only for the edge-driven level. The parallel directive, e.g.,
, can easily be added to each loop, thus according to Algorithm 2, in the gradient level the domain is decomposed as: thread 0 (cells 6, 7, 1, 17, 5, 8), thread 1 (cells 10, 11, 2, 18, 9, 12), thread 2 (cells 14, 15, 3, 19, 13, 16), and thread 3 (cells 4, 20). Similarly, regarding Algorithm 3 it gives in the edge-driven level: thread 0 (edges 1–4, 17–22, 32–33, 37–38, 42, 46), thread 1 (edges 5–8, 23–25, 34, 39, 43, 47), thread 2 (edges 9–12, 26–28, 35, 40, 44, 48), and thread 3 (edges 13–16, 29–31, 36, 41, 45, 49). Meanwhile, the cell-driven level applies a similar decomposition to that of the gradient level. One can see, the largest loop components, e.g., internal edges 1–4, 5–8, etc., are decomposed in a contiguous pattern easing the vectorization implementation, thus efficient. Note the decomposition in
Figure 4 is based on static load balancing that causes load imbalance due to the non-uniform amount of loads assigned to each thread; this load imbalance will become less and less significant as the domain size increases, e.g., to millions of cells. However, another load imbalance issue—which can only be recognized during runtime—appears, namely the one caused by wet–dry problems, where wet cells are computationally more expensive than dry cells. For this, we have developed in [
21] a novel weighted-dynamic load balancing (WDLB) technique that was proven effective to tackle load imbalance due to wet–dry problems. All the parallel and load balancing implementations are described in detail in [
21], thus are not explained here. We also note that we have successfully applied this cell-edge reordering strategy in [
24,
25] for parallelizing the 2D shallow flow simulations using the CU scheme with good scalability. Yet, we will show in the next section that the cell-edge reordering strategy proposed can help in easing all the vectorization implementations.
5. Conclusions
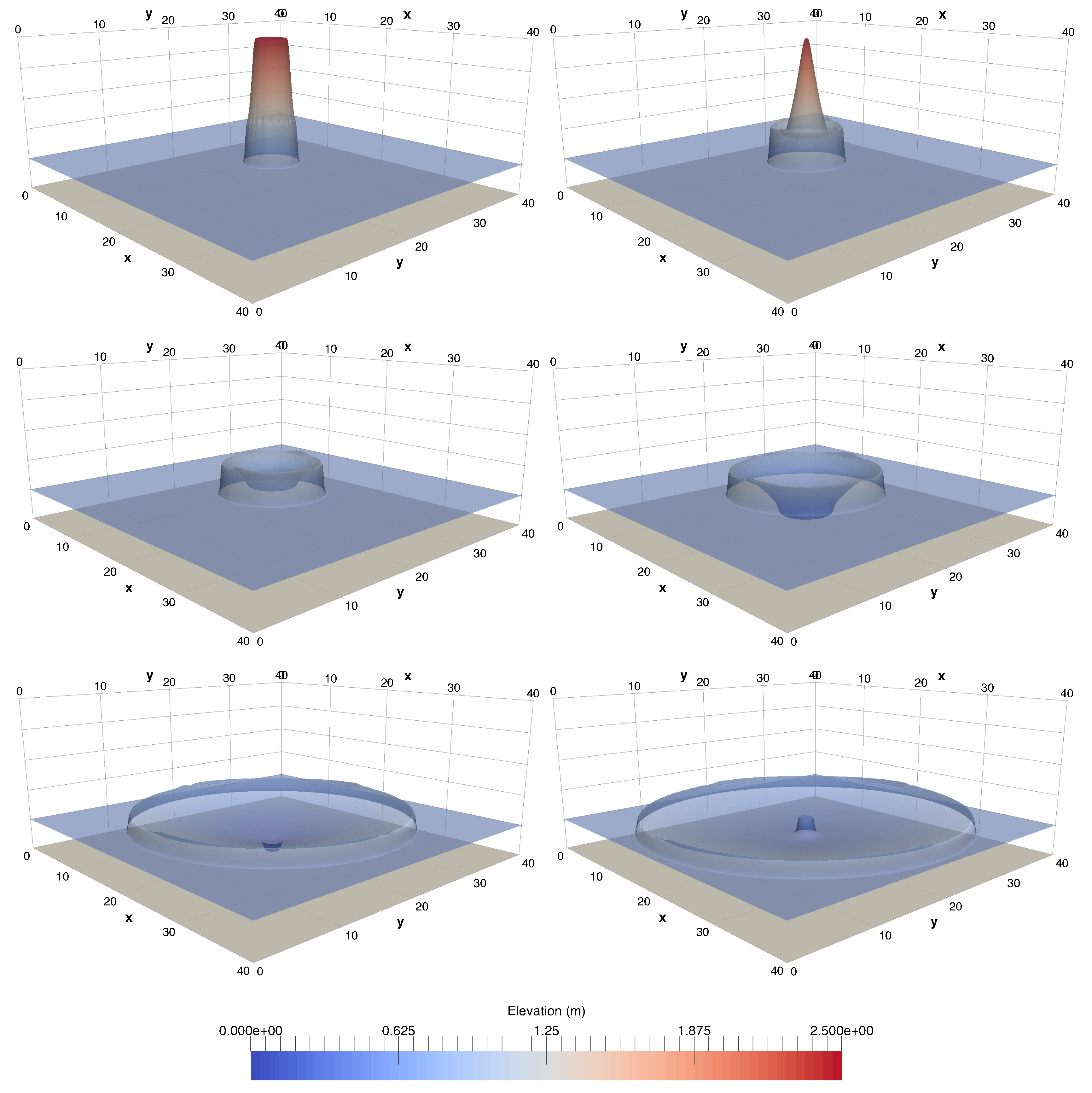
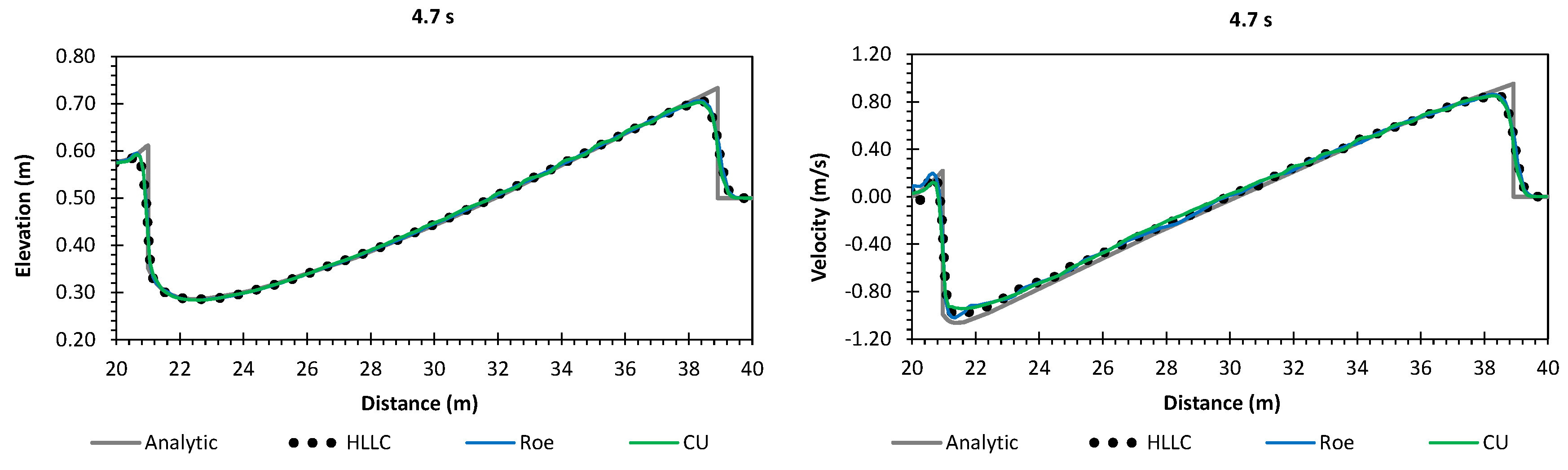
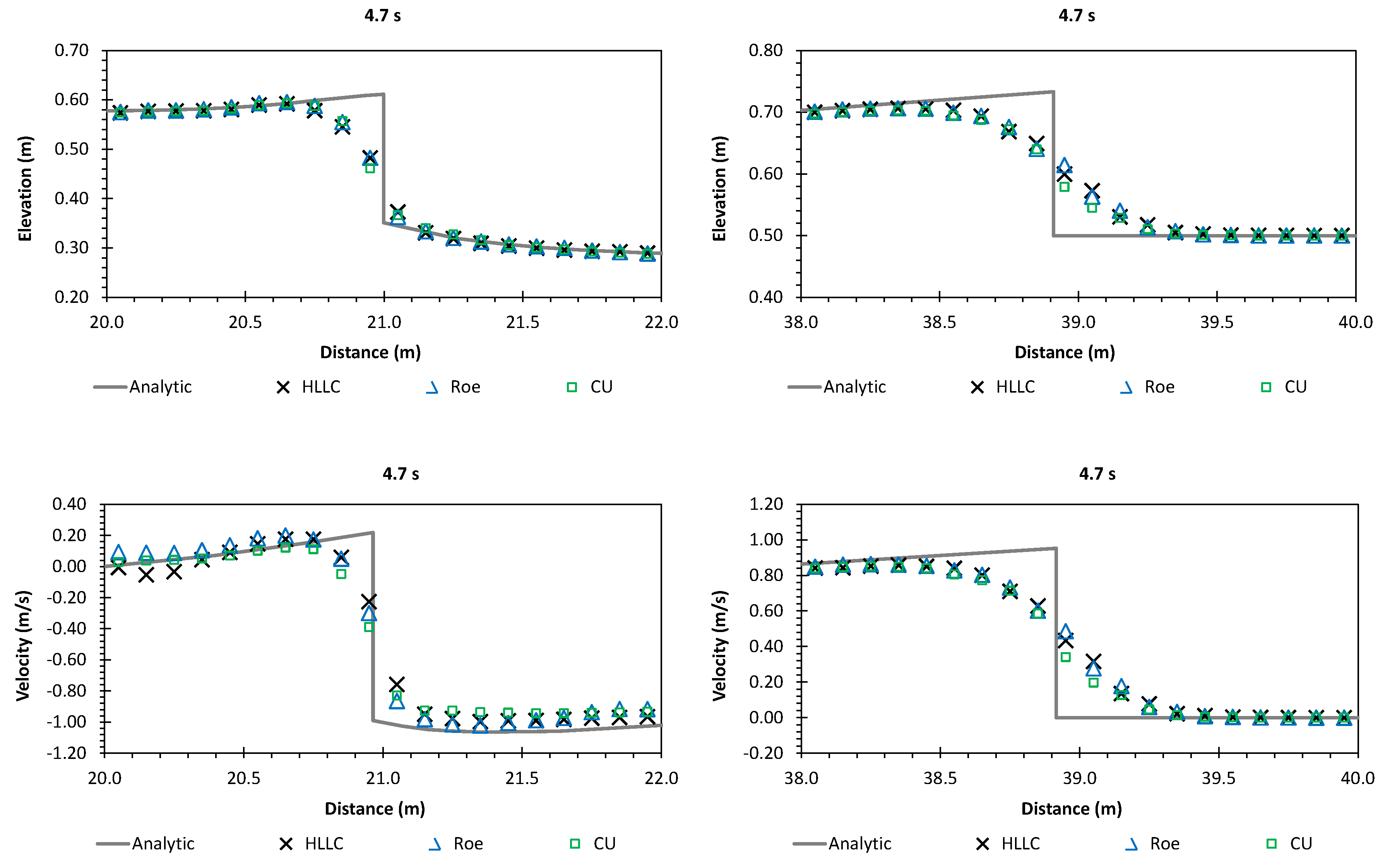
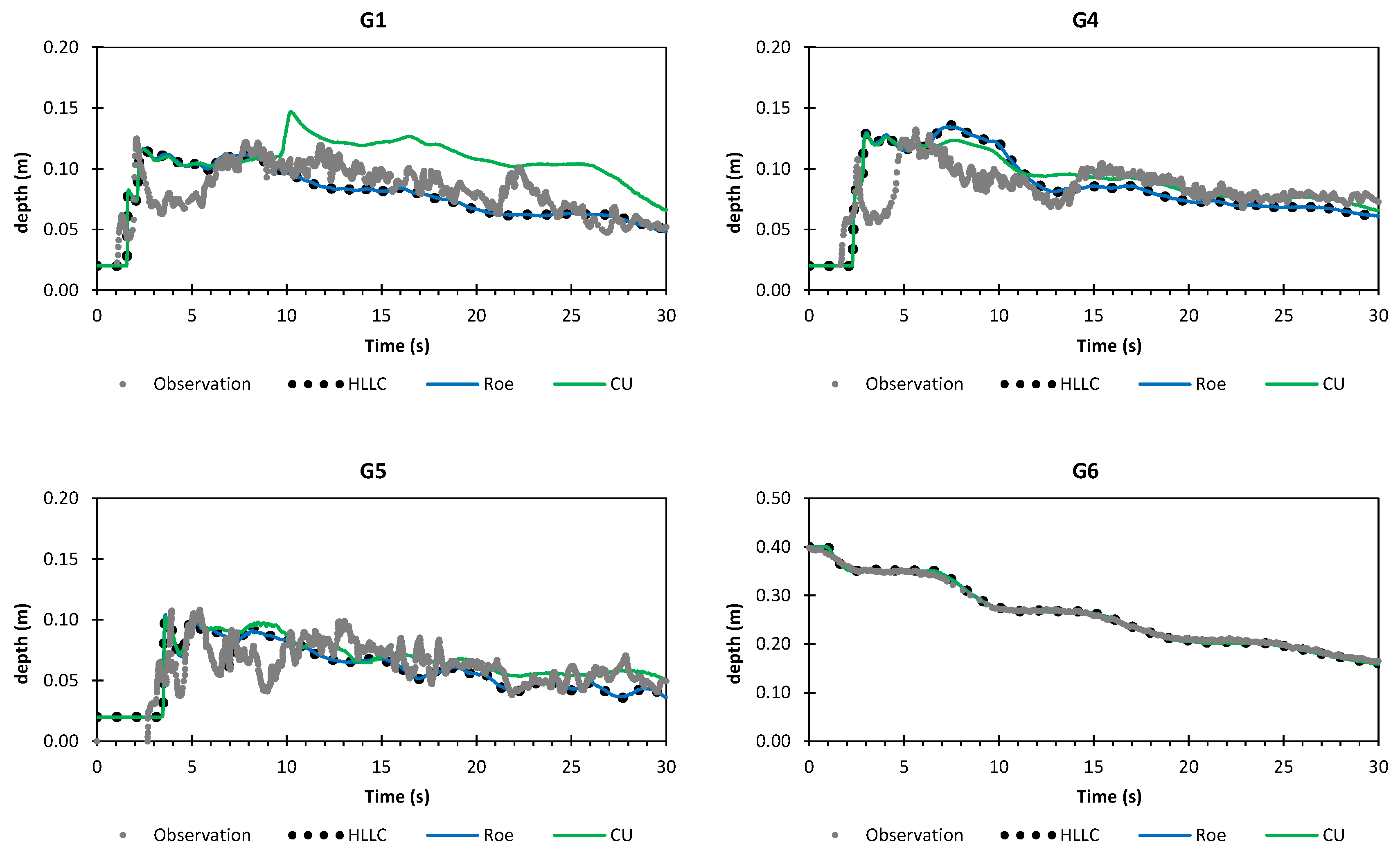
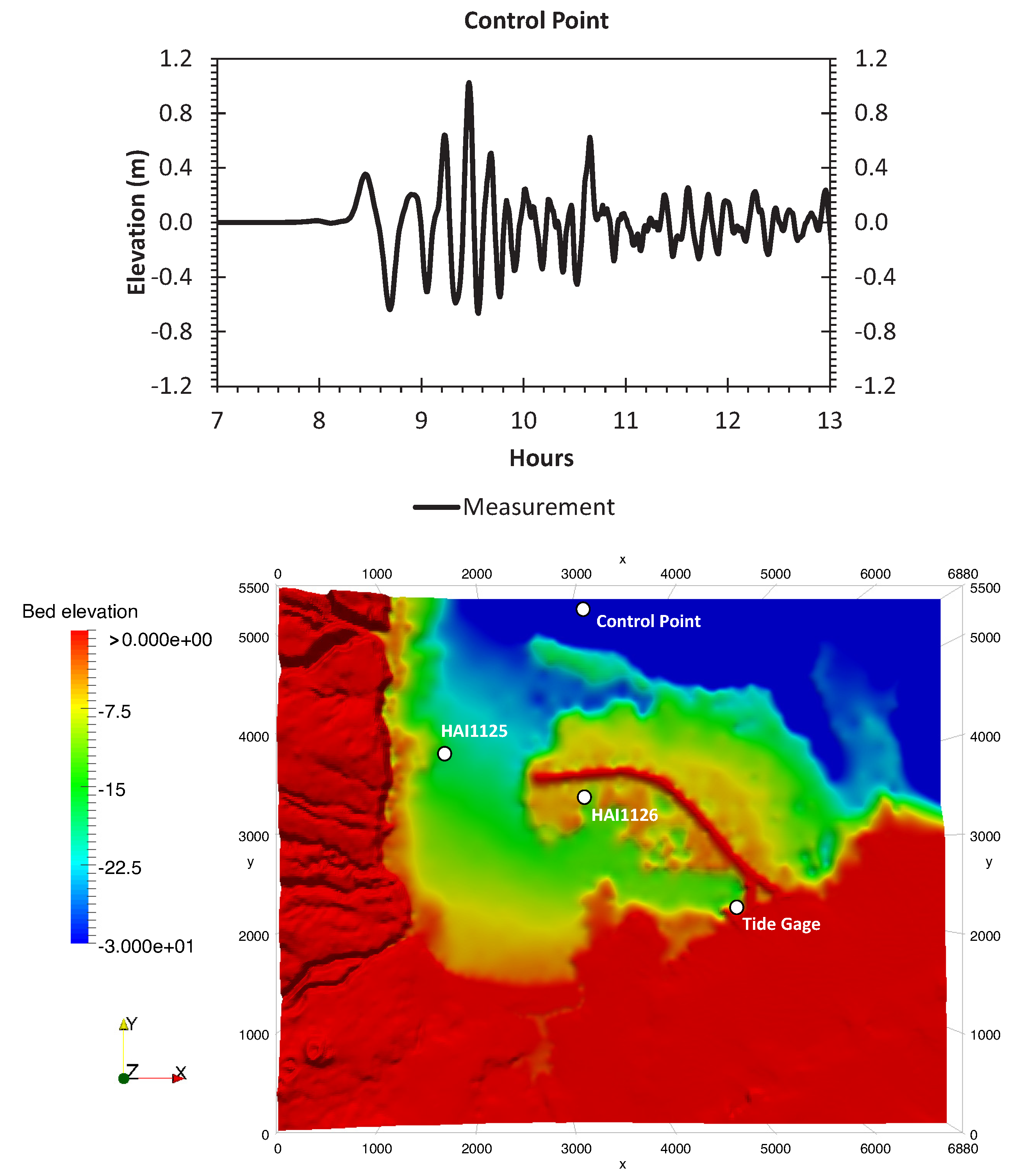
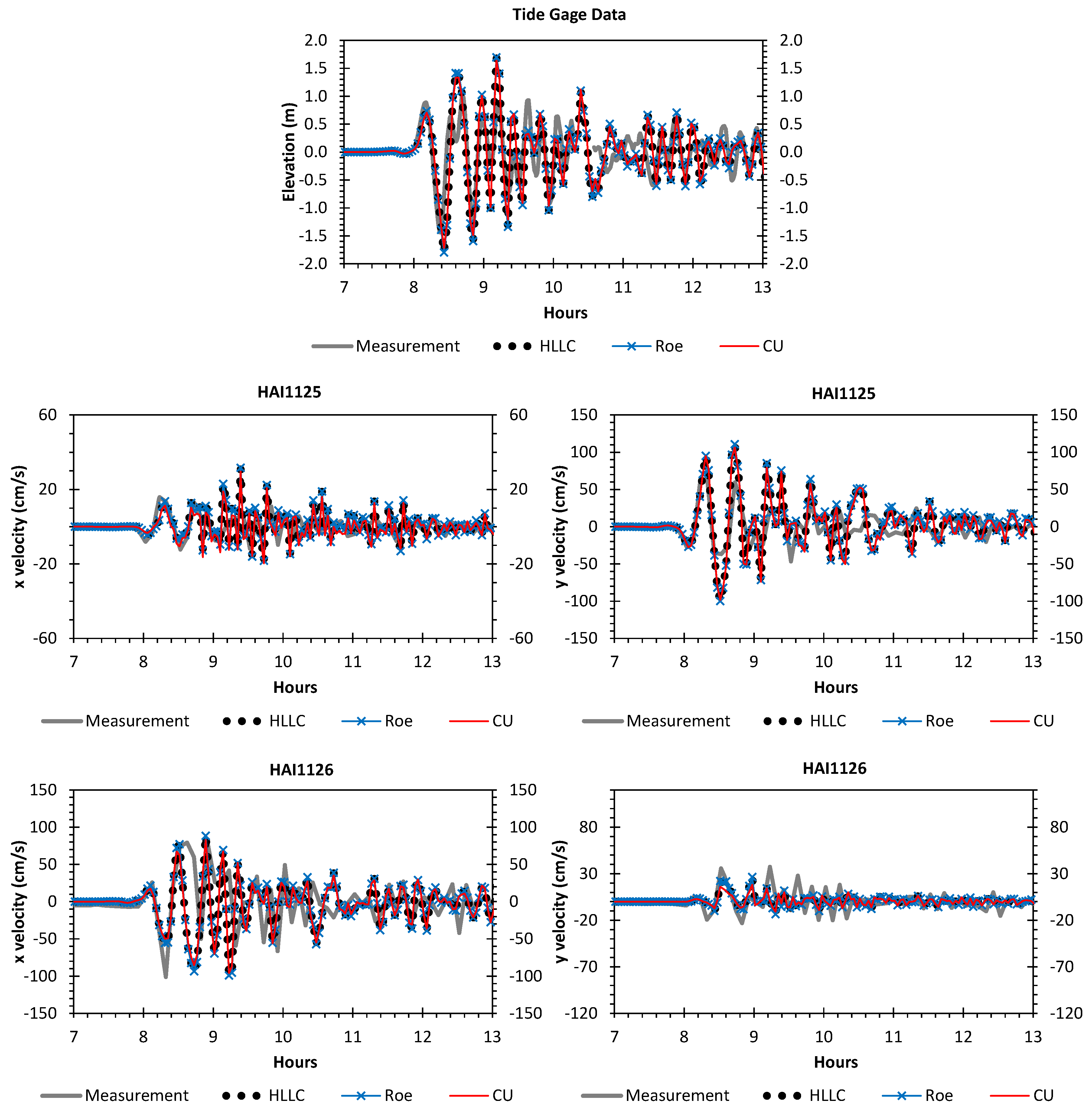
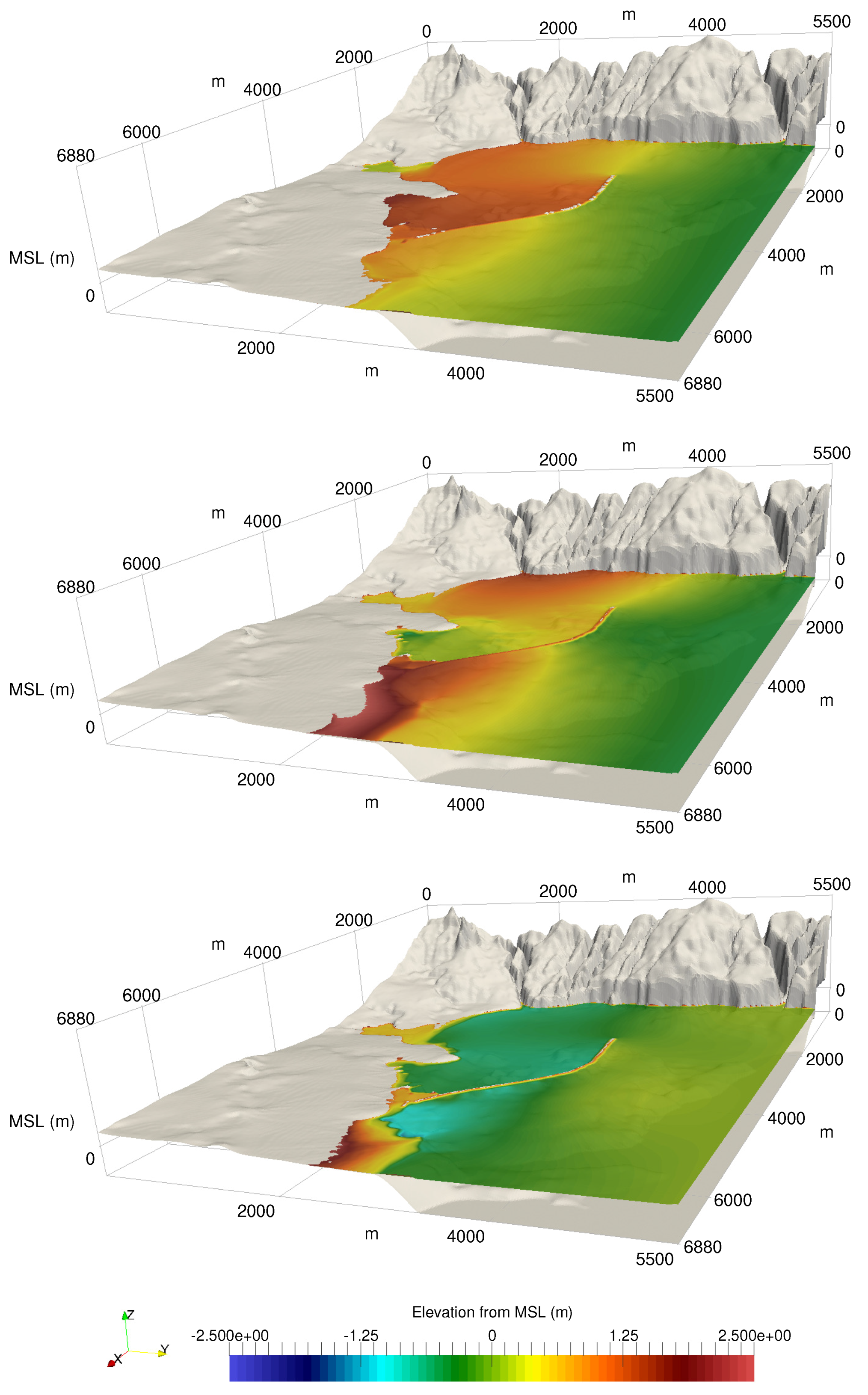
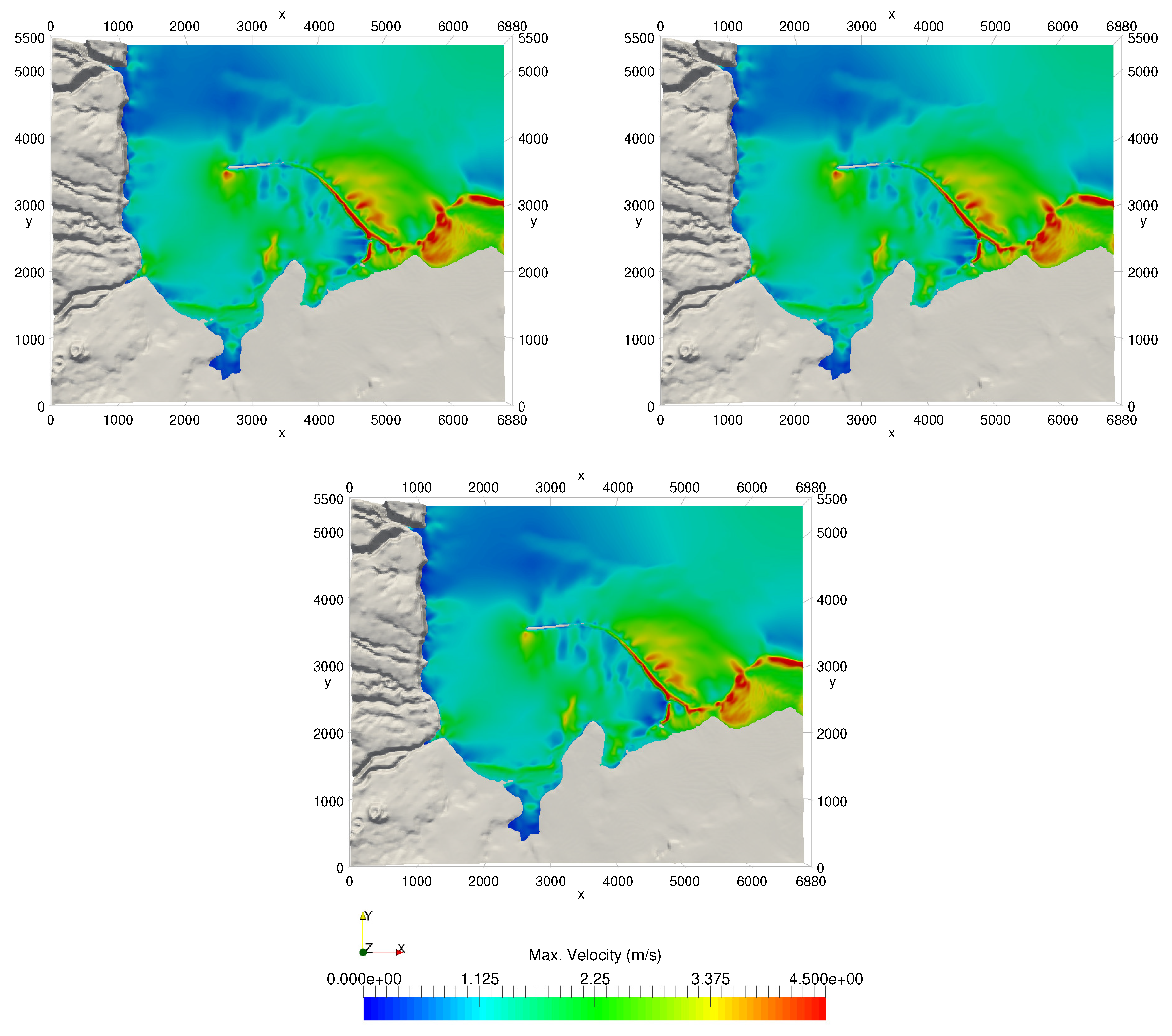
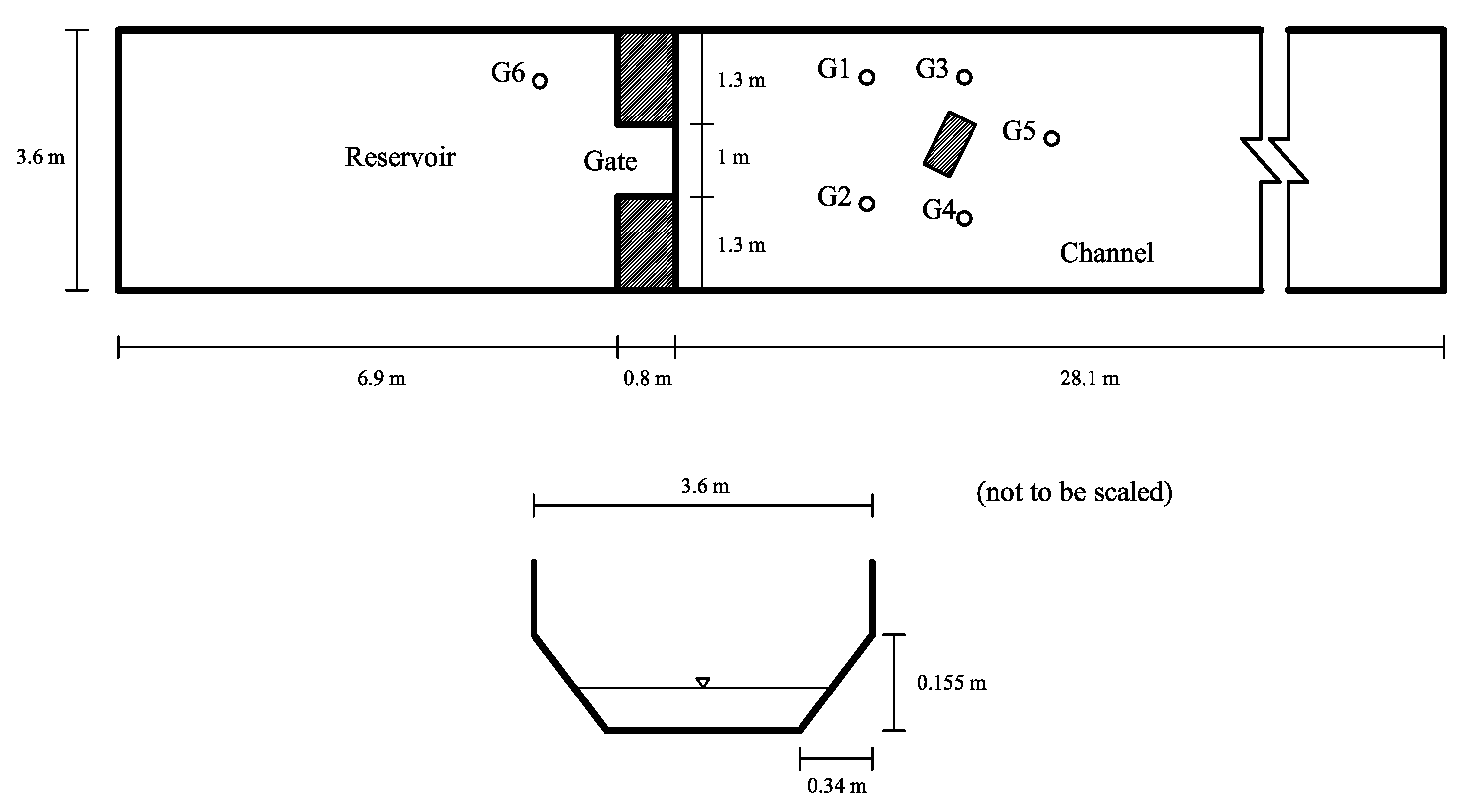
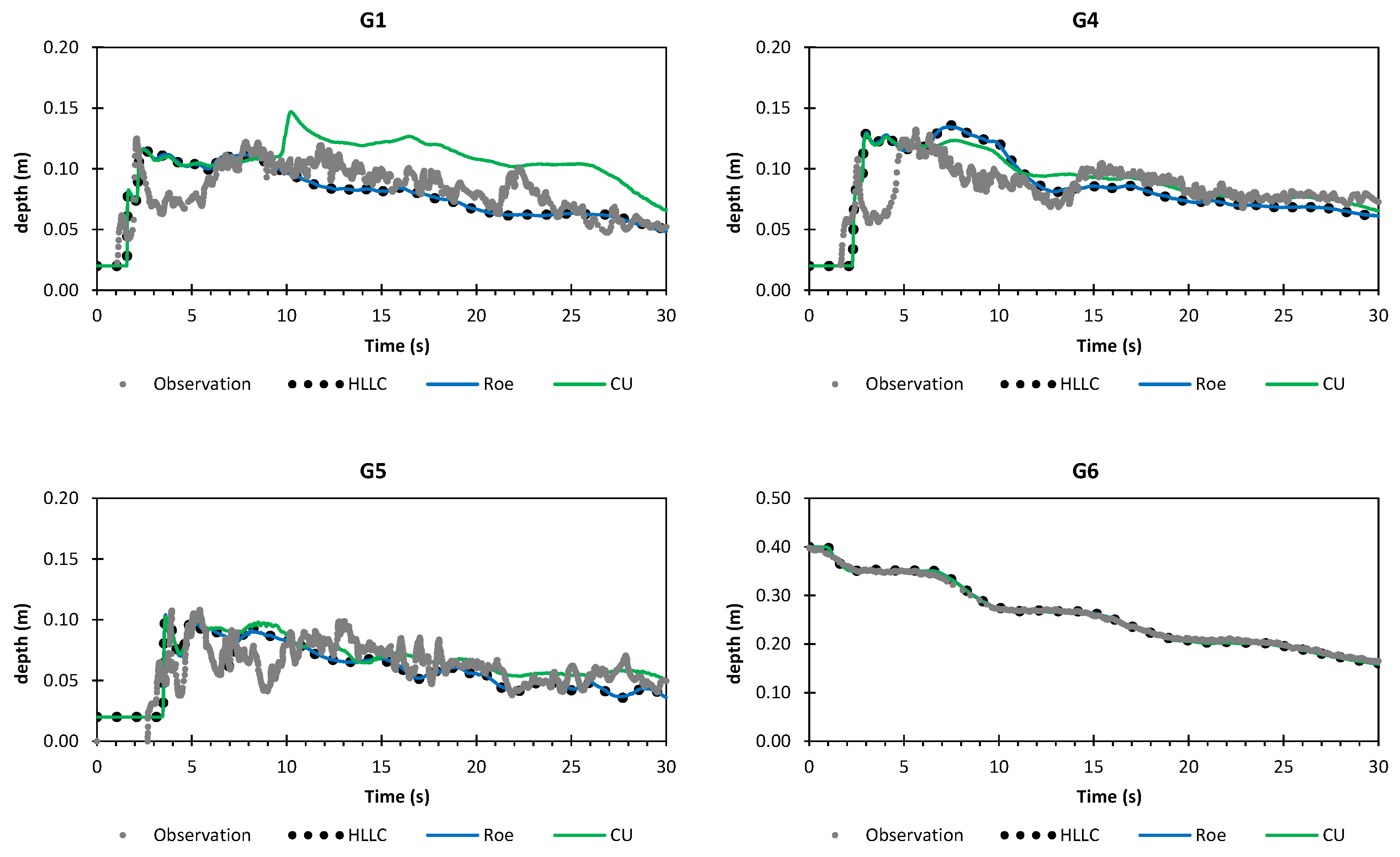
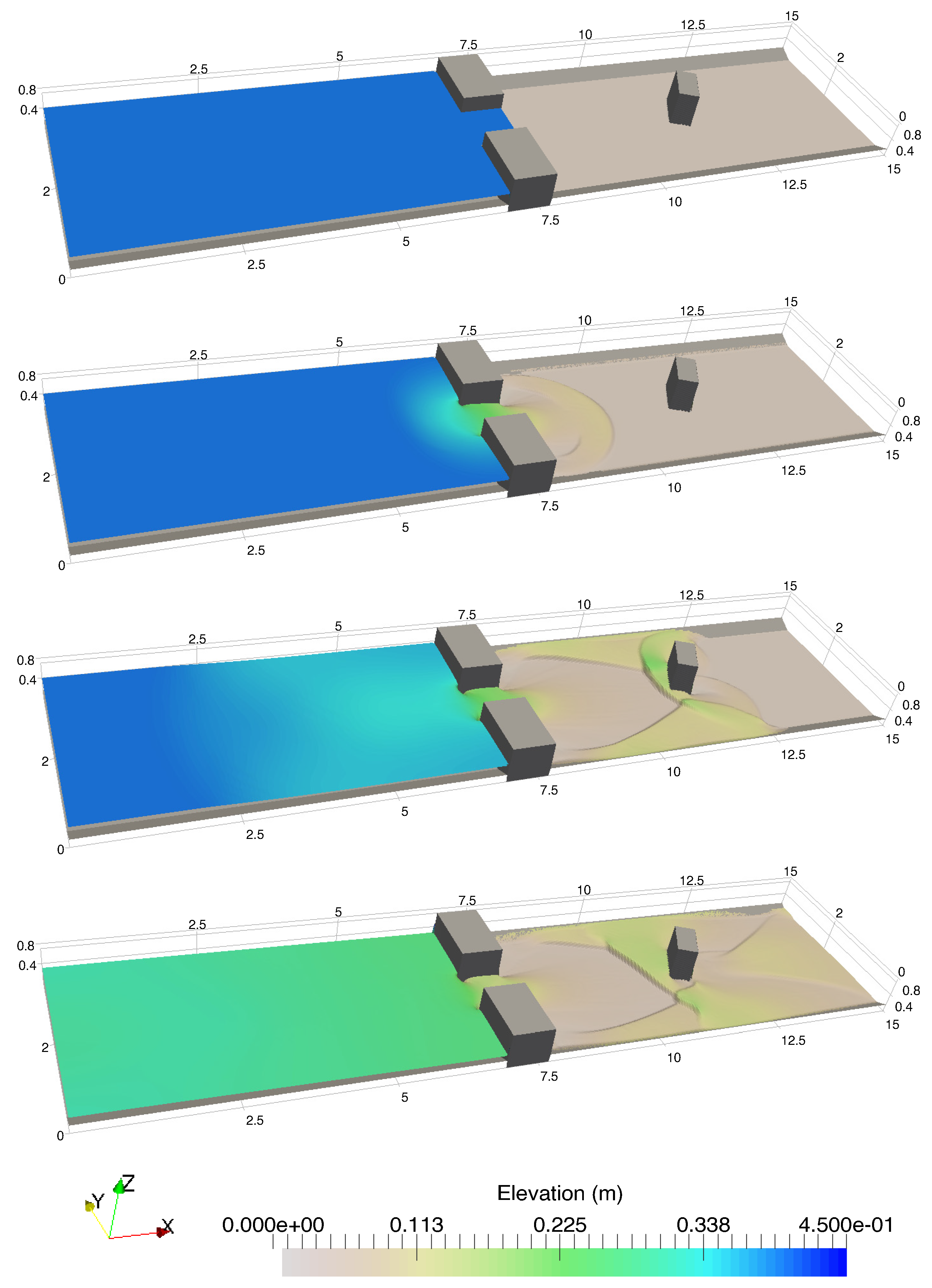
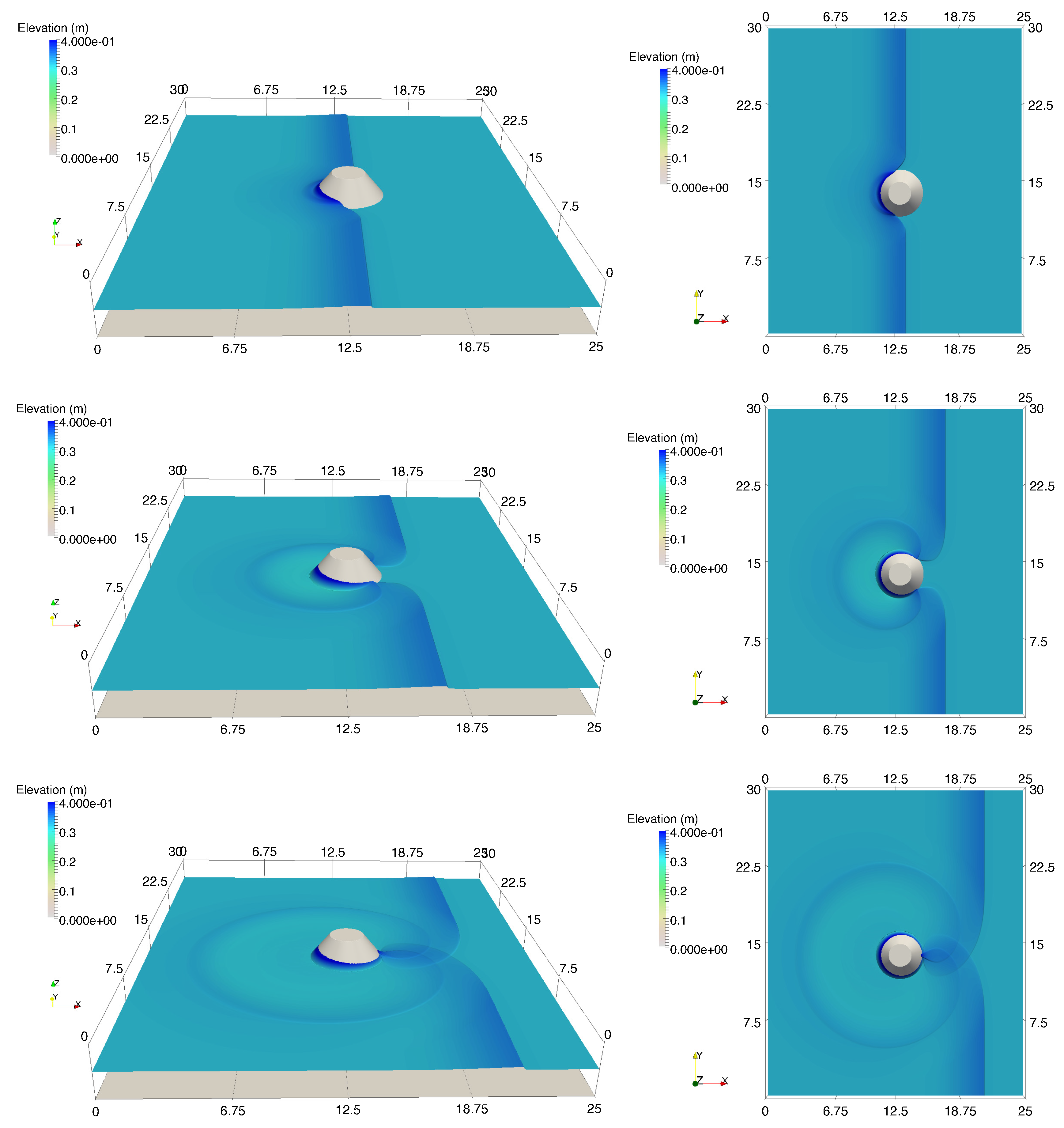
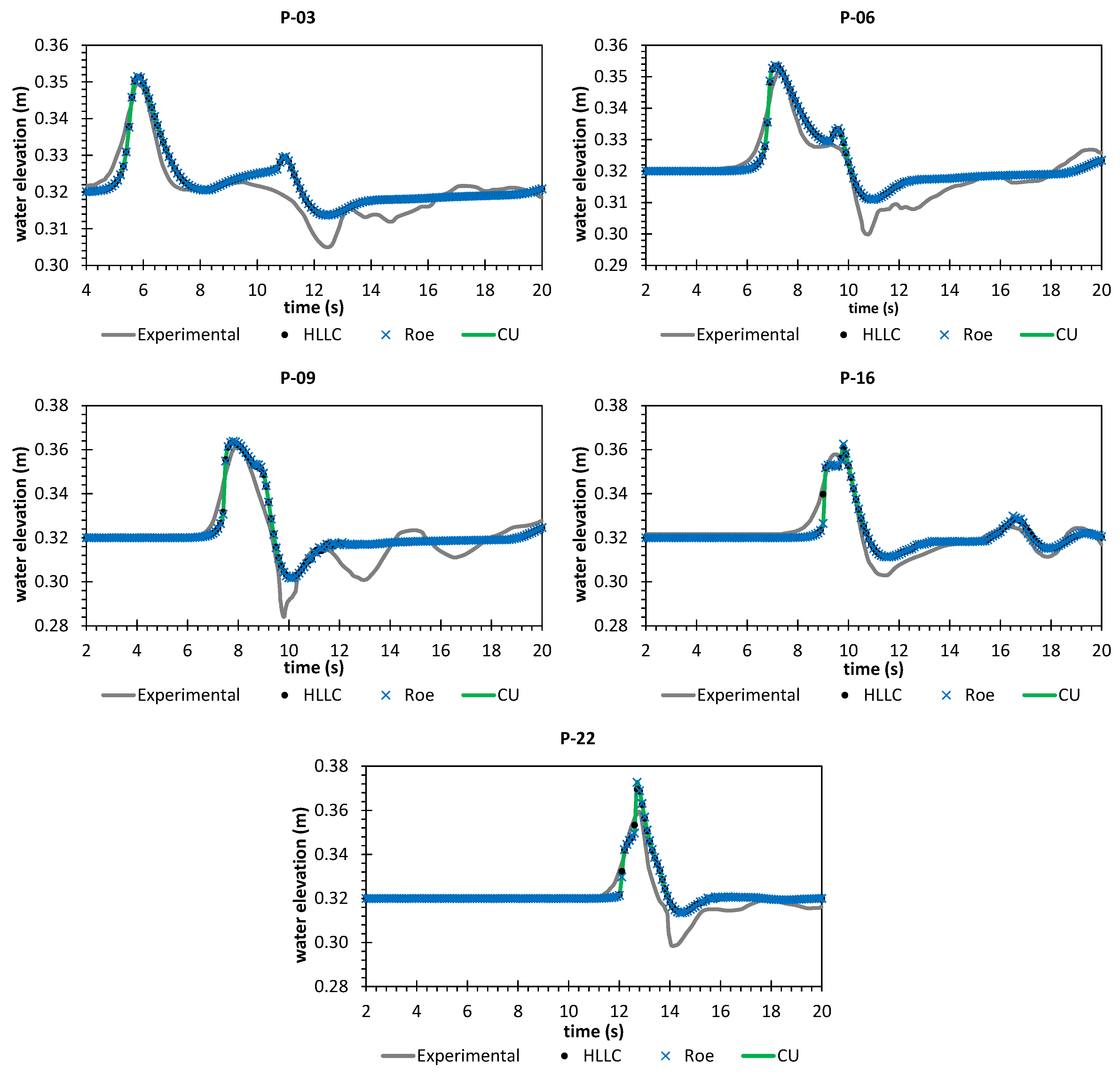
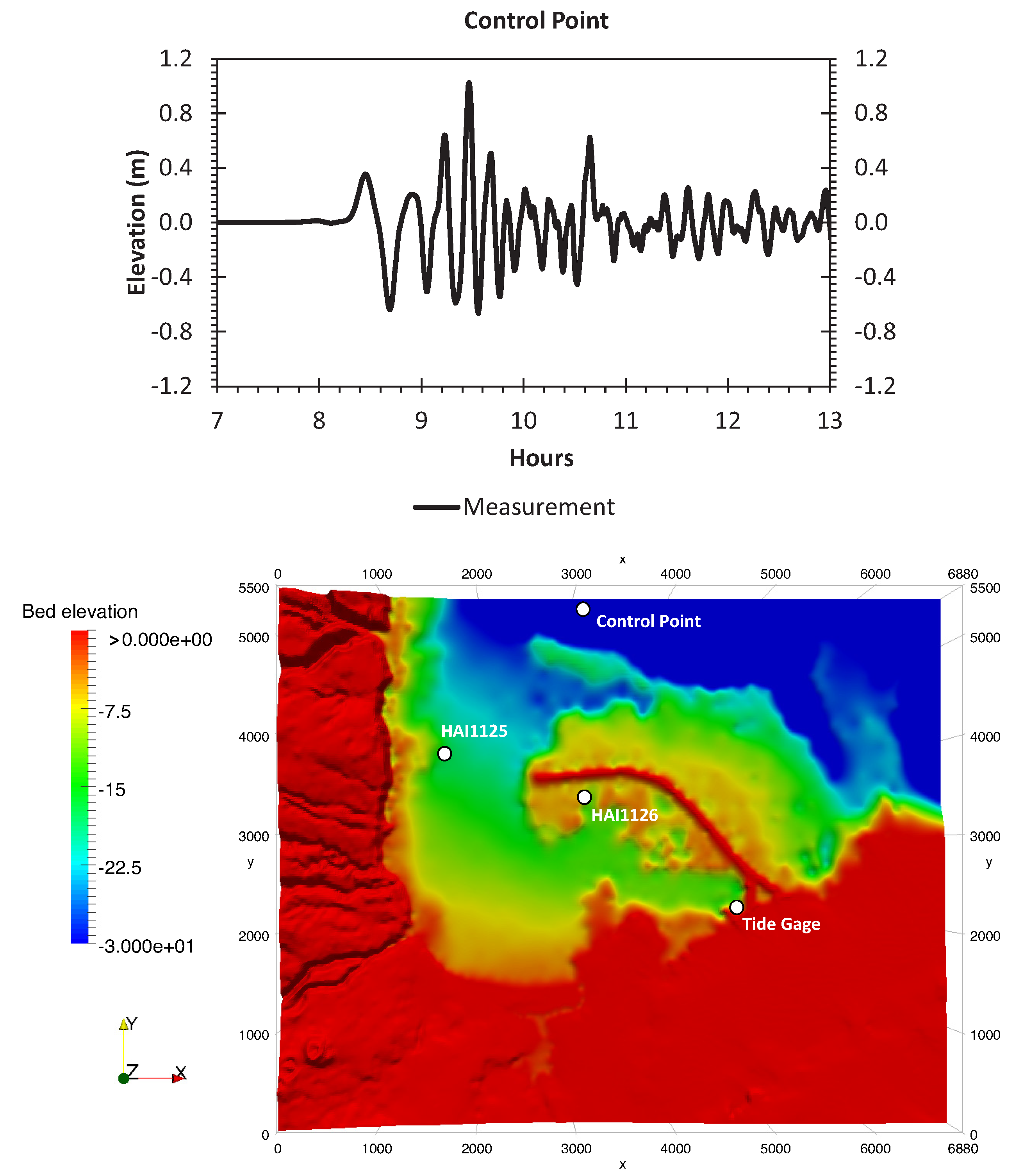
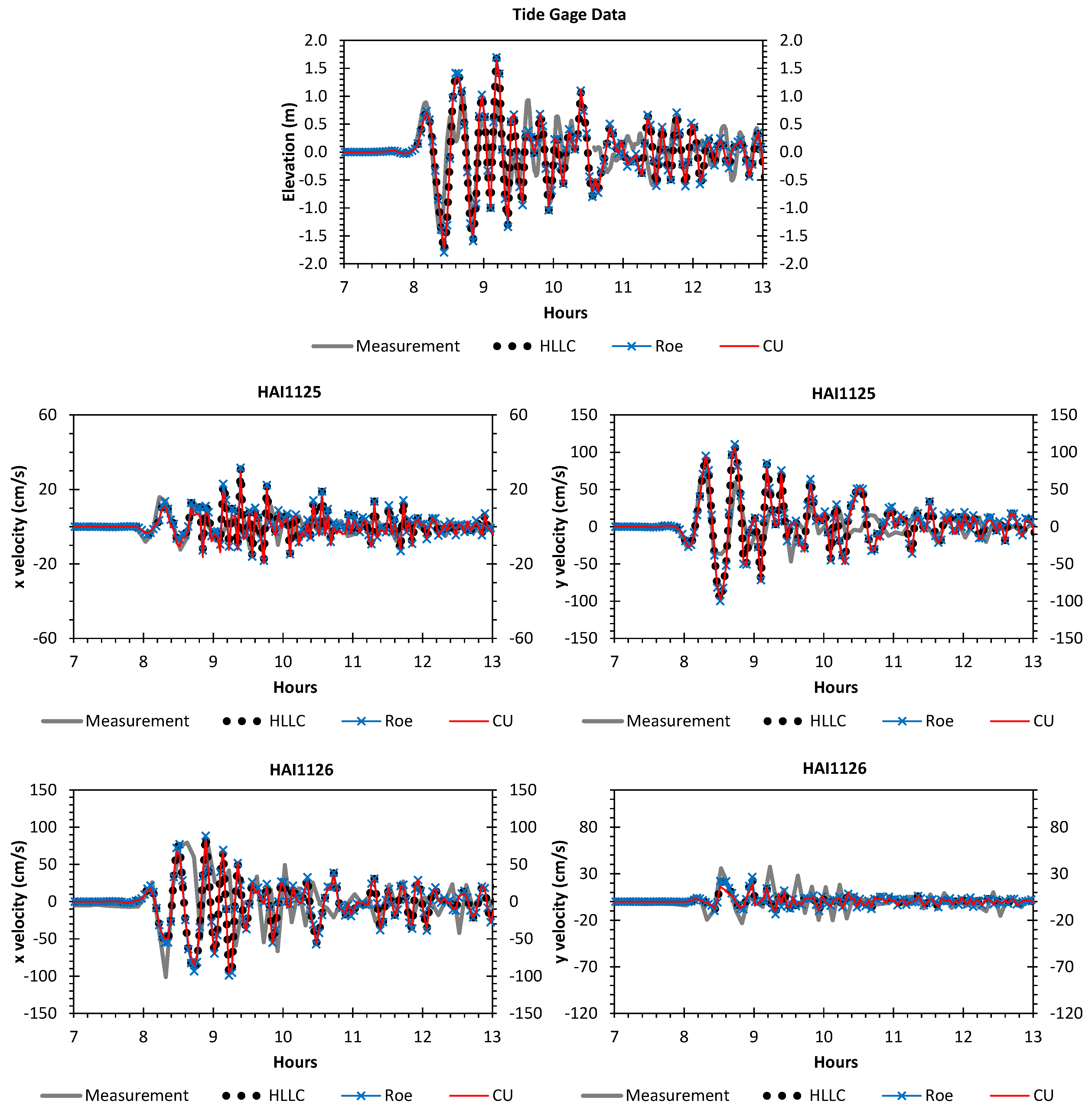
A numerical investigation for studying the accuracy and efficiency of three common shallow water solvers (the HLLC, Roe, and CU schemes) has been presented. Four cases dealing with shock waves and wet–dry phenomenon were selected. All schemes were provided in an in-house code NUFSAW2D, the model of which was of second-order accurate in space wherever the regimes were smooth and robust when dealing with strong shock waves—and of fourth-order accurate in time. To give a fair comparison, all source terms of the 2D SWEs were treated similarly for all schemes, namely the bed-slope terms were computed separately from the convective fluxes using a Riemann-solver-free scheme—and the friction terms were computed semi-implicitly within the framework of the RKFO method.
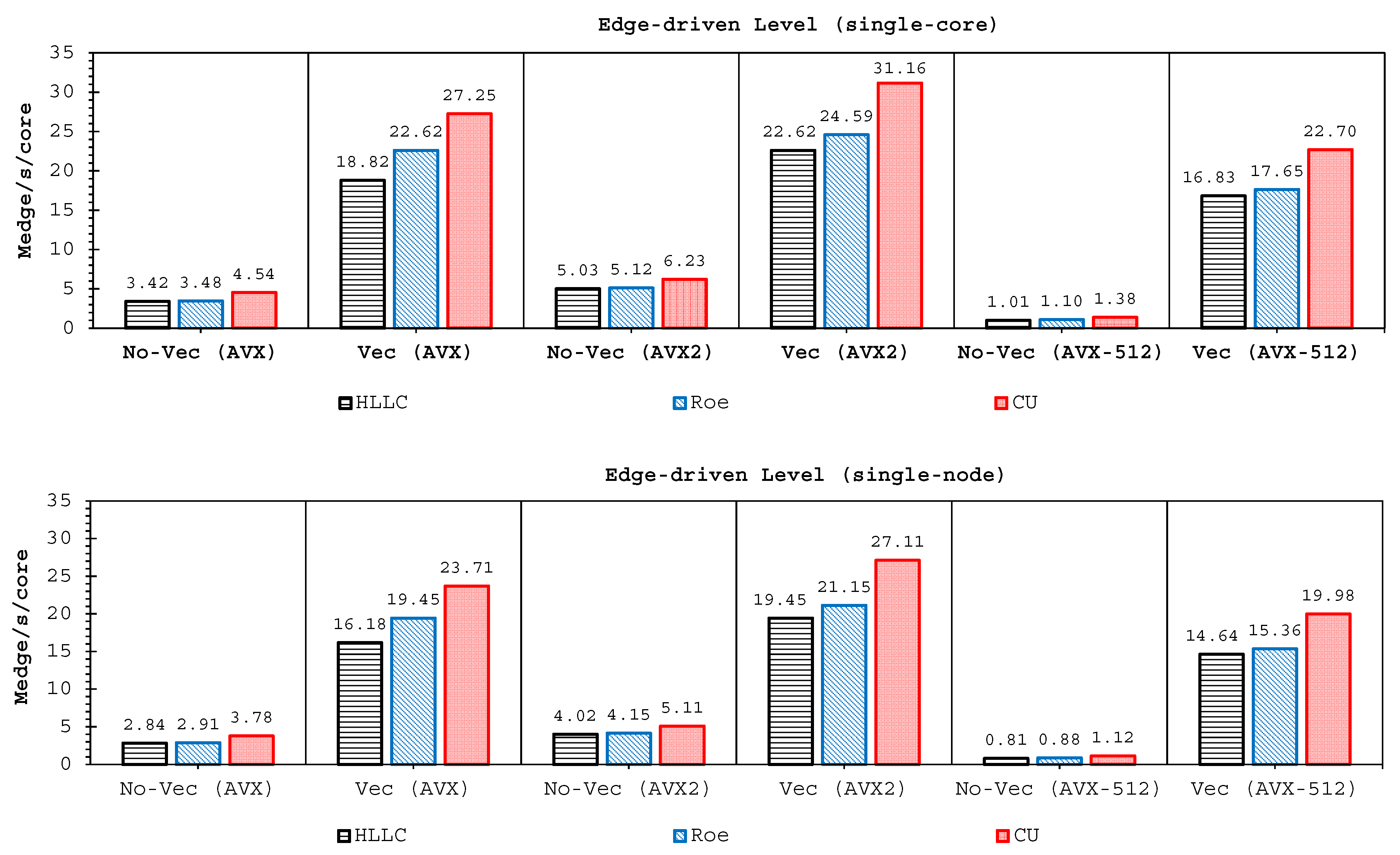
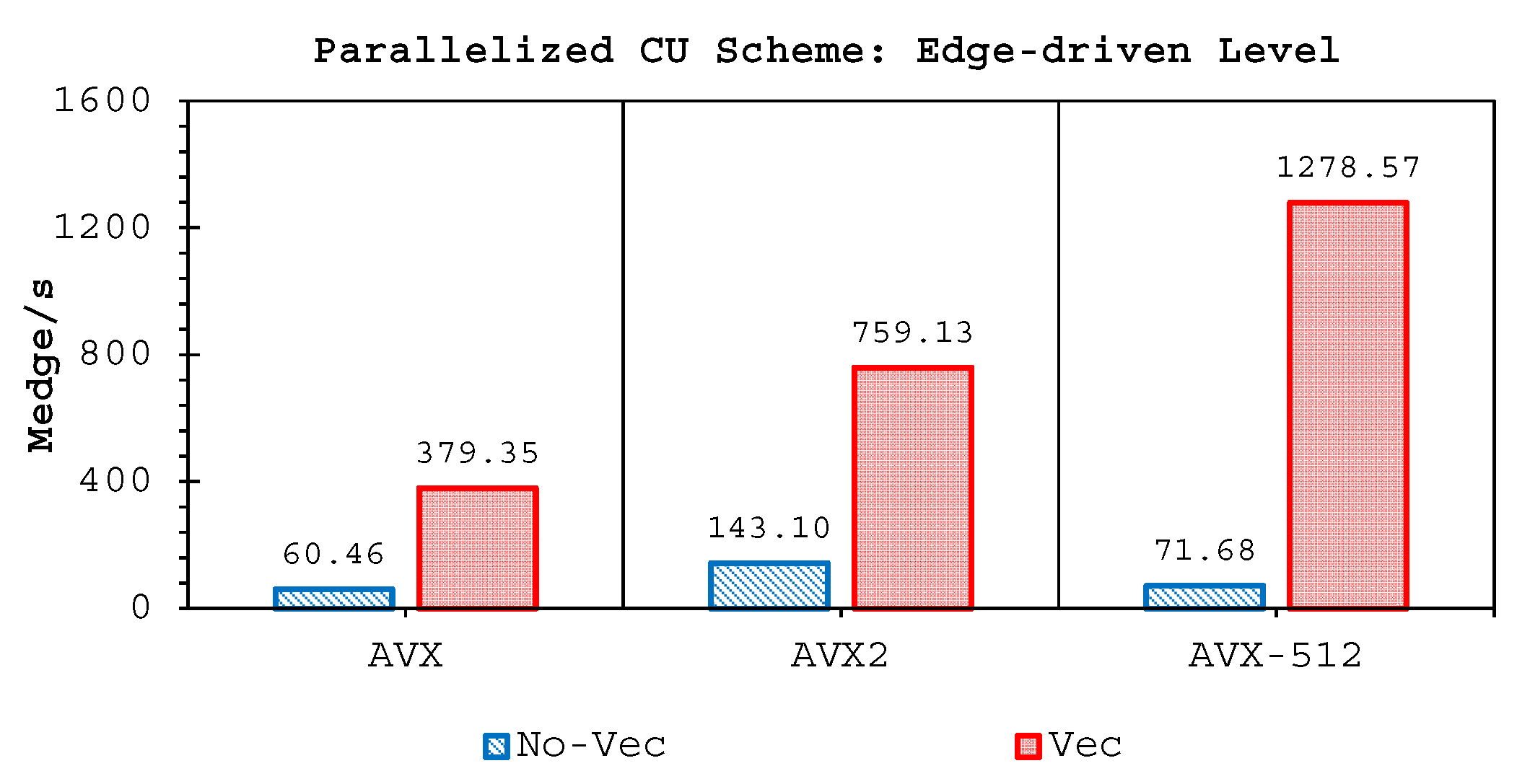
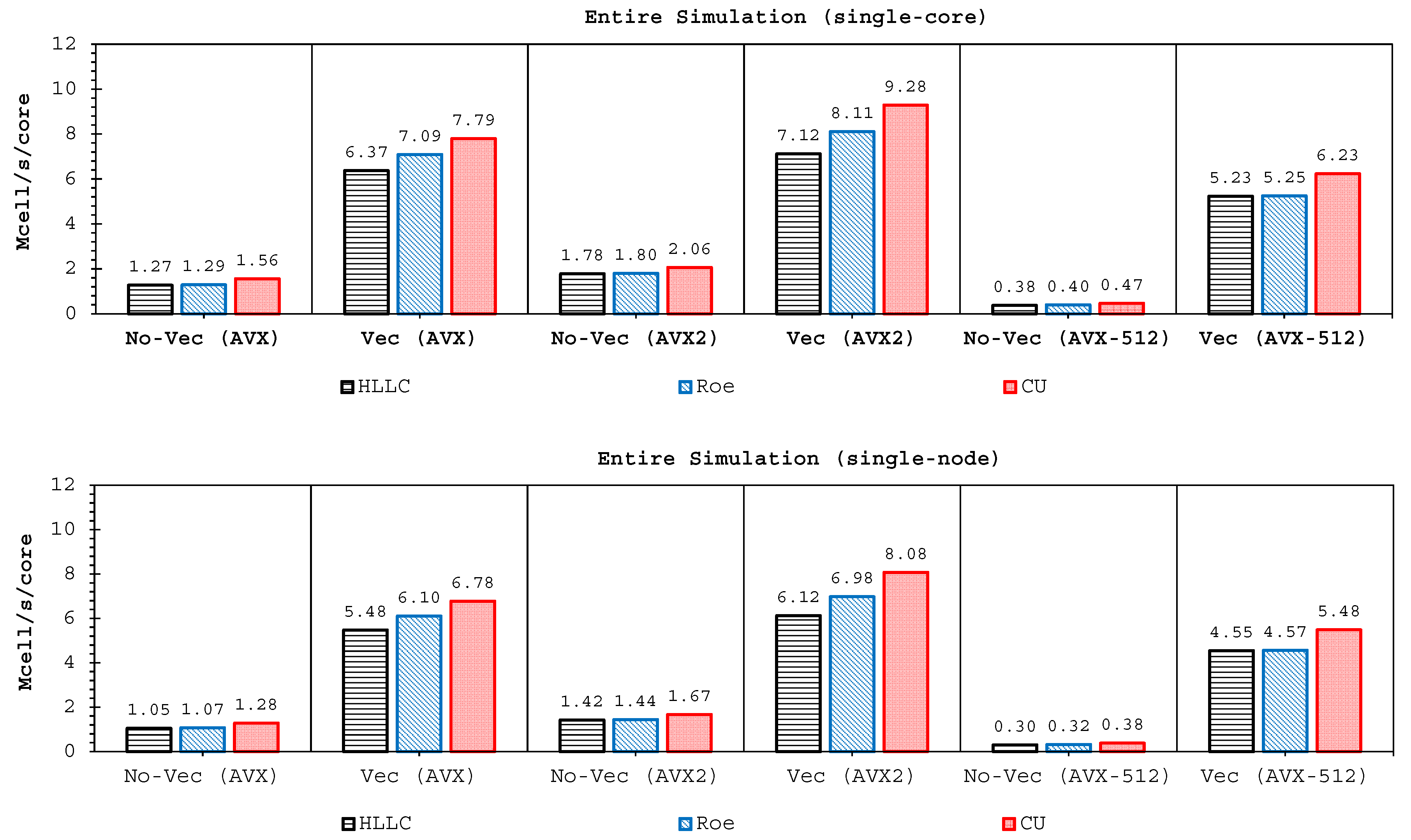
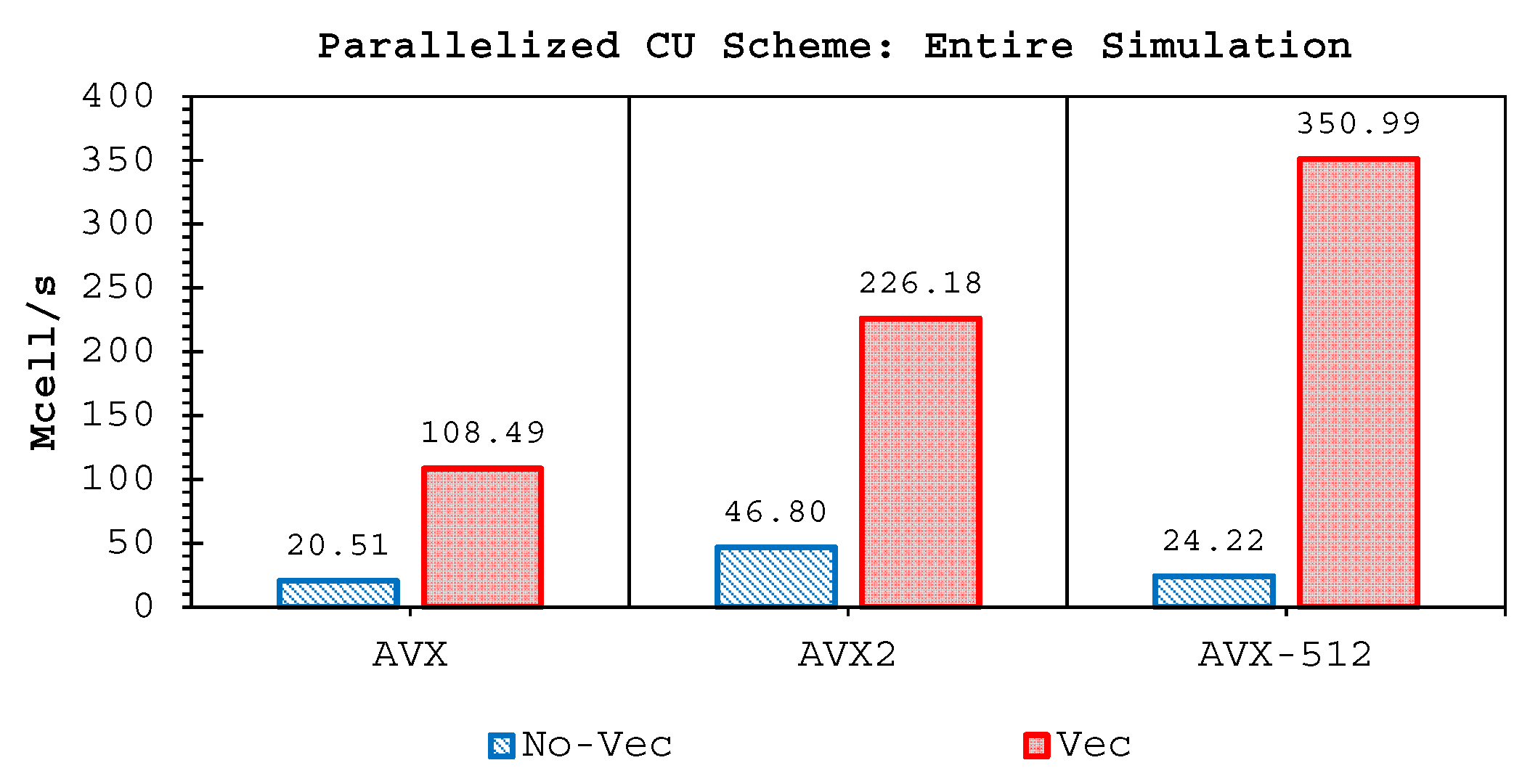
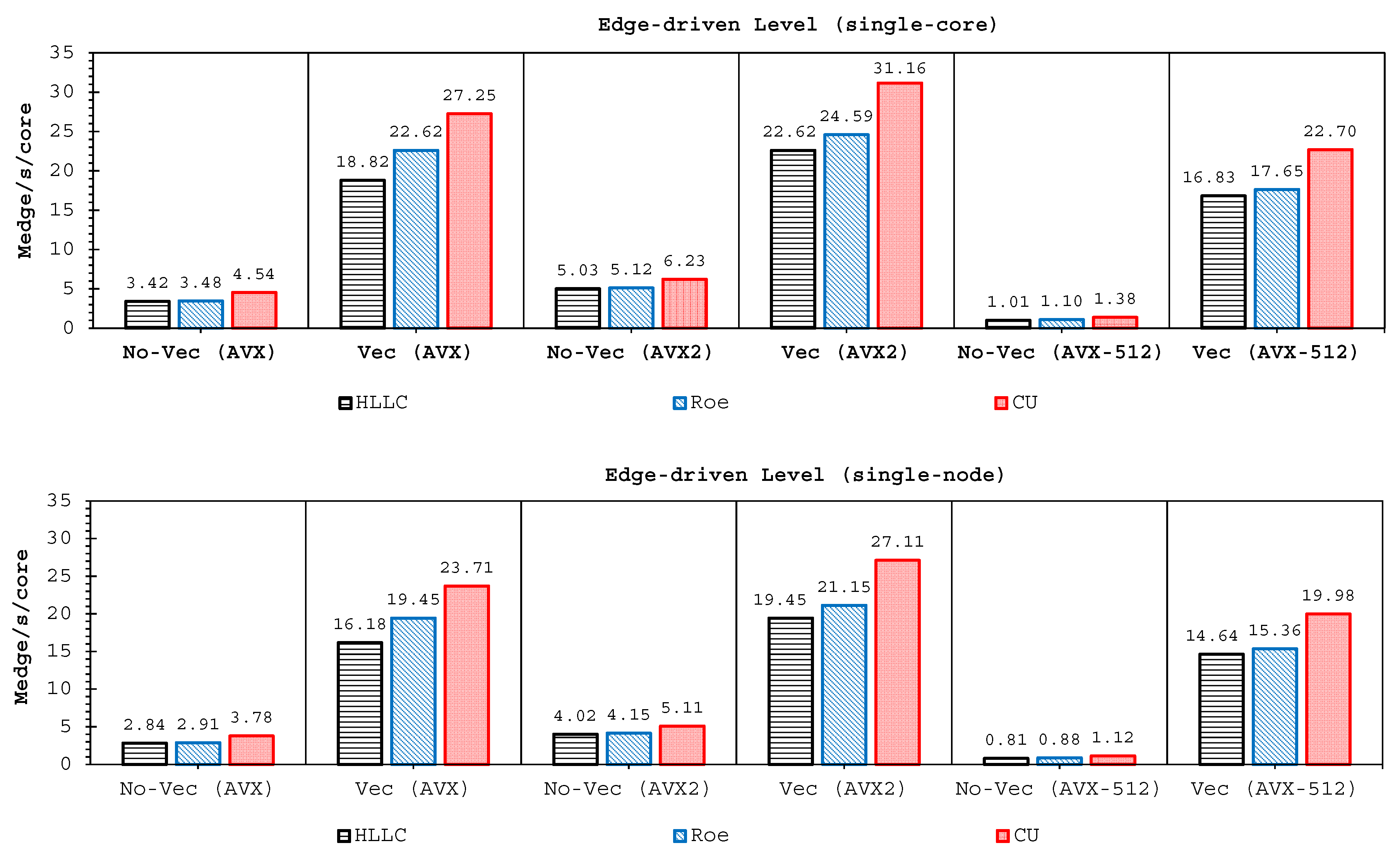
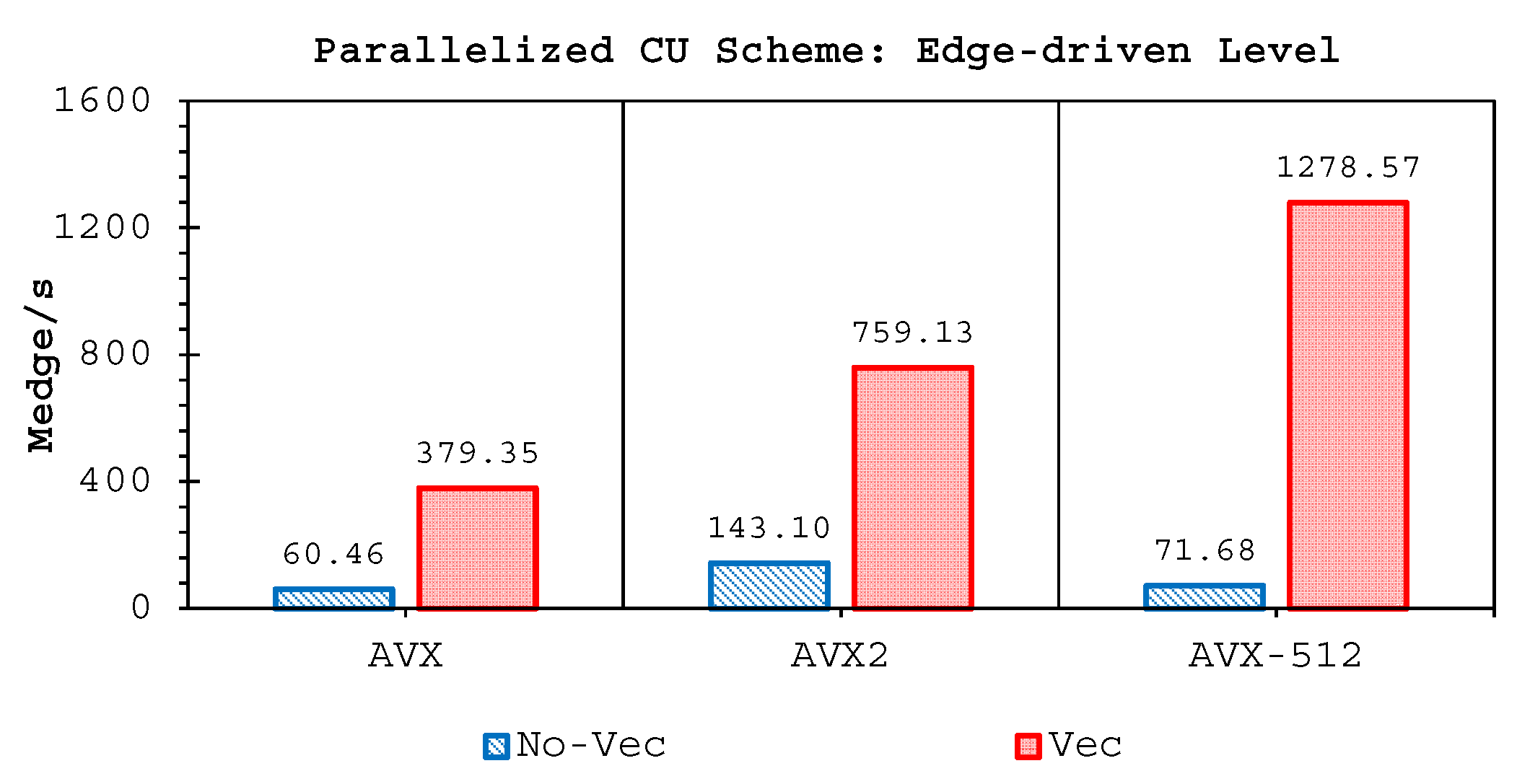
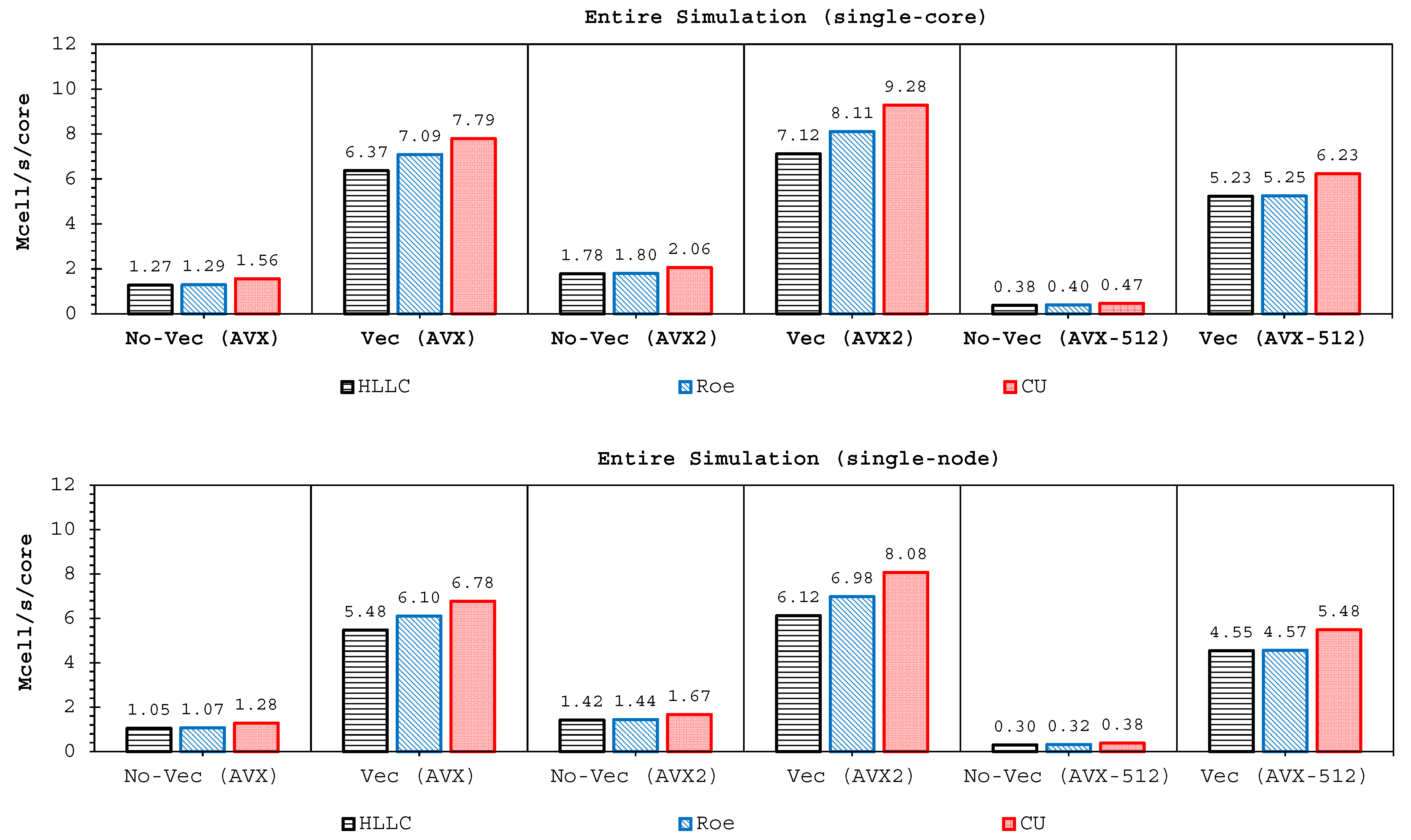
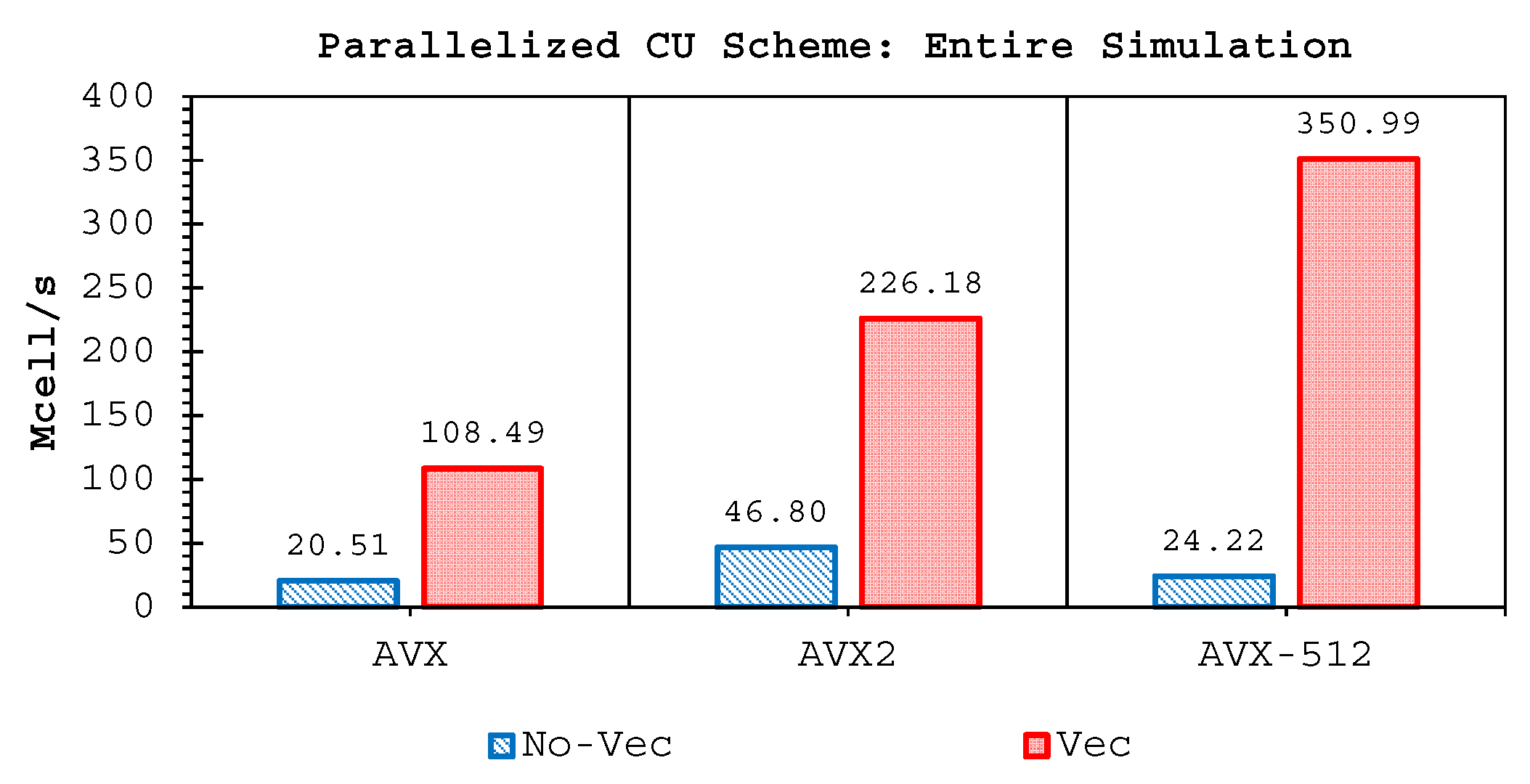
Two important findings have been shown by our simulations. Firstly, highly-efficient vectorization could be applied to the three solvers on all hardware used. This was achieved by guided vectorization, where a cell-edge reordering strategy was employed to ease the vectorization implementations and to support the aligned memory access patterns. Regarding single-core analysis, the vectorization was shown to be able to speed-up the performance of the edge-driven level up to 4.5–6.5× on the AVX/AVX2 machines for eight data per vector and 16.7× on the AVX-512 machine for 16 data per vector—and to accelerate the entire simulation as well by up to 4–5.5× on the AVX/AVX2 machine and 13.91× on the AVX-512 machine. The superlinear speed-up in the edge-driven level especially using the AVX-512 machine could be achieved probably due to improved cache usage, thus less expensive main memory accesses. Regarding single-node analysis, our code could reach in the edge-driven level the improvements of 75.7–121.8× on the AVX/AVX2 machine while on the AVX-512 machine it achieved up to 928.9× speed-up. For updating the entire simulation, our code was able to reach speed-ups of 68.8–109.6× and 774.6× on the AVX/AVX2 and AVX-512 machines, respectively. We observed an interesting phenomenon, where without vectorization the parallelized results of the AVX2 machine outperformed those of the AVX-512 machine in both the edge-driven level and the entire simulation with a factor of up to 2×; the parallelized-vectorized results of the AVX-512 machine became, however, faster by achieving an average factor of 1.6×. This clearly shows that our reordering strategy could efficiently exploit the vectorization support of such a vector-computing machine. Supporting the aligned memory access patterns, the reordering strategy employed has helped in gaining the performances of the “only” vectorized code by averagely 1.45× and 1.4× for the edge-driven level and updating the entire simulation, respectively.
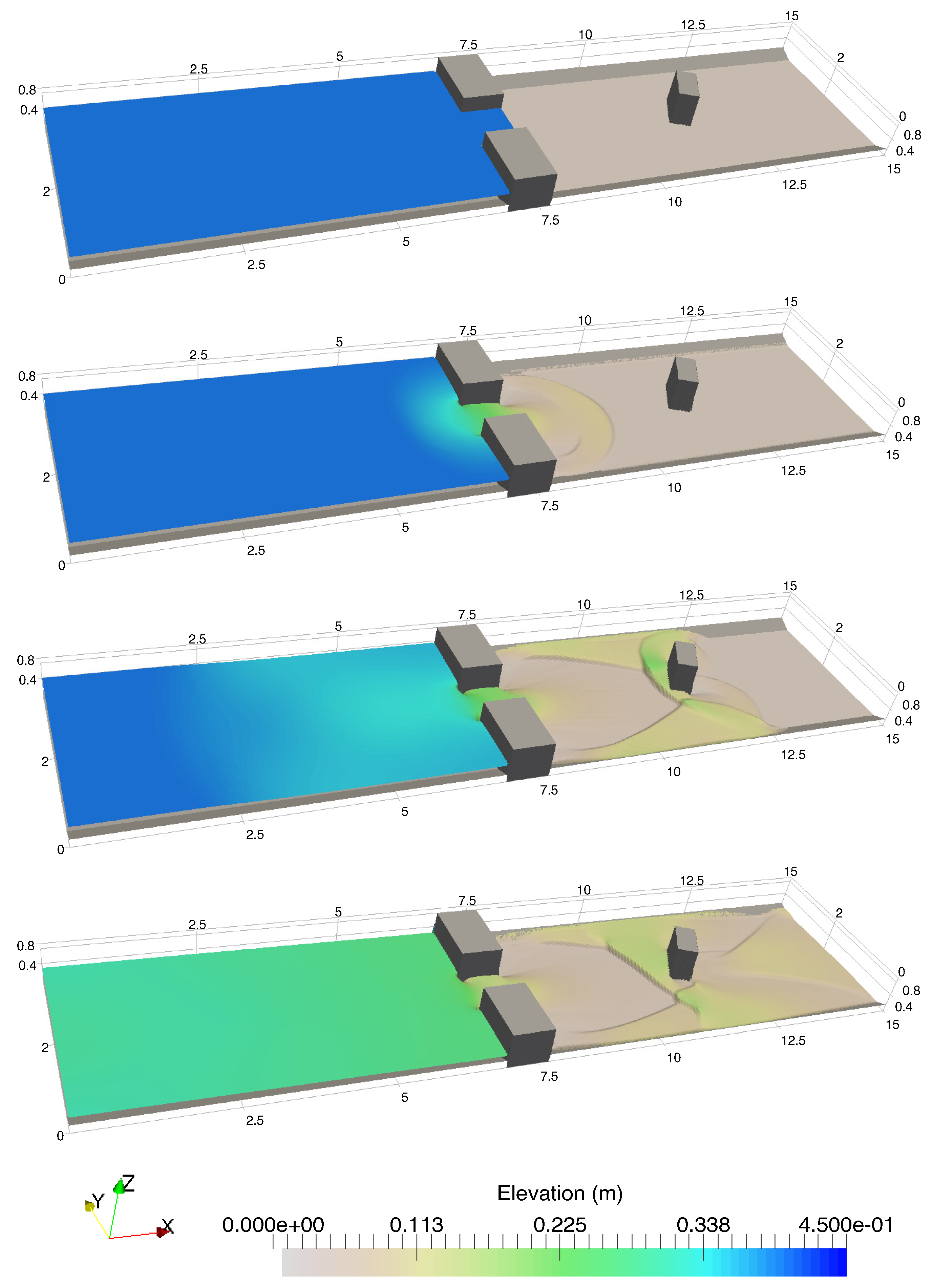
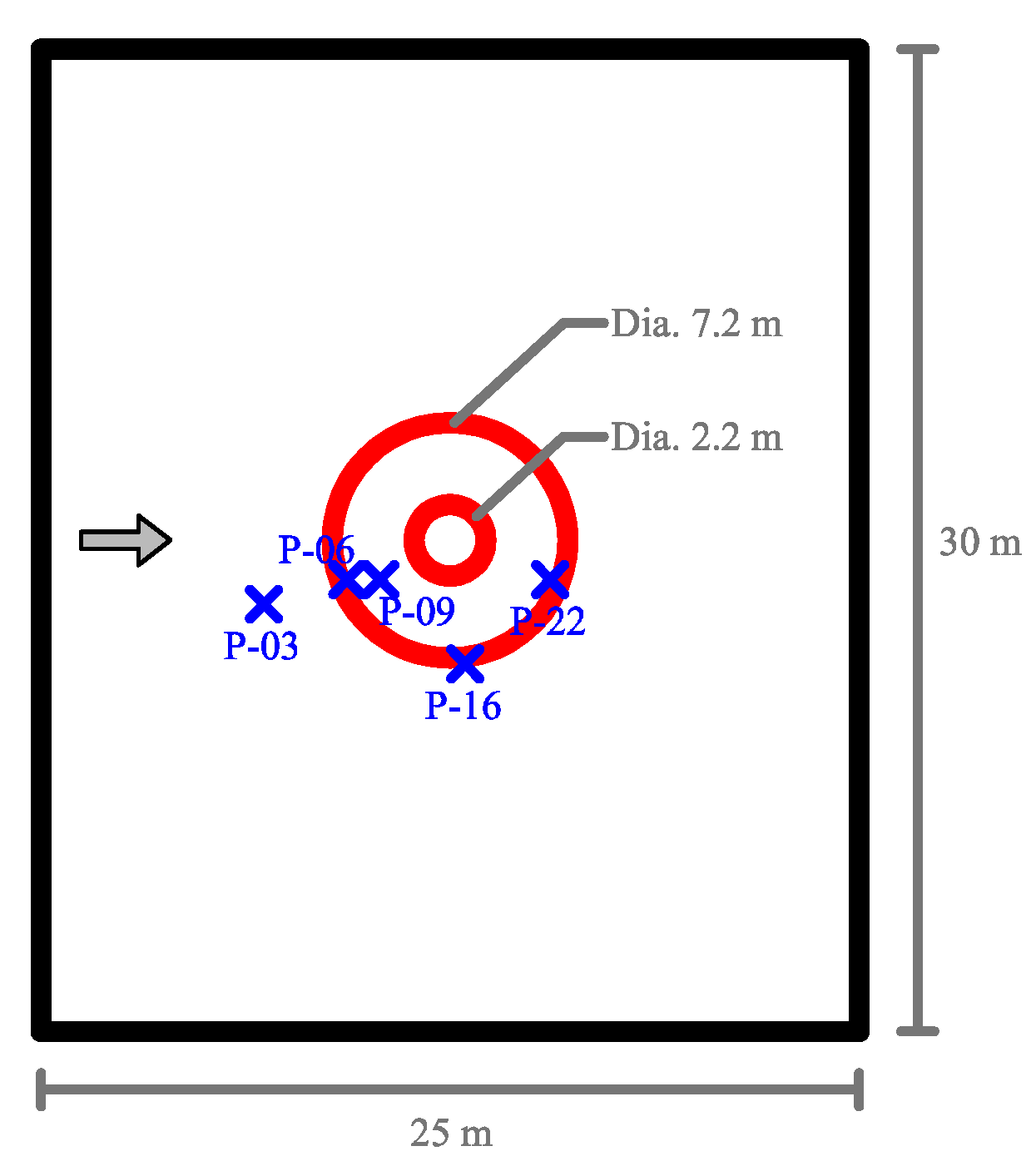
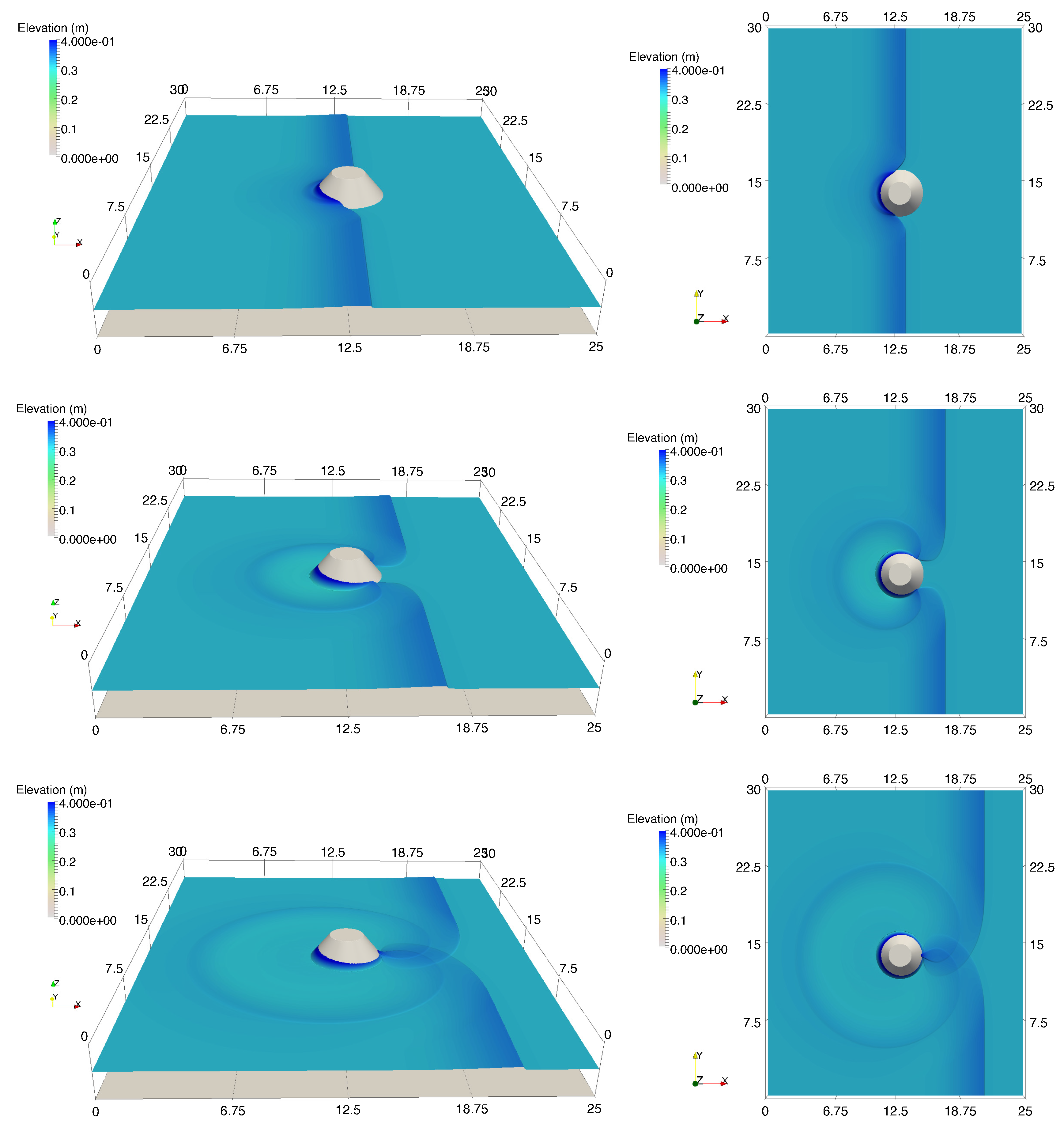
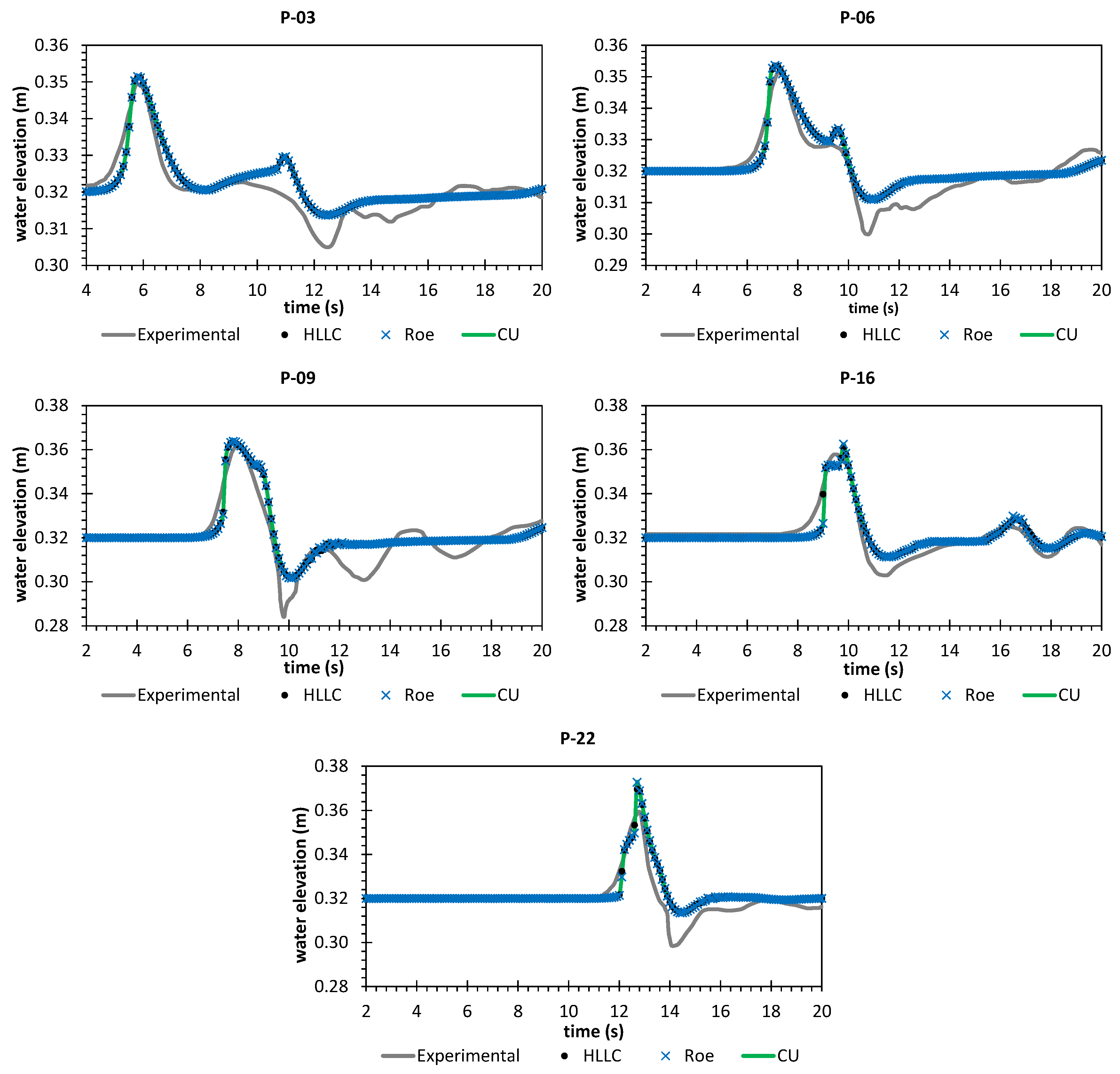
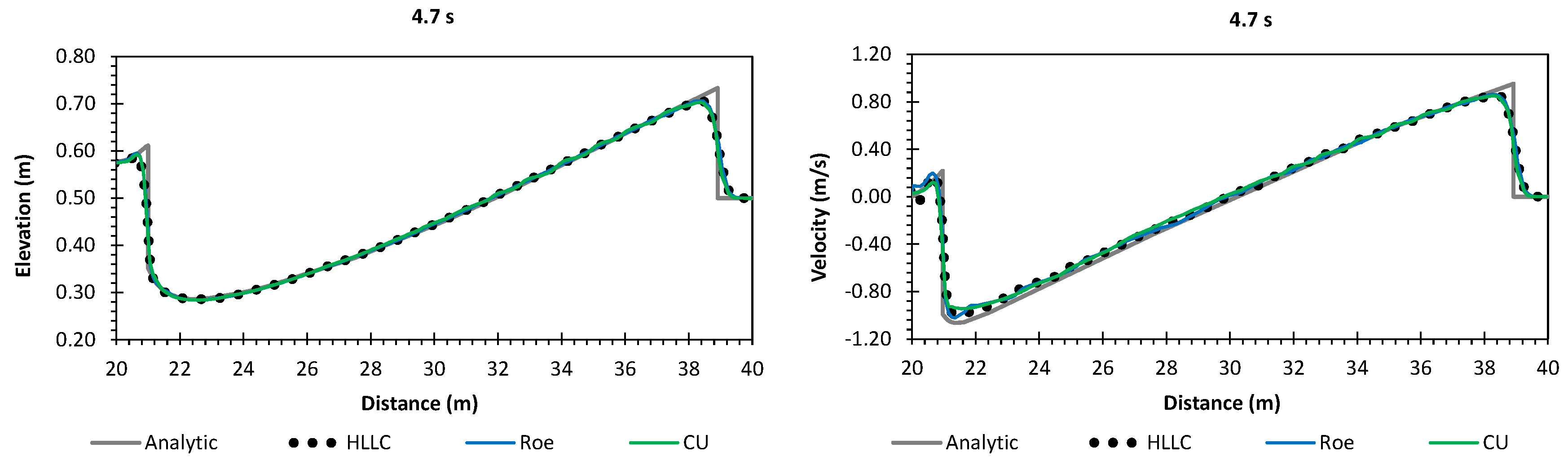
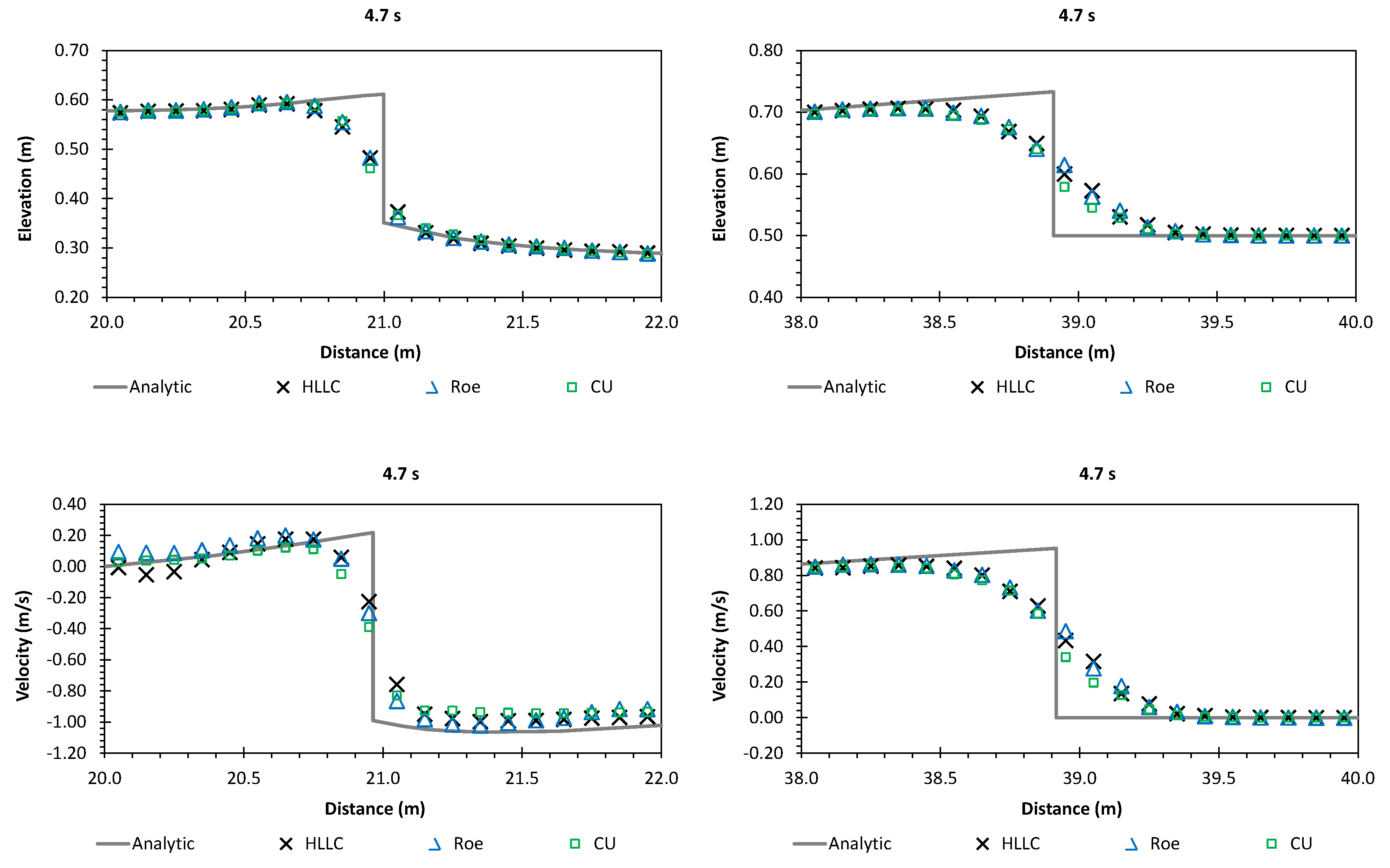
Secondly, we have shown that for the four cases simulated, strong agreements by all schemes were obtained between the numerical results and observed data, where no significant differences were shown for the accuracy. However, in the term of efficiency, the CU scheme was able to outperform the HLLC and Roe schemes with average factors of 1.4× and 1.25×, respectively. Although the vectorization was successful to significantly gain the performance of all solvers, the CU scheme still became the most efficient one among the others. According to this fact, we could conclude that the CU solver as a Riemann-solver-free scheme would in general be able to outperform the Riemann solvers (HLLC and Roe schemes) even for simulations on the next generation of modern hardware. This is because the computational procedures of the CU scheme are acceptably simple especially containing no complex branch statements () such as required by the HLLC and Roe schemes.
Since simulating shallow water flows—especially complex phenomena that require performing long real-time computations as part of disaster planning such as dam-break or tsunami cases—on modern hardware nowadays and even in the future becomes more and more common, focusing simulations only on numerical accuracy but ignoring the performance efficiency is not an option anymore. Wasting the performance is obviously undesirable due to wasting too much time for such long real-time simulations. Modern hardware offers many features for gaining efficiency, one of which is vectorization that can be regarded as the “easiest” way for benefiting from the vector-level parallelism, is thus non-trivial. However, this is not obtained for free; one should at least understand and support—due to the sophisticated memory access patterns—the vectorization concept. The cell-edge reordering strategy employed here is one of the easiest strategies to utilize the vectorization feature of modern hardware that could easily be applied to any CCFV scheme for shallow flow simulations, together with guided vectorization instead of explicitly by low-level vectorization, which might be error-prone and time-consuming. It is worth pointing out that this strategy is also applicable to any compiler with vectorization support, e.g., Gfortran. We observed that the performance obtained with Intel compiler was typically 2–3× higher than that obtained with Gfortran, which we believe is due to the correspondence of Intel compiler and Intel hardware.
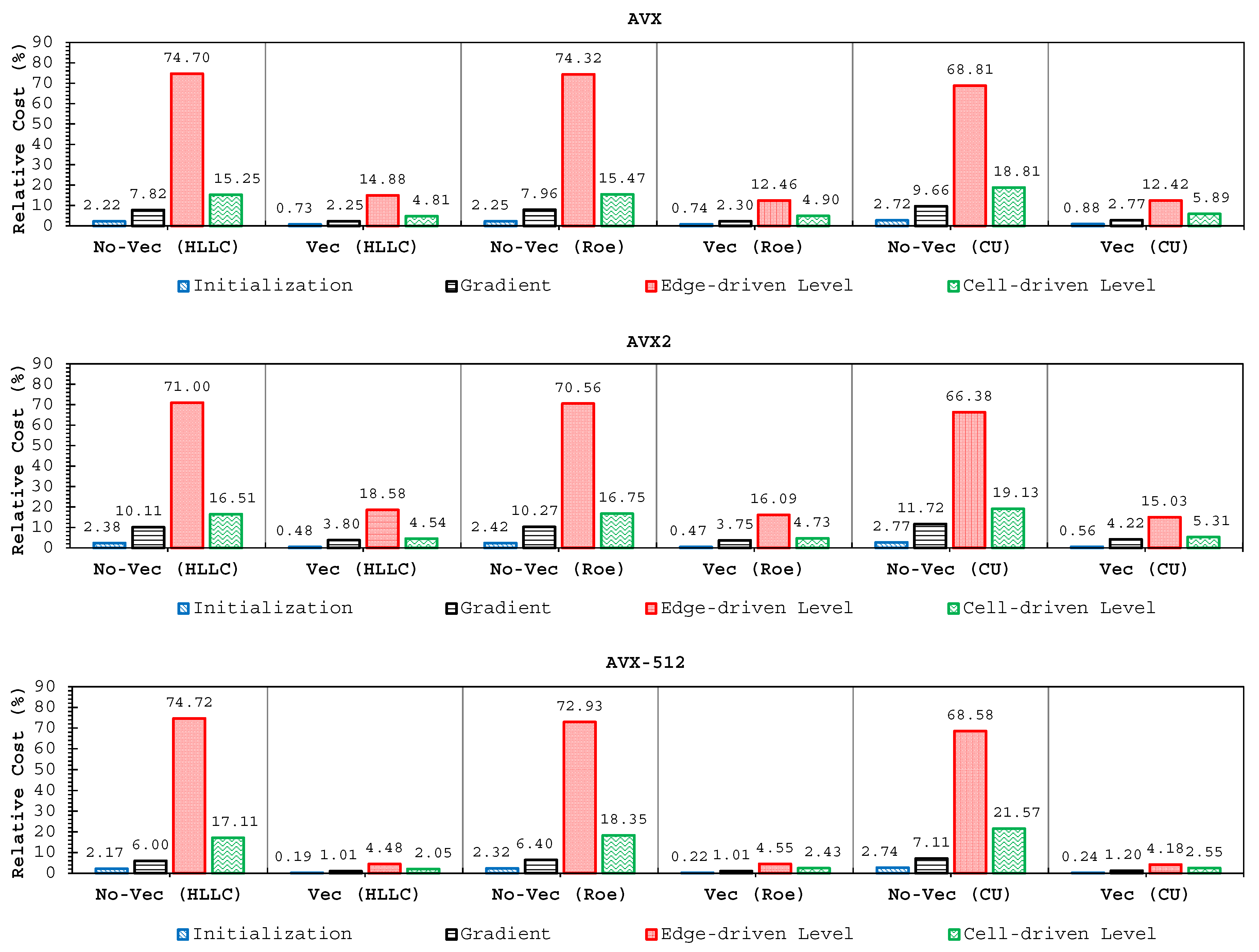
We have also shown that the edge-driven level, especially the reconstruction technique and solver computations, were the most time-consuming part, which required 65–75% of the entire simulation time. This shows that some more “aggressive” optimization techniques still become a hot topic for future studies to make shallow water simulations more efficient, particularly in the edge-driven level. Finally, we conclude that this study would be useful as a consideration for modelers who are interested in developing shallow water codes.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}