Probabilistic Hydrological Post-Processing at Scale: Why and How to Apply Machine-Learning Quantile Regression Algorithms

 , , ,
, , ,  , ,
, ,  , and
, and 
Abstract
1. Introduction
- Explore, through benchmark tests, the modelling possibilities provided by the integration of process-based models and machine-learning quantile regression algorithms for probabilistic hydrological modelling. This exploration encompasses the:
- ✓
- comparative assessment of a representative sample set of machine-learning quantile regression algorithms in two-stage probabilistic hydrological post-processing with emphasis on delivering probabilistic predictions “at scale” (an important aspect within operational settings);
- ✓
- identification of the properties of these algorithms, as well as the properties of the broader algorithmic approaches, by investigating their performance in delivering predictive quantiles and central prediction intervals of various levels; and
- ✓
- exploration of the performance of these algorithms for different flow magnitudes, i.e., in conditions characterized by different levels (i.e., magnitudes) of predictability.
- Formulate practical recommendations and technical advice on the implementation of the algorithms for solving the problem of interest (and other problems of technical nature). An important remark to be made is that these recommendations are not meant in any case to be limited to selecting a single algorithm for all tasks and under all conditions. Each algorithm has its strengths and limitations, which have to be identified so that it finds its place within a broader framework (provided that the algorithm is a good fit for solving the problem of interest). This point of view is in accordance with the ‘‘no free lunch theorem’’ by Wolpert [78].
- Justify and interpret key aspects of the developed methodological framework and its high appropriateness for progressing our understanding on how machine-learning quantile regression algorithms should be used to maximize benefits and minimize risks from their implementation.
2. Background on Methodologies, Models and Algorithms
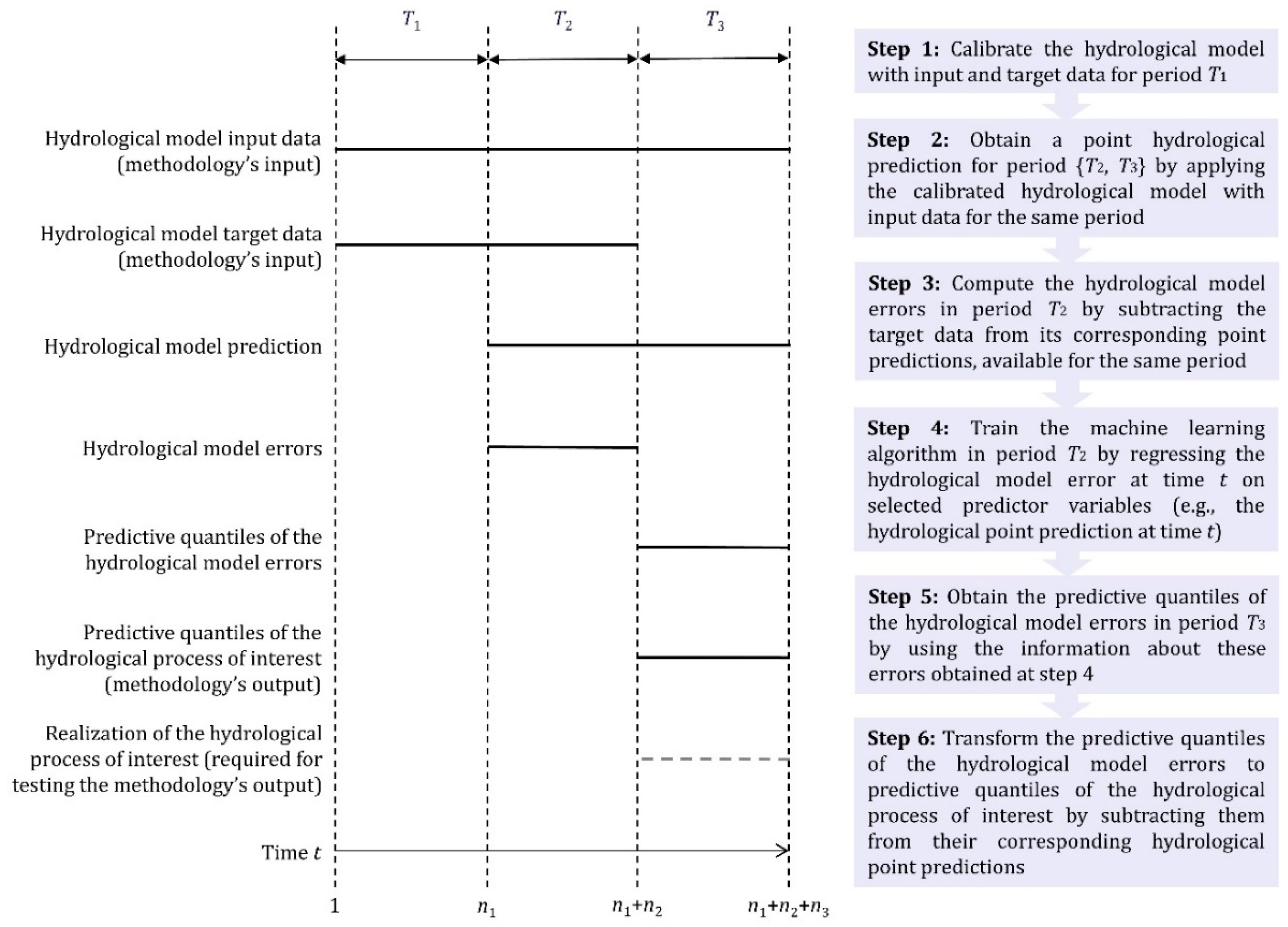
2.1. Multi-Stage Probabilistic Hydrological Post-Processing
2.2. Implemented Hydrological Model
2.3. Assessed Machine-Learning Quantile Regression Algorithms
2.3.1. Theoretical Background and List of Algorithms
2.3.2. Quantile Regression
2.3.3. Quantile Regression Forests and Generalized Random Forests
2.3.4. Gradient Boosting Machine and Model-Based Boosting
2.3.5. Quantile Regression Neural Networks
3. Experimental Data and Methodology
3.1. Rainfall-Runoff Data and Time Periods
3.2. Application of the Hydrological Model
- Data from period T0 are used to warm up the hydrological model.
- Data from period T1 are used to calibrate the hydrological model. For the calibration, we implement the optimization algorithm by Michel [112] for maximizing the Nash–Sutcliffe efficiency criterion [113]. The latter is a well-established criterion for hydrological model calibration. While possible, the implementation of other optimization algorithms and objective functions is out of the scope of the study.
- The calibrated hydrological model is used with daily precipitation and potential evapotranspiration data from period {T2, T3} to predict daily streamflow for the same period.
3.3. Solved Regression Problem and Assessed Configurations
3.4. Performance Assessment
- The goal of probabilistic modelling is to maximize sharpness subject to reliability.
- Reliability refers to the statistical consistency between the probabilistic predictions and the observations.
- Sharpness refers to the narrowness of the prediction intervals.
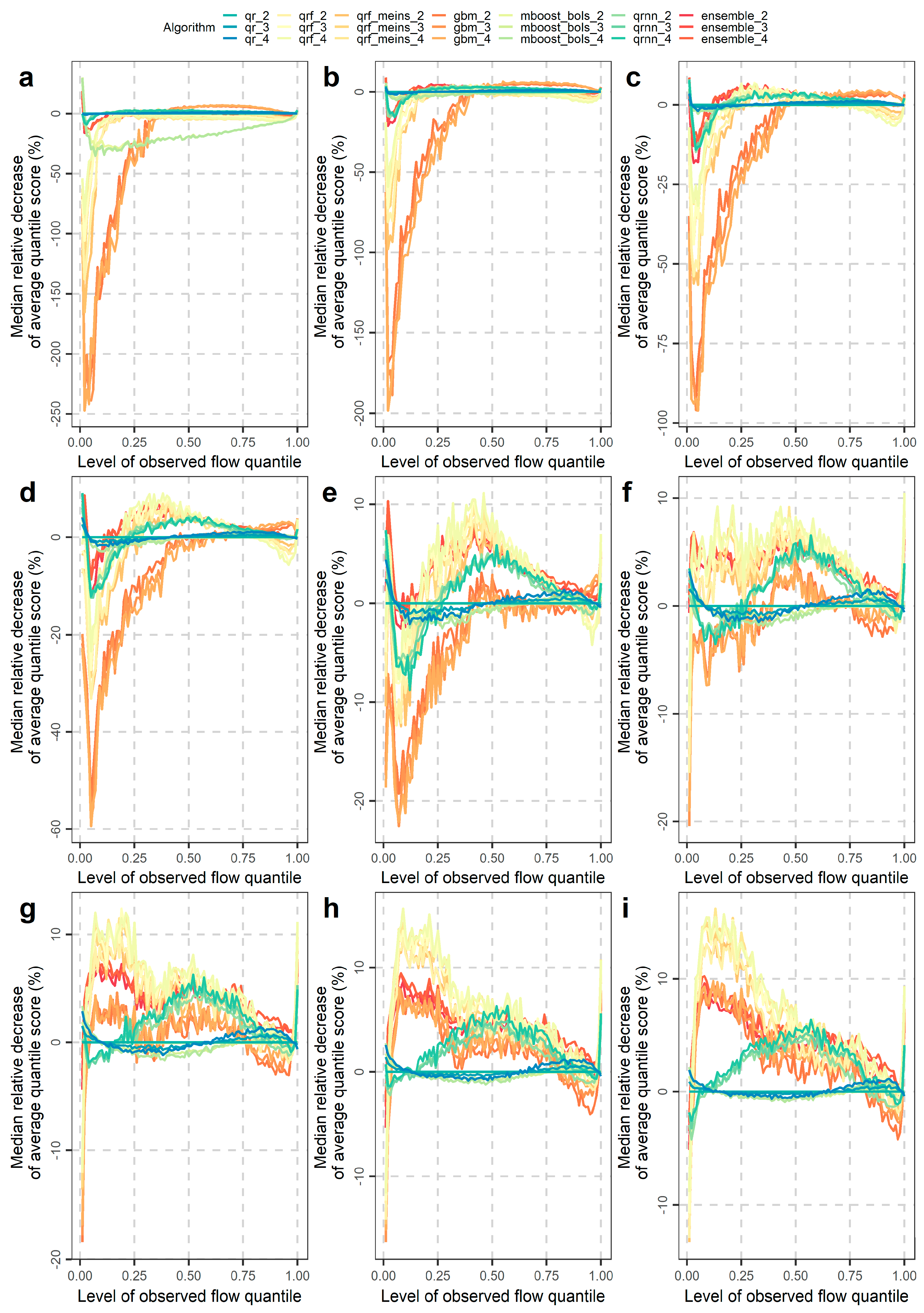
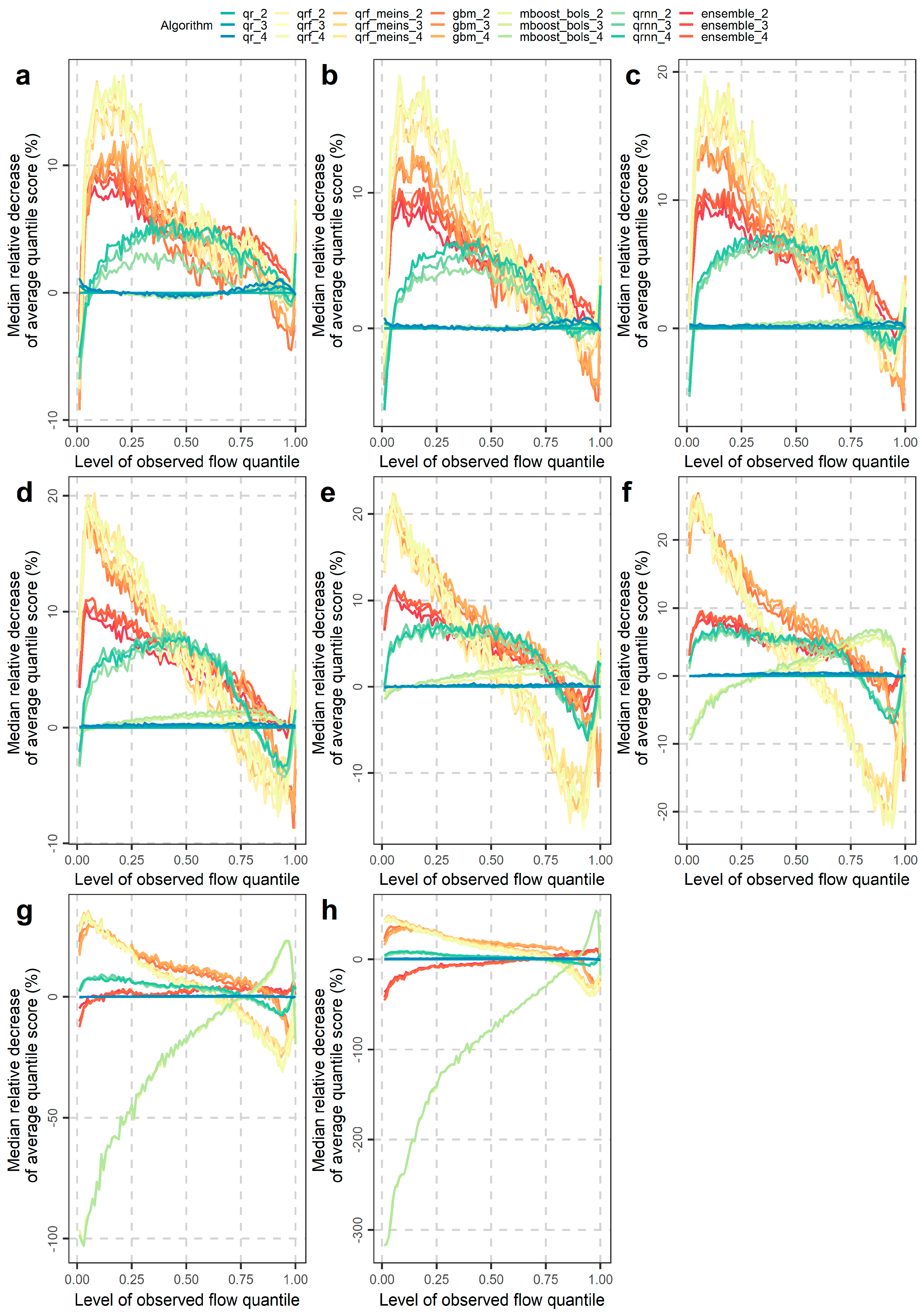
4. Experimental Results and Interpretations
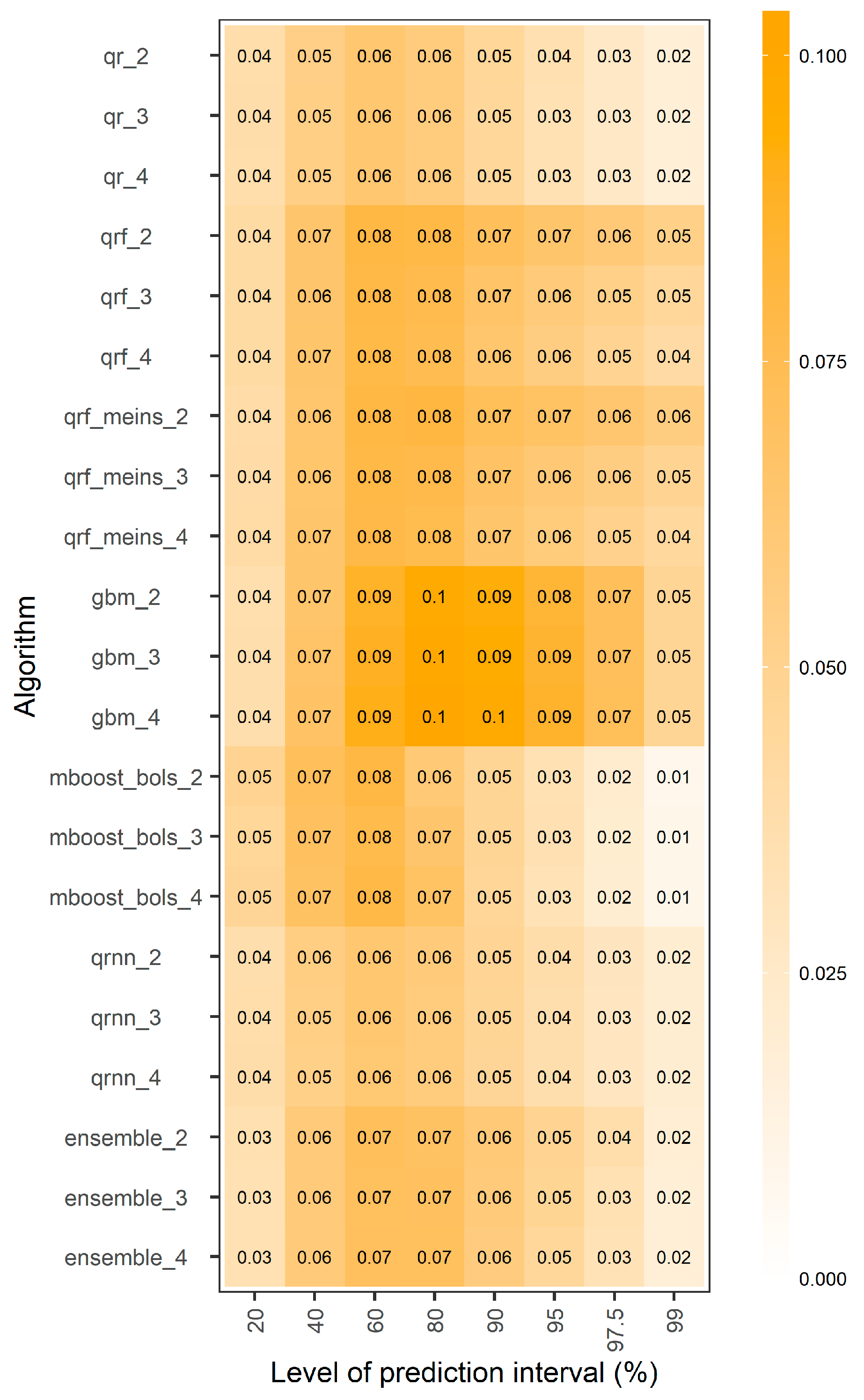
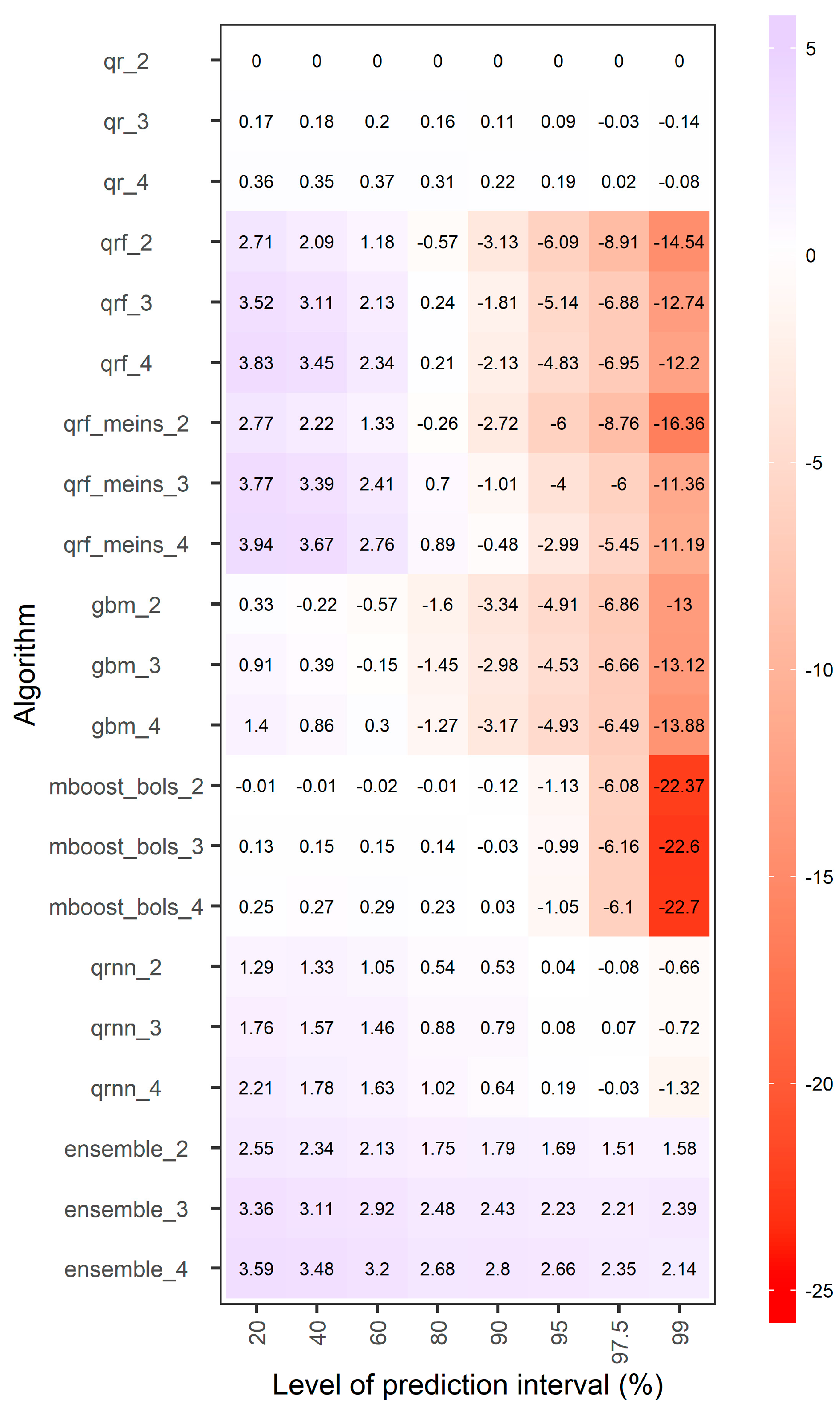
4.1. Overall Assessment of the Machine-Learning Aalgorithms
- More predictor variables result in mostly improved performance for the tree-based methods (qrf, qrf_meins, gbm) and the equal-weight combiner of all algorithms, and slightly less pronounced improvements for qrnn.
- The performance of qr and mboost_bols is found to not be significantly affected by the number of predictor variables.
- The overall best performing algorithm is the equal-weight combiner of all algorithms, offering up to approximately 3.5% decrease in terms of both average interval and quantile scores with respect to qr_2.
- For all prediction intervals, qr performs mostly better than mboost_bols, while it is also better than gbm for the 60%, 80%, 90%, 95%, 97.5% and 99% prediction intervals. Only for the predictive quantiles of levels 0.4, 0.5, 0.6, 0.7 and 0.8, gbm performs better than qr. Still, gbm is not the best-performing algorithm either for these quantiles.
- For the 90%, 95%, 97.5% and 99% prediction intervals, qr performs better than most of the remaining algorithms, while the equal-weight combiner is the best. The latter offers decreases from approximately 1.5% to approximately 2.5% with respect to the former in terms of average interval score, and up to approximately 3.5% decrease in terms of average quantile score. The equal-weight combiner is worse than qr only for the two lower levels of predictive quantiles tested herein.
- For the 90%, 95%, 97.5% and 99% prediction intervals, the tree-based methods are performing poorly, probably because they cannot extrapolate beyond the observed values of the training set.
- For the predictive quantiles of levels 0.3, 0.4, 0.5, 0.6, 0.7 and 0.8, and the 20%, 40% and 60% prediction intervals, qrf and qrf_meins are comparable with (or even better performing than) the equal-weight combiner of all algorithms.
- For all tested levels of predictive quantiles except for 0.005 and 0.0125, and the 20%, 40%, 60%, 80% and 90% prediction intervals, qrnn perform better than qr.
- Different patterns are observed regarding the performance of the algorithms in predicting the targeted quantiles.
- The performance of qrf and qrf_meins could be characterized as symmetric with respect to the predictive quantile of level 0.5, i.e., these machine-learning algorithms show comparably low skill in predicting the upper and lower quantiles that form a specific central prediction interval.
- The same observation does not apply to the remaining machine-learning algorithms. Specifically, gbm is less skilful in predicting the lowest quantiles than the highest ones, probably because of the technical settings of the study, i.e., because we predict the quantiles of the error of the hydrological model and later transform these quantiles to quantiles of daily streamflow.
- The same holds for qrnn and the equal-weight combiner, yet these latter algorithms are more skilful, while mboost_bols is less effective in predicting quantiles of the highest levels.
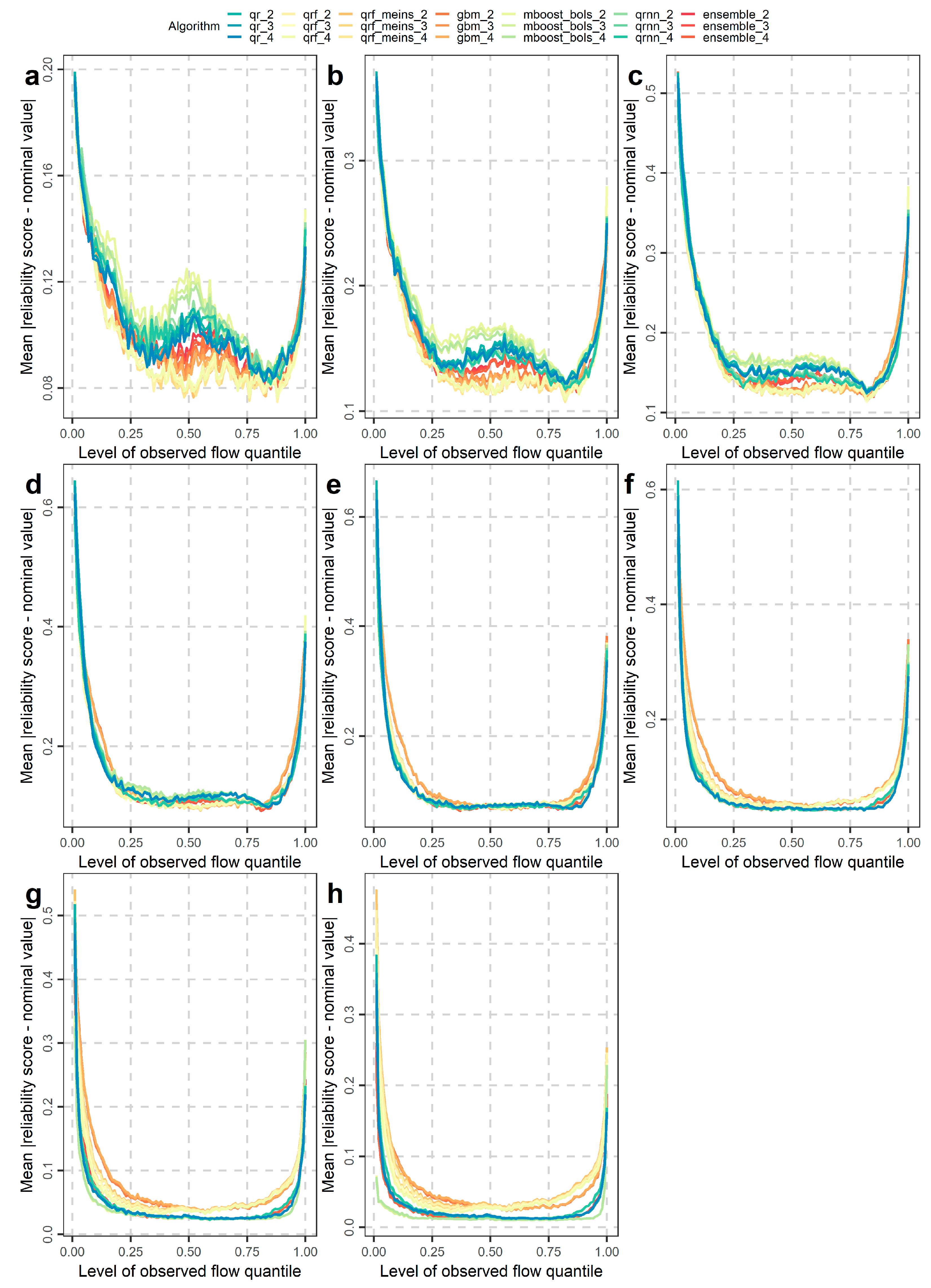
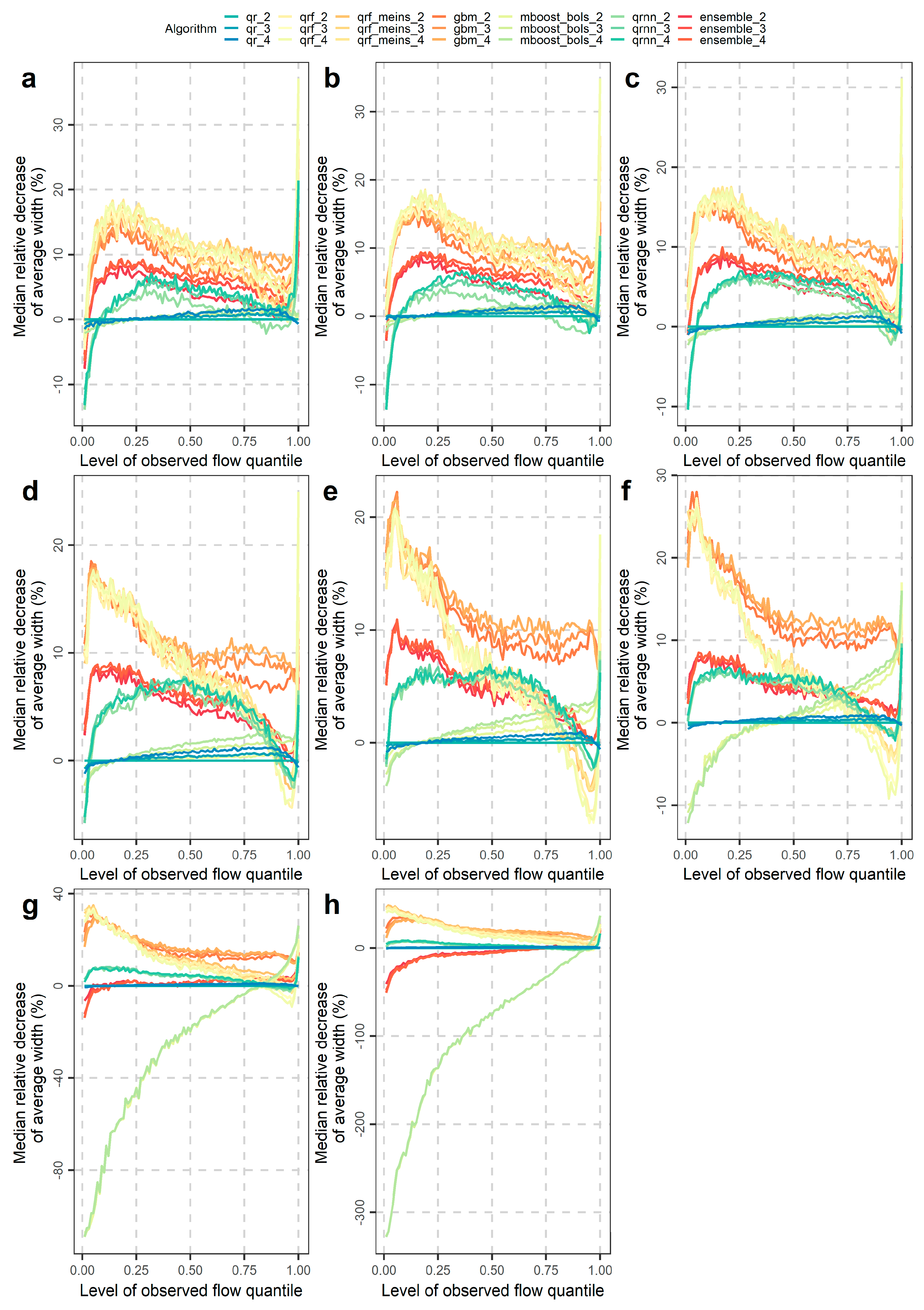
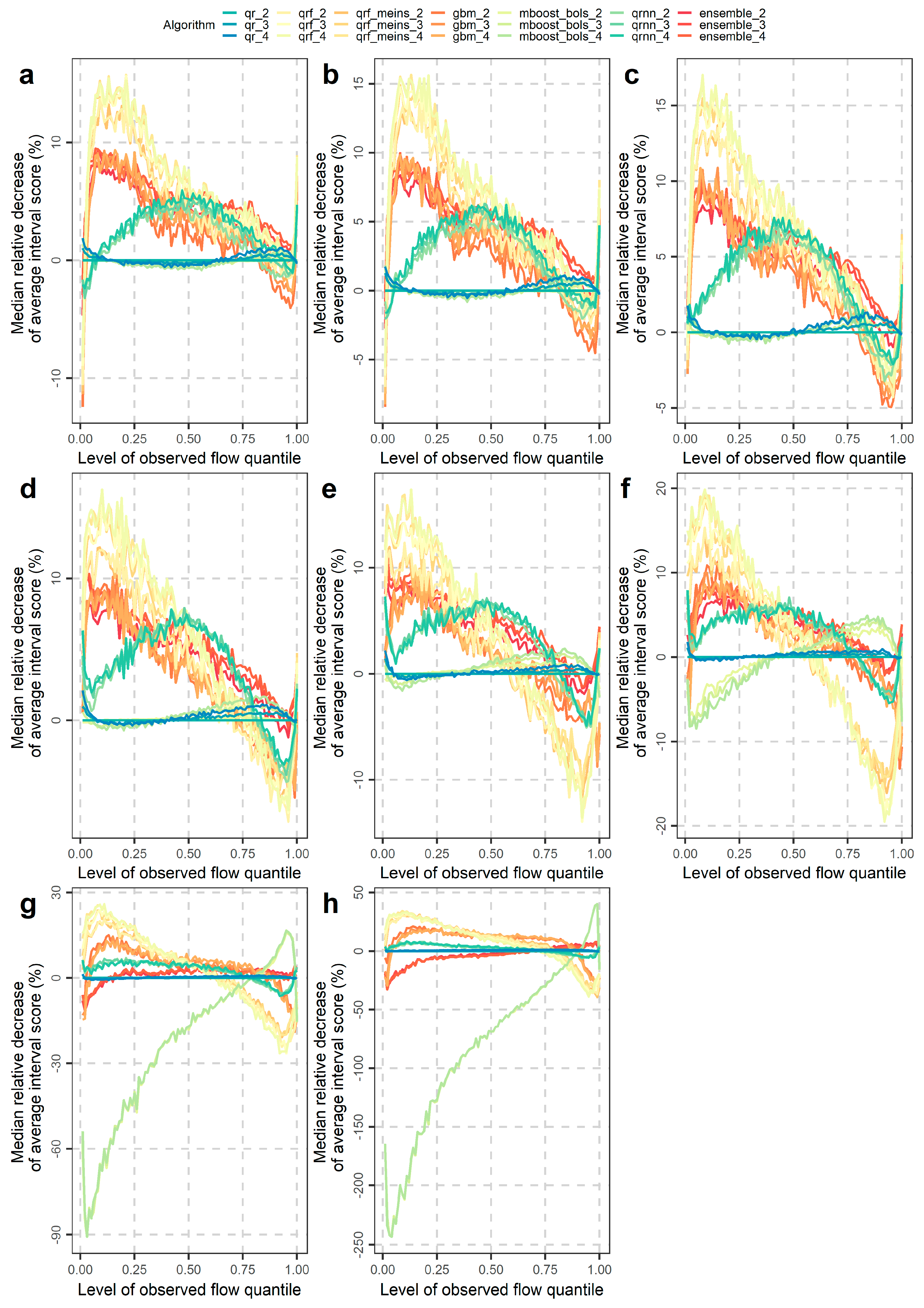
4.2. Investigations for Different Flow Magnitudes
5. Literature-Driven and Evidence-Based Discussions
5.1. Innovations and Highlights in Light of the Literature
- It includes the largest range of methods ever compared in such concepts and a detailed quantitative assessment, using proper scores, and performing investigations for various prediction intervals and flow magnitudes.
- Three of the assessed machine-learning quantile regression algorithms, specifically generalized regression forests, gradient boosting machine and gradient boosting with linear models as base learners, are implemented for the first time to solve the practical problem of interest.
- It deviates from the mainstream culture of “model overselling” [53] or proving that “my model is better than yours” to “justify model development” [121], since it does not aim at promoting the use of any single algorithm. Instead, it formulates practical recommendations, which highlight the need for making the most of all the assessed algorithms (see the related comments in Sivakumar [121]).
- It is one of the very few studies that aim at attracting attention to ensemble learning post-processing methodologies in probabilistic hydrological modelling and hydro-meteorological forecasting.
5.2. Key Perspectives, Technical Considerations and Suggested Mind-Shifts
5.2.1. Contributions and Challenges from an Uncertainty Reduction Perspective
5.2.2. A Culture-Integrating Approach to Probabilistic Hydrological Modelling
5.2.3. Value of Ensemble Learning Hydrological Post-Processing Methodologies
5.2.4. Grounds and Implications of the Proposed Methodological Framework
- identifying the advantages and limitations of more statistical post-processing approaches, utilizing other machine-learning quantile regression algorithms and ensemble learning approaches (implemented with various sets of predictor variables) and/or other hydrological models, provided that these approaches are computationally fast and can be applied in a fully automatic way;
- solving related technical problems at different timescales (e.g., the monthly or seasonal timescales); and
- assessing statistical post-processing approaches in forecasting mode, i.e., by running the hydrological model using forecasts as inputs (instead of using observations).
6. Summary and Take-Home Messages
- Preliminary large-sample investigations should focus on identifying a useful set of statistical post-processing models, such as the one composed by the six machine-learning quantile regression algorithms of this study.
- Machine-learning quantile regression algorithms can effectively serve as statistical post-processing models, since they model heteroscedasticity by perception and construction without requiring multiple fittings, i.e., a different fitting for each season, as applying for the case of conditional distribution models.
- These algorithms are also straightforward-to-apply, fully automatic (i.e., their implementation does not require human intervention), available in open source, and computationally convenient and fast, and thus are highly appropriate for large-sample hydrological studies, while machine-learning methods, in general, are known to be ideal for exploiting computers’ brute force.
- Once a useful set of statistical post-processing models is identified, making the most of it, through model integrations and combinations, should be our target.
- Quantifying both the algorithms’ overall performance (independently of the flow magnitude) and the algorithms’ performance conditional upon the flow magnitude is of practical interest.
- Useful results are mostly those presented per level of prediction interval or predictive quantile, while those summarizing the quality of the entire predictive density (e.g., the continuous ranked probability score—CRPS) might also be of interest.
- Although the separate quantification of reliability and sharpness could be useful (mainly for increasing our understanding on how the algorithms work), what is most useful is computing scores that facilitate an objective co-assessment of these two criteria, such as the (rarely used in the literature) interval and quantile scores.
- The computational requirements might also be an important criterion for selecting an algorithm over others.
- In most cases, finding a balance between computational time and predictive performance is required. In any case, the criteria for selecting a statistical post-processing model should be clear.
- If we are foremost interested in obtaining results fast, then we probably should select quantile regression. This selection should be made keeping in mind that this algorithm is up to approximately 3.5% worse in terms of average quantile score than using the equal-weight combiner of all six algorithms of this study.
- The equal-weight combiner of all six algorithms in this study is identified as the best-performing algorithm overall, confirming the value of ensemble learning in general and ensemble learning via simple quantile averaging in particular. This value is well-recognized in the forecasting literature, but has not received much attention yet in the hydrological modelling and hydro-meteorological forecasting literature, in contrast to the popular concepts of ensemble simulation and ensemble prediction (e.g., via Bayesian model averaging) by exploiting information from multiple hydrological models.
- In spite of its outstanding performance, the equal-weight combiner of the six algorithms of this study is, in turn, expected to perform worse than some of the individual algorithms in many modelling situations.
- In general, no algorithm should be expected to be (or presented as) the best performing with respect to every single criterion.
- By using different algorithms for delivering each predictive quantile (or prediction interval), the risk of producing a probabilistic prediction of bad quality is reduced. Related information on the predictive performance of the algorithms was extensively given in Section 4.1, while a summary is given below:
- ✓
- The equal-weight combiner is the best choice or among the best choices in terms of predictive performance for delivering predictive quantiles of level that is higher than 0.0125; however, it is also the most computationally demanding choice.
- ✓
- Quantile regression is the best choice in terms of predictive performance for predicting low-level quantiles (practically predictive quantiles of level lower than 0.0125) and the third-best choice for predicting high-level quantiles (practically predictive quantiles of level higher than 0.9).
- ✓
- Generalized random forests for quantile regression and generalized random forests for quantile regression emulating quantile regression forests are identified as the best choices or among the best choices in terms of predictive performance, when one is interested in delivering predictive quantiles of levels between 0.2 and 0.8. Since they are less computationally intensive than the equal-weight combiner, they would probably be preferred over the latter for relevant modelling applications.
- ✓
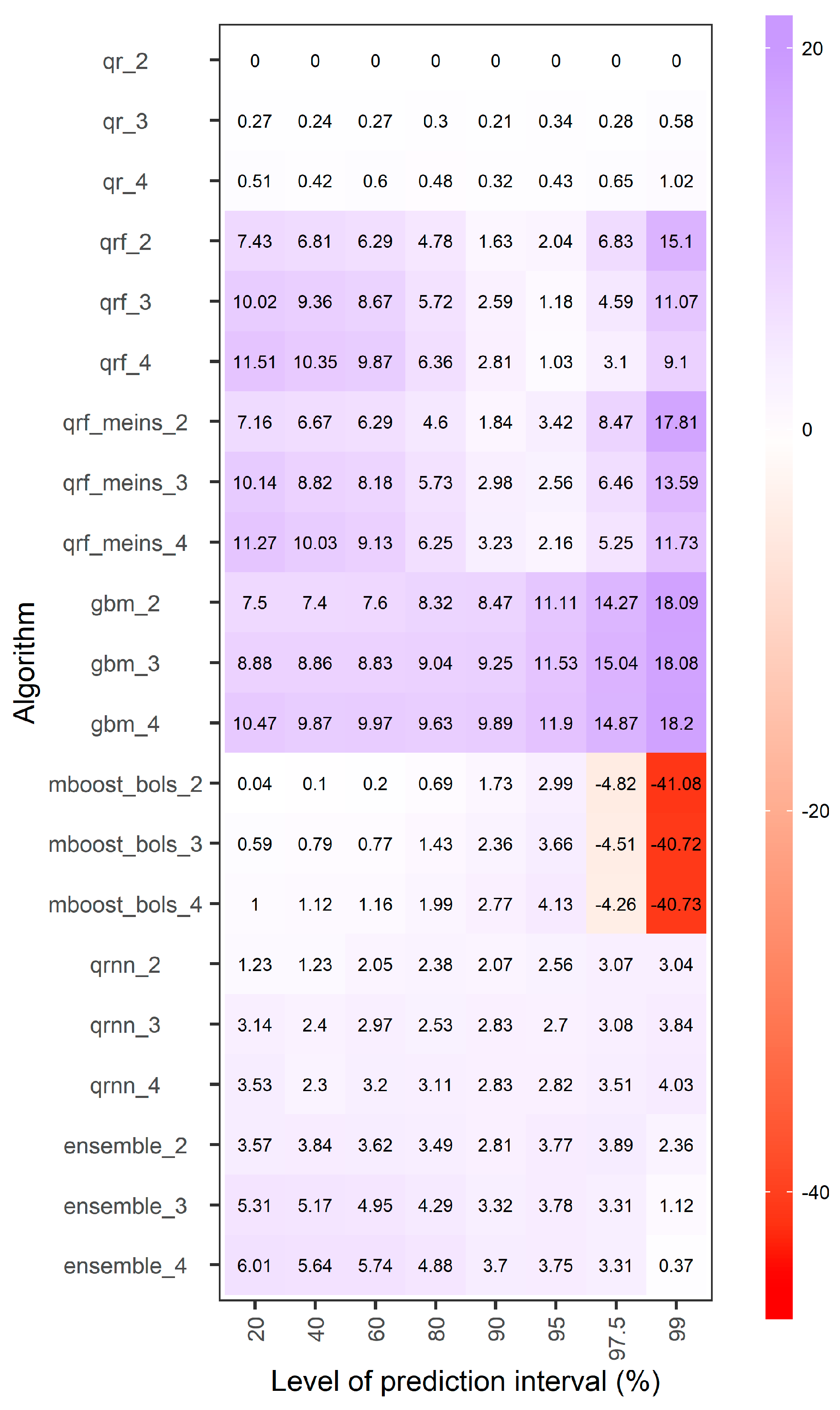
- Improvements up to approximately 1.5% may be achieved for the generalized random forests for quantile regression and the generalized random forests for quantile regression emulating quantile regression forests by using as predictor variables of the regression the hydrological model predictions at times t − 3, t − 2, t − 1 and t instead of using the hydrological model predictions only at times t − 1 and t. By switching from the former set of predictors to the latter one, the improvements for the equal-weight combiner may reach an improvement of approximately 1%.
- ✓
- Quantile regression neural networks is also a well-performing algorithm with respect to the whole picture and less computationally demanding than the equal-weight combiner; nevertheless, it is also the only individual algorithm among the assessed ones that was found to produce significant outliers (for ~2% of the investigated catchments). These performance issues were also manifested in the equal-weight combiner, yet in a less-pronounced degree.
- The overall performance improvements expressed in terms of average interval or quantile score are mostly up to 3%, while only for some extreme cases these improvements may reach up to approximately 20%. These cases concern some predictive quantiles of the lowest and highest levels, for which the tree-based methods, i.e., generalized random forests for quantile regression, generalized random forests for quantile regression emulating quantile regression forests and gradient boosting machine, do not work at their best.
- Unrealistic improvements in the order of 50% and 60%, even up to more than 100%, in terms of overall performance (often appearing in the literature) may result either by chance or by design when using small datasets, while they are highly unlikely to result on a regular basis when using large datasets. Only large-sample studies can produce trustable quantitative results in predictive modelling.
- Conducting large-sample studies is feasible nowadays, due to both the tremendous evolution of personal computers over the past few years and the fact that large datasets (e.g., the CAMELS dataset) are increasingly made available.
- Performance improvements may also be obtained by selecting algorithms according to their skill in predicting low, medium or high flows for the various quantiles (or central prediction intervals). Related information was extensively given in Section 4.2.
- Since we are mostly interested in obtaining results that are useful within operational settings, we have not performed hyperparameter optimization (which would require significantly higher computational time). The results could differ, if such optimization was performed.
- An alternative to hyperparameter optimization is ensemble learning, in the sense that both these procedures aim at improving probabilistic predictions. Here, we have extensively studied this alternative and showed that the improvements achieved are worth-of-attention.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machine-Learning Algorithm | Training R Function | Implementation Notes | R Package |
|---|---|---|---|
| Quantile regression | rq | - | quantreg |
| Generalized random forests for quantile regression | quantile_forest | - | grf |
| Generalized random forests for quantile regression emulating quantile regression forests | quantile_forest | (regression.splitting = TRUE) | grf |
| Gradient boosting machine with trees as base learners | gbm | (distribution = list(name = "quantile", alpha = 0.005), weights = NULL, n.trees = 2000, keep.data = FALSE) | gbm |
| Model-based boosting with linear models as base learners | mboost | (family = QuantReg(tau = τ, qoffset = τ), baselearner = "bols", control = boost_control(mstop = 2000, risk = "inbag")) | mboost |
| Quantile regression neural networks | qrnn.fit | (n.hidden = 1, n.trials = 1) | qrnn |
| Machine-Learning Algorithm | Predicting R Function | R Package |
|---|---|---|
| Quantile regression | predict | quantreg |
| Generalized random forests for quantile regression | predict | quantreg |
| Generalized random forests for quantile regression emulating quantile regression forests | predict | grf |
| Gradient boosting machine with trees as base learners | predict.gbm | gbm |
| Model-based boosting with linear models as base learners | predict | mboost |
| Quantile regression neural networks | qrnn.predict | qrnn |
References
- Taylor, S.J.; Letham, B. Forecasting at scale. Am. Stat. 2018, 72, 37–45. [Google Scholar] [CrossRef]
- Krzysztofowicz, R. Bayesian theory of probabilistic forecasting via deterministic hydrologic model. Water Resour. Res. 1999, 35, 2739–2750. [Google Scholar] [CrossRef]
- Krzysztofowicz, R. The case for probabilistic forecasting in hydrology. J. Hydrol. 2001, 249, 2–9. [Google Scholar] [CrossRef]
- Todini, E. Hydrological catchment modelling: Past, present and future. Hydrol. Earth Syst. Sci. 2007, 11, 468–482. [Google Scholar] [CrossRef]
- Koutsoyiannis, D. HESS Opinions ‘‘A random walk on water’’. Hydrol. Earth Syst. Sci. 2010, 14, 585–601. [Google Scholar] [CrossRef]
- Montanari, A.; Koutsoyiannis, D. A blueprint for process-based modeling of uncertain hydrological systems. Water Resour. Res. 2012, 48, W09555. [Google Scholar] [CrossRef]
- Todini, E. A model conditional processor to assess predictive uncertainty in flood forecasting. Int. J. River Basin Manag. 2008, 6, 123–137. [Google Scholar] [CrossRef]
- Todini, E. Role and treatment of uncertainty in real-time flood forecasting. Hydrol. Process. 2004, 18, 2743–2746. [Google Scholar] [CrossRef]
- Montanari, A. Uncertainty of hydrological predictions. In Treatise on Water Science 2; Wilderer, P.A., Ed.; Elsevier: Amsterdam, The Netherlands, 2011; pp. 459–478. [Google Scholar] [CrossRef]
- Montanari, A. What do we mean by ‘uncertainty’? The need for a consistent wording about uncertainty assessment in hydrology. Hydrol. Process. 2007, 21, 841–845. [Google Scholar] [CrossRef]
- Sivakumar, B. Undermining the science or undermining Nature? Hydrol. Process. 2008, 22, 893–897. [Google Scholar] [CrossRef]
- Ramos, M.H.; Mathevet, T.; Thielen, J.; Pappenberger, F. Communicating uncertainty in hydro-meteorological forecasts: Mission impossible? Meteorol. Appl. 2010, 17, 223–235. [Google Scholar] [CrossRef]
- Ramos, M.H.; Van Andel, S.J.; Pappenberger, F. Do probabilistic forecasts lead to better decisions? Hydrol. Earth Syst. Sci. 2013, 17, 2219–2232. [Google Scholar] [CrossRef]
- Shmueli, G. To explain or to predict? Stat. Sci. 2010, 25, 289–310. [Google Scholar] [CrossRef]
- Perrin, C.; Michel, C.; Andréassian, V. Does a large number of parameters enhance model performance? Comparative assessment of common catchment model structures on 429 catchments. J. Hydrol. 2001, 242, 275–301. [Google Scholar] [CrossRef]
- Perrin, C.; Michel, C.; Andréassian, V. Improvement of a parsimonious model for streamflow simulation. J. Hydrol. 2003, 279, 275–289. [Google Scholar] [CrossRef]
- Mouelhi, S.; Michel, C.; Perrin, C.; Andréassian, V. Stepwise development of a two-parameter monthly water balance model. J. Hydrol. 2006, 318, 200–214. [Google Scholar] [CrossRef]
- Beven, K.J.; Kirkby, M.J. A physically based, variable contributing area model of basin hydrology. Hydrol. Sci. Bull. 1979, 24, 43–69. [Google Scholar] [CrossRef]
- Todini, E. The ARNO rainfall—runoff model. J. Hydrol. 1996, 175, 339–382. [Google Scholar] [CrossRef]
- Jayawardena, A.W.; Zhou, M.C. A modified spatial soil moisture storage capacity distribution curve for the Xinanjiang model. J. Hydrol. 2000, 227, 93–113. [Google Scholar] [CrossRef]
- Fiseha, B.M.; Setegn, S.G.; Melesse, A.M.; Volpi, E.; Fiori, A. Hydrological analysis of the Upper Tiber River Basin, Central Italy: A watershed modelling approach. Hydrol. Process. 2013, 27, 2339–2351. [Google Scholar] [CrossRef]
- Kaleris, V.; Langousis, A. Comparison of two rainfall–runoff models: Effects of conceptualization on water budget components. Hydrol. Sci. J. 2017, 62, 729–748. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning, 2nd ed.; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning, 1st ed.; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Elsevier Inc.: Philadelphia, PA, USA, 2017. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Breiman, L. Statistical modeling: The two cultures (with comments and a rejoinder by the author). Stat. Sci. 2001, 16, 199–231. [Google Scholar] [CrossRef]
- Toth, E.; Montanari, A.; Brath, A. Real-time flood forecasting via combined use of conceptual and stochastic models. Phys. Chem. Earthpart B Hydrol. Ocean. Atmos. 1999, 24, 793–798. [Google Scholar] [CrossRef]
- Coron, L.; Thirel, G.; Delaigue, O.; Perrin, C.; Andréassian, V. The Suite of Lumped GR Hydrological Models in an R package. Environ. Model. Softw. 2017, 94, 166–171. [Google Scholar] [CrossRef]
- Coron, L.; Delaigue, O.; Thirel, G.; Perrin, C.; Michel, C. airGR: Suite of GR Hydrological Models for Precipitation-Runoff Modelling, R Package Version 1.3.2.23. 2019. Available online: https://CRAN.R-project.org/package=airGR (accessed on 15 September 2019).
- Jayawardena, A.W.; Fernando, D.A.K. Use of radial basis function type artificial neural networks for runoff simulation. Comput.-Aided Civ. Infrastruct. Eng. 1998, 13, 91–99. [Google Scholar] [CrossRef]
- Sivakumar, B.; Jayawardena, A.W.; Fernando, T.M.K.G. River flow forecasting: Use of phase-space reconstruction and artificial neural networks approaches. J. Hydrol. 2002, 265, 225–245. [Google Scholar] [CrossRef]
- Koutsoyiannis, D.; Yao, H.; Georgakakos, A. Medium-range flow prediction for the Nile: A comparison of stochastic and deterministic methods. Hydrol. Sci. J. 2008, 53, 142–164. [Google Scholar] [CrossRef]
- Sivakumar, B.; Berndtsson, R. Advances in Data-Based Approaches for Hydrologic Modeling and Forecasting; World Scientific Publishing Company: Singapore, 2010. [Google Scholar] [CrossRef]
- Papacharalampous, G.A.; Tyralis, H.; Koutsoyiannis, D. Univariate time series forecasting of temperature and precipitation with a focus on machine learning algorithms: A multiple-case study from Greece. Water Resour. Manag. 2018, 32, 5207–5239. [Google Scholar] [CrossRef]
- Quilty, J.; Adamowski, J.; Boucher, M.-A. A stochastic data-driven ensemble forecasting framework for water resources: A case study using ensemble members derived from a database of deterministic wavelet-based models. Water Resour. Res. 2019, 55, 175–202. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.A.; Tantanee, S. How to explain and predict the shape parameter of the generalized extreme value distribution of streamflow extremes using a big dataset. J. Hydrol. 2019, 574, 628–645. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.A.; Langousis, A. A brief review of random forests for water scientists and practitioners and their recent history in water resources. Water 2019, 11, 910. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.A. Variable selection in time series forecasting using random forests. Algorithms 2017, 10, 114. [Google Scholar] [CrossRef]
- Xu, L.; Chen, N.; Zhang, X.; Chen, Z. An evaluation of statistical, NMME and hybrid models for drought prediction in China. J. Hydrol. 2018, 566, 235–249. [Google Scholar] [CrossRef]
- Papacharalampous, G.A.; Tyralis, H.; Koutsoyiannis, D. Comparison of stochastic and machine learning methods for multi-step ahead forecasting of hydrological processes. Stoch. Environ. Res. Risk Assess. 2019, 33, 481–514. [Google Scholar] [CrossRef]
- Papacharalampous, G.A.; Tyralis, H.; Koutsoyiannis, D.; Montanari, A. Quantification of predictive uncertainty in hydrological modelling by harnessing the wisdom of the crowd: A large-sample experiment at monthly timescale. arXiv 2019, arXiv:1909.00247. [Google Scholar]
- Tyralis, H.; Papacharalampous, G.A.; Burnetas, A.; Langousis, A. Hydrological post-processing using stacked generalization of quantile regression algorithms: Large-scale application over CONUS. J. Hydrol. 2019, 577, 123957. [Google Scholar] [CrossRef]
- Mamassis, N.; Koutsoyiannis, D. Influence of atmospheric circulation types in space-time distribution of intense rainfall. J. Geophys. Res.-Atmos. 1996, 101, 26267–26276. [Google Scholar] [CrossRef]
- Langousis, A.; Mamalakis, A.; Puliga, M.; Deida, R. Threshold detection for the generalized Pareto distribution: Review of representative methods and application to the NOAA NCDC daily rainfall database. Water Resour. Res. 2016, 52, 2659–2681. [Google Scholar] [CrossRef]
- Papalexiou, S.M.; Koutsoyiannis, D. A global survey on the seasonal variation of the marginal distribution of daily precipitation. Adv. Water Resour. 2016, 94, 131–145. [Google Scholar] [CrossRef]
- Papacharalampous, G.A.; Tyralis, H.; Koutsoyiannis, D. Predictability of monthly temperature and precipitation using automatic time series forecasting methods. Acta Geophys. 2018, 66, 807–831. [Google Scholar] [CrossRef]
- Sivakumar, B.; Woldemeskel, F.M.; Vignesh, R.; Jothiprakash, V. A correlation–scale–threshold method for spatial variability of rainfall. Hydrology 2019, 6, 11. [Google Scholar] [CrossRef]
- Andréassian, V.; Hall, A.; Chahinian, N.; Schaake, J. Introduction and synthesis: Why should hydrologists work on a large number of basin data sets? IAHS Publ. 2006, 307, 1. [Google Scholar]
- Andréassian, V.; Lerat, J.; Loumagne, C.; Mathevet, T.; Michel, C.; Oudin, L.; Perrin, C. What is really undermining hydrologic science today? Hydrol. Process. 2007, 21, 2819–2822. [Google Scholar] [CrossRef]
- Andréassian, V.; Perrin, C.; Berthet, L.; Le Moine, N.; Lerat, J.; Loumagne, C.; Oudin, L.; Mathevet, T.; Ramos, M.-H.; Valéry, A. HESS Opinions ‘‘Crash tests for a standardized evaluation of hydrological models’’. Hydrol. Earth Syst. Sci. 2009, 13, 1757–1764. [Google Scholar] [CrossRef]
- Gupta, H.V.; Perrin, C.; Blöschl, G.; Montanari, A.; Kumar, R.; Clark, M.P.; Andréassian, V. Large-sample hydrology: A need to balance depth with breadth. Hydrol. Earth Syst. Sci. 2014, 18, 463–477. [Google Scholar] [CrossRef]
- Beven, K.J.; Binley, A.M. The future of distributed models: Model calibration and uncertainty prediction. Hydrol. Process. 1992, 6, 279–298. [Google Scholar] [CrossRef]
- Krzysztofowicz, R.; Kelly, K.S. Hydrologic uncertainty processor for probabilistic river stage forecasting. Water Resour. Res. 2000, 36, 3265–3277. [Google Scholar] [CrossRef]
- Kavetski, D.; Franks, S.W.; Kuczera, G. Confronting input uncertainty in environmental modelling. In Calibration of Watershed Models; Duan, Q., Gupta, H.V., Sorooshian, S., Rousseau, A.N., Turcotte, R., Eds.; AGU: Washington, DC, USA, 2002; pp. 49–68. [Google Scholar] [CrossRef]
- Krzysztofowicz, R. Bayesian system for probabilistic river stage forecasting. J. Hydrol. 2002, 268, 16–40. [Google Scholar] [CrossRef]
- Kuczera, G.; Kavetski, D.; Franks, S.; Thyer, M. Towards a Bayesian total error analysis of conceptual rainfall-runoff models: Characterising model error using storm-dependent parameters. J. Hydrol. 2006, 331, 161–177. [Google Scholar] [CrossRef]
- Montanari, A.; Brath, A. A stochastic approach for assessing the uncertainty of rainfall-runoff simulations. Water Resour. Res. 2004, 40, W01106. [Google Scholar] [CrossRef]
- Montanari, A.; Grossi, G. Estimating the uncertainty of hydrological forecasts: A statistical approach. Water Resour. Res. 2008, 44, W00B08. [Google Scholar] [CrossRef]
- Schoups, G.; Vrugt, J.A. A formal likelihood function for parameter and predictive inference of hydrologic models with correlated, heteroscedastic, and non-Gaussian errors. Water Resour. Res. 2010, 46, W10531. [Google Scholar] [CrossRef]
- López López, P.; Verkade, J.S.; Weerts, A.H.; Solomatine, D.P. Alternative configurations of quantile regression for estimating predictive uncertainty in water level forecasts for the upper Severn River: A comparison. Hydrol. Earth Syst. Sci. 2014, 18, 3411–3428. [Google Scholar] [CrossRef]
- Dogulu, N.; López López, P.; Solomatine, D.P.; Weerts, A.H.; Shrestha, D.L. Estimation of predictive hydrologic uncertainty using the quantile regression and UNEEC methods and their comparison on contrasting catchments. Hydrol. Earth Syst. Sci. 2015, 19, 3181–3201. [Google Scholar] [CrossRef]
- Bogner, K.; Liechti, K.; Zappa, M. Post-processing of stream flows in Switzerland with an emphasis on low flows and floods. Water 2016, 8, 115. [Google Scholar] [CrossRef]
- Bogner, K.; Liechti, K.; Zappa, M. Technical note: Combining quantile forecasts and predictive distributions of streamflows. Hydrol. Earth Syst. Sci. 2017, 21, 5493–5502. [Google Scholar] [CrossRef]
- Hernández-López, M.R.; Francés, F. Bayesian joint inference of hydrological and generalized error models with the enforcement of Total Laws. Hydrol. Earth Syst. Sci. Discuss. 2017. [Google Scholar] [CrossRef]
- Papacharalampous, G.A.; Koutsoyiannis, D.; Montanari, A. Quantification of predictive uncertainty in hydrological modelling by harnessing the wisdom of the crowd: Methodology development and investigation using toy models. arXiv 2019, arXiv:1909.00244. [Google Scholar]
- Li, W.; Duan, Q.; Miao, C.; Ye, A.; Gong, W.; Di, Z. A review on statistical postprocessing methods for hydrometeorological ensemble forecasting. Wiley Interdiscip. Rev. Water 2017, 4, e1246. [Google Scholar] [CrossRef]
- Rigby, R.A.; Stasinopoulos, D.M. Generalized additive models for location, scale and shape. J. R. Stat. Soc. Ser. C 2005, 54, 507–554. [Google Scholar] [CrossRef]
- Yan, J.; Liao, G.Y.; Gebremichael, M.; Shedd, R.; Vallee, D.R. Characterizing the uncertainty in river stage forecasts conditional on point forecast values. Water Resour. Res. 2014, 48, W12509. [Google Scholar] [CrossRef]
- Weerts, A.H.; Winsemius, H.C.; Verkade, J.S. Estimation of predictive hydrological uncertainty using quantile regression: Examples from the National Flood Forecasting System (England and Wales). Hydrol. Earth Syst. Sci. 2011, 15, 255–265. [Google Scholar] [CrossRef]
- Taillardat, M.; Mestre, O.; Zamo, M.; Naveau, P. Calibrated ensemble forecasts using quantile regression forests and ensemble model output statistics. Mon. Weather Rev. 2016, 144, 2375–2393. [Google Scholar] [CrossRef]
- Taylor, J.W. A quantile regression neural network approach to estimating the conditional density of multiperiod returns. J. Forecast. 2000, 19, 299–311. [Google Scholar] [CrossRef]
- Lichtendahl, K.C.; Grushka-Cockayne, Y.; Winkler, R.L. Is it better to average probabilities or quantiles? Manag. Sci. 2013, 59, 1594–1611. [Google Scholar] [CrossRef]
- Winkler, R.L. Equal versus differential weighting in combining forecasts. Risk Anal. 2015, 35, 16–18. [Google Scholar] [CrossRef]
- Wolpert, D.H. The lack of a priori distinctions between learning algorithms. Neural Comput. 1996, 8, 1341–1390. [Google Scholar] [CrossRef]
- Papacharalampous, G.; Tyralis, H.; Langousis, A.; Jayawardena, A.W.; Sivakumar, B.; Mamassis, N.; Montanari, A.; Koutsoyiannis, D. Large-scale comparison of machine learning regression algorithms for probabilistic hydrological modelling via post-processing of point predictions. In Geophysical Research Abstracts, Volume 21, Proceedings of the European Geosciences Union (EGU) General Assembly 2019, Vienna, Austria, 7–12 April 2019; EGU2019-3576; European Geosciences Union: Munich, Germany, 2019. [Google Scholar] [CrossRef]
- Klemeš, V. Operational testing of hydrological simulation models. Hydrol. Sci. J. 1986, 31, 13–24. [Google Scholar] [CrossRef]
- Anctil, F.; Perrin, C.; Andréassian, V. Impact of the length of observed records on the performance of ANN and of conceptual parsimonious rainfall-runoff forecasting models. Environ. Model. Softw. 2004, 19, 357–368. [Google Scholar] [CrossRef]
- Oudin, L.; Hervieu, F.; Michel, C.; Perrin, C.; Andréassian, V.; Anctil, F.; Loumagne, C. Which potential evapotranspiration input for a lumped rainfall–runoff model? Part 2—Towards a simple and efficient potential evapotranspiration model for rainfall–runoff modelling. J. Hydrol. 2005, 303, 290–306. [Google Scholar] [CrossRef]
- Oudin, L.; Perrin, C.; Mathevet, T.; Andréassian, V.; Michel, C. Impact of biased and randomly corrupted inputs on the efficiency and the parameters of watershed models. J. Hydrol. 2006, 320, 62–83. [Google Scholar] [CrossRef]
- Oudin, L.; Kay, A.; Andréassian, V.; Perrin, C. Are seemingly physically similar catchments truly hydrologically similar? Water Resour. Res. 2010, 46, W11558. [Google Scholar] [CrossRef]
- Wang, Q.J.; Shrestha, D.L.; Robertson, D.E.; Pokhrel, P. A log-sinh transformation for data normalization and variance stabilization. Water Resour. Res. 2012, 48, W05514. [Google Scholar] [CrossRef]
- Tian, Y.; Xu, Y.P.; Zhang, X.J. Assessment of climate change impacts on river high flows through comparative use of GR4J, HBV and Xinanjiang models. Water Resour. Manag. 2013, 27, 2871–2888. [Google Scholar] [CrossRef]
- Evin, G.; Thyer, M.; Kavetski, D.; McInerney, D.; Kuczera, G. Comparison of joint versus postprocessor approaches for hydrological uncertainty estimation accounting for error autocorrelation and heteroscedasticity. Water Resour. Res. 2014, 50, 2350–2375. [Google Scholar] [CrossRef]
- Lebecherel, L.; Andréassian, V.; Perrin, C. On evaluating the robustness of spatial-proximity-based regionalization methods. J. Hydrol. 2016, 539, 196–203. [Google Scholar] [CrossRef]
- Edijatno; Nascimento, N.O.; Yang, X.; Makhlouf, Z.; Michel, C. GR3J: A daily watershed model with three free parameters. Hydrol. Sci. J. 1999, 44, 263–277. [Google Scholar] [CrossRef]
- Waldmann, E. Quantile regression: A short story on how and why. Stat. Model. 2018, 18, 203–218. [Google Scholar] [CrossRef]
- Koenker, R.W. Quantile regression: 40 years on. Annu. Rev. Econ. 2017, 9, 155–176. [Google Scholar] [CrossRef]
- Koenker, R.W.; Machado, J.A.F. Goodness of fit and related inference processes for quantile regression. J. Am. Stat. Assoc. 1999, 94, 1296–1310. [Google Scholar] [CrossRef]
- Gneiting, T.; Raftery, A.E. Strictly proper scoring rules, prediction, and estimation. J. Am. Stat. Assoc. 2007, 102, 359–378. [Google Scholar] [CrossRef]
- Koenker, R.W.; Bassett, G., Jr. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Koenker, R.W. Quantile Regression; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Meinshausen, N. Quantile regression forests. J. Mach. Learn. Res. 2006, 7, 983–999. [Google Scholar]
- Athey, S.; Tibshirani, J.; Wager, S. Generalized random forests. Ann. Stat. 2019, 47, 1148–1178. [Google Scholar] [CrossRef]
- Mayr, A.; Binder, H.; Gefeller, O.; Schmid, M. The evolution of boosting algorithms. Methods Inf. Med. 2014, 53, 419–427. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef]
- Efron, B.; Hastie, T. Computer Age Statistical Inference, 1st ed.; Cambridge University Press: New York, NY, USA, 2016; ISBN 9781107149892. [Google Scholar]
- Bühlmann, P.; Hothorn, T. Boosting algorithms: Regularization, prediction and model fitting. Stat. Sci. 2007, 22, 477–505. [Google Scholar] [CrossRef]
- Hothorn, T.; Buehlmann, P.; Kneib, T.; Schmid, M.; Hofner, B. mboost: Model-Based Boosting, R Package Version 2.9-1; 2018. Available online: https://cran.r-project.org/web/packages/mboost (accessed on 15 September 2019).
- Hofner, B.; Mayr, A.; Robinzonov, N.; Schmid, M. Model-based boosting in R: A hands-on tutorial using the R package mboost. Comput. Stat. 2014, 29, 3–35. [Google Scholar] [CrossRef]
- Maier, H.R.; Jain, A.; Dandy, G.C.; Sudheer, K.P. Methods used for the development of neural networks for the prediction of water resource variables in river systems: Current status and future directions. Environ. Model. Softw. 2010, 25, 891–909. [Google Scholar] [CrossRef]
- Cannon, A.J. Quantile regression neural networks: Implementation in R and application to precipitation downscaling. Comput. Geosci. 2011, 37, 1277–1284. [Google Scholar] [CrossRef]
- Newman, A.J.; Sampson, K.; Clark, M.P.; Bock, A.; Viger, R.J.; Blodgett, D. A Large-Sample Watershed-Scale Hydrometeorological Dataset for the Contiguous USA; UCAR/NCAR: Boulder, CO, USA, 2014. [Google Scholar] [CrossRef]
- Addor, N.; Newman, A.J.; Mizukami, N.; Clark, M.P. Catchment Attributes for Large-Sample Studies; UCAR/NCAR: Boulder, CO, USA, 2017. [Google Scholar] [CrossRef]
- Newman, A.J.; Clark, M.P.; Sampson, K.; Wood, A.; Hay, L.E.; Bock, A.; Viger, R.J.; Blodgett, D.; Brekke, L.; Arnold, J.R.; et al. Development of a large-sample watershed-scale hydrometeorological data set for the contiguous USA: Data set characteristics and assessment of regional variability in hydrologic model performance. Hydrol. Earth Syst. Sci. 2015, 19, 209–223. [Google Scholar] [CrossRef]
- Addor, N.; Newman, A.J.; Mizukami, N.; Clark, M.P. The CAMELS data set: Catchment attributes and meteorology for large-sample studies. Hydrol. Earth Syst. Sci. 2017, 21, 5293–5313. [Google Scholar] [CrossRef]
- Thornton, P.E.; Thornton, M.M.; Mayer, B.W.; Wilhelmi, N.; Wei, Y.; Devarakonda, R.; Cook, R.B. Daymet: Daily Surface Weather Data on a 1-km Grid for North America, Version 2; Oak Ridge National Lab.: Oak Ridge, TN, USA, 2014. [Google Scholar] [CrossRef]
- Michel, C. Hydrologie Appliquée Aux Petits Bassins Ruraux; Cemagref: Antony, France, 1991. [Google Scholar]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Gneiting, T.; Balabdaoui, F.; Raftery, A.E. Probabilistic forecasts, calibration and sharpness. J. R. Stat. Soc. Ser. B 2007, 69, 243–268. [Google Scholar] [CrossRef]
- Gneiting, T.; Katzfuss, M. Probabilistic forecasting. Annu. Rev. Stat. Appl. 2014, 1, 125–151. [Google Scholar] [CrossRef]
- Dunsmore, I.R. A Bayesian approach to calibration. J. R. Stat. Soc. Ser. B 1968, 30, 396–405. [Google Scholar] [CrossRef]
- Winkler, R.L. A decision-theoretic approach to interval estimation. J. Am. Stat. Assoc. 1972, 67, 187–191. [Google Scholar] [CrossRef]
- Papacharalampous, G.; Tyralis, H.; Langousis, A.; Jayawardena, A.W.; Sivakumar, B.; Mamassis, N.; Montanari, A.; Koutsoyiannis, D. Supplementary material for the paper “Probabilistic hydrological post-processing at scale: Why and how to apply machine-learning quantile regression algorithms”. Figshare 2019. [Google Scholar] [CrossRef]
- Farmer, W.H.; Vogel, R.M. On the deterministic and stochastic use of hydrologic models. Water Resour. Res. 2016, 52, 5619–5633. [Google Scholar] [CrossRef]
- Bock, A.R.; Farmer, W.H.; Hay, L.E. Quantifying uncertainty in simulated streamflow and runoff from a continental-scale monthly water balance model. Adv. Water Resour. 2018, 122, 166–175. [Google Scholar] [CrossRef]
- Sivakumar, B. The more things change, the more they stay the same: The state of hydrologic modelling. Hydrol. Process. 2008, 22, 4333–4337. [Google Scholar] [CrossRef]
- Bakker, K.; Whan, K.; Knap, W.; Schmeits, M. Comparison of statistical post-processing methods for probabilistic NWP forecasts of solar radiation. arXiv 2019, arXiv:1904.07192. [Google Scholar] [CrossRef]
- Blöschl, G.; Bierkens, M.F.P.; Chambel, A.; Cudennec, C.; Destouni, G.; Fiori, A.; Kirchner, J.W.; McDonnell, J.J.; Savenije, H.H.G.; Sivapalan, M.; et al. Twenty-three Unsolved Problems in Hydrology (UPH)–A community perspective. Hydrol. Sci. J. 2019, 64, 1141–1158. [Google Scholar] [CrossRef]
- Efstratiadis, A.; Koutsoyiannis, D. One decade of multi-objective calibration approaches in hydrological modelling: A review. Hydrol. Sci. J. 2010, 55, 58–78. [Google Scholar] [CrossRef]
- Abrahart, R.J.; See, L.M.; Dawson, C.W. Neural network hydroinformatics: Maintaining scientific rigour. In Practical Hydroinformatics; Abrahart, R.J., See, L.M., Solomatine, D.P., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 33–47. [Google Scholar] [CrossRef]
- Ceola, S.; Arheimer, B.; Baratti, E.; Blöschl, G.; Capell, R.; Castellarin, A.; Freer, J.; Han, D.; Hrachowitz, M.; Hundecha, Y.; et al. Virtual laboratories: New opportunities for collaborative water science. Hydrol. Earth Syst. Sci. 2015, 19, 2101–2117. [Google Scholar] [CrossRef]
- Vrugt, J.A. Markov chain Monte Carlo simulation using the DREAM software package: Theory, concepts, and MATLAB implementation. Environ. Model. Softw. 2016, 75, 273–316. [Google Scholar] [CrossRef]
- Vrugt, J.A. MODELAVG: A MATLAB Toolbox for Postprocessing of Model Ensembles. 2016. Available online: https://researchgate.net/publication/299458373 (accessed on 15 September 2019).
- Chatfield, C. What is the ‘best’ method of forecasting? J. Appl. Stat. 1988, 15, 19–38. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 27, 1–22. [Google Scholar] [CrossRef]
- Vrugt, J.A. Merging Models with Data; Topic 6: Model Averaging; 2016. Available online: https://researchgate.net/publication/305175486 (accessed on 15 September 2019).
- Okoli, K.; Breinl, K.; Brandimarte, L.; Botto, A.; Volpi, E.; Di Baldassarre, G. Model averaging versus model selection: Estimating design floods with uncertain river flow data. Hydrol. Sci. J. 2018, 63, 1913–1926. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, N.; Tan, Y.; Hong, T.; Kirschen, D.S.; Kang, C. Combining Probabilistic Load Forecasts. IEEE Trans. Smart Grid 2019, 10, 3664–3674. [Google Scholar] [CrossRef]
- Volpi, E.; Schoups, G.; Firmani, G.; Vrugt, J.A. Sworn testimony of the model evidence: Gaussian Mixture Importance (GAME) sampling. Water Resour. Res. 2017, 53, 6133–6158. [Google Scholar] [CrossRef]
- Sivakumar, B. Hydrologic modeling and forecasting: Role of thresholds. Environ. Model. Softw. 2005, 20, 515–519. [Google Scholar] [CrossRef]
- Papacharalampous, G.A.; Tyralis, H.; Koutsoyiannis, D. One-step ahead forecasting of geophysical processes within a purely statistical framework. Geosci. Lett. 2018, 5, 12. [Google Scholar] [CrossRef]
- Bourgin, F.; Andréassian, V.; Perrin, C.; Oudin, L. Transferring global uncertainty estimates from gauged to ungauged catchments. Hydrol. Earth Syst. Sci. 2015, 19, 2535–2546. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.A.; Langousis, A. Super learning for daily streamflow forecasting: Large-scale demonstration and comparison with multiple machine learning algorithms. arXiv 2019, arXiv:1909.04131. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019; Available online: https://www.R-project.org (accessed on 15 September 2019).
- Dowle, M.; Srinivasan, A. data.table: Extension of ‘data.frame’, R Package Version 1.12.2; 2019. Available online: https://cran.r-project.org/web/packages/data.table (accessed on 15 September 2019).
- Wickham, H.; Hester, J.; Chang, W. devtools: Tools to Make Developing R Packages Easier, R Package Version 2.1.0. 2019. Available online: https://CRAN.R-project.org/package=devtools (accessed on 15 September 2019).
- Wickham, H.; François, R.; Henry, L.; Müller, K. dplyr: A Grammar of Data Manipulation, R Package Version 0.8.3. 2019. Available online: https://CRAN.R-project.org/package=dplyr (accessed on 15 September 2019).
- Greenwell, B.; Boehmke, B.; Cunningham, J.; GBM Developers. gbm: Generalized Boosted Regression Models, R Package Version 2.1.5. 2019. Available online: https://cran.r-project.org/web/packages/gbm (accessed on 15 September 2019).
- Warnes, G.R.; Bolker, B.; Gorjanc, G.; Grothendieck, G.; Korosec, A.; Lumley, T.; MacQueen, D.; Magnusson, A.; Rogers, J. gdata: Various R Programming Tools for Data Manipulation, R Package Version 2.18.0. 2017. Available online: https://CRAN.R-project.org/package=gdata (accessed on 15 September 2019).
- Wickham, H. ggplot2; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Wickham, H.; Chang, W.; Henry, L.; Pedersen, T.L.; Takahashi, K.; Wilke, C.; Woo, K.; Yutani, H. ggplot2: Create Elegant Data Visualisations Using the Grammar of Graphics, R Package Version 3.2.0. 2019. Available online: https://CRAN.R-project.org/package=ggplot2 (accessed on 15 September 2019).
- Kassambara, A. ggpubr: ‘ggplot2’ Based Publication Ready Plots, R Package Version 0.2.1. 2019. Available online: https://cran.r-project.org/web/packages/ggpubr (accessed on 15 September 2019).
- Tibshirani, J.; Athey, S. grf: Generalized Random Forests (Beta), R Package Version 0.10.3. 2019. Available online: https://CRAN.R-project.org/package=grf (accessed on 15 September 2019).
- Xie, Y. knitr: A comprehensive tool for reproducible research in R. In Implementing Reproducible Computational Research; Stodden, V., Leisch, F., Peng, R.D., Eds.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2014. [Google Scholar]
- Xie, Y. Dynamic Documents with R and knitr, 2nd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2015. [Google Scholar]
- Xie, Y. knitr: A General-Purpose Package for Dynamic Report Generation in R, R Package Version 1.23. 2019. Available online: https://CRAN.R-project.org/package=knitr (accessed on 15 September 2019).
- Brownrigg, R.; Minka, T.P.; Deckmyn, A. maps: Draw Geographical Maps, R Package Version 3.3.0. 2018. Available online: https://CRAN.R-project.org/package=maps (accessed on 15 September 2019).
- Cannon, A.J. qrnn: Quantile Regression Neural Network, R Package Version 2.0.4. 2019. Available online: https://cran.r-project.org/web/packages/qrnn (accessed on 15 September 2019).
- Koenker, R.W. quantreg: Quantile Regression, R Package Version 5.42. 2019. Available online: https://CRAN.R-project.org/package=quantreg (accessed on 15 September 2019).
- Wickham, H. The split-apply-combine strategy for data analysis. J. Stat. Softw. 2011, 40, 1–29. [Google Scholar] [CrossRef]
- Wickham, H. plyr: Tools for Splitting, Applying and Combining Data, R Package Version 1.8.4. 2016. Available online: https://cran.r-project.org/web/packages/plyr (accessed on 15 September 2019).
- Wickham, H.; Hester, J.; Francois, R. readr: Read Rectangular Text Data, R Package Version 1.3.1. 2018. Available online: https://CRAN.R-project.org/package=readr (accessed on 15 September 2019).
- Allaire, J.J.; Xie, Y.; McPherson, J.; Luraschi, J.; Ushey, K.; Atkins, A.; Wickham, H.; Cheng, J.; Chang, W.; Iannone, R. rmarkdown: Dynamic Documents for R, R Package Version 1.14. 2019. Available online: https://CRAN.R-project.org/package=rmarkdown (accessed on 15 September 2019).
- Wickham, H. Reshaping data with the reshape package. J. Stat. Softw. 2007, 21, 1–20. [Google Scholar] [CrossRef]
- Wickham, H. reshape2: Flexibly Reshape Data: A Reboot of the Reshape Package, R Package Version 1.4.3. 2017. Available online: https://CRAN.R-project.org/package=reshape2 (accessed on 15 September 2019).
- Gagolewski, M. stringi: Character String Processing Facilities, R Package Version 1.4.3. 2019. Available online: https://CRAN.R-project.org/package=stringi (accessed on 15 September 2019).
- Wickham, H. stringr: Simple, Consistent Wrappers for Common String Operations, R Package Version 1.4.0. 2019. Available online: https://CRAN.R-project.org/package=stringr (accessed on 15 September 2019).












| Statistical Model | Classification | Studies |
|---|---|---|
| Meta-Gaussian bivariate distribution model | Parametric; conditional distribution | References [6,61,62] |
| Generalized additive models (GAMLSS) | Parametric; machine-learning | References [71,72] |
| Quantile regression | Non-parametric; machine-learning; quantile regression | References [45,46,64,65,69,73] |
| Quantile regression forests | References [46,74] | |
| Quantile regression neural networks | References [66,67,75] |
| S/n | Primal Machine-Learning Algorithm | Abbreviation | Section |
|---|---|---|---|
| 1 | Quantile regression | qr | 2.3.2 |
| 2 | Generalized random forests for quantile regression | qrf | 2.3.3 |
| 3 | Generalized random forests for quantile regression emulating quantile regression forests | qrf_meins | 2.3.3 |
| 4 | Gradient boosting machine with trees as base learners | gbm | 2.3.4 |
| 5 | Model-based boosting with linear models as base learners | mboost_bols | 2.3.4 |
| 6 | Quantile regression neural networks | qrnn | 2.3.5 |
| 7 | Equal-weight combiner of the above six algorithms implemented with the same predictor variables | ensemble | - |
| Abbreviations of Assessed Configurations | Predictor Variables of the Regression |
|---|---|
| qr_2, qrf_2, qrf_meins_2, gbm_2, mboost_bols_2, qrnn_2, ensemble_2 | Hydrological model predictions at times t − 1 and t |
| qr_3, qrf_3, qrf_meins_3, gbm_3, mboost_bols_3, qrnn_3, ensemble_3 | Hydrological model predictions at times t − 2, t − 1 and t |
| qr_4, qrf_4, qrf_meins_4, gbm_4, mboost_bols_4, qrnn_4, ensemble_4 | Hydrological model predictions at times t − 3, t − 2, t − 1 and t |
| Score | Definition | Units | Possible Values | Preferred Values | Criterion/Criteria |
|---|---|---|---|---|---|
| Reliability score (RSα) | Equation (5) | - | [0, 1] | Smaller |RSα – (1 – α)| | Reliability |
| Average width (AWα) | Equation (6) | mm/day | [0, +∞) | Smaller AWα | Sharpness |
| Average interval score (AISα) | Equation (7) | mm/day | [0, +∞) | Smaller AISα | Reliability, sharpness |
| Average quantile score (AQSτ) | Equation (8) | mm/day | [0, +∞) | Smaller AQSτ | Reliability, sharpness |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papacharalampous, G.; Tyralis, H.; Langousis, A.; Jayawardena, A.W.; Sivakumar, B.; Mamassis, N.; Montanari, A.; Koutsoyiannis, D. Probabilistic Hydrological Post-Processing at Scale: Why and How to Apply Machine-Learning Quantile Regression Algorithms. Water 2019, 11, 2126. https://doi.org/10.3390/w11102126
Papacharalampous G, Tyralis H, Langousis A, Jayawardena AW, Sivakumar B, Mamassis N, Montanari A, Koutsoyiannis D. Probabilistic Hydrological Post-Processing at Scale: Why and How to Apply Machine-Learning Quantile Regression Algorithms. Water. 2019; 11(10):2126. https://doi.org/10.3390/w11102126
Chicago/Turabian StylePapacharalampous, Georgia, Hristos Tyralis, Andreas Langousis, Amithirigala W. Jayawardena, Bellie Sivakumar, Nikos Mamassis, Alberto Montanari, and Demetris Koutsoyiannis. 2019. "Probabilistic Hydrological Post-Processing at Scale: Why and How to Apply Machine-Learning Quantile Regression Algorithms" Water 11, no. 10: 2126. https://doi.org/10.3390/w11102126
APA StylePapacharalampous, G., Tyralis, H., Langousis, A., Jayawardena, A. W., Sivakumar, B., Mamassis, N., Montanari, A., & Koutsoyiannis, D. (2019). Probabilistic Hydrological Post-Processing at Scale: Why and How to Apply Machine-Learning Quantile Regression Algorithms. Water, 11(10), 2126. https://doi.org/10.3390/w11102126