Prediction of Suspended Sediment Load Using Data-Driven Models

 ,
, 
 , and
, and 
Abstract
1. Introduction
2. Materials and Methods
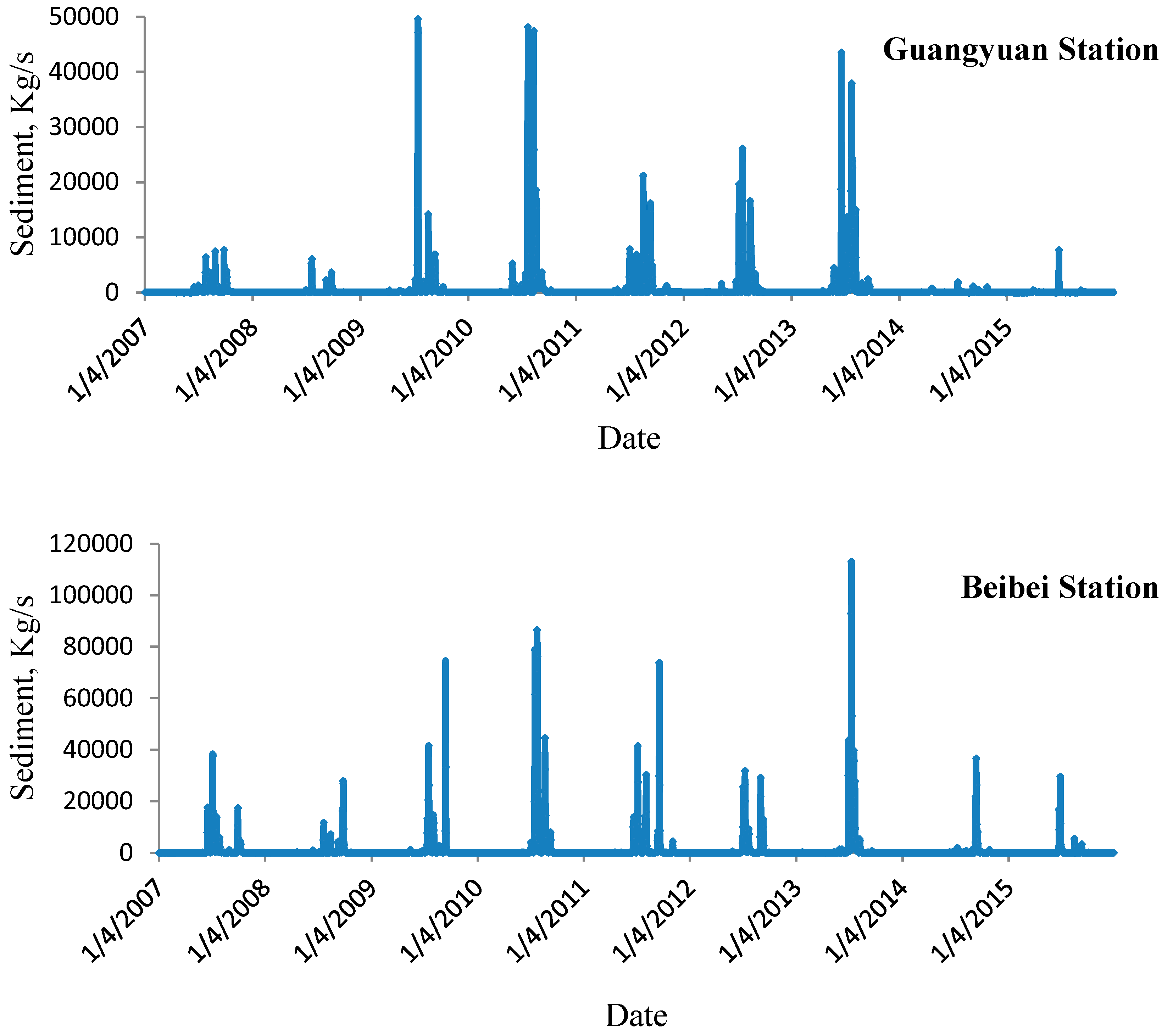
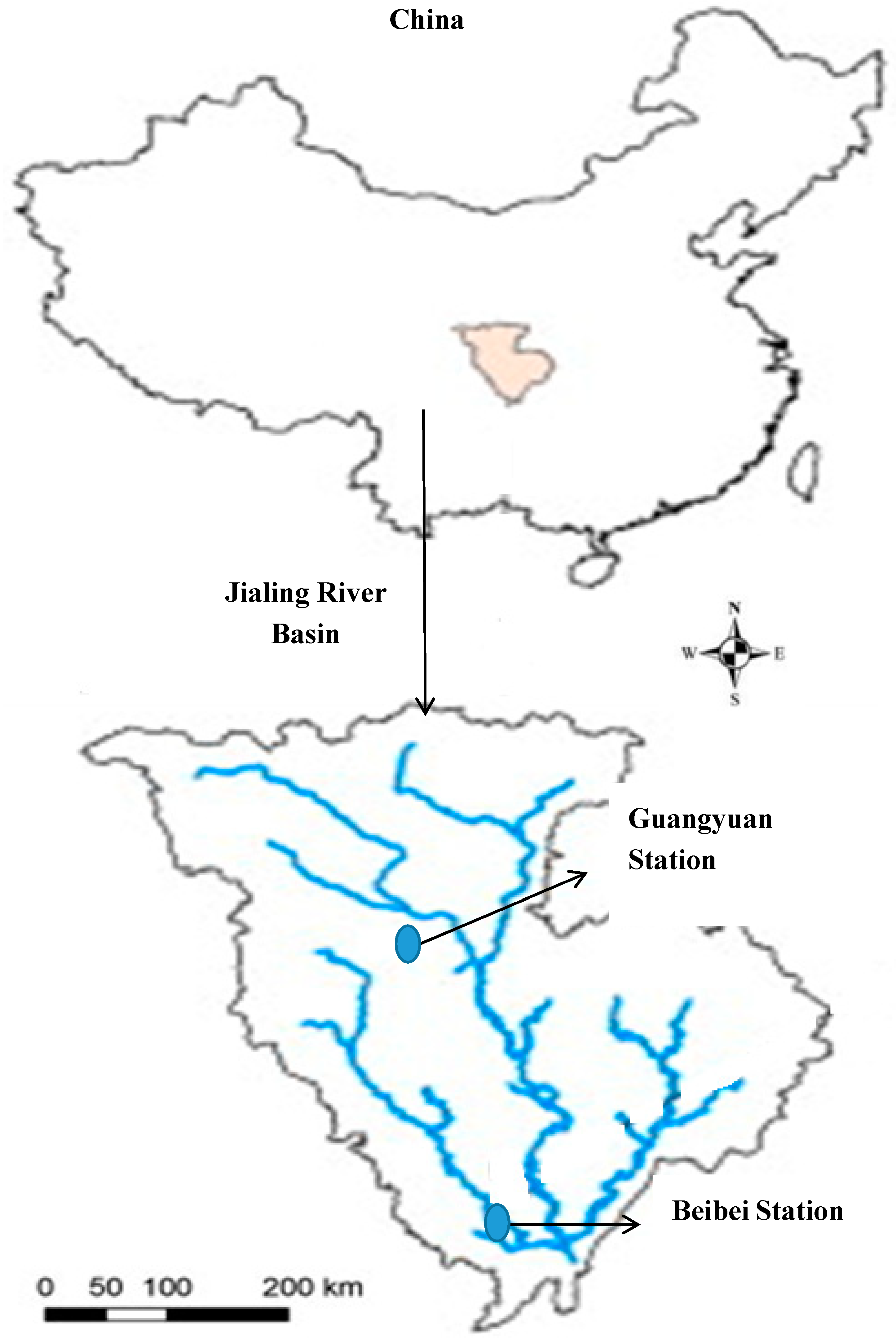
2.1. Study Basin and Data
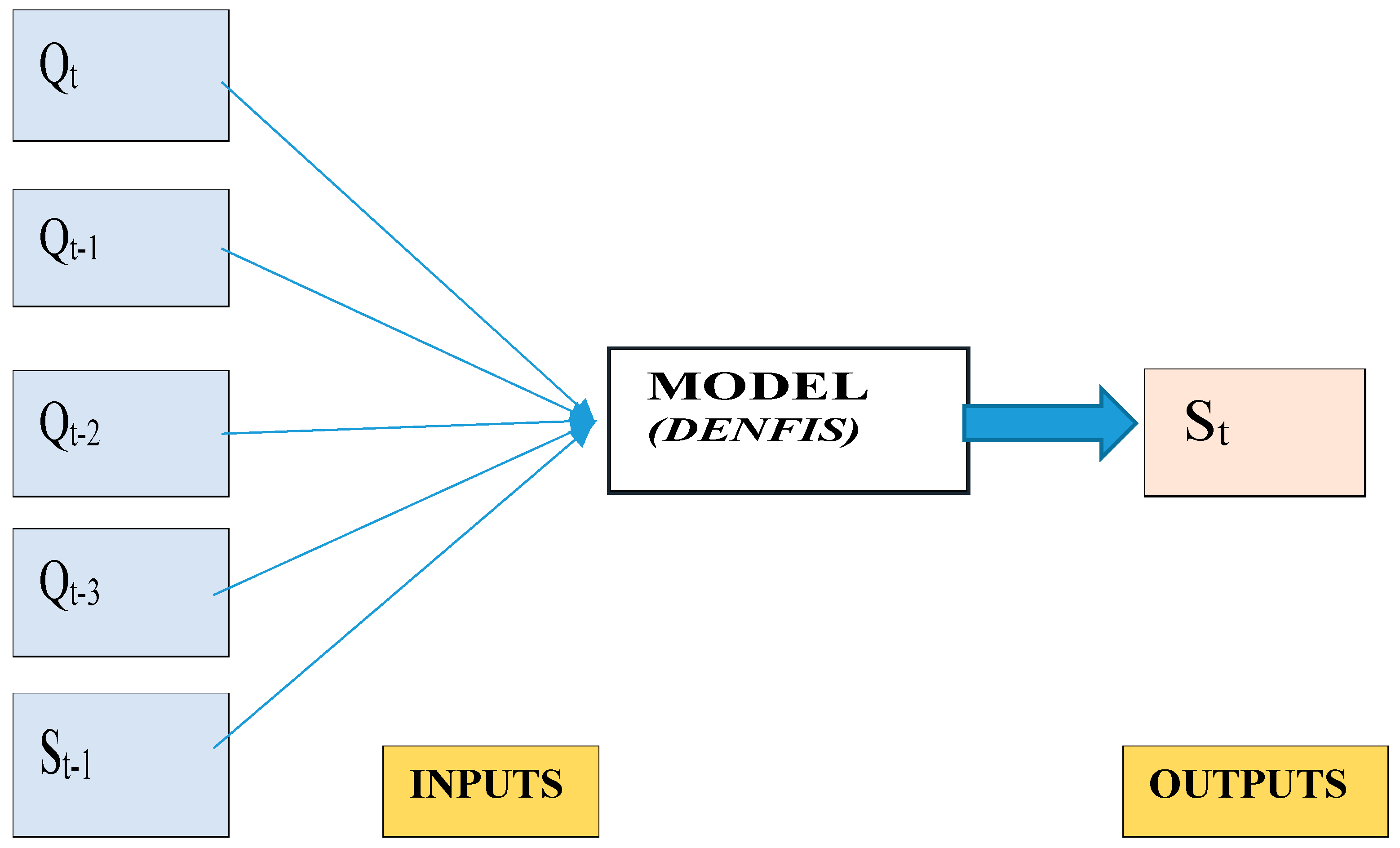
2.2. Used Methods
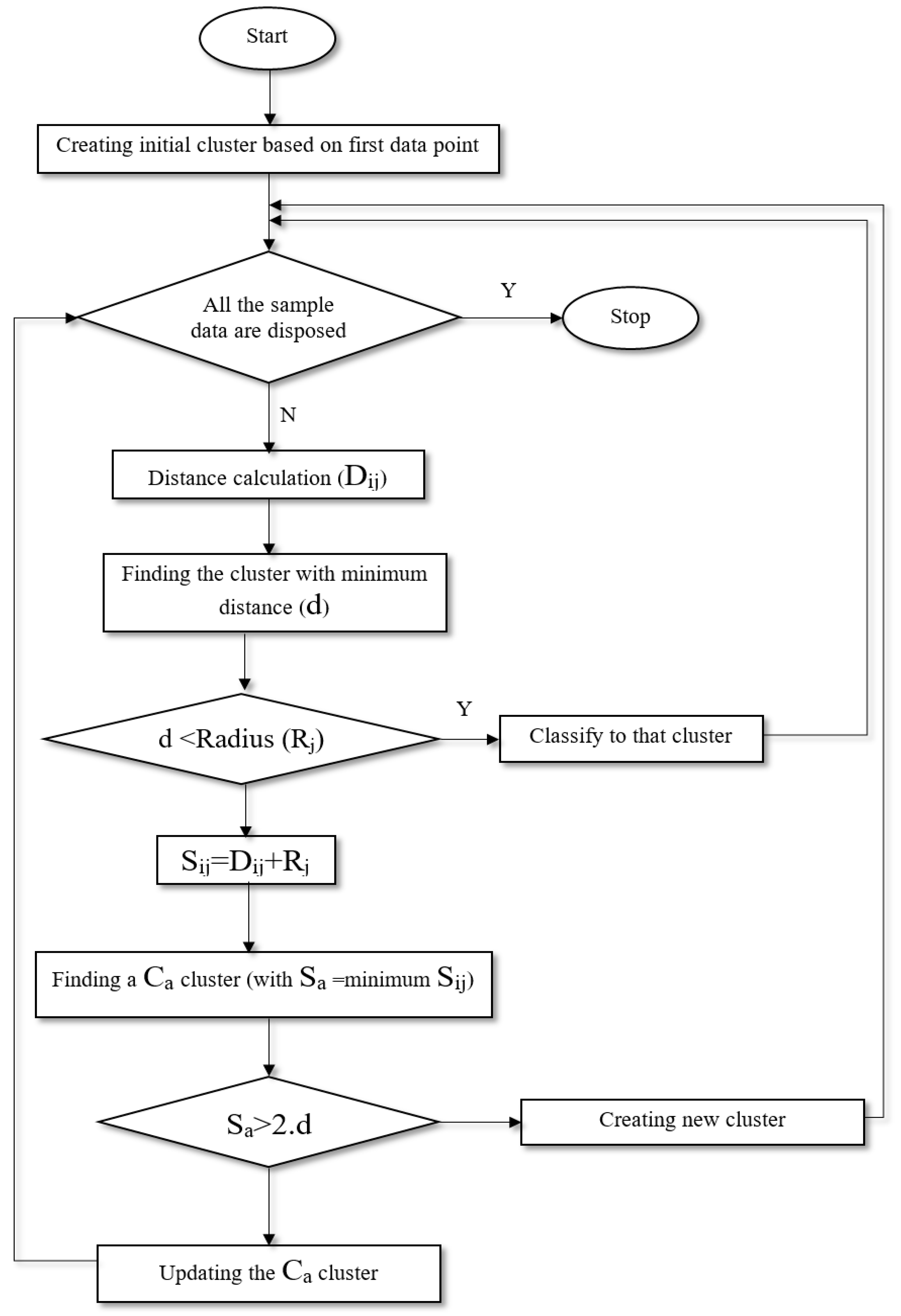
2.2.1. Adaptive Neuro-Fuzzy Inference System with Fuzzy C-Means Clustering (ANFIS-FCM)
2.2.2. Multivariate Adaptive Regression Splines (MARS)
2.2.3. The Evaluation Metrics Used for Model Comparison
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kemp, P.; Sear, D.; Collins, A.; Naden, P.; Jones, I. The impacts of fine sediment on riverine fish. Hydrol. Process. 2011, 25, 1800–1821. [Google Scholar] [CrossRef]
- Ivakhnenko, A.G. The Group Method of Data of Handling; A rival of the method of stochastic approximation. Sov. Autom. Control 1968, 13, 43–55. [Google Scholar]
- Hild, C.; Bozdogan, H. The use of information-based model evaluation criteria in the GMDH algorithm. Syst. Anal. Model. Simul. 1995, 20, 29–50. [Google Scholar]
- Zabihi, M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Behzadfar, M. GIS-based multivariate adaptive regression spline and random forest models for groundwater potential mapping in Iran. Environ. Earth Sci. 2016, 75, 665. [Google Scholar] [CrossRef]
- Mehdizadeh, S.; Behmanesh, J.; Khalili, K. A comparison of monthly precipitation point estimates at 6 locations in Iran using integration of soft computing methods and GARCH time series model. J. Hydrol. 2017, 554, 721–742. [Google Scholar] [CrossRef]
- Adnan, R.M.; Yuan, X.; Kisi, O.; Anam, R. Improving accuracy of river flow forecasting using LSSVR with gravitational search algorithm. Adv. Meteorol. 2017, 2017, 1–23. [Google Scholar] [CrossRef]
- Rahgoshay, M.; Feiznia, S.; Arian, M.; Hashemi, S.A.A. Simulation of daily suspended sediment load using an improved model of support vector machine and genetic algorithms and particle swarm. Arab. J. Geosci. 2019, 12, 277. [Google Scholar] [CrossRef]
- Prasad, R.; Deo, R.C.; Li, Y.; Maraseni, T. Weekly soil moisture forecasting with multivariate sequential, ensemble empirical mode decomposition and Boruta-random forest hybridizer algorithm approach. Catena 2019, 177, 149–166. [Google Scholar] [CrossRef]
- Malik, A.; Kumar, A.; Kisi, O.; Shiri, J. Evaluating the performance of four different heuristic approaches with Gamma test for daily suspended sediment concentration modeling. Environ. Sci. Pollut. Res. 2019, 26, 1–18. [Google Scholar] [CrossRef]
- Adnan, R.M.; Liang, Z.; Trajkovic, S.; Zounemat-Kermani, M.; Li, B.; Kisi, O. Daily streamflow prediction using optimally pruned extreme learning machine. J. Hydrol. 2019, 577, 123981. [Google Scholar] [CrossRef]
- Mustafa, M.R.; Rezaur, R.B.; Saiedi, S.; Isa, M.H. River suspended sediment prediction using various multilayer perceptron neural network training algorithms—A case study in Malaysia. Water Resour. Manag. 2012, 26, 1879–1897. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, C.; Lei, X.; Yuan, Y.; Adnan, R.M. Monthly runoff forecasting based on LSTM-ALO model. Stoch. Environ. Res. Risk Assess. 2018, 32, 2199–2212. [Google Scholar] [CrossRef]
- El-Shafie, A.; Noureldin, A.; Taha, M.; Hussain, A.; Mukhlisin, M. Dynamic versus static neural network model for rainfall forecasting at Klang River Basin, Malaysia. Hydrol. Earth Syst. Sci. 2012, 16, 1151–1169. [Google Scholar] [CrossRef]
- Najah, A.; El-Shafie, A.; Karim, O.A.; Jaafar, O.; El-Shafie, A.H. An application of different artificial intelligences techniques for water quality prediction. Int. J. Phys. Sci. 2011, 6, 5298–5308. [Google Scholar]
- Afan, H.A.; El-Shafie, A.; Yaseen, Z.M.; Hameed, M.M.; Mohtar, W.H.M.W.; Hussain, A. ANN based sediment prediction model utilizing different input scenarios. Water Resour. Manag. 2015, 29, 1231–1245. [Google Scholar] [CrossRef]
- Rajaee, T.; Mirbagheri, S.A.; Zounemat-Kermani, M.; Nourani, V. Daily suspended sediment concentration simulation using ANN and neuro-fuzzy models. Sci. Total Environ. 2009, 407, 4916–4927. [Google Scholar] [CrossRef]
- Lafdani, E.K.; Nia, A.M.; Ahmadi, A. Daily suspended sediment load prediction using artificial neural networks and support vector machines. J. Hydrol. 2013, 478, 50–62. [Google Scholar] [CrossRef]
- Jothiprakash, V.; Garg, V. Reservoir sedimentation estimation using artificial neural network. J. Hydrol. Eng. 2009, 14, 1035–1040. [Google Scholar] [CrossRef]
- Adnan, R.M.; Yuan, X.; Kisi, O.; Adnan, M.; Mehmood, A. Stream Flow Forecasting of Poorly Gauged Mountainous Watershed by Least Square Support Vector Machine, Fuzzy Genetic Algorithm and M5 Model Tree Using Climatic Data from Nearby Station. Water Resour. Manag. 2018, 32, 4469–4486. [Google Scholar] [CrossRef]
- Kisi, Ö. Multi-layer perceptrons with Levenberg-Marquardt training algorithm for suspended sediment concentration prediction and estimation/Prévision et estimation de la concentration en matières en suspension avec des perceptrons multi-couches et l’algorithme d’apprentissage de Levenberg-Marquardt. Hydrol. Sci. J. 2004, 49. [Google Scholar] [CrossRef]
- Singh, A.; Imtiyaz, M.; Isaac, R.K.; Denis, D.M. Comparison of artificial neural network models for sediment yield prediction at single gauging station of watershed in eastern India. J. Hydrol. Eng. 2012, 18, 115–120. [Google Scholar] [CrossRef]
- Afan, H.A.; El-shafie, A.; Mohtar, W.H.M.W.; Yaseen, Z.M. Past, present and prospect of an Artificial Intelligence (AI) based model for sediment transport prediction. J. Hydrol. 2016, 541, 902–913. [Google Scholar] [CrossRef]
- Jang, J.S. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Kisi, O.; Shiri, J.; Karimi, S.; Adnan, R.M. Three different adaptive neuro fuzzy computing techniques for forecasting long-period daily streamflows. In Big Data in Engineering Applications; Springer: Singapore, 2018; pp. 303–321. [Google Scholar]
- Lohani, A.K.; Goel, N.K.; Bhatia, K.S. Deriving stage-discharge-sediment concentration relationships using fuzzy logic. Hydrol. Sci. J. 2007, 52, 793–807. [Google Scholar] [CrossRef]
- Firat, M.; Güngör, M. Monthly total sediment forecasting using adaptive neuro fuzzy inference system. Stoch. Environ. Res. Risk Assess. 2010, 24, 259–270. [Google Scholar] [CrossRef]
- Chang, F.J.; Chiang, Y.M.; Tsai, M.J.; Shieh, M.C.; Hsu, K.L.; Sorooshian, S. Watershed rainfall forecasting using neuro-fuzzy networks with the assimilation of multi-sensor information. J. Hydrol. 2014, 508, 374–384. [Google Scholar] [CrossRef]
- Muhammad Adnan, R.; Yuan, X.; Kisi, O.; Yuan, Y.; Tayyab, M.; Lei, X. Application of soft computing models in streamflow forecasting. Proc. Inst. Civ. Eng. Water Manag. 2017, 172, 123–134. [Google Scholar] [CrossRef]
- Noori, R.; Safavi, S.; Shahrokni, S.A.N. A reduced-order adaptive neuro-fuzzy inference system model as a software sensor for rapid estimation of five-day biochemical oxygen demand. J. Hydrol. 2013, 495, 175–185. [Google Scholar] [CrossRef]
- Kisi, O. Suspended sediment estimation using neuro-fuzzy and neural network approaches/Estimation des matières en suspension par des approches neurofloues et à base de réseau de neurones. Hydrol. Sci. J. 2005, 50, 696. [Google Scholar] [CrossRef]
- Cobaner, M.; Unal, B.; Kisi, O. Suspended sediment concentration estimation by an adaptive neuro-fuzzy and neural network approaches using hydro-meteorological data. J. Hydrol. 2009, 367, 52–61. [Google Scholar] [CrossRef]
- Kisi, O. Modeling discharge-suspended sediment relationship using least square support vector machine. J. Hydrol. 2012, 456, 110–120. [Google Scholar] [CrossRef]
- Yuan, X.; Wu, X.; Tian, H.; Yuan, Y.; Adnan, R.M. Parameter identification of nonlinear Muskingum model with backtracking search algorithm. Water Resour. Manag. 2016, 30, 2767–2783. [Google Scholar] [CrossRef]
- Melesse, A.M.; Ahmad, S.; McClain, M.E.; Wang, X.; Lim, Y.H. Suspended sediment load prediction of river systems: An artificial neural network approach. Agric. Water Manag. 2011, 98, 855–866. [Google Scholar] [CrossRef]
- Najah, A.; El-Shafie, A.; Karim, O.A.; El-Shafie, A.H. Performance of ANFIS versus MLP-NN dissolved oxygen prediction models in water quality monitoring. Environ. Sci. Pollut. Res. 2014, 21, 1658–1670. [Google Scholar] [CrossRef]
- Allawi, M.F.; El-Shafie, A. Utilizing RBF-NN and ANFIS methods for multi-lead ahead prediction model of evaporation from reservoir. Water Resour. Manag. 2016, 30, 4773–4788. [Google Scholar] [CrossRef]
- Ehteram, M.; Afan, H.A.; Dianatikhah, M.; Ahmed, A.N.; Fai, C.M.; Hossain, M.S.; Elshafie, A. Assessing the Predictability of an Improved ANFIS Model for Monthly Streamflow Using Lagged Climate Indices as Predictors. Water 2019, 11, 1130. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Zhang, D.Q.; Chen, S.C. A novel kernelized fuzzy c-means algorithm with application in medical image segmentation. Artif. Intell. Med. 2004, 32, 37–50. [Google Scholar] [CrossRef]
- Li, W.; Yang, Y. A new approach to TS fuzzy modeling using dual kernel-based learning machines. Neurocomputing 2008, 71, 3660–3665. [Google Scholar] [CrossRef]
- Kasabov, N.; Song, Q. DENFIS: Dynamic evolving neural-fuzzy inference system and its application for time series prediction. IEEE Trans. Fuzzy Syst. 2002, 10, 144–154. [Google Scholar] [CrossRef]
- Kisi, O.; Aytek, A. Explicit neural network in suspended sediment load estimation. Neural Netw. World 2013, 23, 587. [Google Scholar] [CrossRef]
- Kisi, O.; Parmar, K.S. Application of least square support vector machine and multivariate adaptive regression spline models in long term prediction of river water pollution. J. Hydrol. 2016, 534, 104–112. [Google Scholar] [CrossRef]
- Heddam, S. Modelling hourly dissolved oxygen concentration (DO) using dynamic evolving neural-fuzzy inference system (DENFIS)-based approach: Case study of Klamath River at Miller Island Boat Ramp, OR, USA. Environ. Sci. Pollut. Res. 2014, 21, 9212–9227. [Google Scholar] [CrossRef] [PubMed]
- Kwin, C.T.; Talei, A.; Alaghmand, S.; Chua, L.H. Rainfall-runoff modeling using dynamic evolving neural fuzzy inference system with online learning. Procedia Eng. 2016, 154, 1103–1109. [Google Scholar] [CrossRef][Green Version]
- Keshtegar, B.; Kisi, O.; Arab, H.G.; Zounemat-Kermani, M. Subset modeling basis ANFIS for prediction of the reference evapotranspiration. Water Resour. Manag. 2018, 32, 1101–1116. [Google Scholar] [CrossRef]
- Adnan, R.M.; Liang, Z.; Yuan, X.; Kisi, O.; Akhlaq, M.; Li, B. Comparison of LSSVR, M5RT, NF-GP, and NF-SC Models for Predictions of Hourly Wind Speed and Wind Power Based on Cross-Validation. Energies 2019, 12, 329. [Google Scholar] [CrossRef]
- Mahdavi-Meymand, A.; Scholz, M.; Zounemat-Kermani, M. Challenging soft computing optimization approaches in modeling complex hydraulic phenomenon of aeration process. ISH J. Hydraul. Eng. 2019, 1–12. [Google Scholar] [CrossRef]
- Kişi, O. Daily pan evaporation modelling using a neuro-fuzzy computing technique. J. Hydrol. 2006, 329, 636–646. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M. Assessment of several nonlinear methods in forecasting suspended sediment concentration in streams. Hydrol. Res. 2016, 48, 1240–1252. [Google Scholar] [CrossRef]
- Karaboga, D.; Kaya, E. Adaptive network based fuzzy inference system (ANFIS) training approaches: A comprehensive survey. Artif. Intell. Rev. 2018, 1–31. [Google Scholar] [CrossRef]
- Saad, R.M.; Almomani, A.; Altaher, A.; Gupta, B.B.; Manickam, S. ICMPv6 flood attack detection using DENFIS algorithms. Indian J. Sci. Technol. 2014, 7, 168. [Google Scholar]
- Amudha, J.; Radha, D. Optimization of Rules in Neuro-Fuzzy Inference Systems. In Computational Vision and Bio Inspired Computing; Springer: Cham, Switzerland, 2018; pp. 803–818. [Google Scholar]
- Friedman, J.H. Multivariate adaptive regression splines. Ann. Stat. 1991, 19, 1–67. [Google Scholar] [CrossRef]
- Wang, L.; Kisi, O.; Zounemat-Kermani, M.; Gan, Y. Comparison of six different soft computing methods in modeling evaporation in different climates. Earth Syst. Sci. Discuss. Earth Syst. Sci. 2016, 247, 1–51. [Google Scholar] [CrossRef]
- Yilmaz, B.; Aras, E.; Nacar, S.; Kankal, M. Estimating suspended sediment load with multivariate adaptive regression spline, teaching-learning based optimization, and artificial bee colony models. Sci. Total Environ. 2018, 639, 826–840. [Google Scholar] [CrossRef] [PubMed]
- Jekabsons, G. ARESLab: Adaptive Regression Splines Toolbox for Matlab/Octave (ver. 1.10. 3); Institute of Applied Computer Systems Riga Technical University: Riga, Latvia, 2016. [Google Scholar]
- MATLAB. MATLAB 2012a for Windows. 2012. Available online: http://cn.mathworks.com/support/compilers/R2012a/win64.html/ (accessed on 15 April 2019).
- Yuan, X.; Ji, B.; Yuan, Y.; Ikram, R.M.; Zhang, X.; Huang, Y. An efficient chaos embedded hybrid approach for hydro-thermal unit commitment problem. Energy Convers. Manag. 2015, 91, 225–237. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistical Parameters | Guangyuan Station | Beibei Station | ||||
|---|---|---|---|---|---|---|
| Whole Data | Training Data | Testing Data | Whole Data | Training Data | Testing Data | |
| Streamflow (m3/s) | ||||||
| xmean | 175.1 | 198.3 | 93.9 | 2136 | 2231 | 1805 |
| xmin | 4.5 | 4.5 | 10.8 | 105 | 105 | 281 |
| xmax | 6290 | 6290 | 1890 | 34,700 | 34,700 | 20,800 |
| Csx | 6.84 | 6.26 | 7.06 | 4.32 | 4.15 | 4.77 |
| Sx | 336 | 372 | 126 | 3230 | 3427 | 2388 |
| 36 | 32 | 20 | 16 | 16 | 12 | |
| Cv (Sx/xmean) | 1.92 | 1.88 | 1.34 | 1.51 | 1.54 | 1.32 |
| Sediment (kg/s) | ||||||
| xmean | 431.9 | 541 | 49.9 | 971 | 1139 | 381 |
| xmin | 0.349 | 0.91 | 0.349 | 0.105 | 0.105 | 1.69 |
| xmax | 49,600 | 49,600 | 7660 | 113,000 | 113,000 | 36,600 |
| Csx | 12.1 | 10.7 | 19.2 | 10.5 | 9.73 | 9.96 |
| Sx | 2673 | 3018 | 321 | 5681 | 6287 | 2533 |
| 115 | 91.7 | 154 | 116 | 99 | 96 | |
| Cv (Sx/xmean) | 6.19 | 5.58 | 6.44 | 5.85 | 5.52 | 6.65 |
| Models | Scenario | Model Inputs | Model Parameters | Training Period | Test Period | ||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | NSE | RMSE | MAE | NSE | ||||
| S1 | Qt, | 0.05 | 1968 | 356 | 0.575 | 217 | 37.9 | 0.541 | |
| S2 | Qt, Qt−1 | 0.14 | 1797 | 366 | 0.646 | 164 | 35.7 | 0.739 | |
| S3 | Qt, Qt−1, Qt−2 | 0.11 | 2257 | 409 | 0.515 | 146 | 34.1 | 0.793 | |
| DENFIS | S4 | Qt, Qt−1, Qt−2, Qt−3 | 0.13 | 2167 | 418 | 0.832 | 134 | 32.2 | 0.861 |
| S5 | Qt, Qt−1, Qt−2, Qt−3, St−1 | 0.12 | 1986 | 353 | 0.567 | 168 | 22.4 | 0.726 | |
| S6 | Qt, Qt−1, Qt−2, Qt−3, St−1, St−2 | 0.11 | 2137 | 403 | 0.499 | 187 | 23.6 | 0.661 | |
| S7 | Qt, Qt−1, Qt−2, Qt−3, St−1, St−2, St−3 | 0.11 | 2340 | 435 | 0.399 | 228 | 29.4 | 0.495 | |
| S1 | Qt, | 5,100 | 1828 | 373 | 0.633 | 294 | 69.4 | 0.164 | |
| S2 | Qt, Qt−1 | 6,10 | 1787 | 367 | 0.650 | 270 | 55.9 | 0.293 | |
| ANFIS-FCM | S3 | Qt, Qt−1, Qt−2 | 4,100 | 1803 | 372 | 0.643 | 295 | 59.9 | 0.157 |
| S4 | Qt, Qt−1, St−1 | 8,90 | 1322 | 243 | 0.808 | 318 | 46.5 | 0.020 | |
| S5 | Qt, Qt−1, St−1, St−2 | 8,70 | 1266 | 228 | 0.824 | 199 | 33.4 | 0.826 | |
| S6 | Qt, Qt−1, St−1, St−2, St−3 | 8,80 | 1807 | 363 | 0.642 | 258 | 52.1 | 0.353 | |
| S1 | Qt, | - | 1760 | 372 | 0.660 | 327 | 65.0 | −0.036 | |
| S2 | Qt, Qt−1 | - | 1758 | 376 | 0.661 | 368 | 80.3 | −0.316 | |
| MARS | S3 | Qt, St−1 | - | 1578 | 337 | 0.727 | 239 | 64.5 | 0.446 |
| S4 | Qt, St−1, St−2 | - | 1614 | 343 | 0.714 | 195 | 62.4 | 0.631 | |
| S5 | Qt, St−1, St−2, St−3 | - | 1595 | 343 | 0.721 | 254 | 60.9 | 0.372 | |
| Models | Scenario | Model Inputs | Model Parameters | Training Period | Test Period | ||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | NSE | RMSE | MAE | NSE | ||||
| S1 | Qt, | 0.01 | 4014 | 663 | 0.593 | 1546 | 229 | 0.628 | |
| S2 | Qt, Qt−1 | 0.17 | 3779 | 656 | 0.639 | 1417 | 233 | 0.687 | |
| S3 | Qt, Qt−1, Qt−2 | 0.02 | 4158 | 711 | 0.563 | 1177 | 204 | 0.784 | |
| DENFIS | S4 | Qt, Qt−1, Qt−2, Qt−3 | 0.06 | 4302 | 732 | 0.532 | 1024 | 169 | 0.837 |
| S5 | Qt, Qt−1, Qt−2, Qt−3, St−1 | 0.15 | 4325 | 753 | 0.527 | 1153 | 184 | 0.793 | |
| S6 | Qt, Qt−1, Qt−2, Qt−3, St−1, St−2 | 0.05 | 3936 | 663 | 0.609 | 797 | 134 | 0.901 | |
| S7 | Qt, Qt−1, Qt−2, Qt−3, St−1, St−2, St−3 | 0.06 | 4237 | 752 | 0.547 | 884 | 149 | 0.878 | |
| S1 | Qt, | 8,20 | 3802 | 656 | 0.635 | 1214 | 228 | 0.770 | |
| S2 | Qt, Qt−1 | 8,10 | 3707 | 663 | 0.653 | 1235 | 224 | 0.762 | |
| ANFIS-FCM | S3 | Qt, Qt−1, Qt−2 | 4,80 | 3742 | 657 | 0.646 | 1171 | 257 | 0.786 |
| S4 | Qt, Qt−1, Qt−2, Qt−3 | 5,30 | 4084 | 801 | 0.579 | 1864 | 328 | 0.459 | |
| S5 | Qt, St−1 | 8,20 | 3685 | 620 | 0.657 | 1312 | 215 | 0.732 | |
| S6 | Qt, St−1, St−2 | 6,60 | 3332 | 606 | 0.720 | 1616 | 229 | 0.784 | |
| S7 | Qt, St−1, St−2, St−3 | 5,50 | 4410 | 871 | 0.509 | 2772 | 407 | −0.197 | |
| S1 | Qt, | - | 3646 | 631 | 0.664 | 1423 | 284 | 0.685 | |
| S2 | Qt, Qt−1 | - | 3596 | 629 | 0.673 | 1509 | 271 | 0.645 | |
| MARS | S3 | Qt, St−1 | - | 3089 | 518 | 0.759 | 1252 | 213 | 0.756 |
| S4 | Qt, St−1, St−2 | - | 2945 | 523 | 0.781 | 1362 | 229 | 0.711 | |
| S5 | Qt, St−1, St−2, St−3 | - | 2905 | 520 | 0.787 | 1397 | 234 | 0.696 | |
| Date | Peaks > 900 kg/s | Relative Error | |||||
|---|---|---|---|---|---|---|---|
| DENFIS kg/s | ANFIS-FCM kg/s | MARS kg/s | DENFIS % | ANFIS-FCM % | MARS % | ||
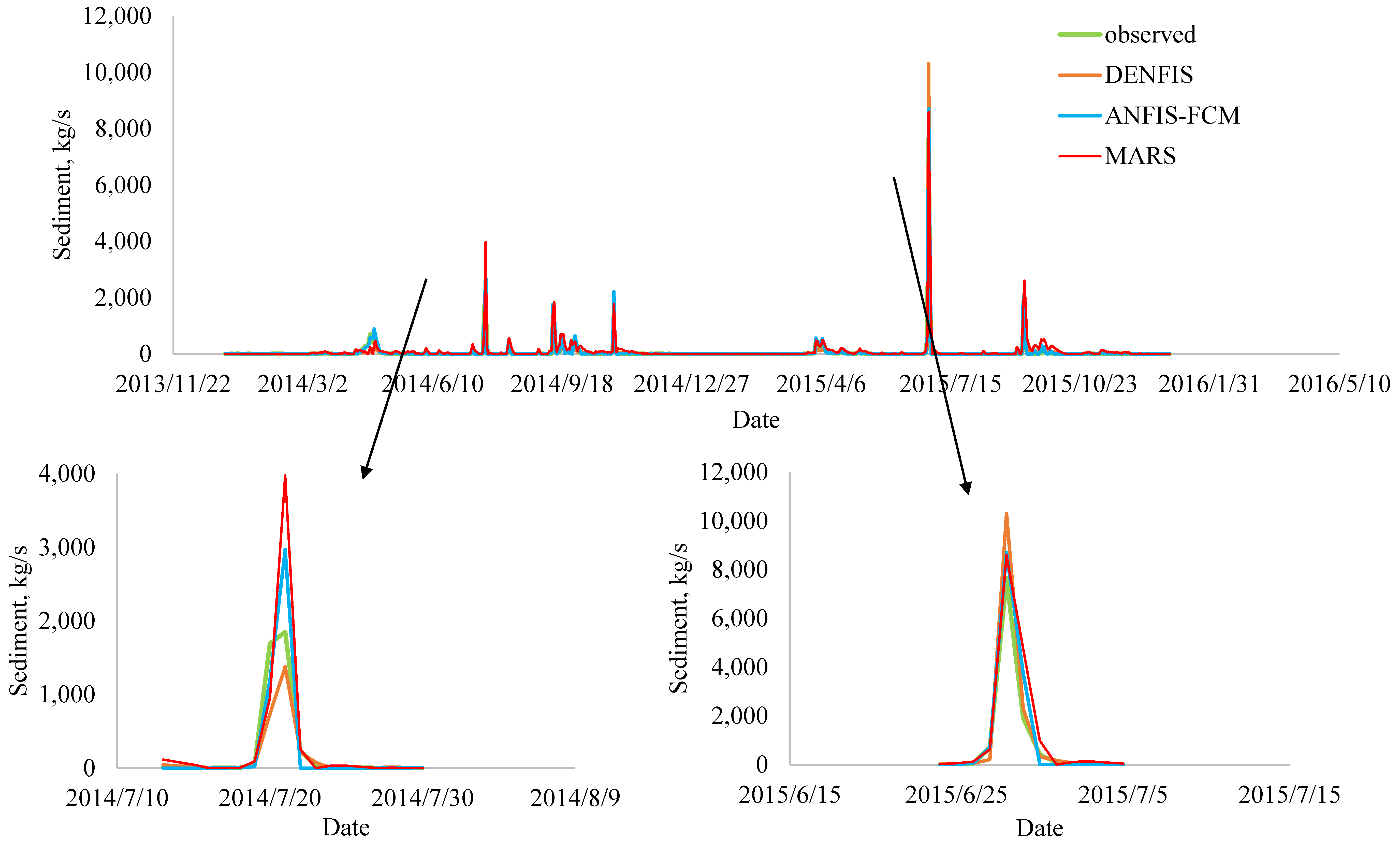
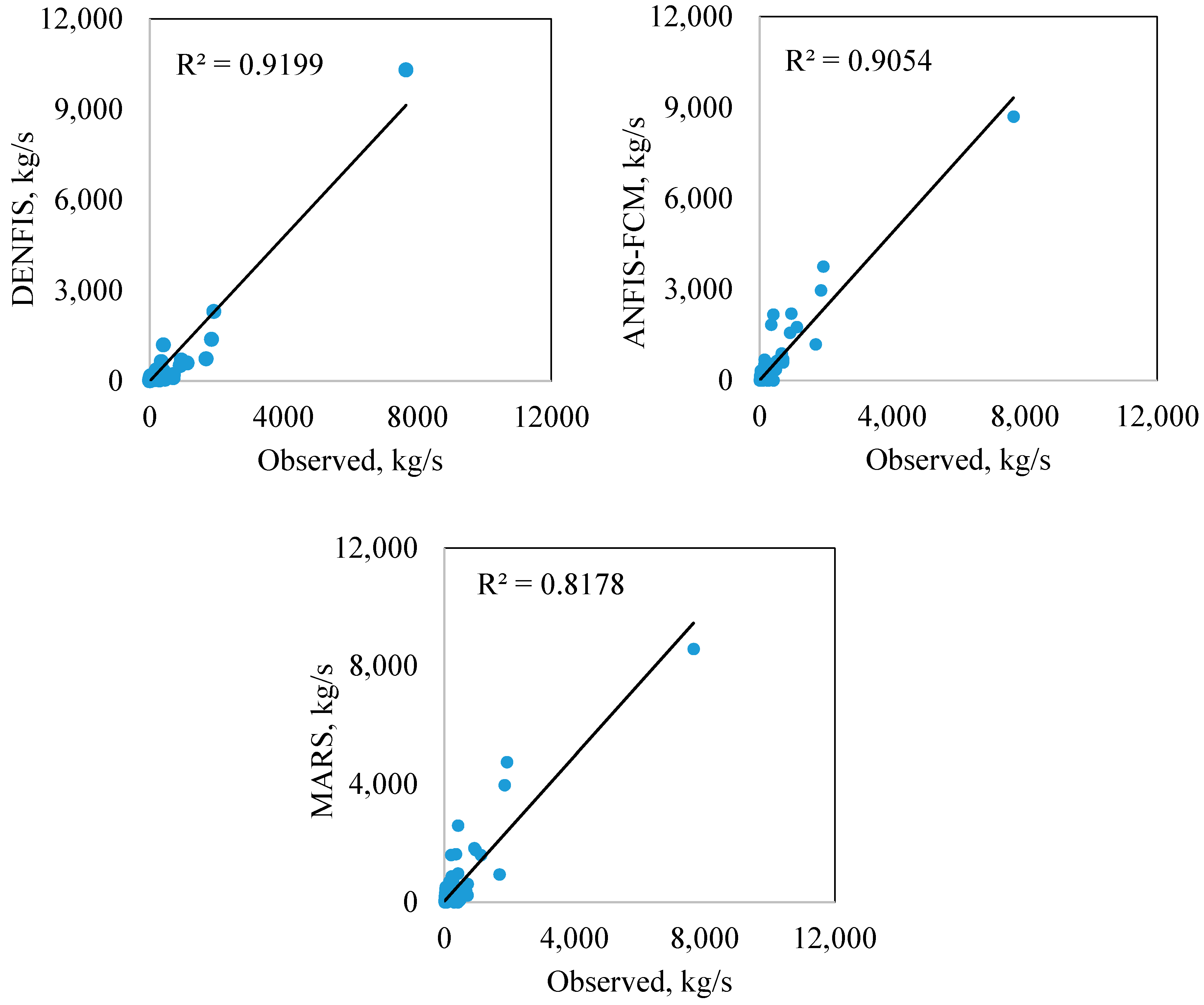
| 7 July 2014 | 1690 | 733.37 | 1191.2 | 946.26 | −56.6 | −29.5 | −44.0 |
| 21 July 2014 | 1850 | 1376.5 | 2970.8 | 3977.1 | −25.6 | 60.6 | 115.0 |
| 11 September 2014 | 1120 | 590.73 | 1764.6 | 1600.9 | −47.3 | 57.6 | 42.9 |
| 12 September 2014 | 917 | 511.98 | 1573.3 | 1839.7 | −44.2 | 71.6 | 100.6 |
| 28 June 2015 | 7660 | 10,309 | 8704.3 | 8585.3 | 34.6 | 13.6 | 12.1 |
| 29 June 2015 | 1920 | 2302.3 | 3756.8 | 4758.9 | 19.9 | 95.7 | 147.9 |
| Total (Absolute) = | 228 | 329 | 462 | ||||
| Date | Peaks > 11,000 kg/s | Relative Error | |||||
|---|---|---|---|---|---|---|---|
| DENFIS kg/s | ANFIS-FCM kg/s | MARS kg/s | DENFIS % | ANFIS-FCM % | MARS % | ||
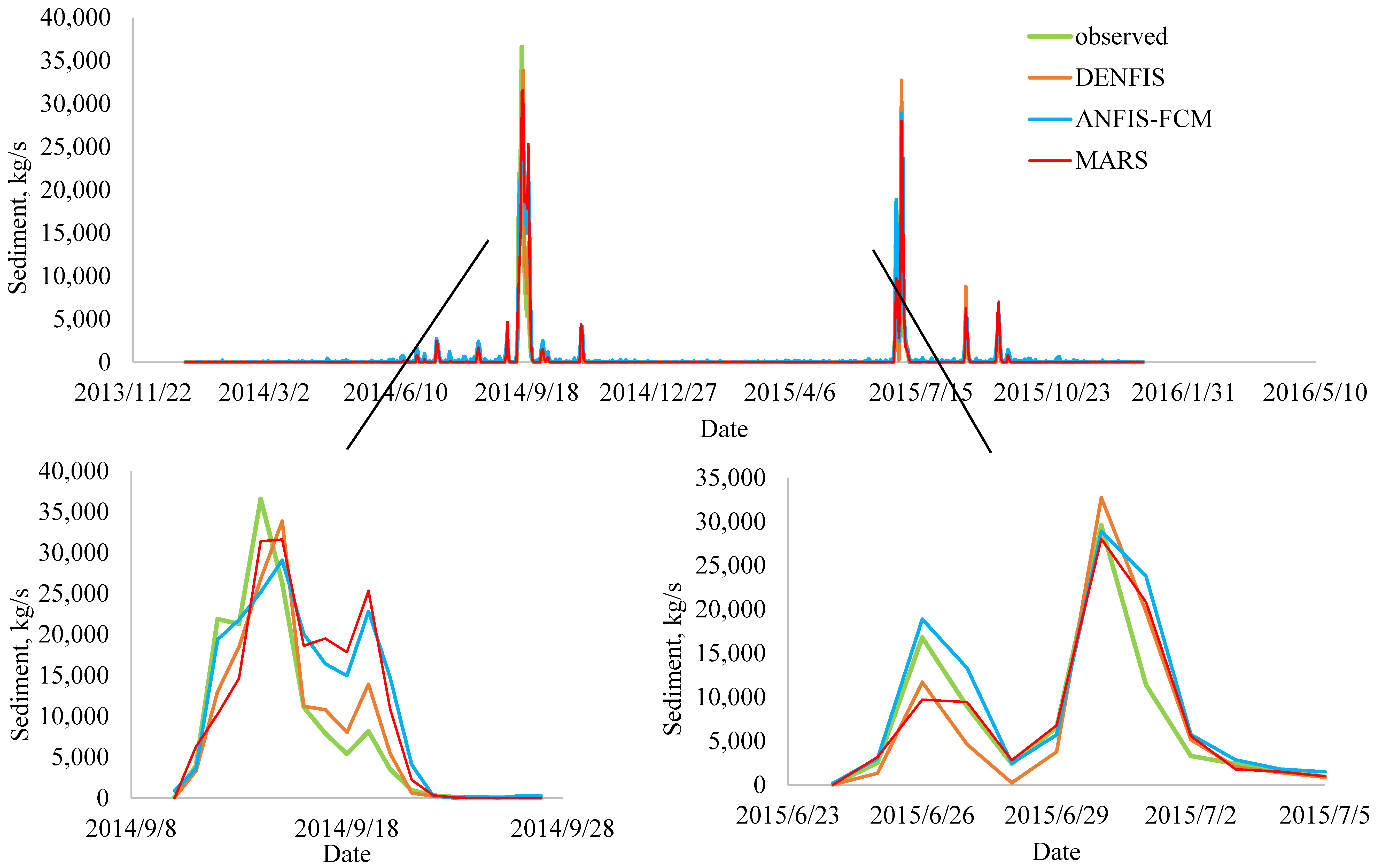
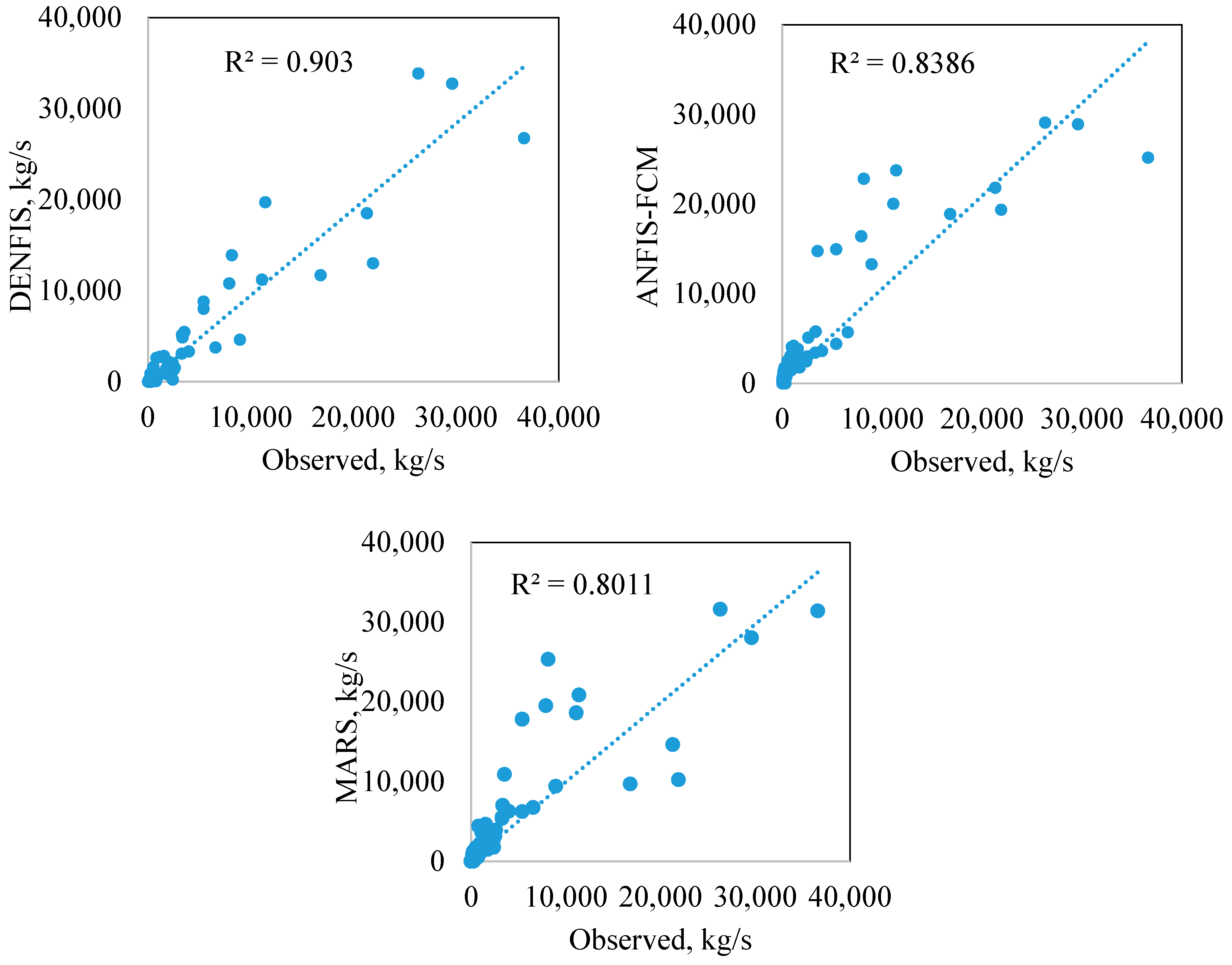
| 12 September 2014 | 21,900 | 13,021 | 19,377 | 10,258 | −40.5 | −11.5 | −53.2 |
| 13 September 2014 | 21,300 | 18,516 | 21,817 | 14,659 | −13.1 | 2.4 | −31.2 |
| 14 September 2014 | 36,600 | 26,760 | 25,166 | 31,414 | −26.9 | −31.2 | −14.2 |
| 15 September 2014 | 26,300 | 33,871 | 29,084 | 31,615 | 28.8 | 10.6 | 20.2 |
| 16 September 2014 | 11,100 | 11,219 | 20,040 | 18,622 | 1.1 | 80.5 | 67.8 |
| 26 June 2015 | 16,800 | 11,704 | 18,896 | 9720.9 | −30.3 | 12.5 | −42.1 |
| 30 June 2015 | 29,600 | 32,742 | 28,895 | 28,031 | 10.6 | −2.4 | −5.3 |
| 1 July 2015 | 11,400 | 19,727 | 23,768 | 20,847 | 73.1 | 108.5 | 82.9 |
| Total (Absolute) = | 224 | 260 | 317 | ||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adnan, R.M.; Liang, Z.; El-Shafie, A.; Zounemat-Kermani, M.; Kisi, O. Prediction of Suspended Sediment Load Using Data-Driven Models. Water 2019, 11, 2060. https://doi.org/10.3390/w11102060
Adnan RM, Liang Z, El-Shafie A, Zounemat-Kermani M, Kisi O. Prediction of Suspended Sediment Load Using Data-Driven Models. Water. 2019; 11(10):2060. https://doi.org/10.3390/w11102060
Chicago/Turabian StyleAdnan, Rana Muhammad, Zhongmin Liang, Ahmed El-Shafie, Mohammad Zounemat-Kermani, and Ozgur Kisi. 2019. "Prediction of Suspended Sediment Load Using Data-Driven Models" Water 11, no. 10: 2060. https://doi.org/10.3390/w11102060
APA StyleAdnan, R. M., Liang, Z., El-Shafie, A., Zounemat-Kermani, M., & Kisi, O. (2019). Prediction of Suspended Sediment Load Using Data-Driven Models. Water, 11(10), 2060. https://doi.org/10.3390/w11102060