2.2. Numerical Code Iber+
Iber+ is a new code that implements a parallelization of the hydraulic module of Iber [
3], which is a hydraulic model that solves 2D shallow water equations using an unstructured finite volume solver. The software package Iber provides a user-friendly graphical user interface for pre- and post-processing and can be freely downloaded from
http://iberaula.es. The Iber code is programmed in Fortran and it is partially parallelized with OpenMP. Even if the computation time is reduced by using this technique, the code is unable to efficiently use current multi-core processors, so the speedup that can be achieved is quite limited. Simulation time becomes critical when addressing certain kinds of problems such as real-time flood forecasting, Monte Carlo-based simulations, high-resolution rainfall–runoff modelling, or long term simulations.
The main aim of the Iber+ code is to significantly improve the computational efficiency of Iber, while being fully compatible with the Iber software. The new code has an object-oriented implementation programmed in C++. It is parallelized for shared memory systems with OpenMP and it also provides an Nvidia CUDA implementation for execution in GPUs.
OpenMP is an API (application programming interface) that allows easy parallelization of traditional loops using compiler directives. However, to achieve significant speedups, there are several aspects to be taken into account. The parallelization of a loop generates an overhead, so the parallelization of low-cycle loops could be counter-productive. It is also important to consider the granularity of loops. Combining simple loops into larger loops can reduce parallelism overhead, however this could affect the automatic vectorization. With vectorization enabled in the compiler, a program can use the SIMD (single instruction multiple data) instruction set, e.g., SSE (streaming SIMD extensions) or AVX (advanced vector extensions), that provides extra computing power in modern CPUs. However, loops that use branching or other complex structures may not be vectorized automatically. On the other hand, the principle of locality is fundamental. Modern CPUs have a complex memory hierarchy, including several levels of cache memory. Accessing a memory position that is not in cache implies a significant penalty. Therefore, memory access patterns should be studied and the design of suitable data structures is fundamental to achieve good performance. For instance, choices between using an array of structures or a structure of arrays should be evaluated for each algorithm.
GPUs use highly parallel architectures that confer them a high amount of computing power. This is needed to render complex 3D computer graphics scenes. Since most GPUs are programmable, the manufacturers provide APIs for GPGPU (general processing graphics processing unit) computing. This technology makes the processing power of GPUs available to problems not necessarily related to graphics. One of the most common GPGPU APIs used for scientific purposes is Nvidia CUDA, providing access to the GPUs with traditional programming languages like C/C++ or Fortran.
Nvidia GPUs are made of a large amount of processors organized in streaming multiprocessors (SMs) employing a single instruction multiple thread (SIMT) architecture. Each SM executes several threads in parallel, in groups of 32, called warps. All the threads start on the same program address but have their own registers. However, one warp can only execute one instruction at a time. If one of the threads branches to a different path than the rest, a divergence occurs. In that case, that path will be executed while the other threads are stalled, and later the other path, until the threads converge again. This procedure can produce a heavy performance penalty if it occurs frequently.
Another critical issue is reduction algorithms. In GPUs, global synchronization is expensive, so this kind of algorithm is not as trivial as in CPUs. To avoid heavy performance penalties, an alternative approach must be employed. In Iber+, the library Nvidia CUB (CUDA unbound) was employed to implement reduction algorithms. CUB is an open-source high performance library [
19] developed by Nvidia that provides reusable pieces of software for CUDA programming.
The last issue to address when programming GPUs is data transfer. Unlike integrated GPUs of mobile devices where the GPU and CPU share the same memory, discrete high-performance GPUs are issued in separate cards with their own memories. The GPU memory is usually faster and smaller than the main system memory and is located in a different address space. As the memory transfers from the system memory to the GPU memory are done via the PCI (peripheral component interconnect) bus, the bandwidth is limited and causes a bottleneck that needs attention. Even though the API can provide a unified address space, data transfers should be carefully made to avoid performance penalties. As data transfers are expensive, it could be more profitable to do certain computations (like reductions) on the GPU and being slower than on the CPU, rather than needing to transfer the data to system memory and run them on the CPU.
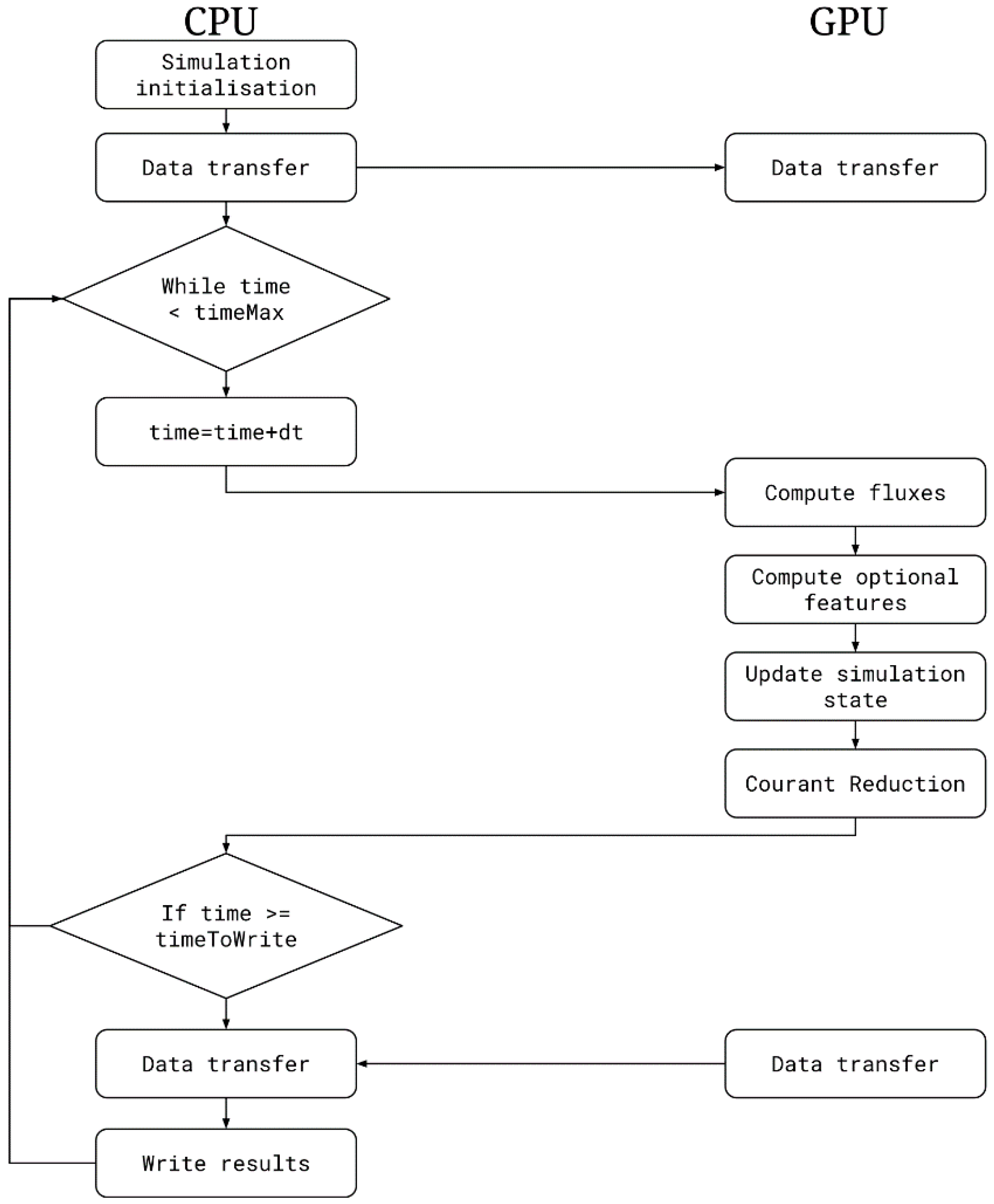
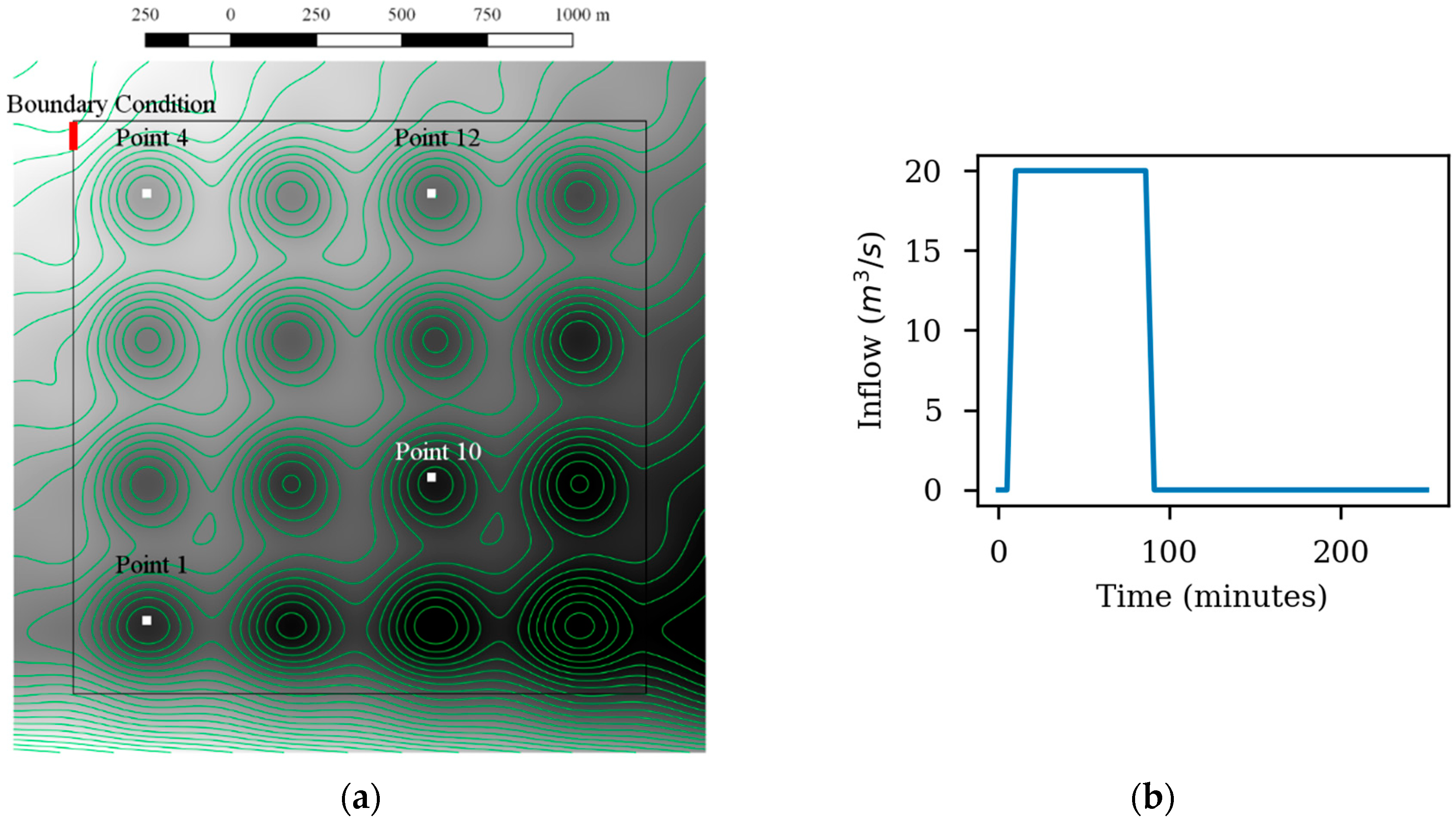
Figure 1 shows the flow chart of the Iber+ execution. Once the simulation is started, most of the computations are performed on the GPU, minimizing the data transfers.
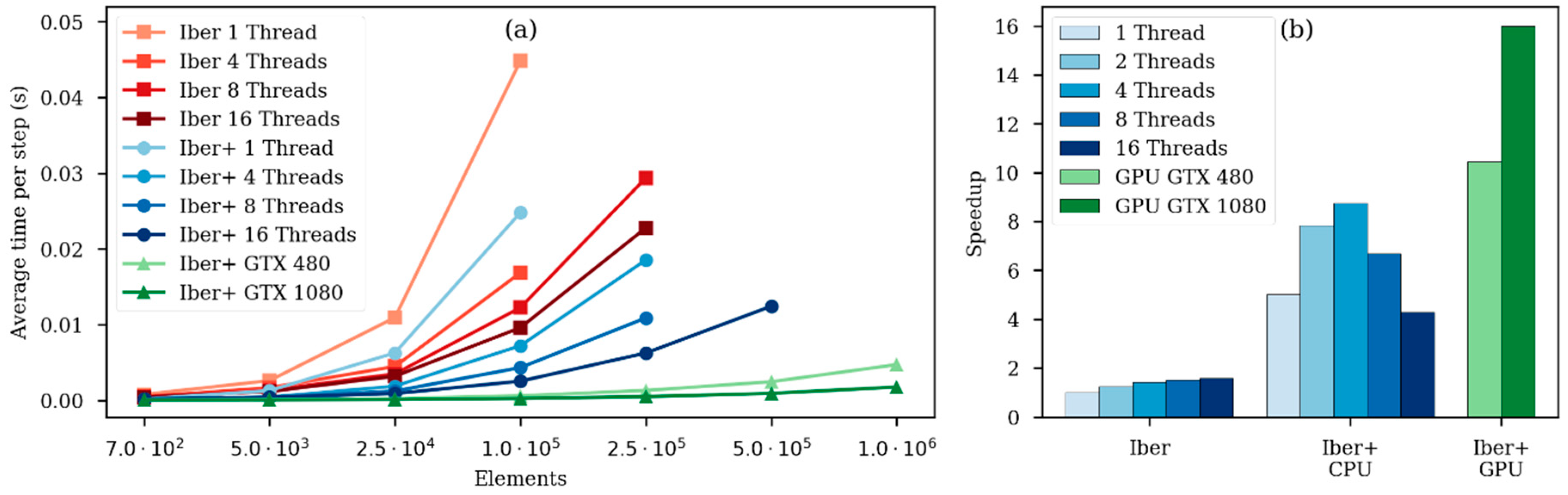
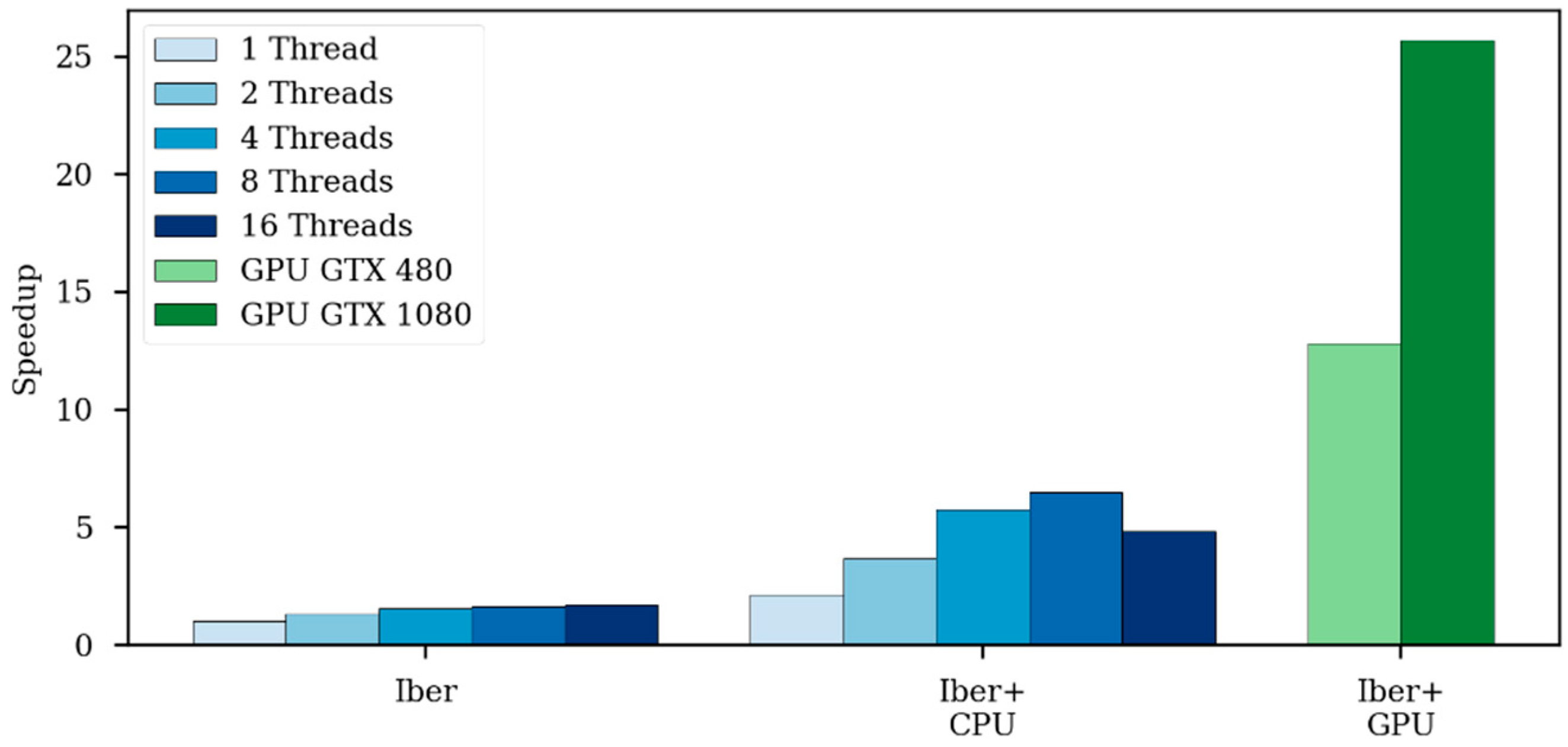
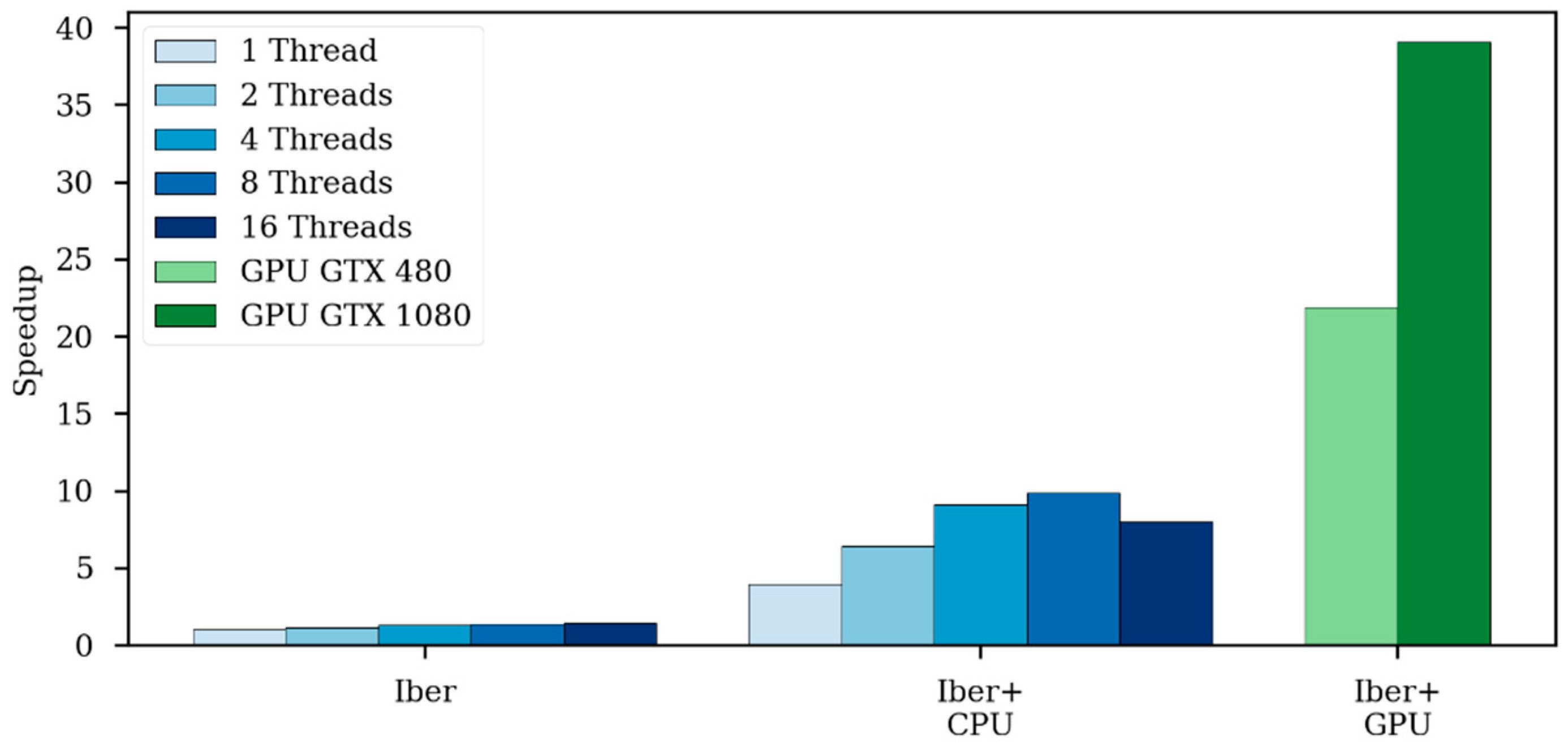
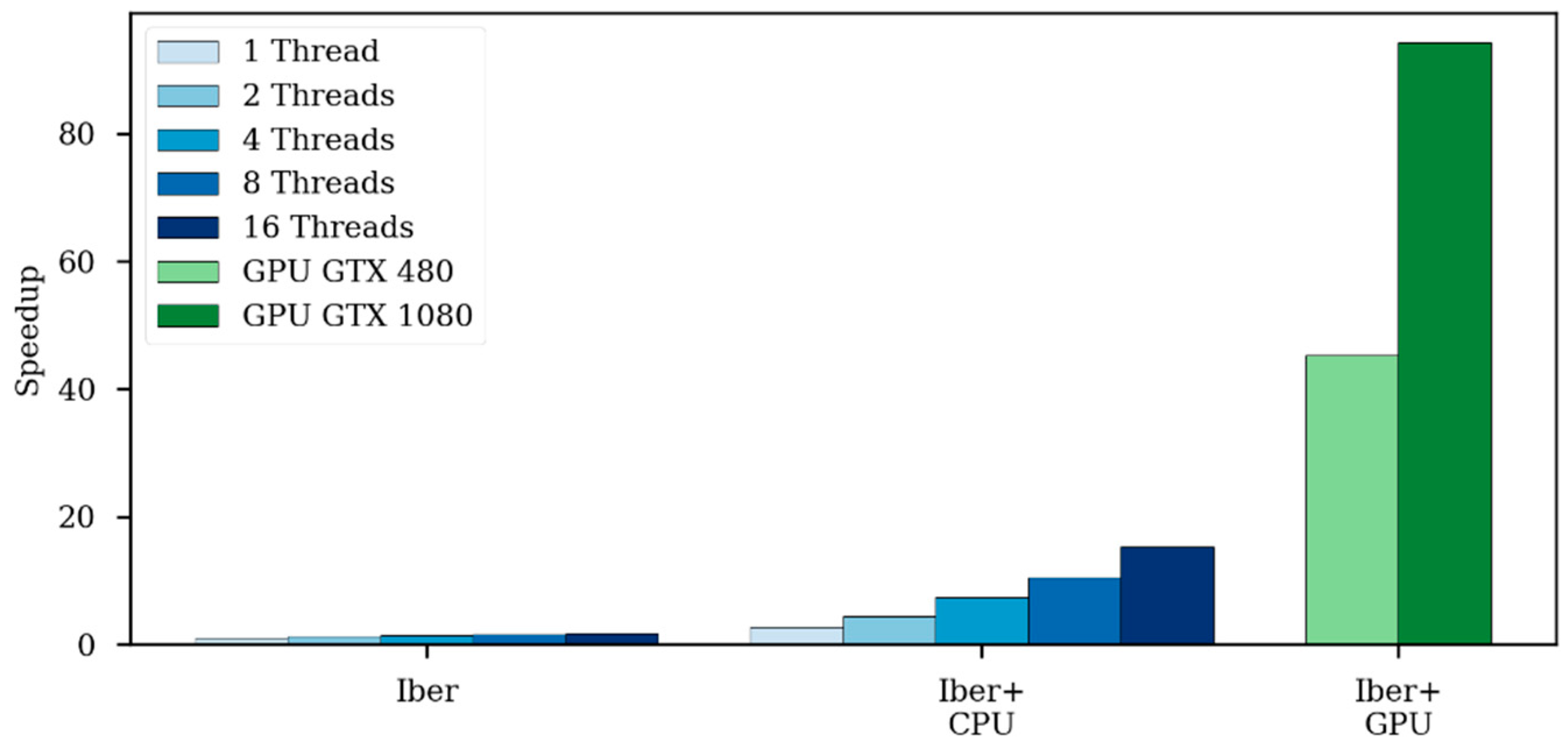
The speedup achieved by using a GPU in respect to the CPU implementation increases as the problem size gets bigger. The speedup increases until the GPU computation capacity is saturated; this occurs when all GPU processors are effectively used.
Both the Iber and Iber+ CPU code uses only double precision computations. However, in GPU computing, using double precision could suppose a considerable performance penalty. Depending on the specific GPU model, the theoretical performance in double precision could be from two to more than ten times slower [
20]. In this work, the GPU computations were performed in single precision because no significant differences were found in the cases analyzed. However, some applications may require the use of double precision arithmetic, so this option will be added in further versions.
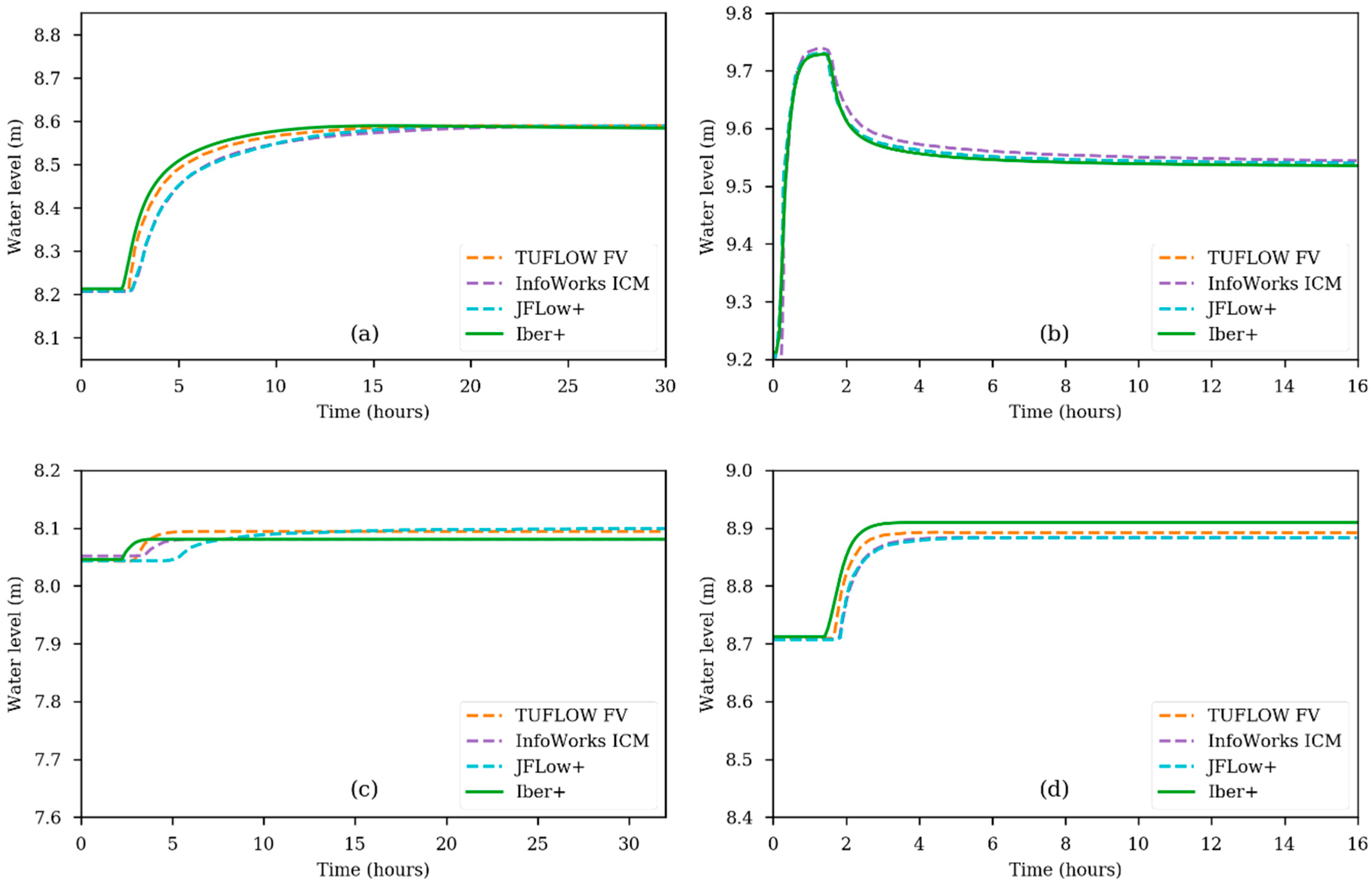
The Iber+ implementation is based on the Iber code, but reimplemented from scratch in C++. No substantial modifications were made to the original algorithms. The computations are made using unstructured meshes and the fluxes are solved at the edges of the underlying graph data structure. However, data structures were revised and optimized to reduce the memory footprint and to improve the memory access patterns. Even though Iber has most of its loops parallelized with OpenMP, these were redesigned in Iber+ to avoid critical regions and data dependencies that limited the speedup that could be achieved. These and other minor optimizations were done for the computation routines. Moreover, I/O (input/output) routines were optimized to avoid unnecessary data reading and writing.
For the GPU implementation, several drawbacks as mentioned previously should be considered. In order to achieve the highest speedup with GPU computing, memory transfers should be reduced as much as possible. Therefore, most of the computation routines were implemented in CUDA. Once the simulation is initialized, the data is transferred to the GPU. Then, most of the simulation is performed on the GPU and the only data transferred from the GPU are the results that should be written to disk or single variables like the time step. Additionally, as the CPU is free while the GPU is performing the computations, the CPU can run other tasks like writing the results to disk in parallel, hence, further improving the overall run time of the simulation.

 ,
, 






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}