


Solar and Wind 24 H Sequenced Prediction Using L-Transform Component and Deep LSTM Learning in Representation of Spatial Pattern Correlation


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- First identification of model initialisation times in applicable data periods.
- Sampling of detected training intervals based on similarity parameters.
- Evolutionarily produced PDE components related to the pattern complexity.
- Self-combination of the most valuable node double inputs in a tree-like structure.
- PDE node transformation and inverse solution based on adapted numerical procedures.
- Optimisation of the network structure and the combinatorial selection of PDE modules.
- Assessment of the testing model in the final computing stage.
2. State of the Art in Solar and Wind Series Daily Similarity Prediction
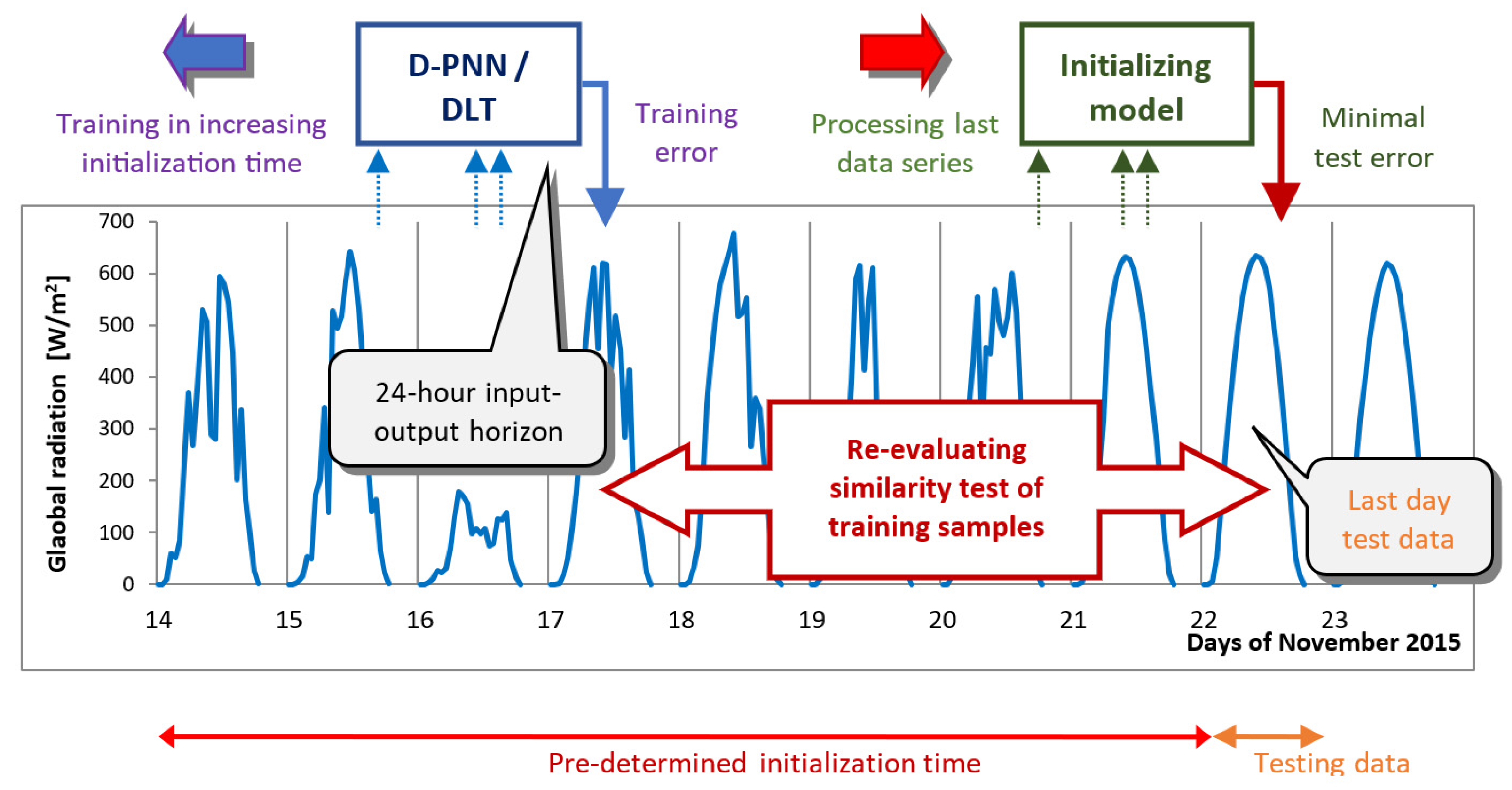
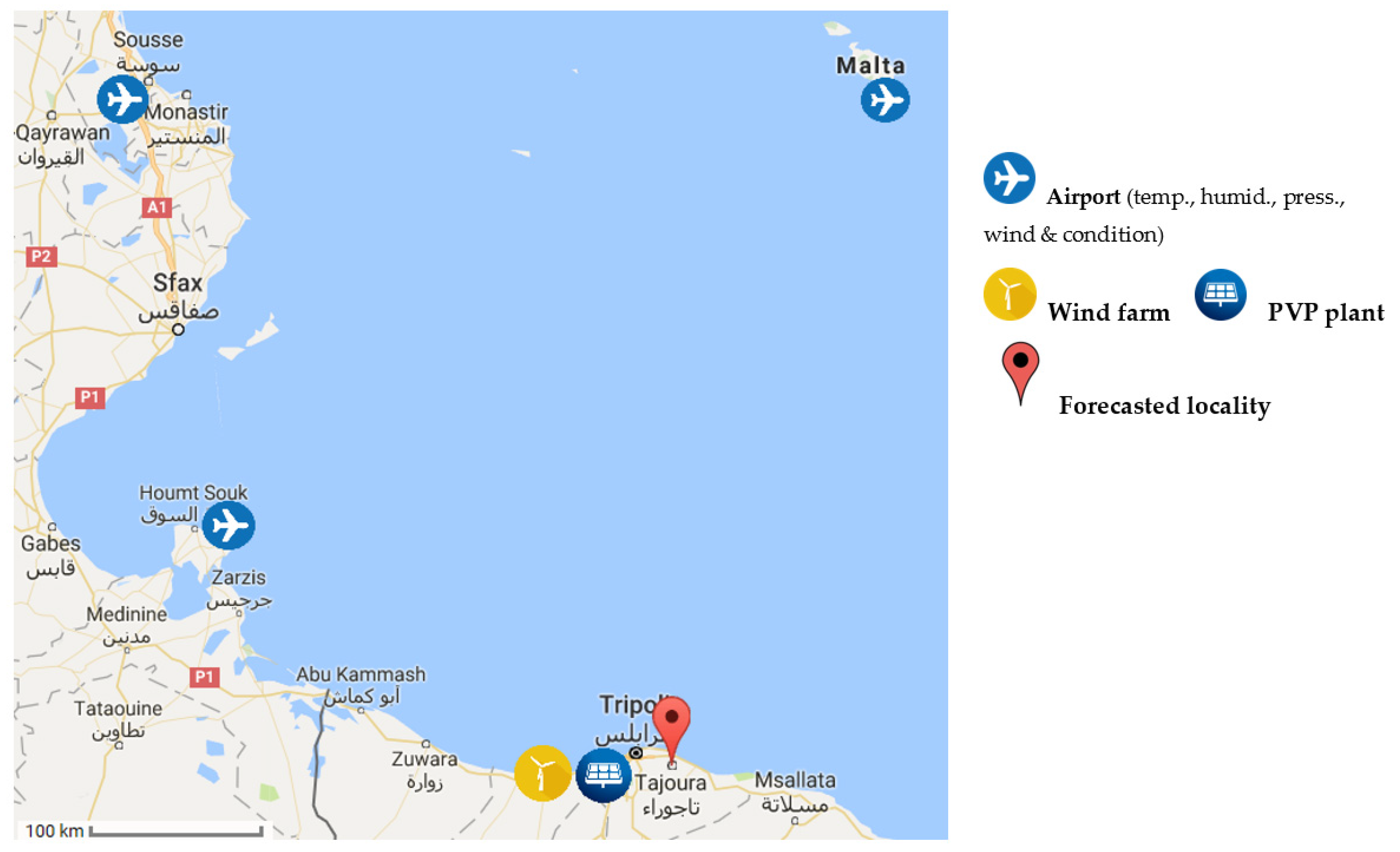
3. Observation Data and Methodology in Solar–Wind Series Mid-Term Forecasting
4. Modelling Using AI Computational Tools
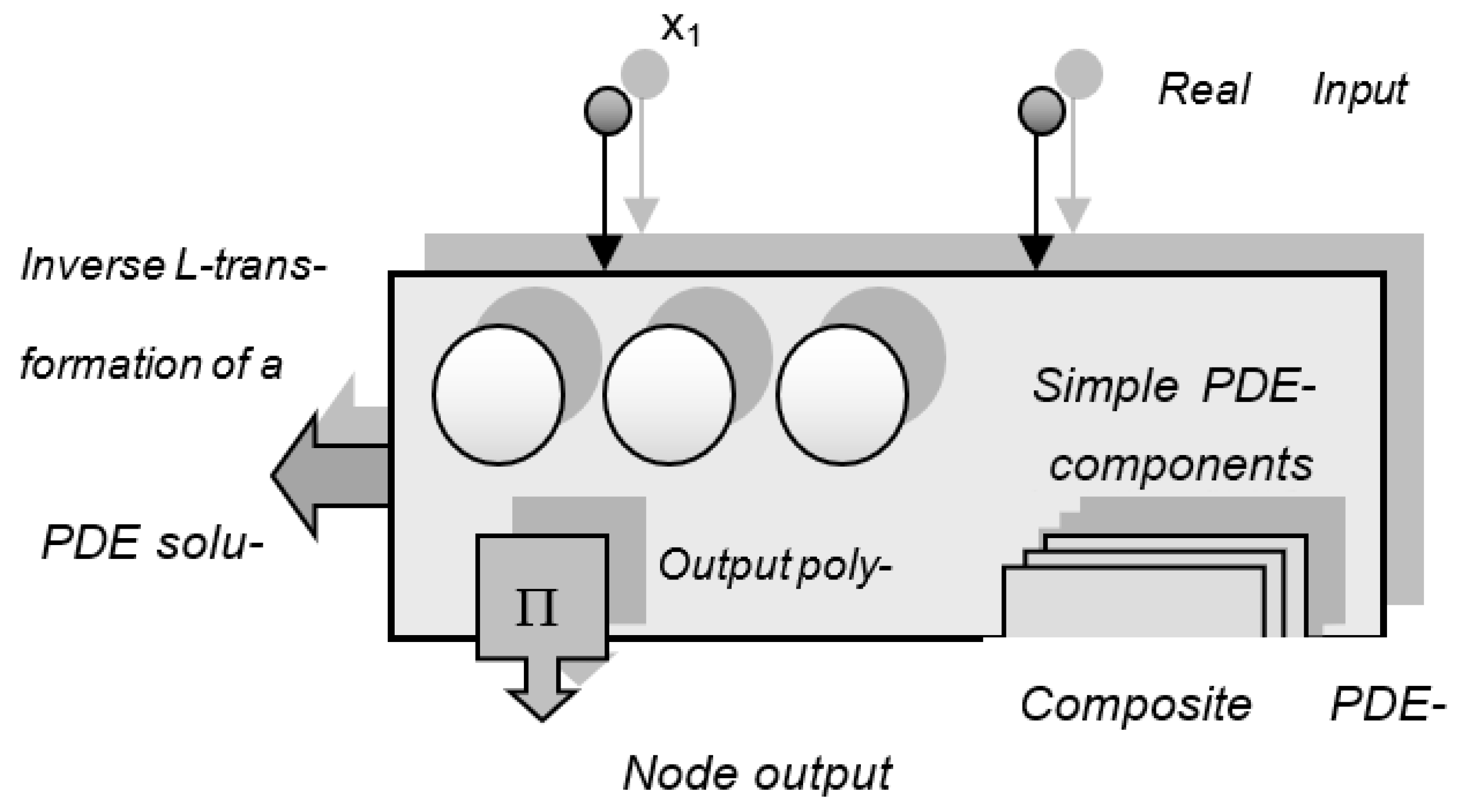
4.1. Differential Learning—An Innovative Neuro-Maths Computational Strategy
- Parsing the n-dimensional PDE into self-recognised PDE node transform solutions
- Progressive evolving trees, adding nodes, one by one, in a back-computing framework
- Automatic selection of single PDE modules in nodes to extend the summary model
- Diverse types of PDE conversion functions using adapted OC in the model composition
- Derivative L-converted PDE and the OC inverse operation to obtain the node originals
- Recognition of the input optima in evolving tree structures producing PDE components
- Input dimensionality is not over-reduced, which prevents model simplification
- Combinatorial PDE node modular solutions in optimal pattern representation
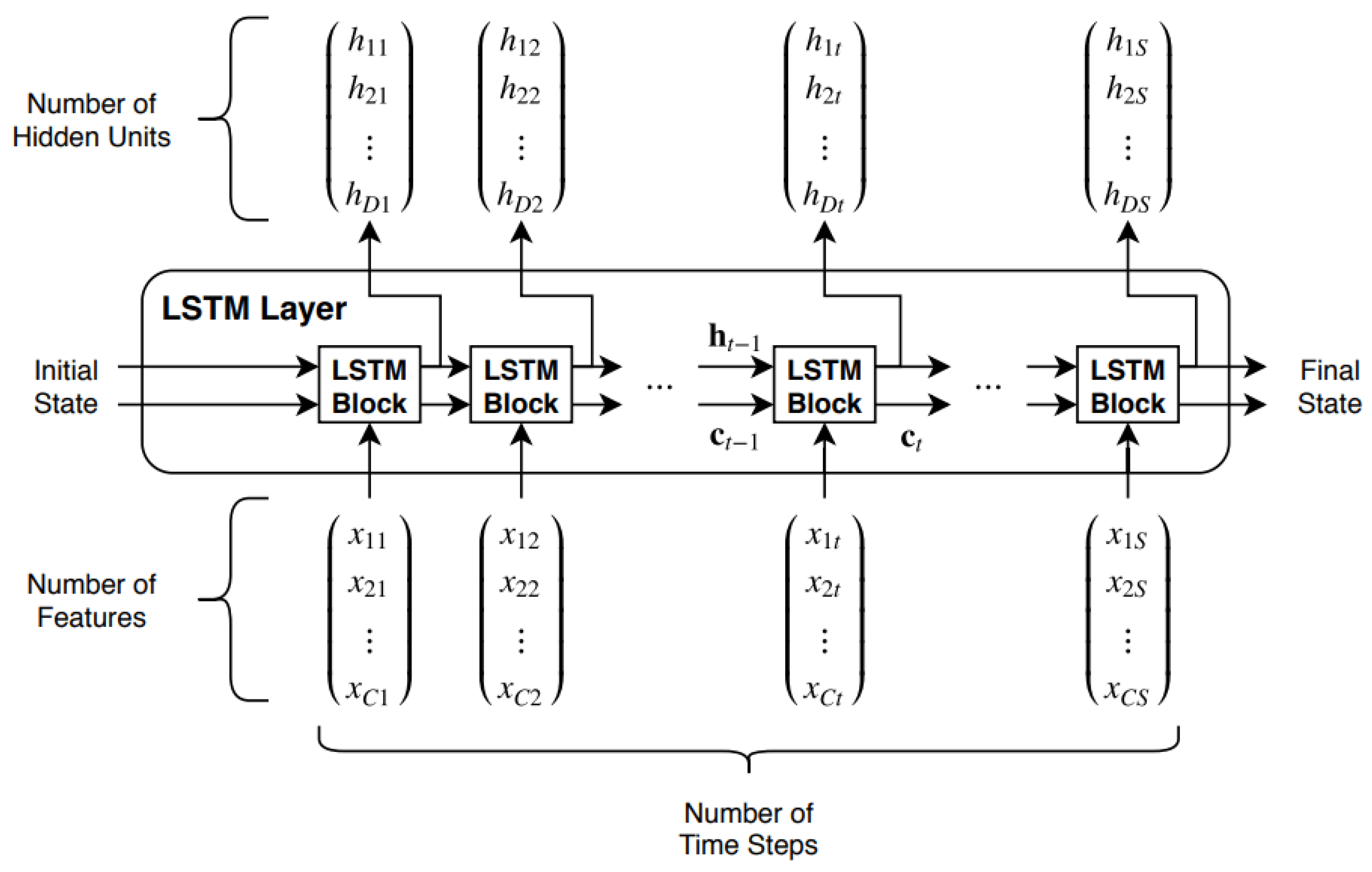
4.2. Matlab—LSTM Deep Learning
- First layer: Sequence input
- Second layer: LSTM network
- Third layer: Fully connecting
- Fourth layer: Dropout
- Fifth layer: Fully connecting (regress)
- Sixth layer: Output net regression
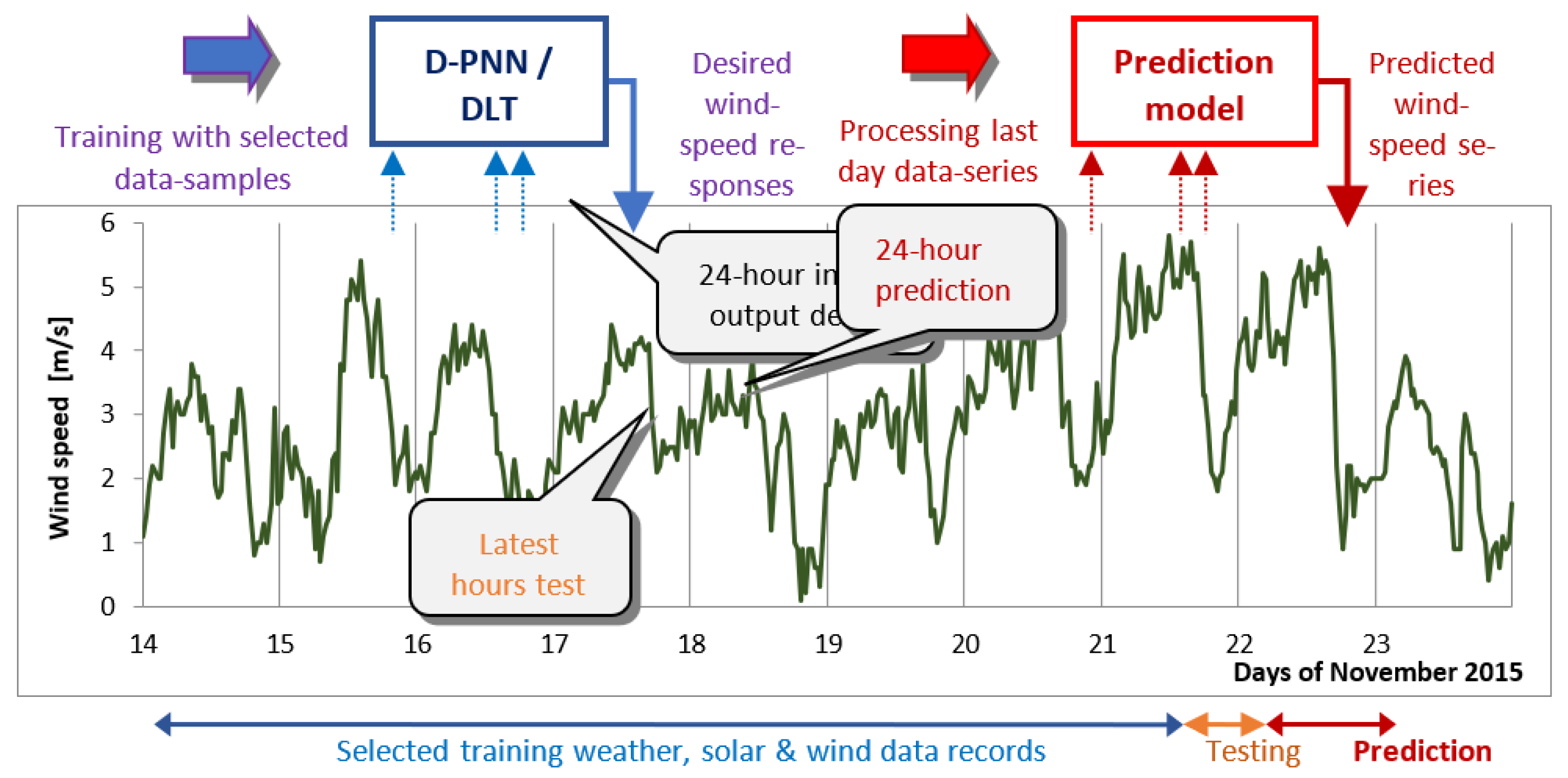
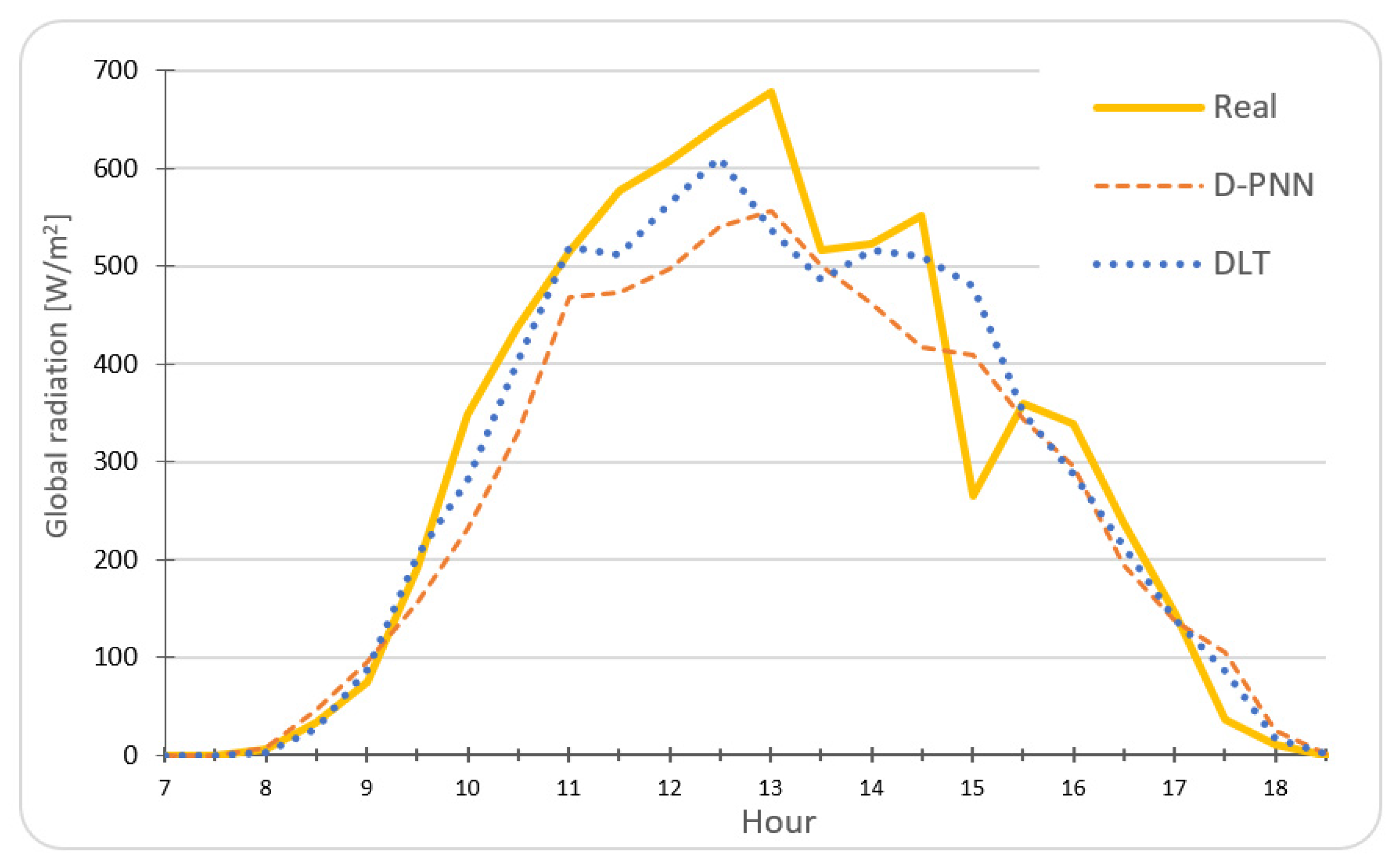
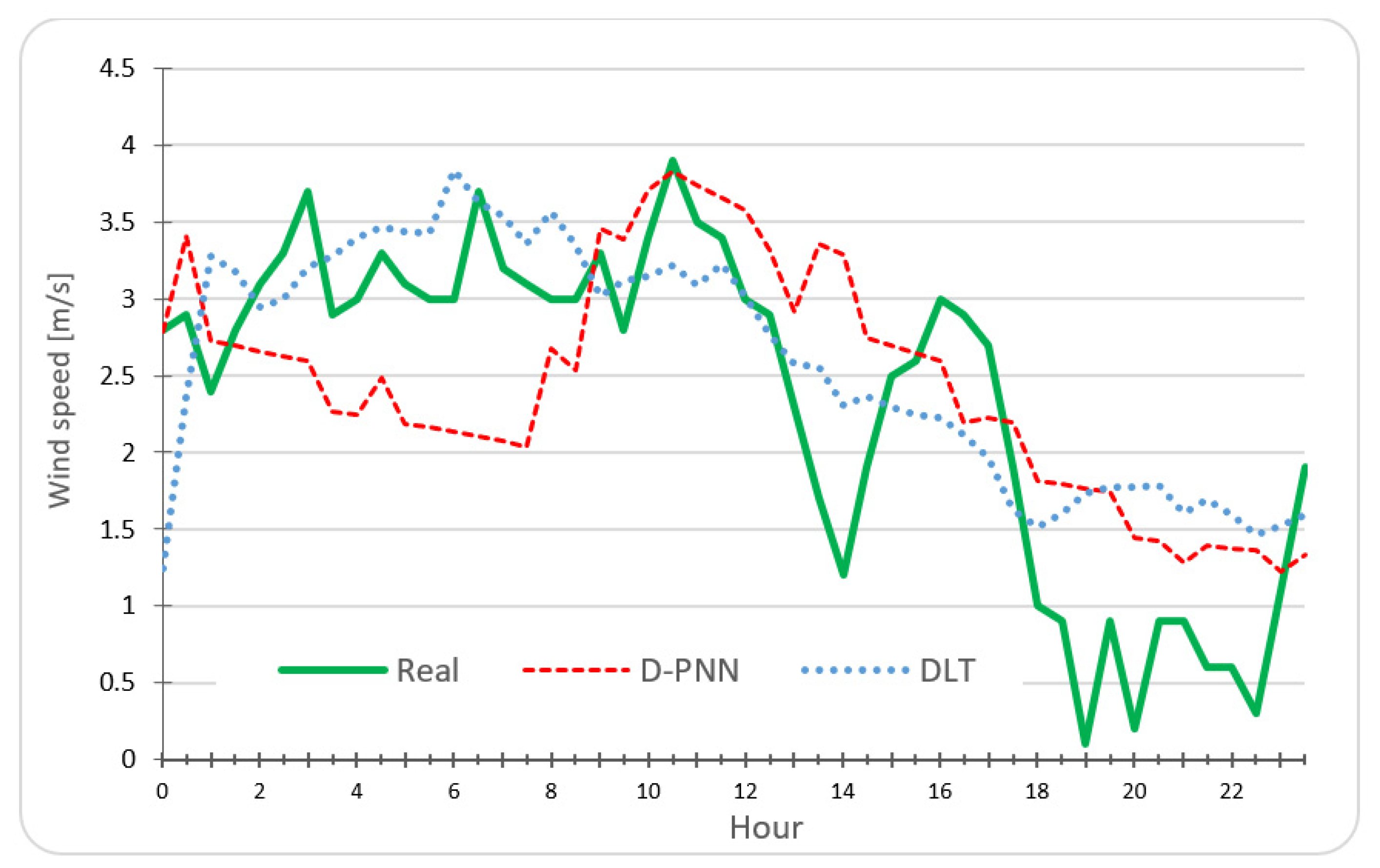
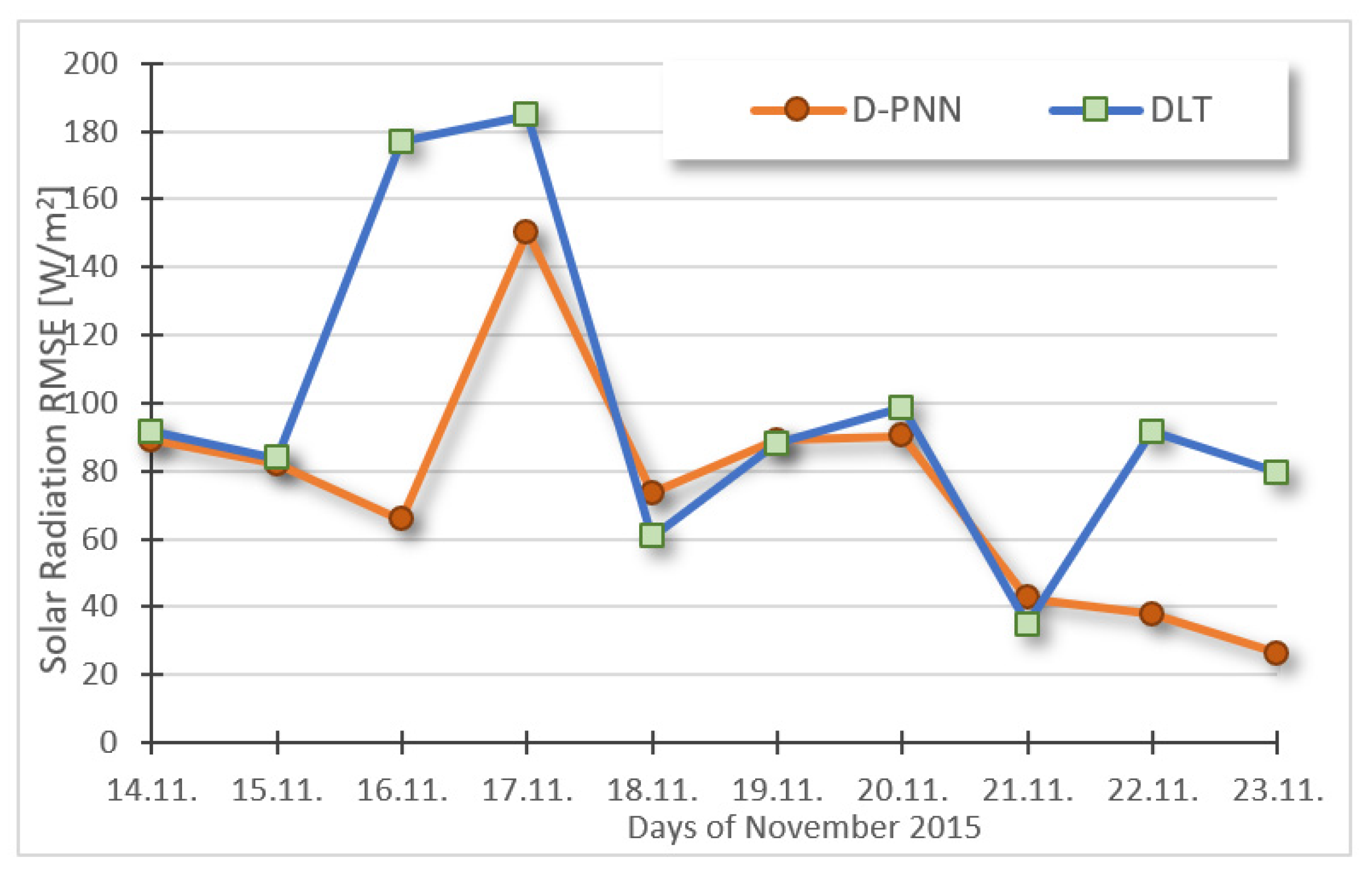
5. Day-Ahead Solar/Wind Statistical Predictions—Data Experiments
6. Day-Ahead Statistical Estimations of Solar/Wind Experiment Evaluation
7. Discussion
8. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Onteru, R.R.; Sandeep, V. An intelligent model for efficient load forecasting and sustainable energy management in sustainable microgrids. Discov. Sustain. 2024, 5, 170. [Google Scholar] [CrossRef]
- Zjavka, L. Wind speed and global radiation forecasting based on differential, deep and stochastic machine learning of patterns in 2-level historical meteo-quantity sets. Complex Intell. Syst. 2023, 9, 3871–3885. [Google Scholar] [CrossRef]
- Zhang, G.; Yang, D.; Galanis, G.; Androulakis, E. Solar forecasting with hourly updated numerical weather prediction. Renew. Sustain. Energy Rev. 2024, 154, 111768. [Google Scholar] [CrossRef]
- Zjavka, L. Power quality validation in micro off-grid daily load using modular differential, lstm deep, and probability statistics models processing nwp-data. Syst. Sci. Control Eng. 2024, 12, 2395400. [Google Scholar] [CrossRef]
- Verbois, A.T.H.; Saint-Drenan, Y.-M.; Blanc, P. Statistical learning for nwp post-processing: A benchmark for solar irradiance forecasting. Sol. Energy 2025, 235, 132–149. [Google Scholar] [CrossRef]
- Zjavka, L.; Sokol, Z. Local improvements in numerical forecasts of relative humidity using polynomial solutions of general differential equations. Q. J. R. Meteorol. Soc. 2018, 144, 780–791. [Google Scholar] [CrossRef]
- Zjavka, L. Photo-voltaic power intra-day and daily statistical predictions using sum models composed from l-transformed pde components in nodes of step by step developed polynomial neural networks. Electr. Eng. 2021, 103, 1183–1197. [Google Scholar] [CrossRef]
- Blaga, R.; Sabadus, A.; Stefu, N.; Dughir, C. A current perspective on the accuracy of incoming solar energy forecasting. Prog. Energy Combust. Sci. 2019, 70, 119–144. [Google Scholar] [CrossRef]
- Mulashani, A.K.; Shen, C.; Kawamala, M. Enhanced group method of data handling (gmdh) for permeability prediction based on the modified levenberg marquardt technique from well log data. Energy 2022, 239, 121915. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, H. Second-order structure optimization of fully complex-valued neural networks. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 8, 2349–2363. [Google Scholar] [CrossRef]
- Ahmed, R.; Sreeram, V.; Mishra, Y.; Arif, M.D. A review and evaluation of the state-of-the-art in pv solar power forecasting: Techniques and optimization. Renew. Sustain. Energy Rev. 2020, 124, 109792. [Google Scholar] [CrossRef]
- Ahmad, H.A.; Xiao, X.; Dong, D. Tuning data preprocessing techniques for improved wind speed prediction. Energy Rep. 2024, 11, 287–303. [Google Scholar] [CrossRef]
- Guermoui, M.; Melgani, F.; Danilo, C. Multi-step ahead forecasting of daily global and direct solar radiation: A review and case study of ghardaia region. J. Clean. Prod. 2018, 201, 716–734. [Google Scholar] [CrossRef]
- Sørensen, M.L.; Nystrup, P.; Bjerregård, M.B.; Møller, J.K.; Bacher, P.; Madsen, H. Recent developments in multivariate wind and solar power forecasting. Energy Environ. 2022, 13, e465. [Google Scholar] [CrossRef]
- Yakoub, G.; Mathew, S.; Leal, J. Power production forecast for distributed wind energy systems using support vector regression. Energy Sci. Eng. 2022, 10, 4662–4673. [Google Scholar] [CrossRef]
- Kumari, P.; Toshniwal, D. Deep learning models for solar irradiance forecasting: A comprehensive review. J. Clean. Prod. 2021, 318, 128566. [Google Scholar] [CrossRef]
- Huang, H.-H.; Huang, Y.-H. Probabilistic forecasting of regional solar power incorporating weather pattern diversity. Energy Rep. 2024, 11, 1711–1722. [Google Scholar] [CrossRef]
- Ding, J.W.; Chuang, M.J.; Tseng, J.S.; Hsieh, I.Y.L. Reanalysis and ground station data: Advanced data preprocessing in deep learning for wind power prediction. Appl. Energy 2024, 375, 124129. [Google Scholar] [CrossRef]
- Lindberg, O.; Lingfors, D.; Arnqvist, J.; van Der Meer, D.; Munkhammar, J. Day-ahead probabilistic forecasting at a co-located wind and solar power park in sweden: Trading and forecast verification. Adv. Appl. Energy 2023, 9, 100120. [Google Scholar] [CrossRef]
- Gupta, P.; Singh, R. Forecasting hourly day-ahead solar photovoltaic power generation by assembling a new adaptive multivariate data analysis with a long short-term memory network. Sustain. Energy Grids Netw. 2023, 35, 101133. [Google Scholar] [CrossRef]
- Wu, Y.; Qian, C.; Huang, H. Enhanced Air Quality Prediction Using a Coupled DVMD Informer-CNN-LSTM Model Optimized with Dung Beetle Algorithm. Entropy 2024, 26, 534. [Google Scholar] [CrossRef] [PubMed]
- Phan, Q.-T.; Wu, Y.-K.; Phan, Q.-D.; Lo, H.-Y. A novel forecasting model for solar power generation by a deep learning framework with data preprocessing and postprocessing. IEEE Trans. Ind. Appl. 2023, 59, 220–233. [Google Scholar] [CrossRef]
- Javaid, A.; Sajid, M.; Uddin, E.; Waqas, A.; Ayaz, Y. Sustainable urban energy solutions: Forecasting energy production for hybrid solar-wind systems. Energy Convers. Manag. 2024, 302, 118120. [Google Scholar] [CrossRef]
- Wang, Y.; Zou, R.; Liu, F.; Zhang, L.; Liu, Q. A review of wind speed and wind power forecasting with deep neural networks. Appl. Energy 2021, 304, 117766. [Google Scholar] [CrossRef]
- Guermoui, M.; Melgani, F.; Gairaa, K.; Mekhalfi, M.L. A comprehensive review of hybrid models for solar radiation forecasting. J. Clean. Prod. 2020, 258, 120357. [Google Scholar] [CrossRef]
- Chen, S.; Li, C.; Stull, R.; Li, M. Improved satellite-based intra-day solar forecasting with a chain of deep learning models. Energy Convers. Manag. 2024, 313, 118598. [Google Scholar] [CrossRef]
- Konstantinou, T.; Hatziargyriou, N. Day-ahead parametric probabilistic forecasting of wind and solar power generation using bounded probability distributions and hybrid neural networks. IEEE Trans. Sustain. Energy 2023, 14, 2109–2120. [Google Scholar] [CrossRef]
- Tamás, F.; Edelmann, M.D.; Székely, G.J. On relationships between the pearson and the distance correlation coefficients. Stat. Probab. Lett. 2024, 169, 108960. [Google Scholar]
- Zjavka, L. Power quality estimations for unknown binary combinations of electrical appliances based on the step-by-step increasing model complexity. Cybern. Syst. 2024, 35, 1184–1204. [Google Scholar] [CrossRef]
- The Centre for Solar Energy Research in Tajoura City, Libya. Available online: www.csers.ly/en (accessed on 8 July 2025).
- Weather Underground Historical Data Series: Luqa, Malta Weather History|Weather Underground (wunderground.com). Available online: www.wunderground.com/history/daily/mt/luqa/LMML (accessed on 8 July 2025).
- Zjavka, L. Power quality 24-hour prediction using differential, deep and statistics machine learning based on weather data in an off-grid. J. Frankl. Inst. 2023, 360, 13712–13736. [Google Scholar] [CrossRef]
- D-PNN Application C++ Parametric Software Incl. Solar, Wind & Meteo Spatial-Data. Available online: https://nextcloud.vsb.cz/s/EFDJ7mRyxfHkjSc (accessed on 8 July 2025).
- Matlab—Statistics and Machine Learning Tool-Box for Regression (SMLT). Available online: www.mathworks.com/help/stats/choose-regression-model-options.html (accessed on 8 July 2025).
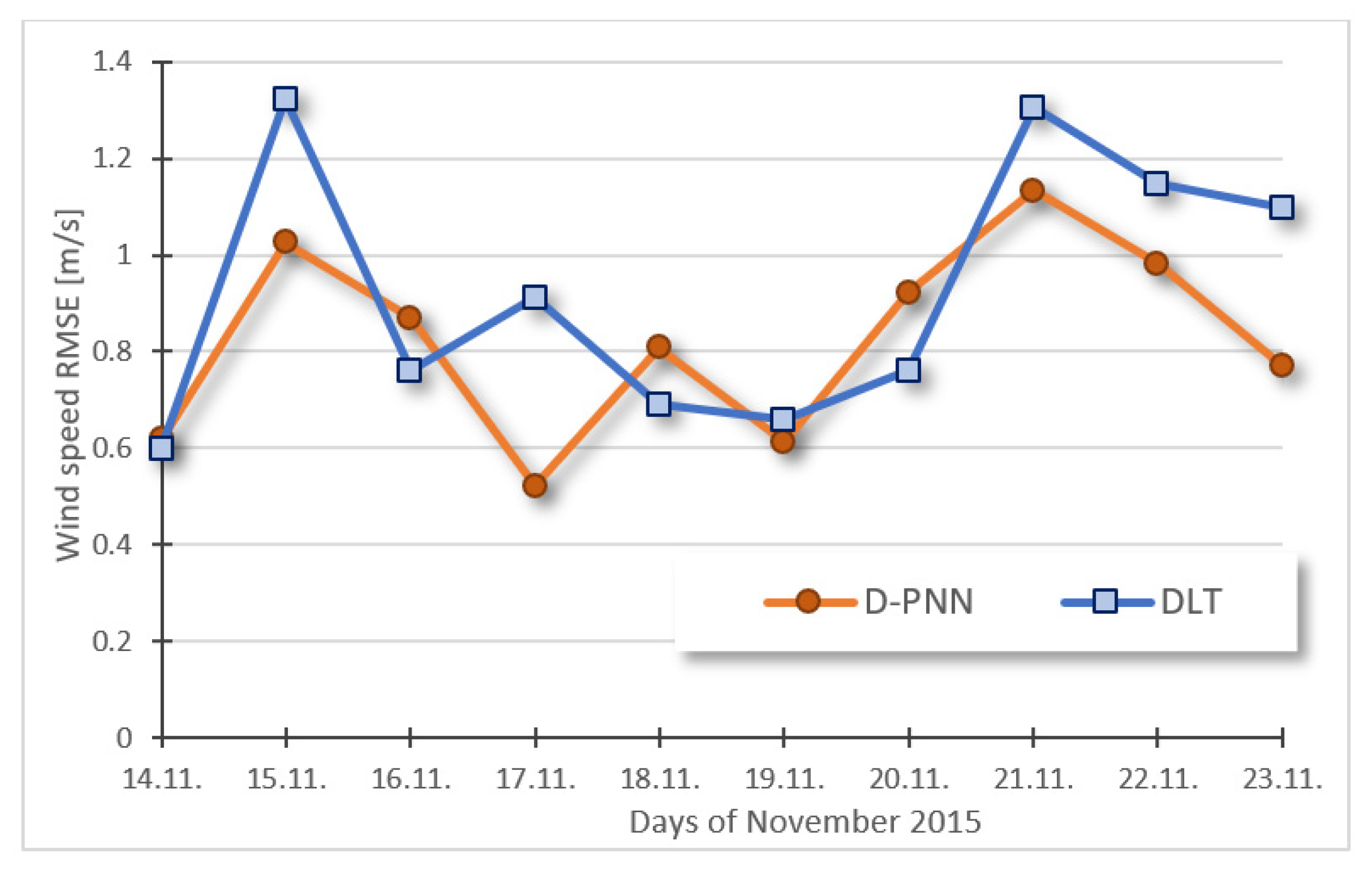

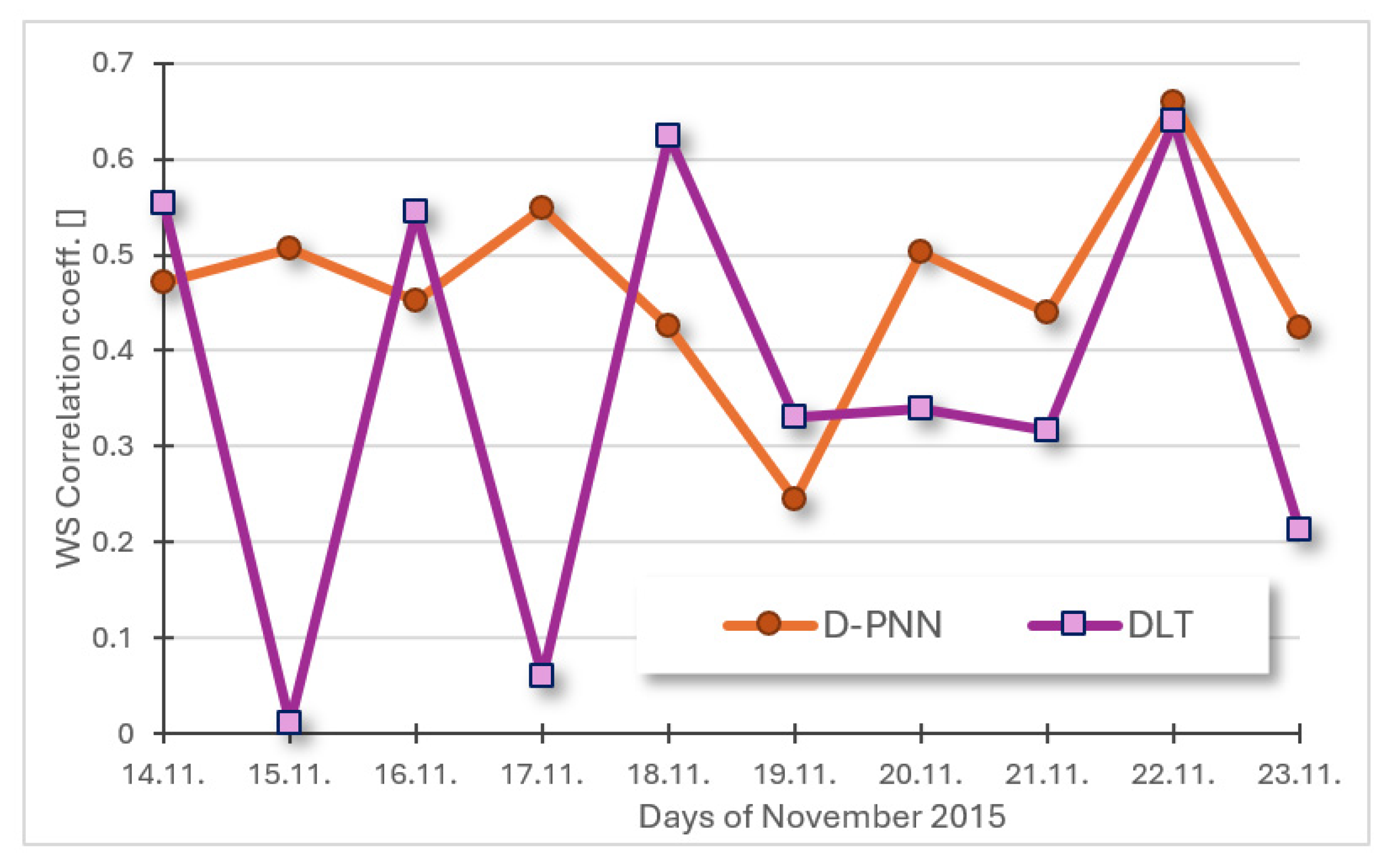

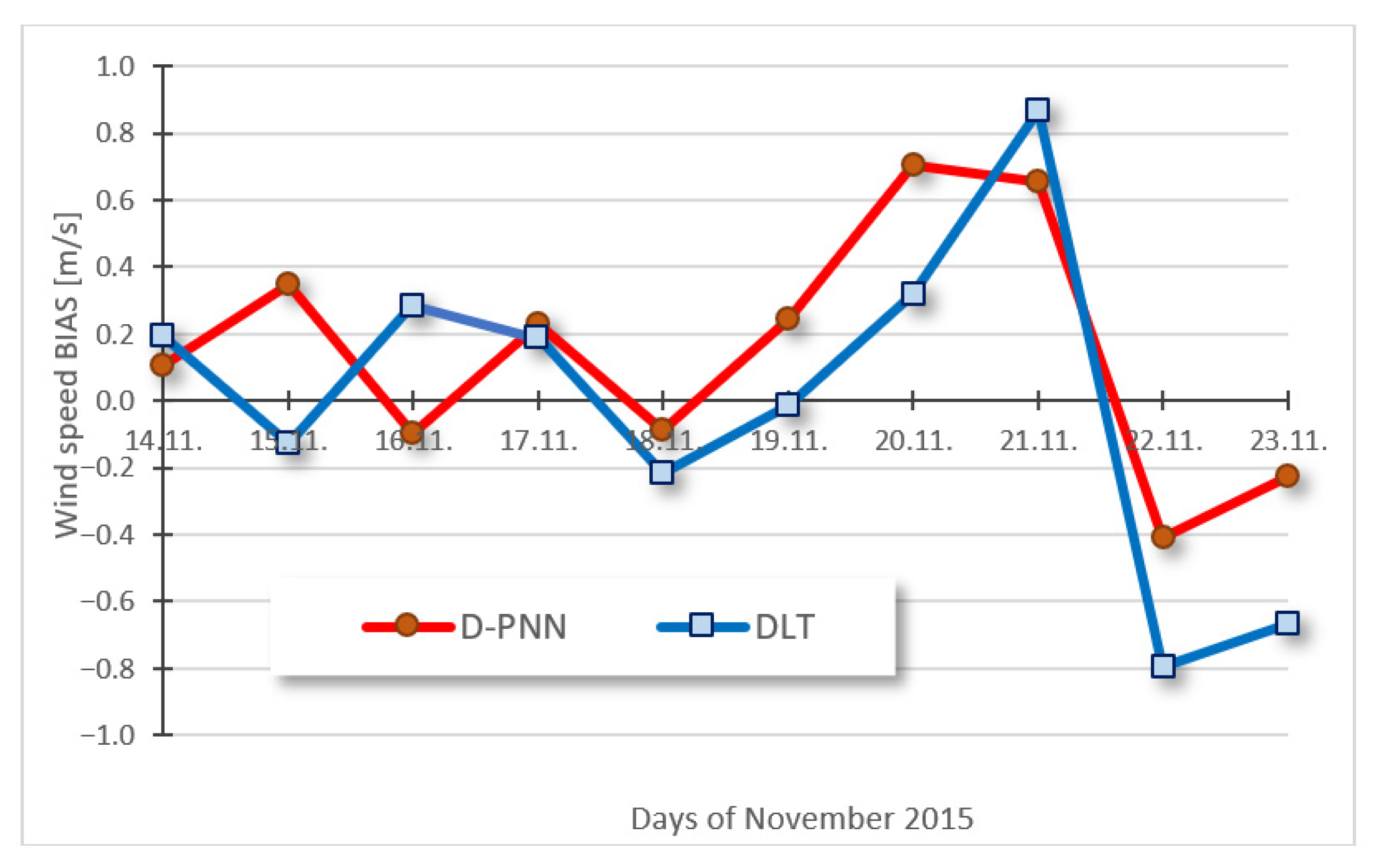
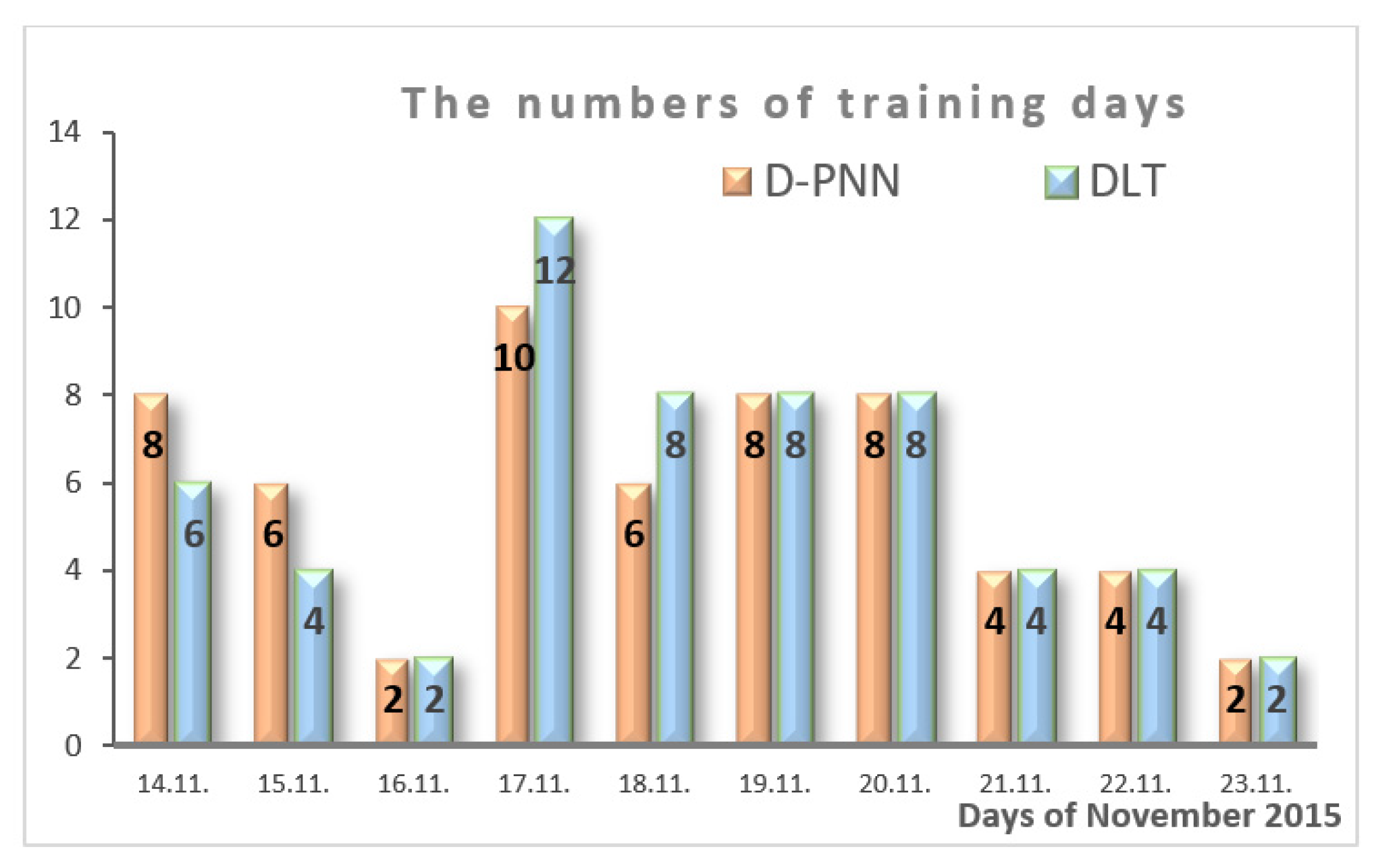
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zjavka, L. Solar and Wind 24 H Sequenced Prediction Using L-Transform Component and Deep LSTM Learning in Representation of Spatial Pattern Correlation. Atmosphere 2025, 16, 859. https://doi.org/10.3390/atmos16070859
Zjavka L. Solar and Wind 24 H Sequenced Prediction Using L-Transform Component and Deep LSTM Learning in Representation of Spatial Pattern Correlation. Atmosphere. 2025; 16(7):859. https://doi.org/10.3390/atmos16070859
Chicago/Turabian StyleZjavka, Ladislav. 2025. "Solar and Wind 24 H Sequenced Prediction Using L-Transform Component and Deep LSTM Learning in Representation of Spatial Pattern Correlation" Atmosphere 16, no. 7: 859. https://doi.org/10.3390/atmos16070859
APA StyleZjavka, L. (2025). Solar and Wind 24 H Sequenced Prediction Using L-Transform Component and Deep LSTM Learning in Representation of Spatial Pattern Correlation. Atmosphere, 16(7), 859. https://doi.org/10.3390/atmos16070859