1. Introduction
Knowing the exact visibility in all directions at the airports, ports, highways, etc. is the key to safe traffic operations. Low visibility due to weather changes represents a great risk, especially for the drivers of vehicles. As a result of their reduced ability to recognize objects, they are very often exposed to traffic accidents [
1,
2]. Meng et al. [
3] also point to the difficulty of managing the logistics of flight operations at airports as a result of efforts to increase safety in conditions of low visibility. Beyond this, inaccurate airport visibility estimates increase maintenance costs for the airlines and can even lead to fatal aviation accidents [
4].
On the other hand, visibility still remains one of the few meteorological variables, the observation of which is nearly unthinkable without trained and experienced human observers. Their work can be supplemented by equipment measurements. These, however, are by far not perfect: the state-of-the-art measuring tools (e.g., transmissometers and forward scatters) are expensive, and at the same time, they are able to provide measurements in the instruments’ location only. Bartok et al. [
5] introduced a camera-based observation system that does not necessarily replace but effectively and synergically amends the standard observations. The paper presented human observations from a remote center that allows an observer to report meteorological conditions remotely, using images from cameras installed at the airport. Bartok et al. [
5] concluded that for a correct estimation of the prevailing visibility, the standard near-the-runway automated sensors alone are inadequate; however, the camera-aided remote human approach to observations seems to be a promising supplement to eliminate the standard sensors’ deficiencies in terms of quality (e.g., high-quality camera records; no more point measurements), objectivity (e.g., a database of archived weather situations), and efficiency (e.g., no need to have an observer physically present at the airport).
A further way to estimate visibility is on the basis of statistical models. They, compared to the equipment measurements, can be cheap in terms of the invested costs; nevertheless, they cannot be considered cheap in terms of the time and human resources necessary for their development and training. The statistical models cover a wide spectrum, starting, for instance, from a simple application of the Koschmieder law, through linear and non-linear models relying on different meteorological variables, up to the highly sophisticated models in the field of image recognition, constructed on the basis of machine learning and deep learning techniques [
6].
In recent years, particularly due to the exponential boom in the field of AI technologies, a plethora of papers focusing on AI-based image recognition and/or classification have been published [
7,
8]. A considerable portion of these studies is based on convolutional neural networks (CNNs) and their innovated architectures, emphasizing their key capabilities such as versatility and robustness [
9]. Chen et al. [
10] concluded that ‘From 2017 to the present, […] CNNs have increasingly demonstrated irreplaceable superiority in image classification.’ The target objects, and consequently, the particular technological equipment and the adopted approaches are manifold, such as medical image recognition [
11], face recognition [
12], the inspection of road material defects [
13], street view image classification [
14], or remote sensing image classification [
15]. In meteorology and fields closely affected by meteorological conditions (such as road traffic and intelligent transportation systems [
16,
17]), the major challenge of the AI-based approaches is reliable object recognition in environments with poor visibility conditions, such as haze, fog, dust, dense rainfall, twilight, night-time, etc. [
18,
19].
Night-time visibility estimation is equally important in aviation and other forms of transportation, as planes, ships, and all forms of public transportation also operate during the night. Good night-time visibility is essential during landing and takeoff (e.g., guided by runway lights, approach lights, and beacons), and also in ground operations such as taxiing. Pedestrians and cyclists are also at higher risk during night-time.
Studies of night-time visibility or light point detection with graphical data as input are, however, often hindered by the lack of high-quality annotated data sets. One such data set was provided in the China Post-Graduate Mathematical Contest in Modeling in 2020 [
20]. The data set contained meteorological data and observation video of one particular night (13 March 2020) and was utilized in several studies [
20,
21,
22,
23]. Nevertheless, beyond the common date, it is hard to track down further details on the data set since different authors refer to different target locations (Chengdu Shuangliu International Airport [
22], Nanjing Lukou Airport [
20], and unspecified site(s) [
21,
23]), different time intervals (from approx. 0:00 a.m. to 8:00 a.m. [
20,
22,
23], and from approx. 0:00 a.m. to 12:00 a.m. [
21]), and what is a pity, the only web address of the reference data set cited in [
20] is no more accessible in 2024.
Quian et al. [
21] performed multiple linear and multiple polynomial regressions to model the dependence between ground meteorological observations and reported visibility. Subsequently, the models were used to annotate the video data set split into separate frames and trained AlexNet [
24] to predict visibility. They report less than 0.25% percentage error in their approach in comparison with the ground truth. However, the test data set consisted of the last 129 frames with essentially the same visibility.
Fu et al. [
22] used a support vector machine model to classify video frames into four visibility categories. They investigated the influence of the thermodynamic image algorithm and gray histogram for feature extraction on model performance. The reported performance for visibility between 400 m and 800 m contained about the same number of hits and misses for both data processing approaches. For other visibility ranges, both models performed significantly better.
Liu et al. [
23] combined two CNN models VGG-16 [
25] and Xception [
26] to classify fog into four categories with an overall accuracy of 87.64%. However, the lowest visibility category ‘thick fog’ performed worse, possibly due to insufficient training data.
Chen et al. [
20] used a Recurrent Neural Network (RNN) to analyze video sequences and predict visibility. They examined the influence of adding meteorological data as an input to the RNN. The mean relative error of the model decreased from 38.5% to 19.72% by incorporating ground meteorological observations such as temperature, air pressure, and wind speed.
The common features of the above referenced works [
20,
21,
22,
23] are (i) their focus on nigh-time conditions, (ii) visibility prediction by means of various AI approaches, and (iii) practically the same, limited data set of inputs. Even though the input figures therein are available with a 15 s frequency, it is questionable whether the video sequences of the length of 8 (12) hours offer sufficient variability of meteorological conditions that are precursors of the low visibility cases. The lack of representativeness is manifested at least by the fixed position of the camera, which does not allow for evaluating the visibility strictly from the aviation perspective, i.e., according to the ICAO (International Civil Aviation Organization) recommendations in all the cardinal directions [
27]. The current paper, therefore, aims at developing a trustworthy model, which attempts to mimic the approach of professional observers, similarly to Bartok et al. [
5]. Our strategy was also inspired by the study of Pavlove et al. [
28] who developed the concept of the ‘remote observer’ towards more automatized ways of the visibility recognition using various approaches of artificial intelligence (two CNN models based on VNET [
29]); however, it was for day-time conditions. It is important to emphasize that unlike the studies above, we are not trying to evaluate the visibility itself or the visibility prediction within different distance intervals relevant to aviation. The current study only deals with the very first (necessary) step towards the automatization of visibility prediction, and it is the analysis of the detectability of light sources in night-time conditions.
The paper is organized as follows: The international standards/requirements for visibility observation, and the camera-based system designed for it, are described in
Section 2 (Materials and Methods). The same section also introduces the principles of the creation of the basic data set of camera images, characterizes the standard and novel approaches of image processing, presents the methods adopted for the automated visibility prediction, and finally, lists the statistics and metrics adopted to evaluate the performance of the constructed models.
Section 3, after a short introduction related to the analysis of low visibility circumstances at the target location, presents the performance of the three constructed models for the prediction of night-time visibility. The first of the models predicts the visibility using a traditional approach (binary thresholding) with modified images as inputs, whereas the core of the remaining two models is an AI-based approach (convolutional neural network) that makes decisions both on the basis of original and modified camera images. The Discussion Section (
Section 4) attempts to inter-compare and interpret the performance of the individual models, and underline their strengths and weaknesses, and the last section (
Section 5) delineates some pathways to extend the current research in the future.
2. Materials and Methods
2.1. Definition of Visibility
Prevailing visibility is one of the most important meteorological variables at airports. The glossary of the International Standards and Recommended Practices, Meteorological Service for International Air Navigation (Annex 3) [
27] adopted by the Convention on International Civil Aviation Organization (ICAO) defines the prevailing visibility as
The greatest visibility value, observed in accordance with the definition of ‘visibility’, which is reached within at least half the horizon circle or within at least half of the surface of the aerodrome. (These areas could comprise contiguous or non-contiguous sectors).
The visibility as defined for aeronautical purposes is the greater of the following:
- (a)
the greatest distance at which a black object of suitable dimensions, situated near the ground, can be seen and recognized when observed against a bright background;
- (b)
the greatest distance at which lights in the vicinity of 1000 candelas can be seen and identified against an unlit background.
Currently, reports of prevailing visibility are typically produced by a human observer at regular time intervals. Typically, (a) is applied during the day and (b) during the night.
In the case of determining visibility during the day, i.e., in daylight conditions, meteorological observers recognize specific objects and their outlines. In night-time conditions, however, the observers rely on the ability to determine the visibility of light sources. In the dark, when observing with the eye, instead of the entire visible scenery, the observer only focuses on light points or light sources. As a result, there is no information available on the edges of the target objects, which makes the AI-based prediction of night vision much more challenging.
2.2. Camera Observation Methodology
The general architecture of the camera-based observation system is as follows: A high-resolution camera with accessories is installed on a higher elevated point at the Poprad–Tatry Airport (Slovakia; ICAO identifier: LZTT) with an obstacle-free view. It sends 8 images of the horizon covering all the cardinal directions (N, NE, E, SE, S, SW, W, and NW) to a central server with a 5 min frequency (this periodicity is customizable). The rotation of the camera is provided by a rotator, which is assumed to always stop precisely in pre-defined positions after turning. If this does not happen (for instance, due to wind gusts or some mechanical failures), slightly shifted camera shots may result, and such camera shifts represent one of the several possible factors influencing the accuracy of automated visibility estimation.
As soon as a 360° camera rotation is completed, pre-defined distance markers (landmarks) are added to the individual camera images. With the help of these markers (by switching their statuses either to ‘visible’ or ‘obscured’), the remote (human) observer can determine the prevailing visibility and save the results to the server [
5].
Figure 1 illustrates the results of such an evaluation both for daylight and night-time observations.
Landmarks with distance labels for all the directions represent an aiding tool for the remote observer. They have to be selected carefully to cover a variety of distances in each direction.
Table 1 shows some basic statistics of the landmarks at the Poprad–Tatry Airport where the marker counts were divided into four distance categories used by the ICAO [
27]. Furthermore,
Figure 2 presents the spatial distribution of the markers in the vicinity of the airport, with the focus on the nearest ones, within the two circles with radii of 0.6 and 1.5 km, corresponding to
Table 1.
Table 1.
The number of landmarks used to identify directional visibility (regardless of whether they serve in daytime and/or night-time conditions) by the camera-based system at the Poprad–Tatry Airport, stratified by the ICAO distance categories.
Table 1.
The number of landmarks used to identify directional visibility (regardless of whether they serve in daytime and/or night-time conditions) by the camera-based system at the Poprad–Tatry Airport, stratified by the ICAO distance categories.
| Distance Interval [m] | Number of Landmarks |
|---|
| 0–600 | 56 |
| 600–1500 | 26 |
| 1500–5000 | 30 |
| >5000 | 41 |
| Total | 153 |
Figure 2.
Spatial distribution of the landmarks with distance labels used to identify directional visibility (regardless of whether they serve in daytime and/or night-time conditions) in the vicinity of the Poprad–Tatry Airport.
Figure 2.
Spatial distribution of the landmarks with distance labels used to identify directional visibility (regardless of whether they serve in daytime and/or night-time conditions) in the vicinity of the Poprad–Tatry Airport.
The basic principles of visibility estimation based on the set of markers assigned to the camera images are as follows:
If all the markers are visible in a given direction, then the visibility is larger than the distance of the most distant marker in this direction.
If some markers are not recognizable in a given direction, then the visibility is determined by the distance of the nearest visible marker preceding the first obscured one.
These principles mimic the procedure that is required of a professional aeronautical observer.
The evaluation of the camera images by a remote (human) observer serves as the ground truth in the analysis of the automated approaches to night-time visibility estimation. Such an evaluation accompanies each camera image, usually in a text file of an XML format. The associated text file involves information on the light sources (their approximate co-ordinates and distance from the camera), information on the date and time of the camera shooting, information on the quality of the individual camera images, and, as mentioned, the expert decision of the human observer on which of the light sources are visible and which are not.
2.3. Classical Methods in Image Processing
The cornerstone of the classical methods of image processing (e.g., texture analysis, pattern recognition/classification) is the detection and description of its key points, and parallel to this, the definition of the adequate descriptors that characterize the structure of the image. Herein, a similar approach is adopted, with (a) the detection and description of the key points, and (b) the morphological reconstruction of the original images. Both procedures will be described in detail in the following two subsections.
2.3.1. Key Point Detection and Description
In the current study of night visibility, light spots represent the key points. We attempted to identify and describe them by means of some standard, widely accepted approaches, i.e.:
SIFT (Scale-Invariant Feature Transform) [
30];
BRIEF (Binary Robust Independent Elementary Features) [
31];
ORB (Oriented FAST and Rotated BRIEF) [
32].
Our preliminary analysis indicated that out of the above-listed approaches, the SIFT method yielded the most acceptable results.
A further step in the standard approach of image processing is feature matching. Its goal is to find matches between the descriptors of the recognized key points in two or more tracked images. From the wide palette of the available methods of feature matching, we used the Brute Force method [
33]. Finally, we adopted the RANSAC (Random Sample Consensus) [
34] algorithm to search for homography and then filter out incorrectly matched pairs of image features.
However, the preliminary testing of this approach revealed that it was unable to identify a significant number of key points, predominantly due to blurred images or a significant presence of fog. Conversely, the application of image sharpening filters led to excessive noise. In some cases where the points were correctly matched, we encountered inaccuracies in the image overlay process. We, therefore, arrived at a conclusion that the standard methods of key point detection and description are unsuited for the identification of light spots in our data set. As a viable alternative to this, we turned our attention to methods of image modification as tools for a binary identification of light spots as detectable or undetectable in a relatively straightforward way.
2.3.2. Image Modification
The term ‘mathematical morphology’ is used to classify methods to extract the useful features of an image that describe the shape of the examined image patches [
35]. A specific case of the application of mathematical morphology is morphological image reconstruction. It is used to extract important features from an image by removing noise, highlighting edges, and filling gaps. It uses two inputs: (i) the input image itself to be modified, and (ii) the structuring element (or structural element or kernel), which is usually a small image (e.g., 3 × 3 or 7 × 7 pixels), and serves as a pattern that defines the details of the effect of the operator on the input image.
Image reconstruction is performed in an iterative manner while trying to preserve important features from the original image. There are several algorithms commonly used in morphological image reconstruction, and one of them is erosion [
35,
36]. Erosion is a morphological operation that reduces the boundaries of a white object in a binary image by removing pixels from its edges. Thus, from a technical point of view, the process of morphological erosion is a unification of the input image and the structuring element.
From the practical point of view, morphological erosion was applied on each image patch with a light spot. As mentioned above, the most important feature of the method is its ability to remove noise and highlight important elements in the original image (mostly light spots). Beyond this, the morphological erosion also filtered out, to some extent, the background of the light spots.
Different sizes of the structuring element were used in our preliminary testing; however, the lowest noise and/or gray artifacts were detected at a value of 7, which then was further used.
From now onward, we will term the results of the processing algorithm by the morphological erosion as ‘modified’ images or image patches, in contrast with the ‘original’ ones.
2.4. Binary Classification of Detectability of Light Spots
Having the original images modified by morphological erosion, the overall task of the prediction of meteorological visibility is reduced to a task of binary classification of the light spots, i.e., to decide whether they are detectable (equivalent to ‘visible’, class ‘1’) or, conversely, undetectable (equivalent to ‘obscured’, class ‘0’). In line with this concept, in the remainder of the paper, we will use the terms ‘prediction of detectability’ in relation to the approaches of the automated detection of light spots from the camera images, and ‘observation of visibility’ in relation to the activities of human observers at the meteorological observatory (ground truth).
To determine whether the light spots are detectable or undetectable, two conceptually different approaches were adopted: a traditional one (binary thresholding) and one making use of a concept of machine learning (using a convolutional neural network).
2.4.1. Binary Thresholding
Binary thresholding (BT) [
35] is a segmentation method used in image processing. It converts black-and-white or gray images into binary ones, containing only pixels with black or white color. It works on a simple principle in which each pixel in the image is replaced by a black pixel if its intensity value is lower than a specified threshold value, and conversely, the pixel is substituted with a white pixel if its intensity value is higher or equal then the threshold. An image is classified as 1 (visible, detectable) if there is at least one white pixel in the binary image. Otherwise, when the image contains only black pixels, it is classified as 0 (invisible, undetectable).
2.4.2. Convolutional Neural Networks
Convolutional neural networks (CNNs) [
37] are one of the most important deep learning methods used to solve problems in the field of computer vision. Convolutional neural networks were inspired by the structure of the visual system, specifically drawing inspiration from the models proposed by Hubel and Wiesel [
38]. Convolutional neural networks constructed in this manner have proven to be effective in processing two-dimensional data with a grid-like topology, such as images and videos. These layers were designed for feature extraction by applying convolution to the input data.
Convolutional neural networks are typically composed of the following types of neuronal layers [
39]:
Convolutional layers. Convolutional layers are used for feature extraction by combining the input of each neuron with the local receptive field of the previous layer [
40]. The goal of this process is to discover meaningful internal representations of objects and signs in the image. Voulodimos et al. [
39] emphasize the importance of applying convolution to the entire image and activation maps or feature maps using kernels of different sizes. This approach leads to the generation of diverse activation maps that highlight local flags, thereby facilitating the detection of their interconnections.
Pooling layers. The essence of pooling layers is the mapping of extracted symptoms [
39]. They reduce the spatial dimensions of the input image for another convolutional layer. Simultaneously, the dimensions of width and height are reduced, while the depth remains unaffected. This is commonly referred to as downsampling since size reduction in the input data leads to a loss of information. This loss leads to computational overhead for other layers, and also acts against information overload.
Flattening layer. This layer converts multidimensional arrays (output from previous layers) to a single linear vector, a format suitable for dense layers.
Dropout layer. The dropout layer is designed to prevent the overfitting of deep learning models. It randomly selects inputs and sets them to 0 with a customizable frequency called the dropout rate.
Dense or fully connected layers. In CNN architectures, fully connected layers are applied after several convolutional and pooling layers. These fully connected layers serve as the basis for the final classification of the input images [
39]. In these layers, neurons are fully connected to all the activations in the previous layer. Thus, their activation can be calculated by matrix multiplication, followed by a deviation correction. Finally, the fully connected layers convert the obtained 2D feature maps to a 1D feature vector.
Herein, a convolutional neural network was proposed as the other approach to a binary classification of the detectability of light points. As part of the proposed approach, we built and trained a model of a CNN with the simplest possible architecture of this network (
Figure 3).
The architecture consists of one convolutional layer with 8 filters of size 3 × 3, followed by a max pooling layer with a 2 × 2 pool size. The output of the convolutional and pooling layers is flattened into a 1D vector, and then passed through a dropout layer to reduce overfitting. Finally, a dense layer with a single neuron and sigmoid activation function is used for binary classification. This architecture is simple yet effective for tasks involving image data with binary outcomes. More specific details about these layers are provided in
Appendix A.
2.5. Data Set Creation
2.5.1. The Initial Data Set
The measurements of visibility took place at the professional meteorological observatory at the Poprad–Tatry Airport (Slovakia). Both the database of the images from the camera observation system (available with a 5 min frequency in 8 cardinal directions; see
Section 2.2), and the evaluation of visibility by professional human observers are available for a 39-month long period, starting with January 2018 and ending with March 2021.
2.5.2. Relevant Sampling
To create a relevant data set, one needs the records of light points found in photos that evenly cover all the periods of the year. The original data set, however, is not balanced since it contains uneven amounts of photos from different months of the year. For this reason, we attempted to pseudo-randomly select a certain amount (~1000) of records for each month over the approximately three-year period to achieve data set relevance. The principles of the procedure are as follows.
The governing rule of the selection was to keep the balance of the selected data set in terms of the visibility/invisibility of the light points. This initial data set, previously estimated by professional human observers and regarded as the ground truth, was available as a collection of XML files. According to the number of records in the minority group (i.e., those with the label ‘1’), the same number of records was selected from the majority group (with the label ‘0’), thus the new data set was created in a 1:1 ratio in terms of the visibility of light points. As a result of processing XML data from the initial data set (see
Section 2.2), an intermediate data set was created with the number of records of approximately 12,000. Nevertheless, this data set had to be further refined/reduced for one of the following three reasons: (a) there was no camera image available to be assigned to the records from the intermediate data set, (b) although the corresponding camera image existed in the intermediate data set, it was either corrupted or was not a black-and-white image (i.e., taken, for instance, during the dusk or dawn), or (c) the overall goal was, again, to reach a balanced status of the data set in terms of visibility of light points by eliminating some records from the intermediate date set. This procedure resulted in the final data set with about 7000 items; more precisely, it consisted of 6892 camera images and the corresponding text/numeric information.
2.5.3. Choice of Sizes of Image Patches
The original camera images were processed by means of the concept of key point images with a default setting, where the individual key points were approximately centered within the square-shaped cut-out of the original image. After experimenting with different sizes of the neighborhood, we have chosen 256 × 256 pixels, which is robust with respect to camera shifts and includes both a light spot and its sufficiently small surroundings.
An example of a night-time image is presented in
Figure 4a. It was taken on 30 August 2019, at 3:00 a.m., at the Poprad–Tatry Airport. The camera, pointing towards the northern direction, shows the silhouette of the High Tatras Mountain in the background, with some night-time public lighting in the villages at the foot of the mountains. In the foreground, there are two significant objects for visibility estimation: the wind bag and the mast, both illuminated at night. All these points in the background and the foreground might be identified as key points using the procedures described in
Section 2.3.2 and
Section 2.4.
Figure 4b emphasizes one of the key points (the wind bag) cut out of the original image with its neighborhood, delineated according to the default settings.
Figure 4c serves as an illustration of a modified image, which is the result of the morphological erosion adopted in
Figure 4b with the aim of highlighting the light spot in the image. Finally,
Figure 4d is the binary image created on the basis of
Figure 4c.
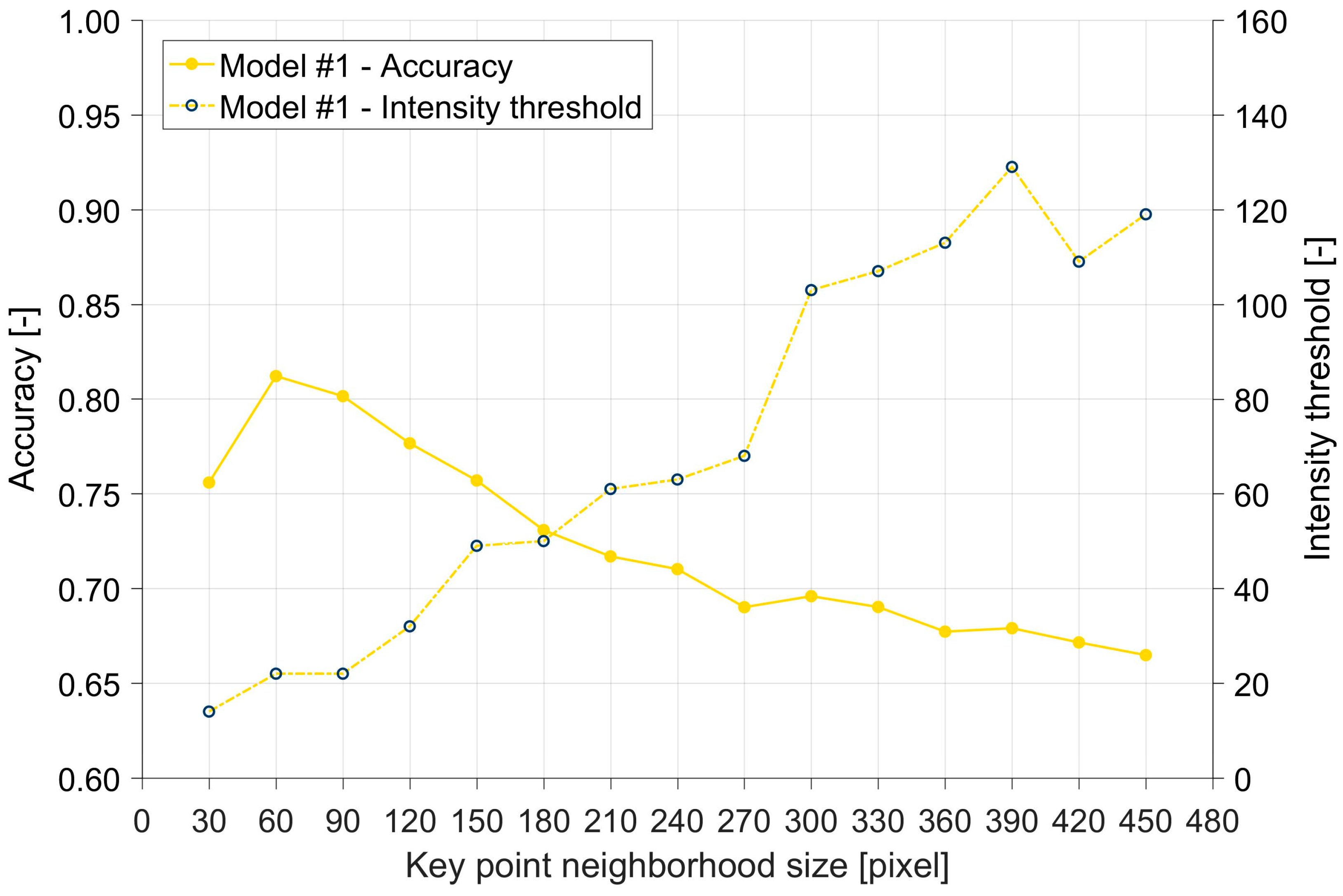
To evaluate the effect of the default settings of the patch size on the final outcomes of the analysis, an experiment using 15 different neighborhood sizes was also conducted. Herein, various neighborhood sizes were defined, ranging from 30 to 450 pixels, with a step of 30 pixels (i.e., a square patch of the size of 30 × 30, 60 × 60, 90 × 90 pixels, etc.). In the end, for each of the ~7000 key points from the final data set, 16 different image patches were prepared, including the default size (256) and an additional 15 from the described experiment (from 30 to 450 pixels). The same procedure was applied both on the ‘original’ and the ‘modified’ images.
2.6. Verification Methodology
Widely known scores were used to evaluate the performance of the proposed models for classifying the detectability of the key points and their neighborhoods. The assessment started with the standard 2 × 2 contingency table, which reflects the goodness of the given constructed model in the light of the observations (ground truth):
True Positives (TP)—They indicate the number of cases when the key point is visible according to the human observers, and also the model-based prediction.
False Negatives (FN)—The key point in the image is visible, but the model finds it undetectable (i.e., type II error).
False Positives (FP)—The key point in the image is invisible; nevertheless, the model declares it detectable (i.e., type I error).
True Negatives (TN)—The key point in the image is invisible, and it is correctly predicted by the model as undetectable, too.
Based on these scores, further, more complex statistical metrics are defined [
42]:
True Positive Rate (TPR)—It is the share of the number of true positive predictions from the total number of positive observations. In other words, it describes what proportion of samples that should have been classified as positive are in that class. This statistic is also known as Probability of Detection (POD).
False positives lead to an overestimation of night visibility since some non-visible light points are marked as ‘detected’. This can potentially lead to a safety issue, as an aircraft could try to land in worse weather conditions than expected.
False negatives lead to an underestimation of the night visibility since visible light points are marked as undetected. This can potentially lead to an unnecessary flight rerouting to a different airport. The consequences would be additional costs for the airline and, increased fuel consumption and CO2 emissions.
In the domain of aviation safety, the metrics that focus on minimizing false positives, namely TNR and FPR, are more relevant than the ones that are aimed at minimizing false negatives. In the remainder of the study (and in the upcoming ones in the future), we, therefore, propose to use the metric FPR as the one to be minimized, and the metric FNR as a satisfying one. This would imply setting an acceptable value of FNR and trying to lower FPR as much as possible.
2.7. Explainable AI
The standard statistical scores and metrics described in
Section 2.6 are excellent tools to inter-compare different models in terms of figures; nevertheless, they do not offer any hint for why they perform the way they do. The possible reasons for the good or bad performance of the individual models have to be examined in a different way, by an analysis of the individual cases of the correctly and incorrectly predicted detectability of key points and their surroundings.
Explainable AI is a novel and useful tool, which generally offers further insight into the processes of how machine learning algorithms make decisions in individual cases [
43,
44]. There is a wide variety of explainable AI tools such as Saliency [
45], Vanilla-gradient [
46], Occlusion Sensitivity [
47], CAM (Class Activation Mapping) [
48], and Grad-CAM (Gradient-Weighted CAM) [
49] algorithms. We have decided not to use CAM because Grad-CAM is considered to be a superior alternative addressing CAM’s drawbacks [
49]. We have tried out the rest of the mentioned explainable AI algorithms during the pilot stage of our study. Both Vanilla-gradient and Saliency visualized the interpretability results based on individual pixels rather than regions on the image, which were often too low-level and out of context for our purposes. In addition, many outputs were not ‘readable’ since an entirely black image was returned as a result. Even though Occlusion Sensitivity was able to highlight interesting regions, it returned both reasonably interpretable and confusing outputs. Moreover, this method was the most time consuming in terms of computational cost. We have thus decided to proceed with the Grad-CAM algorithm since it returned acceptable results, is well studied, robust, relatively fast, and takes into account more of the ‘context’.
The Grad-CAM algorithm uses gradients of any target object, which pass into the final convolutional layer. Its goal is to create a rough localization map highlighting important areas in the image, which serves as the basis for any inference to be made about the studied object.
Aside from the Grad-CAM algorithm, the results from the last layer of the convolutional neural network were analyzed using the Sigmoid activation function. In general, the role of the activation functions (or transfer functions) in machine learning is to transform the input (or several inputs) into an output. In other words, the activation function decides whether to activate the neuron or not, i.e., whether the input information is useful and should be transferred to the next node. The Sigmoid function is a widely used activation function in neural networks, which can be characterized by a non-linear behavior [
50,
51].
In the traditional model of binary thresholding where neither the explainable AI nor any activation functions can apply, the selected cases of correctly and incorrectly predicted visibility were analyzed through a calculation of the maximum pixel intensity in the modified images.
2.8. Computational Details
In the Methods section, two data sets (original and modified images,
Section 2.3) and two methods of the light spots’ detectability prediction (binary thresholding and convolutional neural network,
Section 2.4) were introduced. Herein, we describe the resulting combinations of data sets and methodological approaches (termed as Models #1, #2, and #3) as well as the technical computational details involved. Note that it was not possible to evaluate all 4 combinations of two data sets and two methods since the binary thresholding only works with modified images.
Model #1 to classify key point detectability was constructed based on the method of binary thresholding (
Section 2.4.1) and using the final data set (
Section 2.5.2) of the modified image patches (
Section 2.3.2). For this model, we have decided to keep the data set as is, e.g., it was not split. We compared the BT-based predictions of detectability with the true visibility labels for each key point of the data set. Note that to allow for a proper comparison of the outcomes across different models, these results were normalized to the number of the test set records from models based on the convolutional networks, which is 690 (10% of the size of the data set 6892).
Model #2 utilized a convolutional neural network (CNN,
Section 2.4.2) with the modified images (i.e., pre-processed by a morphological erosion) from the final data set (
Section 2.5.2). Model #3 also followed the design of the experiments using CNN; however, the original images from the final data set were used as inputs. For these models a Monte Carlo cross-validation approach [
52] was adopted, where the training, testing, and validation data sets were created from the final data set in the ratio of 80:10:10. Such a procedure was repeated five times, each time with a different random seed value. The values provided in the tables represent an average of these 5 trainings. All the input images were scaled to the range 0 to 1. The images in the training and validation sets were shuffled. Binary cross-entropy was adopted as the loss function, and ‘Adam’ as the optimizer. The learning rate was standard, namely 0.001. The batch size during training was 32, and the training lasted a maximum of 10 epochs. The method of early stopping was implemented.
4. Discussion
4.1. Statistical Significance of Results
As
Figure 8 indicates, the differences between some models are striking, especially between those based on the AI approaches in comparison with the traditional ones. We, therefore, decided to perform statistical tests to verify the significance of the differences between the individual models. The predicted accuracy values related to different key point neighborhood sizes served as the input data sets in statistical testing. Two pairs of models were compared:
Model #2 vs. Model #1 (i.e., to verify statistical significance resulting from differences in methods);
Model #3 vs. Model #2 (i.e., to verify the statistical significance resulting from the difference in inputs processed by the same methodology).
To determine the significance of the differences between the pairs of models, we primarily decided to perform a statistical
t-test [
56]. Considering the independence of the available samples and the goal of the statistical test itself, the
t-test for independent samples was chosen. Its assumptions, however, were not met. Neither the normal distribution of the data, tested by the Shapiro–Wilk test [
57], nor the equality of variances, tested by Levene’s test [
58], was fulfilled. Given the fulfillment of the assumption of sample independence, we subsequently decided to use an alternative non-parametric test, the Mann–Whitney U-test [
59], which is resistant to the violations of the assumption of normality of the data and capable of comparing the medians of two independent groups.
The results of the Mann–Whitney U-test showed:
4.2. Interpretability of Results
Neural networks traditionally belong to uninterpretable methods, i.e., they are generally considered as ‘black boxes’. Their internal structure can be complex and difficult to interpret directly. When data are fed into a neural network, they pass through several layers of interconnected nodes, each performing some operations on the data. Understanding exactly how these computations lead to a particular output can be challenging, especially in the case of multi-layered deep learning systems. Nevertheless, efforts are being made to increase the interpretability of neural networks to provide insights into which parts of the input data are most influential in producing a given output.
We attempted to interpret the results by means of (i) the Grad-CAM algorithm within the CNN approach (
Section 2.7), (ii) the analysis of the results from the last layer of the CNN using the Sigmoid activation function (again,
Section 2.7), and (iii) the analysis of individual cases of binary thresholding.
4.2.1. Grad-CAM
An example of sample images analyzed by the Grad-CAM algorithm is presented in
Figure 9.
The visible key point labeled as ‘Tatranska Lomnica’ that was correctly predicted by the CNN approach as detectable (i.e., TP) is shown in
Figure 9a.
Figure 9b represents the output of the Grad-CAM algorithm. It puts emphasis on the light sources and their immediate surroundings that represent the monitored key point. In addition to them, however, other light sources are also highlighted, but with lower intensity.
The key point named ‘Wind_Cone’ in
Figure 9c was captured in foggy conditions. We consider the visibility of this point controversial since in some other images in the data set, with meteorological circumstances similar to those in
Figure 9c, the key point was sometimes declared as visible, other times as invisible. According to the output of the Grad-CAM algorithm shown in
Figure 9d, the key point itself was marked as a significant area. In addition to this, further points were identified by the algorithm as significant areas; however, these might represent the fog reflection in the wind cone surroundings. In the end, the AI predicted the detectability in this case as 0, which differs from the true visibility value of this key point observed by humans (i.e., FN).
Figure 9e shows the key point labeled as ‘Runway Light 1’ with incorrectly predicted visibility. Here, the AI approach declared the key point as detectable, whereas, in fact, it was invisible (i.e., FP). According to the Grad-CAM algorithm (
Figure 9f), the most significant area was the part of the mast that did not belong to the key point itself. In fact, the mast represents another key point that is used in determining daytime visibility at the Poprad–Tatry Airport.
This analysis indicates that to achieve the optimal results, a trade-off should be made between the following:
The advantages of larger image patches, with
- o
Higher accuracy of the CNN approach (underpinned by
Figure 8);
- o
Lesser susceptibility to camera shifts (due to vibrations in gusty wind).
The advantages of smaller image patches, with
- o
Lesser contamination by nearby key points or dominant objects.
4.2.2. Sigmoid Activation Function
The Sigmoid activation function was adopted to examine the results from the last layer of the trained CNN, especially the cases with incorrectly predicted visibility. The results from this analysis were highly variable. Depending on the randomly selected subset of the data, the probability of predicting the detectability of key points correctly varied greatly. Their distribution in some cases only approached the extremes of 0 or 1, whereas in others it was around the threshold value of 0.5 (i.e., the probability of a correct prediction was close to random).
4.2.3. Maximum Pixel Intensities
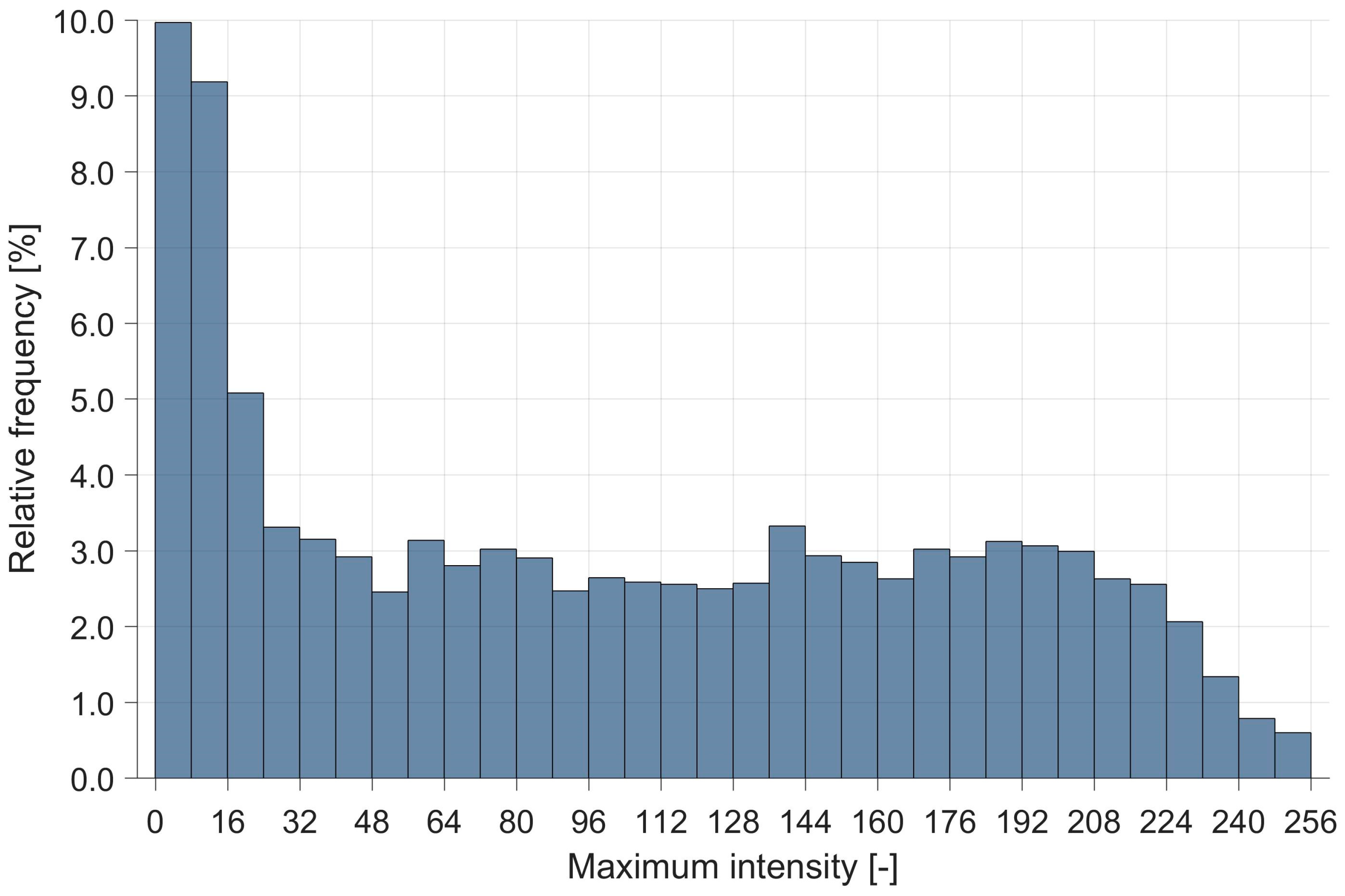
The performance of the binary thresholding method was examined through the maximum pixel intensity values of the modified images that could represent light points. The maxima served to estimate the threshold at which these light points would be classified as detectable or undetectable using the method of binary thresholding.
Figure 10, which shows three different cases of visibility of the key point ‘Wind Cone’, represents an example of such an approach. Each subfigure has a value of maximum intensity assigned, derived from the corresponding modified images. The analysis suggests that the binary thresholding method is interpretable in a more straightforward way, as one can clearly evaluate specific threshold values at which the target objects might be classified as detectable/undetectable.
4.3. Findings in Terms of Related Works
As Ait Ouadil et al. [
6] review, there is an enormous pile of AI-based visibility prediction methods; however, the vast majority of them are devoted to daytime conditions. Our results cannot be compared with them at all, since there is a fundamental difference between the visibility prediction during the day vs. night. The complexity of daytime prediction stems from the wide variability of the objects’ features (shape, size, color, shade, hue, saturation, etc.), although the approaches allow for defining an arbitrary number of auxiliary points (landmarks) for a more accurate prediction. In contrast to this, there are no object features or the possibility to define landmarks in night-time prediction. The difficulties of the night-time approaches follow from the limited amount of available information, i.e., whether the methods are able to detect light sources and distinguish them from the background (surrounding pixels).
We found a very limited number of studies focusing on night-time visibility prediction by various AI approaches [
20,
21,
22,
23]. As mentioned in the Introduction, all four studies used data from one particular day (March 13, 2020 from 0:00 to 8:00) both for the training and testing of the proposed models. We do not consider this data set to be representative of different weather conditions. Aside from this fact, the idea of feeding the data from the Chinese airports into our model indeed emerged, just to see the performance of all the models on the same data set. Nonetheless, as emphasized above, it was impossible to obtain the discussed data set since the only web address cited in [
20] was no more accessible in the period of our model developing and manuscript preparation (2023–2024). Comparing the performance of deep learning models on different data sets is not a viable alternative: it can lead to very misleading results.
Finally, there is one more point which prevented us from a direct comparison with the above referenced four works [
20,
21,
22,
23]. In all of them, the evaluation of the performance was based on visibility—either on visibility as a continuous variable or by means of visibility intervals that are relevant in aviation. In the case of our model, the relatively low number and the spatial distribution of the available light spots in the target location did not let us carry out a similar statistical analysis, allowing at least a rough comparison with the referenced works.
4.4. Potential Drawbacks
Some of the more disputable aspects of our study can be highlighted as follows:
Light spot distribution. The number and the distribution of light spots at the target location have a significant influence on the possibility to evaluate the uncertainty in visibility predictions. Generally, the number/distribution of light spots is affected by the local geographical conditions (hills, valleys, lake/sea/ocean shore, etc.), the population density, the level of industrialization, etc., and these aspects were out of our control.
One testbed, one camera model. The data set was collected at one airport (one geographical location) and with a particular camera model and settings. The inclusion of images collected at multiple locations, with different camera settings could prevent future model drifts, and ensure better transferability by diversifying the training data set. In addition, a more realistic estimate of the real-life performance of the developed models would be possible.
CNN architecture. We adopted a computationally efficient but rather simple CNN architecture. Adding more layers to the CNN will increase both the computational cost and hardware demands, but can lead to more favorable results, especially when combined with a more diverse data set.
No auxiliary data used. The study was only based on graphical inputs and visibility data as the ground truth from professional observers. No other ground meteorological observations were incorporated. Nevertheless, as Chen et al. [
20] report, the inclusion of additional variables can greatly improve the model’s performance.
4.5. Influential Factors and Further Considerations
The quality of the results may have been affected by a number of objective or subjective factors. These are, among others, as follows:
Camera shifts. The correctness of the AI-based prediction of night-time visibility is conditioned on the proper functioning of the camera system. The critical part of the observing system is the rotator, which may provide camera images of lower quality either due to temporary effects (e.g., shaky images due to the wind gusts) or due to long-term effects, which may be caused by gradual wear of some mechanical parts of the rotator. For this reason, a novel ‘static’ solution with no moving parts is being tested recently at a selected testbed. The new construction of the system consists of five high-resolution cameras at fixed positions, which are aimed at covering all four cardinal directions. Five cameras (instead of four that one would naturally assume) are expected to supply satisfactory coverage of the entire horizon with a sufficient reserve for overlapping the neighboring pictures, including the possibility of getting rid of some possible distortions at the edges of the camera pictures. Note that a potential solution with a single (and static) fisheye-lens camera covering the entire hemisphere does not represent a viable solution to our problem. Such an optical tool has widespread applicability in camera-based observing systems; however, they suit better to observing cloud coverage (with a dominant focus mostly in vertical directions) than horizontal visibility (with the areas of the key interest occurring at the edges of a fisheye-lens cameras).
External pollution of the camera. Insects and/or spiders represent occasional disturbing elements in the camera view. Their occurrence can be reduced by a preventive spraying of insecticides around the camera objective. Raindrops and snowflakes are further and more frequently occurring factors affecting the quality of the camera images. Water droplets from the camera lens can be removed by heating the target area; nevertheless, the effect of such an operation manifests itself gradually, resulting in a few images with decreased quality. A further possible solution is the usage of blowing devices that can blow water droplets/pollution from camera lenses just before the moment of image capture; however, the development and deployment of such tools can be expensive. Based on our experience we can underpin that with the usage (and combinations) of adapted HW, camera shields, and water-repellent layer on camera lenses, the effect of extreme weather on the quality of camera images can be significantly reduced. The ultimate effect of these interventions, however, depends on the character of local weather and climatic conditions.
Technical parameters of the camera. It is beneficial to use a camera with a strong microchip that allows at least full HD or higher resolution. Larger microchips are able to detect a higher portion of light, and therefore, the resulting images are less affected by noise, particularly in night-time conditions. Furthermore, it would also be beneficial a higher dynamic range (10 bits or more) of the camera that could better capture the details of the bright and dark parts of the image.
Subjective character of the ground truth. The evaluation of visibility carried out by professional meteorological observers is generally considered as the ground truth. Nevertheless, since the subjective character of the procedure cannot be fully eliminated, the ground truth remains, at least to some degree, questionable. Not seldom there are not fully clear weather conditions where the visibility is determined by different observers in a different way. Moreover, it may also happen that a borderline case can be judged by a given meteorological observer in a different way, when evaluated repeatedly, for instance, using some form of backup. Adoption of machine learning techniques, on the other hand, is a significant step towards the objectivization of the decision procedure since a trained neural network will always decide the same way when evaluating identical camera images repeatedly several times.
Biomedical aspects of night vision. Some humans have better night vision than others due to variations in the structure of their eyes and the functioning of their retinas. The ability to see in low-light conditions, such as at night, is primarily determined by the presence of specialized cells in the retina called rods. Rod cells are highly sensitive to light and are responsible for our ability to see in dim lighting. Individual differences in night vision can be influenced by factors such as the density of rod cells in the retina, the efficiency of the visual processing pathways in the brain, and genetic variations that affect the functioning of these components. Additionally, environmental factors like exposure to bright lights or certain medications can also impact night vision [
60]. Although many studies have confirmed wide variation in night vision in young healthy volunteers, some factors were explained but the majority of the variation in night vision remains unexplained by obvious non-genetic factors and suggesting a strong genetic component [
61]. This medical knowledge gives importance to our solution of the automatic determination of night visibility with cameras because it can bring significant accuracy and objectification.
5. Conclusions
In the presented work, we focused on the issue of the detectability of light points at night. We worked with a data set consisting of (1) camera photos from a selected location (Poprad–Tatry Airport, Slovakia) and (2) the information on whether the key points (light spots) were detectable or not by professional observers.
Multiple sets of images were created for each key point by a cut-out from the original camera images with a number of different key point neighborhood sizes (termed as ‘original’ data set). The ‘modified’ data set of images was created from the ‘original’ one by applying morphological erosion to emphasize the dominant features of the images and suppress detected noise.
The detectability of light points in the images was classified in two ways. The first one was a traditional approach using simple binary thresholding (BT), while the second one was based on one of the progressive AI approaches (convolutional neural network, CNN, with a simple architecture). The individual cases of predicted detectability were analyzed in the light of true visibility values that were determined by human observers.
We primarily compared the use of the standard BT approach with CNN. The two models based on trained CNN achieved remarkably better results in terms of more favorable values of metrics, greater stability, and less susceptibility to errors than the classification by the BT method. The difference in the input image sets (modified vs. original) did not affect the results considerably—some scores/statistics were more favorable for the modified images, others for the original ones. This emphasizes the benefits resulting from image modification, which are mainly the highlighting of dominant features and a lower significance of key points’ background.
We also examined the accuracy of the predictions as a function of the image size around the key points. In these experiments, the CNN classification method showed greater stability since the accuracy of these models grew with increasing pixel size around the key points, whereas an opposite behavior was discernible for the BT method. This finding was also confirmed statistically: the Mann–Whitney U test indicated a significant difference between the CNN and the standard BT classification methods. On the other hand, the difference between the two models based on CNN classification but with different inputs (original vs. modified images) was statistically insignificant.
The rate of misclassification using CNN was lower, and the errors were caused mostly due to the following two reasons: (i) questionable annotations of true visibility of the key points, or (ii) the presence of another dominant point with different visibility. The error rate of classification by binary thresholding was manifested to a greater extent, especially in cases of the presence of other light points, or parts of the gray image with higher intensity.
In the paper, we managed to point out the potential of an automated and AI-based determination of key points’ detectability in the night. The method has shown stability and decent accuracy, which is important in meteorology, and has great perspectives in the everyday routine of professional meteorology, especially in an automated estimation of prevailing visibility. In the current study, we did not make attempts to convert the light points’ detectability into actual values of visibility (expressed in meters). It would be interesting to evaluate the uncertainties in the determination of visibility, stratified according to distance categories (see
Table 1); however, the low number and the spatial distribution of the available light spots in the target location did not allow for a satisfactory statistical analysis. Such a task remains one of the key plans for the future, either by having collected a larger database covering a much longer period or by setting up a further experiment at a different testbed.
While the proposed solution may offer advantages, it is also important to acknowledge its limitations. Here, we list some issues with the potential to enhance the performance of the proposed approach for future work.
Quality control of the annotated data set. One of the foreseeable problems is the difficulty of obtaining an annotated data set with a well-defined visibility of key points. In the current work, several cases were discovered where the annotated true visibility did not correspond to reality, or, at least, it was questionable. Although being aware of this deficiency, we did not ignore these annotations, which could have caused the results to be distorted. We, therefore, suggest a more thorough screening of the annotated data set to improve the automated predictions’ accuracy.
Quality control of the camera images. Another limitation is that we did not directly control the quality of the camera images. As part of their pre-preparation, the images were filtered using additional information about their quality, which we fully relied on. Further undiscovered and unfiltered, low-quality photos (for instance, damaged ones or with low resolution) in the data set could have increased the bias in the results. Therefore, within the field of extension, we call for the investigation of ways to improve the quality of camera images or the implementation of measures to control their quality.
Camera shifts. Our solution does not consider camera movements that could occur over several years due to various unfavorable weather conditions. This could cause shifts between the co-ordinates of the key points and their location in the photos. To overcome this problem, we propose either a software-based or a hardware-based solution. The SW-based solution would involve key point motion analysis techniques in sequential images and their adaptation, for example, using the methods of image registration. The HW-based solution could be a replacement of the critical (moving) part of the system (i.e., a camera mounted on a rotator) by construction with several fixed and high-quality cameras, as indicated in the discussion above.
Deep learning. The aim of the current study was to devise a light-weight neural network suitable for deployment with a low computational cost and moderate hardware requirements. Increasing the complexity of the neural network is expected to lead to better overall performance for accuracy, FNR, and FPR. Although we expect our model to be transferable to other airports in similar meteorological environments, this issue remains to be investigated in further research. In this study, we have decided to address the imbalance of the data set by keeping all the class 0 data and randomly adding class 1, e.g., ensuring that both classes are equally distributed. Other options could be data augmentation [
62] or a higher misclassification cost for wrongly classified minority events [
63,
64,
65,
66].


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}