


Improving Air Quality Prediction via Self-Supervision Masked Air Modeling


Abstract
1. Introduction
- 1.
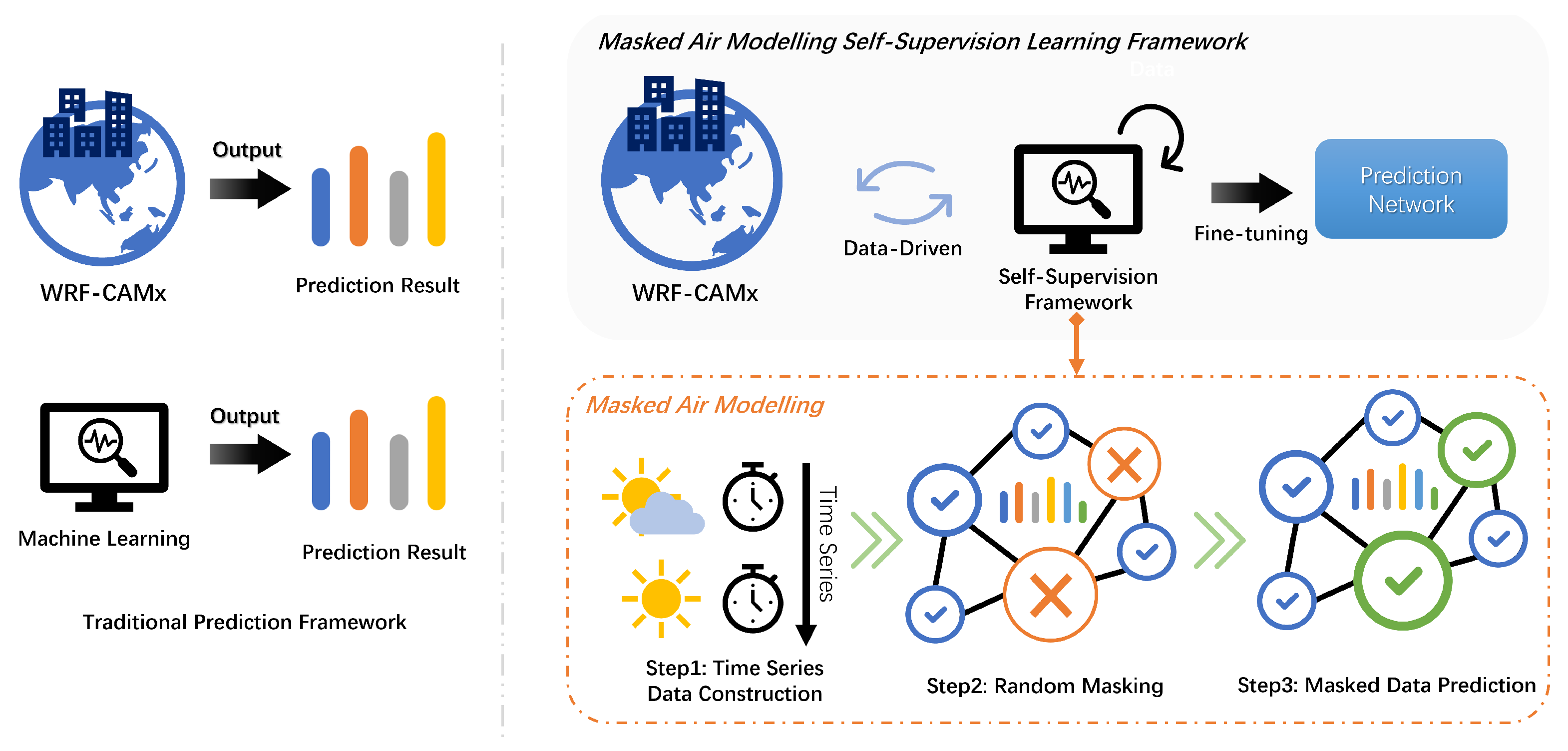
- We propose a hybrid air quality prediction pipeline that not only simulates atmospheric physics and chemical reactions of pollutants, but also inherits the long-range dependency modeling capabilities of the Transformer.
- 2.
- We design an asymmetric Transformer-based encoder–decoder architecture as a promising scheme of masked air modeling, which yields a nontrivial and meaningful self-supervisory sequence representation learning task.
- 3.
- In terms of hour-by-hour simulation performance, the proposed MAM can effectively boost the WRF-CAMx and purely supervisory learning models’ predictive capabilities, which provides more than 26 percent (correlation coefficient) of performance improvements.
2. Related Work
3. Method
3.1. WRF-CAMx Modeling
3.1.1. Simulation Domain
3.1.2. Model Building
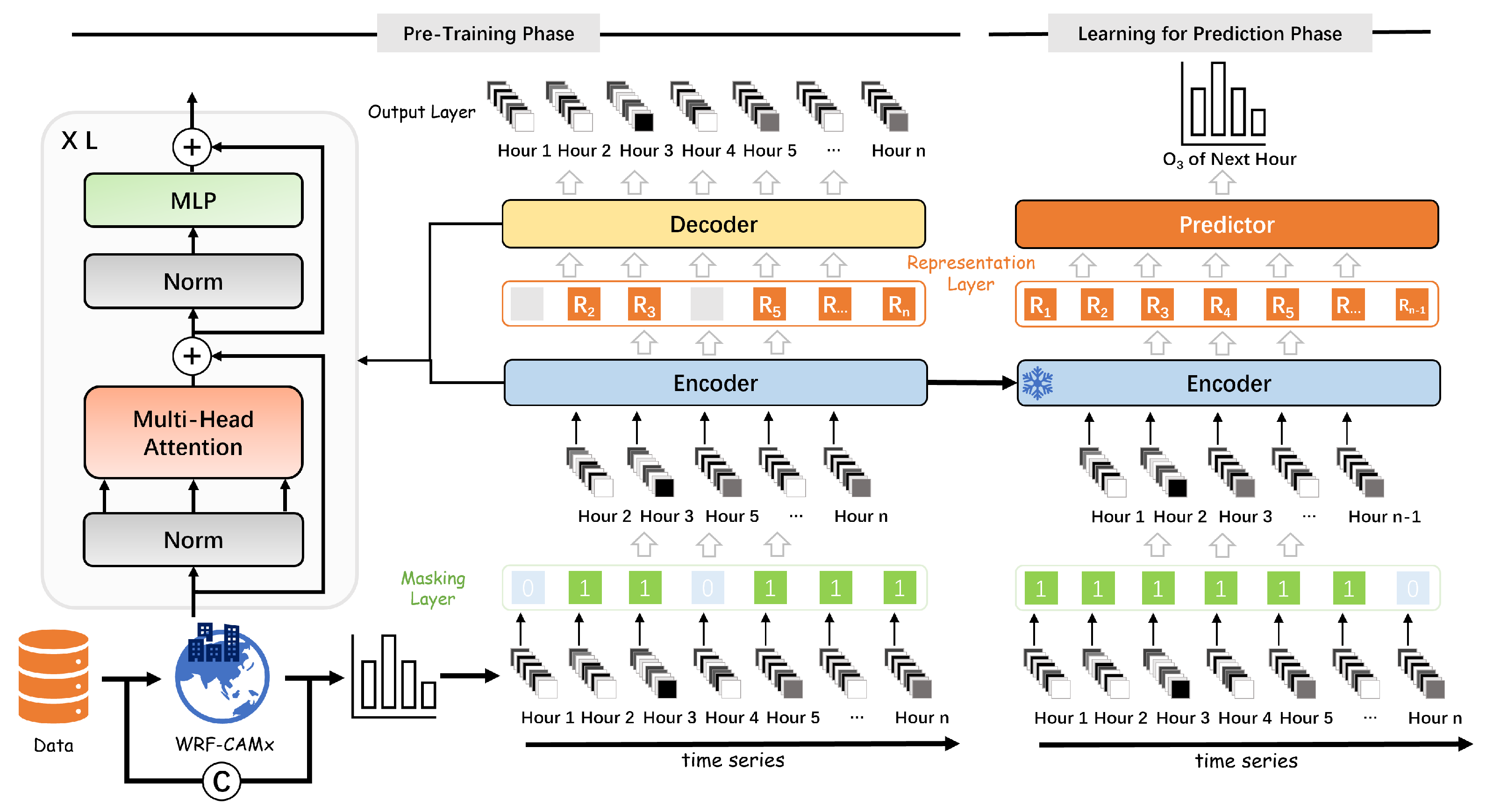
3.2. Masked Air Modeling
3.2.1. Problem Statement
3.2.2. Masked Autoencoders for Context Understanding
3.2.3. Learning Prediction Representation
3.2.4. Loss Function
4. Experiment
4.1. Ground-Level Air Pollutant Measurements
4.2. Performance Metrics
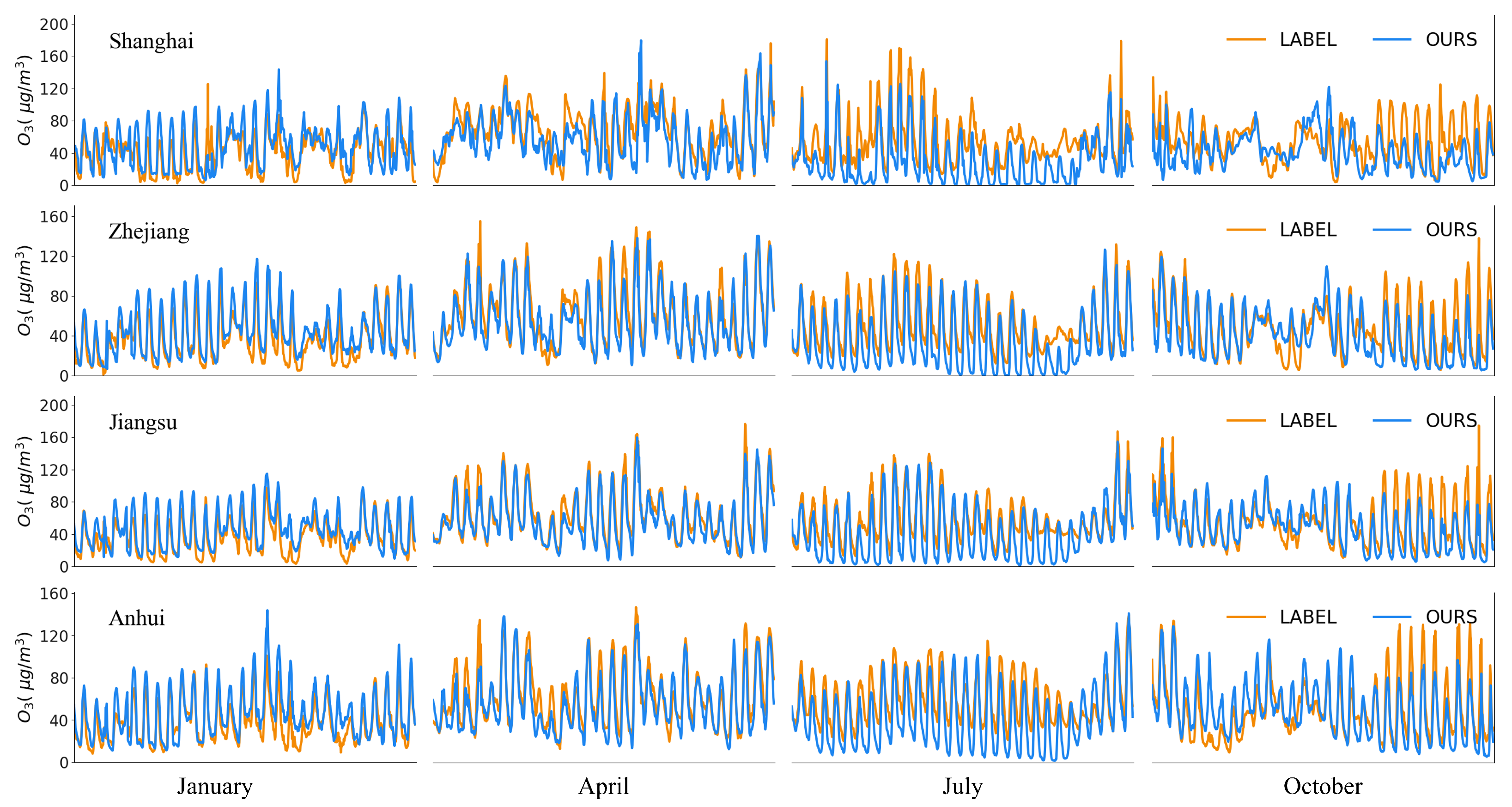
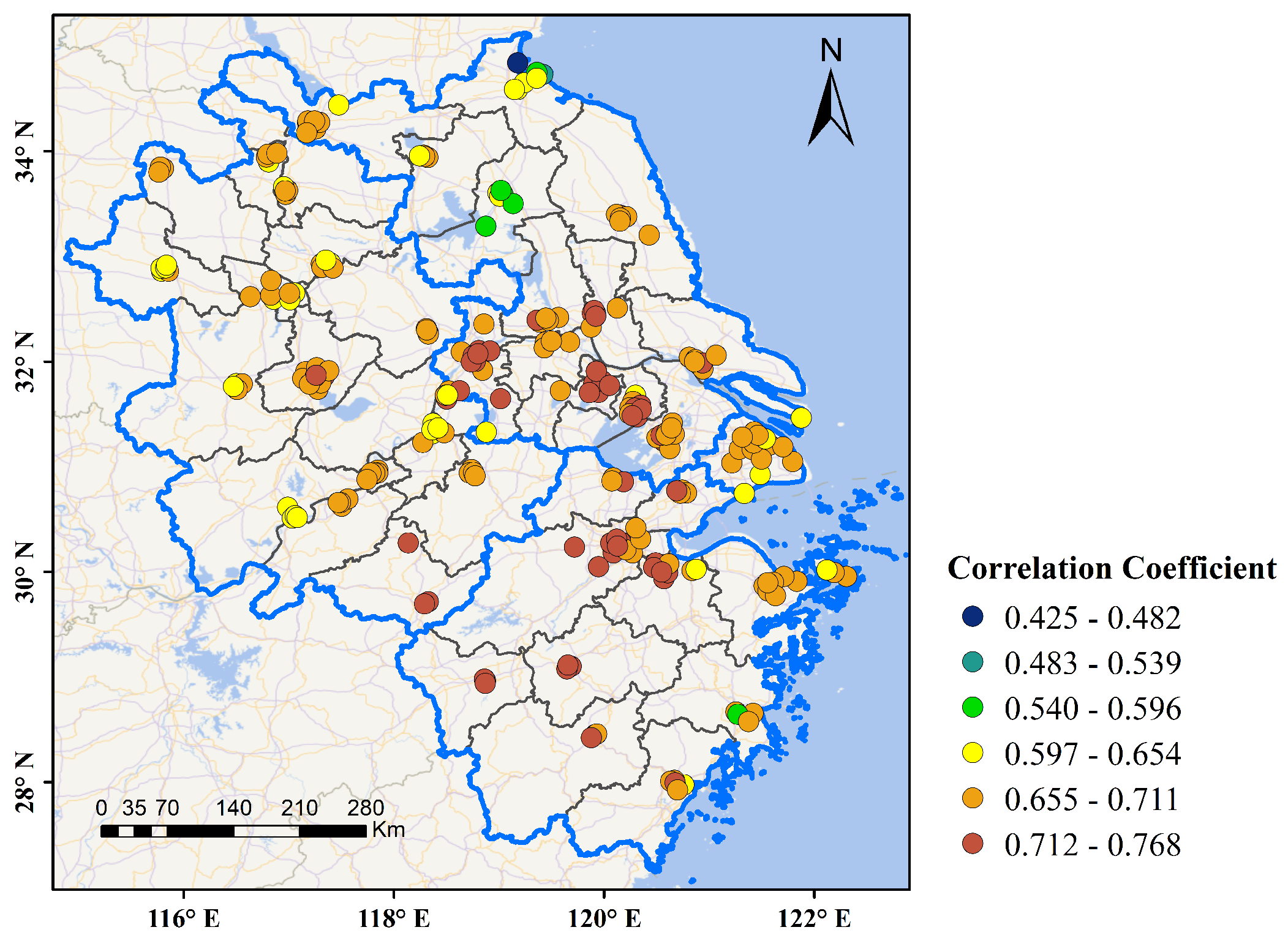
4.3. Results and Discussion
4.3.1. Comparison with Baseline
4.3.2. Comparison with Supervision Models
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lu, X.; Wang, J.; Yan, Y.; Zhou, L.; Ma, W. Estimating hourly PM2.5 concentrations using Himawari-8 AOD and a DBSCAN-modified deep learning model over the YRDUA, China. Atmos. Pollut. Res. 2021, 12, 183–192. [Google Scholar] [CrossRef]
- Chen, W.; Tang, H.; He, L.; Zhang, Y.; Ma, W. Co-effect assessment on regional air quality: A perspective of policies and measures with greenhouse gas reduction potential. Sci. Total. Environ. 2022, 851, 158119. [Google Scholar] [CrossRef] [PubMed]
- Cohen, A.J.; Brauer, M.; Burnett, R.; Anderson, H.R.; Frostad, J.; Estep, K.; Balakrishnan, K.; Brunekreef, B.; Dandona, L.; Dandona, R.; et al. Estimates and 25-year trends of the global burden of disease attributable to ambient air pollution: An analysis of data from the Global Burden of Diseases Study 2015. Lancet 2017, 389, 1907–1918. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Batterman, S. Air pollution and health risks due to vehicle traffic. Sci. Total. Environ. 2013, 450, 307–316. [Google Scholar] [CrossRef] [PubMed]
- Mak, H.W.L.; Ng, D.C.Y. Spatial and socio-classification of traffic pollutant emissions and associated mortality rates in high-density hong kong via improved data analytic approaches. Int. J. Environ. Res. Public Health 2021, 18, 6532. [Google Scholar] [CrossRef]
- Choma, E.F.; Evans, J.S.; Gómez-Ibáñez, J.A.; Di, Q.; Schwartz, J.D.; Hammitt, J.K.; Spengler, J.D. Health benefits of decreases in on-road transportation emissions in the United States from 2008 to 2017. Proc. Natl. Acad. Sci. USA 2021, 118, e2107402118. [Google Scholar] [CrossRef] [PubMed]
- Yao, J.; Brauer, M.; Raffuse, S.; Henderson, S.B. Machine learning approach to estimate hourly exposure to fine particulate matter for urban, rural, and remote populations during wildfire seasons. Environ. Sci. Technol. 2018, 52, 13239–13249. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Rong, Y.; Yong, R.; Qin, D.; Li, M.; Zou, G.; Pan, J. Deep learning for air pollutant concentration prediction: A review. Atmos. Environ. 2022, 290, 119347. [Google Scholar] [CrossRef]
- Wang, W.; An, X.; Li, Q.; Geng, Y.a.; Yu, H.; Zhou, X. Optimization research on air quality numerical model forecasting effects based on deep learning methods. Atmos. Res. 2022, 271, 106082. [Google Scholar] [CrossRef]
- Li, H.; Wang, J.; Yang, H.; Wang, Y. Air quality deterministic and probabilistic forecasting system based on hesitant fuzzy sets and nonlinear robust outlier correction. Knowl.-Based Syst. 2022, 237, 107789. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv, 2018; arXiv:1810.04805. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Zhang, J.; Wei, Y.; Fang, Z. Ozone pollution: A major health hazard worldwide. Front. Immunol. 2019, 10, 2518. [Google Scholar] [CrossRef] [PubMed]
- Anenberg, S.C.; Horowitz, L.W.; Tong, D.Q.; West, J.J. An estimate of the global burden of anthropogenic ozone and fine particulate matter on premature human mortality using atmospheric modeling. Environ. Health Perspect. 2010, 118, 1189–1195. [Google Scholar] [CrossRef] [PubMed]
- Turner, M.C.; Jerrett, M.; Pope III, C.A.; Krewski, D.; Gapstur, S.M.; Diver, W.R.; Beckerman, B.S.; Marshall, J.D.; Su, J.; Crouse, D.L.; et al. Long-term ozone exposure and mortality in a large prospective study. Am. J. Respir. Crit. Care Med. 2016, 193, 1134–1142. [Google Scholar] [CrossRef] [PubMed]
- Mueller, S.F.; Mallard, J.W. Contributions of natural emissions to ozone and PM2.5 as simulated by the community multiscale air quality (CMAQ) model. Environ. Sci. Technol. 2011, 45, 4817–4823. [Google Scholar] [CrossRef] [PubMed]
- Thongthammachart, T.; Araki, S.; Shimadera, H.; Eto, S.; Matsuo, T.; Kondo, A. An integrated model combining random forests and WRF/CMAQ model for high accuracy spatiotemporal PM2.5 predictions in the Kansai region of Japan. Atmos. Environ. 2021, 262, 118620. [Google Scholar] [CrossRef]
- Kitagawa, Y.K.L.; Pedruzzi, R.; Galvão, E.S.; de Araújo, I.B.; de Almeida Alburquerque, T.T.; Kumar, P.; Nascimento, E.G.S.; Moreira, D.M. Source apportionment modelling of PM2.5 using CMAQ-ISAM over a tropical coastal-urban area. Atmos. Pollut. Res. 2021, 12, 101250. [Google Scholar] [CrossRef]
- Wang, P.; Wang, P.; Chen, K.; Du, J.; Zhang, H. Ground-level ozone simulation using ensemble WRF/Chem predictions over the Southeast United States. Chemosphere 2022, 287, 132428. [Google Scholar] [CrossRef] [PubMed]
- Zhou, G.; Xu, J.; Xie, Y.; Chang, L.; Gao, W.; Gu, Y.; Zhou, J. Numerical air quality forecasting over eastern China: An operational application of WRF-Chem. Atmos. Environ. 2017, 153, 94–108. [Google Scholar] [CrossRef]
- Konopka, P.; Grooß, J.U.; Günther, G.; Ploeger, F.; Pommrich, R.; Müller, R.; Livesey, N. Annual cycle of ozone at and above the tropical tropopause: Observations versus simulations with the Chemical Lagrangian Model of the Stratosphere (CLaMS). Atmos. Chem. Phys. 2010, 10, 121–132. [Google Scholar] [CrossRef]
- Koo, Y.S.; Choi, D.R.; Kwon, H.Y.; Jang, Y.K.; Han, J.S. Improvement of PM10 prediction in East Asia using inverse modeling. Atmos. Environ. 2015, 106, 318–328. [Google Scholar] [CrossRef]
- He, L.; Duan, Y.; Zhang, Y.; Yu, Q.; Huo, J.; Chen, J.; Cui, H.; Li, Y.; Ma, W. Effects of VOC emissions from chemical industrial parks on regional O3-PM2.5 compound pollution in the Yangtze River Delta. Sci. Total. Environ. 2024, 906, 167503. [Google Scholar] [CrossRef] [PubMed]
- Pak, U.; Ma, J.; Ryu, U.; Ryom, K.; Juhyok, U.; Pak, K.; Pak, C. Deep learning-based PM2.5 prediction considering the spatiotemporal correlations: A case study of Beijing, China. Sci. Total. Environ. 2020, 699, 133561. [Google Scholar] [CrossRef] [PubMed]
- Vautard, R.; Builtjes, P.H.; Thunis, P.; Cuvelier, C.; Bedogni, M.; Bessagnet, B.; Honore, C.; Moussiopoulos, N.; Pirovano, G.; Schaap, M.; et al. Evaluation and intercomparison of Ozone and PM10 simulations by several chemistry transport models over four European cities within the CityDelta project. Atmos. Environ. 2007, 41, 173–188. [Google Scholar] [CrossRef]
- Stern, R.; Builtjes, P.; Schaap, M.; Timmermans, R.; Vautard, R.; Hodzic, A.; Memmesheimer, M.; Feldmann, H.; Renner, E.; Wolke, R.; et al. A model inter-comparison study focussing on episodes with elevated PM10 concentrations. Atmos. Environ. 2008, 42, 4567–4588. [Google Scholar] [CrossRef]
- Ma, Z.; Dey, S.; Christopher, S.; Liu, R.; Bi, J.; Balyan, P.; Liu, Y. A review of statistical methods used for developing large-scale and long-term PM2.5 models from satellite data. Remote Sens. Environ. 2022, 269, 112827. [Google Scholar] [CrossRef]
- Liu, H.; Yan, G.; Duan, Z.; Chen, C. Intelligent modeling strategies for forecasting air quality time series: A review. Appl. Soft Comput. 2021, 102, 106957. [Google Scholar] [CrossRef]
- Zhang, L.; Lin, J.; Qiu, R.; Hu, X.; Zhang, H.; Chen, Q.; Tan, H.; Lin, D.; Wang, J. Trend analysis and forecast of PM2.5 in Fuzhou, China using the ARIMA model. Ecol. Indic. 2018, 95, 702–710. [Google Scholar] [CrossRef]
- Ma, Z.; Hu, X.; Huang, L.; Bi, J.; Liu, Y. Estimating ground-level PM2.5 in China using satellite remote sensing. Environ. Sci. Technol. 2014, 48, 7436–7444. [Google Scholar] [CrossRef]
- Leong, W.; Kelani, R.; Ahmad, Z. Prediction of air pollution index (API) using support vector machine (SVM). J. Environ. Chem. Eng. 2020, 8, 103208. [Google Scholar] [CrossRef]
- Nieto, P.G.; Lasheras, F.S.; García-Gonzalo, E.; de Cos Juez, F. PM10 concentration forecasting in the metropolitan area of Oviedo (Northern Spain) using models based on SVM, MLP, VARMA and ARIMA: A case study. Sci. Total. Environ. 2018, 621, 753–761. [Google Scholar] [CrossRef]
- Corani, G.; Scanagatta, M. Air pollution prediction via multi-label classification. Environ. Model. Softw. 2016, 80, 259–264. [Google Scholar] [CrossRef]
- Zhan, Y.; Luo, Y.; Deng, X.; Grieneisen, M.L.; Zhang, M.; Di, B. Spatiotemporal prediction of daily ambient ozone levels across China using random forest for human exposure assessment. Environ. Pollut. 2018, 233, 464–473. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Zhang, H.; Palazoglu, A.; Singh, A.; Zhang, W.; Liu, S. Prediction of 24-hour-average PM2.5 concentrations using a hidden Markov model with different emission distributions in Northern California. Sci. Total. Environ. 2013, 443, 93–103. [Google Scholar] [CrossRef]
- Suleiman, A.; Tight, M.; Quinn, A. Applying machine learning methods in managing urban concentrations of traffic-related particulate matter (PM10 and PM2.5). Atmos. Pollut. Res. 2019, 10, 134–144. [Google Scholar] [CrossRef]
- Zamani Joharestani, M.; Cao, C.; Ni, X.; Bashir, B.; Talebiesfandarani, S. PM2.5 prediction based on random forest, XGBoost, and deep learning using multisource remote sensing data. Atmosphere 2019, 10, 373. [Google Scholar] [CrossRef]
- Sayeed, A.; Choi, Y.; Jung, J.; Lops, Y.; Eslami, E.; Salman, A.K. A deep convolutional neural network model for improving WRF simulations. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 750–760. [Google Scholar] [CrossRef] [PubMed]
- He, B.; Zhu, X.; Cang, Z.; Liu, Y.; Lei, Y.; Chen, Z.; Wang, Y.; Zheng, Y.; Cang, D.; Zhang, L. Interpretation and Prediction of the CO2 Sequestration of Steel Slag by Machine Learning. Environ. Sci. Technol. 2023, 57, 17940–17949. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Ying, J.J.C.; Tseng, V.S. Spatio-attention embedded recurrent neural network for air quality prediction. Knowl.-Based Syst. 2021, 233, 107416. [Google Scholar] [CrossRef]
- Zhou, X.; Liu, X.; Lan, G.; Wu, J. Federated conditional generative adversarial nets imputation method for air quality missing data. Knowl.-Based Syst. 2021, 228, 107261. [Google Scholar] [CrossRef]
- Athira, V.; Geetha, P.; Vinayakumar, R.; Soman, K. Deepairnet: Applying recurrent networks for air quality prediction. Procedia Comput. Sci. 2018, 132, 1394–1403. [Google Scholar]
- Wen, C.; Liu, S.; Yao, X.; Peng, L.; Li, X.; Hu, Y.; Chi, T. A novel spatiotemporal convolutional long short-term neural network for air pollution prediction. Sci. Total. Environ. 2019, 654, 1091–1099. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Zou, G.; Qin, D.; Lu, Y.; Jin, Y.; Wang, H. A novel Encoder-Decoder model based on read-first LSTM for air pollutant prediction. Sci. Total. Environ. 2021, 765, 144507. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Shen, S.; He, L.; Chen, W.; Chen, S.; Ma, W. Spatial and Temporal Distribution Characteristics of Ozone Concentration and Source Analysis during the COVID-19 Lockdown Period in Shanghai. Atmosphere 2023, 14, 1563. [Google Scholar] [CrossRef]
- Mak, H.W.L.; Laughner, J.L.; Fung, J.C.H.; Zhu, Q.; Cohen, R.C. Improved satellite retrieval of tropospheric NO2 column density via updating of air mass factor (AMF): Case study of Southern China. Remote Sens. 2018, 10, 1789. [Google Scholar] [CrossRef]
- Basla, B.; Agresti, V.; Balzarini, A.; Giani, P.; Pirovano, G.; Gilardoni, S.; Paglione, M.; Colombi, C.; Belis, C.A.; Poluzzi, V.; et al. Simulations of organic aerosol with CAMx over the Po Valley during the summer season. Atmosphere 2022, 13, 1996. [Google Scholar] [CrossRef]
- Li, M.; Liu, H.; Geng, G.; Hong, C.; Liu, F.; Song, Y.; Tong, D.; Zheng, B.; Cui, H.; Man, H.; et al. Anthropogenic emission inventories in China: A review. Natl. Sci. Rev. 2017, 4, 834–866. [Google Scholar] [CrossRef]
- Zheng, B.; Tong, D.; Li, M.; Liu, F.; Hong, C.; Geng, G.; Li, H.; Li, X.; Peng, L.; Qi, J.; et al. Trends in China’s anthropogenic emissions since 2010 as the consequence of clean air actions. Atmos. Chem. Phys. 2018, 18, 14095–14111. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv, 2020; arXiv:2010.11929. [Google Scholar]
- Trockman, A.; Kolter, J.Z. Mimetic initialization of self-attention layers. In Proceedings of the International Conference on Machine Learning. PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 34456–34468. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Physical parameterization scheme | |
| Longwave radiation | RRTM scheme |
| Shortwave radiation | Goddard scheme |
| Land surface | Noah land surface model |
| Cumulus parameterization | Kain–Fritsch scheme |
| Planetary boundary layer | YSU scheme |
| Chemical parameterization scheme | |
| Gas-phase chemical mechanism | CB05 |
| Particulate matter chemistry | SOAP/CF |
| Dry deposition | Wesely model |
| Wet deposition | Seinfeld and Pandis model |
| Area | Model | January | April | July | October |
|---|---|---|---|---|---|
| Shanghai | Ours WRF-CAMx | 0.713 0.411 | 0.740 0.561 | 0.696 0.409 | 0.541 0.456 |
| Zhejiang | Ours WRF-CAMx | 0.765 0.551 | 0.741 0.491 | 0.753 0.525 | 0.646 0.525 |
| Jiangsu | Ours WRF-CAMx | 0.756 0.545 | 0.771 0.568 | 0.711 0.534 | 0.660 0.554 |
| Anhu | Ours WRF-CAMx | 0.731 0.472 | 0.735 0.413 | 0.711 0.440 | 0.615 0.416 |
| Model | BIAS | RMSE | IOA | COR |
|---|---|---|---|---|
| Transformer + MAM (Ours) | −4.349 | 23.627 | 0.820 | 0.689 |
| Transformer | −6.678 | 25.264 | 0.719 | 0.596 |
| FNN | 29.688 | 37.421 | 0.604 | 0.585 |
| RF | 9.864 | 22.981 | 0.733 | 0.584 |
| WRF-CAMx | −12.578 | 32.403 | 0.666 | 0.473 |
| Transformer + MAM (w/o WRF-CAMx) | −4.971 | 25.171 | 0.746 | 0.611 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; He, L.; Shen, S.; Zhang, Y.; Ma, W. Improving Air Quality Prediction via Self-Supervision Masked Air Modeling. Atmosphere 2024, 15, 856. https://doi.org/10.3390/atmos15070856
Chen S, He L, Shen S, Zhang Y, Ma W. Improving Air Quality Prediction via Self-Supervision Masked Air Modeling. Atmosphere. 2024; 15(7):856. https://doi.org/10.3390/atmos15070856
Chicago/Turabian StyleChen, Shuang, Li He, Shinan Shen, Yan Zhang, and Weichun Ma. 2024. "Improving Air Quality Prediction via Self-Supervision Masked Air Modeling" Atmosphere 15, no. 7: 856. https://doi.org/10.3390/atmos15070856
APA StyleChen, S., He, L., Shen, S., Zhang, Y., & Ma, W. (2024). Improving Air Quality Prediction via Self-Supervision Masked Air Modeling. Atmosphere, 15(7), 856. https://doi.org/10.3390/atmos15070856