
Study on Wind Profile Characteristics Using Cluster Analysis




Abstract
1. Introduction
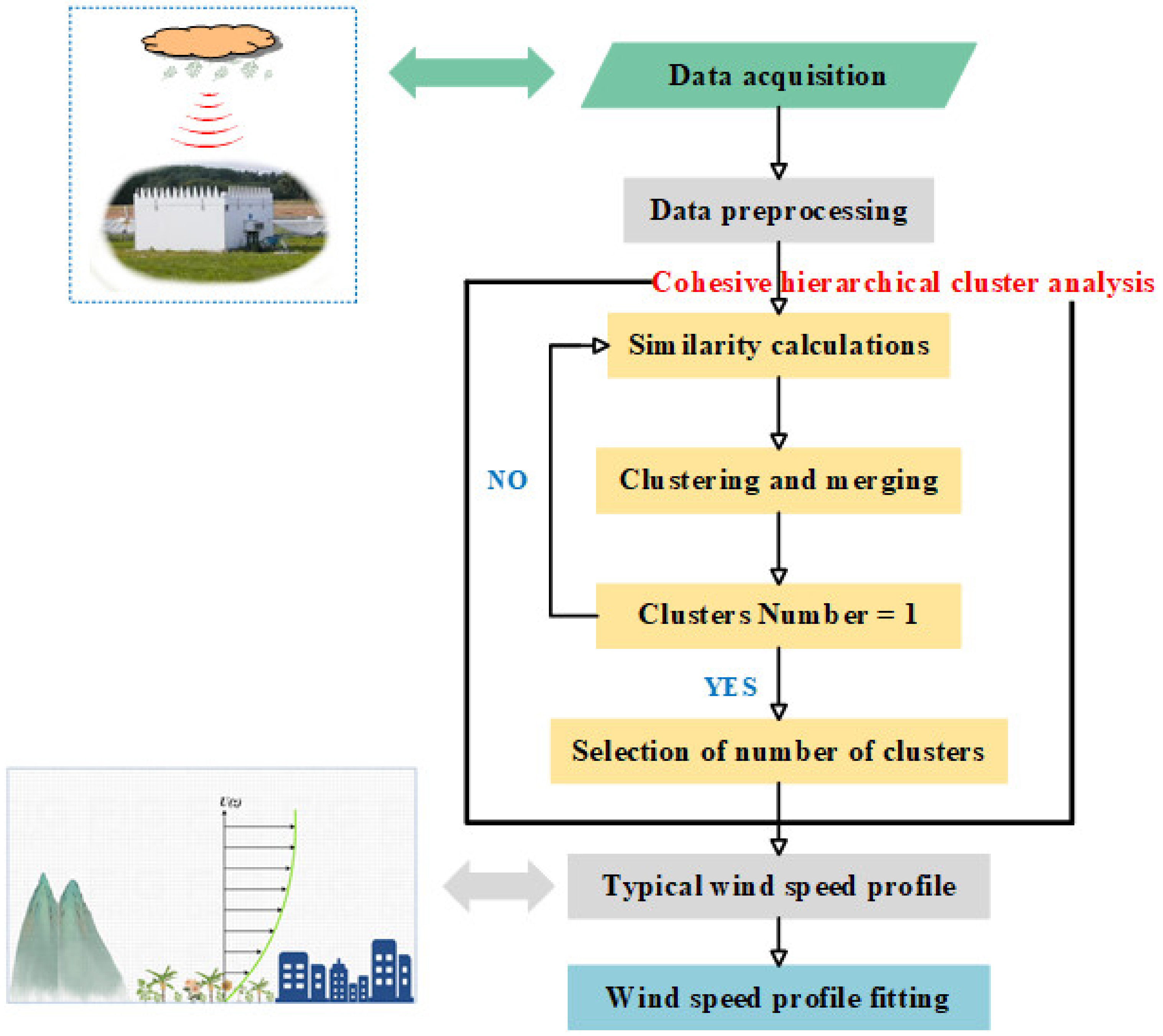
2. Methodology
2.1. Cluster Analysis
2.1.1. Sample Distance Measurement
2.1.2. Sample Similarity Measurement
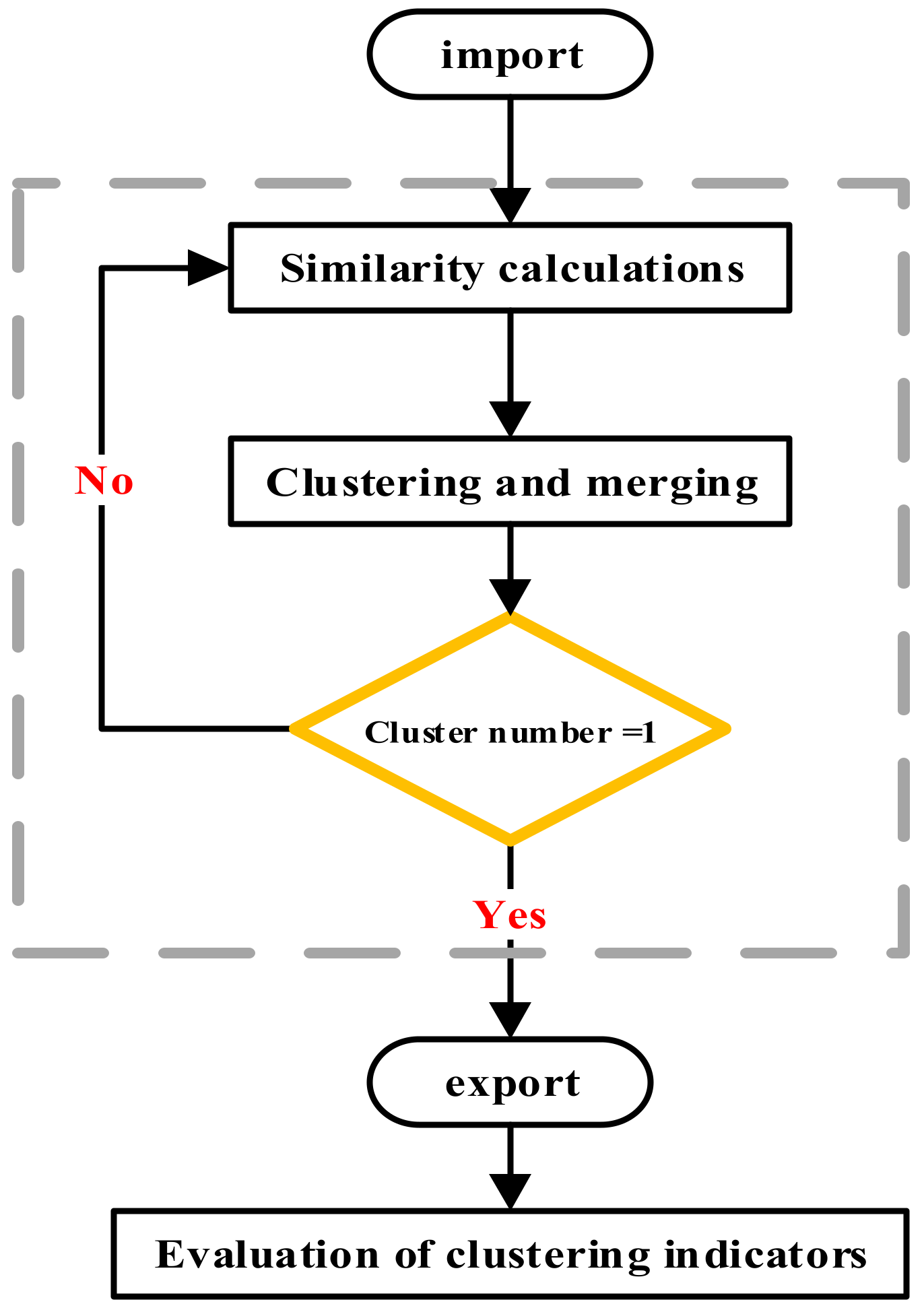
2.1.3. Agglomerative Hierarchical Clustering Analysis
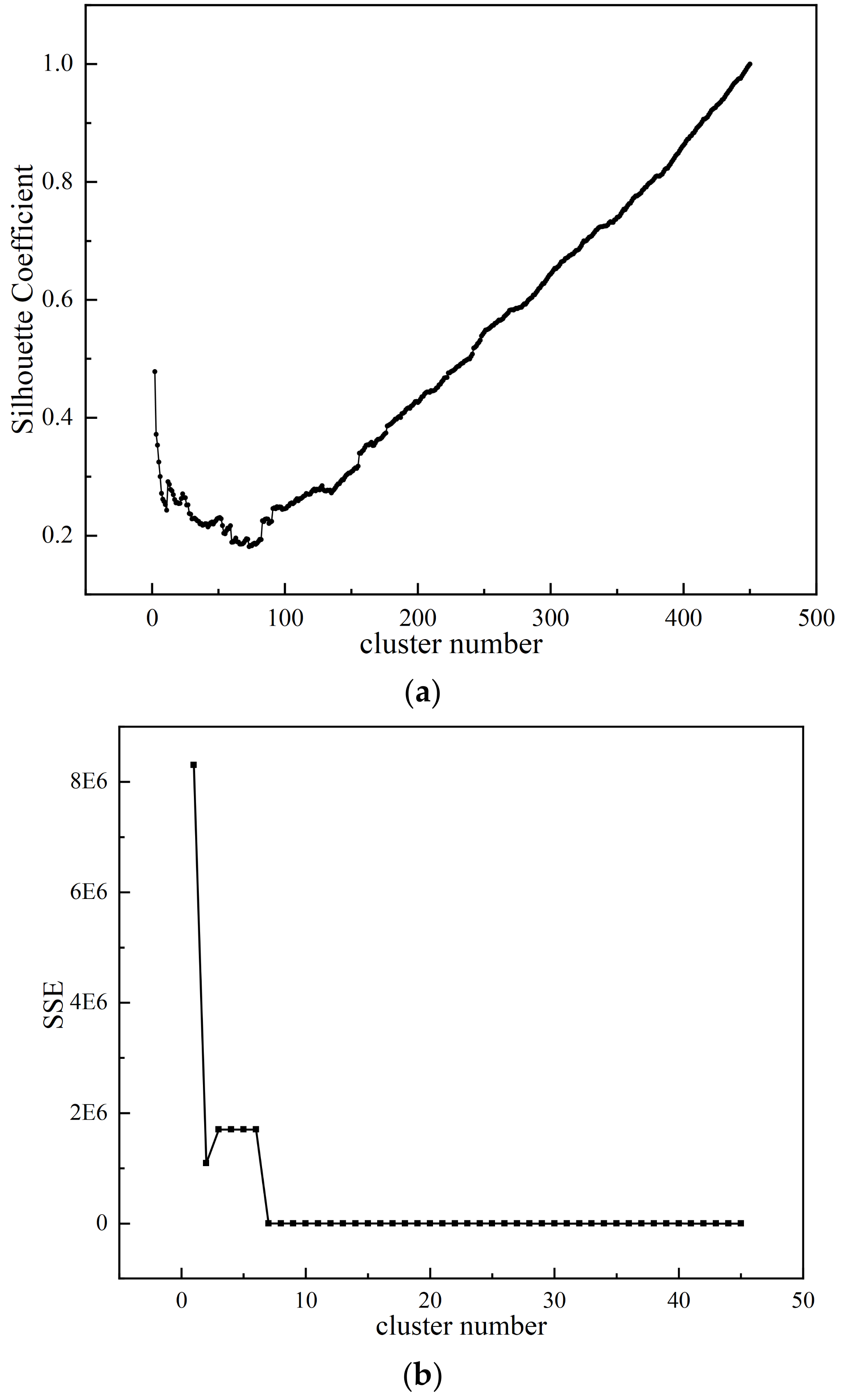
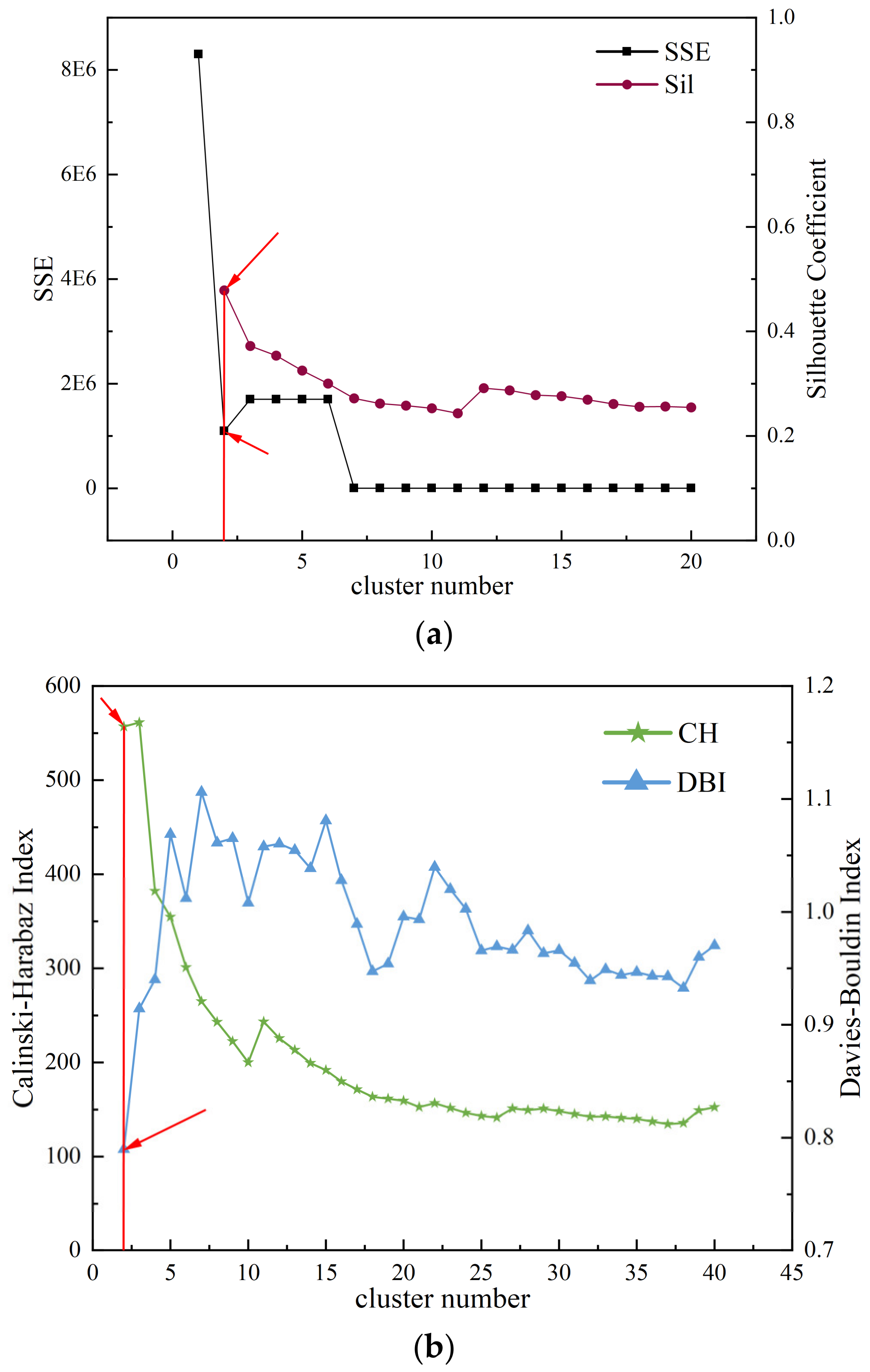
2.1.4. Validation of Clustering Results
2.1.5. Selection of Clustering Results
2.2. Wind Profile Fitting
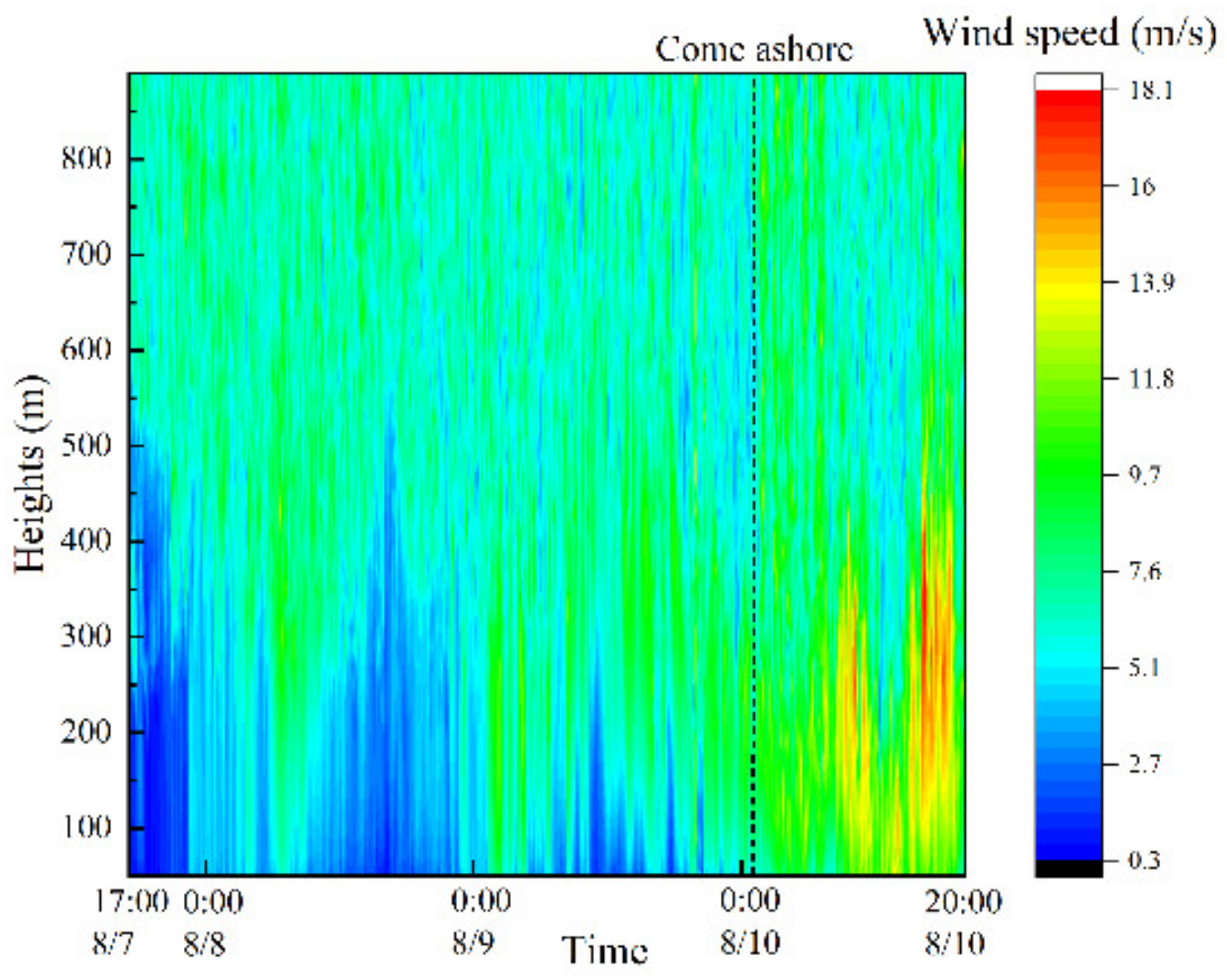
3. Data Acquisition
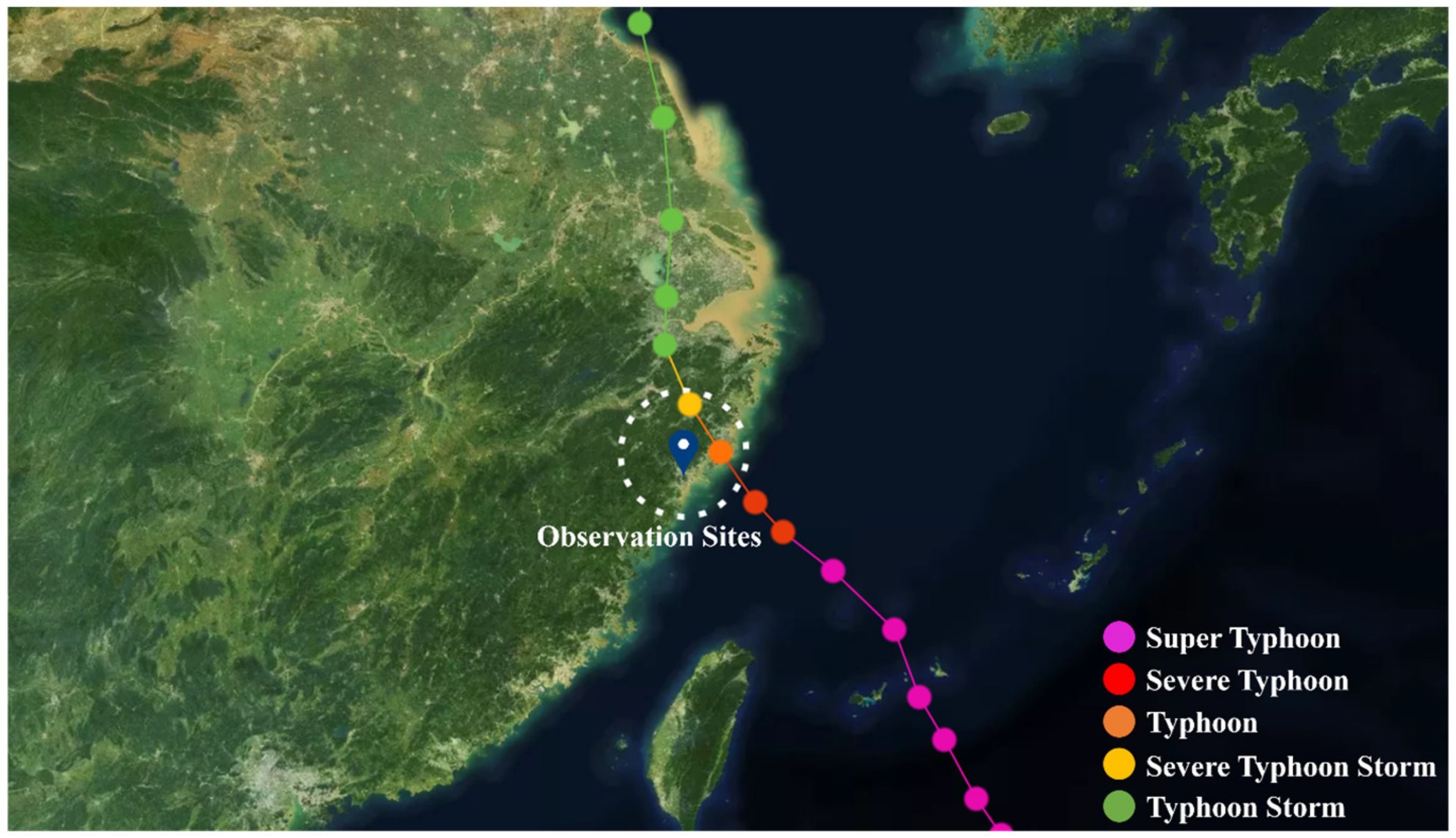
3.1. Observation Sites
3.2. Observation Instrument
4. Data Preprocessing
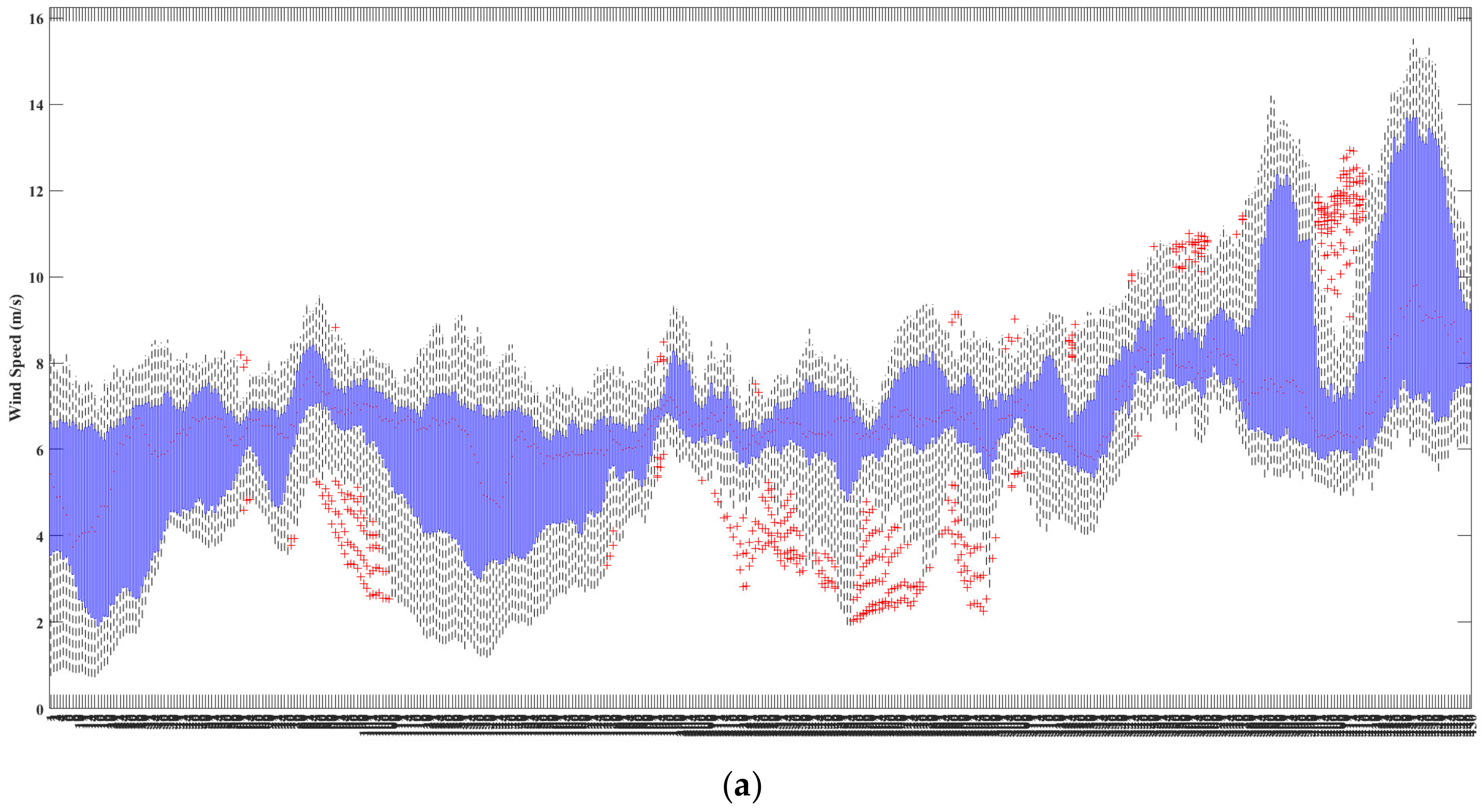
4.1. Data Sample Control
4.2. Data Smoothing
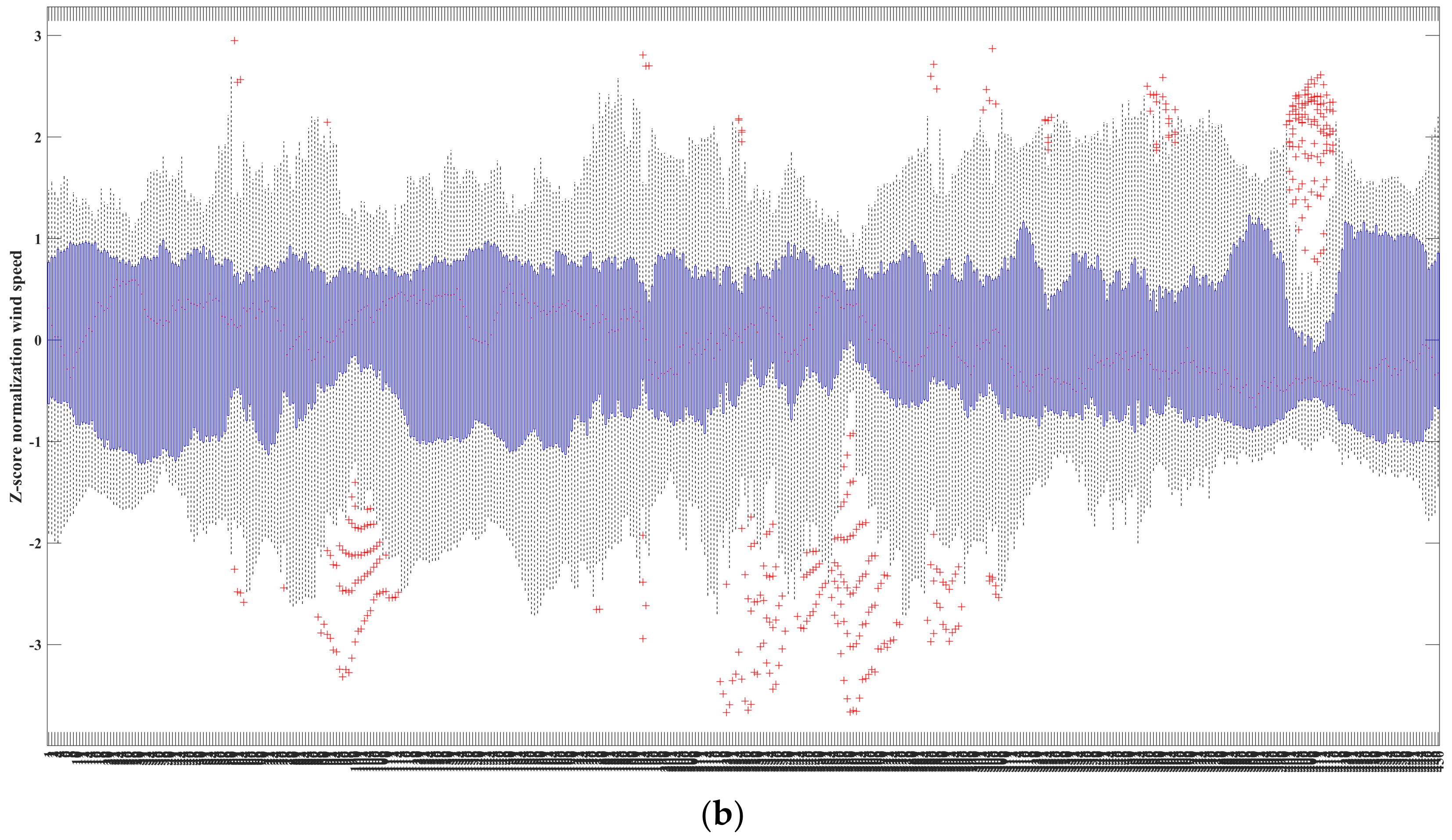
4.3. Data Standardization
5. Results and Discussion
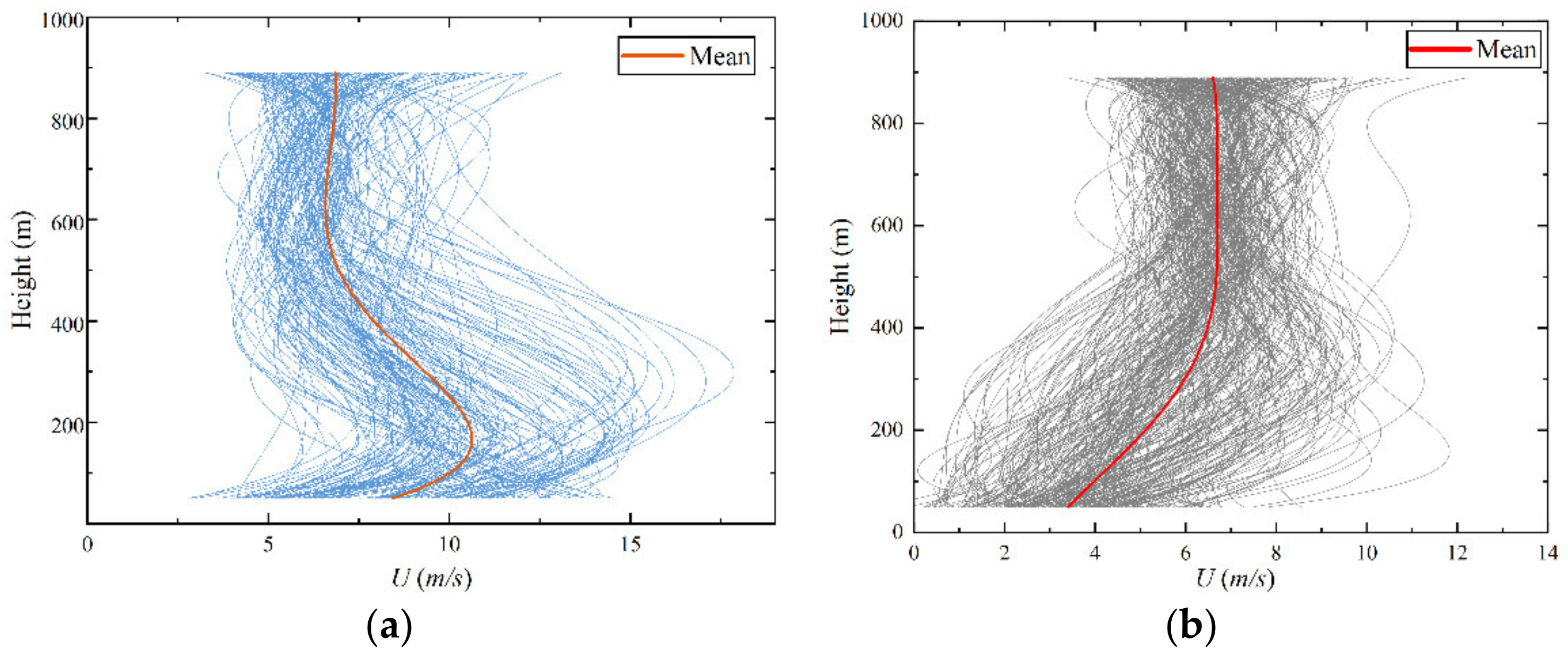
5.1. Results of Agglomerative Hierarchical Clustering Analysis
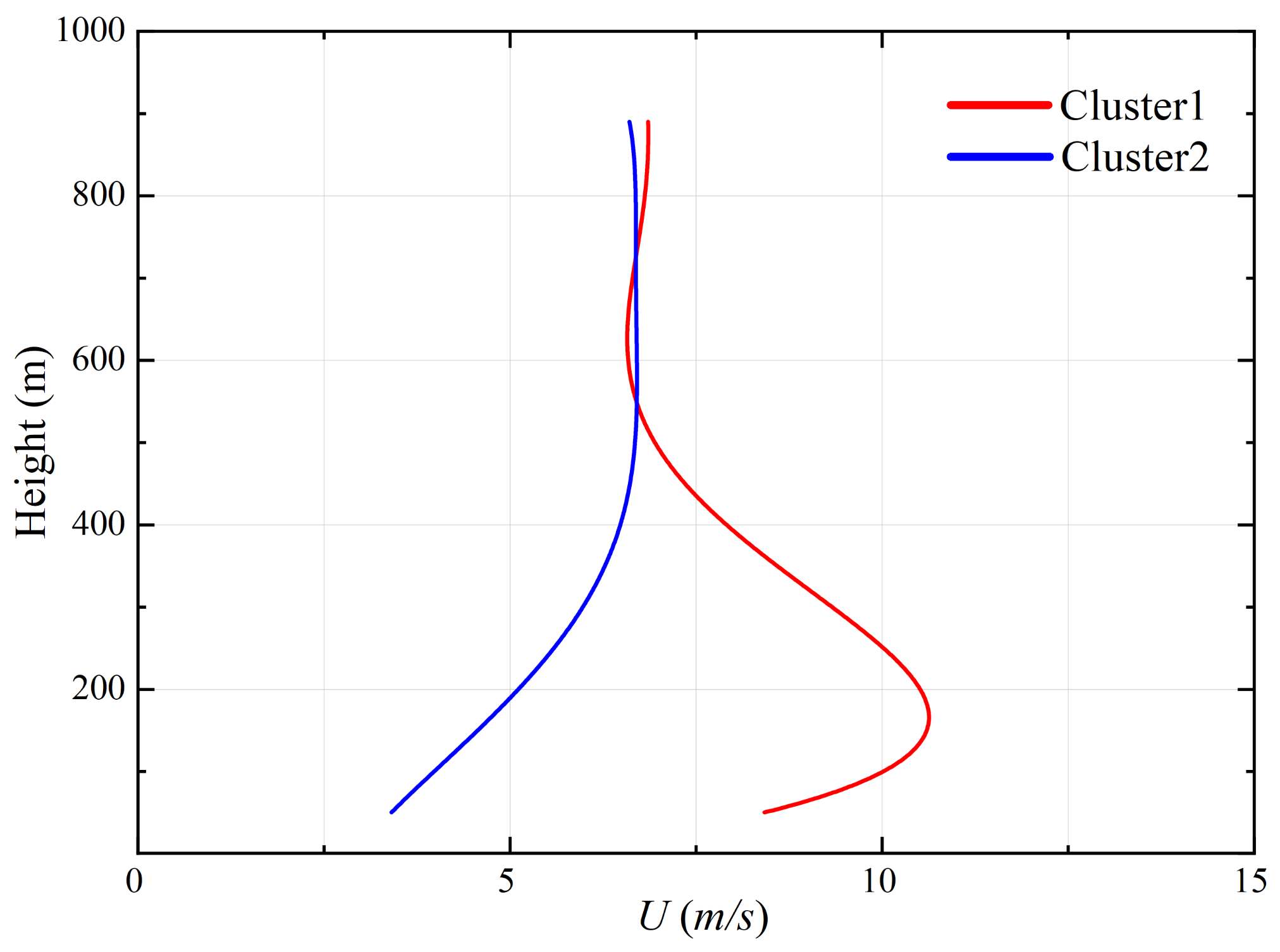
5.2. Typical Wind Profile
5.3. Results of the Wind Profile Fitting Analysis
6. Conclusions
- Since the measured data of Typhoon Lekima are not suitable for direct clustering analysis, this paper smoothes the measured data and uses the z-score normalization method to standardize the data, which reveals the potential patterns and trends of the data. Then, the agglomerative hierarchical clustering analysis method is used to effectively classify Typhoon Lekima. The Euclidean distance and Pearson correlation coefficient are used as measurement criteria, and the contour coefficient and sum of squared clustering error are used as clustering evaluation indexes. The results show that the clustering effect is good. Finally, the optimal number of clusters is selected by combining the contour coefficient and the sum of squared clustering error, the CH index, and the DB index.
- Based on the agglomerative hierarchical clustering analysis, the mean wind profile of Typhoon Lekima can be divided into two types. In this paper, the two typical mean wind profiles are named cluster 1 and cluster 2. For cluster 2, the wind speed gradually increases with increasing height and then gradually stabilizes. For cluster 1, there is an obvious low-level jet phenomenon, and the wind speed first increases, then decreases, and then slightly increases with the increase in height.
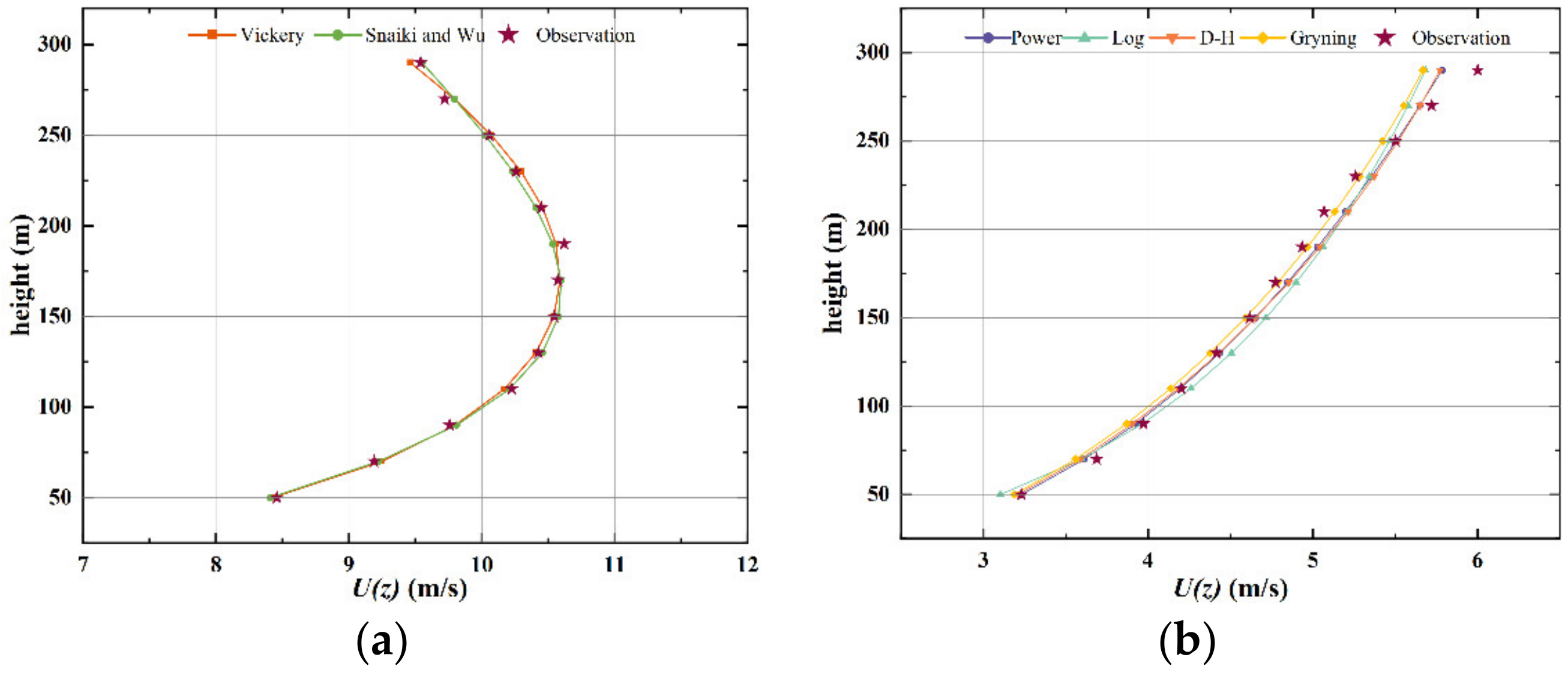
- After cluster analysis, this paper also carried out fitting processing. The average wind speed profile of cluster 1 shows an inverse C shape, and there is a low-level jet phenomenon near the vertical height of about 50–300 m, and the average wind speed appears near the height of 200 m. The empirical form of the wind speed profile used for fitting in this paper is the Vickery model and the Snaiki and Wu model. In terms of the overall fitting effect, the Vickery model is superior to the Snaiki and Wu model. Especially at the height of 130–270 m, the Vickery model can better describe the average wind profile of cluster 1.
- The average wind profile of cluster 2 is fitted by four calculation models: the Power-law model, Log-law model, Deaves–Harris model, and Gryning model. In general, the fitting effects of the four models are good, and the coefficient of the goodness of fit can reach more than 0.97. Among them, the Power-law model has a better fitting effect when the height is 50–150 m and 250–300 m, and the Gryning model has a better fitting effect when the height is 150–250 m. It is worth noting that when the height is greater than 250 m, the fitting effect of the four models on the cluster 2 mean wind profile gradually deteriorates with the increase in height.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ciarlatani, M.F.; Huang, Z.; Philips, D.; Gorlé, C. Investigation of Peak Wind Loading on a High-Rise Building in the Atmospheric Boundary Layer Using Large-Eddy Simulations. J. Wind Eng. Ind. Aerodyn. 2023, 236, 105408. [Google Scholar] [CrossRef]
- Ricci, M.; Patruno, L.; Kalkman, I.; De Miranda, S.; Blocken, B. Towards LES as a Design Tool: Wind Loads Assessment on a High-Rise Building. J. Wind Eng. Ind. Aerodyn. 2018, 180, 1–18. [Google Scholar] [CrossRef]
- Dongmei, H.; Shiqing, H.; Xuhui, H.; Xue, Z. Prediction of Wind Loads on High-Rise Building Using a BP Neural Network Combined with POD. J. Wind Eng. Ind. Aerodyn. 2017, 170, 1–17. [Google Scholar] [CrossRef]
- Mohammadi, A.; Azizinamini, A.; Griffis, L.; Irwin, P. Performance Assessment of an Existing 47-Story High-Rise Building under Extreme Wind Loads. J. Struct. Eng. 2019, 145, 04018232. [Google Scholar] [CrossRef]
- Zheng, X.-W.; Li, H.-N.; Yang, Y.-B.; Li, G.; Huo, L.-S.; Liu, Y. Damage Risk Assessment of a High-Rise Building against Multihazard of Earthquake and Strong Wind with Recorded Data. Eng. Struct. 2019, 200, 109697. [Google Scholar] [CrossRef]
- Tieleman, H.W. Strong Wind Observations in the Atmospheric Surface Layer. J. Wind Eng. Ind. Aerodyn. 2008, 96, 41–77. [Google Scholar] [CrossRef]
- Song, L.; Chen, W.; Wang, B.; Zhi, S.; Liu, A. Characteristics of Wind Profiles in the Landfalling Typhoon Boundary Layer. J. Wind Eng. Ind. Aerodyn. 2016, 149, 77–88. [Google Scholar] [CrossRef]
- Lin, L.; Chen, K.; Xia, D.; Wang, H.; Hu, H.; He, F. Analysis on the Wind Characteristics under Typhoon Climate at the Southeast Coast of China. J. Wind Eng. Ind. Aerodyn. 2018, 182, 37–48. [Google Scholar] [CrossRef]
- Han, Z.; Wang, X.; Tang, Y.; Yue, C.; Ao, X. Characteristic Analysis of Measured Winds under Typhoon Chan-hom and Normal Climate at Xujiahui in Shanghai. Meteorol. Sci. Technol. 2020, 48, 529–536. Available online: https://jglobal.jst.go.jp/en/detail?JGLOBAL_ID=202002232011931521 (accessed on 3 June 2024).
- Chen, T.; Fu, J.Y.; Chan, P.W.; He, Y.C.; Liu, A.M.; Zhou, W. Wind Characteristics in Typhoon Boundary Layer at Coastal Areas Observed via a Lidar Profiler. J. Wind Eng. Ind. Aerodyn. 2023, 232, 105253. [Google Scholar] [CrossRef]
- Tamura, Y.; Iwatani, Y.; Hibi, K.; Suda, K.; Nakamura, O.; Maruyama, T.; Ishibashi, R. Profiles of Mean Wind Speeds and Vertical Turbulence Intensities Measured at Seashore and Two Inland Sites Using Doppler Sodars. J. Wind Eng. Ind. Aerodyn. 2007, 95, 411–427. [Google Scholar] [CrossRef]
- Franklin, J.L.; Black, M.L.; Valde, K. GPS Dropwindsonde Wind Profiles in Hurricanes and Their Operational Implications. Weather Forecast. 2003, 18, 32–44. [Google Scholar] [CrossRef]
- Shu, Z.R.; Li, Q.S.; He, Y.C.; Chan, P.W. Vertical Wind Profiles for Typhoon, Monsoon and Thunderstorm Winds. J. Wind Eng. Ind. Aerodyn. 2017, 168, 190–199. [Google Scholar] [CrossRef]
- Tse, K.T.; Li, S.W.; Chan, P.W.; Mok, H.Y.; Weerasuriya, A.U. Wind Profile Observations in Tropical Cyclone Events Using Wind-Profilers and Doppler SODARs. J. Wind Eng. Ind. Aerodyn. 2013, 115, 93–103. [Google Scholar] [CrossRef]
- Beu, C.M.L.; Landulfo, E. Machine Learning-Based Estimate of The Wind Speed Over Complex Terrain Using the LSTM Recurrent Neural Network. Wind Energy Sci. Discuss. 2023, 2023, 1–31. [Google Scholar]
- Li, F.; Xie, Z.; Yang, Y.; Yu, X. Investigations of Synoptic Wind Profile Patterns in Complex Urban Areas Based on LiDAR Measurements. Build. Environ. 2023, 242, 110573. [Google Scholar] [CrossRef]
- Schelbergen, M.; Kalverla, P.C.; Schmehl, R.; Watson, S.J. Clustering Wind Profile Shapes to Estimate Airborne Wind Energy Production. Wind Energy Sci. 2020, 5, 1097–1120. [Google Scholar] [CrossRef]
- Mohandes, M.; Rehman, S.; Rahman, S.M. Estimation of Wind Speed Profile Using Adaptive Neuro-Fuzzy Inference System (ANFIS). Appl. Energy 2011, 88, 4024–4032. [Google Scholar] [CrossRef]
- Liu, Z.; Zheng, C.; Wu, Y.; Song, Y. Investigation on Characteristics of Thousand-Meter Height Wind Profiles at Non-Tropical Cyclone Prone Areas Based on Field Measurement. Build. Environ. 2018, 130, 62–73. [Google Scholar] [CrossRef]
- Burlando, M.; Antonelli, M.; Ratto, C.F. Mesoscale Wind Climate Analysis: Identification of Anemological Regions and Wind Regimes. Int. J. Climatol. 2008, 28, 629–641. [Google Scholar] [CrossRef]
- Janse Van Vuuren, C.Y.; Vermeulen, H.J. Clustering of Wind Resource Data for the South African Renewable Energy Development Zones. J. Energy South. Afr. 2019, 30, 126–143. [Google Scholar] [CrossRef]
- Müllner, D. Modern Hierarchical, Agglomerative Clustering Algorithms. arXiv 2011, arXiv:1109.2378. [Google Scholar]
- Kim, B.; Kim, J.; Yi, G. Analysis of Clustering Evaluation Considering Features of Item Response Data Using Data Mining Technique for Setting Cut-Off Scores. Symmetry 2017, 9, 62. [Google Scholar] [CrossRef]
- Nainggolan, R.; Perangin-angin, R.; Simarmata, E.; Tarigan, A.F. Improved the Performance of the K-Means Cluster Using the Sum of Squared Error (SSE) Optimized by Using the Elbow Method. J. Phys. Conf. Ser. 2019, 1361, 012015. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Calinski, T.; Harabasz, J. A Dendrite Method for Cluster Analysis. Commun. Stat.—Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Powell, M.D.; Vickery, P.J.; Reinhold, T.A. Reduced Drag Coefficient for High Wind Speeds in Tropical Cyclones. Nature 2003, 422, 279–283. [Google Scholar] [CrossRef] [PubMed]
- Giammanco, I.M.; Schroeder, J.L.; Powell, M.D. GPS Dropwindsonde and WSR-88D Observations of Tropical Cyclone Vertical Wind Profiles and Their Characteristics. Weather Forecast. 2013, 28, 77–99. [Google Scholar] [CrossRef]
- Davenport, A.G. Rationale for Determining Design Wind Velocities. J. Struct. Div. 1960, 86, 39–68. [Google Scholar] [CrossRef]
- Li, Q.S.; Zhi, L.; Hu, F. Field Monitoring of Boundary Layer Wind Characteristics in Urban Area. Wind Struct. 2009, 12, 553–574. [Google Scholar] [CrossRef]
- Cook, N.J. The Deaves and Harris ABL Model Applied to Heterogeneous Terrain. J. Wind Eng. Ind. Aerodyn. 1997, 66, 197–214. [Google Scholar] [CrossRef]
- Kustas, W.P.; Brutsaert, W. Wind Profile Constants in a Neutral Atmospheric Boundary Layer over Complex Terrain. Bound.-Layer Meteorol. 1986, 34, 35–54. [Google Scholar] [CrossRef]
- Simiu, E.; Scanlan, R.H. Wind Effects on Structures: Fundamentals and Applications to Design; John Wiley: New York, NY, USA, 1996; Volume 688. [Google Scholar]
- Li, Q.S.; Zhi, L.; Hu, F. Boundary Layer Wind Structure from Observations on a 325m Tower. J. Wind Eng. Ind. Aerodyn. 2010, 98, 818–832. [Google Scholar] [CrossRef]
- Deaves, D. A Mathematical Model of the Structure of Strong Winds. CIRIA Rep. 76 Const. Ind. Res. Inf. Assoc. 1978. [Google Scholar]
- Gryning, S.-E.; Batchvarova, E.; Brümmer, B.; Jørgensen, H.; Larsen, S. On the Extension of the Wind Profile over Homogeneous Terrain beyond the Surface Boundary Layer. Bound.-Layer Meteorol. 2007, 124, 251–268. [Google Scholar] [CrossRef]
- Vickery, P.J.; Wadhera, D.; Powell, M.D.; Chen, Y. A Hurricane Boundary Layer and Wind Field Model for Use in Engineering Applications. J. Appl. Meteorol. Climatol. 2009, 48, 381–405. [Google Scholar] [CrossRef]
- Snaiki, R.; Wu, T. A Semi-Empirical Model for Mean Wind Velocity Profile of Landfalling Hurricane Boundary Layers. J. Wind Eng. Ind. Aerodyn. 2018, 180, 249–261. [Google Scholar] [CrossRef]
- Imron, M.A.; Prasetyo, B. Improving Algorithm Accuracy K-Nearest Neighbor Using Z-Score Normalization and Particle Swarm Optimization to Predict Customer Churn. J. Soft Comput. Explor. 2020, 1, 56–62. [Google Scholar] [CrossRef]
- Kepert, J.; Wang, Y. The Dynamics of Boundary Layer Jets within the Tropical Cyclone Core. Part II: Nonlinear Enhancement. J. Atmos. Sci. 2001, 58, 2485–2501. [Google Scholar] [CrossRef]
- Gunter, W.S.; Schroeder, J.L. High-Resolution Full-Scale Measurements of Thunderstorm Outflow Winds. J. Wind Eng. Ind. Aerodyn. 2015, 138, 13–26. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project | Value |
|---|---|
| Beam width | Typical 7~12° (depends on frequency) |
| Height resolution | Adjustable, 5 m ≤ ΔH ≤ 50 mIncrements ≥ 5 m, typical 10~30 m |
| Maximum measuring height | Nominally > 1500 m (not available in adverse weather conditions) |
| Minimum measuring height | ≥15 m, adjustable, increment ≥5 m |
| Wind direction | 0 to 360° |
| Wind direction accuracy | 1~3° (wind speed > 5 m/s)3~5° (wind speed <5 m/s) |
| Vertical wind speed | −10~10 m/s |
| Horizontal wind components | ±50 m/s |
| Vertical wind speed accuracy | 0.03~0.1 m/s |
| Horizontal wind speed accuracy | 0.1~0.3 m/s |
| Typhoon Samples | Vickery | Snaiki and Wu | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Cluster 1 | u* | z0 | a | n | H* | R2 | u* | z0 | η0 | R2 | |
| 1.11 | 2.34 | 0.4 | 2.0 | 153.49 | 0.992 | 0.21 | 7.69 × 10−4 | 24.88 | 0.987 | ||
| Cluster 2 | Power-law model | Log-law model | Deaves–Harris model | Gryning model | |||||||
| α | R2 | u* | z0 | R2 | u* | z0 | R2 | u* | z0 | R2 | |
| 0.33 | 0.987 | 0.587 | 6.041 | 0.971 | 0.278 | 0.873 | 0.984 | 0.266 | 0.762 | 0.984 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Tian, S.; Fu, B.; Zhang, M.; Wang, X.; Zheng, S.; Zhang, C.; Zhou, L. Study on Wind Profile Characteristics Using Cluster Analysis. Atmosphere 2024, 15, 708. https://doi.org/10.3390/atmos15060708
Wang Y, Tian S, Fu B, Zhang M, Wang X, Zheng S, Zhang C, Zhou L. Study on Wind Profile Characteristics Using Cluster Analysis. Atmosphere. 2024; 15(6):708. https://doi.org/10.3390/atmos15060708
Chicago/Turabian StyleWang, Yanru, Shengbao Tian, Bin Fu, Maoyu Zhang, Xu Wang, Shuqin Zheng, Chuanxiong Zhang, and Lei Zhou. 2024. "Study on Wind Profile Characteristics Using Cluster Analysis" Atmosphere 15, no. 6: 708. https://doi.org/10.3390/atmos15060708
APA StyleWang, Y., Tian, S., Fu, B., Zhang, M., Wang, X., Zheng, S., Zhang, C., & Zhou, L. (2024). Study on Wind Profile Characteristics Using Cluster Analysis. Atmosphere, 15(6), 708. https://doi.org/10.3390/atmos15060708