Cloud Top Height Retrieval from FY-4A Data: A Residual Module and Genetic Algorithm Approach


Abstract
1. Introduction
2. Methodology
2.1. Overall Architecture
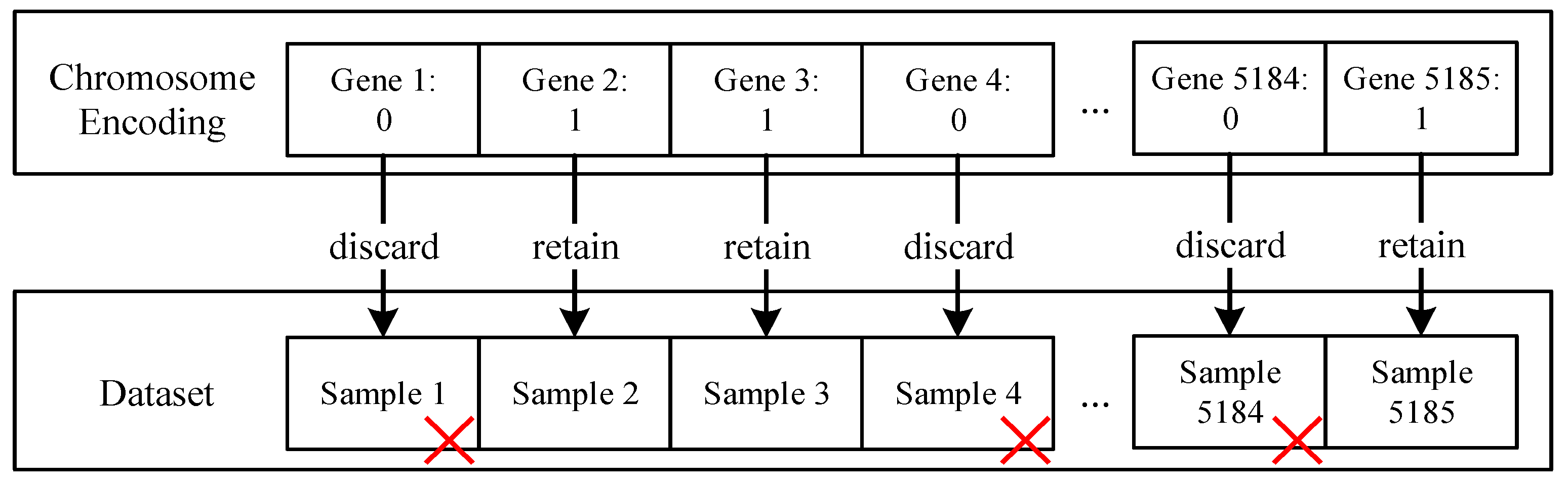
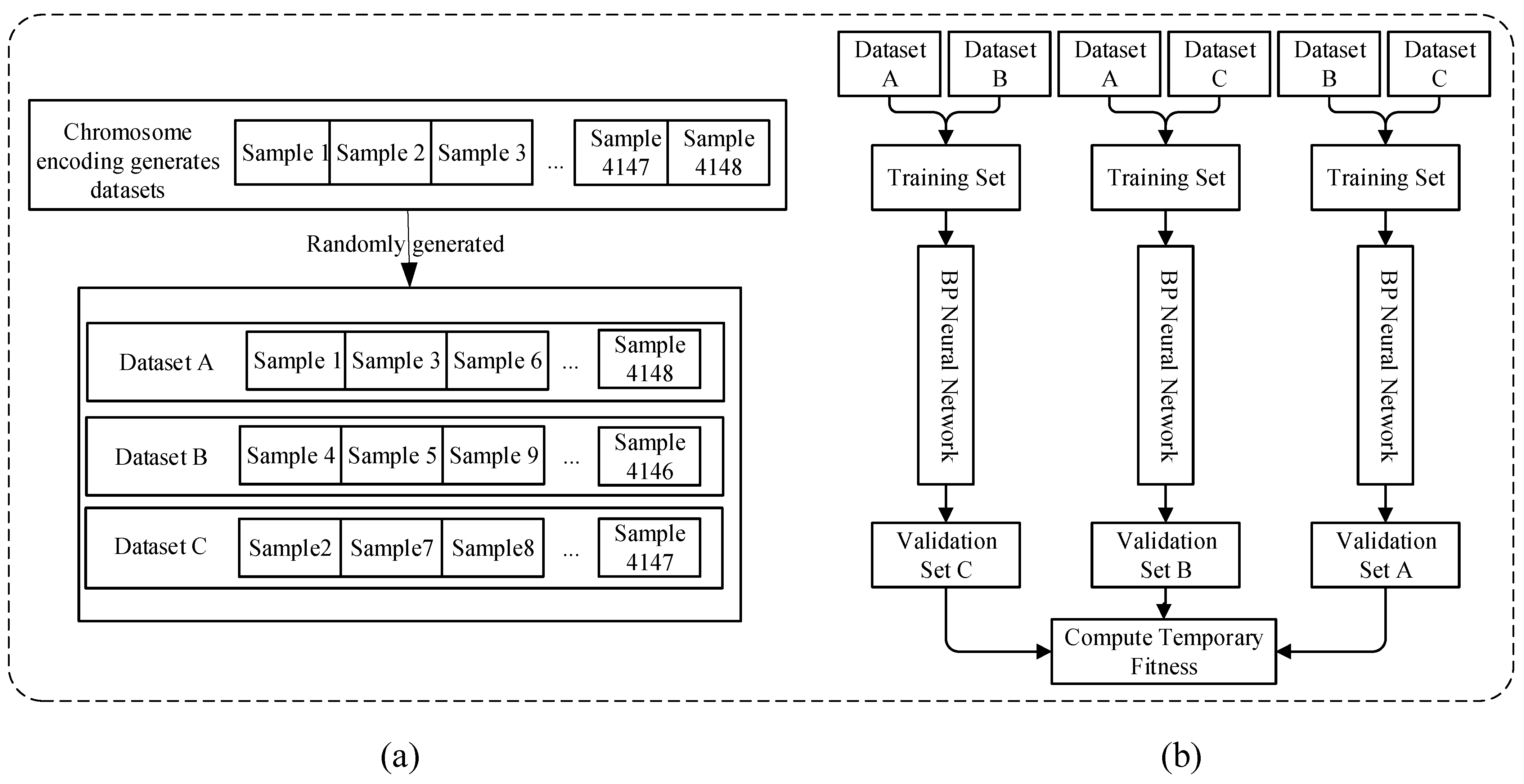
2.2. Genetic Algorithm Module
| Algorithm 1: Genetic Algorithm for Data Selection. |
| Input: population size n, number of genes per chromosome m, maximum number of iterations maxIterations, probability of mutation mutationRate, probability of crossover crossoverRate Output: BestChromosome, the best solution found
|
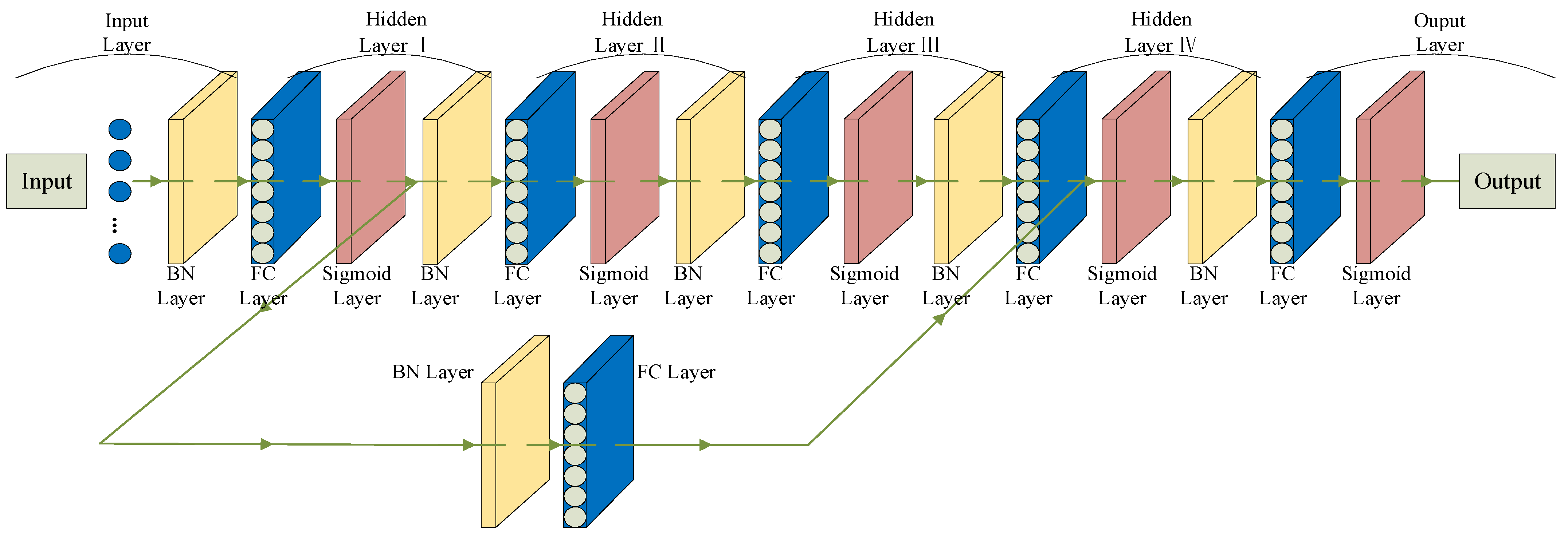
2.3. Residual-Enhanced NN
3. Model Evaluation
3.1. Data Processing
3.1.1. Spatially and Temporally Matching of Satellite and Ground Observations
3.1.2. Data Quality Control
3.2. Evaluation Metrics
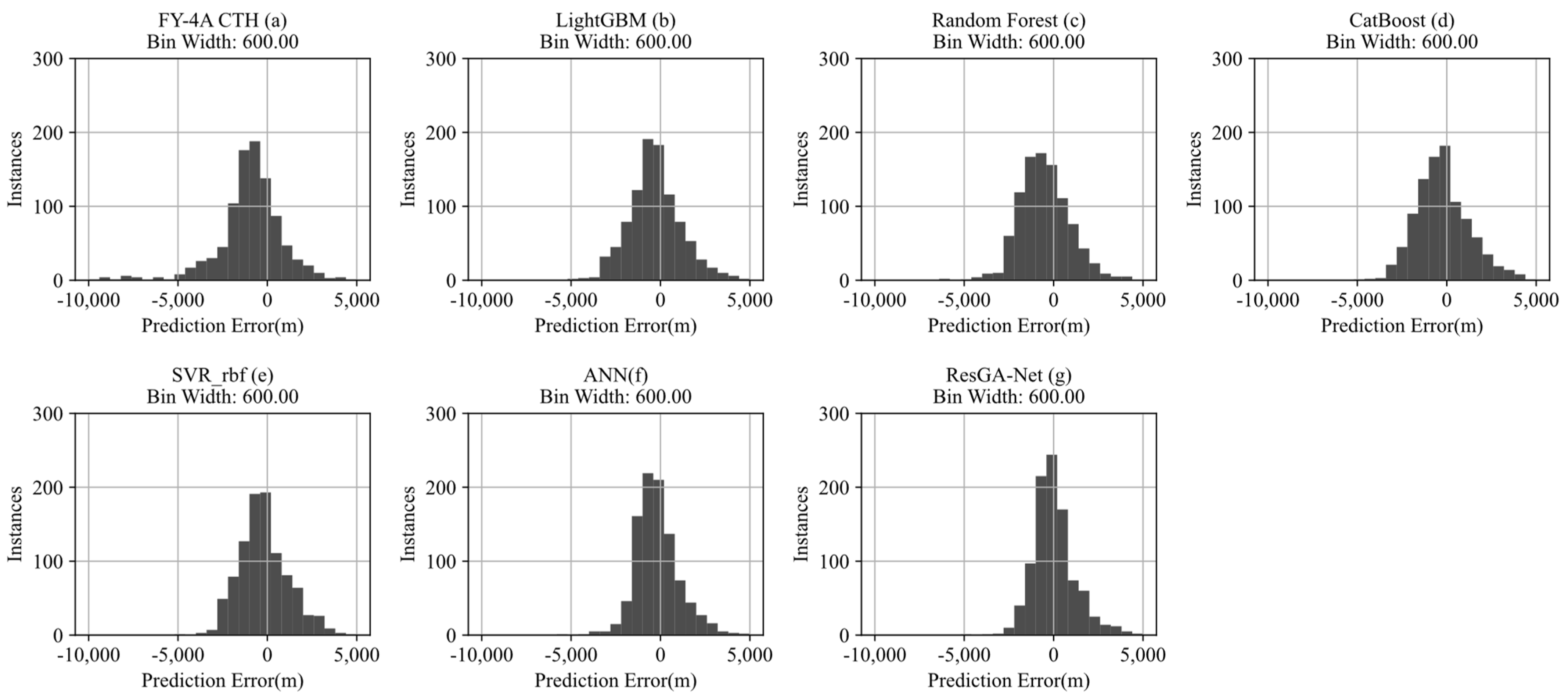
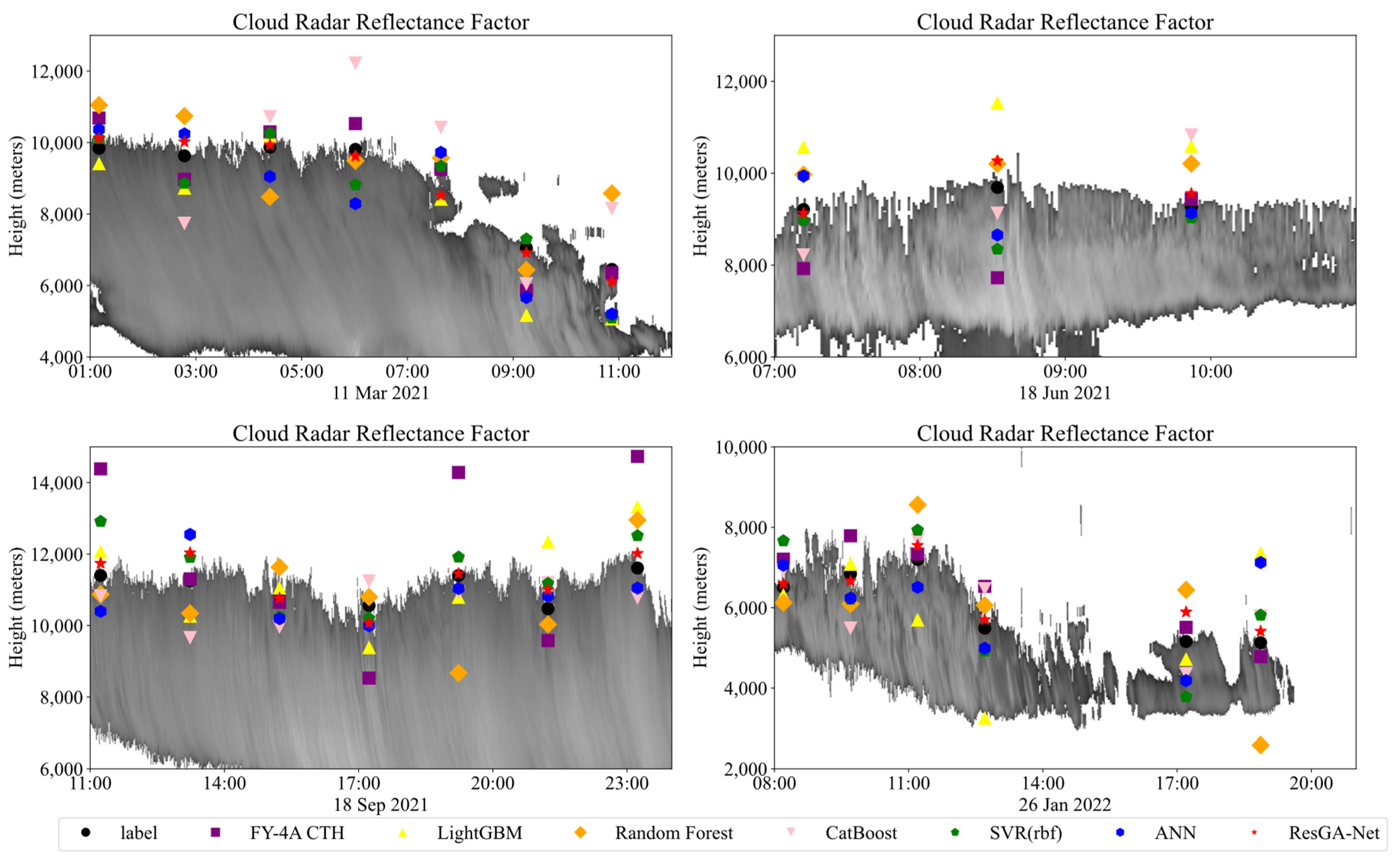
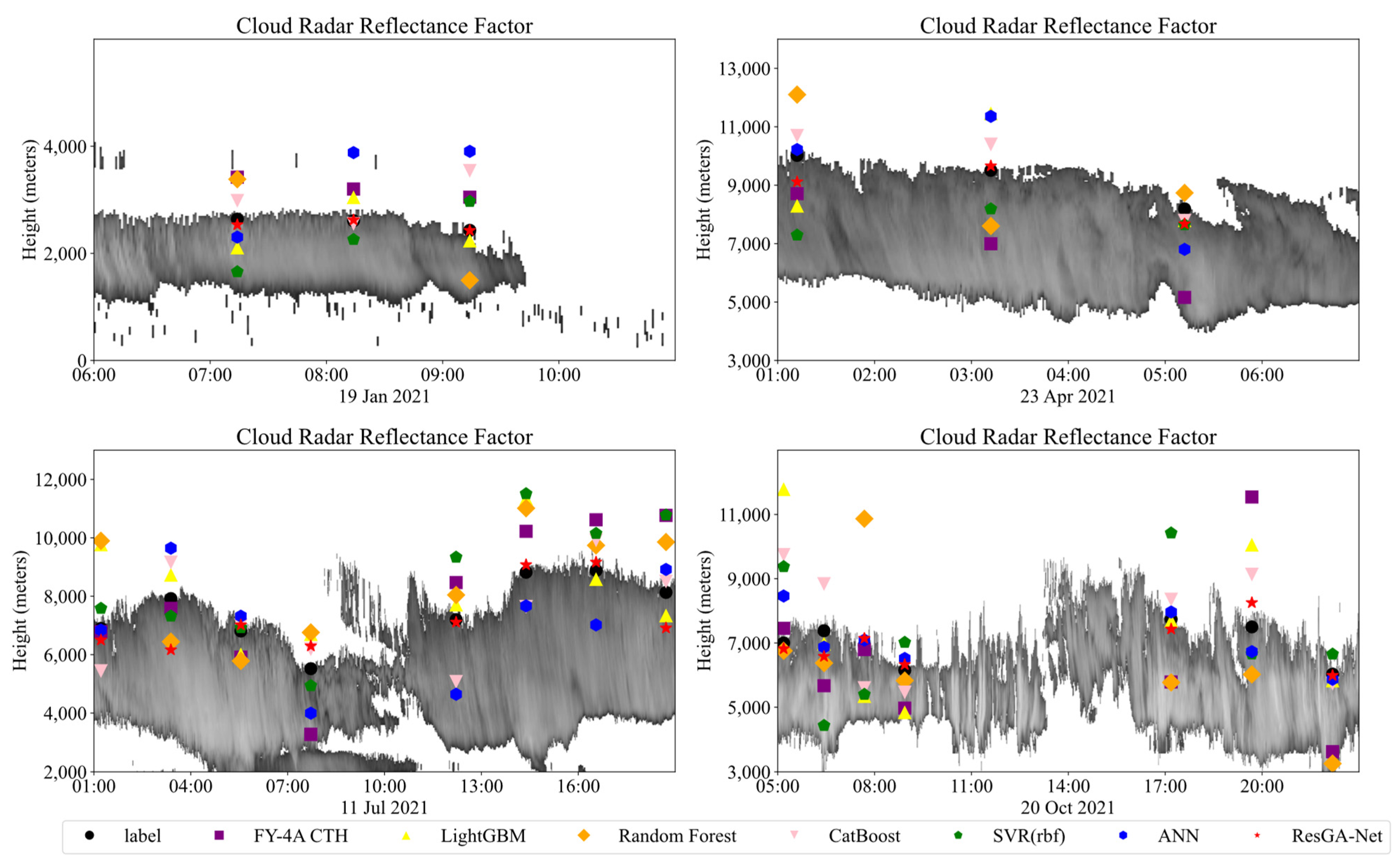
3.3. Results and Analysis
3.4. Ablation Study
3.5. Regional Adaptability Validation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, C.F.; Yang, Y.K. Progress and challenges of ground-based cloud remote sensing. Torrential Rain Disasters 2021, 40, 243–258. [Google Scholar]
- Cao, Y.N.; Wei, H.L.; Dai, C.M.; Zhang, X.H. Retrieval of cloud optical thickness and cloud top height of convective clouds from AIRS infrared hyperspectral satellite data. Spectrosc. Spectr. Anal. 2015, 35, 1208–1213. [Google Scholar]
- McFarquhar, G.M.; Bretherton, C.; Marchand, R.; Protat, A.; DeMott, P.J.; Alexander, S.P.; Roberts, G.C.; Twohy, C.H.; Toohey, D.; Siems, S.; et al. Observations of clouds, aerosols, precipitation, and surface radiation over the Southern Ocean: An overview of CAPRICORN, MARCUS, MICRE and SOCRATES. Bull. Am. Meteorol. Soc. 2020, 102, E894–E928. [Google Scholar] [CrossRef]
- Liu, L.; Sun, X.J.; Gao, T.C. Retrieval of cloud parameters using ground-based infrared hyperspectral emissivity data (Part 1): Cloud phase discrimination. Spectrosc. Spectr. Anal. 2016, 36, 3885–3894. [Google Scholar]
- Li, Z.; Niu, F.; Fan, J.; Liu, Y.; Rosenfeld, D.; Ding, Y. Long-term impacts of aerosols on the vertical development of clouds and precipitation. Nat. Geosci. 2011, 4, 888–894. [Google Scholar] [CrossRef]
- Hong, Y.; Hsu, K.L.; Sorooshian, S.; Gao, X. Precipitation estimation from remotely sensed imagery using an artificial neural network cloud classification system. J. Appl. Meteorol. 2004, 43, 1834–1853. [Google Scholar] [CrossRef]
- Gultepe, I.; Sharman, R.; Williams, P.D.; Zhou, B.; Ellrod, G.; Minnis, P.; Trier, S.; Griffin, S.; Yum, S.S.; Gharabaghi, B.; et al. A review of high impact weather for aviation meteorology. Pure Appl. Geophys. 2019, 176, 1869–1921. [Google Scholar] [CrossRef]
- Zhu, X.L.; Qian, Y.Y.; Yan, W.; Li, G.; An, H. Application of cloud base height inversion algorithm based on multi-satellite observation results in China offshore waters. J. Meteorol. Sci. 2019, 39, 467–476. [Google Scholar]
- Lu, Y.J.; Chen, G.Y.; Gong, K.J. Overview of researches on cloud sounding methods. Meteorol. Sci. Technol. 2012, 40, 689–697. [Google Scholar]
- Duan, L.; Zhang, Y.; Guo, Y.P.; Zhao, Z. Research on Inversion of Convective Cloud Top Height Based on Infrared Brightness Temperature Method. Infrared 2022, 43, 33–40. [Google Scholar]
- Gu, C.M.; Wang, Y.F.; Zhang, X.H.; Zhong, B.; Ma, X. Effects of cloud parameter on brightness temperature computation in microwave band. J. Appl. Meteorol. Sci. 2016, 27, 380–384. [Google Scholar]
- Lee, J.; Shin, D.B.; Chung, C.Y.; Kim, J. A cloud top-height retrieval algorithm using simultaneous observations from the Himawari-8 and FY-2E satellites. Remote Sens. 2020, 12, 1953. [Google Scholar] [CrossRef]
- Li, Q.; Sun, X.; Wang, X. Reliability evaluation of the joint observation of cloud top height by FY-4A and Himawari-8. Remote Sens. 2021, 13, 3851. [Google Scholar] [CrossRef]
- Du, C.; Ren, H.; Qin, Q.; Meng, J.; Zhao, S. A practical split-window algorithm for estimating land surface temperature from Landsat 8 data. Remote Sens. 2015, 7, 647–665. [Google Scholar] [CrossRef]
- Liang, Y.; Li, W.; Huang, Y. Retrieval of Semi-transparent Cloud Top Height Using Split Window Histograms Method. Acta Sci. Nat. Univ. Pekin. 2019, 55, 461–472. [Google Scholar]
- Hamada, A.; Nishi, N. Development of a cloud-top height estimation method by geostationary satellite split-window measurements trained with CloudSat data. J. Appl. Meteorol. Climatol. 2010, 49, 2035–2049. [Google Scholar] [CrossRef]
- Nishi, N.; Hamada, A.; Hirose, H. Improvement of cirrus cloud-top height estimation using geostationary satellite split-window measurements trained with CALIPSO data. SOLA 2017, 13, 240–245. [Google Scholar] [CrossRef]
- Menzel, W.P.; Frey, R.A.; Zhang, H.; Wylie, D.P.; Moeller, C.C.; Holz, R.E.; Maddux, B.; Baum, B.A.; Strabala, K.I.; Gumley, I.E. MODIS global cloud-top pressure and amount estimation: Algorithm description and results. J. Appl. Meteorol. Climatol. 2008, 47, 1175–1198. [Google Scholar] [CrossRef]
- Wang, F.; Zhao, Y. Cloud Top Height Retrieval Algorithm for Fengyun-4 Geostationary Meteorological Satellite. J. Sichuan Norm. Univ. (Nat. Sci. Ed.) 2021, 44, 412–418. [Google Scholar]
- Yu, Z.F.; Wang, Y.; Ma, S.; Ai, W.H. An Ensemble Learning-Based Method for FY-4A Cloud Base Height Retrieval. Acta Opt. Sin. 2023, 43, 49–62. [Google Scholar]
- Dong, Y.; Sun, X.; Li, Q. A Method for Retrieving Cloud-Top Height Based on a Machine Learning Model Using the Himawari-8 Combined with Near Infrared Data. Remote Sens. 2022, 14, 6367. [Google Scholar] [CrossRef]
- Rysman, J.F.; Claud, C.; Dafis, S. A machine learning algorithm for retrieving cloud top height with passive microwave radiometry. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4500605. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Yu, P.S. An effective and efficient algorithm for high-dimensional outlier detection. VLDB J. 2005, 14, 211–221. [Google Scholar] [CrossRef]
- Zhang, T.H.; Bao, Y.S.; Qian, Y.Z.; Lin, L.B.; Liu, X.L.; Li, L.; Hou, Y.; Lei, H.Y.; Li, G.W.; Ma, J.; et al. Atmospheric temperature and humidity profile retrievals based on BP neural network and genetic algorithm. J. Trop. Meteorol. 2020, 36, 97–107. [Google Scholar]
- Li, T.; Li, N.P.; Qian, Q.; Xu, W.; Ren, Y.; Xia, J.Y. Inversion of temperature and humidity profile of microwave radiometer based on bp network. Intell. Autom. Soft Comput. 2021, 29, 741–755. [Google Scholar] [CrossRef]
- Li, T.; Qiao, C.; Wang, L.; Chen, J.; Ren, Y. An algorithm for precipitation correction in flood season based on dendritic neural network. Front. Plant Sci. 2022, 13, 862558. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning 2015, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Huang, Y.X.; Ma, S.; Bai, H. Error analysis of cloud top height detection using stereoscopic observation method. J. Infrared Millim. Waves 2012, 31, 314–318. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm/Evaluation Metric | RMSE (m) | MAE (m) | PCC | SRCC |
|---|---|---|---|---|
| FY-4A CTH | 1814.0 | 1406.8 | 0.752 | 0.760 |
| LightGBM | 1648.2 | 1287.7 | 0.778 | 0.765 |
| Random Forest | 1524.6 | 1193.5 | 0.795 | 0.746 |
| CatBoost | 1475.9 | 1177.2 | 0.801 | 0.778 |
| SVR_rbf | 1456.1 | 1091.8 | 0.808 | 0.792 |
| ANN | 1332.6 | 1072.4 | 0.814 | 0.806 |
| ResGA-Net (ours) | 1126.5 | 917.6 | 0.836 | 0.832 |
| Algorithm/Evaluation Metric | RMSE (m) | MAE (m) | PCC | SRCC |
|---|---|---|---|---|
| ANN | 1332.6 | 1072.4 | 0.814 | 0.806 |
| ResGA-Net w/o GA | 1281.3 | 1041.5 | 0.819 | 0.815 |
| ResGA-Net w/o Residual-Enhanced NN | 1179.1 | 966.9 | 0.830 | 0.824 |
| ResGA-Net (ours) | 1126.5 | 917.6 | 0.836 | 0.832 |
| Algorithm/Evaluation Metric | RMSE (m) | MAE (m) | PCC | SRCC |
|---|---|---|---|---|
| FY-4A CTH | 1953.8 | 1542.3 | 0.738 | 0.745 |
| LightGBM | 1732.4 | 1368.7 | 0.761 | 0.758 |
| Random Forest | 1609.8 | 1297.4 | 0.776 | 0.763 |
| CatBoost | 1565.5 | 1265.7 | 0.787 | 0.769 |
| SVR_rbf | 1506.3 | 1142.9 | 0.792 | 0.789 |
| ANN | 1412.0 | 1086.1 | 0.806 | 0.802 |
| ResGA-Net (ours) | 1182.2 | 949.3 | 0.829 | 0.825 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Chen, N.; Tao, F.; Hu, S.; Xue, J.; Han, R.; Wu, D. Cloud Top Height Retrieval from FY-4A Data: A Residual Module and Genetic Algorithm Approach. Atmosphere 2024, 15, 643. https://doi.org/10.3390/atmos15060643
Li T, Chen N, Tao F, Hu S, Xue J, Han R, Wu D. Cloud Top Height Retrieval from FY-4A Data: A Residual Module and Genetic Algorithm Approach. Atmosphere. 2024; 15(6):643. https://doi.org/10.3390/atmos15060643
Chicago/Turabian StyleLi, Tao, Niantai Chen, Fa Tao, Shuzhen Hu, Jianjun Xue, Rui Han, and Di Wu. 2024. "Cloud Top Height Retrieval from FY-4A Data: A Residual Module and Genetic Algorithm Approach" Atmosphere 15, no. 6: 643. https://doi.org/10.3390/atmos15060643
APA StyleLi, T., Chen, N., Tao, F., Hu, S., Xue, J., Han, R., & Wu, D. (2024). Cloud Top Height Retrieval from FY-4A Data: A Residual Module and Genetic Algorithm Approach. Atmosphere, 15(6), 643. https://doi.org/10.3390/atmos15060643