1. Introduction
Approaching precipitation forecasting predicts the intensity of precipitation within the next 0–6 h, enabling early warning for potential disasters such as heavy rain and flooding. This forecasting holds significant importance for people’s daily lives. In comparison with medium- to long-term precipitation forecasts, accurate approaching predictions garner considerable attention in the meteorological services sector, because intense approaching rainfall, if not addressed promptly, can have adverse effects on agriculture, industry, and tertiary sectors such as transportation services. Therefore, it is crucial for both individuals and governments to forecast approaching precipitation in advance and issue warnings, enabling appropriate response measures. Hence, enhancing the accuracy and timeliness of approaching precipitation forecasting bears great practical significance [
1,
2].
Traditional approaching precipitation forecasting primarily relies on radar extrapolation methods, mainly including Tracking Radar Echoes by Correlation (TREC), Storm Cell Identification and Tracking (SCIT), and optical flow [
3,
4,
5]. These methods extrapolate future frames of radar echo images based on past frames, resulting in high computational efficiency and relatively clear predictive images, making them the mainstream approach in traditional forecasting. However, due to their neglect of the fundamental nonlinear characteristics of atmospheric motion and inadequate utilization of historical radar echo data, relying solely on given radar echo images for extrapolation lacks historical patterns, resulting in lower prediction accuracy and inability to meet practical application needs. On the other hand, Numerical Weather Prediction (NWP), which parameterizes weather conditions through a series of physical equations, is also not suitable for use in the field of approaching forecasting because of its short lead time and high computational cost [
6,
7]. Therefore, how to obtain more accurate approaching precipitation forecasts at lower costs has been a significant concern in the meteorological services sector.
With the rapid advancement of deep learning in recent years and the improvement in computer hardware and software, artificial intelligence has found wide-ranging applications across various industries with notably impressive results [
8,
9,
10]. Researchers in the meteorological field also have gradually begun to explore the application of deep learning techniques in weather forecasting such as using channel attention mechanisms for lightning forecasting, generative adversarial networks for short-term precipitation forecasting, and encoder–decoder structures for quantitative precipitation forecasting [
11,
12,
13]. Precipitation forecasting necessitates considering spatial correlations, temporal dependencies, and interdependencies among meteorological elements, with the most representative approaches undoubtedly being Long Short-Term Memory (LSTM) architectures and convolutional neural network (CNN) architectures.
The LSTM architecture, based on the Markov assumption, is well-suited for handling long time series due to the presence of its hidden layers, which capture temporal features through recurrent connections. Furthermore, the inclusion of gating units helps mitigate the issues of gradient explosion and vanishing gradients. Shi et al. proposed the convolutional LSTM (ConvLSTM) model for approaching precipitation forecasting, innovatively substituting convolutional operations for fully connected operations in the encoder–decoder architecture [
14]. This model effectively addresses the original decoder’s limitations in capturing spatial features over long periods, serving as a foundational model in the field of deep learning for precipitation prediction. Subsequently, Shi et al. further improved the model by introducing optical flow into Trajectory GRU (TrajGRU) [
15], enhancing the transfer of high-level features by reversing the prediction direction, thus enabling the encoder to receive and process more comprehensive feature information. However, the introduction of optical flow significantly slowed down the training speed. The proposal of a predictive recurrent neural network (PredRNN) [
16] effectively alleviated this issue by completing the transfer from high- to low-level information through a zigzag structure, addressing the inability to pass information layer by layer between adjacent layers. PredRNN has since been designated as the foundational model for approaching precipitation forecasting by the China Meteorological Administration. The subsequent model, PredRNN+, further streamlined the flow of information, enhancing the ability to forecast approaching sudden events by increasing network depth to capture more spatiotemporal features [
17]. Memory In Memory (MIM) networks attempt to introduce memory modules to model the nonstationary and approximately stationary characteristics of spatiotemporal information by multiple differentiations to transform non-stationary processes into stationary ones [
18]. The MotionRNN model enhances optimizer performance, learns instantaneous changes, and accumulates motion trends by incorporating MotionGRU between layers to capture transient changes and motion trends [
19]. These are all representative models based on the recurrent neural network architecture.
The forecasting model based on convolutional neural network architecture is exemplified by the U-net [
20], which was originally applied in the field of biomedical image segmentation. Subsequently, meteorologists viewed the prediction problem as an image-to-image translation task and began applying the U-net model to precipitation forecasting [
21]. In 2020, researchers adapted predictive headers to replace the original classification headers. They integrated temporal and spatial information specific to radar data and proposed a versatile radar precipitation forecasting model called RainNet [
22], which demonstrated universality for radar precipitation forecasting tasks. Furthermore, Shen et al. proposed a new radar echo extrapolation model named ADC_Net based on dilated convolutions and attention mechanisms to enhance the utilization and accuracy of radar extrapolation information, effectively improving the accuracy of radar echo extrapolation [
23].
Although the current two architectures perform well in the field of approaching precipitation, most current research is solely based on radar data without considering the relationship between other meteorological elements in the upper atmosphere and rainfall. The extrapolation of a single element cannot accurately capture the occurrence of a sudden event, and therefore the predictive ability for events such as convective initiation and dissipation often falls short of forecasts. Furthermore, as neural networks become deeper, the feature information extracted at shallow layers is prone to disturbances during transmission, resulting in iterative errors. Errors propagate through the network as information is passed layer by layer. Consequently, as the forecast lead time increases, the network’s predictive performance rapidly declines.
To address these issues, this study proposes a Residual Spatiotemporal Convolutional Network (ResSTConvNet) based on multisource fused data. This network replaces the LSTM architecture with separate three-dimensional convolutions, adopts a pure convolutional architecture for feature capturing, and fits spatiotemporal information using residual fitting blocks, thereby improving operational speed and reducing memory usage.
The following sections of this article are arranged in the following structure.
Section 2 describes the data and methodology.
Section 3 describes the ResSTConvNet model in detail.
Section 4 presents the experimental results used to evaluate the model.
Section 5 provides a conclusion.
2. Materials and Methods
2.1. Study Area
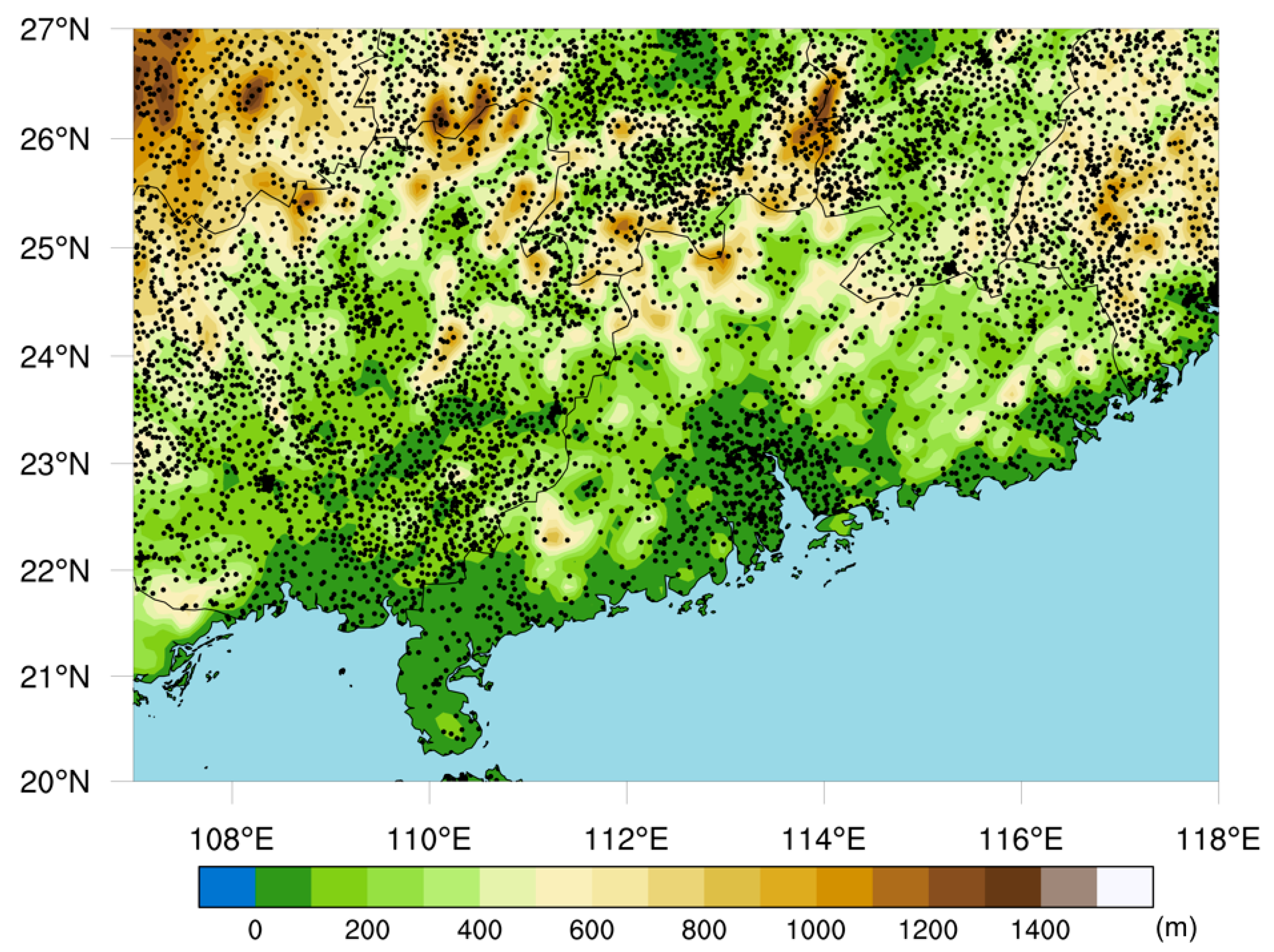
The study area of this research is located in Southern China, primarily encompassing the provinces of Guangdong and Guangxi and surrounding areas, as shown in
Figure 1. The latitude and longitude coordinates range from 20° to 27° N and 107° to 118° E, respectively. This region is influenced by a subtropical monsoon climate, leading to frequent occurrences of short-term heavy rainfall. The frequency of short-duration heavy rainfall and the maximum hourly rainfall intensity in this region are among the highest in China. Additionally, the southern region boasts a well-established meteorological detection network, providing a wealth of high-quality meteorological data. The densely populated urban agglomerations in the Guangdong–Hong Kong–Macao Greater Bay Area are highly susceptible to the impacts of heavy rainfall, which can significantly affect agriculture, industry, and the service sector. Therefore, effective and accurate approaching precipitation forecasting is crucial for the daily lives and economic development of the people in this region.
2.2. Dataset Preprocessing and Selection of Meteorological Elements
This study combines ground precipitation data with upper-air meteorological element data as the dataset. The upper-air data utilize hourly data from the European Centre for Medium-Range Weather Forecasts (ECMWF) ERA5 reanalysis, with a spatial resolution of 0.25° × 0.25°. Surface observation data utilize hourly rainfall data from all national and automatic weather stations within the selected region provided by the China Meteorological Administration. Within the study area, there are a total of 301 national stations and 6579 automatic regional stations contributing to the dataset. The station locations are annotated in
Figure 1. The rainfall data from observation stations undergo quality control processing, excluding data from malfunctioning stations. Subsequently, inverse distance weighting interpolation is employed to interpolate station data onto grid points, matching the temporal and spatial resolution of the upper-air data, thus enabling multimodal data fusion. If there are any missing or omitted data in either dataset, the corresponding samples are removed. Additionally, we replaced all extreme values below 0 and above 1000 with missing values to avoid the abnormal impact of individual extreme values on the overall performance of the model. Ground observation data and upper-air reanalysis data are fused and concatenated based on meteorological elements to form the experimental dataset.
According to the requirements of deep learning training, the total dataset is divided into training, validation, and test sets. The ten years of data from 2010 to 2020 are allocated according to the ratio of 8:1:1, as shown in
Table 1. The selected meteorological elements include the most fundamental elements in the weather system, including temperature, pressure, humidity, U-wind, and V-wind. Details can be found in
Table 2.
2.3. Evaluation Metrics
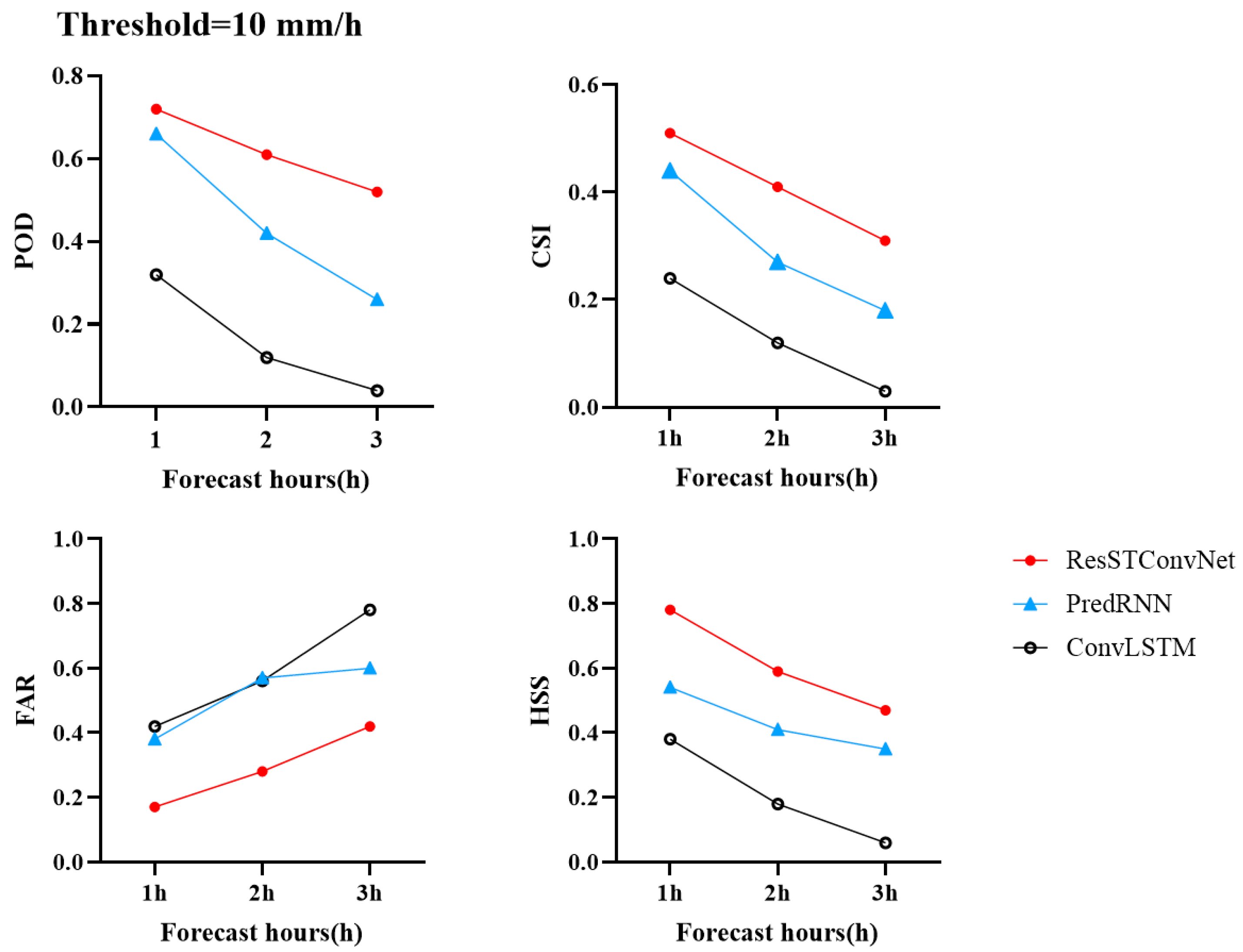
The evaluation of precipitation forecasting results in this study primarily includes both qualitative and quantitative aspects, comprising four common categorical metrics: Probability of Detection (POD); False Alarm Rate (FAR); Critical Success Index (CSI); Heidke Skill Score (HSS); and two continuous metrics, Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE).
In order to calculate the four categorical indicators, it is necessary to establish a binary confusion matrix based on the two-class classification. This involves using a probability threshold method, where a grid point is assigned a value of 1 if the data at that point exceed the set threshold, and 0 otherwise. Subsequently, by comparing the predicted results with the actual values, the following values are calculated: TP (true positive, when prediction = 1 and truth = 1), FN (false negative, when prediction = 0 and truth = 1), FP (false positive, when prediction = 1 and truth = 0), and TN (true negative, when prediction = 0 and truth = 0). Finally, the calculation of the relevant parameters is carried out according to the following formula:
To assess the prediction capability regarding precipitation intensity, we also computed the MAE and RMSE between the predicted values and the ground truth. These metrics focus on the differences in intensity. The specific formulas for calculation are as follows:
X and Y, respectively, represent the forecasted precipitation results and the actual ground observation results, where m × n represents the grid points within the research area. The smaller the difference value between the predicted values and the observed values, the better the prediction performance.
2.4. Baseline Methods
The baseline models in this study mainly included ConvLSTM, U-net, ResNet, and PredRNN. The details are as follows:
ConvLSTM: ConvLSTM is defined as the cornerstone network in the field of precipitation forecasting. In this experiment, a three-layer network is chosen with hidden layer sizes of [64, 64, 128], and the learning rate is set to 0.001. Based on the scale and characteristics of the processed data, the kernel size and padding are respectively set to [3, 3] and 1, and the bias is set to 0, aiming to restore the original feature map size as much as possible. Due to the model’s susceptibility to overfitting, the number of epochs is set to 50, which is deemed sufficient.
U-net: Compared with ConvLSTM, U-net utilizes a U-shaped architecture predominantly composed of convolutional pooling layers. The basic network for feature extraction is a convolutional neural network. Training proceeds through four convolutional layers, with channel sizes of 64, 128, 256, and 512, respectively. Similarly, the kernel size and padding are, respectively, set to [3, 3] and 1 for all layers. After each convolutional operation, there is a corresponding average pooling layer. Following the downsampling layer, the image is restored through skip connections to four upsampling layers.
ResNet: We construct a simple three-layer residual block with the aim of observing whether the residual block has a positive effect on predicting extreme values. The input and output channel sizes of the convolutional layers are both set to 1, and only single ground observation data are used for experimentation.
PredRNN: In this experiment, PredRNN utilized a three-layer basic model, maintaining consistency with ConvLSTM’s parameter configuration on important parameters. The configuration of memory modules and recurrent units corresponds to the number of input channels and spatial ranges.
To ensure that other parameters do not affect the network training effectiveness, the learning rate for the aforementioned models is set to 0.001, and the training epochs are all set to 50.
3. Model Construction
In this section, the proposed ResSTConvNet model is discussed in detail. First, we present the overall architecture of our model and the basic information flow, explaining the data transmission direction. Subsequently, we elaborate on channel attention, spatiotemporal feature information flow, and residual fitting connection, explaining how ResSTConvNet uses these modules to accomplish feature extraction and data transmission.
3.1. Overall Network
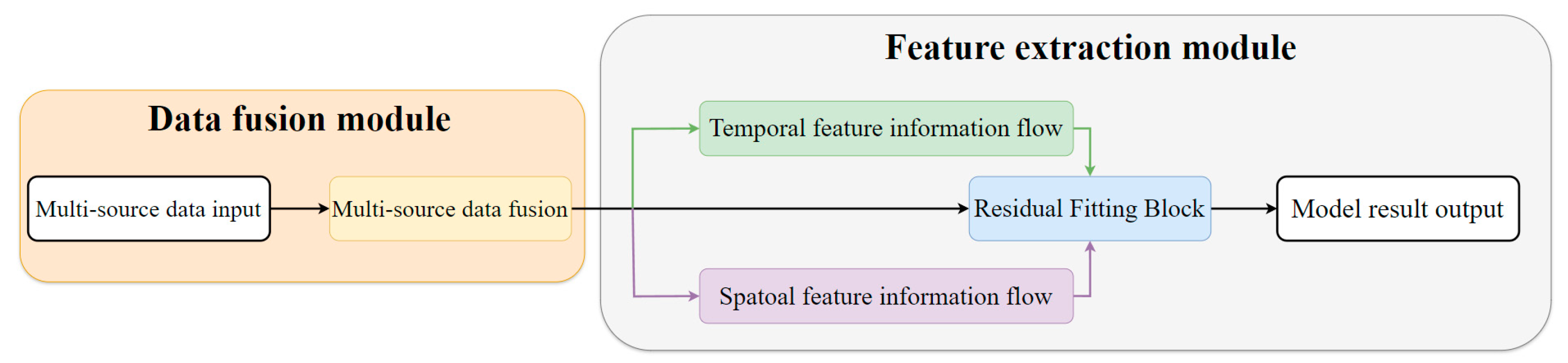
This section aims to introduce the overall network of ResSTConvNet, which mainly includes the attention weight allocation module, the spatiotemporal feature information flow, and the residual fitting module. The overall framework is illustrated in
Figure 2. The data pass through the data fusion block, undergo feature extraction, and are merged in the residual fitting block to obtain the final prediction results. The details of these three modules are elaborated in the following sections.
3.2. Channel Attention
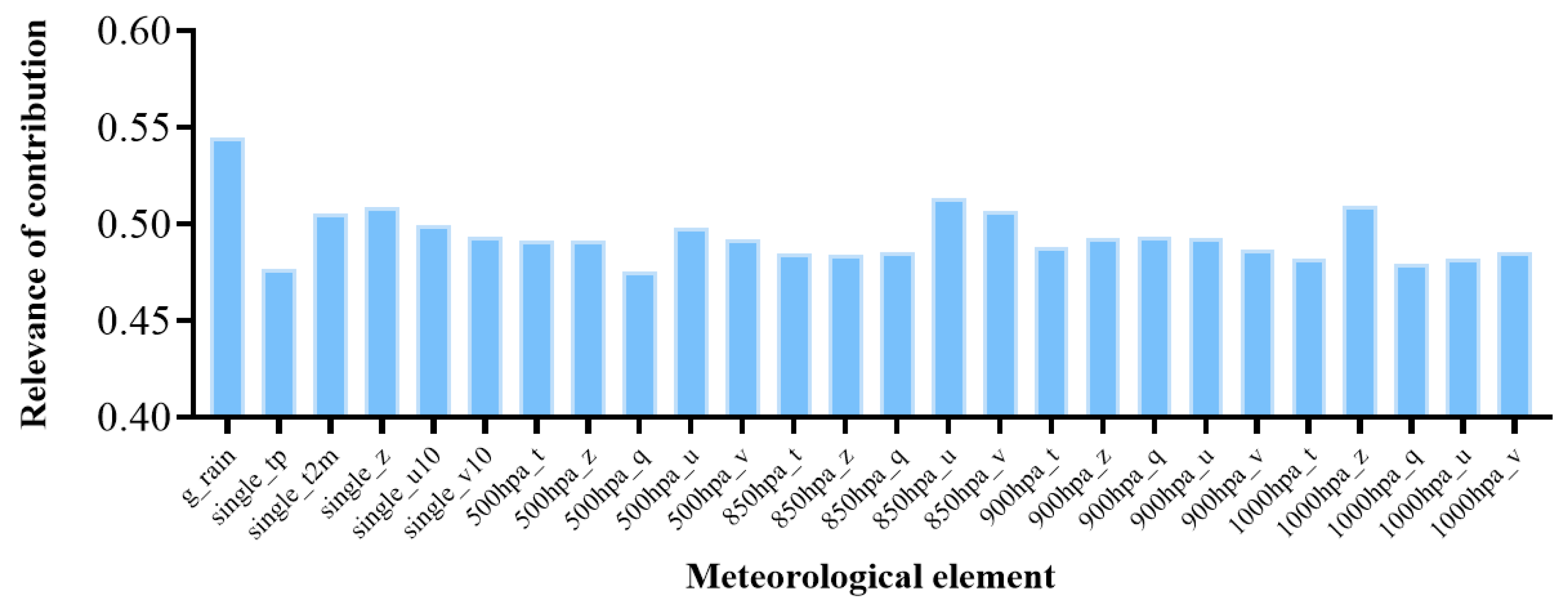
This section introduces high-altitude variables to establish a comprehensive meteorological system for deducing future precipitation conditions. Each meteorological element in
Table 2 can be regarded as a channel of input, equivalent to modeling a multichannel correlation problem. The contribution of each variable to the final prediction is allocated through channel attention mechanisms.
Because this module only needs to consider the channel feature distribution at the same moment and does not need to consider temporal features, the classic channel attention mechanism is adopted for feature calibration [
24]. As shown in
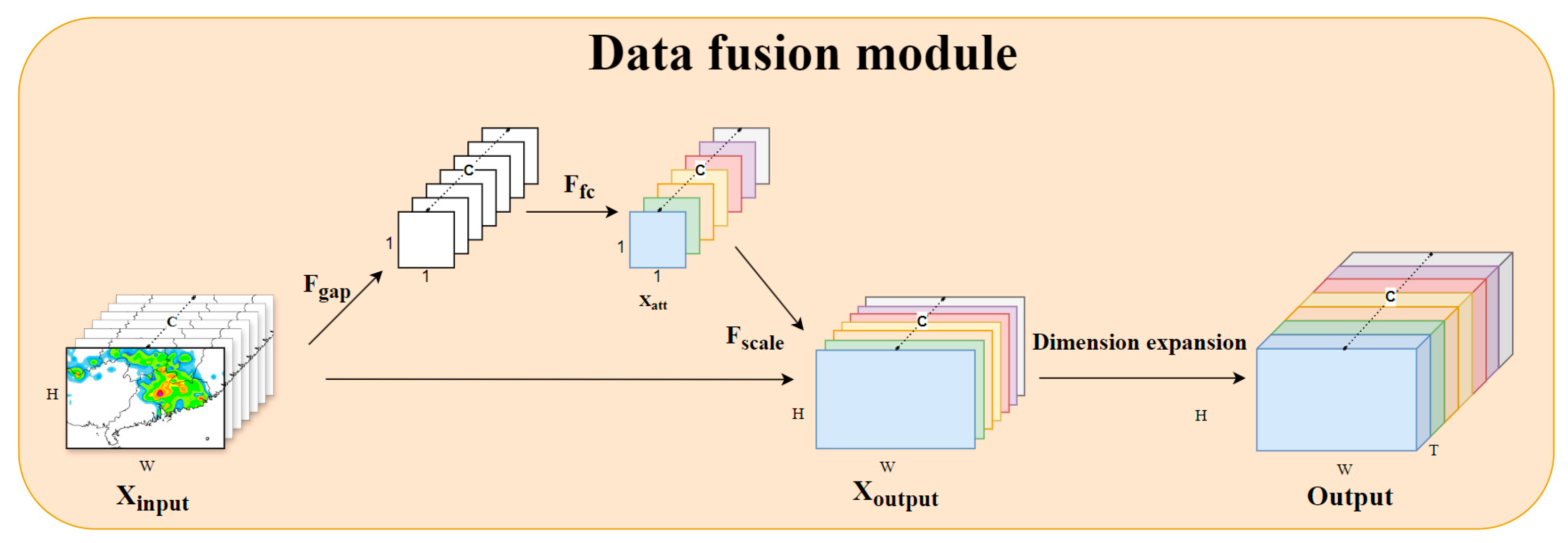
Figure 3, multiple channel variables at the same moment are concatenated by channel to obtain a three-dimensional input
, where C refers to the number of channels, and each meteorological element is regarded as a channel. H × W represents the spatial range selected, namely the spatial range of the obtained feature map. Global Average Pooling (GAP) is used to aggregate the spatial feature maps of each channel by averaging the information of all points in space into a single value, generating a contribution descriptor of size C × 1 × 1. This descriptor represents the proportion of information for each channel in the global receptive field. Adopting average pooling can suppress spatial information interference and extract channel correlation to the greatest extent. Then, two fully connected layers are used to activate channel samples for subsequent gradient backtracking and dynamically allocate to obtain weights
. The weight values are multiplied by the input, which is the scaling operation in attention allocation, as shown in Equation (7):
The output is obtained as . At this point, the weight allocation for channel correlation is completed. After completing the weight allocation for each channel data at each moment, they are concatenated along the time dimension to perform time dimension expansion, resulting in a four-dimensional , where T refers to time. With this, the fusion of multiple data sources is completed, and the output results are fed into the subsequent feature capture module.
3.3. Spatiotemporal Feature Information Flow
Due to the extensive application and excellent performance of convolution in the field of image processing [
25,
26], many meteorologists have also begun to adopt convolution for predicting meteorological elements in weather forecasting. The advantage of convolution lies in its ability to fuse spatial information in a local receptive field and explicitly model spatial correlations. With its local perception capability, convolution establishes nonlinear relationships for subtle changes in adjacent spaces, focusing on the trend of changes in neighboring areas.
Due to the strong temporal correlation in meteorological element prediction tasks, traditional two-dimensional convolution lacks the capability to extract features from long time sequences. Therefore, there is an urgent need for dimension expansion, making three-dimensional convolution the preferred choice. However, basic experiments have revealed that directly using three-dimensional convolutional networks for prediction yields minimal improvement compared with two-dimensional convolution. This is because three-dimensional convolution kernels cannot simultaneously extract features from both time and space dimensions using a single convolution kernel. Moreover, the parameter volume required for computation increases with dimensionality, resulting in slower execution speeds and making optimization difficult.
Tran et al. (2018) proposed a solution involving separable three-dimensional convolution [
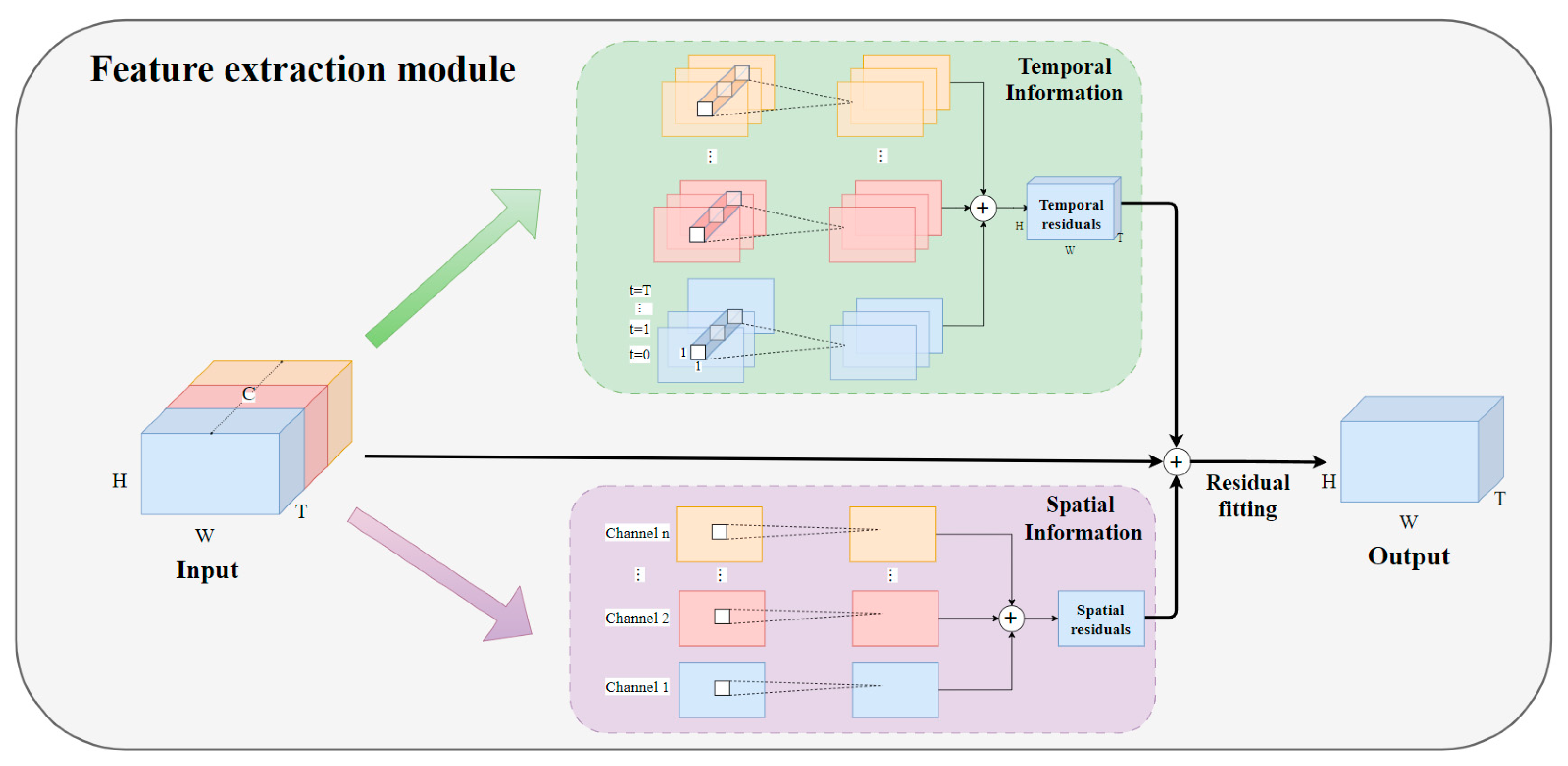
27], decomposing 3D convolution into R(2 + 1)D, which is accomplished by multiple convolutions after separation. They introduced ReLU layers between each convolution block to increase the network’s nonlinearity and performed feature extraction in steps to enhance network complexity. Based on this, the feature extraction module in this paper also decomposes 3D convolution. The original three-dimensional convolution is split into two simultaneous steps: the temporal feature information flow and the spatial feature information flow. After performing the corresponding convolution calculations, feature fusion is carried out, effectively separating the temporal and spatial feature extraction components. The main structure is illustrated in
Figure 4.
The focus of temporal information feature extraction lies in capturing information from adjacent time steps. The output obtained from the preceding data fusion module is directly used as the input
for the temporal information flow, and it undergoes three-dimensional convolution operations, as depicted by the Temporal Information Block in
Figure 4. In a complete three-dimensional convolution, the convolution kernel typically has dimensions of t × h × w. Here, spatial dimension information is disregarded, and a t × 1 × 1 temporal convolution kernel is employed, treating the spatial dimension operation at each time step as a 1 × 1 convolution. This approach emphasizes the correlation of each channel across adjacent time steps. The blue, red, and yellow feature maps in
Figure 4 represent different meteorological elements. After performing three-dimensional convolution on each meteorological element, the resulting feature maps are summed to obtain the feature map for temporal information.
The spatial information extraction is accomplished using the most commonly used two-dimensional convolutional layers in Computer Vision. This module focuses on extracting spatial information, with each time step value calculated independently. Firstly, the input undergoes dimension permutation, concatenating the inputs according to the number of channels. Unlike temporal information, which performs convolution operations on adjacent time steps each time, spatial information conducts two-dimensional convolution operations only on the values of a single time step at a time. Finally, the feature maps obtained from all channels are summed to obtain the spatial feature map. In order to minimize the loss of spatial features for image prediction, the relationship between padding and kernel size for the convolution operation is designed as , ensuring that the output size matches the input image size. Through convolutional operations, spatial information flow is obtained, gradually encoding implicit and abstract spatial features.
3.4. Residual Fitting Connection
Predicting heavy rainfall has always been a major challenge in the field of precipitation forecasting. Precipitation data are inherently discrete, and it is possible for a region to experience no rainfall for consecutive months, resulting in a dataset with a large number of missing values. Moreover, the characteristic of neural network outputs tends to be smooth, which can easily lead the model to ignore extreme values, causing false alarms or misses in predicting heavy rainfall events. The residual fitting module proposed by He et al. effectively addresses this issue [
28]. As indicated by the black arrows in
Figure 4, both Temporal Information and Spatial Information no longer directly predict the results but instead predict the change values. These change values are then fitted with the input through residual fitting. This approach better preserves useful information learned in the early stages of the network, preventing it from being continuously iterated or canceled out during transmission, thereby minimizing the loss of original information. The decomposed convolution extracts rich temporal and spatial information, fitting with the original input from two dimensions, resulting in a model that captures more comprehensive spatiotemporal features. Consequently, the predicted images produced by this model will be clearer, and the forecasting accuracy for extreme values will also be correspondingly improved.
5. Conclusions
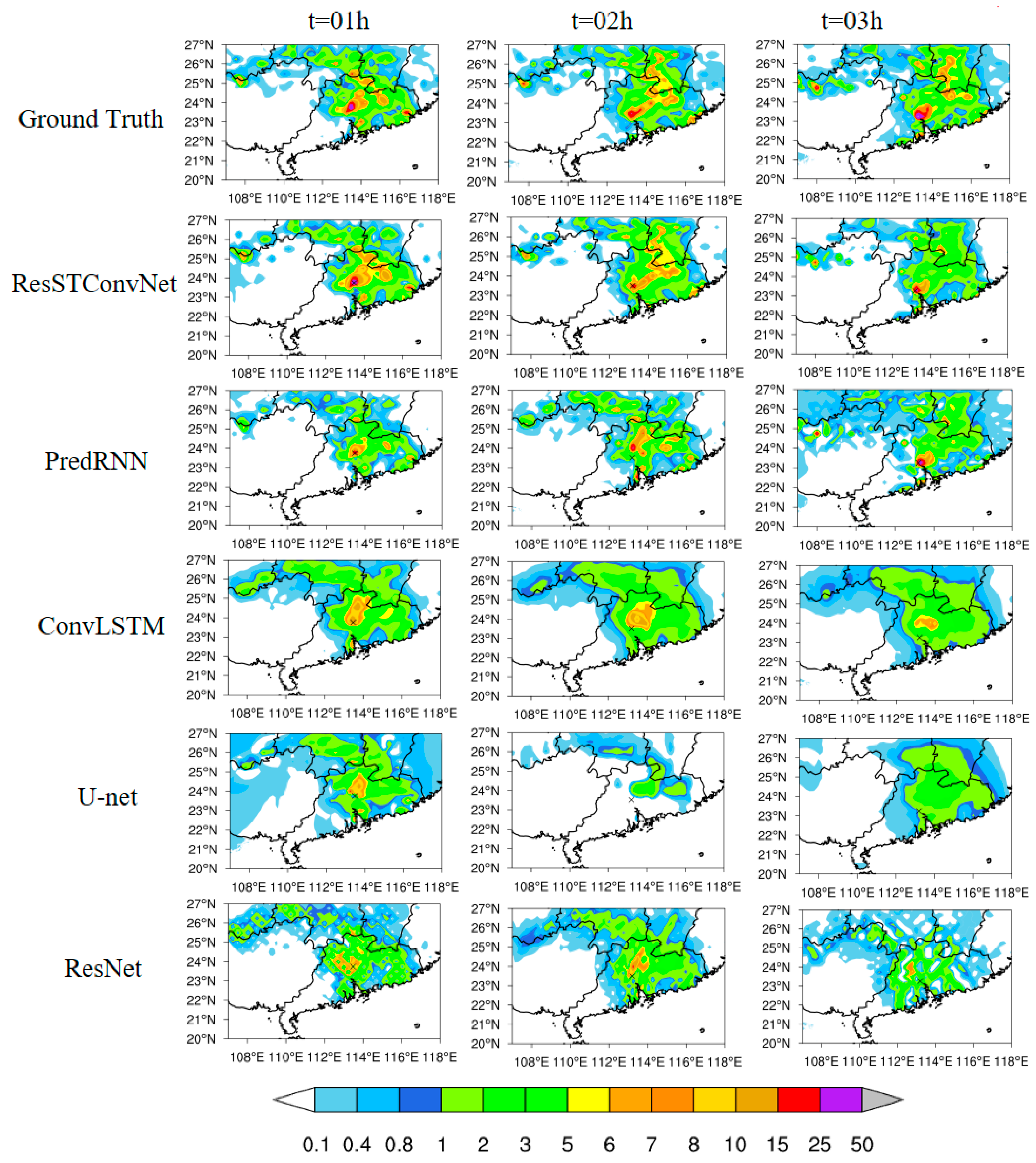
In this paper, we proposed the ResSTConvNet model for short-term (0–3 h) precipitation forecasting, which can integrate ground observation data and high-altitude reanalysis data by allocating channel weights. In the feature extraction module, we designed a pure convolutional structure instead of the traditional LSTM structure, saving memory space while improving operational speed. Additionally, we employed a residual fitting module for final feature fitting, enabling the model to better capture long-term memory information and spatial features, particularly in extreme value extraction. Experimental results on the test set demonstrate that ResSTConvNet achieves better performance than the baseline model across key indicators.
However, this network still has certain limitations and challenges. Although pure convolutional networks offer improvements in space utilization and running speed compared with networks based on LSTM, the use of three-dimensional convolutions for temporal information flow still increases data volume dimensionally. Therefore, the training requirements for this network remain relatively high. Furthermore, although the issue of excessive smoothing during convolution operations is mitigated through residual connections, the fundamental problem of the forecast results tending toward an average is not resolved. As the forecast lead time reaches three hours, a significant loss of spatial features still occurs. In the field of precipitation forecasting, the accuracy of forecasting extreme precipitation is crucial, as it has the greatest impact on people’s daily lives and work. Hence, addressing and overcoming this challenge will be a key focus of future work. Additionally, further experiments can be conducted to explore the selection of upper-level meteorological variables. More levels and additional meteorological variables can be added to the model for screening and experimentation to further improve the accuracy of the model’s predictive capabilities.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}