
Spatial–Temporal Temperature Forecasting Using Deep-Neural-Network-Based Domain Adaptation




Abstract
:1. Introduction
2. Proposed Method
2.1. Time-Series Forecasting Problem
2.2. Proposed Deep Neural Network
- Primary variable projection: projects low-dimensional inputs into a high-dimensional representation; it is used for projecting maximum temperature into a high-dimensional space.
- Secondary variable projection: projects low-dimensional inputs into a high-dimensional representation with the same projection dimension as the primary variable projection; it is used for projecting covariates into a high-dimensional space.
- Transformer encoder: learns dependency across time and feature spaces of the primary and secondary variables and encodes it as a memory state.
- Transformer decoder: produces a high-dimensional representation of the unobserved maximum temperature from the memory state with given covariates.
- Output layer: maps the high-dimension representation of the unobserved maximum temperature into single values.
2.3. Domain Adaptation
Domain Adaptation Strategies
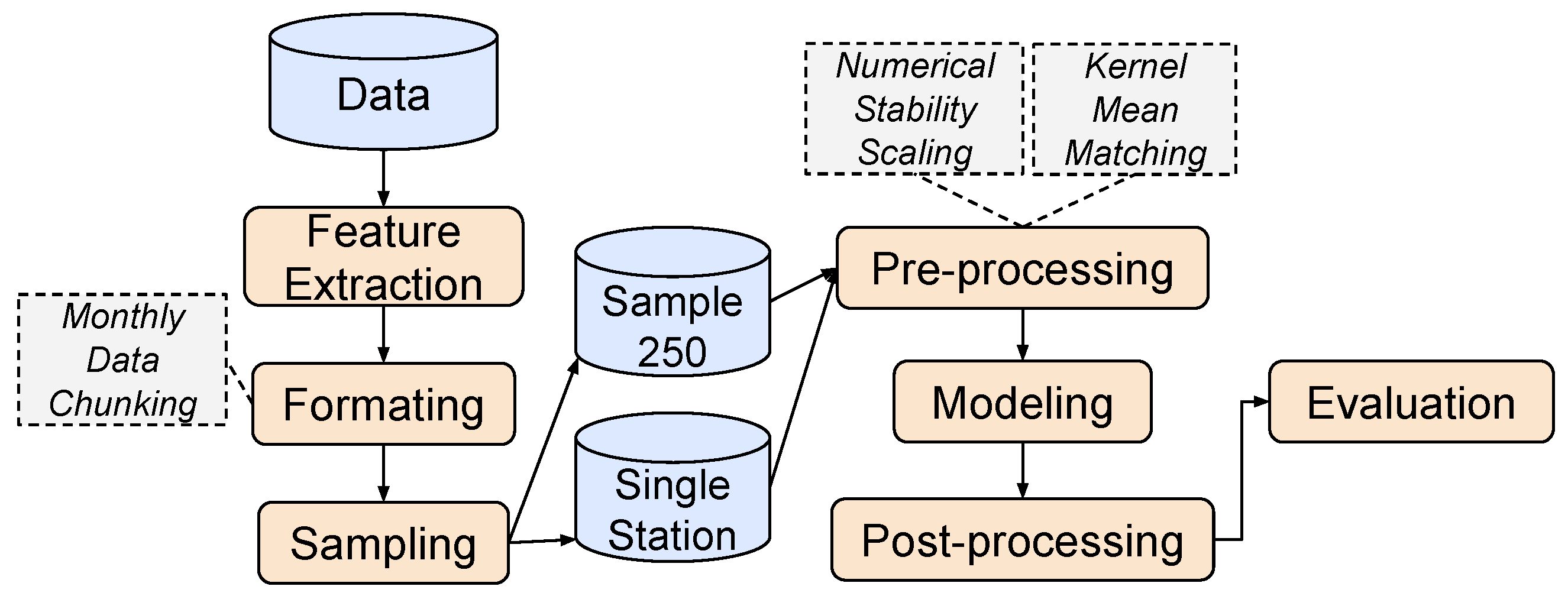
3. Numerical Experiments
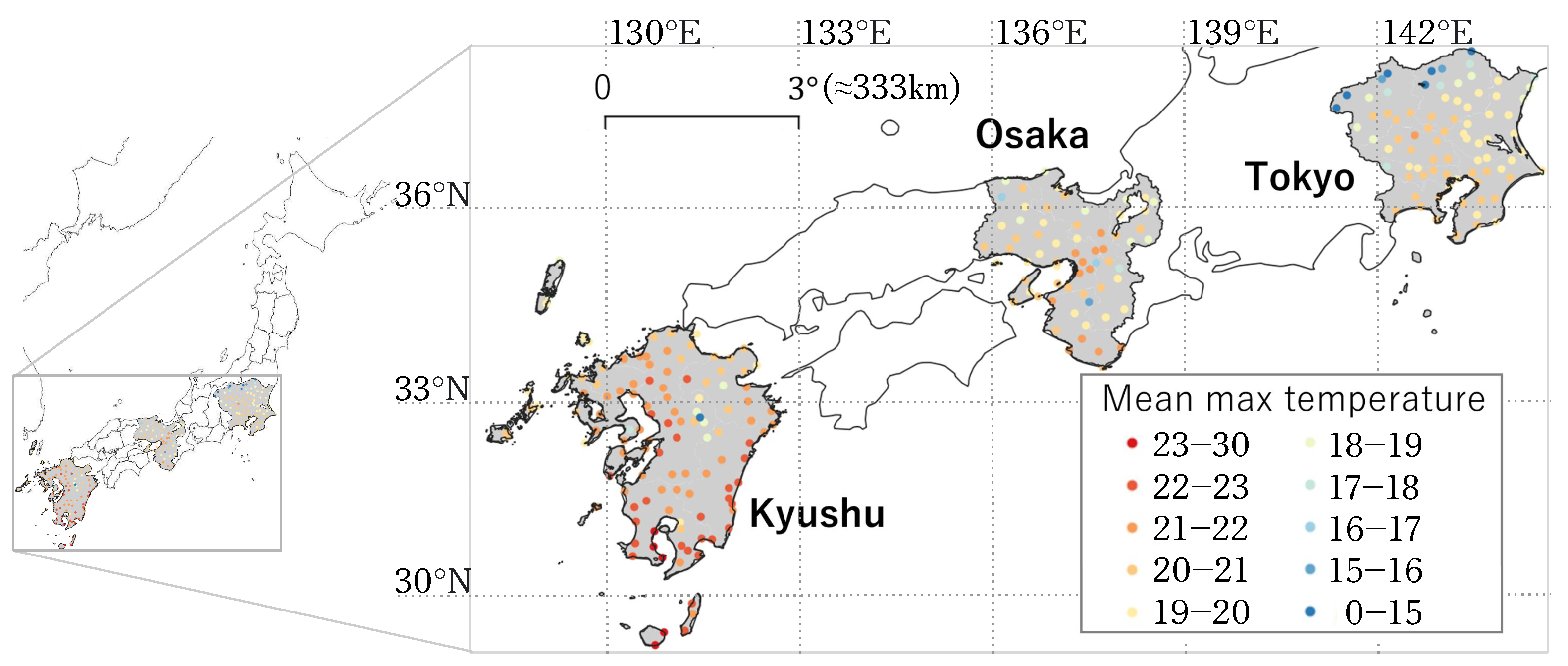
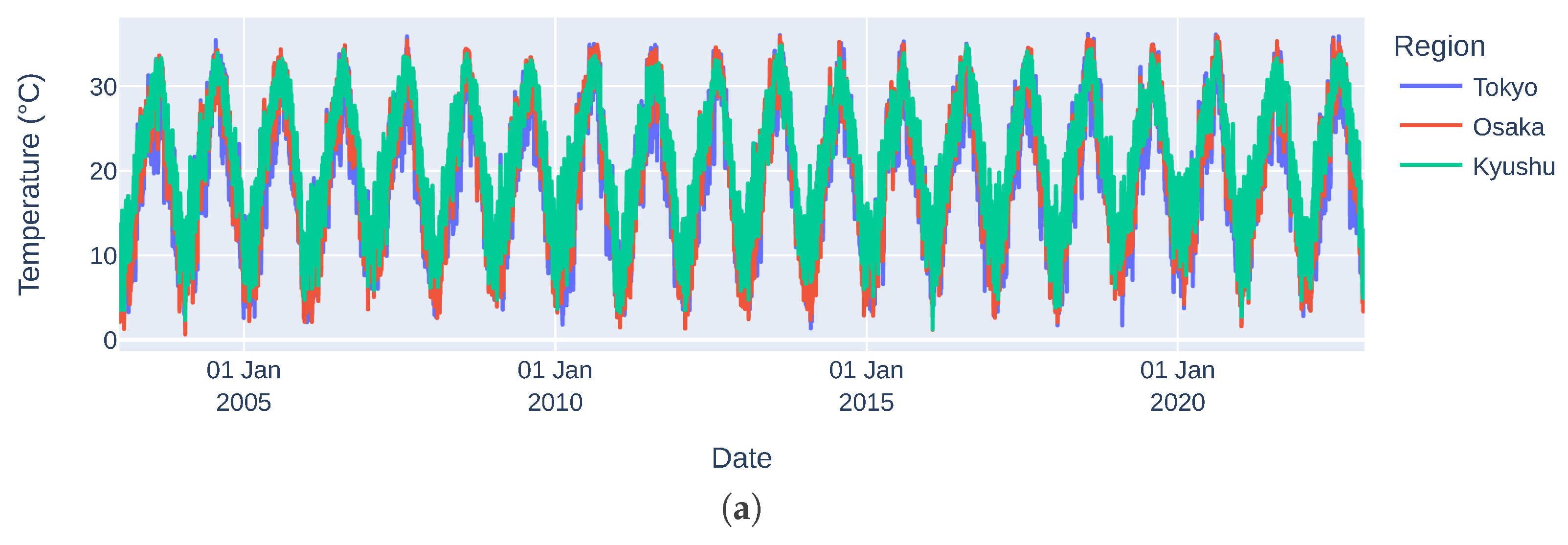
3.1. Choice of Covariates and Data Pre-Processing
- : Maximum daily temperature;
- : Longitude;
- : Latitude;
- : Station elevation;
- : Record year;
- : Solar declination angle [17] estimated from recording date using
- : Solar noon angle = latitude − solar declination angle.
3.2. Model Settings
- Sample 250 data setting: We randomly sampled 250 instances from the full set of training data along with 50% (e.g., approximately 300 instances for Tokyo–Osaka) of the full set of validation data for the target domain. Thirty such samples were prepared.
- Single Station data setting: We separately evaluated each station in the target domain. In each single-station experiment, the target-domain train/validation/test datasets were for that station alone while the source-domain data were for all stations in the source-domain region.
- High-dimensional representation size : 32, 64, or 128.
- Number of layers in transformer encoder and transformer decoder modules: 2.
- Optimization algorithm: Adam [18] with a learning rate of 0.001, training with a batch size of 50, and a maximum of 1000 iterations.
- The best set of model parameters was selected using validation dataset .
- The RBF kernel coefficient in Equation (17) was .
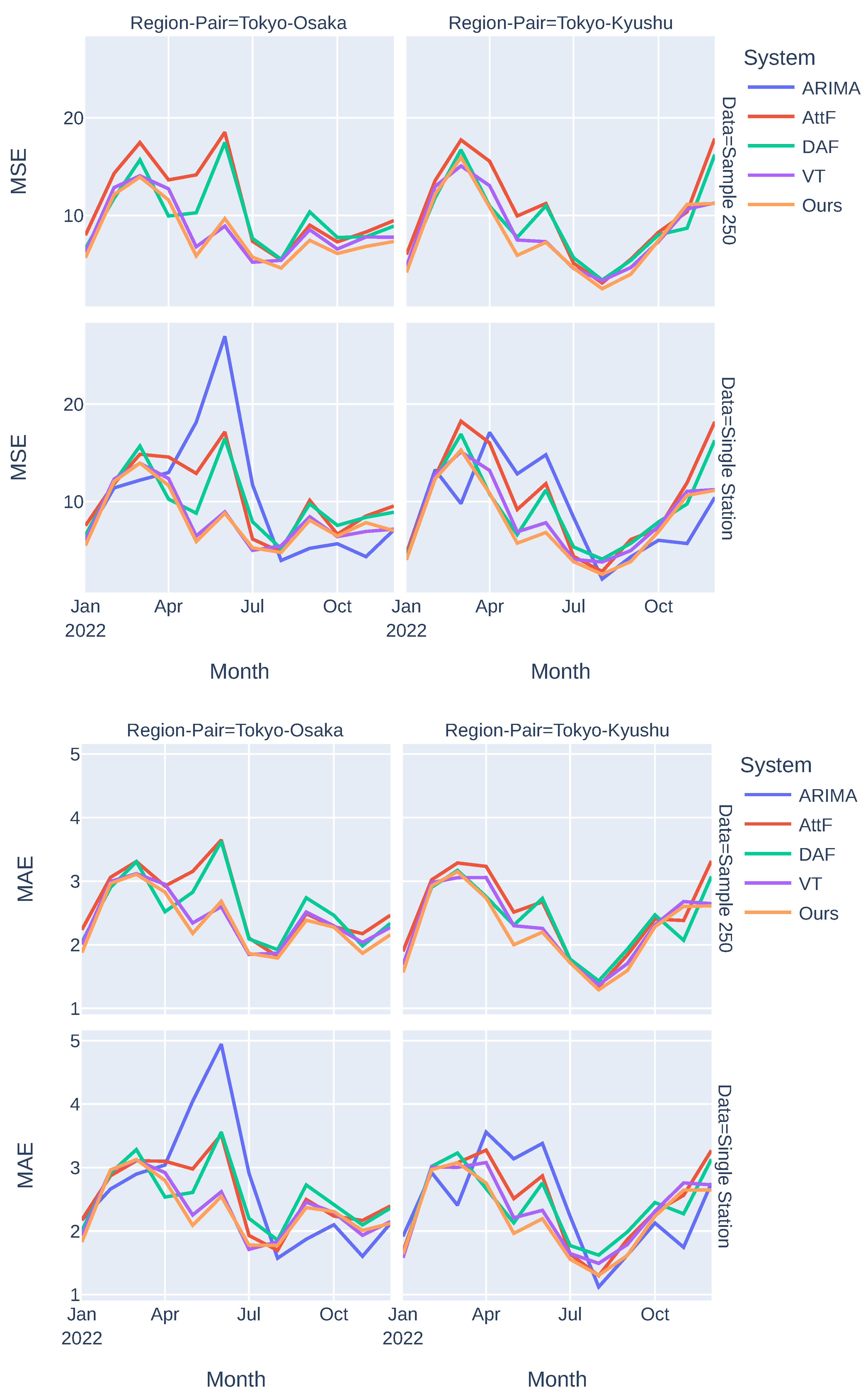
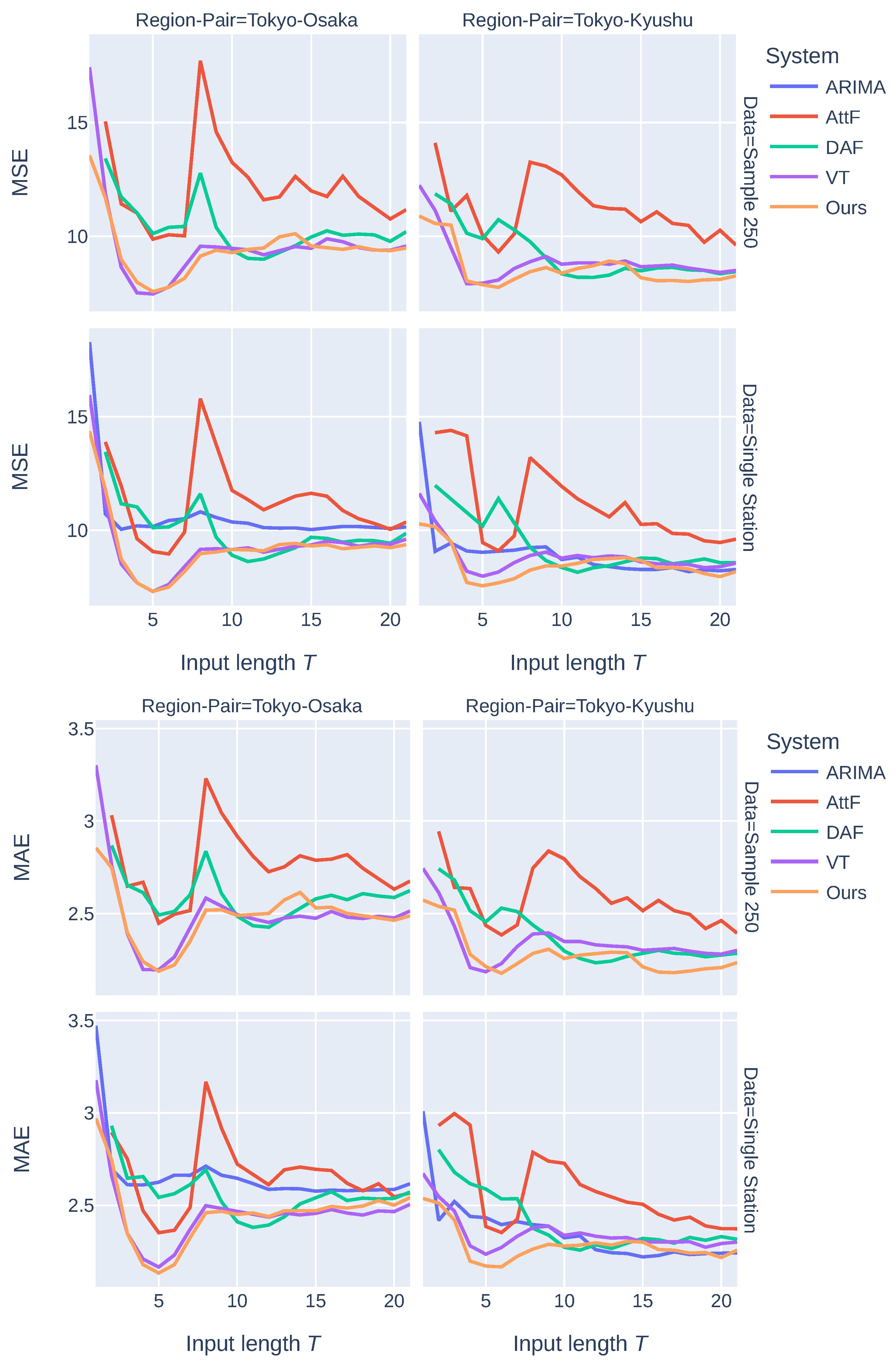
3.3. Evaluation
- Domain: Two source–target-domain pairs were considered: Tokyo–Osaka and Tokyo–Kyushu.
- Data: Two low-resource data settings (Sample 250 and Single Station) were used.
- Model: Three values of a high-dimensional representation size () were used. The evaluation results reported later are the averaged evaluation metric values of all models with all three different representation sizes.
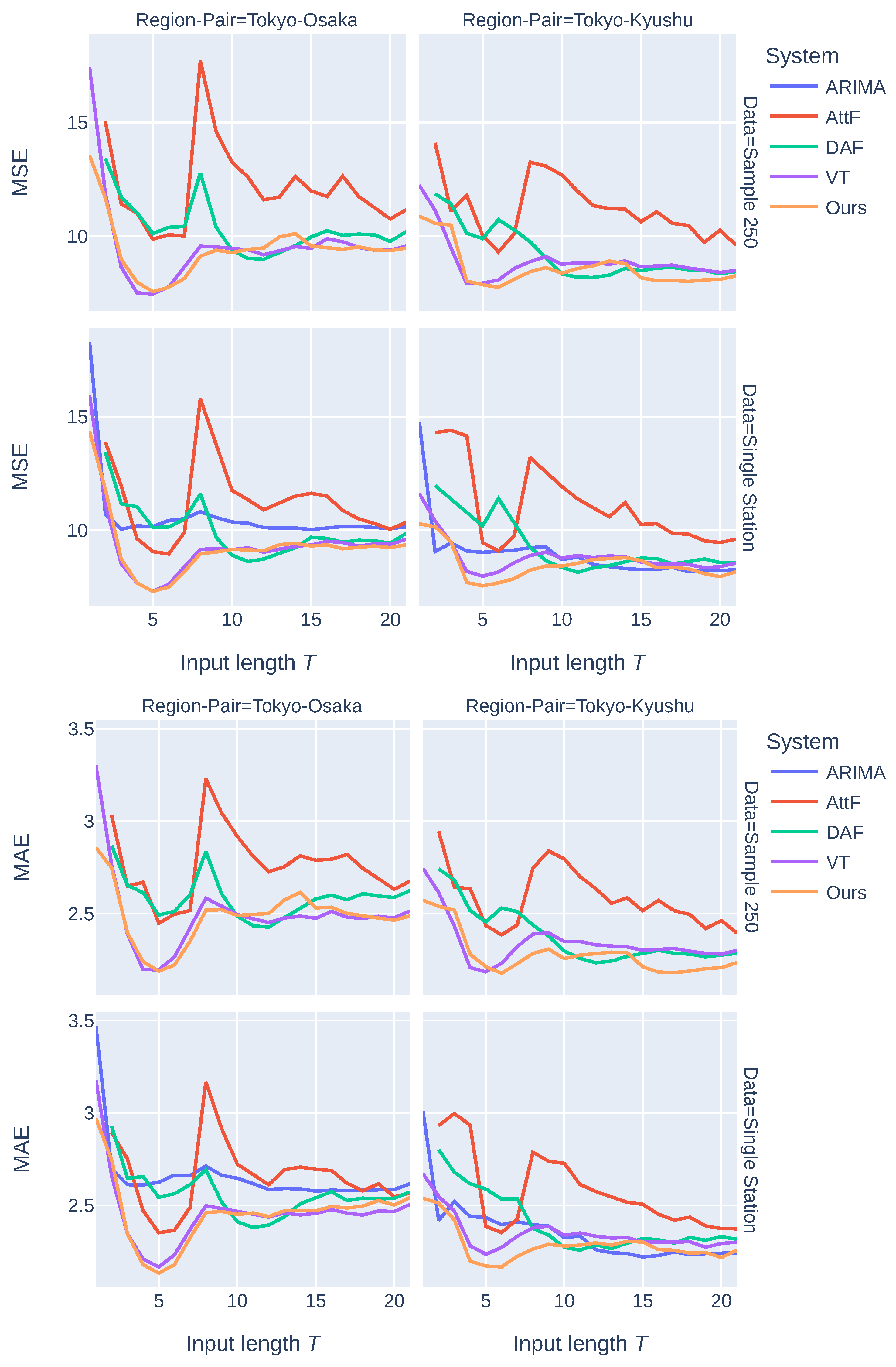
- Input Length : was used as the representative input length for comparing our system with three baseline systems; the version of our system with the best performance was analyzed for different input lengths.
- Loss:
- Baseline systems:
- –
- VT: Our (vanilla) transformer-based architecture in a non-domain adaptation setting, which is equivalent to setting .
- –
- DAF [11]: An advanced domain adaptation method for time-series forecasting that uses attention sharing in combination with domain discrimination. It was not evaluated for this particular temperature forecasting problem.
- –
- AttF [11]: The non-domain adaptation part of DAF (i.e., without shared attention and domain discrimination) and trained on only the target-domain data.
- –
- ARIMA [19]: A commonly used baseline for time-series forecasting in non-domain adaptation settings. The parameters were obtained using the same training data as those for the other evaluated systems.
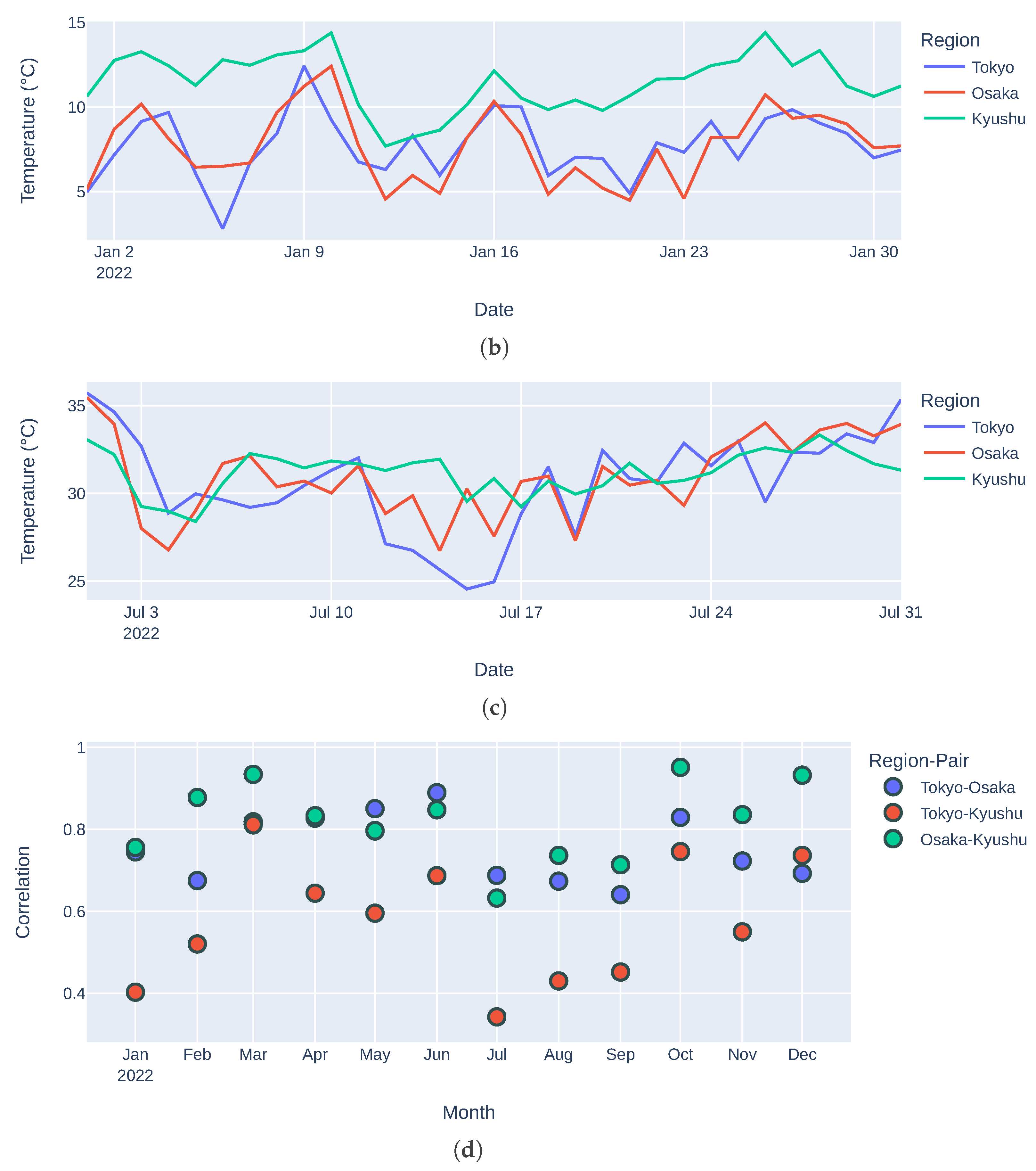
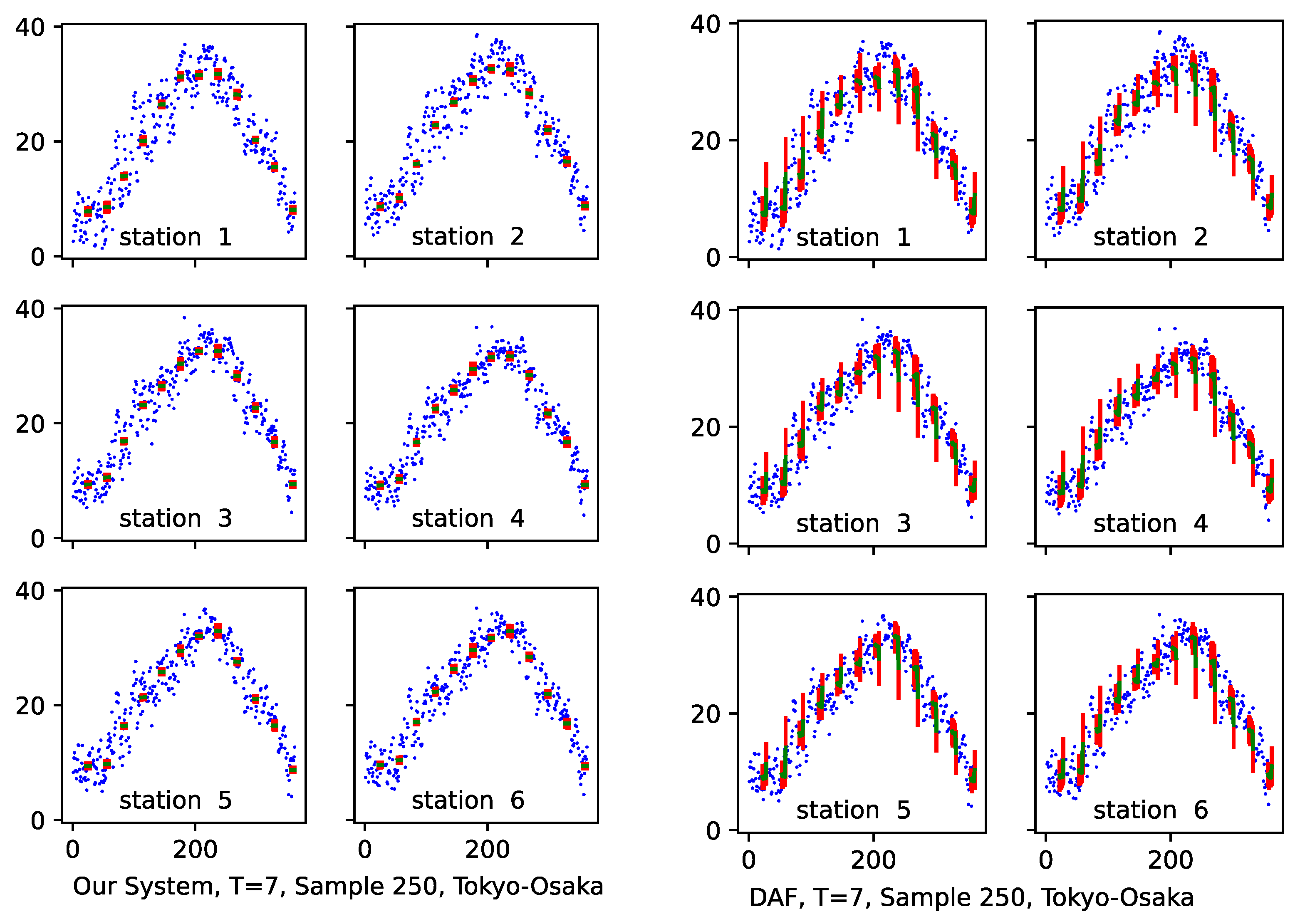
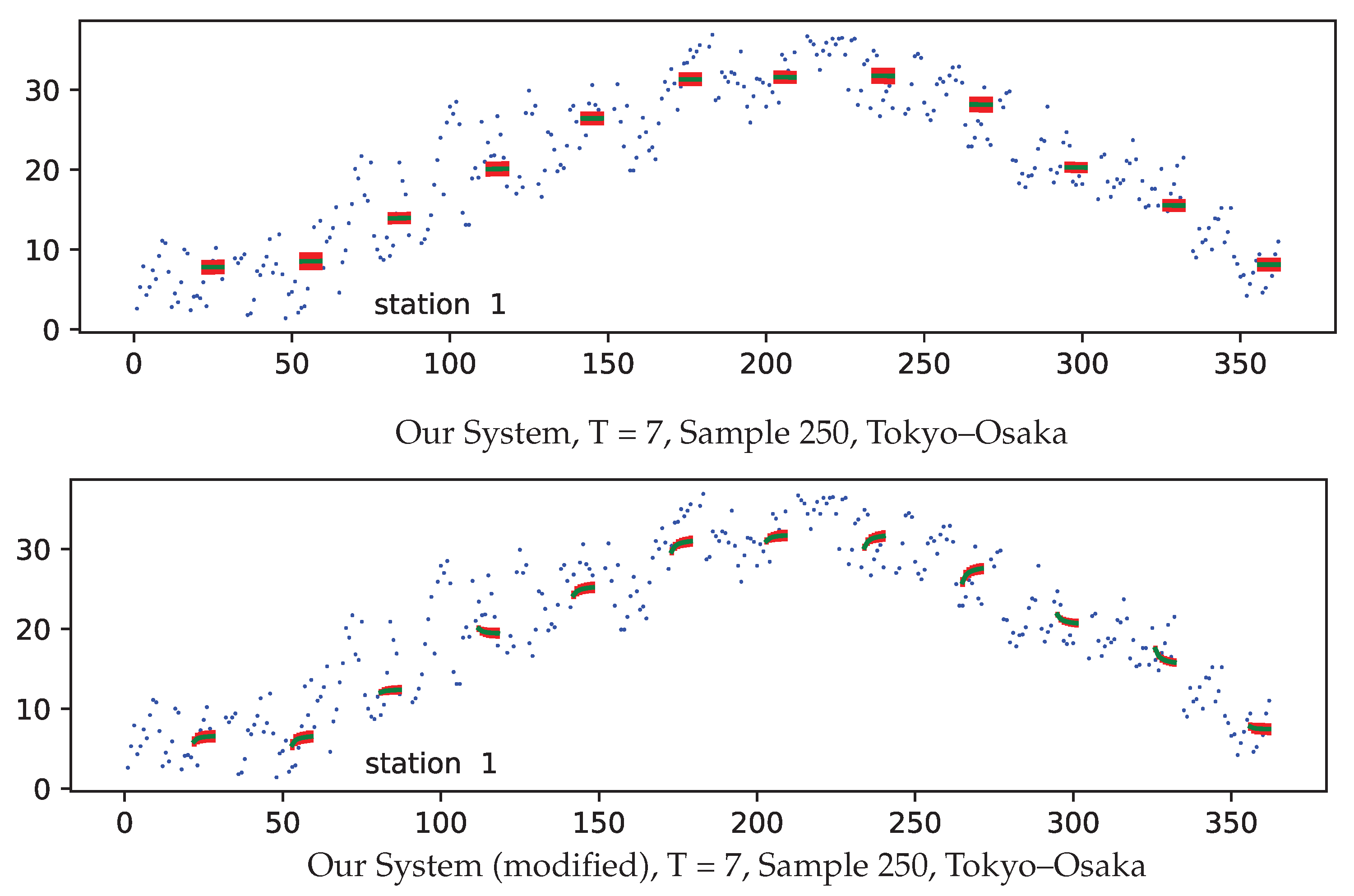
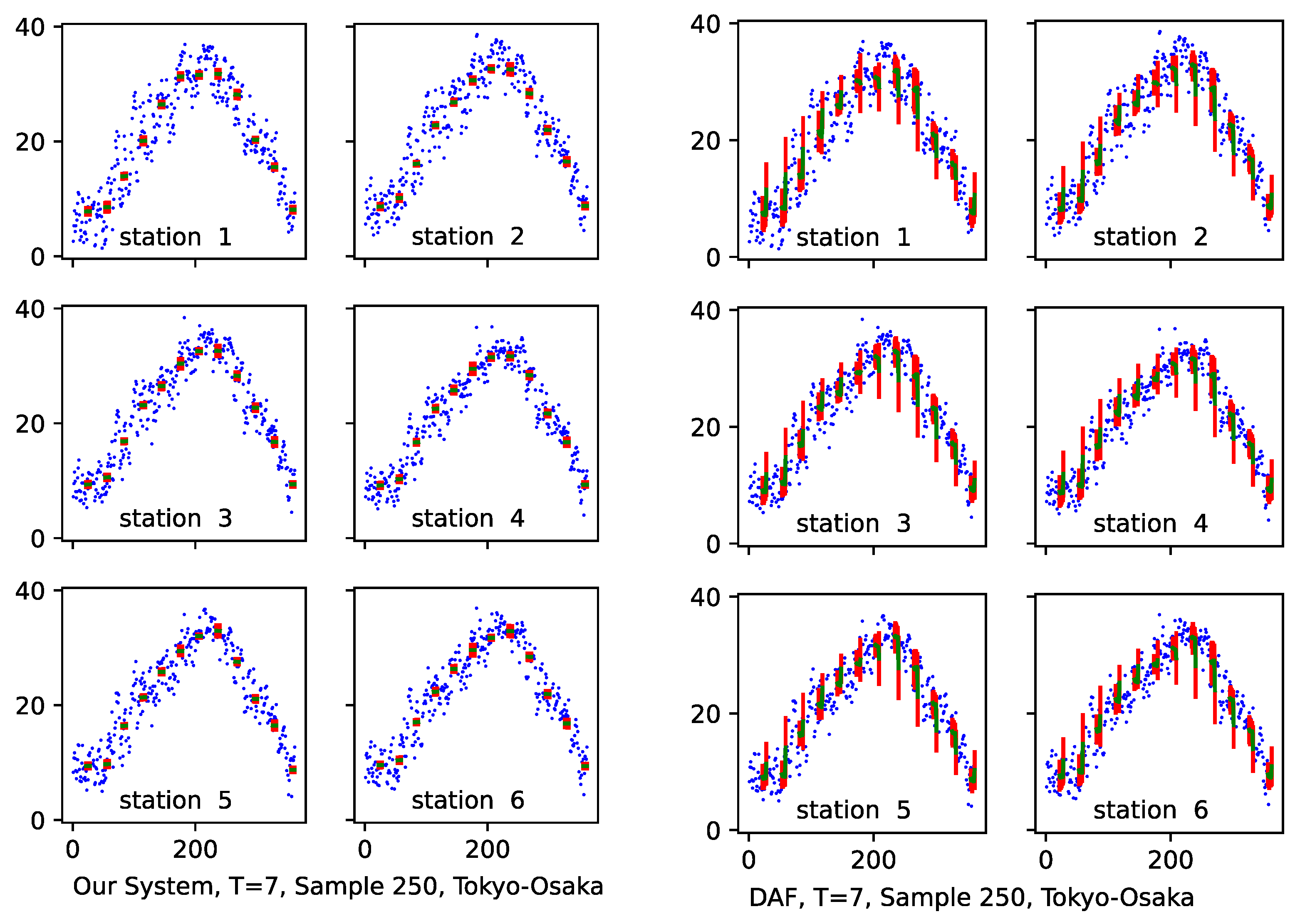
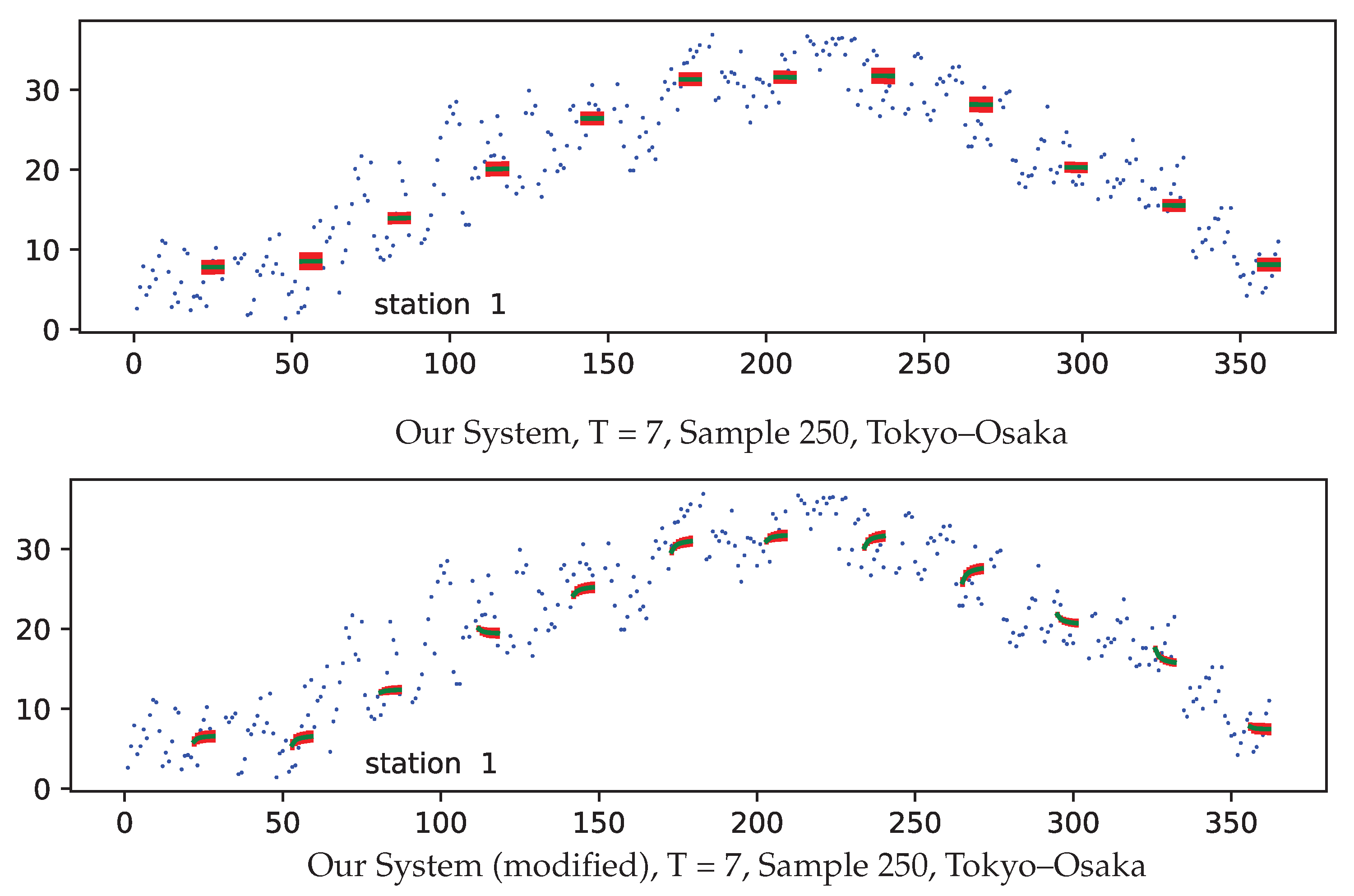
3.4. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DNN | Deep neural network |
| KMM | Kernel mean matching |
| MSE | Mean squared error |
| MAE | Mean absolute error |
References
- Lee, S.; Lee, Y.S.; Son, Y. Forecasting daily temperatures with different time interval data using deep neural networks. Appl. Sci. 2020, 10, 1609. [Google Scholar] [CrossRef]
- Jasiński, T. Use of new variables based on air temperature for forecasting day-ahead spot electricity prices using deep neural networks: A new approach. Energy 2020, 213, 118784. [Google Scholar] [CrossRef]
- Rasp, S.; Lerch, S. Neural networks for postprocessing ensemble weather forecasts. Mon. Weather. Rev. 2018, 146, 3885–3900. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30.
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Crabtree, C.J.; Zappalá, D.; Hogg, S.I. Wind energy: UK experiences and offshore operational challenges. Proc. Inst. Mech. Eng. Part A J. Power Energy 2015, 229, 727–746. [Google Scholar] [CrossRef]
- Sun, Q.; Yang, L. From independence to interconnection—A review of AI technology applied in energy systems. CSEE J. Power Energy Syst. 2019, 5, 21–34. [Google Scholar]
- Zhou, G.; Xie, Z.; Huang, X.; He, T. Bi-transferring deep neural networks for domain adaptation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 322–332. [Google Scholar]
- Singhal, P.; Walambe, R.; Ramanna, S.; Kotecha, K. Domain Adaptation: Challenges, Methods, Datasets, and Applications. IEEE Access 2023, 11, 6973–7020. [Google Scholar] [CrossRef]
- Cifuentes, J.; Marulanda, G.; Bello, A.; Reneses, J. Air temperature forecasting using machine learning techniques: A review. Energies 2020, 13, 4215. [Google Scholar] [CrossRef]
- Jin, X.; Park, Y.; Maddix, D.; Wang, H.; Wang, Y. Domain adaptation for time series forecasting via attention sharing. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 10280–10297. [Google Scholar]
- Bernstein, A.S.; Sun, S.; Weinberger, K.R.; Spangler, K.R.; Sheffield, P.E.; Wellenius, G.A. Warm season and emergency department visits to US Children’s Hospitals. Environ. Health Perspect. 2022, 130, 017001. [Google Scholar] [CrossRef] [PubMed]
- Nakamura, S.; Kusaka, H.; Sato, R.; Sato, T. Heatstroke risk projection in Japan under current and near future climates. J. Meteorol. Soc. Japan Ser. II 2022, 100, 597–615. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Huang, J.; Gretton, A.; Borgwardt, K.; Schölkopf, B.; Smola, A. Correcting sample selection bias by unlabeled data. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–9 December 2006; Volume 19. [Google Scholar]
- Iqbal, M. An Introduction to Solar Radiation; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Shumway, R.H.; Stoffer, D.S.; Shumway, R.H.; Stoffer, D.S. ARIMA models. In Time Series Analysis and Its Applications: With R Examples; Springer: Berlin/Heidelberg, Germany, 2017; pp. 75–163. [Google Scholar]
- Conover, W.J. Practical Nonparametric Statistics; John Wiley & Sons: Hoboken, NJ, USA, 1999; Volume 350. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 international conference on engineering and technology (ICET), Antalya, Turkey, 21–23 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; Volume 34, pp. 22419–22430. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tokyo | Osaka | Kyushu | |
|---|---|---|---|
| No. of data instances | 14,869 | 11,678 | 20,095 |
| No. of stations | 75 | 59 | 102 |
| Longitude | 138.4–140.9 | 134.3–136.4 | 128.7–132.0 |
| Latitude | 34.9–37.2 | 33.4–35.8 | 27.4–34.7 |
| Elevation (m) | 2–1292 | 2–795 | 2–678 |
| Average maximum temperature (°C) | 19.2 | 19.9 | 21.5 |
| Median maximum temperature (°C) | 19.5 | 20.5 | 22.2 |
| Evaluation Metric: MSE | ||||
|---|---|---|---|---|
| Sample 250 | Sample 250 | Single Station | Single Station | |
| System | Tokyo–Osaka | Tokyo–Kyushu | Tokyo–Osaka | Tokyo–Kyushu |
| ARIMA | - | - | 10.51 | 9.13 |
| AttF | 10.02 | 10.10 | 9.92 | 9.75 |
| DAF | 10.43 | 10.28 | 10.49 | 10.32 |
| Ours, = 1 (VT) | 8.66 | 8.58 | 8.40 | 8.58 |
| Ours, = 0.5 | 8.46 | 8.28 | 8.16 | 8.16 |
| Ours, = 0 | 8.22 | 8.36 | 8.22 | 8.15 |
| Ours, = 0.5 & KMM | 8.38 | 8.37 | 8.14 | 8.16 |
| Ours, = 0 & KMM | 8.15 | 8.11 | 8.19 | 7.87 |
| Evaluation Metric: MAE | ||||
| Sample 250 | Sample 250 | Single Station | Single Station | |
| System | Tokyo–Osaka | Tokyo–Kyushu | Tokyo–Osaka | Tokyo–Kyushu |
| ARIMA | - | - | 2.66 | 2.41 |
| AttF | 2.52 | 2.44 | 2.49 | 2.42 |
| DAF | 2.60 | 2.51 | 2.61 | 2.54 |
| Ours, = 1 (VT) | 2.42 | 2.32 | 2.37 | 2.33 |
| Ours, = 0.5 | 2.34 | 2.29 | 2.33 | 2.26 |
| Ours, = 0 | 2.33 | 2.30 | 2.34 | 2.25 |
| Ours, = 0.5 & KMM | 2.35 | 2.29 | 2.31 | 2.28 |
| Ours, = 0 & KMM | 2.35 | 2.23 | 2.33 | 2.22 |
| Evaluation Metric: MSE | ||||
|---|---|---|---|---|
| Sample 250 | Sample 250 | Single Station | Single Station | |
| System | Tokyo–Osaka | Tokyo–Kyushu | Tokyo–Osaka | Tokyo–Kyushu |
| 32 | 8.25 | 7.85 | 8.18 | 7.67 |
| 64 | 7.79 | 8.00 | 8.09 | 7.82 |
| 128 | 8.40 | 8.49 | 8.29 | 8.12 |
| Evaluation Metric: MAE | ||||
| Sample 250 | Sample 250 | Single Station | Single Station | |
| System | Tokyo–Osaka | Tokyo–Kyushu | Tokyo–Osaka | Tokyo–Kyushu |
| 32 | 2.36 | 2.20 | 2.31 | 2.21 |
| 64 | 2.34 | 2.20 | 2.31 | 2.23 |
| 128 | 2.36 | 2.28 | 2.35 | 2.24 |
| Sample 250 | Sample 250 | Single Station | Single Station | |
|---|---|---|---|---|
| System | Tokyo–Osaka | Tokyo–Kyushu | Tokyo–Osaka | Tokyo–Kyushu |
| Ours, = 0 & KMM | 8.15 | 8.11 | 8.19 | 7.87 |
| Ours, = 0 & KMM, modified | 9.66 | 7.94 | 9.75 | 8.42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, V.; Septier, F.; Murakami, D.; Matsui, T. Spatial–Temporal Temperature Forecasting Using Deep-Neural-Network-Based Domain Adaptation. Atmosphere 2024, 15, 90. https://doi.org/10.3390/atmos15010090
Tran V, Septier F, Murakami D, Matsui T. Spatial–Temporal Temperature Forecasting Using Deep-Neural-Network-Based Domain Adaptation. Atmosphere. 2024; 15(1):90. https://doi.org/10.3390/atmos15010090
Chicago/Turabian StyleTran, Vu, François Septier, Daisuke Murakami, and Tomoko Matsui. 2024. "Spatial–Temporal Temperature Forecasting Using Deep-Neural-Network-Based Domain Adaptation" Atmosphere 15, no. 1: 90. https://doi.org/10.3390/atmos15010090
APA StyleTran, V., Septier, F., Murakami, D., & Matsui, T. (2024). Spatial–Temporal Temperature Forecasting Using Deep-Neural-Network-Based Domain Adaptation. Atmosphere, 15(1), 90. https://doi.org/10.3390/atmos15010090