


Multi-Scale Reconstruction of Turbulent Rotating Flows with Generative Diffusion Models

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
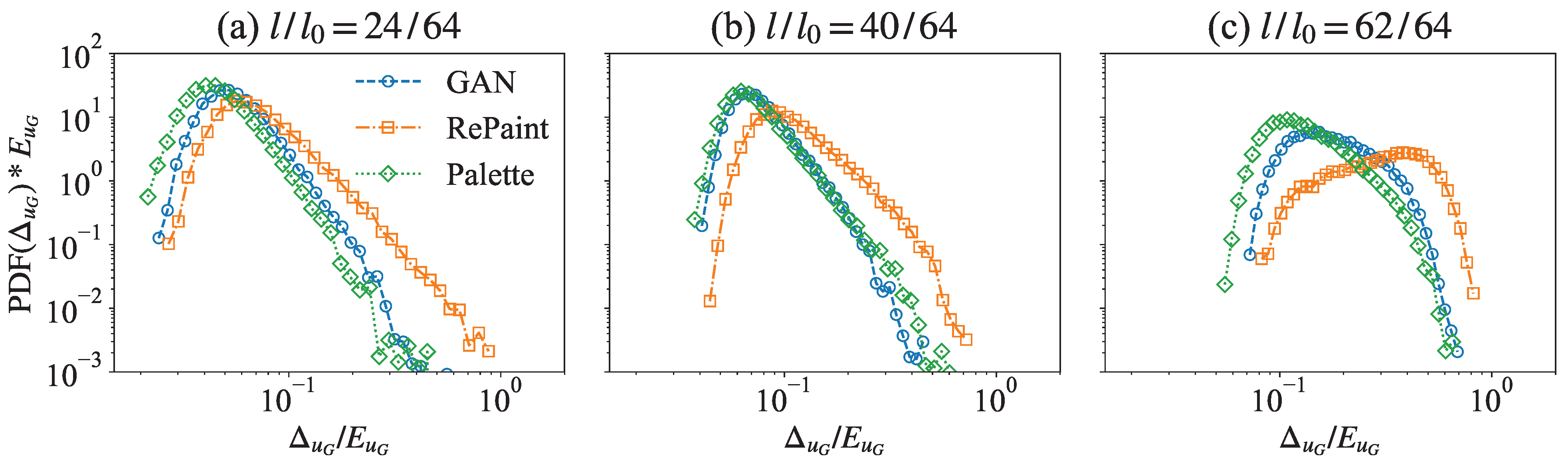{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methods
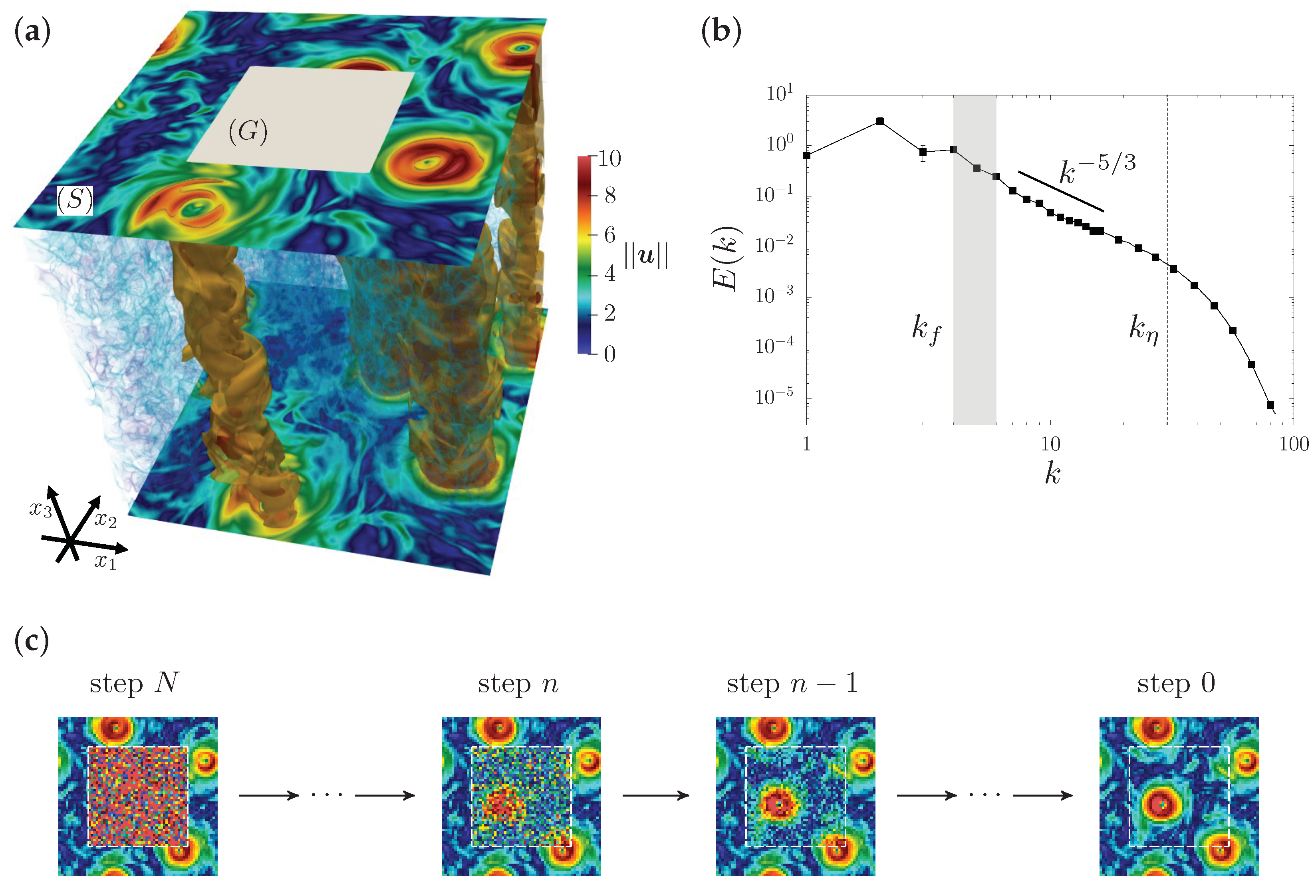
2.1. Problem Setup and Data Preparation
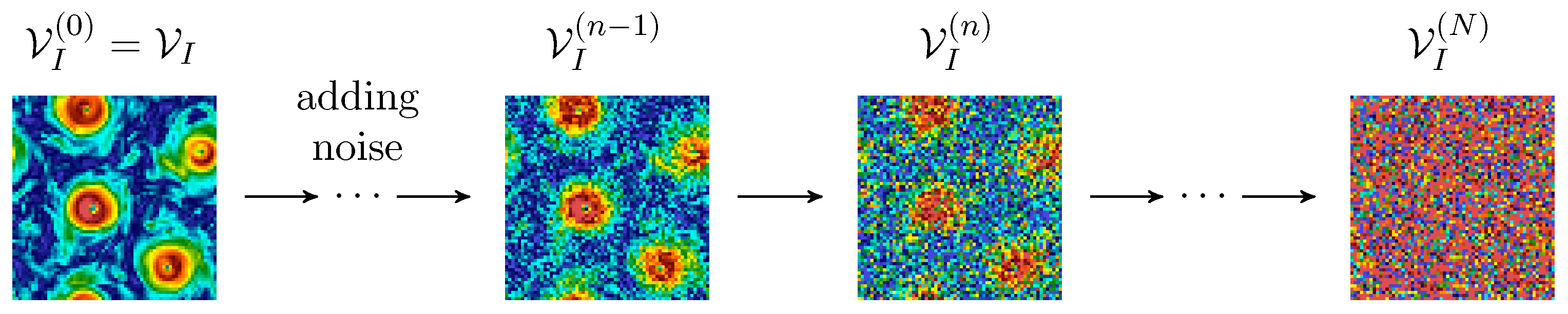
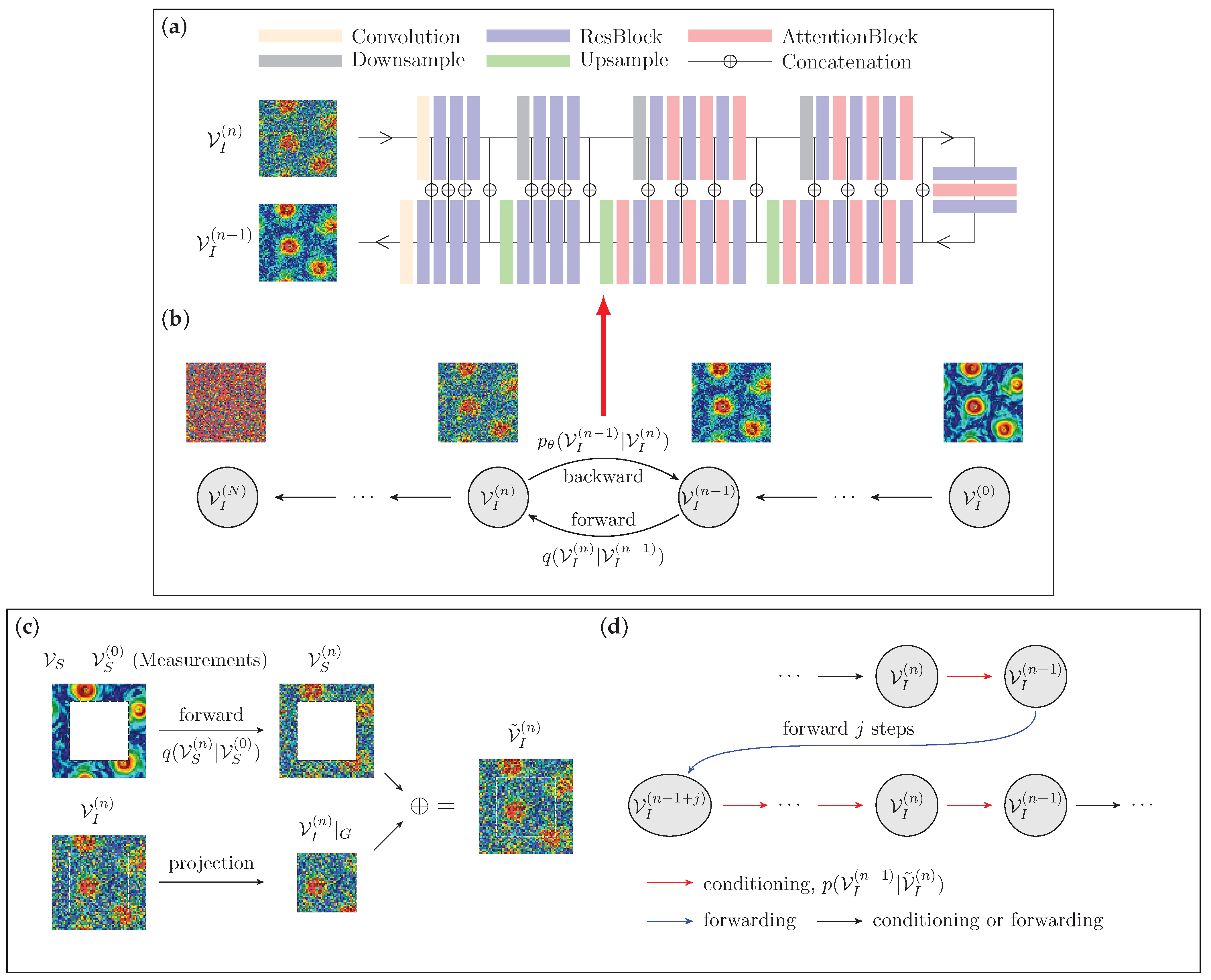
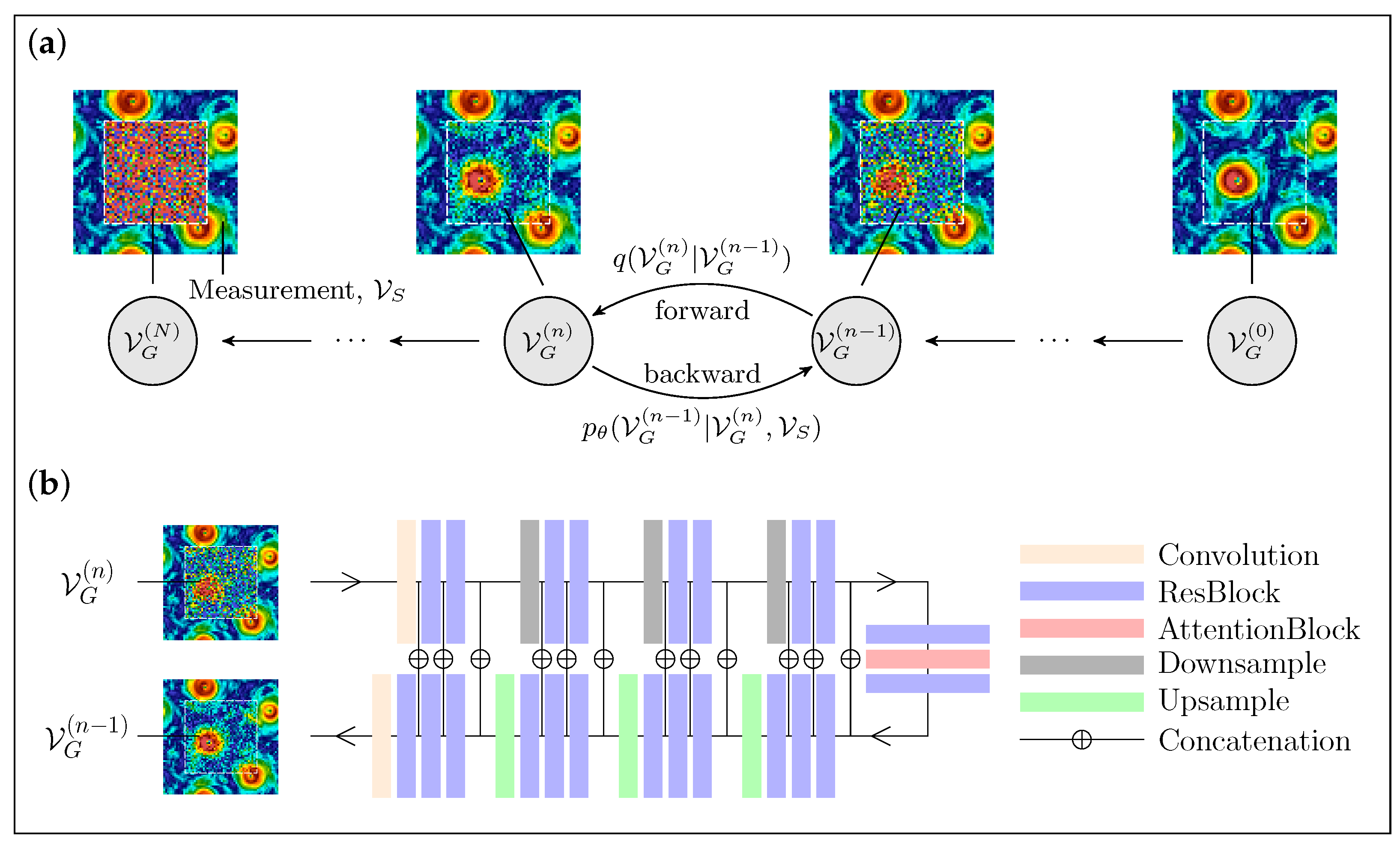
2.2. DM Framework for Flow Field Generation
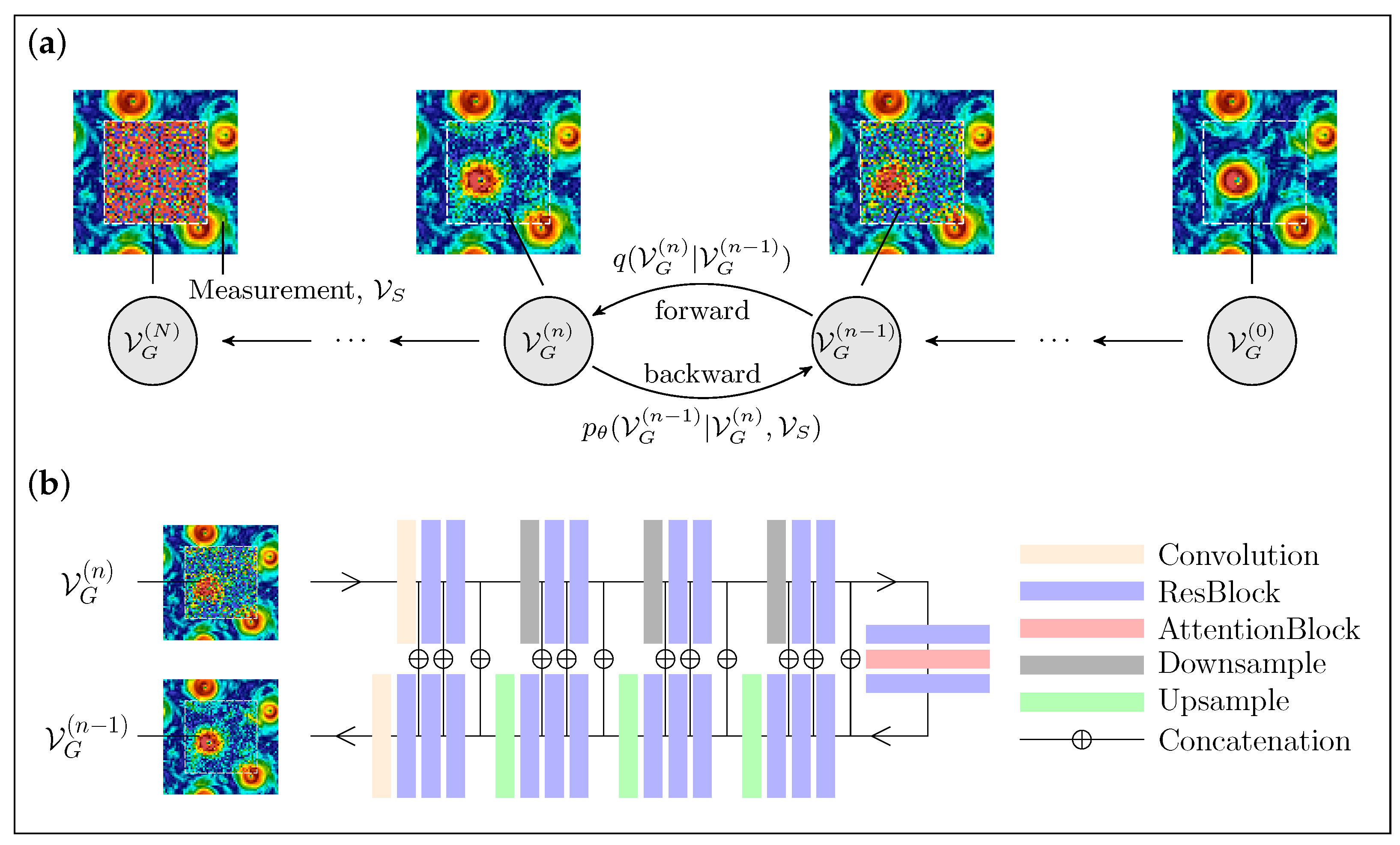
2.3. Flow Field Data Augmentation with DMs: RePaint and Palette Strategies
3. Comparative Analysis of DMs and the GAN in Flow Reconstruction
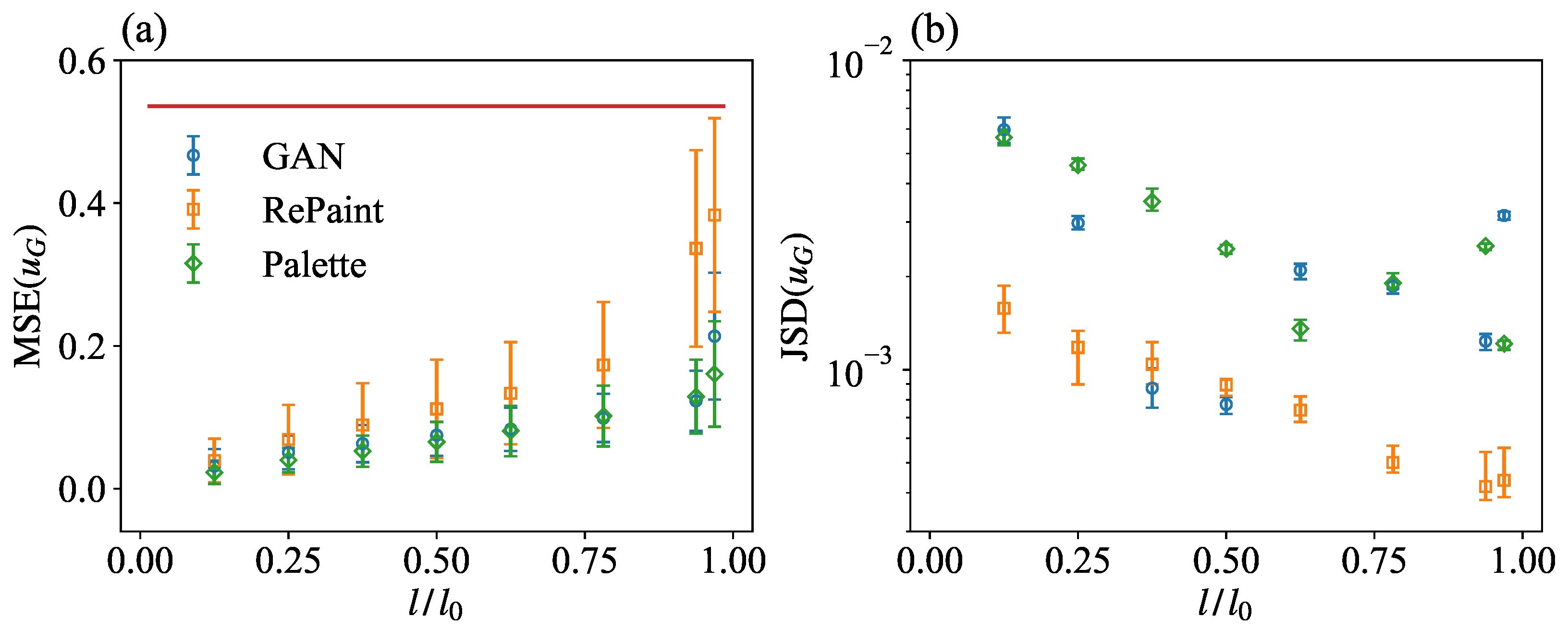
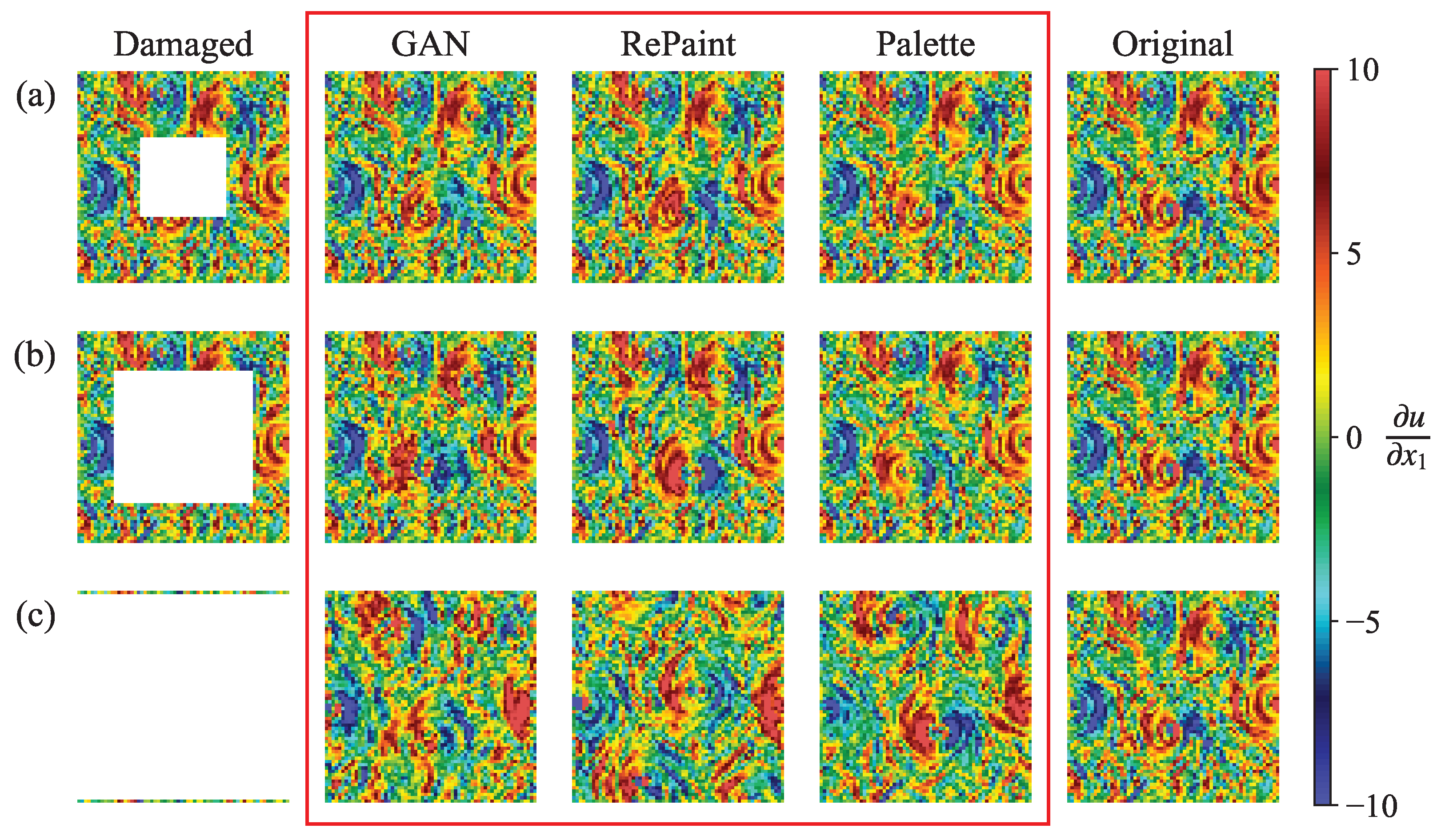
3.1. Large-Scale Information
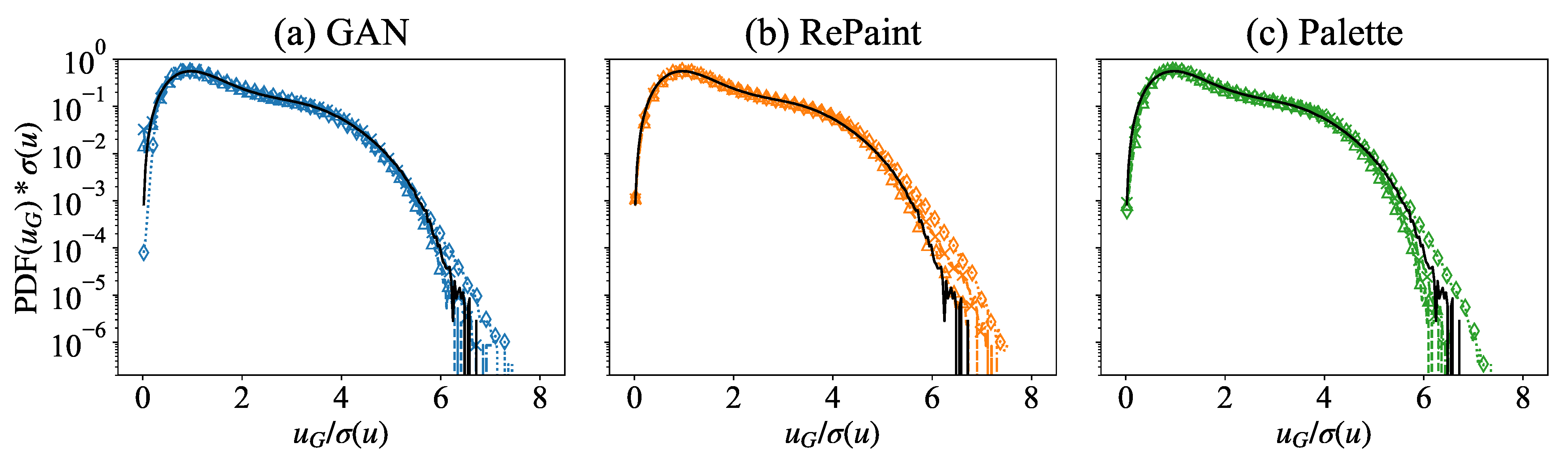
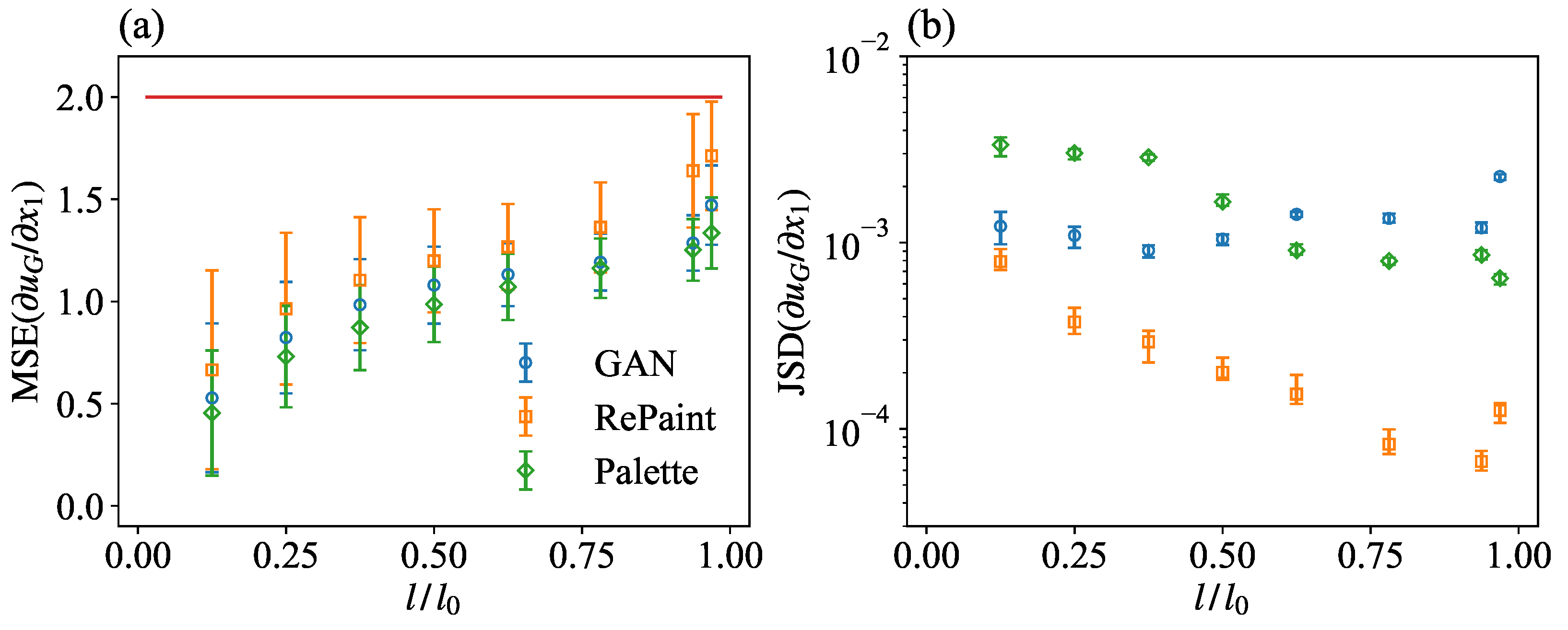
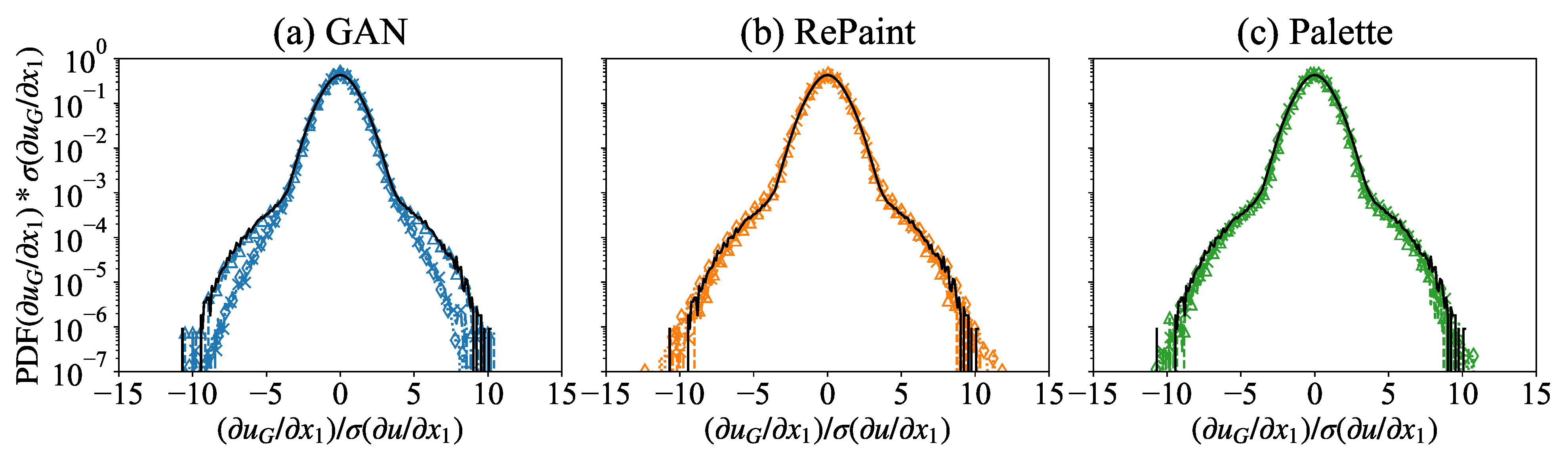
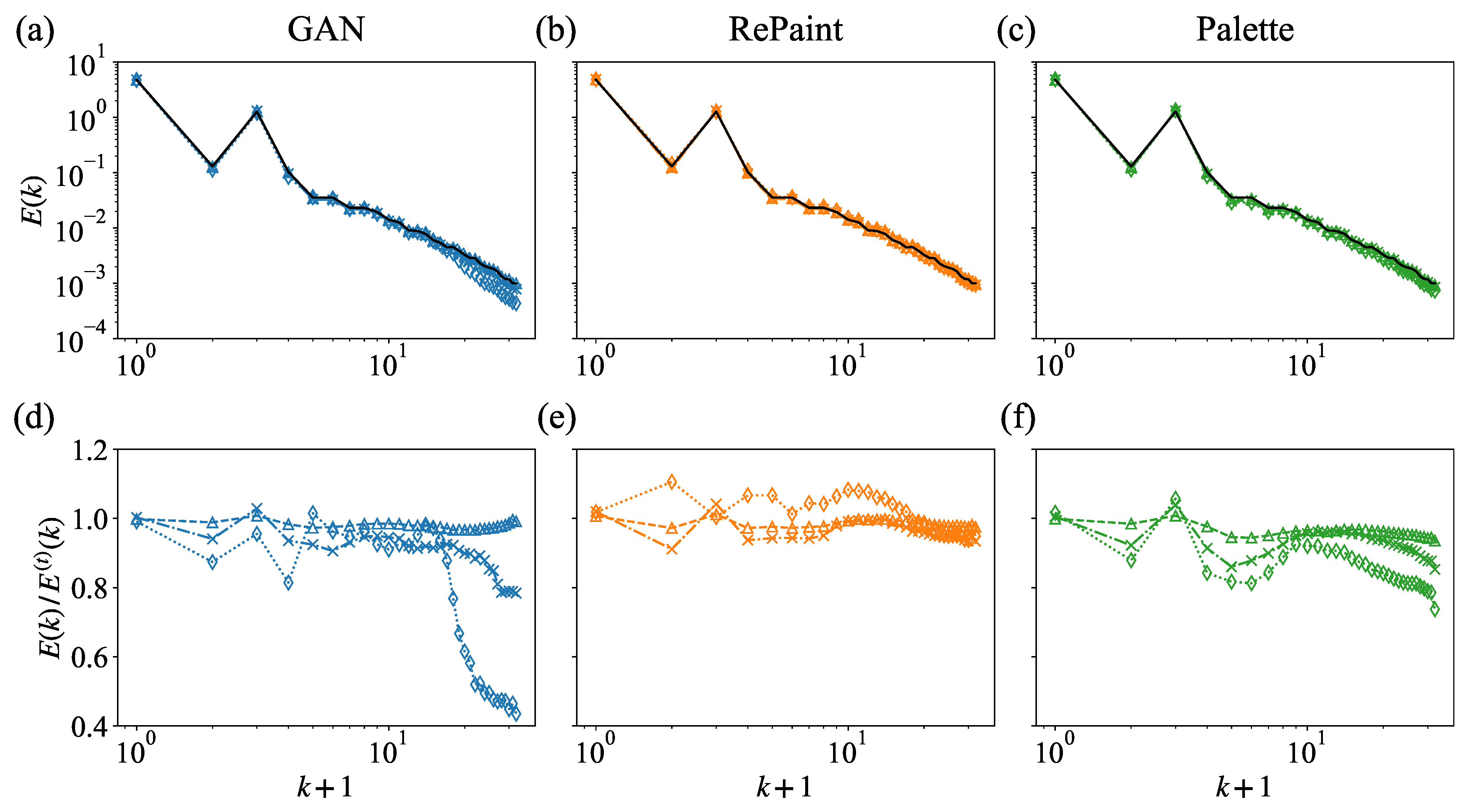
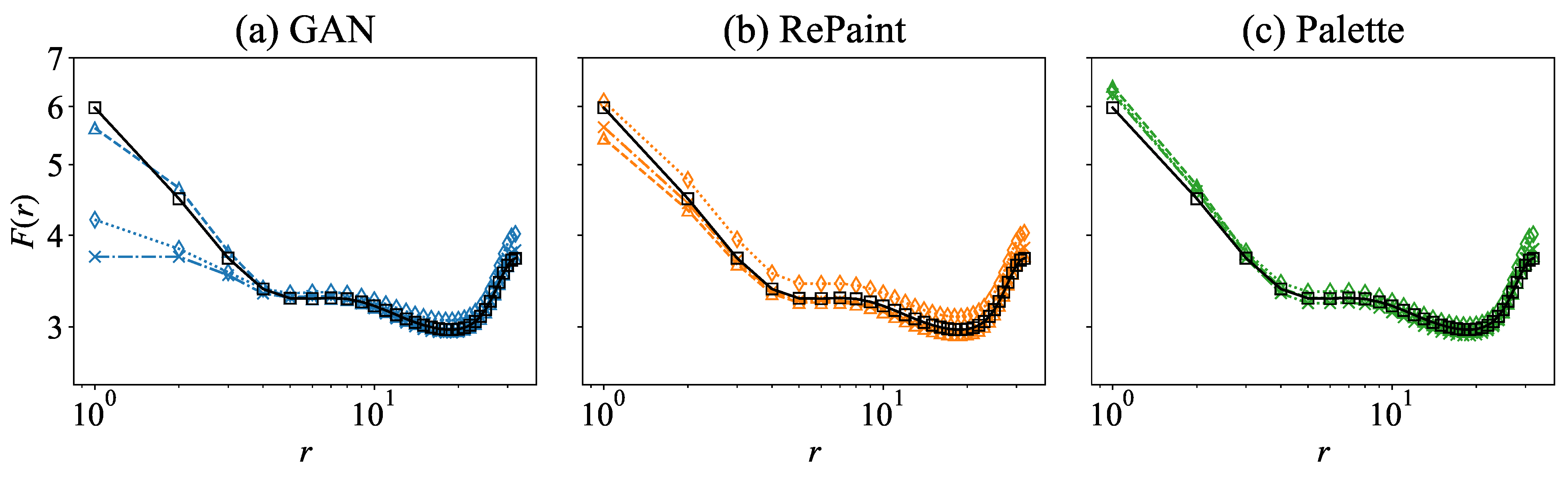
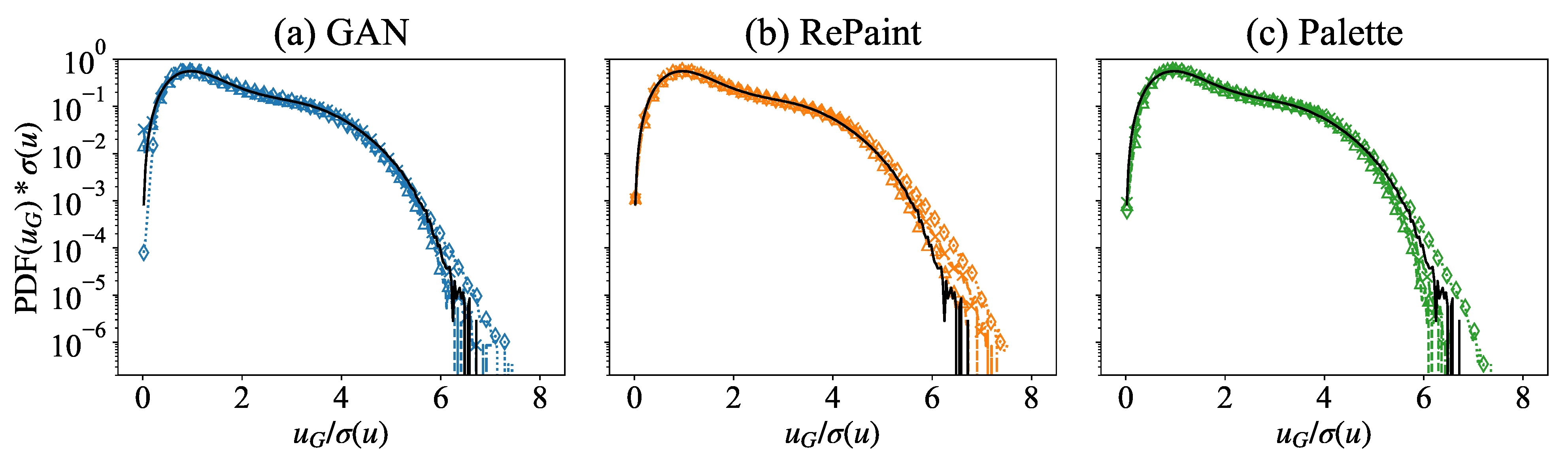
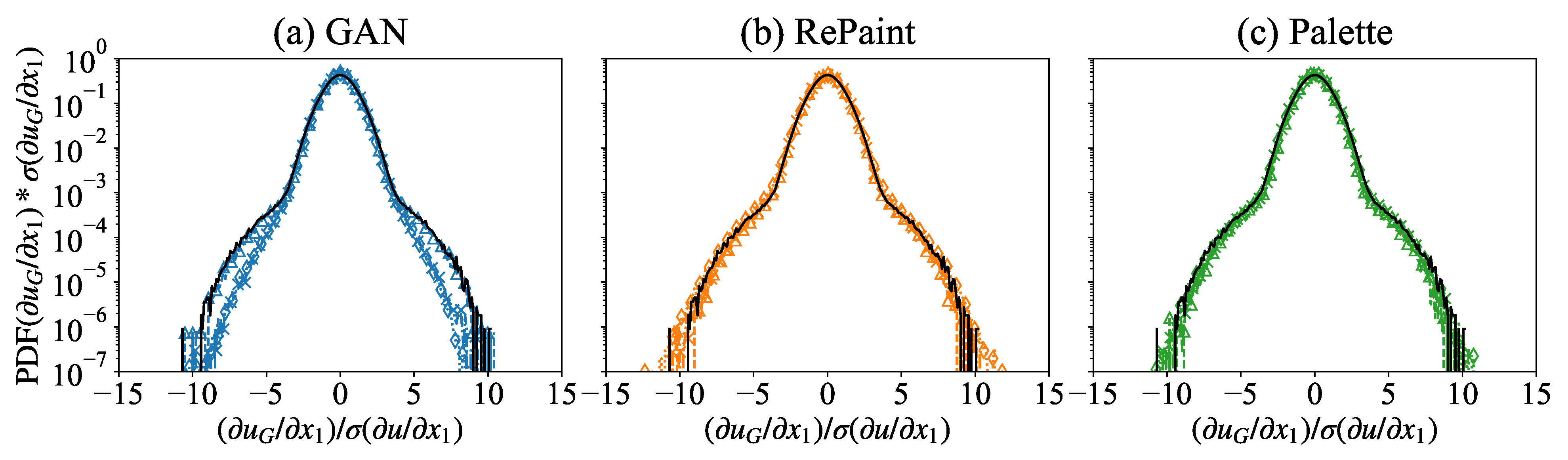
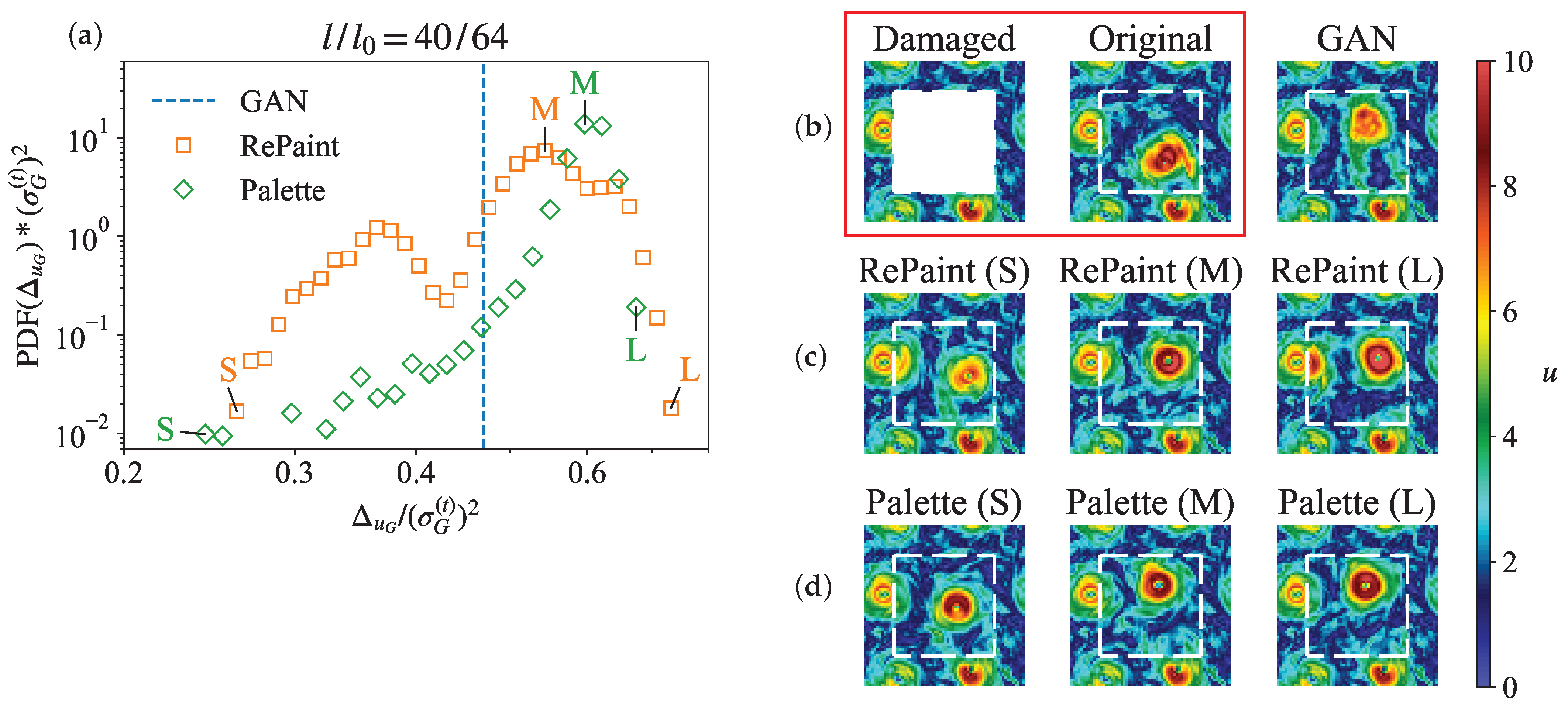
3.2. Multi-Scale Information
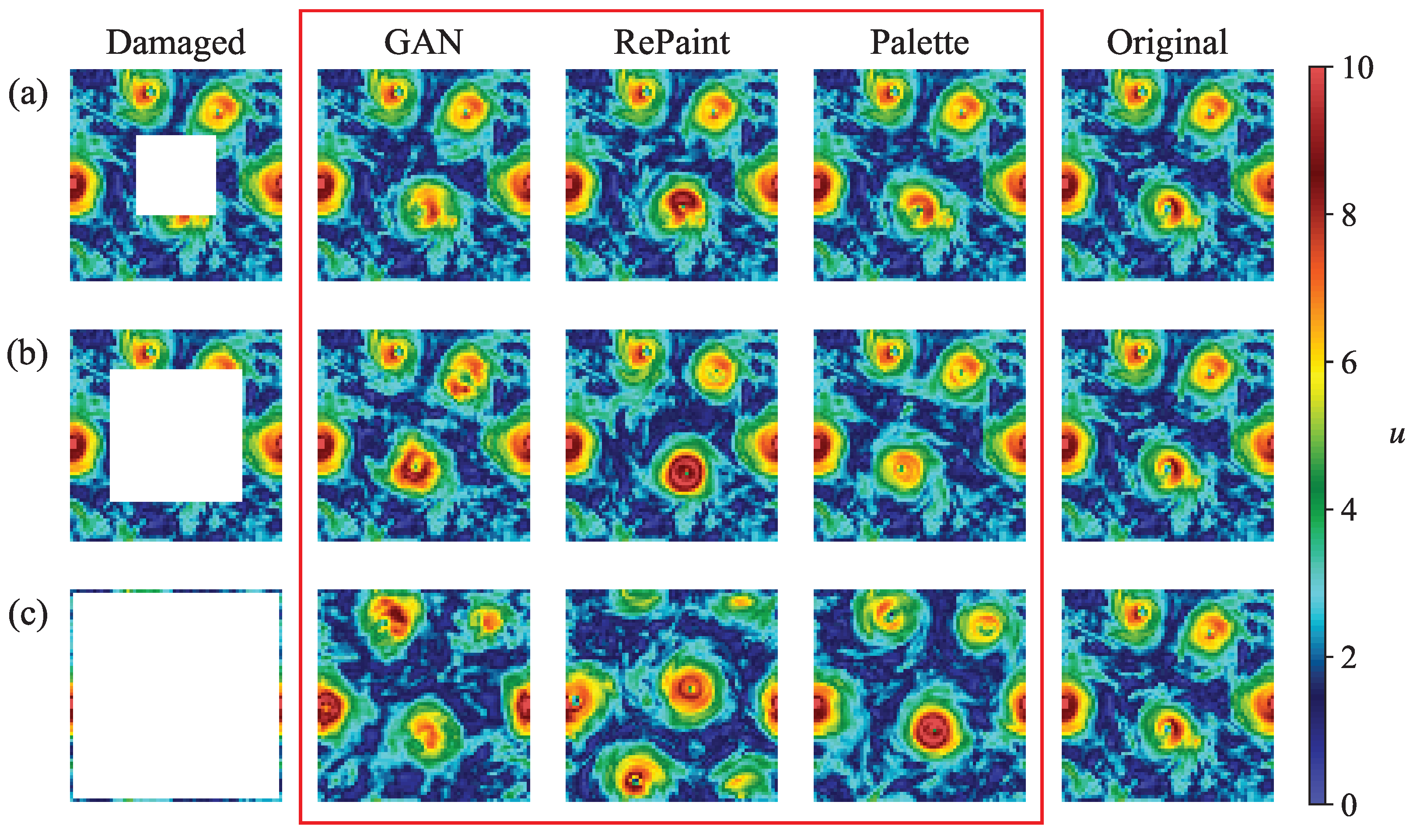
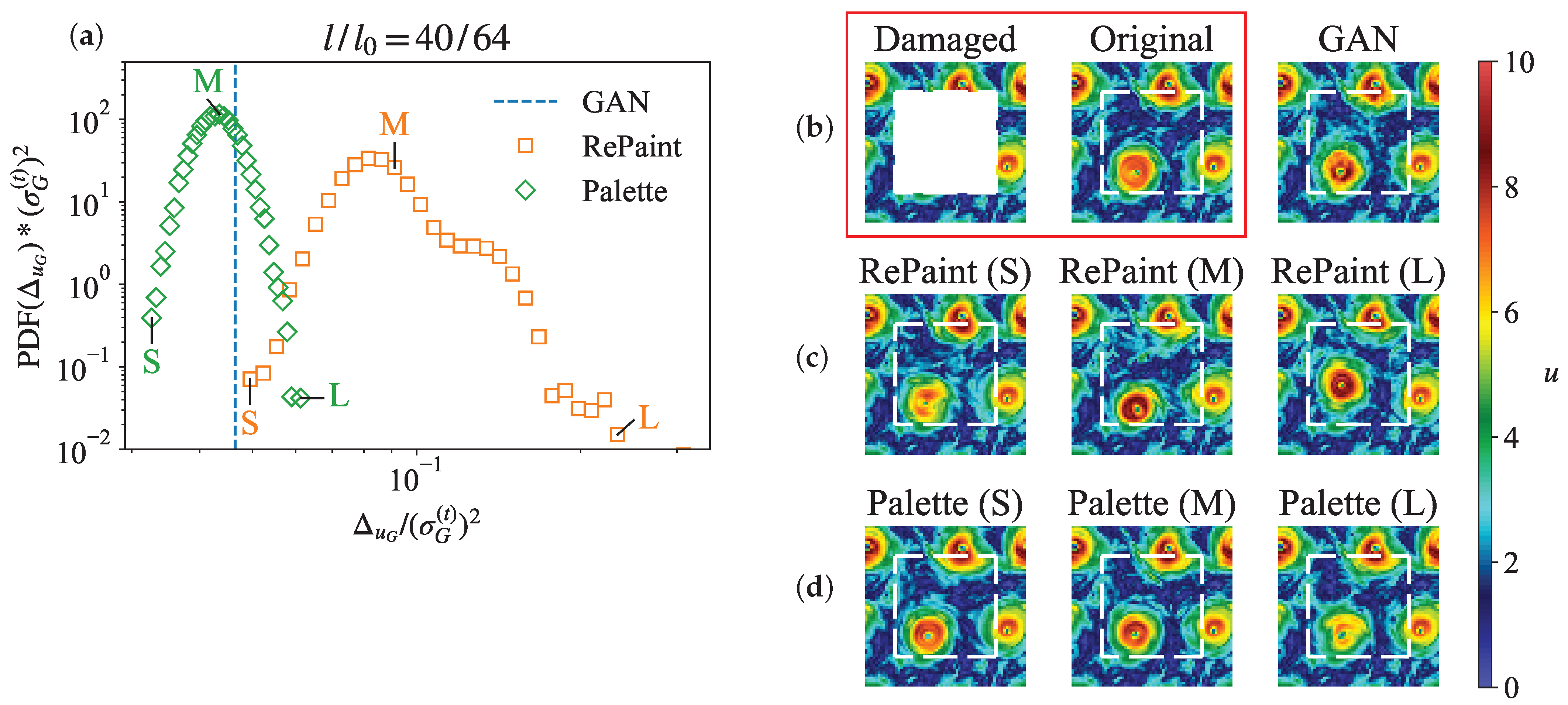
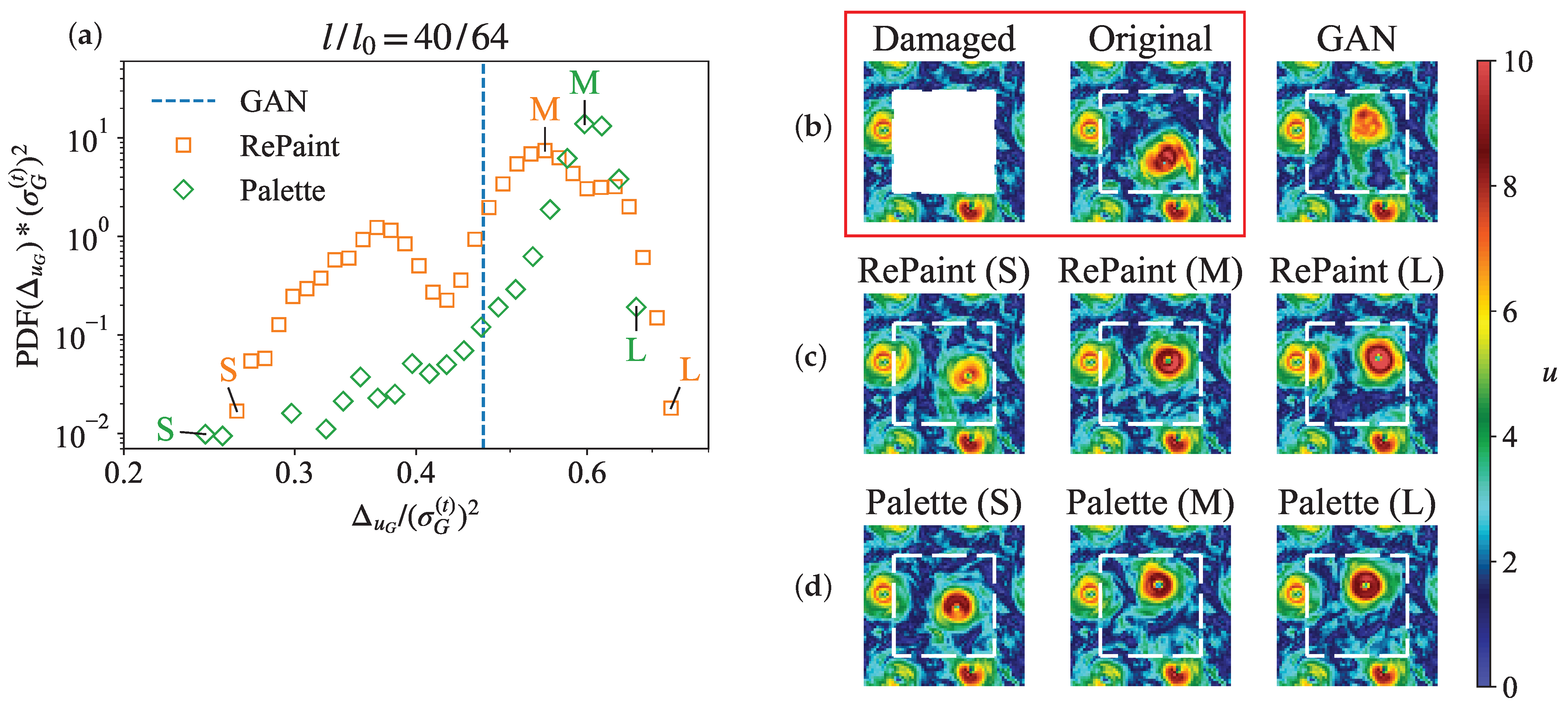
4. Probabilistic Reconstructions with DMs
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 2D | Two-dimensional |
| DM | Diffusion model |
| GAN | Generative adversarial network |
| POD | Proper orthogonal decomposition |
| Probability density function | |
| 3D | Three-dimensional |
| DNS | Direct numerical simulation |
| MSE | Mean squared error |
| JS | Jensen–Shannon |
| KL | Kullback–Leibler |
Appendix A. Training Objective of DM for Flow Field Generation
Appendix B. Implementation Details of DMs for Flow Field Reconstruction
References
- Le Dimet, F.X.; Talagrand, O. Variational algorithms for analysis and assimilation of meteorological observations: Theoretical aspects. Tellus A Dyn. Meteorol. Oceanogr. 1986, 38, 97–110. [Google Scholar] [CrossRef]
- BEll, M.J.; Lefèbvre, M.; Le Traon, P.Y.; Smith, N.; Wilmer-Becker, K. GODAE: The global ocean data assimilation experiment. Oceanography 2009, 22, 14–21. [Google Scholar] [CrossRef]
- Edwards, C.A.; Moore, A.M.; Hoteit, I.; Cornuelle, B.D. Regional ocean data assimilation. Annu. Rev. Mar. Sci. 2015, 7, 21–42. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Zaki, T.A. State estimation in turbulent channel flow from limited observations. J. Fluid Mech. 2021, 917, A9. [Google Scholar] [CrossRef]
- Storer, B.A.; Buzzicotti, M.; Khatri, H.; Griffies, S.M.; Aluie, H. Global energy spectrum of the general oceanic circulation. Nat. Commun. 2022, 13, 5314. [Google Scholar] [CrossRef] [PubMed]
- Shen, H.; Li, X.; Cheng, Q.; Zeng, C.; Yang, G.; Li, H.; Zhang, L. Missing information reconstruction of remote sensing data: A technical review. IEEE Geosci. Remote Sens. Mag. 2015, 3, 61–85. [Google Scholar] [CrossRef]
- Zhang, Q.; Yuan, Q.; Zeng, C.; Li, X.; Wei, Y. Missing data reconstruction in remote sensing image with a unified spatial–temporal–spectral deep convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4274–4288. [Google Scholar] [CrossRef]
- Merchant, C.J.; Embury, O.; Bulgin, C.E.; Block, T.; Corlett, G.K.; Fiedler, E.; Good, S.A.; Mittaz, J.; Rayner, N.A.; Berry, D.; et al. Satellite-based time-series of sea-surface temperature since 1981 for climate applications. Sci. Data 2019, 6, 223. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, X.; Ao, Z.; Xiao, K.; Yan, C.; Xin, Q. Gap-Filling and Missing Information Recovery for Time Series of MODIS Data Using Deep Learning-Based Methods. Remote Sens. 2022, 14, 4692. [Google Scholar] [CrossRef]
- Sammartino, M.; Buongiorno Nardelli, B.; Marullo, S.; Santoleri, R. An Artificial Neural Network to Infer the Mediterranean 3D Chlorophyll-a and Temperature Fields from Remote Sensing Observations. Remote Sens. 2020, 12, 4123. [Google Scholar] [CrossRef]
- Courtier, P.; Thépaut, J.N.; Hollingsworth, A. A strategy for operational implementation of 4D-Var, using an incremental approach. Q. J. R. Meteorol. Soc. 1994, 120, 1367–1387. [Google Scholar]
- Yuan, Z.; Wang, Y.; Wang, X.; Wang, J. Adjoint-based variational optimal mixed models for large-eddy simulation of turbulence. arXiv 2023, arXiv:2301.08423. [Google Scholar]
- Houtekamer, P.L.; Mitchell, H.L. A sequential ensemble Kalman filter for atmospheric data assimilation. Mon. Weather Rev. 2001, 129, 123–137. [Google Scholar] [CrossRef]
- Mons, V.; Du, Y.; Zaki, T.A. Ensemble-variational assimilation of statistical data in large-eddy simulation. Phys. Rev. Fluids 2021, 6, 104607. [Google Scholar] [CrossRef]
- Everson, R.; Sirovich, L. Karhunen–Loeve procedure for gappy data. JOSA A 1995, 12, 1657–1664. [Google Scholar] [CrossRef]
- Borée, J. Extended proper orthogonal decomposition: A tool to analyse correlated events in turbulent flows. Exp. Fluids 2003, 35, 188–192. [Google Scholar] [CrossRef]
- Venturi, D.; Karniadakis, G.E. Gappy data and reconstruction procedures for flow past a cylinder. J. Fluid Mech. 2004, 519, 315–336. [Google Scholar] [CrossRef]
- Tinney, C.; Ukeiley, L.; Glauser, M.N. Low-dimensional characteristics of a transonic jet. Part 2. Estimate and far-field prediction. J. Fluid Mech. 2008, 615, 53–92. [Google Scholar] [CrossRef]
- Discetti, S.; Bellani, G.; Örlü, R.; Serpieri, J.; Vila, C.S.; Raiola, M.; Zheng, X.; Mascotelli, L.; Talamelli, A.; Ianiro, A. Characterization of very-large-scale motions in high-Re pipe flows. Exp. Therm. Fluid Sci. 2019, 104, 1–8. [Google Scholar] [CrossRef]
- Yildirim, B.; Chryssostomidis, C.; Karniadakis, G. Efficient sensor placement for ocean measurements using low-dimensional concepts. Ocean Model. 2009, 27, 160–173. [Google Scholar] [CrossRef]
- Güemes, A.; Sanmiguel Vila, C.; Discetti, S. Super-resolution generative adversarial networks of randomly-seeded fields. Nat. Mach. Intell. 2022, 4, 1165–1173. [Google Scholar] [CrossRef]
- Li, T.; Buzzicotti, M.; Biferale, L.; Bonaccorso, F. Generative adversarial networks to infer velocity components in rotating turbulent flows. Eur. Phys. J. E 2023, 46, 31. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Buzzicotti, M.; Biferale, L.; Bonaccorso, F.; Chen, S.; Wan, M. Multi-scale reconstruction of turbulent rotating flows with proper orthogonal decomposition and generative adversarial networks. J. Fluid Mech. 2023, 971, A3. [Google Scholar] [CrossRef]
- Buzzicotti, M. Data reconstruction for complex flows using AI: Recent progress, obstacles, and perspectives. Europhys. Lett. 2023, 142, 23001. [Google Scholar] [CrossRef]
- Fukami, K.; Fukagata, K.; Taira, K. Super-resolution reconstruction of turbulent flows with machine learning. J. Fluid Mech. 2019, 870, 106–120. [Google Scholar] [CrossRef]
- Liu, B.; Tang, J.; Huang, H.; Lu, X.Y. Deep learning methods for super-resolution reconstruction of turbulent flows. Phys. Fluids 2020, 32, 025105. [Google Scholar] [CrossRef]
- Kim, H.; Kim, J.; Won, S.; Lee, C. Unsupervised deep learning for super-resolution reconstruction of turbulence. J. Fluid Mech. 2021, 910, A29. [Google Scholar] [CrossRef]
- Buzzicotti, M.; Bonaccorso, F.; Di Leoni, P.C.; Biferale, L. Reconstruction of turbulent data with deep generative models for semantic inpainting from TURB-Rot database. Phys. Rev. Fluids 2021, 6, 050503. [Google Scholar] [CrossRef]
- Guastoni, L.; Güemes, A.; Ianiro, A.; Discetti, S.; Schlatter, P.; Azizpour, H.; Vinuesa, R. Convolutional-network models to predict wall-bounded turbulence from wall quantities. J. Fluid Mech. 2021, 928, A27. [Google Scholar] [CrossRef]
- Matsuo, M.; Nakamura, T.; Morimoto, M.; Fukami, K.; Fukagata, K. Supervised convolutional network for three-dimensional fluid data reconstruction from sectional flow fields with adaptive super-resolution assistance. arXiv 2021, arXiv:2103.09020. [Google Scholar]
- Yousif, M.Z.; Yu, L.; Hoyas, S.; Vinuesa, R.; Lim, H. A deep-learning approach for reconstructing 3D turbulent flows from 2D observation data. Sci. Rep. 2023, 13, 2529. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Smith, R.C. Uncertainty Quantification: Theory, Implementation, and Applications; Siam: Philadelphia, PA, USA, 2013; Volume 12. [Google Scholar]
- Hatanaka, Y.; Glaser, Y.; Galgon, G.; Torri, G.; Sadowski, P. Diffusion Models for High-Resolution Solar Forecasts. arXiv 2023, arXiv:2302.00170. [Google Scholar]
- Asahi, Y.; Hasegawa, Y.; Onodera, N.; Shimokawabe, T.; Shiba, H.; Idomura, Y. Generating observation guided ensembles for data assimilation with denoising diffusion probabilistic model. arXiv 2023, arXiv:2308.06708. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Nichol, A.Q.; Dhariwal, P. Improved denoising diffusion probabilistic models. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8162–8171. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Chen, N.; Zhang, Y.; Zen, H.; Weiss, R.J.; Norouzi, M.; Chan, W. Wavegrad: Estimating gradients for waveform generation. arXiv 2020, arXiv:2009.00713. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Shu, D.; Li, Z.; Farimani, A.B. A physics-informed diffusion model for high-fidelity flow field reconstruction. J. Comput. Phys. 2023, 478, 111972. [Google Scholar] [CrossRef]
- Yang, G.; Sommer, S. A Denoising Diffusion Model for Fluid Field Prediction. arXiv 2023, arXiv:2301.11661. [Google Scholar]
- Li, T.; Biferale, L.; Bonaccorso, F.; Scarpolini, M.A.; Buzzicotti, M. Synthetic lagrangian turbulence by generative diffusion models. arXiv 2023, arXiv:2307.08529. [Google Scholar]
- Pouquet, A.; Sen, A.; Rosenberg, D.; Mininni, P.D.; Baerenzung, J. Inverse cascades in turbulence and the case of rotating flows. Phys. Scr. 2013, 2013, 014032. [Google Scholar] [CrossRef]
- Oks, D.; Mininni, P.D.; Marino, R.; Pouquet, A. Inverse cascades and resonant triads in rotating and stratified turbulence. Phys. Fluids 2017, 29, 111109. [Google Scholar] [CrossRef]
- Alexakis, A.; Biferale, L. Cascades and transitions in turbulent flows. Phys. Rep. 2018, 767, 1–101. [Google Scholar] [CrossRef]
- Buzzicotti, M.; Aluie, H.; Biferale, L.; Linkmann, M. Energy transfer in turbulence under rotation. Phys. Rev. Fluids 2018, 3, 034802. [Google Scholar] [CrossRef]
- Li, T.; Wan, M.; Wang, J.; Chen, S. Flow structures and kinetic-potential exchange in forced rotating stratified turbulence. Phys. Rev. Fluids 2020, 5, 014802. [Google Scholar] [CrossRef]
- Herring, J.R. Statistical theory of quasi-geostrophic turbulence. J. Atmos. Sci. 1980, 37, 969–977. [Google Scholar] [CrossRef]
- Herring, J. The inverse cascade range of quasi-geostrophic turbulence. Meteorol. Atmos. Phys. 1988, 38, 106–115. [Google Scholar] [CrossRef]
- Herring, J.R.; Métais, O. Numerical experiments in forced stably stratified turbulence. J. Fluid Mech. 1989, 202, 97–115. [Google Scholar] [CrossRef]
- Lugmayr, A.; Danelljan, M.; Romero, A.; Yu, F.; Timofte, R.; Van Gool, L. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11461–11471. [Google Scholar]
- Saharia, C.; Ho, J.; Chan, W.; Salimans, T.; Fleet, D.J.; Norouzi, M. Image super-resolution via iterative refinement. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4713–4726. [Google Scholar] [CrossRef]
- Saharia, C.; Chan, W.; Chang, H.; Lee, C.; Ho, J.; Salimans, T.; Fleet, D.; Norouzi, M. Palette: Image-to-image diffusion models. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; pp. 1–10. [Google Scholar]
- Cambon, C.; Mansour, N.N.; Goderferd, F. Energy transfer in rotating turbulence. J. Fluid Mech. 1997, 337, 303–332. [Google Scholar] [CrossRef]
- Goderferd, F.; Moisy, F. Structure and Dynamics of Rotating Turbulence: A Review of Recent Experimental and Numerical Results. Appl. Mech. Rev. 2015, 67, 030802. [Google Scholar] [CrossRef]
- McWilliams, J.C. Fundamentals of Geophysical Fluid Dynamics; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Brandenburg, A.; Svedin, A.; Vasil, G.M. Turbulent diffusion with rotation or magnetic fields. Mon. Not. R. Astron. Soc. 2009, 395, 1599. [Google Scholar] [CrossRef]
- Biferale, L.; Bonaccorso, F.; Buzzicotti, M.; Di Leoni, P.C. TURB-Rot. A large database of 3D and 2D snapshots from turbulent rotating flows. arXiv 2020, arXiv:2006.07469. [Google Scholar]
- Sawford, B. Reynolds number effects in Lagrangian stochastic models of turbulent dispersion. Phys. Fluids A Fluid Dyn. 1991, 3, 1577–1586. [Google Scholar] [CrossRef]
- Buzzicotti, M.; Bhatnagar, A.; Biferale, L.; Lanotte, A.S.; Ray, S.S. Lagrangian statistics for Navier–Stokes turbulence under Fourier-mode reduction: Fractal and homogeneous decimations. New J. Phys. 2016, 18, 113047. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Feller, W. On the theory of stochastic processes, with particular reference to applications. In Selected Papers I; Springer: Berlin/Heidelberg, Germany, 2015; pp. 769–798. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 2256–2265. [Google Scholar]
- Richardson, E.; Alaluf, Y.; Patashnik, O.; Nitzan, Y.; Azar, Y.; Shapiro, S.; Cohen-Or, D. Encoding in style: A stylegan encoder for image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 2287–2296. [Google Scholar]
- Chung, H.; Kim, J.; Mccann, M.T.; Klasky, M.L.; Ye, J.C. Diffusion posterior sampling for general noisy inverse problems. arXiv 2022, arXiv:2209.14687. [Google Scholar]
- Zhang, G.; Ji, J.; Zhang, Y.; Yu, M.; Jaakkola, T.S.; Chang, S. Towards Coherent Image Inpainting Using Denoising Diffusion Implicit Models. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-form image inpainting with gated convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4471–4480. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. arXiv 2020, arXiv:2010.02502. [Google Scholar]
- Salimans, T.; Ho, J. Progressive distillation for fast sampling of diffusion models. arXiv 2022, arXiv:2202.00512. [Google Scholar]
- Stevens, R.J.; Meneveau, C. Flow structure and turbulence in wind farms. Annu. Rev. Fluid Mech. 2017, 49, 311–339. [Google Scholar] [CrossRef]
- Gharaati, M.; Xiao, S.; Wei, N.J.; Martínez-Tossas, L.A.; Dabiri, J.O.; Yang, D. Large-eddy simulation of helical-and straight-bladed vertical-axis wind turbines in boundary layer turbulence. J. Renew. Sustain. Energy 2022, 14, 053301. [Google Scholar] [CrossRef]
- Potisomporn, P.; Vogel, C.R. Spatial and temporal variability characteristics of offshore wind energy in the United Kingdom. Wind Energy 2022, 25, 537–552. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Weng, L. What Are Diffusion Models? 2021. Available online: lilianweng.github.io (accessed on 15 November 2023).
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Lanotte, A.S.; Buzzicotti, M.; Bonaccorso, F.; Biferale, L. Multi-Scale Reconstruction of Turbulent Rotating Flows with Generative Diffusion Models. Atmosphere 2024, 15, 60. https://doi.org/10.3390/atmos15010060
Li T, Lanotte AS, Buzzicotti M, Bonaccorso F, Biferale L. Multi-Scale Reconstruction of Turbulent Rotating Flows with Generative Diffusion Models. Atmosphere. 2024; 15(1):60. https://doi.org/10.3390/atmos15010060
Chicago/Turabian StyleLi, Tianyi, Alessandra S. Lanotte, Michele Buzzicotti, Fabio Bonaccorso, and Luca Biferale. 2024. "Multi-Scale Reconstruction of Turbulent Rotating Flows with Generative Diffusion Models" Atmosphere 15, no. 1: 60. https://doi.org/10.3390/atmos15010060
APA StyleLi, T., Lanotte, A. S., Buzzicotti, M., Bonaccorso, F., & Biferale, L. (2024). Multi-Scale Reconstruction of Turbulent Rotating Flows with Generative Diffusion Models. Atmosphere, 15(1), 60. https://doi.org/10.3390/atmos15010060