MSLKNet: A Multi-Scale Large Kernel Convolutional Network for Radar Extrapolation

 ,
, 
Abstract
:1. Introduction
- We reconsider the convolutional attention structure and design the multi-scale large kernel (MSLK) convolution module to acquire a multi-scale radar echo background from local to global.
- We propose a new CNN-based radar extrapolation architecture to reduce extrapolation accumulated errors by building a MIMO-based model. Moreover, an information recalling scheme is applied to further preserve the visual details of the predictions.
- Comprehensive experiments are conducted on two real dual-polarization radar echo datasets.
2. Related Work
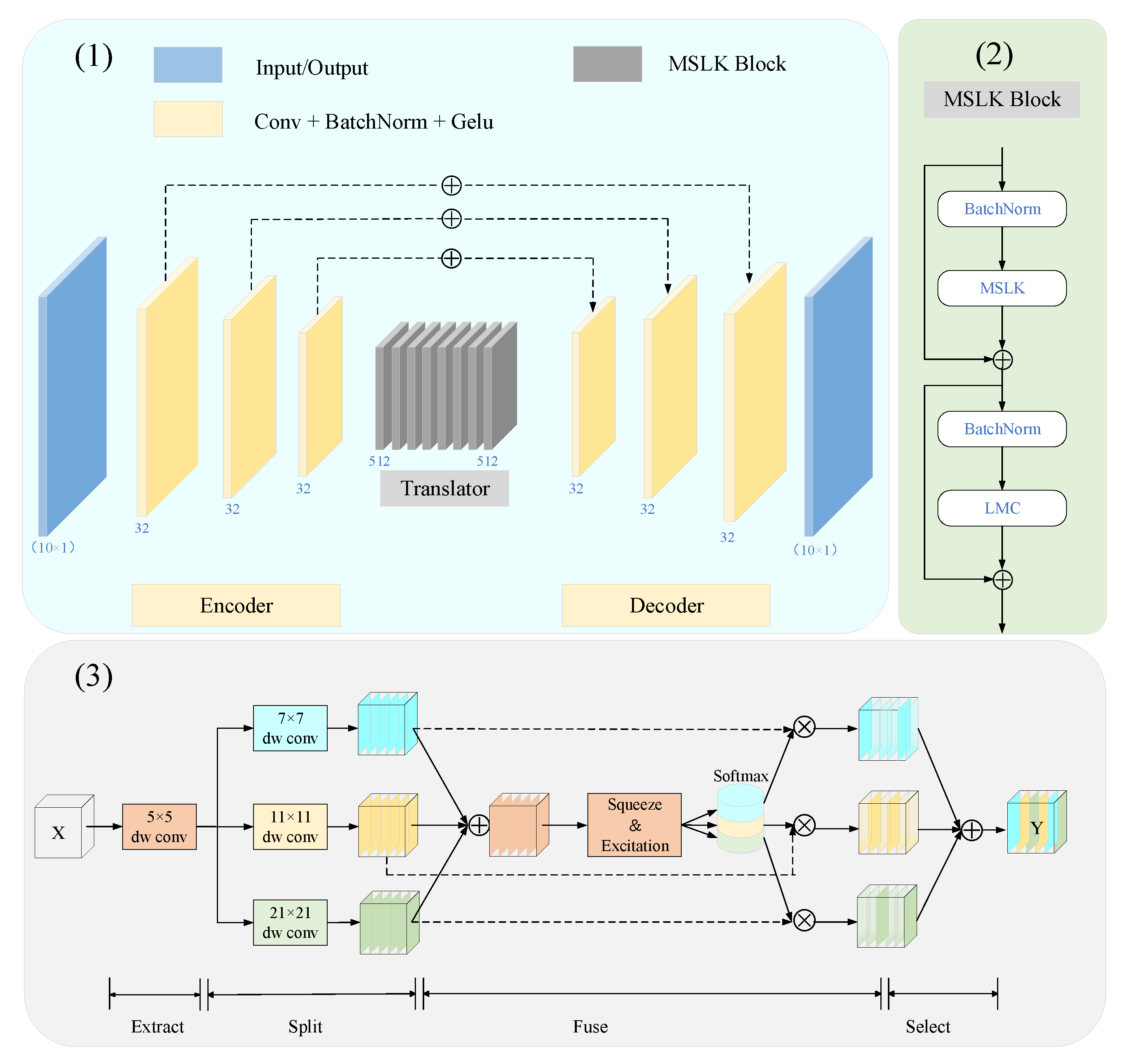
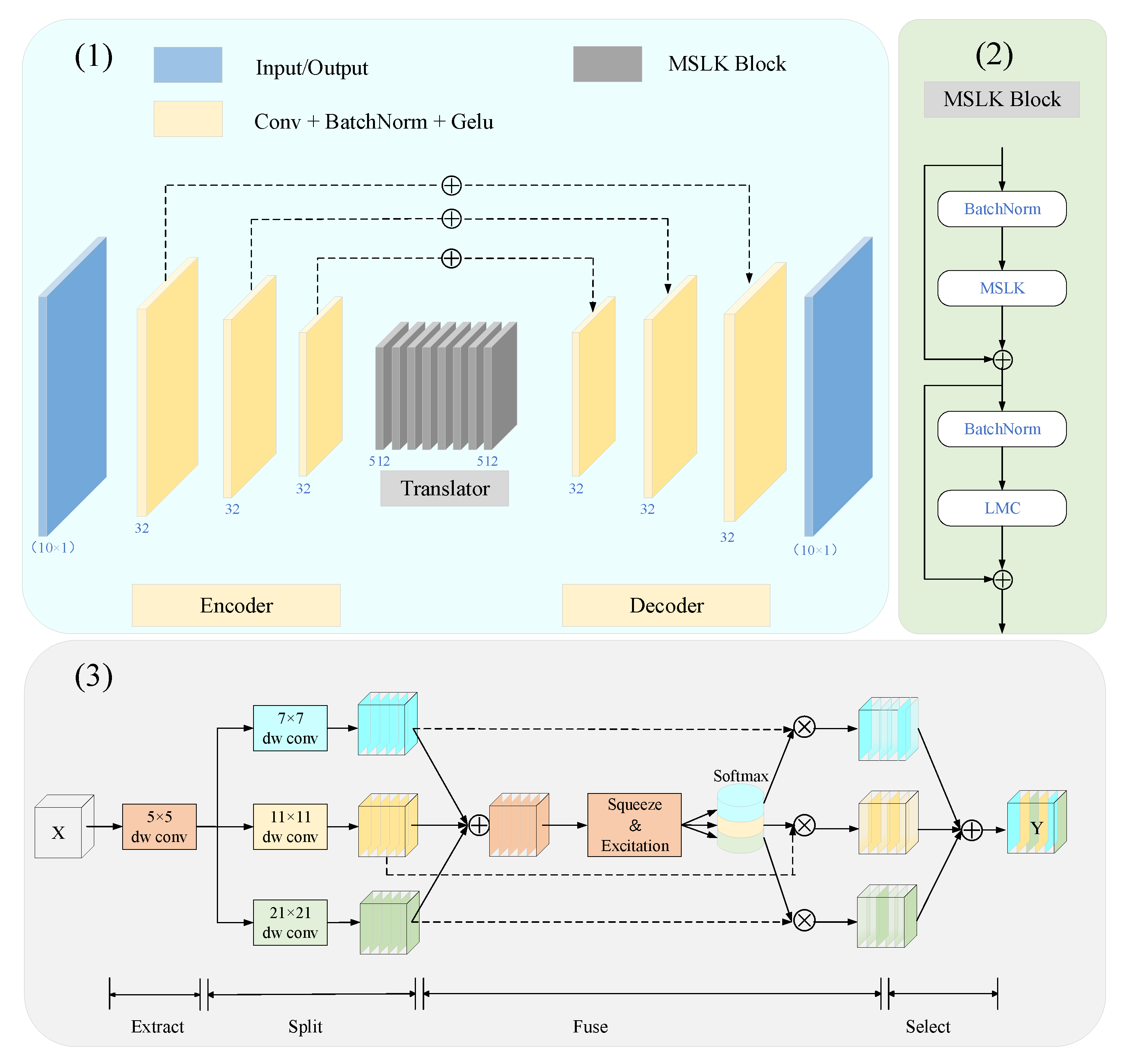
3. Approach
3.1. Problem Formulation
3.2. Overview
3.3. Multi-Scale Large Kernel Convolution (MSLK)
3.4. Local Motion Concern (LMC)
3.5. Information Recall Scheme
4. Experiment
4.1. Datasets
4.1.1. Nanjing Dual-Polarization Radar Dataset
4.1.2. Shijiazhuang Dual-Polarization Radar Dataset
4.2. Experiment Setup
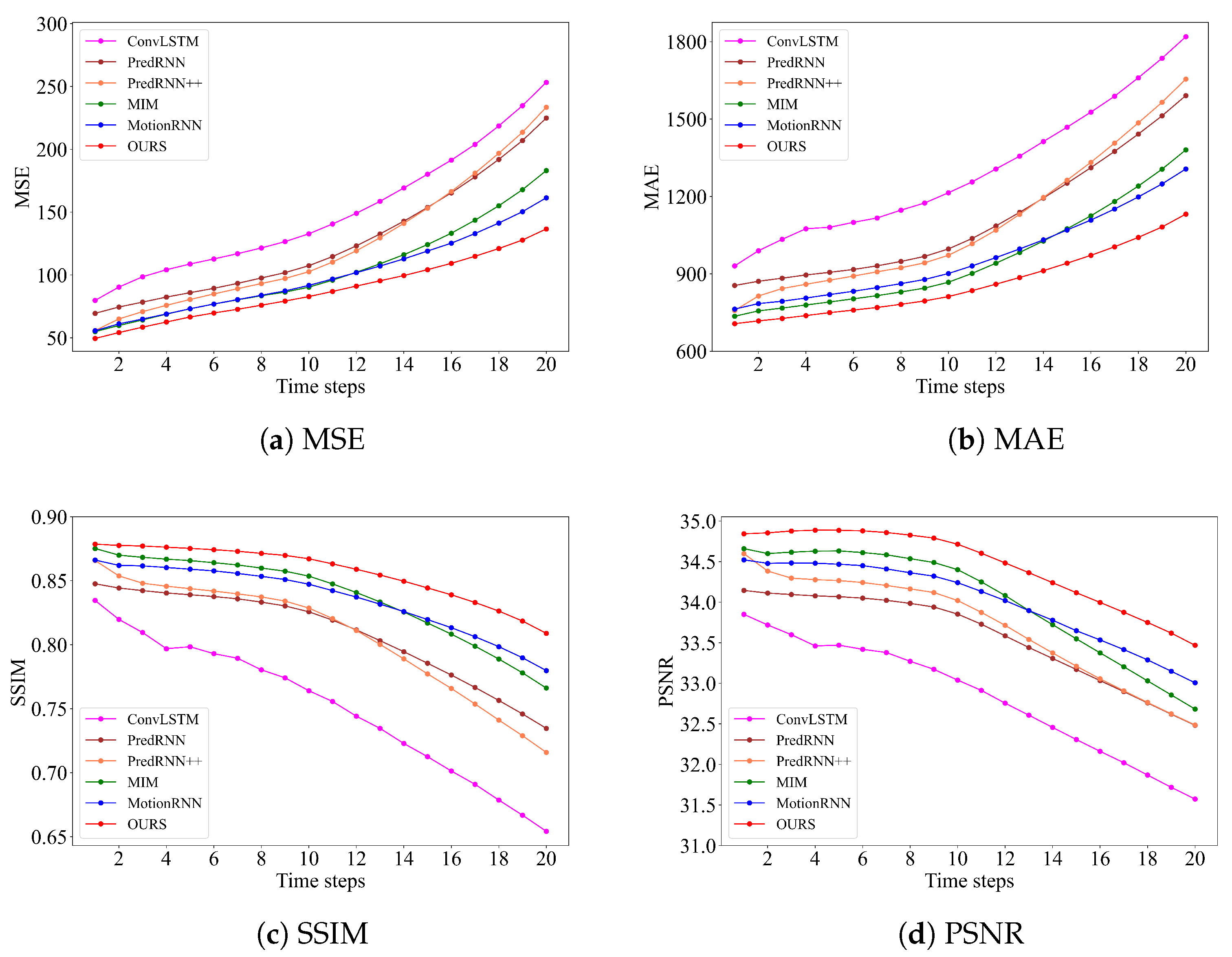
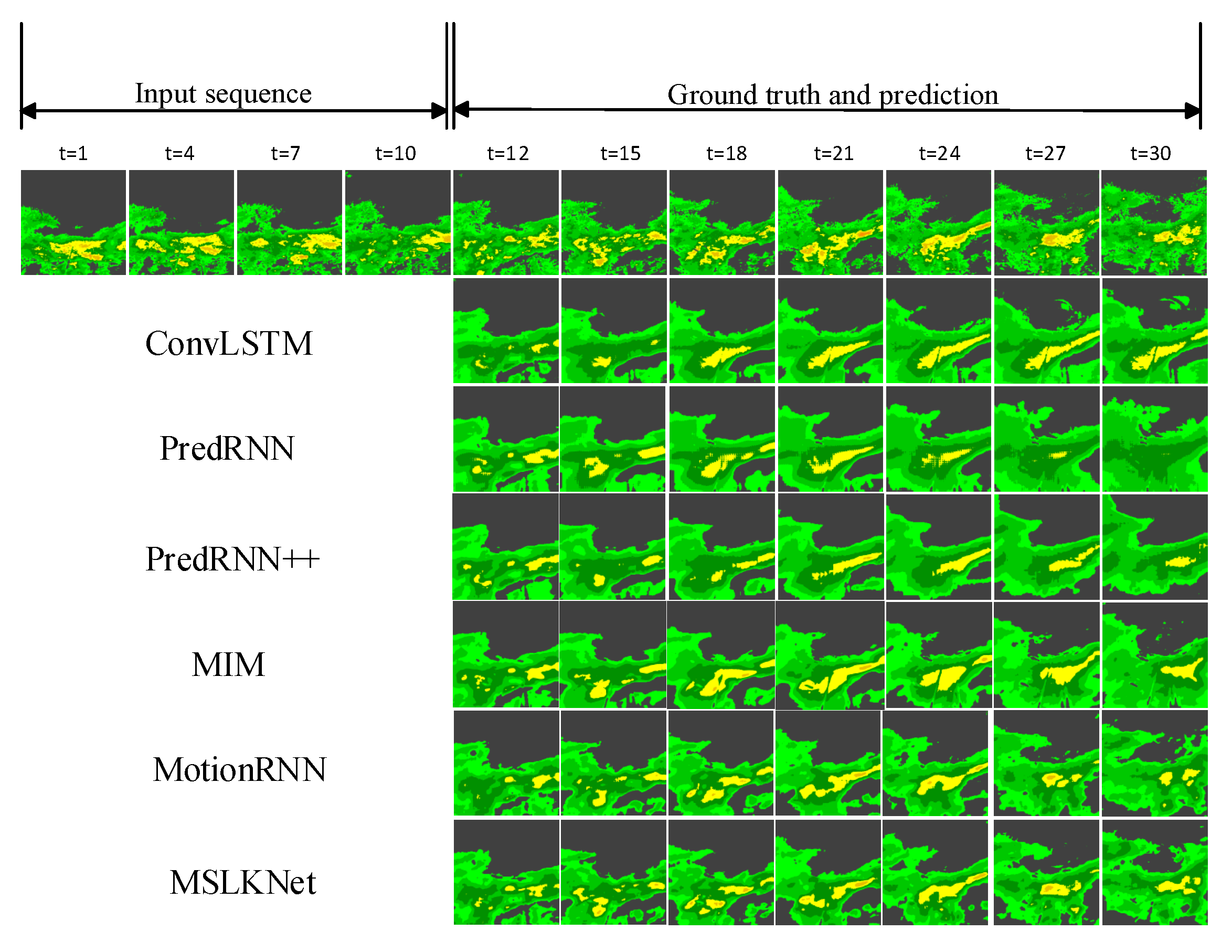
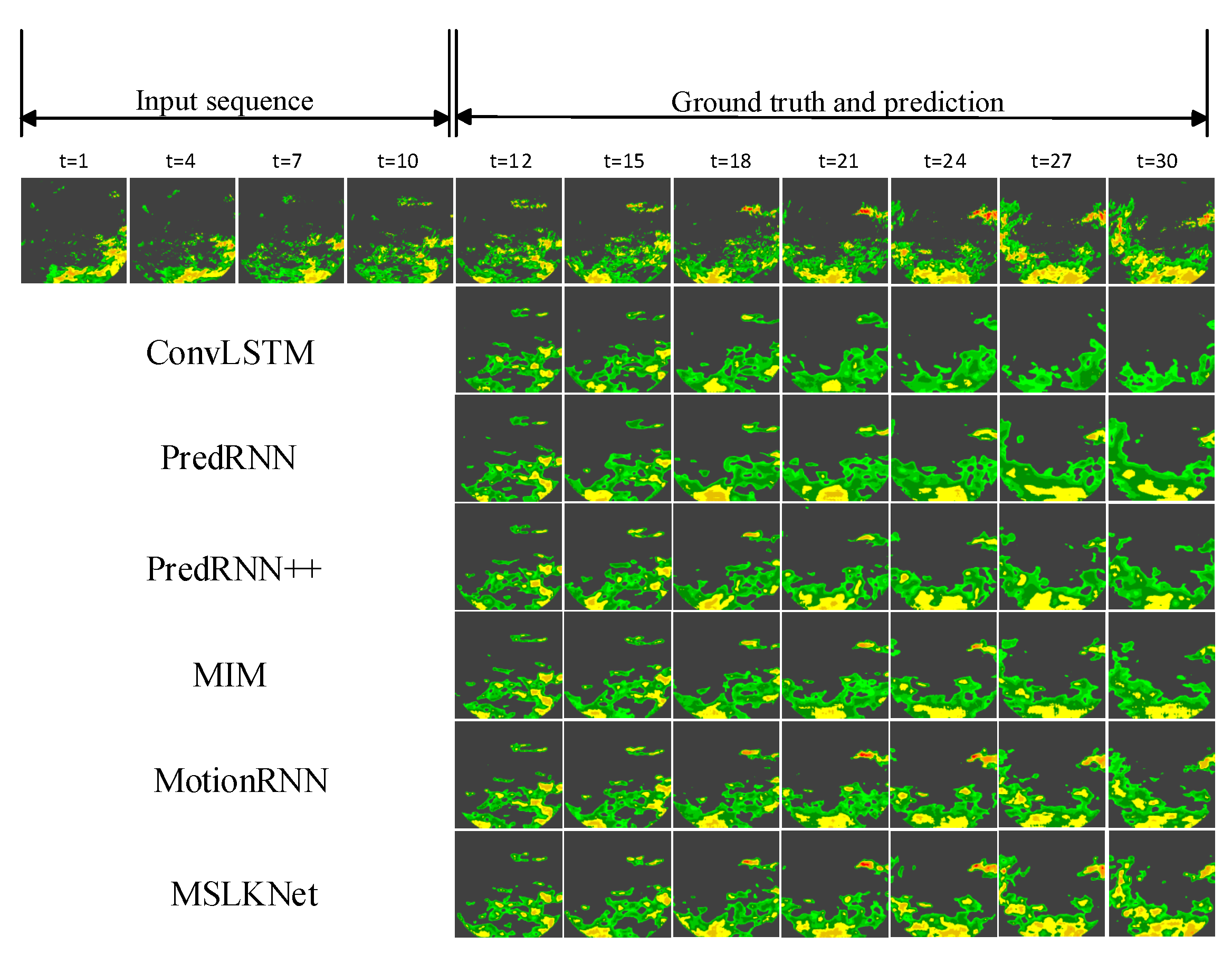
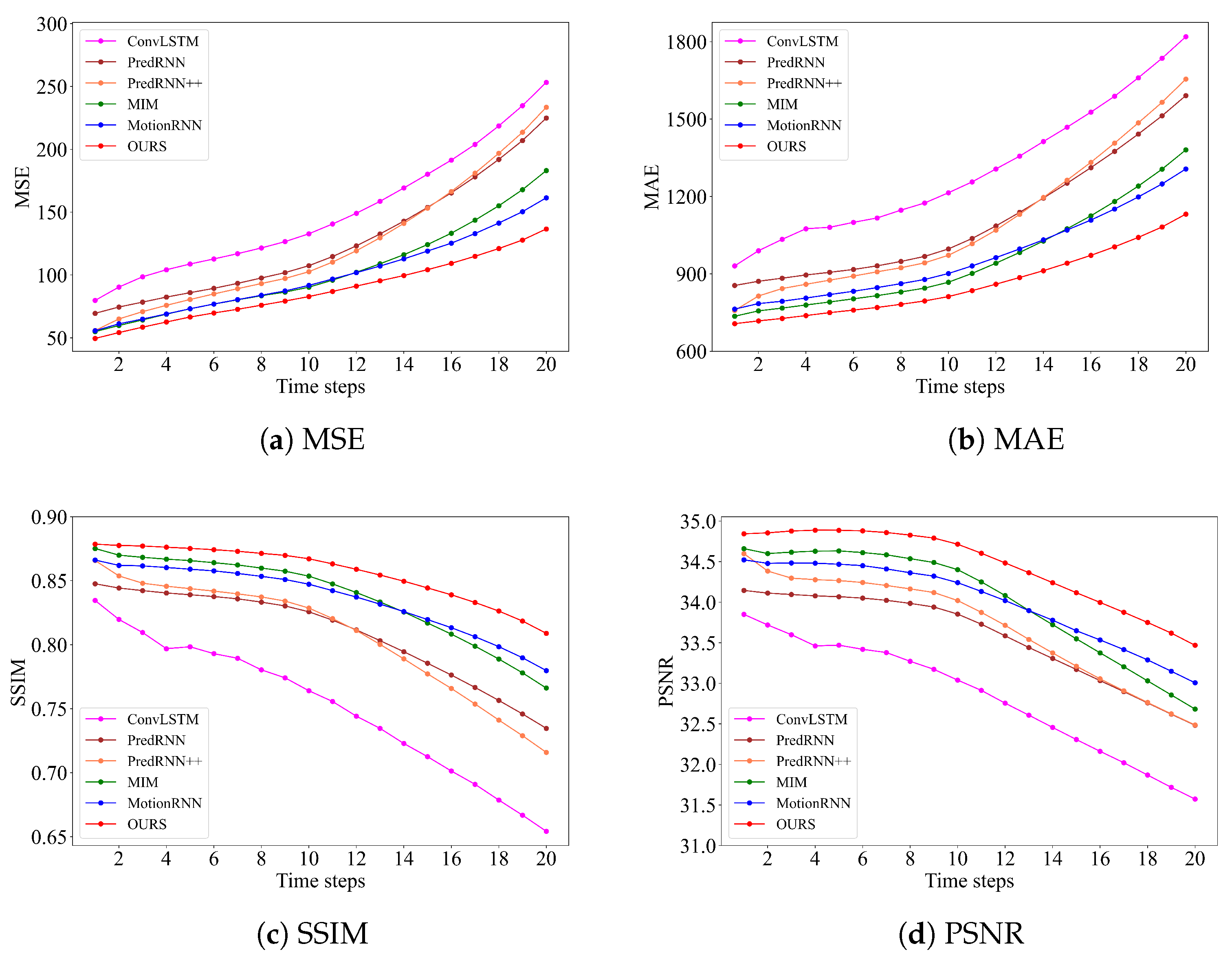
4.3. Results
4.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Browning, K.A.; Collier, C. Nowcasting of precipitation systems. Rev. Geophys. 1989, 27, 345–370. [Google Scholar] [CrossRef]
- Célleri, R. The Role of Weather Radar in Rainfall Estimation and Its Application in Meteorological and Hydrological Modelling—A Review. Remote Sens. 2021, 13, 351. [Google Scholar]
- Hapsari, R.I.; Oishi, S.; Sunada, K.; Sano, T.; Sisinggih, D. Ensemble short-term rainfall-runoff prediction and its application in urban flood risk mapping. In Proceedings of the International Conference on Flood Management, Dhaka, Bangladesh, 9–11 March 2013. [Google Scholar]
- Castro, R.; Souto, Y.M.; Ogasawara, E.; Porto, F.; Bezerra, E. STConvS2S: Spatiotemporal Convolutional Sequence to Sequence Network for Weather Forecasting. Neurocomputing 2020, 426, 285–298. [Google Scholar] [CrossRef]
- Tran, Q.K.; Song, S.K. Multi-Channel Weather Radar Echo Extrapolation with Convolutional Recurrent Neural Networks. Remote Sens. 2019, 11, 2303. [Google Scholar] [CrossRef]
- Li, L.; Schmid, W.; Joss, J. Nowcasting of motion and growth of precipitation with radar over a complex orography. J. Appl. Meteorol. 1995, 34, 1286–1300. [Google Scholar] [CrossRef]
- Johnson, J.T.; Mackeen, P.L.; Witt, A.; Mitchell, E.D.W.; Stumpf, G.J.; Eilts, M.D.; Thomas, K.W. The Storm Cell Identification and Tracking Algorithm: An Enhanced WSR-88D Algorithm. Wea Forecast. 1998, 13, 263–276. [Google Scholar] [CrossRef]
- Ayzel, G.; Heistermann, M.; Winterrath, T. Optical flow models as an open benchmark for radar-based precipitation nowcasting (rainymotion v0.1). Geosci. Model Dev. 2019, 12, 1387–1402. [Google Scholar] [CrossRef]
- Huang, X.; Ma, Y.; Hu, S. Extrapolation and effect analysis of weather radar echo sequence based on deep learning. Acta Meteorol. Sin. 2021, 79, 817–827. [Google Scholar]
- Ma, Z.; Zhang, H.; Liu, J. Preciplstm: A meteorological spatiotemporal lstm for precipitation nowcasting. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4109108. [Google Scholar] [CrossRef]
- Gao, Z.; Tan, C.; Wu, L.; Li, S.Z. Simvp: Simpler yet better video prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3170–3180. [Google Scholar]
- Ning, S.; Lan, M.; Li, Y.; Chen, C.; Chen, Q.; Chen, X.; Han, X.; Cui, S. MIMO is all you need: A strong multi-in-multi-out baseline for video prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 1975–1983. [Google Scholar]
- Tuli, S.; Dasgupta, I.; Grant, E.; Griffiths, T.L. Are convolutional neural networks or transformers more like human vision? arXiv 2021, arXiv:2105.07197. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Song, K.; Yang, G.; Wang, Q.; Xu, C.; Liu, J.; Liu, W.; Shi, C.; Wang, Y.; Zhang, G.; Yu, X.; et al. Deep learning prediction of incoming rainfalls: An operational service for the city of Beijing China. In Proceedings of the 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019; pp. 180–185. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Trebing, K.; Stanczyk, T.; Mehrkanoon, S. SmaAt-UNet: Precipitation nowcasting using a small attention-UNet architecture. Pattern Recognit. Lett. 2021, 145, 178–186. [Google Scholar] [CrossRef]
- Pan, X.; Lu, Y.; Zhao, K.; Huang, H.; Wang, M.; Chen, H. Improving Nowcasting of convective development by incorporating polarimetric radar variables into a deep-learning model. Geophys. Res. Lett. 2021, 48, e2021GL095302. [Google Scholar] [CrossRef]
- Kaparakis, C.; Mehrkanoon, S. WF-UNet: Weather Fusion UNet for Precipitation Nowcasting. arXiv 2023, arXiv:2302.04102. [Google Scholar]
- Fernández, J.G.; Mehrkanoon, S. Broad-UNet: Multi-scale feature learning for nowcasting tasks. Neural Netw. 2021, 144, 419–427. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.Y.; Wong, W.k.; Woo, W.C. Deep learning for precipitation nowcasting: A benchmark and a new model. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P.S. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Wang, Y.; Gao, Z.; Long, M.; Wang, J.; Philip, S.Y. Predrnn++: Towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5123–5132. [Google Scholar]
- Wang, Y.; Zhang, J.; Zhu, H.; Long, M.; Wang, J.; Yu, P.S. Memory in memory: A predictive neural network for learning higher-order non-stationarity from spatiotemporal dynamics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9154–9162. [Google Scholar]
- Wang, Y.; Jiang, L.; Yang, M.H.; Li, L.J.; Long, M.; Fei-Fei, L. Eidetic 3D LSTM: A model for video prediction and beyond. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wu, H.; Yao, Z.; Wang, J.; Long, M. MotionRNN: A flexible model for video prediction with spacetime-varying motions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15435–15444. [Google Scholar]
- Yu, W.; Lu, Y.; Easterbrook, S.; Fidler, S. Crevnet: Conditionally reversible video prediction. arXiv 2019, arXiv:1910.11577. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Rao, Y.; Zhao, W.; Tang, Y.; Zhou, J.; Lim, S.N.; Lu, J. Hornet: Efficient high-order spatial interactions with recursive gated convolutions. Adv. Neural Inf. Process. Syst. 2022, 35, 10353–10366. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31 × 31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Liu, S.; Chen, T.; Chen, X.; Chen, X.; Xiao, Q.; Wu, B.; Kärkkäinen, T.; Pechenizkiy, M.; Mocanu, D.; Wang, Z. More convnets in the 2020s: Scaling up kernels beyond 51 × 51 using sparsity. arXiv 2022, arXiv:2207.03620. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Liu, Z.N.; Cheng, M.M.; Hu, S.M. Visual attention network. Comput. Vis. Media 2023, 9, 733–752. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Huang, H.; Zhao, K.; Zhang, G.; Lin, Q.; Wen, L.; Chen, G.; Yang, Z.; Wang, M.; Hu, D. Quantitative precipitation estimation with operational polarimetric radar measurements in southern China: A differential phase–based variational approach. J. Atmos. Ocean. Technol. 2018, 35, 1253–1271. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Putman, W. The finite-volume dynamical core on the cubed-sphere. In Proceedings of the 2006 ACM/IEEE Conference on Supercomputing, Las Vegas, NV, USA, 26 June–1 July 2006; p. 173-es. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Flops (G) | Training Time (s) | MSE ↓ | MAE ↓ | SSIM ↑ | PSNR ↑ | CSI ↑ |
|---|---|---|---|---|---|---|---|
| ConvLSTM | 14.9 | 416 | 149.89 | 1300.66 | 0.751 | 32.84 | 0.021 |
| PredRNN | 30.1 | 508 | 127.19 | 1119.07 | 0.808 | 33.55 | 0.036 |
| PredRNN++ | 41.3 | 541 | 122.99 | 1095.49 | 0.807 | 33.70 | 0.046 |
| MIM | 44.9 | 587 | 102.80 | 955.57 | 0.833 | 34.01 | 0.042 |
| MotionRNN | 33.4 | 569 | 99.62 | 964.65 | 0.836 | 34.04 | 0.051 |
| MSLKNet | 12.7 | 371 | 88.11 | 864.83 | 0.857 | 34.51 | 0.058 |
| Model | Flops (G) | Training Time (s) | MSE ↓ | MAE ↓ | SSIM ↑ | PSNR ↑ | CSI ↑ |
|---|---|---|---|---|---|---|---|
| ConvLSTM | 24.4 | 737 | 238.60 | 2338.89 | 0.772 | 34.86 | 0.083 |
| PredRNN | 49.3 | 911 | 190.26 | 2018.65 | 0.791 | 34.95 | 0.162 |
| PredRNN++ | 67.6 | 1401 | 166.52 | 1875.35 | 0.805 | 35.18 | 0.153 |
| MIM | 73.6 | 1432 | 153.98 | 1790.89 | 0.812 | 35.30 | 0.167 |
| MotionRNN | 54.7 | 1317 | 134.31 | 1704.20 | 0.821 | 35.34 | 0.181 |
| MSLKNet | 20.9 | 680 | 124.59 | 1653.01 | 0.825 | 35.56 | 0.192 |
| Model | MSE ↓ | SSIM ↑ | PSNR ↑ |
|---|---|---|---|
| Basenet | 131.12 | 0.783 | 33.39 |
| MSLKNet w/o MSLK | 97.25 | 0.835 | 33.96 |
| MSLKNet w/o LMC | 106.01 | 0.823 | 33.82 |
| MSLKNet w/o recall | 92.07 | 0.854 | 34.46 |
| MSLKNet | 88.11 | 0.857 | 34.51 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, W.; Wang, C.; Shen, K.; Zhang, L.; Lim Kam Sian, K.T.C. MSLKNet: A Multi-Scale Large Kernel Convolutional Network for Radar Extrapolation. Atmosphere 2024, 15, 52. https://doi.org/10.3390/atmos15010052
Tian W, Wang C, Shen K, Zhang L, Lim Kam Sian KTC. MSLKNet: A Multi-Scale Large Kernel Convolutional Network for Radar Extrapolation. Atmosphere. 2024; 15(1):52. https://doi.org/10.3390/atmos15010052
Chicago/Turabian StyleTian, Wei, Chunlin Wang, Kailing Shen, Lixia Zhang, and Kenny Thiam Choy Lim Kam Sian. 2024. "MSLKNet: A Multi-Scale Large Kernel Convolutional Network for Radar Extrapolation" Atmosphere 15, no. 1: 52. https://doi.org/10.3390/atmos15010052
APA StyleTian, W., Wang, C., Shen, K., Zhang, L., & Lim Kam Sian, K. T. C. (2024). MSLKNet: A Multi-Scale Large Kernel Convolutional Network for Radar Extrapolation. Atmosphere, 15(1), 52. https://doi.org/10.3390/atmos15010052