1. Introduction
In recent years, air pollution has become an important issue of global concern, particularly in many developing and developed cities. Through industrial and urban activities such as fossil fuel combustion, construction work, and industrial emissions, hazardous or excessive gases, particles, and biomolecules are released into the atmosphere, leading to a deterioration in air quality and the occurrence of air pollution [
1]. Notably, nitrogen dioxide (NO
2), carbon monoxide (CO), carbon dioxide (CO
2), ozone (O
3), sulfur dioxide (SO
2), and fine particulate matter such as PM
2.5 and PM
10 have been recognized by numerous studies as major pollutants causing air pollution [
2,
3]. Air pollution has had significant effects on public health and the environment [
4,
5,
6], including causing various diseases such as lung diseases, heart diseases, lung tumors, and strokes [
7,
8,
9], leading to high mortality rates worldwide [
10,
11].
Due to the harmful effects of air pollution on human health, the public has shown a keen interest in future air quality trends [
12]. Accurately identifying areas of severe air pollution, implementing real-time monitoring, and exploring effective methods for air pollution prediction have become vital means to address environmental problems, formulate corresponding policies, and reduce health risks [
13].
The Air Quality Index (AQI), often referred to as a comprehensive indicator of overall air pollution levels based on multiple air pollutants [
14], evaluates air pollution levels by merging the concentrations of various pollutants into a single numerical form. According to the environmental air quality standards (GB3095-2012), the AQI calculation system covers six pollutants, including ozone (O
3), carbon monoxide (CO), nitrogen dioxide (NO
2), sulfur dioxide (SO
2), PM
2.5, and PM
10 [
15]. When quantifying the scale of air pollution, AQI is divided into six different categories based on the health effects of air pollution. Therefore, AQI can also show the relationship between air quality and human health. Predicting AQI helps to detect air pollution risks promptly, prevent direct public exposure to environments with harmful gases, and protect human health. It can also assist governments in formulating relevant policies, provide planning references for future industrial operations, and improve air quality. In reality, when interpreting air quality levels, it is challenging to understand the overall level of air pollution from the raw data of various pollutants. To address this issue, researchers have begun to increasingly utilize AQI prediction [
16,
17,
18,
19].
Past research on AQI has attempted to use various statistical and machine learning methods for air quality prediction, such as regression models, neural networks, and decision trees [
20,
21,
22]. Specifically, commonly used algorithms include the most basic, Linear Regression (LR, MLR) [
23], K-nearest neighbor (KNN) [
24], support vector machine (SVR) [
25], Long Short-Term Memory (LSTM) [
26] for solving time-series prediction, and ensemble models such as Random Forest (RF) [
27] and Extreme Gradient Boosting (XGBT) [
28].
However, these methods typically operate in a single model, requiring meticulous feature selection and model tuning, and may perform poorly on specific problems and datasets. Additionally, most studies are limited to modeling single pollutants and AQI, focusing on regions in Europe and the Americas [
20]. Recently, ensemble learning and hybrid learning models, as powerful machine learning methods, have been widely applied to air pollution prediction [
29,
30], as combinations of multiple learning models can significantly enhance prediction accuracy and stability. However, comprehensive and effective comparisons of the mechanism differences and the performance merits and demerits between single models, ensemble learning models, and hybrid models, as well as the selection of the optimal method for predicting air quality, have rarely been explored in current research. Only a small number of studies specifically compare the performance of different types of algorithms while analyzing practical problems. For example, Li et al. used seven algorithm models to predict the severity of aircraft icing. They divided the algorithms into traditional algorithms and integrated algorithms and compared the performance and characteristics of the different algorithms [
31]. Senthil Kumar et al. classified 11 algorithms into Bayesian models, regression models, ensemble models, instance-based models, and tree-based models when predicting air quality and compared the models in detail [
29].
This study aims to construct multiple classes of machine learning models, including single models, ensemble models, and hybrid models, for predicting the AQI in major urban agglomerations in China. We will evaluate the performance of different models in air quality prediction and analyze the differences in performance and the applicability of various types of models. The RF ensemble model and the LSTM-SVR hybrid model constructed in our research show superior predictive performance. This work makes the following contributions:
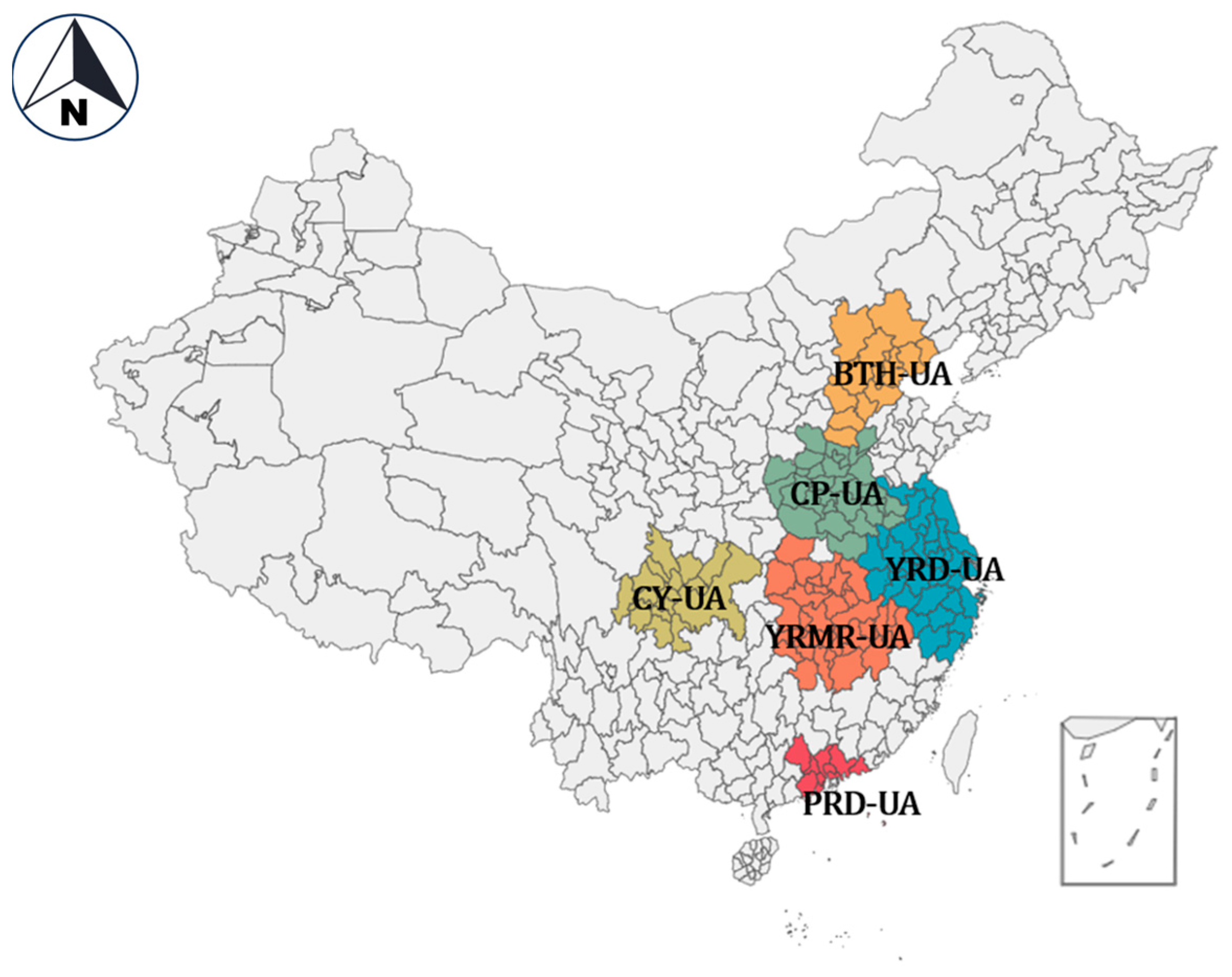
We have accumulated air quality data from six major urban agglomerations in China and established four single models (LR, KNN, SVR, LSTM), three ensemble models (RF, XGBT, LGBM), and one hybrid model LSTM-SVR. By considering six concentrations of six air pollutants and five meteorological factors, we predict AQI values, effectively and comprehensively comparing the effectiveness of different types of algorithm models in predicting air quality.
The predictive performance of all models was evaluated through RMSE, MAE, and R2. The ensemble model RF and the hybrid model LSTM-SVR showed good performance, with LSTM-SVR exhibiting lower RMSE in BTH-UA and CP-UA areas. The constructed hybrid model LSTM-SVR has certain practical significance for predicting air quality in high-pollution areas.
2. Related Work
Predicting the AQI (Air Quality Index) represents a complex, multi-factorial problem, where six principal air pollutants form the direct influencing factors of AQI. Thus, the primary prediction data types utilized for analysis are air quality data and concentration data for various pollutants. Many empirical tests demonstrate a correlation between air quality and an array of socioeconomic factors. Some static natural factors, such as land use types, altitude, and slope, also exhibit a certain negative correlation with the AQI [
32,
33,
34]. However, these factors mainly present themselves in panel data, lacking dynamism, and spatial econometrics is generally employed to analyze the differences in AQI influencing factors across regions.
When constructing machine learning models to predict AQI, most studies focus on building models that combine real-time AQI indices with other real-time monitoring data. For example, Liang et al. utilized AQ (air quality data, including six types of pollutant concentration), MET (real-time meteorological data), and time (time data) as predictive data, with the dataset recording the hourly air pollution concentration and meteorological conditions at three air monitoring stations in Taiwan [
30]. On one hand, since the monitoring of six air pollutants is based on their concentration time series, meteorological data recorded in the same time-series format can be easily acquired and better simulate the real-time evolution of the air quality environment. On the other hand, substantial research has proved that numerous meteorological factors are essential in affecting air quality, thus broadening the model’s feature selection.
Various machine learning methods have been widely adopted and compared for their predictive performance in AQI forecasting for air pollutants. These studies have also verified the effectiveness of machine learning in predicting air quality. Castelli et al. used Support Vector Regression (SVR) to study six AQI categories defined by the U.S. Environmental Protection Agency, based on the hourly concentration of five air pollutants and AQI indices in California, achieving an accuracy of 90.02% on the training set and 94.1% on the validation set [
35]. Liu et al. employed SVR and Random Forest Regression (RFR) to establish regression models for predicting the AQI in Beijing and the NO
X (nitrogen oxides) concentration in an Italian city, evaluating the models’ performance using the Root Mean Square Error (RMSE), correlation coefficient (r), and determination coefficient (R
2). The results revealed that the SVR-based model performed well for AQI prediction (RMSE = 7, R
2 = 0.9776, r = 0.9887) [
36]. Li et al. combined GNSS Radio Occultation (GNSS-RO) observation with weather-modeling AQI data and utilized LSTM, GNN, and DNN neural network models to train the AQI prediction model, finding that the LSTM model had the best predictive accuracy, with an RMSE of 2.4% [
37]. Many studies have shown that ensemble learning generally outperforms regression, support vector machines, and neural networks in predicting air quality [
21]. Senthil Kumar et al. conducted a detailed analysis and comparison using a total of 11 algorithms, including Bayesian models, regression models, ensemble models, instance-based models, and tree-based models, for predicting environmental air quality indices in southern Indian cities. The research indicated that ensemble classification models and density-based clustering methods provided better results in handling air quality data [
29].
With the constant proliferation of machine learning algorithms, several studies have attempted to combine various algorithms to create hybrid models, seeking to overcome the deficiencies of existing algorithm and achieve improved prediction outcomes. Janarthanan et al., aiming to predict the air quality in Chennai city, adopted a combination of Support Vector Regression (SVR) and Long Short-Term Memory (LSTM)-based deep learning models to classify AQI values [
23]. LSTM was used to preserve both long- and short-term memory, overcoming the vanishing gradient problem of Recurrent Neural Networks (RNNs) and being suitable for time-series data prediction. The proposed deep learning model offered precise and specific AQI values for urban locations, enhancing prediction accuracy. In another Indian study, Sarkar et al. trained several individual machine learning and deep learning models, including LSTM, LR, GRU, KNN, and SVM, to predict air quality in Delhi and built a hybrid LSTM-GRU model for AQI prediction. When compared to other models, the proposed hybrid model exhibited predictive performance advantages, with an MAE value of 36.11 and an R² value of 0.84 [
38]. Zhang et al. focused on the impact of PM
2.5 concentration on air quality, incorporating Variational Mode Decomposition (VMD) and Bidirectional Long Short-Term Memory networks (BiLSTMs) to create a hybrid deep learning model VMD-BiLSTM for predicting PM
2.5 variations in Chinese cities [
39]. VMD first decomposed the original complex PM
2.5 time-series data into multiple sub-signal components, effectively avoiding prediction lag, and then BiLSTM predicted each sub-signal component separately. Experiments comparing various VMD hybrid models found the VMD-BiLSTM model to be superior to all compared models. Mao et al. built a neural network with Time-Sliding Long Short-Term Memory Extension Model (TS-LSTME) to forecast the 24 h average PM
2.5 concentration in the Jing-Jin-Ji region of China, finding it to have a higher correlation coefficient R
2 (0.87) and better stability and performance compared to the MLR, SVR, LSTM, and LSTME models [
40].
From the studies above, it can be discerned that research on AQI (Air Quality Index) prediction is markedly limited. Although many studies have utilized real-time monitoring data, enabling fairly accurate predictions of AQI for a specific region in the near future, the majority of research has concentrated on comparisons of the accuracy of various algorithms. There is a lack of horizontal accuracy comparisons of the same algorithm across different regions. With the development of industries and cities, the change mechanisms of AQI are becoming increasingly complex over time. As a result, the prediction of air quality is becoming more challenging, and the applicability of general single models is progressively waning. A substantial shift toward the use of ensemble and hybrid models in research has become mainstream. The implementation of these models has been proven to effectively overcome some of the shortcomings present in existing algorithms, thereby achieving higher predictive performance.
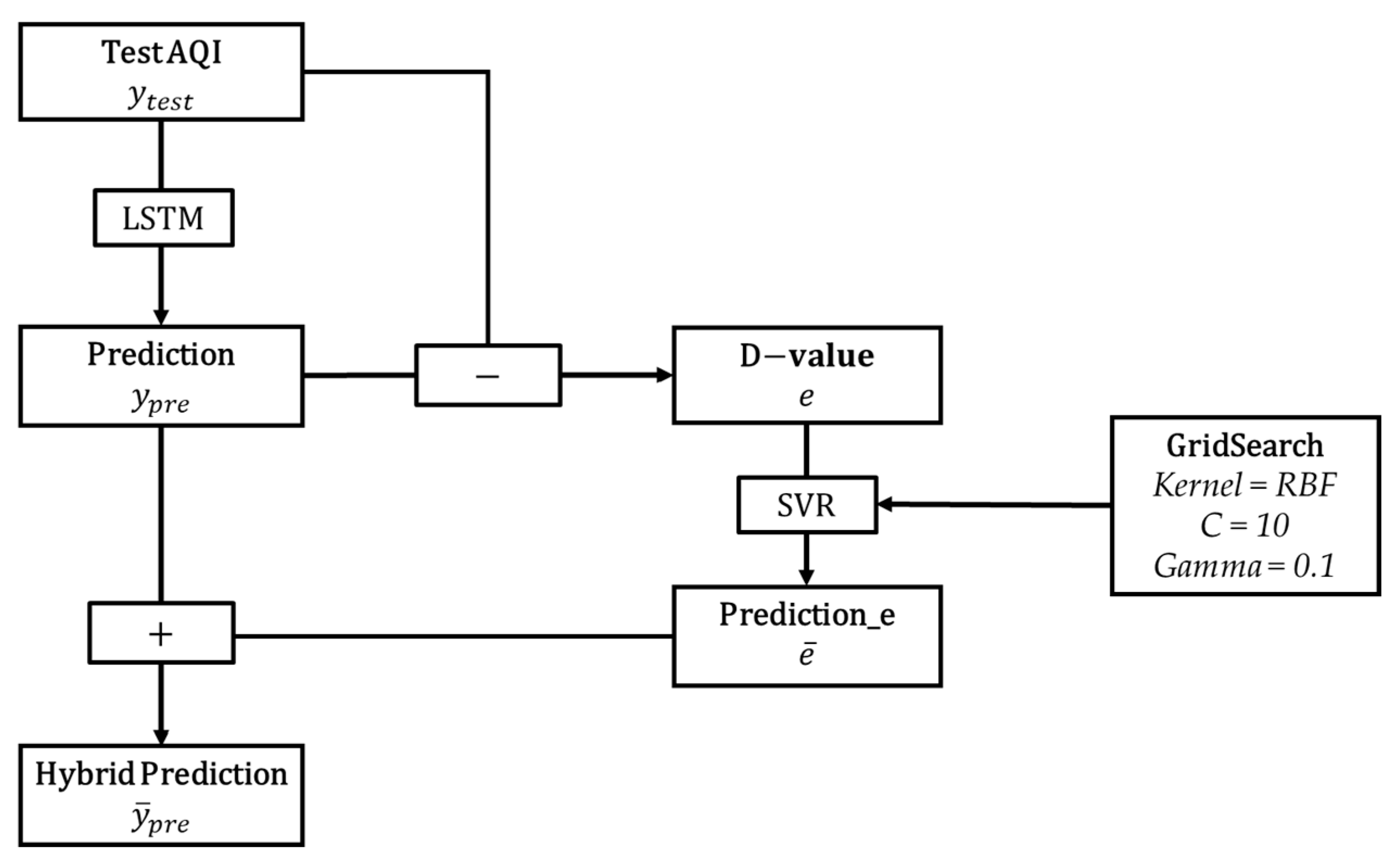
To overcome the above two challenges, this paper aims to realize the interregional comparison of the performance of models for air quality prediction and explore the differences between the three types of algorithmic models: he single model, the ensemble model, and the hybrid model. This research gathered daily mean Air Quality Index, air pollutant concentration data, and meteorological data from six major urban agglomerations in China, encompassing 95 cities, for the years 2017 to 2020. Subsequently, various models were developed, including Linear Regression (LR), K-Nearest Neighbor (KNN), Support Vector Regression (SVR), Long Short-Term Memory (LSTM) networks, ensemble models like Random Forest (RF), Extreme Gradient Boosting (XGBT), and Light Gradient Boosting Machine (LGBM). Additionally, considering prior research on single-model prediction, where the LSTM model was found to be suitable for time-series forecasting and widely applied in air quality prediction, and SVR displayed good performance in AQI prediction, being the optimal model in several studies [
28,
29], this paper further combined the independent SVR and LSTM models to construct an LSTM-SVR hybrid model. These models were employed to predict the Air Quality Index for six urban agglomerations in China, and the performance of the models in predicting different urban agglomerations was compared.
Figure 1 presents the analytical framework of this paper.
5. Discussion
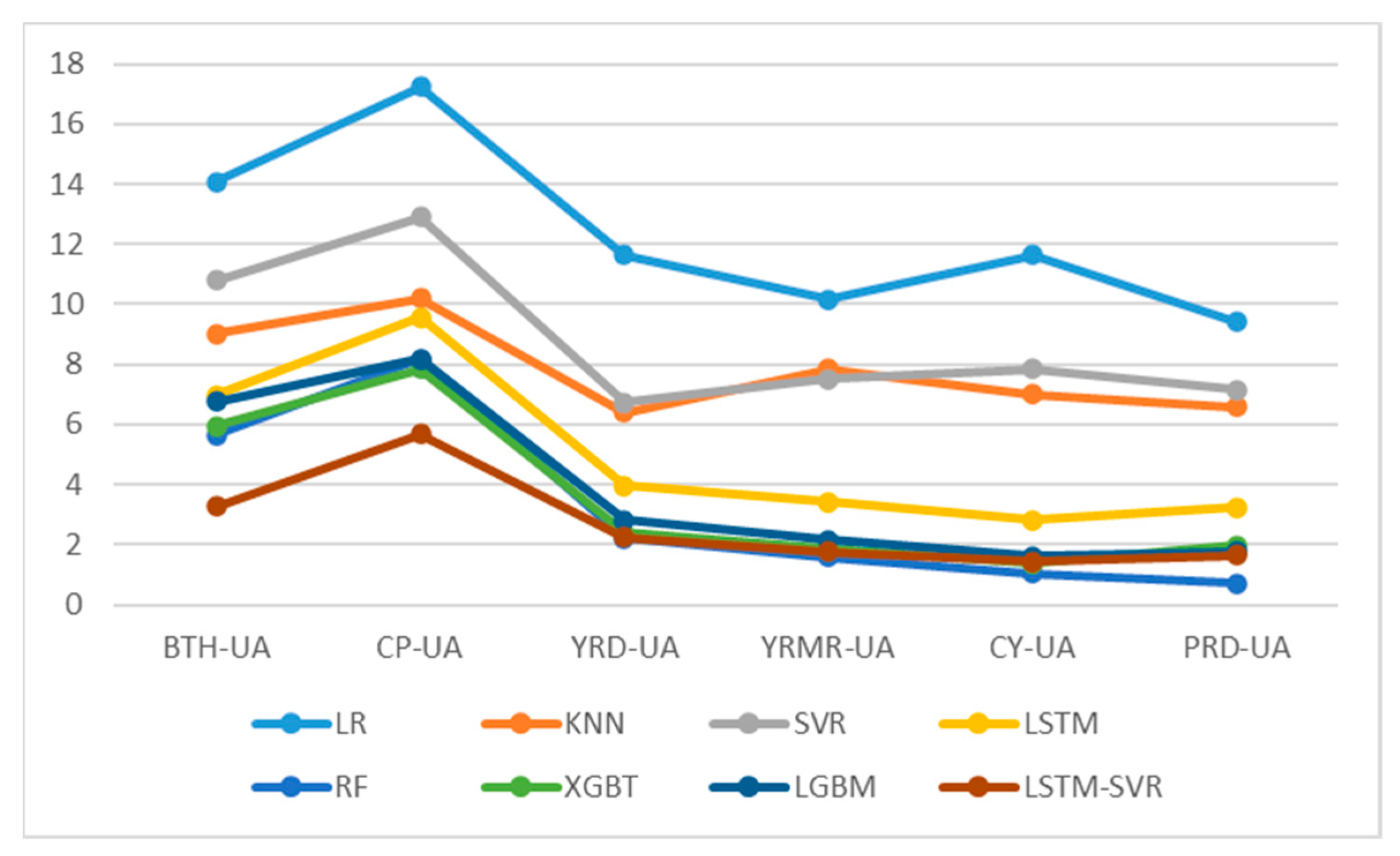
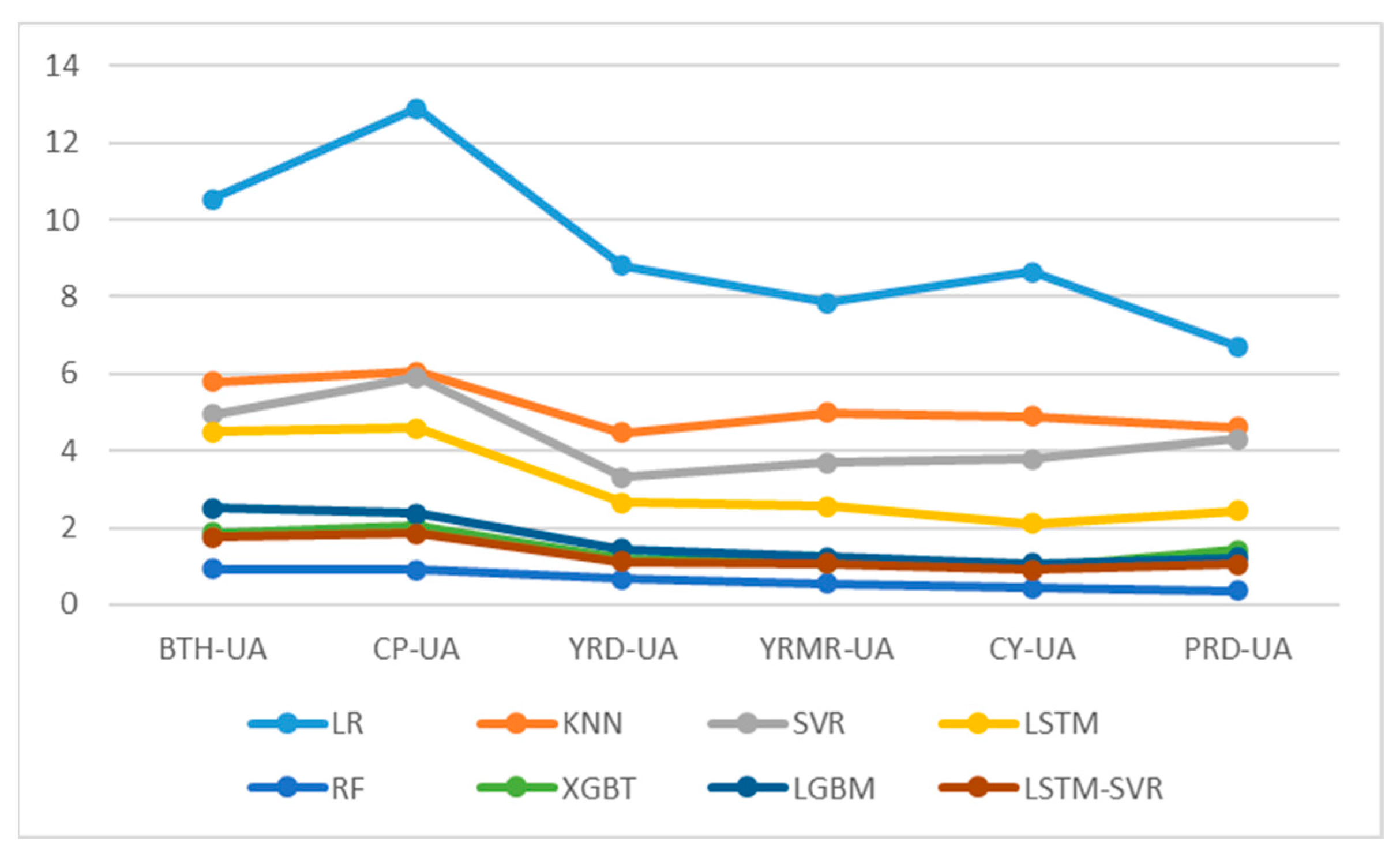
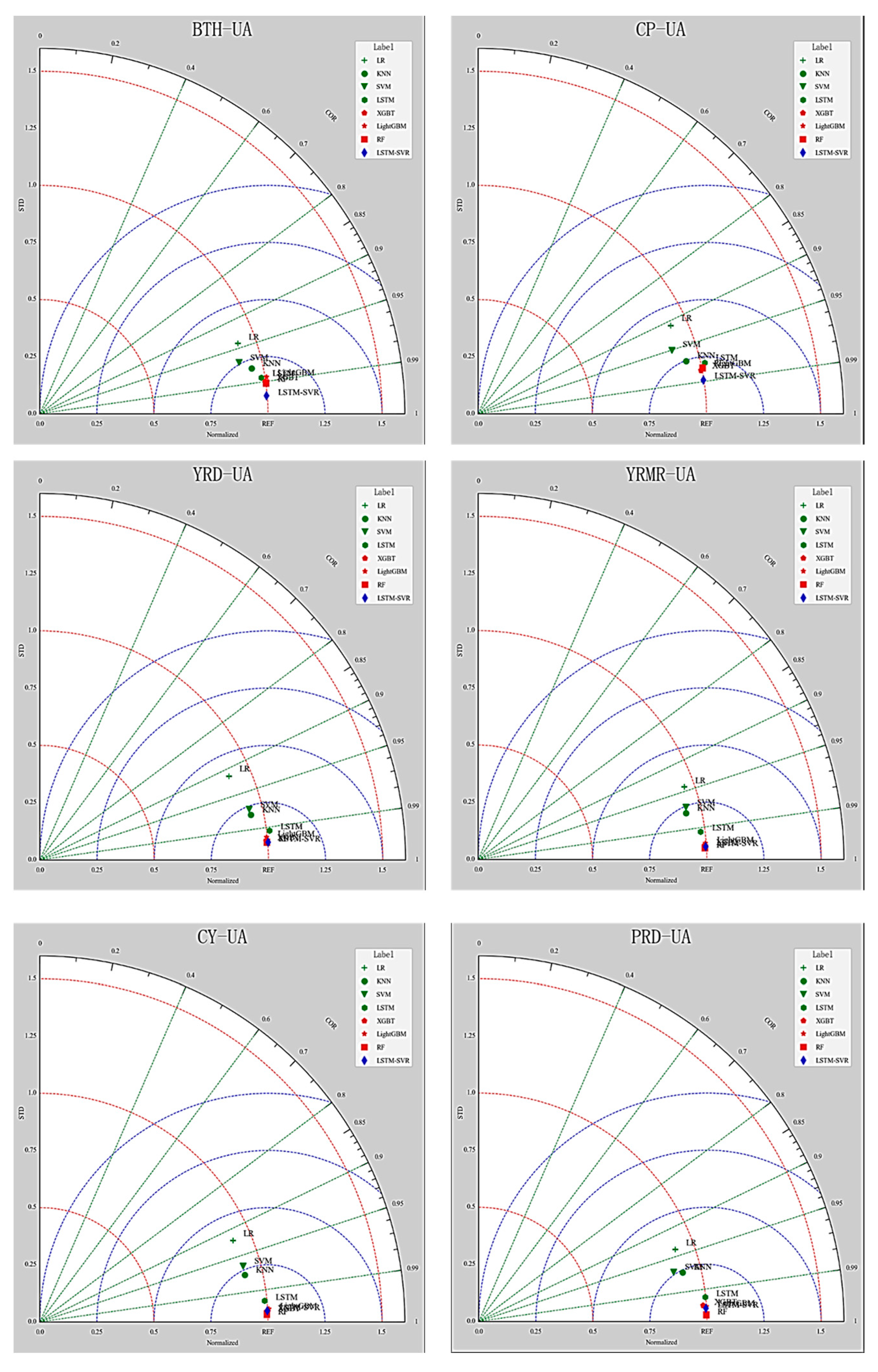
This section discusses the comparative predictive performance of eight models for AQI prediction in six urban agglomerations. The predictive accuracy of the algorithm in each urban agglomeration was obtained based on R2, RMSE, and MAE, comparing the predictive performance between machine learning models and the predictive accuracy among urban agglomerations.
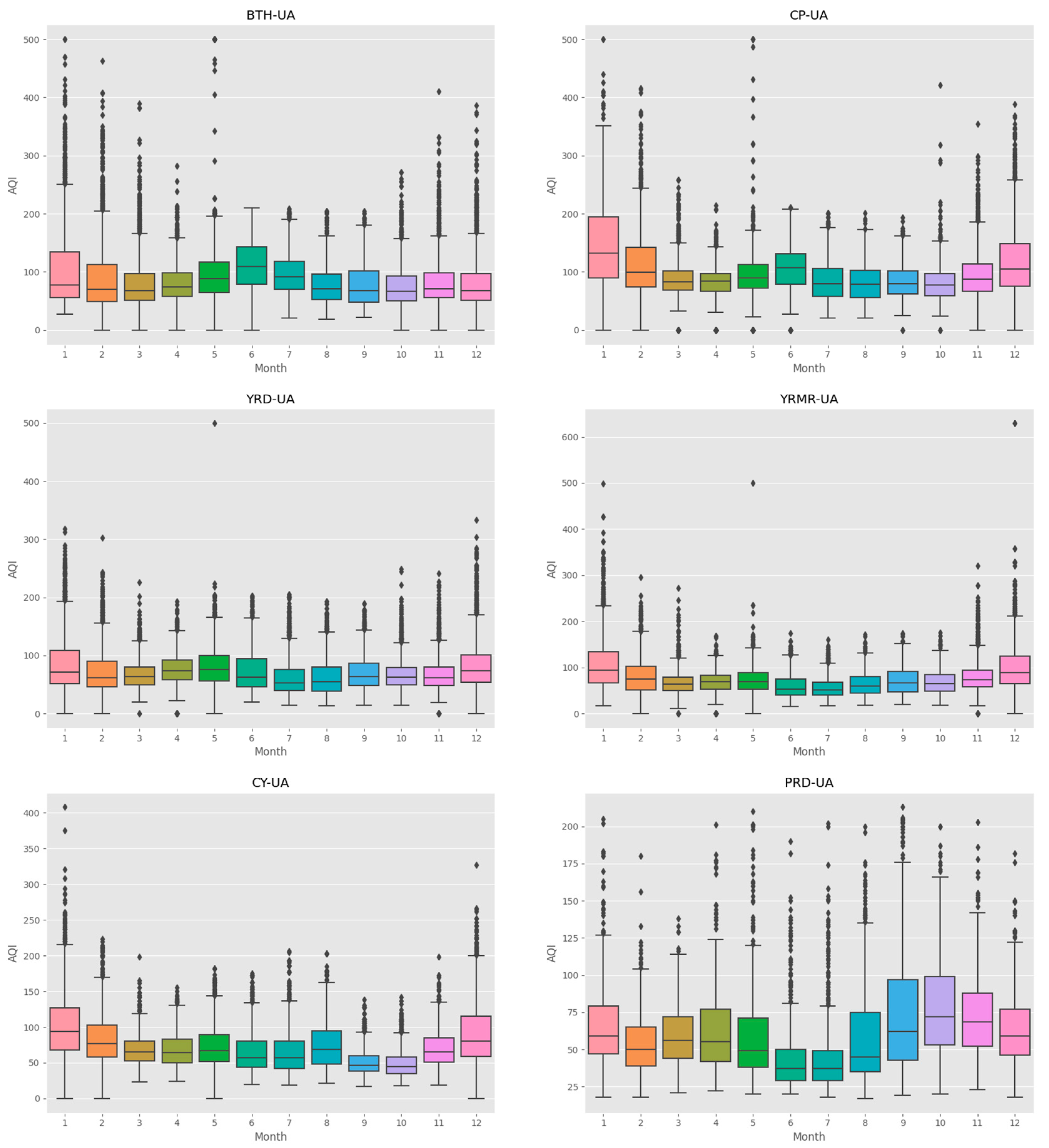
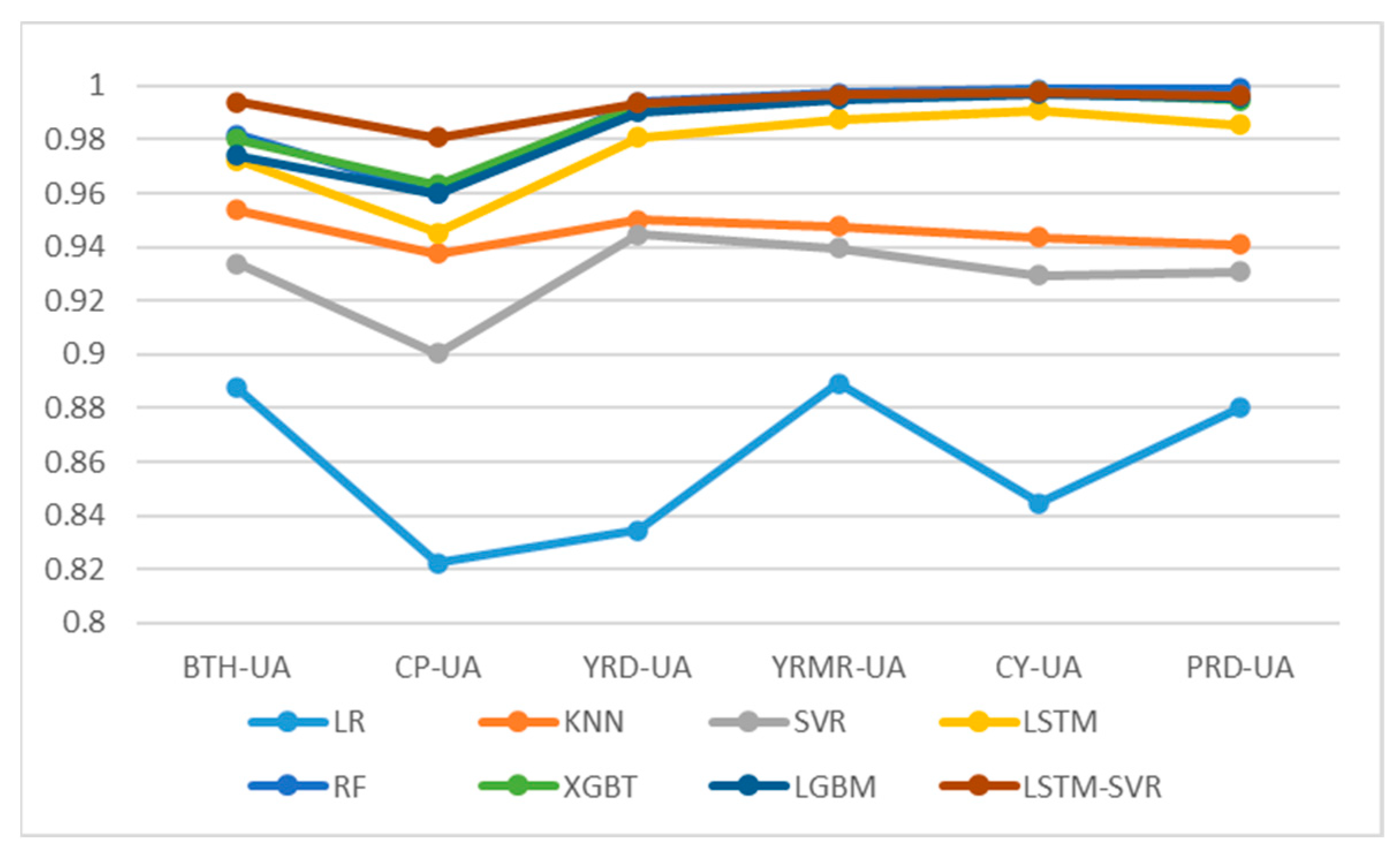
In the comparison of predictive accuracy among urban agglomerations, the Mean-UA levels of RMSE and MAE are arranged in order from poor to good, according to the order of CP-UA, BTH-UA, YRD-UA, YMRM-UA, CY-UA, and PRD-UA. CP-UA has the worst overall predictive accuracy among all urban agglomerations, while PRD-UA has the best predictive accuracy. This may be related to the level of air pollution in the urban agglomerations, as CP-UA and PRD-UA are the areas with the highest and lowest annual average AQI index, respectively. Previous studies have shown that prediction accuracy in China’s northern regions, where air pollution is severe, will significantly decrease due to the more diverse and complex factors causing the increase in various air pollutants [
52]. In the comparison of
Figure 6,
Figure 7 and
Figure 8, it can be found that single models have significant differences in predictive performance in different urban agglomerations, while the differences in performance in ensemble learning models are smaller. A few algorithms with higher predictive accuracy easily coincide in their performance curves on YRMR-UA, CY-UA, and PRD-UA, and there is a noticeable gap in BTH-UA, CP-UA, and YRD-UA. With the best predictive performance, the LSTM and RF models further narrow the differences in predictive performance among urban agglomerations, making the predictive performance curves more even. This indicates that the best-performing LSTM-SVR and RF can further reduce the differences in predictive accuracy among different urban agglomerations, further enhance the predictive performance in areas with serious air pollution like BTH-UA, CP-UA, and YRD-UA, and solve the problem of low prediction accuracy in areas with severe pollution.
In the comparison of predictive performance among eight different algorithmic models, based on the Mean-ML of R
2, RMSE, and MAE, the simplest LR model has the worst predictive performance, the LSTM model has the best performance in single models, and SVR and KNN perform similarly. Ensemble algorithm models generally perform significantly better than single models. Among them, RF has the best predictive performance, where R
2, RMSE, and MAE are all better than those from the other two algorithms, and it obtained the best MAE value. XGBT is generally superior to LGBM, but LGBM also has the advantage of low time consumption. The hybrid model algorithm LSTM-SVR that we constructed obtained the best R
2 and RMSE among the developed models and was only slightly worse than RF on MAE. Compared to RF, LSTM-SVR significantly reduced the RMSE values in the heavily polluted BTH-UA and CP-UA regions, while the RMSE values obtained in predicting YRD-UA, YRMR-UA, CY-UA, and PRD-UA were all worse than RF. The LSTM-SVR model has a good effect on enhancing the accuracy of AQI prediction in high-pollution areas. LSTM-SVR’s performance is also far better than the LSTM model. This indicates that the constructed LSTM-SVR hybrid model has significant predictive advantages compared to single models and some ensemble models, providing an effective method for regional air quality prediction, and the hybrid model prediction has further development prospects [
53].
6. Conclusions
Currently, with the development of industry and cities, the intensification of air pollution, and the increasingly complex situation faced by air quality monitoring and forecasting, the pursuit of accurate, efficient, and stable air quality prediction is of great importance for environmental governance and sustainable development.
Considering pollution source information and meteorological data to simulate air quality is widely used in most studies [
54,
55]. This study utilized air pollutant concentration and meteorological data from 2017 to 2020 in six Chinese urban agglomerations to simulate air quality conditions [
56]. To predict air quality, this study employed seven single models and ensemble models of machine learning methods and constructed a hybrid LSTM-SVR model to predict air quality in the six urban agglomerations. Using R
2, RMSE, and MAE as evaluation metrics, a comprehensive comparison of the predictive performance of eight algorithm models was made from the perspectives of differences in models and differences in urban agglomerations [
57].
The results show that in areas where air pollution is more severe, the situation faced by the model prediction is more complex, and the prediction accuracy has decreased. The more accurate RF and LSTM-SVR models can effectively improve the prediction accuracy of air quality in areas with severe air pollution. Comparing the overall performance of eight prediction models, the constructed hybrid model LSTM-SVR achieved the best R
2 and RMSE; the ensemble model RF obtained the best MAE; and XGBT and LGBM were also noteworthy in their predictive effects. These results also confirmed that hybrid models and ensemble models are generally superior to prediction methods using single models [
58,
59], and LSTM-SVR has been proven to be a reliable method for predicting AQI. This contributes to the practical application of air pollution control and promotes ecological governance and green development in China [
60].
This study also has many shortcomings. First, the research only considered meteorological conditions and the concentration of air pollutants in predicting the air quality index, and since the data time series is measured daily, some factors that are difficult to calculate as daily averages but are well-studied, such as population elements, economic activities, and geographical environment, were not considered in the model analysis. Second, the data from different sites in each urban agglomeration did not form effective clusters in the research, and each site was an independent time-series data set, resulting in fragmented time-series data being fed into the model, which could have caused some prediction interference. Third, the model algorithms compared in the study were not comprehensive enough, such as the lack of comparison with the performance of the stacking model in ensemble learning. Fourth, this study only explored the predictive performance of different models and did not further delve into measuring the feature importance of AQI using high-performing models, performing feature selection, or constructing new features. So this article only provides a better model-selection perspective in AQI prediction, but there is not much discussion on analyzing the causes that affect the quality of AQI and providing decision-making opinions for specific pollutant treatment. In subsequent research, we will further overcome these shortcomings and improve the depth and breadth of the application of artificial intelligence technology in air quality prediction.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}