
Forecasting PM10 Concentrations in the Caribbean Area Using Machine Learning Models



Abstract
1. Introduction
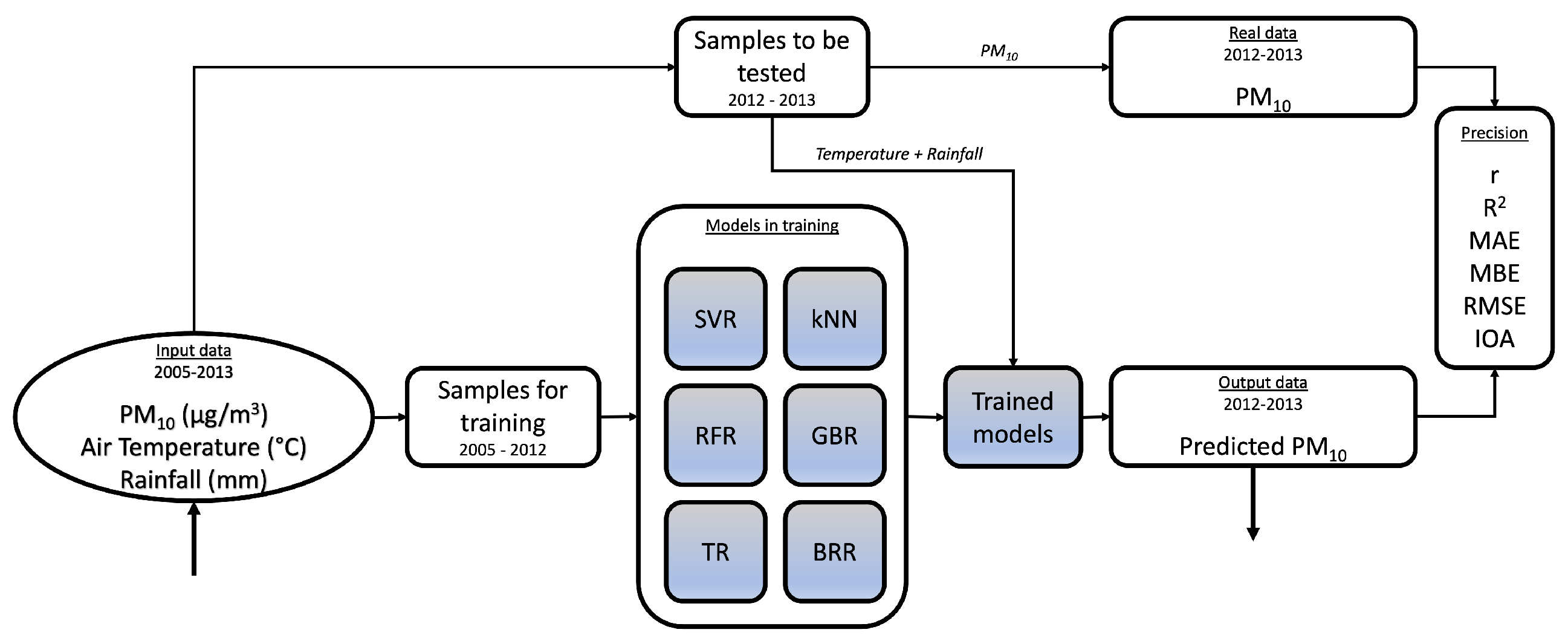
2. Data Presentation
3. Theoretical Framework
3.1. Machine Learning Models
3.1.1. Support Vector Regression (SVR)
3.1.2. k-Nearest Neighbor Regression (kNN)
3.1.3. Random Forest Regression (RFR)
- The number of trees in the forest: the more trees we have, the more accurate the model is. Nevertheless, this increases the time of RF computations;
- Max depth: the depth of each tree;
- Bootstrap: this technique is used in RF to improve the robustness of forecasting. Bootstrap is performed to reduce the variance in each training sample of a tree. Consequently, this avoids overfitting [60];
- Criterion: a function to measure the quality of a split. Here, the squared error was chosen in order to minimize the mean-squared error of the current tree given the split.
3.1.4. Gradient Boosting Regression (GBR)
3.1.5. Tweedie Regression (TR)
3.1.6. Bayesian Ridge Regression (BRR)
3.2. Evaluation of Forecast Performance
4. Results and Discussion
4.1. Data Analysis
4.2. Machine Learning Process
- For SVR, the kernel RBF was used with a large C (∼1000) and a small (∼0.01);
- For kNN, k = 3 using ;
- For RFR, the parameters were chosen according to a trade-off between the time of process and accuracy. Thus, the bootstrap method was activated with the criterion squared error for high-quality data slicing. For the best accuracy, 100 trees (tree number) were specified in the forest with a max depth until all leaves were pure;
- For GBR, the same parameters as those of RFR were used, i.e., 100 trees and squared error function as the criterion. Furthermore, the squared error function was selected as a loss function with a learning rate of 0.1 to reduce the effect of the first tree in the decision tree;
- For BRR, parameters were chosen to stop the algorithm when the process converged to ∼.
4.3. Machine Learning Forecasting
4.4. Performance Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Saco, P.; McDonough, K.; Rodriguez, J.; Rivera-Zayas, J.; Sandi, S. The role of soils in the regulation of hazards and extreme events. Philos. Trans. R. Soc. B 2021, 376, 20200178. [Google Scholar] [CrossRef] [PubMed]
- Euphrasie-Clotilde, L.; Plocoste, T.; Brute, F. Particle Size Analysis of African Dust Haze over the Last 20 Years: A Focus on the Extreme Event of June 2020. Atmosphere 2021, 12, 502. [Google Scholar] [CrossRef]
- Plocoste, T. Multiscale analysis of the dynamic relationship between particulate matter (PM10) and meteorological parameters using CEEMDAN: A focus on “Godzilla” African dust event. Atmos. Pollut. Res. 2022, 13, 101252. [Google Scholar] [CrossRef]
- Urrutia-Pereira, M.; Rizzo, L.; Staffeld, P.; Chong-Neto, H.; Viegi, G.; Solé, D. Dust from the Sahara to the American Continent: Health impacts: Dust from Sahara. Allergol. Immunopathol. 2021, 49, 187–194. [Google Scholar] [CrossRef] [PubMed]
- Gyan, K.; Henry, W.; Lacaille, S.; Laloo, A.; Lamsee-Ebanks, C.; McKay, S.; Antoine, R.; Monteil, M. African dust clouds are associated with increased paediatric asthma accident and emergency admissions on the Caribbean island of Trinidad. Int. J. Biometeorol. 2005, 49, 371–376. [Google Scholar] [CrossRef]
- Monteil, M. Saharan dust clouds and human health in the English-speaking Caribbean: What we know and don’t know. Environ. Geochem. Health 2008, 30, 339–343. [Google Scholar] [CrossRef]
- Cadelis, G.; Tourres, R.; Molinié, J. Short-term effects of the particulate pollutants contained in Saharan dust on the visits of children to the emergency department due to asthmatic conditions in Guadeloupe (French Archipelago of the Caribbean). PLoS ONE 2014, 9, e91136. [Google Scholar] [CrossRef]
- Akpinar-Elci, M.; Martin, F.; Behr, J.; Diaz, R. Saharan dust, climate variability, and asthma in Grenada, the Caribbean. Int. J. Biometeorol. 2015, 59, 1667–1671. [Google Scholar] [CrossRef]
- Viel, J.; Michineau, L.; Garbin, C.; Monfort, C.; Kadhel, P.; Multigner, L.; Rouget, F. Impact of Saharan Dust on Severe Small for Gestational Births in the Caribbean. Am. J. Trop. Med. Hyg. 2020, 102, 1463–1465. [Google Scholar] [CrossRef]
- Carlson, T.; Prospero, J. The large-scale movement of Saharan air outbreaks over the northern equatorial Atlantic. J. Appl. Meteorol. Climatol. 1972, 11, 283–297. [Google Scholar] [CrossRef]
- Prospero, J.; Carlson, T. Vertical and areal distribution of Saharan dust over the western equatorial North Atlantic Ocean. J. Geophys. Res. 1972, 77, 5255–5265. [Google Scholar] [CrossRef]
- Prospero, J.; Delany, A.; Delany, A.; Carlson, T. The Discovery of African Dust Transport to the Western Hemisphere and the Saharan Air Layer: A History. Bull. Am. Meteorol. Soc. 2021, 102, E1239–E1260. [Google Scholar] [CrossRef]
- Prospero, J.; Collard, F.; Molinié, J.; Jeannot, A. Characterizing the annual cycle of African dust transport to the Caribbean Basin and South America and its impact on the environment and air quality. Glob. Biogeochem. Cycles 2014, 28, 757–773. [Google Scholar] [CrossRef]
- Plocoste, T.; Calif, R.; Euphrasie-Clotilde, L.; Brute, F. The statistical behavior of PM10 events over guadeloupean archipelago: Stationarity, modelling and extreme events. Atmos. Res. 2020, 241, 104956. [Google Scholar] [CrossRef]
- Plocoste, T.; Euphrasie-Clotilde, L.; Calif, R.; Brute, F. Quantifying spatio-temporal dynamics of African dust detection threshold for PM10 concentrations in the Caribbean area using multiscale decomposition. Front. Environ. Sci. 2022, 10, 907440. [Google Scholar] [CrossRef]
- Schepanski, K. Transport of mineral dust and its impact on climate. Geosciences 2018, 8, 151. [Google Scholar] [CrossRef]
- Plocoste, T.; Calif, R. Is there a causal relationship between Particulate Matter (PM10) and air Temperature data? An analysis based on the Liang-Kleeman information transfer theory. Atmos. Pollut. Res. 2021, 12, 101177. [Google Scholar] [CrossRef]
- Plocoste, T. Detecting the Causal Nexus between Particulate Matter (PM10) and Rainfall in the Caribbean Area. Atmosphere 2022, 13, 175. [Google Scholar] [CrossRef]
- Elminir, H.K. Relative influence of air pollutants and weather conditions on solar radiation—Part 1: Relationship of air pollutants with weather conditions. Meteorol. Atmos. Phys. 2007, 96, 245–256. [Google Scholar] [CrossRef]
- Plocoste, T.; Calif, R.; Euphrasie-Clotilde, L.; Brute, F. Investigation of local correlations between particulate matter (PM10) and air temperature in the Caribbean basin using Ensemble Empirical Mode Decomposition. Atmos. Pollut. Res. 2020, 11, 1692–1704. [Google Scholar] [CrossRef]
- Zhu, L.; Liu, J.; Cong, L.; Ma, W.; Ma, W.; Zhang, Z. Spatiotemporal characteristics of particulate matter and dry deposition flux in the Cuihu wetland of Beijing. PLoS ONE 2016, 11, e0158616. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Liu, J.; Zhai, J.; Cong, L.; Wang, Y.; Ma, W.; Zhang, Z.; Li, C. Comparison of dry and wet deposition of particulate matter in near-surface waters during summer. PLoS ONE 2018, 13, e0199241. [Google Scholar] [CrossRef] [PubMed]
- Fan, J.; Wang, Y.; Rosenfeld, D.; Liu, X. Review of aerosol–cloud interactions: Mechanisms, significance, and challenges. J. Atmos. Sci. 2016, 73, 4221–4252. [Google Scholar] [CrossRef]
- Plocoste, T.; Carmona-Cabezas, R.; Gutiérrez de Ravé, E.; Jimnez-Hornero, F. Wet scavenging process of particulate matter (PM10): A multivariate complex network approach. Atmos. Pollut. Res. 2021, 12, 101095. [Google Scholar] [CrossRef]
- Sugihara, G.; May, R.; Ye, H.; Hsieh, C.; Deyle, E.; Fogarty, M.; Munch, S. Detecting causality in complex ecosystems. Science 2012, 338, 496–500. [Google Scholar] [CrossRef] [PubMed]
- Konovalov, I.; Beekmann, M.; Meleux, F.; Dutot, A.; Foret, G. Combining deterministic and statistical approaches for PM10 forecasting in Europe. Atmos. Environ. 2009, 43, 6425–6434. [Google Scholar] [CrossRef]
- Lee, H.; Liu, Y.; Coull, B.; Schwartz, J.; Koutrakis, P. A novel calibration approach of MODIS AOD data to predict PM2.5 concentrations. Atmos. Chem. Phys. 2011, 11, 7991–8002. [Google Scholar] [CrossRef]
- Chen, Y.; Shi, R.; Shu, S.; Gao, W. Ensemble and enhanced PM10 concentration forecast model based on stepwise regression and wavelet analysis. Atmos. Environ. 2013, 74, 346–359. [Google Scholar] [CrossRef]
- Djalalova, I.; Delle Monache, L.; Wilczak, J. PM2.5 analog forecast and Kalman filter post-processing for the Community Multiscale Air Quality (CMAQ) model. Atmos. Environ. 2015, 108, 76–87. [Google Scholar] [CrossRef]
- Kloog, I.; Chudnovsky, A.A.; Just, A.C.; Nordio, F.; Koutrakis, P.; Coull, B.A.; Lyapustin, A.; Wang, Y.; Schwartz, J. A new hybrid spatio-temporal model for estimating daily multi-year PM2.5 concentrations across northeastern USA using high resolution aerosol optical depth data. Atmos. Environ. 2014, 95, 581–590. [Google Scholar] [CrossRef]
- Hu, X.; Belle, J.H.; Meng, X.; Wildani, A.; Waller, L.A.; Strickland, M.J.; Liu, Y. Estimating PM2.5 concentrations in the conterminous United States using the random forest approach. Environ. Sci. Technol. 2017, 51, 6936–6944. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.; Wang, Y.; Li, S.; Cao, W.; Ren, H.; Knibbs, L.D.; Abramson, M.J.; Guo, Y. Spatiotemporal patterns of PM10 concentrations over China during 2005–2016: A satellite-based estimation using the random forests approach. Environ. Pollut. 2018, 242, 605–613. [Google Scholar] [CrossRef] [PubMed]
- Choubin, B.; Moradi, E.; Golshan, M.; Adamowski, J.; Sajedi-Hosseini, F.; Mosavi, A. An ensemble prediction of flood susceptibility using multivariate discriminant analysis, classification and regression trees, and support vector machines. Sci. Total Environ. 2019, 651, 2087–2096. [Google Scholar] [CrossRef]
- Mahesh, B. Machine learning algorithms-a review. Int. J. Sci. Res. 2020, 9, 381–386. [Google Scholar]
- Choubin, B.; Abdolshahnejad, M.; Moradi, E.; Querol, X.; Mosavi, A.; Shamshirband, S.; Ghamisi, P. Spatial hazard assessment of the PM10 using machine learning models in Barcelona, Spain. Sci. Total Environ. 2020, 701, 134474. [Google Scholar] [CrossRef] [PubMed]
- Zickus, M.; Greig, A.; Niranjan, M. Comparison of four machine learning methods for predicting PM10 concentrations in Helsinki, Finland. Water Air Soil Pollut. Focus 2002, 2, 717–729. [Google Scholar] [CrossRef]
- Brodley, C.E. Addressing the selective superiority problem: Automatic algorithm/model class selection. In Proceedings of the Tenth International Conference on Machine Learning, Amherst, MA, USA, 27–29 June 1993; pp. 17–24. [Google Scholar]
- Raimondo, G.; Montuori, A.; Moniaci, W.; Pasero, E.; Almkvist, E. A machine learning tool to forecast PM10 level. In Proceedings of the AMS 87th Annual Meeting, San Antonio, TX, USA, 14–18 January 2007; pp. 13–18. [Google Scholar]
- Voukantsis, D.; Karatzas, K.; Kukkonen, J.; Räsänen, T.; Karppinen, A.; Kolehmainen, M. Intercomparison of air quality data using principal component analysis, and forecasting of PM10 and PM2.5 concentrations using artificial neural networks, in Thessaloniki and Helsinki. Sci. Total Environ. 2011, 409, 1266–1276. [Google Scholar] [CrossRef]
- de Gennaro, G.; Trizio, L.; Di Gilio, A.; Pey, J.; Pérez, N.; Cusack, M.; Alastuey, A.; Querol, X. Neural network model for the prediction of PM10 daily concentrations in two sites in the Western Mediterranean. Sci. Total Environ. 2013, 463, 875–883. [Google Scholar] [CrossRef]
- Debry, E.; Mallet, V. Ensemble forecasting with machine learning algorithms for ozone, nitrogen dioxide and PM10 on the Prev’Air platform. Atmos. Environ. 2014, 91, 71–84. [Google Scholar] [CrossRef]
- Taspinar, F. Improving artificial neural network model predictions of daily average PM10 concentrations by applying principle component analysis and implementing seasonal models. J. Air Waste Manag. Assoc. 2015, 65, 800–809. [Google Scholar] [CrossRef]
- Suleiman, A.; Tight, M.; Quinn, A. Applying machine learning methods in managing urban concentrations of traffic-related particulate matter (PM10 and PM2.5). Atmos. Pollut. Res. 2019, 10, 134–144. [Google Scholar] [CrossRef]
- Bozdağ, A.; Dokuz, Y.; Gökçek, Ö.B. Spatial prediction of PM10 concentration using machine learning algorithms in Ankara, Turkey. Environ. Pollut. 2020, 263, 114635. [Google Scholar] [CrossRef] [PubMed]
- Kim, B.Y.; Lim, Y.K.; Cha, J.W. Short-term prediction of particulate matter (PM10 and PM2.5) in Seoul, South Korea using tree-based machine learning algorithms. Atmos. Pollut. Res. 2022, 13, 101547. [Google Scholar] [CrossRef]
- Kujawska, J.; Kulisz, M.; Oleszczuk, P.; Cel, W. Machine Learning Methods to Forecast the Concentration of PM10 in Lublin, Poland. Energies 2022, 15, 6428. [Google Scholar] [CrossRef]
- Plocoste, T.; Calif, R.; Jacoby-Koaly, S. Multi-scale time dependent correlation between synchronous measurements of ground-level ozone and meteorological parameters in the Caribbean Basin. Atmos. Environ. 2019, 211, 234–246. [Google Scholar] [CrossRef]
- Plocoste, T.; Jacoby-Koaly, S.; Molinié, J.; Petit, R. Evidence of the effect of an urban heat island on air quality near a landfill. Urban Clim. 2014, 10, 745–757. [Google Scholar] [CrossRef]
- Plocoste, T.; Dorville, J.; Monjoly, S.; Jacoby-Koaly, S.; André, M. Assessment of Nitrogen Oxides and Ground-Level Ozone behavior in a dense air quality station network: Case study in the Lesser Antilles Arc. J. Air Waste Manag. Assoc. 2018, 68, 1278–1300. [Google Scholar] [CrossRef]
- Plocoste, T.; Calif, R.; Jacoby-Koaly, S. Temporal multiscaling characteristics of particulate matter PM10 and ground-level ozone O3 concentrations in Caribbean region. Atmos. Environ. 2017, 169, 22–35. [Google Scholar] [CrossRef]
- Plocoste, T.; Pavón-Domínguez, P. Multifractal detrended cross-correlation analysis of wind speed and solar radiation. Chaos Interdiscip. J. Nonlinear Sci. 2020, 30, 113109. [Google Scholar] [CrossRef]
- Gani, W.; Taleb, H.; Limam, M. Support vector regression based residual control charts. J. Appl. Stat. 2010, 37, 309–324. [Google Scholar] [CrossRef]
- Singh, A.; Kotiyal, V.; Sharma, S.; Nagar, J.; Lee, C.C. A machine learning approach to predict the average localization error with applications to wireless sensor networks. IEEE Access 2020, 8, 208253–208263. [Google Scholar] [CrossRef]
- Bodaghi, A.; Ansari, H.R.; Gholami, M. Optimized support vector regression for drillingrate of penetration estimation. Open Geosci. 2015, 7, 870–879. [Google Scholar] [CrossRef]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. Adv. Neural Inf. Process. Syst. 1996, 9. [Google Scholar]
- Guo, Y.; Li, X.; Bai, G.; Ma, J. Time series prediction method based on LS-SVR with modified gaussian RBF. In Proceedings of the International Conference on Neural Information Processing, Doha, Qatar, 12–15 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 9–17. [Google Scholar]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Cheng, D. Learning k for knn classification. ACM Trans. Intell. Syst. Technol. (TIST) 2017, 8, 1–19. [Google Scholar] [CrossRef]
- Ban, T.; Zhang, R.; Pang, S.; Sarrafzadeh, A.; Inoue, D. Referential knn regression for financial time series forecasting. In Proceedings of the International Conference on Neural Information Processing, Daegu, Republic of Korea, 3–7 November 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 601–608. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Segal, M.R. Machine Learning Benchmarks and Random Forest Regression; Technical Report; University of California: California, CA, USA, 2004. [Google Scholar]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobotics 2013, 7, 21. [Google Scholar] [CrossRef]
- Keprate, A.; Ratnayake, R.C. Using gradient boosting regressor to predict stress intensity factor of a crack propagating in small bore piping. In Proceedings of the 2017 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Singapore, 10–13 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1331–1336. [Google Scholar]
- Smyth, G.K. Regression analysis of quantity data with exact zeros. In Proceedings of the Second Australia–Japan Workshop on Stochastic Models in Engineering, Technology and Management, Gold Coast, Australia, 17–19 July 1996; Citeseer: Princeton, NJ, USA, 1996; pp. 572–580. [Google Scholar]
- Yang, Y.; Yang, Y. Hybrid prediction method for wind speed combining ensemble empirical mode decomposition and Bayesian ridge regression. IEEE Access 2020, 8, 71206–71218. [Google Scholar] [CrossRef]
- Ul-Saufie, A.Z.; Yahya, A.S.; Ramli, N.A.; Hamid, H.A. Comparison between multiple linear regression and feed forward back propagation neural network models for predicting PM10 concentration level based on gaseous and meteorological parameters. Int. J. Appl. Sci. Technol. 2011, 1, 42–49. [Google Scholar]
- Willmott, C.J.; Robeson, S.M.; Matsuura, K. A refined index of model performance. Int. J. Climatol. 2012, 32, 2088–2094. [Google Scholar] [CrossRef]
- Fu, M.; Wang, W.; Le, Z.; Khorram, M.S. Prediction of particular matter concentrations by developed feed-forward neural network with rolling mechanism and gray model. Neural Comput. Appl. 2015, 26, 1789–1797. [Google Scholar] [CrossRef]
- Papoulis, A.; Pillai, S.U. Probability, Random Variables, and Stochastic Processes; Tata McGraw-Hill Education: New York, NY, USA, 2002. [Google Scholar]
- Windsor, H.; Toumi, R. Scaling and persistence of UK pollution. Atmos. Environ. 2001, 35, 4545–4556. [Google Scholar] [CrossRef]
- Barkstrom, B.R.; Smith, G.L. The earth radiation budget experiment: Science and implementation. Rev. Geophys. 1986, 24, 379–390. [Google Scholar] [CrossRef]
- Martinez, C.; Goddard, L.; Kushnir, Y.; Ting, M. Seasonal climatology and dynamical mechanisms of rainfall in the Caribbean. Clim. Dyn. 2019, 53, 825–846. [Google Scholar] [CrossRef]
- Martinez, C.; Kushnir, Y.; Goddard, L.; Ting, M. Interannual variability of the early and late-rainy seasons in the Caribbean. Clim. Dyn. 2020, 55, 1563–1583. [Google Scholar] [CrossRef]
- Alexis, E.; Plocoste, T.; Nuiro, S.P. Analysis of Particulate Matter (PM10) Behavior in the Caribbean Area Using a Coupled SARIMA-GARCH Model. Atmosphere 2022, 13, 862. [Google Scholar] [CrossRef]
- Clergue, C.; Dellinger, M.; Buss, H.; Gaillardet, J.; Benedetti, M.; Dessert, C. Influence of atmospheric deposits and secondary minerals on Li isotopes budget in a highly weathered catchment, Guadeloupe (Lesser Antilles). Chem. Geol. 2015, 414, 28–41. [Google Scholar] [CrossRef]
- Rastelli, E.; Corinaldesi, C.; Dell’Anno, A.; Martire, M.; Greco, S.; Facchini, M.; Rinaldi, M.; O’Dowd, C.; Ceburnis, D.; Danovaro, R. Transfer of labile organic matter and microbes from the ocean surface to the marine aerosol: An experimental approach. Sci. Rep. 2017, 7, 11475. [Google Scholar] [CrossRef]
- Plocoste, T.; Carmona-Cabezas, R.; Jiménez-Hornero, F.; Gutiérrez de Ravé, E. Background PM10 atmosphere: In the seek of a multifractal characterization using complex networks. J. Aerosol Sci. 2021, 155, 105777. [Google Scholar] [CrossRef]
- Plocoste, T.; Carmona-Cabezas, R.; Jiménez-Hornero, F.J.; Gutiérrez de Ravé, E.; Calif, R. Multifractal characterisation of particulate matter (PM10) time series in the Caribbean basin using visibility graphs. Atmos. Pollut. Res. 2021, 12, 100–110. [Google Scholar] [CrossRef]
- Künzli, N.; Kaiser, R.; Medina, S.; Studnicka, M.; Chanel, O.; Filliger, P.; Herry, M.; Horak, F.; Puybonnieux-Texier, V.; Quénel, P.; et al. Public-health impact of outdoor and traffic-related air pollution: A European assessment. Lancet 2000, 356, 795–801. [Google Scholar] [CrossRef]
- He, H.; Pan, W.; Lu, W.; Xue, Y.; Peng, G. Multifractal property and long-range cross-correlation behavior of particulate matters at urban traffic intersection in Shanghai. Stoch. Environ. Res. Risk Assess. 2016, 30, 1515–1525. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| T | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Year | ||||||||||||
| 2005 (N = 354) | 27.3 | 15.3 | 2.3 | 9.1 | 26.2 | 1.6 | −0.5 | 2.5 | 5.4 | 11.0 | 3.9 | 22.3 |
| 2006 (N = 358) | 27.8 | 16.6 | 1.7 | 5.5 | 26.1 | 1.5 | −0.3 | 2.1 | 4.1 | 7.7 | 3.3 | 15.4 |
| 2007 (N = 357) | 27.8 | 17.5 | 2.5 | 12.8 | 26.3 | 1.4 | −0.2 | 2.1 | 2.8 | 5.9 | 4.2 | 25.5 |
| 2008 (N = 355) | 24.9 | 13.1 | 3.2 | 18.3 | 25.7 | 1.6 | −0.2 | 2.1 | 4.4 | 8.5 | 3.4 | 16.2 |
| 2009 (N = 365) | 24.8 | 14.5 | 3.0 | 14.9 | 26.1 | 1.5 | −0.1 | 1.9 | 3.5 | 7.7 | 5.8 | 47.8 |
| 2010 (N = 354) | 27.5 | 19.7 | 2.9 | 15.0 | 26.7 | 1.3 | −0.2 | 2.2 | 4.9 | 11.1 | 5.3 | 45.1 |
| 2011 (N = 352) | 24.4 | 13.8 | 2.0 | 7.3 | 25.9 | 1.5 | −0.1 | 2.1 | 5.8 | 12.9 | 5.6 | 46.5 |
| 2012 (N = 351) | 28.4 | 17.2 | 1.3 | 3.9 | 26.2 | 1.5 | −0.4 | 2.2 | 3.9 | 8.7 | 4.6 | 29.4 |
| Parameter 1 | Parameter 2 | Parameter 3 | Parameter 4 | |
|---|---|---|---|---|
| SVR | RBF function | C ∼ 1000 | γ ∼ 0.01 | - |
| kNN | k = 3 | Euclidean distance | - | - |
| RFR | tree number ∼ 100 | max depth | square error | - |
| GBR | Loss function | true number ∼ 100 | v ∼ 0.1 | square error |
| TR | ξ ∼ 1.5 | max iter ∼ 100 | tolerance ∼ 1 × 10−6 | - |
| BRR | a ∼ 1 | max iter ∼ 200 | tolerance ∼ 1 × 10−6 | - |
| SVR | kNN | RFR | GBR | TR | BRR | |
|---|---|---|---|---|---|---|
| r | 0.7641 | 0.6763 | 0.7524 | 0.7831 | 0.7443 | 0.7666 |
| 0.5839 | 0.4573 | 0.5661 | 0.6132 | 0.5540 | 0.5877 | |
| 7.1298 | 8.4067 | 7.2015 | 6.8479 | 7.7303 | 7.4590 | |
| −2.8139 | −0.4023 | −0.2696 | −1.1010 | −1.2586 | −0.5722 | |
| 11.2348 | 12.4251 | 10.9713 | 10.4400 | 11.3701 | 10.7435 | |
| 0.7259 | 0.6768 | 0.7232 | 0.7368 | 0.7028 | 0.7133 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Plocoste, T.; Laventure, S. Forecasting PM10 Concentrations in the Caribbean Area Using Machine Learning Models. Atmosphere 2023, 14, 134. https://doi.org/10.3390/atmos14010134
Plocoste T, Laventure S. Forecasting PM10 Concentrations in the Caribbean Area Using Machine Learning Models. Atmosphere. 2023; 14(1):134. https://doi.org/10.3390/atmos14010134
Chicago/Turabian StylePlocoste, Thomas, and Sylvio Laventure. 2023. "Forecasting PM10 Concentrations in the Caribbean Area Using Machine Learning Models" Atmosphere 14, no. 1: 134. https://doi.org/10.3390/atmos14010134
APA StylePlocoste, T., & Laventure, S. (2023). Forecasting PM10 Concentrations in the Caribbean Area Using Machine Learning Models. Atmosphere, 14(1), 134. https://doi.org/10.3390/atmos14010134