1. Introduction
The increase in air pollution in urban areas is a concern on a global scale. Such pollution occurs especially due to anthropogenic activities, such as industrialization, the growth of urbanization, automotive vehicles powered by fossil fuels and agricultural burning [
1]. According to United Nations, more than half of the world lives in urban regions (around 55%) and this number is increasing, considering some European countries, such as the United Kingdom, with more than 83% of the population living in urban environments, a figure that continues to increase over time. Consequently, humans have been constantly exposed to variety of harmful components from many sources, mainly those from road vehicles, which are the dominant source of ambient air pollutants, such as particulate matter (PM), nitrogen oxide (NOx), carbon monoxide (CO) and volatile organic compounds (VOCs) [
2].
Among these pollutants, PM can be highlighted as one of most critical, as it can cause numerous adverse effects on human health, such as asthma attacks, chronic bronchitis, diabetes, cardiovascular disease and lung cancer [
3], and it is strongly associated with respiratory diseases in children [
2].
PM is an atmospheric pollutant composed of a mixture of solid and liquid particles suspended in the air [
2]. These kinds of particles can be directly emitted through anthropogenic or non-anthropogenic activities, and they are classified according to their aerodynamic diameter and their impacts on human health. PM
2.5 includes fine particles with a diameter up to 2.5 µm, which can enter the cardiorespiratory systems. The World Health Organization (WHO) estimates that long-term exposure to PM
2.5 increases long-term risk of cardiopulmonary mortality by 6% to 13% per 10 µg/m
3 of PM
2.5 [
4]. Furthermore, results from the European project Aphekom indicate that the life expectancy of the most polluted cities could be increased by approximately 20 months if long-term exposure to PM
2.5 were reduced to the annual limits established by the WHO [
2].
For these reasons, countries have been encouraged to adopt of even more stringent standards and actions to help control and reduce temporal PM concentrations in urban environments [
4]. Hence, the construction of models that predict the concentration of this component up to 24 h ahead in densely populated areas with lower computational complexity and cost arises as a key and strategic tool to assist the monitoring process, support control and preventive actions to improve air quality and, consequently, reduce impacts on the health of the population.
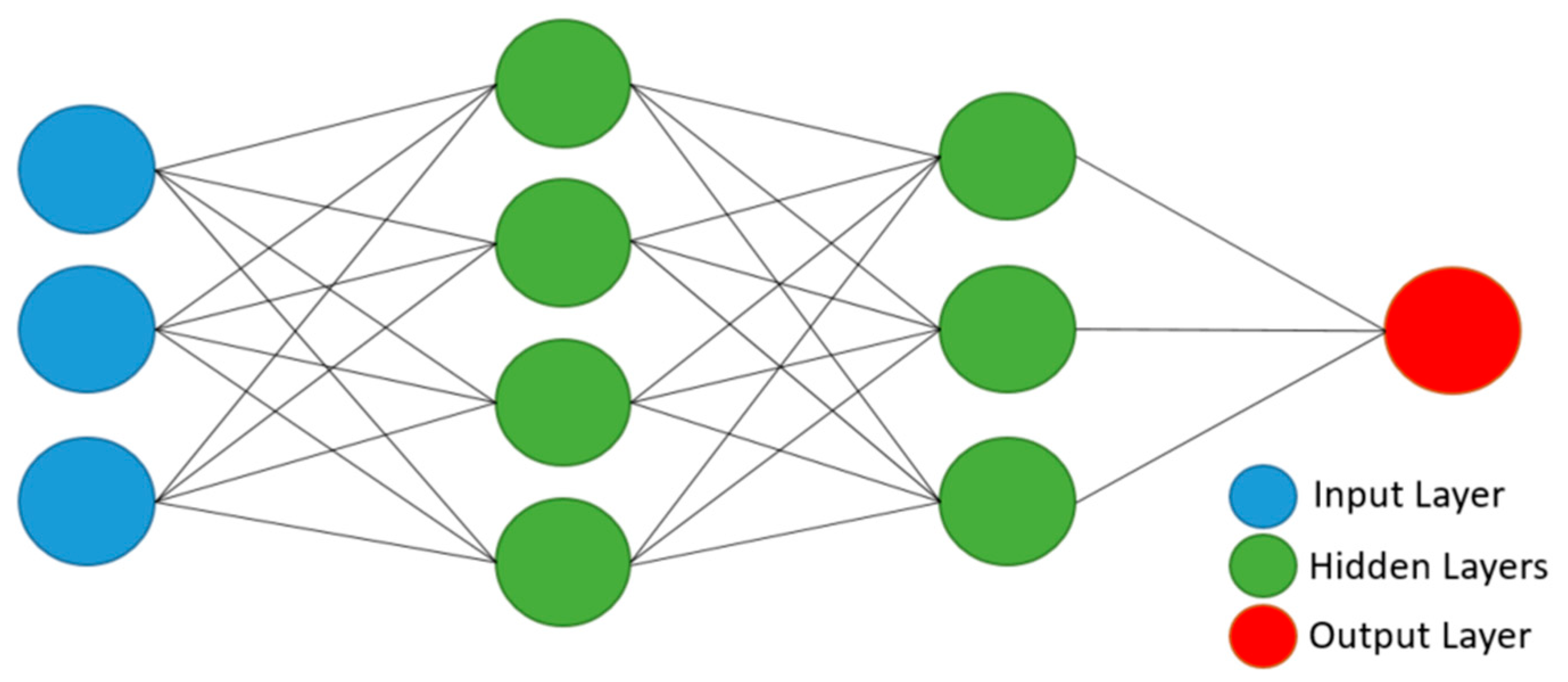
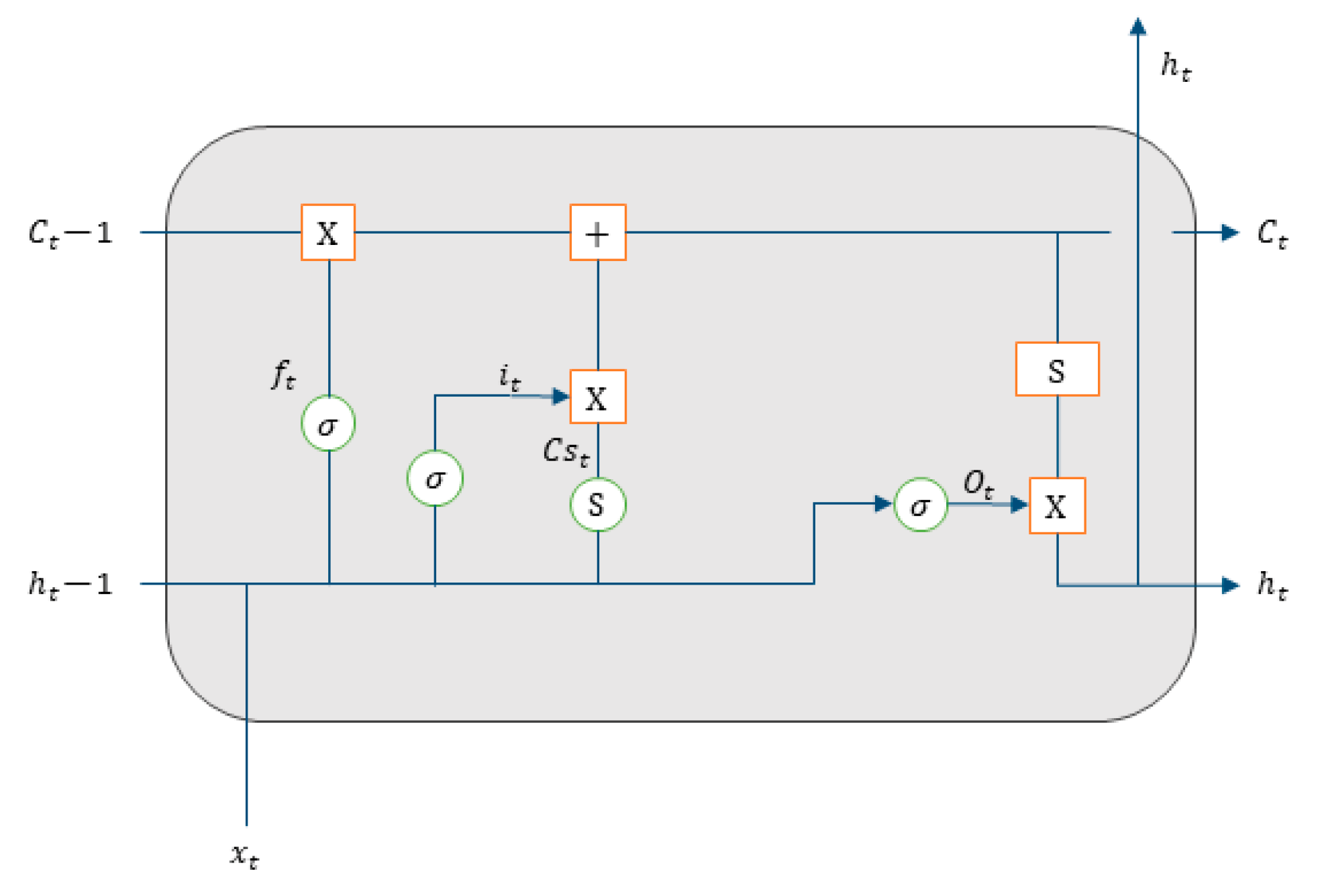
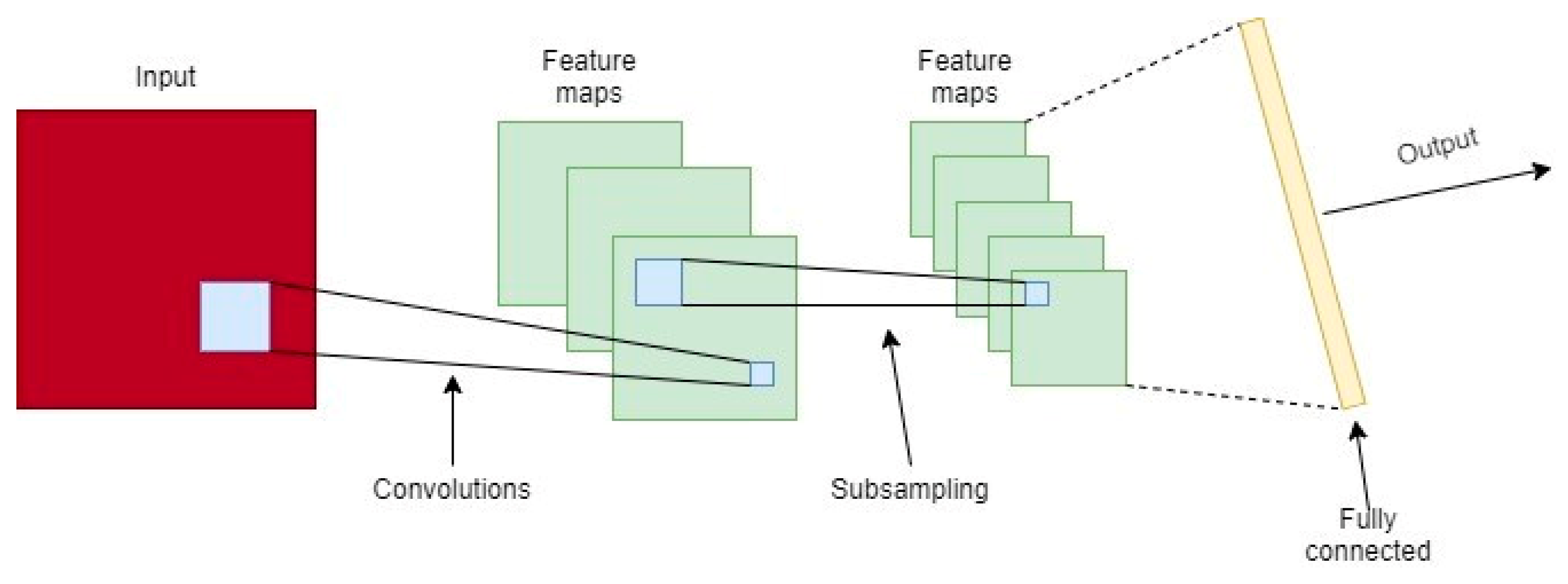
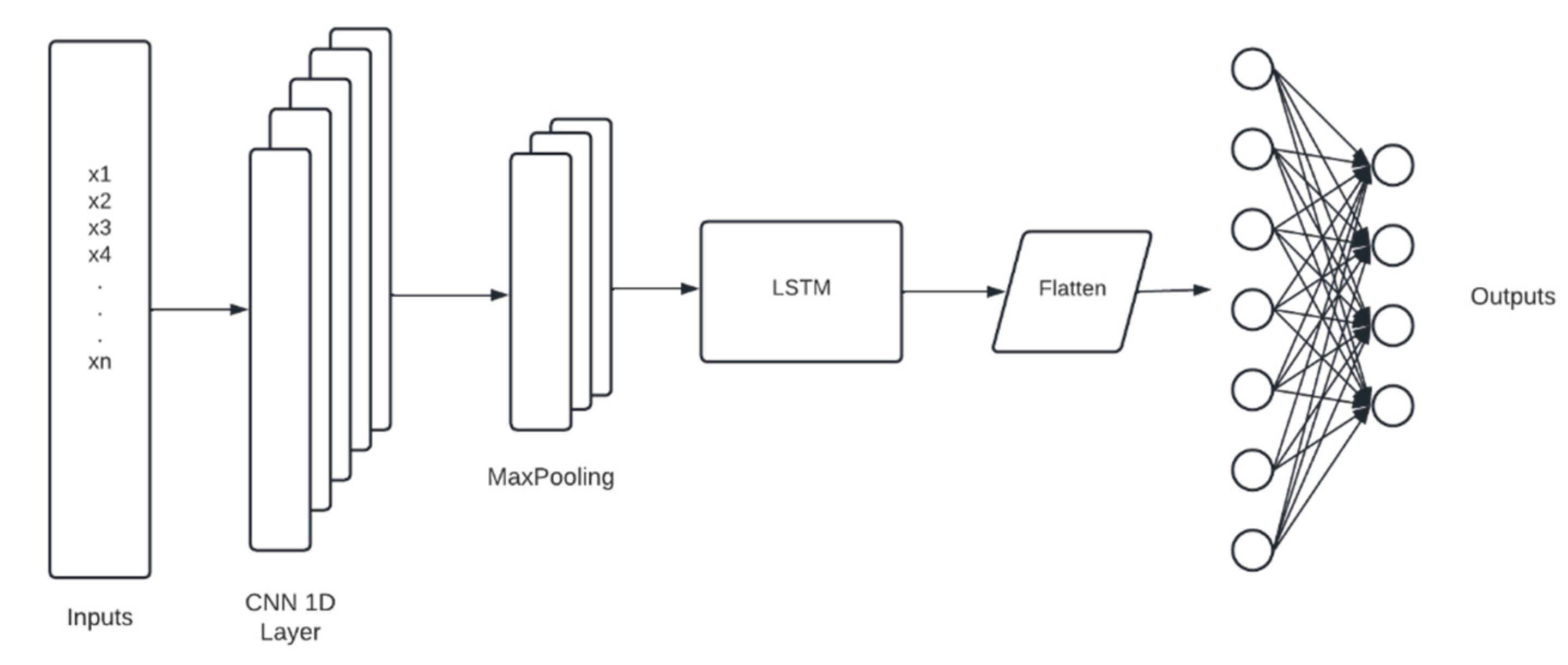
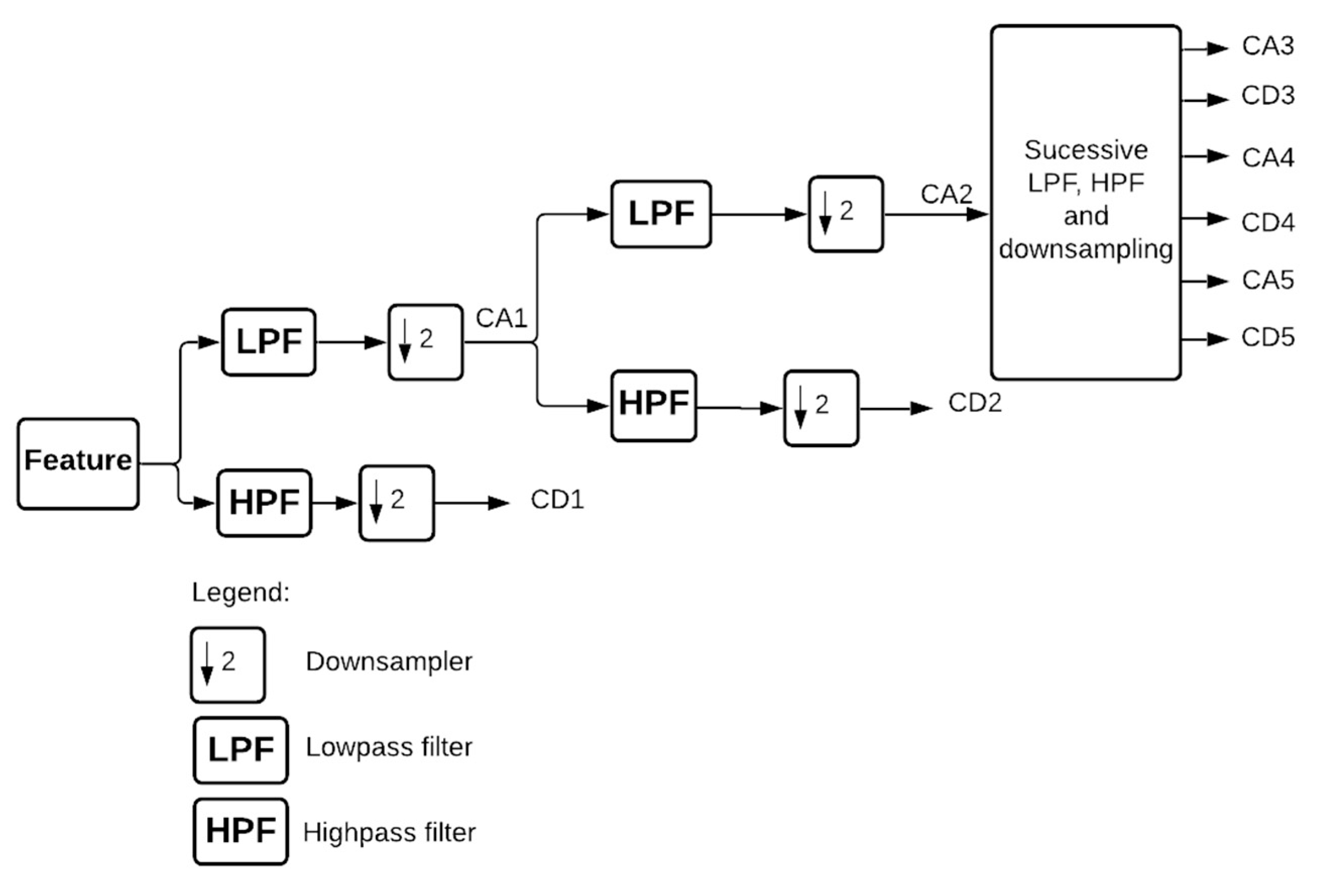
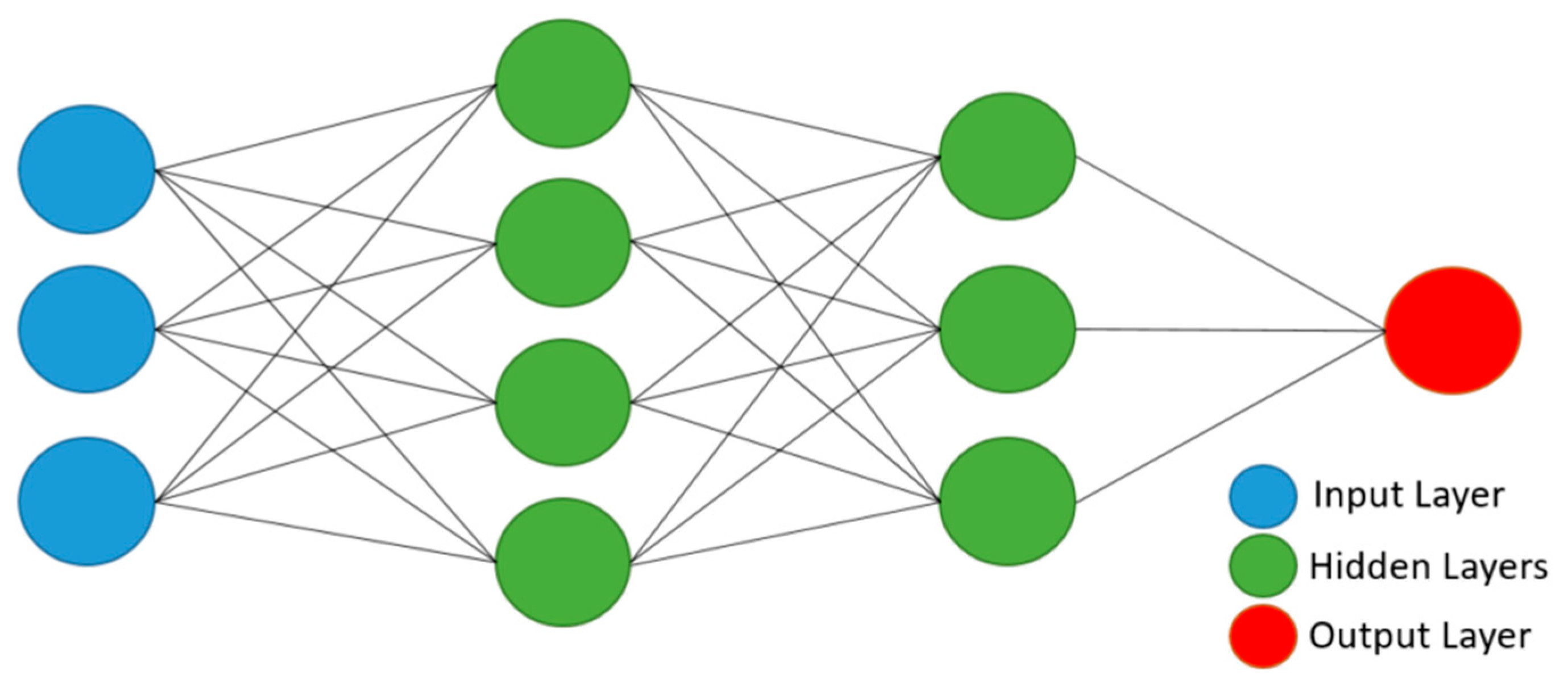
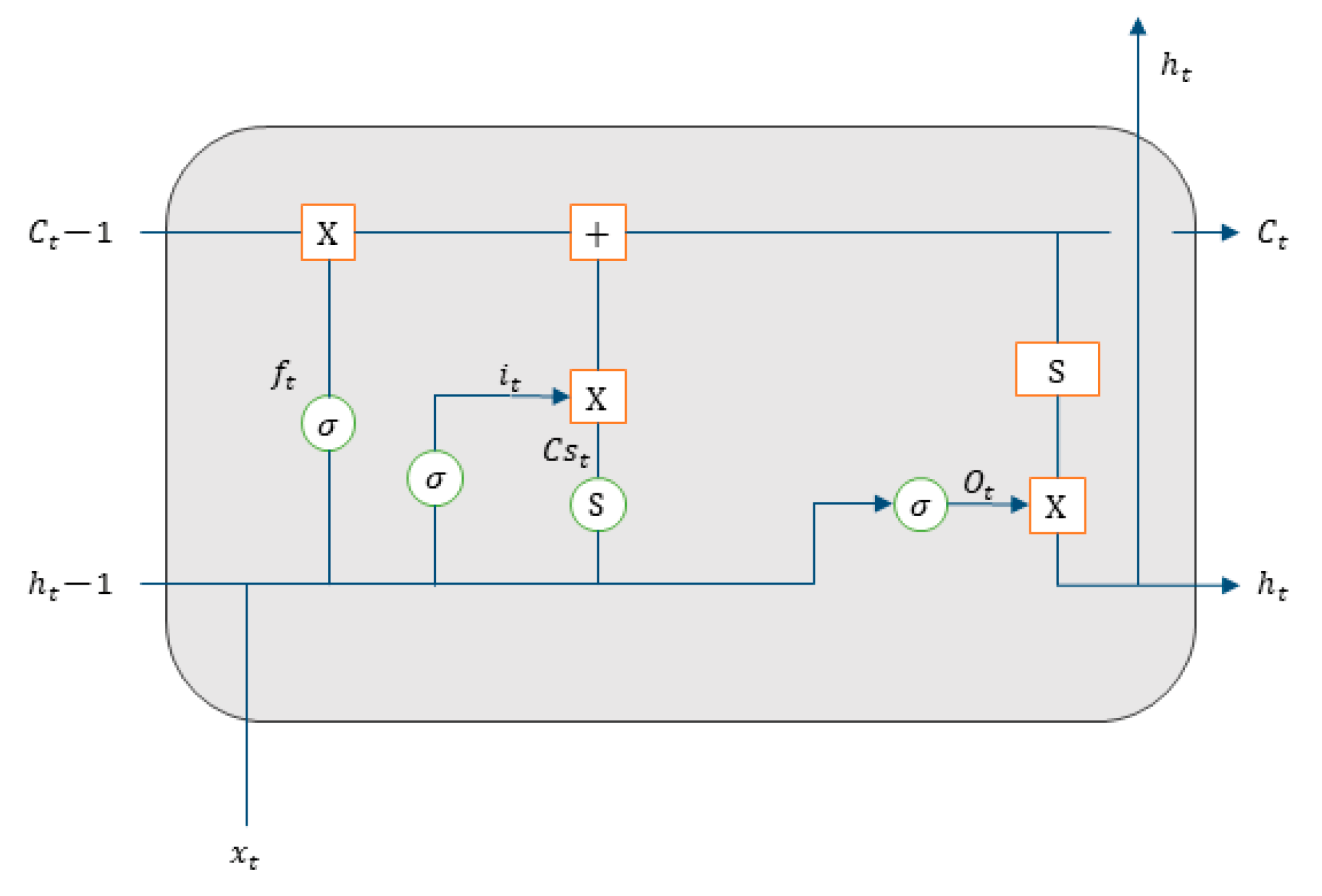
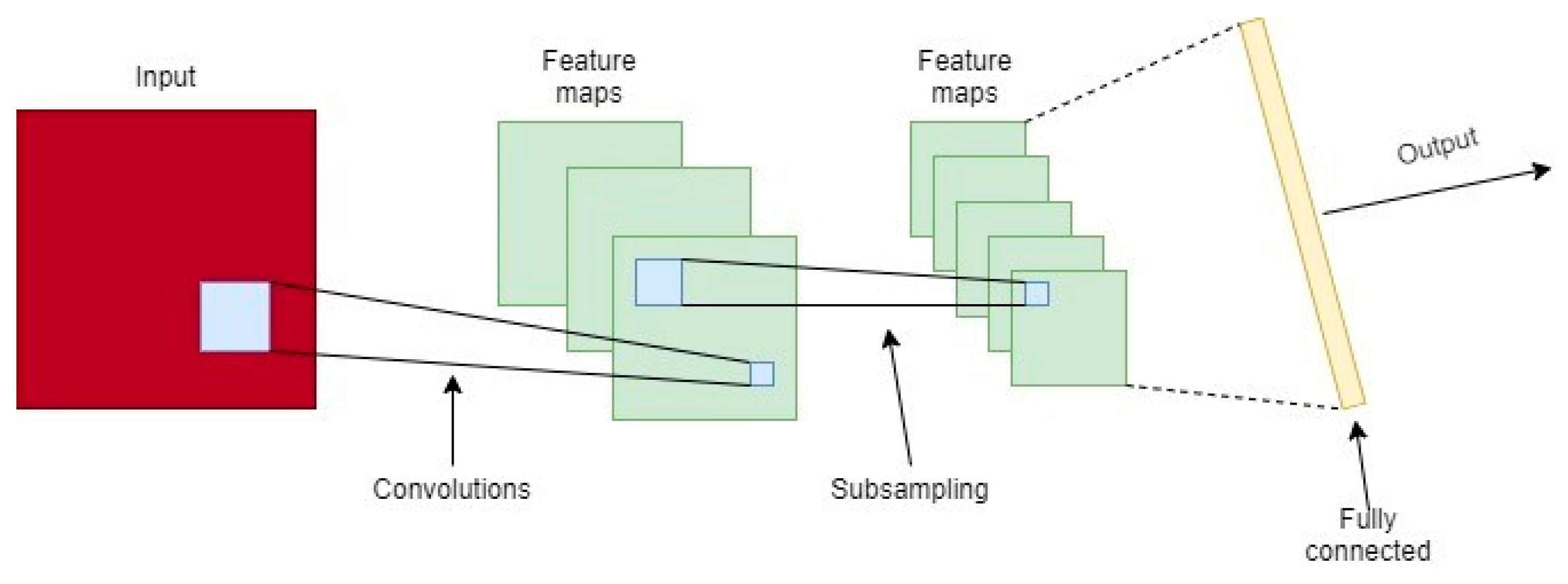
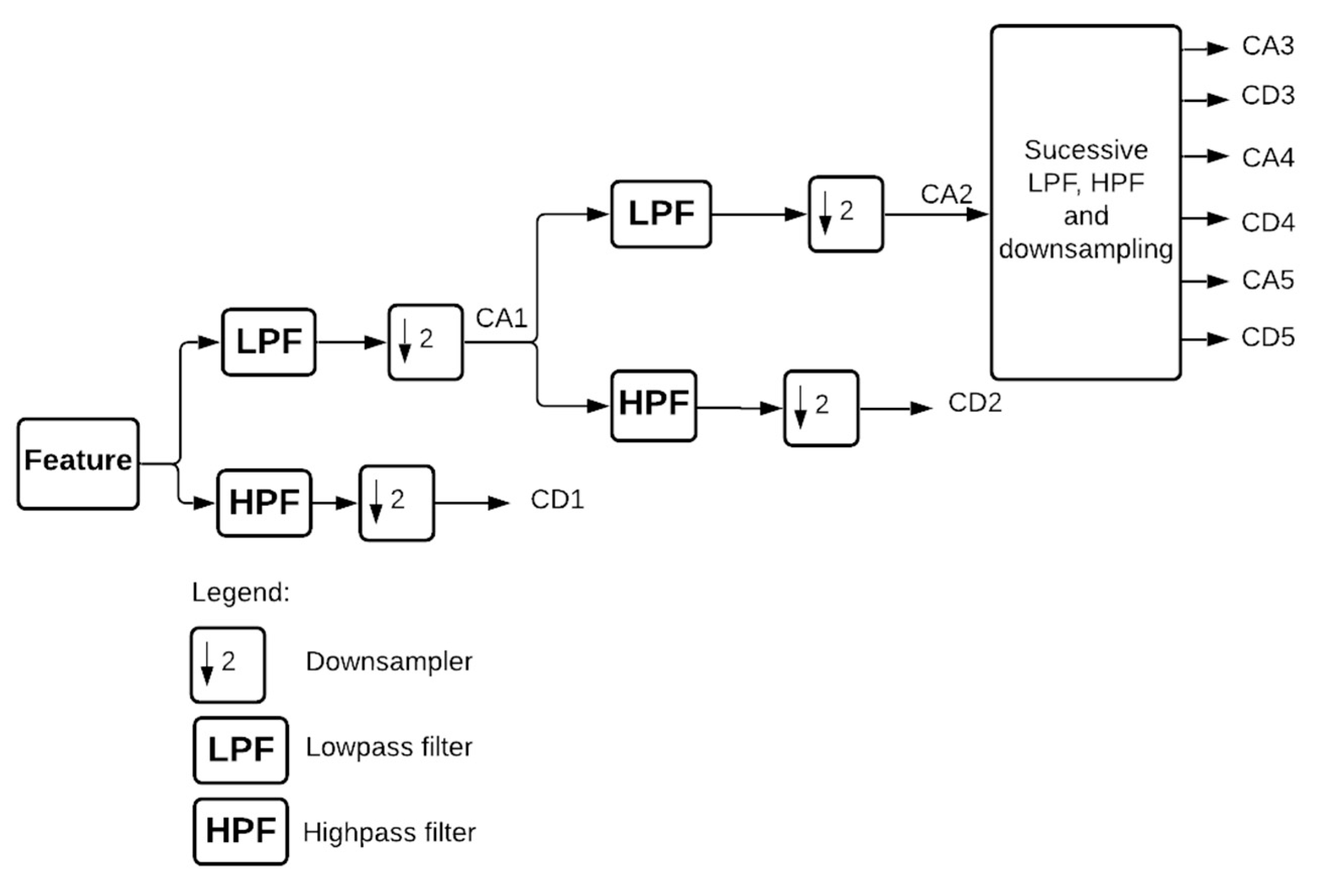
Thus, the objective of this work is to build and evaluate the performance of four deep artificial neural network (DNN) models to predict hourly concentrations of PM2.5 up to 24 h ahead of time, as well as the impact on model performance of applying five-level discrete wavelet transform (DWT) on the data as a feature augmentation method. The DNN types applied were multilayer perceptron (MLP), long short-term memory (LSTM), one-dimensional convolutional neural network (1D-CNN) and a hybrid model (LSTM with 1D-CNN). To train and test the DNN models, data from densely populated areas in Surrey County, UK, characterized by high vehicle traffic were used and augmented by the addition of new features based on the reconstructed detail and approximation signals of wavelet transform from levels 1 to 5. In order to assess the performance of the deep neural networks in the prediction task, all results were compared to a linear regression model as a baseline. Then, they were statistically evaluated according to the following metrics: mean squared error (MSE), mean absolute error (MAE), Pearson’s r and normalized mean squared error (NMSE).
This paper is organized into five sections. In
Section 1, we introduce the background and research gaps in the topic areas. In
Section 2, we explore the related works in the area of air pollutant forecasting. In
Section 3, we present the case study, data, basic concepts of DNN, DWT and additional methods used in this work. In
Section 4, we present and discuss the results. Finally, in
Section 5, we highlight the main points and present our conclusions, indicating aspects to be explored in future investigations.
2. Related Works
In recent years, several methods have been applied to the task of forecasting air pollution components, mainly using statistical, econometric and deep learning models. Zhang et al. [
5] and Badicu et al. [
6] assessed the Autoregressive Integrated Moving Average Model (ARIMA), a powerful statistical model, to predict PM concentrations. The former used monthly PM
2.5 data from the city Fuzhou, China during the period from August 2014 to July 2016 to train the model and predicted the period of July 2016 to July 2017. The training results presented a mean absolute error (MAE) of 11.4%, with the highest error values in cold seasons, when the real values from PM
2.5 were higher than those predicted by the model. The latter worked with data from Bucharest, Romania, considering the period of March to May 2019 with a frequency of 15 min to predict PM
10 and PM
2.5 concentrations. The results showed that in 89% of cases, the predicted values were under an acceptable limit of uncertainty. However, this kind of approach has some limitations in long-term forecasting, as it uses only past data and it has difficulty reaching high peaks, such as in [
5], where it was not able to reach the real peaks of PM
2.5.
Considering these limitations, artificial intelligence (AI) methodologies have been used to improve forecasting performance due to their ability to learn from complex nonlinear patterns, their robustness and self-adaptation and their ability to, once correctly trained, perform predictions with limited computational resources and cost when compared to other approaches, such as numerical modeling. Reis Jr. et al. [
7] analyzed the use of recurrent neural networks (RNNs) and convolutional neural networks (CNNs) to predict short-term (24 h) ozone concentration. They compared the performance of CNN, recurrent neural network long short-term memory (LSTM) and gated recurrent unit (GRU) structures with a simple multi-layer perceptron (MLP) model. The data were collected between 2001 and 2005 in the region of Vitória in southeastern Brazil. The results showed that the LSTM topology presented an average performance similar to that of MLP but with slightly worse results. However, when considering individual time steps, the LSTM presented the most suitable results for the 9th hour, demonstrating the potential of LSTM for learning long-term behaviors. Ozone forecasting up to 24 h in advance was also evaluated by Alves et al. [
8] using the same data but comparing only the MLP model with baseline models: the persistence model and the lasso regression technique. The MLP model proved to be the most effective according to statistical analyses, outperforming the others in almost all forecasting steps, except for the 1st hour.
Regarding PM forecasting, the use of MLP topology to forecast PM particles was investigated by Ahani et al. [
9], who compared its performance is with that of the ARIMAX model (ARIMA with exogenous variables) to predict PM
2.5 up to 10 h ahead using different feature selection methods. The applied data were from Tehran City, the capital of Iran, and represented a period from 2011 to 2015. The ARIMAX model presented a smaller RMSE in almost all time steps considered, except for the second and the last time steps, for which the MLP presented similar results. This shows that, despite its higher capacity, the single application of artificial neural network (ANN) structures in some data may not outperform simpler methodologies. Thus, it is possible to assess complementary methodologies to make them even more robust. Yang et al. [
10] used four different DNN topologies to predict PM
2.5 and PM
10, including two hybrid models. The DNNs used were GRU, LSTM, CNN-GRU and CNN-LSTM. Data from 2015 to 2018 were used to make predictions 15 days in advance. The results demonstrated that 15-day predictions remained reliable; however, the most accurate forecasts are up to 7 days in advance. The hybrid models outperformed the single models for all stations, and the CNN-LSTM model produced the fewest errors.
Despite the research that has been conducted using ANNs to predict air pollution components, forecasting accuracy depends on the quality of data provided to the model. This means that the results can still be improved by different representations of data, which can reveal hidden patterns, as well as the application of feature augmentation techniques. Therefore, various studied involving preprocessing methods for time series, such as wavelets, have demonstrated the benefits of their application in improving the performance of ANNs in the task of forecasting PM concentrations. For instance, Wang et al. [
11] presented the advantages of using hybrid models combining machine learning techniques and wavelet transforms to predict PM
2.5 signal. The prediction was performed 1 h ahead by decomposition of PM
2.5 data in low- and high-frequency components that capture the trend and noise from the original signal. The temporal resolution of data was the hourly average concentration in the period from 2016 to 2017. The machine learning methods used were a backpropagation neural network (BPNN) and a support vector machine (SVM). The results indicate that hybrid models are more accurate and stable when using wavelets, highlighting their importance in detecting time and frequency behaviors. Bai et al. [
12] also used a BPNN model based on wavelet decomposition to forecast air pollutant (PM
10, SO
2 and NO
2) concentrations but with additional information concerning meteorological conditions. The BPNN model was employed to generate wavelet coefficients of the concentrations of air pollutants for the next day, and then the signals were reconstructed to generate the predictions. The forecasting horizon was the mean of the next 24 h. Findings showed that the results of the W-BPNN model were closer to observed data than those of the BPNN model alone, meaning that the multiresolution data provided by wavelets improve the accuracy of air pollutant concentration forecasting.
Qiao et al. [
13] used a hybrid stacked autoencoder (SAE) to solve the LSTM vanishing gradient problem and used wavelet transform (WT) to decompose PM
2.5 time series into coefficients as the inputs of an ANN structure to predict average PM
2.5 1 day ahead. LSTM outputs were used to reconstruct the signal and generate the predictions. The data were from January 2014 to June 2019, and the resulting model outperformed the six other baseline models, with an MAE of approximately 3.0. The baseline models were SAE-BP (SAE back propagation), SAE-ELM (SAE extreme learning machine), SAE-BiLSTM (SAE bidirectional LSTM) and the same machine learning models without SAE (LSTM, BP and ELM (extreme learning machine)). Results showed that SAE-LSTM predictions were the best compared with the other models, satisfactorily solving the vanishing gradient problem.
Huang et al. [
14] developed a hybrid CNN-LSTM model to predict the concentrations of PM
2.5 one hour ahead using both air pollution and past meteorological data. They compared their solution with other traditional machine learning techniques and found that it achieved the best results for this task. Li et al. [
15] developed another hybrid CNN-LSTM deep neural network to predict PM
2.5 concentrations for the next day, comparing their proposed model with univariate and multivariate approaches and LSTM architecture, achieving the best results with their approach. Mirzadeh et al. [
16] evaluated a traditional machine learning technique called support vector regression (SVR) with WT to predict PM
10, PM
2.5, SO
2, NO
2, CO and O
3 in Isfahan, Iran, finding that SVR with WT presented better results and lower uncertainty than the other tested models. The same authors [
17] conducted a study to evaluate how WT and traditional AI techniques could be combined to improve the prediction of short (few hours) and long-term (daily) concentrations of PM
2.5 using an adaptive neuro-fuzzy inference system (ANFIS), SVR and a shallow ANN. Their results showed that WT combined with SVR and ANFIS achieved the best experimental results among the tested models. Liu et al. [
18] presented a combined weighted forecasting model (CWFM) for air pollution concentration forecasting using WT, bidirectional (Bi)-LSTM, Bi-GRU and LSTM, along with a weight assignment, and compared the results of the combined approach with each individual model for prediction of NO
2 air pollutants. They concluded that the combined approach presented a better performance than each individual model. Jusong et al. [
19] developed a hybrid 3D-CNN and Bi-LSTM deep neural network using WT, feature selection and clustering techniques to predict PM
2.5 concentrations up to 10h ahead, achieving the best results compared to other techniques. Araujo et al. [
20] also evaluated the combination of WT and ANNs to predict air pollution applied to tropospheric O
3 forecasting, finding that WT enhanced the ANN’s ability to forecast air pollution concentrations.
Despite previous studies with the aim of predicting PM2.5 using machine/deep learning and WT, in the present study, we aim to innovate by systematically constructing and evaluating four different types of DNN combined with systematic selection and application of five different levels of WT, with the aim of predicting hourly PM2.5 concentrations up to 24 h ahead for a highly urbanized region in the UK. This research can provide new and valuable information with respect to how to effectively apply deep learning and WT for PM2.5 forecasting, improving the ability of regulatory, government or other agencies to adopt preventive or contingency measures to improve air quality and reduce air pollution impacts on human health in urban areas.
5. Conclusions
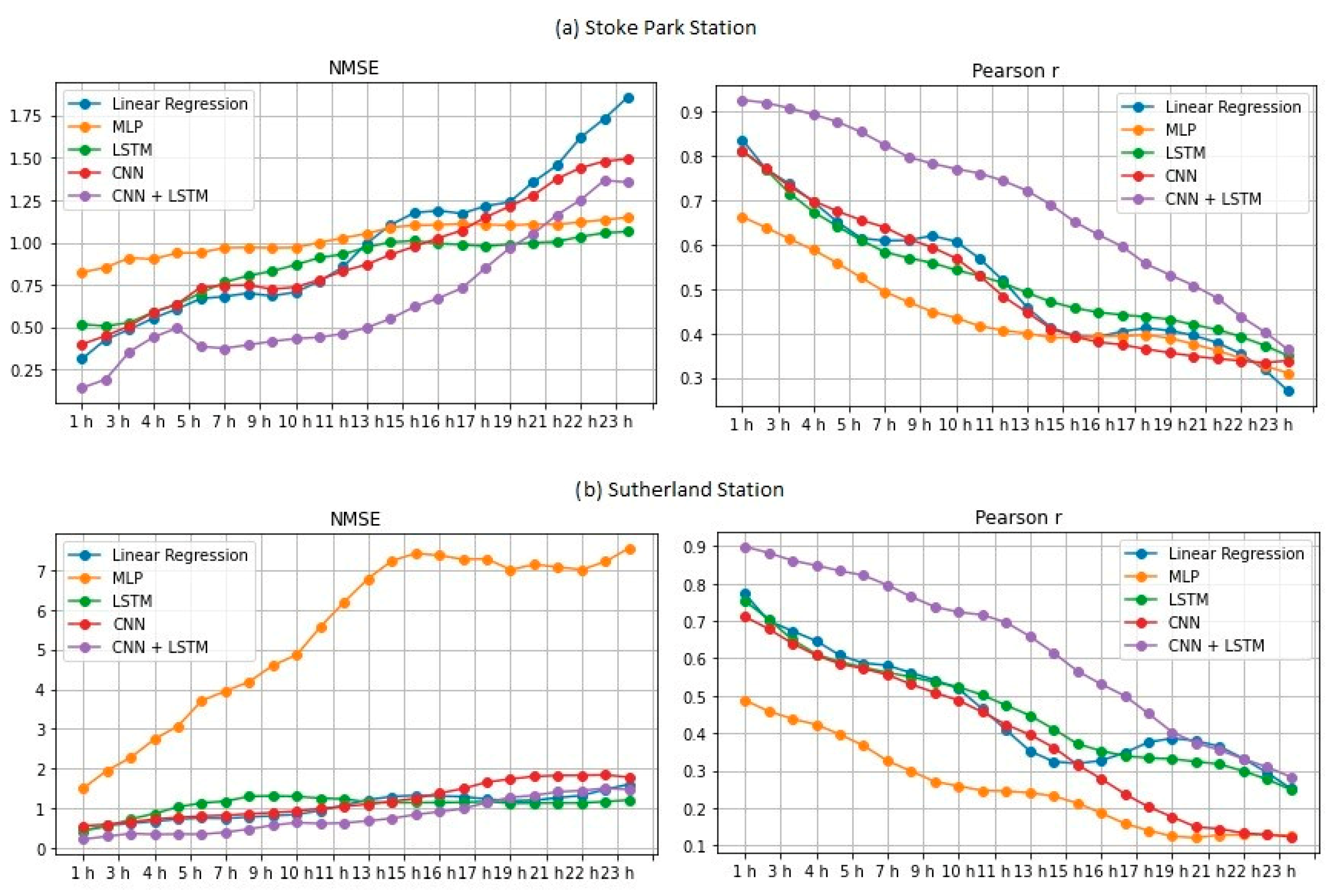
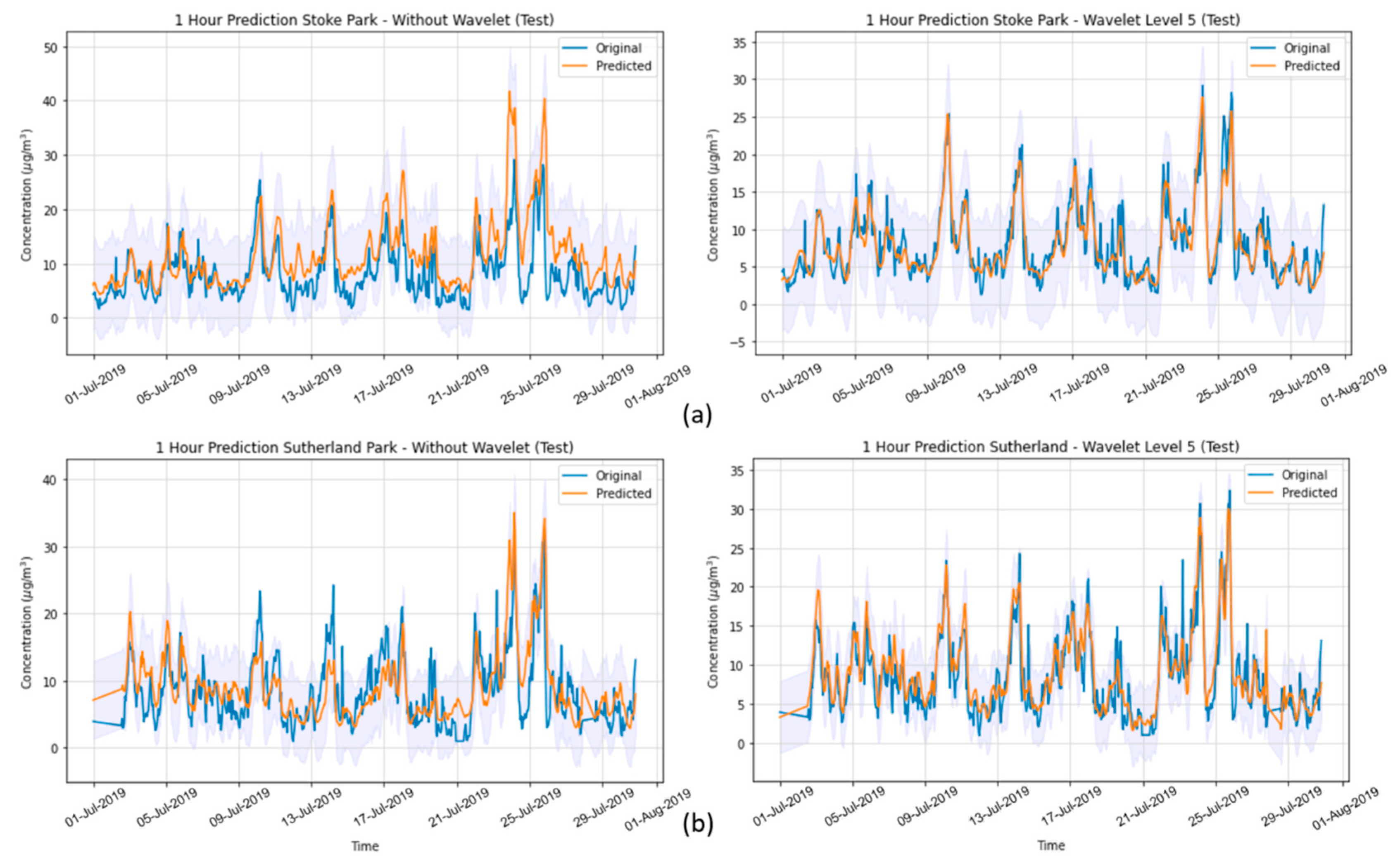
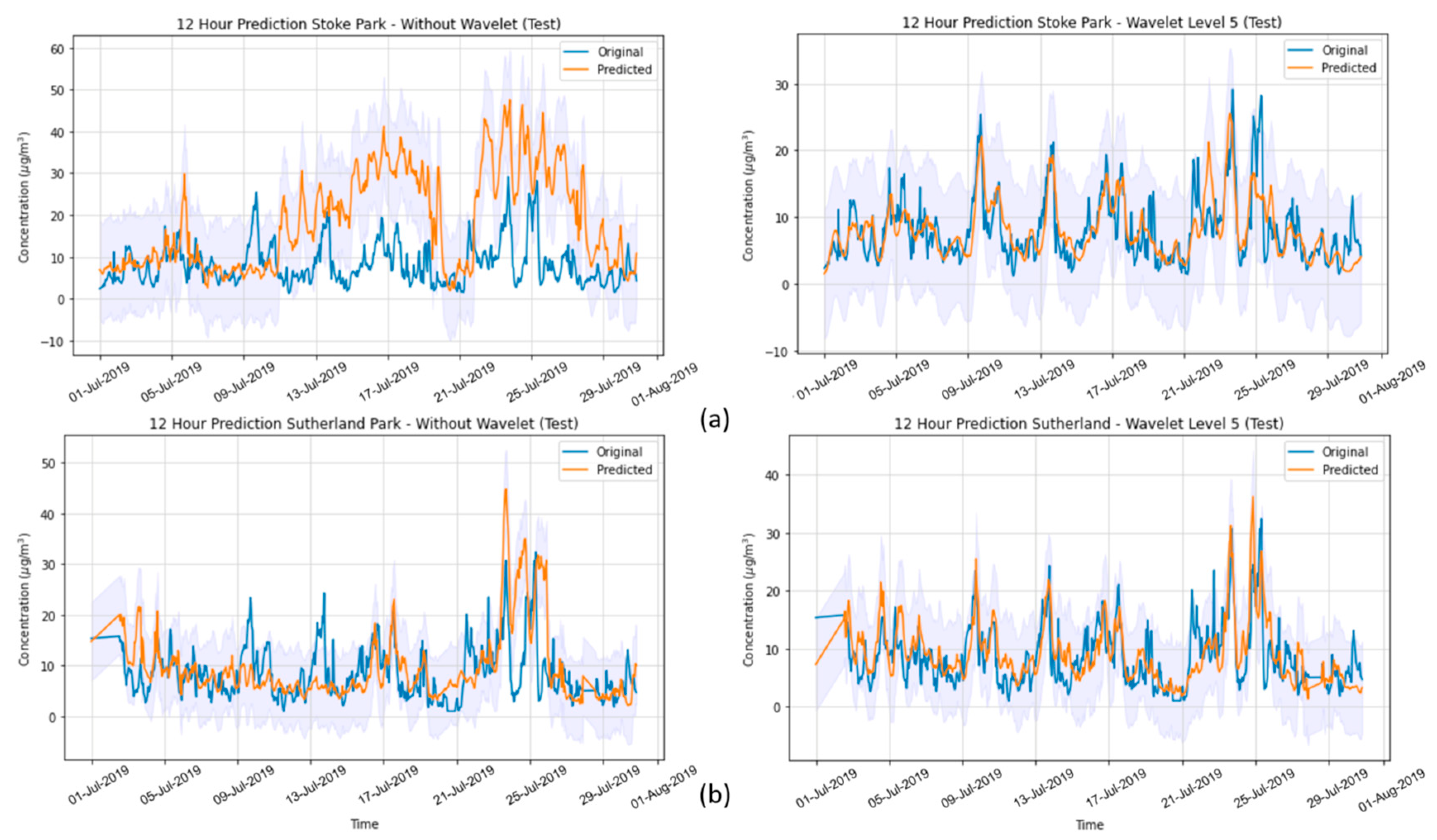
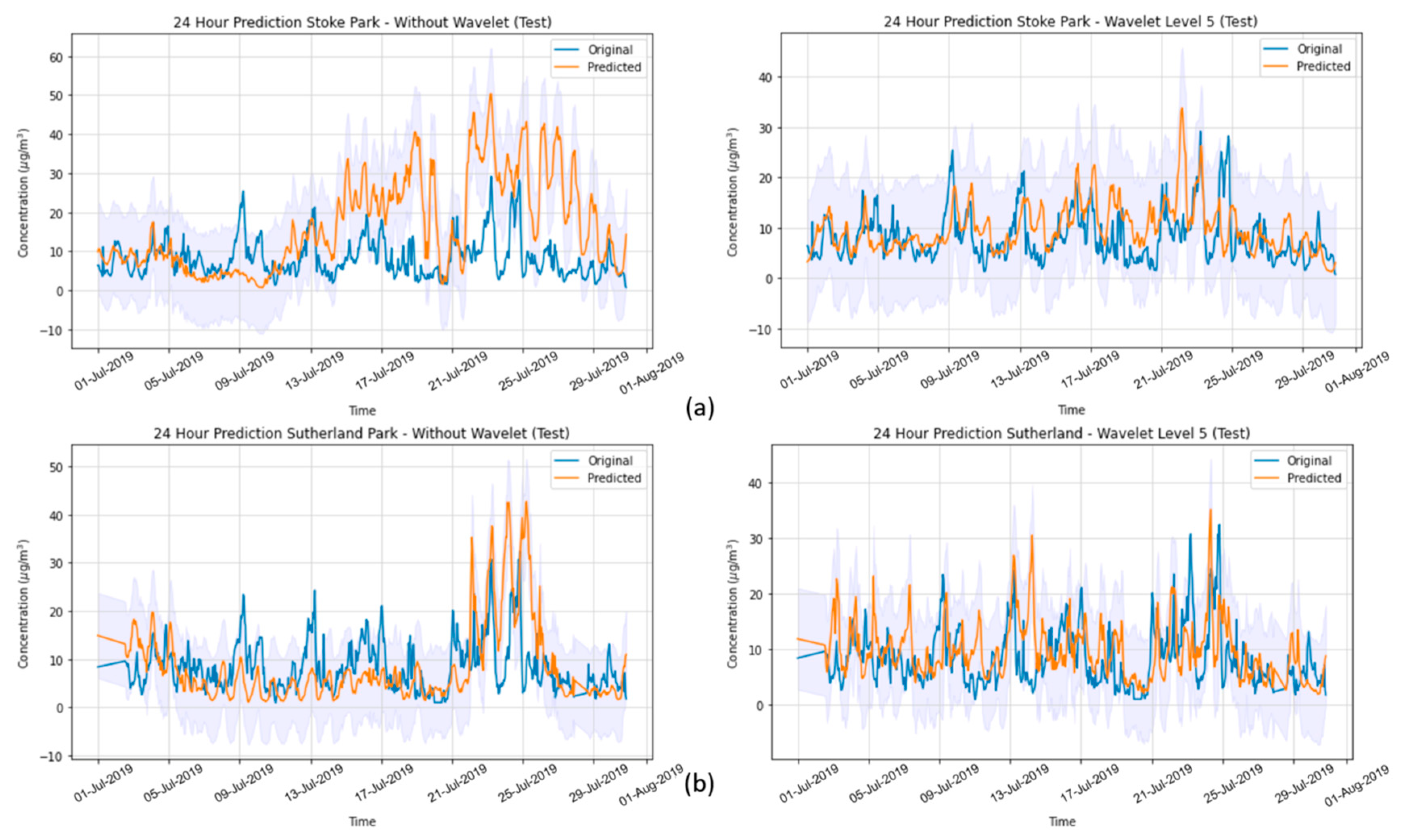
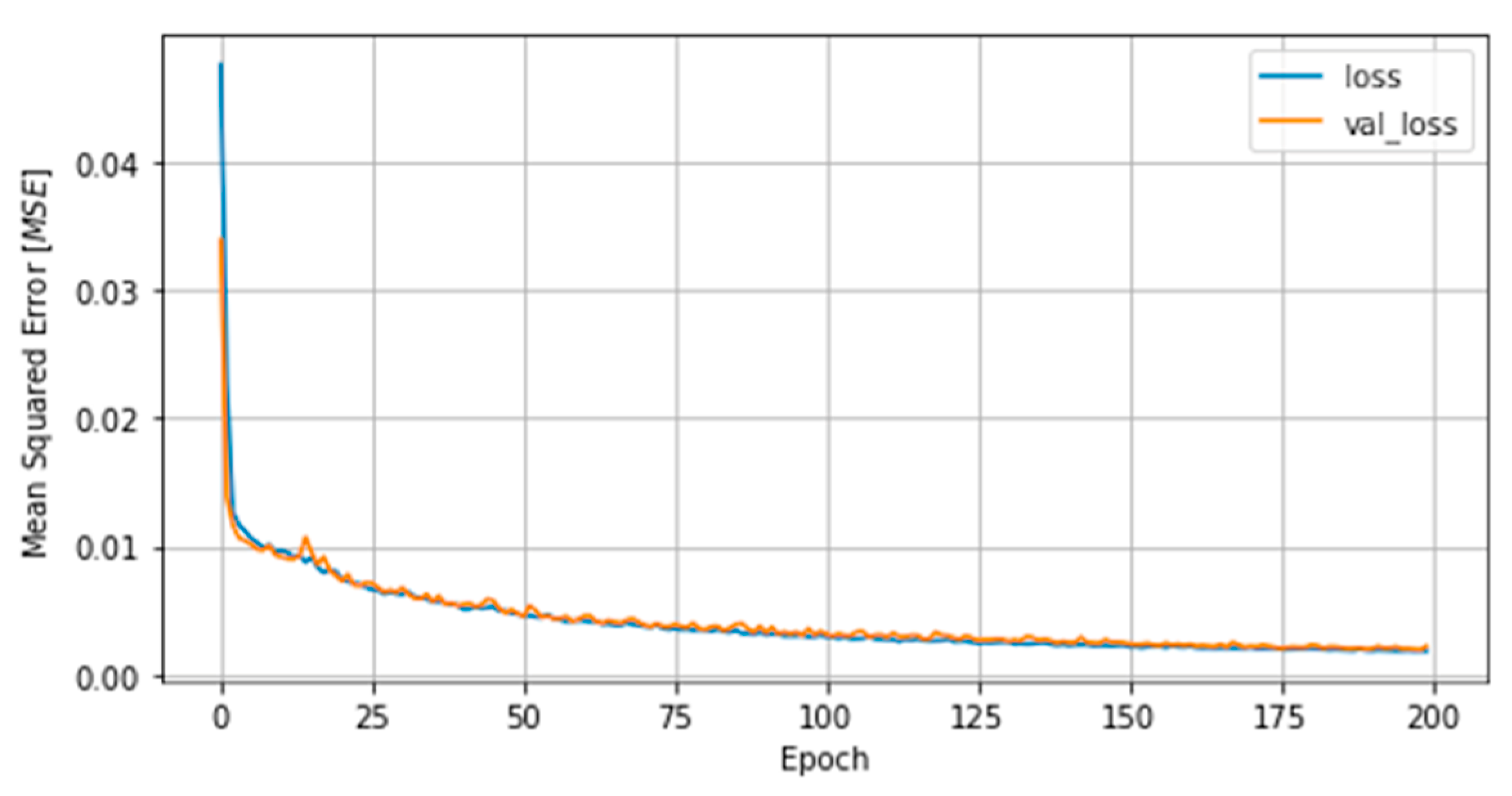
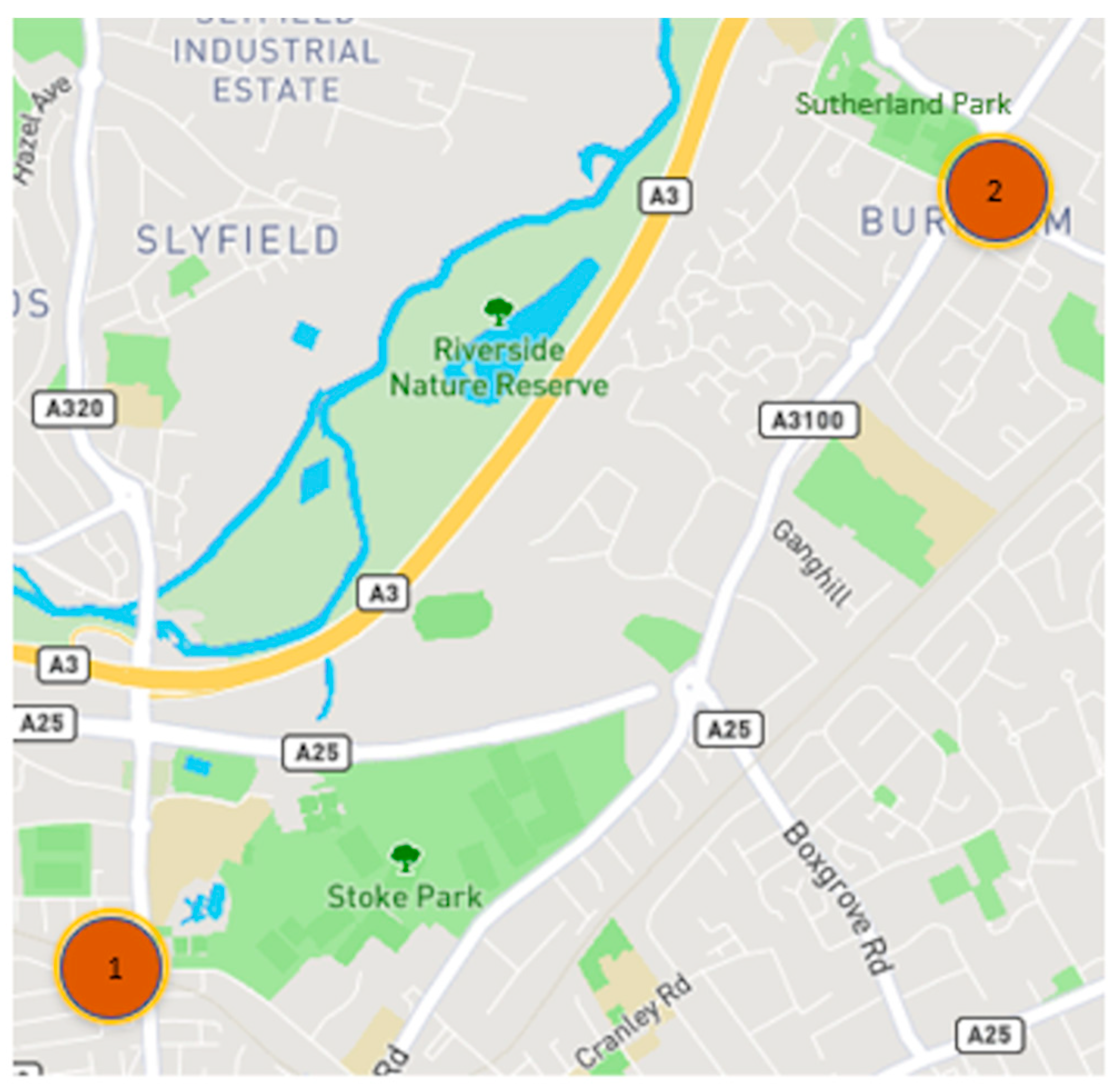
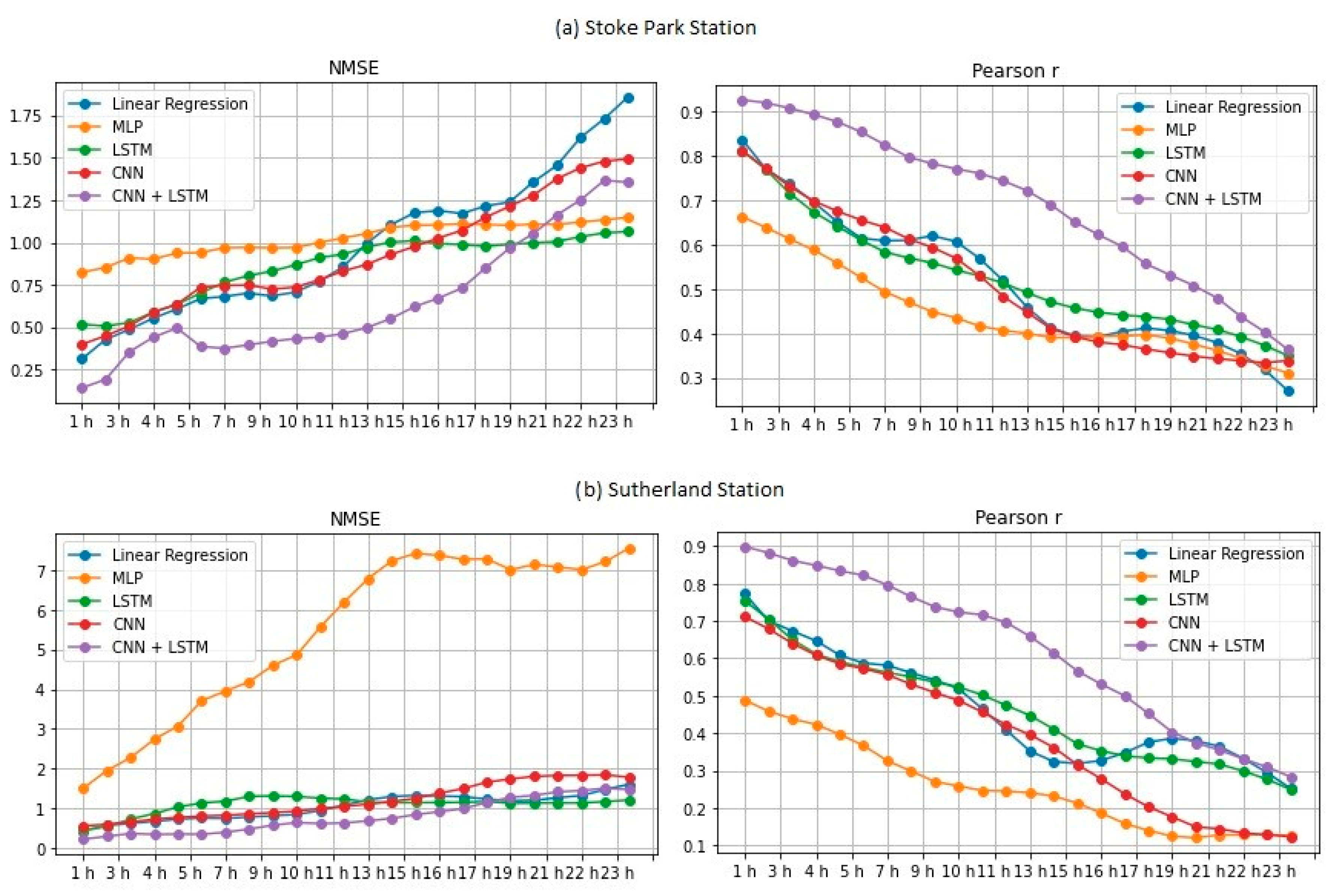
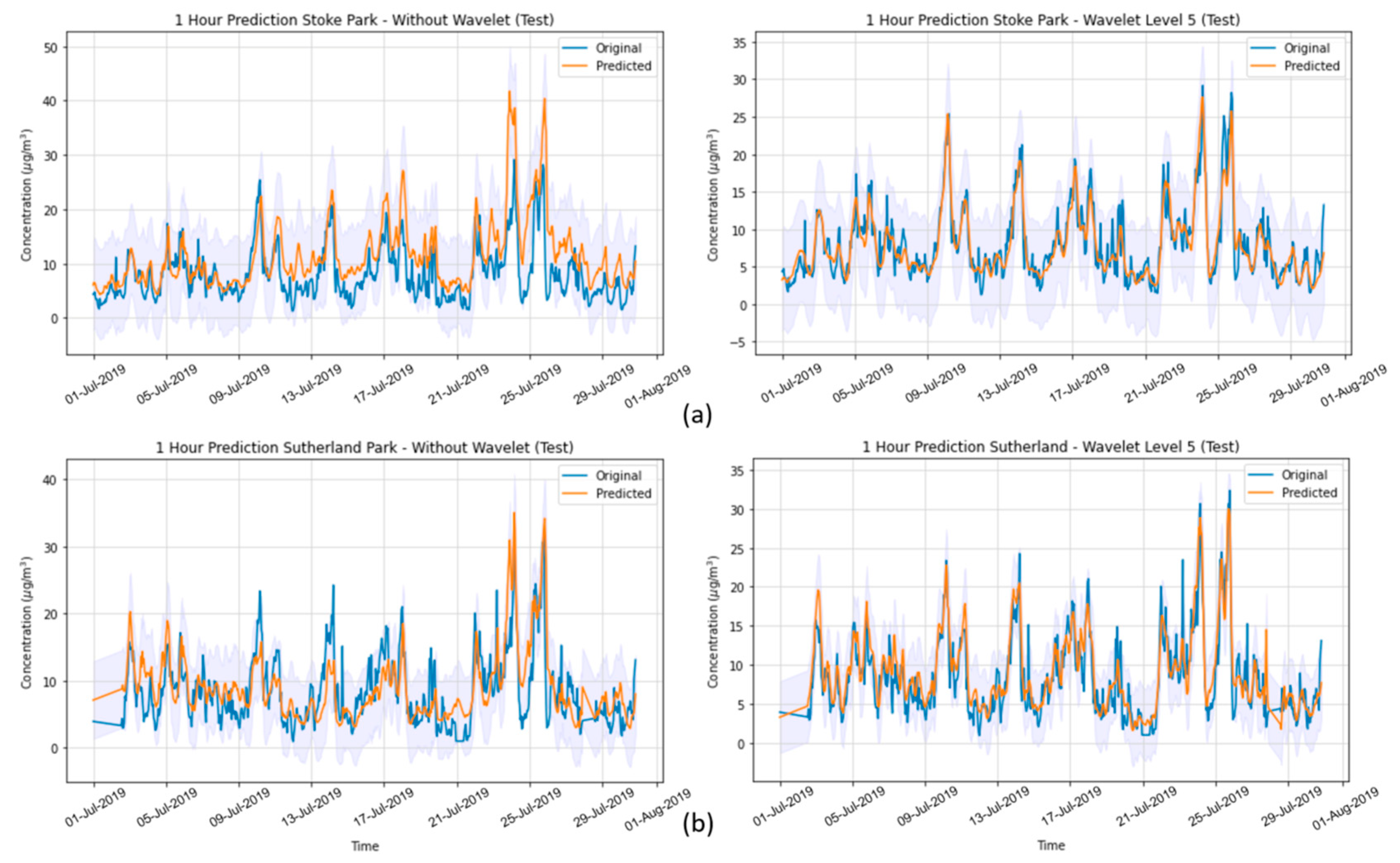
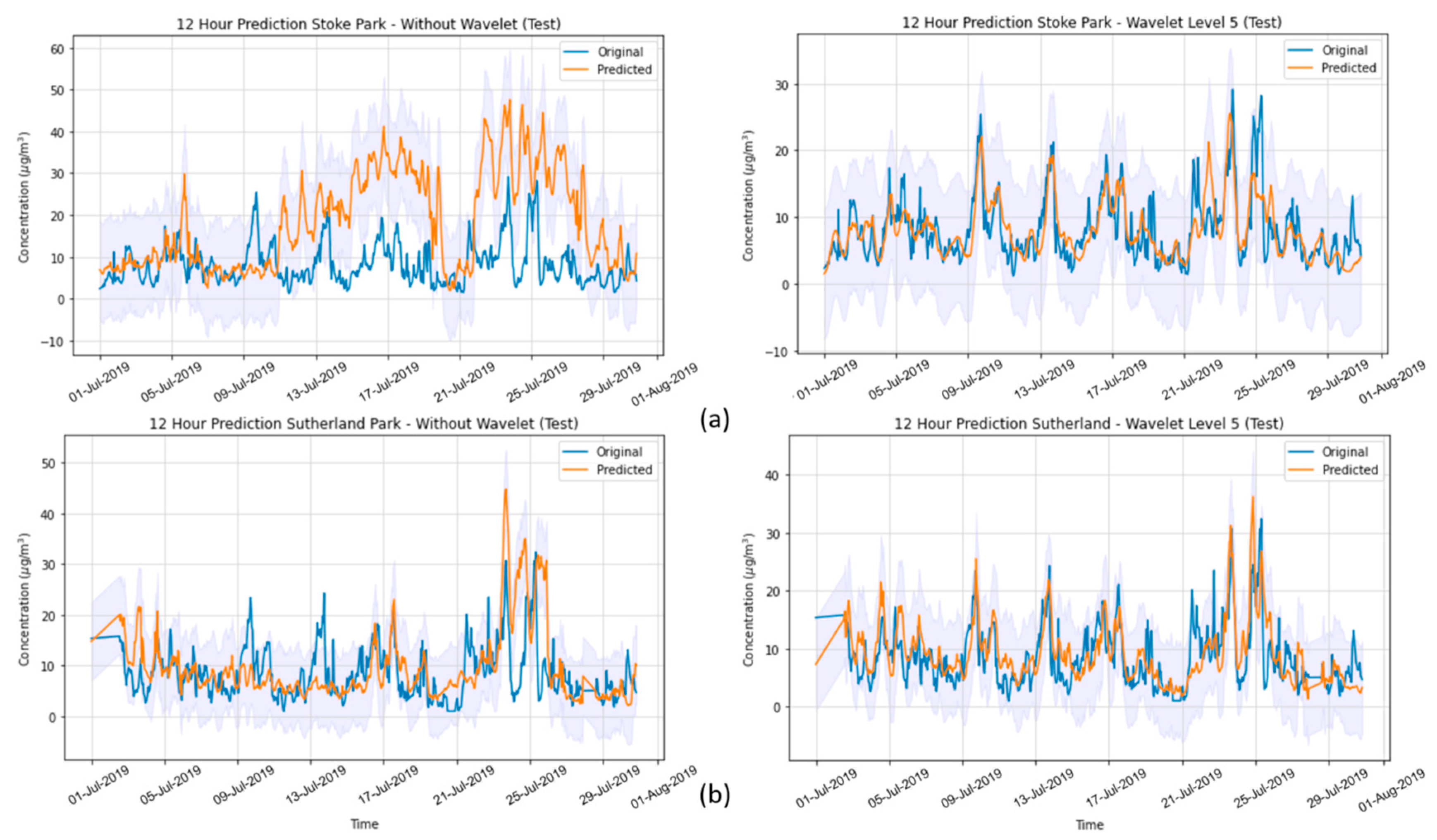
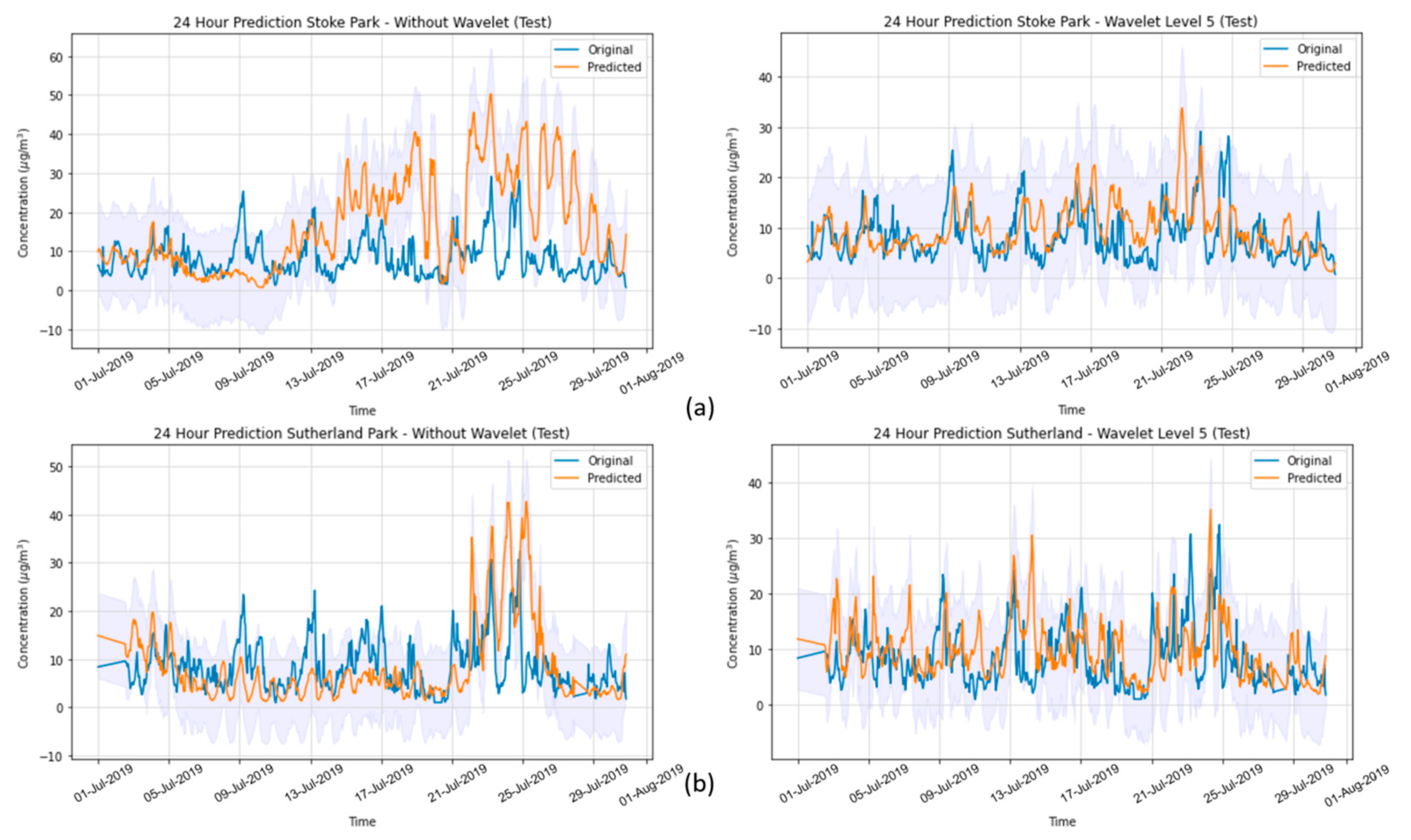
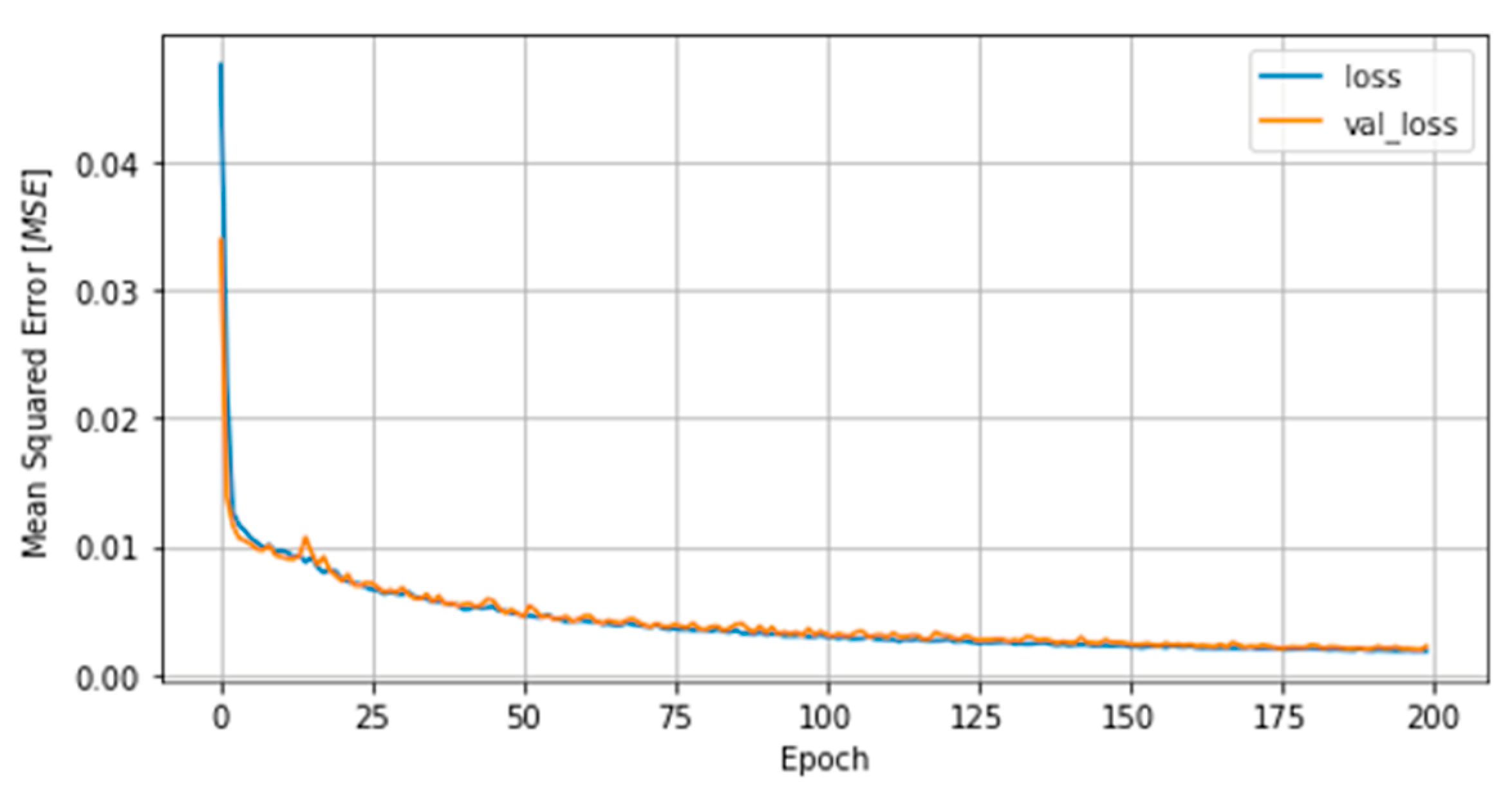
In the present study, we systematically evaluated different deep learning models, along with WT, to predict the concentration of PM2.5 up to 24 h ahead in two open-road regions of Surrey, UK, characterized by the proximity of parks where children and adults perform recreational activities by the high vehicle traffic, which are relevant factors with respect to air pollution monitoring and assessment. The methodology implemented consisted of developing and validating the use of deep learning associated with WT and comparing the results of the tested models with those of simpler methodologies. Different deep neural network topologies were implemented, namely MLP, LSTM, 1D-CNN and 1DCNN-LSTM, with and without WT, along with a linear regressor model as a baseline. The results showed that the best performance was achieved by the 1DCNN-LSTM model among all other DNN architectures, with WT applied on the time series data. The final deep neural network model captured the real data behavior and presented a good generalization of the problem in test data, despite being related to a period of data that was never seen by the model during the training and validation.
WT was implemented with the aim of decomposing the original time-series signals into several low- and high-frequency components, extracting some information from the data that was not yet available. This increased the results of all deep neural networks, which is in line with other previously developed studies [
12,
13,
22]. Our results highlight the positive impact of with respect to improving DNN performance and how this approach is appropriate to deal with complex problems.
Thus, this methodology proved to have a great potential for use in by academics, authorities, industry and society to construct and validate deep learning models to predict hour PM2.5 concentrations in advance for the next 24 h with good performance. This research provides a solid basis for understanding, developing, and evaluating deep learning models for this task, enabling the adoption of preventive or mitigation actions when necessary, such as alerting people to avoid highly polluted areas when the predictions of PM2.5 concentrations reach hazardous levels, avoiding imminent health risks associated with exposure to air pollutants.
In future studies, this methodology can be assessed in other places and scenarios under varying conditions to verify its robustness. Furthermore, other deep neural network approaches and models can be implemented, such as transformers or physics-informed neural networks (PINNs), including feature augmentation methodologies, to assess their capability of predicting long-term PM2.5 concentrations with high fidelity.




 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}