


Predicting Risks of a COVID-19 Outbreak by Using Outdoor Air Pollution Indicators and Population Flow with Queuing Theory



Abstract
1. Introduction
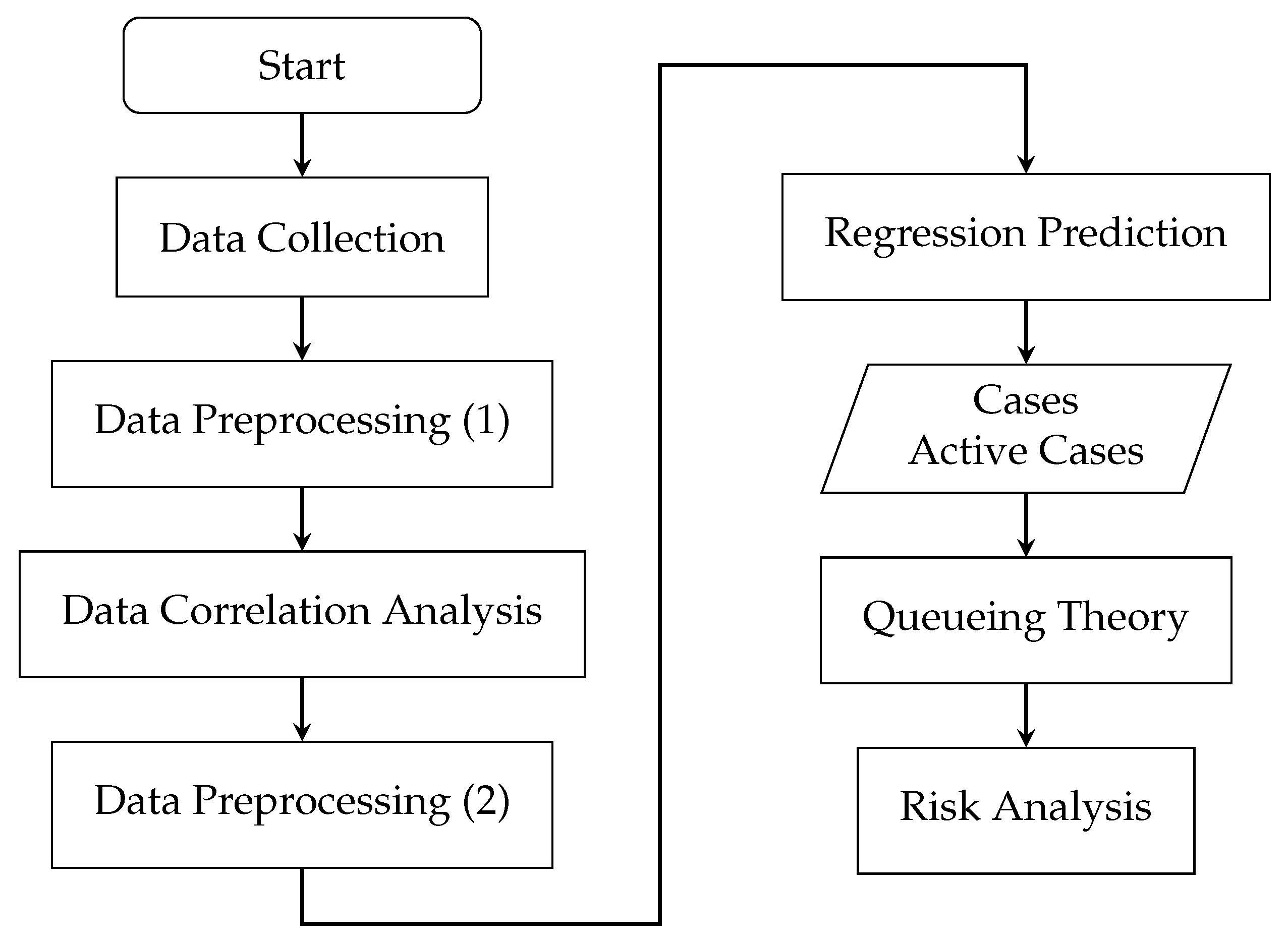
2. Materials and Methods
2.1. Data
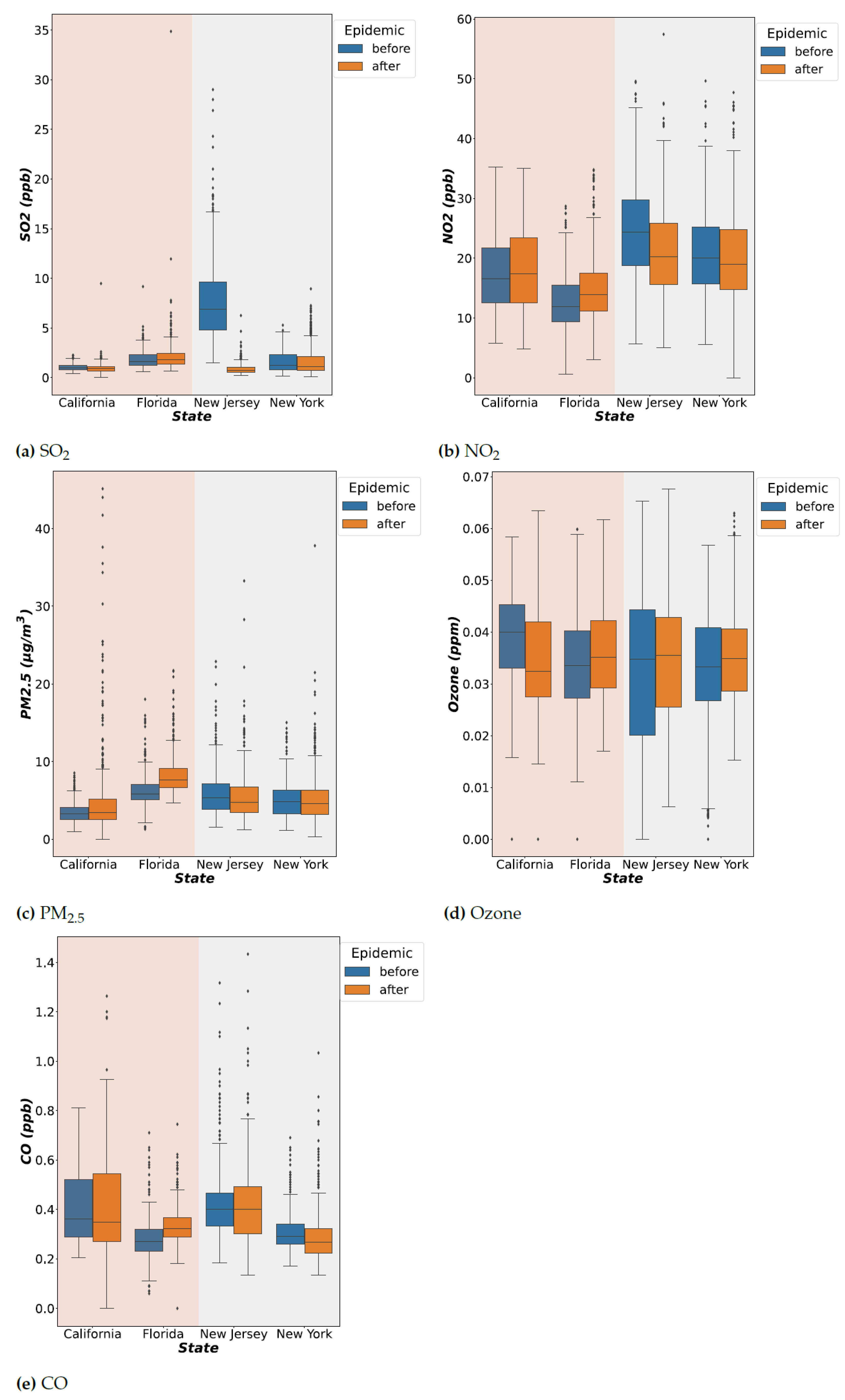
2.2. Data Preprocessing
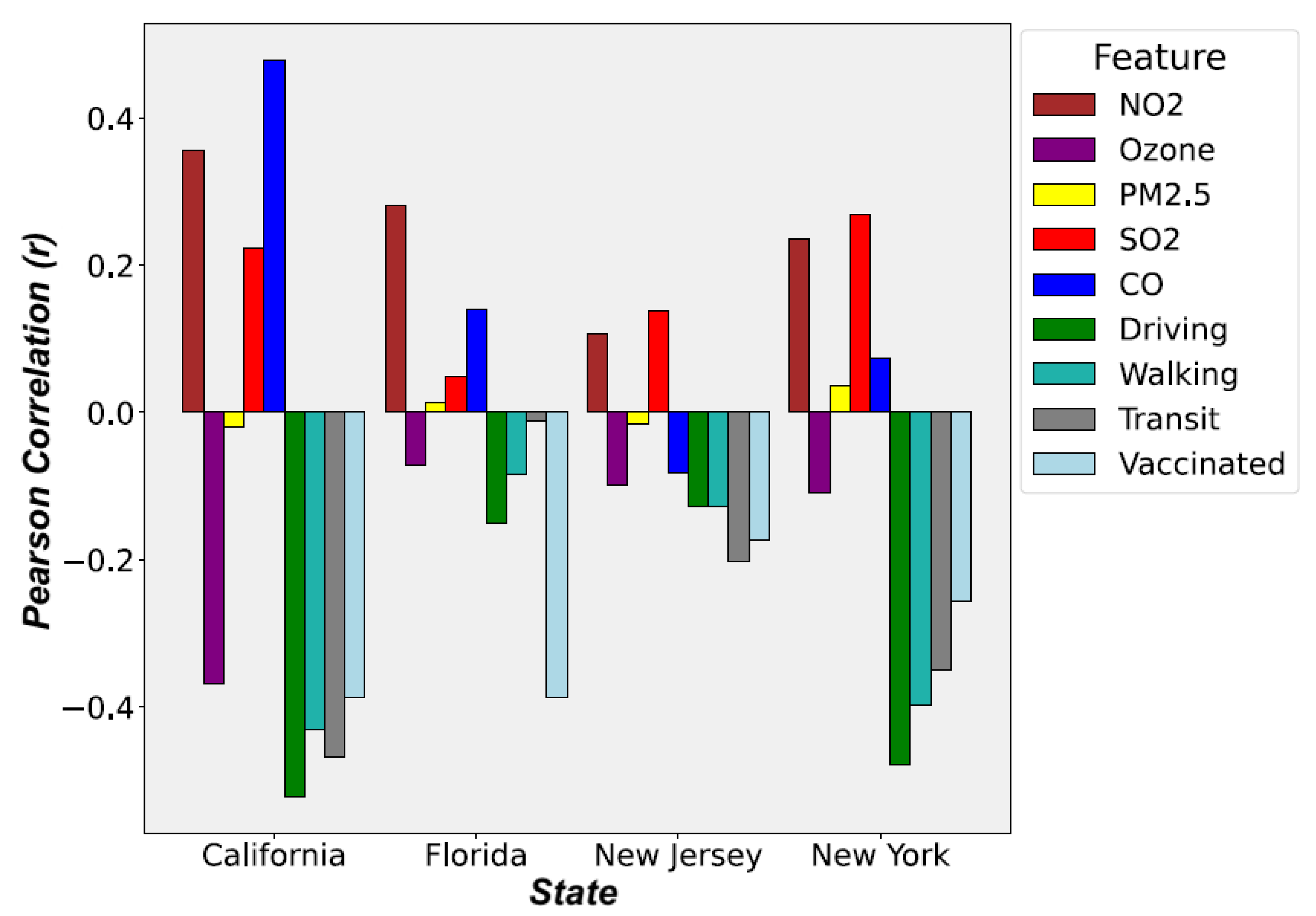
2.3. Data Correlation Analysis
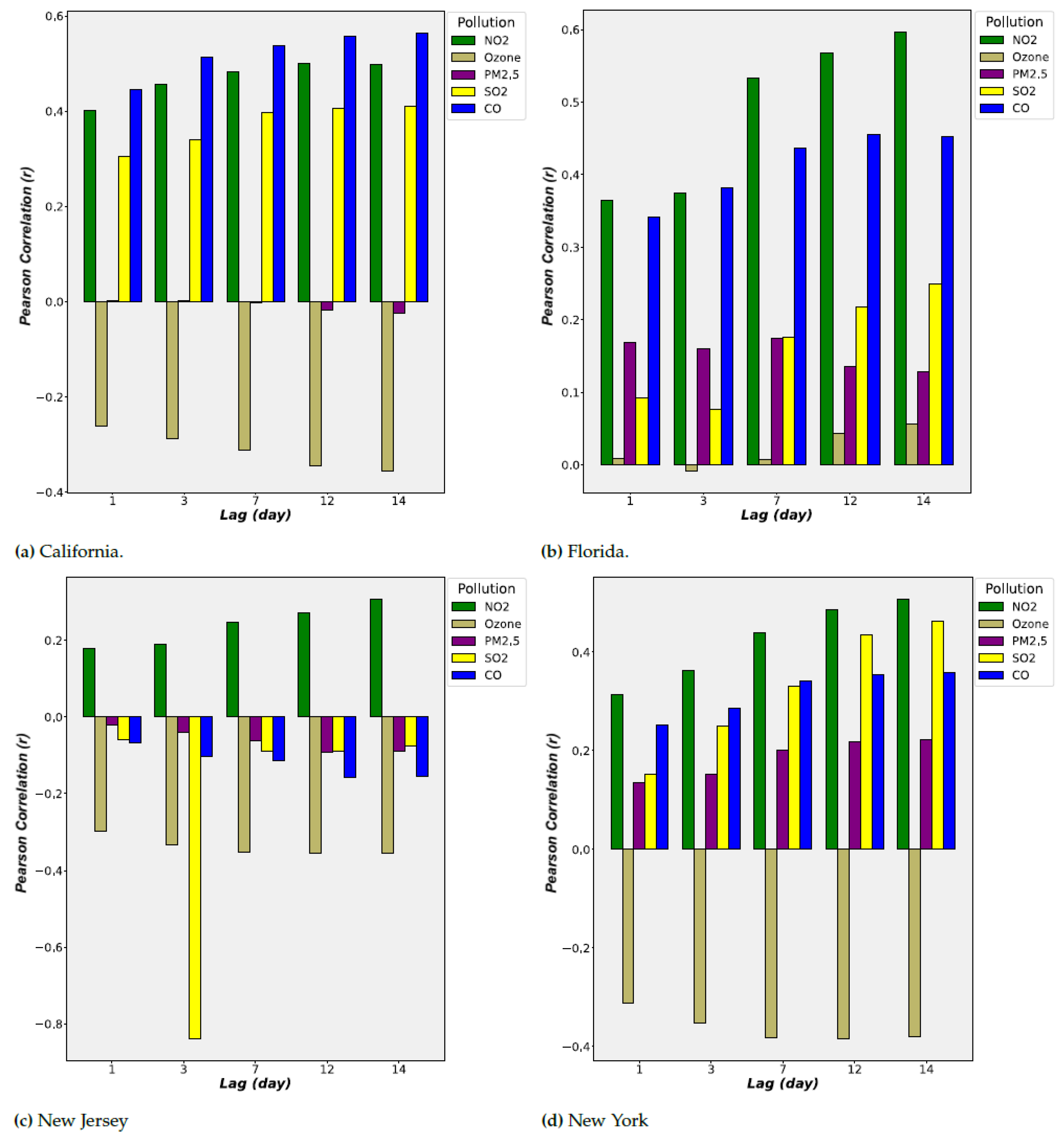
2.4. Hysteresis (Lagged) Effect
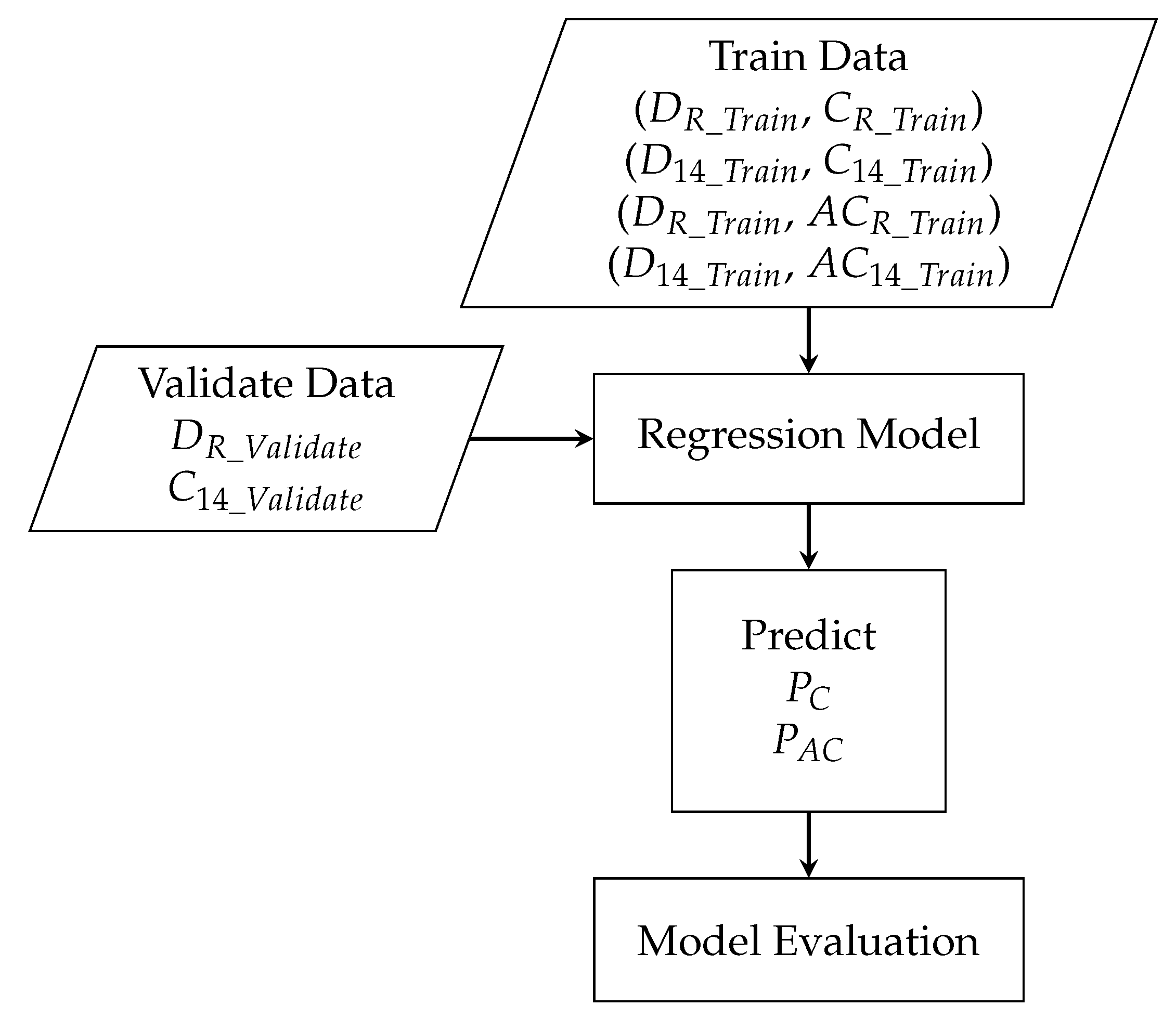
2.5. Data Partitioning and Merging
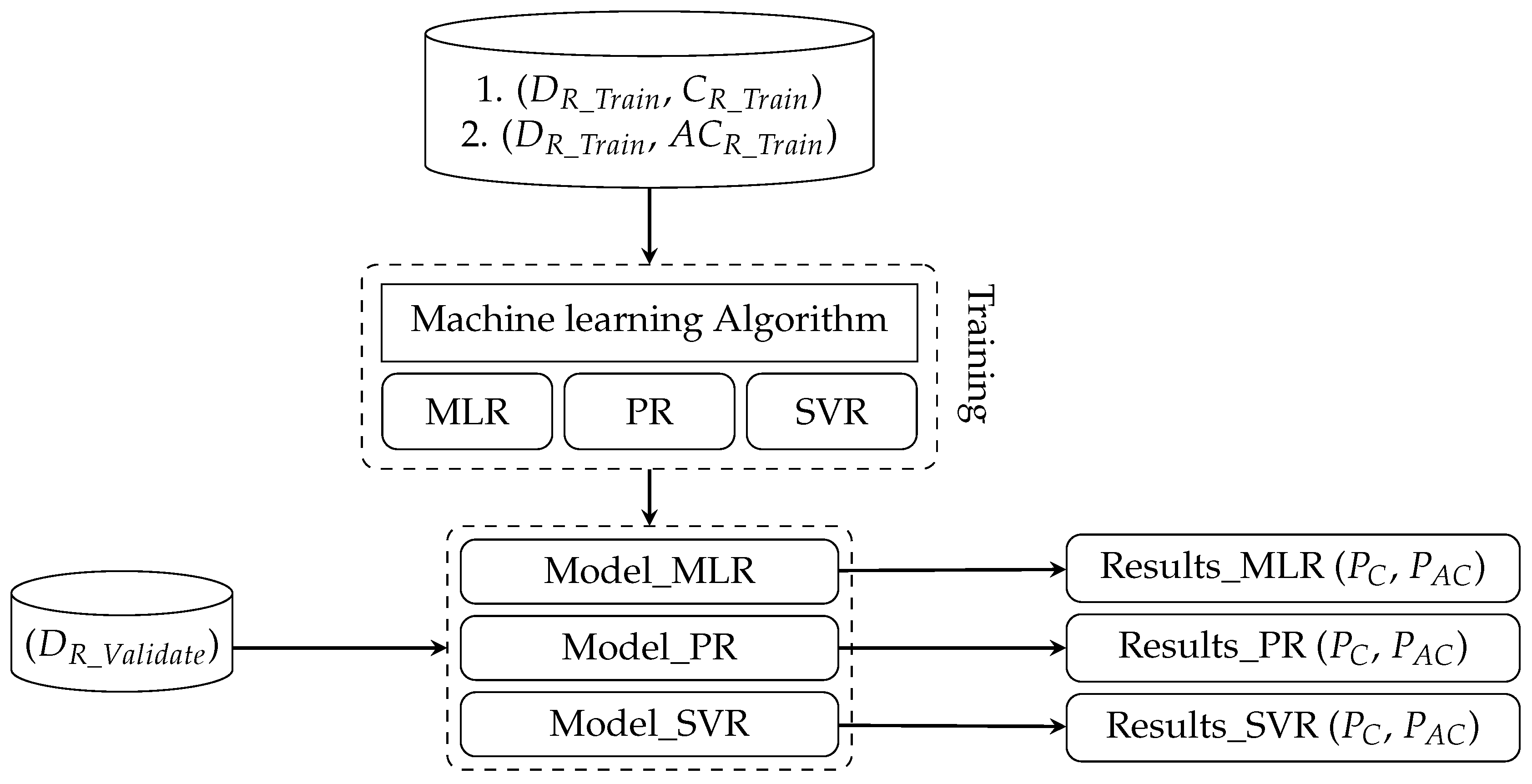
2.5.1. Data for Machine Learning Models
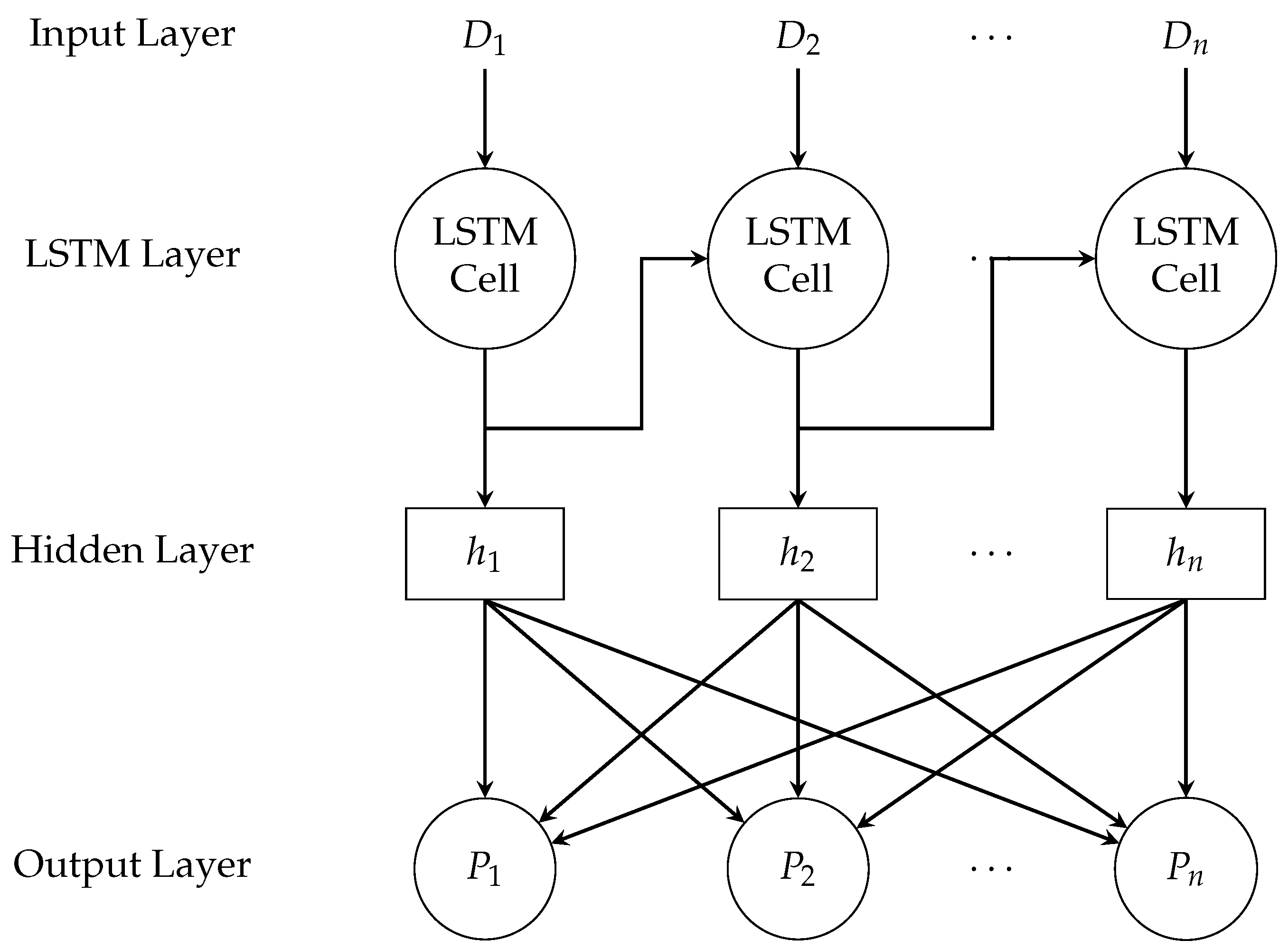
2.5.2. Data for Long Short-Term Memory (LSTM) Networks
2.6. Method
2.6.1. Machine Learning Models
2.6.2. Long Short-Term Memory (LSTM) Networks
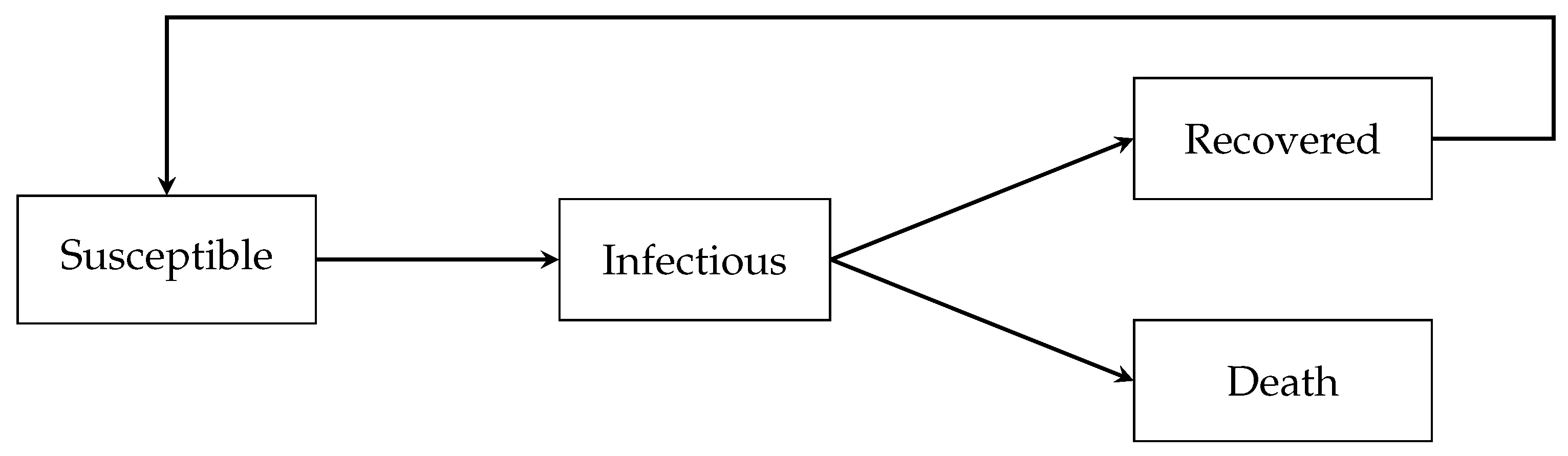
2.6.3. Queuing Model
2.6.4. Risk Analysis for COVID-19 Outbreak
- 1.
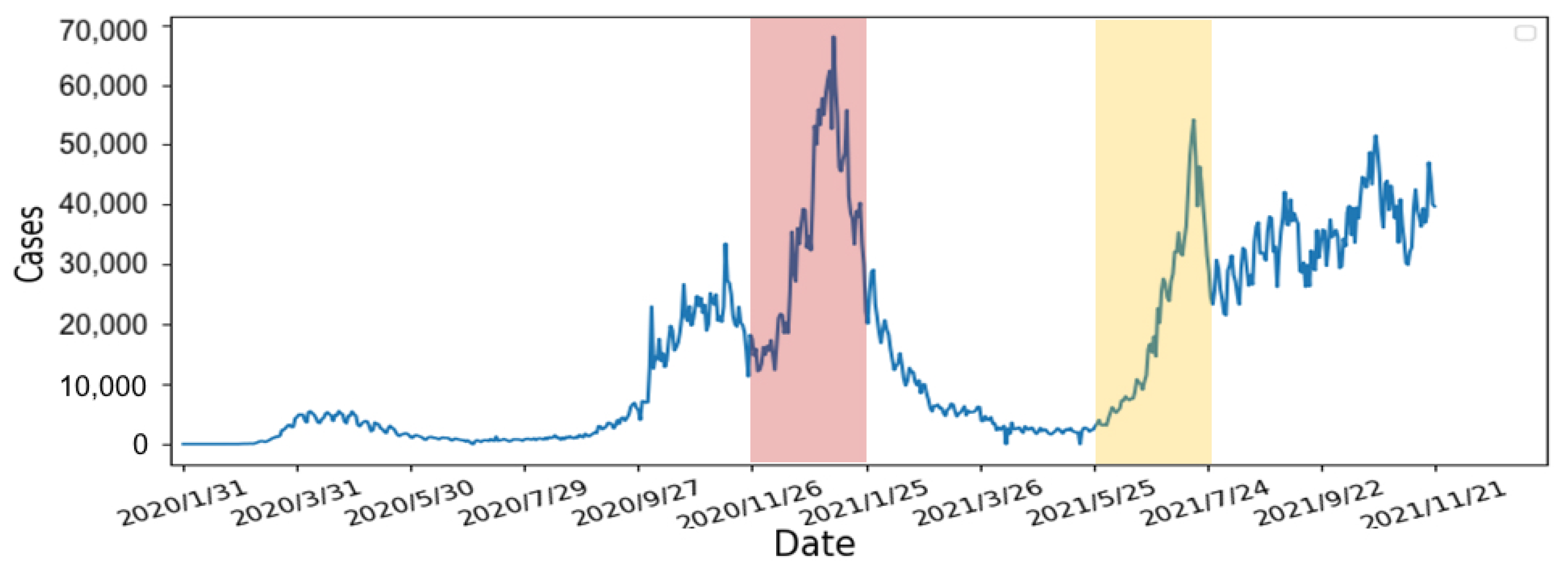
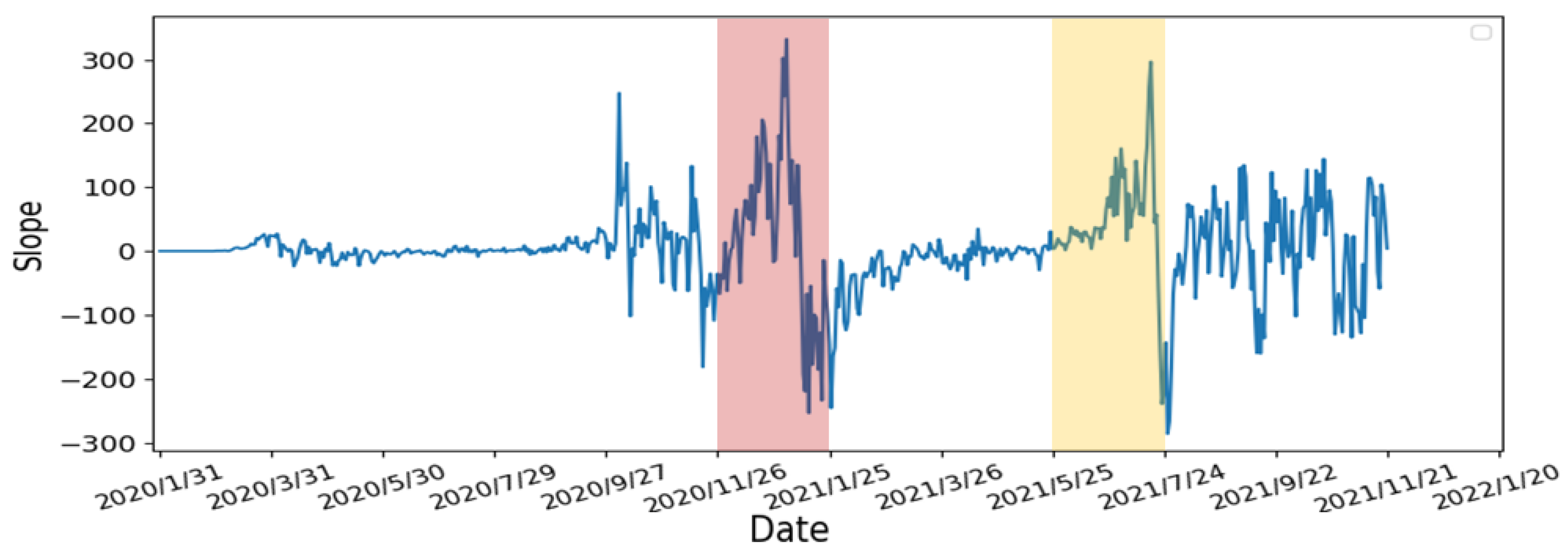
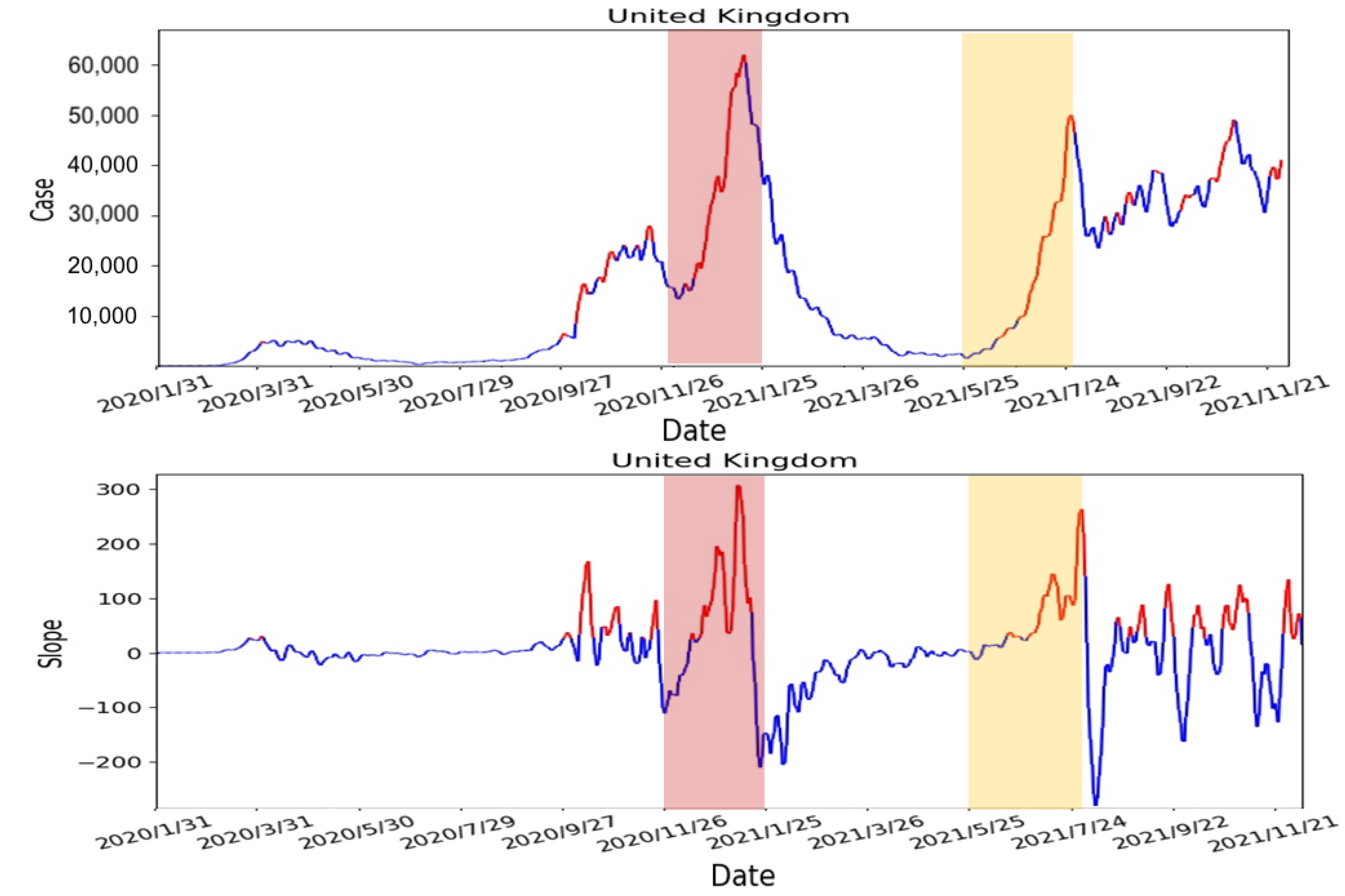
- Calculate the slope of the number of confirmed cases: We use 7 days as one unit of the sliding window to calculate the slope of the number of confirmed cases. According to other studies [32,33], people are not willing to undergo screening due to weekends and holidays. Moreover, the screening policy in the United States is different from others. As the result, the number of confirmed cases can fluctuate rapidly. Therefore, we averaged the data over 7 days to avoid fluctuations to obtain a smoother slope. The calculated slope results are shown in Figure 11. From the results, there are rapidly rising and falling slopes in the two selected periods. This indicated that the slope can indeed represent the rise and fall of the number of confirmed cases.
- 2.
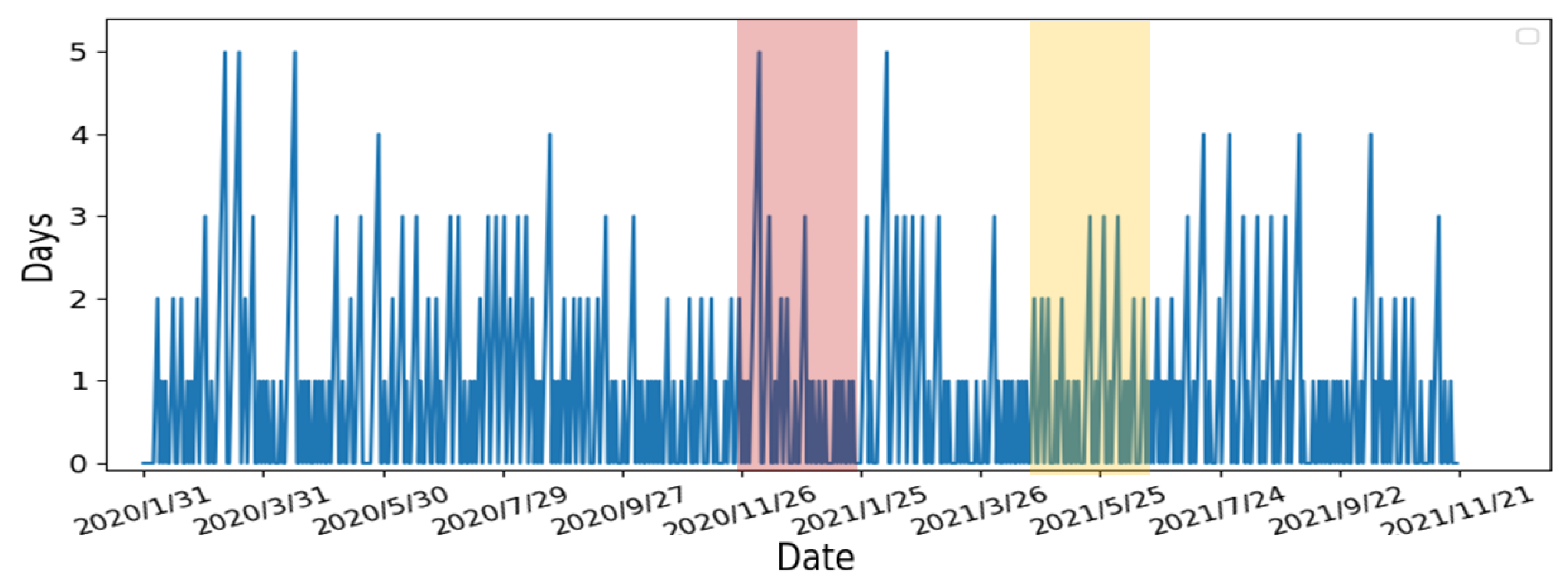
- Calculate the number of days the slope continues to grow: In order to determine the number of consecutive days in which the slope continues to increase, we compare each day’s slope with its previous day. When the slope of the current day is greater than the slope of the previous day, a continuous increase in the slope is observed and vice versa. If the number of consecutive days is large, it represented the number of confirmed cases continuing to increase with non-linear growth. From Figure 12, the number of consecutive growing days is 5 days long for the first period (i.e., 26 November 2020–25 January 2021), highlighted in red, and 3 days long for the second period (i.e., 25 May 2021–24 July 2021), highlighted in yellow.
- 3.
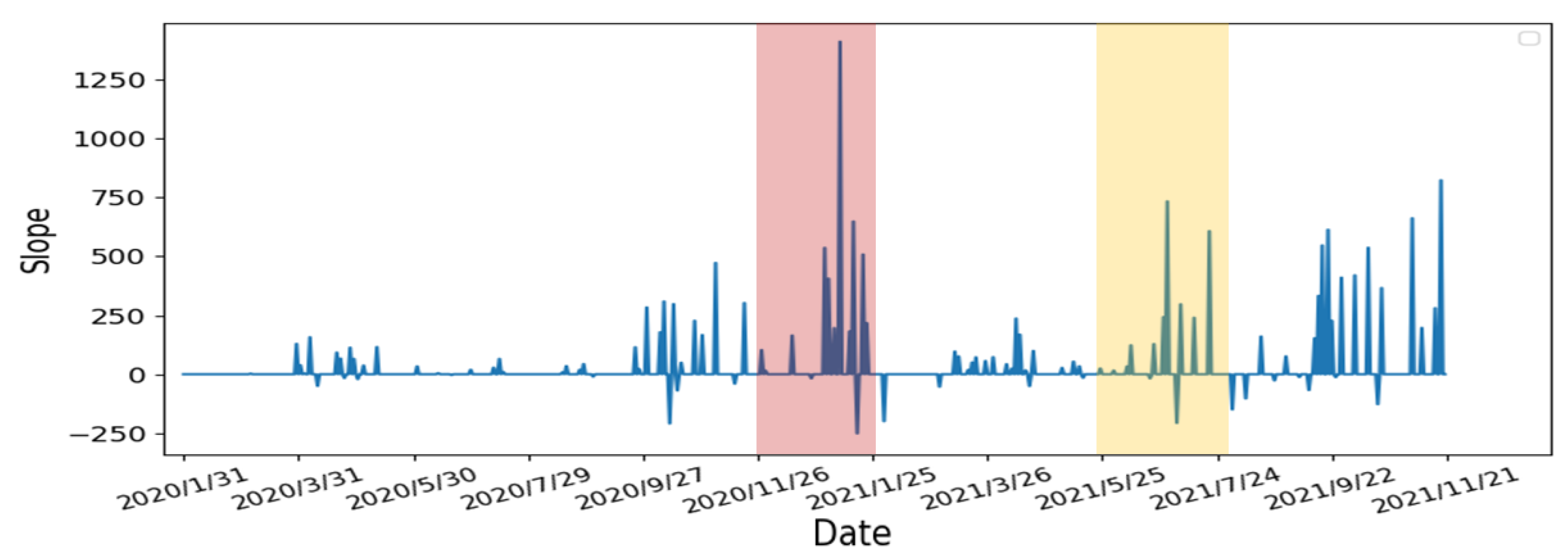
- Re-calculate the slope of the starting and ending points of the continuous days: From the previous step, we re-calculate the slope using starting day of the continuous period to capture the continuous growth slope features. The results are shown in Figure 13. Compare to the two periods, the slope’s growth peaks are higher and denser in the first period, which means that the two periods have different numbers of confirmed cases, growth rates, and lengths of days. The continuous growth slope features are useful in the risk analysis.
- 4.
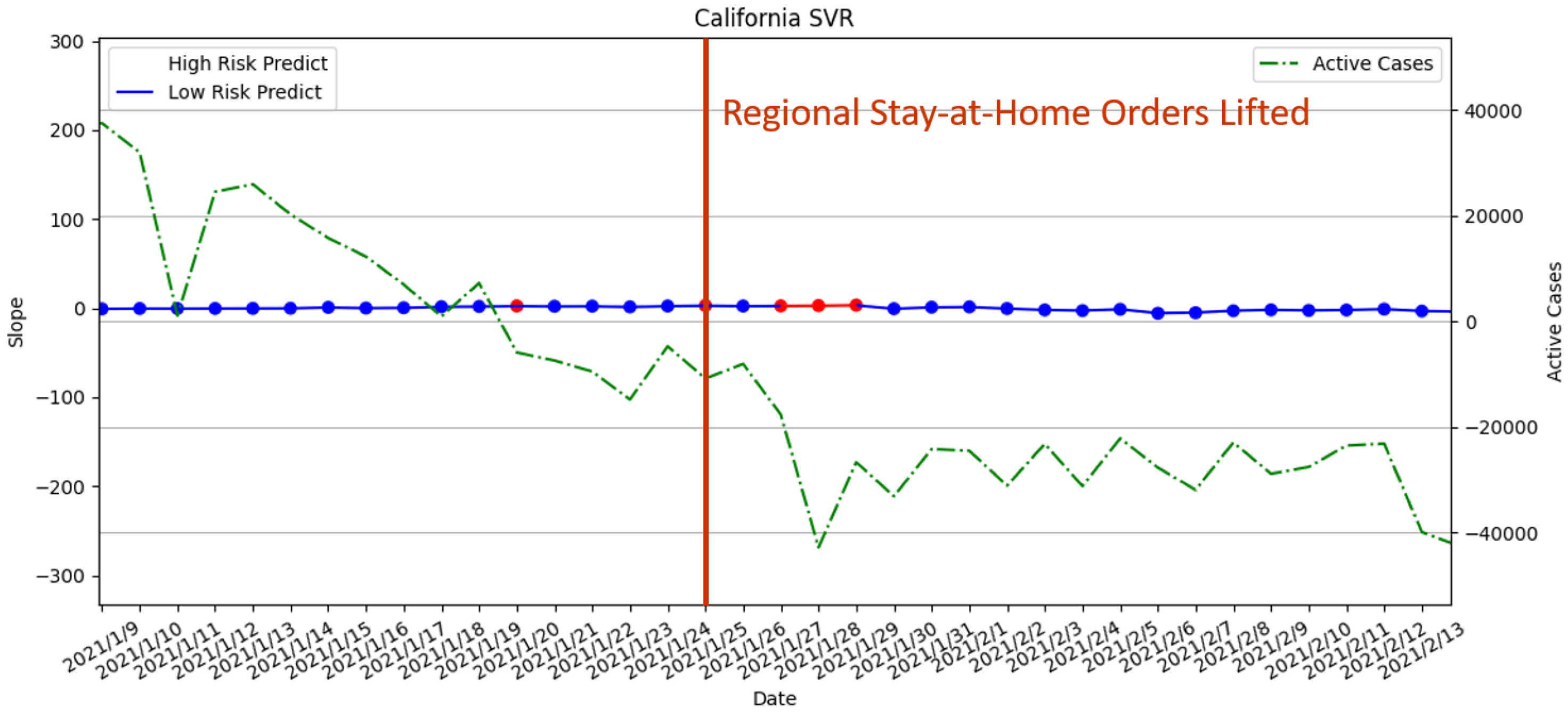
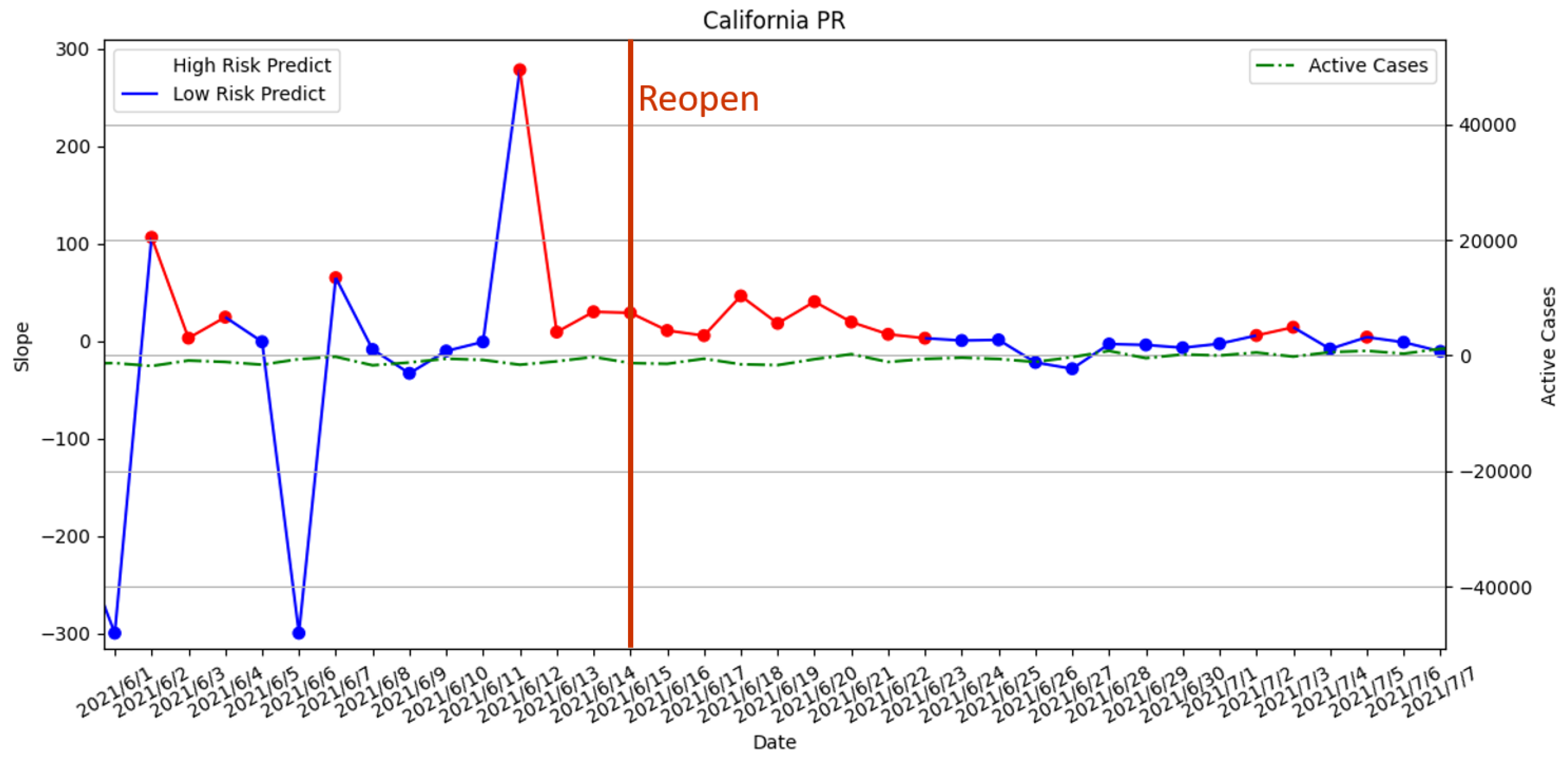
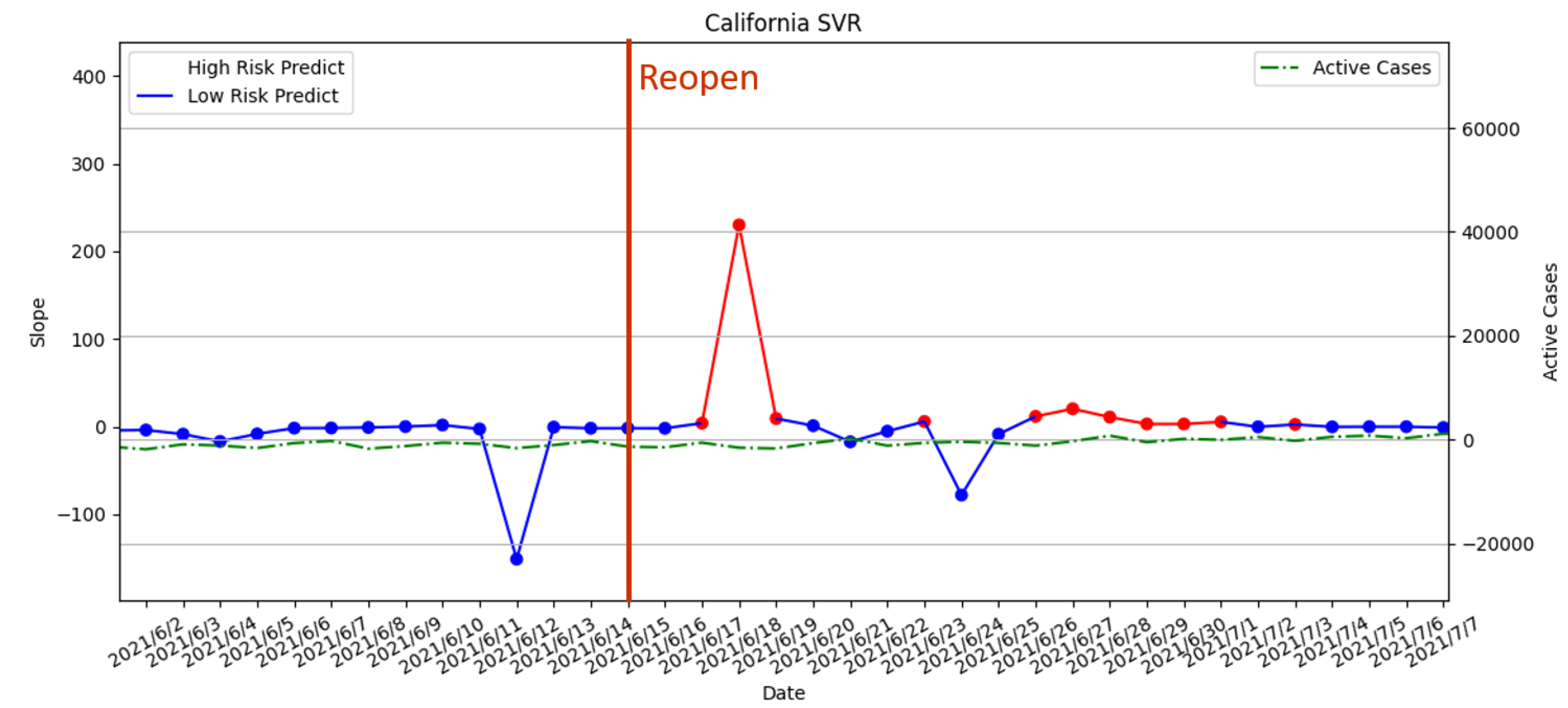
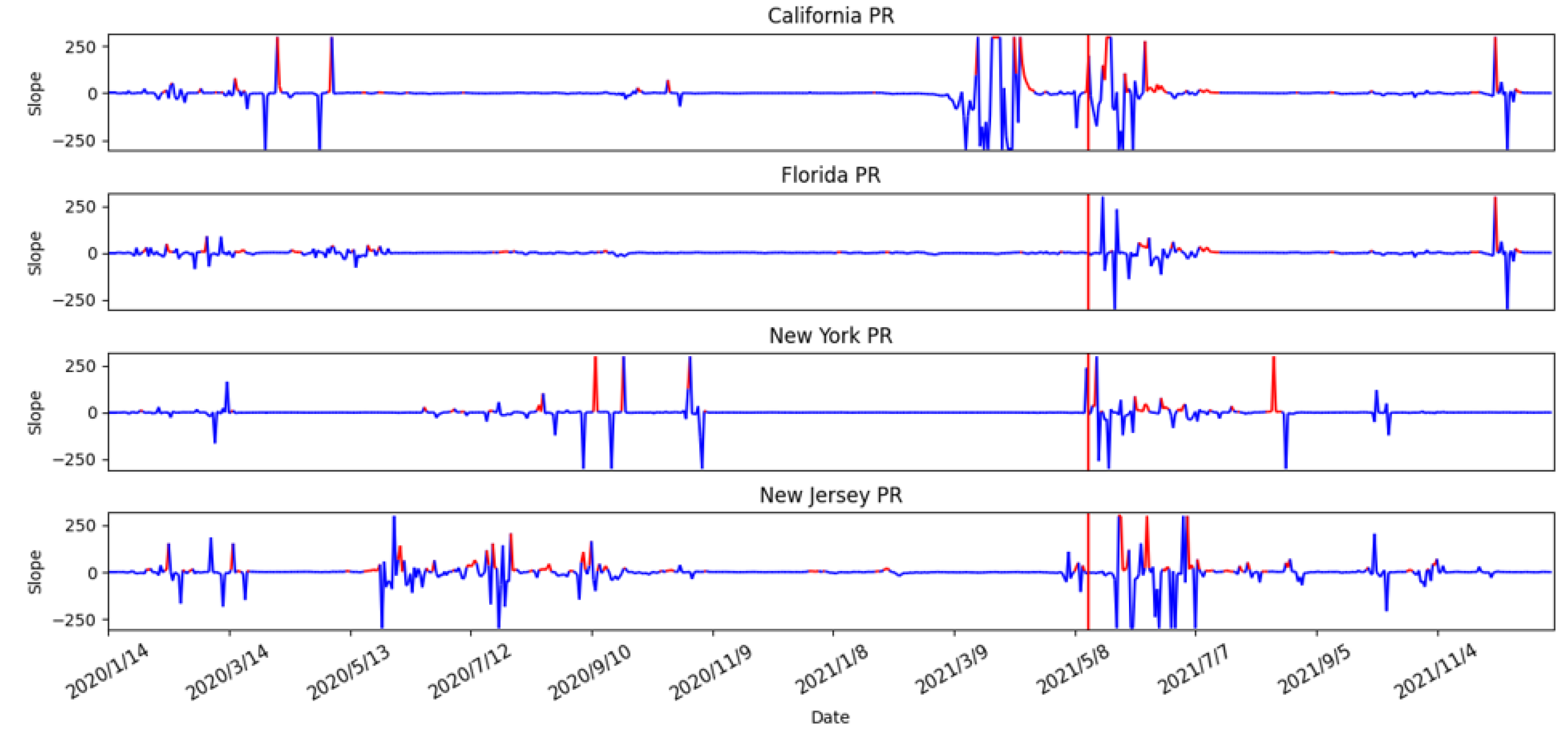
- Average the slope to obtain the threshold: Using the results from Step 3, we calculate the average of the slopes as the threshold for the high-risk period. The result is shown in Figure 14. The risk analysis flags slopes that exceed the threshold as high-risk warnings. In Figure 14, we used red segments to mark the high-risk periods and blue segments for low-risk periods. The results showed that the risk analysis correctly marks the periods with a high growth rate of the number of confirmed cases as high-risk periods. In this study, we will use the average wait time W predicted by the Queuing theory in the previous section of our risk analysis to evaluate whether each of the four states’ prevention measures is appropriate.
3. Results
3.1. Evaluation of Learning Models
3.2. Epidemic Prevention Policies in the USA
3.3. Evaluation of Prevention Policies with Our Risk Analysis
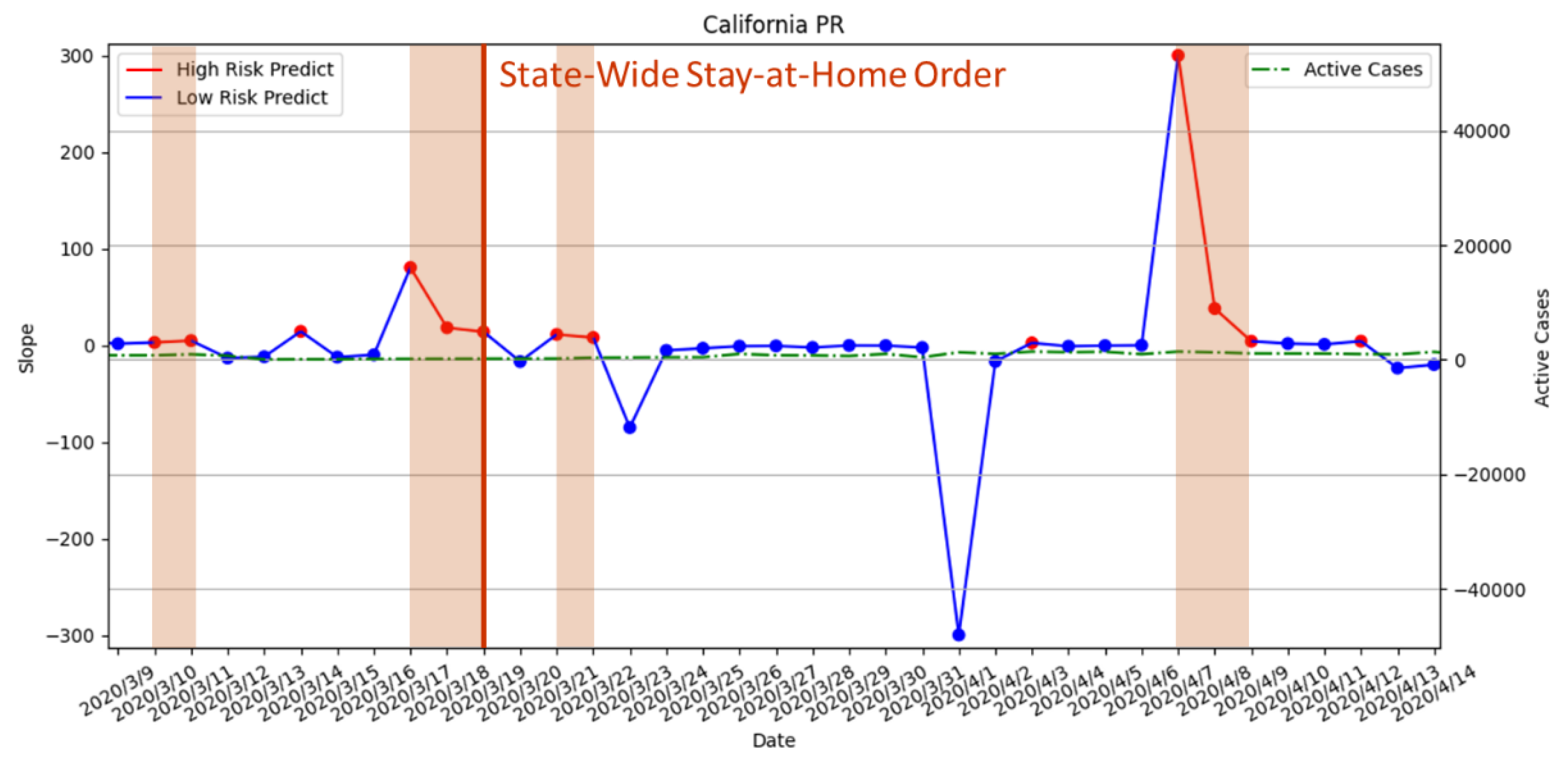
- 19 March 2020—Statewide stay-at-home order enforced;
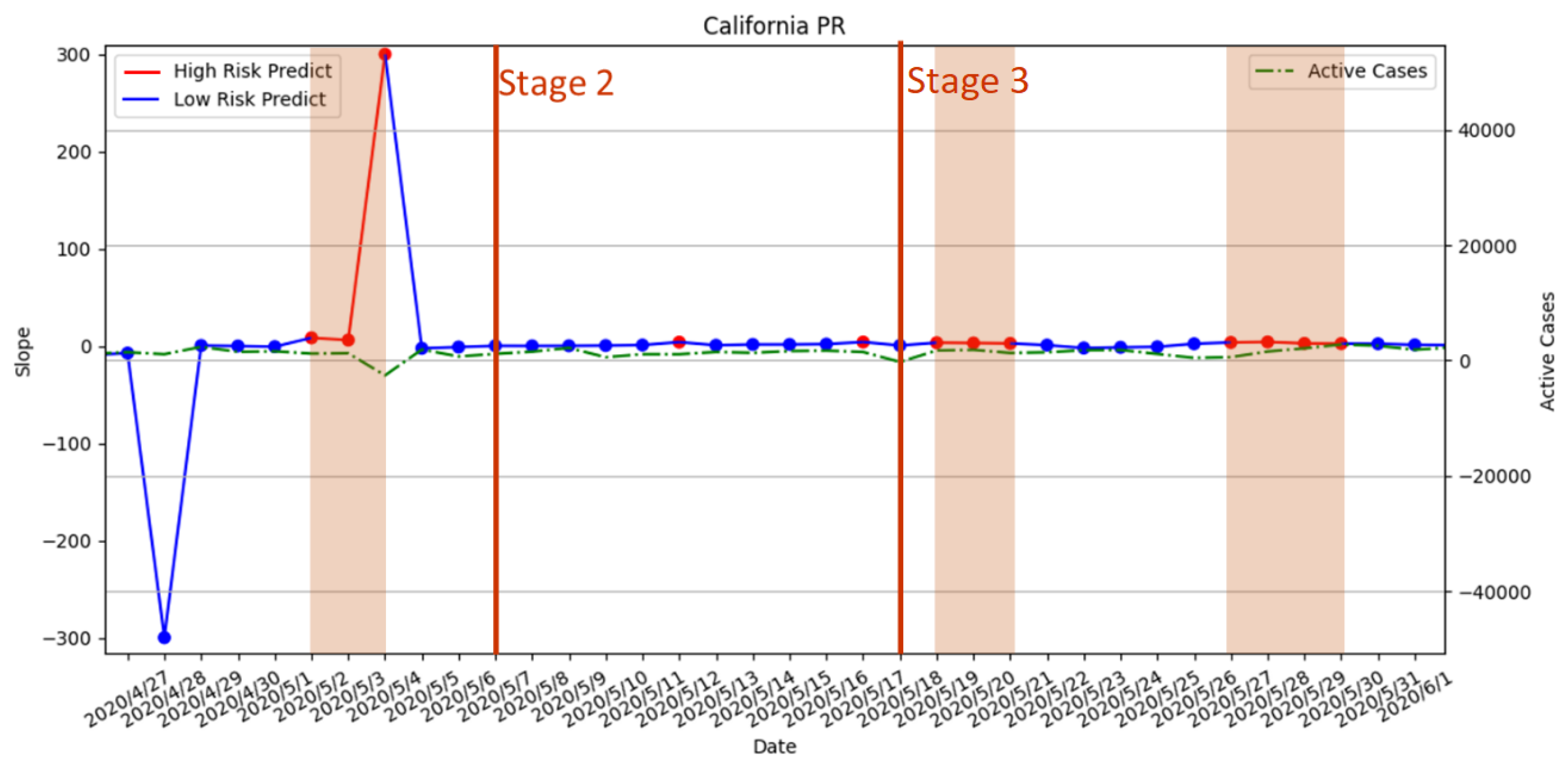
- 7 May 2020—Stage 2 policy executed;
- 18 May 2020—Stage 3 policy executed;
- 19 November 2020—Curfew policy enforced;
- 25 November 2021—Parts of the state’s stay-at-home order lifted;
- 15 June 2021—Reopening policy executed.
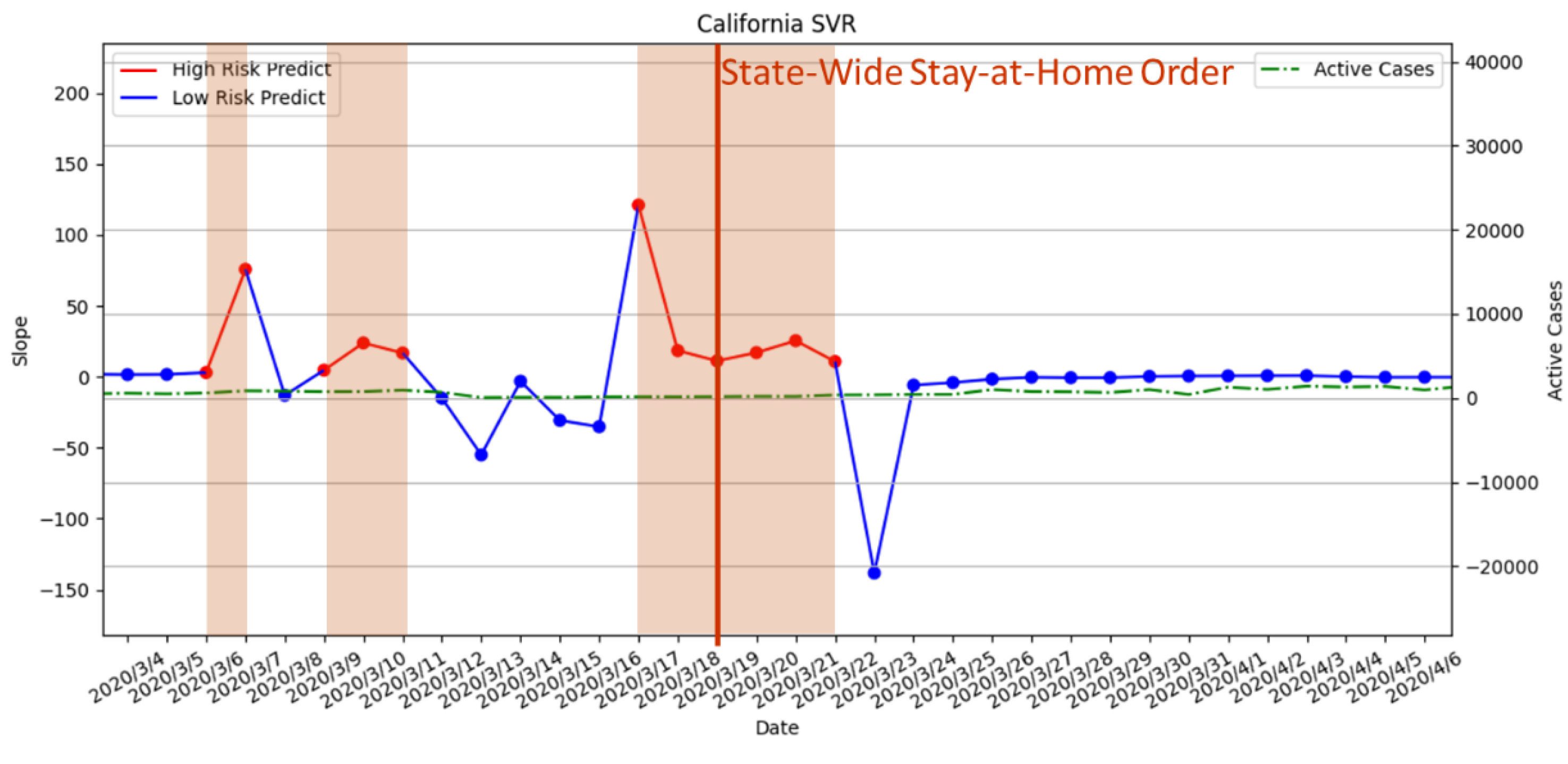
3.3.1. Statewide Stay-at-Home Order Enforced on 19 March 2020
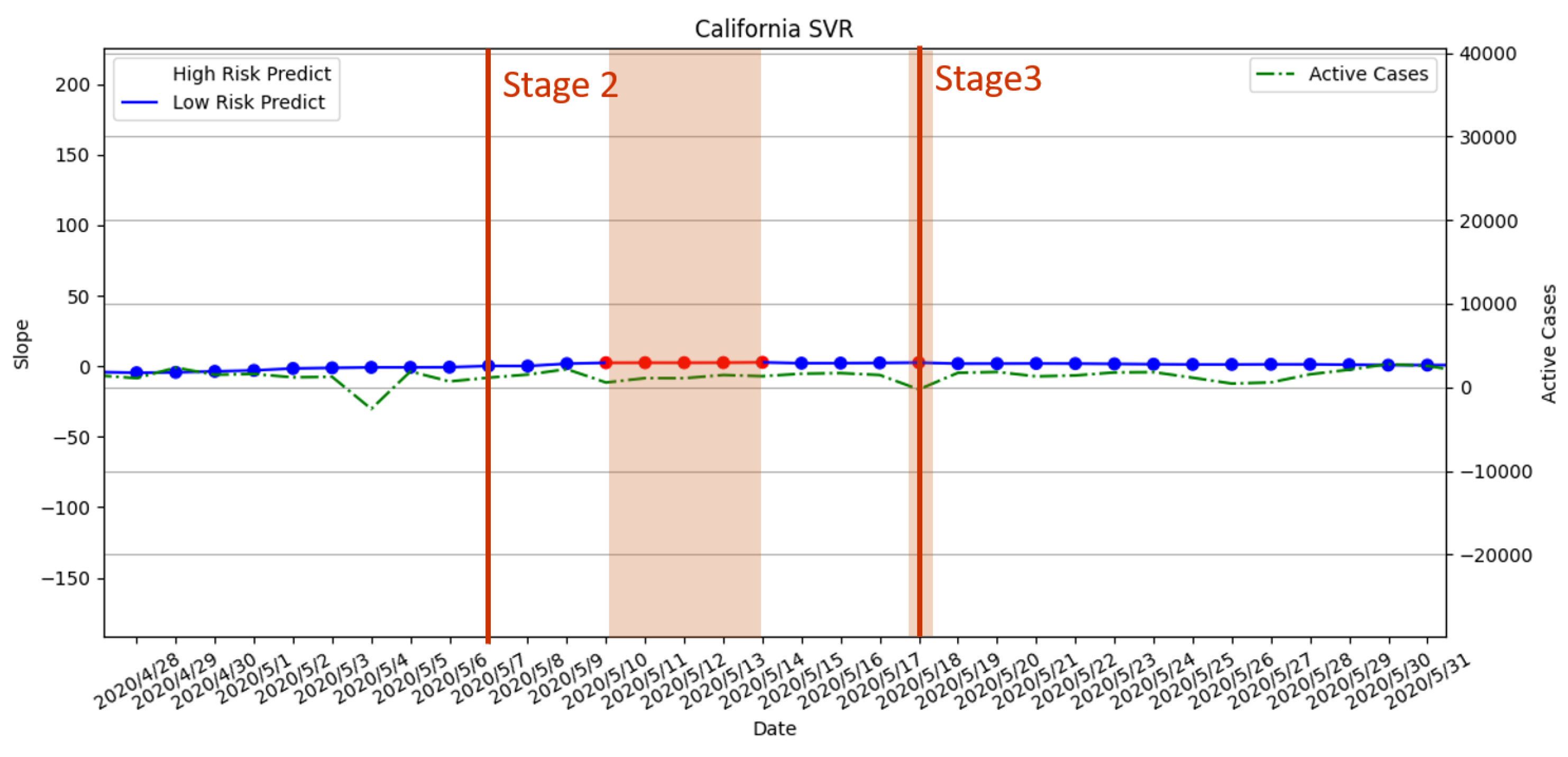
3.3.2. Stage 2 and Stage 3 Policies Executed on 7 May 2020 and 18 May 2020
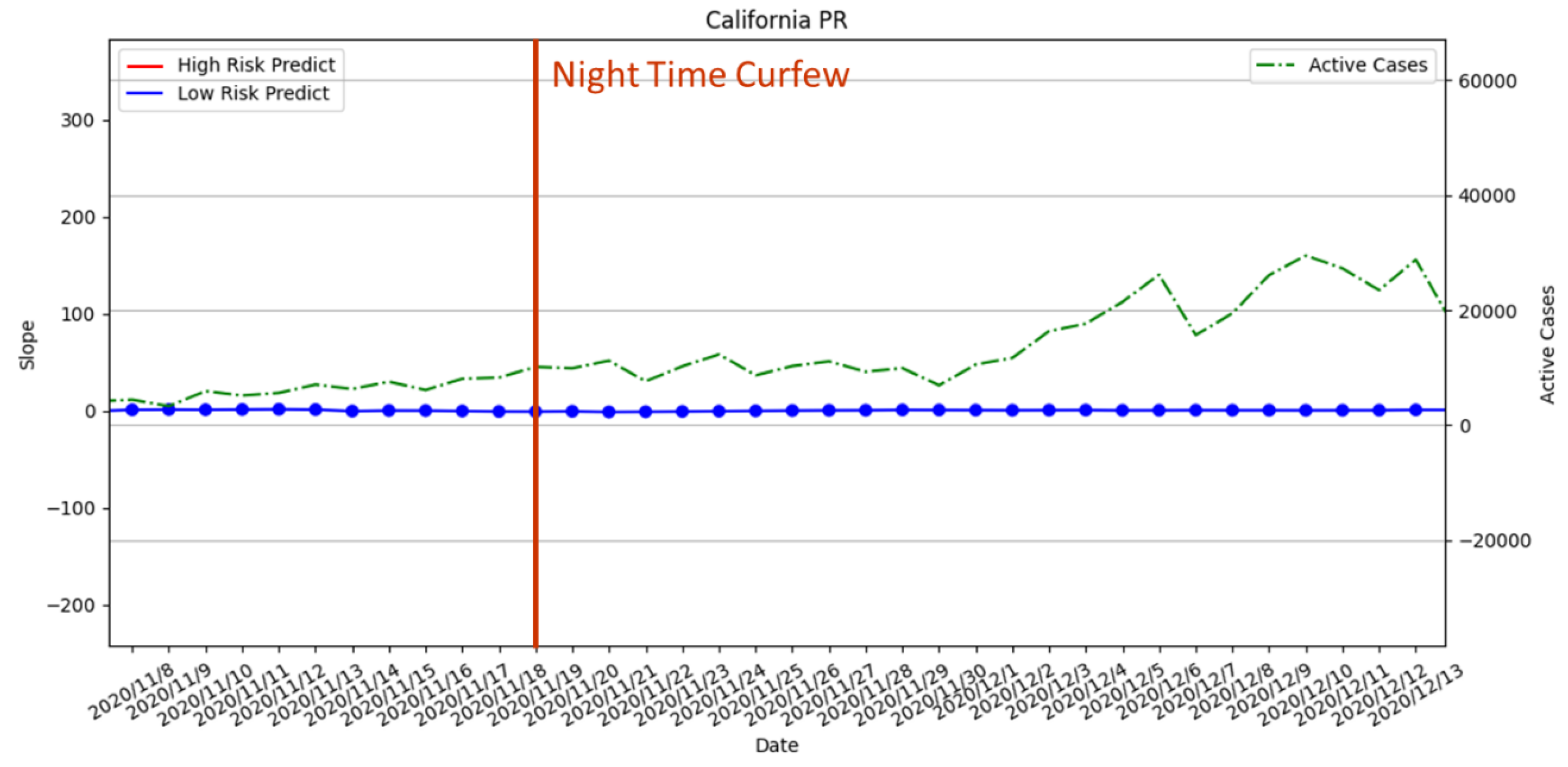
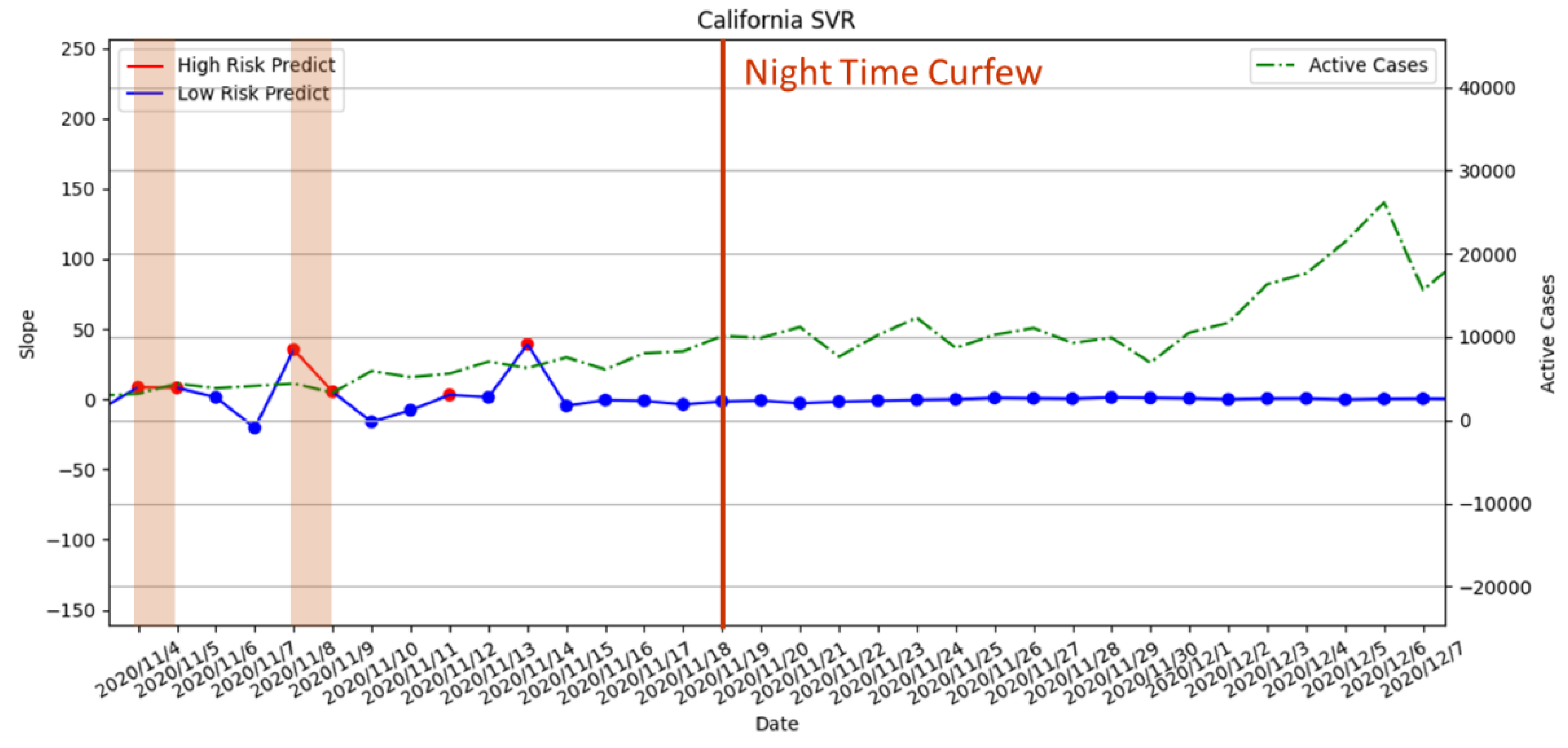
3.3.3. Curfew Policy Enforced on 19 November 2020
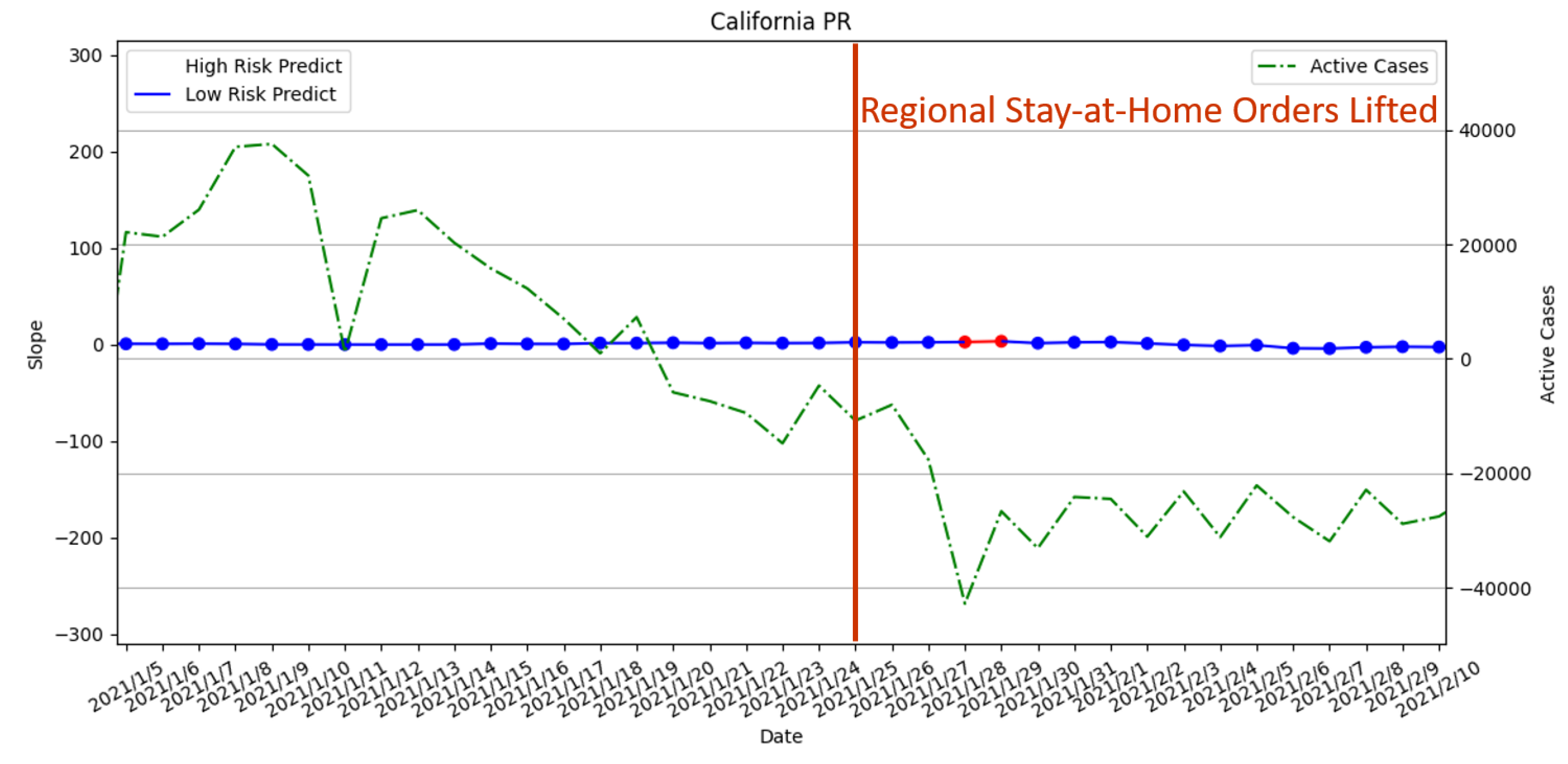
3.3.4. Regional Stay-at-Home Orders Lifted on 25 January 2021
3.3.5. Reopening Policy Executed on 15 June 2021
3.3.6. Risk Assessment with PR of the Four States
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Modes of Transmission of Virus Causing COVID-19: Implications for IPC Precaution Recommendations—who.int. Available online: https://www.who.int/news-room/commentaries/detail/modes-of-transmission-of-virus-causing-covid-19-implications-for-ipc-precaution-recommendations (accessed on 10 August 2022).
- Guarnieri, M.; Balmes, J.R. Outdoor air pollution and asthma. Lancet 2014, 383, 1581–1592. [Google Scholar] [CrossRef]
- Goldizen, F.C.; Sly, P.D.; Knibbs, L.D. Respiratory effects of air pollution on children. Pediatr. Pulmonol. 2016, 51, 94–108. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.Q.; Mei, X.D.; Feng, D. Air pollution and chronic airway diseases: What should people know and do? J. Thorac. Dis. 2015, 8, E31. [Google Scholar]
- Setti, L.; Passarini, F.; de Gennaro, G.; Di Gil, A.; Palmisani, J.; Buono, P.; Fornari, G.; Perrone, M.G.; Piazzalunga, A.; Barbieri, P.; et al. Evaluation of the potential relationship between Particulate Matter (PM) pollution and COVID-19 infection spread in Italy. Soc. Ital. Med. Ambient. 2020, 1. Available online: https://www.aircentre.org/wp-content/uploads/2020/04/Setti_et_al_2020.pdf (accessed on 16 October 2022).
- Gupta, A.; Bherwani, H.; Gautam, S.; Anjum, S.; Musugu, K.; Kumar, N.; Anshul, A.; Kumar, R. Air pollution aggravating COVID-19 lethality? Exploration in Asian cities using statistical models. Environ. Dev. Sustain. 2021, 23, 6408–6417. [Google Scholar] [CrossRef] [PubMed]
- Beckerman, B.; Jerrett, M.; Brook, J.R.; Verma, D.K.; Arain, M.A.; Finkelstein, M.M. Correlation of nitrogen dioxide with other traffic pollutants near a major expressway. Atmos. Environ. 2008, 42, 275–290. [Google Scholar] [CrossRef]
- Chen, Z.L.; Zhang, Q.; Lu, Y.; Guo, Z.M.; Zhang, X.; Zhang, W.J.; Guo, C.; Liao, C.H.; Li, Q.L.; Han, X.H.; et al. Distribution of the COVID-19 epidemic and correlation with population emigration from Wuhan, China. Chin. Med. J. 2020, 133, 1044–1050. [Google Scholar] [CrossRef] [PubMed]
- U.S. Centers for Disease Control and Prevention (CDC). COVID-19 Vaccination Work. Available online: https://www.cdc.gov/coronavirus/2019-ncov/vaccines/effectiveness/work.html (accessed on 8 October 2022).
- United States COVID—Coronavirus Statistics—Worldometer—worldometers.info. 2022. Available online: https://www.worldometers.info/coronavirus/country/us/ (accessed on 24 August 2022).
- Understanding the COVID-19 Pandemic. 2022. Available online: https://usafacts.org/issues/coronavirus/ (accessed on 24 August 2022).
- Download Daily Data | US EPA—epa.gov. Available online: https://www.epa.gov/outdoor-air-quality-data/download-daily-data (accessed on 24 August 2022).
- COVID-19—Mobility Trends Reports—Apple—covid19.apple.com. Available online: https://covid19.apple.com/mobility (accessed on 10 January 2022).
- Mobile OS share in North America 2018–2021 | Statista—statista.com. Available online: https://www.statista.com/statistics/1045192/share-of-mobile-operating-systems-in-north-america-by-month/ (accessed on 1 July 2022).
- Coronavirus (COVID-19) Vaccinations—ourworldindata.org. Available online: https://ourworldindata.org/covid-vaccinations (accessed on 24 August 2022).
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Li, X. Association between population mobility reductions and new COVID-19 diagnoses in the United States along the urban–rural gradient, February–April, 2020. Prev. Chronic Dis. 2020, 17, 200241. [Google Scholar] [CrossRef] [PubMed]
- Tabachnick, B.G.; Fidell, L.S.; Ullman, J.B. Using Multivariate Statistics; Pearson: Boston, MA, USA, 2007; Volume 5. [Google Scholar]
- Draper, N.R.; Smith, H. Applied Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 1998; Volume 326. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ho, Y.H.; Tai, Y.J.; Chen, L.J. COVID-19 Pandemic Analysis for a Country’s Ability to Control the Outbreak Using Little’s Law: Infodemiology Approach. Sustainability 2021, 13, 5628. [Google Scholar] [CrossRef]
- Cooper, R.B. Queueing Theory. In Proceedings of the ACM ’81 Conference, Los Angeles, CA, USA, 9–11 November 1981; Association for Computing Machinery: New York, NY, USA, 1981; pp. 119–122. [Google Scholar] [CrossRef]
- Little, J.D. A proof for the queuing formula: L = λ W. Oper. Res. 1961, 9, 383–387. [Google Scholar] [CrossRef]
- Heesterbeek, J.A.P. A brief history of R 0 and a recipe for its calculation. Acta Biotheor. 2002, 50, 189–204. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Rocklöv, J. The reproductive number of the Delta variant of SARS-CoV-2 is far higher compared to the ancestral SARS-CoV-2 virus. J. Travel Med. 2021, 28, taab124. [Google Scholar] [CrossRef] [PubMed]
- Gallagher, J. Covid: Is There a Limit to How Much Worse Variants Can Get? Available online: https://www.bbc.com/news/health-57431420 (accessed on 10 August 2022).
- Boarman, A. Omicron is the Dominant COVID Variant for Two Reasons. 2021. Available online: https://vitals.sutterhealth.org/omicron-is-the-us-dominant-covid-variant-for-two-reasons/ (accessed on 10 August 2022).
- Locatelli, I.; Trächsel, B.; Rousson, V. Estimating the basic reproduction number for COVID-19 in Western Europe. PLoS ONE 2021, 16, e0248731. [Google Scholar] [CrossRef] [PubMed]
- Knight, J.; Mishra, S. Estimating effective reproduction number using generation time versus serial interval, with application to COVID-19 in the Greater Toronto Area, Canada. Infect. Dis. Model. 2020, 5, 889–896. [Google Scholar] [CrossRef] [PubMed]
- Coronavirus (COVID-19) Cases—ourworldindata.org. Available online: https://ourworldindata.org/covid-cases (accessed on 24 August 2022).
- Simpson, R.B.; Lauren, B.N.; Schipper, K.H.; McCann, J.C.; Tarnas, M.C.; Naumova, E.N. Critical periods, critical time points and day-of-the-week effects in covid-19 surveillance data: An example in Middlesex County, Massachusetts, USA. Int. J. Environ. Res. Public Health 2022, 19, 1321. [Google Scholar] [CrossRef] [PubMed]
- Aragão, D.P.; Dos Santos, D.H.; Mondini, A.; Gonçalves, L.M.G. National holidays and social mobility behaviors: Alternatives for forecasting COVID-19 deaths in Brazil. Int. J. Environ. Res. Public Health 2021, 18, 11595. [Google Scholar] [CrossRef] [PubMed]
- Bickel, P.J.; Doksum, K.A. Mathematical Statistics: Basic Ideas and Selected Topics, Volumes I-II Package; Chapman and Hall/CRC: Boca Raton, FL, USA, 2015. [Google Scholar]
- Steel, R.G.D.; Torrie, J.H. Principles and procedures of statistics. In Principles and Procedures of Statistics; McGraw-Hill Book Company, Inc.: New York, NY, USA; Toronto, ON, Canda; London, UK, 1960. [Google Scholar]
- Impact of Opening and Closing Decisions in California, New Cases—Johns Hopkins—coronavirus.jhu.edu. Available online: https://coronavirus.jhu.edu/data/state-timeline/new-confirmed-cases/california (accessed on 24 August 2022).
- Wikipedia Contributors. COVID-19 Pandemic in California—Wikipedia, The Free Encyclopedia. 2022. Available online: https://en.wikipedia.org/w/index.php?title=COVID-19_pandemic_in_California&oldid=1100583819 (accessed on 24 August 2022).
- Wikipedia Contributors. Timeline of the COVID-19 pandemic in the United States (2021)—Wikipedia, The Free Encyclopedia. 2022. Available online: https://en.wikipedia.org/w/index.php?title=Timeline_of_the_COVID-19_pandemic_in_the_United_States_(2021)&oldid=1072395501 (accessed on 22 August 2022).


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| California | Florida | New Jersey | New York | |
|---|---|---|---|---|
| Population | 39,538,223 | 21,538,187 | 9,288,994 | 20,201,249 |
| Land Area (km2) | 423,970 | 170,304 | 22,588 | 141,299 |
| Density (per km) | 93.25 | 126.46 | 411.23 | 142.97 |
| California | Florida | New Jersey | New York | |
|---|---|---|---|---|
| Period 1 | 13 January 2020–18 March 2020 | 13 January 2020–31 March 2020 | 13 January 2020–20 March 2020 | 13 January 2020–20 March 2020 |
| Period 2 | 19 March 2020–7 May 2020 | 1 April 2020–30 March 2020 | 21 March 2020–9 June 2020 | 21 March 2020–14 May 2020 |
| Period 3 | 8 May 2020–4 November 2021 | 1 May 2020–4 November 2021 | 10 June 2020–4 November 2021 | 15 May 2020–4 November 2021 |
| State | Period | NO | Ozone | PM | SO | CO | Driving | Walking | Transit | Vaccinated |
|---|---|---|---|---|---|---|---|---|---|---|
| California | Period 1 | −0.564 ** | 0.130 | −0.533 ** | −0.321 ** | −0.578 ** | −0.463 ** | −0.483 | −0.802 ** | 0 |
| Period 2 | −0.148 | 0.280 * | 0.302 * | −0.032 | −0.151 | 0.211 | 0.283 * | −0.355 * | 0 | |
| Period 3 | 0.356 ** | −0.369 ** | −0.020 | 0.224 ** | 0.479 ** | −0.522 ** | −0.430 ** | −0.468 ** | −0.387 ** | |
| Florida | Period 1 | −0.055 | 0.034 | 0.424 ** | 0.462 ** | −0.022 | −0.603 ** | −0.589 ** | −0.693 ** | 0 |
| Period 2 | 0.260 | 0.028 | −0.086 | −0.064 | 0.038 | −0.363 * | −0.357 | −0.305 | 0 | |
| Period 3 | 0.281 ** | −0.071 | 0.014 | 0.049 | 0.141 ** | −0.151 ** | −0.084 | −0.011 | −0.388 ** | |
| New Jersey | Period 1 | −0.066 | 0.152 | −0.073 | −0.074 | −0.020 | −0.492 ** | −0.363 ** | −0.609 ** | 0 |
| Period 2 | 0.186 | 0.167 | −0.070 | −0.193 | −0.103 | −0.161 | −0.183 | −0.270 * | 0 | |
| Period 3 | 0.107 * | −0.098 * | −0.016 | 0.139 ** | −0.081 | −0.127 ** | −0.128 ** | −0.203 ** | −0.173 ** | |
| New York | Period 1 | −0.186 | 0.232 | −0.230 | 0.005 | −0.182 | −0.365 ** | −0.362 ** | −0.592 ** | 0 |
| Period 2 | −0.124 | −0.060 | 0.023 | −0.043 | −0.147 | −0.084 | −0.167 | −0.188 | 0 | |
| Period 3 | 0.235 ** | −0.108 * | 0.036 | 0.269 ** | 0.073 | −0.479 ** | −0.397 ** | −0.350 ** | −0.257 ** |
| PR | MLR | SVR | LSTM | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| State | MSE | R-Square | MSE | R-Square | MSE | R-Square | MSE | R-Square | ||||||||
| CA | 32.4 | 47 | 8860 | 6545.1 | 137.8 | 123.9 | 5160 | 895.5 | 48.3 | 58.3 | 8303.7 | 4995.2 | 67.6 | 59.7 | 7356.3 | 5708.3 |
| FL | 145.7 | 58 | 6513.9 | 3388.9 | 183.8 | 71.3 | 5601.9 | 1866.4 | 101 | 101 | 7583.8 | 7583.8 | 173.6 | 27.1 | 5315.1 | 2485.7 |
| NJ | 39.3 | 50.2 | 6278.7 | 4654.9 | 67.9 | 71 | 3572.1 | 2446.7 | 62.1 | 55.4 | 4120.6 | 4109 | 71.5 | 73 | 98.2 | −904.5 |
| NY | 23.8 | 35.5 | 7527.4 | 4912 | 55.5 | 57.6 | 4234.3 | 1753.2 | 42 | 46.6 | 5644.1 | 3320.4 | 109.4 | 81.4 | 5735.7 | 4202.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chiang, Y.-F.; Chu, K.-U.; Chen, L.-J.; Ho, Y.-H. Predicting Risks of a COVID-19 Outbreak by Using Outdoor Air Pollution Indicators and Population Flow with Queuing Theory. Atmosphere 2022, 13, 1727. https://doi.org/10.3390/atmos13101727
Chiang Y-F, Chu K-U, Chen L-J, Ho Y-H. Predicting Risks of a COVID-19 Outbreak by Using Outdoor Air Pollution Indicators and Population Flow with Queuing Theory. Atmosphere. 2022; 13(10):1727. https://doi.org/10.3390/atmos13101727
Chicago/Turabian StyleChiang, Yi-Fang, Ka-Ui Chu, Ling-Jyh Chen, and Yao-Hua Ho. 2022. "Predicting Risks of a COVID-19 Outbreak by Using Outdoor Air Pollution Indicators and Population Flow with Queuing Theory" Atmosphere 13, no. 10: 1727. https://doi.org/10.3390/atmos13101727
APA StyleChiang, Y.-F., Chu, K.-U., Chen, L.-J., & Ho, Y.-H. (2022). Predicting Risks of a COVID-19 Outbreak by Using Outdoor Air Pollution Indicators and Population Flow with Queuing Theory. Atmosphere, 13(10), 1727. https://doi.org/10.3390/atmos13101727