2.2.1. Multi-ConvGRU
The ConvLSTM [
12] combines LSTM and CNN; the former learns time series data well, while the latter is skilled in learning spatial data. This model can model complex spatiotemporal data in the real world and extract the 3D features of tropical cyclones. In order to simplify the parameters of the spatiotemporal sequence and accelerate the training, we replace the ConvLSTM with ConvGRU. The formulas of ConvGRU [
20] are calculated as follows:
where * represents the convolution operation and
represents the Hadamard product.
Although the ConvGRU solves the weaknesses of too many learning parameters and slow learning speed of the spatiotemporal sequence, there are still some problems on insufficient feature extraction when processing atmospheric reanalysis data. This is because the traditional ConvGRU performs a GRU operation after convolving the input image and the hidden state once. In order to overcome the problems of large-scale spatial feature learning, we adopt the multi-ConvGRU model. Compared with ConvGRU, this method introduces a multi-convolution module as input, and realizes nonlinear transformation through multiple convolutions, which achieves the effect of extracting deeper nonlinear features. The formulas of the multi-ConvGRU model [
19] are given by:
where * is the convolution operation and
represents the Hadamard product.
is the multi-convolution module, which is denoted as
.
It can be clearly seen that the multi-convolution module can extract more complex information from the input . For atmospheric reanalysis data with relatively low accuracy, it can better extract the characteristics of tropical cyclones and their surrounding environment, which improves the accuracy of the model.
2.2.2. Convolutional Block Attention
After constructing the 3D time series structure of tropical cyclones, learning the regularity of this structure is a complex spatiotemporal learning problem. Therefore, we introduce the Convolutional Block Attention Module (CBAM) [
21] to copy the influences of the isobaric surface.
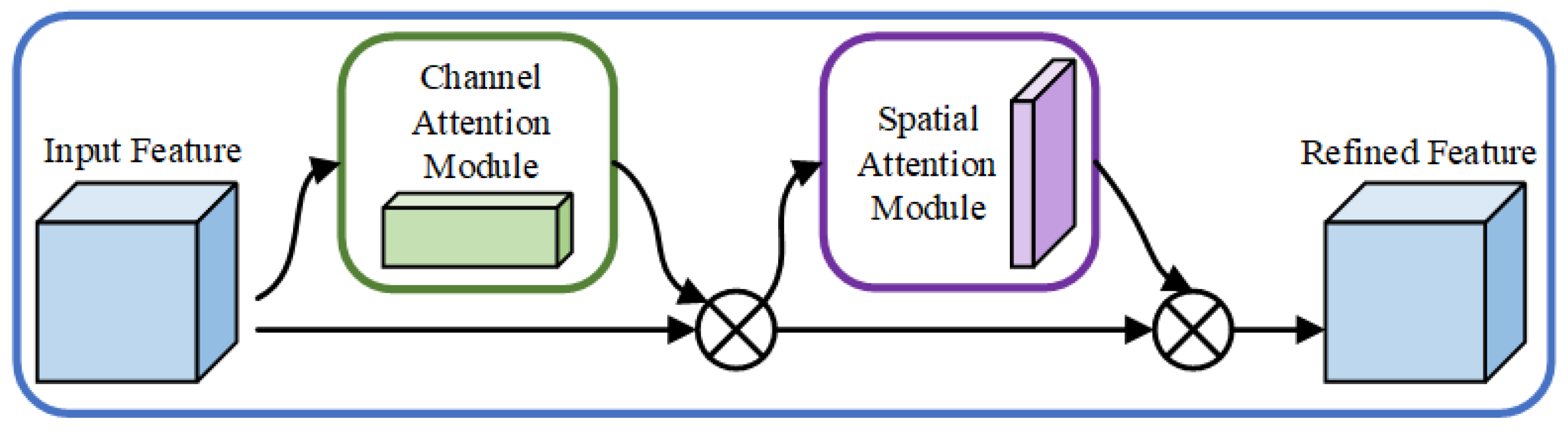
The Convolutional Attention Module (CBAM) is mainly composed of two parts, including the channel attention mechanism and the spatial attention mechanism, and its overall framework is shown in
Figure 4. The attention module pays attention to the correlation between different channels and obtains the weights of different channels by calculation, which will be applied to the extracted channels to learn the characteristics of different channels. The role of the spatial attention module is to capture the spatial correlation between different pixel locations in the feature map, since pixels at different locations are of differing importance for the network to learn.
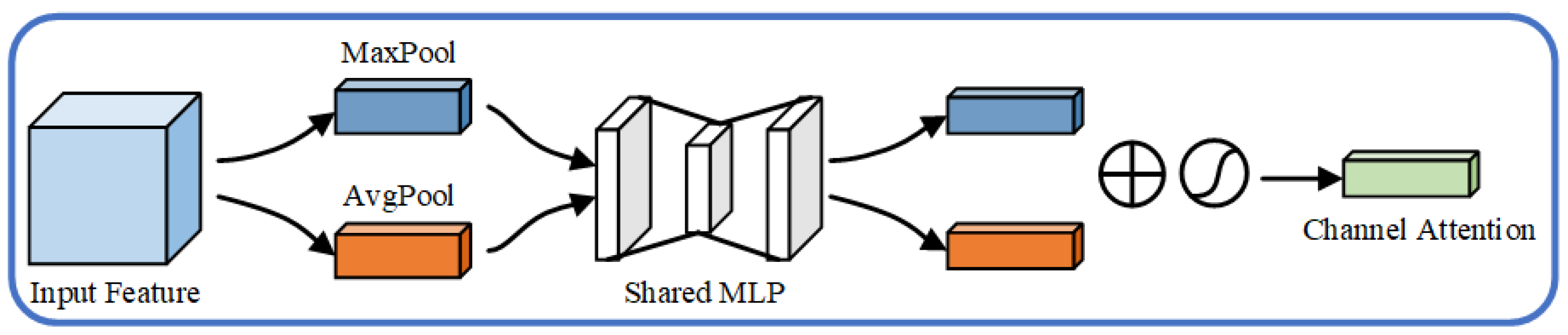
The structure of the channel attention module is shown in
Figure 5. It reduces the dimension of the input features and performs max pooling and average pooling, respectively. Then, two
feature vectors are obtained, both of which contain the global distribution of the input features in the channel dimension. At the same time, in order to reduce the amount of calculation, a convolution is adopted to reduce the dimension of the two feature vectors, so that the numbers of channels are reduced to
of the previous. Meanwhile, the two reduced feature vectors are superimposed, which are fused by a
convolution, and the numbers of channels are restored to the original number
C. Finally, through a sigmoid function, the channel attention matrix
is obtained. The matrix is multiplied by the input elements to realize the adaptive adjustments of the original input characteristics in the channel dimension. The calculation process of the channel attention module [
21] is shown in Formula (9):
where
represents the sigmoid function,
and
, which, respectively, represent the weights of the two
convolution kernels. Meanwhile, the
represents the RuLU activation function, and the
and
, respectively, represent the feature vectors after max pooling and average pooling.
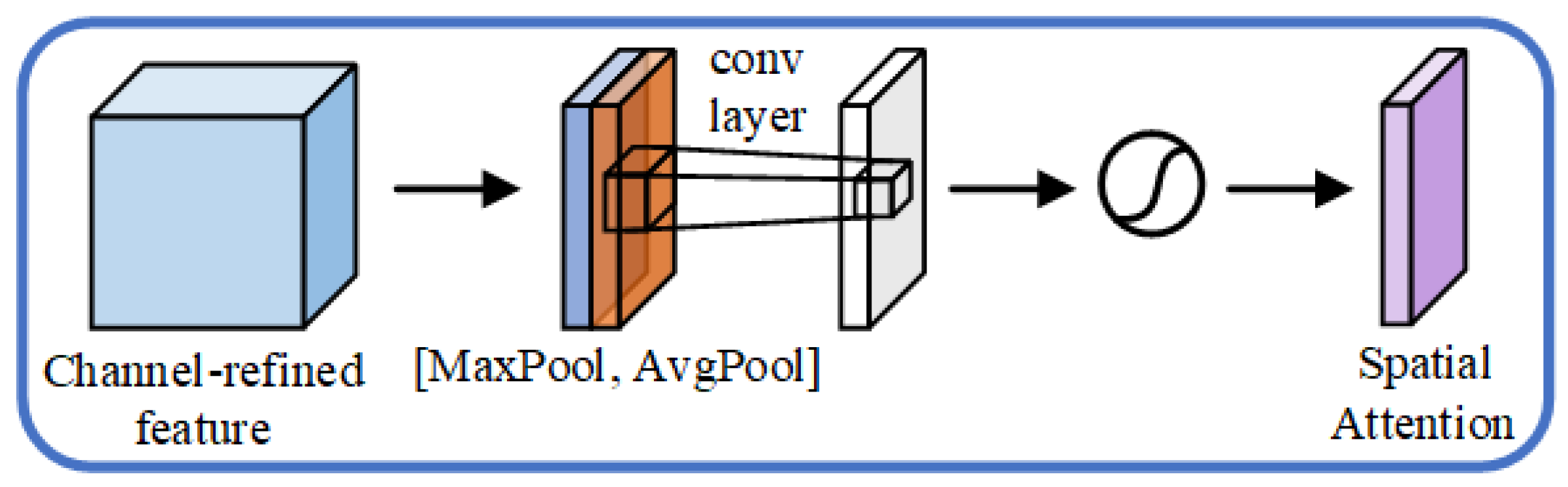
The process of the spatial attention module is similar to that of the channel attention module. The structure is shown in
Figure 6. Firstly, the max-pooling and average-pooling operations are performed on the features extracted by channel attention along the channel, respectively, and the input feature maps of
are compressed into two single-channel feature maps of
, which shows the distribution of the input over the spatial dimension. Secondly, two single-channel feature maps are spliced in the channel dimension, and then fused using the convolution operation to obtain a feature map of
. Then, the spatial attention matrix
is achieved through a sigmoid function. The matrix is multiplied by the elements of the original input features, resulting in a feature representation refined by two attentions. The calculation process of the spatial attention module is shown in Formula (10):
where
represents the feature extracted by the attention module, and
represents the weights of the
convolution kernel. Two different feature descriptions
and
, respectively, represent the feature map after max pooling and average pooling.
2.2.3. Deep and Cross Fusion Method
After obtaining the 2D and 3D time-series characteristics of tropical cyclones, it is necessary to fuse the two features. In this paper, Deep and Cross Network (DCN) [
22] is adopted to solve the problem of CTR estimation for large-scale sparse features. This model is a follow-up study of the Wide and Deep [
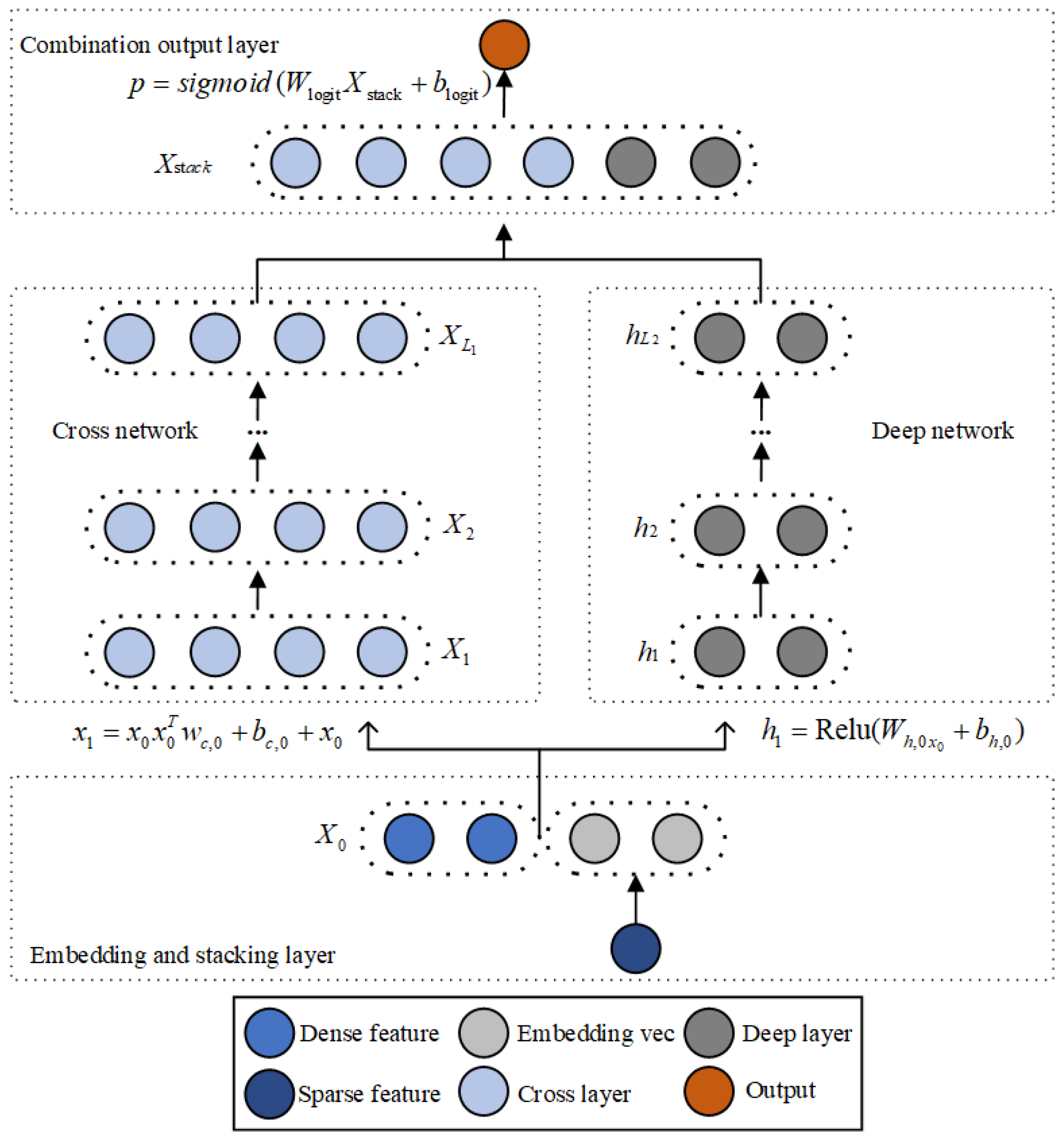
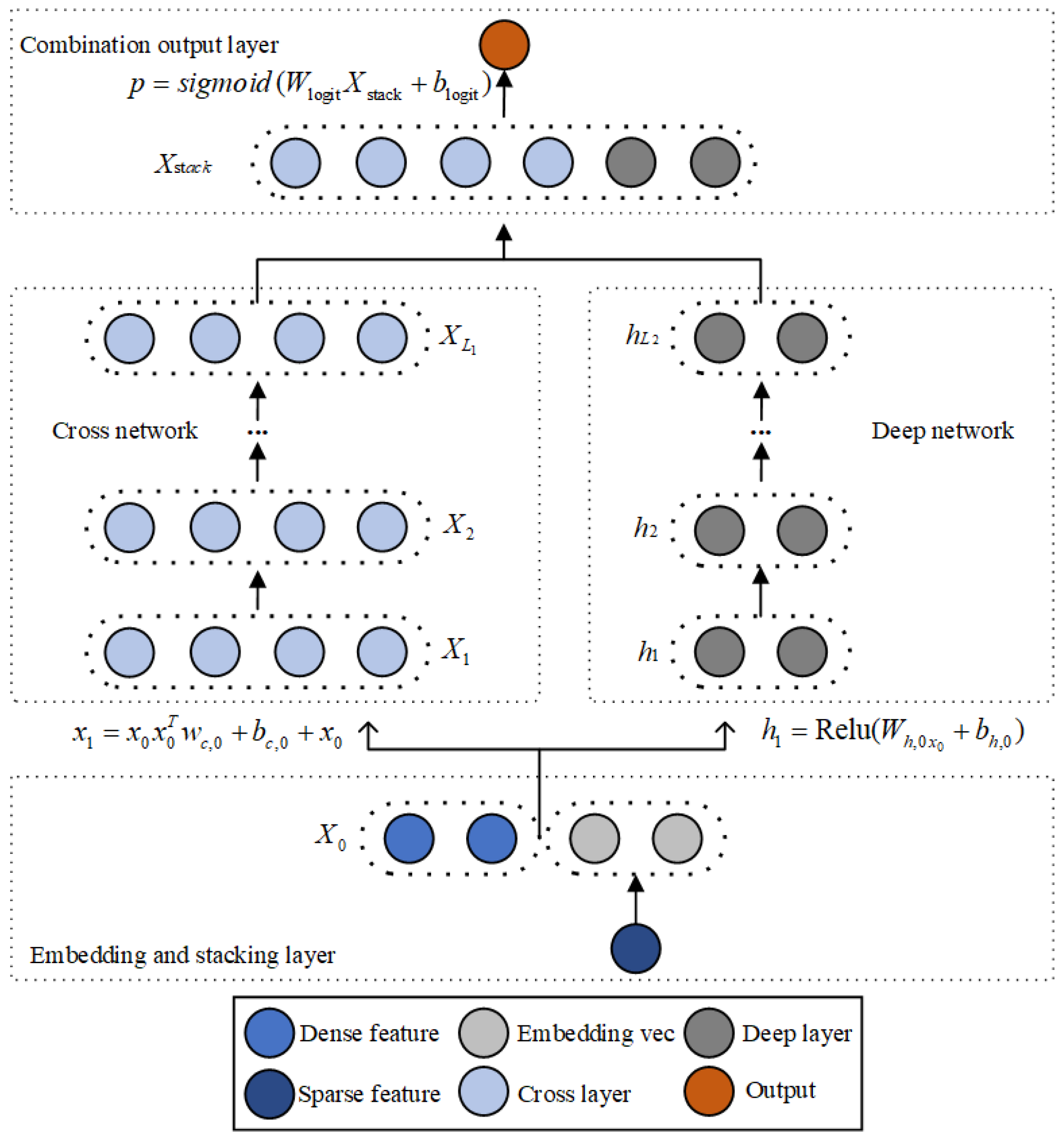
23] model, which replaces the wide part with the cross part implemented by a special network structure. The DCN can automatically construct limited high-order cross-features and learn the corresponding weights in the case of sparse and dense inputs, without manual feature engineering or exhaustive searching. The structure of Deep and Cross is shown in
Figure 7.
A DCN model starts with an embedding and stacking layer, followed by a cross network and a deep network in parallel. These are followed by a combination layer which combines the outputs from the two networks.
We take the 2D features of tropical cyclones as dense features (light blue circles in
Figure 7) and 3D features as sparse features (dark blue circles in
Figure 7). After embedding, they are transformed into low-dimensional dense features. The embedding operation [
22] is shown in Formula (11).
where
is the embedding vector of the
category feature, corresponding to the 3D features after the embedding operation, and
is the embedding matrix. Finally, this layer needs to combine dense features with the 3D features transformed by embedding, and then the vector is shown in Formula (12).
where the vector
represents the combination of the 2D and 3D features of the tropical cyclones.
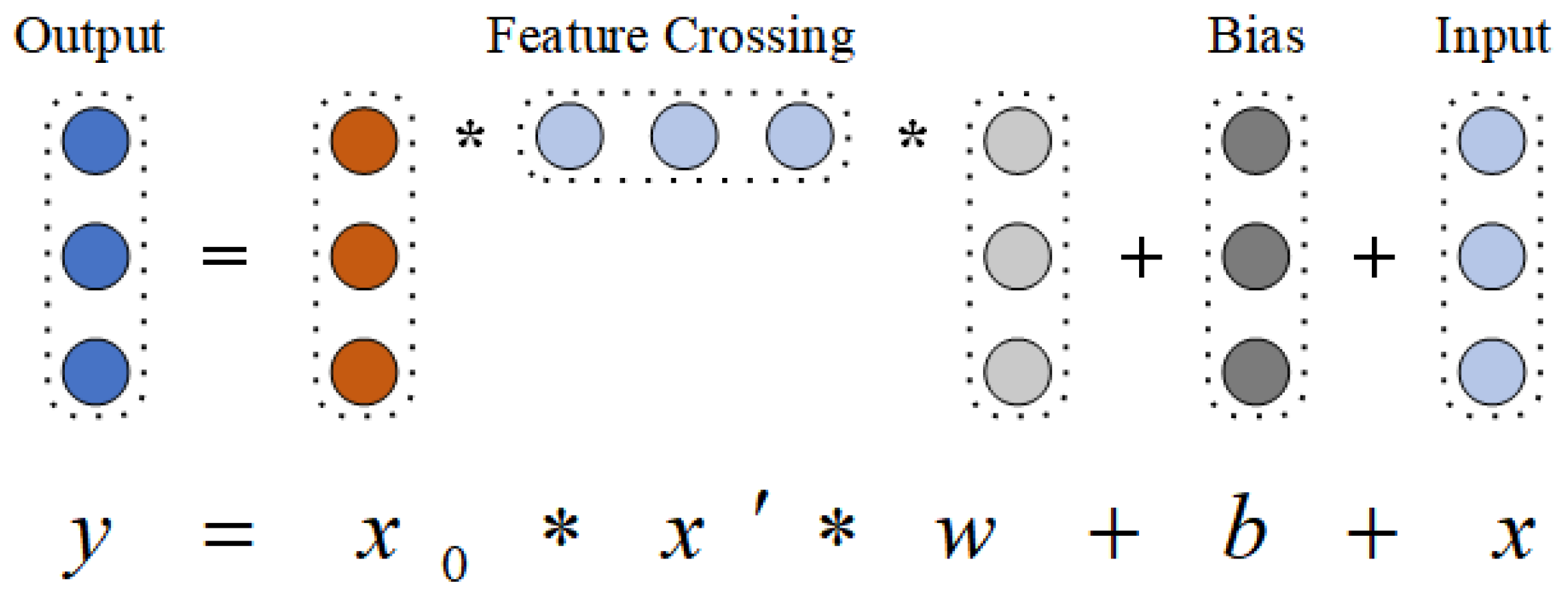
For the cross network, the purpose of the network is to increase the interaction between different features. The cross network is represented by multiple cross layers. Assuming that the output vector of the
layer is
, then for the
layer, the output vector is
, as shown in Formula (13).
where
and
are the weight and bias of the
layer. After each intersection layer completes the feature intersection, it will add the original input of the layer. The visualization of a cross layer is shown in
Figure 8.
Each layer adds an n-dimensional weight vector , where represents the dimension of the input vector, and the input vector is retained at each layer. Finally, after the 2D time series characteristics of tropical cyclones are operated by the cross network, a 2D model of tropical cyclones with memory has been established.
For the deep network, the network is a fully connected feedforward neural network, and each deep layer has the following formula:
where
,
are the
and
hidden layer, respectively.
,
are parameters for the
deep layer, and
is the RuLU function.
We take the 3D time series features of tropical cyclones based on the CBAM and multi-ConvGRU as deep part, which builds a generalized 3D model of tropical cyclones through deep learning and can be used to extract the deep features of tropical cyclones.
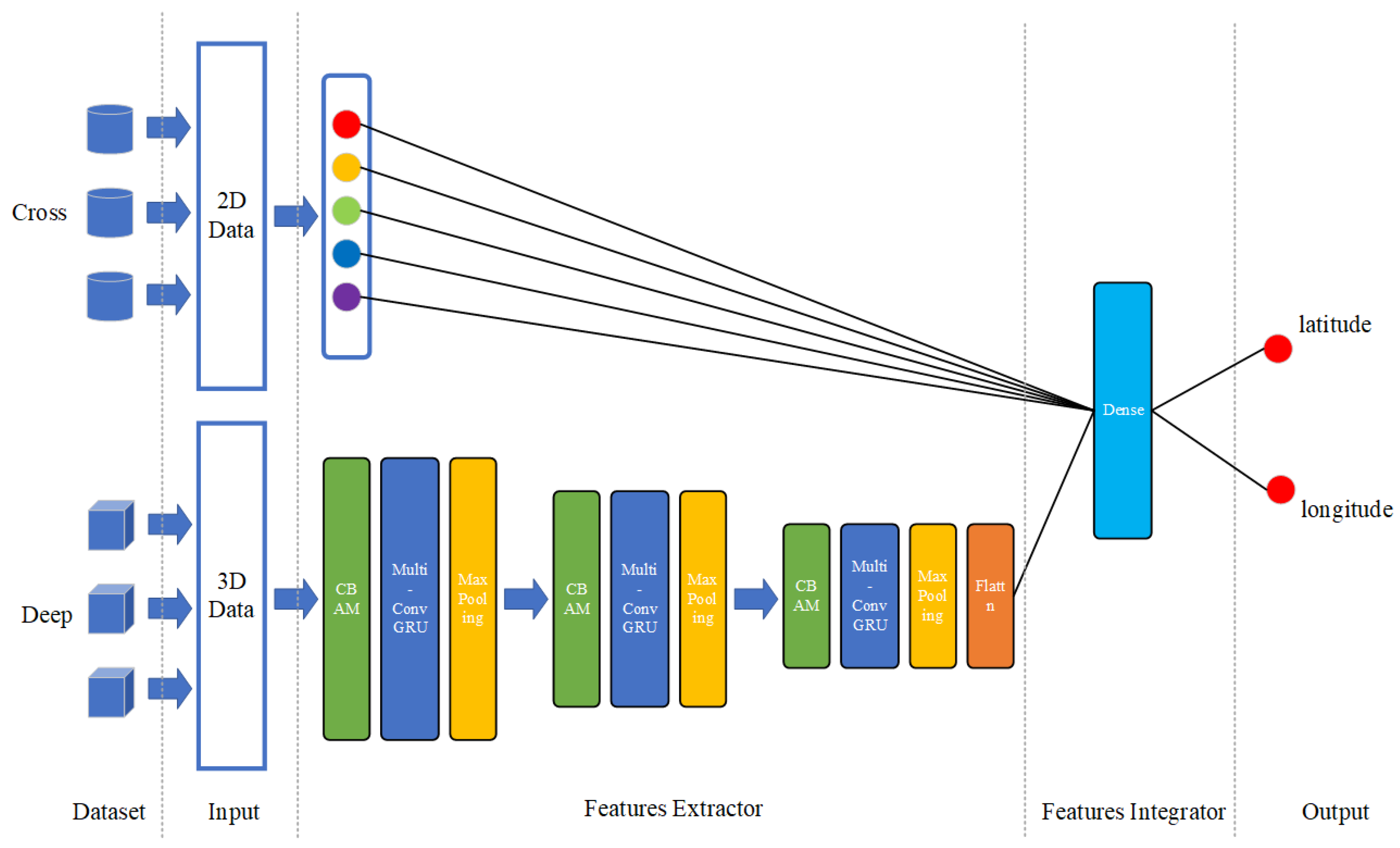
Since we adopt two dimensions of tropical cyclone data, after fusing the 2D and 3D features, we also add a neural network as the fusion network of the two features. The structure of the network is shown in
Figure 9.
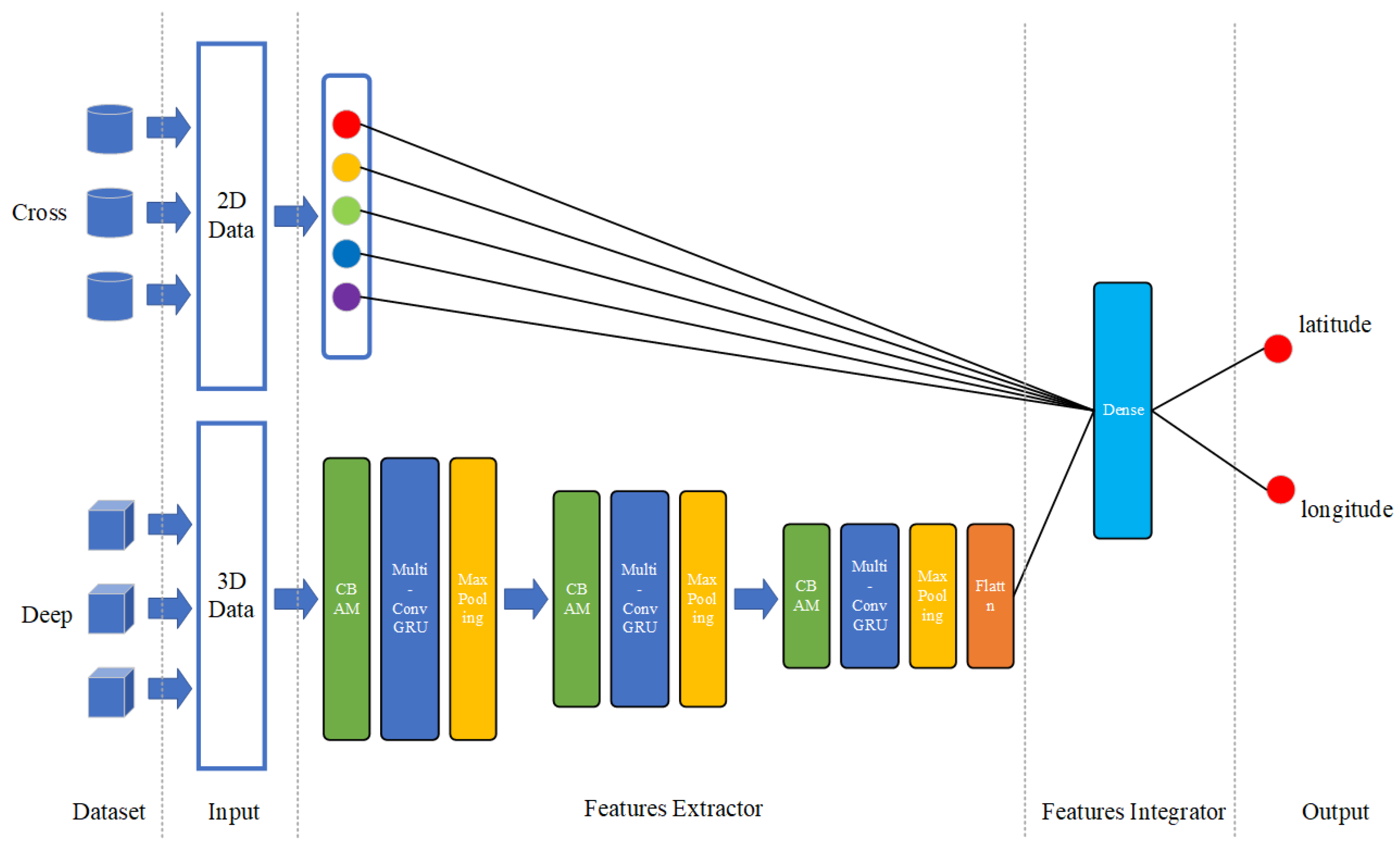
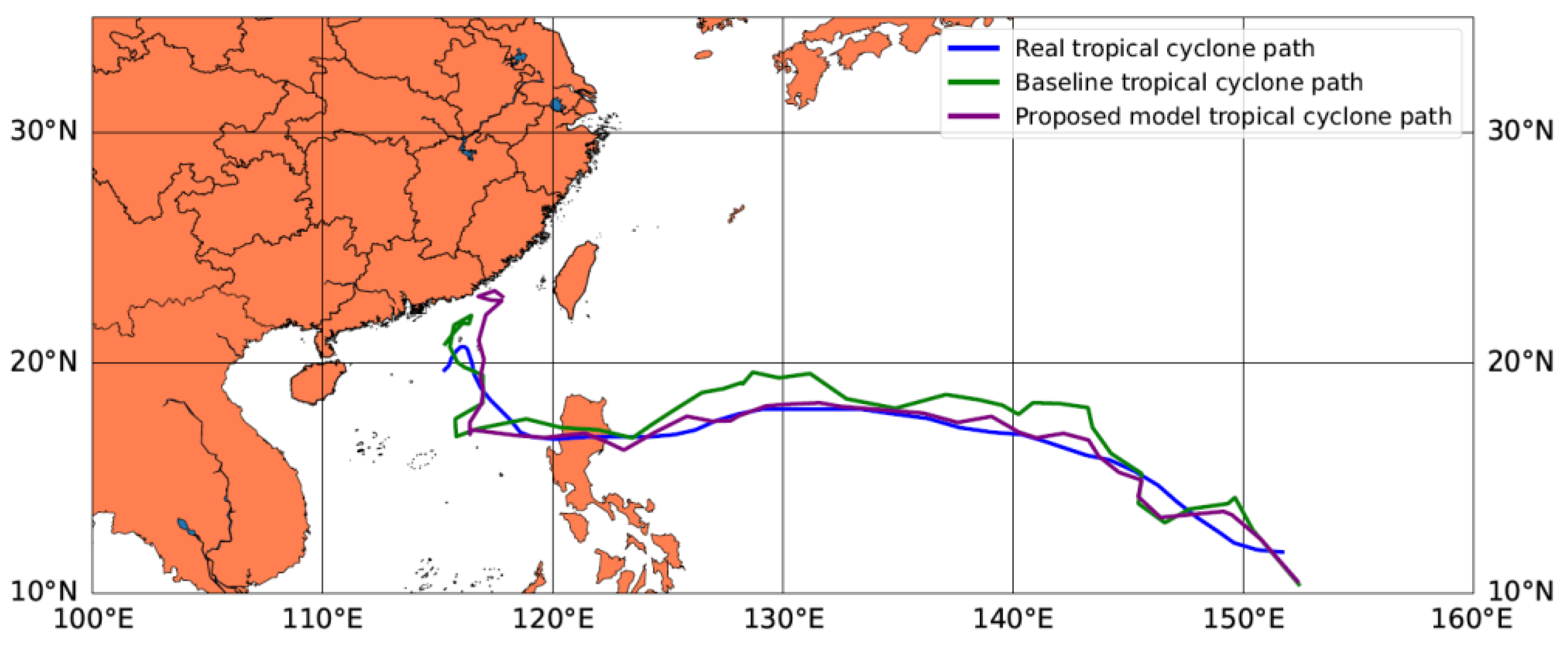
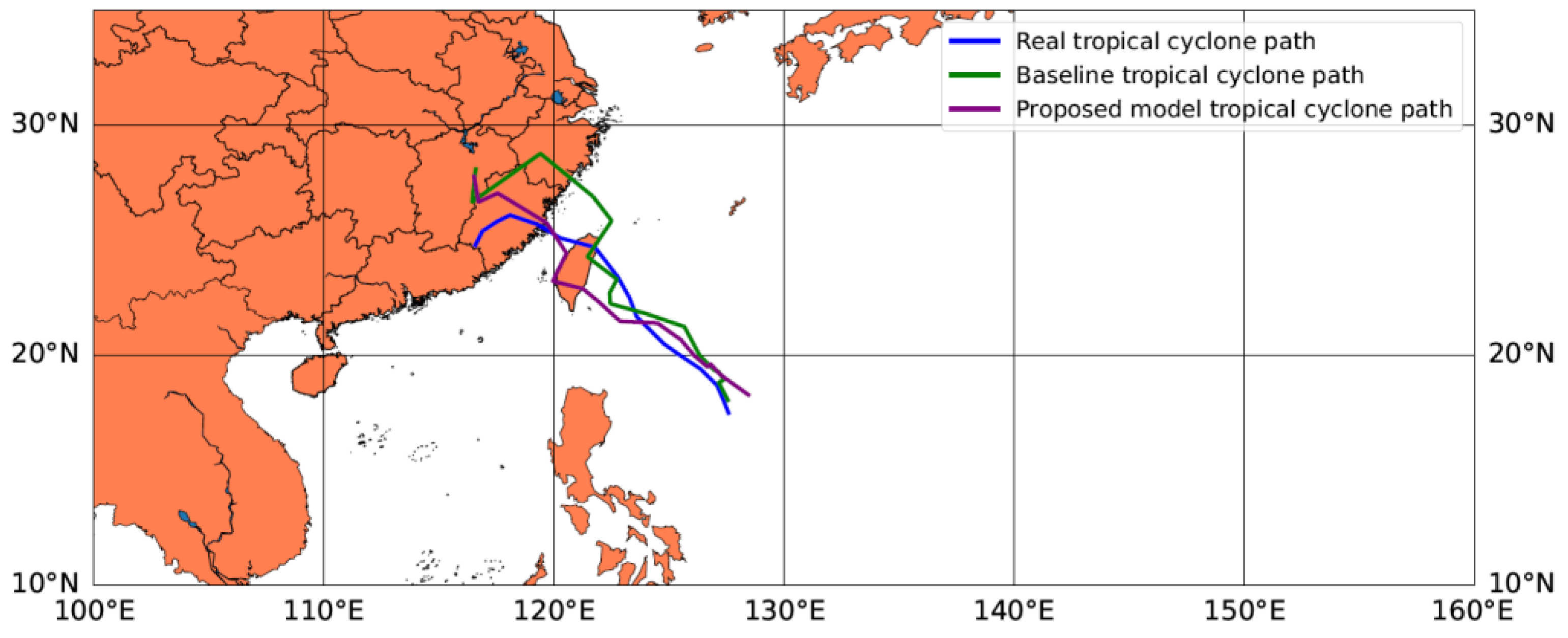
For the cross part, the 2D time series structure of tropical cyclones is constructed according to the CMA dataset, and CNN is adopted as the cross-part model. For the deep part, the 3D time series structure of the tropical cyclones and its surroundings are constructed according to the geopotential variables. Then, we use three network layers including the CBAM layer, multi-ConvGRU layer, and max pooling layer as a stacking block. Thereafter, the stacked layers are repeated three times, where the first two times are processed on multiple time dimensions, whereas the last time is processed in the current time dimension. The network finally flattens all the features and obtains the features of the cross part and the deep part. We jointly train the two parts and add a layer of neural network to integrate the features of the two parts. Finally, the network forecasts the central latitude and longitude of a tropical cyclone for the next 24 h.
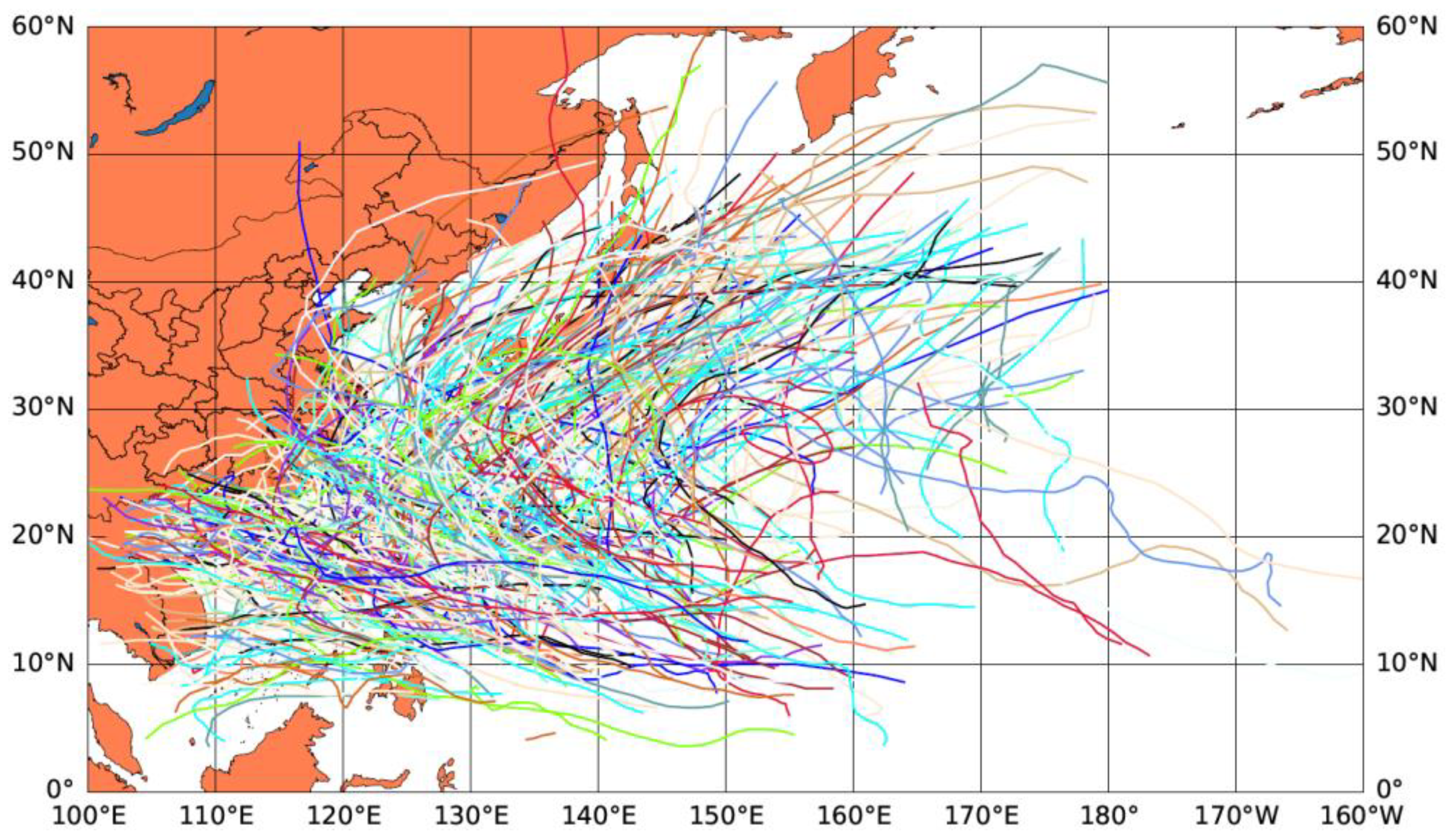
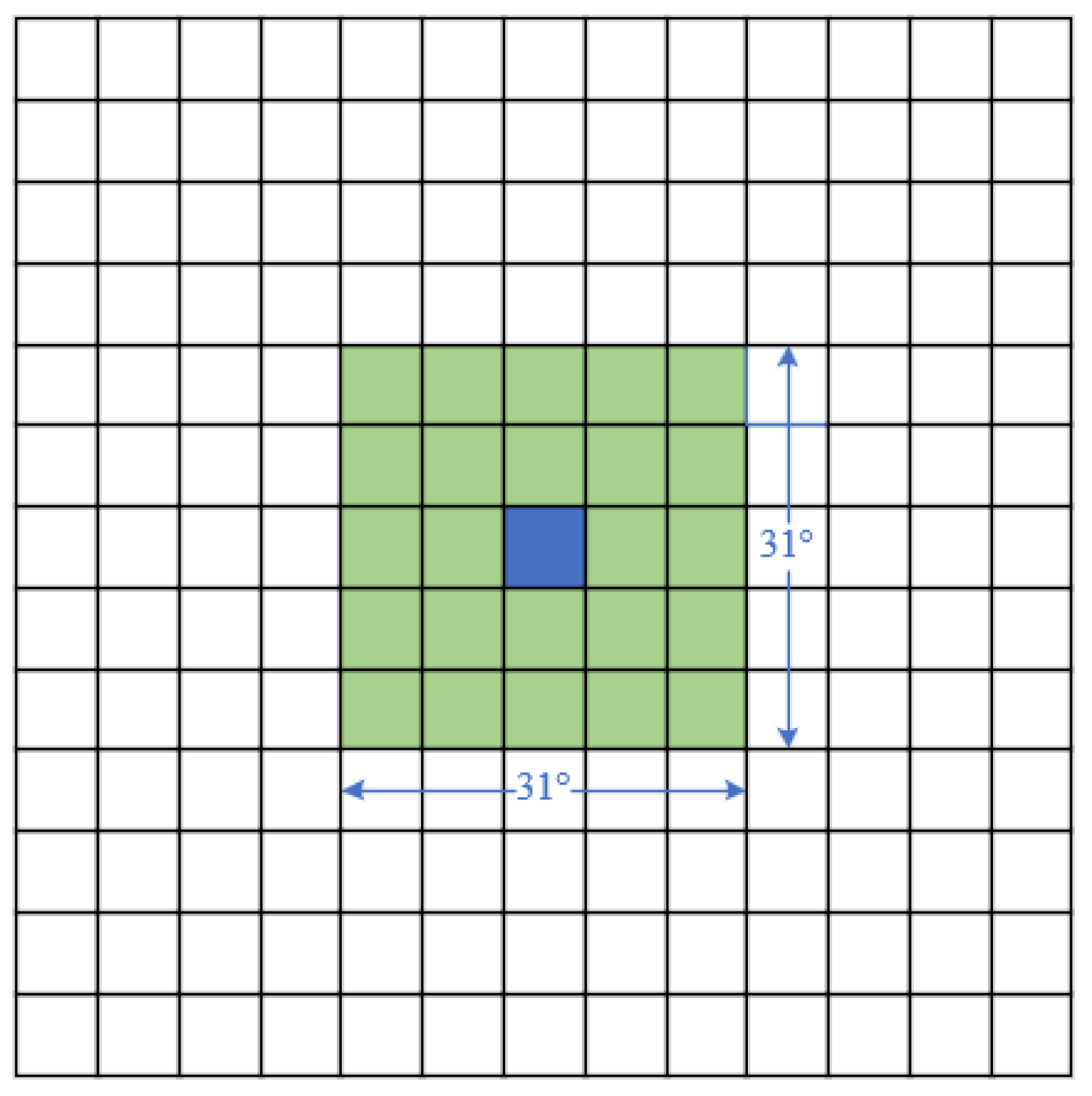
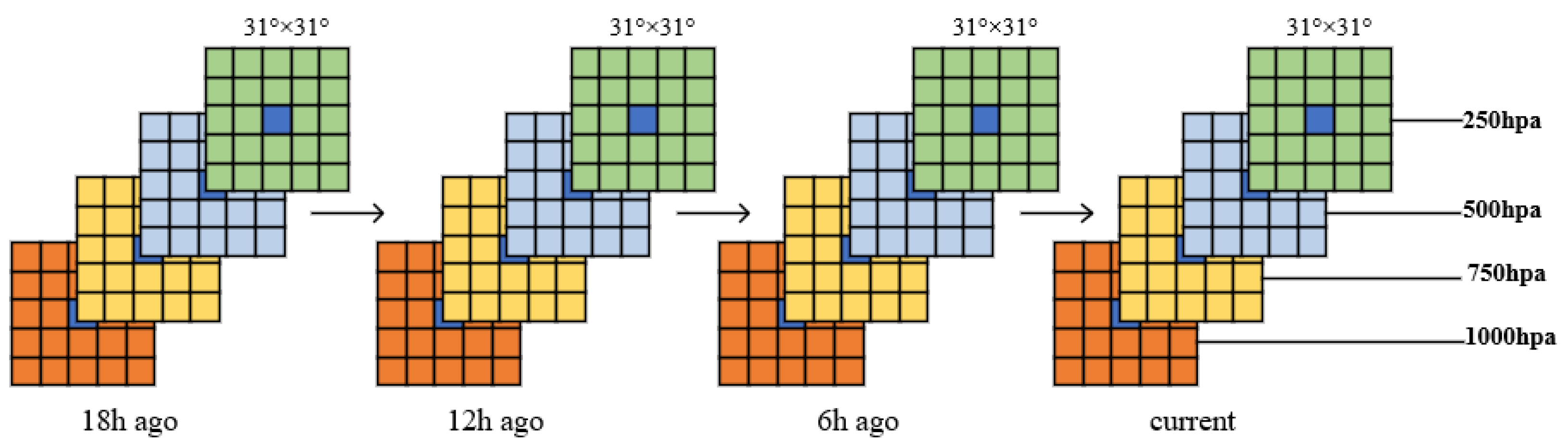
According to the pre-processing of 3D data in Chapter 3, we obtain the 3D time series structure of a tropical cyclone. Since the batch size of data has been set to 128, the shape of the input data is (128, 4, 4, 31, 31), which means (batch, timesteps, channels, height, width). After the input data operated by the three stacking blocks and FC, the shape of the output data is (128, 128). The process of data flow is shown in
Table 2. At the same time, we obtain the 2D typhoon data processed by CLIPER, the shape of which is (128, 53). Then, we combine the cross and deep features in a dense layer, whose shape is (128, 128 + 53). After two Full Connection Layers, the shape of the output data is (128, 2), which represents the forecasting latitude and longitude of each batch. We obtain the latitude and longitude of the tropical cyclone in the next 24 h.








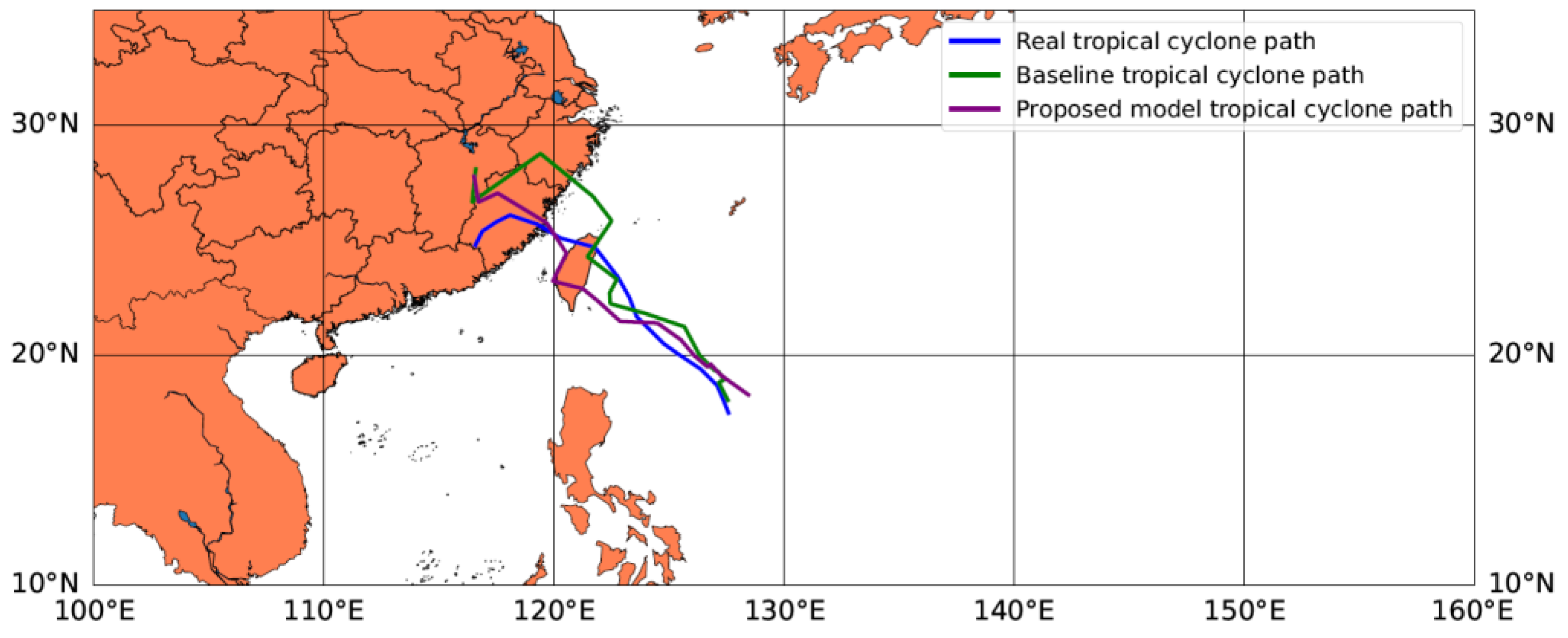

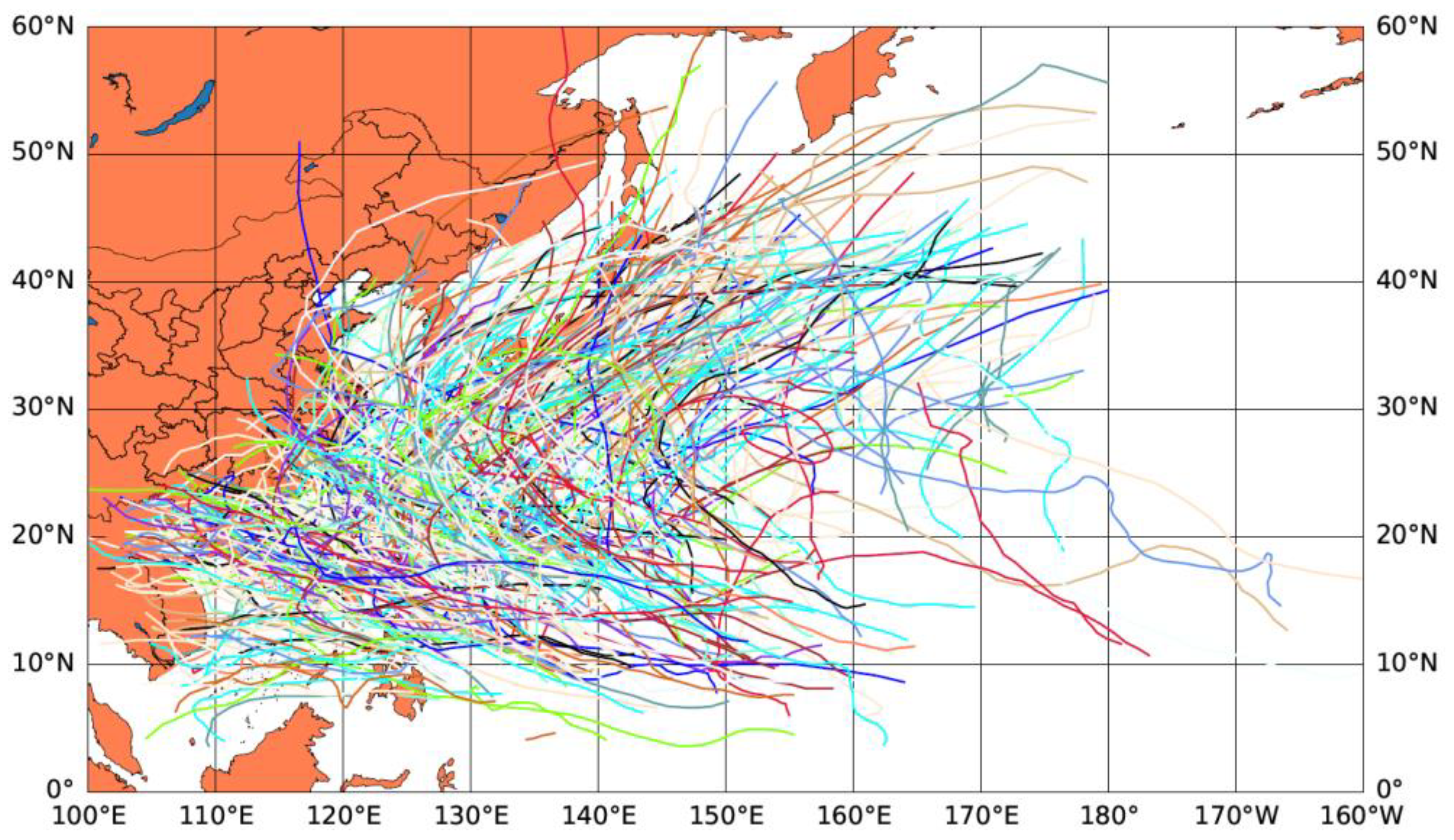{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}