1. Introduction
Precipitation nowcasting usually refers to the forecasting of precipitation up to 2 h in the future using observed information to predict the evolution of precipitation in a certain area over the short term. The main challenge in nowcasting is currently understanding the evolution and prediction of micro- and meso-scale weather. These types of weather are responsible for the occurrence and development of extreme weather events that rapidly evolve irregularly and non-linearly, which is challenging for existing early warning and forecasting systems to predict. Therefore, how to effectively use observed meteorological information and establish a forecasting method for nowcasting are problems in current meteorological services and research [
1].
At present, two methods are mainly used for forecasting weather processes in meteorological services: methods based on the results of numerical weather prediction models and methods based on radar extrapolation [
2]. For synoptic-scale weather systems, numerical weather prediction models can describe the continuous change in meteorological elements in time and space through basic atmospheric equations, obtaining reasonably accurate forecast results. However, for micro- and meso-scale weather systems, numerical weather prediction models are not suitable for forecasting severe local weather events in the next few hours because of the low temporal and spatial resolution of the observed data and inability to model the nonlinear processes in meso-scale and micro-scale weather systems [
3]. Several studies have further demonstrated that numerical weather forecasting is often ineffective for micro- and meso-scale weather systems [
4,
5,
6]. Radar is the most effective tool for nowcasting [
7], and its echoes directly reflect the area and magnitude of current precipitation. Radar extrapolation can predict upcoming weather processes to a certain extent [
8,
9]. Currently, conventional radar extrapolation methods based on centroid tracking, such as TITAN (Thunderstorm Identification, Tracking, Analysis and Nowcasting) [
10] and SCIT (Storm Cell Identification and Tracking) [
11], as well as those based on cross-correlation [
12] and optical flow methods [
13], are widely used in radar-based nowcasting. However, these methods usually only extrapolate the motion vector obtained after simple calculations on the radar echo maps at several moments to predict the changes in the radar echo observations at the next moment. Moreover, they often treat the echo as a rigid body for extrapolation. Obviously, for echoes with a dynamic characteristic, the methods mentioned above have inherent shortcomings, which leads to low accuracy in the prediction results and short prediction time ranges.
As a new branch of machine learning, deep learning has led to great advances in techniques and theory [
14], achieving excellent results in many fields, such as machine vision [
15,
16,
17], speech recognition [
18,
19,
20], natural language processing [
21,
22,
23], and autonomous driving [
24,
25,
26]. The success of deep learning has made it an important foundation for innovations and developments in other fields. Since the deployment of a new generation of weather radar networks in China [
27], large amounts of historical observation data have been collected, which can be used to help deep learning models fully extract and learn the characteristics of the spatiotemporal evolution of echoes so that these models can be applied to nowcasting.
Recently, researchers have introduced deep learning techniques into the field of meteorological precipitation nowcasting. Nitish et al. [
28] extended the sequence-to-sequence framework proposed by Sutskever et al. [
29], using an encoder Long Short-Term Memory (LSTM) to map the input sequence to a fixed length vector and then using a decoder LSTM to learn the representation of the video sequence. However, the model proposed by Nitish et al. [
28] can only learn the temporal correlations in video sequences. To obtain the spatial characteristics of a video sequence, Shi et al. [
30] proposed the ConvLSTM model for precipitation nowcasting. Their results show that the predictions of this model are better than those of the variational optical flow method and the Fully-Connected LSTM (FC-LSTM) [
31], which has a fully connected structure and can clearly capture the spatial and temporal characteristics of radar echo maps. Because the recursive convolutional structure in the ConvLSTM model is position invariant, Shi et al. [
32] also proposed the Trajectory Gated Recurrent Unit (TrajGRU) model, which has a spatiotemporal variable structure and uses a weighted loss function to optimize the model in order to improve precipitation nowcasting performance. The models mentioned above are based on Convolutional Recurrent Neural Network (ConvRNN) and have made some progress in precipitation nowcasting. Nevertheless, the aforementioned ConvRNN models perform operations separately on the input data, hidden states, and model outputs. This raises the question as to how to make the ConvRNN capture the inherent interaction between input data and hidden state in a single layer.
To learn the inherent interaction between the current input radar echo map and the previous output state of a network (as proposed by Melis et al. [
33]) as well as improve the accuracy and timeliness of prediction, this study proposes the addition of a convolution-based preprocessing operation in the Convolutional GRU(ConvGRU) [
34] between the current input data and the previous output state to capture the relationship between them. A GRU network performs similarly to LSTM but has lower memory requirements, saving considerable computing time [
35]. A six-layer encoder–forecaster framework was adopted in this study to efficiently capture the spatiotemporal characteristics of radar echo sequences. The HKO-7 radar echo map dataset was used to experimentally evaluate the performance and accuracy of the model.
The rest of this paper is organized as follows: in
Section 2, we introduced the relative work on spatiotemporal prediction. In
Section 3, we introduce the proposed model, M-ConvGRU, in detail.
Section 4 presents an evaluation of the model through experiments. Finally, we summarize our work and discuss future work in
Section 5.
2. Related Works
ConvLSTM, ConvGRU, and TrajGRU have been proposed to conduct spatiotemporal sequence prediction. They all use convolution operations (two-dimensional) to replace the fully connected operations in the step-by-step transitions between traditional RNN units (one-dimensional). Wang et al. [
36] proposed Predictive Recurrent Neural Network (PredRNN) and designed a new spatiotemporal LSTM (ST-LSTM) unit to simultaneously extract and store spatiotemporal features, achieving good results on three video datasets (including radar echo datasets). Sato et al. [
37] proposed the Predictive Coding Network (PredNet) model, which introduces a jump connection structure and hollow convolution in the model to improve the prediction performance of short-term forecasts. To solve the problem of blur in extrapolated images, Lin et al. [
38] proposed an adversarial ConvGRU model that obtains better experimental results than the ConvGRU model and an optical flow method. Jing et al. [
39] proposed a multi-level correlation method that incorporates adversarial training methods so that the prediction results retain more echo details. Agrawal et al. [
40] used a U-Net structure for precipitation nowcasting based entirely on a convolutional neural network; its performance was better than that of the NOAA (National Oceanic and Atmospheric Administration) short-term forecast model. Jing et al. [
41] proposed the Hierarchical Prediction Recurrent Neural Network (HPRNN) to address the increase in prediction error over time. They verified the effectiveness of the model on short-term to long-term radar echo extrapolation on the HKO-7 (from the Hong Kong Observatory) dataset. Although these methods have surpassed the extrapolation performance of traditional methods to some extent, the accuracy of long-term echo prediction decreases rapidly with time, failing to meet practical forecast requirements. In this paper, we use the convolution operation between input data and hidden state in a single layer and embed it into the ConvGRU to capture the inherent features of the radar echo sequence.
3. Proposed Modified Convolutional Gated Recurrent Unit (M-ConvGRU) Model
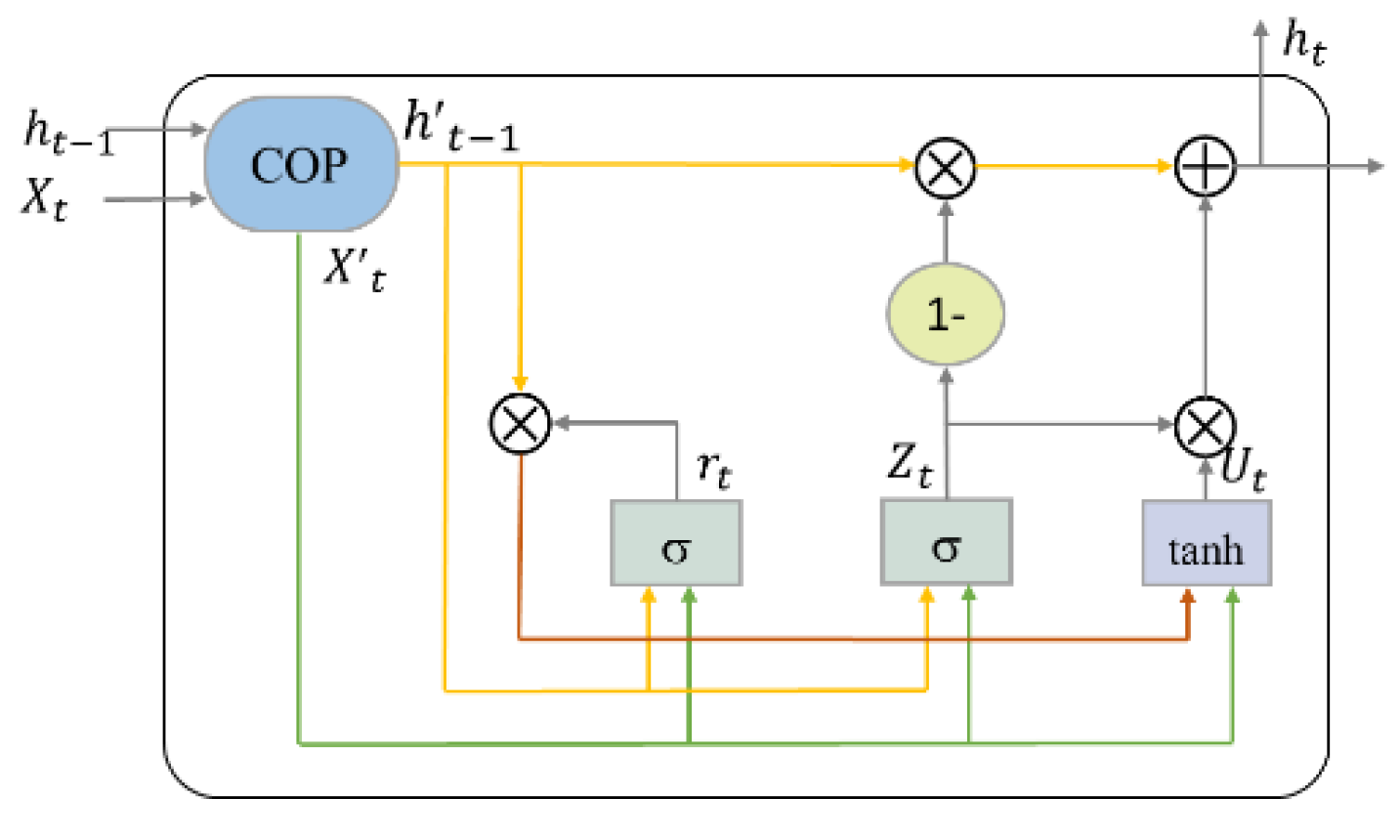
Like ConvLSTM, M-ConvGRU can effectively capture the spatial characteristics of an image while reducing the complexity of the model. Before the current input data and the previous output state of the network are incorporated into the ConvGRU neuron, convolution-based gate preprocessing is performed to capture the contextual relationship between the input data and the previous output of the model. The structure of a single GRU neuron in the model proposed in this study is shown in
Figure 1.
Figure 2 presents the convolution-based preprocessing between the current input data and the previous output state of the neuron, where COP stands for convolution-based preprocessing.
The main formula of M-ConvGRU is as follows [
32], where “*” is the convolution operation and “
” is the Hadamard product:
The bias terms are omitted here for notational simplicity. Here, represent the update gate, reset gate, new information, and memory state, respectively. is the input, and and are the sigmoid function and activation, respectively. and are the height and width, respectively, of the state and input tensors, and are the channel sizes of the state and input tensors, respectively. Whenever there is a new input, the reset gate clears the previous state. The update gate controls the amount of new information written to that state.
As
Figure 2 shows, the input
X is controlled by the output of the previous step
. The gated input is then used similarly to gate the output of the previous time step. After several rounds of mutual gating, the last updated
X and
are fed into ConvGRU. The updated
X and
are obtained using the following mathematical formulas [
33]:
Hyperparameter
is the number of gating operations, where
, and the value is set to 5 in this study [
33]. By adding operations to the input data and hidden states, the contextual features of the video sequence can be learned, and the inherent interaction of the spatiotemporal sequence can be captured effectively.
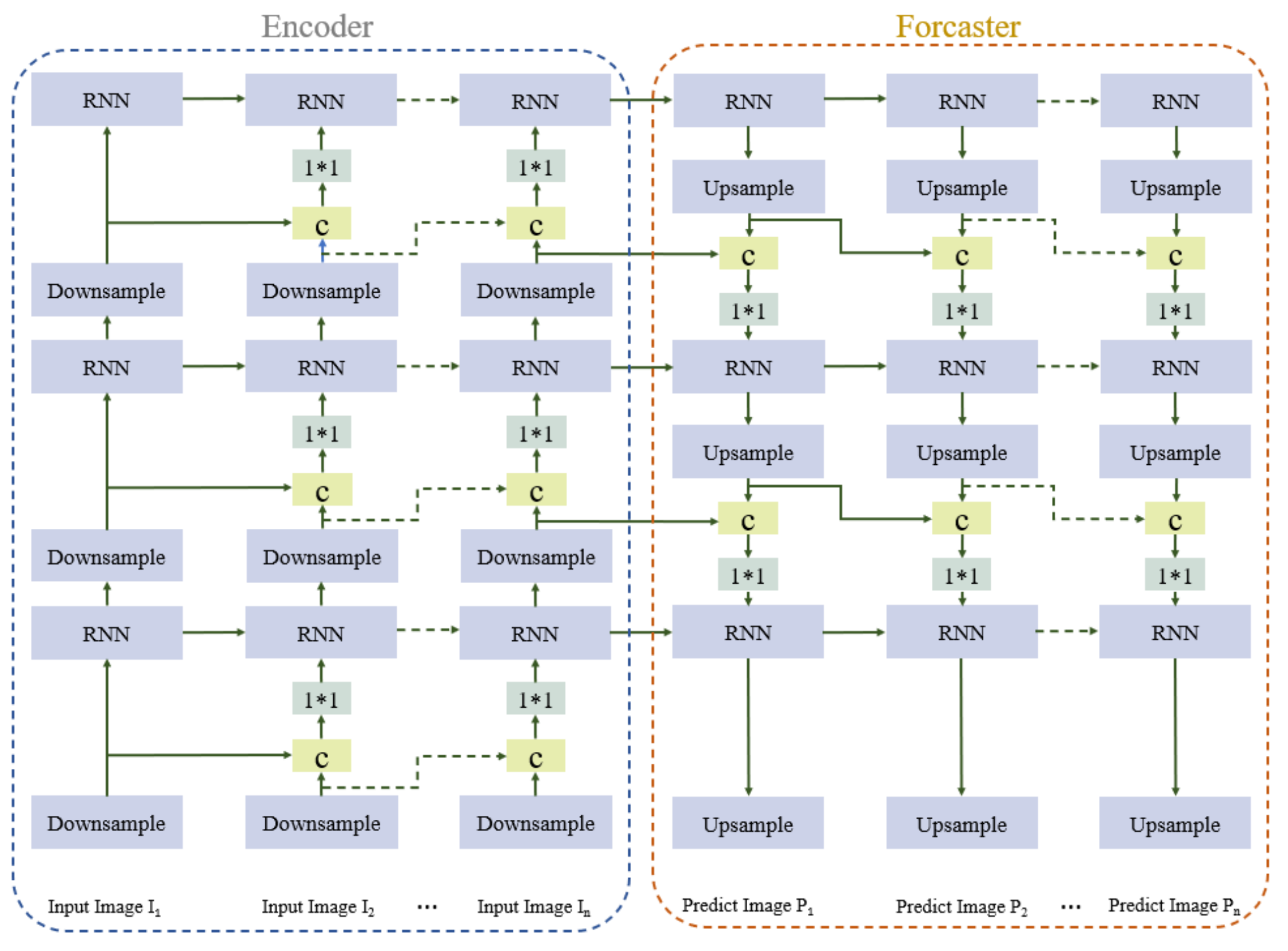
To ensure that the model is able to represent spatiotemporal features well and effectively predict changes in radar echo maps, an encoder–forecaster structure similar to that in Shi et al. [
32] is employed to predict spatiotemporal sequences. The architecture of the encoder–forecaster network is shown in
Figure 3. The encoder module comprises three downsampling layers and three Recurrent Neural Network (RNN) layers and learns low- to high-dimensional image features. The downsampling layer reduces the size of the feature image. It captures the spatial features of the image through convolution, whereas the RNN layer learns the temporal features of the radar echo sequence. The forecaster module consists of three upsampling layers and three RNN layers and outputs the predicted radar echo maps. The RNN layer learns the image sequence features. The upsampling layer increases the image feature size through deconvolution and guides the update of the low-level state according to the high-level features.
4. Experiments and Results
It is difficult to predict changes in weather radar echoes because convective weather develops non-linearly, irregularly, and continuously merges and splits. To verify the ability of the model to extrapolate radar echoes with such characteristics, we selected the HKO-7 public radar echo dataset, which was collected by the Hong Kong Observatory. This dataset consists of daily radar constant altitude plan position indicator (CAPPI) graphs from 2009 to 2015, of which there are 240 per day (the radar echo data are updated every 6 min). The logarithmic radar reflectivity factors (dBZ) are linearly converted to pixel value through
. The image’s resolution is 480
480 pixels, which includes a 512 km
512 km range centered in Hong Kong. The rainfall information was used to select 993 days with rainfall to form the final dataset. Of these, 812 days were used for training, 50 days were used for validation, and 131 days were used for testing. To evaluate the performance of the proposed model, we compared the proposed model, M-ConvGRU, and the ConvLSTM model. In the training process, the batch size of the model was set to four, and the number of iterations was 100,000. The Adam is chosen as the optimizer, and its learning rate is equal to
, and betas are set (0.5, 0.999) [
32].
In meteorological services, different levels of attention are often given to different precipitation intensities; therefore, the overall performance of the model under different precipitation levels should be used to evaluate the quality of the model. According to the Z–R relationship (the relationship between echo intensity and precipitation) in the HKO-7 dataset, radar reflectivity data can be converted into precipitation (mm/h). Precipitation can be divided into five levels according to the threshold,
, values of
,
,
,
, and
. When evaluating the predictive ability of the model, the ground truth radar and predicted echo pixel values were converted into a precipitation coefficient matrix, and
was used to binarize the precipitation coefficient matrix. The metrics TP (prediction = 1, truth = 1), FN (prediction = 0, truth = 1), FP (prediction = 1, truth = 0), and TN (prediction = 0, truth = 0) were calculated. The false alarm rate (FAR), critical success index (CSI), and Heidke skill score (HSS) for each precipitation level were calculated as follows [
42]:
The lower the FAR value, the better the prediction effect, and the higher the CSI and HSS values, the better the prediction performance. The traditional mean absolute error (MAE) and mean squared error (MSE) were used to compare the prediction results of the two models. However, because the frequency of different rainfall levels is highly imbalanced, we also used the method in Shi et al. [
32] to calculate the balanced mean absolute error (B-MAE) and balanced mean squared error (B-MSE), which use a weighted loss function for heavy rainfall, where a strong echo is given a greater weight.
Table 1 shows the sum of MAE, MSE, B-MAE and B-MSE of each pixel pair in the central 240
240 area of the predicted images and the ground truth radar echo maps, respectively. The M-ConvGRU model obtained values that are lower than those of ConvLSTM, indicating that its prediction results are better.
Figure 4 shows the change in CSI scores of the two models with respect to forecast time when the precipitation is greater than 0.5, 5, and 30 mm/h. When the precipitation is greater than 0.5 mm/h, the CSI score of each model is the highest. There is little difference between the scores of the two groups when the forecast is shorter than 30 min. As the prediction time increases, the CSI value of the M-ConvGRU gradually decreases from 0.76 to 0.44, but the CSI value of M-ConvGRU is significantly higher than that of ConvLSTM in later periods. When the precipitation is greater than 5 mm/h, the CSI scores of the M-ConvGRU decreases from 0.62 to 0.26, but the M-ConvGRU score is still higher than that of ConvLSTM for the same forecast period. When the precipitation is greater than 30 mm/h, the CSI scores of the M-ConvGRU decreases from 0.43 to 0.09. Although the CSI score is substantially lower, the score of M-ConvGRU for predictions up to an hour is significantly higher than that of ConvLSTM. This is because both the probability of heavy rainfall and its area are small; therefore, the CSI value of heavy rainfall is also small. A characteristic of the prediction task is that the CSI value decreases with prediction time. The results also have high uncertainty, and this uncertainty increases with time.
In the experiments, the radar echo map at five consecutive timesteps was used to predict the radar echo map of the next 20 timesteps; that is, the historical 0.5-h data were used to predict the echo data in the next 2 h. Two cases were selected from the test set for analysis so that the prediction performance can be understood more intuitively. These two cases represent the general characteristics of micro- and meso-scale weather; have regions with strong echoes; and include the generation, development, and dissipation stages of the convective process.
Figure 5 presents the result for the first case. Here, both models predict the development of most echoes at 6 min. Parts of the echo details are lost at 30 min, but the changes in position and movement of the strong echo are still extrapolated. M-ConvGRU predicts the strongest echo regions better than ConvLSTM. After 1 h, because the extrapolation time is too long, the forecast image can only be reconstructed according to the echo characteristics learned by the model. Nevertheless, some strong echo regions can still be extrapolated. When compared with the ground truth, it is clear that the edge details of the echoes at different intensities in the radar echo map predicted by the models are gradually lost, which is consistent with the change in CSI score with respect to forecast time shown in
Figure 4.
To quantitatively compare the prediction results of case 1, we provide the FAR, CSI, and HSS values of the predicted frames obtained by the two models at 6, 30, and 60 min in
Table 2,
Table 3 and
Table 4, respectively. As the prediction time increases, the CSI and HSS values decrease, and the FAR value increases. The increase in rainfall intensity also shows the same pattern as the forecast time. The scores of M-ConvGRU at 6 min and 30 min are substantially higher than those of ConvLSTM at 60 min; however, a better value is obtained only when
. The overall conclusion is that M-ConvGRU can obtain better prediction results than ConvLSTM at different rainfall intensities.
Figure 6 shows the visualization results for case 2. The overall echo intensity in this case is not as strong as that in case 1. Both models accurately predict the location of the strong echo at 6 min. By 30 min, as in case 1, although some echo details are lost, M-ConvGRU still effectively predicts the position of the strongest echo, but ConvLSTM does not. After 1 h, owing to the long extrapolation time, the prediction results have lost more details. The location of the strong echo area in the ground truth map is similar, but it is difficult to distinguish in the predicted maps. In the predicted maps, these regions are merged into a larger echo, resulting in a predicted strong echo area that is significantly larger than that in the ground truth. This problem needs to be addressed in future studies.
Table 5,
Table 6 and
Table 7 respectively show the FAR, CSI, and HSS values of the predicted frames obtained by the two models for case 2 at 6, 60, and 120 min. Some results are missing because the predicted radar echoes from the rain intensity were lower than the currently set threshold as time increased; therefore, the data do not exist. The CSI and HSS values decrease with forecast time and rainfall intensity. By contrast, the FAR value increases with the forecast time and rainfall intensity. Overall, the prediction score of M-ConvGRU at 6, 60, and 120 min is better than that of ConvLSTM.
5. Conclusions and Discussion
This study investigated a deep learning-based echo image extrapolation model used for 0–2 h precipitation nowcasting based on weather radar. The proposed M-ConvGRU model performs a convolution-based operation between the current input and previous output states before being incorporated into the ConvGRU neuron to obtain the contextual relationship between them. The experiment was carried out on the HKO-7 dataset, and the prediction results of ConvLSTM proposed by Shi et al. [
30] were compared with those of M-ConvGRU, yielding the following main conclusions:
The visualization results and quantitative index score analysis of two example cases show that M-ConvGRU can effectively capture the spatiotemporal characteristics of radar echo maps. Moreover, the position and intensity of its predicted radar echoes are closer to the ground truth.
The test results reveal that the B-MAE and B-MSE of M-ConvGRU are slightly lower than ConvLSTM, but the MAE and MSE of M-ConvGRU are 6.29% and 10.25% lower than ConvLSTM. Moreover, the CSI scores of M-ConvGRU is better than ConvLSTM. These numerical results show that the proposed deep learning model has learned the characteristics of more advanced and abstract spatiotemporal sequences, thereby improving radar echo precipitation nowcasting ability and accuracy to a certain extent.
Although M-ConvGRU improves prediction accuracy, there are still many problems in the later stages of prediction; for example, many details will gradually be lost in the prediction results, and the model cannot guarantee that the input sequence has the best prediction performance for different thresholds at each time. These problems also inevitably appear in the results of ConvLSTM [
30], PredRNN [
33], and HPRNN [
38]. Possible reasons for this are as follows: First, the prediction task itself has the characteristic of great uncertainty. Second, prediction errors will increase exponentially as the extrapolation progresses, and future information will be extrapolated from increasingly inaccurate past information.
Currently, the application of deep learning in meteorology is still in the exploratory stage, and there is still much room for improvement in the combination of the physical concept model of meteorology and extrapolation over time. Based on this work, we will consider incorporating meteorological elements into the radar echo extrapolation model, such as wind speed, temperature, air pressure, etc., in order to fully reflect the convection process’s spatiotemporal characteristics.



 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}