
Combination of Using Pairwise Comparisons and Composite Reference Series: A New Approach in the Homogenization of Climatic Time Series with ACMANT

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. State of the Art of Time Series Comparison and Inhomogeneity Detection in the Homogenization of Climatic Time Series
2.1. Comparison of Time Series
- (i)
- Composite reference series. In starting a homogenization, the candidate series and its neighbor series all may include inhomogeneities. The purpose of using composite reference series is to reduce the effects of inhomogeneities of the neighbor series by averaging the series and their inhomogeneities. Peterson and Easterling [1] suggested the use of weighted averages where the weights are the squared spatial correlations of the first difference series (i.e., series of increments between adjacent values).
- (ii)
- Pairwise comparisons. In a pairwise comparison, the differences between the candidate series and its neighbor series are examined one by one. When an inhomogeneity appears similarly in each relative time series, it belongs to the candidate series, while when an inhomogeneity appears only in the comparison with one neighbor series, then this belongs to the neighbor series. This seems to be easy, but when the signal-to-noise ratio (SNR) is low (e.g., for multiple inhomogeneities, for unusual local weather anomalies, etc.), inhomogeneities do not seem to be significant in a few or many of the relative time series, or they appear with imprecise timings, which may complicate the correct evaluation of the inhomogeneity detection results of individual time series comparisons. Therefore, the evaluation of pairwise comparisons is often performed manually, preferably together with metadata use [7,8,9]. Menne and Williams [10] constructed an automatic homogenization method with pairwise comparisons, the Pairwise Homogenization Algorithm (PHA), and this has been applied to some large global or regional datasets [11,12,13]. Ref. [5] reported that PHA provides one of the most accurate regional mean trends among the tested homogenization methods, except for low SNR datasets. However, the homogenization accuracy for individual station series is notably lower with PHA than with some other tested methods. Note that PHA does not include iterations for removing inhomogeneities of neighbor series before their use for a candidate series.
2.2. Detection of Inhomogeneities
- (i)
- Detection of different kinds of inhomogeneities
- (ii)
- Use of parameters estimated from the sample
- (a)
- Non-parametric methods [28] have the advantages that their results are not affected by possible asymmetries of the probability distribution, and are relatively insensitive to possible occurrences of outlier values. However, the homogenization accuracy tends to be slightly lower with them than with the best break detection methods [27,29], due to the reduced information provided by them (i.e., they do not calculate shift size).
- (b)
- In the ideal case, section mean values are estimated from the sample, but other estimated parameters (when necessary) are estimated from the whole time series. Such methods are the sequential t-test with identical standard deviation on both sides of a break [30], tests of accumulated anomalies [31,32] and a few versions of maximum likelihood methods, e.g., SNHT. By definition, a maximum likelihood method searches the time point where the probability of break occurrence is maximal, and tests show that the best performing break detection methods belong to this group. Note, however, that the manual break detection is the easiest with the visual examination of accumulated anomalies, hence the latter can be the most advantageous when low SNR and metadata favor manual break detection. The SNHT break detection method is one of the most widely used and also one of the best performing methods (note that with SNHT one can refer either to the whole homogenization method or to its break detection method, and here we discuss strictly only the break detection segment of SNHT). Before using SNHT, time series (T) must be normalized by extracting their average and dividing the values by the empirical standard deviation. Then, at any point j of T, the SNHT statistic (SSNHT) is calculated by Equation (3):
- (c)
- Sometimes both the section means and section standard deviations are estimated from the sample, based on the reasoning that, at break points, often not only the mean changes, but also other properties of the probability distribution. Such changes affect the correct break detection even when only the breaks of the section means are searched. Although this reasoning is theoretically correct, the potential benefit of including the changes of standard deviation in the calculations might be completely lost and even overcompensated by the estimation errors which are generally larger for empirical standard deviations than for averages. These methods are usually never subjected to method comparison tests on large datasets, as their use is more complicated and computationally time consuming in comparison with other methods. I do not recommend their use, in spite of their seeming mathematical elegance.
- (iii)
- Solutions for multiple structures of inhomogeneities
3. ACMANT and Its Development with the Combined Time Series Comparison
3.1. Presentation of ACMANT
- (i)
- Adaptation of earlier knowledge in ACMANT
- (ii)
- Own innovative ideas
- Bias sizes of temperature, relative humidity, sunshine duration and radiation often have semi-sinusoid annual cycles, since the impacts of technical changes are often closely connected to the natural solar radiation. As the natural annual cycle of radiation can be fairly approached with a sinusoid curve in middle and high latitudes, the use of the model of a sinusoid annual cycle with modes in the solstices is advantageous for the estimation of the intra-annual variation of the station effect. This idea is used in the elaboration of both the break detection and bias correction methods for the relevant homogenization tasks. Regarding the break detection part, the solution is the bivariate detection for annual means (variable A) and summer–winter differences (variable B). Annual values (y) of B are defined by the weighted average of monthly mean temperatures where the weights (w) are specific for calendar months (m):
- Bivariate detection for breaks of precipitation total where the year can be divided into a rainy season and snowy season—Technical problems with snow amount measurement differ from those of the liquid precipitation measurement, therefore in the ideal case rain and snow amounts should be homogenized separately. However, precipitation total time series usually include the data without separations according to precipitation form. This issue is treated by separating the year into a rainy season and a snowy season (where applicable), and applying a bivariate homogenization similar to the one for radiation-dependent inhomogeneities. More details about the precipitation homogenization with ACMANT have been described [36,50].
- Detection and correction of short-term platform-shaped inhomogeneities—Temporally existing technical problems or observation errors may result in temporal, platform-shaped changes in the temporal evolution of the station effect [43,51]. Therefore, a specific break detection segment is included in ACMANT for the removal of biases of 1–28 months in duration. Naturally, only relatively large biases can be detected with sufficient certainty for such short periods, therefore such inhomogeneities are referred also to as outlier periods. Note that the special treatment of such biases is needed in ACMANT, because the time span between two consecutive breaks is at least 3 years in the principal break detection segment of ACMANT.
- The principal break detection is performed on time series of annual resolution, and initially, the minimum time span between two consecutive breaks is three years. In subsequent steps, break positions are refined by using monthly data and also on daily scales in case of daily data homogenization. In such refinements, subsections supposed to include only one break are examined, thus the calculations are relatively simple, and the whole break detection procedure is relatively fast. Final break positions may include consecutive breaks much closer than 3 years both for the break position refinements and for the independently detected short-term, platform-shaped inhomogeneities. However, there appears to be a potential weakness, i.e., when several large breaks occur within a short section, this detection algorithm may be inaccurate. Note, however, that such accumulation of breaks with sufficient SNR for their accurate detection is rare. The most important benefit of the ACMANT break detection scheme is not the saving of computation time, but the reduction in parameter estimations from the inhomogeneous sample: when breaks are searched in data of daily resolution, the consideration of seasonal cycle and autocorrelation is indispensable [38,52].
- Ensemble homogenization—In time series homogenization, the estimated adjustment terms for bias removal often have considerable uncertainty, which may originate from break detection uncertainties or adjustment term calculation uncertainties. The core idea of ensemble homogenization in ACMANT is that uncertainty ranges are monitored by the repeated execution of some homogenization steps with slightly differing conditions. With using the average of the uncertainty range in the final corrections, the probability of committing large errors decreases, and the homogenization accuracy generally increases. Based on experiments (not shown), when ensemble estimations are made in an intermediate phase of the homogenization procedure, the optimum adjustment terms are usually smaller than the average of the uncertainty range, since the choice of slightly lowered adjustment terms reduces the risk of error accumulations by the subsequent steps of the homogenization procedure. Note that the idea of ensemble homogenization is not fully new in ACMANT. In MASH [18], the adjustment terms of a given iteration step are calculated as the minimum of several distinct estimations based on the use of varied relative time series. However, ACMANT is the first method in which the ensemble of this kind of operation is named ensemble homogenization.
- (iii)
- Tests with benchmark datasets.
3.2. Homogenization Accuracy According to MULTITEST
3.3. Break Detection with Combined Time Series Comparison
3.4. ACMANTv5
- Subnetworks (when generated automatically) can be edited,
- Default minimum threshold of spatial correlation (0.4) can be altered,
- List of detected breaks of the first homogenization cycle will be editable,
- User may introduce metadata, which will be considered in the pairwise homogenization step as a detection result with weight = 1 by an imaginary relative time series.
4. Efficiency of ACMANTv5
5. Concluding Remarks
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Peterson, T.C.; Easterling, D.R. Creation of homogeneous composite climatological reference series. Int. J. Climatol. 1994, 14, 671–679. [Google Scholar] [CrossRef]
- Moberg, A.; Alexandersson, H. Homogenization of Swedish temperature data. II: Homogenized gridded air temperature compared with a subset of global gridded air temperature since 1861. Int. J. Climatol. 1997, 17, 35–54. [Google Scholar] [CrossRef]
- Azorin-Molina, C.; Vicente-Serrano, S.M.; McVicar, T.R.; Jerez, S.; Sanchez-Lorenzo, A.; López-Moreno, J.-I.; Revuelto, J.; Trigo, R.M.; Lopez-Bustins, J.A.; Espírito-Santo, F. Homogenization and assessment of observed near-surface wind speed trends over Spain and Portugal, 1961–2011. J. Clim. 2014, 27, 3692–3712. [Google Scholar] [CrossRef]
- Yosef, Y.; Aguilar, E.; Pinhas, A. Detecting and adjusting artificial biases of long-term temperature records in Israel. Int. J. Climatol. 2018, 38, 3273–3289. [Google Scholar] [CrossRef]
- Domonkos, P.; Guijarro, J.A.; Venema, V.; Brunet, M.; Sigró, J. Efficiency of time series homogenization: Method comparison with 12 monthly temperature test datasets. J. Clim. 2021, 34, 2877–2891. [Google Scholar] [CrossRef]
- Guijarro, J.A. Homogenization of Climatic Series with Climatol. 2018. Available online: http://www.climatol.eu/homog_climatol-en.pdf (accessed on 2 September 2021).
- Kuglitsch, F.G.; Toreti, A.; Xoplaki, E.; Della-Marta, P.M.; Luterbacher, J.; Wanner, H. Homogenization of daily maximum temperature series in the Mediterranean. J. Geophys. Res. 2009, 114, D15108. [Google Scholar] [CrossRef] [Green Version]
- Brunetti, M.; Caloiero, T.; Coscarelli, R.; Gullà, G.; Nanni, T.; Simolo, C. Precipitation variability and change in the Calabria region (Italy) from a high resolution daily dataset. Int. J. Climatol. 2012, 32, 57–73. [Google Scholar] [CrossRef]
- Mamara, A.; Argiriou, A.A.; Anadranistakis, M. Detection and correction of inhomogeneities in Greek climate temperature series. Int. J. Climatol. 2014, 34, 3024–3043. [Google Scholar] [CrossRef]
- Menne, M.J.; Williams, C.N. Homogenization of temperature series via pairwise comparisons. J. Clim. 2009, 22, 1700–1717. [Google Scholar] [CrossRef] [Green Version]
- Trewin, B. A daily homogenized temperature data set for Australia. Int. J. Climatol. 2013, 33, 1510–1529. [Google Scholar] [CrossRef]
- Dunn, R.J.H.; Willett, K.M.; Morice, C.P.; Parker, D.E. Pairwise homogeneity assessment of HadISD. Clim. Past 2014, 10, 1501–1522. [Google Scholar] [CrossRef] [Green Version]
- Menne, M.J.; Williams, C.N.; Gleason, B.E.; Rennie, J.J.; Lawrimore, J.H. The global historical climatology network monthly temperature dataset, version 4. J. Clim. 2018, 31, 9835–9854. [Google Scholar] [CrossRef]
- Vertačnik, G.; Dolinar, M.; Bertalanič, R.; Klančar, M.; Dvoršek, D.; Nadbath, M. Ensemble homogenization of Slovenian monthly air temperature series. Int. J. Climatol. 2015, 35, 4015–4026. [Google Scholar] [CrossRef]
- Begert, M.; Schlegel, T.; Kirchhofer, W. Homogeneous temperature and precipitation series of Switzerland from 1864 to 2000. Int. J. Climatol. 2005, 25, 65–80. [Google Scholar] [CrossRef]
- Szentimrey, T. Methodological questions of series comparison. In Proceedings of the Sixth Seminar for Homogenization and Quality Control in Climatological Databases, Budapest, Hungary, 26–30 May 2008; WCDMP-No. 76. Lakatos, M., Szentimrey, T., Bihari, Z., Szalai, S., Eds.; WMO: Geneva, Switzerland, 2010; pp. 1–7. [Google Scholar]
- Maronna, R.; Yohai, V.J. A bivariate test for the detection of a systematic change in mean. J. Am. Stat. Assoc. 1978, 73, 640–645. [Google Scholar] [CrossRef]
- Szentimrey, T. Multiple analysis of series for homogenization (MASH). In Proceedings of the Second Seminar for Homogenization of Surface Climatological Data, Budapest, Hungary, 9–13 November 1998; WCDMP-41. Szalai, S., Szentimrey, T., Szinell, C., Eds.; WMO: Geneva, Switzerland, 1999; pp. 27–46. [Google Scholar]
- Venema, V.; Mestre, O.; Aguilar, E.; Auer, I.; Guijarro, J.A.; Domonkos, P.; Vertačnik, G.; Szentimrey, T.; Štěpánek, P.; Zahradníček, P.; et al. Benchmarking monthly homogenization algorithms. Clim. Past 2012, 8, 89–115. [Google Scholar] [CrossRef] [Green Version]
- Caussinus, H.; Mestre, O. Detection and correction of artificial shifts in climate series. J. R. Stat. Soc. Ser. C Appl. Stat. 2004, 53, 405–425. [Google Scholar] [CrossRef]
- Mestre, O.; Domonkos, P.; Picard, F.; Auer, I.; Robin, S.; Lebarbier, E.; Böhm, R.; Aguilar, E.; Guijarro, J.A.; Vertačnik, G.; et al. HOMER: Homogenization software in R—Methods and applications. Időjárás Quart. J. Hung. Met. Serv. 2013, 117, 47–67. [Google Scholar]
- Rustemeier, E.; Kapala, A.; Meyer-Christoffer, A.; Finger, P.; Schneider, U.; Venema, V.; Ziese, M.; Simmer, C.; Becker, A. AHOPS Europe—A gridded precipitation data set from European homogenized time series. In Proceedings of the Ninth Seminar for Homogenization and Quality Control in Climatological Databases; Szentimrey, T., Lakatos, M., Hoffmann, L., Eds.; WCDMP-85; WMO: Geneva, Switzerland, 2017; pp. 88–101. [Google Scholar]
- Chimani, B.; Venema, V.; Lexer, A.; Andre, K.; Auer, I.; Nemec, J. Inter-comparison of methods to homogenize daily relative humidity. Int. J. Climatol. 2018, 38, 3106–3122. [Google Scholar] [CrossRef]
- Alexandersson, H.; Moberg, A. Homogenization of Swedish temperature data. Part I: Homogeneity test for linear trends. Int. J. Climatol. 1997, 17, 25–34. [Google Scholar] [CrossRef]
- Vincent, L.A. A technique for the identification of inhomogeneities in Canadian temperature series. J. Clim. 1998, 11, 1094–1104. [Google Scholar] [CrossRef]
- Alexandersson, H. A homogeneity test applied to precipitation data. J. Climatol. 1986, 6, 661–675. [Google Scholar] [CrossRef]
- Domonkos, P. Efficiencies of inhomogeneity-detection algorithms: Comparison of different detection methods and efficiency measures. J. Climatol. 2013, 2013, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Wilcoxon, F. Individual comparisons by ranking methods. Biom. Bull. 1945, 1, 80–83. [Google Scholar] [CrossRef]
- Van Malderen, R.; Pottiaux, E.; Klos, A.; Domonkos, P.; Elias, M.; Ning, T.; Bock, O.; Guijarro, J.; Alshawaf, F.; Hoseini, M.; et al. Homogenizing GPS integrated vapor time series: Benchmarking break detection methods on synthetic datasets. Earth Space Sci. 2020, 7, e2020EA001121. [Google Scholar] [CrossRef] [Green Version]
- Ducré-Robitaille, J.-F.; Vincent, L.A.; Boulet, G. Comparison of techniques for detection of discontinuities in temperature series. Int. J. Climatol. 2003, 23, 1087–1101. [Google Scholar] [CrossRef]
- Craddock, J.M. Methods of comparing annual rainfall records for climatic purposes. Weather 1979, 34, 332–346. [Google Scholar] [CrossRef]
- Buishand, T.A. Some methods for testing the homogeneity of rainfall records. J. Hydrol. 1982, 58, 11–27. [Google Scholar] [CrossRef]
- Solow, A. Testing for climatic change: An application of the two-phase regression model. J. Clim. Appl. Meteorol. 1987, 26, 1401–1405. [Google Scholar] [CrossRef] [Green Version]
- Easterling, D.R.; Peterson, T.C. A new method for detecting undocumented discontinuities in climatological time series. Int. J. Climatol. 1995, 15, 369–377. [Google Scholar] [CrossRef]
- Caussinus, H.; Lyazrhi, F. Choosing a linear model with a random number of change-points and outliers. Ann. Inst. Stat. Math. 1997, 49, 761–775. [Google Scholar] [CrossRef]
- Domonkos, P. ACMANTv4: Scientific Content and Operation of the Software; 71p. Available online: https://github.com/dpeterfree/ACMANT (accessed on 2 September 2021).
- Li, S.; Lund, R. Multiple changepoint detection via genetic algorithms. J. Clim. 2012, 25, 674–686. [Google Scholar] [CrossRef]
- Hewaarachchi, A.P.; Li, Y.; Lund, R.; Rennie, J. Homogenization of daily temperature data. J. Clim. 2017, 30, 985–999. [Google Scholar] [CrossRef]
- Toreti, A.; Kuglitsch, F.G.; Xoplaki, E.; Luterbacher, J. A novel approach for the detection of inhomogeneities affecting climate time series. J. Appl. Meteorol. Climatol. 2012, 51, 317–326. [Google Scholar] [CrossRef]
- Schwaller, L.; Robin, S. Exact Bayesian inference for off-line change-point detection in tree-structured graphical models. arXiv 2016, arXiv:1603.07871 [stat.ML]. [Google Scholar] [CrossRef]
- Picard, F.; Lebarbier, E.; Hoebeke, M.; Rigaill, G.; Thiam, B.; Robin, S. Joint segmentation, calling and normalization of multiple CGH profiles. Biostatistics 2011, 12, 413–428. [Google Scholar] [CrossRef] [Green Version]
- Menne, M.J.; Williams, C.N. Detection of undocumented changepoints using multiple test statistics and composite reference series. J. Clim. 2005, 18, 4271–4286. [Google Scholar] [CrossRef]
- Domonkos, P. Efficiency evaluation for detecting inhomogeneities by objective homogenisation methods. Theor. Appl. Climatol. 2011, 105, 455–467. [Google Scholar] [CrossRef]
- Coll, J.; Domonkos, P.; Guijarro, J.; Curley, M.; Rustemeier, E.; Aguilar, E.; Walsh, S.; Sweeney, J. Application of homogenization methods for Ireland's monthly precipitation records: Comparison of break detection results. Int. J. Climatol. 2020, 40, 6169–6188. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.L.; Wen, Q.H.; Wu, Y. Penalized maximal t test for detecting undocumented mean change in climate data series. J. Appl. Meteor. Climatol. 2007, 46, 916–931. [Google Scholar] [CrossRef]
- Wang, X.L. Penalized maximal F test for detecting undocumented mean shift without trend change. J. Atmos. Oceanic Technol. 2008, 25, 368–384. [Google Scholar] [CrossRef]
- Domonkos, P. Adapted Caussinus-Mestre algorithm for networks of temperature series (ACMANT). Int. J. Geosci. 2011, 2, 293–309. [Google Scholar] [CrossRef] [Green Version]
- Vincent, L.A.; Zhang, X.; Bonsal, B.R.; Hogg, W.D. Homogenization of daily temperatures over Canada. J. Clim. 2002, 15, 1322–1334. [Google Scholar] [CrossRef]
- Lindau, R.; Venema, V. On the reduction of trend errors by the ANOVA joint correction scheme used in homogenization of climate station records. Int. J. Climatol. 2018, 38, 5255–5271. [Google Scholar] [CrossRef] [Green Version]
- Domonkos, P. Homogenization of precipitation time series with ACMANT. Theor. Appl. Climatol. 2015, 122, 303–314. [Google Scholar] [CrossRef]
- Rienzner, M.; Gandolfi, C. A composite statistical method for the detection of multiple undocumented abrupt changes in the mean value within a time series. Int. J. Climatol. 2011, 31, 742–755. [Google Scholar] [CrossRef]
- Lund, R.; Wang, X.L.; Lu, Q.Q.; Reeves, J.; Gallagher, C.; Feng, Y. Changepoint detection in periodic and autocorrelated time series. J. Clim. 2007, 20, 5178–5190. [Google Scholar] [CrossRef] [Green Version]
- Killick, R.E. Benchmarking the Performance of Homogenisation Algorithms on Daily Temperature Data. Ph.D. Thesis, University of Exeter, Exeter, UK, 2016. Available online: http://hdl.handle.net/10871/23095 (accessed on 2 September 2021).
- Domonkos, P.; Coll, J. Homogenisation of temperature and precipitation time series with ACMANT3: Method description and efficiency tests. Int. J. Climatol. 2017, 37, 1910–1921. [Google Scholar] [CrossRef] [Green Version]
- Domonkos, P.; Coll, J. Time series homogenisation of large observational datasets: The impact of the number of partner series on the efficiency. Clim. Res. 2017, 74, 31–42. [Google Scholar] [CrossRef]
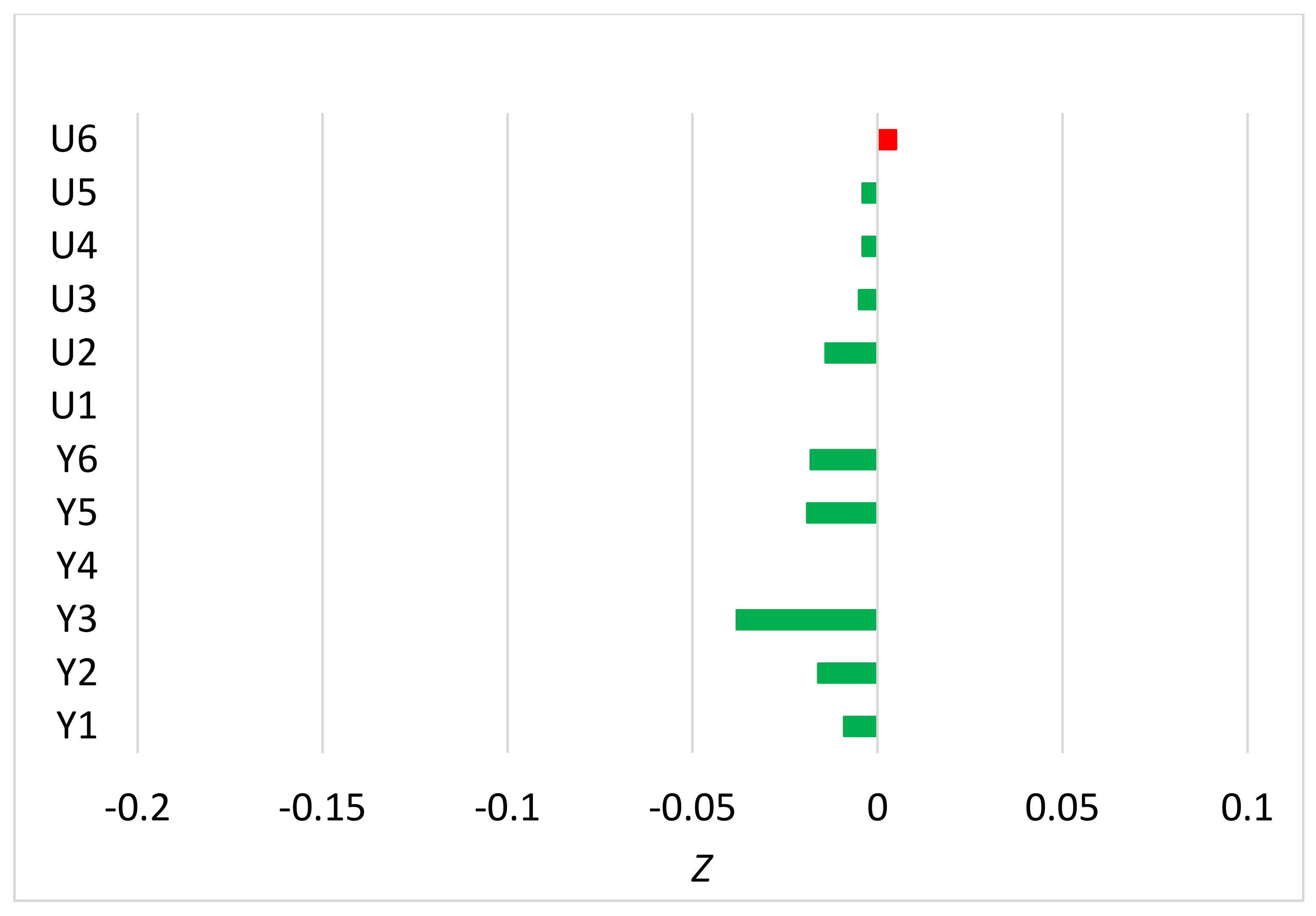
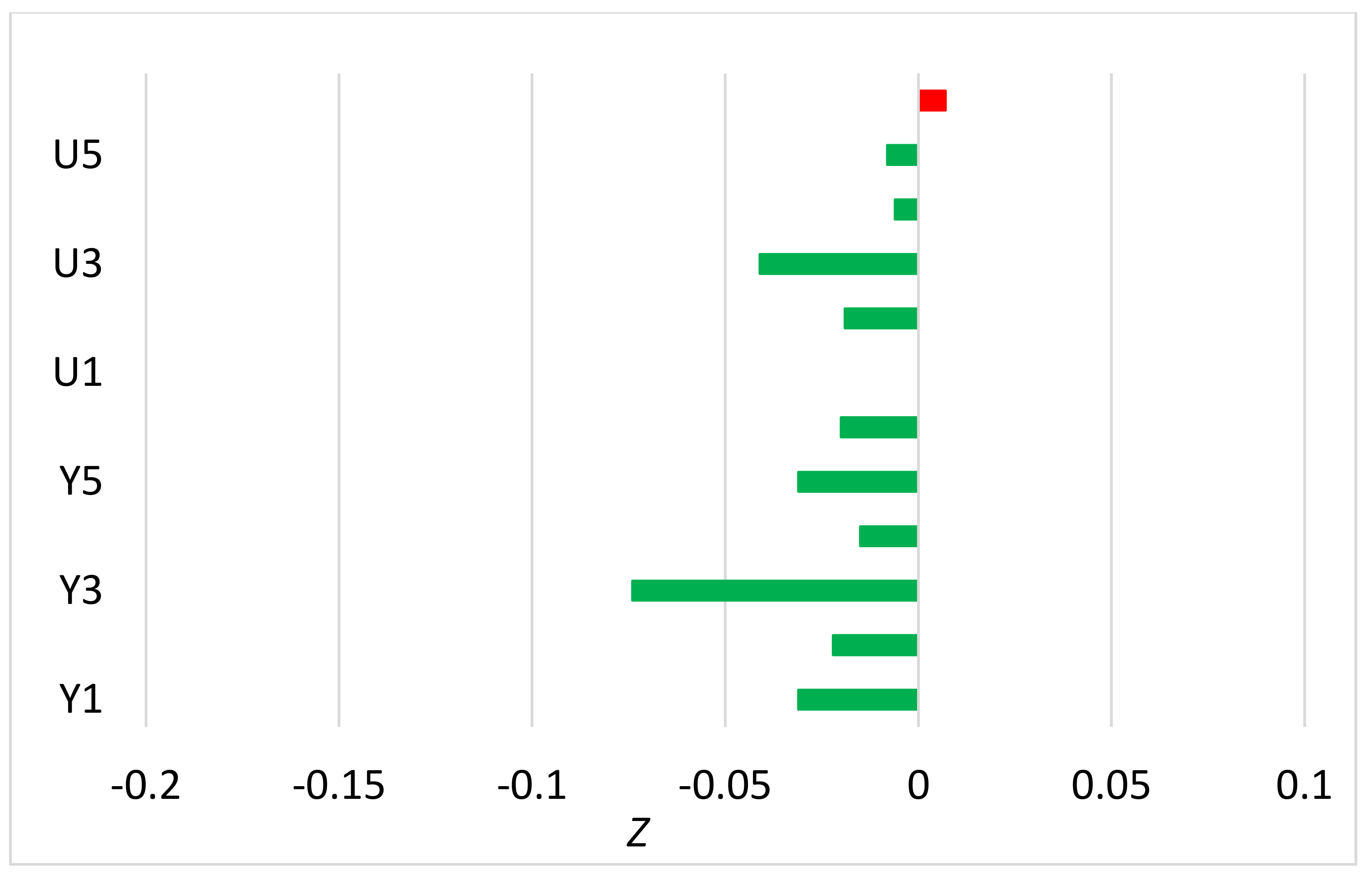
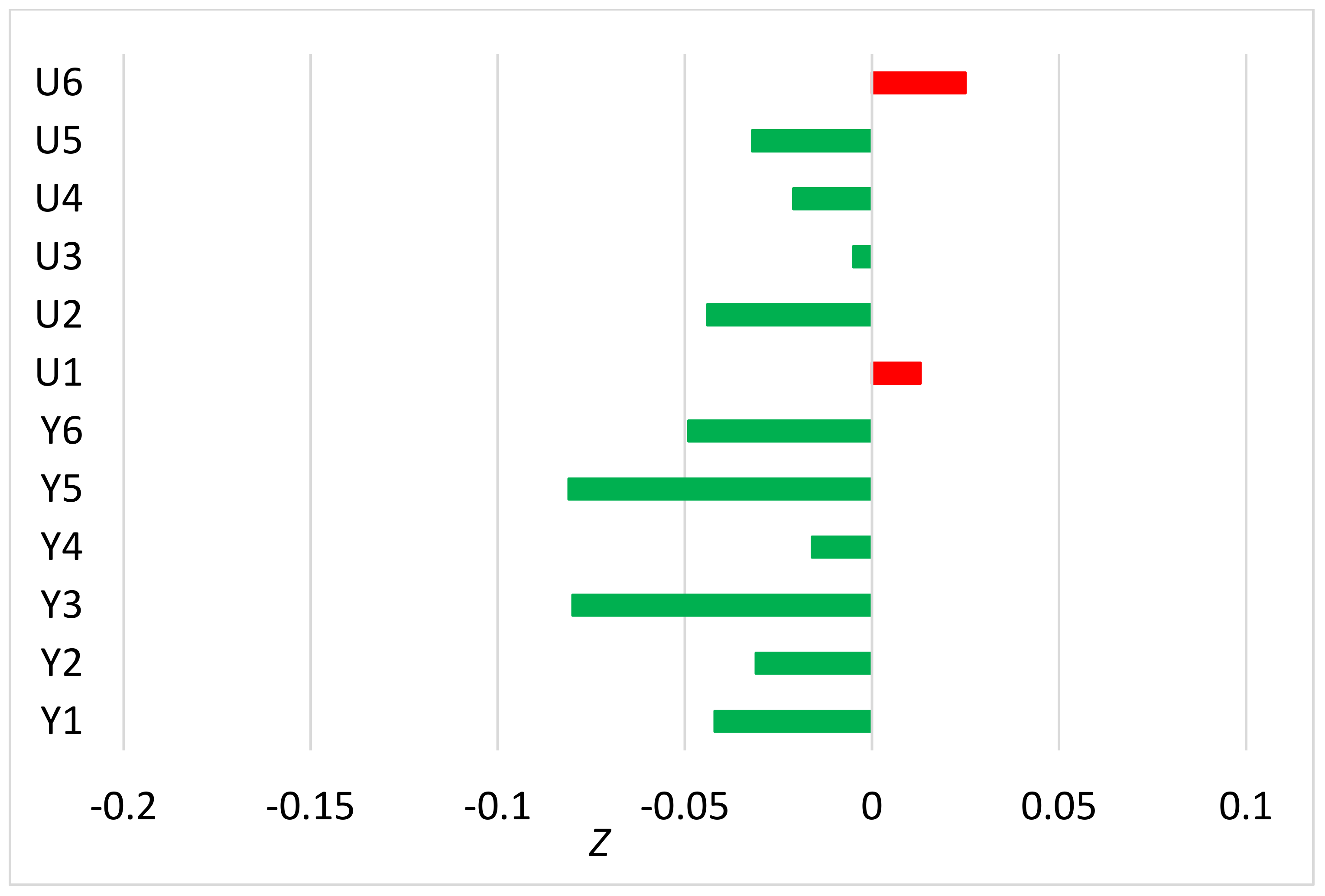
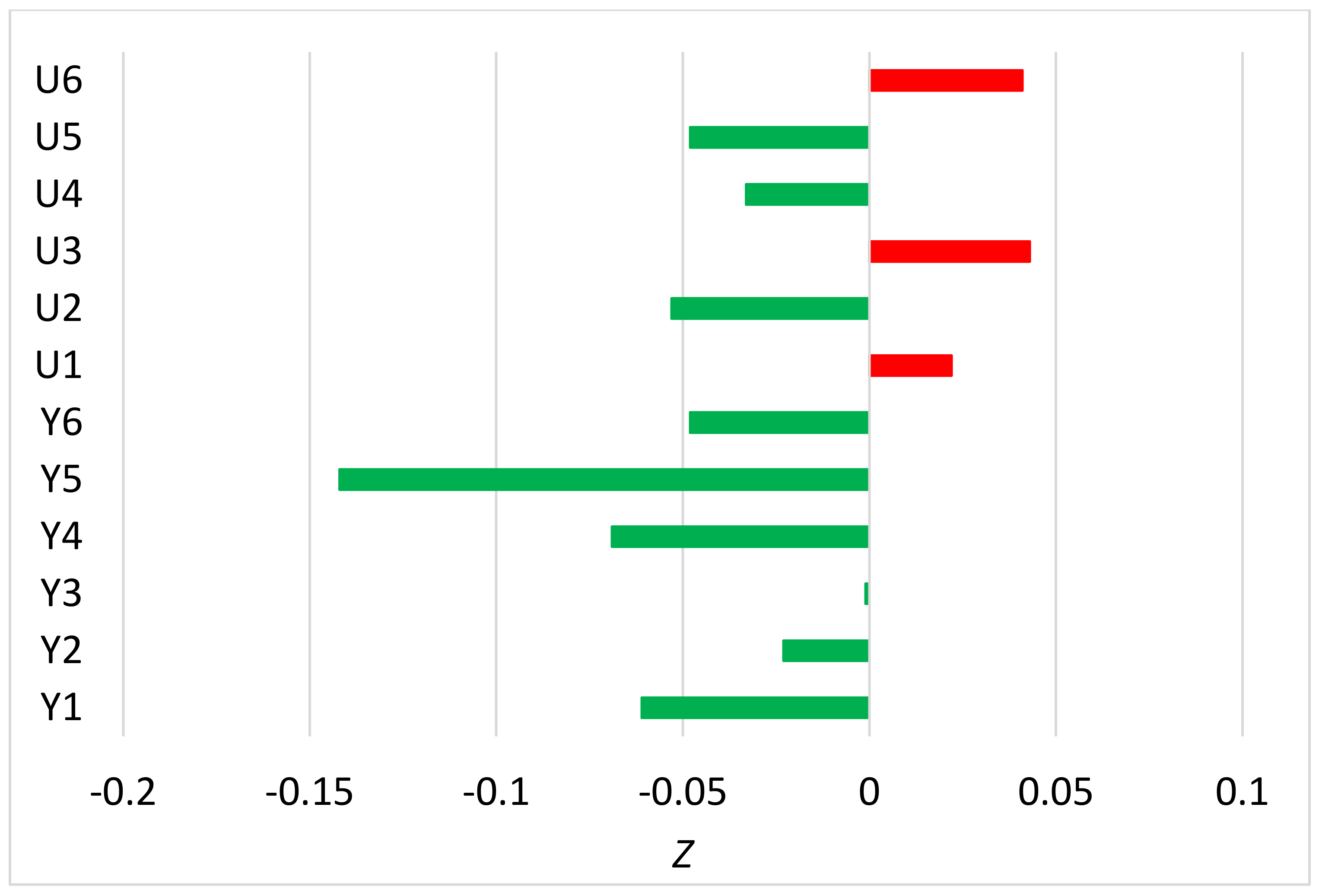
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Domonkos, P. Combination of Using Pairwise Comparisons and Composite Reference Series: A New Approach in the Homogenization of Climatic Time Series with ACMANT. Atmosphere 2021, 12, 1134. https://doi.org/10.3390/atmos12091134
Domonkos P. Combination of Using Pairwise Comparisons and Composite Reference Series: A New Approach in the Homogenization of Climatic Time Series with ACMANT. Atmosphere. 2021; 12(9):1134. https://doi.org/10.3390/atmos12091134
Chicago/Turabian StyleDomonkos, Peter. 2021. "Combination of Using Pairwise Comparisons and Composite Reference Series: A New Approach in the Homogenization of Climatic Time Series with ACMANT" Atmosphere 12, no. 9: 1134. https://doi.org/10.3390/atmos12091134
APA StyleDomonkos, P. (2021). Combination of Using Pairwise Comparisons and Composite Reference Series: A New Approach in the Homogenization of Climatic Time Series with ACMANT. Atmosphere, 12(9), 1134. https://doi.org/10.3390/atmos12091134