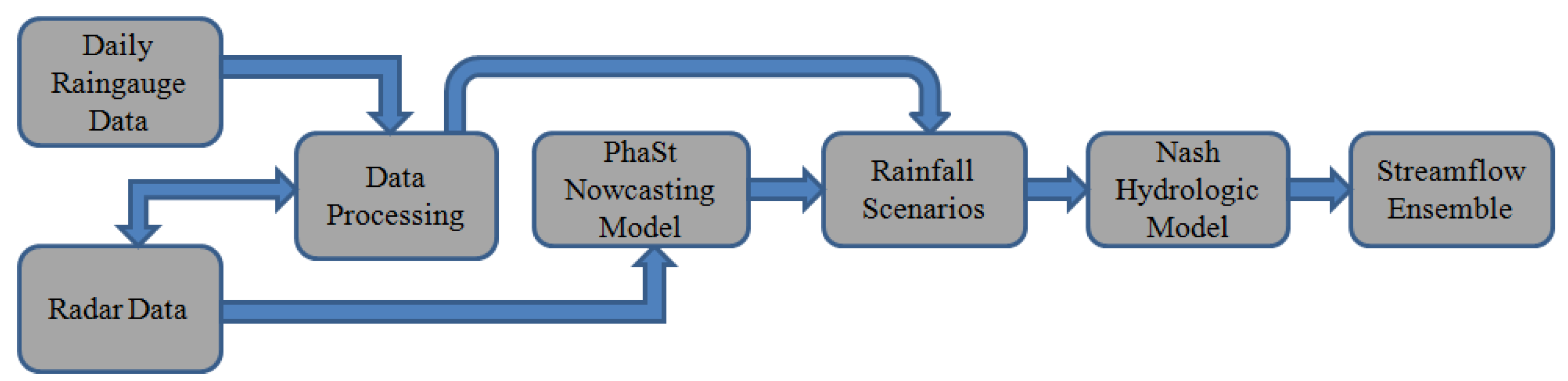
3.1. Analysis 1: Nowcast Discharge Performance with Respect to Observed Discharge
As mentioned above, in this first phase the comparison is of purely modelling type: the performance of the forecast flow with respect to observed flow was estimated, in terms of correct forecast, false alarm and missed alarm rates. Please note that by observed flow it is here meant the discharge simulated with the observed rainfall data only, from the initialization of the model run till the now bar. One could relate these scores to the specific PhaSt component, rather than to the model chain as a whole. For the given boundary conditions and thresholds, both nowcast and observed streamflow are computed with the same model and parameter values, while the estimated rainfall input is the only varying forcing. This is why analysis 3 accounts for observed criticalities, too.
From the information thus obtained, summarized in a file for each event (
Section 2), a procedure was automated to obtain, for each event and each basin: the number of activations, correct forecast—in the case of both exceedance and null exceedance—false alarm and missed alarm rates; the values for Tw1 and Tw2. Computing the scores both by event and by basin and storing this information, in addition to the total contingency tables—structured as in
Table 5—is useful for: verifying the results; investigating a particular event: if the scores are low it could be due to PhaSt; investigate a particular basin: if the scores are low it could be due to inadequate thresholds (see Analysis 3); look for a correlation between the average Tw per basin and the basin area, in the hypothesis that very low Tw—may also be due to the small size of the drainage areas.
For simplicity, we called the threshold exceedance errors missed alarm and false alarm, without considering further evaluations made by the operator.
The sample used and the contingency tables for each threshold are reported below. In
Table 6, the actual sample is given by the number of the activations, which is basically the number of records structured as in
Table 3. The number of events and basins considered is reported, too, together with the total correct forecast rates.
Table 7a,b show the contingency tables for thresholds 1 and 2, respectively, structured as in
Table 5.
Results are overall better for threshold 2 (Thr2) than threshold 1 (Thr1), which is more important since more directly related to criticalities in the territory. According to the pre-established criteria (
Table 4), the correct forecast rate (CFR) resulted to be sufficient for Thr1 and satisfactory for Thr2, about 17% higher. As displayed in
Table 7a,b, the greatest contribution to the percent of correct forecasts, in particular as regards threshold 2, is given by the non-exceedances rather than the exceedances. Events with damage are investigated more thoroughly in analyses 2 and 3. False alarm rates (FAR) were comparable and resulted to be good in both cases while missed alarm rates (MAR) for Thr1 were satisfactory and very good for Thr2, as they reduced by around a third. So, Thr2 FAR was higher than MAR, which indicates a positive bias which is still preferable to a negative bias.
As mentioned above, these results represent the overall scores over the whole time period and basins considered; we now wish to investigate what the scores are for each of the 99 events. Results are summarised in
Table 8, which can be read as follows: considering the first two columns, 10 out of 99 events (so, about 10%) had a very good correct forecast rate for threshold 1, so between 90 and 100% correct forecasts; 36 events had very good correct forecast rate respect to threshold 1, so between 0 and 10%; and so on.
The results are promising particularly with regard to forecast threshold 2 exceedances: 86 events had satisfactory to very good correct forecast rate (more than 70%), while 6 only had poor rates; 92 events recorded a good to very good missed alarm rate (less than 20%) and 80 events had good to very good false alarm rate.
Below is the relative frequency histogram of the warning times Tw (
Figure 5a). The warning times were divided for both the pre-alarm and alarm thresholds Thr1 and Thr2 into 13 classes, of 10 min each, coherently with the temporal resolution of the model (
Section 2.1), except for the last class which incorporates all Tw greater or equal to 120 min. When a threshold exceedance is observed before it could be forecast, Tw = 0 is assigned; this often occurred at the catchment’s activations, basically when the first hydrograph is saved. If there are no observed exceedances or there are not at all, Tw = NaN is assigned. Therefore, the Tw sample is always equal to or smaller than the total activation sample: this was 1898 and 921 for Tw1 and Tw2, respectively.
Figure 5b represents the same sample in form of a boxplot, as additional help for us to understand how these values are distributed. The width of the whiskers is delimited by the values of μ +/− 3 ∙ σ, where μ = mean value of Tw, σ = standard deviation of Tw.
It can be deduced that Tw1 and Tw2 have a left-skewed distribution so that higher values of Tw appear with a lower frequency. Higher values of Tw2 appear with higher frequency than Tw1, as expected, as Tw1 is exceeded sooner. Their average values are Tw1 values higher than 50 min and Tw2 values higher than 70 min can be considered outliers.
Out of these values, two more samples were then extracted, for each threshold: average warning time in each event, Tw
ea, and average warning time by basin, Tw
ba. We wanted to investigate these derived distributions to have an insight on what the mean warning time, in every situation operators have to face, is and to search for any correlation between a basin and its mean warning time. Tw
ea sample size corresponds therefore to the number of events considered, 99, and Tw
ba corresponds to the number of basins, 219. Unfortunately, only a very small sample is available for each basin, on average 9 for Tw1 and 4 for Tw2, therefore the reliability of the estimated mean warning time for a basin is very low. For each event, these values increase to 19 and 10, which means that, on average, the mean warning time for a specific event is computed on 19 values for Tw1
ea and 10 values for Tw2
ea, which is still a small sample, but almost doubled. During the more severe or widespread events, the forecast and observed threshold exceedances were so many that we can compute the mean warning time over more than a hundred values (
Table 9).
Moreover, no significant correlation was found between Tw1
ba nor Tw2
ba and the drainage area dimensions, which was around 10% for the former or even lower for the latter. This might lead to the conclusion that the warning time depends mostly on the particular hydrometeorological event dynamics and the configuration of the nowcast rainfall field, rather than on the specific basin and its geomorphological characteristics, but this could further be investigated again in the future when a larger sample will be available for each basin. Probably, since the time of concentration of basin measures a basin response time, this could happen because we are considering basins of comparable sizes and possibly a stronger correlation would be found comparing a set of basins with greater variance as for their dimensions. For all these reasons, we reported statistics of event-averaged warning times.
Table 10 compares the interquartile range and mean values of Tw and Tw
ea, related to both thresholds, including information on the related sample sizes.
This means that among the whole dataset of warning times the mean value is sufficient for both cases; the third quartile of Tw2, particularly, is satisfactory. As for the event-averaged warning times, values are similar. The median is poor but still increases. The mean values decrease by around 5 and 10 min relatively to threshold 1 and 2, respectively. The 75th percentiles increase by 5 min for Thr1 and decrease by 5 min for Thr2.
3.2. Analysis 2: Modelling Performance Related to the Observed Zonal Criticalities
As mentioned in
Section 2.2, in this analysis, in addition to the results obtained from the comparison of forecast and observed threshold exceedances, a previous study on the observed criticalities by alert area was used. In summary, the same procedure was adopted as in analysis 1, but since in
Table 7a,b the greatest contribution to the percentage of correct predictions is given by the non-exceedances rather than the correct ones, we focused on the events with damage (
Table 2). Results are shown in
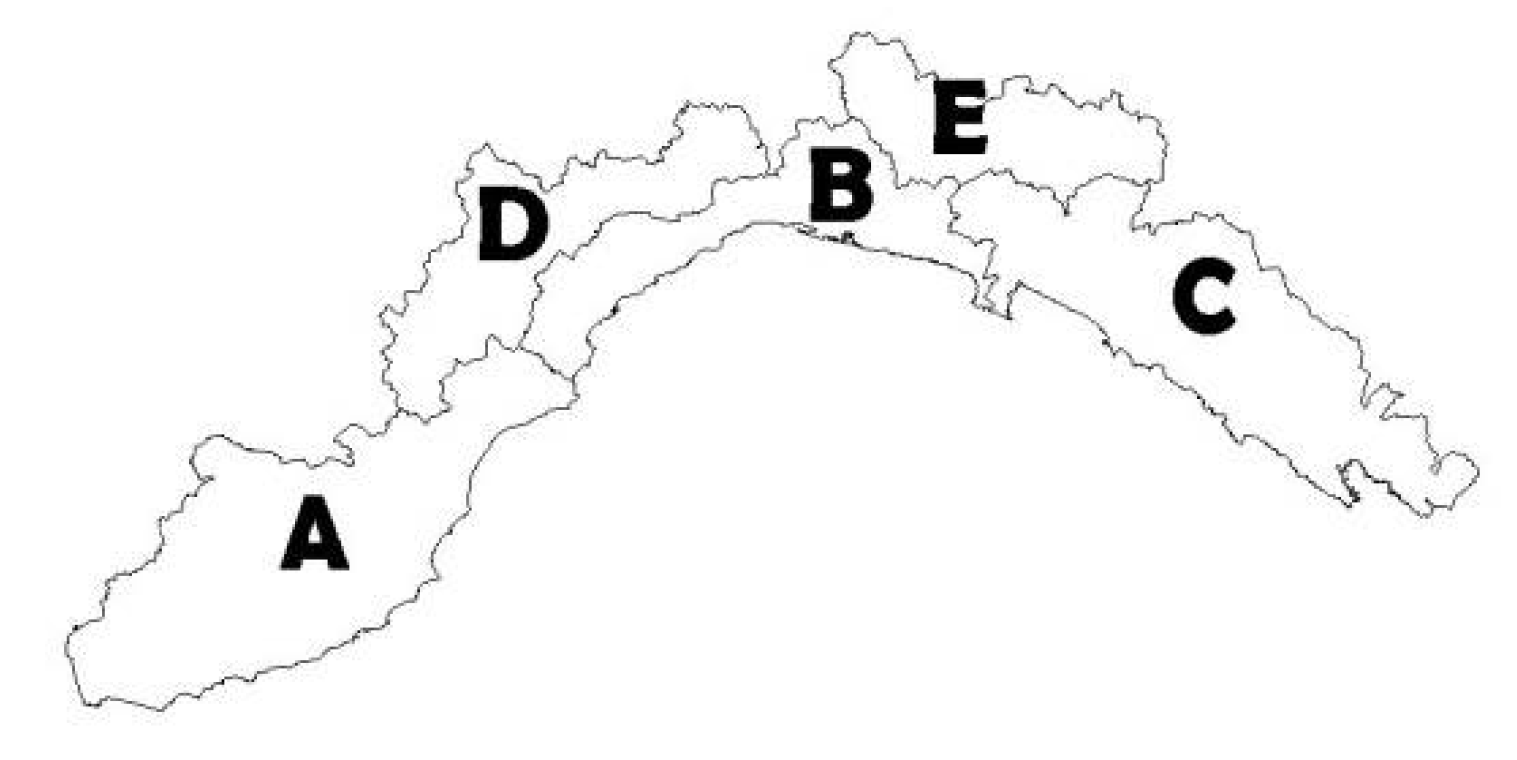
Table 11. The first row includes results for analysis 1, for comparison; the second row shows results considering events with damage or any other criticality; the third row considers the 62 cross-sections included in the A area and the events which had impacts, at least, on the A area; similarly, for B and C warning areas. D and E warning areas were excluded due to the very limited activation sample size available for them (23 and 32), for which the scores cannot be considered as reliable as for the other areas. A comparison is though possible between A, B, ad C areas, for which we wanted to check for any bias with respect to the overall results, e.g., if an area was characterized by a sensibly higher false or missed alarm rate or shorter warning times.
Considering the selection of critical events over the whole region, the sample is reduced by about 30% only, coherently with the fact that we observed the most activations during those events, but results did not substantially change from those in analysis 1. As expected, there was an increase in correct threshold 1 and 2 exceedances, i.e., +4% and 3%, respectively, but in favour of a decrease in correct non-exceedances, while the false and missed alarm rates remain practically unchanged. This may be due to the fact that many events had consequences on medium-large basins only, typically at the occurrence of non-convective meteorological events, characterised by higher cumulated rainfall values rather than intensities, or that these damages occurred in areas where no cross-sections are modelled in this chain or that criticalities were related to landslides and similar phenomena. Therefore, a more detailed analysis including information regarding observed criticalities is reported in
Section 3.
As for the three warning areas considered, the A area showed a worse performance in terms of missed alarms, for both thresholds. FAR1 values are comparable. Overall, B and C area basins had comparable scores, with the higher rate of correct forecasts, both good as for threshold 2, and both good to very good FAR2 and MAR2, around 10% or less. These results may provide directions for further investigations about PhaSt performances for these particular events or maybe the cross-section thresholds; the latter aspect is better analysed in
Section 3.
The statistics related to the warning times follow, including, again for comparison, results from analysis 1 (
Table 12).
As for the warning times, results for the A and C areas are more similar and slightly better than in the B area. Mean Tw1 and 75th percentiles in the B area are about 5 to 10 min lower than in A, for instance. The frequency of higher anticipation times on threshold 2 exceedances is higher for A and C, where the 50th, and the 75th percentile in C, increases by 10 min; this might seem little for larger basins but it can acquire more relevance in the smallest drainage areas and be somehow useful during the operational phases.
3.3. Analysis 3: Modelling Performance Related to Observed Criticalities at the Basins Scale
As mentioned, the preparatory work for the latter analysis concerned the verification of the criticalities which occurred in the region, this time at the basin scale. As part of its activities, when a relevant hydrometeorological event occurs, ARPAL publishes a Hydrometeorological Event Report (REM). As a first step, based on such reports, the events causing severe ground effects or any other criticalities were selected. Then, the availability of the relative simulations in the archive was checked and, based on the available official information sources, namely the Civil Protection archives, the largest possible number of basins were listed, in which these criticalities were found. Comparing model results with observed impacts implies that here it is not sufficient to look at threshold forecast exceedances, but at basins activations, too: e.g., when the damage occurred in a drainage area whose corresponding cross-section did not activate at all, this implies a missed alarm. Unfortunately, the limited availability of information further reduced the sample; indeed, in order not to alter the results, in particular the percentage of correct non-activations and false alarms (the cases of observed zero criticality tend to be more numerous, at least apparently), the events with little information available had to be excluded. In addition, events which, despite having caused criticalities on medium-large basins, had no consequences on small basins were also excluded; the same was done when the damage reported was extremely localized or for which it was impossible to identify the basins, or, even if the basin was present in the damage file, it bore insufficient information. The result was a dataset of 25 events.
If the observed criticality flag was 0 (see
Section 2), the modelling was considered correct in cases where: there was no activation; there was activation only; the basin activated with forecast threshold 1 exceedance, as these cases do not imply the occurrence of a criticality; on the other hand, a forecast threshold 2 exceedance was considered a false alarm.
If the observed criticality flag was equal to 1:
if there was no activation, the case is considered as a missed alarm;
if the basin activated, the case is considered as an underestimation, rather than a full missed alarm, since the model provided somehow a signal on that basin, even if not sufficiently clear; at the operational level, however, that signal can cause those who monitor in SOR to follow the situation with greater attention and proceed with further evaluations;
if the basin activated with forecast threshold 1 (only threshold 1) exceedance, we can consider this case can be considered a less serious underestimation than in the case of activation alone;
if threshold 2 is exceeded, that is correct modelling.
It is necessary to focus on the case of multiple activations during the same event, too. For a given basin and event, for example, the following case could occur: during a hydrometeorological event, damage occurs in a drainage area; the corresponding cross-section had activated twice, the first time without alarm threshold exceedance, the second time with exceedance. While the exceedance has to be correct, we cannot say anything about the first outcome, since we do not know the time at which the damage occurred and we would have to store information about the exact forecast time (
Table 13). Looking for such additional information would be inefficient, besides these cases occurred with very low frequency. Therefore, they were excluded, without substantially affecting the activation sample size.
This is not an issue in the case of null observed criticality, as the flag is taken as a reference for all activations. The total sample size used to compute the scores is summarised in
Table 14. This is even higher than the one used in
Section 3.2, since, previously, activations only were considered.
Based on the previous considerations, the contingency tables had a slightly more complex structure as in
Table 15, which reports the scores resulting from the model forecast.
Table 16 sums up all correct forecasts and all underestimations from the previous
Table 15.
By summing up all correct predictions (84.2%) and totally wrong ones (missed and false alarms, 10.7%), promising scores are obtained.
The analysis was repeated, this time considering the observed discharge, too (i.e., simulated with observed rainfall field), to measure how much the modelling chain as a whole can detect criticalities, since, even while these are occurring, it is possible, although with a delay, to intervene and activate the rescue chain. To more easily visualise at a glance how these scores changed in comparison with the ones derived by analysing the forecast discharge scenarios only, the scores which, with respect to
Table 15, have improved or worsened, are highlighted in green or red, respectively (
Table 17). In
Table 18 is possible to see a compact representation of results of
Table 17.
As expected, the underestimation rate decreased in favour of an increase in minor underestimations and criticality detection rate, with the contribution of observed discharges; on the other hand, false alarms also increase, accompanied by a decrease in correct activations. The latter can be explained on one hand by the need to intervene on the thresholds; on the other hand, it must be accounted for that there are necessarily limits in the analysis of criticalities at the basin scale, due to the limited information availability: while, when damage is found, the criticality flag 1 is assigned with certainty, the null flag is always doubt.
By summing up all correct predictions (83.8%) and totally wrong ones (missed and false alarms, 12.7%), similar scores are obtained.
Afterwards, the scores conditionally on the occurrence, or not, of any criticality or damage were computed. Sättele et al. [
18] estimate the reliability of a warning system for a debris flow alarm system by firstly computing the probability of detection, POD, and the probability of false alarms, PFA, given that a hazard event occurs or not. They estimate POD as the expected value of the ratio between the number of detected events by the number of total events and PFA as the expected value of the number of days with false alarms by the number of event-free days. Here, we are considering a (limited) set of hydrometeorological events, each one of them recording the occurrence, or not, of any criticality for each basin. Events with criticalities were therefore isolated to compute the scores conditionally on the occurrence of any criticality or damage, to further investigate correct criticality detections in relation to missed alarms, given that criticality occurs; similarly, the probability of false alarm, given that any criticality does not occur, was then estimated considering criticality-free events only. Criticality detection means alarm threshold exceedance. If we define
POD and
PFA based on these criteria, we obtain:
Please note that by this definition of
POD we do not refer to the number of total rainfall events, but to the number of observed criticalities and impacts on the territory, only; similarly, when defining
PFA, we do not refer to the number of rainfall event-free days, but, out of these events, to which ones resulted in null criticalities, for specific basins. The resulting probability is not then a false alarm probability, e.g., per year, but per event, or, practically, per model simulation. This choice derives from the model nature and structure, too: as mentioned above (
Section 2), the model chain is a monitoring chain, which does not run continuously, but at the occurrence of significant precipitation events, only. Therefore, exploiting the previously made classification in hit cases (correct threshold 2 exceedances), neutral cases (correct non-exceedances), false and missed alarms and by isolating the criticalities occurrences, [
4], we obtain the scores as in
Table 19. The first row is derived by considering nowcast scenarios, only; the second row accounts for both discharge nowcast and simulation with observed rainfall field.
The missed alarm rate cannot change, since derives from non-activation, therefore no observed or nowcast discharge is available.
By applying the second method, the activations without any exceedance decrease by more than 10%, as mentioned above, in favour of a slight increase in the minor underestimations, which only apparently did not point an improvement out, and an increase by about 10% in the correct detections, which reach up to about 50%.
Now, one could consider these outcomes from a more operative point of view. When a severe event occurs, characterized by very intense rainfall intensities, any cross-section activation leads the operator to focus on the area. Then, he/she does not interpret model results in an aseptic manner but proceeds with further evaluations. For instance, when an intense storm cell rapidly moves over an area so that alarm discharge flow is being nowcast at a specific cross-section, over which the most intense part of the cell is predicted to be localised, then the neighbouring cross-sections, which might not yet predict a threshold 2, or 1, exceedance will be kept under close observation, too. Therefore, we can try and sum up the correct detections with the minor underestimations, reaching up to 65% and any kind of signal, including activations only, reaching up to 82%. This means that, even with some delay and underestimations, the model chain provides a signal for more than 80% of the cases, which can be considered a good score.
The analogous table for PFA was not reported, since results did not substantially change with respect to
Table 17: an overall PFA estimate of about 10% was obtained.
Besides the above considerations, it should be emphasized that analysis 3 is limited by the availability of information. Furthermore, in general, many false alarms may result from the impossibility of verifying that a criticality had occurred in the area or the choice of some too conservative thresholds; that is, it could be later investigated whether there are cases of exceeding the threshold both in the observation and in the forecast but the damage is null and verify this aspect.
Finally, similarly to
Section 3.1, after estimating the overall scores we can have a look more in detail at the scores for each, this time not event, but basin. This choice is made, of course, because criticalities are evaluated at the basin scale and they can be correlated with the threshold values estimations.
Table 20 summarises the scores computed for the 219 basins and can be read as follows: considering the last row, 52% of the basins had very good PFA, so between 0 and 10%; 31% of the basins had good PFA, so between 10 and 20%; and so on.
It is very important to highlight that we computed PFA as the ratio between the number of false exceedances during hydrometeorological events with no damage and the number of total hydrometeorological events in the region, not the total number of days with no event at all. In other words., the total number of hydrometeorological events with no damage on a basin was used, and not the total number of days with no damage on that basin. This is why the PFA may apparently seem too high.
Even though such values are not highly reliable due to the limited sample available for each basin, they allow us to assign a priority for a deeper further analysis. For instance, one could focus on the basins which provided the poorest scores in terms of false and missed alarm and investigate whether the discharge thresholds need to be modified, for instance with the support of up-to-date site-specific hydraulic studies.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}