
Basic Statistical Estimation Outperforms Machine Learning in Monthly Prediction of Seasonal Climatic Parameters

 , ,
, ,  ,
,  and
and
Abstract
1. Introduction
2. Literature Review and Scope of the Research
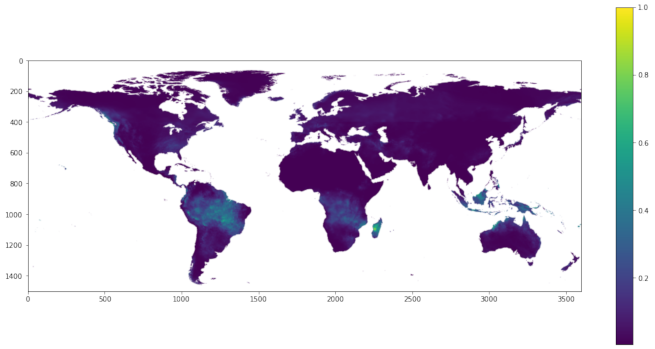
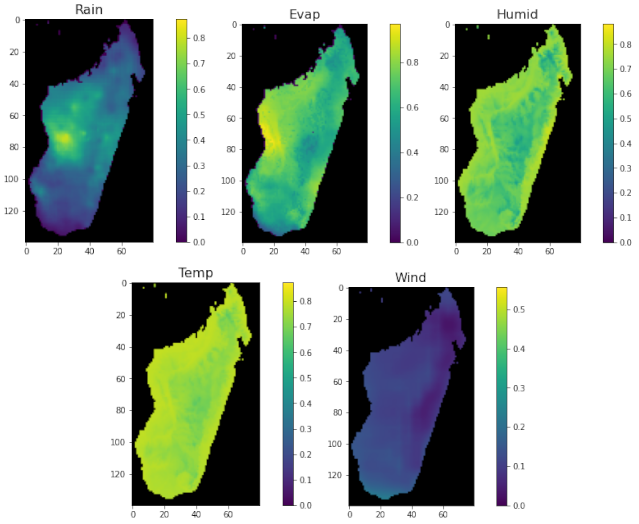
3. Data and Area of Interest
4. Methodology
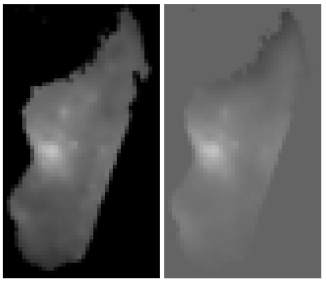
4.1. Image Pre-Processing
4.2. Data Preparation
4.3. Feature Selection
- f[0]: same-pixel values from frames 12 months previous;
- f[11]: same-pixel values from the previous month;
- f[0, 11]: same-pixel values from 12 months previous and the previous month;
- f[0, 1, 2, 11]: same-pixel values from months previous and the previous month;
- f[0, 1, 10, 11]: same-pixel values from months previous and the previous two months.
- The coordinates of the pixel of interest;
- Monthly time stamp where .
- Past-pixel features only (five variants, as listed above);
- feature set only;
- feature set only;
- Past-pixel features (five variants) plus .
4.4. Tools and Evaluation Methods
4.4.1. Machine Learning Algorithms
4.4.2. Performance Metrics
| Algorithm 1 Computation of MAE for the difference between baseline and ML algorithms. |
form in range(M) do omit image m from list of M images ▹ for the reduced list of images end for |
4.4.3. Baselines and Statistical Estimators
5. Results
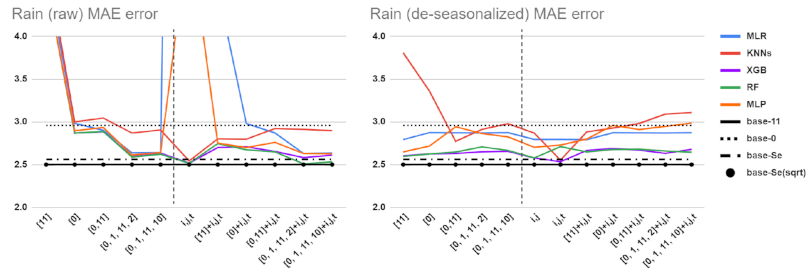
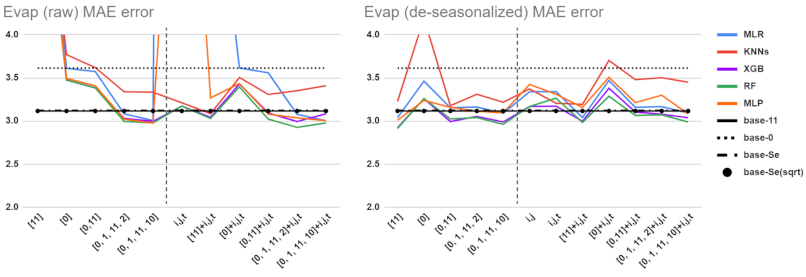
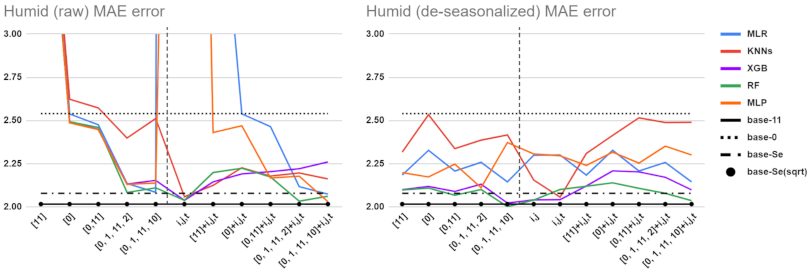
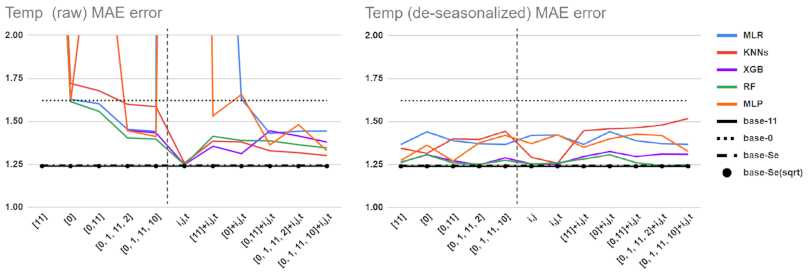
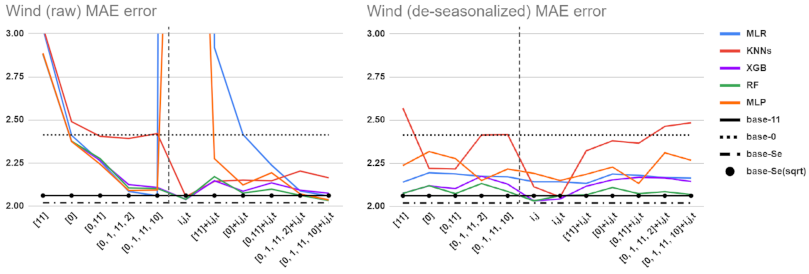
5.1. Performance Comparisons for Different Baselines, Feature Sets, and Preprocessing Methods
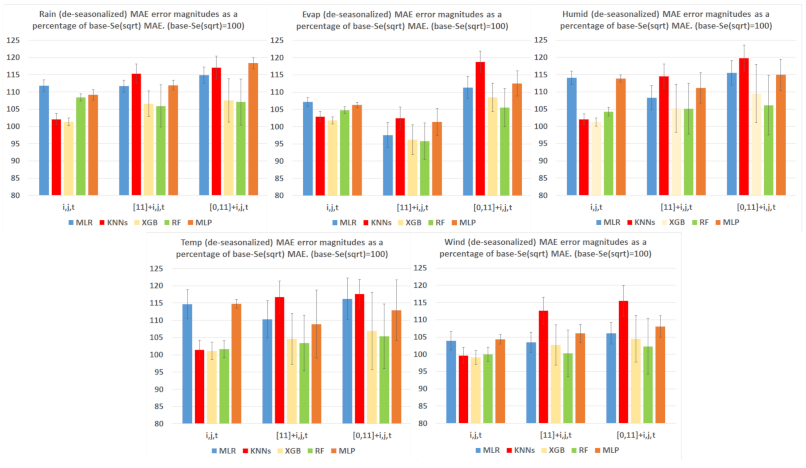
5.2. Detailed Comparison of ML Tools and Feature Sets
5.3. Data Shuffling
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ML | Machine learning |
| ANNs | Artificial neural networks |
| Base-0,…,base-11 | Baseline estimators based on previous lags (see Section 4.4.3) |
| Base-Se | Seasonal baseline computed from same-month averages (see Section 4.4.3) |
| Base-Se(sqrt) | Seasonal baseline computed from regularized same-month averages |
| (see Section 4.4.3) | |
| CNNs | Convolution neural networks |
| LSTMs | Long short term memory |
| ConvLSTMs | Convolutions layers with Long short term memory |
| MLP | Multilayer perceptron |
| RF | Random forest |
| SVMs | Support vector machines |
| XGB | Extreme gradient boosting |
| MLR | Multi linear regression |
| KNN | K-nearest neighbour |
| RMSE | Root mean square error |
| MAE | Mean absolute error |
| Rain | Rainfall |
| Temp | Temperature |
| Evap | Evaporation |
| Humid | Humidity |
| FEWS NET | Famine Early Warning Systems Network |
| FLDAS | FEWS NET Land Data Assimilation System |
References
- Miller, H.J.; Goodchild, M.F. Data-driven geography. GeoJournal 2015, 80, 449–461. [Google Scholar] [CrossRef]
- Hey, T.; Tansley, S.; Tolle, K. The Fourth Paradigm: Data-Intensive Scientific Discovery; Microsoft research Redmond: Redmond, WA, USA, 2009; Volume 1. [Google Scholar]
- Manyika, J.; Chui, M.; Brown, B.; Bughin, J.; Dobbs, R.; Roxburgh, C.; Hung Byers, A. Big Data: The Next Frontier for Innovation, Competition, and Productivity; McKinsey Global Institute: New York, NY, USA, 2011. [Google Scholar]
- Kitchin, R. Big Data, new epistemologies and paradigm shifts. Big Data Soc. 2014, 1, 2053951714528481. [Google Scholar] [CrossRef]
- Ardabili, S.; Mosavi, A.; Dehghani, M.; Várkonyi-Kóczy, A.R. Deep learning and machine learning in hydrological processes climate change and earth systems a systematic review. In International Conference on Global Research and Education; Springer: Berlin/Heidelberg, Germany, 2019; pp. 52–62. [Google Scholar]
- Monteleoni, C.; Schmidt, G.A.; McQuade, S. Climate informatics: Accelerating discovering in climate science with machine learning. Comput. Sci. Eng. 2013, 15, 32–40. [Google Scholar] [CrossRef]
- Buontempo, C.; Hewitt, C.D.; Doblas-Reyes, F.J.; Dessai, S. Climate service development, delivery and use in Europe at monthly to inter-annual timescales. Clim. Risk Manag. 2014, 6, 1–5. [Google Scholar] [CrossRef]
- Steinert, M.; Leifer, L. Scrutinizing Gartner’s hype cycle approach. In Proceedings of the Picmet 2010 Technology Management for Global Economic Growth, Phuket, Thailand, 18–22 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1–13. [Google Scholar]
- Dacrema, M.F.; Cremonesi, P.; Jannach, D. Are we really making much progress? A worrying analysis of recent neural recommendation approaches. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 101–109. [Google Scholar]
- Lin, J. The neural hype and comparisons against weak baselines. In ACM SIGIR Forum; ACM: New York, NY, USA, 2019; Volume 52, pp. 40–51. [Google Scholar]
- Hussein, E.A.; Ghaziasgar, M.; Thron, C. Regional Rainfall Prediction Using Support Vector Machine Classification of Large-Scale Precipitation Maps. arXiv 2020, arXiv:2007.15404. [Google Scholar]
- Ludewig, M.; Jannach, D. Evaluation of session-based recommendation algorithms. User Model. User-Adapt. Interact. 2018, 28, 331–390. [Google Scholar] [CrossRef]
- Cristian, M. Average monthly rainfall forecast in Romania by using K-nearest neighbors regression. Analele Univ. Constantin Brâncuşi Din Târgu Jiu Ser. Econ. 2018, 1, 5–12. [Google Scholar]
- Karimi, H.A. Big Data: Techniques and Technologies in Geoinformatics; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Armstrong, T.G.; Moffat, A.; Webber, W.; Zobel, J. Improvements that do not add up: Ad-hoc retrieval results since 1998. In Proceedings of the 18th ACM conference on Information and knowledge management, Hong Kong, China, 2–6 November 2009; pp. 601–610. [Google Scholar]
- Du, Y.; Berndtsson, R.; An, D.; Zhang, L.; Yuan, F.; Uvo, C.B.; Hao, Z. Multi-Space Seasonal Precipitation Prediction Model Applied to the Source Region of the Yangtze River, China. Water 2019, 11, 2440. [Google Scholar] [CrossRef]
- Lakshmaiah, K.; Krishna, S.M.; Reddy, B.E. Application of referential ensemble learning techniques to predict the density of rainfall. In Proceedings of the 2016 International Conference on Electrical, Electronics, Communication, Computer and Optimization Techniques (ICEECCOT), Mysuru, India, 9–10 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 233–237. [Google Scholar]
- Lee, J.; Kim, C.G.; Lee, J.E.; Kim, N.W.; Kim, H. Application of artificial neural networks to rainfall forecasting in the Geum River basin, Korea. Water 2018, 10, 1448. [Google Scholar] [CrossRef]
- Beheshti, Z.; Firouzi, M.; Shamsuddin, S.M.; Zibarzani, M.; Yusop, Z. A new rainfall forecasting model using the CAPSO algorithm and an artificial neural network. Neural Comput. Appl. 2016, 27, 2551–2565. [Google Scholar] [CrossRef]
- Duong, T.A.; Bui, M.D.; Rutschmann, P. A comparative study of three different models to predict monthly rainfall in Ca Mau, Vietnam. In Wasserbau-Symposium Graz 2018. Wasserwirtschaft–Innovation aus Tradition. Tagungsband. Beiträge Zum 19; Gemeinschafts-Symposium der Wasserbau-Institute TU München, TU Graz und ETH Zürich: Graz, Austria, 2018; p. Paper–G5. [Google Scholar]
- Gao, L.; Wei, F.; Yan, Z.; Ma, J.; Xia, J. A Study of Objective Prediction for Summer Precipitation Patterns Over Eastern China Based on a Multinomial Logistic Regression Model. Atmosphere 2019, 10, 213. [Google Scholar] [CrossRef]
- Mishra, N.; Kushwaha, A. Rainfall Prediction using Gaussian Process Regression Classifier. Int. J. Adv. Res. Comput. Eng. Technol. (IJARCET) 2019, 8. [Google Scholar]
- Aguasca-Colomo, R.; Castellanos-Nieves, D.; Méndez, M. Comparative analysis of rainfall prediction models using machine learning in islands with complex orography: Tenerife Island. Appl. Sci. 2019, 9, 4931. [Google Scholar] [CrossRef]
- Sulaiman, J.; Wahab, S.H. Heavy rainfall forecasting model using artificial neural network for flood prone area. In IT Convergence and Security 2017; Springer: Berlin/Heidelberg, Germany, 2018; pp. 68–76. [Google Scholar]
- Chhetri, M.; Kumar, S.; Pratim Roy, P.; Kim, B.G. Deep BLSTM-GRU Model for Monthly Rainfall Prediction: A Case Study of Simtokha, Bhutan. Remote Sens. 2020, 12, 3174. [Google Scholar] [CrossRef]
- Bojang, P.O.; Yang, T.C.; Pham, Q.B.; Yu, P.S. Linking Singular Spectrum Analysis and Machine Learning for Monthly Rainfall Forecasting. Appl. Sci. 2020, 10, 3224. [Google Scholar] [CrossRef]
- Canchala, T.; Alfonso-Morales, W.; Carvajal-Escobar, Y.; Cerón, W.L.; Caicedo-Bravo, E. Monthly Rainfall Anomalies Forecasting for Southwestern Colombia Using Artificial Neural Networks Approaches. Water 2020, 12, 2628. [Google Scholar] [CrossRef]
- Mehr, A.D.; Nourani, V.; Khosrowshahi, V.K.; Ghorbani, M.A. A hybrid support vector regression–firefly model for monthly rainfall forecasting. Int. J. Environ. Sci. Technol. 2019, 16, 335–346. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W.C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. arXiv 2015, arXiv:1506.04214. [Google Scholar]
- Manandhar, S.; Dev, S.; Lee, Y.H.; Meng, Y.S.; Winkler, S. A data-driven approach for accurate rainfall prediction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9323–9331. [Google Scholar] [CrossRef]
- Jing, J.; Li, Q.; Peng, X. MLC-LSTM: Exploiting the Spatiotemporal Correlation between Multi-Level Weather Radar Echoes for Echo Sequence Extrapolation. Sensors 2019, 19, 3988. [Google Scholar] [CrossRef]
- Sato, R.; Kashima, H.; Yamamoto, T. Short-term precipitation prediction with skip-connected prednet. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2018; pp. 373–382. [Google Scholar]
- Ayzel, G.; Heistermann, M.; Sorokin, A.; Nikitin, O.; Lukyanova, O. All convolutional neural networks for radar-based precipitation nowcasting. Procedia Comput. Sci. 2019, 150, 186–192. [Google Scholar] [CrossRef]
- Singh, S.; Sarkar, S.; Mitra, P. A deep learning based approach with adversarial regularization for Doppler weather radar ECHO prediction. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 5205–5208. [Google Scholar]
- Chen, L.; Cao, Y.; Ma, L.; Zhang, J. A Deep Learning Based Methodology for Precipitation Nowcasting with Radar. Earth Space Sci. 2020, 7, e2019EA000812. [Google Scholar] [CrossRef]
- Tran, Q.K.; Song, S.k. Computer vision in precipitation nowcasting: Applying image quality assessment metrics for training deep neural networks. Atmosphere 2019, 10, 244. [Google Scholar] [CrossRef]
- Shi, E.; Li, Q.; Gu, D.; Zhao, Z. Convolutional Neural Networks Applied on Weather Radar Echo Extrapolation. DEStech Trans. Comput. Sci. Eng. 2017. [Google Scholar] [CrossRef]
- Castro, R.; Souto, Y.M.; Ogasawara, E.; Porto, F.; Bezerra, E. STConvS2S: Spatiotemporal Convolutional Sequence to Sequence Network for weather forecasting. Neurocomputing 2020, 426, 285–298. [Google Scholar] [CrossRef]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Philip, S.Y. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms. Adv. Neural Inf. Process. Syst. 2017, 879–888. [Google Scholar]
- Tran, Q.K.; Song, S.k. Multi-Channel Weather Radar Echo Extrapolation with Convolutional Recurrent Neural Networks. Remote Sens. 2019, 11, 2303. [Google Scholar] [CrossRef]
- Zhang, P.; Jia, Y.; Gao, J.; Song, W.; Leung, H.K. Short-term rainfall forecasting using multi-layer perceptron. IEEE Trans. Big Data 2018, 6, 93–106. [Google Scholar] [CrossRef]
- Oswal, N. Predicting rainfall using machine learning techniques. arXiv 2019, arXiv:1910.13827. [Google Scholar]
- Balamurugan, M.; Manojkumar, R. Study of short term rain forecasting using machine learning based approach. Wirel. Netw. 2019, 1–6. [Google Scholar] [CrossRef]
- Nourani, V.; Uzelaltinbulat, S.; Sadikoglu, F.; Behfar, N. Artificial intelligence based ensemble modeling for multi-station prediction of precipitation. Atmosphere 2019, 10, 80. [Google Scholar] [CrossRef]
- Xu, L.; Chen, N.; Zhang, X.; Chen, Z. A data-driven multi-model ensemble for deterministic and probabilistic precipitation forecasting at seasonal scale. Clim. Dyn. 2020, 54, 1–20. [Google Scholar] [CrossRef]
- Mehdizadeh, S.; Behmanesh, J.; Khalili, K. New approaches for estimation of monthly rainfall based on GEP-ARCH and ANN-ARCH hybrid models. Water Resour. Manag. 2018, 32, 527–545. [Google Scholar] [CrossRef]
- Shenify, M.; Danesh, A.S.; Gocić, M.; Taher, R.S.; Wahab, A.W.A.; Gani, A.; Shamshirband, S.; Petković, D. Precipitation estimation using support vector machine with discrete wavelet transform. Water Resour. Manag. 2016, 30, 641–652. [Google Scholar] [CrossRef]
- Banadkooki, F.B.; Ehteram, M.; Ahmed, A.N.; Fai, C.M.; Afan, H.A.; Ridwam, W.M.; Sefelnasr, A.; El-Shafie, A. Precipitation forecasting using multilayer neural network and support vector machine optimization based on flow regime algorithm taking into account uncertainties of soft computing models. Sustainability 2019, 11, 6681. [Google Scholar] [CrossRef]
- Haidar, A.; Verma, B. Monthly rainfall forecasting using one-dimensional deep convolutional neural network. IEEE Access 2018, 6, 69053–69063. [Google Scholar] [CrossRef]
- Zhan, C.; Wu, F.; Wu, Z.; Chi, K.T. Daily Rainfall Data Construction and Application to Weather Prediction. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Hokkaido, Japan, 26–29 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Weesakul, U.; Kaewprapha, P.; Boonyuen, K.; Mark, O. Deep learning neural network: A machine learning approach for monthly rainfall forecast, case study in eastern region of Thailand. Eng. Appl. Sci. Res. 2018, 45, 203–211. [Google Scholar]
- Chattopadhyay, A.; Hassanzadeh, P.; Pasha, S. Predicting clustered weather patterns: A test case for applications of convolutional neural networks to spatio-temporal climate data. Sci. Rep. 2020, 10, 1–13. [Google Scholar] [CrossRef]
- Patel, M.; Patel, A.; Ghosh, D. Precipitation nowcasting: Leveraging bidirectional lstm and 1d cnn. arXiv 2018, arXiv:1810.10485. [Google Scholar]
- Zhuang, W.; Ding, W. Long-lead prediction of extreme precipitation cluster via a spatiotemporal convolutional neural network. In Proceedings of the 6th International Workshop on Climate Informatics: CI, Boulder, CO, USA, 22–23 September 2016. [Google Scholar]
- Boonyuen, K.; Kaewprapha, P.; Srivihok, P. Daily rainfall forecast model from satellite image using Convolution neural network. In Proceedings of the 2018 IEEE International Conference on Information Technology, Bhubaneswar, India, 19–21 December 2018; pp. 1–7. [Google Scholar]
- Boonyuen, K.; Kaewprapha, P.; Weesakul, U.; Srivihok, P. Convolutional Neural Network Inception-v3: A Machine Learning Approach for Leveling Short-Range Rainfall Forecast Model from Satellite Image. In International Conference on Swarm Intelligence; Springer: Berlin/Heidelberg, Germany, 2019; pp. 105–115. [Google Scholar]
- Hussein, E.A.; Thron, C.; Ghaziasgar, M.; Bagula, A.; Vaccari, M. Groundwater Prediction Using Machine-Learning Tools. Algorithms 2020, 13, 300. [Google Scholar] [CrossRef]
- Aswin, S.; Geetha, P.; Vinayakumar, R. Deep learning models for the prediction of rainfall. In Proceedings of the 2018 International Conference on Communication and Signal Processing (ICCSP), Tamilnadu, India, 3–5 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 0657–0661. [Google Scholar]
- Amiri, M.A.; Amerian, Y.; Mesgari, M.S. Spatial and temporal monthly precipitation forecasting using wavelet transform and neural networks, Qara-Qum catchment, Iran. Arab. J. Geosci. 2016, 9, 421. [Google Scholar] [CrossRef]
- Abbot, J.; Marohasy, J. Forecasting Monthly Rainfall in the Western Australian Wheat-Belt up to 18-Months in Advance Using Artificial Neural Networks. In Australasian Joint Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2016; pp. 71–87. [Google Scholar]
- Damavandi, H.G.; Shah, R. A Learning Framework for An Accurate Prediction of Rainfall Rates. arXiv 2019, arXiv:1901.05885. [Google Scholar]
- Abbot, J.; Marohasy, J. Application of artificial neural networks to forecasting monthly rainfall one year in advance for locations within the Murray Darling basin, Australia. Int. J. Sustain. Dev. Plan. 2017, 12, 1282–1298. [Google Scholar] [CrossRef]
- Mohamadi, S.; Ehteram, M.; El-Shafie, A. Accuracy enhancement for monthly evaporation predicting model utilizing evolutionary machine learning methods. Int. J. Environ. Sci. Technol. 2020, 17, 3373–3396. [Google Scholar] [CrossRef]
- Delleur, J.W.; Kavvas, M.L. Stochastic models for monthly rainfall forecasting and synthetic generation. J. Appl. Meteorol. 1978, 17, 1528–1536. [Google Scholar] [CrossRef]
- Barnett, A.G.; Baker, P.; Dobson, A. Analysing seasonal data. R J. 2012, 4, 5–10. [Google Scholar] [CrossRef][Green Version]
- Nielsen, A. Practical Time Series Analysis: Prediction with Statistics and Machine Learning; O’Reilly: Newton, MA, USA, 2020. [Google Scholar]
- Kumar, D.; Singh, A.; Samui, P.; Jha, R.K. Forecasting monthly precipitation using sequential modelling. Hydrol. Sci. J. 2019, 64, 690–700. [Google Scholar] [CrossRef]
- Ramsundram, N.; Sathya, S.; Karthikeyan, S. Comparison of decision tree based rainfall prediction model with data driven model considering climatic variables. Irrig. Drain. Syst. Eng. 2016. [Google Scholar] [CrossRef]
- Sardeshpande, K.D.; Thool, V.R. Rainfall Prediction: A Comparative Study of Neural Network Architectures. In Emerging Technologies in Data Mining and Information Security; Springer: Berlin/Heidelberg, Germany, 2019; pp. 19–28. [Google Scholar]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.Y.; Wong, W.k.; Woo, W.c. Deep learning for precipitation nowcasting: A benchmark and a new model. Adv. Neural Inf. Process. Syst. 2017, 5617–5627. [Google Scholar]
- McNally, A. FLDAS Noah Land Surface Model L4 Global Monthly 0.1 × 0.1 degree (MERRA-2 and CHIRPS). Atmos. Compos. Water Energy Cycles Clim. Var. 2018. [Google Scholar] [CrossRef]
- Loeser, C.; Rui, H.; Teng, W.L.; Ostrenga, D.M.; Wei, J.C.; Mcnally, A.L.; Jacob, J.P.; Meyer, D.J. Famine Early Warning Systems Network (FEWS NET) Land Data Assimilation System (LDAS) and Other Assimilated Hydrological Data at NASA GES DISC. In Proceedings of the 100th American Meteorological Society Annual Meeting, St. Boston, MA, USA, 12–16 January 2020. [Google Scholar]
- Nematchoua, M.K. A study on outdoor environment and climate change effects in Madagascar. J. Build. Sustain. 2017, 1, 12. [Google Scholar]
- Tadross, M.; Randriamarolaza, L.; Rabefitia, Z.; Zheng, K. Climate Change in Madagascar; Recent Past and Future; World Bank: Washington, DC, USA, 2008; Volume 18. [Google Scholar]
- Szabó, A.; Raveloson, A.; Székely, B. Landscape evolution and climate in Madagascar: Lavakization in the light of archive precipitation data. Cuad. Investig. GeogrÁFica/Geogr. Res. Lett. 2015, 41, 181–204. [Google Scholar] [CrossRef]
- Harvey, C.A.; Rakotobe, Z.L.; Rao, N.S.; Dave, R.; Razafimahatratra, H.; Rabarijohn, R.H.; Rajaofara, H.; MacKinnon, J.L. Extreme vulnerability of smallholder farmers to agricultural risks and climate change in Madagascar. Philos. Trans. R. Soc. B Biol. Sci. 2014, 369, 20130089. [Google Scholar] [CrossRef]
- Ingram, J.C.; Dawson, T.P. Climate change impacts and vegetation response on the island of Madagascar. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2005, 363, 55–59. [Google Scholar] [CrossRef]
- Sanchez-Pi, N.; Marti, L.; Abreu, A.; Bernard, O.; de Vargas, C.; Eveillard, D.; Maass, A.; Marquet, P.A.; Sainte-Marie, J.; Salomon, J.; et al. Artificial Intelligence, Machine Learning and Modeling for Understanding the Oceans and Climate Change. In NeurIPS 2020 Workshop-Tackling Climate Change with Machine Learning; 2020; Available online: https://hal.archives-ouvertes.fr/hal-03138712 (accessed on 19 April 2021).
- Stein, A.L. Artificial Intelligence and Climate Change. Yale J. Reg. 2020, 37, 890. [Google Scholar]
- Abudu, S.; Cui, C.; King, J.P.; Moreno, J.; Bawazir, A.S. Modeling of daily pan evaporation using partial least squares regression. Sci. China Technol. Sci. 2011, 54, 163–174. [Google Scholar] [CrossRef]
- Pinheiro, A.; Vidakovic, B. Estimating the square root of a density via compactly supported wavelets. Comput. Stat. Data Anal. 1997, 25, 399–415. [Google Scholar] [CrossRef]
- Qiu, M.; Zhao, P.; Zhang, K.; Huang, J.; Shi, X.; Wang, X.; Chu, W. A short-term rainfall prediction model using multi-task convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 395–404. [Google Scholar]
- Cramer, S.; Kampouridis, M.; Freitas, A.A.; Alexandridis, A.K. An extensive evaluation of seven machine learning methods for rainfall prediction in weather derivatives. Expert Syst. Appl. 2017, 85, 169–181. [Google Scholar] [CrossRef]
- Cao, Y.; Li, Q.; Shan, H.; Huang, Z.; Chen, L.; Ma, L.; Zhang, J. Precipitation Nowcasting with Star-Bridge Networks. arXiv 2019, arXiv:1907.08069. [Google Scholar]
- Klein, B.; Wolf, L.; Afek, Y. A dynamic convolutional layer for short range weather prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4840–4848. [Google Scholar]
- Mukhopadhyay, A.; Shukla, B.P.; Mukherjee, D.; Chanda, B. A novel neural network based meteorological image prediction from a given sequence of images. In Proceedings of the 2011 Second International Conference on Emerging Applications of Information Technology, Kolkata, India, 19–20 February 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 202–205. [Google Scholar]
- Vandekerckhove, J.; Matzke, D.; Wagenmakers, E.J. Model comparison and the principle of parsimony. In Oxford Handbook of Computational and Mathematical Psychology; Oxford University Press: Oxford, UK, 2015; pp. 300–319. [Google Scholar]
- Dash, Y.; Mishra, S.K.; Panigrahi, B.K. Rainfall prediction for the Kerala state of India using artificial intelligence approaches. Comput. Electr. Eng. 2018, 70, 66–73. [Google Scholar] [CrossRef]
- Purushotham, S.; Meng, C.; Che, Z.; Liu, Y. Benchmarking deep learning models on large healthcare datasets. J. Biomed. Inform. 2018, 83, 112–134. [Google Scholar] [CrossRef] [PubMed]
- Leming, M.; Górriz, J.M.; Suckling, J. Ensemble deep learning on large, mixed-site fMRI datasets in autism and other tasks. arXiv 2020, arXiv:2002.07874. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.W.; Lin, X. Big data deep learning: Challenges and perspectives. IEEE Access 2014, 2, 514–525. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, L.T.; Chen, Z.; Li, P. A survey on deep learning for big data. Inf. Fusion 2018, 42, 146–157. [Google Scholar] [CrossRef]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API Design for machine learning software: Experiences from the scikit-learn project. arXiv 2013, arXiv:1309.0238. [Google Scholar]
- Stigler, S.M. Studies in the History of Probability and Statistics. XXXII: Laplace, Fisher, and the discovery of the concept of sufficiency. Biometrika 1973, 60, 439–445. [Google Scholar] [CrossRef]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Brassington, G. Mean absolute error and root mean square error: Which is the better metric for assessing model performance? Egu Gen. Assem. Conf. Abstr. 2017, 19, 3574. [Google Scholar]
- Efron, B.; Stein, C. The jackknife estimate of variance. Ann. Stat. 1981, 9, 586–596. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | Value |
|---|---|
| Latitude Extent | – S |
| Longitude Extent | – E |
| Spatial Resolution | |
| Temporal Resolution | Monthly |
| Temporal Coverage | January 1982 to December 2000 |
| Dimension (lat × lon) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hussein, E.A.; Ghaziasgar, M.; Thron, C.; Vaccari, M.; Bagula, A. Basic Statistical Estimation Outperforms Machine Learning in Monthly Prediction of Seasonal Climatic Parameters. Atmosphere 2021, 12, 539. https://doi.org/10.3390/atmos12050539
Hussein EA, Ghaziasgar M, Thron C, Vaccari M, Bagula A. Basic Statistical Estimation Outperforms Machine Learning in Monthly Prediction of Seasonal Climatic Parameters. Atmosphere. 2021; 12(5):539. https://doi.org/10.3390/atmos12050539
Chicago/Turabian StyleHussein, Eslam A., Mehrdad Ghaziasgar, Christopher Thron, Mattia Vaccari, and Antoine Bagula. 2021. "Basic Statistical Estimation Outperforms Machine Learning in Monthly Prediction of Seasonal Climatic Parameters" Atmosphere 12, no. 5: 539. https://doi.org/10.3390/atmos12050539
APA StyleHussein, E. A., Ghaziasgar, M., Thron, C., Vaccari, M., & Bagula, A. (2021). Basic Statistical Estimation Outperforms Machine Learning in Monthly Prediction of Seasonal Climatic Parameters. Atmosphere, 12(5), 539. https://doi.org/10.3390/atmos12050539