1. Introduction
Water vapor is a minor constituent of the Earth’s atmosphere and is mainly distributed in the lower atmosphere. Although it occupies a small portion of the atmosphere’s mass, it plays key roles in weather and climate systems due to the changeability of its content [
1,
2,
3]. Traditional techniques for detecting water vapor include water vapor radiometry, radiosonde and satellite remote sensing, but they cannot satisfy the demands of developing meteorological applications in an increasing trend due to their respective limited resolutions. The technique for sensing water vapor with the Global Navigation Satellite System (GNSS) benefits from its low cost, high precision, high spatiotemporal resolution and all-weather operation, etc. It has become more attractive than traditional techniques as a result of its advantages [
4,
5,
6]. The precipitable water vapor (PWV) value derived from GNSS, which refers to the depth of water in a column of the atmosphere if all the water vapor in the column condenses into liquid water, has been in widespread use in many fields, such as in research on climate change, weather forecasting and the monitoring of extreme weather events [
3,
7,
8,
9,
10,
11,
12].
Water vapor is partly responsible for the delay when the electromagnetic signal emitted from a navigation satellite travels through the neutral atmosphere. The delay created by water vapor measured along the zenith direction is known as zenith wet delay (ZWD) [
13]. Thus, there should be some connection between ZWD and PWV. Askne et al. [
14] concretized this connection and derived the conversion formula between ZWD and PWV: once the ZWD is estimated from GNSS measurements, the PWV can be calculated by multiplying ZWD with a conversion factor
.
is a nonlinear function of the weighted mean temperature (
) and can be calculated by integrating the water vapor pressure and absolute temperature of each height level along the zenith direction [
15]. Therefore, the key to deriving accurate PWV from GNSS measurements is to obtain an accurate
.
The atmospheric profiles measured by sounding balloons released from radiosonde stations give the closest results to the actual situation; thus,
calculated by numerical integration from these balloons should be the most accurate, but they are rarely applied in actual GNSS–ZWD and PWV conversion due to the sparse distribution of radiosonde stations and poor temporal resolution of observation data [
4,
16]. The products from numerical weather prediction (NWP) models generally have higher spatiotemporal resolutions, such as reanalysis data from the European Center for Medium-Range Weather Forecasts (ECMWF) and the America National Centers for Environmental Prediction (NCEP), but they are typically updated with some time delay on the web and thus cannot be applied to real-time or even near-real-time
estimation [
17,
18]. Therefore, an empirical
model with good performance could help to enhance the utility and efficiency of obtaining
, thus enabling real-time conversion from ZWD to PWV in GNSS meteorology.
Many empirical
models have been developed in recent years. These models can be broadly divided into two categories according to their application conditions and modeling principles. One is called as the surface meteorological factor (SMF) model, which represents a series of models developed based upon the relations between
and surface meteorological elements (e.g., surface temperature
, pressure
and water vapor pressure
). Measured surface meteorological elements are required to calculate
with SMF models. The most typical and widely used SMF model is the Bevis model, which is established based upon the approximate linearity between
and
[
19]. The other category is the non-meteorological factor (NMF) model, which refers to models established according only to the spatiotemporal variation characteristics of
, such as the Global Weighted Mean Temperature (GWMT) model [
20], Global Pressure and Temperature 2 wet (GPT2w) model [
21], Global Weighted Mean Temperature-Diurnal (GWMT-D) model [
22], Global Tropospheric Model (GTrop) model [
23], Hourly Global Pressure and Temperature (HGPT) model [
24] and GTm_R [
25] model etc. The Earth’s surface is usually divided into a series of grids according to latitude and longitude in the development of NMF models, and a trigonometric function is used to simulate the periodic variation characteristics of
over each single grid. The input variables of NMF models are usually the geographic coordinates of a specific location and the day of year (
); sometimes the hour of day (
) is included, but no meteorological element is required as an input when calculating
with NMF models. However, many studies have shown that the
values derived from NMF models were usually less accurate than those from SMF models [
17,
23,
26]. In reality, surface or near-to-surface meteorological elements at a specific location are not difficult to measure.
Bevis et al. [
19] first specified the formula for calculating
as
with 8718 radiosonde profiles of 13 stations distributed in North America. However, it was found that the coefficients of the Bevis formula vary with the geographical location and season [
27,
28,
29], so it is necessary to estimate the coefficients through measurements in a specific region and period of time. Li et al. [
29] established regional
models for the Hunan region, China, including models with one meteorological factor (
–
), two meteorological factors (
–
) and three meteorological factors (
–
). It was found that the two-meteorological-factor model and three-meteorological-factor model performed similarly, and they both outperformed the one-meteorological-factor model. Yao et al. [
26] established a one-meteorological-factor model (GTm) and a multi-meteorological-factor model (PTm) with data from 135 radiosonde stations distributed globally; the results showed that the PTm model was about 0.5 K better than the GTm model in terms of the root-mean-square error. They further took the seasonal and geographic variation characteristics of the
–
and
–
relations into account to develop the GTm-I model and PTm-I model, the accuracy of which were greatly improved compared with the GTm model and PTm model, respectively, on a global scale. Jiang et al. [
28] developed a time-varying grid global
–
model (TVGG) considering the significant spatiotemporal variation characteristics of the
–
relation. However, the relations between
and surface meteorological elements are very complex [
30] and are difficult to simulate sufficiently with a simple linear equation. Ding [
17] first tried the neural network technique to develop the first-generation neural network-based
(NN-I) model for global users, but this required the
estimates of the GPT2w model (an excellent empirical model for estimating slant delays as well as other meteorological elements in the troposphere) and measured
as inputs. NN-I model shows excellent performance for predicting
values on a global scale, but its accuracy in a specific region has yet to be verified.
Most of the published
models that consider the geographic and seasonal variation of relations between
and surface meteorological elements are designed for global users. There is still a lack of
models designed for users in China. China has a vast territory with complex terrain and diverse climate system, but the distribution of radiosonde stations is limited and extremely uneven, so
models with good performance are urgently needed to carry out nationwide GNSS water vapor remote sensing. In this study, we took into account the geographic and seasonal variation characteristics of
, as well as the relations between
and surface meteorological elements (
,
), and adopted the neural network technique to develop
models applicable to China and adjacent areas. The definition of
and methods for determining
values are introduced in
Section 2, the modeling process of new models are presented in
Section 3, their generalization performances are discussed in
Section 4, and the accuracies of new models compared with several representative published models are presented in
Section 5.
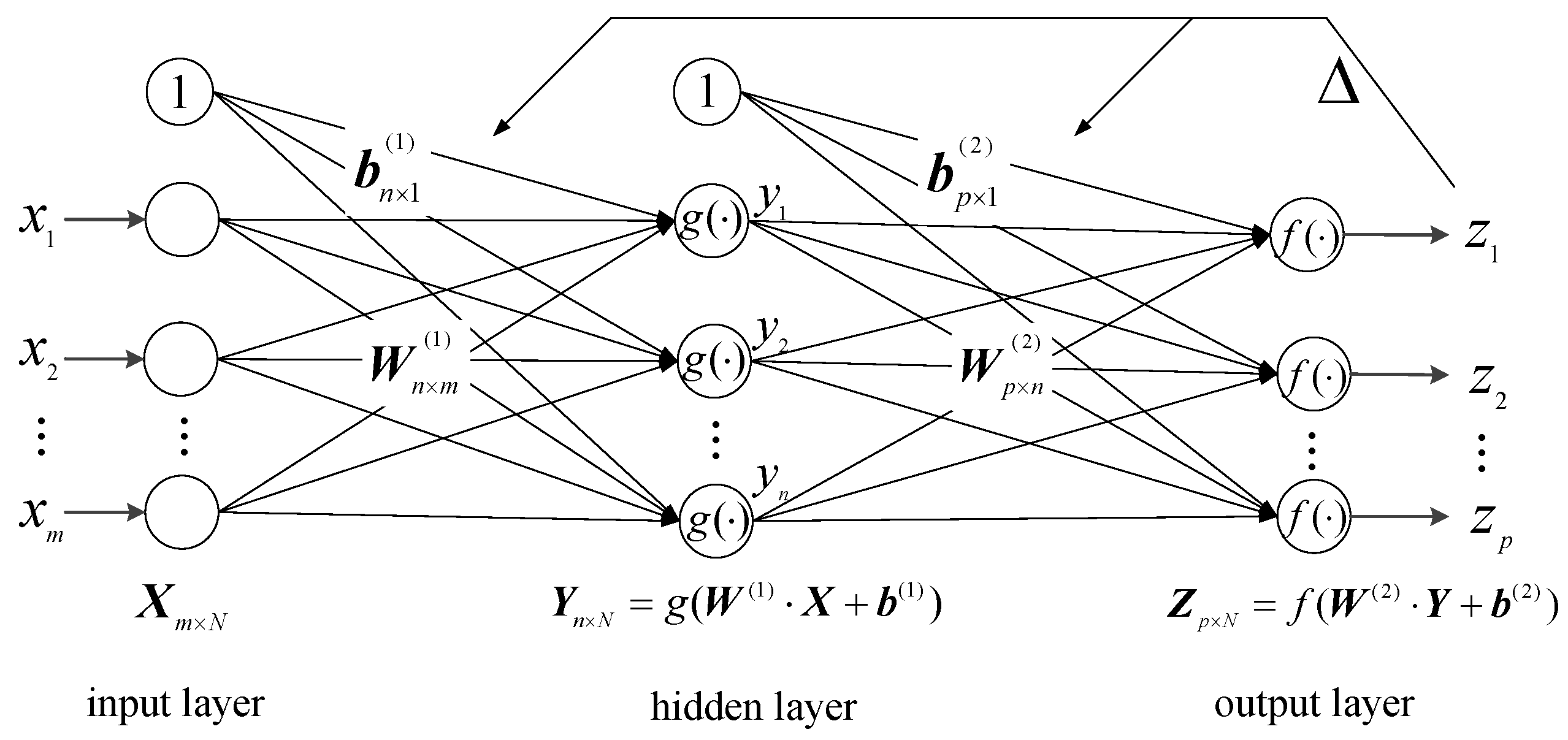
4. The Generalization Performance of New Models
The generalization performance is very important for a neural network model when it is used for prediction. On the one hand, the optimal structure of a TFNN is usually determined after a series of sensitivity tests, since the number of neurons in the hidden layer (
) would affect the generalization performance of the TFNN regressing model; on the other hand, the interannual or interdecadal variation tendency of
may result in deviation when calculating
with new models as the datasets for modeling in this study ran from 2001 to 2013. Therefore, the generalization performances of new models are discussed in this section. The mean bias error (MBE) and root-mean-square error (RMSE) were used to evaluate model accuracy.
where
and
are the
values measured by radiosounding and
values calculated with
models, respectively.
4.1. The Generalization Performance of TFNNs
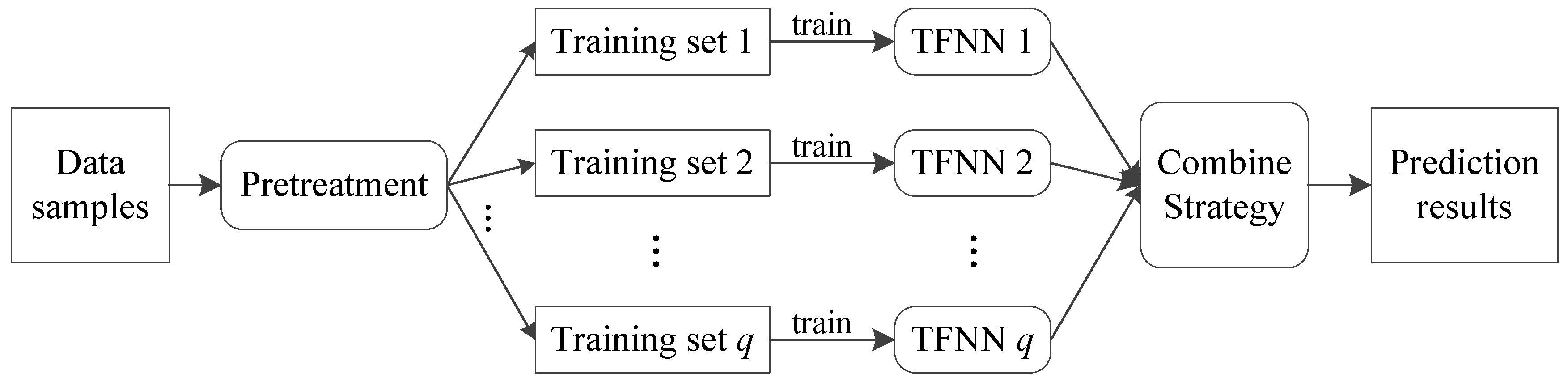
As the initial weight and bias values of the TFNN are usually randomly generated at the beginning of training, the weight and bias values of a TFNN model adjusted after training are often inconsistent, even if they are trained with the same training samples. Thus, each TFNN structure was trained repeatedly; the training samples were re-sampled and the initial weight and bias values were re-assigned at the beginning of each training mission. A total of 300,000 samples were randomly selected, and they were divided into three parts: 70% for training, 15% for cross-validation and 15% for testing in each training mission.
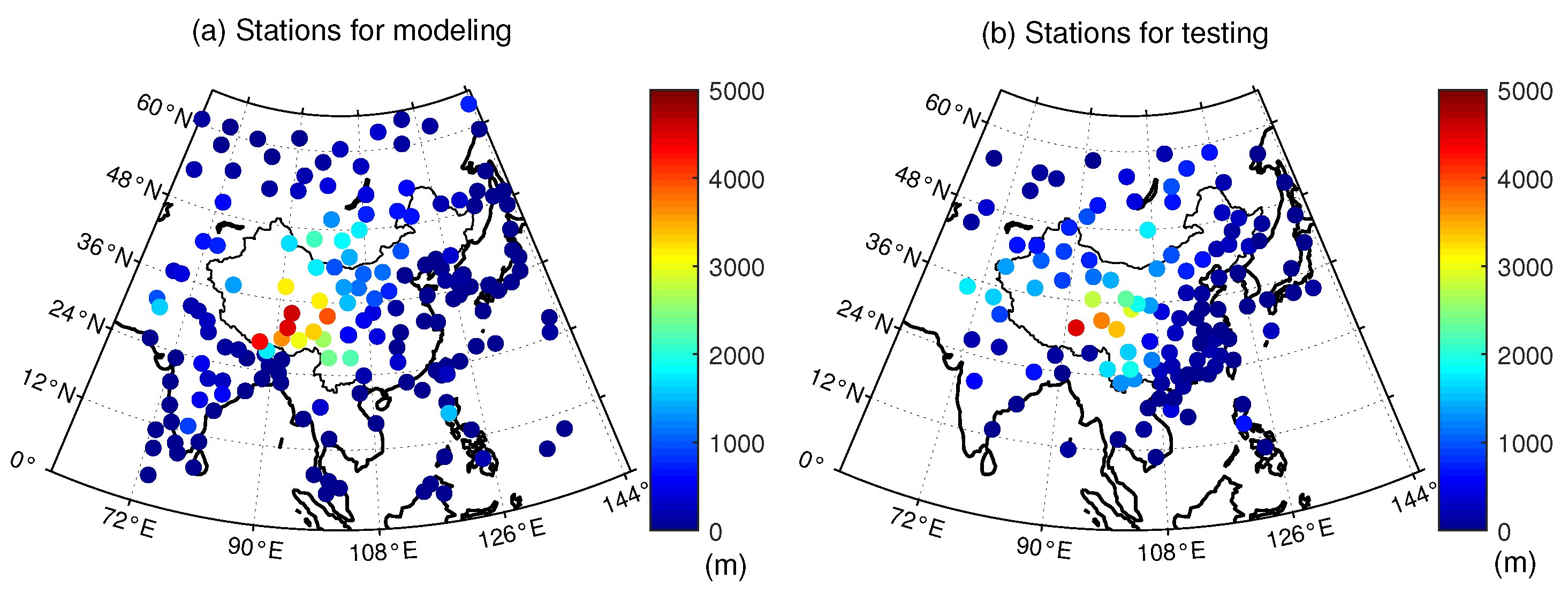
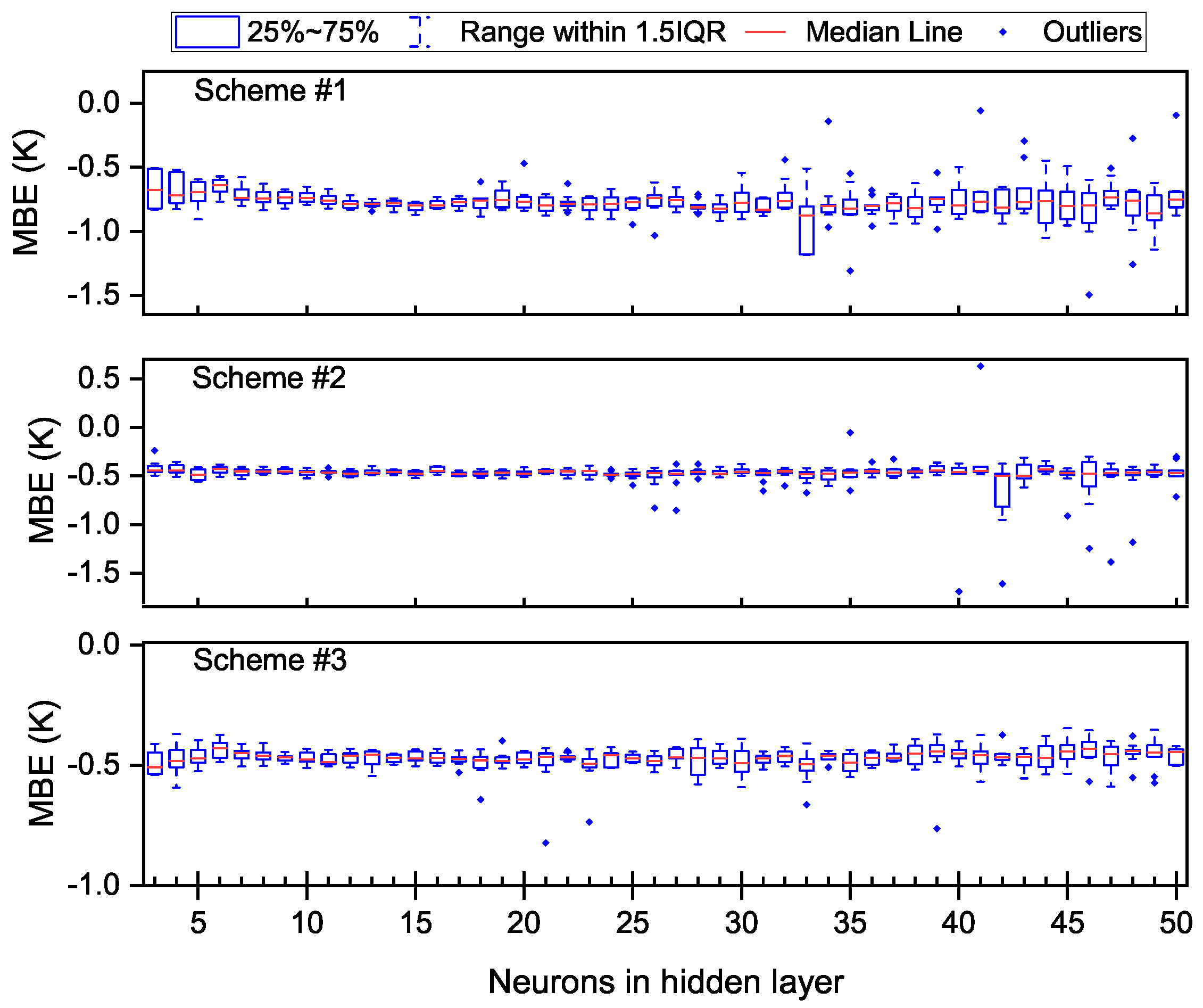
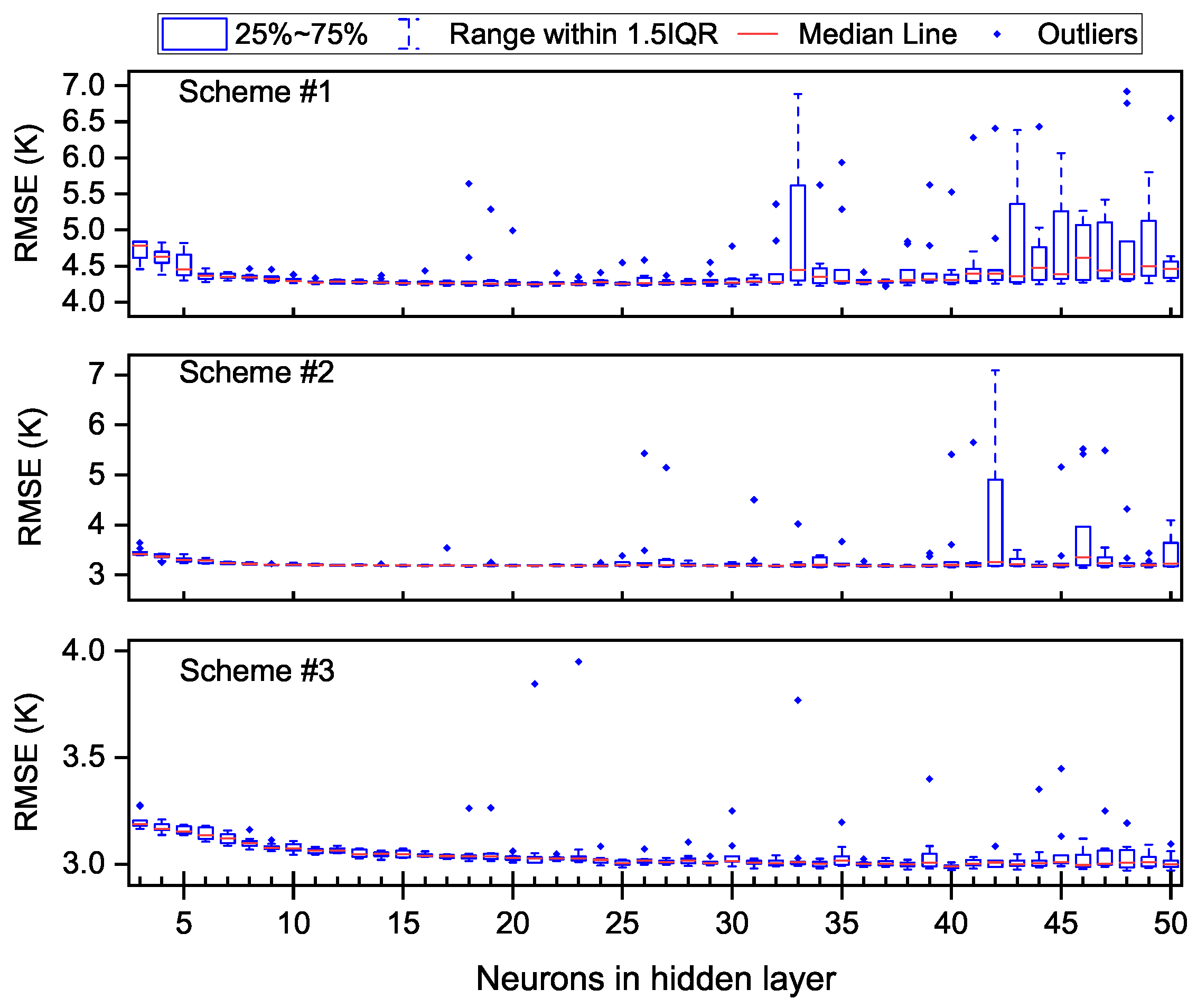
A series of training missions (10 times for each TFNN structure) were carried out, and their generalization performances were discussed. The accuracy of each training mission was evaluated with a total of 113,866 atmospheric profiles measured from 2014 to 2015 at 119 radionsonde stations (see
Figure 3); the MBEs and RMSEs of each modeling scheme are shown in
Figure 4 and
Figure 5.
From
Figure 4 and
Figure 5, one can see that the fluctuation of MBEs and RMSEs increased with the increasing number of neurons in the hidden layer. In terms of MBEs, the MBEs of different TFNN structures were almost always less than 0 K; the reason for this may be that the dataset for modeling ran from 2001 to 2013 but the interannual variation of
was not taken into account. Outliers could be found for all of the three modeling schemes when
was larger than 16; in particular, scheme #1 and scheme #2 had outliers larger than 0 K when the
was larger than 40. Larger negative biases are also common in all modeling schemes when there are more neurons. In the aspect of RMSEs, the largest RMSE of each modeling scheme even reached 7.0 K, 6.5 K and 4.0 K, respectively, while the minimum RMSE always remained at a low level regardless of the neural network structure. Another phenomenon regarding RMSE was that when
was smaller than 10, the RMSE decreased as the
increased, especially for scheme #1 and scheme #3.
Such large differences in model accuracy between different TFNNs made it risky to choose a specific training result as the final parameter of a model; the overall negative biases of most TFNNs in the estimation of also negatively impacted the utility of the model. Therefore, some measures should be taken into account to improve the generalization performance of TFNN models and eliminate the bias in estimation caused by the interannual variation of .
4.2. Strengthening the Generalization Performance of TFNN Models with Ensemble Learning
The training samples of each training mission (which overlapped with each other) and the initial weights were different, and thus the performance of each TFNN was different. If only one individual TFNN were used as the final model, that might lead to poor generalization performance due to poor selection; combining multiple TFNNs is expected to effectively reduce this risk. As the training missions were independent of each other, we adopted the simple averaging method to combine the individual TFNNs, as follows:
where
is the
value calculated by the
k-th TFNN. However, some experiments were required to determine the optimal ensemble size (
) to ensure the generalization performance of models after combination. From the perspective of bias-variance decomposition, ensemble learning (bagging, for example) mainly focuses on reducing variance, so attention was mainly paid to the RMSEs of models with different ensemble sizes.
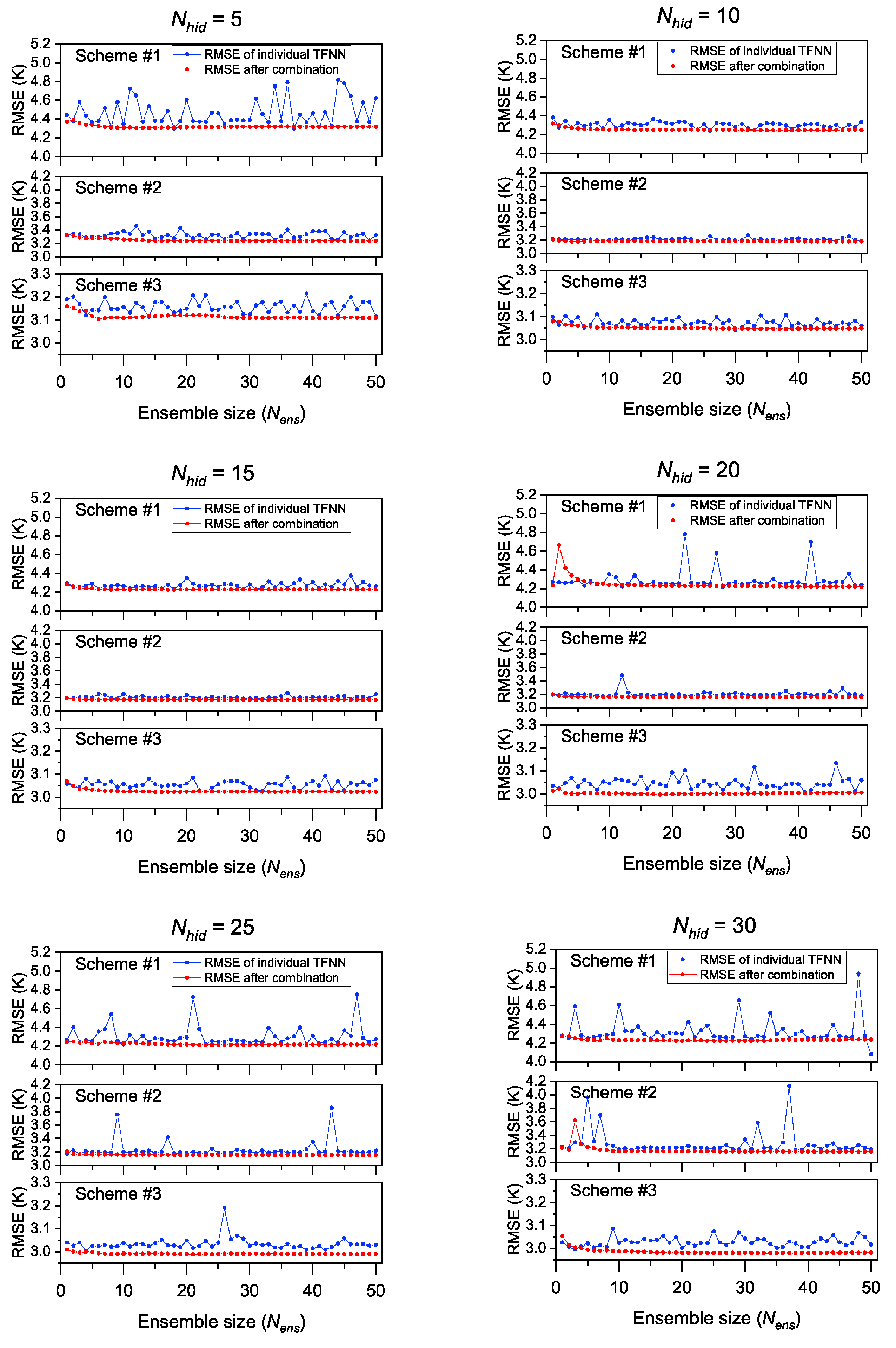
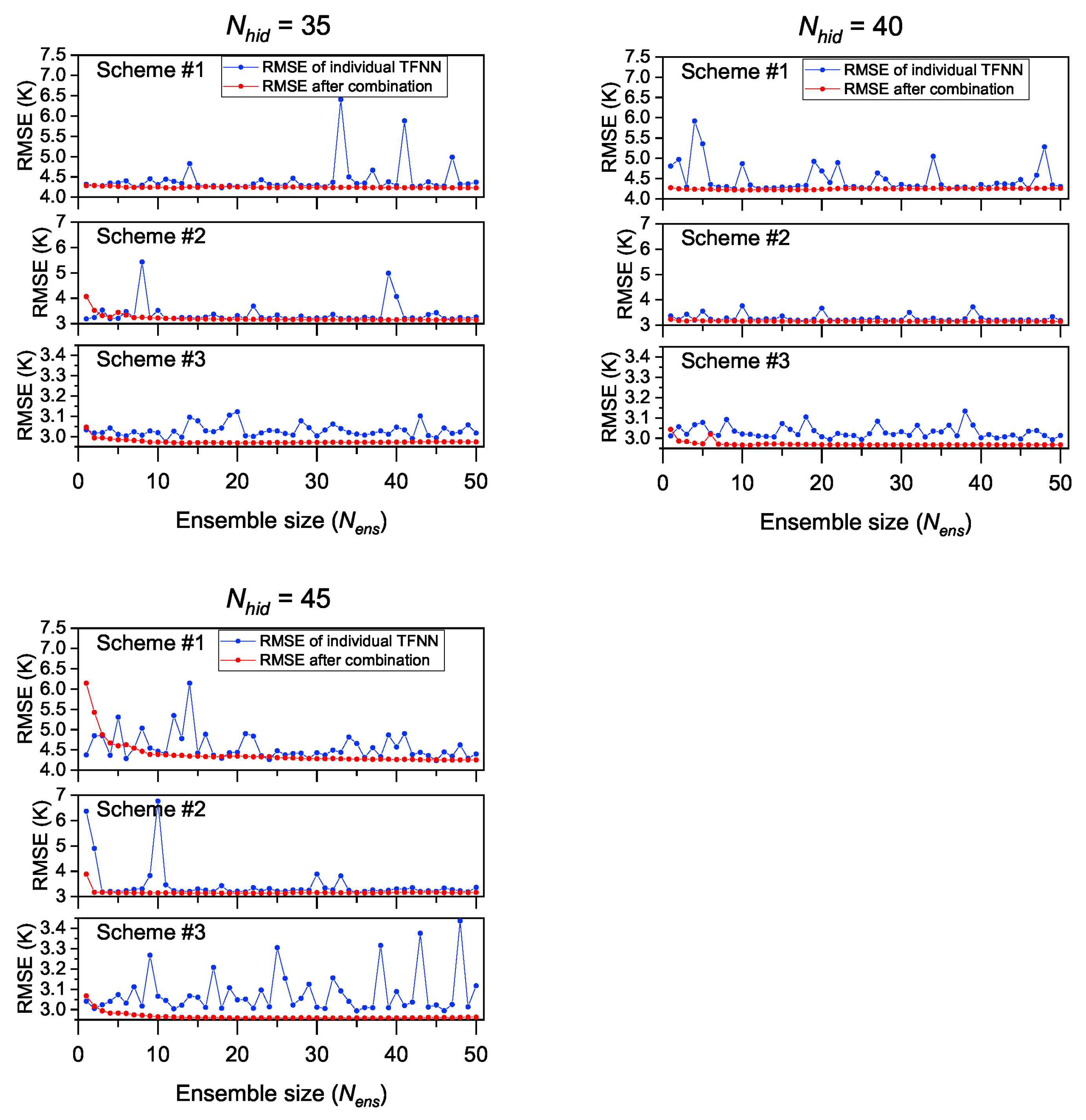
Figure 6 and
Figure 7 show the RMSEs of models with different ensemble size (
) when
.
As can be seen from
Figure 6 and
Figure 7, the generalization performances of different TFNNs were quite different from each other, especially when there were more neurons in the hidden layer, which is consistent with the results verified in
Section 4.1. However, general improvements in RMSE were found for each modeling scheme when we combined multiple individual TFNNs; the accuracy of the results after combination showed remarkable improvement compared with individual TFNNs in most cases.
From the perspective of each modeling scheme, there was no obvious abnormal RMSE for scheme #1 when the
was 10 or 15, and the RMSE values were generally between 4.2 K and 4.4 K, but great fluctuations could be found when
was larger than 20, with the maximal RMSE even reaching 4.9 K to 6.5 K when the
was between 20 and 45. When
was 5, the fluctuation of RMSE was also obvious, ranging from 4.3 K to 4.8 K. However, the uncertainties in
calculation disappeared after combination, even when the
was larger than 20. Regarding scheme #2, a similar situation to scheme #1 can be observed, in that the RMSEs were between 3.20 K and 3.25 K when the
was 10 or 15, but larger RMSEs were shown when the
was larger than 20; particularly large RMSE values could be found when
was 35 or 45, with maximal values of 5.5 K and 6.8 K, respectively. When the
was 5, the fluctuation of RMSEs was not drastic, but their values were larger than those in case of
= 10. The improvement of the generalization performance of scheme #2 using ensemble learning was also significant, especially when
was larger than 20. However, scheme #3 performed differently to scheme #1 and scheme #2. Only when
was very large (for example,
= 45) did the abnormal RMSEs increase significantly. In other times, the differences of RMSEs between individual TFNNs was not obvious, fluctuating by approximate 0.1 K. By combining different TFNNs, the influence of TFNN with poor generalization performance on
calculation was also effectively eliminated. We can also see from
Figure 6 and
Figure 7 that the ensemble size did not need to be set to be overly large: a
of about 10 could achieve the effect of improving the generalization performance of the TFNN models.
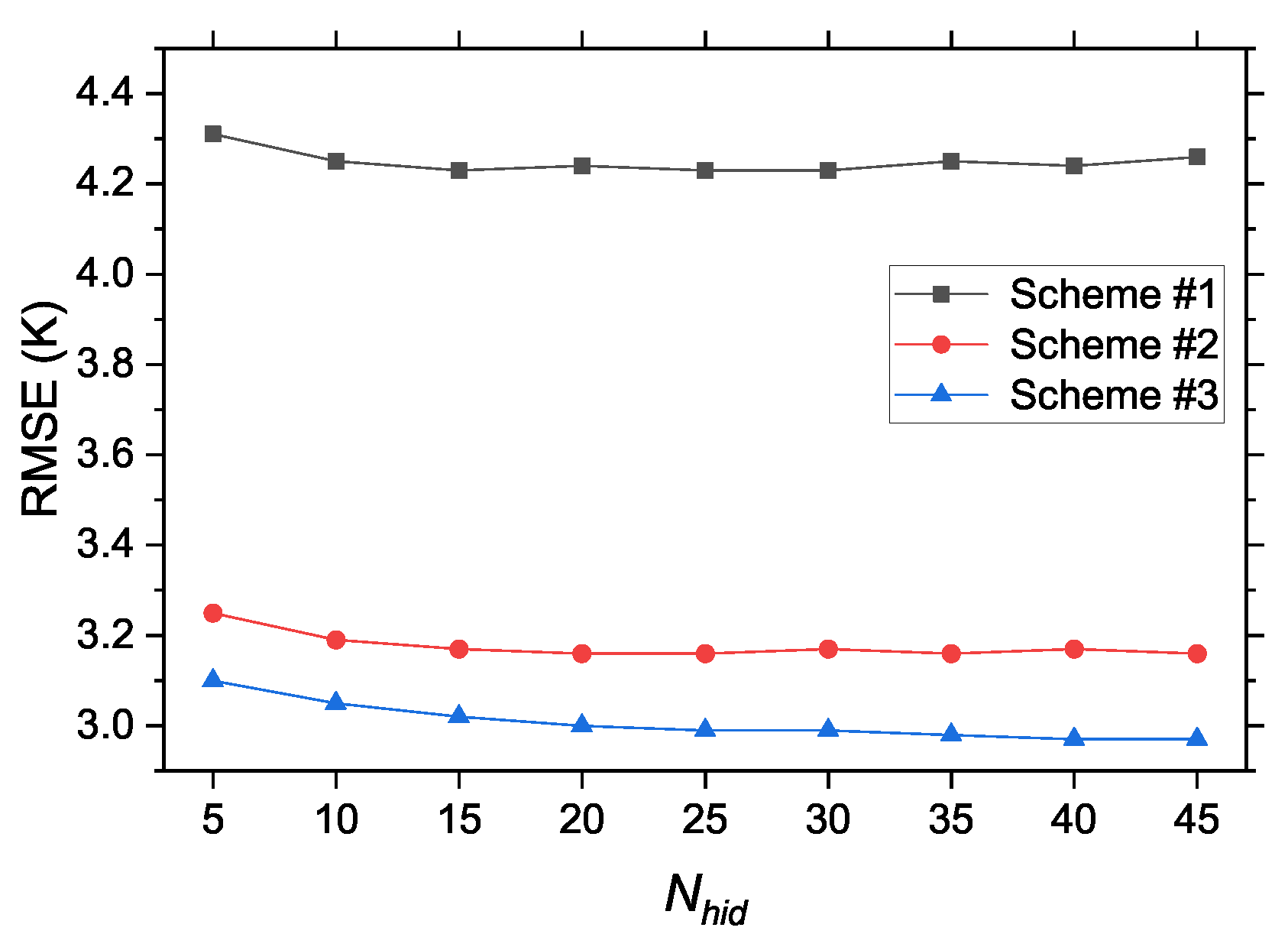
In general, the generalization performances of individual TFNNs fluctuated, and with the increase of
, the generalization performance changed drastically. The uncertainty of the generalization performance could be significantly reduced by combining different TFNNs, but a balance should be struck between improving model accuracy and reducing uncertainty risk. We compared the combination results of different modeling schemes when the number of neurons in the hidden layer was 5 to 45; the results are shown in
Figure 8.
One can see from
Figure 8 that the RMSE of each modeling scheme after combination decreased with the increasing
, but the improvement in model accuracy was not significant when the
was large; e.g., it only improved by approximately 0.05 K for scheme #1, 0.1 K for scheme #2 and 0.15 K for scheme #3 when
ranged from 5 to 45. This improvement was insignificant, but a risk of overfitting may occur due to the increasing complexity of the neural network structure. From the analysis of
Figure 6 and
Figure 7, little difference can be seen in terms of the generalization performance if different individual TFNNs when
was 10 or 15, and the accuracy of results after combination was only slightly poorer than when there were more neurons in the hidden layer.
4.3. The Impact of Interannual Variations of
The interannual variation trend of
has been demonstrated in many previous studies [
4,
23,
36,
42]. It has been shown in the literature [
42] that
has an increasing trend over the long term on a global scale and increases by about 0.24 K per decade in the north temperate zone, while the radiosonde stations used for modeling in this study are mainly distributed at latitudes between
N and
N. It is necessary to discuss the biases of new models caused by long-term trends of
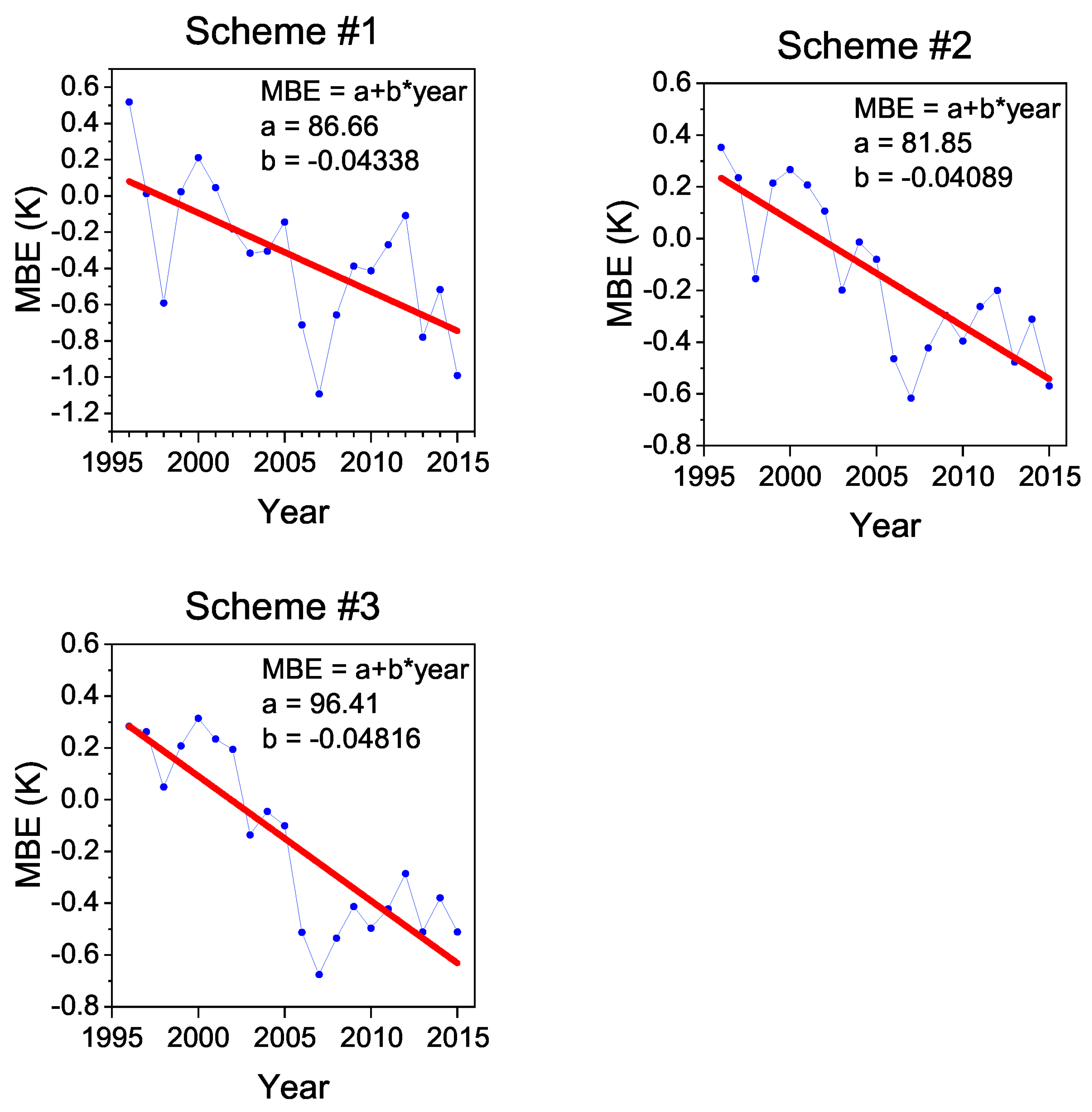
, since the data for modeling in this study were all from 2001 to 2013. The yearly biases of the three modeling schemes from 1996 to 2015 are shown in
Figure 9.
From
Figure 9, an approximately linear trend in bias can be found for all the modeling schemes: their decline rates are −0.043 K/year, −0.041 K/year and −0.048 K/year, respectively. There is an obvious decreasing trend in
biases calculated with neural network models, which presents a challenge for the generalization performance of new models.
However, the neural networks are actually much better at interpolation than extrapolation; thus, the
was considered to be one of the input variables to simulate the periodic variation characteristics of
within the year, but parameters of interannual variation of
were not included in new models. The negative bias of
estimation caused by long-term trends of
cannot be ignored, so an external correction to new models was considered in this study:
where
is the
value calculated by an individual TFNN,
is the ensemble size and
a and
b are the correction parameters for interannual bias, which can be seen in
Figure 9.
4.4. Discussion
The ANN technique shows a powerful capability to capture the spatiotemporal variation characteristics of in this study. In this section, thousands of experiments showed that the robustness of TFNN models was good enough, but uncertain risks in model accuracy were shown when the model was validated with data that were not involved in modeling, which is expressed as the generalization performance of TFNN fluctuating drastically when its structure changes. In previous studies, some researchers tried to demonstrate the feasibility of the neural network technique in modeling, but they only used the results of a certain training mission as the final model parameter; the generalization performance of these models were not sufficiently considered, and the models probably incur great uncertainty risks when they are put to actual use. The ensemble learning method was proposed in this study to make up for this defect, and the test results showed that the generalization performance of new models was effectively enhanced. Moreover, the significant negative bias in the estimation with new models caused by the interannual variation of cannot be ignored, and thus an external correction was made to the results of TFNN models after combination.
We set the ensemble size of TFNN models as 10 and the number of hidden layer neurons as 10 or 15 and made a simple external correction to the results after combination. The three models developed in this study are named the NMFTm model (corresponding to modeling scheme #1; no meteorological factor is required), SMFTm model (corresponding to modeling scheme #2; a single meteorological factor is needed) and MMFTm model (corresponding to modeling scheme #3; multiple meteorological factors are needed), respectively, and were able to meet the requirements of calculation under different application conditions.
5. Model Accuracies Compared with Other Published Models
In order to examine the accuracies of new models, comparisons between new models and several representative published models are presented in this section. These models are the GTm_R model, Bevis model, TVGG model, NN-I model and GTm-I/PTm-I model. There are some differences in the calculation of with these models:
No meteorological factor is required for the GTm_R model and NMFTm model;
Only is required for the Bevis model, GTm-I model, TVGG model and SMFTm model;
Both and are necessary for the PTm-I model and MMFTm model.
Measured profiles of 119 radiosonde stations were utilized, and the mean bias error (MBE) and root-mean-square error (RMSE) were used to evaluate the model accuracy. The values of the new models corresponding to the results presented in this section were all 10.
5.1. Accuracies for All Testing Samples from 2016 to 2018
We first tested the performance of different models with a total of 191,812 radiosonde profiles measured from 2016 to 2018, as with the data used in
Section 4; these data were also independently and identically distributed to the dataset for modeling. The MBE and RMSE for different models are shown in
Table 3; the MBE and RMSE of each station (named as S_MBE and S_RMSE) are also calculated and their respective mean values (named as MS_MBE and MS_RMSE) are shown in
Table 3.
From
Table 3, one can see that the GTm_R model, TVGG model and GTm-I/PTm-I model showed much larger biases (both in MBE and MS_MBE) than the Bevis model, NN-I model and new models. The reason for this is that the GTm_R model, TVGG model and GTm-I/PTm-I model were all developed using reanalysis data (ERA-Interim), while the others were developed using data collected by radiosounding. As mentioned in
Section 2.2, data collected via radiosounding are closest to the actual situation and undoubtedly the most appropriate dataset for developing a regional
model that is close to reality. The Bevis model is a classic
model, and its bias is the smallest of all the published models. The biases of the SMFTm model and MMFTm model with enhanced generalization capability were much better than the NN-I model in terms of MBE and MS_MBE. The NMFTm model showed the largest bias of the new models, but great improvement can be seen compared with the GTm_R model. It is worth mentioning that the published models listed in this study were all developed with historical datasets, but the interannual or interdecadal variation tendency of
was not taken into account; this may be another important reason for the large negative biases of these models when verified with the data from 2016 to 2018.
In terms of RMSE, larger RMSEs can be seen for the GTm_R model and Bevis model. GTm-I model performed a little better because it is a grid model and combines the modeling ideas of the GTm_R model and the Bevis model; that is, the Bevis formula is first used for modeling and then the annual and semi-annual variation characteristics of residuals caused by the Bevis formula are simulated. The performance of the PTm-I model improved by 9% in RMSE (0.4 K) compared to the GTm-I model as the surface water vapor pressure was taken into account in the development of the PTm-I model; it can be seen that the introduction of water vapor pressure into modeling is very beneficial to the improvement of model accuracy. The TVGG model follows a similar modeling approach to the GTm-I model, but it is further optimized; that is, the coefficients of the Bevis formula at each grid are calculated rather than regressing on a global scale, and the resulting residuals are finally simulated with a trigonometric function. An improvement of approximately 9% (0.3 K) in RMSE could be found for the TVGG model compared to the GTm-I model; thus, we only consider TVGG model in the following analysis since their modeling principles are basically the same.
The NN-I model uses the the coefficients of the GPT2w model to describe the periodic variations of
and uses neural network as modeling tool, and it showed the best accuracy on a global scale of all the published models listed in this study; it can also be seen from
Table 3 that its RMSE (MS_RMSE) within the study area was far smaller than the other published models. However, the NN-I model also has drawbacks; i.e., it relies on the
values derived from the GPT2w model and it is developed for global users, but only one set of weight and bias values after a certain training mission is provided, and its accuracy in a specific region has not been verified yet. The complexity of the model can be reduced and the generalization performance can be strengthened by optimizing the modeling process. The new models were all developed based upon the dataset within the study area, and their generalization performances were strengthened via the ensemble learning method. It can be seen from
Table 3 that the RMSE of the SMFTm model was 9.3% better than the NN-I model, and when we further incorporated the water vapor pressure into modeling, the MMFTm model outperformed the NN-I model by 14.5% in terms of RMSE, and the improvement in accuracy of the MMFTm model compared with SMFTm model was also quite obvious (0.18 K for RMSE and 0.16 K for MS_RMSE). Although the accuracy of the NMFTm model was not greatly improved compared with the GTm_R model (they both correspond to the category of NMF models), it has the advantage of being simple and universal for the users within the study area.
5.2. Accuracies Tested by Single Testing Stations
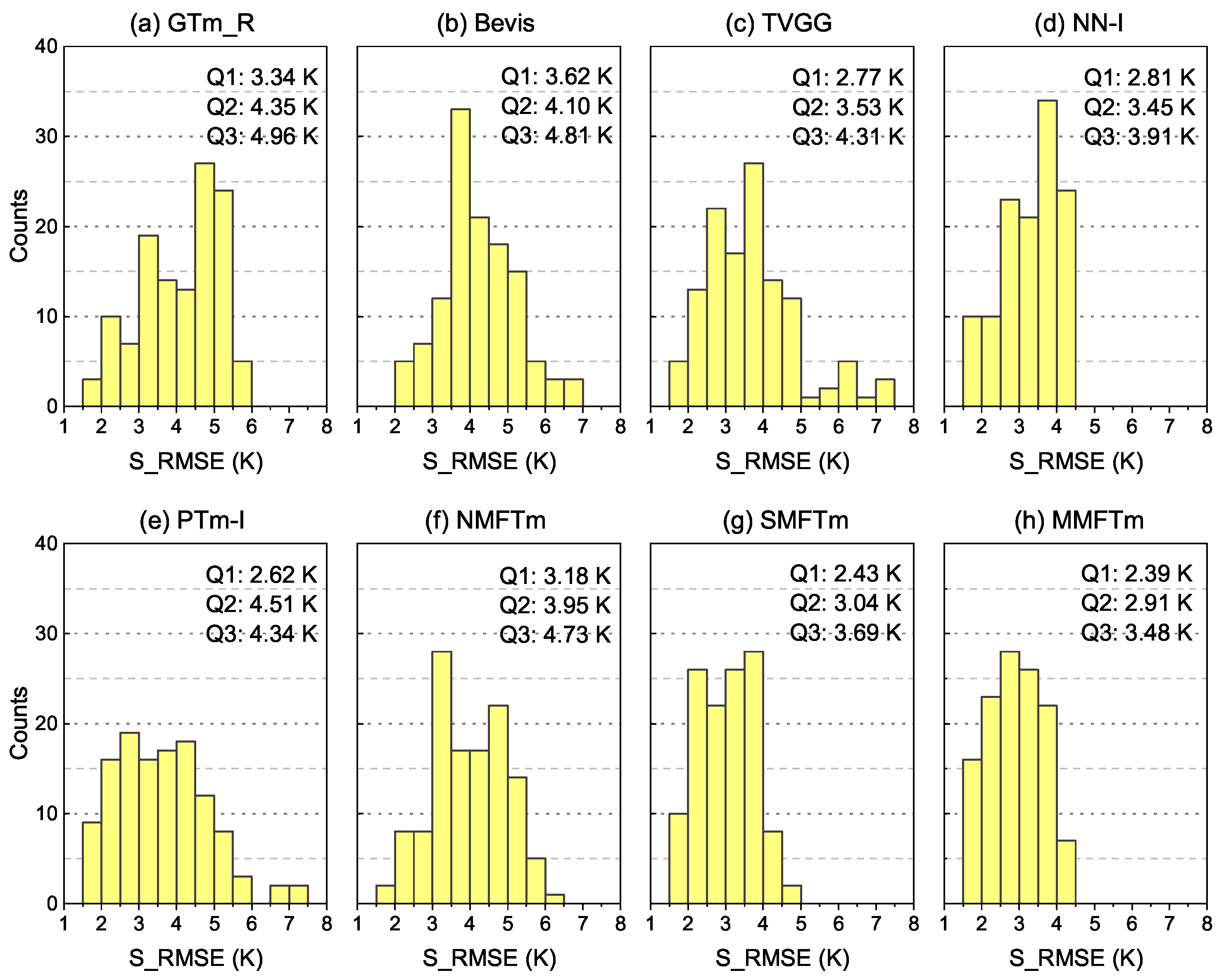
We further compared the performance of different models at each single testing station. The distribution and statistics of S_MBE and S_RMSE for different models can be seen in
Figure 10,
Figure 11,
Figure 12 and
Figure 13.
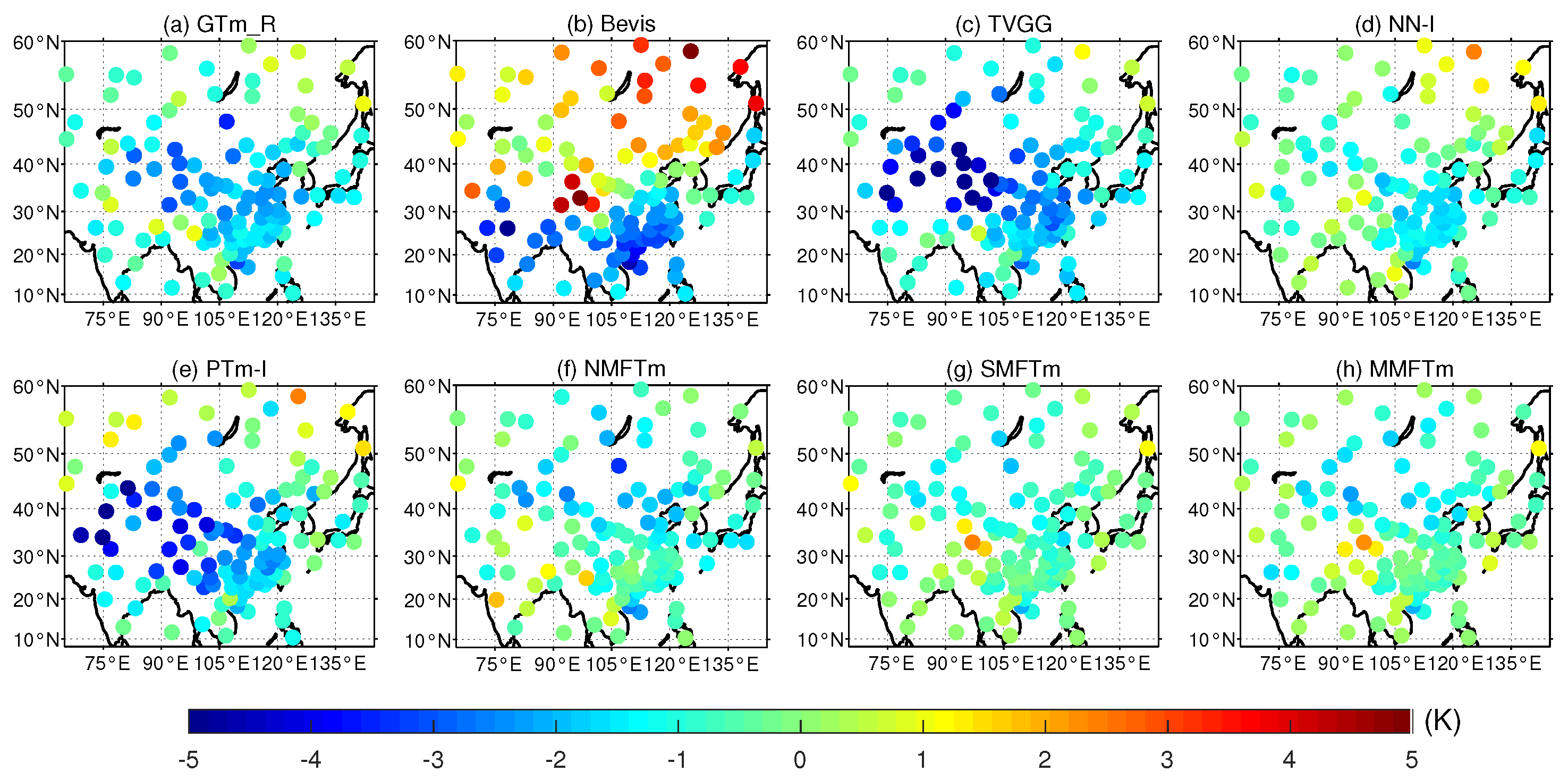
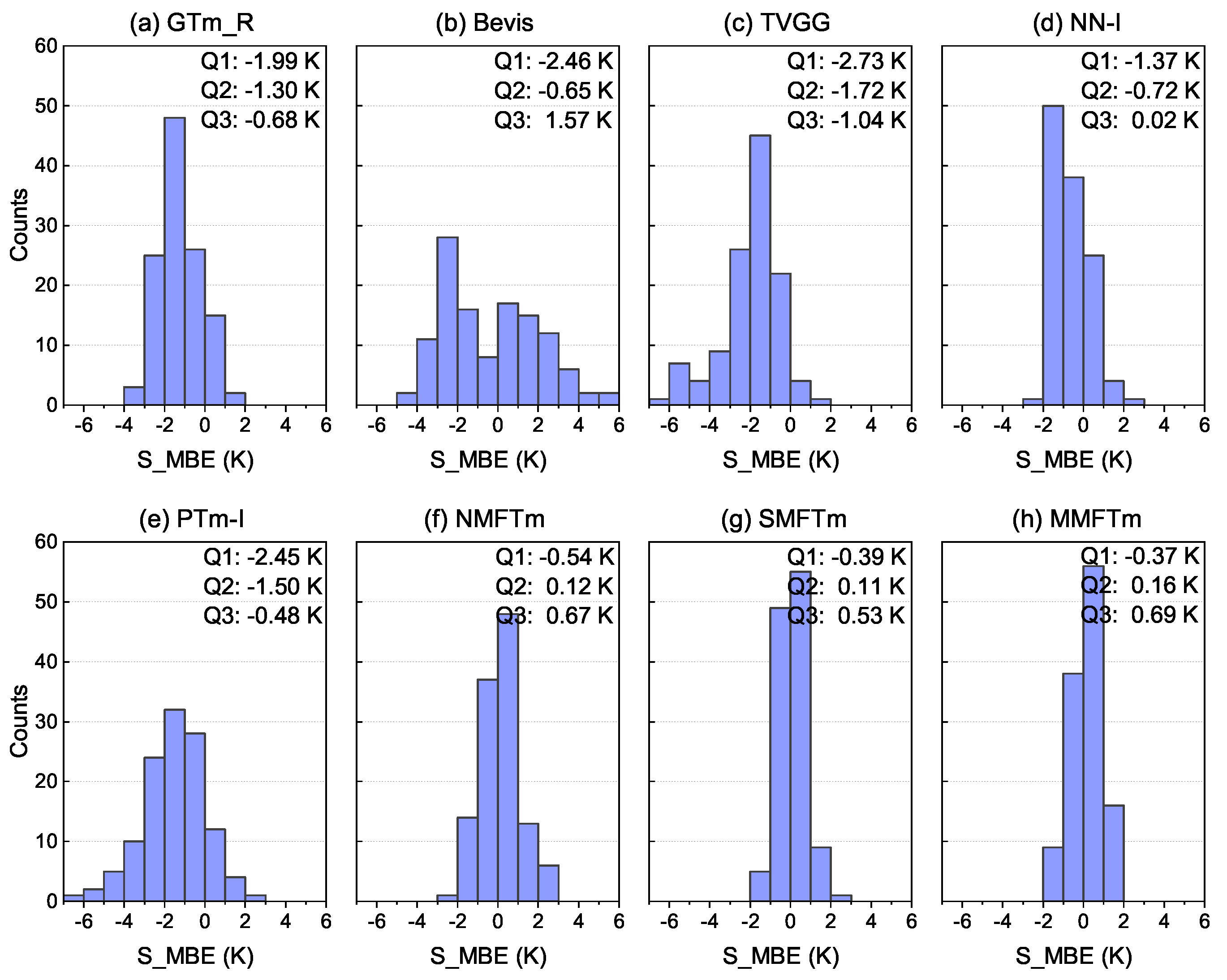
Figure 10 and
Figure 11 show that the TVGG model and PTm-I model exhibited significantly larger systemic negative biases than other competing models; both of them had a large proportion of S_MBEs over −1.0 K, and these testing stations with larger biases were mainly distributed in the western and northwestern regions of China. The GTm_R model also showed a systemic negative bias, but its S_MBEs mainly ranged between −2.5 K and 0.5 K, and the bias was mainly contributed by stations in the northern region of China. Although the S_MBEs of the Bevis model were evenly distributed from −4.0 K to 4.0 K, the absolute S_MBEs over 2.0 K accounted for more than half of the total and the biases of stations distributed in the study area were distinctly different; that is, stations located at latitude below
N had negative biases while the majority of stations located further north had large positive biases, which indicates that the Bevis model is not applicable to China and adjacent areas. The S_MBEs of neural network-based models (including NN-I model and new models) were almost concentrated in the range from −2.0 K to 1.0 K and were therefore better than those of other competing models, but slight systemic negative biases could be found for the NN-I model. Both the SMFTm model and MMFTm model outperformed the NN-I model: their S_MBEs in most testing stations were between −1.0 K and 1.0 K, and the Q1 (25th percentile), Q2 (50th percentile) and Q3 (75th percentile) values were closer to 0 K than other models. Large negative biases could be found for the NMFTm model in the northern part of the study area, but overall, it performed better than the GTm_R model, Bevis model, TVGG model and PTm-I model in terms of S_MBE.
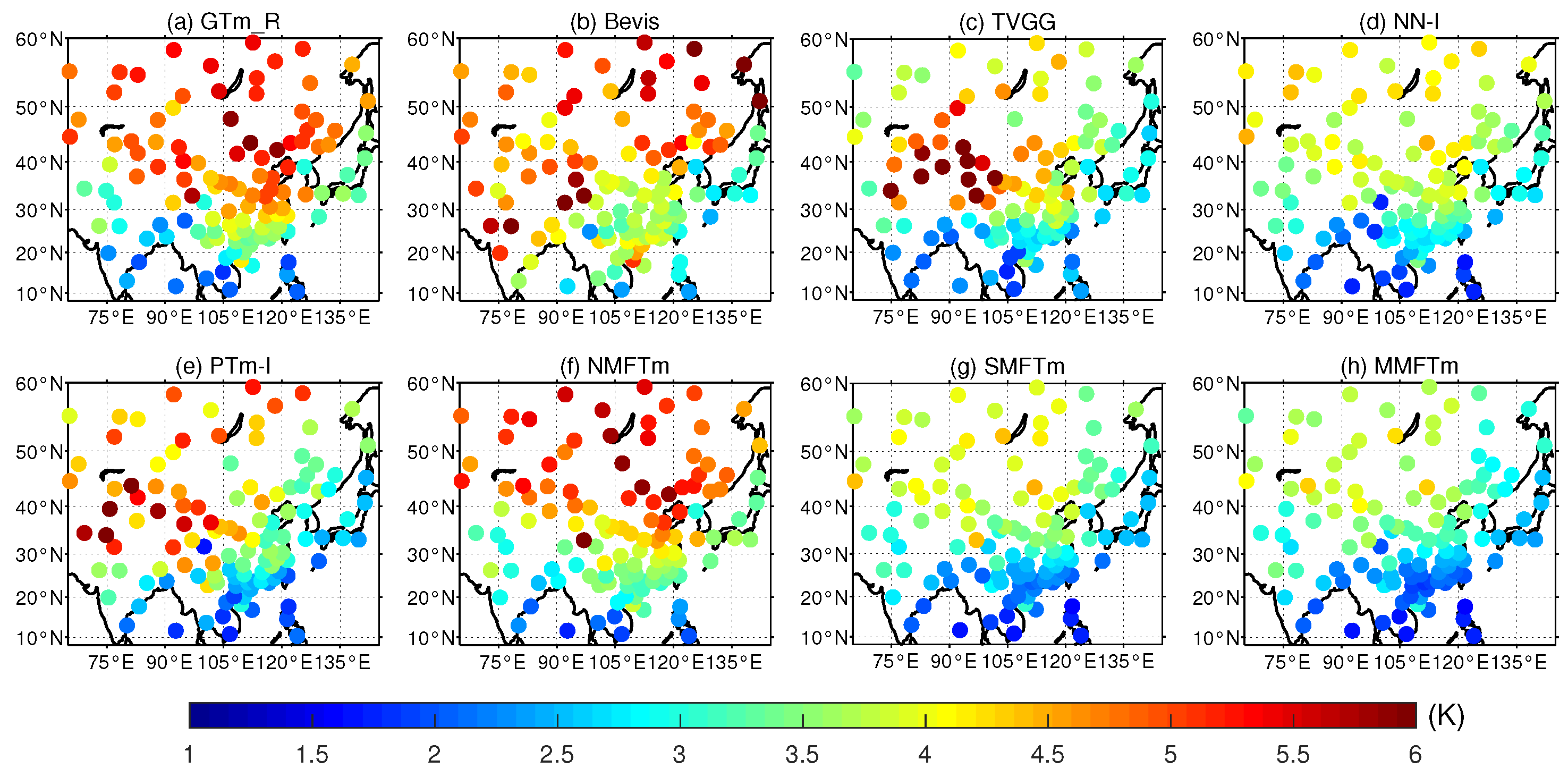
With regard to S_RMSE, one can see from
Figure 12 and
Figure 13 that both the GTm_R model and NMFTm model showed a very large S_RMSE in the northern part of the study area. Although the GTm_R model is a grid model with a spatial resolution of
, its advantage in accuracy over neural network-based NMFTm model is not obvious; it did not even match the NMFTm model in many places, such as at latitudes between
N and
N. It is worth noting that both the GTm_R model and NMFTm model correspond to the category of NMF models, and their S_RMSEs in most testing stations were in the range between 4.0 K and 6.0 K; the error of converting GNSS–ZWD to PWV caused by these models cannot be ignored in practice. The Bevis model, although a very classic SMF model, does not take into account the impact of geographic location on model accuracy, and thus its accuracy in the northern part of the study area was not significantly improved compared with NMF models. The TVGG model and PTm-I model are both grid SMF models, and the impact of geographic location differences were considered, meaning that they outperformed tge Bevis model in most areas; however, a significantly large RMSE could still be found in the northwestern region of China. There are two main reasons for this: (a) the data source for modeling was reanalysis data derived from the assimilation system, (b) the impact of height differences between the target location and grid points was not taken into account. The flaws of the GTm_R model, Bevis model, TVGG model and PTm-I model were clearly overcome by the neural network-based SMF models including the NN-I model, SMFTm model and MMFTm model. From
Figure 12, one can see that the S_RMSEs of stations at the latitudes from
N to
N and stations in the southeastern part of China from SMFTm model and MMFTm model were smaller than those from the NN-I model. From
Figure 13, much smaller Q1 values and Q3 values could be seen for the SMFTm model and MMFTm model compared with other competing models.
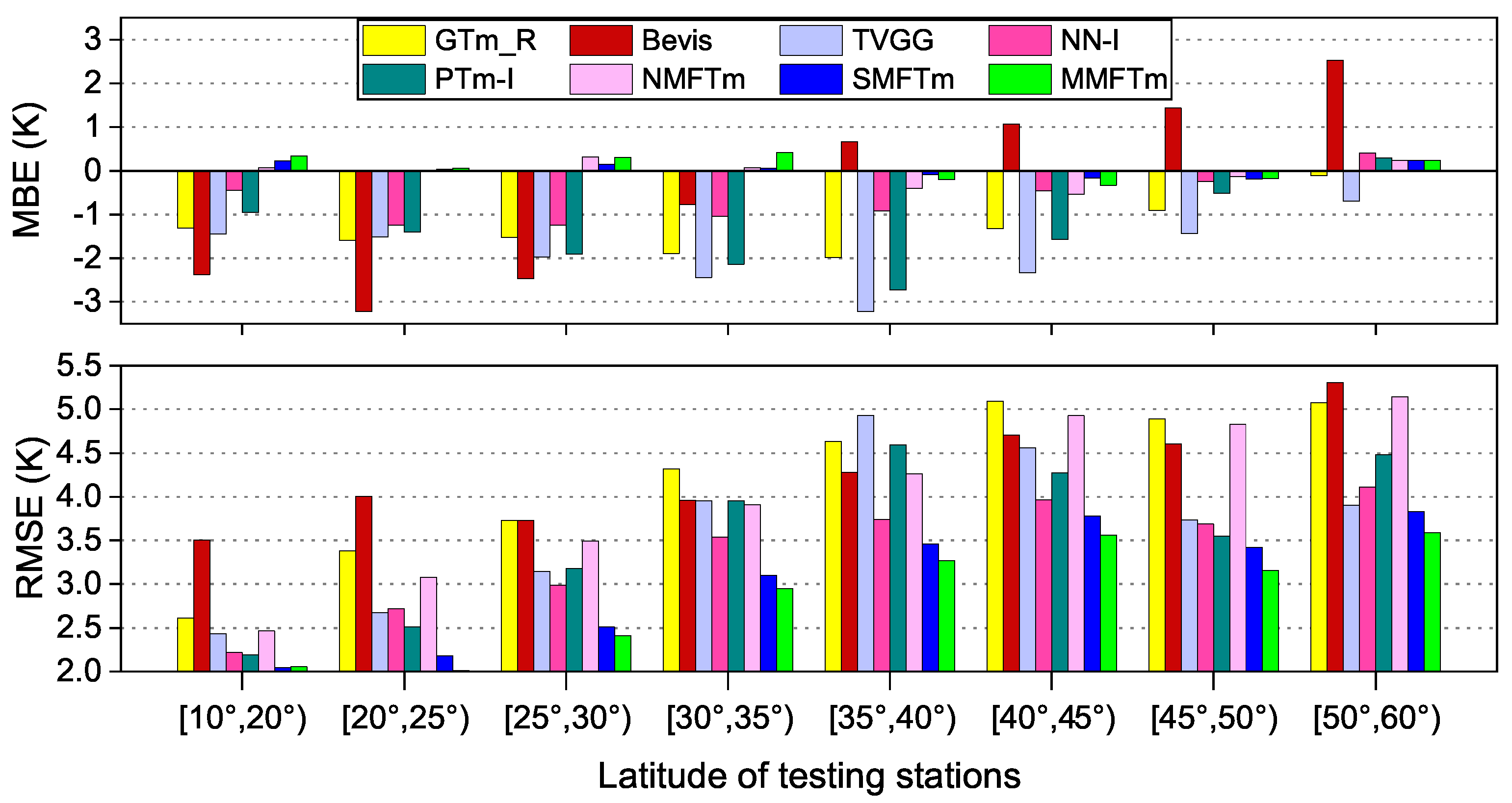
5.3. Accuracies at Different Latitudes
The solar radiation intensity at different latitudes was inconsistent, which was the most important reason for the regional differences of
, and many studies have shown the strong correlation between
and geographic location (mainly latitude). We sorted the testing dataset into eight groups, each with a latitude span of
. The MBE and RMSE of each group are shown in
Figure 14.
Figure 14 shows that the GTm_R model, TVGG model and PTm-I model had remarkable negative biases at almost all the latitude ranges, while the Bevis model showed great negative bias at stations located south of
N, but a marked positive bias could be seen at stations further north, which corresponds to the results shown in
Figure 10. The neural network-based models, however, showed much smaller biases at all the latitude ranges; a large negative bias of the NN-I model could be seen mainly at the latitude range of [
N,
N], and the NMFTm model showed a larger negative bias at the latitude from
N to
N. The SMFTm model and MMFTm model performed best in terms of the MBE.
In terms of RMSE, RMSE values were smaller at low latitudes, but a larger RMSE could be found at higher latitudes for all the competing models. The Bevis model showed the largest RMSE at low latitudes, and its performance was even poorer than the GTm_R model and NMFTm model; it even failed to show an advantage in accuracy over the NMF model as latitude increased. Other SMF models except for the PTm-I model showed much smaller RMSEs, but the performance of PTm-I model was still inferior to the TVGG model, NN-I model and SMFTm model in almost all the latitude ranges, even though it took the surface water vapor pressure into account. The performances of the TVGG model at different latitude ranges were different: its RMSE first increased and then decreased with increasing latitude. Improvements in RMSE could be found for the SMFTm model at all the latitude ranges compared with the NN-I model. The RMSE of the MMFTm model was always the smallest if all the competing models, and a significant improvement could also be seen compared with the SMFTm model.
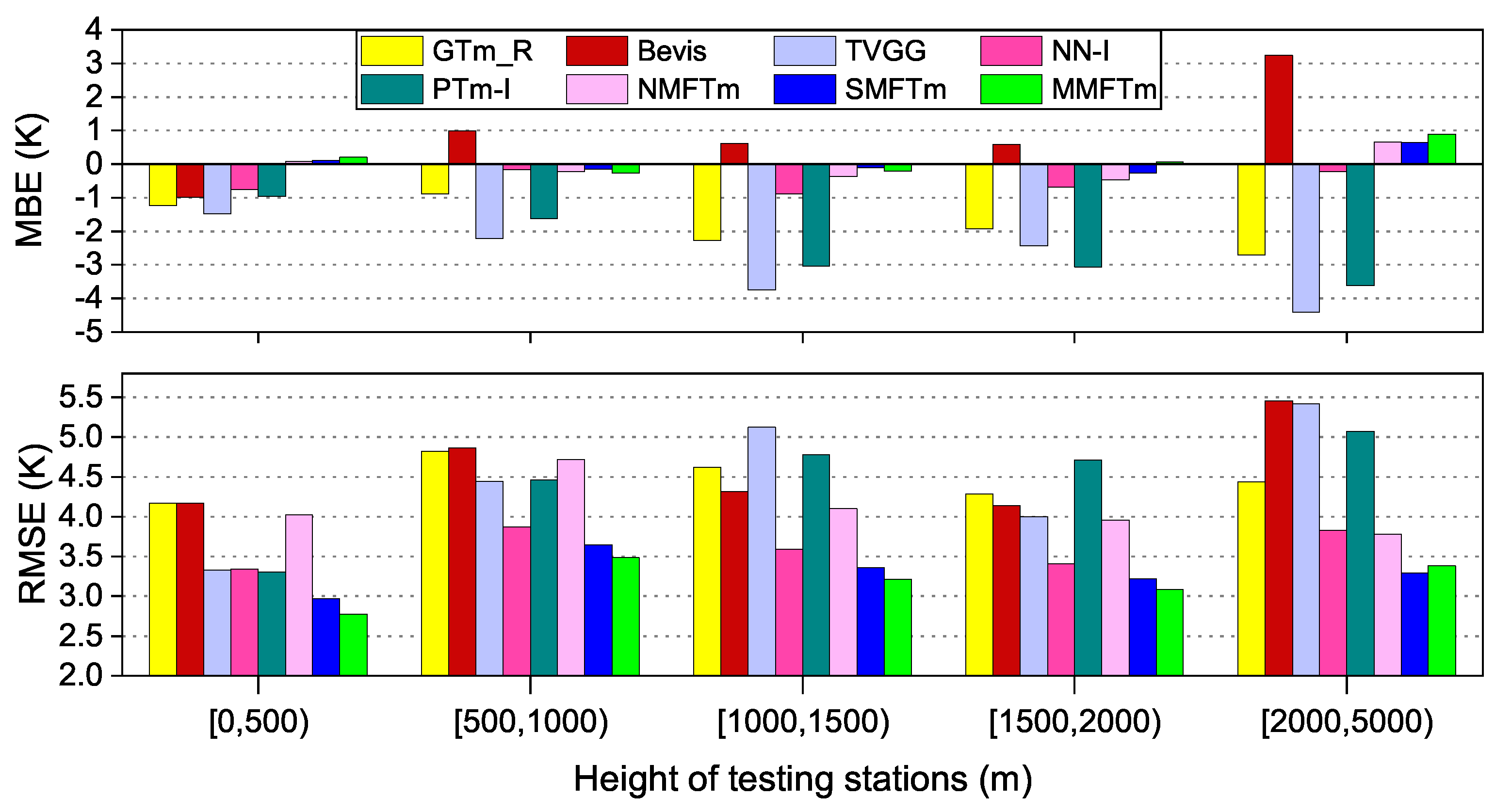
5.4. Accuracies at Different Heights
The height (height above sea level) of the station is considered as an input variable in the development of new models. We compared the MBE and RMSE at different height ranges for different competing models. The testing dataset was sorted into five groups according to height: i.e., below 500 m, 500–1000, 1000–1500, 1500–2000 and above 2000 m. The results are shown in
Figure 15.
From
Figure 15, very large biases could be found at the heights over 500 m for TVGG model and PTm-I model, since they do not take the height as input variable. GTm_R model reduces the bias of
estimation caused by the height differences between target location and grid points, but remarkable bias can still be found at the heights over 1000 m. Bevis model performs well at the heights below 2000 m in terms of MBE, while significant positive biases could be found at the heights over 2000 m. NN-I model actually takes into account the impact of height differences by setting a constant lapse rate of −5.1 K/km [
17], the results show that its bias at each height range is also very small. The new models, however, all take the height above sea level as one of the input variables, and their biases are very small at all the height ranges.
In the aspect of RMSE, the largest RMSE of GTm_R model can be found at the heights from 500 m to 1000 m, the performance of NMFTm model is similar to that of GTm_R model, but slight improvement can be found at the heights over 1000 m. As TVGG model and PTm-I model do not incorporate the height into the model, their RMSEs are closer to those of neural network-based models when the height is less than 500 m, but with the height increases, their performance are even poorer than those of NMF models. Bevis model performs the poorest at almost all the height ranges, since Bevis model doesn’t contain any information about the geographic location or terrain. Significant improvement is shown for SMFTm model and MMFTm model at the heights below 500 m and heights over 2000 m compared with NN-I model, but their advantages are not obvious at the height from 500 m to 2000 m. MMFTm model has marked advantages over SMFTm model at low altitudes, but this accuracy advantage disappears at the heights over 2000 m.
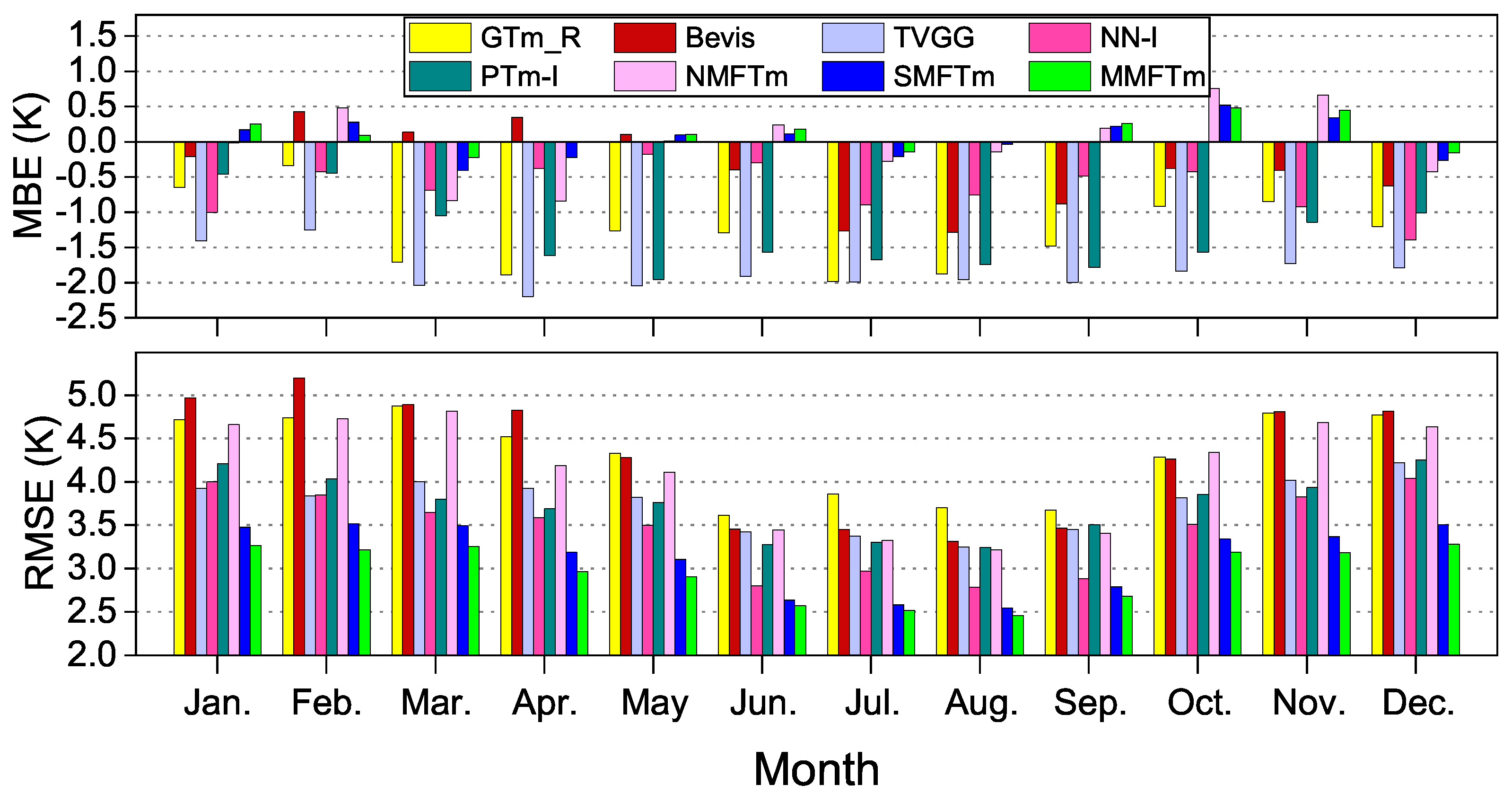
5.5. Accuracies in Different Months
The seasonal accuracies of different models were also examined in this study. We calculated the monthly MBE and RMSE for different models with radiosonde data from 2016 to 2018, the results are shown in
Figure 16.
From
Figure 16, much larger biases can be found during spring and summer months than those in winter for almost all the competing models. It can be seen that the biases of NMFTm model are much smaller than those of GTm_R model in summer and autumn months (from May to November), but they behave similarly in other months. Unlike the other models, Bevis model shows small positive biases in the first half of the year, and significant negative biases in other months. TVGG model always shows the largest negative biases throughout the year, PTm-I model is slightly improved, but it can still be seen that the negative biases are obvious throughout the year except for winter months. The neural network-based SMF models behave similarly and much smaller negative biases can be found for them throughout the year compared with most of other competing models. The improvements of SMFTm model and MMFTm model are significant compared with NN-I model in winter months.
On the RMSE side, one can see the opposite pattern of seasonal variation characteristic from the MBEs case for most of the competing models i.e., RMSEs are much smaller in summer months than those in other months. The reason is that the variation characteristic of
during the summer is easier to be simulated than that in winter months [
26,
29]. The RMSEs of both GTm_R model and NMFTm model are much larger than those of SMF models almost throughout the year, but the RMSEs of NMFTM model are significantly smaller compared with GTm_R model in summer months. In the aspect of SMF models, Bevis model performs the poorest since it doesn’t consider the seasonal variation charateristics of
, TVGG model and PTm-I model perform similarly because the
and even
were taken into account as the input variables, but they both show larger RMSEs than those of neural network-based SMF models. The PTm-I model even failes to perform as well as the TVGG model in some cases, even though the water vapor pressure was taken into account as one of the input variables. NN-I model outperforms TVGG model and PTm-I model throughout the year, particularly during summer months. SMFTm model shows much higher accuracy than NN-I model especially in winter months, the improvement of MMFTm model over SMFTm model is also significant throughout the year. We believe that the water vapor pressure should still be considered as an important input variable in
modeling.
5.6. Discussion
From the comparative analysis above, we find that the new models developed in this study showed better performance than other published models under the same application conditions. The NMFTm model presented some improvements over the GTm_R model in almost all aspects, but its greatest advantage lies in its simplicity and utility. The SMFTm model only took as one of the model inputs, but its accuracy in terms of the RMSE improved by 27.5%, 16.3% and 9.3% over the Bevis model, TVGG model and NN-I model, respectively; its advantages could be found not only in the RMSE of single stations, but also at different latitudes and heights, as well as in different months. Both the MMFTm model and PTm-I model considered the surface water vapor pressure as one of the input variables, but the accuracy of MMFTm model was 20.2% better than that of the PTm-I model. Moreover, the MMFTm model showed the best performance of all the competing models from different perspectives.
The variations of are complex and closely related to weather conditions, but its spatiotemporal variation characteristics follow distinct rules that have been described in previous studies. On the global scale, the variation of shows obvious characteristics of latitude distribution and is related to topography and land-sea distribution. In terms of specific regions, in most regions exhibits an evident periodicity of properties, including annual, semiannual and diurnal variation characteristics, which are the basis of modeling. In the analysis presented in this section, significant differences in accuracy are shown for different models, and we think that the reasons for this result can be summarized as follows:
- (1).
The data sources for modeling: The GTm_R model, TVGG model and GTm-I/PTm-I model were all developed using reanalysis data, and uncertainties exist in extracting meteorological elements and calculating from reanalysis data, resulting in large biases for these models, which can be seen in many respects from the comparisons above. The Bevis model, NN-I model and new models, however, were all developed using the data collected by sounding balloons; their biases are smaller and the models are closer to the actual situation.
- (2).
The surface meteorological elements: The GTm_R model and NMFTm model are NMF models, and their accuracies are not as good as those of other models because the surface meteorological elements are not involved in the model. The performance of the TVGG model was poorer than that of the PTm-I model since the PTm-I model further considers the surface water vapor pressure as one of the inputs. This is also the case for the performance of NN-I model and SMFTm model, which was not as good as that of the MMFTm model. We believe that the water vapor pressure should be an indispensable factor in the development of models with better accuracy.
- (3).
The geographic location information: The variation characteristics of at different latitudes and land–sea distributions are different, and so are the relations between and surface meteorological elements. Generally, we can deal with this problem in two ways: (a) constructing grid models—the GTm_R model, TVGG model and PTm-I model correspond to this case—and (b) taking the geographic location information as the inputs of the model—all of the neural network-based models fall into this case. The performance of the Bevis model is inferior to those of other SMF models precisely because it does not consider the differences of variation characteristics of in different geographic locations. However, it is difficult to determine which method is better from the comparative results, because the model accuracy is affected by multiple factors.
- (4).
The impact of height differences: The GTm_R model and NMFTm model both take into account the impact of height differences between the target location and grid points, and their accuracies are nearly equal. The Bevis model, TVGG model and PTm-I model, however, do not consider the height correction, and their accuracies are greatly affected by the height of the testing stations. The NN-I model actually considers the influence of height differences, but only sets the height lapse rate to a constant; thus, its accuracy is not as good as that of the SMFTm and MMFTm model at most height ranges. The heights of stations are introduced into the new models as one of the input variables, meaning that they perform better than other competing models under the same application conditions at all of the height ranges.
- (5).
Seasonal factors: In addition to the Bevis model, other competing models introduced seasonal factors as one of the inputs (). From the comparisons above, the Bevis model can be seen to perform the poorest in each month; its accuracy is even inferior to the NMF models throughout the year. In fact, the seasonal variation characteristics of are the basis of modeling, and therefore seasonal factors should be regarded as a necessary input variable of a model.
- (6).
The long-term trend of : Many previous studies have shown that the has an increasing trend over the long term on a global scale, which is an important factor that must be taken into account in modeling. The NMF models can simulate the long-term trend of and add an approximate linear correction. As for the SMFTm models, an external correction could be made according to the verification results because a variety of meteorological elements are involved in the model.
- (7).
The optimization of modeling process for neural network-based models: Neural network-based models show some differences in performance. We considered the problem of model generalization in the development of new models and adopted the ensemble learning method to enhance their generalization ability. From the above comparisons in various aspects, the accuracies of the SMFTm model and MMFTm model were significantly improved compared with the first generation of the neural network-based model.
The performances of the new models developed in this study were better than those of other models listed in this paper under the same application conditions. There are many reasons for their advantages; i.e., they benefit not only from the powerful nonlinear mapping ability of neural network technique but also from the quality control of data sources, optimal neural network structure, reasonable input variables and the further optimization of the model through ensemble learning, etc. New models can meet the needs of users under different application conditions within the study area. However, it can be seen from the comparisons in this section that there are significant regional and seasonal differences in the accuracy of the current
models, whether grid models or neural network models, and the weather system is complex and diverse, including various temporal and spatial scale changes [
43,
44], so more associated meteorological elements should be incorporated into
modeling to improve the model accuracy and eliminate these differences; however, further verification is needed.
6. Conclusions and Outlook
In this study, a non-meteorological-factor model (NMFTm), a single-meteorological-factor model (SMFTm) and a multi-meteorological-factor model (MMFTm) based on neural network technique were developed. The new models can be used to estimate the weighted mean temperature in China and adjacent areas under different application conditions. The new models were robust enough and their generalization performances were further strengthened by adopting the ensemble learning method; test results showed that the methods could efficiently reduce the uncertainty risks in model accuracy, thus enhancing their generalization performance. The accuracies of the new models were examined with data from 119 radiosonde stations distributed in the study area, and comprehensive comparisons (including total accuracies, spatial distribution and statistics of accuracies at single testing stations, accuracies at different latitudes and heights, seasonal accuracies, etc.) with six other representative published models were also carried out. Test results indicated that the new models showed better performance in terms of accuracy than other competing models under the same application conditions from multiple perspectives. The NMFTm model is superior to the latest non-meteorological model and has the advantages of simplicity and utility. Both the SMFTm model and MMFTm model showed better accuracy than all the published models listed in this paper; the SMFTm model and MMFTm model were shown to be approximately 9.3% and 14.5% superior to the NN-I model, with the best accuracy so far in terms of root-mean-square error. More importantly, all the new models showed stronger generalization performance than the previous neural network-based models.
This study concluded that the performances of NMFTm, SMFTm and MMFTm models developed by the neural network technique optimized by the ensemble learning method are better than those of other competing models under the same application conditions, and these models show a powerful capability to capture the regional spatiotemporal variation characteristics of and simulate the relations between and various surface meteorological elements. Therefore, the approach proposed in this study should be extended to more relevant research fields of GNSS meteorology. In further analyses, the measured atmospheric profile data for global distribution from multiple observation systems including radiosonde, GNSS radio occultation and radiometry, etc., can be used to develop global models under different application conditions. With such a large number of available atmospheric profile data sources, the values at different heights in the troposphere can be calculated, and models applicable to the whole near-Earth space on a global scale will be considered for development in follow-up studies. Such models would facilitate real-time conversion from GNSS–ZWD to PWV and be of great significance to the study of the spatiotemporal variation characteristics of water vapor globally.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}