A Novel Hybrid Machine Learning Method (OR-ELM-AR) Used in Forecast of PM2.5 Concentrations and Its Forecast Performance Evaluation

 ,
, 
Abstract
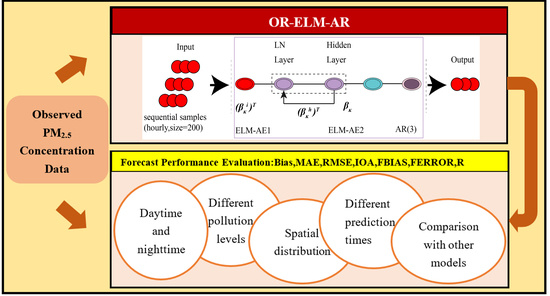
1. Introduction
2. Methods and Data Source
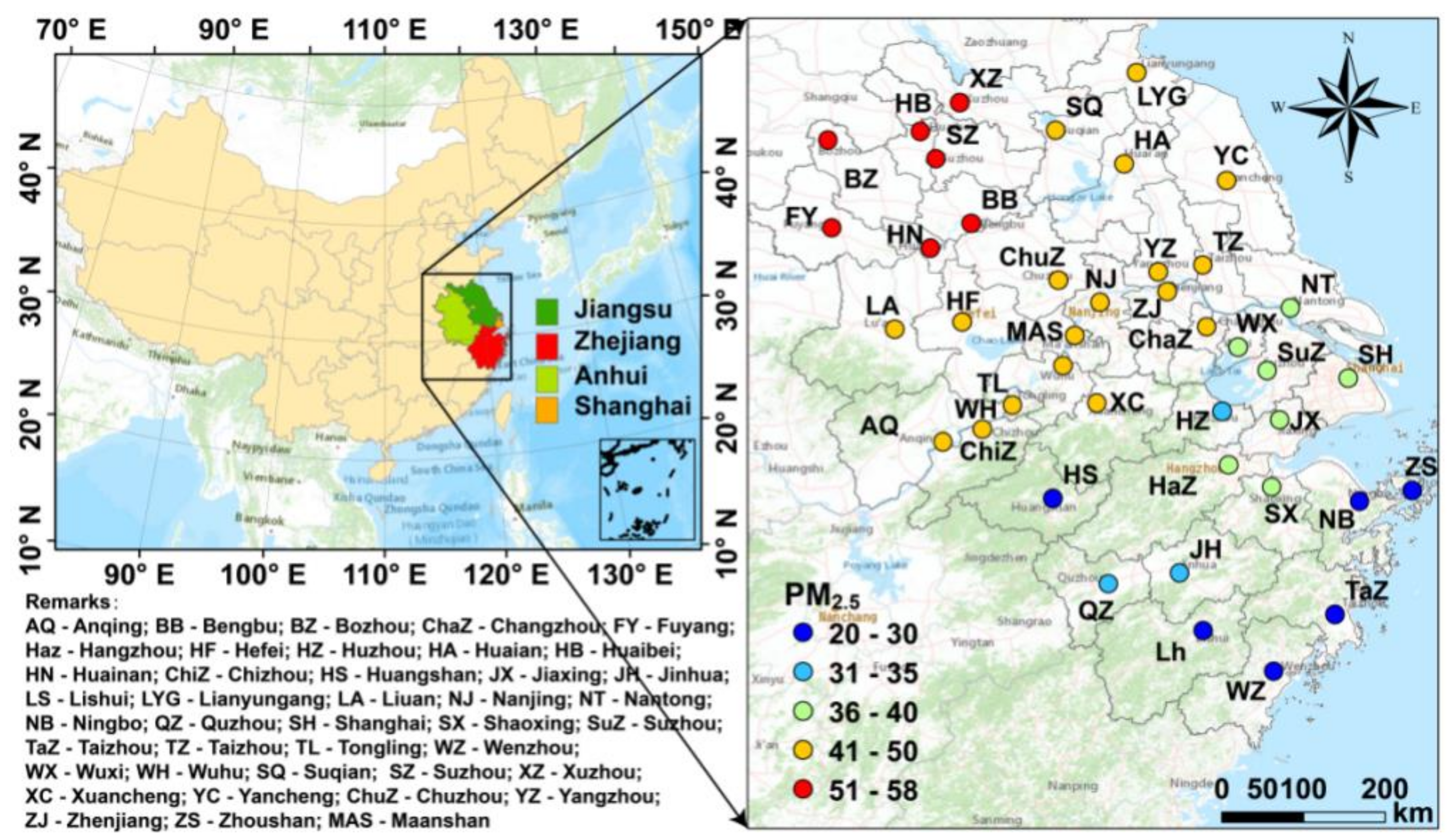
2.1. Study Domain and Data Source
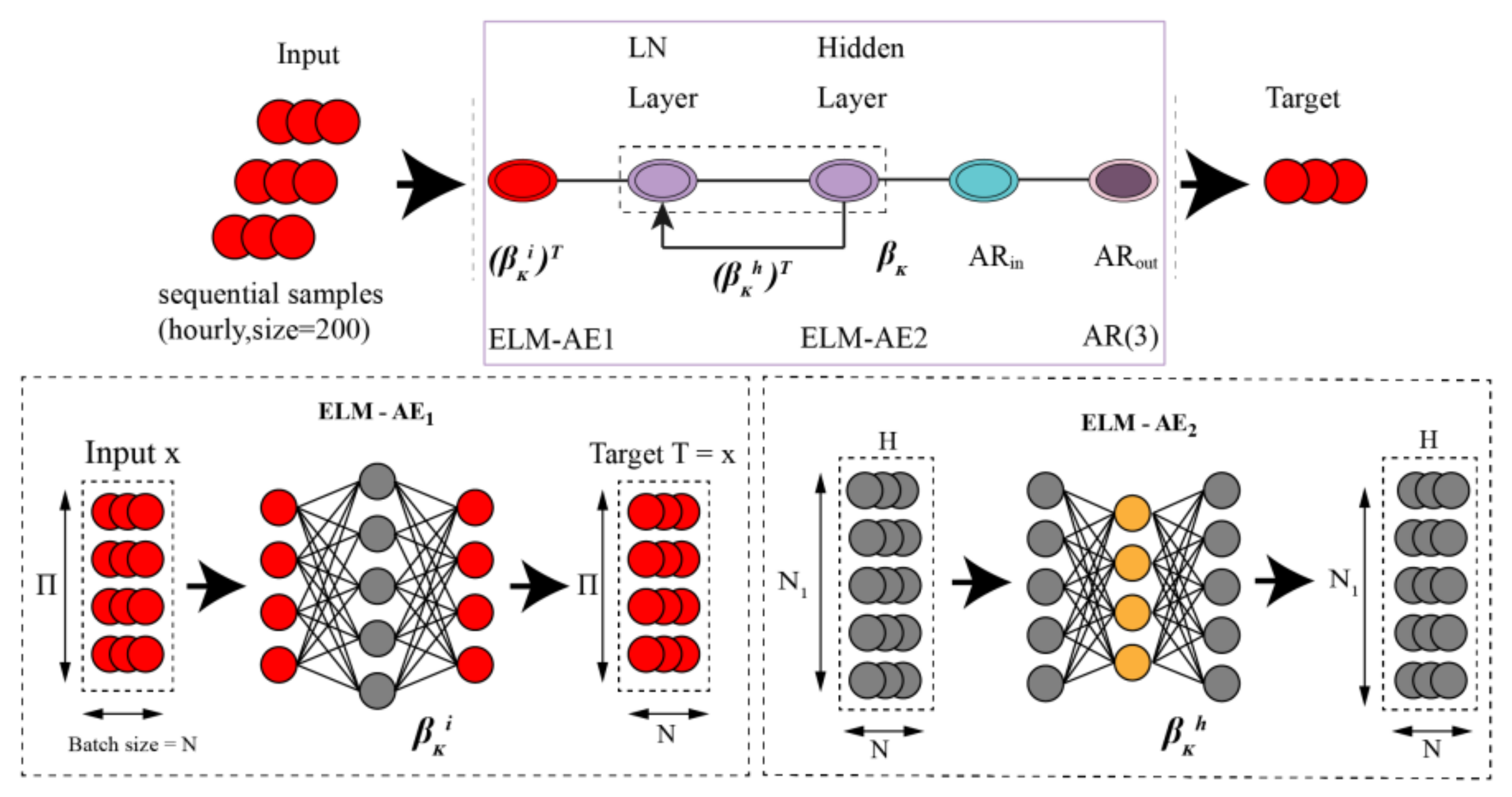
2.2. Model Framework of OR-ELM-AR and Forecasting Process
2.3. Evaluation Methods
3. Results
3.1. General Temporal-Spatial Patterns of PM2.5 Pollution
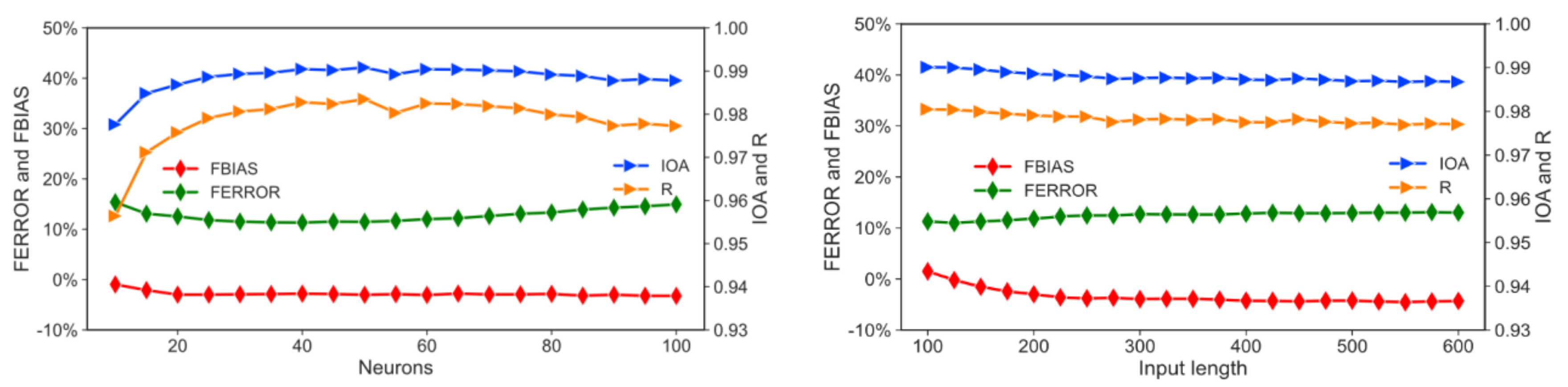
3.2. Optimization of Model Parameters
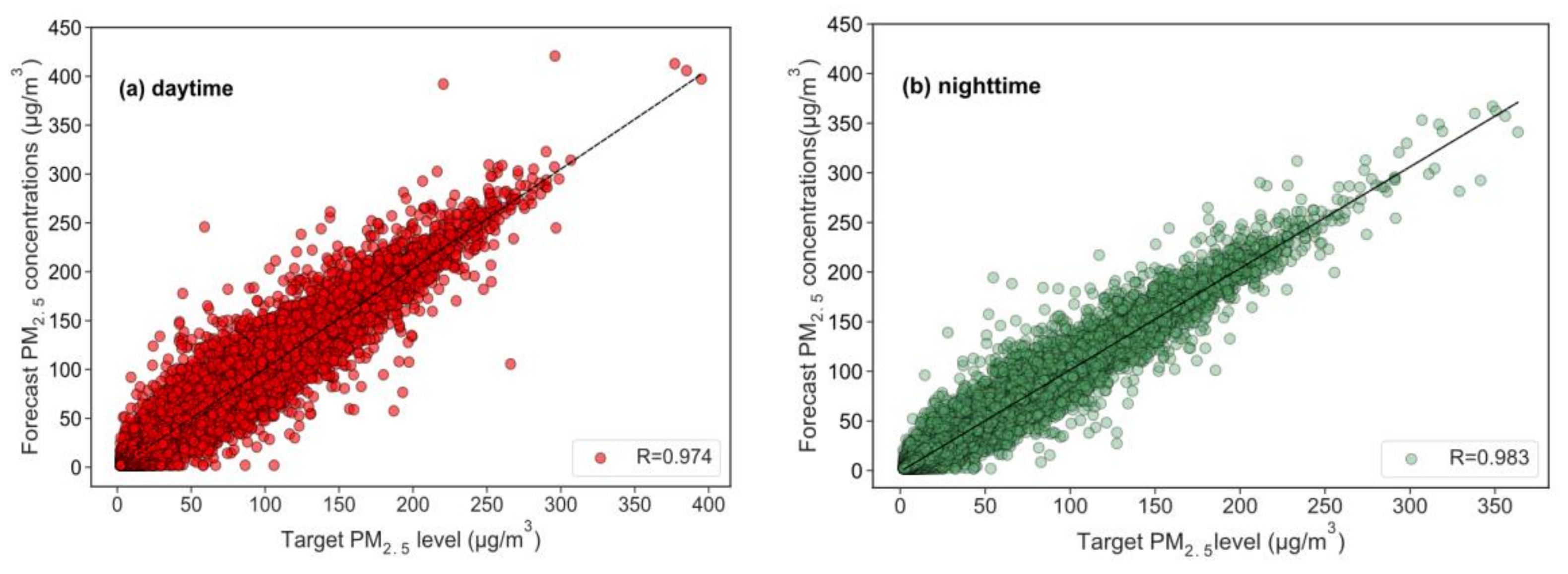
3.3. Comparison of Daytime and Nighttime Forecast Performance
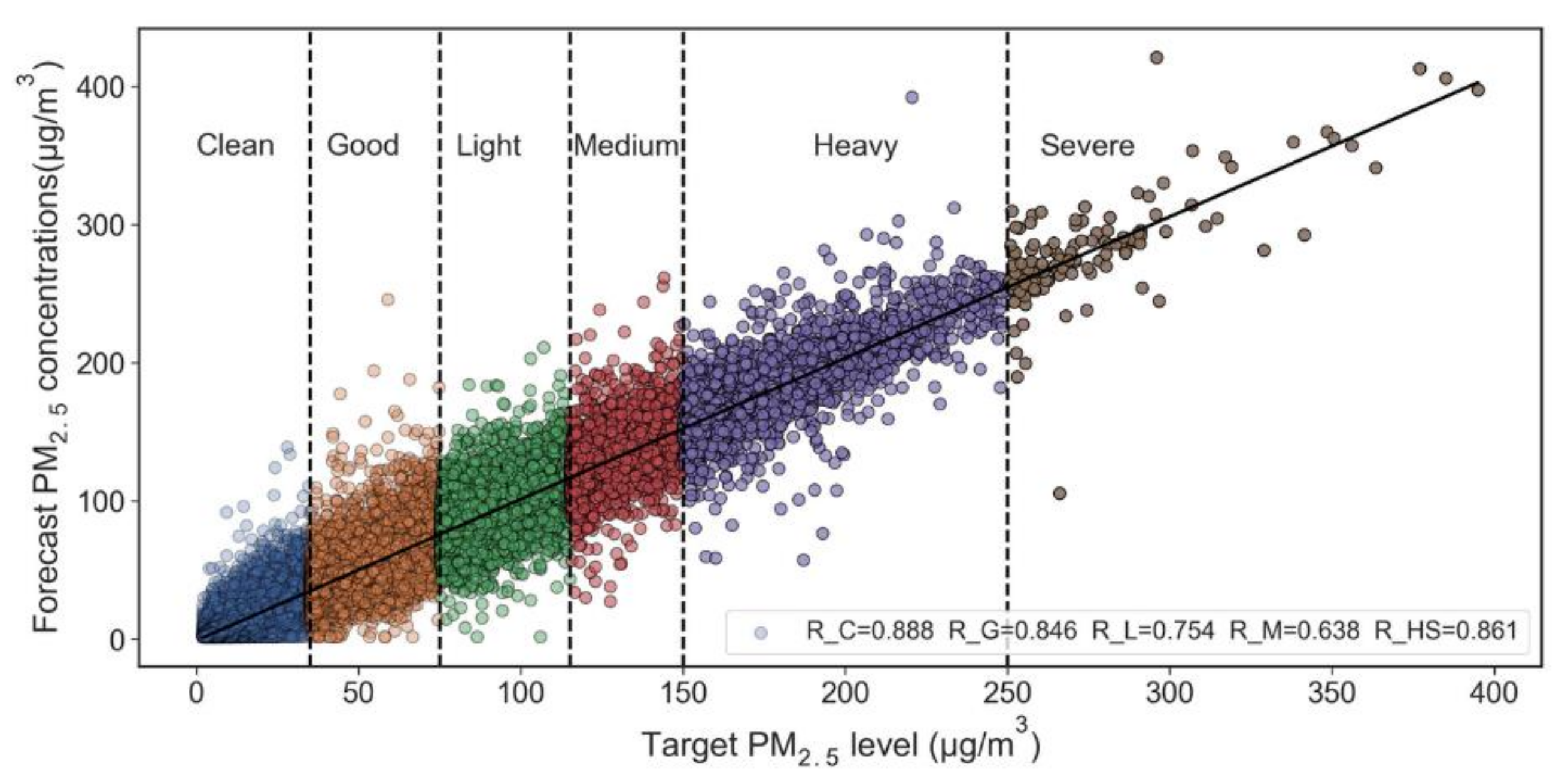
3.4. Forecast Performance at Different Pollution Levels
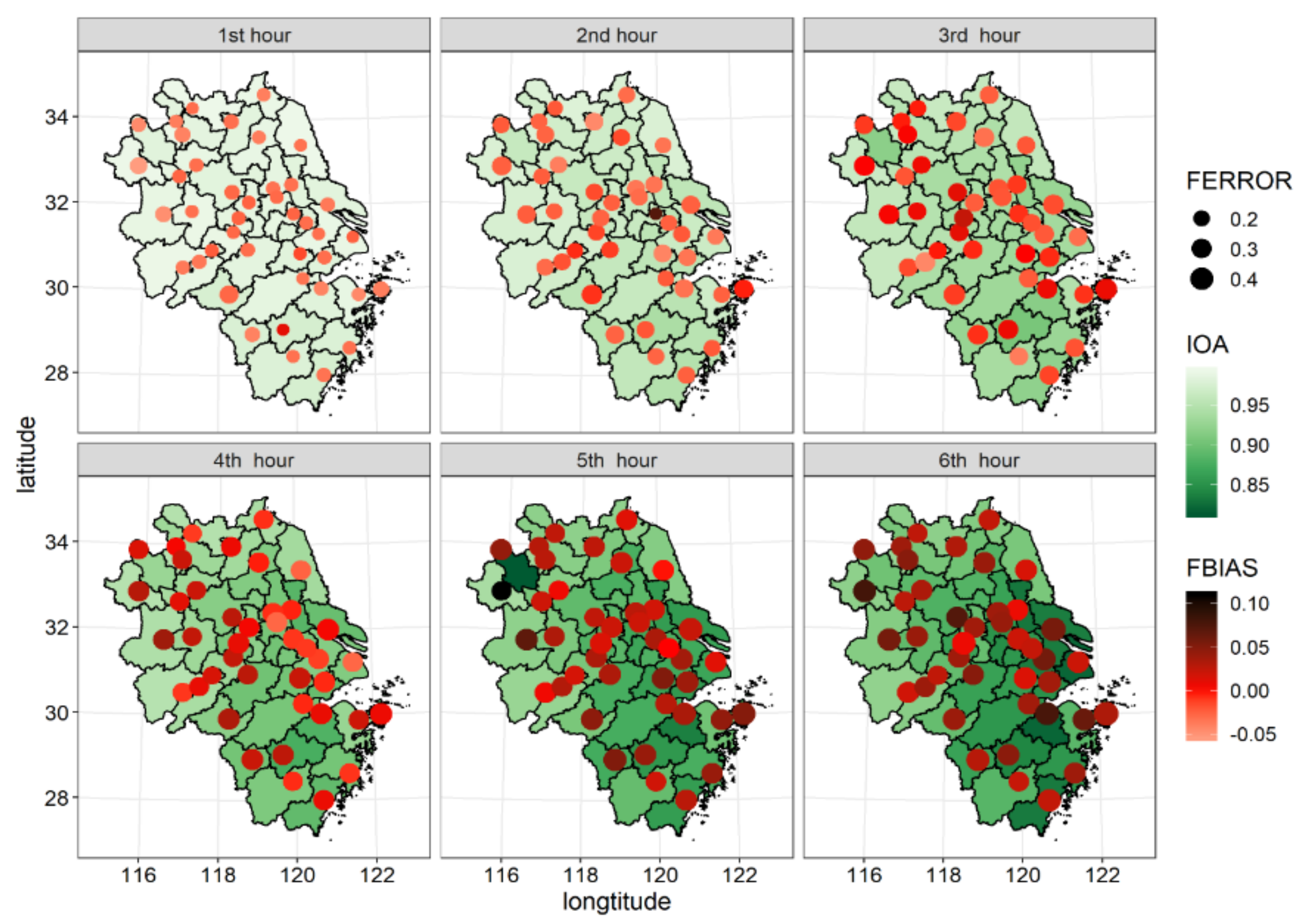
3.5. Spatial Forecast Performance
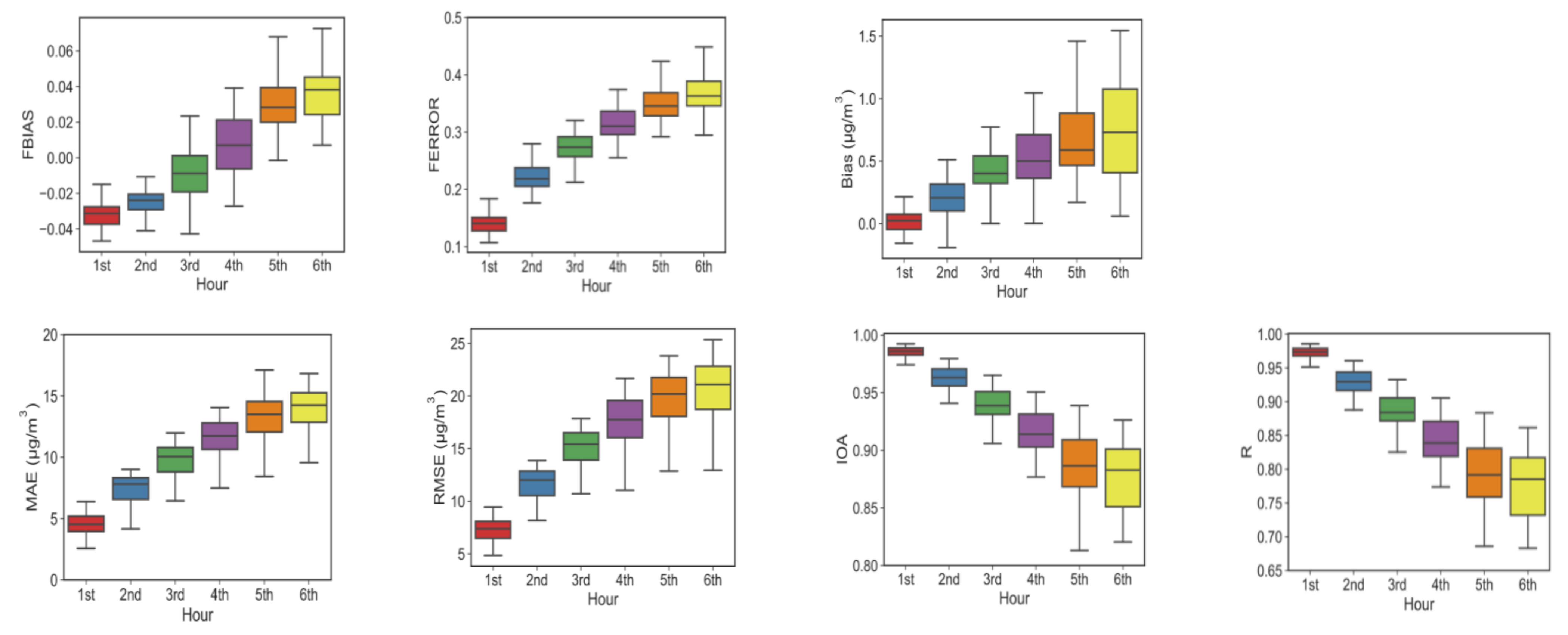
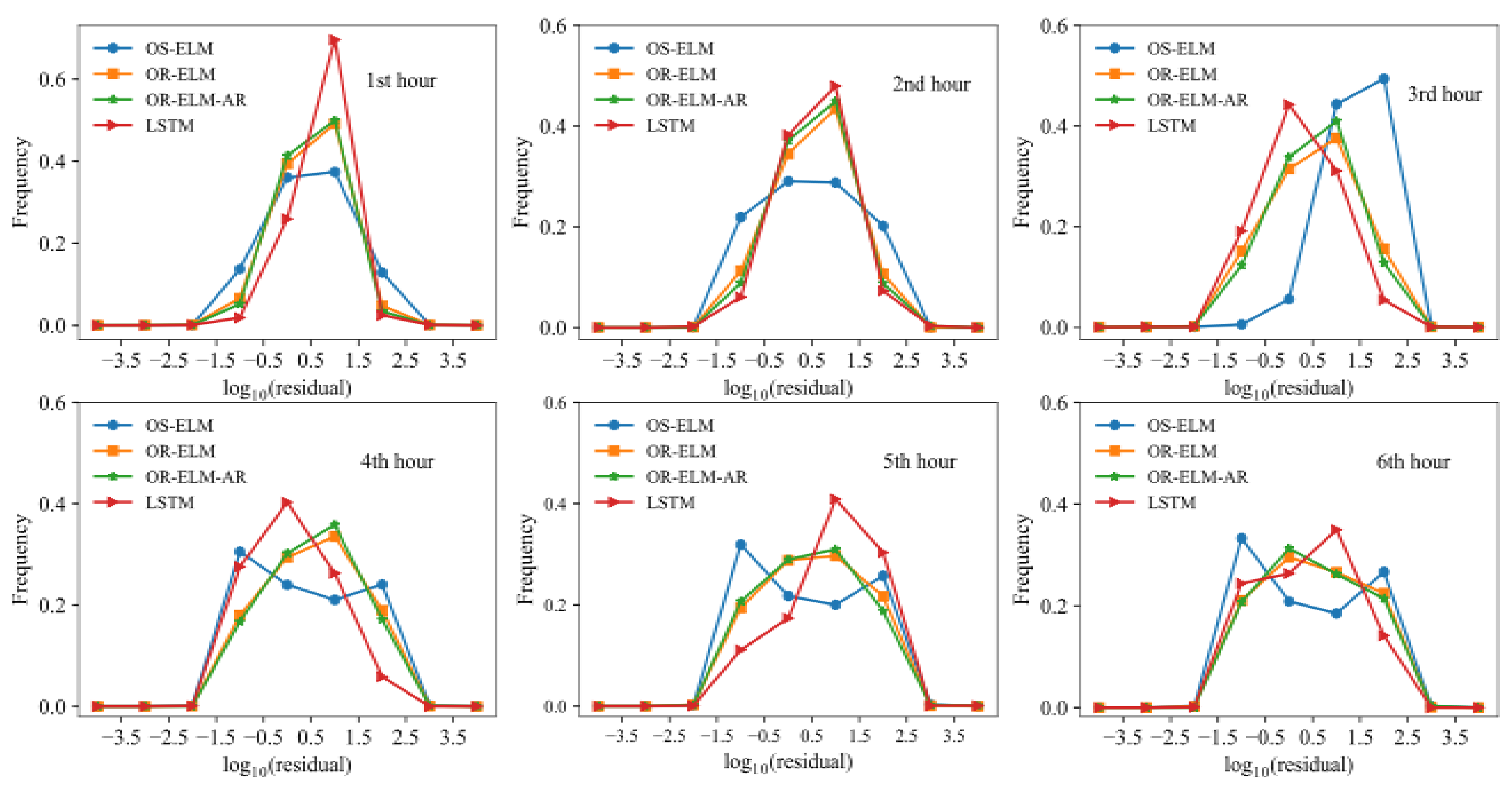
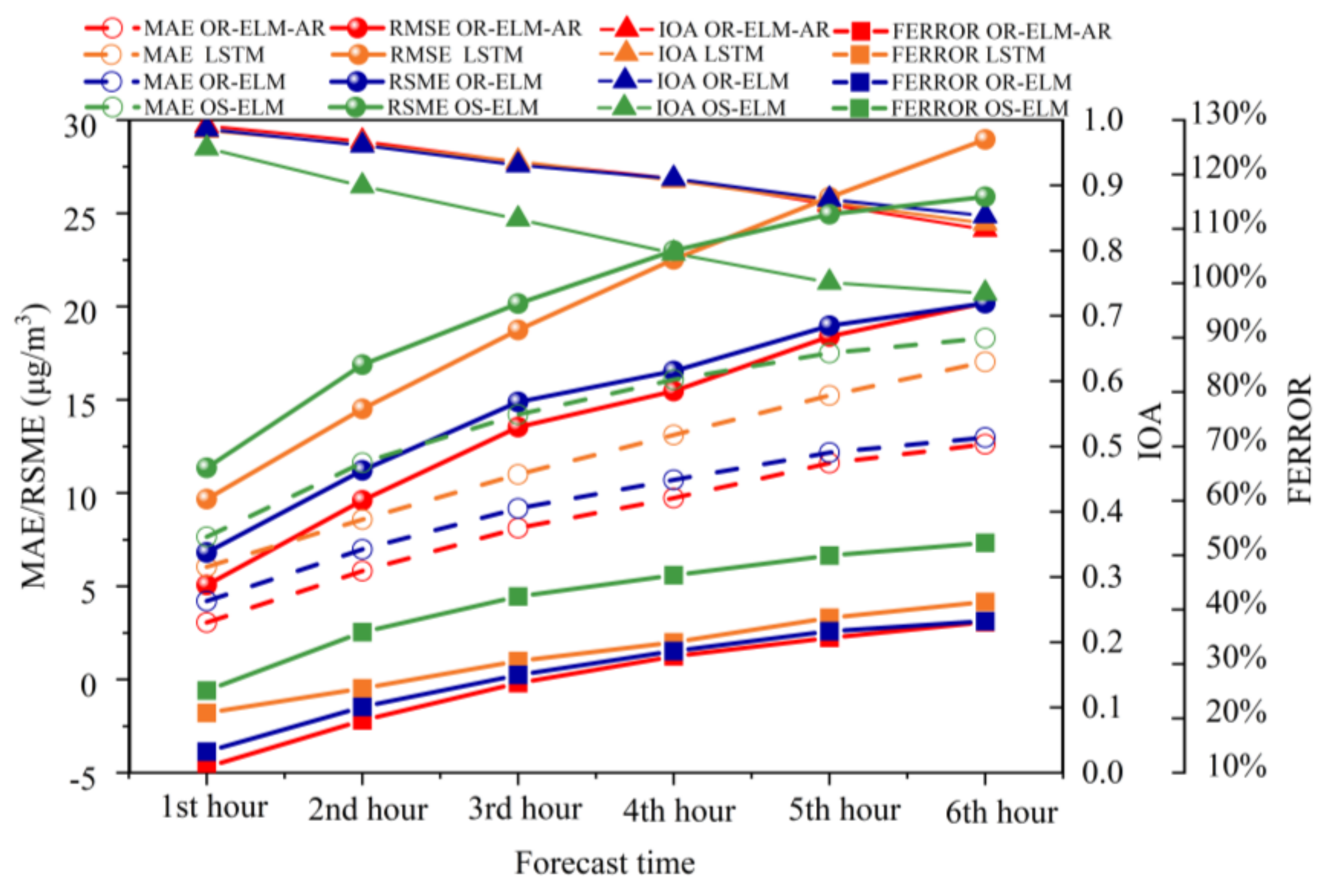
3.6. Comparison with Other Models
4. Conclusions
- (1)
- The PM2.5 forecast ability of OR-ELM-AR at nighttime is slightly better than that of daytime, mainly due to several influencing factors, such as more man-made sources and more changeable meteorological conditions in the daytime;
- (2)
- OR-ELM-AR model has better forecast performance for low and high levels of PM2.5 pollution than that for intermediate pollution levels. Especially in the cases of heavy and extreme heavy pollution, this model can respond to large temporal variations in concentration in time, with a higher correlation coefficient between the forecast values with the observed values. Compared with the intermediate polluted cities in the center part of the YRD region, the forecast performance is better for cities in the north part with heaviest pollution and cities in the southern and western part with the least pollution in the YRD region;
- (3)
- The OR-ELM-AR model gains much smaller RMSE and MAE values and slightly smaller FERROR values than the OR-ELM model by the embedded AR algorithm. The OS-ELM model has the worst forecast performance;
- (4)
- The OR-ELM-AR model has a much better ability of quick response than the LSTM model based on both RMSE and MAE metrics with the forecast times varying from 1st hour to 6th hour in advance, although their IOA values are close.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chang, X.; Wang, S.; Zhao, B.; Xing, J.; Liu, X.; Wei, L.; Song, Y.; Wu, W.; Cai, S.; Zheng, H.; et al. Contributions of inter-city and regional transport to PM2.5 concentrations in the Beijing-Tianjin-Hebei region and its implications on regional joint air pollution control. Sci. Total Environ. 2019, 660, 1191–1200. [Google Scholar] [CrossRef]
- Cheng, N.; Zhang, D.; Li, Y.; Xie, X.; Chen, Z.; Meng, F.; Gao, B.; He, B. Spatio-temporal variations of PM2.5 concentrations and the evaluation of emission reduction measures during two red air pollution alerts in Beijing. Sci. Rep. 2017, 7, 8220. [Google Scholar] [CrossRef]
- Huang, L.; An, J.; Koo, B.; Yarwood, G.; Yan, R.; Wang, Y.; Huang, C.; Li, L. Sulfate formation during heavy winter haze events and the potential contribution from heterogeneous SO2 + NO2 reactions in the Yangtze River Delta region, China. Atmos. Chem. Phys. 2019, 19, 14311–14328. [Google Scholar] [CrossRef]
- Li, K.; Jacob, D.J.; Liao, H.; Zhu, J.; Shah, V.; Shen, L.; Bates, K.H.; Zhang, Q.; Zhai, S. A two-pollutant strategy for improving ozone and particulate air quality in China. Nat. Geosci. 2019, 12, 906–910. [Google Scholar] [CrossRef]
- Kan, H.; Chen, R.; Tong, S. Ambient air pollution, climate change, and population health in China. Environ. Int. 2012, 42, 10–19. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Wang, Y.; Guo, J.; Zhao, C.; Cribb, M.C.; Dong, X.; Fan, J.; Gong, D.; Huang, J.; Jiang, M.; et al. East Asian Study of Tropospheric Aerosols and their Impact on Regional Clouds, Precipitation, and Climate (EAST-AIR CPC). J. Geophys. Res. Atmos. 2019, 124, 13026–13054. [Google Scholar] [CrossRef]
- Lin, H.; Ma, W.; Qiu, H.; Wang, X.; Trevathan, E.; Yao, Z.; Dong, G.H.; Vaughn, M.G.; Qian, Z.; Tian, L. Using daily excessive concentration hours to explore the short-term mortality effects of ambient PM2.5 in Hong Kong. Environ. Pollut. 2017, 229, 896–901. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.J.; Kuo, P.H. A Deep CNN-LSTM Model for Particulate Matter (PM2.5) Forecasting in Smart Cities. Sensors (Basel) 2018, 18, 2220. [Google Scholar] [CrossRef]
- Wang, Y.; Bao, S.; Wang, S.; Hu, Y.; Shi, X.; Wang, J.; Zhao, B.; Jiang, J.; Zheng, M.; Wu, M.; et al. Local and regional contributions to fine particulate matter in Beijing during heavy haze episodes. Sci. Total Environ. 2017, 580, 283–296. [Google Scholar] [CrossRef]
- Zheng, B.; Zhang, Q.; Zhang, Y.; He, K.B.; Wang, K.; Zheng, G.J.; Duan, F.K.; Ma, Y.L.; Kimoto, T. Heterogeneous chemistry: A mechanism missing in current models to explain secondary inorganic aerosol formation during the January 2013 haze episode in North China. Atmos. Chem. Phys. 2015, 15, 2031–2049. [Google Scholar] [CrossRef]
- Liu, D.; Sun, K. Short-term PM2.5 forecasting based on CEEMD-RF in five cities of China. Environ. Sci. Pollut. Res. Int. 2019, 26, 32790–32803. [Google Scholar] [CrossRef]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J. Artificial neural networks forecasting of PM2.5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Wang, D.; Wei, S.; Luo, H.; Yue, C.; Grunder, O. A novel hybrid model for air quality index forecasting based on two-phase decomposition technique and modified extreme learning machine. Sci. Total Environ. 2017, 580, 719–733. [Google Scholar] [CrossRef] [PubMed]
- Park, J.-M.; Kim, J.-H. Online recurrent extreme learning machine and its application to time-series prediction. In Proceedings of the International Joint Conference on Neural Networks (IJCNN) 2017, Anchorage, AK, USA, 14–19 May 2017; pp. 1983–1990. [Google Scholar] [CrossRef]
- Marsha, A.; Larkin, N.K. A statistical model for predicting PM2.5 for the western United States. J. Air Waste Manag. Assoc. 2019, 69, 1215–1229. [Google Scholar] [CrossRef] [PubMed]
- Feng, R.; Zheng, H.-J.; Gao, H.; Zhang, A.-R.; Huang, C.; Zhang, J.-X.; Luo, K.; Fan, J.-R. Recurrent Neural Network and random forest for analysis and accurate forecast of atmospheric pollutants: A case study in Hangzhou, China. J. Clean. Product. 2019, 231, 1005–1015. [Google Scholar] [CrossRef]
- Mao, X.; Shen, T.; Feng, X. Prediction of hourly ground-level PM2.5 concentrations 3 days in advance using neural networks with satellite data in eastern China. Atmos. Pollut. Res. 2017, 8, 1005–1015. [Google Scholar] [CrossRef]
- Gao, S.; Huang, Y.; Zhang, S.; Han, J.; Wang, G.; Zhang, M.; Lin, Q. Short-term runoff prediction with GRU and LSTM networks without requiring time step optimization during sample generation. J. Hydrol. 2020, 589, 125188. [Google Scholar] [CrossRef]
- Díaz-Robles, L.A.; Ortega, J.C.; Fu, J.S.; Reed, G.D.; Chow, J.C.; Watson, J.G.; Moncada-Herrera, J.A. A hybrid ARIMA and artificial neural networks model to forecast particulate matter in urban areas: The case of Temuco, Chile. Atmos. Environ. 2008, 42, 8331–8340. [Google Scholar] [CrossRef]
- Zhou, Q.; Jiang, H.; Wang, J.; Zhou, J. A hybrid model for PM(2).(5) forecasting based on ensemble empirical mode decomposition and a general regression neural network. Sci. Total Environ. 2014, 496, 264–274. [Google Scholar] [CrossRef]
- Murray, N.L.; Holmes, H.A.; Liu, Y.; Chang, H.H. A Bayesian ensemble approach to combine PM2.5 estimates from statistical models using satellite imagery and numerical model simulation. Environ. Res. 2019, 178, 108601. [Google Scholar] [CrossRef]
- Yu, L.; Dai, W.; Tang, L. A novel decomposition ensemble model with extended extreme learning machine for crude oil price forecasting. Eng. Appl. Artif. Intell. 2016, 47, 110–121. [Google Scholar] [CrossRef]
- Zhang, N.N.; Ma, F.; Qin, C.B.; Li, Y.F. Spatiotemporal trends in PM2.5 levels from 2013 to 2017 and regional demarcations for joint prevention and control of atmospheric pollution in China. Chemosphere 2018, 210, 1176–1184. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Yan, S.; Li, J.; Qu, G.; Li, Y.; Lang, J.; Gu, R. A Sequence-to-Sequence Air Quality Predictor Based on the n-Step Recurrent Prediction. IEEE Access 2019, 7, 43331–43345. [Google Scholar] [CrossRef]
- Bueno, A.; Coelho, G.P.; Bertini, J.R. Online sequential learning based on extreme learning machines for particulate matter forecasting. In Proceedings of the 2017 Brazilian Conference on Intelligent Systems (BRACIS), Uberlandia, Brazil, 2–5 October 2017; pp. 169–174. [Google Scholar] [CrossRef]
- Huang, G.; Liang, N.; Rong, H.; Saratchandran, P.; Sundararajan, N. On-line sequential extreme learning machine. In Proceedings of the IASTED International Conference on Computational Intelligence, Calgary, AB, Canada, 4–6 July 2005. [Google Scholar]
- Liu, H.; Xu, Y.; Chen, C. Improved pollution forecasting hybrid algorithms based on the ensemble method. Appl. Math. Model. 2019, 73, 473–486. [Google Scholar] [CrossRef]
- James, J. Robustness of simple trend-following strategies. Quant. Financ. 2003, 3, C114–C116. [Google Scholar] [CrossRef]
- Kanada, M.; Dong, L.; Fujita, T.; Fujii, M.; Inoue, T.; Hirano, Y.; Togawa, T.; Geng, Y. Regional disparity and cost-effective SO2 pollution control in China: A case study in 5 mega-cities. Energy Policy 2013, 61, 1322–1331. [Google Scholar] [CrossRef]
- Li, J.; Du, H.; Wang, Z.; Sun, Y.; Yang, W.; Li, J.; Tang, X.; Fu, P. Rapid formation of a severe regional winter haze episode over a mega-city cluster on the North China Plain. Environ. Pollut. 2017, 223, 605–615. [Google Scholar] [CrossRef]
- Wang, Q.; Kwan, M.P.; Zhou, K.; Fan, J.; Wang, Y.; Zhan, D. The impacts of urbanization on fine particulate matter (PM2.5) concentrations: Empirical evidence from 135 countries worldwide. Environ. Pollut. 2019, 247, 989–998. [Google Scholar] [CrossRef]
- Zhai, S.; Jacob, D.J.; Wang, X.; Shen, L.; Li, K.; Zhang, Y.; Gui, K.; Zhao, T.; Liao, H. Fine particulate matter (PM2.5) trends in China, 2013–2018: Separating contributions from anthropogenic emissions and meteorology. Atmos. Chem. Phys. 2019, 19, 11031–11041. [Google Scholar] [CrossRef]
- Zhang, Q.; Quan, J.; Tie, X.; Li, X.; Liu, Q.; Gao, Y.; Zhao, D. Effects of meteorology and secondary particle formation on visibility during heavy haze events in Beijing, China. Sci. Total Environ. 2015, 502, 578–584. [Google Scholar] [CrossRef]
- Zhao, B.; Wang, S.; Ding, D.; Wu, W.; Chang, X.; Wang, J.; Xing, J.; Jang, C.; Fu, J.S.; Zhu, Y.; et al. Nonlinear relationships between air pollutant emissions and PM2.5-related health impacts in the Beijing-Tianjin-Hebei region. Sci. Total Environ. 2019, 661, 375–385. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Deng, F.; Cai, Y.; Chen, J. Long short-term memory-Fully connected (LSTM-FC) neural network for PM2.5 concentration prediction. Chemosphere 2019, 220, 486–492. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistic | Definition | Notes |
|---|---|---|
| Mean error (bias) | Concentration units | |
| Mean absolute error (MAE) | Concentration units | |
| Root-mean-squared error (RMSE) | Concentration units | |
| Index of agreement (IOA) | Unitless, 0 ≤ IOA ≤ 1 | |
| Fractional bias (FBIAS) | −2 ≤ FBIAS ≤ 2 | |
| Fractional error (FERROR) | 0 ≤ FERROR ≤ 2 | |
| Correlation (R) | −1 ≤ corr ≤ 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, G.; Yu, E.; Wang, Y.; Li, H.; Cheng, D.; Huang, L.; Liu, Z.; Manomaiphiboon, K.; Li, L. A Novel Hybrid Machine Learning Method (OR-ELM-AR) Used in Forecast of PM2.5 Concentrations and Its Forecast Performance Evaluation. Atmosphere 2021, 12, 78. https://doi.org/10.3390/atmos12010078
Lu G, Yu E, Wang Y, Li H, Cheng D, Huang L, Liu Z, Manomaiphiboon K, Li L. A Novel Hybrid Machine Learning Method (OR-ELM-AR) Used in Forecast of PM2.5 Concentrations and Its Forecast Performance Evaluation. Atmosphere. 2021; 12(1):78. https://doi.org/10.3390/atmos12010078
Chicago/Turabian StyleLu, Guibin, Enping Yu, Yangjun Wang, Hongli Li, Dongpo Cheng, Ling Huang, Ziyi Liu, Kasemsan Manomaiphiboon, and Li Li. 2021. "A Novel Hybrid Machine Learning Method (OR-ELM-AR) Used in Forecast of PM2.5 Concentrations and Its Forecast Performance Evaluation" Atmosphere 12, no. 1: 78. https://doi.org/10.3390/atmos12010078
APA StyleLu, G., Yu, E., Wang, Y., Li, H., Cheng, D., Huang, L., Liu, Z., Manomaiphiboon, K., & Li, L. (2021). A Novel Hybrid Machine Learning Method (OR-ELM-AR) Used in Forecast of PM2.5 Concentrations and Its Forecast Performance Evaluation. Atmosphere, 12(1), 78. https://doi.org/10.3390/atmos12010078