Smart Climate Hydropower Tool: A Machine-Learning Seasonal Forecasting Climate Service to Support Cost–Benefit Analysis of Reservoir Management

 ,
,  , , ,
, , ,  and
and
Abstract
1. Introduction
2. Material and Methods
2.1. Data
2.2. Machine Learning Techniques
2.2.1. Support Vector Regression (SVR)
2.2.2. Gaussian Processes (GP)
2.2.3. Long Short-Term Memory (LSTM)
2.2.4. Non-Linear Autoregressive Neural Network, Exogenous Outputs (NARX)
2.2.5. Deep-Learning Neural Networks (DL)
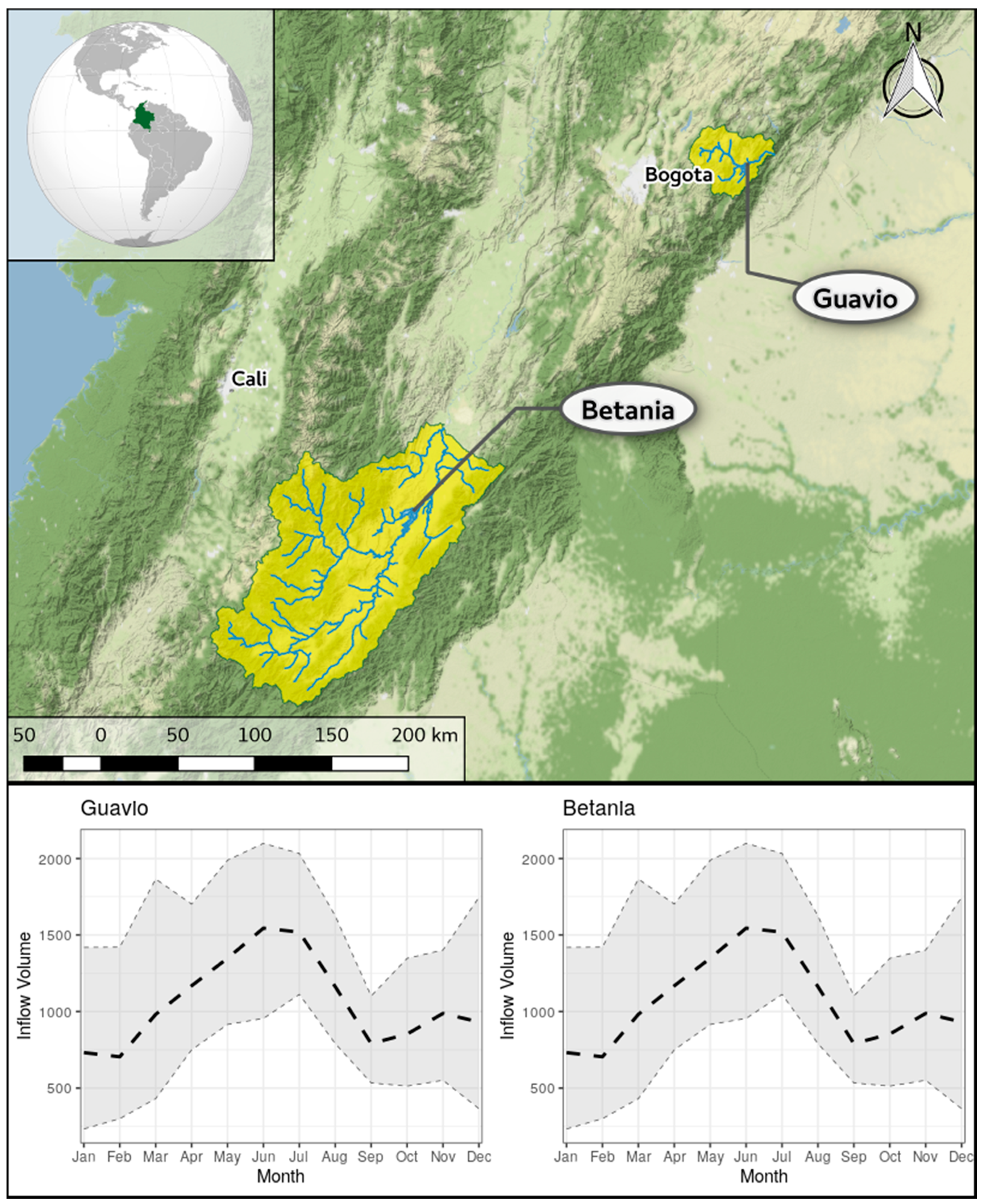
2.3. Case Study Areas
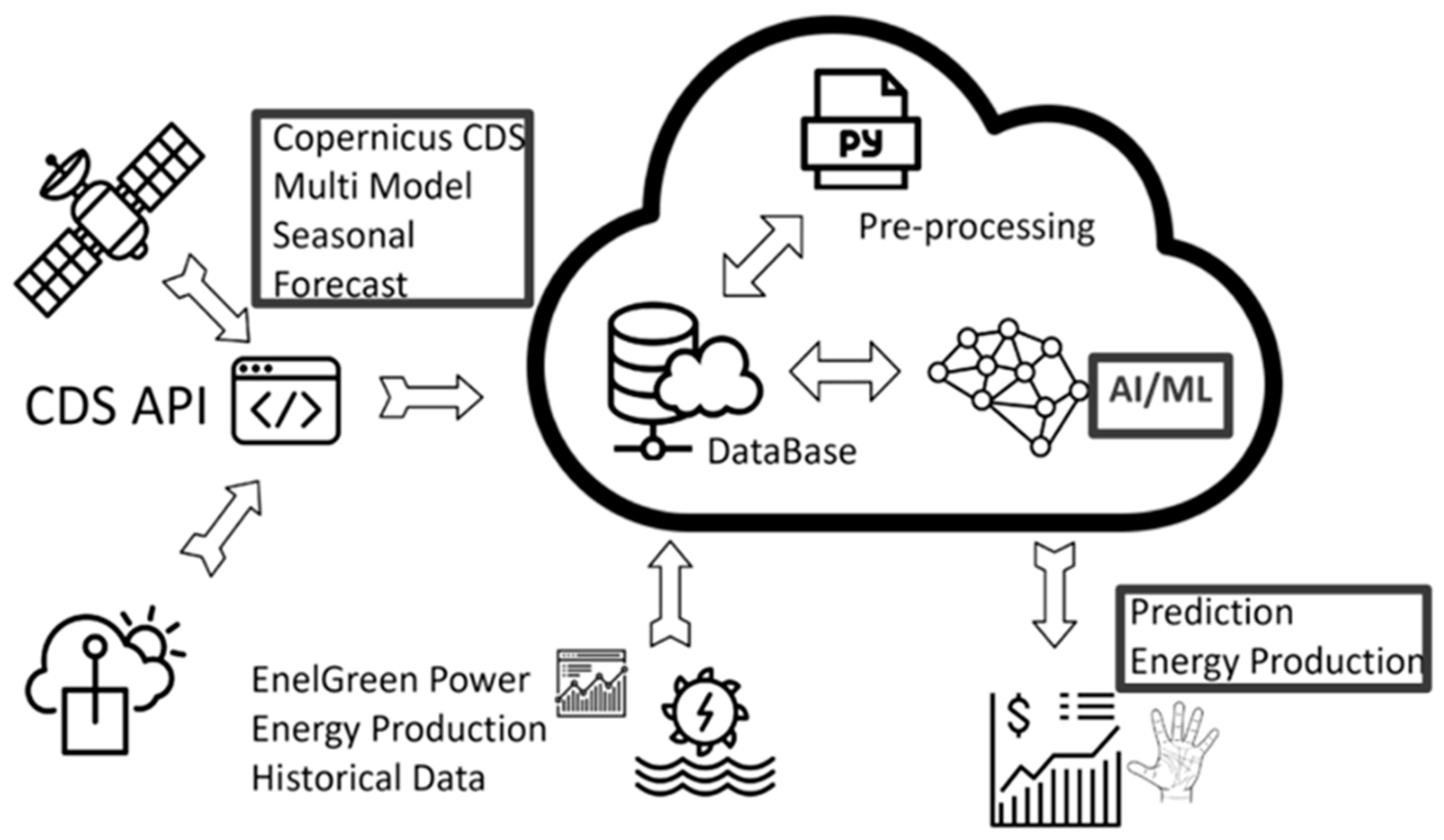
2.4. SCHT as a Climate Service
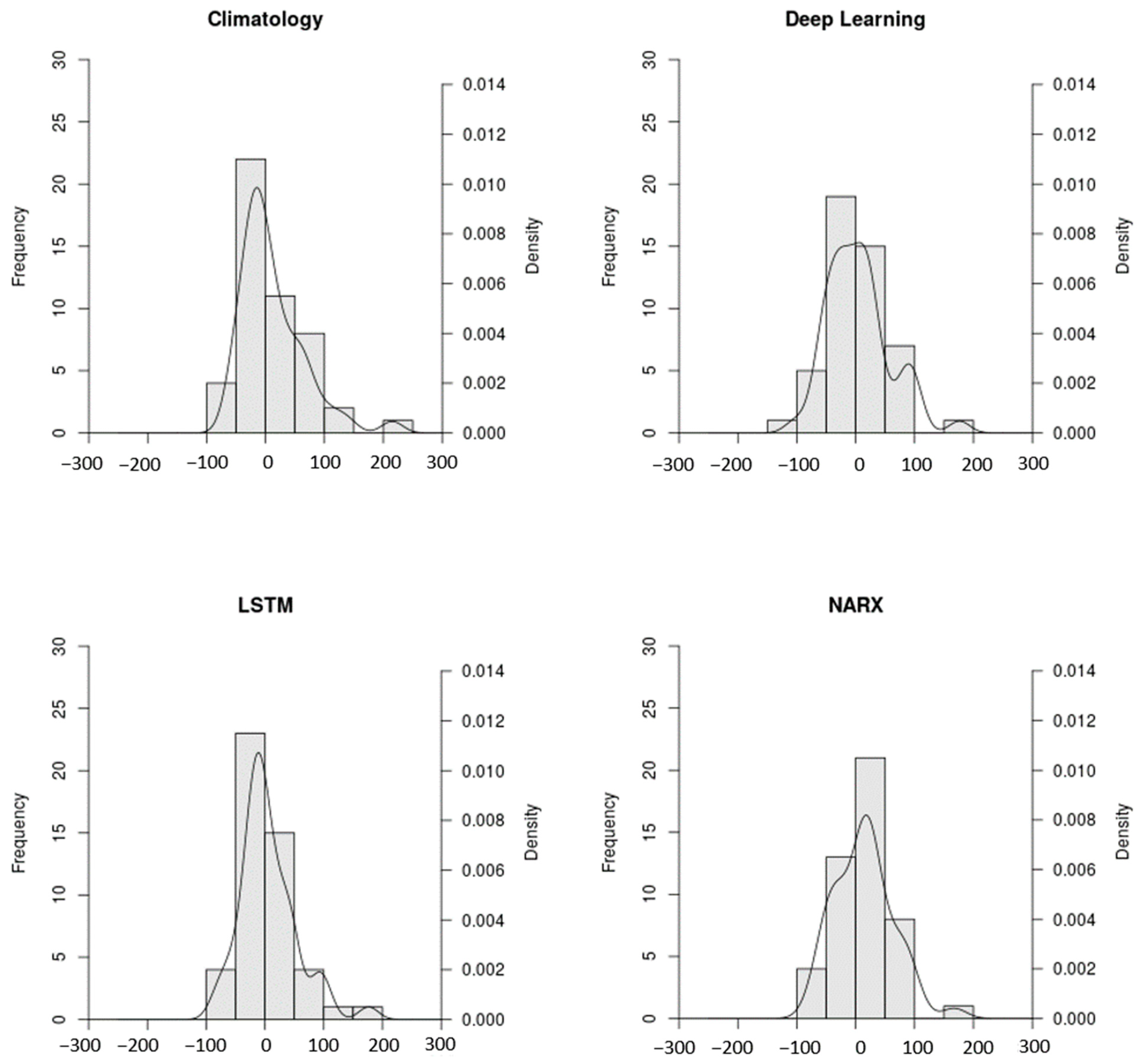
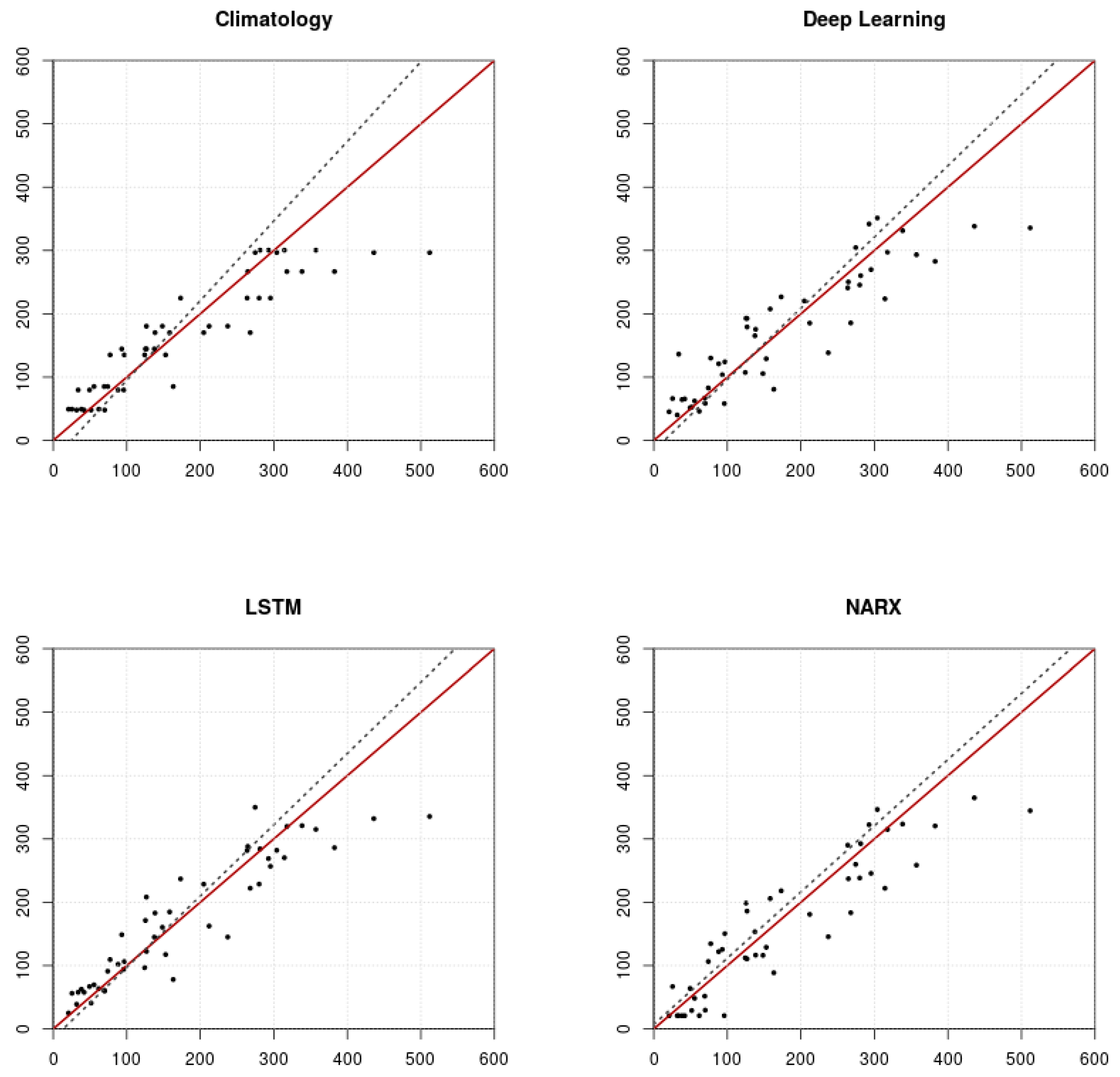
3. Results and Discussion
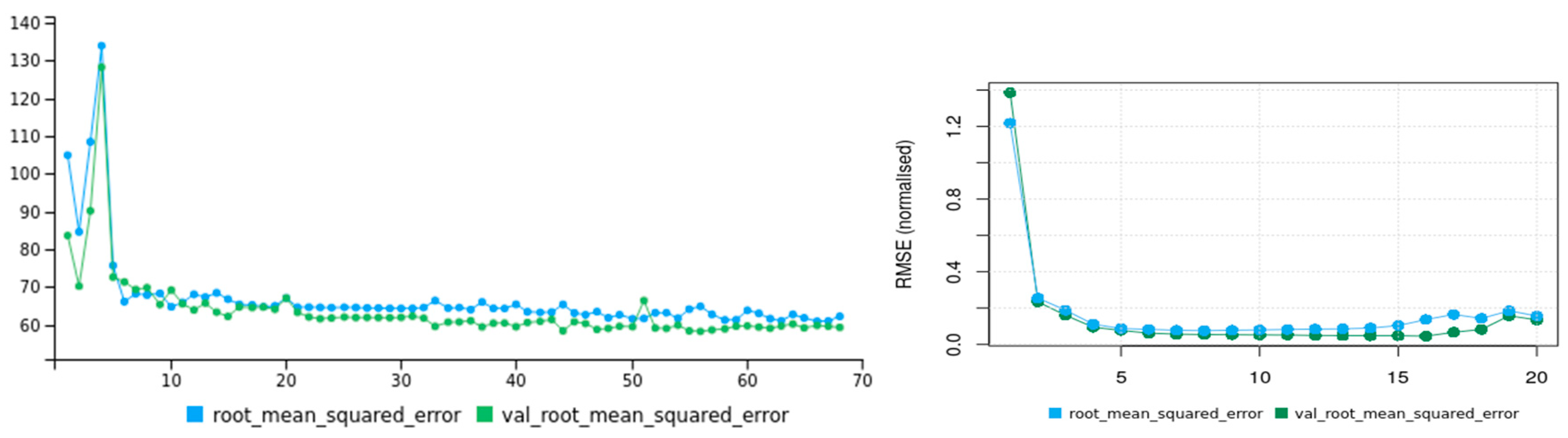
3.1. Technical Aspects of SCHT
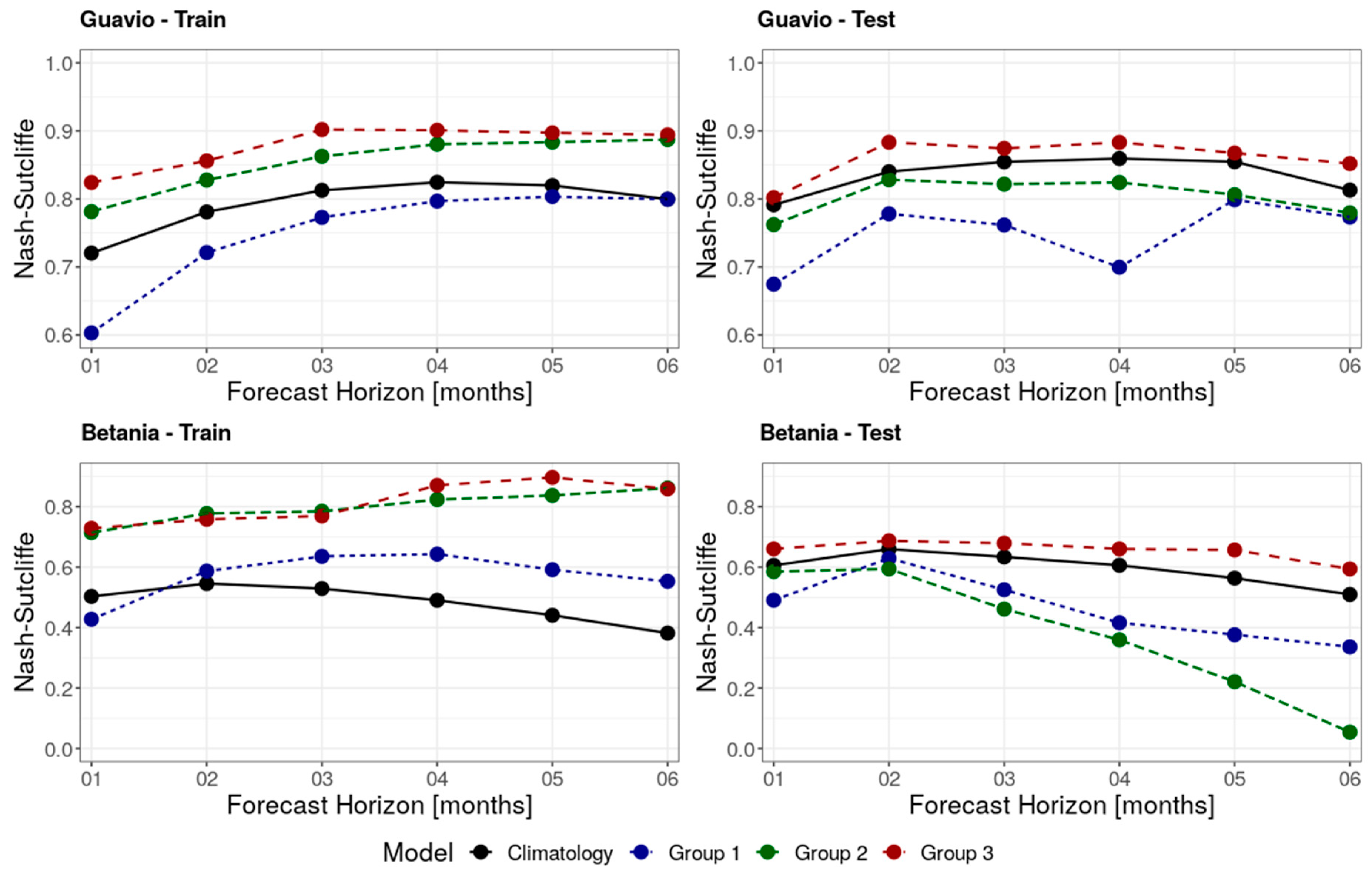
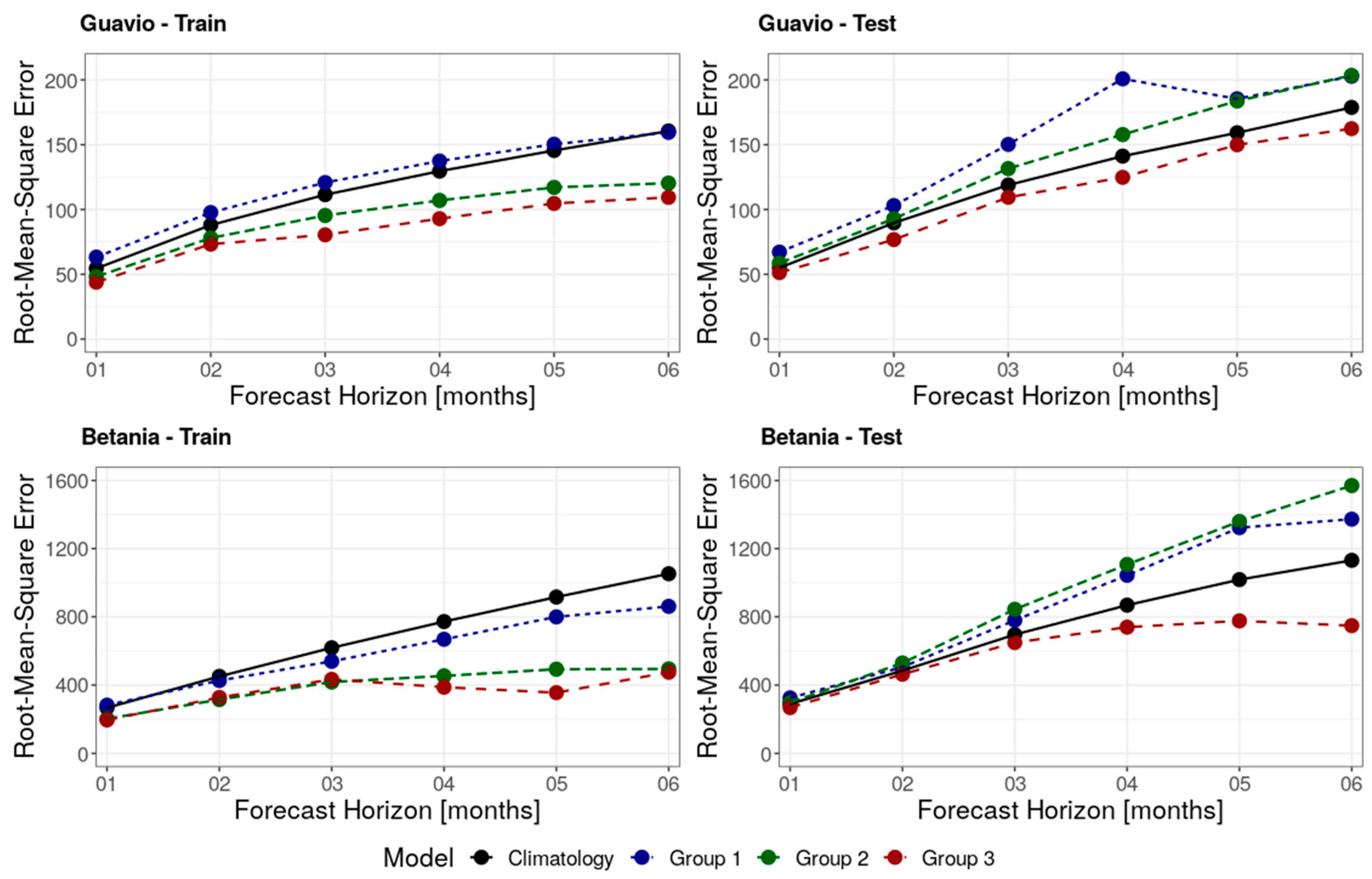
- Group 1: Climatology, persistence, and multiple linear regression (MLR).This group includes the range of methods and models that are used as simple validation metrics for the more complex machine learning models.
- Group 2: Gaussian processes (GP) and support vector machine (SVM) models.This group includes the range of machine learning methods and models that do not use a validation dataset as a means for early stopping the training procedure.
- Group 3: Non-linear autoregressive neural networks (NARX), long short-term memory (LSTM), and deep-learning (DL) models.This group includes the range of machine learning methods and models that use a validation dataset as a means for early stopping the training procedure.
3.2. SCHT as a Climate Service
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jacobson, M.Z. Review of solutions to global warming, air pollution, and energy security. Energy Environ. Sci. 2009, 2, 148–173. [Google Scholar] [CrossRef]
- Tahara, K.; Kojima, T.; Inaba, A. Evaluation of CO2 payback time of power plants by LCA. Energy Convers. Manag. 1997, 38 (Suppl. 1), 615–620. [Google Scholar] [CrossRef]
- Yüksel, I. Hydropower for sustainable water and energy development. Renew. Sustain. Energy Rev. 2010, 14, 462–469. [Google Scholar] [CrossRef]
- Edenhofer, O. Technical summary. In Climate Change 2014: Impacts, Adaptation, and Vulnerability. Part A: Global and Sectoral Aspects. Contribution of Working Group II to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Field, C.B., Barros, V.R., Dokken, D.J., Mach, K.J., Mastrandrea, M.D., Bilir, T.E., Chatterjee, M., Ebi, K.L., Estrada, Y.O., Eds.; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2014; pp. 35–94. [Google Scholar]
- Berga, L. The role of hydropower in climate change mitigation and adaptation: A review. Engineering 2016, 2, 313–318. [Google Scholar] [CrossRef]
- IEA. World Energy Outlook 2019: Executive Summary. Available online: https://www.iea.org/reports/world-energy-outlook-2019 (accessed on 30 November 2020).
- Gernaat, D.E.H.J.; Bogaart, P.W.; van Vuuren, D.P.; Biemans, H.; Niessink, R. High-resolution assessment of global technical and economic hydropower potential. Nat. Energy 2017, 2, 821–828. [Google Scholar] [CrossRef]
- Zhou, Y.; Hejazi, M.; Smith, S.; Edmons, J.; Li, H.; Clarke, L.; Calvin, K.; Thomson, A. A comprehensive view of global potential for hydro-generated electricity. Energy Environ. Sci. 2015, 8, 2622–2633. [Google Scholar] [CrossRef]
- IRENA. Renewable Energy Techlogies: Cost Analysis Series, Hydropower. 2012. Available online: https://www.irena.org/publications/2012/Jun/Renewable-Energy-Cost-Analysis---Hydropower (accessed on 30 November 2020).
- Schaeffer, R.; Szklo, A.S.; de Lucena, A.F.; Borba, B.S.; Nogueira, L.P.; Fleming, F.P.; Troccoli, A.; Harrison, M.; Boulahya, M.S. Energy sector vulnerability to climate change: A review. Energy 2012, 38, 1–12. [Google Scholar] [CrossRef]
- Li, H.; Luo, L.; Wood, E.F.; Schaake, J. The role of initial conditions and forcing uncertainties in seasonal hydrologic forecasting. J. Geophys. Res. Atmos. 2009, 114, 1–10. [Google Scholar] [CrossRef]
- Arias, M.E.; Farinosi, F.; Lee, E.; Livino, A.; Briscoe, J.; Moorcroft, P.R. Impacts of climate change and deforestation on hydropower planning in the Brazilian Amazon. Nat. Sustain. 2020, 3, 430–436. [Google Scholar] [CrossRef]
- Sohoulande, C.D.D. Streamflow drought interpreted using SWAT model simulations of past and future hydrologic scenarios: Application to neches and trinity river basins, Texas. J. Hydrol. Eng. 2019, 24, 5019024. [Google Scholar] [CrossRef]
- Turner, S.W.D.; Bennett, J.C.; Robertson, D.E.; Galelli, S. Complex relationship between seasonal streamflow forecast skill and value in reservoir operations. Hydrol. Earth Syst. Sci. 2017, 21, 4841–4859. [Google Scholar] [CrossRef]
- Zapata, S.; Castaneda, M.; Garces, E.; Franco, C.J.; Dyner, I. Assessing security of supply in a largely hydroelectricity-based system: The Colombian case. Energy 2018, 156, 444–457. [Google Scholar] [CrossRef]
- Ahmad, S.K.; Hossain, F. Maximizing energy production from hydropower dams using short-term weather forecasts. Renew. Energy 2020, 146, 560–1577. [Google Scholar] [CrossRef]
- Gubler, S.; Sedlmeier, K.; Bhend, J.; Avalos, G.; Coelho, C.A.S.; Escajadillo, Y.; Jacques-Coper, M.; Martinez, R.; Schwierz, C.; de Skansi, M. Assessment of ECMWF SEAS5 seasonal forecast performance over South America. Weather Forecast 2020, 35, 561–584. [Google Scholar] [CrossRef]
- Block, P. Tailoring seasonal climate forecasts for hydropower operations. Hydrol. Earth Syst. Sci. 2011, 15, 1355–1368. [Google Scholar] [CrossRef]
- Bazile, R.; Boucher, M.A.; Perreault, L.; Leconte, R. Verification of ECMWF System 4 for seasonal hydrological forecasting in a northern climate. Hydrol. Earth Syst. Sci. 2017, 21, 5747–5762. [Google Scholar] [CrossRef]
- Anghileri, D.; Monhart, S.; Zhou, C.; Bogner, K.; Castelletti, A.; Burlando, P.; Zappa, M. The value of subseasonal hydrometeorological forecasts to hydropower operations: How much does preprocessing matter? Water Resour. Res. 2019, 55, 10159–10178. [Google Scholar] [CrossRef]
- Hao, Z.; Singh, V.P.; Xia, Y. Seasonal drought prediction: Advances, challenges, and future prospects. Rev. Geophys. 2018, 56, 108–141. [Google Scholar] [CrossRef]
- Li, S.; Robertson, A.W. Evaluation of submonthly precipitation forecast skill from global ensemble prediction systems. Mon. Weather Rev. 2015, 143, 2871–2889. [Google Scholar] [CrossRef]
- Vitart, F. Madden—Julian Oscillation prediction and teleconnections in the S2S database. Q. J. R. Meteorol. Soc. 2017, 143, 2210–2220. [Google Scholar] [CrossRef]
- Yuan, X.; Roundy, J.K.; Wood, E.F.; Sheffield, J. Seasonal forecasting of global hydrologic extremes: System development and evaluation over GEWEX basins. Bull. Am. Meteorol. Soc. 2015, 96, 1895–1912. [Google Scholar] [CrossRef]
- Fan, F.M.; Pontes, P.R.M.; Buarque, D.C.; Collischonn, W. Evaluation of upper Uruguay river basin (Brazil) operational flood forecasts. RBRH 2017, 22. [Google Scholar] [CrossRef]
- Long, Y.; Wang, H.; Jiang, C.; Ling, S. Seasonal inflow forecasts using gridded precipitation and soil moisture information: Implications for reservoir operation. Water Resour. Manag. 2019, 33, 3743–3757. [Google Scholar] [CrossRef]
- Morss, R.E.; Demuth, J.L.; Lazo, J.K. Communicating uncertainty in weather forecasts: A survey of the U.S. public. Weather Forecast 2008, 23, 974–991. [Google Scholar] [CrossRef]
- Doblas-Reyes, F.J.; Weisheimer, A.; Deque, M.; Keenlyside, N.; McVean, M.; Murphy, J.M.; Rogel, P.; Smith, D.; Palmer, T.N. Addressing model uncertainty in seasonal and annual dynamical ensemble forecasts. Q. J. R. Meteorol. Soc. 2009, 135, 1538–1559. [Google Scholar] [CrossRef]
- Wang, E.; Zhang, Y.; Luo, J.; Chiew, F.H.S.; Wang, Q.J. Monthly and seasonal streamflow forecasts using rainfall-runoff modeling and historical weather data. Water Resour. Res. 2011, 47, 1–13. [Google Scholar] [CrossRef]
- Teweldebrhan, A.; Burkhart, J.; Schuler, T.; Hjorth-Jensen, M. Coupled machine learning and the limits of acceptability approach applied in parameter identification for a distributed hydrological model. Hydrol. Earth Syst. Sci. Discuss. 2019, 24, 1–25. [Google Scholar] [CrossRef]
- Hamlet, A.F.; Huppert, D.; Lettenmaier, D.P. Economic value of long-lead streamflow forecasts for columbia river hydropower. J. Water Resour. Plan. Manag. 2002, 128, 91–101. [Google Scholar] [CrossRef]
- Poff, N.L.; Tokar, S.; Johnson, P. Stream hydrological and ecological responses to climate change assessed with an artificial neural network. Limnol. Oceanogr. 1996, 41, 857–863. [Google Scholar] [CrossRef]
- Campolo, M.; Soldati, A.; Andreussi, P. Artificial neural network approach to flood forecasting in the River Arno. Hydrol. Sci. J. 2002, 48, 381–398. [Google Scholar] [CrossRef]
- Mutlu, E.; Chaubey, I.; Hexmoor, H.; Bajwa, S.G. Comparison of artificial neural network models for hydrologic predictions at multiple gauging stations in an agricultural watershed. Hydrol. Process. 2008, 22, 5097–5106. [Google Scholar] [CrossRef]
- Essenfelder, A.H. Short-Term Forecast of a River Flow Using Artificial Neural Networks; Federal University of Paraná: Parana, Brazil, 2009. [Google Scholar]
- Zhang, X.; Liang, F.; Yu, B.; Zong, Z. Explicitly integrating parameter, input, and structure uncertainties into Bayesian Neural Networks for probabilistic hydrologic forecasting. J. Hydrol. 2011, 409, 696–709. [Google Scholar] [CrossRef]
- Callegari, M.; Mazzoli, P.; De Gregorio, L.; Notarnicola, C.; Pasolli, L.; Petitta, M.; Pistocchi, A. Seasonal river discharge forecasting using support vector regression: A case study in the Italian Alps. Water 2015, 7, 2494–2515. [Google Scholar] [CrossRef]
- De Gregorio, L.; Callegari, M.; Mazzoli, P.; Bagli, S.; Broccoli, D.; Pistocchi, A.; Notarnicola, C. Operational river discharge forecasting with support vector regression technique applied to alpine catchments: Results, advantages, limits and lesson learned. Water Resour. Manag. 2018, 32, 229–242. [Google Scholar] [CrossRef]
- Essenfelder, A.H.; Giupponi, C. A coupled hydrologic-machine learning modelling framework to support hydrologic modelling in river basins under Interbasin Water Transfer regimes. Environ. Model. Softw. 2020, 131, 104779. [Google Scholar] [CrossRef]
- Johnson, S.J.; Stockdale, T.N.; Ferranti, L.; Balmaseda, M.A.; Molteni, F.; Magnusson, L.; Tietsche, S.; Decremer, D.; Weisheimer, A.; Balsamo, G.; et al. SEAS5: The new ECMWF seasonal forecast system. Geosci. Model Dev. 2019, 12, 1087–1117. [Google Scholar] [CrossRef]
- MINTIC. Caudales Medios Mensuales. Ministerio de Tecnologías de la Información y las Comunicaciones, 2020. Available online: https://www.datos.gov.co/Ambiente-y-Desarrollo-Sostenible/Caudales-Medios-Mensuales/45cv-fhv9 (accessed on 14 July 2019).
- Haylock, M.R.; Hofstra, N.; Klein Tank, A.M.G.; Klok, E.J.; Jones, P.D.; New, M. A European daily high-resolution gridded data set of surface temperature and precipitation for 1950–2006. J. Geophys. Res. Atmos. 2008, 113. [Google Scholar] [CrossRef]
- Gedeon, T.D. Data mining of inputs: Analysing magnitude and functional measures. Int. J. Neural Syst. 1997, 8, 209–218. [Google Scholar] [CrossRef]
- Bergmeir, C.; Hyndman, R.J.; Koo, B. A note on the validity of cross-validation for evaluating autoregressive time series prediction. Comput. Stat. Data Anal. 2018, 120, 70–83. [Google Scholar] [CrossRef]
- Sohoulande, C.D.D.; Martin, J.; Szogi, A.; Stone, K. Climate-driven prediction of land water storage anomalies: An outlook for water resources monitoring across the conterminous United States. J. Hydrol. 2020, 588, 125053. [Google Scholar] [CrossRef]
- Krysanova, V.; Donnelly, C.; Gelfan, A.; Gerten, D.; Arheimer, B.; Hattermann, F.; Kundzewicz, Z.W. How the performance of hydrological models relates to credibility of projections under climate change. Hydrol. Sci. J. 2018, 63, 696–720. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Binger, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Rasmussen, C.E. Gaussian processes in machine learning. In Revised Lectures, Proceedings of the Advanced Lectures on Machine Learning: ML Summer Schools, Canberra, Australia, 2–14 February 2003, Tübingen, Germany, 4–16 August 2003; Bousquet, O., von Luxburg, U., Rätsch, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 63–71. [Google Scholar]
- Kim, H.-C.; Lee, J. Clustering based on gaussian processes. Neural Comput. 2017, 19, 3088–3107. [Google Scholar] [CrossRef] [PubMed]
- Karatzoglou, A.; Smola, A.; Hornik, K.; Zeileis, A. kernlab—An {S4} Package for Kernel Methods in {R.}. J. Stat. Softw. 2004, 11, 1–20. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Net. 2014, 5, 157. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall–runoff modelling using long short-term memory (LSTM) networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef]
- Fan, H.; Jiang, M.; Xu, L.; Zhu, H.; Cheng, J.; Jiang, J. Comparison of long short term memory networks and the hydrological model in runoff simulation. Water 2020, 12, 175. [Google Scholar] [CrossRef]
- Allaire, J.J.; Tang, Y. Tensorflow: R Interface to ‘TensorFlow’. 2020. Available online: https://tensorflow.rstudio.com/ (accessed on 30 November 2020).
- Allaire, J.J.; Chollet, F. “keras: R Interface to ‘Keras’”. 2020. Available online: https://github.com/rstudio/keras (accessed on 30 November 2020).
- Ramachandran, P.; Zoph, B.; Le, Q.V. Swish: A self-gated activation function. Neural and Evolutionary Computing. arXiv 2017, arXiv:1710.05941v1. [Google Scholar]
- Heermann, P.D.; Khazenie, N. Classification of multispectral remote sensing data using a back-propagation neural network. IEEE Trans. Geosci. Remote Sens. 1992, 30, 81–88. [Google Scholar] [CrossRef]
- Giacinto, G.; Roli, F. Design of effective neural network ensembles for image classification purposes. Image Vis. Comput. 2001, 19, 699–707. [Google Scholar] [CrossRef]
- Essenfelder, A.H. Climate Change and Watershed Planning: Understanding the Related Impacts and Risks; Universita’ Ca’ Foscari Venezia: Venezia, Italy, 2017. [Google Scholar]
- Hsieh, W.W. Machine Learning Methods in the Environmental Sciences: Neural Networks and Kernels; Cambridge University Press: New York, NY, USA, 2009. [Google Scholar]
- Maier, H.R.; Dandy, G.C. Neural networks for the prediction and forecasting of water resources variables: A review of modelling issues and applications. Environ. Model. Softw. 2000, 15, 101–124. [Google Scholar] [CrossRef]
- Han, J. Application of Artificial Neural Networks for Flood Warning Systems; North Carolina State University: Raleigh, NC, USA, 2002. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Sit, M.; Demiray, B.Z.; Xiang, Z.; Ewing, G.J.; Sermet, Y.; Demir, I. A comprehensive review of deep learning applications in hydrology and water resources. Water Sci. Technol. 2020. [Google Scholar] [CrossRef]
- LeDell, E.; Gill, N.; Aiello, S.; Fu, A.; Candel, A.; Click, C.; Kraljevic, T.; Nykodym, T.; Aboyoun, P.; Kurka, M.; et al. h2o: R Interface for the ‘H2O’ Scalable Machine Learning Platform. 2020. Available online: https://rdrr.io/cran/h2o/ (accessed on 30 November 2020).
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Rudnick, H.; Velasquez, C. Learning from developing country power market experiences: The Case of Colombia. World Bank Policy Res. Work. Pap. 2019, 8771. [Google Scholar] [CrossRef]
- Morcillo, J.D.; Angulo, F.; Franco, C.J. Analyzing the hydroelectricity variability on power markets from a system dynamics and dynamic systems perspective: Seasonality and ENSO phenomenon. Energies 2020, 13, 2381. [Google Scholar] [CrossRef]
- Larosa, F.; Mysiak, J. Mapping the Landscape of Climate Services. Available online: https://iopscience.iop.org/article/10.1088/1748-9326/ab304d (accessed on 30 November 2020).
- McRae, S.; Wolak, F. Retail electricity pricing in Colombia and the efficient deployment of distributed Generation. Business 2019. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Description | Time Series of Observed Hydrometeorological Data from Ground Stations | Seasonal Forecast System, as Monthly Statistics on Single Levels from 2017 to Present |
|---|---|---|
| Spatial coverage | Local (case study areas) | Global |
| Spatial resolution | N/A | 1° × 1° |
| Temporal coverage | 1993 to present | 2017 to present (forecasts) 1993 to 2016 (hindcasts) |
| Temporal resolution | Monthly | Monthly |
| File format | ASCII | NetCDF |
| Data type | Tabular | Grid multiband |
| Data provider | Hydrographic offices SCHT users | CMCC, through Copernicus CDS |
| Variable Code | Variable Description |
|---|---|
| TARGET | Accumulated inflow river discharge to the reservoir of a hydropower plant. The value of this variable changes with respect to the forecast horizon (e.g., if the forecast horizon is 3 months, then the TARGET value is the total accumulated inflow river discharge for the forthcoming 3 months). Observed data. |
| T0x | Previous x month(s) accumulated inflow river discharge to the reservoir of a hydropower plant. Values of x range from 1 to 6 months in the past. Observed data. |
| T12 | Accumulated inflow river discharge to the reservoir of a hydropower plant of the previous year for the same month of forecast. Observed data. |
| P-x | Accumulated precipitation volume for the forthcoming x month(s). Seasonal forecast data. |
| T-x | Average temperature for the forthcoming x month(s). Seasonal forecast data. |
| Group | Model | Forecast Horizon (month) | BETANIA | GUAVIO | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Nash-Sutcliffe | Root-Mean-Squared Error | Nash-Sutcliffe | Root-Mean-Squared Error | |||||||||||
| Training | Validation | Testing | Training | Validation | Testing | Training | Validation | Testing | Training | Validation | Testing | |||
| Group 1 | Climatology | 1 | 0.50 | - | 0.61 | 267.0 | - | 289.6 | 0.72 | - | 0.79 | 54.5 | - | 55.0 |
| 2 | 0.55 | - | 0.66 | 450.7 | - | 484.5 | 0.78 | - | 0.84 | 88.0 | - | 89.7 | ||
| 3 | 0.53 | - | 0.63 | 618.2 | - | 695.6 | 0.81 | - | 0.85 | 111.4 | - | 118.9 | ||
| 4 | 0.49 | - | 0.61 | 771.9 | - | 867.9 | 0.82 | - | 0.86 | 129.6 | - | 141.2 | ||
| 5 | 0.44 | - | 0.56 | 915.4 | - | 1017.8 | 0.82 | - | 0.85 | 145.5 | - | 159.2 | ||
| 6 | 0.38 | - | 0.51 | 1052.4 | - | 1131.1 | 0.80 | - | 0.81 | 160.6 | - | 178.7 | ||
| Persistance | 1 | 0.15 | - | 0.24 | 349.4 | - | 402.3 | 0.34 | - | 0.47 | 84.1 | - | 87.3 | |
| 2 | 0.50 | - | 0.62 | 474.8 | - | 510.8 | 0.57 | - | 0.63 | 122.8 | - | 135.7 | ||
| 3 | 0.62 | - | 0.67 | 555.3 | - | 664.1 | 0.66 | - | 0.68 | 150.3 | - | 177.0 | ||
| 4 | 0.67 | - | 0.64 | 708.6 | - | 782.5 | 0.70 | - | 0.71 | 170.0 | - | 203.8 | ||
| 5 | 0.57 | - | 0.57 | 881.2 | - | 1005.7 | 0.73 | - | 0.72 | 179.3 | - | 221.4 | ||
| 6 | 0.50 | - | 0.50 | 892.9 | - | 1184.3 | 0.74 | - | 0.73 | 182.5 | - | 226.5 | ||
| MLR | 1 | 0.63 | - | 0.63 | 230.2 | - | 281.9 | 0.75 | - | 0.76 | 51.2 | - | 59.1 | |
| 2 | 0.72 | - | 0.61 | 354.5 | - | 520.9 | 0.81 | - | 0.86 | 82.1 | - | 83.8 | ||
| 3 | 0.76 | - | 0.28 | 443.6 | - | 978.1 | 0.85 | - | 0.75 | 100.6 | - | 154.7 | ||
| 4 | 0.77 | - | 0.00 | 523.7 | - | 1479.0 | 0.87 | - | 0.53 | 112.7 | - | 257.4 | ||
| 5 | 0.76 | - | 0.00 | 601.1 | - | 1946.3 | 0.86 | - | 0.82 | 126.3 | - | 175.6 | ||
| 6 | 0.77 | - | 0.00 | 637.3 | - | 1803.8 | 0.86 | - | 0.78 | 135.3 | - | 203.1 | ||
| Group 2 | GP | 1 | 0.69 | - | 0.60 | 209.7 | - | 291.5 | 0.78 | - | 0.77 | 48.8 | - | 57.2 |
| 2 | 0.76 | - | 0.61 | 330.5 | - | 520.3 | 0.82 | - | 0.82 | 78.9 | - | 94.5 | ||
| 3 | 0.78 | - | 0.48 | 427.1 | - | 827.5 | 0.86 | - | 0.82 | 97.2 | - | 133.2 | ||
| 4 | 0.80 | - | 0.37 | 479.8 | - | 1093.2 | 0.87 | - | 0.82 | 109.7 | - | 160.7 | ||
| 5 | 0.81 | - | 0.24 | 528.3 | - | 1343.0 | 0.88 | - | 0.80 | 118.3 | - | 188.3 | ||
| 6 | 0.83 | - | 0.04 | 553.5 | - | 1581.1 | 0.88 | - | 0.77 | 124.4 | - | 208.9 | ||
| SVM | 1 | 0.74 | - | 0.57 | 194.9 | - | 302.5 | 0.79 | - | 0.75 | 47.6 | - | 60.2 | |
| 2 | 0.80 | - | 0.58 | 300.0 | - | 537.6 | 0.83 | - | 0.83 | 77.2 | - | 91.3 | ||
| 3 | 0.79 | - | 0.44 | 408.9 | - | 859.2 | 0.87 | - | 0.83 | 93.6 | - | 129.9 | ||
| 4 | 0.84 | - | 0.34 | 427.4 | - | 1120.1 | 0.89 | - | 0.83 | 104.3 | - | 154.8 | ||
| 5 | 0.86 | - | 0.20 | 457.3 | - | 1375.9 | 0.89 | - | 0.82 | 115.8 | - | 179.2 | ||
| 6 | 0.89 | - | 0.07 | 435.3 | - | 1560.2 | 0.89 | - | 0.79 | 116.3 | - | 198.0 | ||
| Group 3 | NARX | 1 | 0.75 | 0.52 | 0.61 | 185.3 | 248.1 | 286.6 | 0.84 | 0.75 | 0.82 | 41.1 | 63.2 | 51.4 |
| 2 | 0.73 | 0.60 | 0.66 | 345.9 | 393.6 | 478.1 | 0.84 | 0.84 | 0.88 | 75.3 | 92.0 | 79.4 | ||
| 3 | 0.77 | 0.75 | 0.69 | 429.5 | 419.0 | 630.9 | 0.91 | 0.90 | 0.87 | 77.4 | 100.9 | 112.5 | ||
| 4 | 0.90 | 0.87 | 0.70 | 363.7 | 369.8 | 662.2 | 0.92 | 0.89 | 0.87 | 88.1 | 124.9 | 125.2 | ||
| 5 | 0.88 | 0.65 | 0.68 | 423.7 | 464.1 | 728.8 | 0.89 | 0.88 | 0.87 | 114.5 | 144.0 | 148.4 | ||
| 6 | 0.95 | 0.75 | 0.61 | 276.3 | 520.3 | 683.0 | 0.88 | 0.85 | 0.84 | 122.8 | 168.4 | 162.2 | ||
| DL | 1 | 0.72 | 0.45 | 0.72 | 198.5 | 262.8 | 245.8 | 0.81 | 0.72 | 0.80 | 44.8 | 66.1 | 53.8 | |
| 2 | 0.74 | 0.60 | 0.68 | 343.0 | 393.2 | 468.7 | 0.87 | 0.83 | 0.90 | 66.5 | 93.7 | 71.2 | ||
| 3 | 0.76 | 0.70 | 0.66 | 444.2 | 459.5 | 645.8 | 0.90 | 0.85 | 0.88 | 80.2 | 122.2 | 105.8 | ||
| 4 | 0.87 | 0.74 | 0.65 | 373.2 | 503.8 | 774.4 | 0.87 | 0.90 | 0.90 | 102.7 | 122.8 | 121.9 | ||
| 5 | 0.94 | 0.70 | 0.63 | 202.4 | 529.4 | 810.9 | 0.86 | 0.89 | 0.87 | 108.0 | 139.8 | 150.5 | ||
| 6 | 0.79 | 0.57 | 0.59 | 608.5 | 831.2 | 763.6 | 0.87 | 0.82 | 0.88 | 110.7 | 181.7 | 153.0 | ||
| LSTM | 1 | 0.71 | 0.46 | 0.65 | 203.4 | 259.8 | 272.1 | 0.82 | 0.74 | 0.78 | 45.6 | 60.6 | 48.6 | |
| 2 | 0.81 | 0.52 | 0.71 | 293.0 | 431.7 | 443.4 | 0.85 | 0.78 | 0.87 | 77.9 | 96.9 | 79.7 | ||
| 3 | 0.78 | 0.74 | 0.68 | 426.2 | 503.7 | 670.1 | 0.89 | 0.86 | 0.87 | 83.7 | 115.5 | 110.0 | ||
| 4 | 0.84 | 0.68 | 0.64 | 425.4 | 562.2 | 780.6 | 0.92 | 0.88 | 0.88 | 88.0 | 129.6 | 127.3 | ||
| 5 | 0.86 | 0.68 | 0.66 | 440.3 | 516.6 | 787.6 | 0.94 | 0.86 | 0.86 | 91.4 | 152.8 | 150.9 | ||
| 6 | 0.83 | 0.57 | 0.58 | 539.9 | 837.3 | 797.3 | 0.93 | 0.80 | 0.84 | 94.6 | 189.7 | 171.9 | ||
| Scenario | Metric | Perfect Forecast | Climatology | SCHT |
|---|---|---|---|---|
| Betania (6 months) | Forecast values (mm3) | 8418.5 | 7528.1 | 8017 |
| Absolute error with respect to observation (mm3) | 0 | 890.4 | 401.5 | |
| Potential benefits with respect to climatology (in thousands $) | 237.44 | 0 | 130.38 | |
| Guavio (3 months) | Forecast values (mm3) | 668.6 | 566 | 647.1 |
| Absolute error with respect to observation (mm3) | 0 | 102.6 | 21.5 | |
| Potential benefits with respect to climatology (in thousands $) | 460 | 0 | 363.48 | |
| Total potential benefits with respect to climatology (in thousands $) | 697.44 | 0 | 493.86 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Essenfelder, A.H.; Larosa, F.; Mazzoli, P.; Bagli, S.; Broccoli, D.; Luzzi, V.; Mysiak, J.; Mercogliano, P.; dalla Valle, F. Smart Climate Hydropower Tool: A Machine-Learning Seasonal Forecasting Climate Service to Support Cost–Benefit Analysis of Reservoir Management. Atmosphere 2020, 11, 1305. https://doi.org/10.3390/atmos11121305
Essenfelder AH, Larosa F, Mazzoli P, Bagli S, Broccoli D, Luzzi V, Mysiak J, Mercogliano P, dalla Valle F. Smart Climate Hydropower Tool: A Machine-Learning Seasonal Forecasting Climate Service to Support Cost–Benefit Analysis of Reservoir Management. Atmosphere. 2020; 11(12):1305. https://doi.org/10.3390/atmos11121305
Chicago/Turabian StyleEssenfelder, Arthur H., Francesca Larosa, Paolo Mazzoli, Stefano Bagli, Davide Broccoli, Valerio Luzzi, Jaroslav Mysiak, Paola Mercogliano, and Francesco dalla Valle. 2020. "Smart Climate Hydropower Tool: A Machine-Learning Seasonal Forecasting Climate Service to Support Cost–Benefit Analysis of Reservoir Management" Atmosphere 11, no. 12: 1305. https://doi.org/10.3390/atmos11121305
APA StyleEssenfelder, A. H., Larosa, F., Mazzoli, P., Bagli, S., Broccoli, D., Luzzi, V., Mysiak, J., Mercogliano, P., & dalla Valle, F. (2020). Smart Climate Hydropower Tool: A Machine-Learning Seasonal Forecasting Climate Service to Support Cost–Benefit Analysis of Reservoir Management. Atmosphere, 11(12), 1305. https://doi.org/10.3390/atmos11121305