1. Introduction
In the last several decades, abnormal weather, such as cold weather, heavy snow, heavy rain, and drought, has been occurring more and more frequently in all parts of the world, causing human injury and death, property damage, and health and environmental problems [
1]. In other words, weather change has a direct negative impact on the daily quality of life. In particular, unexpectedly increased temperatures harm outdoor workers [
2]. Temperature forecasts can be used to determine what to wear on a given day and to plan one’s work outside [
3]. Depending on the applications of the temperature forecast, a suitable model should be designed at a specific site or a region with at least 10 days’ prediction [
4].
Meteorological institutes usually forecast prediction results based on numerical weather prediction (NWP) models that predict the weather based on current weather conditions [
5]. In general, NWP models target the forecasts for large geometrical areas, such as the East Asian region, and they are good at handling weather that is complexly connected with various factors that dynamically influence the subsequent day’s weather. However, NWP often produces biased temperatures in proportion to the increase of the local elevation and topographical complexity [
6]. Moreover, predicting spatial and temporal changes in temperature for areas composed of complex topography remains a challenge to NWP models [
7].
Over recent decades, to train these irregularities, deep learning models have been developed to predict weather change that involves atmospheric time series data. For example, a multi-layer perceptron (MLP) model, which is a neural network with one hidden layer, was proposed to deal with maximum ozone levels in Texas metropolitan areas [
8]. Next, a three-layer deep neural network (DNN) model was proposed to predict the air pollution levels of cities in China [
9]. In addition, the temperature prediction accuracy of a DNN-based model was compared with those of traditional mathematical models, and it was discovered that the DNN provided comparable accuracy and offered the advantage of including data that are not used in traditional equations [
10].
Therefore, the purpose of this study is to design a temperature prediction model based on a DNN by using real observed weather data. Among different kinds of neural networks, the proposed prediction model is constructed based on a long short-term memory (LSTM) neural network, which is a type of recurrent neural network (RNN). This is because the LSTM architecture is more appropriate for weather data than a feedforward DNN or a typical RNN structure due to the time-series characteristics of weather data [
11]. In order to train a deep learning model, a huge amount of training data is needed, but these data should not be defective. However, there is a limitation to collecting weather data since we are unable to measure data that have been missed. Thus, the collected data are apt to be incomplete, with random or extended gaps. Therefore, the proposed temperature prediction model incorporates a function for missing data refinement into the LSTM framework in order to restore missing weather data. The proposed model is composed of four stages. In the first stage, the model detects whether or not any component of the input data is missing. The second stage of the model training constructs an LSTM-based refinement model using all the training data. Then, the third stage of the proposed model tries to predict the temperature for the missing vector components. The last stage retrains the temperature prediction model using the refined data.
As mentioned in [
4], the proposed model also aims at predicting temperature up to 14 days in advance using 24 h weather data as the input, and it can also provide 6, 12, and 24 h temperature predictions. In order to compare the performance of the proposed model, four different temperature prediction models are considered: (1) a prediction model using a DNN, (2) a prediction model using a conventional LSTM without any refinement function, (3) a prediction model using an LSTM with a simple gap-filling method by linearly interpolating missed data from past and future data, and (4) a unified model (UM), which is a mathematical model currently used by the meteorological office in Korea. Then, the performances of the different temperature prediction models are compared by measuring the root-mean-squared errors (RMSEs) between the real observed and predicted temperatures for the different models.
The remainder of this paper is organized as follows.
Section 2 discusses the methodology of deep learning-based temperature prediction models. Then,
Section 3 proposes an LSTM-based temperature prediction model along with the proposed refinement function.
Section 4 evaluates the performance of the proposed model and compares it with that of other deep learning models and a UM model. Finally,
Section 5 summarizes and concludes this paper.
3. A Proposed LSTM-Based Temperature Prediction Model with Missing Data Refinement
According to our preliminary experiments on an LSTM-based temperature prediction model, as described in
Section 2.3, the temperature prediction can work accurately to some degree. However, as mentioned in
Section 1, it is a difficult task to collect a huge amount of training data without any defects. In other words, the collected data are apt to be incomplete, with random or extended gaps. To this end, this section proposes a new temperature prediction model based on LSTM so the proposed model intrinsically has a function for missing data refinement to restore the missing weather data.
3.1. Investigation of Weather Factors Correlated to Temperature
This subsection investigates the weather factors that affect temperature. To this end, the weather data released by the Meteorological Office of South Korea (KMA) [
23] are used. In particular, the weather data are composed of hourly measurements for temperature, wind direction, wind speed, relative humidity, cumulative precipitation, vapor pressure, and barometric pressure, collected over 36 years (from November 1981 to December 2016). Then, the correlation coefficient between the temperature and each of other weather factors is computed for all 36 years (
Table 1). As shown in the table, temperature is highly correlated with wind speed, wind direction, and humidity. Therefore, wind speed, wind direction, and humidity are used for temperature prediction throughout this paper.
3.2. Proposed Refinement Function Using LSTM
As mentioned in the previous subsection, three weather factors (wind speed, wind direction, and humidity) are correlated with temperature. Thus, if temperature data are missed at given times but there are other weather factors available, these missed data can be restored by using the correlated characteristics. Based on this fact, a refinement function of the proposed model is realized by also using the LSTM that works as a correlator between other weather factors and temperature.
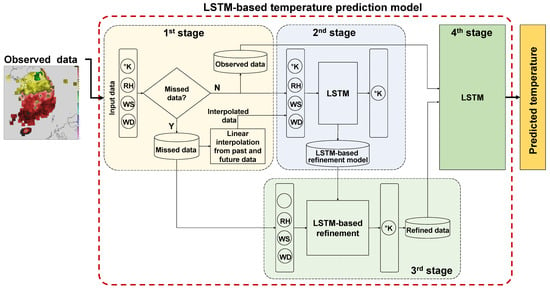
Figure 4 shows the architecture of the proposed LSTM-based temperature prediction model with a missing data refinement function incorporated. The proposed model is composed of four processing stages. The first stage detects whether or not any component of an input vector is missed, where each input vector is composed of 4-dimensional weather data (temperature, RH, wind speed, and wind direction). If one or more components are missed, then each missed component is linearly interpolated with past and future observed data. This process is done for all the training data.
Next, the second stage constructs an LSTM-based refinement model using all the training data, in which the missed data are already linearly interpolated. The LSTM-based refinement model is composed of one input layer, two LSTM layers, and one output layer, where 4-dimensional weather data are also used for an input vector, as shown in the second stage of
Figure 4.
After training the LSTM-based refinement model, the third stage of the proposed model predicts temperature for the times when the temperature data, which were already detected in the first stage, are missing. By doing this, the missed temperature data are replaced with the predicted data; this process is referred to as a refinement function. The last stage of the proposed model is identical to that of the conventional LSTM model, as described in
Section 2.3. The difference between the conventional LSTM model and the proposed one is in that in the proposed model, the missing data are refined through the refinement function and then are combined with the collected data without any missing components to train the LSTM.
3.3. Selection of Hyperparameters of LSTM
As weather is a chaotic process, many different factors play pivotal roles in controlling the change of a weather variable. Likewise, the deep structure of a neural network functions as very complex logic; thus, changing the network factors affects the prediction results. The network factors, called neural network hyperparameters, include the learning rate, batch size, number of epochs, regularization, weight initialization, number of hidden layers, number of nodes, etc. [
24].
For hidden layers, activation functions determine whether the input feature is considered to be connected to the output nodes. In general, the activation functions need to be bounded. If the value of an activation function is above a certain bound, it is considered activated. If it is less than the bound, it is discarded. To make the proposed LSTM-based prediction model focus on weather data, especially temperature, we need to use several activation functions, such as linear, sigmoid, and ReLU functions. To this end, each of these three activation functions is employed in this model, and one of them is chosen for the best prediction accuracy. The ReLU was ultimately selected through this process and will be discussed in
Section 4.3.
Similarly, the effect of different combinations of the numbers of LSTM layers and hidden nodes on the prediction accuracy is investigated by changing the LSTM layers from 2 to 6 and 192 to 480, with 96 hops for the hidden nodes. As a result, the number of LSTM layers is selected as 4, and the number of hidden nodes is selected as 384.
4. Experiments and Discussion
This section first briefly reviews a unified model (UM) that delivers the forecast results. Then, the database used in this paper is described. After that, the prediction accuracy of the proposed LSTM-based temperature prediction model is evaluated, where three LSTM models with the refinement function proposed in
Section 3.2 are individually trained for hourly temperature predictions such as 6, 12, 24 h predictions. In addition, the other two LSTMs with the proposed refinement function are trained for 7 and 14 day temperature predictions. To compare the performance of the proposed model, the DNNs and conventional LSTMs in
Section 2.1 and
Section 2.3, respectively, are implemented for 6, 12, and 24 h temperature predictions, where missing data were simply ignored. Next, the conventional LSTMs were also implemented for 7 and 14 day temperature predictions, where two simple strategies for processing missing data, such as ignorance and linear interpolation, are applied. Finally, the prediction accuracy of the proposed model is compared with that of the UM model with the same weather data.
Note here that different LSTMs are evaluated using different values of the hyperparameters to examine the effectiveness of the hyperparameter set on the prediction accuracy, as described in
Section 3.3. Therefore, throughout this paper, the numbers in the parentheses after LSTM, denoted as LSTM(
x,
y), mean that the number of LSTM layers is
x, and the number of hidden nodes is
y.
4.1. UM Model
The KMA has been conducting weather forecasts since 2010 based on the unified model (UM) developed by the U.K. Met Office [
25]. The weather forecasting system of KMA consists of three NWP systems: Global Data Assimilation and Prediction System (GDAPS), Regional Data Assimilation and Prediction System (RDAPS), and Local Data Assimilation and Prediction System (LDAPS). The predictions of GDAPS and RDAPS are used as the boundary conditions for the operations of RDAPS and LDAPS, the domains of which are represented in
Figure 5. As shown in the figure, RDPAS and LDAPS cover East Asia and South Korea with horizontal resolutions of 12 km × 12 km and 1.5 km × 1.5 km, respectively. Both systems have 70 sigma vertical layers, but the top heights are set to 80 km and 40 km for the RDAPS and LDAPS, respectively.
Table 2 summarizes the physical options used for the operation of the UM-based NWP system in KMA. The temperature predicted by the proposed LSTM-based model was compared with that by the UM LDAPS, which was obtained from the official data archive [
23].
4.2. Database
In this study, we prepared the weather data released by the KMA, where the observations for all the observations including temperature, relative humidity, wind speed, and wind direction were made every hour [
31]. The weather data were observed for around 37 years (from November 1981 to December 2017) from three different locations in South Korea (Seoul, Gyeonggi, and Jeolla), and these data were divided into two datasets: the data for around 36 years (from November 1981 to December 2016) were used as a training set, and the data for one year (from January 2017 to December 2017) as a test set. Note here that the period of weather data recording for the training set did not overlap that for the test data. Therefore, all the prediction models in this paper were trained and evaluated by using the training data and test data, respectively, unless there was no additional explanation for the training and test set. In addition, each prediction model per location was constructed, and the prediction accuracy for the model was averaged over three locations.
The performance was averaged over the three different prediction models. Moreover, some of the weather factors in the training set were missing, with 38%, 21%, 19%, and 11% missing data for relative humidity, wind speed, wind direction, and temperature, respectively. Since the number of missing data was relatively large, we developed a technique for dealing with the missed data, as described in
Section 3.2. The performance comparison was done by calculating the RMSE and mean bias error (MBE) between the real observed temperature,
and the predicted temperature,
at a time,
t, which are defined as
and
where
N is the total number of times for the evaluation.
4.3. Comparison Between DNN and LSTM
In this subsection, we compare the prediction accuracy of the RMSE between the DNN model in
Section 2.1 and the LSTM model in
Section 2.3. Here, the architectures of the DNN and the LSTM model follow the previous works in [
12,
21], respectively. In particular, the numbers of LSTM layers and hidden nodes were set to 2 and 192, respectively. In both the DNN-based and LSTM-based temperature prediction models, the missing data were simply ignored for training and testing the models. In addition, each DNN or LSTM was implemented with three different activation functions: linear, sigmoid, and ReLU.
Table 3 compares RMSEs of DNN- and LSTM-based temperature prediction models according to different activation functions. It was shown from the table that LSTM(2,192) provided a lower RMSE than the DNN for all activation functions and three different time steps. In addition, the RMSEs of LSTM employing the ReLU activation function were smaller than those employing the linear and sigmoid activation functions for all three time-steps. Based on this experiment, the ReLU activation function was only considered for the following discussion, as mentioned in
Section 3.3.
4.4. Comparison of LSTMs with Different Refinement Functions
Table 4 shows the performance comparison of LSTMs according to different missing data refinement functions for 6, 12, and 24 h temperature predictions. Here, the numbers of LSTM layers and hidden nodes were also set to 2 and 192, respectively, resulting in LSTM(2,192). However, instead of ignoring missing data, the linear interpolation refinement that interpolated the missing data with adjacent observed temperature data was incorporated into LSTM(2,192). As a result, it is shown in the table that LSTM(2,192) with linear interpolation greatly reduced the RMSE compared to the RMSE ignoring the missing data. Next, our proposed LSTM-based refinement function was applied to LSTM(2,192). Consequently, the LSTM(2,192) with LSTM-refinement further reduced the RMSE, especially for 12 and 24 h temperature predictions.
Next, in order to examine the effectiveness of the different hyperparameters on the performance of LSTM with the proposed LSTM-based refinement function, several evaluations on LSTM were conducted by changing both the number of LSTM layers from 2 to 6 and the number of hidden nodes from 192 to 480. In this experiment, the training dataset described in
Section 4.2 was split into subsets: one is the data set for around 34 years from November 1981 to December 2014, denoted as the 34-dataset, and the other is for the two years of data from January 2015 to December 2016, denoted as the 2-dataset. Then, each LSTM was trained and evaluated using the 34-dataset and 2-dataset, respectively, to set the hyperparameters. Note that there was no overlap between the 2-dataset in this subsection and the test set described in
Section 4.2.
Table 5 compares the RMSEs according to different numbers of LSTM layers and hidden nodes, where the proposed LSTM-based refinement function was applied for 24 h temperature prediction. As shown in the table, we achieved the lowest RMSE when the numbers of LSTM layers and hidden nodes were set to 4 and 384, respectively, with a smaller number of hyperparameters than LSTM(4,480) or LSTM(5,384). Based on these, the performances of LSTM(4,384) for different prediction time periods were compared.
4.5. Comparison of LSTMs for Short and Long Period Temperature Prediction
First, LSTM(4,384) was trained using three different refinement approaches: (1) the ignorance of missing data (i.e., without refinement), (2) linear interpolation, and (3) the proposed LSTM-based refinement function.
Table 6 compares the average RMSEs and MBEs of the three LSTMs and the UM for 6, 12, and 24 h temperature prediction. As shown in the table, the LSTM-based prediction models with/without refinement functions gave a lower average RMSE and MBEs than the UM for all the different time steps. Moreover, similar to
Table 4, the LSTM(4,384) with a refinement function, such as linear interpolation or LSTM refinement, reduced the RMSE compared to that without any refinement. In particular, the LSTM(4,384) with the proposed LSTM-based refinement function was better than that with linear interpolation. Note here that the prediction accuracies for 12 h temperature prediction was a little worse than those for 24 h prediction. This was because the input data to the LSTM were composed of the data observed at the current time and previous 11 h, while the target was advanced by 12 h, which might result in the day-night reversal due to the time difference between the input and target data of the models. This could be mitigated when the input data would be selected according to the target time.
Next, the proposed LSTM-based temperature prediction model was extended to predict 7 and 14 day future temperatures, and its RMSE was compared with the RMSEs by using the LSTM(4,384) without any refinement and with linear interpolation. As shown in
Table 7, the tendency toward RMSE and MBE reduction for this long period temperature prediction was similar to that for 6, 12, and 24 h prediction. Interestingly, the proposed model with the LSTM-refinement had a 3.06 RMSE for 14 day prediction, which was lower than the DNN for 24 h predictions, as shown in the third row of
Table 3. Moreover, the RMSE of the proposed LSMT-based model seems to be lower than that reported in [
32], where a RMSE around 3 was achieved for 69–91 h (around 4 day) predictions and an RMSE of around 4 for 261–283 h (around 12 day) predictions.
4.6. Comparison with the UM Model
As mentioned above, in order to assess the potential usability of the proposed LSTM-based temperature prediction model, the accuracy comparison between the proposed model and LDAPS was conducted for 24 h temperature predictions from January 2017 to December 2017. In addition, the temperature predicted by the proposed model was compared with the forecast results of the UM model. It was confirmed that average RMSEs were 1.39, 1.45, and 1.52 for all 6, 12, and 24 h temperature predictions, respectively, as shown in the last row of
Table 6. Note that unfortunately the KMA only provided up to a 48 h prediction of LDAPS; thus, we could not compare the performance for 7 and 14 day temperature predictions. Based on this experiment, which used one-year weather data, the proposed LSTM-based temperature prediction model achieved a lower RMSE for 24 h predictions than the UM model.
Figure 6 illustrates a time-series plot of the observed and predicted temperature data for two months (August to October 2017) in Seoul, Korea for 24-h (1-day) prediction. In the figure, four different models are compared, including the three models described in
Table 6 and the UM LDAPS. As shown in the figure, the 24 h temperatures predicted by the proposed LSTM-based model employing the LSTM-refinement were, on average, close to those of the observed data. In particular, the proposed model had a lower average RMSE measured from August to October 2017 than LDAPS.
However, when the season changed, the proposed LSTM-based temperature prediction model was less accurate than that for the other periods. For example, we divided the 24 h prediction results of
Figure 6 at weekly intervals, as shown in
Figure 7, where each bar in the figure was drawn after averaging the RMSE over each week, and the vertical line at the top of each bar denotes the MBE of each RMSE. As shown in the figure, the week that contained the lowest temperature from the graph had a relatively higher RMSE than that of the other weeks. Nevertheless, it was shown that the proposed LSTM-based model still achieved better performance than LDAPS over the entire two month duration.
Finally,
Figure 8 illustrates a time-series plot of the observed and predicted temperature data for two months (August to October 2017) in Seoul, Korea for 7 day and 14 day predictions. Note that only three different models in
Table 7 were compared in this figure, because KMA only provided up to 48 h prediction result for LDAPS, as mentioned earlier. As shown in the figure, as the prediction period increased as 7 and 14 days, the prediction errors of the proposed LSTM-based temperature prediction model with LSTM-refinement were significantly smaller than those of other models, which implies that the LSTM-refinement contributed to providing a better fit to the pattern of the real observed data than linear interpolation. Similar to
Figure 7 and
Figure 9a,b show the averaged RMSEs and MBEs over each week for 7 day and 14 day temperature predictions shown in
Figure 8a,b, respectively. It was clear that the proposed model achieved lower RMSEs than other LSTM-based prediction models for all the weeks.
5. Conclusions
In this paper, a neural network-based temperature prediction model has been proposed to keep track of temperature variations from 6 h to 14 day time periods through a consideration of the major influences of the primary weather variable. The proposed model was based on an LSTM neural network to fit the time-series data. In particular, the missing data, which frequently occur in the collected weather database, were refined by using an LSTM framework with temperature, relative humidity, wind speed, and wind direction. Then, the proposed LSTM-based model was implemented to predict temperature for short time periods such as 6, 12, and 24 h. In addition, it was also extended to predict temperature for relatively long time periods, such as 7 and 14 days. The performance evaluation used actual weather data for 37 years (from 1981 to 2017) at three different locations in South Korea, including hourly-based measurements for temperature, humidity, wind speed, and wind direction. In addition, the RMSE between observed and predicted temperatures was measured for each of the neural network models.
First, the effectiveness of the hyperparameters in the LSTM on prediction accuracy was examined. As a result, the number of LSTM layers and the number of hidden nodes were set to 4 and 384, respectively, for the proposed model. Next, the performance of the proposed model was evaluated and compared with that of the conventional LSTM-based and DNN-based models with either no refinement or linear interpolation refinement. Results showed that the proposed LSTM-based model gave the RMSE of 0.79 degrees Celsius for 24 h predictions while the conventional LSTM without any refinement and with linear interpolation had RMSEs of 1.02 and 0.84 degrees Celsius, respectively, and the UM model based on LDAPS provided by the Meteorological Office of South Korea achieved an RMSE of 1.52 degrees Celsius. In addition, the proposed LSTM-based model employing LSTM-refinement achieved RMSEs of 2.81 and 3.06 degrees Celsius for 7 and 14 day predictions, respectively, while the conventional LSTM-based model with linear interpolation provided RMSEs of 3.05 and 3.21 degrees Celsius for 7 and 14 day predictions, respectively.
However, the prediction accuracy of the proposed model needs to be improved during periods of seasonal changes, when sudden temperature changes occur. According to the 24 h temperature prediction from August 2017 to October 2017, the proposed LSTM-based model during September 2017 provided a slightly higher average RMSE than the average RMSE over one year, while the proposed LSTM-based model still had a lower average RMSE than LDAPS during September 2017. Since the improvement of the prediction accuracy in this period will have a great influence on the improvement of the overall temperature prediction model, we are considering extending our research to improve prediction accuracy during the season-changing period by, for example, using a new form of neural networks, which have an attention architecture for tracking transient data changes.
Moreover, weather data, such as relative humidity, wind speed, and wind direction, were used to refine the missing data in this paper. Although this paper shows the validity of the performance of the proposed model based on the result for temperature prediction, we indicate that this model is also applicable to not only temperature but also to other weather factors. However, as a future work, we are interested in constructing a deep learning model for predicting temperature by directly using more weather factors, including soil temperatures or aerosols. In other words, all the weather data available will be brought together as input features for a DNN, which will be both a temperature predictor and a missing data refiner.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}