Comparative Study on Probabilistic Forecasts of Heavy Rainfall in Mountainous Areas of the Wujiang River Basin in China Based on TIGGE Data



Abstract
1. Introduction
2. Multi-Model Ensemble Post-Processing Methods
2.1. The BMA Model
2.2. The LR Model
3. Data and Methods of Verification and Evaluation
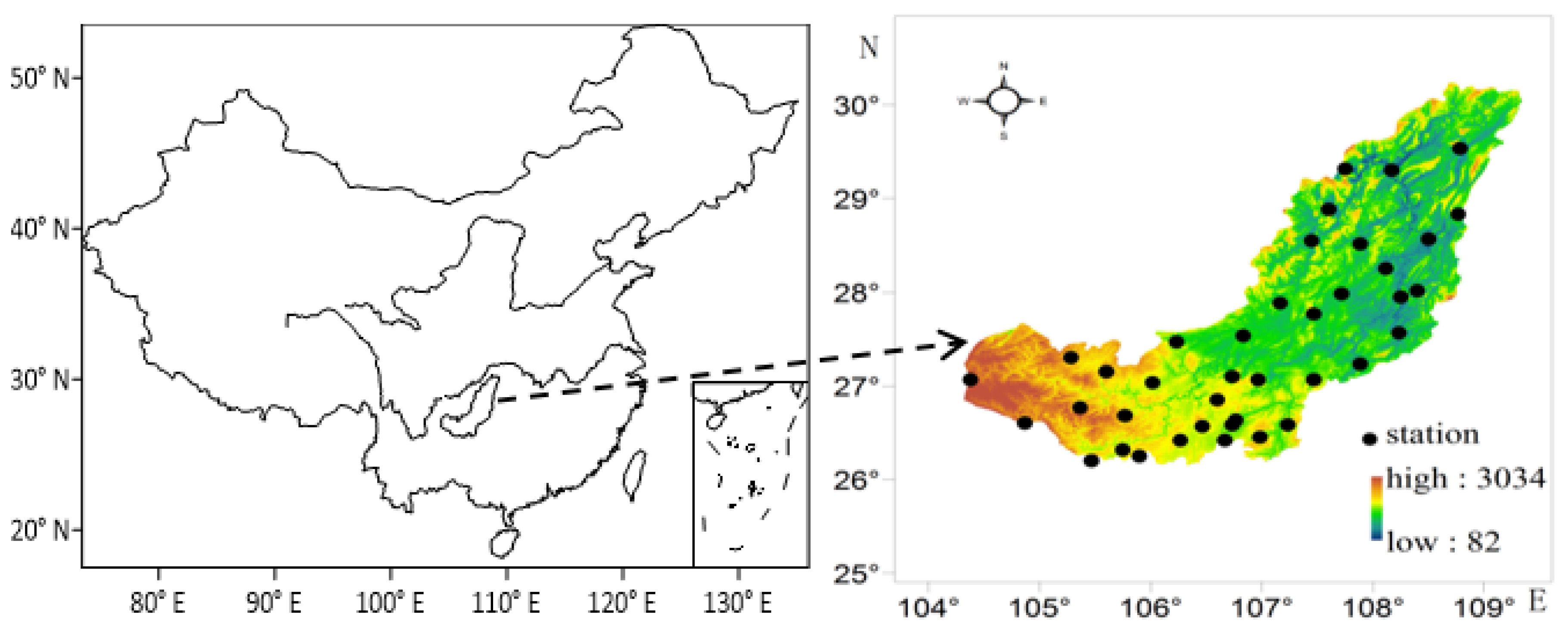
3.1. The Study Area and Datasets
3.2. Verification and Evaluation Methods
4. Results
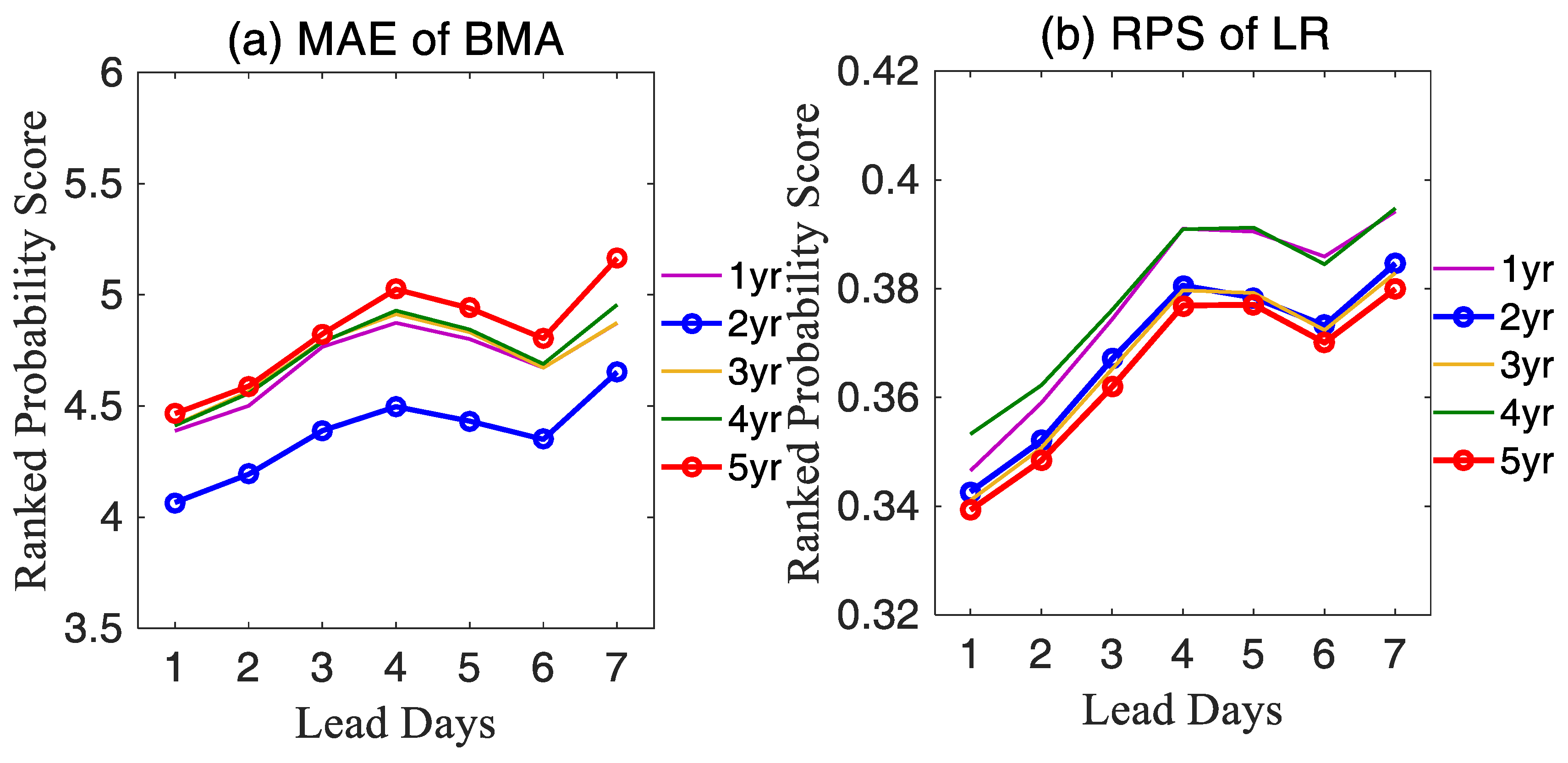
4.1. The Length of Training Period
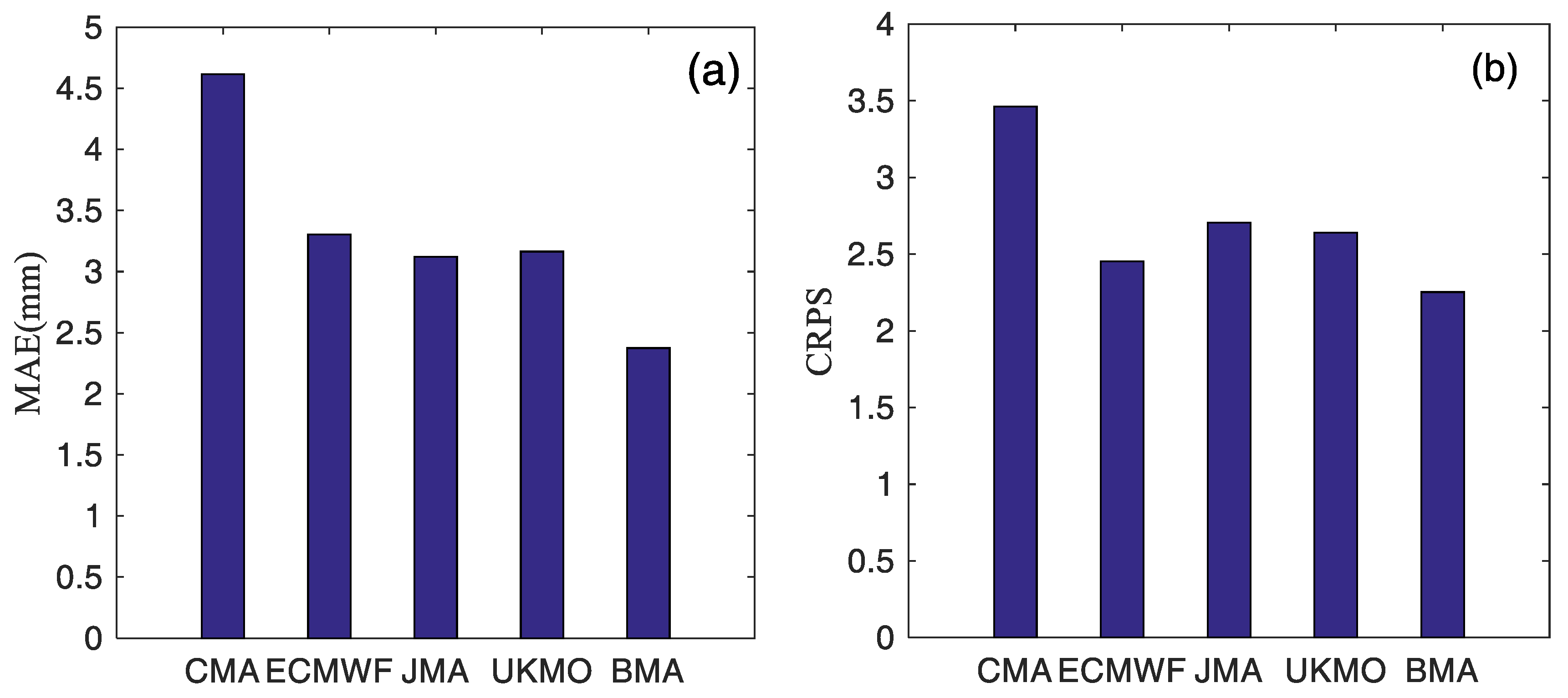
4.2. Comparison, Verification, and Evaluation of Different Models
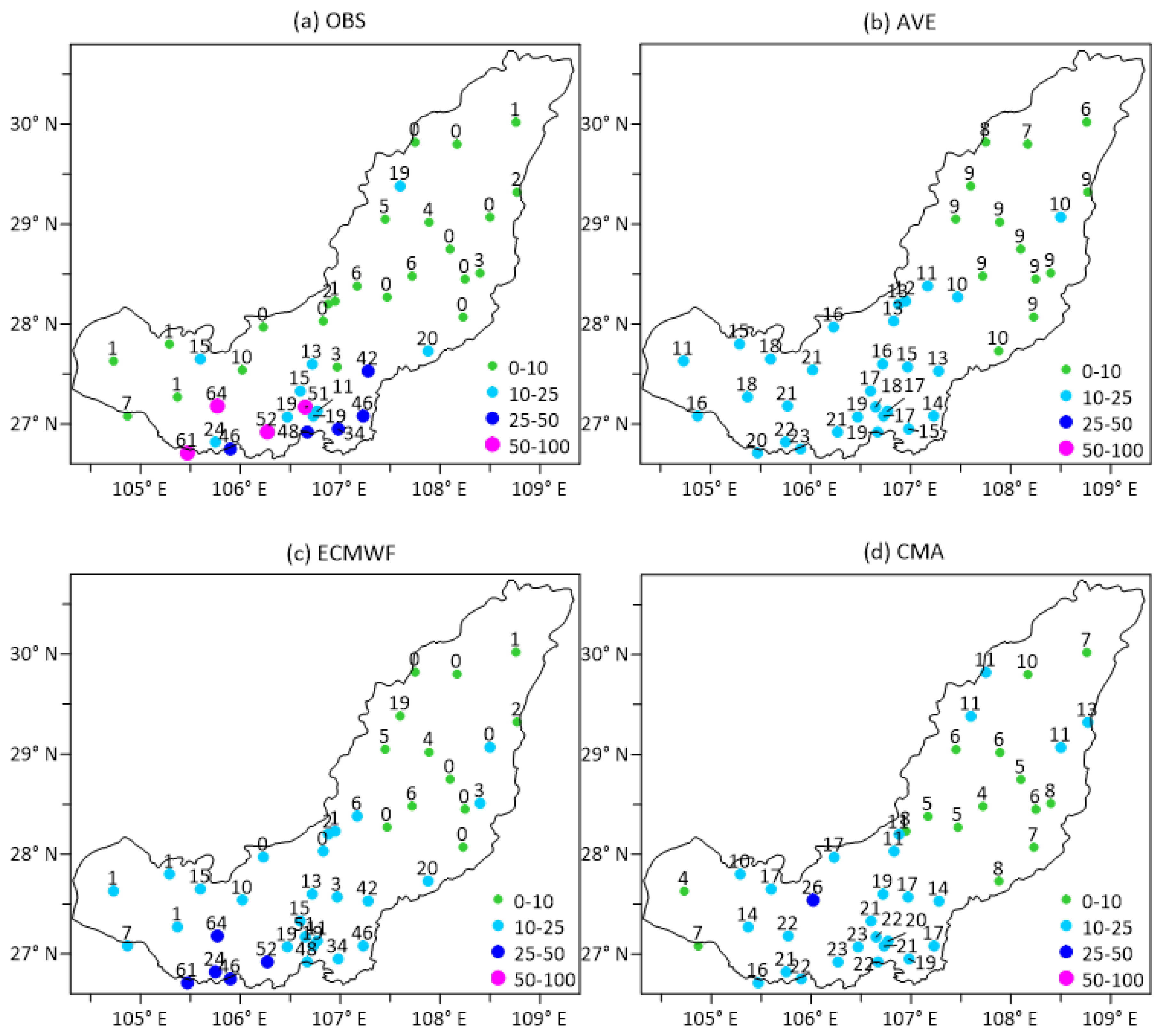
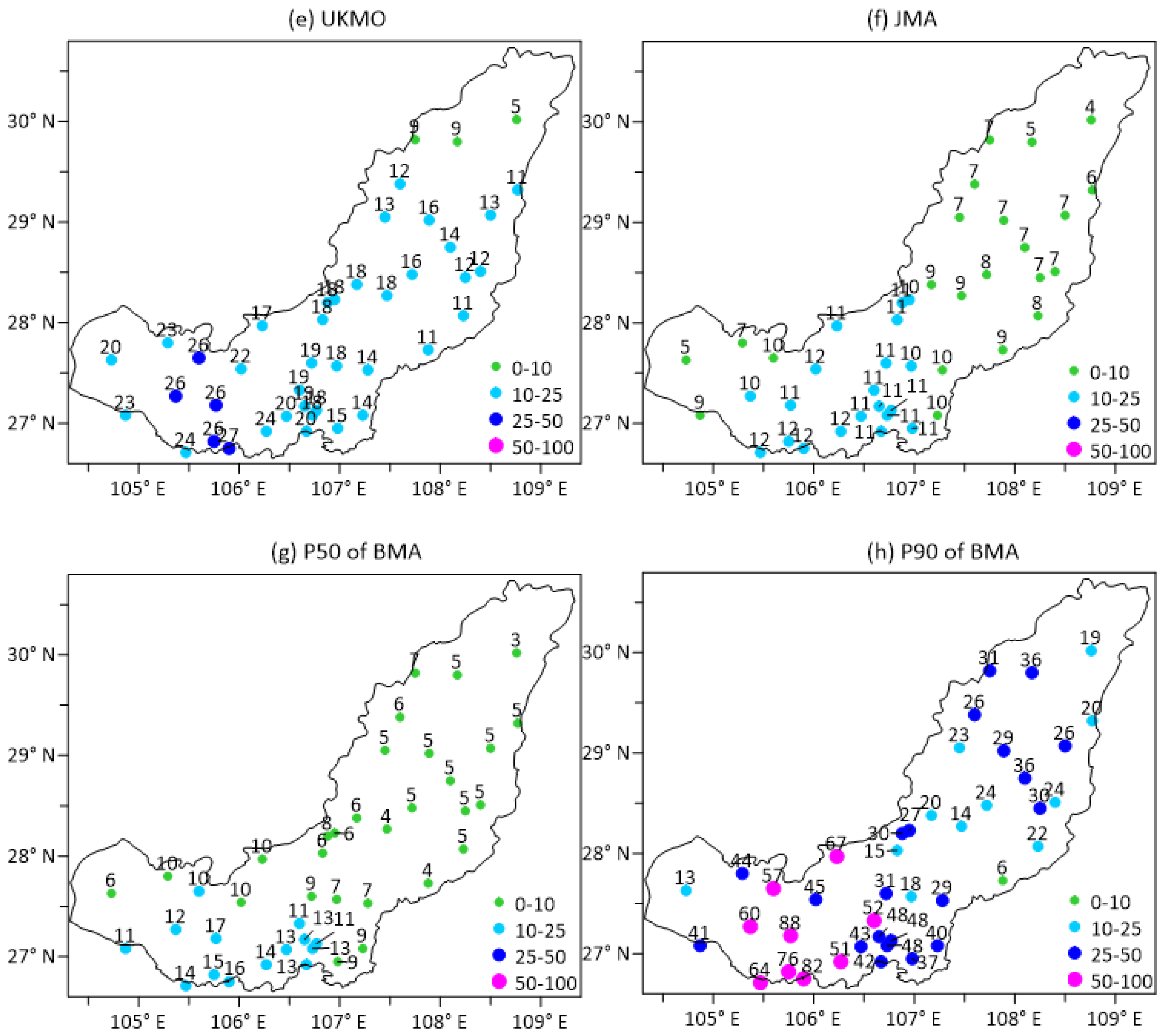
4.3. Case Study of Heavy Rainfall Forecasting
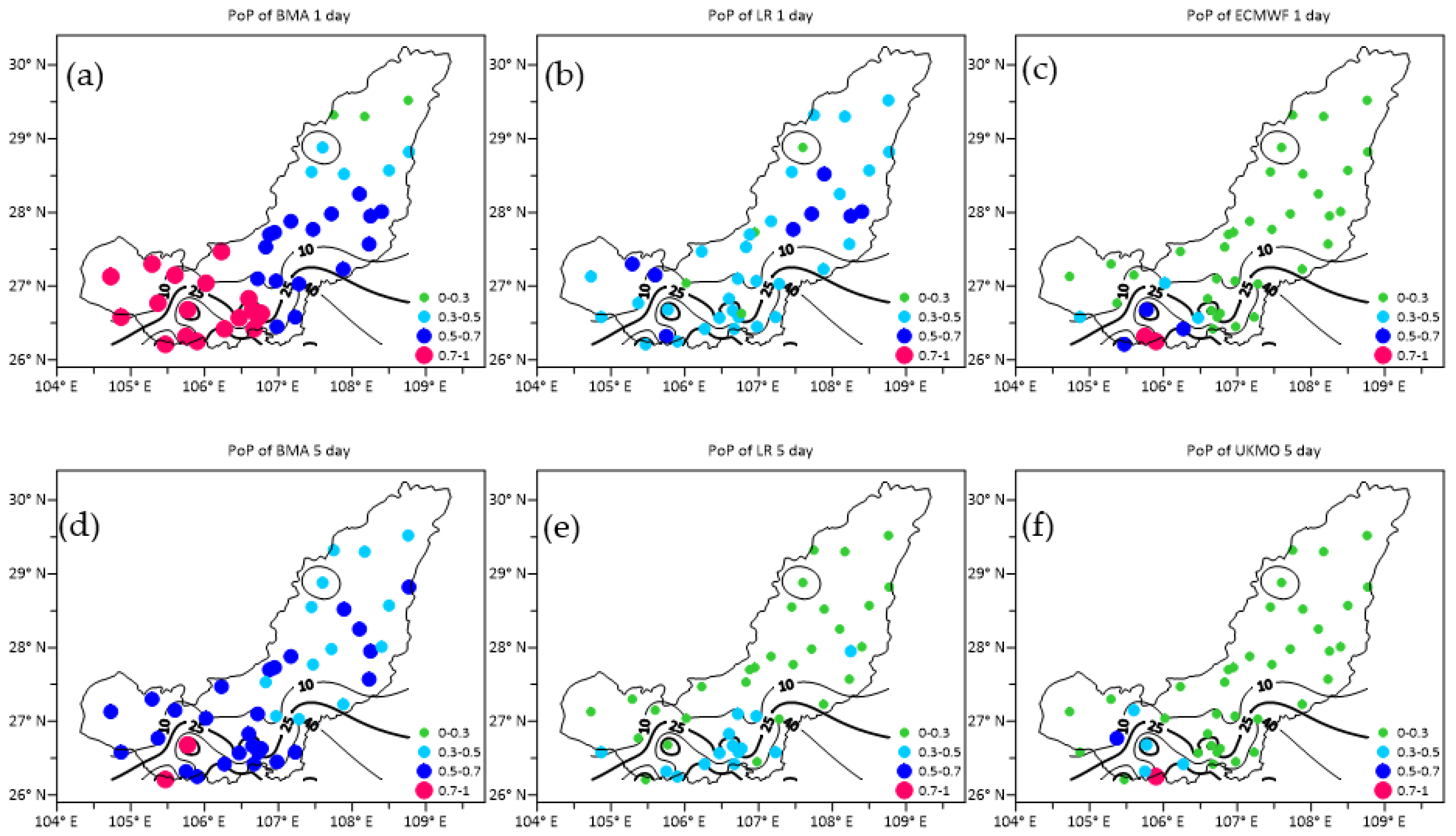
4.3.1. Comparison of Probability Forecasts
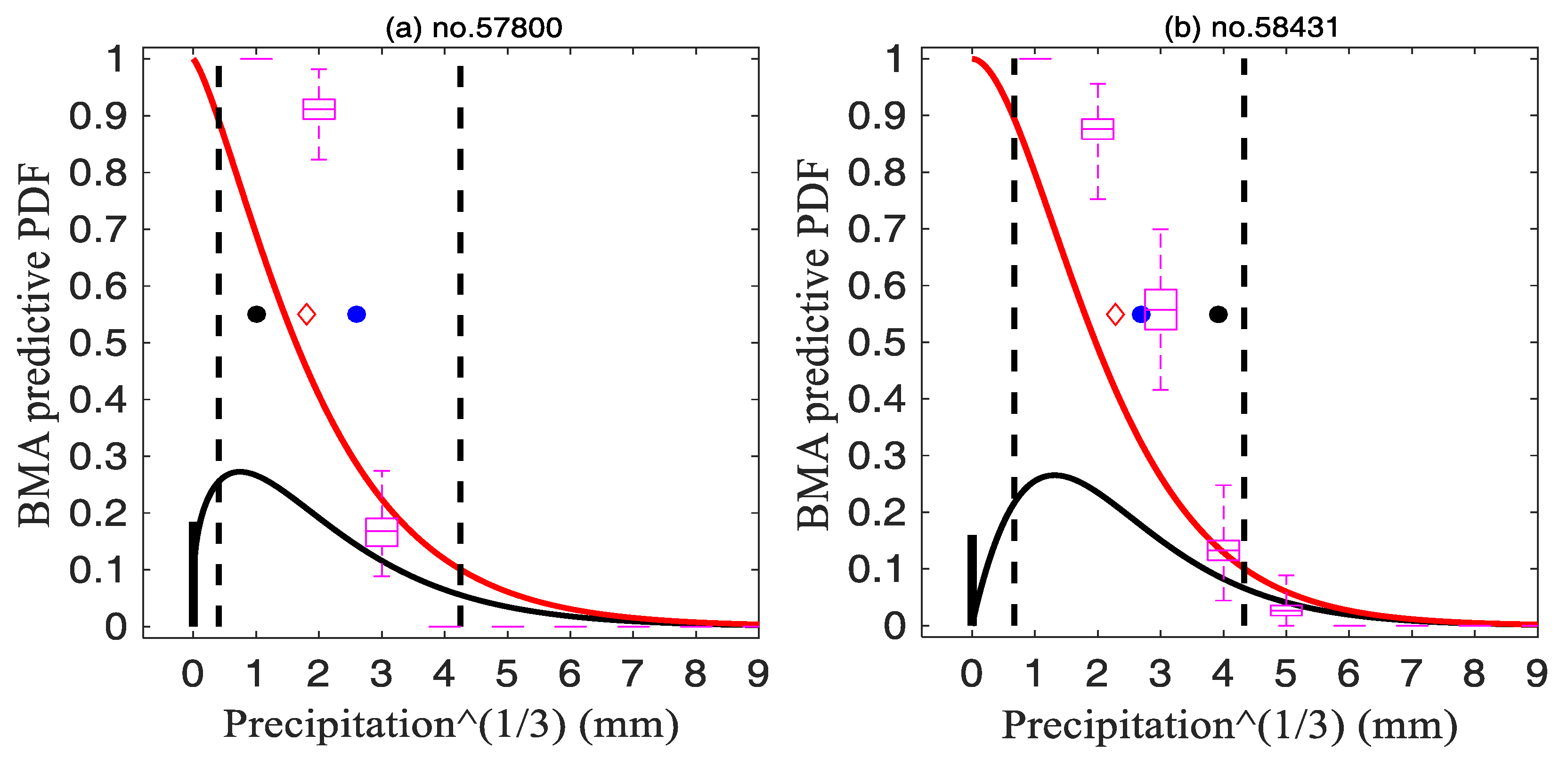
4.3.2. The Deterministic Forecast
4.4. Verifications over the Season
5. Conclusions and Discussion
- The BMA forecasting model was sensitive to the length of the training period and the forecast quality of the model around the forecast period. Additionally, for the forecast skill, a longer training period is not necessarily better. The training period of 2 years was the best for BMA, whereas the LR model required more statistical samples compared with the BMA method. The LR prediction effect was optimal when the length of the training period was 5 years.
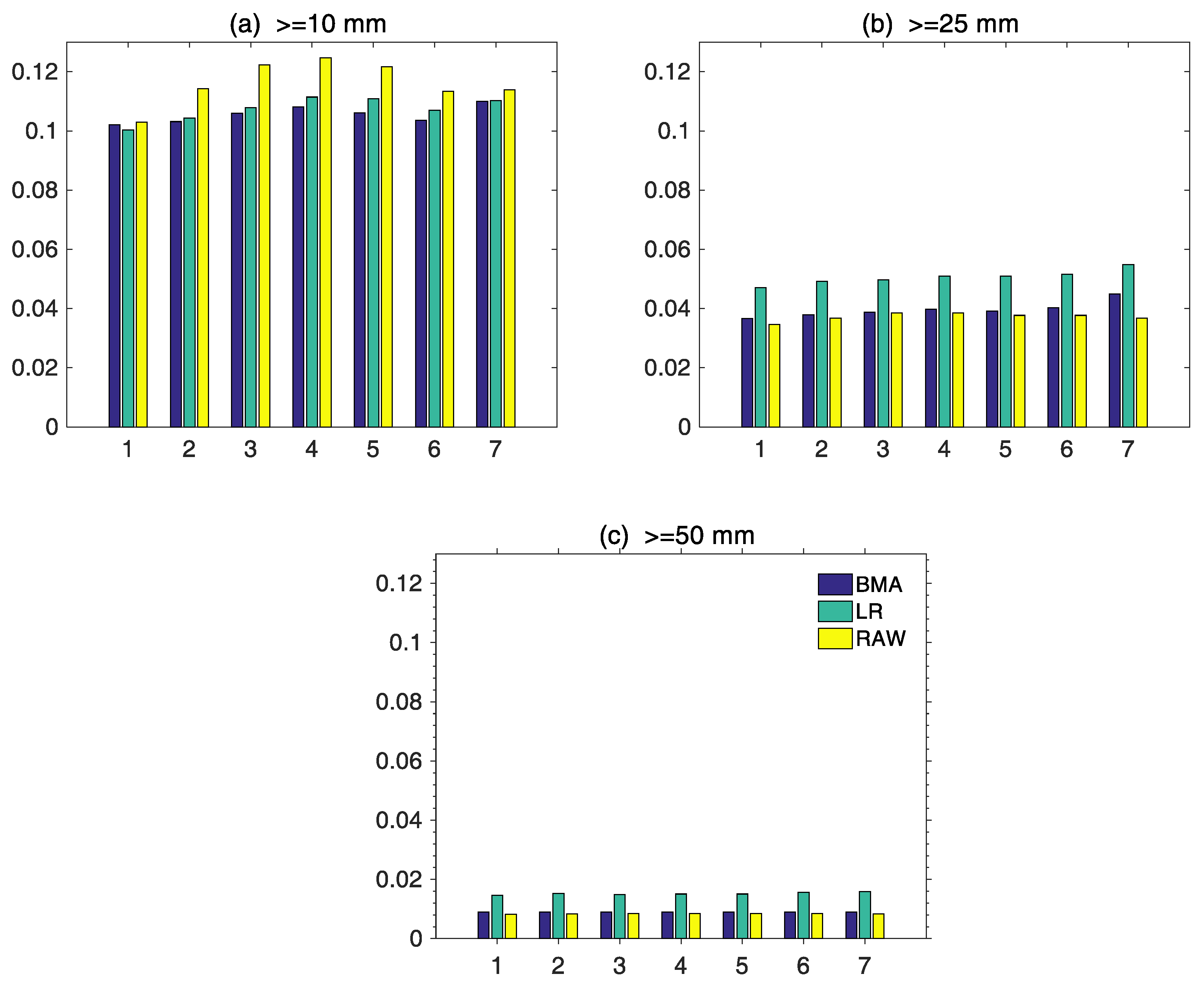
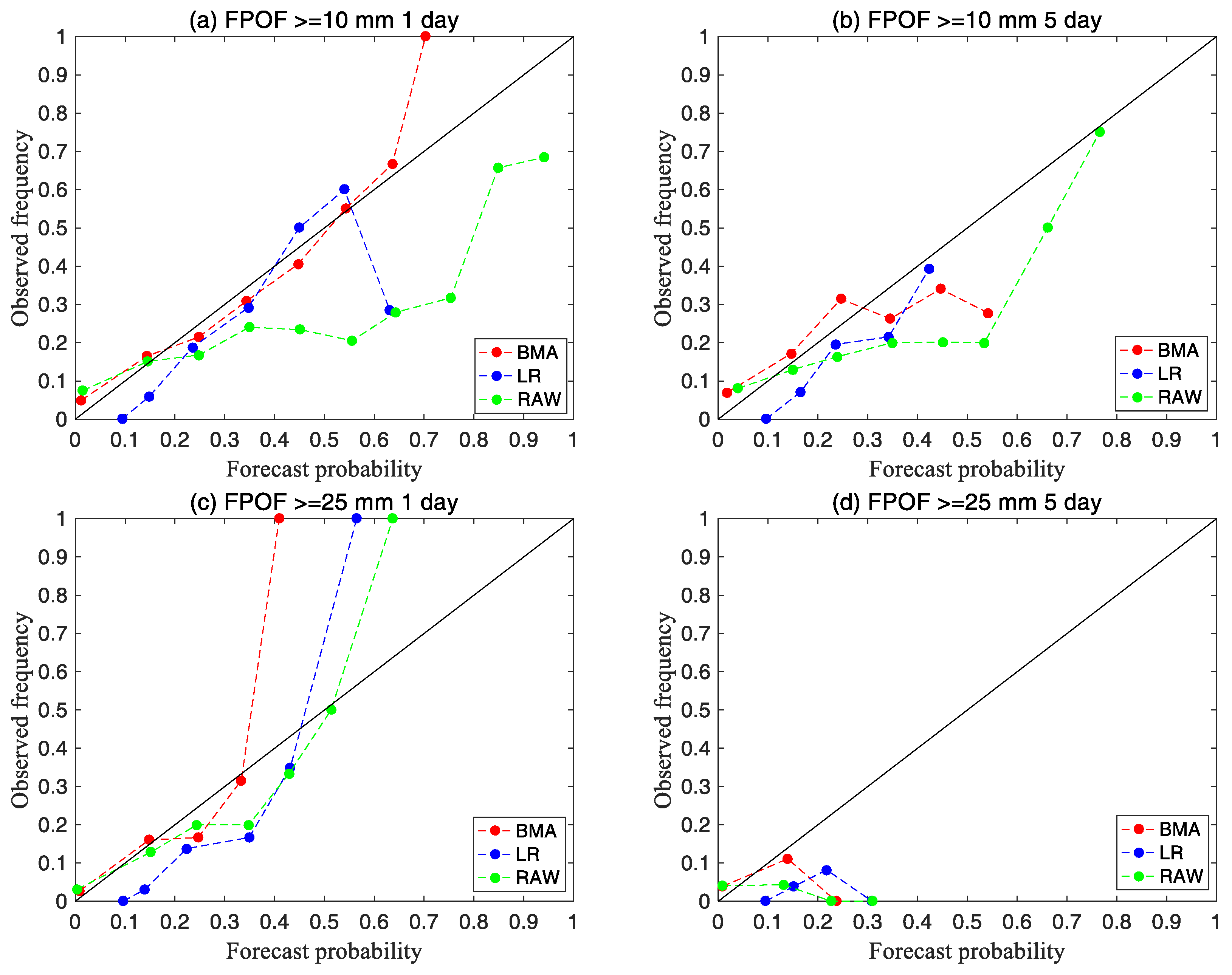
- The multi-model ensemble prediction method was not always superior to RAW under any lead time or at any precipitation level. According to the BS, for precipitation events exceeding 10 mm with lead times of 1–7 days, the BMA forecasting technique outperformed the LR and the RAW with lead times of 2–7 days, while for heavy precipitation events exceeding 25 mm and 50 mm, the forecast skill of RAW was equivalent to that of BMA, whose improvement is little. This can be due to two reasons. First, the four-model multi-member ensemble average forecast used in this study was equivalent to the BMA ensemble of the four members. Compared with the multiple and comprehensive forecast results obtained by the four models with 131 members, the improvement was greatly limited. Second, the correcting effect of the BMA method itself has certain limitations. According to the verification results, for heavy and moderate rainfall events, forecasts of BMA and the LR were more reliable than those of the RAW, and the BMA model shows the best performance.
- The LR and the RAW could only provide the probability forecast at a certain threshold, while the BMA had the advantage of producing a highly concentrated full PDF curve and rendering the deterministic forecast. The PDF curve can control the uncertainty range of forecast results, and can also render quantitative forecasts through analyzing the percentile data. With respect to heavy precipitation forecasting, it is recommended to refer to forecasting results at the 75th–90th percentiles, which are more reasonable. Nevertheless, extreme weather events with low probability forecasts cannot be ignored because they might also occur. As for the light precipitation event, the BMA forecast results at the 50th percentile were closer to the observation.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gneiting, T.; Raftery, A.E. Weather forecasting with ensemble methods. Science 2005, 310, 248–249. [Google Scholar] [CrossRef] [PubMed]
- Tebaldi, C.; Knutti, R. The use of multi-model ensembles in probabilistic climate projections. Philos. Trans. Roy. Soc. London 2007, 365, 2053–2075. [Google Scholar] [CrossRef]
- Zhi, X.F.; Qi, H.X.; Bai, Y.Q.; Lin, C.Z. A comparison of three kinds of multimodel ensemble forecast techniques based on the TIGGE data. Acta. Meteorol. Sin. 2012, 1, 41–51. [Google Scholar] [CrossRef]
- Zhi, X.F.; Chen, W. New achievements of international atmospheric research in THORPEX program. Trans. Atmos. Sci. 2010, 33, 504–511. [Google Scholar]
- Swinbank, R.; Kyouda, M.; Buchanan, P.; Froude, L.; Hamill, T.M.; Hewson, T.D.; Keller, J.H.; Matsueda, M.; Methven, J.; Pappenberger, F.; et al. The TIGGE project and its achievements. BAMS 2016, 97, 49–67. [Google Scholar] [CrossRef]
- Krishnamurti, T.N.; Kishtawal, C.M.; LaRow, T.E.; Bachiochi, D.R.; Zhan, Z.; Williford, C.E.; Gadgil, S.; Surendran, S. Improved weather and seasonal climate forecasts from a multimodel superensemble. Science 1999, 285, 1548–1550. [Google Scholar] [CrossRef] [PubMed]
- Krishnamurti, T.N.; Kishtawal, C.M.; Shin, D.W.; Williford, C.E. Improving tropical precipitation forecasts from multianalysis superensemble. J. Clim. 2000, 13, 4217–4227. [Google Scholar] [CrossRef]
- Maxime, T.; Olivier, M.; Michaël, Z.; Philippe, N. Calibrated ensemble forecasts using quantile regression forests and ensemble model output statistics. Mon. Weather Rev. 2016, 144, 2375–2393. [Google Scholar]
- Ebert, E.E. Ability of a poor man’s ensemble to predict the probability and distribution of precipitation. Mon. Weather Rev. 2001, 129, 2461–2480. [Google Scholar] [CrossRef]
- Hamill, T.M.; Whiltaker, J.S.; Wei, X. Ensemble reforecasting: Improving medium range forecast skill using retrospective forecasting. Mon. Weather Rev. 2004, 132, 1434–1447. [Google Scholar] [CrossRef]
- Hamill, T.M.; Whiltaker, J.S. Probabilistic quantitative precipitation forecasts based on reforecast analogs: Theory and application. Mon. Weather Rev. 2006, 134, 3209–3229. [Google Scholar] [CrossRef]
- Theis, S.E.; Hense, A.; Damrath, U. Probabilistic precipitation forecasts from a deterministic model: A pragmatic approach. Meteorol. Appl. 2005, 12, 257–268. [Google Scholar] [CrossRef]
- Ebert, E. Fuzzy verification of high-resolution girded forecasts: A review and proposed framework. J. Appl. Meteorol. 2008, 15, 51–64. [Google Scholar] [CrossRef]
- SchÖlzel, C.; Hense, A. Probabilistic assessment of regional climate change in Southwest Germany by ensemble dressing. Clim. Dyn. 2011, 36, 2003–2014. [Google Scholar] [CrossRef]
- Johnson, A.; Wang, X.G. Verification and calibration of neighborhood and object-based probabilistic precipitation forecasts from a multi-model convection-allowing ensemble. Mon. Weather Rev. 2012, 140, 3054–3077. [Google Scholar] [CrossRef]
- Novak, D.R.; Bailey, C.; Brill, K.F.; Burke, P.; Hogsett, W.A.; Rausch, R.; Schichtel, M. Precipitation and temperature forecast performance at the weather prediction center. Weather Forecast. 2014, 29, 489–504. [Google Scholar] [CrossRef]
- Raftery, A.E.; Gneiting, T.; Balabdaoui, F.; Polakowski, M. Using Bayesian model averaging to calibrate forecast ensembles. Mon. Weather Rev. 2005, 133, 1155–1174. [Google Scholar] [CrossRef]
- Wilson, L.J.; Beauregard, S.; Raftery, A.E.; Verret, R. Calibrated surface temperature forecasts from the Canadian ensemble prediction system using Bayesian model averaging. Mon. Weather Rev. 2007, 135, 1364–1385. [Google Scholar] [CrossRef]
- Sloughter, J.M.; Raftery, A.E.; Gneiting, T.; Fraley, C. Probabilistic quantitative precipitation forecasting using bayesian model averaging. Mon. Weather Rev. 2007, 135, 3209–3220. [Google Scholar] [CrossRef]
- Sloughter, J.M.; Gneiting, T.; Raftery, A.E. Probabilistic wind speed forecasting using ensembles and Bayesian model averaging. J. Am. Stat. Assoc. 2010, 105, 25–35. [Google Scholar] [CrossRef]
- Schefzik, R.; Thorarinsdottir, T.L.; Gneiting, T. Uncertainty quantification in complex simulation models using ensemble copula coupling. Stat. Sci. 2013, 28, 616–640. [Google Scholar] [CrossRef]
- Wilks, D.S.; Hamill, T.M. Comparison of ensemble-MOS methods using GFS reforecasts. Mon. Weather Rev. 2007, 135, 2379–2390. [Google Scholar] [CrossRef]
- Hamill, T.M.; Hagedorn, R.; Whitaker, J.S. Probabilistic forecast calibration using ECMWF and GFS ensemble reforecasts. Part II: Precipitation. Mon. Weather Rev. 2008, 36, 2620–2632. [Google Scholar] [CrossRef]
- Roulston, M.S.; Smith, L.A. Combining dynamical and statistical ensembles. Tellus A 2003, 55, 16–30. [Google Scholar] [CrossRef]
- Wang, X.; Bishop, C.H. Improvement of ensemble reliability with a new dressing kernel. Q. J. R. Meteorol. Soc. 2005, 131, 965–986. [Google Scholar] [CrossRef][Green Version]
- Keune, J.; Christian, O.; Hense, A. Multivariate probabilistic analysis and predictability of medium-range ensemble weather forecasts. Mon. Weather Rev. 2014, 142, 4074–4090. [Google Scholar] [CrossRef]
- Liu, J.G.; Xie, Z.H. BMA probabilistic quantitative precipitation forecasting over the Huaihe Basin Using TIGGE multimodel ensemble forecasts. Mon. Weather Rev. 2014, 142, 1542–1555. [Google Scholar] [CrossRef]
- Zhu, J.S.; Kong, F.Y.; Ran, L.K.; Lei, H.C. Bayesian model averaging with stratified sampling for probabilistic quantitative precipitation forecasting in northern China during summer 2010. Mon. Weather Rev. 2015, 143, 3628–3641. [Google Scholar] [CrossRef]
- Kim, Y.D.; Kim, W.S.; Ohn, I.S.; Kim, Y.O. Leave-one-out Bayesian model averaging for probabilistic ensemble forecasting. Commun. Stat. Appl. Methods 2017, 24, 67–80. [Google Scholar] [CrossRef]
- Zhi, X.F.; Ji, L.Y. BMA probabilistic forecasting of the 500 hPa geopotential height over northern hemisphere using TIGGE multimodel ensemble forecasts. AIP Conf. Proc. 2018. [Google Scholar] [CrossRef]
- Zhang, H.P.; Chu, P.S.; He, L.K.; Unger, D. Improving the CPC’s ENSO forecasts using Bayesian model averaging. Clim. Dyn. 2019, 53, 3373–3385. [Google Scholar] [CrossRef]
- Ji, L.Y.; Zhi, X.F.; Zhu, S.P.; Fraedrich, K. Probabilistic precipitation forecasting over East Asia using Bayesian model averaging. Weather Forecast. 2019, 34, 377–392. [Google Scholar] [CrossRef]
- Yang, R.W.; Zhao, L.N.; Gong, Y.F.; Li, X.M.; Cao, Y. Comparative analysis of integrated bias correction to ensemble forecast of precipitation in southeast China. Torrential Rain Disasters 2017, 36, 507–517. [Google Scholar]
- Yin, Z.Y.; Peng, T.; Wang, J.C. Experiments of Bayesian probability flood forecasting based on the AREM model. Torrential Rain Disasters 2012, 31, 59–65. [Google Scholar]
- Mizukami, N.K.; Smith, M.B. Analysis of inconsistencies in multi-year gridded quantitative precipitation estimate over complex terrainand its impact on hydro-logic modeling. J. Hydrol. 2012, 428, 129–141. [Google Scholar] [CrossRef]
- Mizukami, N.K.; Martyn, P.C.; Andrew, G.S.; Levi, D.B.; Marketa, M.E.; Jeffrey, R.A.; Subhrendu, G. Hydrologic Implications of Different Large-Scale Meteorological Model Forcing Datasets in Mountainous Regions. J. Hydrol. 2014, 15, 474–488. [Google Scholar] [CrossRef]
- Henn, B.; Newman, A.J.; Livneh, B.; Daly, C.; Lundquist, J.D. An assessment of differences in gridded precipitation datasets in complex terrain. J. Hydrol. 2018, 556, 1205–1219. [Google Scholar] [CrossRef]
- Murphy, A.H. A note on the ranked probability score. J. Appl. Meteorol. 1971, 10, 155–157. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Centers | Country | Model Spectral Resolution | Ensemble Members (Perturbed) | Spatial Resolution | Forecast Length (Days) |
|---|---|---|---|---|---|
| ECMWF | Europe | T399L62/T255L62 | 50 | 0.5° × 0.5° | 15 |
| UKMO | United Kingdom | 11 | 0.5° × 0.5° | 7 + 6 h | |
| CMA | China | T213L31 | 14 | 0.5° × 0.5° | 15 |
| JMA | Japan | 26 | 0.5° × 0.5° | 11 | |
| NCEP | America | T126L28 | 20 | 0.5° × 0.5° | 16 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, H.; Zhi, X.; Peng, T.; Bai, Y.; Lin, C. Comparative Study on Probabilistic Forecasts of Heavy Rainfall in Mountainous Areas of the Wujiang River Basin in China Based on TIGGE Data. Atmosphere 2019, 10, 608. https://doi.org/10.3390/atmos10100608
Qi H, Zhi X, Peng T, Bai Y, Lin C. Comparative Study on Probabilistic Forecasts of Heavy Rainfall in Mountainous Areas of the Wujiang River Basin in China Based on TIGGE Data. Atmosphere. 2019; 10(10):608. https://doi.org/10.3390/atmos10100608
Chicago/Turabian StyleQi, Haixia, Xiefei Zhi, Tao Peng, Yongqing Bai, and Chunze Lin. 2019. "Comparative Study on Probabilistic Forecasts of Heavy Rainfall in Mountainous Areas of the Wujiang River Basin in China Based on TIGGE Data" Atmosphere 10, no. 10: 608. https://doi.org/10.3390/atmos10100608
APA StyleQi, H., Zhi, X., Peng, T., Bai, Y., & Lin, C. (2019). Comparative Study on Probabilistic Forecasts of Heavy Rainfall in Mountainous Areas of the Wujiang River Basin in China Based on TIGGE Data. Atmosphere, 10(10), 608. https://doi.org/10.3390/atmos10100608