Improving the Gene Ontology Resource to Facilitate More Informative Analysis and Interpretation of Alzheimer’s Disease Data

 , , , ,
, , , ,  and
and
Abstract
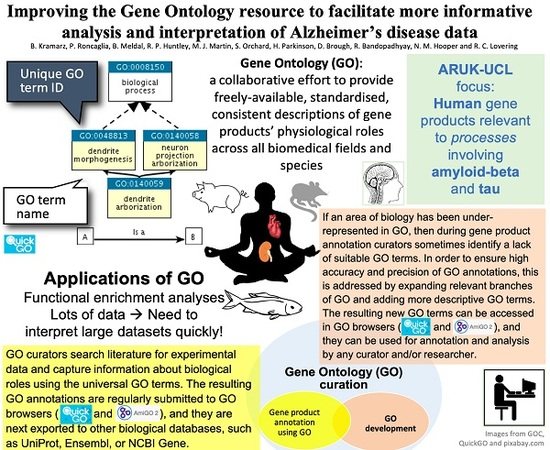
1. Introduction
2. Materials and Methods
2.1. Community Involvement
2.2. Selection of Experimental Data to Annotate
2.3. Gene Ontology Annotation of Proteins and Protein Complexes—Manual Curation Process
2.4. Ontology Development and Integration of Resources
2.5. Functional Analysis of Hippocampal Proteomic Data
3. Results
3.1. Assignment of Database Identifiers
3.2. Gene Ontology Annotation
3.3. Gene Ontology Development and Revisions
3.3.1. New and Revised Gene Ontology Terms
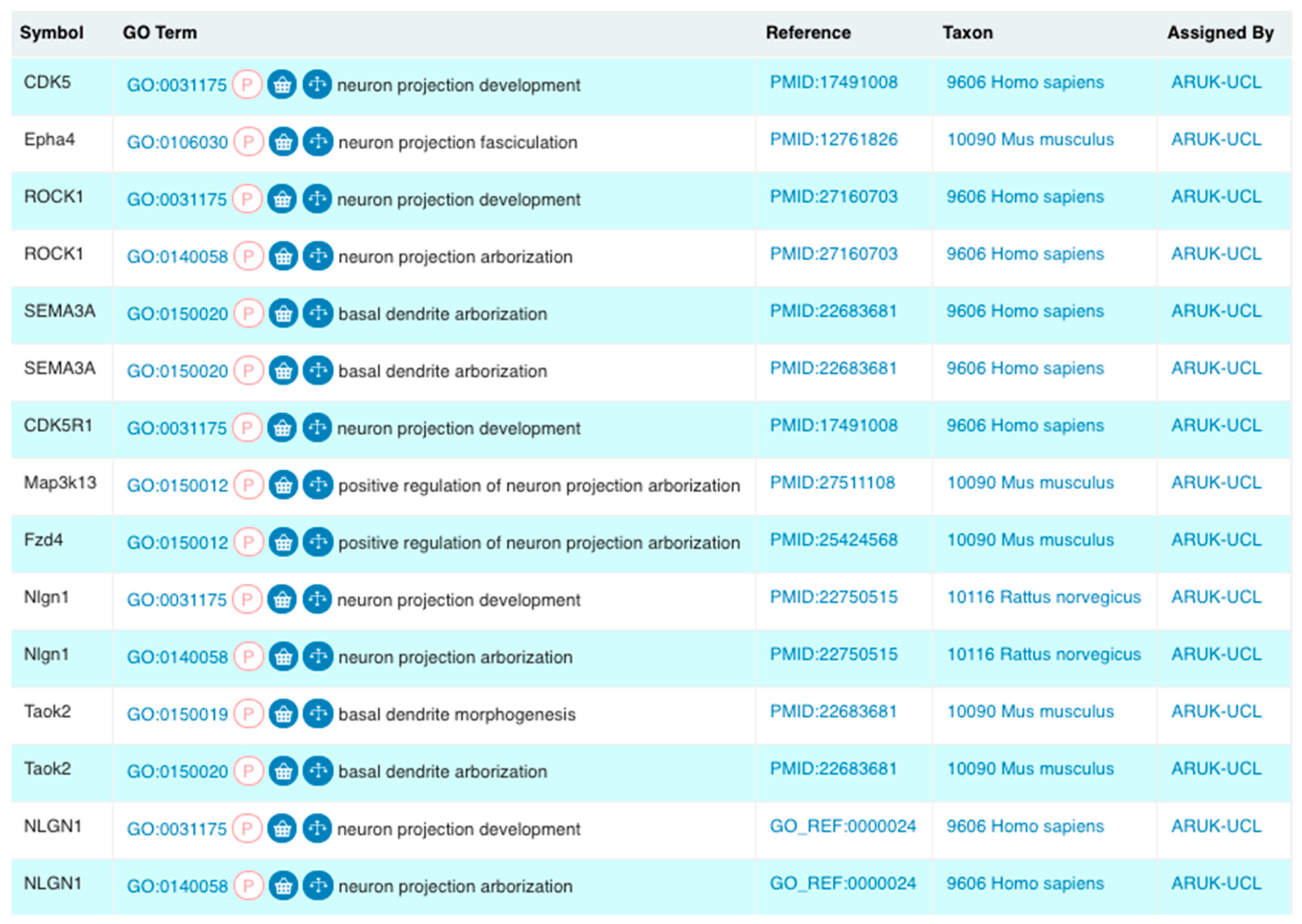
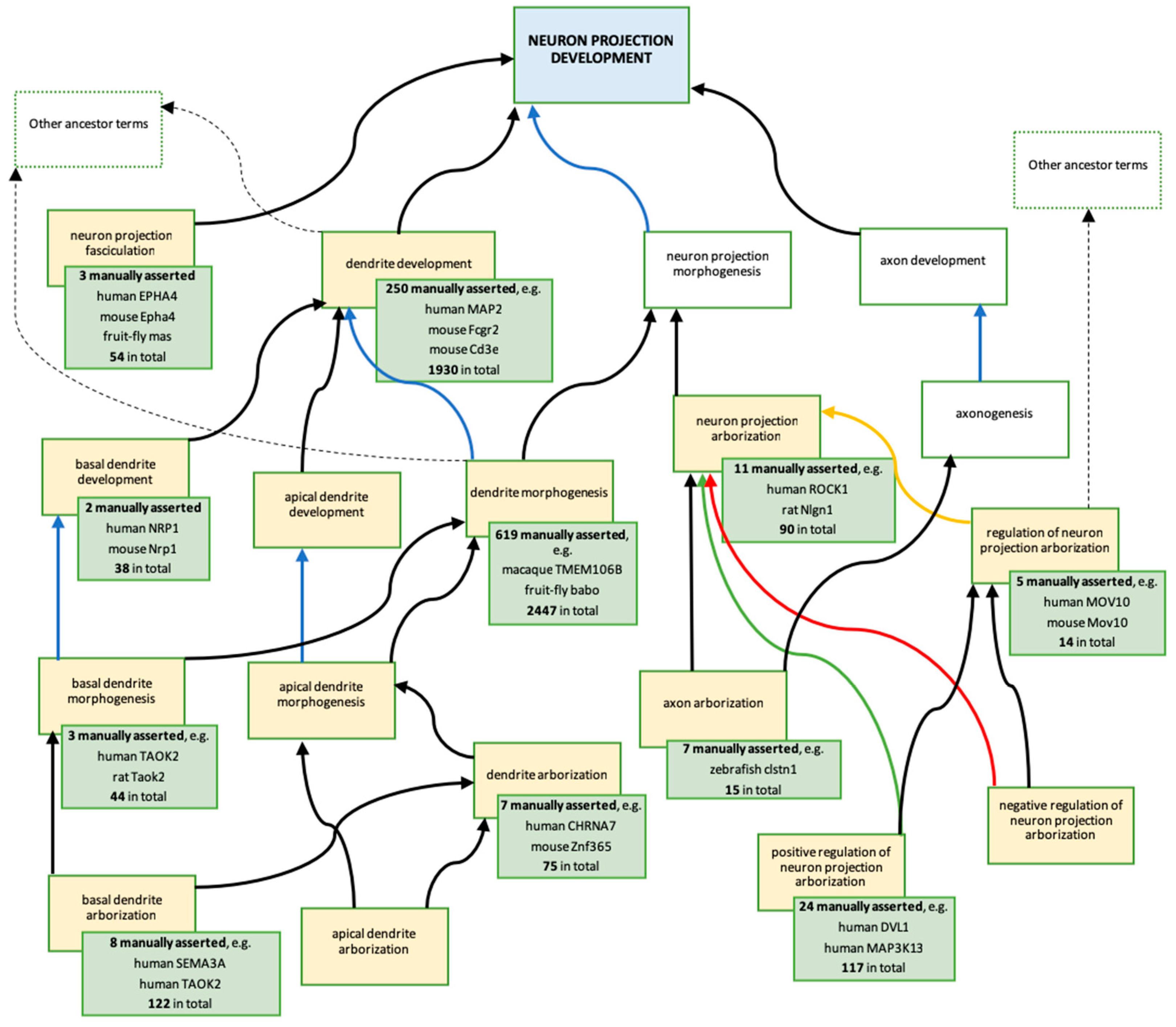
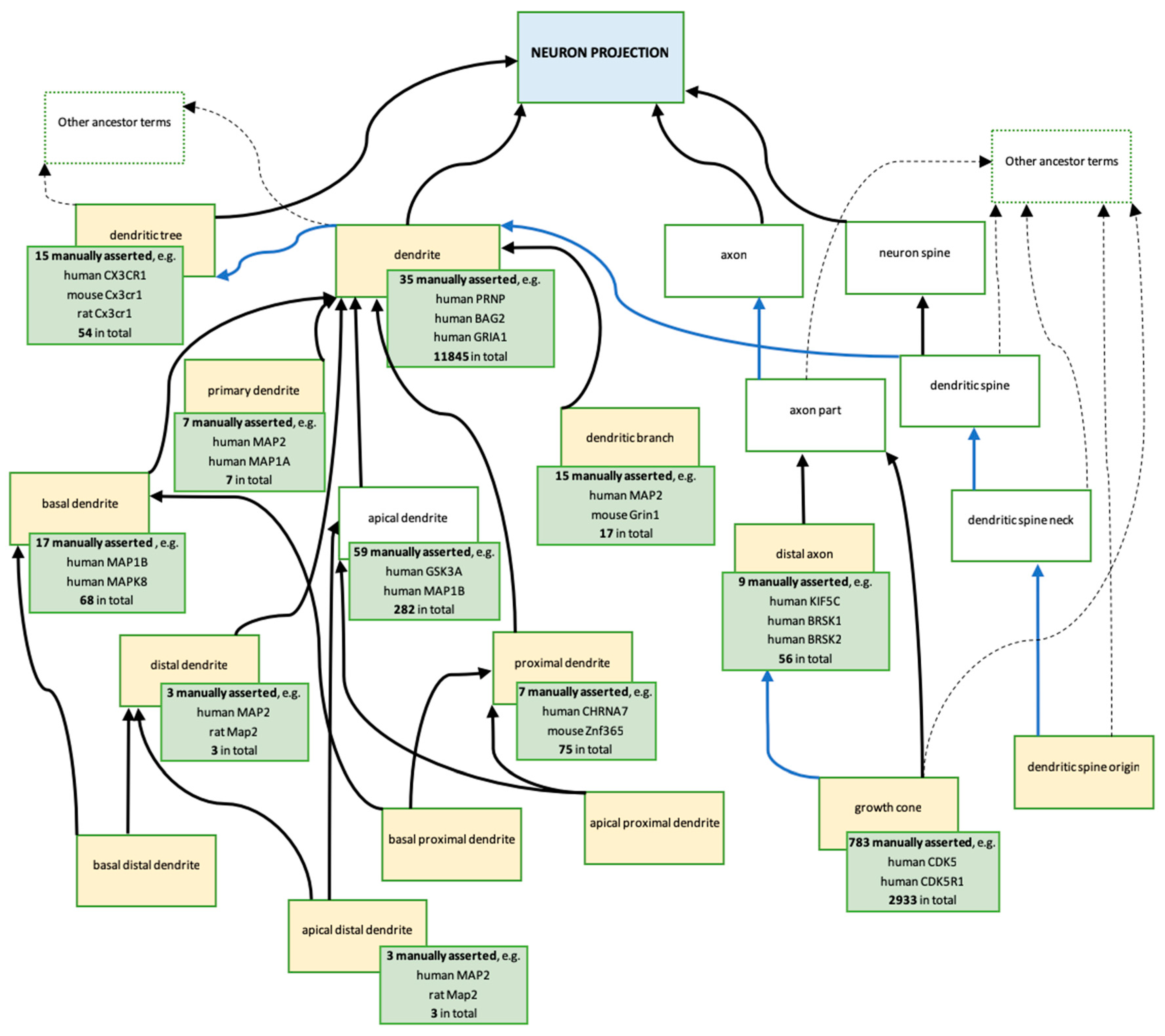
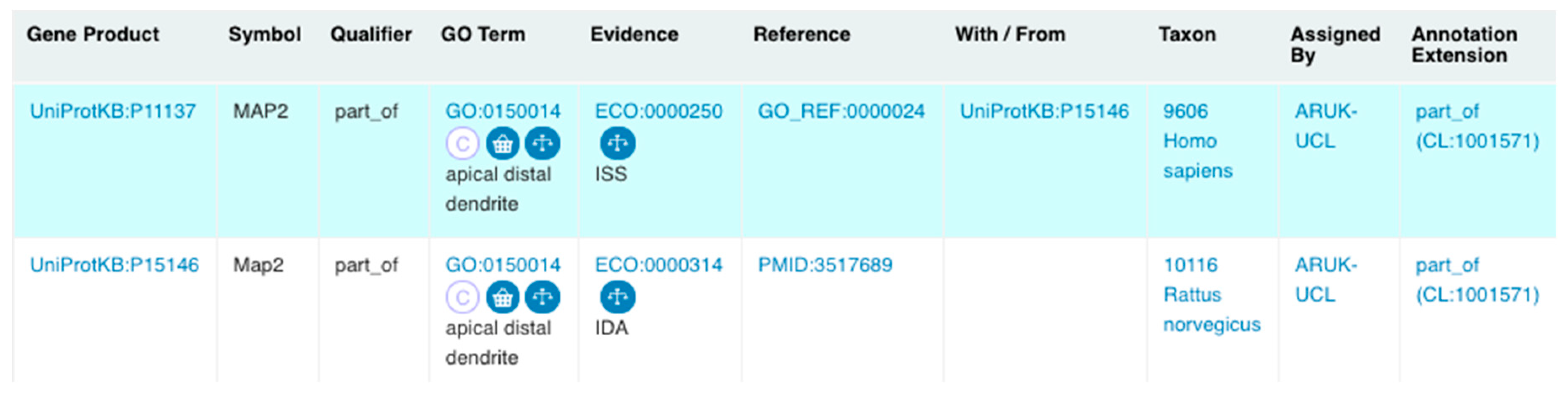
3.3.2. Revisions and Development of Neuron Projection Gene Ontology Branches
3.3.3. Concerted Effort of GO Consortium Members: Revisions of ‘Synaptic Vesicle Endocytosis’
3.3.4. Challenges Related to Emphasis on ‘Normal’ Processes
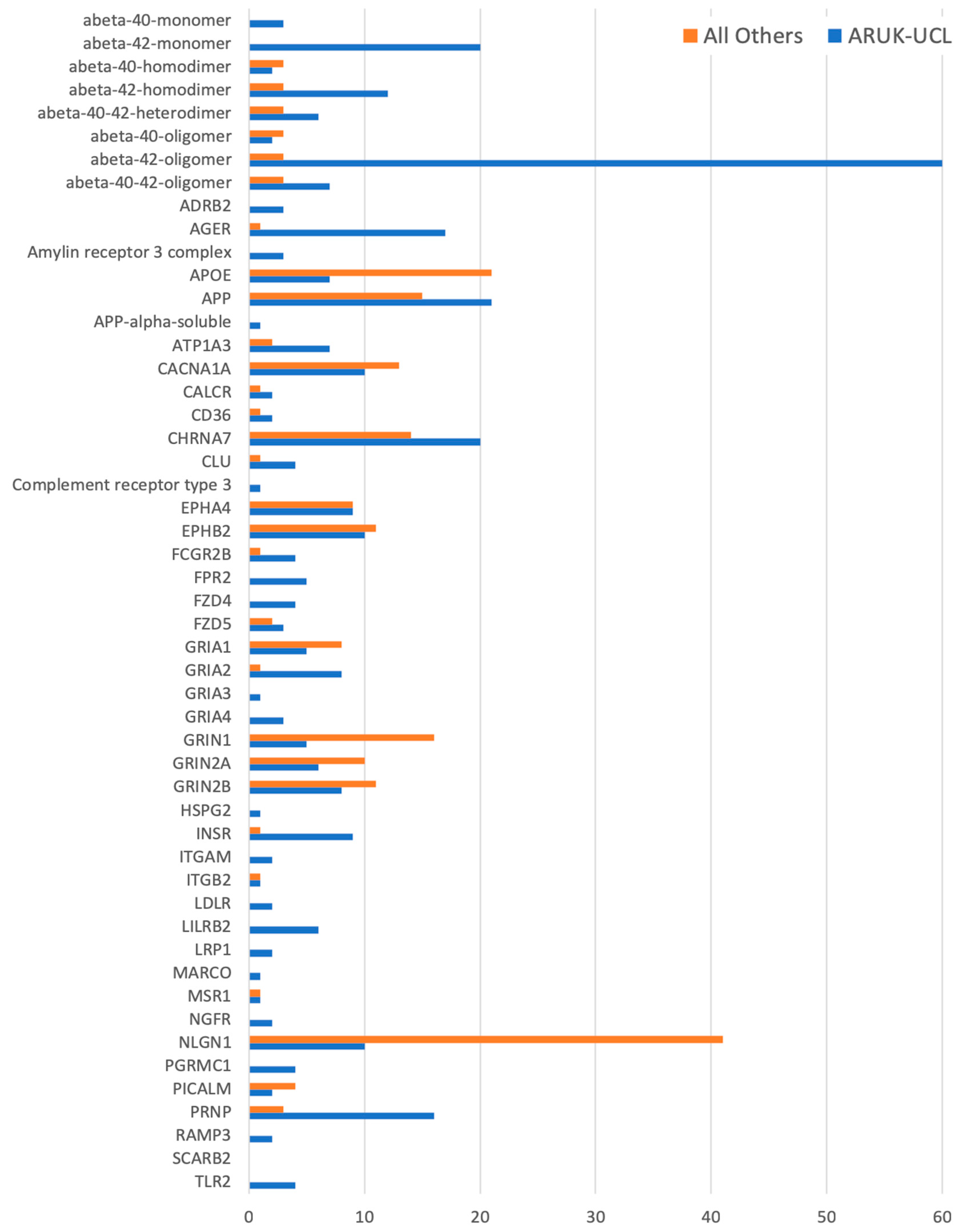
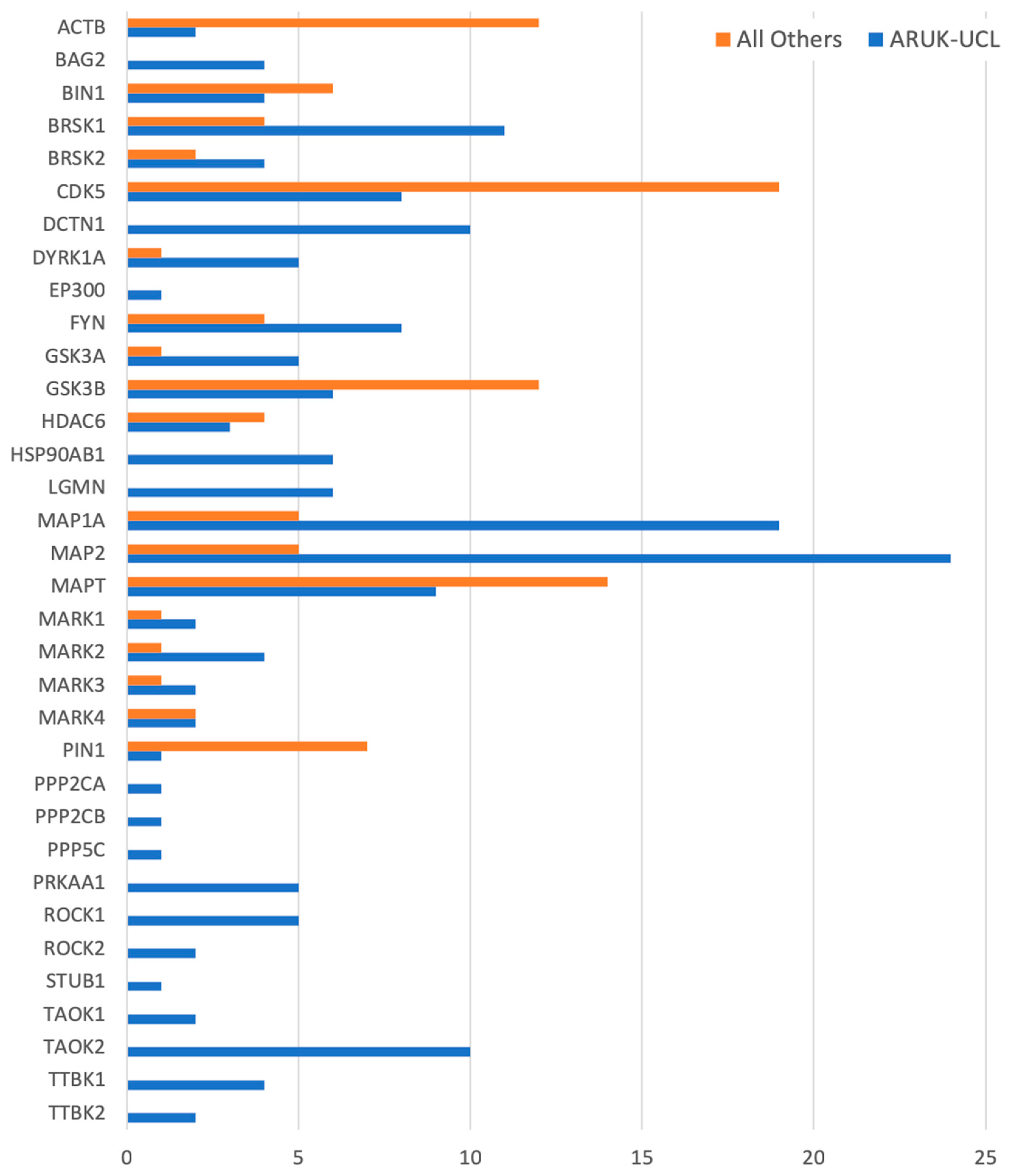
3.4. Impact of Improved GO Annotation on Data Analysis
4. Discussion
4.1. Cellular Events Underlying Dementia
4.2. Representing Neurobiology Using Gene Ontology
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Van Cauwenberghe, C.; Van Broeckhoven, C.; Sleegers, K. The genetic landscape of Alzheimer disease: Clinical implications and perspectives. Genet. Med. 2016, 18, 421–430. [Google Scholar] [CrossRef] [PubMed]
- Sassi, C.; Nalls, M.A.; Ridge, P.G.; Gibbs, J.R.; Ding, J.; Lupton, M.K.; Troakes, C.; Lunnon, K.; Al-Sarraj, S.; Brown, K.S.; et al. ABCA7 p.G215S as potential protective factor for Alzheimer’s disease. Neurobiol. Aging 2016, 46, 235.e1–235.e9. [Google Scholar] [CrossRef] [PubMed]
- Barnes, D.E.; Yaffe, K. The projected effect of risk factor reduction on Alzheimer’s disease prevalence. Lancet Neurol. 2011, 10, 819–828. [Google Scholar] [CrossRef]
- Cooper-Knock, J.; Kirby, J.; Ferraiuolo, L.; Heath, P.R.; Rattray, M.; Shaw, P.J. Gene expression profiling in human neurodegenerative disease. Nat. Rev. Neurol. 2012, 8, 518–530. [Google Scholar] [CrossRef] [PubMed]
- Guerreiro, R.; Wojtas, A.; Bras, J.; Carrasquillo, M.; Rogaeva, E.; Majounie, E.; Cruchaga, C.; Sassi, C.; Kauwe, J.S.; Younkin, S.; et al. TREM2 variants in Alzheimer’s disease. N. Engl. J. Med. 2013, 368, 117–127. [Google Scholar] [CrossRef] [PubMed]
- Kang, M.G.; Byun, K.; Kim, J.H.; Park, N.H.; Heinsen, H.; Ravid, R.; Steinbusch, H.W.; Lee, B.; Park, Y.M. Proteogenomics of the human hippocampus: The road ahead. Biochim. Biophys. Acta 2015, 1854, 788–797. [Google Scholar] [CrossRef] [PubMed]
- Guio-Vega, G.P.; Forero, D.A. Functional genomics of candidate genes derived from genome-wide association studies for five common neurological diseases. Int. J. Neurosci. 2017, 127, 118–123. [Google Scholar] [CrossRef]
- Ebbert, M.T.; Ridge, P.G.; Kauwe, J.S. Bridging the gap between statistical and biological epistasis in Alzheimer’s disease. Biomed. Res. Int. 2015, 2015, 870123. [Google Scholar] [CrossRef]
- Cambiaghi, A.; Ferrario, M.; Masseroli, M. Analysis of metabolomic data: Tools, current strategies and future challenges for omics data integration. Brief Bioinform. 2017, 18, 498–510. [Google Scholar] [CrossRef]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene ontology: Tool for the unification of biology. The Gene Ontology Consortium. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef]
- Fabregat, A.; Sidiropoulos, K.; Garapati, P.; Gillespie, M.; Hausmann, K.; Haw, R.; Jassal, B.; Jupe, S.; Korninger, F.; McKay, S.; et al. The Reactome pathway knowledgebase. Nucleic Acids Res. 2016, 44, D481–D487. [Google Scholar] [CrossRef] [PubMed]
- Kanehisa, M.; Sato, Y.; Kawashima, M.; Furumichi, M.; Tanabe, M. KEGG as a reference resource for gene and protein annotation. Nucleic Acids Res. 2016, 44, D457–D462. [Google Scholar] [CrossRef] [PubMed]
- Orchard, S.; Ammari, M.; Aranda, B.; Breuza, L.; Briganti, L.; Broackes-Carter, F.; Campbell, N.H.; Chavali, G.; Chen, C.; del-Toro, N.; et al. The MIntAct project—IntAct as a common curation platform for 11 molecular interaction databases. Nucleic Acids Res. 2014, 42, D358–D363. [Google Scholar] [CrossRef] [PubMed]
- Meldal, B.H.M.; Bye, A.J.H.; Gajdos, L.; Hammerova, Z.; Horackova, A.; Melicher, F.; Perfetto, L.; Pokorny, D.; Lopez, M.R.; Turkova, A.; et al. Complex Portal 2018: Extended content and enhanced visualization tools for macromolecular complexes. Nucleic Acids Res. 2018. [Google Scholar] [CrossRef] [PubMed]
- Reimand, J.; Arak, T.; Adler, P.; Kolberg, L.; Reisberg, S.; Peterson, H.; Vilo, J. g:Profiler—A web server for functional interpretation of gene lists (2016 update). Nucleic Acids Res. 2016. [Google Scholar] [CrossRef] [PubMed]
- Richardson, J.E.; Bult, C.J. Visual annotation display (VLAD): A tool for finding functional themes in lists of genes. Mamm. Genome 2015, 26, 567–573. [Google Scholar] [CrossRef] [PubMed]
- Huang, D.W.; Sherman, B.T.; Lempicki, R.A. Systematic and integrative analysis of large gene lists using DAVID Bioinformatics Resources. Nat. Protoc. 2009, 4, 44–57. [Google Scholar] [CrossRef]
- Alam-Faruque, Y.; Huntley, R.P.; Khodiyar, V.K.; Camon, E.B.; Dimmer, E.C.; Sawford, T.; Martin, M.J.; O’Donovan, C.; Talmud, P.J.; Scambler, P.; et al. The impact of focused Gene Ontology curation of specific mammalian systems. PLoS ONE 2011, 6, e27541. [Google Scholar] [CrossRef]
- Patel, S.; Roncaglia, P.; Lovering, R.C. Using Gene Ontology to describe the role of the neurexin-neuroligin-SHANK complex in human, mouse and rat and its relevance to autism. BMC Bioinform. 2015, 16, 186. [Google Scholar] [CrossRef]
- Gray, K.A.; Yates, B.; Seal, R.L.; Wright, M.W.; Bruford, E.A. Genenames.org: The HGNC resources in 2015. Nucleic Acids Res. 2015, 43, D1079–D1085. [Google Scholar] [CrossRef]
- Masino, A.J.; Dechene, E.T.; Dulik, M.C.; Wilkens, A.; Spinner, N.B.; Krantz, I.D.; Pennington, J.W.; Robinson, P.N.; White, P.S. Clinical phenotype-based gene prioritization: An initial study using semantic similarity and the human phenotype ontology. BMC Bioinform. 2014, 15, 248. [Google Scholar] [CrossRef] [PubMed]
- Kametani, F.; Hasegawa, M. Reconsideration of amyloid hypothesis and tau hypothesis in Alzheimer’s Disease. Front. Neurosci. 2018, 12, 25. [Google Scholar] [CrossRef] [PubMed]
- Hardy, J.; Allsop, D. Amyloid deposition as the central event in the aetiology of Alzheimer’s disease. Trends Pharmacol. Sci. 1991, 12, 383–388. [Google Scholar] [CrossRef]
- Goedert, M. Tau protein and the neurofibrillary pathology of Alzheimer’s disease. Ann. N. Y. Acad. Sci. 1996, 777, 121–131. [Google Scholar] [CrossRef] [PubMed]
- Goedert, M. Tau protein and the neurofibrillary pathology of Alzheimer’s disease. Trends Neurosci. 1993, 16, 460–465. [Google Scholar] [CrossRef]
- Selkoe, D.J.; Hardy, J. The amyloid hypothesis of Alzheimer’s disease at 25 years. EMBO Mol. Med. 2016, 8, 595–608. [Google Scholar] [CrossRef] [PubMed]
- De Strooper, B.; Karran, E. The cellular phase of Alzheimer’s disease. Cell 2016, 164, 603–615. [Google Scholar] [CrossRef] [PubMed]
- Schott, J.M.; Revesz, T. Inflammation in Alzheimer’s disease: Insights from immunotherapy. Brain 2013, 136, 2654–2656. [Google Scholar] [CrossRef] [PubMed]
- Nelson, A.R.; Sweeney, M.D.; Sagare, A.P.; Zlokovic, B.V. Neurovascular dysfunction and neurodegeneration in dementia and Alzheimer’s disease. Biochim. Biophys. Acta 2016, 1862, 887–900. [Google Scholar] [CrossRef] [PubMed]
- Kundra, R.; Ciryam, P.; Morimoto, R.I.; Dobson, C.M.; Vendruscolo, M. Protein homeostasis of a metastable subproteome associated with Alzheimer’s disease. Proc. Natl. Acad. Sci. USA 2017, 114, E5703–E5711. [Google Scholar] [CrossRef] [PubMed]
- Cuyvers, E.; Sleegers, K. Genetic variations underlying Alzheimer’s disease: Evidence from genome-wide association studies and beyond. Lancet Neurol. 2016, 15, 857–868. [Google Scholar] [CrossRef]
- Shen, L.; Jia, J. An Overview of genome-wide association studies in Alzheimer’s disease. Neurosci. Bull. 2016, 32, 183–190. [Google Scholar] [CrossRef] [PubMed]
- De Matos, M.R.; Ferreira, C.; Herukka, S.K.; Soininen, H.; Janeiro, A.; Santana, I.; Baldeiras, I.; Almeida, M.R.; Lleo, A.; Dols-Icardo, O.; et al. Quantitative genetics validates previous genetic variants and identifies novel genetic players influencing Alzheimer’s disease cerebrospinal fluid biomarkers. J. Alzheimers Dis. 2018, 66, 639–652. [Google Scholar] [CrossRef] [PubMed]
- Abu-Rumeileh, S.; Mometto, N.; Bartoletti-Stella, A.; Polischi, B.; Oppi, F.; Poda, R.; Stanzani-Maserati, M.; Cortelli, P.; Liguori, R.; Capellari, S.; Parchi, P. Cerebrospinal fluid biomarkers in patients with frontotemporal dementia spectrum: A single-center study. J. Alzheimers Dis. 2018, 66, 551–563. [Google Scholar] [CrossRef] [PubMed]
- Verheijen, J.; Sleegers, K. Understanding Alzheimer disease at the interface between genetics and transcriptomics. Trends Genet. 2018, 34, 434–447. [Google Scholar] [CrossRef] [PubMed]
- Espuny-Camacho, I.; Arranz, A.M.; Fiers, M.; Snellinx, A.; Ando, K.; Munck, S.; Bonnefont, J.; Lambot, L.; Corthout, N.; Omodho, L.; et al. Hallmarks of Alzheimer’s disease in stem-cell-derived human neurons transplanted into mouse brain. Neuron 2017, 93, 1066–1081. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Patassini, S.; Rustogi, N.; Riba-Garcia, I.; Hale, B.D.; Phillips, A.M.; Waldvogel, H.; Haines, R.; Bradbury, P.; Stevens, A.; et al. Regional protein expression in human Alzheimer’s brain correlates with disease severity. bioRxiv 2018. [Google Scholar] [CrossRef]
- Kunkle, B.W.; Grenier-Boley, B.; Sims, R.; Bis, J.C.; Naj, A.C.; Boland, A.; Vronskaya, M.; van der Lee, S.J.; Amlie-Wolf, A.; Bellenguez, C.; et al. Meta-analysis of genetic association with diagnosed Alzheimer’s disease identifies novel risk loci and implicates Abeta, Tau, immunity and lipid processing. bioRxiv 2018. [Google Scholar] [CrossRef]
- Patel, S.; Park, M. Gene prioritization for imaging genetics studies using gene ontology and a stratified false discovery rate approach. Front. Neuroinform. 2016, 10, 14. [Google Scholar] [CrossRef]
- Denny, P.; Feuermann, M.; Hill, D.P.; Lovering, R.C.; Plun-Favreau, H.; Roncaglia, P. Exploring autophagy with Gene Ontology. Autophagy 2018, 14, 419–436. [Google Scholar] [CrossRef]
- Jarosz-Griffiths, H.H.; Noble, E.; Rushworth, J.V.; Hooper, N.M. Amyloid-beta receptors: The good, the bad, and the prion protein. J. Biol. Chem. 2016, 291, 3174–3183. [Google Scholar] [CrossRef]
- Guo, T.; Noble, W.; Hanger, D.P. Roles of tau protein in health and disease. Acta Neuropathol. 2017, 133, 665–704. [Google Scholar] [CrossRef]
- The Gene Ontology Consortium. Expansion of the Gene Ontology knowledgebase and resources. Nucleic Acids Res. 2017, 45, D331–D338. [Google Scholar] [CrossRef]
- NCBI PubMed. Available online: https://www.ncbi.nlm.nih.gov/pubmed/ (accessed on 30 May 2018).
- Balakrishnan, R.; Harris, M.A.; Huntley, R.; Van Auken, K.; Cherry, J.M. A guide to best practices for Gene Ontology (GO) manual annotation. Database 2013, 2013, bat054. [Google Scholar] [CrossRef]
- Huntley, R.P.; Harris, M.A.; Alam-Faruque, Y.; Blake, J.A.; Carbon, S.; Dietze, H.; Dimmer, E.C.; Foulger, R.E.; Hill, D.P.; Khodiyar, V.K.; et al. A method for increasing expressivity of Gene Ontology annotations using a compositional approach. BMC Bioinform. 2014, 15, 155. [Google Scholar] [CrossRef]
- Pundir, S.; Martin, M.J.; O’Donovan, C.; UniProt Consortium. UniProt tools. Curr. Protoc. Bioinform. 2016, 53, 1–15. [Google Scholar]
- The RNAcentral Constortium. RNAcentral: A hub of information for non-coding RNA sequences. Nucleic Acids Res. 2018. [Google Scholar] [CrossRef]
- Gene Ontology Consortium. Gene Ontology Evidence Code Documentation. 2016. Available online: http://www.geneontology.org/page/guide-go-evidence-codes (accessed on 10 May 2017).
- Huntley, R.P.; Sawford, T.; Mutowo-Meullenet, P.; Shypitsyna, A.; Bonilla, C.; Martin, M.J.; O’Donovan, C. The GOA database: Gene Ontology annotation updates for 2015. Nucleic Acids Res. 2015, 43, D1057–D1063. [Google Scholar] [CrossRef]
- Huntley, R.P.; Binns, D.; Dimmer, E.; Barrell, D.; O’Donovan, C.; Apweiler, R. QuickGO: A user tutorial for the web-based Gene Ontology browser. Database 2009, 2009, bap010. [Google Scholar] [CrossRef]
- Binns, D.; Dimmer, E.; Huntley, R.; Barrell, D.; O’Donovan, C.; Apweiler, R. QuickGO: A web-based tool for Gene Ontology searching. Bioinformatics 2009, 25, 3045–3046. [Google Scholar] [CrossRef]
- EMBL-EBI, QuickGO. Available online: https://www.ebi.ac.uk/QuickGO/ (accessed on 30 October 2018).
- Carbon, S.; Ireland, A.; Mungall, C.J.; Shu, S.; Marshall, B.; Lewis, S. AmiGO: Online access to ontology and annotation data. Bioinformatics 2009, 25, 288–289. [Google Scholar] [CrossRef]
- AmiGO 2. Available online: http://amigo.geneontology.org/amigo/landing (accessed on 30 May 2018).
- Brown, G.R.; Hem, V.; Katz, K.S.; Ovetsky, M.; Wallin, C.; Ermolaeva, O.; Tolstoy, I.; Tatusova, T.; Pruitt, K.D.; Maglott, D.R.; Murphy, T.D. Gene: A gene-centered information resource at NCBI. Nucleic Acids Res. 2015, 43, D36–D42. [Google Scholar] [CrossRef]
- Newman, V.; Moore, B.; Sparrow, H.; Perry, E. The Ensembl Genome Browser: Strategies for accessing eukaryotic genome data. Methods Mol. Biol. 2018, 1757, 115–139. [Google Scholar]
- Griffiths-Jones, S.; Grocock, R.J.; van Dongen, S.; Bateman, A.; Enright, A.J. miRBase: microRNA sequences, targets and gene nomenclature. Nucleic Acids Res. 2006, 34, D140–D144. [Google Scholar] [CrossRef]
- Kibbe, W.A.; Arze, C.; Felix, V.; Mitraka, E.; Bolton, E.; Fu, G.; Mungall, C.J.; Binder, J.X.; Malone, J. Disease Ontology 2015 update: An expanded and updated database of human diseases for linking biomedical knowledge through disease data. Nucleic Acids Res. 2015, 43, D1071–D1078. [Google Scholar] [CrossRef]
- GitHub. Available online: https://github.com/ (accessed on 30 October 2018).
- AmiGO 2. Available online: http://amigo.geneontology.org/amigo/landing (accessed on 30 May 2018).
- Lopez-Toledano, M.A.; Shelanski, M.L. Neurogenic effect of beta-amyloid peptide in the development of neural stem cells. J. Neurosci. 2004, 24, 5439–5444. [Google Scholar] [CrossRef]
- EMBL-EBI. Complex Portal. Available online: https://www.ebi.ac.uk/complexportal/home (accessed on 30 October 2018).
- Huntley, R.P.; Sawford, T.; Martin, M.J.; O’Donovan, C. Understanding how and why the Gene Ontology and its annotations evolve: The GO within UniProt. Gigascience 2014, 3, 4. [Google Scholar] [CrossRef]
- Citri, A.; Malenka, R.C. Synaptic plasticity: Multiple forms, functions, and mechanisms. Neuropsychopharmacology 2008, 33, 18–41. [Google Scholar] [CrossRef]
- Puzzo, D.; Privitera, L.; Leznik, E.; Fa, M.; Staniszewski, A.; Palmeri, A.; Arancio, O. Picomolar amyloid-beta positively modulates synaptic plasticity and memory in hippocampus. J. Neurosci. 2008, 28, 14537–14545. [Google Scholar] [CrossRef]
- Perez-Nievas, B.G.; Stein, T.D.; Tai, H.C.; Dols-Icardo, O.; Scotton, T.C.; Barroeta-Espar, I.; Fernandez-Carballo, L.; de Munain, E.L.; Perez, J.; Marquie, M.; et al. Dissecting phenotypic traits linked to human resilience to Alzheimer’s pathology. Brain 2013, 136, 2510–2526. [Google Scholar] [CrossRef]
- Shimoyama, M.; De Pons, J.; Hayman, G.T.; Laulederkind, S.J.; Liu, W.; Nigam, R.; Petri, V.; Smith, J.R.; Tutaj, M.; Wang, S.J.; et al. The Rat Genome Database 2015: Genomic, phenotypic and environmental variations and disease. Nucleic Acids Res. 2015, 43, D743–D750. [Google Scholar] [CrossRef]
- Milosevic, I. Revisiting the role of clathrin-mediated endoytosis in synaptic vesicle recycling. Front. Cell. Neurosci. 2018, 12, 27. [Google Scholar] [CrossRef]
- Gan, Q.; Watanabe, S. Synaptic vesicle endocytosis in different model systems. Front. Cell. Neurosci. 2018, 12, 171. [Google Scholar] [CrossRef]
- Chen, G.; Chen, K.S.; Knox, J.; Inglis, J.; Bernard, A.; Martin, S.J.; Justice, A.; McConlogue, L.; Games, D.; Freedman, S.B.; et al. A learning deficit related to age and beta-amyloid plaques in a mouse model of Alzheimer’s disease. Nature 2000, 408, 975–979. [Google Scholar] [CrossRef]
- Janus, C.; Pearson, J.; McLaurin, J.; Mathews, P.M.; Jiang, Y.; Schmidt, S.D.; Chishti, M.A.; Horne, P.; Heslin, D.; French, J.; et al. A beta peptide immunization reduces behavioural impairment and plaques in a model of Alzheimer’s disease. Nature 2000, 408, 979–982. [Google Scholar] [CrossRef]
- Westerman, M.A.; Cooper-Blacketer, D.; Mariash, A.; Kotilinek, L.; Kawarabayashi, T.; Younkin, L.H.; Carlson, G.A.; Younkin, S.G.; Ashe, K.H. The relationship between Abeta and memory in the Tg2576 mouse model of Alzheimer’s disease. J. Neurosci. 2002, 22, 1858–1867. [Google Scholar] [CrossRef]
- Takeda, S.; Hashimoto, T.; Roe, A.D.; Hori, Y.; Spires-Jones, T.L.; Hyman, B.T. Brain interstitial oligomeric amyloid-beta increases with age and is resistant to clearance from brain in a mouse model of Alzheimer’s disease. FASEB J. 2013, 27, 3239–3248. [Google Scholar] [CrossRef]
- Shankar, G.M.; Leissring, M.A.; Adame, A.; Sun, X.; Spooner, E.; Masliah, E.; Selkoe, D.J.; Lemere, C.A.; Walsh, D.M. Biochemical and immunohistochemical analysis of an Alzheimer’s disease mouse model reveals the presence of multiple cerebral Abeta assembly forms throughout life. Neurobiol. Dis. 2009, 36, 293–302. [Google Scholar] [CrossRef]
- Yankner, B.A.; Duffy, L.K.; Kirschner, D.A. Neurotrophic and neurotoxic effects of amyloid-beta protein: Reversal by tachykinin neuropeptides. Science 1990, 250, 279–282. [Google Scholar] [CrossRef]
- Barghorn, S.; Nimmrich, V.; Striebinger, A.; Krantz, C.; Keller, P.; Janson, B.; Bahr, M.; Schmidt, M.; Bitner, R.S.; Harlan, J.; et al. Globular amyloid-beta-peptide oligomer—A homogenous and stable neuropathological protein in Alzheimer’s disease. J. Neurochem. 2005, 95, 834–847. [Google Scholar] [CrossRef]
- Nimmrich, V.; Grimm, C.; Draguhn, A.; Barghorn, S.; Lehmann, A.; Schoemaker, H.; Hillen, H.; Gross, G.; Ebert, U.; Bruehl, C. Amyloid-β oligomers (A-β1-42 globulomer) suppress spontaneous synaptic activity by inhibition of P/Q-type calcium currents. J. Neurosci. 2008, 28, 788–797. [Google Scholar] [CrossRef]
- Noguchi, A.; Matsumura, S.; Dezawa, M.; Tada, M.; Yanazawa, M.; Ito, A.; Akioka, M.; Kikuchi, S.; Sato, M.; Ideno, S.; et al. Isolation and characterization of patient-derived, toxic, high mass amyloid-β-protein (A-β) assembly from Alzheimer disease brains. J. Biol. Chem. 2009, 284, 32895–32905. [Google Scholar] [CrossRef]
- Ohnishi, T.; Yanazawa, M.; Sasahara, T.; Kitamura, Y.; Hiroaki, H.; Fukazawa, Y.; Kii, I.; Nishiyama, T.; Kakita, A.; Takeda, H.; et al. Na, K-ATPase α3 is a death target of Alzheimer patient amyloid-β assembly. Proc. Natl. Acad. Sci. USA 2015, 112, E4465–E4474. [Google Scholar] [CrossRef]
- Malhotra, A.; Younesi, E.; Gundel, M.; Muller, B.; Heneka, M.T.; Hofmann-Apitius, M. ADO: A disease ontology representing the domain knowledge specific to Alzheimer’s disease. Alzheimers Dement. 2014, 10, 238–246. [Google Scholar] [CrossRef]
- Drame, K.; Diallo, G.; Delva, F.; Dartigues, J.F.; Mouillet, E.; Salamon, R.; Mougin, F. Reuse of termino-ontological resources and text corpora for building a multilingual domain ontology: An application to Alzheimer’s disease. J. Biomed. Inform. 2014, 48, 171–182. [Google Scholar] [CrossRef]
- Refolo, L.M.; Snyder, H.; Liggins, C.; Ryan, L.; Silverberg, N.; Petanceska, S.; Carrillo, M.C. Common Alzheimer’s disease research ontology: National institute on aging and Alzheimer’s association collaborative project. Alzheimers Dement. 2012, 8, 372–375. [Google Scholar] [CrossRef]
- Liggins, C.; Snyder, H.M.; Silverberg, N.; Petanceska, S.; Refolo, L.M.; Ryan, L.; Carrillo, M.C. International Alzheimer’s disease research portfolio (IADRP) aims to capture global Alzheimer’s disease research funding. Alzheimers Dement. 2014, 10, 405–408. [Google Scholar] [CrossRef]
- Zhang, X.; Hu, B.; Ma, X.; Moore, P.; Chen, J. Ontology driven decision support for the diagnosis of mild cognitive impairment. Comput. Methods Prog. Biomed. 2014, 113, 781–791. [Google Scholar] [CrossRef]
- Lovering, R.C.; Roncaglia, P.; Howe, D.G.; Laulederkind, S.J.F.; Khodiyar, V.K.; Berardini, T.Z.; Tweedie, S.; Foulger, R.E.; Osumi-Sutherland, D.; Campbell, N.H.; et al. Improving Interpretation of cardiac phenotypes and enhancing discovery with expanded knowledge in the gene ontology. Circ. Genom Precis Med. 2018, 11, e001813. [Google Scholar] [CrossRef]
- Ferrari, R.; Grassi, M.; Salvi, E.; Borroni, B.; Palluzzi, F.; Pepe, D.; D’avila, F.; Padovani, A.; Archetti, S.; Rainero, I.; et al. A genome-wide screening and SNPs-to-genes approach to identify novel genetic risk factors associated with frontotemporal dementia. Neurobiol. Aging 2015, 36, 2904.e13–2904.e26. [Google Scholar] [CrossRef]
- Welton, J.L.; Loveless, S.; Stone, T.; Von Ruhland, C.; Robertson, N.P.; Clayton, A. Cerebrospinal fluid extracellular vesicle enrichment for protein biomarker discovery in neurological disease; multiple sclerosis. J. Extracell. Vesicles 2017, 6, 1369805. [Google Scholar] [CrossRef]
- Hirsch, T.; Rothoeft, T.; Teig, N.; Bauer, J.W.; Pellegrini, G.; De Rosa, L.; Scaglione, D.; Reichelt, J.; Klausegger, A.; Kneisz, D.; et al. Regeneration of the entire human epidermis using transgenic stem cells. Nature 2017, 551, 327–332. [Google Scholar] [CrossRef]
- Ittner, L.M.; Ke, Y.D.; Delerue, F.; Bi, M.; Gladbach, A.; Van Eersel, J.; Wolfing, H.; Chieng, B.C.; Christie, M.J.; Napier, I.A.; et al. Dendritic function of tau mediates amyloid-beta toxicity in Alzheimer’s disease mouse models. Cell 2010, 142, 387–397. [Google Scholar] [CrossRef]
- Iqbal, K.; Liu, F.; Gong, C.X.; Grundke-Iqbal, I. Tau in Alzheimer disease and related tauopathies. Curr. Alzheimer Res. 2010, 7, 656–664. [Google Scholar] [CrossRef]
- Butterfield, D.A.; Boyd-Kimball, D. Amyloid-beta-peptide(1-42) contributes to the oxidative stress and neurodegeneration found in Alzheimer disease brain. Brain Pathol. 2004, 14, 426–432. [Google Scholar] [CrossRef]
- Mudher, A.; Colin, M.; Dujardin, S.; Medina, M.; Dewachter, I.; Alavi Naini, S.M.; Mandelkow, E.M.; Mandelkow, E.; Buee, L.; Goedert, M.; et al. What is the evidence that tau pathology spreads through prion-like propagation? Acta Neuropathol. Commun. 2017, 5, 99. [Google Scholar] [CrossRef]
- Kaufman, S.K.; Thomas, T.L.; Del Tredici, K.; Braak, H.; Diamond, M.I. Characterization of tau prion seeding activity and strains from formaldehyde-fixed tissue. Acta Neuropathol. Commun. 2017, 5, 41. [Google Scholar] [CrossRef]
- Kaufman, S.K.; Del Tredici, K.; Thomas, T.L.; Braak, H.; Diamond, M.I. Tau seeding activity begins in the transentorhinal/entorhinal regions and anticipates phospho-tau pathology in Alzheimer’s disease and PART. Acta Neuropathol. 2018, 136, 57–67. [Google Scholar] [CrossRef]
- DeVos, S.L.; Corjuc, B.T.; Oakley, D.H.; Nobuhara, C.K.; Bannon, R.N.; Chase, A.; Commins, C.; Gonzalez, J.A.; Dooley, P.M.; Frosch, M.P.; et al. Synaptic tau seeding precedes tau pathology in human Alzheimer’s disease brain. Front. Neurosci. 2018, 12, 267. [Google Scholar] [CrossRef]
- Hyttinen, J.M.; Amadio, M.; Viiri, J.; Pascale, A.; Salminen, A.; Kaarniranta, K. Clearance of misfolded and aggregated proteins by aggrephagy and implications for aggregation diseases. Ageing Res. Rev. 2014, 18, 16–28. [Google Scholar] [CrossRef]
- Rodrigue, K.M.; Kennedy, K.M.; Park, D.C. Beta-amyloid deposition and the aging brain. Neuropsychol. Rev. 2009, 19, 436–450. [Google Scholar] [CrossRef]
- Kamenetz, F.; Tomita, T.; Hsieh, H.; Seabrook, G.; Borchelt, D.; Iwatsubo, T.; Sisodia, S.; Malinow, R. APP processing and synaptic function. Neuron 2003, 37, 925–937. [Google Scholar] [CrossRef]
- Cirrito, J.R.; Yamada, K.A.; Finn, M.B.; Sloviter, R.S.; Bales, K.R.; May, P.C.; Schoepp, D.D.; Paul, S.M.; Mennerick, S.; Holtzman, D.M. Synaptic activity regulates interstitial fluid amyloid-beta levels in vivo. Neuron 2005, 48, 913–922. [Google Scholar] [CrossRef]
- Li, X.; Uemura, K.; Hashimoto, T.; Nasser-Ghodsi, N.; Arimon, M.; Lill, C.M.; Palazzolo, I.; Krainc, D.; Hyman, B.T.; Berezovska, O. Neuronal activity and secreted amyloid-beta lead to altered amyloid-beta precursor protein and presenilin 1 interactions. Neurobiol. Dis. 2013, 50, 127–134. [Google Scholar] [CrossRef]
- Cao, L.; Schrank, B.R.; Rodriguez, S.; Benz, E.G.; Moulia, T.W.; Rickenbacher, G.T.; Gomez, A.C.; Levites, Y.; Edwards, S.R.; Golde, T.E.; et al. Abeta alters the connectivity of olfactory neurons in the absence of amyloid plaques in vivo. Nat. Commun. 2012, 3, 1009. [Google Scholar] [CrossRef]
- Denny, P.; Feuermann, M.; Hill, D.P.; Roncaglia, P.; Lovering, R.C. Exploring autophagy with Gene Ontology. F1000Research (Poster) 2016. Available online: https://f1000research.com/posters/5-754 (accessed on 30 October 2018). [CrossRef]
- Foulger, R.E.; Denny, P.; Hardy, J.; Martin, M.J.; Sawford, T.; Lovering, R.C. Using the Gene Ontology to annotate key players in Parkinson’s disease. Neuroinformatics 2016, 14, 297–304. [Google Scholar] [CrossRef]
- Gene Ontology Consortium, SynGO—Synapse Biology. 2018. Available online: http://www.geneontology.org/page/syngo-synapse-biology (accessed on 30 October 2018).
- Thurmond, J.; Goodman, J.L.; Strelets, V.B.; Attrill, H.; Gramates, L.S.; Marygold, S.J.; Matthews, B.B.; Millburn, G.; Antonazzo, G.; Trovisco, V.; et al. FlyBase 2.0: the next generation. Nucleic Acids Res. 2018. [Google Scholar] [CrossRef]
- Li, Q.; Barres, B.A. Microglia and macrophages in brain homeostasis and disease. Nat. Rev. Immunol. 2018, 18, 225–242. [Google Scholar] [CrossRef]
- UCL Functional Gene Annotation, Neurological Gene Ontology. Available online: https://www.ucl.ac.uk/functional-gene-annotation/neurological (accessed on 30 October 2018).
- Meldal, B.H.; Forner-Martinez, O.; Costanzo, M.C.; Dana, J.; Demeter, J.; Dumousseau, M.; Dwight, S.S.; Gaulton, A.; Licata, L.; Melidoni, A.N.; et al. The complex portal—an encyclopaedia of macromolecular complexes. Nucleic Acids Res. 2015, 43, D479–D484. [Google Scholar] [CrossRef]
- GOA Contact Us. Available online: https://www.ebi.ac.uk/GOA/contactus (accessed on 30 October 2018).
- Contributing to GO. Available online: http://geneontology.org/page/contributing-go (accessed on 30 October 2018).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ARUK-UCL GO Annotation Project: Priorities and Curation Summary | Total | |
|---|---|---|
| Prioritised human gene products | 84 | |
| Prioritised human amyloid-beta-relevant gene products # | 50 | |
| Prioritised human tau-relevant gene products ## | 34 | |
| All species | Human | |
| PubMed identifiers (PMIDs) curated * | 226 | 191 |
| GO annotations ** | 3886 | 2770 |
| Gene products annotated ** | 561 | 308 |
| GO annotations associated with 84 human gene products prioritised for annotation *# | n/a | 2055 |
| New Complex Portal (CP) entries *** | 18 | 6 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kramarz, B.; Roncaglia, P.; Meldal, B.H.M.; Huntley, R.P.; Martin , M.J.; Orchard, S.; Parkinson, H.; Brough, D.; Bandopadhyay, R.; Hooper, N.M.; et al. Improving the Gene Ontology Resource to Facilitate More Informative Analysis and Interpretation of Alzheimer’s Disease Data. Genes 2018, 9, 593. https://doi.org/10.3390/genes9120593
Kramarz B, Roncaglia P, Meldal BHM, Huntley RP, Martin MJ, Orchard S, Parkinson H, Brough D, Bandopadhyay R, Hooper NM, et al. Improving the Gene Ontology Resource to Facilitate More Informative Analysis and Interpretation of Alzheimer’s Disease Data. Genes. 2018; 9(12):593. https://doi.org/10.3390/genes9120593
Chicago/Turabian StyleKramarz, Barbara, Paola Roncaglia, Birgit H. M. Meldal, Rachael P. Huntley, Maria J. Martin , Sandra Orchard, Helen Parkinson, David Brough, Rina Bandopadhyay, Nigel M. Hooper, and et al. 2018. "Improving the Gene Ontology Resource to Facilitate More Informative Analysis and Interpretation of Alzheimer’s Disease Data" Genes 9, no. 12: 593. https://doi.org/10.3390/genes9120593
APA StyleKramarz, B., Roncaglia, P., Meldal, B. H. M., Huntley, R. P., Martin , M. J., Orchard, S., Parkinson, H., Brough, D., Bandopadhyay, R., Hooper, N. M., & Lovering, R. C. (2018). Improving the Gene Ontology Resource to Facilitate More Informative Analysis and Interpretation of Alzheimer’s Disease Data. Genes, 9(12), 593. https://doi.org/10.3390/genes9120593